Title: Multiagent Reinforcement Learning for Liquidity Games
ArXiv ID: 2601.00324
Date: 2026-01-01
Authors: Alicia Vidler, Gal A. Kaminka
📝 Abstract
Making use of swarm methods in financial market modeling of liquidity, and techniques from financial analysis in swarm analysis, holds the potential to advance both research areas. In swarm research, the use of game theory methods holds the promise of explaining observed phenomena of collective utility adherence with rational self-interested swarm participants. In financial markets, a better understanding of how independent financial agents may self-organize for the betterment and stability of the marketplace would be a boon for market design researchers. This paper unifies Liquidity Games, where trader payoffs depend on aggregate liquidity within a trade, with Rational Swarms, where decentralized agents use difference rewards to align self-interested learning with global objectives. We offer a theoretical frameworks where we define a swarm of traders whose collective objective is market liquidity provision while maintaining agent independence. Using difference rewards within a Markov team games framework, we show that individual liquidity-maximizing behaviors contribute to overall market liquidity without requiring coordination or collusion. This Financial Swarm model provides a framework for modeling rational, independent agents where they achieve both individual profitability and collective market efficiency in bilateral asset markets.
📄 Full Content
Cleared trading volume, and the system's ability to achieve it efficiently, is commonly referred to as liquidity. In modern markets, it is an emergent and desired property of decentralized interactions among heterogeneous agents, not a fixed attribute. It denotes the ease of trading an asset quickly and at low cost without materially moving its price (Frank J. Fabozzi 2005). To quote Kevin Warsh, a member of the U.S. Federal Reserve Board of Governors: "Liquidity is confidence".
Increasing market liquidity is a challenging problem. Market clearing-turning intent into executed tradescomes from myriad local choices (quotes, inventories, risk limits) that produce system-level effects (such as aggregate trading volumes). However, since agent coalition and coordination are typically illegal in real-world modern financial markets, these local choices are required to be uncoordi-nated. The trading intents (and their execution) of independent learners (agents) must be based on their strictly local rewards, that have no clear link to market-wide objectives.
In this paper, we address the tension between the selfinterested decisions of the independent agents, and the desired maximal liquidity of market-wide trading volumes. Specifically, we unify Liquidity Games (LG), a game-theoretic model of liquidity formation (Vidler and Walsh 2024b), with a decentralized multiagent reinforcement learning method, rational swarms (Kaminka 2025).
Here, multiple financial agents (investors, banks, or market makers) act on local information. Their collective decisions determine system-level liquidity patterns. The decentralized learning framework allows independent learners to act in a way that increases liquidity, while remaining independently self-interested.
Concretely, we cast the market system as a Markov teamgame, i.e., a fully cooperative stochastic repeated game, where agents theoretically receive the same global (systemlevel) payoff resulting from their joint actions. we treat aggregate cleared volume as a global measure of liquidity. This is a system-level performance measure of the quantity of orders that are actually executed (i.e., matched and settled) within a period, as distinct from quoted or submitted volume (Bank of England 2015). Aggregated cleared volume is the desired property to be maximized. Following (Kaminka 2025), we address the challenge resulting from the fact that agents are unable to receive (observe) this joint payoff, but are only exposed to a local proxy of it. Instead, each agent learns using a local difference reward (marginal contribution to liquidity), yielding an individual reward signal that is aligned with global liquidity. This allows fully independent learning with no orchestration or collusion. We examine two hypotheses:
[H1]: Liquidity with difference rewards. In bilateral trading with random pairing, agents trained with difference rewards will achieve higher aggregate liquidity and individual trading quantities than those using other local or global signals, or baselines without learning, thereby maximizing local utility and global utility without coordination.
[H2]: Robustness under exact match. In exact-match Liquidity Games (no partial fills), agents trained with difference rewards will learn policies that achieve and arXiv:2601.00324v1 [cs.AI] 1 Jan 2026 maintain higher matching efficiency and will reach a high trade success threshold earlier in training than agents using alternative reward designs. We examine these hypotheses across different clearing regimes, which define how trade offers convert to executed transactions and thereby shape the global objective G (cleared volume and hence, liqudity). We explore two regimes: (i) partial fill, allowing fractional execution (which we term MinFill regime) and (ii) exact match, requiring full quantity alignment between buyers and sellers following (Vidler and Walsh 2024b).
We show using difference rewards provides advantages over alternative learning and non-learning methods. Anticipating our results, under a partial clearing rule (MinFill), difference reward agents achieve the highest total liquidity and clearing efficiency; under exact matching, they remain competitive, rapidly reaching ∼ 70% trade success despite stricter constraints.
This paper is structured as follows. First, we explore the relevant literature. Then, we detail the methodology and framework to combine difference reward functions of distributed multiagent reinforcement learning and the game theoretic model of bond markets focused on liquidity. In the following sections, we outline specific instances of the combined paradigm and discuss the results.
A Literature Review
Traditional economic theory has employed several mathematical frameworks to model agent interactions in financial markets, each offering distinct perspectives on collective behavior and market dynamics. Financial markets can be modeled as multiagent environments (MAS) where heterogeneous participants, ranging from retail traders to institutional algorithms, interact under shared protocols and constraints (Vidler and Walsh 2024a;Epstein and Axtell 1996;Epstein and Schneider 2010;Hull 2022). The degree of agent heterogeneity varies between market segments, shaping systemic behavior and stability (Vidler and Walsh 2024a). We suggest that there are theoretical and structural analogies between agents in financial markets (Vidler 2025), and multiagent reinforcement learning by independent learners in swarms (Kaminka 2025). These can provide a foundation for understanding distributed decision-making in economic contexts.
Regulated Interaction and Implicit Coordination. Unlike engineered MAS, financial systems restrict explicit cooperation due to legal prohibitions on collusion and information sharing (Federal Reserve Bank of New York 2021; Bank of England 2015). Despite this, coordination can still emerge implicitly through indirect channels such as strategic signaling, herding, and reaction to shared market data, resembling the stigmergic interactions observed in swarm systems. These markets thus function as decentralized, swarmlike systems, where coordination arises without central control. This analogy motivates our view of financial markets as distributed systems that process information and adapt dynamically, which we expand on below.
Distributed Information Processing. Financial markets aggregate private information through the distributed trading mechanism, where individual beliefs are expressed through price signals (equity markets) and available liquidity (bond markets). This resembles distributed sensing in swarms. In some markets, such as government bonds, this process affects liquidity (Pinter 2023;Pinter, Wang, and Zou 2024;Vidler 2025). System-level feedback highlights the tension in the system: Markets (systems) can adapt through feedback, but this adaptive capacity works best in smooth, unobstructed environments. When faced with significant challenges or resistance, the system’s ability to maintain stable operation while adapting becomes limited. In bond markets, this has translated into several systemic shocks in the past few years in the UK and US markets alone ((Pinter 2023), (Duffie 2020)). Our work, in part, is motivated by these challenges and the opportunity to link markets when global goals are crucial (i.e. functioning bond markets) but where individual agents are both selfish and unable to explicitly coordinate to maximize global outcomes. We introduce literature specifically relevant to bond market liquidity below.
Liquidity in bilateral, over-the-counter (OTC) markets emerges from decentralized interactions between counterparties rather than from centralized order books. Many institutional settings, including government bonds, concentrate asset trading. For example, in the UK market for government bonds (the gilt market), bonds are issued and traded via a network of regulated dealers (GEMMs)1 , with broadly comparable arrangements in Australia, the US, and Canada (Cheshire 2015). While institutional details vary, large investors in such markets typically transact through these intermediaries (or their functional equivalents). Large participants supply quotes and warehouse risk but face balancesheet, capital, and regulatory constraints (Pinter, Wang, and Zou 2024;Czech and Pinter 2022).
Across bilateral OTC environments, transaction prices are often anchored to public benchmarks or reference rates rather than discovered solely within each local match. Liquidity constraints arise from limits on inventories, funding capacity, and the topology of trading relationships (Duffie and Singleton 2015;Frank J. Fabozzi 2005;Pinter 2023). As a result, liquidity is an emergent property of many decentralized decisions (such as inventory management and risk tolerance) rather than a centrally controlled input (Frank J. Fabozzi 2005). Supervisors and monitoring authorities (Bank of England 2015) observe cleared volume: the amount of bonds which convert into executed trades, a metric that is used to asses market liquidity. In this paper we will refer to market liquidity and liquidity, interchangeably.
Gaps remain in how liquidity can be modeled as a global outcome emerging from local agent behavior. Existing approaches capture either structural features of market microstructure or the strategic interactions of participants. We address this by contributing a model that integrates the Liquidity Game (which formalizes the constraints and incentives of bilateral OTC trading (Vidler and Walsh 2024b)) with decentralized multiagent learning via rational swarms (Kaminka 2025). This unified framework allows agents to act independently using local rewards, yet collectively reproduce system-level liquidity through emergent clearing (trading of bonds). We add to this further by allowing agents to “learn” how to trade larger volumes, which increased aggregate system liquidity. It thereby connects micro-level decision processes with macro-level market outcomes, providing a new method for studying liquidity formation without centralized coordination and agent policy learning.
Game Theory. Game-theoretic approaches have been applied to financial markets, but most frameworks analyze micro-level interactions rather than holistic market behavior, limiting insight into the emergent properties of largescale systems of independent trading agents, such as liquidity analysis. The central challenge is scaling game-theoretic insights to capture the complex interdependencies in multi participant markets.
Against this backdrop, applications of heterogeneous and homogeneous multiagent systems span small and largescale settings, notably in game theory, negotiation, and fairness (Wooldridge 2009;Axtell and Farmer 2022;Parkes 2006;Shoham and Leyton-Brown 2008;Fatima, Kraus, and Wooldridge 2014), with related lines in (Fagiolo et al. 2017;Lussange et al. 2020;Vermeir and Bersini 2015). The foundations for agent reasoning and communication provide logic-based frameworks for cooperation (Fatima, Kraus, and Wooldridge 2014;Klügl, Fehler, and Herrler 2005;Thangarajah, Padgham, and Harland 2002). Extensions to automated negotiation and decision making under uncertainty blend game theory and AI (Baumeister 2019), with results on repeated interaction and “playing the wrong game” bounds (Burkov and Chaib-Draa 2014;Meir and Parkes 2018). Research on goal modeling within ABMs includes (Winikoff et al. 2002) and simulations are found to be crucial for reproducing complex dynamics (Bai, Raskob, and Müller 2020). These ideas underpin autonomous bidding agents (including financial agents) and market-oriented MAS explored in (Wellman, Greenwald, and Stone 2007;Lin et al. 2014;Shoham 2008). We make use of these elements and extend LG to include multiagent learning abilities, with the goal that market participant (agents) learn the best strategy for trading to mazimize their own liquidity (selfishly) while benefiting overall from global maximized market liquidity.
Markov Games and Market Memory. Markov decision processes and stochastic (Markov) games have found widespread application in financial modeling due to their mathematical tractability and the assumption of memoryless state transitions (Shapley 1953;Littman 1994). The Markov property assumes that future market states depend only on current conditions, independent of historical tra-jectories. However, this assumption has faced increasing scrutiny, as empirical evidence points to long-memory and path-dependent behavior in returns, volatility, and liquidity (order flow) (Ding, Granger, and Engle 1993;Lillo andFarmer 2004, 2005). In particular, volatility dynamics exhibits rough (fractional) behavior that departs from Markovian models (Gatheral, Jaisson, and Rosenbaum 2018). Similarly, trading systems comprise repeated games, where participants see value in learning features of the counterparties they trade with (Massa and Simonov 2003).
Across these approaches, a gap remains: existing models do not reconcile local agent incentives (with or without learning) and the emergence of global liquidity as an outcome.
We address this gap by contributing a unified framework that combines the structural rigor of the Liquidity Game (Vidler and Walsh 2024b) with decentralized learning via rational swarms (Kaminka 2025). We show agents can learn locally, while preserving legal non-coordination, yielding a scalable, adaptive model of how liquidity emerges endogenously in complex financial systems.
Reward mechanisms in multiagent financial systems span individual incentives and system level objectives (Wooldridge and Jennings 1995;Shoham 2008). At the agent level, rewards naturally map to monetary gains from trading. At the collective level, rewards correspond to attributes of market qualities such as stability, liquidity, and sustained participation. In certain markets (such as bond markets), agents derive direct benefit from liquidity (facility to transact the bonds they wish, at the time they desire) rather than from directional price dynamics.
This paper seeks to unify two aspects of financial and swarm research: we build a unified framework for swarmscale market liquidity that marries LG’s (payoffs tied to aggregate liquidity (Vidler and Walsh 2024b)) with Rational Swarms (self-interested agents aligned via difference rewards (Kaminka 2025;Tumer and Agogino 2007)) inside a Markov team-game formalism. We make explicit that the difference reward is the marginal contribution of the agent to a global liquidity objective, providing a transparent, incentive compatible signal that preserves the independence of the agent and avoids coordination or collusion. This shifts the focus from two-party transactions to emergent, large population dynamics, linking individual trading incentives to system-level properties such as overall market liquidity.
In this section we detail our theoretical model definition.
The following subsections specify the environment (random pairing, clearing rules), agent types, and learning signals. All are defined relative to a bilateral trading market in which the team objective is aggregate liquidity G (total cleared volume).
Liquidity Games are introduced in (Vidler and Walsh 2024b) and are defined as a “noncooperative, simultaneous move game between two agents (or players), modeling a bilateral market mechanism”. Specific to the game is the unique feature of endogenous payoff.
Definition 1 (Liquidity Game). A game instance is a tuple I = (N, B, U ) defined as follows:
• Players. N = {i, j} is the set of players, with |N | = 2.
• Bond balances. Each player i ∈ N holds a private bond balance
where x, y ∈ Z are public market parameters. Typically x = 0 and y = c, where c is the total issuance of the given bond (publicly available). • Actions. The set of permitted actions for player i is
and an action a i ∈ A i represents the number of bonds played by player i in a round. Equivalently,
• Utilities. The utility (reward) function u i :
We model the process as a repeated (one-shot) stage game, where each episode the game state resets and multiple bilateral agent games occur each episode such that each agent has the opportunity to trade one time only per episode. Within the stage game between two agents, simultaneously without the use of prices, each player adopts a (potentially) heterogeneous strategy by privately selecting a parcel a i ∈ B i with 0 ≤ |a i | ≤ |B i | to trade, aiming to move their bond balance toward, but not below, zero while concealing true inventory to preserve informational advantages and satisfy regulatory norms. Choices may be formed on beliefs about the counterparty and agents reflect human players who typically seek full clearance in a single move. Two game regimes are utilised: trades execute only if the submitted quantities are mutually acceptable and the “Minfill” regime where the minumum is traded. Whilst outside the scope of this work, we note that these player preferences can be incorporated in more complex and richer game settings (such as penalty methods) and we leave this to future work.
In the classic game of (Vidler and Walsh 2024b) payoff and welfare for a one-shot, simultaneous variant has one player, a seller with B i > 0 and a buyer with B j < 0 each choosing a non-negative action a k ∈ Z ≥0 with a k ≤ |B k |. Trade clears only on an exact positive match: q = a i if a i = a j > 0, else q = 0. The payoff for each player is q. This captures the shared goal of moving balances toward zero; any mismatch (or a zero submission) leaves positions unchanged.
Agents can belong to one of two mutually exclusive groups i.e. large or small firm size.
Let there be a finite set of agents N = {1, . . . , n}. Each agent i ∈ N belongs to one of two mutually exclusive types:
The type θ i represents the firm size of agent i. The size of the firm affects the mean of the bond pay-off distribution in any trade, but not its tail behaviour.
We extend LG’s in two ways to increase the richness of their applicability:
Clearing Rules: A trade is said to have occurred at the lower of |a i | and |a j | such that the minimum liquidity would be transacted between parties. We call this the “MinFill” variant. This then naturally extends the concept of the difference reward to be the value differential between what each agent had wished to trade, and what was traded. Formally
We see that in Definition 1 there is the possibility for at least two policies to exist in the market: 1. LG-Exact (baseline). Trade occurs iff a i = a j > 0. The quantity traded is q = a i , and u i (q) = q. 2. LG-MinFill (extension). Trade occurs whenever a i > 0 and a j > 0, with traded quantity q = min(a i , a j ). The payoff is u i (q) = q. Unless stated otherwise, the equilibrium statements for the baseline refer to LG-Exact, and the learning experiments marked “MinFill” implement the second rule. We note that in LG-Exact, every diagonal profile (a, a) with a ∈ {1, . . . , min(|B i |, |B j |)} is a pure Nash equilibrium (and (0, 0) is also an equilibrium). In LG-MinFill, the unique pure Nash equilibrium is a ⋆ i = a ⋆ j = min(|B i |, |B j |). In extending LG’s to two regimes we generalize beyond strict constraints.
We extend the game to a repeated stage game, where initial agent balances are reset each episode, but agents can learn what is the optimal amount of bonds to try to trade. Namely, agents seek to learn the amount of bond to offer that maximizes the trade amount. The learning needs to take as context the probability what sort of agent is on the other side of the trade (which impacts the possible trade quantity), whilst seeking to maximize the total liquidity generated in a trade.
We adopt difference reward of (Tumer and Agogino 2007) as each agent’s reward signal. We build extensively on work by (Kaminka 2025) which demonstrates the power of rational decentralized swarm agents to provide for environment level benefits. For agent i with joint outcome z and counterfactual z -i (the system without i), the difference reward measures the agent’s marginal contribution to the global objective G and is defined as:
(1) In our setting, G is a liquidity metric, so D i quantifies how much agent i improves market liquidity while preserving agent independence and avoiding explicit coordination. The difference reward measures the marginal contribution of an agent’s presence to the overall system performance. Such marginal contribution can be quantified through metrics such as total trading volume for example. In this way, applying difference rewards to bilateral trading environments (such as bonds as one example (Vidler and Walsh 2024b) would allow a framework to evaluate the nonlinear impact of agent inclusion versus exclusion, extending beyond simple proportional contributions to capture emergent effects arising from agent interactions. We propose making use of this approach to understand market liquidity.
This pairing of Liquidity Games (endogenous G) with Rational Swarms (difference rewards) aligns rational learning individually with the market-level goal while avoiding explicit coordination. We note that this “marginal contribution” view is conceptually analogous to familiar ideas of risk attribution (e.g., marginal or incremental contributions to portfolio risk) (Hull 2018).
In this section we detail our programmatic model testing environment. The code base implements a multiagent simulation environment to investigate coordination and liquidity provision in a simplified market setting. We use the simulation environment to explore the impact of different clearing rules and reward mechanisms on agent behavior and aggregate market outcomes.
The core of the simulation is the LiquidityGameEnv class, which models a market with a fixed number of agents (n agents). In each episode (time step), the agents are randomly paired. Within each pair, agents simultaneously announce an amount of liquidity they are willing to offer for trade to their compatriot. Such details are never broadcast to other agents. The actual amount traded depends on the chosen clearing rule. After trades occur, agents’ balances are updated, and a new episode begins with agents having potentially altered balances. Agents are designated as small or large based on their initial balance ranges (max balance small and max balance large), allowing for the study of asymmetric liquidity endowments.
See Figure 1 for a schematic representation of the interaction model.
Simulation settings. We make use of estimated agent numbers within real life markets in (Pinter 2023) and set agents to 1300, with large and small participants set at 33% and 66% respectively (drawing approximate values from (Vidler and Walsh 2024b). The analysis is run on 10,000 episodes. The initial balance caps for each agent in each episode are set to small ≤ 10 units; large ≤ 40 units, where the agents initialize a balance as a random value between 1 and the cap at each episode, inline with the probability of being part of a large or small agent cohort. Our goal remains to test the ability for agents learning what amount of bonds to offer to trade such that they maximize their traded quantities and liquidity of the environment as a whole. Learning Agents (Tabular Q-Learning)
We make use of simple Q learning agents. However, the simulation compares the performance of learning agents employing different reward mechanisms against non-learning baseline agents. All learning agents share the same tabular Q-learning core and differ only in the reward signal (difference, local, or global).
State s is the agent’s current balance; the action set is A(s) = {1, . . . , s} (offered amount). The Q-table has one row per discrete balance and one column per feasible action.
Update. After taking a in s and observing reward r and next state s ′ ,
, with fixed α = 0.1. The reward term r is instantiated by the chosen signal; no other hyperparameters differ across signals.
Action selection (epsilon-greedy). With probability ϵ = 0.2 the agent explores by sampling uniformly from A(s); otherwise it exploits, choosing any a ∈ arg max a ′ Q(s, a ′ ) (ties broken uniformly at random).
The learning agents are differentiated by the reward mode used to compute the signal they receive after each step.
Diff Reward: Agents receive a difference reward, approximating their marginal contribution to the liquidity in the system. The reward for an agent is the quantity traded in their pair minus the quantity that would have been traded if they had offered zero (while their partner’s offer remained the same). Under the MinFill rule, this simplifies to the trade quantity q. 2. Local Reward: Agents receive a reward based on a local utility function: R i = 2q -a i -π ij , where q is the trade quantity, a i is the agent’s offer, and π ij is a penalty for repeating a partner from the previous step, designed to explore adverse selection and set to a modest penalty of 0.1 units. 3. Global Reward: Agents receive the total liquidity cleared across all pairs in the market during that step. This requires agents to learn to contribute to the global outcome without direct individual feedback on their impact.
Baseline Agents Two non-learning baseline strategies are implemented for comparison:
random Agent: In each step, random agents offer a uniformly random amount between 1 and their current balance (inclusive). 2. greedy Agent: In each step, greedy agents offer their entire current balance for trade. This strategy aims to maximize individual trade volume by being “greedy”.
A penalty is applied to the recorded liquidity for greedy agents under the MinFill rule if they offer more than their partner, reflecting a potential cost to over-offering and it set to 20% of the excess offered amount. In this way the agent is designed to be penalized for pure greed.
The simulation tracks several metrics per episode to evaluate the performance of different configurations: agent type (learning, non learning and different learning methods) and clearing rule (exact and MinFill).
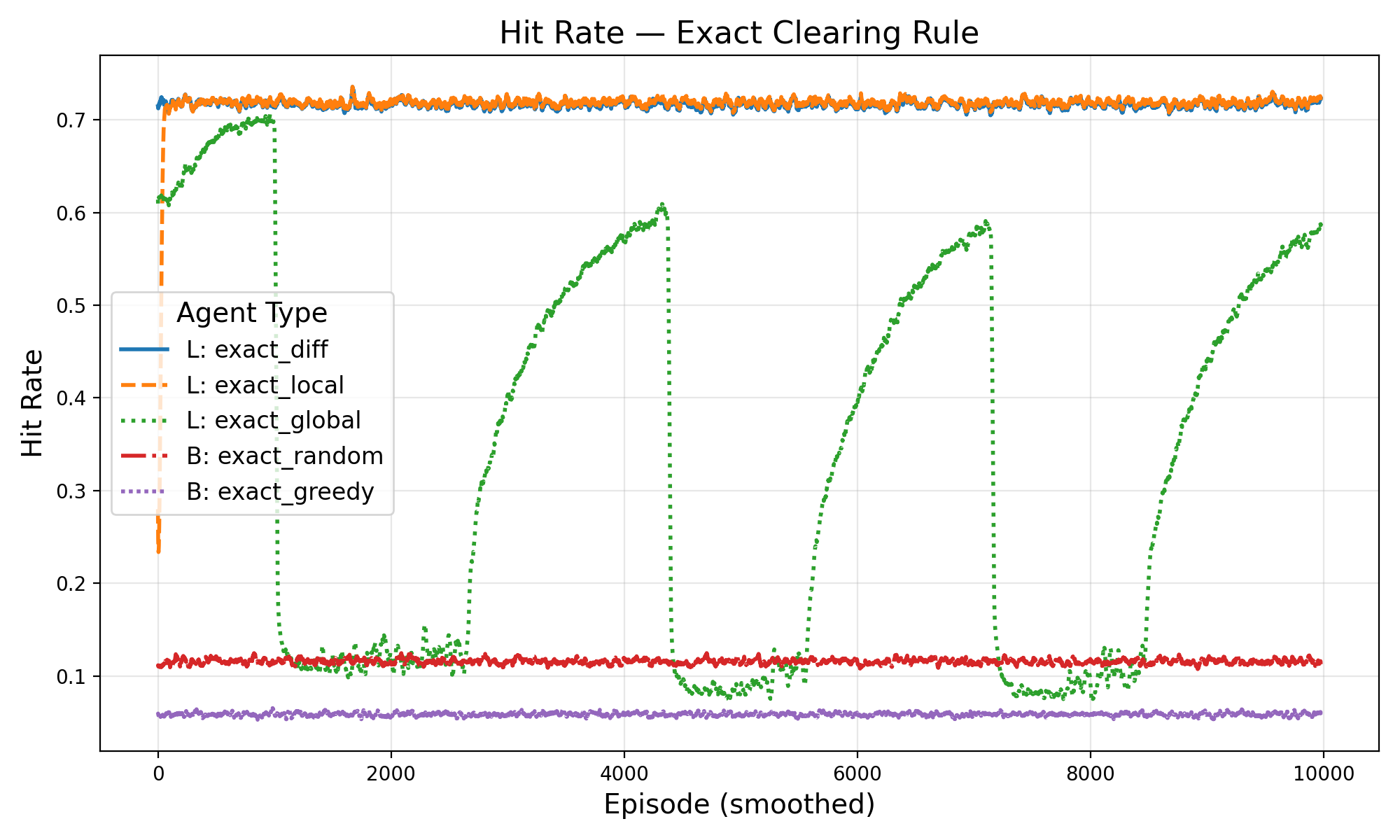
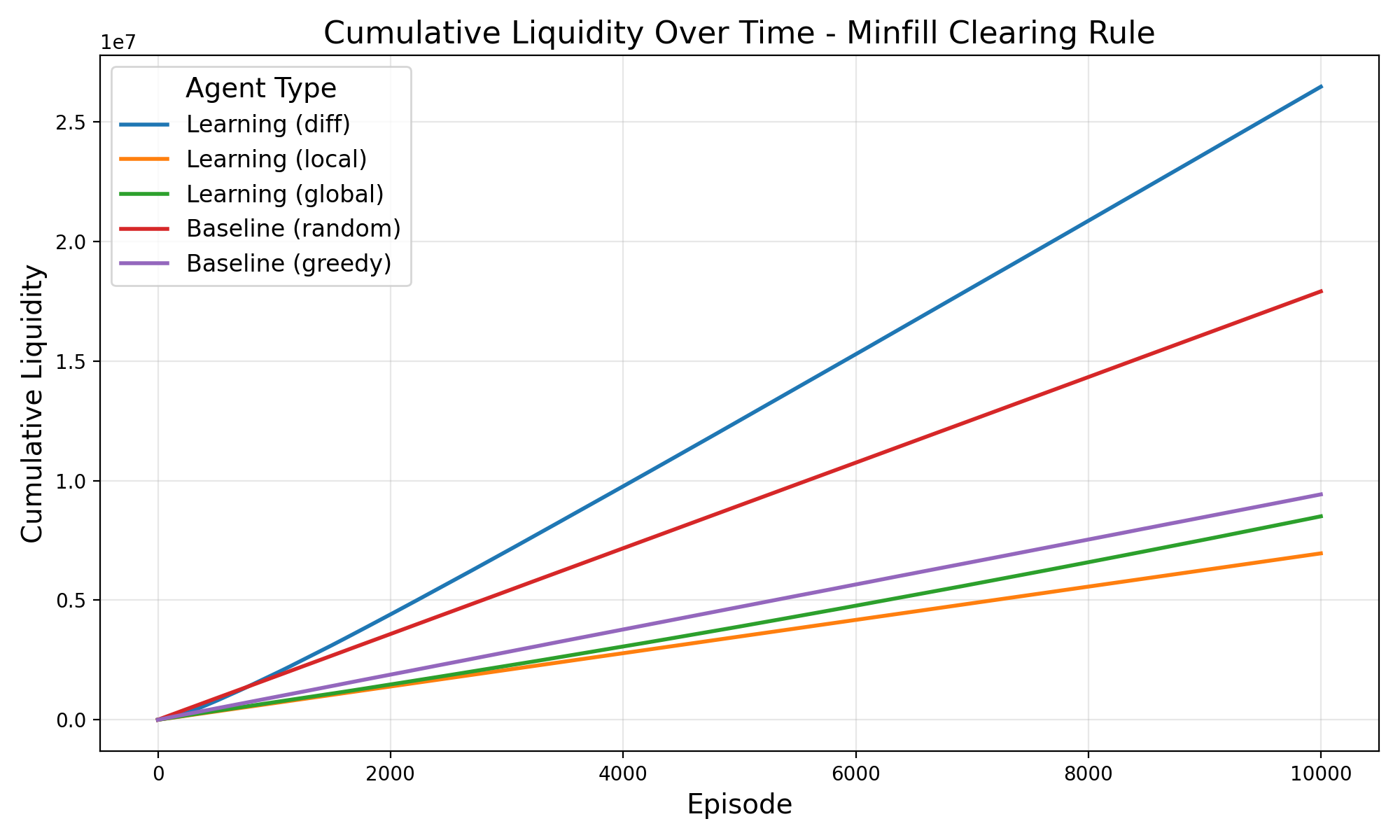
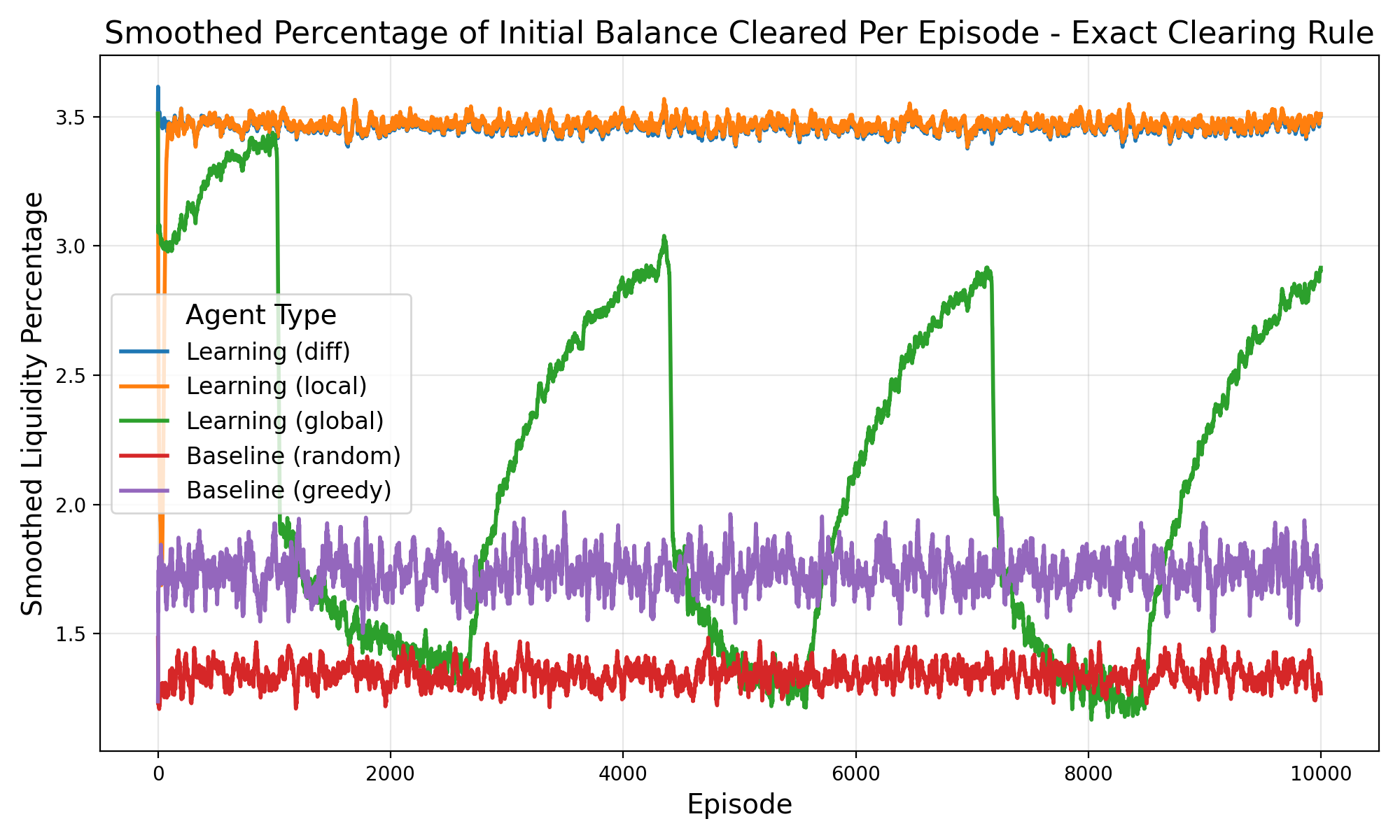
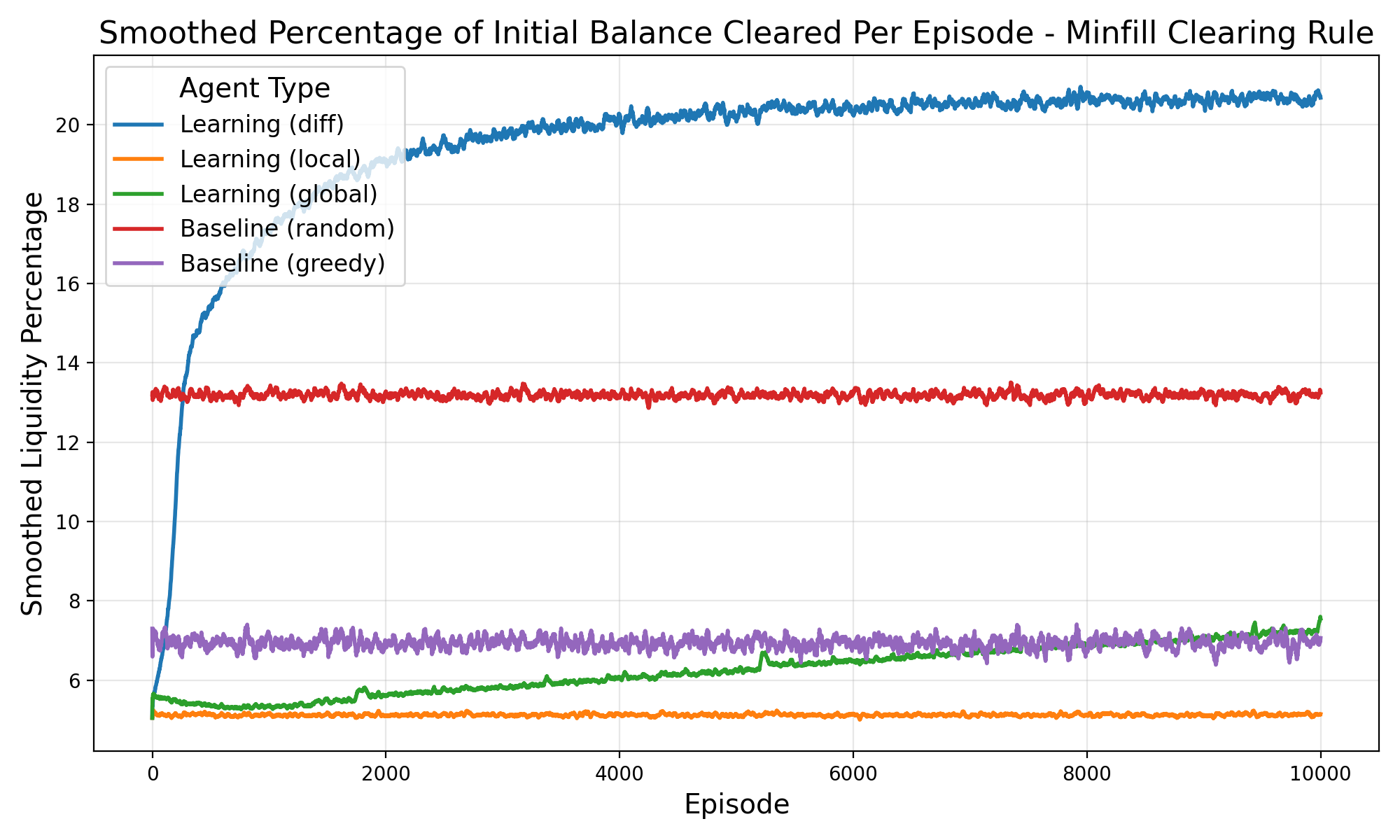
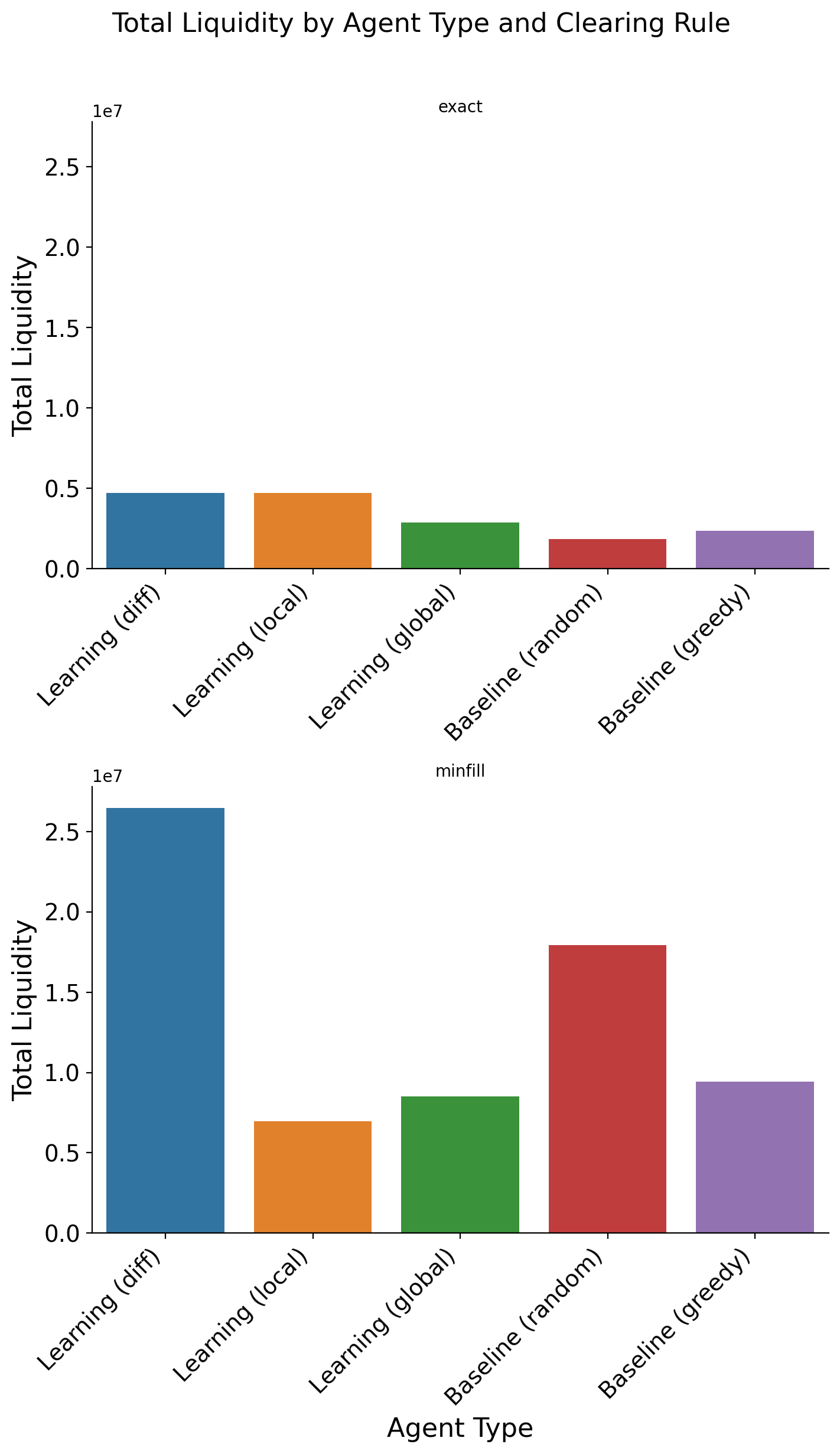
• Cumulative Liquidity over episodes G(z): The sum of quantities traded across all pairs in a given episode (reported in Figure 3 and2). • Convergence on clearing rates: Looking at the smoothed percentage of each episodes initial balance that is traded between agents per episode. (see Figure 5). • Hit Rate: The fraction of paired agents that successfully complete a trade with q > 0 (see Figure 4).
By running experiments across the different clearing rules, reward modes, and baseline strategies, with configurable heterogeneity, the code base allows for a comprehensive analysis of factors influencing liquidity in this decentralized simulated market environment.
The experimental results demonstrate the effectiveness of the difference reward learning framework across different market clearing mechanisms (see Figure 2). Under the ‘minfill’ clearing rule, which permits partial order execution, the difference reward approach achieves the highest total liquidity cleared, outperforming both alternative learning methods (‘Learning (global)’ and ‘Learning (local)’) and baseline agents. This superiority is particularly pronounced compared to ’exact’ clearing, where the difference reward method maintains strong performance while other learning approaches converge to similar levels, although still exceeding the baseline benchmarks, as seen in Figure 5 and Figure 6. As expected, regimes that permit partial clearing produced higher levels of liquidity, although learning agents in exact fill environments that used difference rewards were able to trade still successfully 70% of the time despite constraints (Figure 4. These findings support difference rewards as a practical, incentive-compatible signal for liquidity provision when microstructure.
While the ’exact’ rule constrains overall performance and compresses differences between methods, the difference reward framework remains competitive, highlighting its robustness across varying market microstructures and its potential as a powerful approach for multiagent coordination in financial market simulations.
In this work, we show how to integrate Liquidity Games with decentralized difference-reward learning (Rational Swarms) to test whether self-interested agents can increase liquidity for themselves and the market. The results support both hypotheses. H1: Under the partial clearing rule (MinFill), the difference reward agents achieved the highest aggregate liquidity and per agent throughput, outperforming alternative local/global signals and non-learning baselines. H2: Even under exact-fill constraints, where performance gaps compress difference-reward agents, adapted quickly, reaching ∼ 70% trade-success rates early in training and sustaining them thereafter. These findings indicate that difference rewards provide a practical and incentivecompatible signal for liquidity provision across microstructure regimes, with especially strong gains when partial clears are permitted. These results are particular helpful in the decentralized system where agent co-ordination is not acceptable. Difference rewards implement marginal-contribution utilities: agents optimize private payoffs that track their contribution to total liquidity, promoting welfare-improving outcomes in bilateral markets.
In this paper, we demonstrate that by combining Liquidity Games with Rational Swarms, it is possible to design lo-cal incentives such that myopic best responses yield system level gains, turning the liquidity externality into an individually rational objective. This offers a practical template for scalable market design without the need for central coordinators or agent co-ordination.
Limitations and next steps. Our experiments use stylized dynamics (random pairing, reset endowments, no price formation), so external validity requires caution. Future work will (i) add persistent state and frictions (inventory, transaction costs), (ii) test richer clearing mechanisms and market impact models, and (iii) analyze sensitivity to agent heterogeneity and partial observability. Extending the analysis to real data or hybrid ABM-RL settings can further probe how difference rewards scale.