Euler Nets Outsmart LLMs in Simple Reasoning Tasks
📝 Original Paper Info
- Title: An AI Monkey Gets Grapes for Sure -- Sphere Neural Networks for Reliable Decision-Making- ArXiv ID: 2601.00142
- Date: 2026-01-01
- Authors: Tiansi Dong, Henry He, Pietro Liò, Mateja Jamnik
📝 Abstract
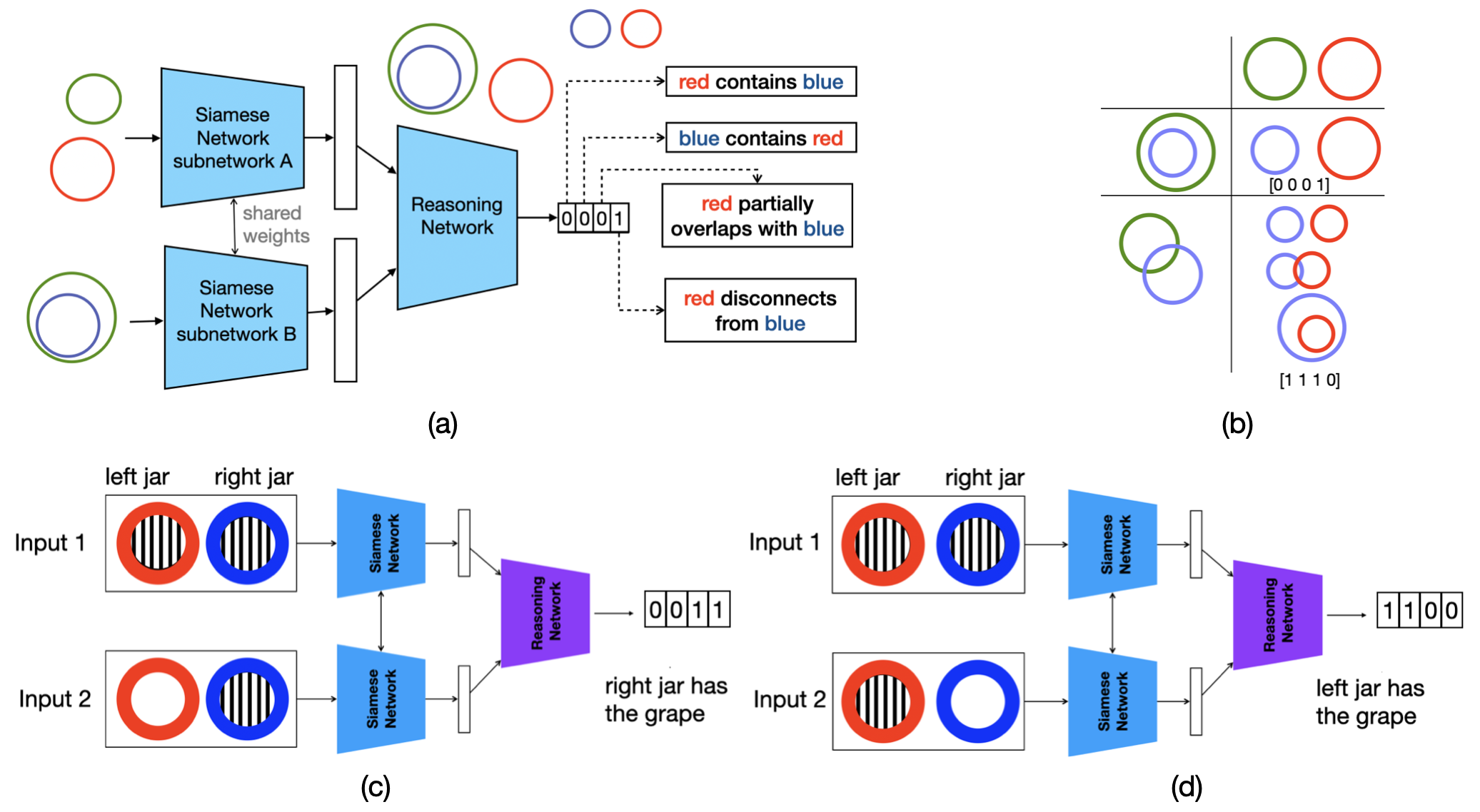
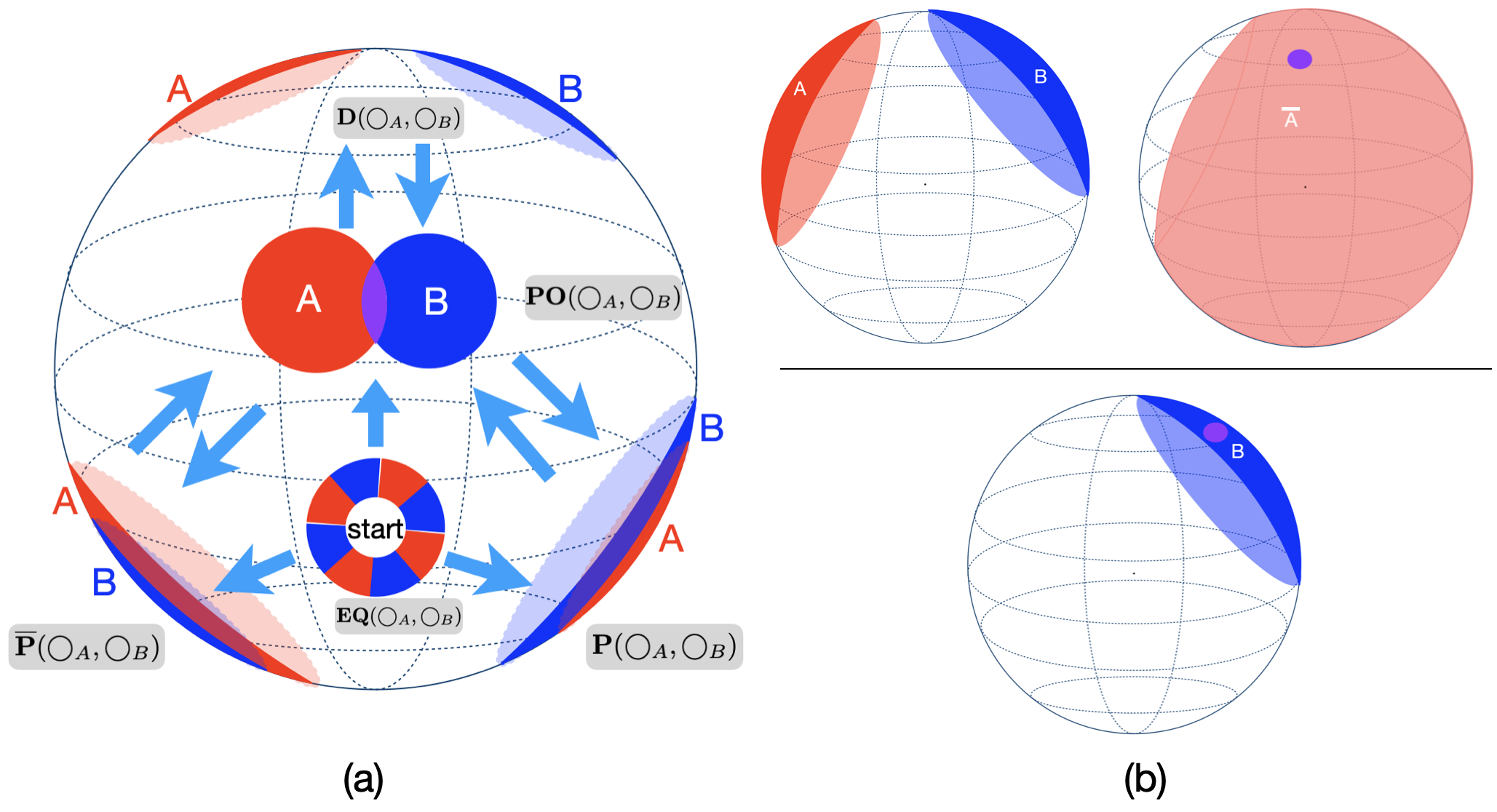
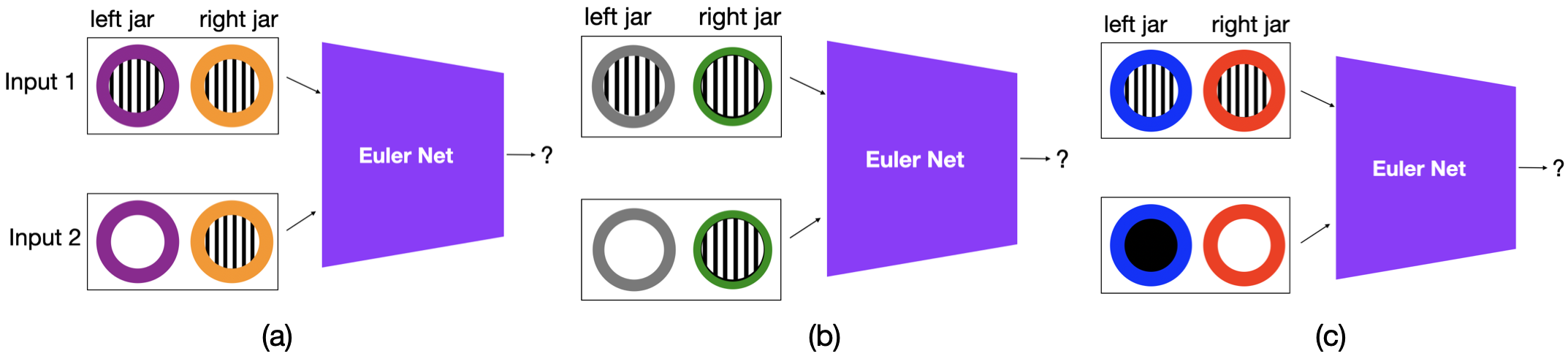
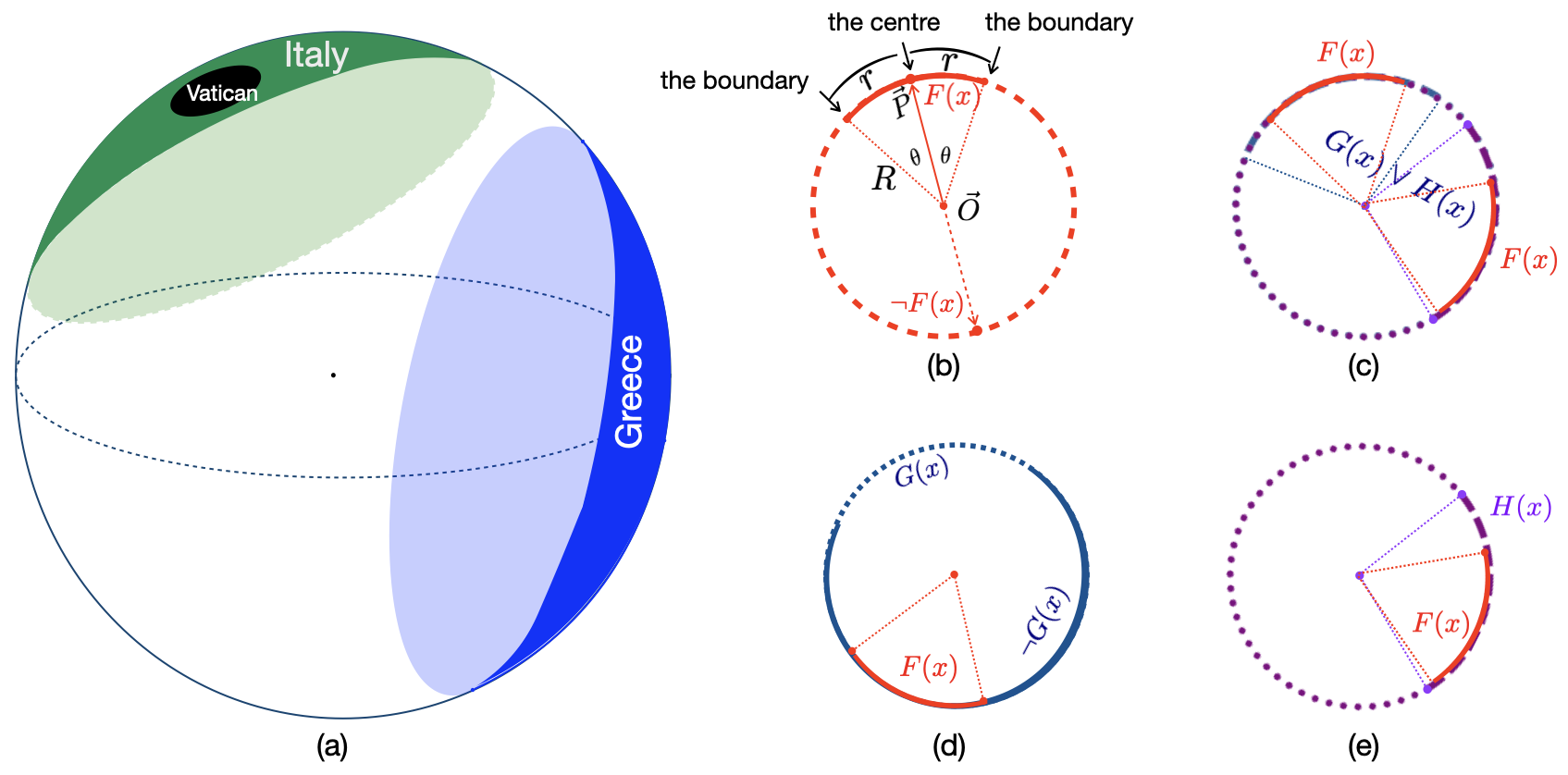
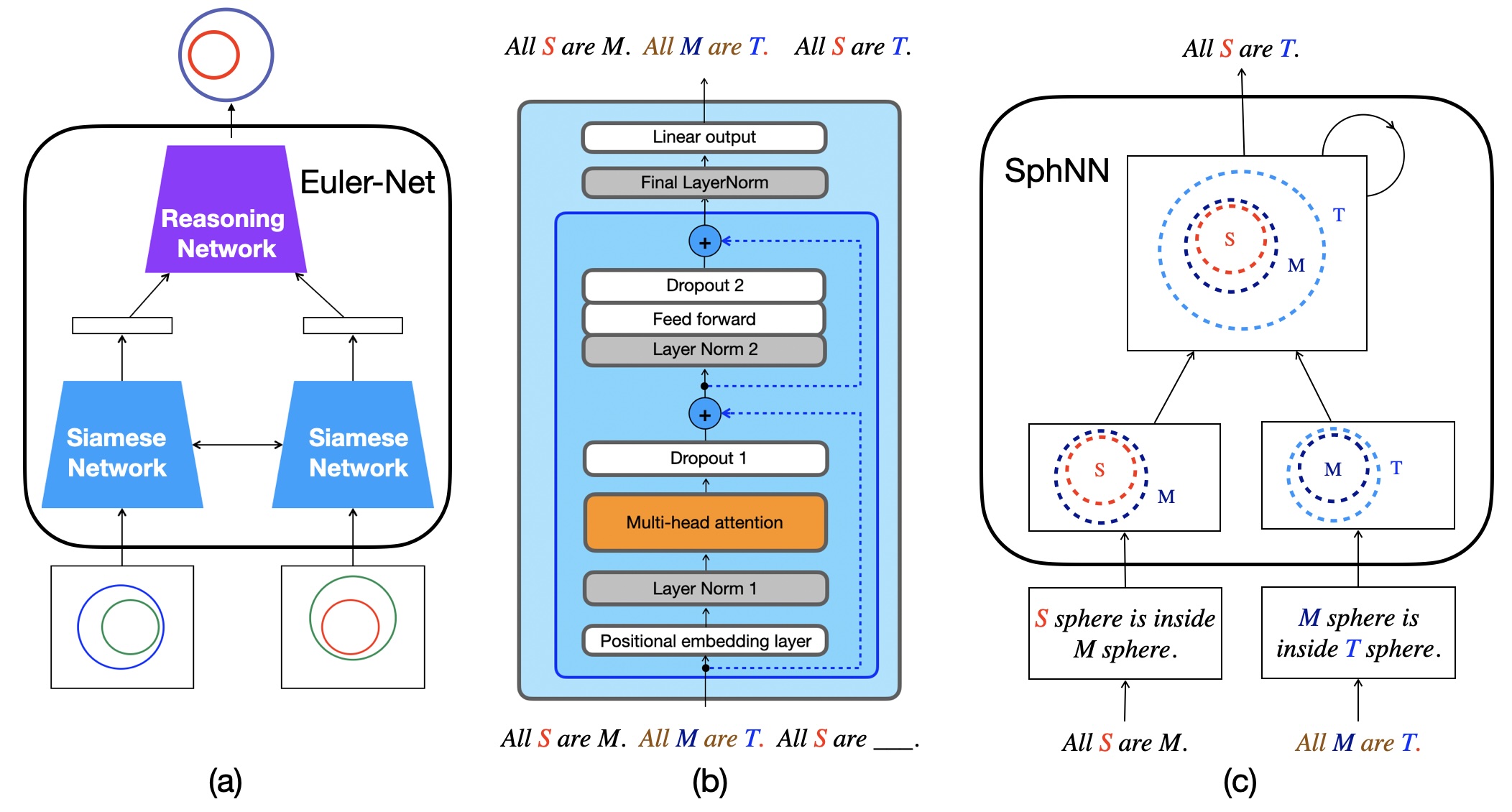
This paper compares three methodological categories of neural reasoning: LLM reasoning, supervised learning-based reasoning, and explicit model-based reasoning. LLMs remain unreliable and struggle with simple decision-making that animals can master without extensive corpora training. Through disjunctive syllogistic reasoning testing, we show that reasoning via supervised learning is less appealing than reasoning via explicit model construction. Concretely, we show that an Euler Net trained to achieve 100.00% in classic syllogistic reasoning can be trained to reach 100.00% accuracy in disjunctive syllogistic reasoning. However, the retrained Euler Net suffers severely from catastrophic forgetting (its performance drops to 6.25% on already-learned classic syllogistic reasoning), and its reasoning competence is limited to the pattern level. We propose a new version of Sphere Neural Networks that embeds concepts as circles on the surface of an n-dimensional sphere. These Sphere Neural Networks enable the representation of the negation operator via complement circles and achieve reliable decision-making by filtering out illogical statements that form unsatisfiable circular configurations. We demonstrate that the Sphere Neural Network can master 16 syllogistic reasoning tasks, including rigorous disjunctive syllogistic reasoning, while preserving the rigour of classical syllogistic reasoning. We conclude that neural reasoning with explicit model construction is the most reliable among the three methodological categories of neural reasoning.💡 Summary & Analysis
1. **Contribution 1: Systematic Methodology** - The study presents a systematic approach to comparing various training methods, deepening the understanding of improving image classification model performance. This is akin to trying different recipes with the same ingredients. 2. **Contribution 2: Performance Analysis Across Datasets** - Provides an in-depth understanding of how each learning method performs across diverse datasets. It’s like observing how a plant grows differently under various climatic conditions. 3. **Contribution 3: Insights into Model Suitability** - Offers key factors for model selection by identifying which training methods work best on specific datasets, similar to knowing which running shoes are ideal for particular racing conditions.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)