In Line with Context Repository-Level Code Generation via Context Inlining
📝 Original Paper Info
- Title: In Line with Context Repository-Level Code Generation via Context Inlining- ArXiv ID: 2601.00376
- Date: 2026-01-01
- Authors: Chao Hu, Wenhao Zeng, Yuling Shi, Beijun Shen, Xiaodong Gu
📝 Abstract
Repository-level code generation has attracted growing attention in recent years. Unlike function-level code generation, it requires the model to understand the entire repository, reasoning over complex dependencies across functions, classes, and modules. However, existing approaches such as retrieval-augmented generation (RAG) or context-based function selection often fall short: they primarily rely on surface-level similarity and struggle to capture the rich dependencies that govern repository-level semantics. In this paper, we introduce InlineCoder, a novel framework for repository-level code generation. InlineCoder enhances the understanding of repository context by inlining the unfinished function into its call graph, thereby reframing the challenging repository understanding as an easier function-level coding task. Given a function signature, InlineCoder first generates a draft completion, termed an anchor, which approximates downstream dependencies and enables perplexity-based confidence estimation. This anchor drives a bidirectional inlining process: (i) Upstream Inlining, which embeds the anchor into its callers to capture diverse usage scenarios; and (ii) Downstream Retrieval, which integrates the anchor's callees into the prompt to provide precise dependency context. The enriched context, combining draft completion with upstream and downstream perspectives, equips the LLM with a comprehensive repository view.💡 Summary & Analysis
1. This paper introduces a new way to understand function roles in code generation by considering their position within the repository's call graph. 2. It proposes the **InlineCoder** framework, which enhances context understanding by directly embedding functions into their calling contexts, thereby improving upon traditional retrieval methods. 3. The effectiveness of **InlineCoder** is demonstrated through extensive evaluations on multiple benchmarks.📄 Full Paper Content (ArXiv Source)
With the rapid development of code LLMs, repository-level code generation has attracted growing attention in recent years . Unlike function-level generation, repository-level generation requires reasoning over entire repositories, accounting for coding conventions, API usage, and intricate inter-function dependencies . Success in this setting demands not only syntactically correct and semantically valid code but also consistency with the repository’s broader design and dependencies .
A key obstacle in repository-level generation is the repository context itself. While it contains the crucial information needed for accurate generation, directly feeding the entire repository into an LLM is infeasible due to context window limitations and the overwhelming amount of irrelevant or redundant code . This raises a central challenge: How can we distill and represent the most relevant context from a vast codebase to support effective code generation?
Prior work has approached this challenge through various retrieval strategies. The most common is retrieval-augmented generation (RAG), which retrieves similar code snippets to the unfinished function . However, similarity does not necessarily imply relevance in code: lexically similar snippets may be functionally unrelated, leading to noisy or misleading prompts. Agent-based pipelines further extend these capabilities by enabling iterative retrieval and LLM-guided evaluation of retrieval targets . More advanced methods incorporate program analysis, such as control-flow or data-flow graphs, to capture semantic dependencies more accurately . While effective for fine-grained tasks such as line-level completion or API prediction, these methods rely heavily on local context and often fail to generalize to function-level generation, where entire implementations must be synthesized from scratch.
To overcome these limitations, we propose InlineCoder, a novel framework for repository-level code generation. Our key insight is that a function’s role within a repository is determined by its position in the repository’s call stack: it is constrained by its upstream callers (how it is used) while its implementation depends on its downstream callees (what it depends on). InlineCoder enhances context understanding by inlining the unfinished function into its call chain, thereby reformulating repo-level generation into the much easier function-level generation task. Given a function signature, InlineCoder first produces a draft implementation–an anchor to approximate potential dependencies. This draft then drives a bidirectional inlining process: (1) Upstream Inline, where we inline the anchor into its callers to provide rich usage scenarios. (2) Downstream Retrieval, where we incorporate all invoked callees by the draft, capturing its dependency context. Finally, we integrate the draft code with the inlined context into a comprehensive prompt, enabling the LLM to generate the final, contextually-aware code.
We evaluate InlineCoder on two widely-used repository-level code
generation benchmarks, DevEval and
RepoExec , using three backbone LLMs:
DeepSeek-V3 , Qwen3-Coder , and GPT5-mini . InlineCoder
demonstrates the best overall performance. Notably, on
RepoExec, it achieves average relative
gains of 29.73% in EM, 20.82% in ES, and 49.34% in BLEU
compared to the strongest baseline. Ablation studies confirm that each
component of InlineCoder contributed to the final effectiveness.
Moreover, targeted analyses on specific code structures, as well as
experiments across repositories from diverse domains and under varied
contextual environments, demonstrate that InlineCoder consistently
yields significant gains—highlighting its robustness and
generalizability for repository-level code generation.
The main contributions of this paper are as follows:
-
We propose a novel repository-level code generation framework that situates the target function within its upstream (callers) and downstream (callee) contexts.
-
We are the first to inline a function into its callers’ context, allowing the LLM to gain a deeper understanding of the function’s intended purpose and usage patterns.
-
We conduct extensive evaluations on multiple benchmarks. Results demonstrate that our method achieves consistent improvements over state-of-the-art baselines across diverse context environment and across multiple domains.
Motivation
 style="width:100.0%" />
style="width:100.0%" />
A central challenge in repository-level code generation lies in effectively incorporating repository context into models . Current approaches typically adopt a retrieval-based framework, where relevant snippets are selected based on text similarity or structural proximity. While this strategy provides local context, it rarely offers a systematic way to represent how a function is actually used by its callers (upstream) or how it depends on its callees (downstream) .
Some recent efforts attempt to incorporate call-chain information, but they often do so by simply prepending retrieved functions before the unfinished target signature . This linear concatenation neglects the functional role of the target within its true calling environment. As a result, the model may remain unaware of input/output constraints or calling conventions, leading to an incomplete or misleading understanding of function semantics. Without adapting retrieved snippets to the actual calling sites, models can easily fail to infer correct variable bindings, return types, or the appropriate API variants used across the repository .
Figure 1 (a) illustrates an example
of these shortcomings. Conventional methods often isolate the target
function and attach utility functions or snippets above it, failing to
capture genuine calling relationships. Consequently, the model
incorrectly calls the unrelated utility extract_functions and produces
a dict instead of the expected list[str].
This example motivates a new paradigm of context incorporation, as
illustrated in
Figure 1 (b): we can inline the
target function directly within its calling context, thereby providing
Inlined Context. This approach transforms structured call-graph
information into a form that the model can readily interpret, exposing
crucial signals such as variable bindings, return formats, and valid API
usage. As the example shows, the inlined context enables the model to
generate repository-consistent code: the correct function now returns a
list[str] and invokes the appropriate callees. By coupling targeted
context retrieval with inlining, our method enables context-aware,
repository-aligned code generation that addresses the shortcomings of
conventional retrieval-based strategies.
Methodology
Overall Framework
Given the signature of an unfinished function $`x`$ within a repository $`\mathcal{D}`$, the goal of repo-level code generation is to produce the function body $`y`$ by leveraging contextual information $`\mathcal{C}`$ from $`\mathcal{D}`$. The main challenge of this task is to extract useful context $`\mathcal{C}`$ as accurately as possible and let the model understand the information in context $`\mathcal{C}`$, which entails reasoning over entire repositories, understanding complex dependencies across functions, classes, and modules.
 style="width:95.0%" />
style="width:95.0%" />
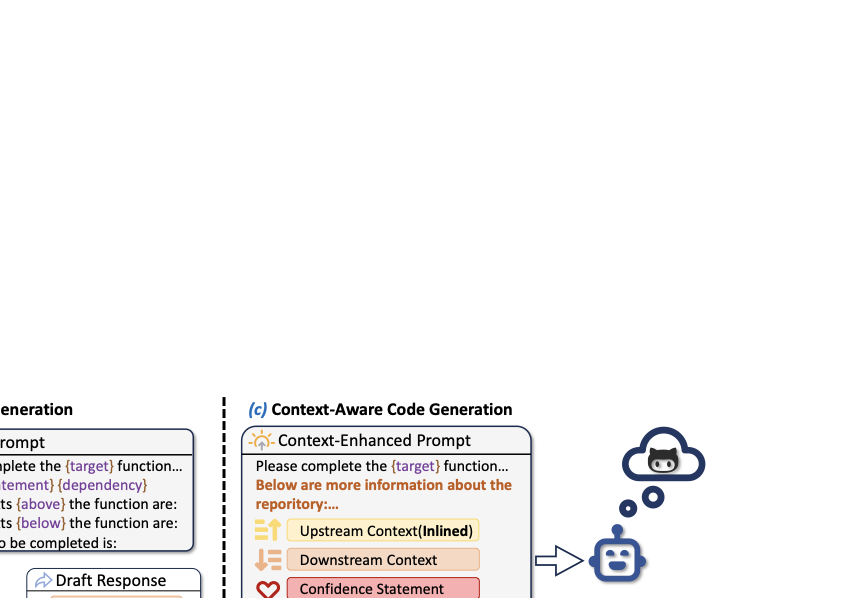
To tackle this challenge, we propose InlineCoder, a novel framework for repository-level code generation. Unlike previous techniques that retrieve similar snippets in the context, the core idea of InlineCoder is to situate the target function within its call-graph environment. As illustrated in Figure 2, InlineCoder follows a three-stage pipeline:
1) DraftGeneration (Section 3.2): Given the base prompt built around the target function signature, InlineCoder first produces a preliminary implementation of the unfinished function, which serves as an anchor. This draft not only offers an approximate view of potential downstream dependencies to help situate the target function within the repository’s call graph but also provides a basis for Perplexity evaluation.
2) Context Inlining (Section 3.3): The draft is then inlined into its callers to capture upstream usage scenarios, while relevant callee implementations are retrieved and incorporated downstream. This process yields a coherent, linearized representation that flattens both upstream and downstream contextual information into a unified view for the model.
3) Context Integration (Section 3.4): InlineCoder integrates all relevant information into a context-enhanced prompt that consists of: (a) the base prompt (function signature + imports), (b) the retrieved upstream and downstream context, and (c) the initial draft. This enriched prompt provides the LLM with comprehensive guidance, enabling it to generate the final implementation that is both semantically accurate and consistent with the repository environment. The details of each stage are elaborated in the following subsections.
DraftGeneration
The draft generation stage produces a preliminary implementation of the target function, referred to as the anchor. This draft then serves as a semantically enriched artifact that guides subsequent retrieval and provides a reference point for the final generation.
To generate this draft, we first build an initial prompt that offers the LLM a comprehensive view of local context and dependencies. We collect all import statements from the target file and append the full code of all directly referenced dependencies (e.g., variables, functions, classes) discovered within the repository, maintaining the original import order. This cross-file reference information is provided by the datasets (i.e., REPOEXEC and DevEval ) We then add the signature of the unfinished function along with its natural language description.
This structured prompt is then fed to the LLM, which produces both a candidate implementation of the function body (draft) and a list of the API calls used within it. The resulting draft plays a dual role: On one hand, it acts as a seed for retrieval; the identified API calls provide explicit, high-confidence signals for the subsequent Downstream Retrieval process. On the other hand, it serves as a reference for generation; the draft is used to calculate a perplexity-based confidence score to inform the final generation stage, and it also acts as a draft implementation that can be refined during final generation.
Context Inlining
Building on the initial implementation during draft generation, we introduce a dual-pronged inlining process to assemble both its upstream and downstream context. The core insight is grounded in the observation that a function’s role is defined by its position within the repository’s call graph. Its behavior is constrained by its upstream callers (how it is used), while its implementation depends on its downstream callees (what it depends on).
Upstream Inlining
 />
/>
Upstream inlining aims to provide the LLM with a rich understanding of how the target function is intended to be used. The process starts by identifying all callers of the target function. We traverse the repository’s AST to identify all call sites where the target function is invoked. For each call site, we extract the corresponding calling function, which we refer to as a caller. Unlike traditional methods that merely prepend caller context to the prompt, InlineCoder proposes a novel context inlining technique . As shown in Figure 3, we embed the draft directly into its callers, producing a coherent, linearized representation of the function context. This is achieved through a four-step transformation:
-
Parameter Substitution: Let $`\text{Args} = [a_1, a_2, \ldots, a_m]`$ denote the argument list at the call site, and $`\text{Params} = [p_1, p_2, \ldots, p_m]`$ denote the formal parameters in the callee definition. We define a substitution function over identifiers:
MATH\begin{equation} \label{eq: sigma} \sigma : \mathcal{I} \to \mathcal{I}', \quad \sigma(x) = \begin{cases} a_i & \text{if } x = p_i \in \text{Params}, \\[2mm] x & \text{otherwise}, \end{cases} \end{equation}Click to expand and view morewhere $`\mathcal{I}`$ is the identifier set of the callee body, and $`\mathcal{I}'`$ denotes the set of identifiers after substitution.
We lift $`\sigma`$ to statements, $`\mathcal{S} \to \mathcal{S}'`$, by recursively applying it to all identifiers in a statement $`s \in \mathcal{S}`$, where $`\mathcal{S}`$ is the set of statements in the callee body, and $`\mathcal{S}'`$ denotes the statements after identifier substitution.
For the callee body $`\text{Body}_f = \{s_1, \ldots, s_N\}`$, the parameter-substituted body is:
MATH\begin{equation} \sigma(\text{Body}_f) = \{\, \sigma(s) \mid s \in \text{Body}_f \,\} \subseteq \mathcal{S}'. \end{equation}Click to expand and view more -
Return Normalization: We define a transformation function $`\tau: \mathcal{S} \to \mathcal{S}`$ operating on statements:
MATH\begin{equation} \label{eq: tau} \tau(s) = \begin{cases} \texttt{result = exp} & \text{if } s \equiv \texttt{return $exp$}, \\[4pt] \texttt{result = None} & \text{if } s \equiv \texttt{return}, \\[4pt] s & \text{otherwise}. \end{cases} \end{equation}Click to expand and view moreLifting $`\tau`$ to statement sets, we obtain the normalized body:
MATH\begin{equation} \tau(\text{Body}) = \{\, \tau(s) \mid s \in \text{Body} \,\}. \end{equation}Click to expand and view more -
Assignment Redirection: Suppose the original call site has the form
x = f($`a_1, \ldots, a_m`$). After parameter substitution and return normalization, this assignment is redirected tox = result, binding the call result to the caller’s variable. -
Inline Expansion: The transformed callee body is obtained by sequentially applying the parameter substitution $`\sigma`$ (defined in Equation [eq: sigma]) and return normalization $`\tau`$ (defined in Equation [eq: tau]):
MATH\begin{equation} \text{Body}_f^{*} = \tau\big(\sigma(\text{Body}_f)\big). \end{equation}Click to expand and view moreInline expansion replaces the original call with $`\text{Body}_f^{*}`$, preserving indentation and surrounding syntactic structure in the caller’s function.
This inlining process ensures semantic equivalence while making the target function’s intended behavior explicit in context. By embedding the draft implementation directly into its upstream caller bodies, the procedure converts a distributed, structured set of cross-file call relations into a single, linearized function-local environment. As a result, the LLM receives a compact, execution-oriented view of the target function’s role, which facilitates the inference of input/output expectations, preserves the logical flow of computations, and highlights the relationships between variables and control structures. This transformation also reduces ambiguity and eliminates the distractions inherent in separately retrieved snippets, enabling the model to focus on the essential behavioral patterns of the target function within its repository context.
Downstream Retrieval
 />
/>
Downstream retrieval aims to equip the LLM with the dependent functions of the target function. While the draft may initially implement functionality from scratch, high-quality code often depends on existing functions within the repository. To identify these dependent functions, we consider two complementary sources: (i) parsing the draft’s AST to extract all invoked function calls, denoted as $`Q_{\text{AST}}`$, and (ii) collecting the LLM-generated list of predicted callees, denoted as $`Q_{\text{LLM}}`$. We then explicitly take their union to construct the overall query vocabulary:
\begin{equation}
Q = Q_{\text{AST}} \cup Q_{\text{LLM}} = \{q_1, q_2, \ldots, q_m\},
\end{equation}where each $`q_i`$ denotes a candidate function name. Given a repository represented as a collection of function units $`\mathcal{F} = \{f_1, f_2, \ldots, f_n\}`$, each with an associated function identifier $`\texttt{name}(f_j)`$, we apply a substring-based retrieval strategy:
\begin{equation}
\mathcal{G} = \{ f_j \in \mathcal{F} \;\mid\; \exists q_i \in Q, \; q_i \subseteq \texttt{name}(f_j) \}.
\end{equation}where $`\mathcal{G}`$ denotes the set of candidate downstream functions. $`\mathcal{G}`$ is finally used to form the downstream context, providing enhancements to Prompt. To prevent data leakage, we exclude the target function itself from $`\mathcal{G}`$. The objective is to maximize coverage of potentially useful repository APIs that the target function may leverage, thereby providing the LLM with a richer and more accurate implementation environment.
Thus, downstream retrieval bridges the gap between a noisy, from-scratch draft and a concise, high-quality solution grounded in repository knowledge by ensuring that the retrieved functions are tightly aligned with the model’s actual generation trajectory. This process enables the system to surface the most relevant utility functions exactly when they are needed, avoiding both under-retrieval (missing key APIs) and over-retrieval (introducing irrelevant noise). As a result, the LLM is equipped with a targeted and contextually coherent function set, which maximizes reuse of repository knowledge and ultimately promotes higher-quality, repository-consistent code generation.
Context-Aware Code Generation
Having gathered both the draft implementation and enriched contextual information, we guide the LLM to produce the final code.
We allow the model to operate in a dual mode: it may either reuse the initial draft or refine it based on the enriched context. The draft serves as a valuable starting point, but it may contain inaccuracies or incomplete logic. To calibrate how much the model should rely on this draft, we introduce a confidence mechanism based on perplexity (PPL) . For a draft implementation $`R = (r_1, \dots, r_M)`$ conditioned on the base prompt $`B`$, the PPL is defined as:
\begin{equation}
\label{eq: ppl}
\mathrm{PPL}(R \mid B) = \exp\left( -\frac{1}{M} \sum_{j=1}^{M} \log p\bigl(r_j \mid B, r_{<j}\bigr) \right).
\end{equation}where $`p(r_j \mid B, r_{ We categorize the model’s confidence in the draft code
(Section 3.4) into three levels based on
their perplexity: low confidence (PPL$`>`$2), medium confidence
(PPL$`\in`$[1.3, 2]), and high confidence (PPL$`<`$1.3). The
thresholds are carefully tuned so that roughly 40% of the samples fall
into the low-confidence group, 40% into the medium-confidence group, and
20% into the high-confidence group. In case of high confidence (low PPL), the model is prompted to trust and
closely follow the draft. When the draft obtains medium confidence, the
model is advised to modify or improve the draft. In cases of low
confidence, the model is prompted to critically reassess the draft, with
freedom to regenerate from scratch. Each confidence level is mapped to a
natural-language guidance integrated into the final prompt: High confidence: “The current implementation and the comments are
good, please refer to it and keep these comments.” Medium confidence: “The current implementation is somewhat
uncertain and comments are reasonable. Please refer to it partially.” Low confidence: “The current implementation is not confidently
correct. Please consider regenerating it.” The final prompt, as illustrated in
Figure 5, aggregates all contextual
signals, including imports, enriched context, the generation mode
guidance, the draft, and the target signature. This structural prompt
provides the LLM with a multi-perspective view: repository dependencies,
usage patterns, prior draft guidance, and explicit task specifications,
enabling the model to generate a final function body that is
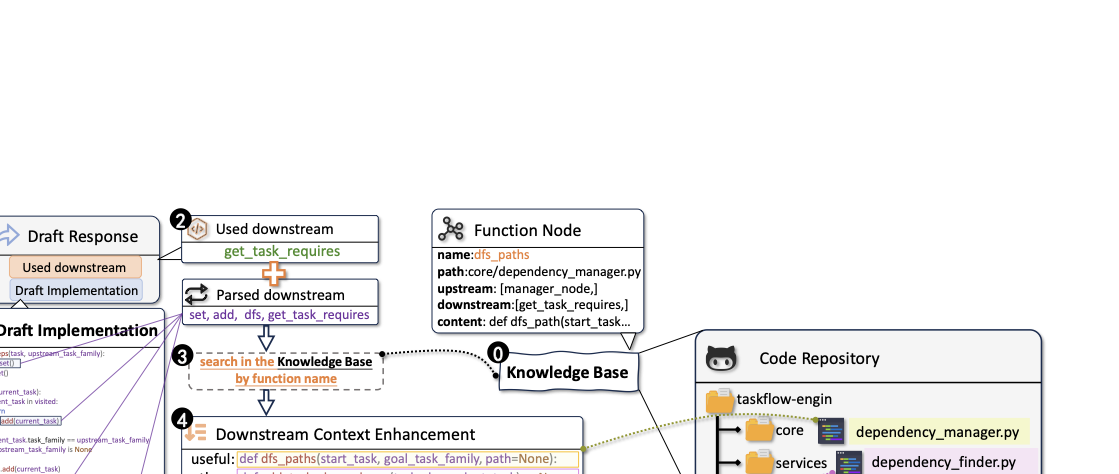
contextually grounded, semantically consistent, and repository-aware. Figure 4 shows a working example
illustrating the entire workflow. (1) The model produces a complex draft
that attempts to reimplement a depth-first search (DFS) procedure from
scratch, without leveraging existing utilities in the repository. (2)
Based on this draft response, two sources of potential callees are
extracted—function calls parsed from the AST and the LLM-predicted
callees—which are unified into a query set $`Q`$. (3) This query is then
used to search within the repository’s knowledge base via substring
matching, yielding a candidate set $`\mathcal{C}`$ of downstream
functions. Among these retrieved functions, the system identifies the
existing utility We comprehensively evaluate the effectiveness of InlineCoder by
addressing the following research questions (RQs): (Overall Effectiveness): How does InlineCoder perform on
repository-level code generation tasks compared to state-of-the-art
baselines? (Ablation Study): To what extent do the key components of
InlineCoder contribute to its overall performance? (Qualitative Analysis): How does the upstream-downstream retrieval
mechanism in InlineCoder provide effective context for code
generation? (Domain Generalization): How does the performance of InlineCoder
generalize across different programming domains? We conduct our experiments on two prominent repository-level code
generation benchmarks: DevEval and REPOEXEC . We focus on completing
the entire body of the unfinished functions. DevEval is a repository-level benchmark that aligns with
real-world codebases, providing 1,825 annotated samples in Python from
115 repositories across 10 domains to systematically evaluate LLMs’
coding abilities. REPOEXEC is a benchmark for repository-level code generation that
provides 355 functions in Python with ground-truth annotations. Following established practices in repository-level code generation
research , we evaluate the quality of the generated code from multiple
dimensions using the following metrics. Let $`y`$ denote the reference
code snippet (ground truth), and $`\tilde{y}`$ denote the generated code
produced by the model. Identifiers such as variable names, API calls,
and function names are extracted from a code snippet $`y`$ into a set
$`I(y)`$. These definitions form the basis for the following evaluation
metrics. Exact Match (EM) checks whether the generated code exactly matches
the reference snippet, yielding a binary score. Edit Similarity (ES) provides a finer-grained measure based on
Levenshtein distance, computed as where $`\mathrm{Lev}(y,\tilde{y})`$ denotes the Levenshtein distance
between $`y`$ and $`\tilde{y}`$, defined as the minimum number of
insertions, deletions, or substitutions required to transform $`y`$
into $`\tilde{y}`$. BLEU evaluates the n-gram overlap between the candidate and the
reference, defined as where $`p_n`$ is the modified n-gram precision, $`w_n`$ are weights
(typically uniform, $`w_n = \tfrac{1}{N}`$), and
$`\mathrm{BP} = \min\left(1, e^{1 - \tfrac{|\tilde{y}|}{|y|}}\right)`$
is the brevity penalty. Identifier Match F1 (ID.F1) evaluates identifier-level overlap,
such as API and variable names, with the F1 score. Let $`I(y)`$ and
$`I(\tilde{y})`$ denote the sets of identifiers extracted from the
reference and generated code, respectively. Precision, recall, and the
ID.F1 score are defined as We did not adopt execution-based metrics such as Pass@k (the passing
rate of generated code on test cases). Unlike programming-contest
benchmarks , repository-level code completion tasks differ substantially
in structure and dependencies . In our experiments, we also observed
that execution-based scores fluctuate considerably across runs. The same
model outputs often result in test failures due to subtle environmental
issues that are unrelated to the model itself. These fluctuations could
lead to misleading or non-comparable Pass@k results. We compare InlineCoder against a suite of baselines spanning a large
variety of techniques, including in-file context methods,
text-similarity-based retrieval, and static-analysis-based approaches. In-File leverages the full in-file context without utilizing any
cross-file information. Vanilla follows the basic prompt construction provided in existing
benchmarks such as DevEval and RepoExec , where related repository
context is merely prepended before the target function without deep
integration. RepoCoder is a retrieval-augmented framework that iteratively
combines similarity-based retrieval with code LLMs to exploit
repository-level context for code completion. Specifically, we
implemented its function body completion pipeline, using
UniXcoder1 as the embedding model. For evaluation, we adopted the
results from the third retrieval-iteration stage, as reported to be
the most effective in the original work. DRACO enhances repository-level code completion via
dataflow-guided retrieval, constructing a repo-specific context graph
to provide precise and relevant information for LLMs. We have adapted
the prompt template of this baseline method to support the complete
function body completion task. GraphCoder employs a graph-based retrieval-generation framework
using code context graphs and a coarse-to-fine retrieval process to
acquire repository-specific knowledge more effectively. We have
adapted the prompt template of this baseline method to support the
complete function body completion task. For the draft generation stage, we employed the identical Vanilla
prompts used in the baseline methods for each dataset: the basic prompt
construction methods provided by DevEval and REPOEXEC, respectively. For
context retrieval, we parse Python code and build call graphs with the
assistance of Tree-Sitter2 and Pydepcall3. To evaluate our framework across different models, we used three
advanced backbone LLMs: Table [tab:total_dev_eval] and
[tab:total_repo_exec] compare
the performance of various methods on the DevEval and RepoExec datasets
across three backbone models. Overall, InlineCoder achieves substantial and stable improvements across
all three backbones. Notably, InlineCoder achieves stable improvement
compared to Vanilla, a baseline method which is also used in the draft
generation stage of InlineCoder. To quantify the gains, we compute the
relative percentage improvements over the strongest baseline for each
backbone model, and then report the averaged results across the three
models. On DevEval, the average relative improvements reach 5.13% in
EM, 10.86% in ES, and 10.67% in BLEU; on RepoExec, the gains are
even larger, with 29.73% in EM, 20.82% in ES, and 49.34% in
BLEU, highlighting InlineCoder’s robustness across models and datasets. The In-File baseline—using only intra-file context—remains competitive,
sometimes outperforming GraphCoder and DRACO. This suggests that
preserving local context is critical. By contrast, GraphCoder and DRACO
often underperform because they were originally designed for line-level
completion and rely on assumptions (e.g., partial function bodies or
dataflow analysis) that do not hold in function-body generation.
Additionally, they discard in-file context, which can contain crucial
local information, further limiting their effectiveness in
repository-level code generation. We notice that the EM scores in our experiments are relatively lower
compared to those reported in prior work. This discrepancy arises from
differences in completion objectives: while previous studies primarily
evaluate single-line completion, our task requires completing entire
function bodies, which is inherently more challenging. We conduct an ablation study on the
DevEval dataset using the DeepSeek-V3
backbone. The ablated variants include: removing upstream context
retrieval (w/o upstream), removing
usage-context inlining (w/o inline),
removing downstream context retrieval (w/o
downstream), removing the confidence statement derived from the
draft’s perplexity (w/o confidence), and
removing the draft implementation itself from the context-aware code
generation (w/o draft). As shown in
Table [tab:ablation_DevEval],
eliminating any key component results in performance degradation, which
confirms their effectiveness. Removing the draft implementation causes
the largest drop, showing that anchoring generation to concrete
candidates is crucial for accuracy and semantic alignment. The removal
of inlining and upstream/downstream context also consistently
degrades performance, underscoring their complementary roles. Notably,
the performance of w/o inline is
comparable to that of w/o upstream,
suggesting that upstream information alone provides limited benefit if
not properly linearized. Finally, removing the confidence statement
leads to moderate but stable drops, showing that perplexity-based
scoring helps select more effective prompts.
To further investigate the role of upstream context in function
completion, we focus on the generation of the As shown in
Table [tab:validation_upstream],
InlineCoder consistently achieves the best performance across all
metrics. In particular, InlineCoder improves EM scores by 2.07% on
return statements. While RepoCoder also leverages iterative generation,
it still falls short of InlineCoder, suggesting that naive
multi-generation alone is insufficient. Instead, incorporating
structured upstream usage information provides more reliable guidance
for producing accurate final statements. These findings confirm that
upstream information plays a crucial role in shaping the correctness and
naturalness of the return expressions, complementing the benefits of
inlining and retrieval strategies demonstrated in earlier experiments.
To investigate the role of downstream information in improving
function-call correctness, we conducted a targeted evaluation on the
generated invocation statements using the
DevEval dataset with the DeepSeek-V3
backbone. For each generated function, we extracted all invocation
statements and compared them against the reference annotations. We
adopted several evaluation metrics to assess this alignment, including
EM, Jaccard Similarity, F1 Score, Coverage, and Downstream Invocation
Recall (DIR) . These metrics collectively measure the accuracy and
completeness of both callee names and full invocation instances. For
comparison, we also conducted experiments on Vanilla, RepoCoder, and
InlineCoder. As shown in
Table [tab:validation_downstream],
the proposed context-aware generation (InlineCoder) achieves the
overall best performance. In particular, InlineCoder improves EM by
4.27% on function-call statements. These results demonstrate that
incorporating downstream information substantially improves the
correctness and coverage of invocation statements, thereby strengthening
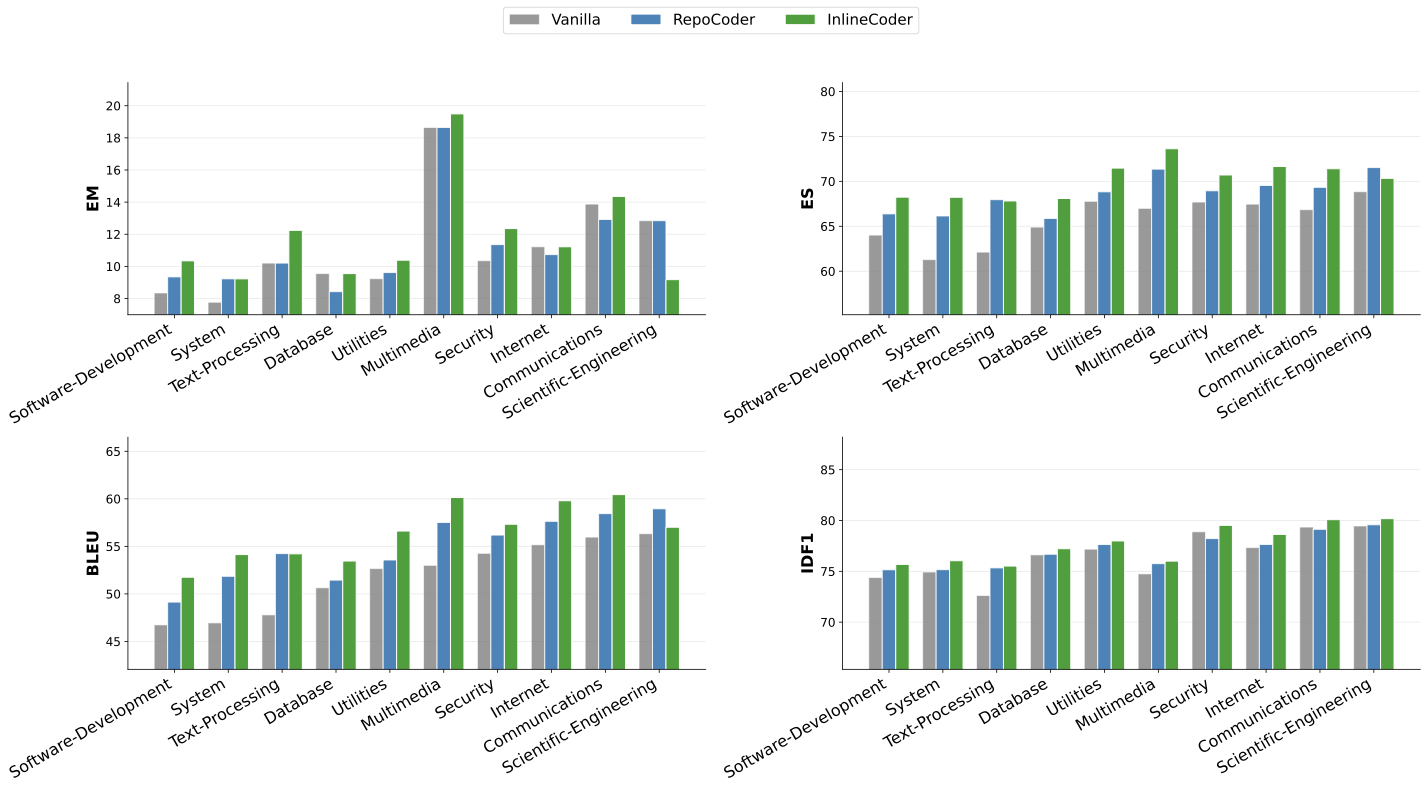
the functional reliability of generated code. To further investigate the generalizability of our approach across
different domains, we adopt the domain taxonomy provided by the
DevEval dataset and evaluate four
metrics: EM, ES, BLEU, and ID.F1. Experiments are conducted on the
DevEval dataset using the DeepSeek-V3 backbone. The results over ten
domains are summarized in
Figure 6. In terms of Exact Match (EM), InlineCoder achieves the best performance
in 9 out of 10 domains. For ES, it outperforms the baselines in 8
domains. On BLEU, InlineCoder leads in 9 domains, while on ID.F1, it
achieves the best results across all 10 domains. Compared to the Vanilla
baseline, InlineCoder demonstrates consistent improvements in almost all
domains. The only relatively weaker performance is observed in the
Scientific-Engineering domain, which may be attributed to the nature
of this domain: its tasks are primarily oriented towards scientific
computing, where the cross-function invocation structure is relatively
sparse. Consequently, the downstream and upstream information leveraged
by our method provides limited additional benefit in this domain. Figure 7 presents a case study comparing
InlineCoder against other baselines. The target function for completion
is This case study demonstrates the effectiveness of InlineCoder’s in
capturing both upstream and downstream contexts. Through function
inlining, InlineCoder successfully identifies and leverages crucial
contextual information that directly impacts implementation correctness.
In contrast, baseline approaches such as RepoCoder, which relies on
similarity-based retrieval, and DRACO, which employs dataflow analysis,
retrieve contextual information that, although structurally relevant,
offers limited utility for the specific implementation task. The advantages of our approach are particularly evident in two key
aspects. First, in handling downstream dependencies, only InlineCoder
correctly utilizes the Figure 8 provides another case about
how our confidence statement mitigates anchoring bias. In “Base
Generation,” the LLM defaults to general priors (e.g.,
Conversely, when InlineCoder identifies the draft as a medium-confidence
result, it prepends a confidence statement. This re-frames the task from
simple generation to active modification, forcing the LLM to re-evaluate
its draft against the inlined information. Consequently, the model
successfully identifies structural discrepancies and adopts correct
conventions, demonstrating that while context inlining provides the
necessary knowledge, confidence guidance serves as the essential trigger
to ensure repository-level information is utilized rather than
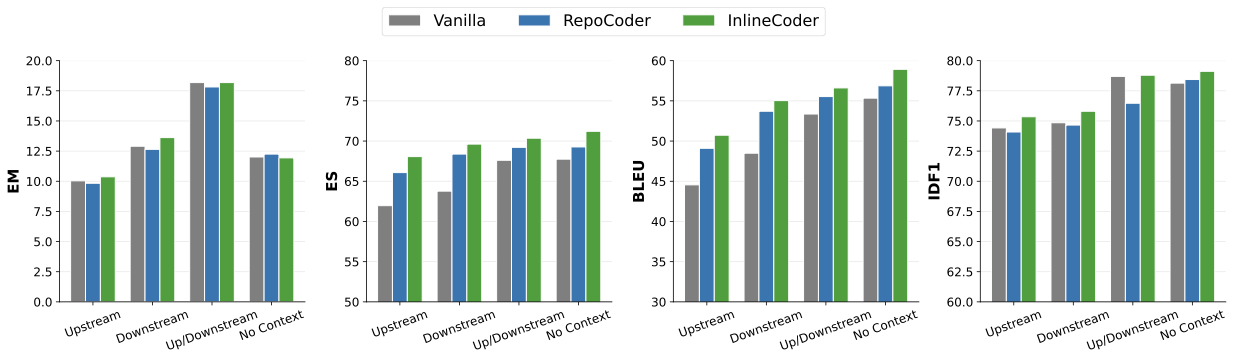
overshadowed by initial model biases. Figure 9 illustrates how repository
environments influence the effectiveness of InlineCoder. To quantify
this impact, we performed a stratified analysis on the
DevEval dataset — a benchmark curated
from real-world Python projects on GitHub — using DeepSeek-V3,
categorizing samples into four groups based on their inherent structural
characteristics: Upstream (16.38%), Downstream (15.29%),
Up/Downstream (6.03%), and No Context (74.36%). Here, the No
Context group represents isolated functions that naturally lack
caller-callee dependencies in their original repositories, rather than
intentionally removing their contexts. The results show that InlineCoder consistently outperforms baselines in
nearly all scenarios. Notably, we observe that overall scores in the No
Context setting are generally higher than those in context-dependent
categories. This is attributed to the fact that functions without
upstream or downstream relations are typically independent, resulting in
a lower reliance on repository-wide information. The inherent simplicity
of these standalone tasks leads to higher baseline performance.
Conversely, the lower scores observed in complex repository environments
(i.e., those with caller-callee relationships) suggest that the primary
challenge lies in the model’s difficulty in comprehending and
integrating intricate structural context. Furthermore, across the four categories, InlineCoder achieves the most
significant performance gain in the Upstream setting. This substantial
improvement empirically validates the effectiveness of our design in
capturing and utilizing upstream caller information. Like most existing repository-level code generation benchmarks , our
empirical evaluation is conducted on Python repositories, which may
limit the generalizability of our findings to other programming
languages or different types of software projects. We mitigate this
threat in two ways. First, we evaluate our method on two distinct
datasets that span multiple domains and project scales. Second, the
fundamental principle of InlineCoder—leveraging upstream usage context
and downstream dependency context—is language-agnostic. The framework
relies on Abstract Syntax Tree (AST) analysis, a standard technique
applicable to virtually all modern programming languages. Although our
implementation is specific to Python, the core methodology can be
readily extended to other programming languages such as Java, C++, or
TypeScript. And in strongly typed languages such as C++, AST analysis
can also provide more upstream and downstream information. Code Large Language Models (LLMs), such as Code Llama , DeepSeek-Coder ,
and Qwen-Coder , have demonstrated remarkable potential in automating
software development tasks . By internalizing extensive code knowledge
from vast corpora into billions of parameters, these models can solve a
wide array of general-purpose programming problems . Building upon these
foundational capabilities, repository-level code generation has evolved
significantly , with prior work broadly categorized into
retrieval-augmented generation , graph-based and structured retrieval ,
agentic/iterative refinement , static-analysis-informed prompting , and
fine-tuning . Early efforts demonstrated that retrieving relevant code snippets from
the repository can substantially improve generation quality. Methods
such as RepoCoder , RepoFuse , and RepoFusion leverage retrieval
mechanisms to supply the model with repository-wide context.
LongCodeZip selects multiple relevant contexts based on the inherent
perplexity from LLMs. Other works explore prompt selection strategies to
choose the most useful snippets from large repositories . These
approaches establish the value of repository-level context but typically
rely on similarity or topical relevance rather than relational
call-graph signals. To capture structural relationships beyond lexical similarity, a line of
work constructs graph representations of code. CodexGraph builds code
graph databases that enable structured querying, while GraphCoder
models control-flow and data dependencies using context graphs.
RepoHyper and related approaches use semantic repo-level graphs with
search-expand-refine strategies to locate relevant code elements . These
methods enhance retrieval precision by leveraging structural
relationships; however, they are primarily oriented toward identifying
structurally similar or semantically related code snippets, rather than
explicitly incorporating upstream or downstream usage signals into the
prompts. Agentic frameworks and iterative planners perform multi-step reasoning
and use external tools (static analysis, testing, or execution) to
refine outputs. Examples include CodeRAG, which combines dual graphs
with agentic reasoning and specialized tools for graph traversal and
code testing ; RRR, which allows iterative exploration using static
analysis ; and CodePlan, which frames repo-level coding as a planning
problem with incremental dependency analysis . These works highlight the
benefit of multi-step problem decomposition but do not systematically
leverage caller–callee signals encoded by call graphs as prompt
augmentations. Several works incorporate static analysis to prune or enrich the prompt
context. STALL+ integrates static analysis into prompting, decoding, and
post-processing stages ; DRACO uses dataflow-guided retrieval to focus
on flow-relevant fragments ; and hierarchical methods model repositories
at function granularity with topological dependencies to reduce noisy
context . These techniques enhance relevance and reduce noise; however,
they remain primarily focused on context selection or compression,
rather than the injection of explicit upstream/downstream usage
information or confidence signals derived from preliminary model
outputs. Other lines of work focus on domain-specialized model training
strategies : RTLRepoCoder fine-tunes for Verilog completion ,
curriculum datasets target hard patterns . There are also efforts to
improve retrievers (e.g., via reinforcement learning) and to combine
retrieval with reinforcement or reflexive training . In contrast to these works, InlineCoder introduces several key
novelties. First, unlike traditional RAG or graph-based methods that
rely on surface-level similarity or static structures, our approach
reframes repository-level generation as a function-level task by
inlining the unfinished function into its call stack, capturing both
upstream usage constraints and downstream dependencies dynamically.
Second, we leverage a draft completion as an anchor to drive
bidirectional retrieval, enabling precise context integration without
extensive fine-tuning. This allows for iterative refinement that
enhances generation precision and repository coherence, addressing
limitations in existing methods that often overlook orthogonal
dimensions of function dependencies and usages. In this paper, we present InlineCoder, a novel repository-level code
generation framework that enhances LLMs by inlining relevant upstream
and downstream context from the code repository. By systematically
integrating contextual information from both function callers and
callees, InlineCoder provides a richer, more natural understanding of
the target function’s environment in the specific repository. Extensive
experiments on the DevEval and
REPOEXEC datasets show that InlineCoder
consistently outperforms strong baselines across multiple metrics.
Ablation studies and targeted analyses confirm that the core innovation
of inlining—incorporating both upstream and downstream context—is the
primary driver behind significant improvements in return statement
accuracy and function-call precision. Beyond these empirical gains,
InlineCoder demonstrates robust generalization across diverse
programming domains and maintains stable performance when integrated
with different backbone LLMs. All code and data used in this study are publicly available at:
https://github.com/ythere-y/InlineCoder
. This research is funded by the National Key Research and Development
Program of China (Grant No. 2023YFB4503802), the National Natural
Science Foundation of China (Grant No. 62232003), and the Natural
Science Foundation of Shanghai (Grant No. 25ZR1401175).
 style="width:100.0%" />
style="width:100.0%" />
dfs_paths. (4) In the next stage, this downstream
information $`\mathcal{C}`$ is injected into the prompt as additional
context. (5) The model is then guided to perform the final Context-Aware
Code Generation.Experiment Setup
Datasets
Evaluation Metrics
\begin{equation}
\mathrm{ES}(y,\tilde{y}) = 1 - \frac{\mathrm{Lev}(y,\tilde{y})}{\max(|y|,|\tilde{y}|)},
\end{equation}\begin{equation}
\mathrm{BLEU} = \mathrm{BP} \cdot \exp \left( \sum_{n=1}^{N} w_n \log p_n \right),
\end{equation}\begin{equation}
Precision = \frac{|I(y) \cap I(\tilde{y})|}{|I(\tilde{y})|}, \quad
Recall = \frac{|I(y) \cap I(\tilde{y})|}{|I(y)|}, \quad
\mathrm{ID.F1} = \frac{2 \cdot Precision \cdot Recall}{Precision + Recall}.
\end{equation}Baselines
Implementation Details
DeepSeek-V34 , Qwen3-Coder5 , and
GPT-5-mini6 . We employ Qwen2.5-Coder-1.5B7 as the probability
estimator for confidence estimation in the final stage. We configure
each model to its native context window size to accommodate long input
sequences, as our evaluation tasks require substantial context but
generate concise outputs. The configured input limits are 128000 tokens
for DeepSeek-V3, 262144 tokens for Qwen3-Coder, and 400000 tokens
for GPT-5-mini. Output generation was limited to 10000 tokens for all
models to ensure focused completions. To ensure deterministic and
reproducible decoding, all models used a temperature of 0.0, rendering
the top-$`p`$ sampling parameter ineffective. All experiments were run
on a compute server with Intel Xeon Silver 4214R CPUs and NVIDIA A40
GPUs.Experiments Results
RQ1: Overall Effectiveness
RQ2: Ablation Study
Configuration
DeepSeek-V3
2-5
EM
ES
BLEU
ID.F1
InlineCoder
11.56
70.50
57.12
78.01
w/o upstream
9.48 (-2.12)
65.12 (-5.38)
51.34 (-5.78)
77.43 (-0.58)
w/o inline
9.15 (-2.41)
65.95 (-4.55)
52.35 (-4.77)
78.01 (0.00)
w/o downstream
9.75 (-1.81)
65.87 (-4.63)
52.25 (-4.87)
77.60 (-0.41)
w/o confidence
10.74 (-0.82)
67.79 (-2.71)
54.24 (-2.88)
77.30 (-0.71)
w/o draft
7.67 (-3.89)
59.09 (-11.41)
44.24 (-12.88)
76.29 (-1.72)
RQ3: Qualitative Analysis
Methods
EM
BLEU
ES
Vanilla
35.40
50.17
58.72
RepoCoder
37.15
52.77
61.57
InlineCoder
37.92
53.80
62.51
Improved performance on return statements
return statement, which
is typically located at the last line of the target function.
Specifically, we extract the final line of code from both the baseline
generations and InlineCoder, and evaluate their accuracy against the
reference code. Following common practice in single-line code
evaluation, we adopt EM, BLEU, and ES as metrics, all of which were
introduced in Section 4.2. Experiments are conducted on the
DevEval dataset using the DeepSeek-V3
backbone. We compare InlineCoder with two representative methods:
Vanilla and RepoCoder (a strong baseline leveraging multiple
generations).
Methods
EM
Jaccard
F1
Coverage
DIR
Vanilla
29.86
53.10
60.67
63.16
69.21
RepoCoder
21.48
52.80
63.01
65.13
70.45
InlineCoder
30.74
54.99
62.88
65.40
71.86
Improved performance on function-call statements
RQ4: Domain Generalization
 style="width:100.0%" />
style="width:100.0%" />
Case Study
 style="width:100.0%" />
style="width:100.0%" />
parse_unique_urlencoder. The figure is organized in a 2×5 grid,
where the top row displays key contextual information retrieved by
different approaches from the repository, while the bottom row shows the
ground truth reference implementation alongside generations from
InlineCoder and baseline methods.parse_qs utility function with proper
parameters. While RepoCoder attempts to use a similarly named
parse_qsl function, its parameter usage differs significantly from the
reference implementation. This precision in API usage stems directly
from InlineCoder’s downstream retrieval mechanism, which not only
identifies the correct utility function but also captures its
implementation details, ensuring accurate function names and parameter
specifications. Second, InlineCoder demonstrates effectiveness in
handling return value. As the case shows, InlineCoder consistently
generates the correct return type dict. In contrast, baseline methods
exhibit inconsistent behavior—sometimes returning dict, but also
frequently producing str, int, or None. This accuracy in return
type handling is achieved through InlineCoder’s upstream inlining, which
identifies the caller function safe_parse_query. style="width:100.0%" />
style="width:100.0%" />
packet.timestamp) instead of capturing enhanced context information.
Without confidence guidance, the model exhibits strong self-repetition,
replicating its initial erroneous draft verbatim despite the presence of
the correct inlined context.Discussion
Performance Analysis Across Various Context Environments
 style="width:100.0%" />
style="width:100.0%" />
Threats to Validity
Related Work
Retrieval-augmented generation.
Graph-based and structured retrieval.
Agentic and iterative refinement.
Static analysis and context pruning.
Fine-tuning methods.
Conclusion
Data Availability
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct ↩︎
-
gpt-5-mini-2025-08-07 from https://platform.openai.com/docs/models/gpt-5-mini ↩︎