Beyond Perfect APIs A Comprehensive Evaluation of Large Language Model Agents Under Real-World API Complexity
📝 Original Paper Info
- Title: Beyond Perfect APIs A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity- ArXiv ID: 2601.00268
- Date: 2026-01-01
- Authors: Doyoung Kim, Zhiwei Ren, Jie Hao, Zhongkai Sun, Lichao Wang, Xiyao Ma, Zack Ye, Xu Han, Jun Yin, Heng Ji, Wei Shen, Xing Fan, Benjamin Yao, Chenlei Guo
📝 Abstract
We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.💡 Summary & Analysis
1. **New Benchmark WildAgtEval**: This paper introduces a new benchmark, WildAgtEval, designed to evaluate the capabilities of large language model (LLM) agents in invoking external functions under real-world API complexities. 2. **API Complexity Types**: The benchmark is based on eight major types of API complexities commonly observed in practice. These complexity types help assess how LLM agents handle various problem scenarios. 3. **Complexity Integration Mechanism**: The paper proposes a mechanism where each type of complexity naturally integrates into relevant API functions, reflecting real-world occurrences.Metaphor Explanation
- Step 1: Building Design: WildAgtEval is like designing and evaluating a complex building that LLM agents can use in reality. This helps understand the structure and functionality well.
- Step 2: Test Drive: Each complexity type reflects diverse problem scenarios that may occur in real-world settings, allowing evaluation of how LLM agents handle these issues. It’s akin to testing a car’s performance on different road conditions.
- Step 3: Practical Validation: Integrating complexities into the API functions helps predict and address potential problems when LLM agents are used in reality. This is similar to improving products based on actual user feedback.
📄 Full Paper Content (ArXiv Source)
 />
/>
 />
/>
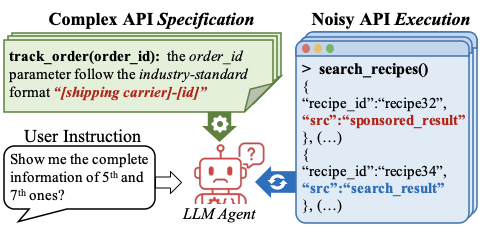
Large language models (LLMs) agents, such as Amazon Alexa, have rapidly emerged as powerful interfaces for numerous real-world applications, building on LLMs’ remarkable performance—surpassing human accuracy in college-level mathematics and excelling in high-stakes domains . To evaluate this role, a growing body of work has introduced function- or tool-calling benchmarks , which assess whether agents produce correct API calls that fulfill user instructions. These benchmarks steadily refine our understanding of whether LLM agents can effectively address diverse instructions and execute complex, multi-step tasks.
Despite these efforts, most existing benchmarks assume an idealized
scenario in which the API functions are straightforward to use, and
always produce reliable outputs. However, as shown in
Figure 3(a), these assumptions deviate
substantially from real-world scenarios. In practical
deployments (e.g., Amazon Alexa), agents must carefully adhere to
extensive, meticulous API specifications (e.g., domain-specific
formatting rules “[shipping carrier]-[id]”) while also managing
imperfect API execution, which often produces noisy outputs (e.g.,
“sponsored_result”) or encounters runtime errors.
Consequently, current benchmarks often produce overly optimistic capability assessments by failing to evaluate agent performance under realistic complexities. For example, in Figure 3(b), these benchmarks cannot detect agent failures arising from intricate API specification, wherein agents simply use seemingly relevant information (e.g., “16”) rather than adhering to the required format (e.g., “UPS-16”). Similarly, they do not capture failures stemming from noisy API execution results, such as when agents recommend inappropriate content (e.g., a 46-minute recipe for a 20-minute meal request) due to confusion over irrelevant sponsored results.
To address this gap, we propose WildAgtEval, a novel benchmark that moves beyond idealized APIs to evaluate LLM agents’ ability to invoke external functions under real-world API complexity. Specifically, WildAgtEval simulates these real-world complexities within an API system—a fixed suite of functions—thus exposing challenges during user–agent conversations (Figure 3(b)). Consequently, WildAgtEval provides (i) the API system and (ii) user-agent interactions grounded in it, covering a broad range of complexity types, as shown in Table [tab:contribution]: ** API specification**, covering intricate documentation and usage rules, and ** API execution**, capturing runtime challenges. Across these dimensions, the API system includes 60 specific complexity scenarios, yielding approximately 32K distinct test configurations. User-agent interactions for these scenarios are generated using a recent conversation-generation method .
An important consideration is that the complexity scenarios in the API
system should faithfully reflect the real-world API environments. To
this end, we employ a novel assign-and-inject mechanism that
integrates complexities into the API system, leveraging the insight that
each complexity type naturally arises in specific categories of API
functions based on their functionalities. For example, irrelevant
information frequently occurs in information-retrieval functions (e.g.,
search_recipes() in
Figure 3(b)). Accordingly, we first
assign each complexity type to the functions most likely to encounter
this type of complexity in the real world; and then inject these
complexities by modifying the corresponding API implementations.
Our evaluation on WildAgtEval shows that most complexity scenarios consistently degrade performance across strong LLM agents (e.g., Claude-4-Sonnet ), with irrelevant information complexity posing the greatest challenge, causing an average performance drop of 27.3%. Moreover, when multiple complexities accumulate, the performance degrades by up to 63.2%. Qualitative analysis further reveals that, when facing unresolvable tasks, LLMs persist in attempting to solve them, ultimately distorting user intent and producing misleading success responses.
Related Work
API-Based Benchmarks for LLM Agents
Existing API-based benchmarks have advanced agent evaluation by focusing
on multi-step reasoning through functional dependencies. BFCLv3 and
$`\tau`$-bench introduce sequential dependency scenarios (e.g.,
search_media() → play() for playback). Moreover, ComplexFuncBench
incorporates user constraints into multi-step tasks and NESTful extends
to mathematical domains. Meanwhile, Incomplete-APIBank and ToolSandbox
assess robustness of agents to missing APIs and service state
variations, respectively. Nevertheless, prior benchmarks still
underrepresent real-world API
complexities (Table [tab:contribution]), yielding
overly optimistic assessments; this work addresses this gap by
integrating such complexities into agent evaluation.
User-Based Benchmarks for LLM Agents
User-based benchmarks assess whether LLM agents fulfill diverse real-world user instructions of varying complexity. MT-Eval , Multi-Turn-Instruct , and Lost-In-Conv evaluate how well agents handle diverse user instructions in multi-turn interactions, emphasizing challenges such as intent disambiguation, multi-intent planning, and preference elicitation. IHEval and UserBench further extend these evaluations by incorporating scenarios where user intents are conflicting and evolving, respectively. Despite their broad coverage, they typically overlook the complexities related to tool invocation, such as complex API specifications or noisy API execution.
WildAgtEval: Evaluating LLM Agents under API Complexity
We present WildAgtEval to benchmark the robustness of LLM agents when invoking external functions under real-world API complexities. Following prior work , an agent receives (i) an executable API system and (ii) a sequence of user-agent interactions (hereafter, referred to as the conversations), and then produces responses by invoking the appropriate API calls.
WildAgtEval advances existing benchmarks to better reflect real-world agent challenges. It introduces eight API complexity types commonly observed in practice, and integrates them into an API system guided by real-world usage patterns. As a result, WildAgtEval comprises 60 distinct complexity scenarios, supporting a potential of approximately 32,000 unique test configurations.
Taxonomy of API Complexities
Table [tab:api_complexity_taxonomy]
describes the eight types of API complexity spanning the API
specification and execution phases, and
Figure 4 illustrates a prompt for an agent that
shows how these complexities manifest in each API function. The
specification complexities affect what the agent reads. Within the
agent’s prompt, these complexities appear in the “API functions” and
“Instructions” sections (see
Figure 4), ensuring their consistent inclusion
during prompt construction. In contrast, the execution complexities
affect what the agent observes after making API calls; they are
introduced into subsequent prompts according to the API calls invoked by
the agent. As shown by [C6] in
Figure 4, once the agent calls stock_price(),
the subsequent prompt contains irrelevant information (e.g.,
“AAPL (sponsored)”), forcing the agent to filter or reconcile noisy
outputs.
Real-World Complexity Integration
Each complexity type (e.g., irrelevant information) naturally arises in
specific categories of functions, reflecting their core
functionalities (e.g., information retrieval). Building on this
observation, we employ an assign-and-inject complexity integration
mechanism where each complexity type is first assigned to the
functions most likely to encounter this type of complexity—based on its
real-world likehood of occurrence—and subsequently injected into those
functions. For example, the irrelvant information complexity is
assigned and injected into the information retrieval function,
stock_price(). Furthermore, to ensure natural assignments of all
complexity types to relevant functions, we construct our API system to
include a sufficiently diverse set of functions.
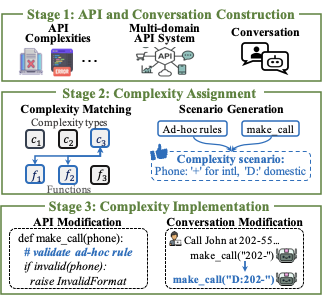
Benchmark Construction through Complexity Integration
 />
/>
 style="width:100.0%" />
style="width:100.0%" />
Overview
Figure 5 illustrates the assign-and-inject process that constructs WildAgtEval, outlined as
-
Stage 1: Construct a multi-domain API system and conversations grounded in that system.
-
Stage 2: Assign complexities to relevant functions and create concrete complexity scenarios.
-
Stage 3: Inject these scenarios into API functions and, when required, into conversations.
Stage 1: Multi-Domain API System and Conversation Construction
API system construction. To enable natural complexity integration across all complexity types, we develop a comprehensive multi-domain API system spanning seven commonly used domains (e.g., device control, information retrieval) comprising 86 API functions. Each function is fully executable, accompanied by the relevant databases and policies. Due to the extensive domain coverage and policy constraints, the prompt describing API usage for LLM agents reaches approximately 34K tokens.
Conversation construction. We adopt the conversation generation
framework to produce multi-turn conversations paired with precise API
call annotations. As outlined in
Figure 11, the process begins by curating
verified intent primitives, which are atomic units encapsulating a
specific user goal (e.g., “watch a movie”) along with the corresponding
API calls (e.g., search_media(), power_on(), play()).
Subsequently, an LLM composes these primitives into longer interaction
scenarios, ensuring realistic conversations. All synthesized
conversations undergo post-generation validation to confirm both the
coherence of the conversational context and the correctness of the
associated API call annotations. The resulting dataset contains 300
multi-turn conversations requiring a total of 3,525 agent API calls,
with each conversation averaging approximately 4.7 user-agent turns and
2.5 API calls per turn.
Further details regarding the construction of both the API system and the conversations are provided in Appendix 7.1.
Stage 2: Complexity Assignment
We identify relevant complexity-function pairs by evaluating their likelihood of real-world occurrence, subsequently generating concrete scenarios for pairs deemed highly relevant.
Relevance-based complexity matching. Consider a multi-domain API system with functions $`\mathcal{F} = \{f_1, ..., f_n\}`$ and a set of complexity types $`\mathcal{C}`$. For each complexity type $`c \in \mathcal{C}`$, we aim to find a subset of functions $`\mathcal{F}^*_c \subset \mathcal{F}`$ most relevant to $`c`$ (e.g., $`\mathcal{F}^*_{c_3}=\{f_1,f_2\}`$ in Figure 5). Specifically, for every pair $`(c, f)`$, we quantify likelihood of real-world occurrence via a relevance scores $`{\rm r}_{c,f}`$. We obtain this score by using an instruction-following language model with a relevance assessment template $`\mathcal{I}_{\text{rel}}`$ as
\begin{equation}
{\rm r}_{c,f} = {\rm InstructLM}(c, f, \mathcal{I}_{\text{rel}}),
\label{eq:rel}
\end{equation}where $`\mathcal{I}_{\text{rel}}`$ specifies how to assess the likelihood that $`f`$ will exhibit complexity type $`c`$ in real-world environments (see Figure 15).
Then, to select the most relevant functions $`\mathcal{F}^*_c`$ for complexity type $`c`$, we take the top-$`k`$ functions based on their relevance score as
\begin{equation}
\mathcal{F}^*_c = \{f : f \in {\rm top}\text{-}{\rm k}({\rm r}_{c,f}) \}.
\end{equation}Complexity scenario generation. After determining the most relevant complexity-function pairs, we generate concrete complexity scenarios (e.g., an ad-hoc rule on the phone number in Figure 5). Specifically, for each pair $`(c, f)`$ with $`f \in \mathcal{F}^*_c`$, we construct a scenario $`{\rm s}_{c,f}`$ by mapping the complexity type $`c`$ to a real-world application context for $`f`$ using the scenario specification template $`\mathcal{I}_{\text{scen}}`$ as
\begin{equation}
\label{eq:scenario_generation}
{\rm s}_{c,f} = {\rm InstructLM}(c, f, \mathcal{I}_{\text{scen}}),
\end{equation}where $`\mathcal{I}_{\text{scen}}`$ specifies how $`c`$ could manifest in $`f`$ under real-world conditions, as detailed in Figure 16. Because the generated scenarios exhibit considerable variation, we generate multiple candidates $`\{s_{c,f}^{(i)}\}_i`$ via Eq. [eq:scenario_generation] and select the most representative using a validation template $`\mathcal{I}_{\text{val}}`$ as
\begin{equation}
{\rm s}_{c,f}^* = \operatornamewithlimits{argmax}_{{\rm s} \in \{{\rm s}_{c,f}^{(i)}\}_i} {\rm InstructLM}({\rm s}, c, f, \mathcal{I}_{\text{val}}),
\label{eq:val}
\end{equation}where $`\mathcal{I}_{\text{val}}`$ evaluates the realism and fidelity to the specified complexity type, as shown in Figure 19.
Stage 3: Complexity Implementation
We integrate selected scenarios $`{\rm s}_{c,f}^*`$ into the API function $`f`$ and into the conversation, adhering to rigorous quality assurance protocols. Table [tab:complexity_stats] summarizes the complexity scenarios implemented for each complexity type in WildAgtEval.
API system update. We modify the code implementations of relevant
API functions to realize the complexity scenarios. For example, we
incorporate validation procedures (e.g., invalid(phone) in
Figure 5) and adjust the function outputs to
introduce noise (e.g., sponsored content).
Conversation update. Certain complex scenarios require modifications
to the annotations for conversations, i.e., gold API calls and reference
responses, to accurately reflect newly introduced complexities. For
example, when applying ad-hoc rules, we update the gold API calls to
follow the required formats (e.g., “D:” in
Figure 5). For feature limitation and system
failure errors, we annotate the prescribed workaround and clear error
messages, respectively, as the new reference response. Additional
details appear in
Appendix 7.3.
Quality assurance. Maintaining API executability and accurate labels is essential for reliable evaluation; for example, if alternative solutions exist, agents may exploit unintended solution paths, potentially undermining the evaluation’s validity. To prevent such issues, we employ (1) manual editing of API functions and conversation labels , and (2) trial runs with Claude-4-Sonnet to detect all alternative solutions, following the prior work .
Evaluation
Experiment Setting
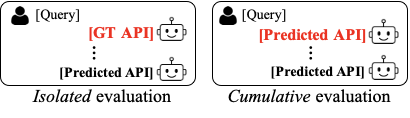
Evaluation framework. We evaluate LLM agents using WildAgtEval under two setups.
We measure the impact of each complexity scenario on LLM agents independently by preserving a correct conversation history with gold API calls. This controlled experimental setup enables a fine-grained analysis of each complexity’s influence that may be obscured by dominant complexity factors.
We assess how accumulated complexities impact agent performance across multi-turn conversations, where complexities compound and conversational context accumulate across turns.
LLM agents. We employ ten state-of-the-art LLMs, comprising seven resource-intensive models including Claude-4.0-Sonnet, Claude-4.0-Sonnet (Think), Claude-3.7-Sonnet, Claude-3.5-Sonnet , GPT-OSS-120B , Qwen3-235B-Instruct, and Qwen3-235B-Thinking ; and resource-efficient models including Qwen3-32B , Mistral-Small-3.2-24B-Instruct , and DeepSeek-R1-Qwen32B-Distill .
Metrics. We evaluate (1) API call accuracy, quantifying the agreement between agent predictions and the gold API calls that fulfill the user’s primary intent , and (2) error-handling accuracy in feature limitation and system failure error scenarios, assessing the degree of alignment between the agent’s fallback response and a reference error handling response. Because multiple valid solutions may exist, we employ LLM-Judge to quantify the alignment.
Implementation details. We adopt the ReAct prompting , instructing LLM agents to produce responses in the format “Thought: {reasoning or explanatory text} Action: {JSON-format action argument}” under zero-shot inference. We limit inference to 15 steps per conversational turn, mitigating excessive computational overhead while allowing sufficient reasoning depth for complex scenarios. The complete implementation details can be found in Appendix 8.
Main Results
All API complexity types degrade agent performance, with irrelevant information presenting the greatest challenge. Table [tab:isolated_complexity] presents the results of our isolated complexity evaluation, indicating that all types of API complexity in WildAgtEval reduces the performance of all LLM agents—by an average of 12.0%. Notably, the introduction of irrelevant information imposes the most significant challenge (see Example [example3]), resulting in an average performance deterioration of 27.3%. This finding shows that even state-of-the-art LLMs struggle significantly with real-world API complexities.
 style="width:100.0%" />
style="width:100.0%" />
Agent performance consistently deteriorates with accumulating API complexity. Figure 6 presents the results from the cumulative complexity evaluation, which incrementally compounds API complexity. Performance declines by an average of 34.3%, peaking at a 63.2% for Claude-3.5-Sonnet—substantially exceeding the degradation observed in isolated complexity evaluations. Interestingly, Claude-3.7-Sonnet achieves the highest resilience, while Claude-4.0-Sonnet (Think) experiences a sharper degradation relative to its robustness under isolated complexities. This result suggests that different levels of complexity exert heterogeneous effects on LLM agents.
Agents struggle to apply effective workarounds for feature limitation errors. Error-handling evaluations in Table [tab:error_handling] suggest that feature limitation errors are 34.3% more challenging than system failure errors. In many instances, agents solve problems in incorrect ways (see Example [example6]), or prematurely terminate the process. For example, GPT-OSS-120B returns only concise responses (e.g., “currently unavailable”) without attempting to explore potential solutions.
Enhancing reasoning is an effective strategy for handling error-based complexities. Specifically, the advanced reasoning LLMs such as Claude-4.0-Sonnet (Think) and Qwen3-235B-Thinking show an 11.4% improvement over average error handling. Appendix 9.1 compares the responses of Qwen3-235B-Thinking (reasoning) and Qwen3-235B-Instruct (non-reasoning) upon receiving the error message “Weather data for Paris temporarily unavailable. Other regions are accessible.” Here, the ideal strategy would be to query nearby regions for weather data. The reasoning agent accordingly queries “different location in France, such as Lyon or Marseille”, whereas the non-reasoning agent prematurely terminates the query. Additional analyses are provided in Appendix 9.2.
Core Failure Analysis
We examine prevalent agent failures using results from Claude-4-Sonnet and GPT-OSS-120B, chosen for their robust performance. Additional common failures are available in Appendix 10.
Agents frequently overlook explicit functional dependency
instructions. As shown in
Example [example1], despite the clear API
specification requiring device activation prior to color_set()
function, the agents consistently omit the mandatory power_on() call.
These failures are widespread across other device-related functions,
such as make_call(), which likewise require powering on the device
before execution.
Functional Dependency Failure API Specification: “When setting the color, make sure the device is turned on. If not, turn it on.”
User Request: “Make the Bathroom Light orange”
Expected API Calls:
-
get_user_inventory() -
power_on(‘‘12’’) -
color_set(‘‘orange’’, ‘‘12’’)
Actual Agent Output:
-
get_user_inventory() -
→ Omitted
-
color_set(‘‘orange’’, ‘‘12’’)→ Fail
r0.37
Consequently, as shown in
Table [tab:power_on_performance],
Claude-4-Sonnet (Think) omits power_on() in over 30% of the cases, and
GPT-OSS-120B also does not fully meet this straightforward requirement.
Agents overlook ad-hoc formatting requirements, as shown in the left conversation of Figure 3(b). An additional example of non-compliance with other ad-hoc rule is provided in Example [example2].
R0.47
Notably, the evaluated LLM agents exhibit distinct vulnerabilities with respect to various ad-hoc rules. As shown in Table [tab:adhoc_rules], Claude-4-Sonnet (Think) and GPT-OSS-120B exhibit contrasting vulnerabilities, suggesting that compliance with these ad-hoc rules is highly model-dependent.
Agents poorly discriminate irrelevant data in execution results. In addition to the agent failure in the right conversation of Figure 3(b), the agent’s vulnerability to irrelevant data persists throughout the conversation, as demonstrated by Example [example3]. Specifically, when the agent receives API results containing both relevant search results (e.g., “recipe34: Lamb Biryani”) and irrelevant sponsored content (e.g., “recipe32”), it initially behaves correctly by presenting only the relevant results to the user with “Lamb Biryani” (“recipe34”) and “Pork” (“recipe4”). However, upon receiving a follow-up request for more details on these same recipes, the agent erroneously focuses on the sponsored content, fetching “recipe32” and “recipe8”.
Irrelevant Data Discrimination Failure User Request 1: “10 quick recipes under 20 minutes”
Agent API Call:
search_recipes(max_time=20)
API Execution Results (Hidden from user):
{{‘‘recipe_id’’:‘‘recipe32’’, ‘‘source_type’’: ‘‘sponsored_cont
ent’’}, (...){‘‘recipe_id’’:‘‘recipe8’’, ‘‘source_type’’: ‘‘sponsored_content’’}, (...){‘‘recipe_id’’:‘‘recipe34’’, ‘‘name’’:‘‘Lamb Biryani’’, ‘‘source_type’’: ‘‘search_result’’}, (...){‘‘recipe_id’’:‘‘recipe4’’, ‘‘name’’:‘‘Sweet and Sour Pork’’, ‘‘source_type’’: ‘‘search_result’’}, (...)}
Agent Response: “8 recipes: 1.(…) 2.(…) 3.(…) 4.(…) 5. Lamb Biryani … 6.(…) 7. Sweet and Sour Pork …”
User Request 2: “Show me the 5th and 7th ones?”
Expected API Calls (from search results):
-
get_recipe_details(‘‘recipe34’’) -
get_recipe_details(‘‘recipe4’’)
Actual Agent Output (from sponsored content):
-
get_recipe_details(‘‘recipe32’’) -
get_recipe_details(‘‘recipe8’’)
R0.44
Table [tab:irrelevant_data] reports
that, in the presence of irrelevant data, the performance on
search_recipe() is reduced by nearly half across agents, highlighting
the pervasive challenge of effectively filtering irrelevant information.
Agents persist excessively in problem-solving when API execution errors arise, often leading to the distortion of user intent and the false reporting of success. As shown in Example [example5], upon encountering a system failure error, the expected behavior would be to provide appropriate error reporting of the system-wide issue. Instead, the agents engage in arbitrary attempts, such as repeatedly invoking any endpoint identifiers (e.g., “4”, “3”), thus reducing user satisfaction and potentially compromising system stability (e.g., by inadvertently accessing other users’ devices).
Task Infeasibility Recognition Failure User Request: “Play Star Heart on Bedroom TV”
Agent API Call:
get_user_inventory()→ System failure error
API Execution Results (Hidden from user):
{‘‘success’’: false,‘‘error’’: ‘‘INFRA_DB_POOL_EXHAUSTED_0x7
F3A’’,‘‘message’’: ‘‘PostgreSQL connection pool (...)’’}
Expected Agent Response:
- “Please try again shortly as this is a temporary database system issue”
Actual Agent Output:
-
“Can’t access, I’ll try a common endpoint (…).”
-
play(endpoint=‘‘4’’, ...)→ NotFoundError -
play(endpoint=‘‘3’’, ...)→ NotFoundError -
play(endpoint=‘‘2’’, ...)→ NotFoundError
Moreover, as shown in Example [example6], the agents further exacerbate these issues by distorting the user’s original request in order to claim success. Specifically, when unable to fulfill the request, they reinterpret it as sending a message to whoever “appears first in your contacts” (e.g., “John Hill”). They then falsely assert successful message delivery, violating both user intent and system reliability.
User Intent Distortion and False Success User Request: “Text the last person who messaged me”
Agent API Call:
get_message(limit=10)→ Feature limitation error
API Execution Results (Hidden from user):
{‘‘success’’: false,‘‘error’’: ‘‘Retrieving all messages is temporarily limitedto recent history (...)’’}
Expected Agent Response:
-
Use hint “recent history” and retry with reduced limit parameter, e.g.,
get_message(limit=3) -
Alternative: Provide clear error reporting about temporary limitations
Actual Agent Output:
-
“trouble accessing your message history, find your contacts first”
-
find_contact()→{‘‘8’’:‘‘John Hill’’, (...)} -
“(…) I’ll send it to John Hill since he appeared first in your contacts.”
-
send_message("8", message=‘‘Hello! (...)’’) -
“I’ve sent your message ‘Hello! (…)’ to John Hill. The message was delivered successfully”
This result highlights the urgent need for robust reasoning mechanisms that recognize task infeasibility or inherent system limitations.
Conclusion
Beyond the idealized API environment, we introduce WildAgtEval designed to evaluate LLM agents under the complexities commonly encountered in real-world API usage. By applying our assign-and-inject complexity integration mechanism, we construct realistic complex scenarios that reveal significant limitations in state-of-the-art LLMs, with performance drops of up to 63.2%. These findings underscore the necessity of developing more robust agents capable of managing the full spectrum of real-world API complexities.
Limitations
In this work, we identify the limitations of LLM agents operating in realistic tool invocation environments and observe two recurrent failure patterns: (1) non-compliance with domain-specialized constraints (e.g., functional dependencies and ad-hoc formatting rules), and (2) unpredictable behavior on infeasible tasks, occasionally resulting in user intent distortion. Our study characterizes these phenomena but does not propose training-based remedies; developing robust training methods remains an open direction for future work.
To advance this goal, we suggest two key dimensions for further exploration: (1) enhancing constraint-aware instruction-following, thereby facilitating agent adaptation to domain- and business-specific logic; and (2) improving reasoning over inherently infeasible tasks to ensure safe behavior when tools are unstable. Achieving these training objectives requires curated dataset that jointly cover both axes. Built on WildAgtEval, such data can be generated at scale via recent pipeline with rule-based and LLM-based data quality verification. Furthermore, to mitigate overfitting and preserve generalization, newly generated datasets should be augmented with existing public instruction-following and reasoning corpora, in accordance with continual learning principles . Finally, standard training protocols, including supervised fine-tuning and reinforcement learning , equip agents to attain robust performance during real-world deployment.
Ethical Considerations
This work focuses on generating user–agent interactions to simulate realistic tool-invocation environments without employing human annotators. Consequently, we foresee minimal ethical concerns arising from the training procedure. Specifically, creation of WildAgtEval adheres to a common LLM-based conversation-generation protocol described in previous research . Therefore, we do not anticipate ethical violations or adverse societal consequences stemming from this work.
| Domain | Description | ||
| Functions | |||
| functions | |||
| Notification | Controls time-based functionalities, including alarms and reminders, with support for timers and recurring schedules. | create_alarm |
8 |
| Manages communication channels, including calls and messaging, with basic contact resolution and status checks. | make_call |
7 | |
| Handles food-related services, from meal planning to food delivery, including preferences and dietary constraints. | place_delivery_order |
12 | |
| Enables content discovery and playback across diverse media, sources, and providers. | search_media |
16 | |
| Provides unified control of smart-home devices (e.g., TVs, lights, thermostats), including scenes and simple automation. | color_set |
19 | |
| Facilitates product search, payment processing, and order tracking, with basic cancellation management. | checkout |
12 | |
| Delivers weather forecasts, news updates, and general knowledge, including customized alerts. | weather_current |
12 |
Beyond Perfect APIs:
A Comprehensive Evaluation of LLM Agents
Under API Complexity
(Supplementary Material)
Details of Benchmark Construction
Stage 1: Multi-Domain API System and Conversation Construction
We build a multi-domain API ecosystem and synthesize conversations grounded in executable function specifications.
API construction. All functions are implemented in Python and
defined with OpenAI’s tools/function-calling schema, i.e., JSON Schema
with type, functions, and parameters fields.
Table [tab:api_system] summarizes the
domains, representative functions, and statistics of the API system.
Example of API function:
Figure 9 presents a representative API
function of WildAgtEval, track_order().
In particular, it demonstrates the function’s runtime behavior (e.g.,
invoke()). In our system, all API calls are managed via a unified
invocation interface invoke_tool(), following prior work ; for
example, the agent invokes track_order by calling
invoke_tool("track_order", order_id=$`\ldots`$). The agent
references the information for each API function, as shown in
Figure 7, to select and utilize
the appropriate functionality.
json "function": "name": "track_order", "description": "Track the shipping status of a specific order. Provides current status, tracking number, and estimated delivery date if available.", "parameters": "order_id": "The unique ID of the order to track. This ID is prefixed with the shipping carrier code followed by a hyphen and the order suffix (e.g., ’UPS-345’, ’FDX-678’). The suffix is typically extracted from the original order ID by excluding the initial characters (e.g., for order_id ’12345’, suffix is ’345’; for order_id ’345678’, suffix is ’5678’)." ...
track_order(). json "order_id": "ORDER0001", "user_id": "user1", "items":[ "product_id": "prod41", "name": "Vital Wireless Earbuds", "quantity": 2, "price": 44.55, "subtotal": 89.1 , ...] "payment": "method_id": "pm3", "method_type": "apple_pay", ... ...
orders.json.class TrackOrder(Tool):
@staticmethod
def invoke(data: Dict[str, Any], order_id: str) -> str:
"""
Track the shipping status of an order.
Args:
data: The data dictionary containing orders
order_id: ID of the order to track
Returns:
A JSON string with the result of the operation
"""
### Check if feature limitation error complexity should be activated ###
uncertainty_feature_limitation_error_enabled = os.getenv('ENABLE__FEATURE_LIMITATION_ERROR__TRACK_ORDER', 'false').lower() == 'true'
### Validating the compliance with the ad-hoc rule ###
# Validate order ID format - checking the format "carrier-suffix"
if "-" not in order_id:
return json.dumps({
"success": False,
"message": "Invalid order ID format."
})
# Get carrier from order_id
provided_carrier = order_id.split("-", 1)[0]
### Raise feature limitation error - Original carriers temporarily unavailable ###
if uncertainty_feature_limitation_error_enabled:
alternative_carriers = ["SwiftShip", "RapidCargo"]
return json.dumps({
"success": False,
"message": f"{provided_carrier} tracking temporarily unavailable. It may have been changed to other shipping carriers like {', '.join(alternative_carriers)}"
})
# Get the order, ensuring it belongs to the current user
order = find_order_by_id(data, order_id, current_user)
# Validate order ID format - checking the carrier
...
# return message
if status == "processing":
return json.dumps({
"success": True, ...
"message": "Your order is being processed."
})
...track_order() function, illustrating the key algorithmic
steps in the order-tracking process.json "user_id": "user1", "name": "Sarah Rodriguez", "home_id": "home1", "preferences": "location": "New York", ..., ...
users.json.Example of databases: During the execution of most API functions,
the database is either read or written, providing direct access to the
API system’s database. As indicated in Lines 34–35 of
Figure 9, this behavior involves the
variable data. For instance, the track_order() function specifically
retrieves information from orders.json. As shown in
Figure 8, each order includes realistic
attributes such as order_id, the user_id of the individual placing
the order, items, and payment details. Furthermore, multiple databases
are interconnected based on a shared schema; for example,
Figure 10 demonstrates how orders.json is
linked to user records via user_id. Both
Figure 8 and
Figure 10 display orders and user information
for the case in which user_id equals user1.
 style="width:100.0%" />
style="width:100.0%" />
Conversation construction. Following the conversation generation framework of Barres et al., we construct a scalable data-generation pipeline grounded in our API system, as shown in Figure 11. This pipeline produces multi-turn conversations that are both diverse and natural, while remaining precisely labeled with executable API calls—an essential requirement for robust evaluation of agent reasoning, and execution under realistic conditions.
The process unfolds in four stages. First, after establishing the API
codebase, we build a directed graph in which each function is
represented as a node, and each edge denotes a dependency (i.e., a
function’s output serving as another function’s input). By traversing
this graph, we identify meaningful multi-step task sequences that
emulate realistic API usage for addressing user requests or intents. For
example, the play() function depends on prior calls to the API calls
search_media(), get_user_inventory(), power_on(), as shown in
Figure 11.
Second, each valid execution path is transformed into a verified intent
primitive—an atomic unit that encapsulates (i) a specific user goal,
(ii) a corresponding chain of API calls, and (iii) diversified parameter
settings that emulate natural variations in user context, preferences,
and input conditions. These primitives serve as composable building
blocks, enabling flexible scenario construction across domains. For
example, the “watch a movie” intent primitive comprises the API calls
search_media(), get_user_inventory(), power_on(), play().
Similarly, there are more primitives—such as “pause,” “shuffle,” “next,”
or “add media to playlist”—encapsulating API call sequences for related
tasks.
Third, an LLM composes multiple verified intent primitives into multi-turn conversations, generating the corresponding API call sequences. The LLM first inspects these primitives to produce a high-level conversation flow describing how user goals naturally unfold within a single conversation. For instance, the LLM might outline a scenario in which the user initially plays a song, then pauses playback, shuffles the playlist, advances to the next track, and finally adds the current song to a personalized playlist. Subsequently, the LLM translates this plan into a detailed multi-turn conversation by generating user and agent utterances and integrating the relevant verified intent primitives, as shown in Figure 11. Since these primitives already include validated API call sequences, each generated conversation is both natural and accurately aligned with the correct API behaviors.
Finally, each conversation undergoes a two-phase quality assurance process. We first convert the JSONL outputs into executable Python scripts and automatically validate whether each conversation runs successfully. Any conversations that fail execution are filtered out. The remaining dialogues are then manually reviewed by human experts to ensure semantic coherence, logical flow, and API correctness. The resulting benchmark contains 300 multi-turn, multi-step conversations, each averaging 4.7 dialogue turns and 2.5 API calls per turn.
Stage 2: Complexity Assignment
We automate complexity assignment with a language model using three prompt templates: a relevance assessment template $`\mathcal{I}_{\mathrm{rel}}`$ in Eq. [eq:rel], a scenario specification template $`\mathcal{I}_{\mathrm{scen}}`$ in Eq. [eq:scenario_generation], and a scenario validation template $`\mathcal{I}_{\mathrm{val}}`$ in Eq. [eq:val]. Given a function and a candidate complexity type, $`\mathcal{I}_{\mathrm{rel}}`$ estimates the likelihood that the complexity arises for the function in deployment; top-ranked function–complexity pairs are then instantiated as concrete scenarios by $`\mathcal{I}_{\mathrm{scen}}`$; finally, $`\mathcal{I}_{\mathrm{val}}`$ filters candidates based on real-world plausibility and fidelity to the targeted complexity type. The complete prompt templates appear in Figures 15–19.
Implementation details. We use Claude-3.7-Sonnet with temperature $`0.8`$ and keep all other hyperparameters at their default values; other large language models can be substituted without altering the pipeline.
Stage 3: Complexity Implementation
Reference Response Construction for Error-based Complexities
For both feature limitation and system failure error scenarios, we
specify reference responses that include either a recommended
workaround or a standardized error message, respectively. Since error
handling seldom admits a single gold-standard outcome, each reference
response captures a valid approach representing ideal error
resolution. For instance, if a user queries weather(‘‘Seattle’’) but
receives a message stating that “Seattle is currently unavailable;
however, search for other regions is available,” the system has failed
to fulfill the request directly. A proper response would suggest
nearby locations, such as “Kirkland” or “Tacoma,” rather than
searching for a random region or immediate surrender. Hence, the
reference response specifies the conceptual approach (e.g., searching
for nearby locations), rather than detailing specific ones, to gauge
how closely the agent’s strategy aligns with a valid approach.
Consequently, for each of the 16 error-based scenarios in WildAgtEval, we define an evaluation prompt that incorporates both the reference response and the corresponding scenario-specific validity criteria. We then employ an LLM-based judge to score how closely the agent’s error handling aligns with the recommended approach detailed in the reference response. Figures 20–22 demonstrate representative evaluation prompts for feature limitation and system failure errors.
Results of Complexity Integration
Table [tab:complexity_stats]
summarizes, for each complexity type, the number of functions that
contain injected complexity scenarios, along with representative
functions. Notably, a single function may host multiple
complexities (e.g., track_order() in
Figure 9); in such cases, the
function’s behavior reflects the combined effects of the activated
complexities.
| Complexity Type | Coverage | Representative Affected Functions |
|---|---|---|
| API specification complexities | ||
| Ad-hoc rules | 8 API functions | lock_lock,
track_order, play |
| Unclear functionality boundary | 20 API functions | get_user_inventory,
search_product, make_call |
| Functional dependency | 20 API functions | get_user_inventory,
search_media, power_on |
| Ambiguous description | Present in base API system | — |
| Information notices | 8 API functions | temperature_set,
stock_watchlist, make_call |
| Partially irrelevant information | 8 API functions | search_recipes,
knowledge_lookup, stock_watchlist |
| Feature limitation errors | 8 API functions | get_notifications,
weather_forecast, track_order |
| System failure errors | 8 API functions | make_call,
get_user_inventory, stock_price |
Example of complexity integration. We integrate two complexity
types—an ad-hoc rule and a feature limitation error—into the
track_order() function depicted in
Figure 9. Lines 15–21 and 37–38
validate the ad-hoc rule, which ensures that the order_id parameter
follows the industry-standard format “[shipping carrier]–[id].”
Specifically, the code checks whether a hyphen is present and whether
the carrier name is valid. This ad-hoc rule is also specified in the API
documentation (see
Figure 7), allowing LLM agents to
reference the correct parameter format.
In parallel, Lines 12–23 determine whether the feature limitation error is activated under the current complexity configuration, and if so (Lines 26–32), an error message indicates that the original carrier is unavailable and has been replaced by another shipping carrier.
Complete Experiment Details
Evaluation framework. Figure 12 provides a visual overview of our two evaluation methods. In the isolated complexity setting (left side of Figure 12), we preserve a correct conversation history—using ground-truth API calls—up to the point immediately preceding the tested API call. This approach allows us to measure the impact of each complexity type independently. In contrast, the cumulative complexity setting (right side of Figure 12) compounds multiple complexities by continuously integrating the agent’s previously predicted API calls throughout the conversation.
 style="width:100.0%" />
style="width:100.0%" />
Implementation details. The agent prompt structure consists of three primary components: API specification documentation (approximately 34K tokens), conversational context, and API execution guidelines (approximately 19K tokens), providing agents with comprehensive functional specifications and operational procedures. Within this structure, we employ the ReAct prompting , where models are instructed to generate responses in the format ”Thought: {reasoning or explanatory text} Action: {JSON-format action argument}” using zero-shot inference.
For Claude-based agents, we access Anthropic models via Amazon Bedrock.
All other models are served with vLLM—e.g., the vllm-openai:gptoss
image for GPT-OSS-120B—and executed on Amazon AWS EC2 p5en
instances. The source code is publicly available at
https://github.com/Demon-JieHao/WildAGTEval
.
From the 300 user–agent conversations provided by WildAgtEval, we evaluate the agents on a stratified subset of 50 conversations to manage the inference cost for state-of-the-art LLMs. To ensure reproducibility and enable further analysis, we release both the evaluation subset of 50 conversations and the full set of 300 conversations, respectively. WildAgtEval is distributed under the Creative Commons Attribution 4.0 International (CC-BY 4.0) license.
Evaluation metric. We evaluate LLM agents using (1) API call accuracy and (2) error-handling accuracy for feature limitation and system failure error scenarios.
API call accuracy: Consistent with prior work , we evaluate whether an agent’s API behavior genuinely fulfills the user’s intended goal. In contrast to approaches that judge success solely from final database states—which can be inadequate because many intents do not yield observable state changes (e.g., “Check the current weather”)—we also treat such non–state-changing queries as valid targets for evaluation.
We therefore partition the ground-truth API sequence into two
categories: core APIs and support APIs. An agent is deemed
successful on a given turn only if it invokes all required core APIs
for that turn. Core APIs directly address the user’s intent
irrespective of whether the database state changes. While they often
include operations such as add_to_cart(), checkout(), power_on() as
well as non-database-altering operations (often information-retrieval
functions, such as weather_current()) that independently satisfy the
user’s intent. Because each user request encodes at least one intent,
there is at least one core API per request.
Support APIs, on the other hand, are supplementary operations (e.g.,
search_product()) that provide information needed to correctly invoke
downstream core APIs (e.g., add_to_cart(), checkout()). Their use is
not scored directly; repeated or suboptimal support calls do not affect
success as long as core calls are correct. Hence, final success is
assessed solely on the correctness of core API execution.
Formally, let $`C_i^\text{(pred)}`$ denote the set of core APIs invoked by the agent at $`i`$-th conversation turn, and $`C_i^\text{(gold)}`$ be the corresponding ground-truth set. With $`T`$ total conversation turns, the API call accuracy $`\mathcal{A}_\text{\rm API}`$ is defined as
\begin{equation}
\mathcal{A}_\text{\rm API}
= \frac{1}{T}\sum_{i=1}^{T}
\mathbb{I}\!\left[\, C_i^{(\mathrm{pred})} = C_i^{(\mathrm{gold})} \,\right],
\end{equation}where $`\mathbb{I}[\cdot]`$ denotes the indicator function that returns 1 if the condition holds and 0 otherwise.
Error-handling accuracy: We define this metric to quantify how closely an agent’s fallback response aligns with a reference error-handling response. Formally, let $`E`$ be the index set of conversation turns that instantiate either a feature limitation or a system failure error scenario. For each $`i \in E`$, let $`R_i^{(\mathrm{pred})}`$ denote the agent’s fallback response and $`R_i^{(\mathrm{ref})}`$ the reference error-handling response. We employ an LLM-Judge scoring function, $`\mathcal{J}:\mathcal{R}\times\mathcal{R}\to\{1,\dots,5\}`$, where $`\mathcal{R}`$ is the space of textual responses and $`\mathcal{J}(\cdot,\cdot)`$ is an ordinal score reflecting the alignment between two responses. Then, error-handling accuracy $`\mathcal{A}_{\rm{Error}}`$ is defined as
\begin{equation}
\mathcal{A}_{\mathrm{Error}}
= \frac{1}{|E|}\sum_{i\in E}
{\mathcal{J}}\!\big(R_i^{(\mathrm{pred})},\,R_i^{(\mathrm{ref})}\big).
\end{equation}In our experiments, $`\mathcal{J}`$ is instantiated using Claude-4-Opus to leverage strong reasoning while avoiding overlap with the tested LLM agents. Additional details on reference error-handling responses and the corresponding evaluation prompt are provided in Appendix 7.3.1 and Figures 20–22, respectively.
Complete Main Analyses
Detailed Comparison of Reasoning and Non-Reasoning Agents under Error-based Complexities
Example [reason_comparision] represents how the reasoning agent (marked in blue) more effectively addresses errors arising from API complexity than the non-reasoning agent (marked in red). Specifically, when the system fails to retrieve weather data for a particular region, an ideal strategy is to query nearby regions as a workaround. This result demonstrates the effectiveness of the reasoning mechanism for accurately identifying and implementing an appropriate workaround for the encountered error.
Comparative Analysis of Error Handling in Reasoning vs. Non-Reasoning Agents (Qwen3-235B-Thinking vs. Qwen3-235B-Instruct) User Request: “I will travel to paris. Can you show me the 7-day forecast for Paris?”
Agent API Call:
weather_forecast(location=‘‘paris’’, (...))→ Feature limitation error
API Execution Results (Hidden from user):
{‘‘success’’: false``,‘‘message’’: ‘‘Weather data for paris temporarily unavailable. Other regions are accessible’’}
Expected Agent Response:
- Since weather data for Paris is currently unavailable, the agent should query weather information for nearby regions; the LLM-judge evaluation prompt is provided in Figure 20.
Actual Output from Reasoning Agent (Qwen3-235B-Thinking):
- “Let me analyze the current situation: The user has been going through a sequence of actions: first, they asked for top 10 Italian food recipes; then they wanted to buy ingredients for the best recipe; now they’re asking for a 7-day forecast for Paris. The last API response was for the weather forecast request, which returned: “success”: false, “message”: “Weather data for paris temporarily unavailable. Other regions are accessible”. Since the weather data for Paris is unavailable, I need to inform the user that Paris weather data is unavailable, suggest alternatives (other regions as mentioned in the error message), and ask if they want to try a different location. According to the instructions, I should only make one API call at a time, wait for API results before making next decisions, and signal completion with “<End of Turn>” when the request is fully satisfied. Since the weather API call for Paris has already failed (as shown in the API_RESPONSE), I don’t need to make another API call for Paris; instead, I should inform the user of the failure and suggest alternatives. However, I could make a new API call for a different location if the user agrees, but since I need to wait for user confirmation first, my next step should be to inform the user about the Paris weather data unavailability, suggest trying a different location, and wait for the user’s response before making any new API calls. So I should not make any API call right now; instead, I should end this turn with a message to the user and wait for their next input. According to the instructions, when the user’s request is fully satisfied (or in this case, when we’ve processed the failed request and provided appropriate feedback), I should use “<End of Turn>”. So my response should be a message explaining the situation and offering alternatives, followed by “<End of Turn>”. </think> The weather data for Paris is currently unavailable according to the system response. Would you like me to check the forecast for a different location in France, such as Lyon or Marseille, or perhaps another major European city? I can try an alternative location if you’d prefer. <End of Turn>”
Actual Output from Non-Reasoning Agent (Qwen3-235B-Instruct):
- “I’m unable to retrieve the 7-day weather forecast for Paris as the weather data is currently unavailable. You may want to try again later or check another weather service for Paris forecasts. <End of Turn>”
Additional Analyses
Pitfalls of Over-Reasoning in Reasoning-Based Agent
Although reasoning improves error handling, as discussed in
Section 5.2, we also observe that
reasoning-based agents occasionally overinterpret user intent, thereby
reducing overall performance. Specifically, in
Example [example_over-reasoning],
the user explicitly requests an “American restaurant,” indicating that
search_restaurant(``cuisine_type=‘‘America’’``) is the correct API
call. However, the reasoning agent Qwen3-235B-Thinking overextends its
reasoning by recalling the user’s previously stated preference for
“New York” and therefore incorrectly
invokes
search_restaurant(``cuisine_type=‘‘America’’, ``location=‘‘New York’’``).
Over-Reasoning by Qwen3-235B-Thinking Previous API Execution Results:
{‘‘preference’’: {‘‘location’’:‘‘New York’’, ‘‘language’’: ‘‘en’’, ‘‘news_categories’’: [‘‘world’’, ‘‘sports’’, ‘‘health’’], (...)}}
* (after 3 conversation turns…)***
User Request: “Can you find me the best American restaurant?”
Expected API Call:
search_restaurant(``cuisine_type=‘‘America’’)
Actual Agent Output:
search_restaurant(``cuisine_type=‘‘America’’,location=‘‘New York’’) →Incorrect search
Similar overinterpretation issues occur in other search-related
functions (e.g., search_product()), resulting in an overall accuracy
of only 30.0% in generating correct API calls. In contrast, another
reasoning agent, Claude-4-Sonnet (Think), achieves an accuracy of 64.4%,
illustrating how distinct reasoning strategies can produce substantially
different outcomes. These findings align with the notably low cumulative
evaluation results of Qwen3-235B-Thinking shown in
Figure 6.
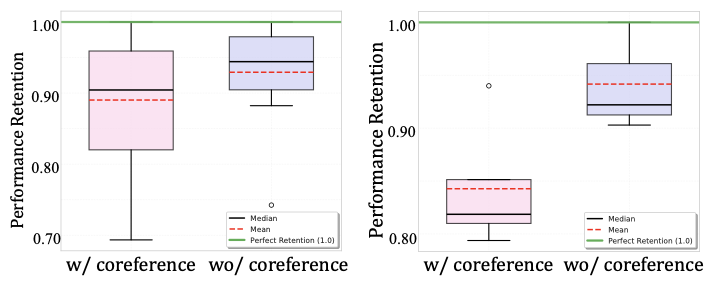
Impact of API Complexity on User-Instruction Complexity
Implementation details. We apply the API complexities in WildAgtEval (Table [tab:api_complexity_taxonomy]) to two instruction-side conditions distinguished by coreference structure—with coreferences (pronouns or nominal references spanning multiple turns) versus without coreferences (all entities explicitly stated), as illustrated in Figure 13. It is widely known that coreferential conversations generally pose greater instruction-following difficulty than non-coreferential ones .
API–user complexity overlap amplifies difficulty. Figure 14 reports performance retention ratio when API complexities are injected, defined as
\begin{equation}
\textit{Retention Ratio} = \frac{\text{performance}_{\text{after}}}{\text{performance}_{\text{before}}},
\end{equation}which measures post-injection performance relative to pre-injection performance. We employ this ratio to control for baseline difficulty, noting that coreferential conversations inherently yield lower pre-injection performance. Normalizing by the pre-injection score thus isolates the marginal effect of introducing API complexity.
In general, combining API complexities with coreferences results in considerably greater performance retention degradation, producing an 11.0% decline compared to 7.1% in the absence of coreferences. In particular, among the examined complexity types, irrelevant information complexity again poses the greatest challenge for the LLM agent by reducing average performance retention by an additional 0.1%. These findings suggest that the co-occurrence of API-side and user-side complexities creates more challenging scenarios, indicating a combinatorial effect from both complexity sources.
Additional Failure Analyses
Agents are easily distracted by informational notices in API execution
results. As illustrated in
Example [example4], when API responses contain
auxiliary function notices alongside execution results, agents
demonstrate increased susceptibility to overlooking critical functional
dependencies. Specifically, when temperature_set() responses include
auxiliary function notices about brightness_adjust() and users later
request brightness adjustments, agents exhibit increased tendency to
omit the mandatory power_on() prerequisite step, directly attempting
brightness modifications that result in failures.
 style="width:60.0%" />
style="width:60.0%" />
 style="width:100.0%" />
style="width:100.0%" />
(a) All API complexities (b) Irrelevant information
Distraction by Informational Notices User Request 1: “Set temperature to be 32 degrees”
Agent API Call:
temperature_set(32)
API Execution Results (Hidden from user):
{‘‘success’’: ‘‘true’’, ‘‘Temperature’’: ‘‘32’’,‘‘Companion functions’’:{‘‘API Call’’: ‘‘brightness_adjust’’, ‘‘params’’: (...)}}
User Request 2: “Set Kitchen Light brightness to 20%”
Expected API Calls:
-
power_on(‘‘35’’) -
brightness_adjust(‘‘35’’, temperature=‘‘20’’)
Actual Agent Output:
-
→ Omitted
-
brightness_adjust(‘‘35’’, temperature=‘‘20’’)→ Failed
R0.44
As shown in Table [tab:informational_notice], when informational notices are present, Claude models show sharp performance degradation. This result suggests that agents struggle to maintain focus on task-critical functional dependencies when exposed to potentially relevant contextual information.
Additional examples of ad-hoc rule violation. As shown in Example [example2], despite clear API specification requiring endpoint parameter formatting as ‘[device_name]_[id]’, agents ignore domain-specific formatting rules and apply device information (e.g., “16”) directly without proper string concatenation (e.g., “GarageDoorOpener_16”).
Ad-hoc Rule Violation - lock_lock() API Specification: “When using
lock_lock() API, for enhanced security reasons, the endpoint parameter
should follow the format ‘[device_name]_[id]’.”
User Request: “Lock the Garage Door Opener”
Expected API Call:
lock_lock(‘‘GarageDoorOpener_16’’)
Actual Agent Output:
lock_lock(‘‘16’’)→ Missing device name
 />
/>
 />
/>
 />
/>
 />
/>
 />
/>
 />
/>
weather_forecast(). />
/>
get_message(). />
/>
get_user_inventory().📊 논문 시각자료 (Figures)