JP-TL-Bench A New Gauge for Japanese-English Translation Excellence
📝 Original Paper Info
- Title: JP-TL-Bench Anchored Pairwise LLM Evaluation for Bidirectional Japanese-English Translation- ArXiv ID: 2601.00223
- Date: 2026-01-01
- Authors: Leonard Lin, Adam Lensenmayer
📝 Abstract
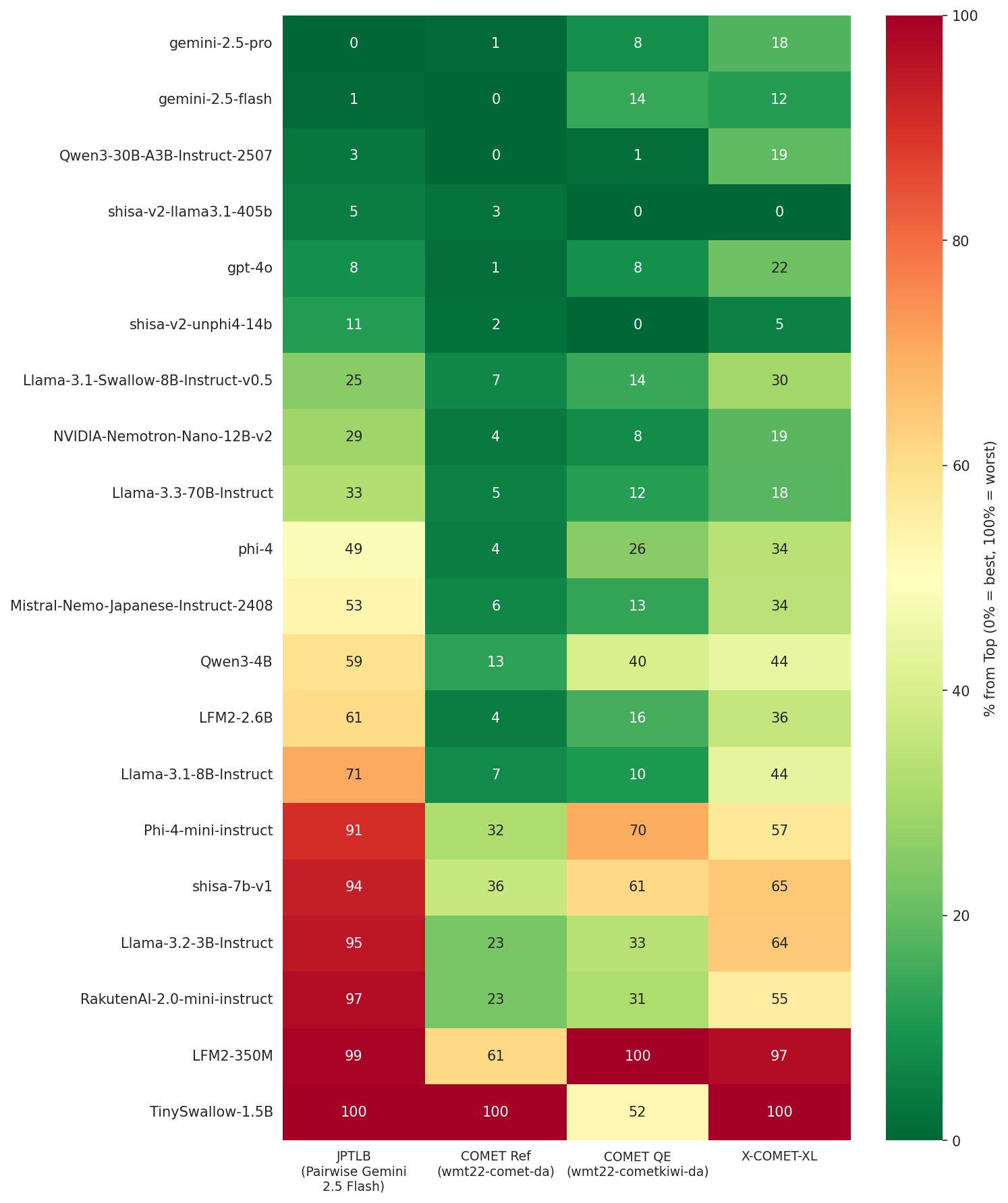
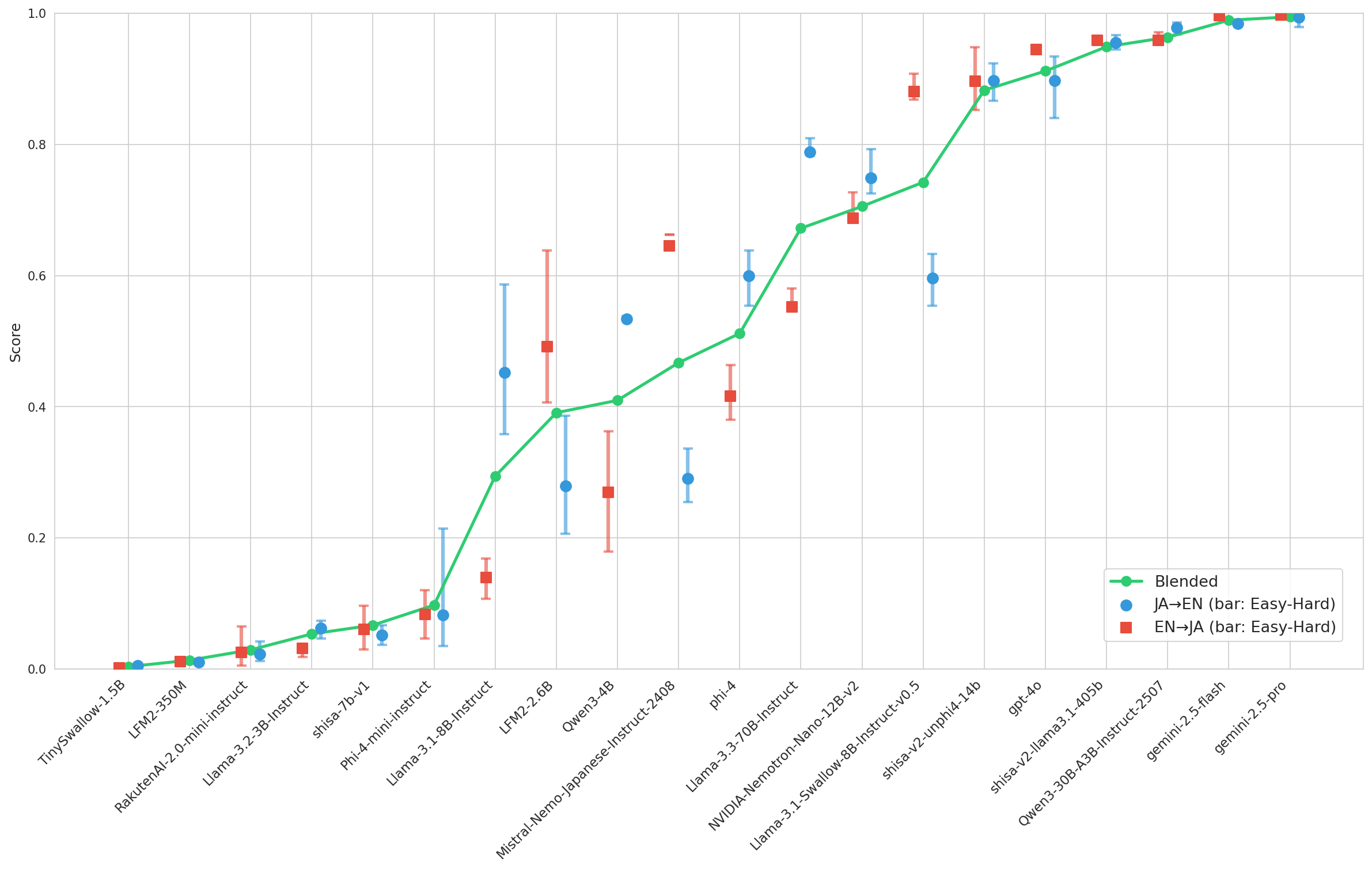
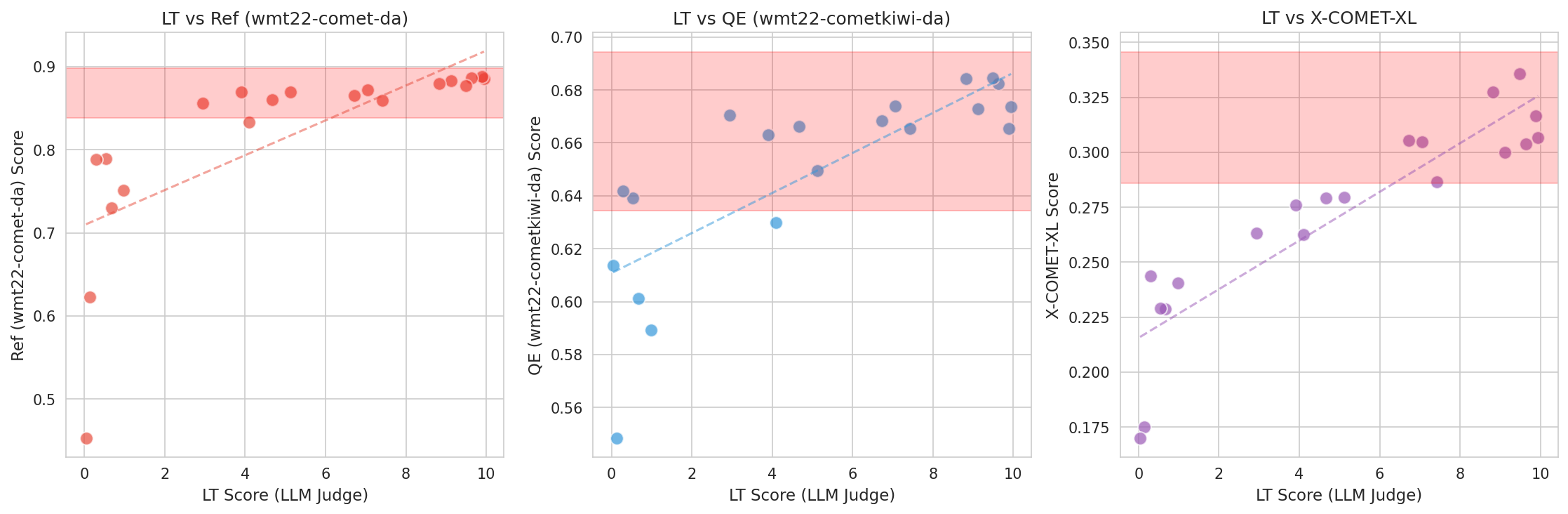
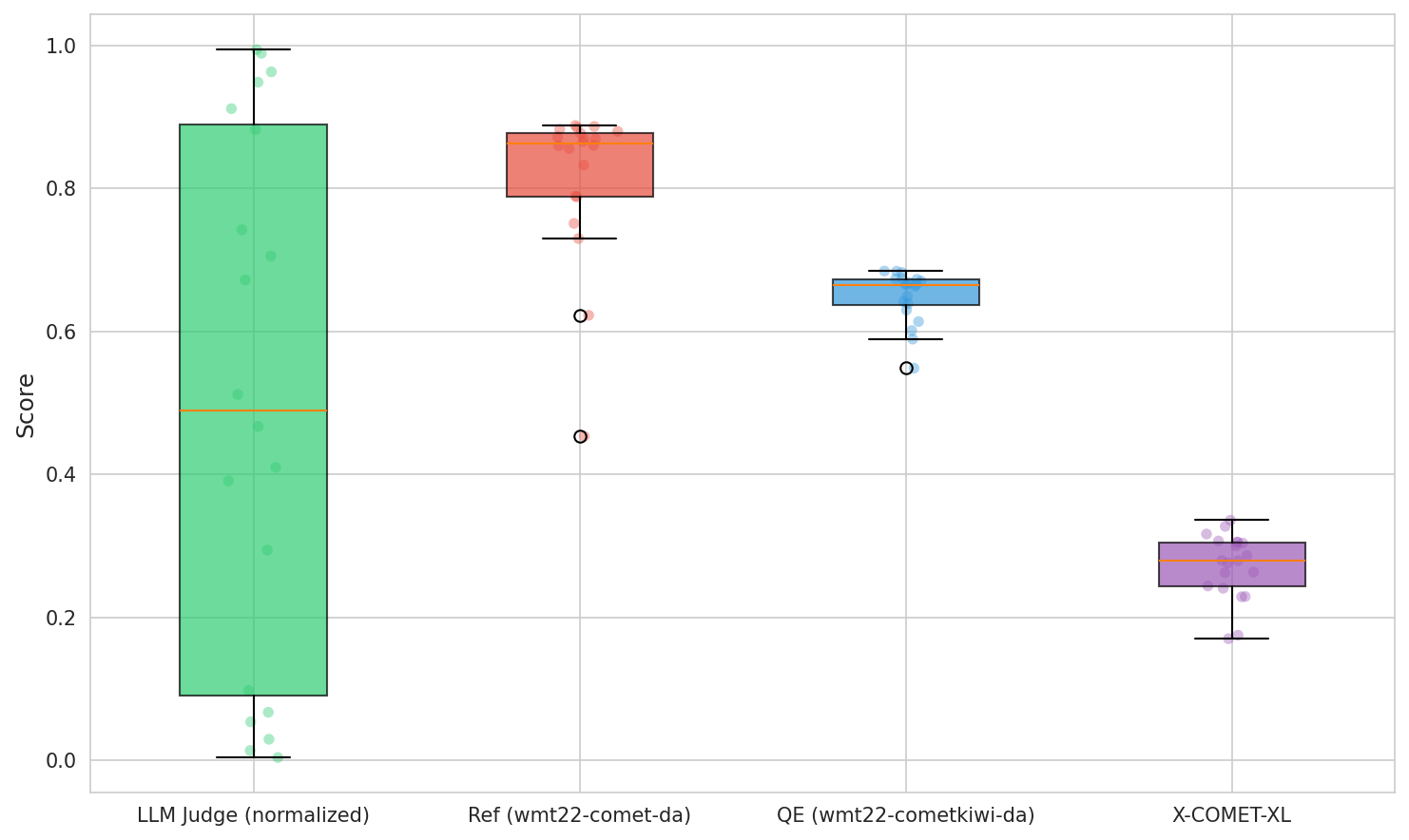
We introduce JP-TL-Bench, a lightweight, open benchmark designed to guide the iterative development of Japanese-English translation systems. In this context, the challenge is often "which of these two good translations is better?" rather than "is this translation acceptable?" This distinction matters for Japanese-English, where subtle choices in politeness, implicature, ellipsis, and register strongly affect perceived naturalness. JP-TL-Bench uses a protocol built to make LLM judging both reliable and affordable: it evaluates a candidate model via reference-free, pairwise LLM comparisons against a fixed, versioned anchor set. Pairwise results are aggregated with a Bradley-Terry model and reported as win rates plus a normalized 0-10 "LT" score derived from a logistic transform of fitted log-strengths. Because each candidate is scored against the same frozen anchor set, scores are structurally stable given the same base set, judge, and aggregation code.💡 Summary & Analysis
**Simple Explanation:** 1. Supervised learning is like having a teacher guide you, effective in structured data environments. 2. Unsupervised learning is akin to self-discovery; it's great at finding hidden patterns within unstructured datasets. 3. Reinforcement learning operates similarly to how dogs learn new tricks from their trainers—it excels in dynamic and interactive scenarios.Sci-Tube Style Script:
- Beginner: Supervised learning is like a teacher guiding you through your lessons, effective with clear data.
- Intermediate: Unsupervised learning is similar to exploring a playground by yourself and discovering new things; it’s good at uncovering hidden patterns in complex datasets.
- Advanced: Reinforcement learning resembles how dogs learn from their trainers through positive reinforcement—it excels in environments that require constant interaction and feedback.
📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)