Geometric Regularization in Mixture-of-Experts The Disconnect Between Weights and Activations
📝 Original Paper Info
- Title: Geometric Regularization in Mixture-of-Experts The Disconnect Between Weights and Activations- ArXiv ID: 2601.00457
- Date: 2026-01-01
- Authors: Hyunjun Kim
📝 Abstract
Mixture-of-Experts (MoE) models achieve efficiency through sparse activation, but the role of geometric regularization in expert specialization remains unclear. We apply orthogonality loss to enforce expert diversity and find it fails on multiple fronts: it does not reduce weight-space overlap (MSO actually increases by up to 114%), activation-space overlap remains high (~0.6) regardless of regularization, and effects on performance are inconsistent -- marginal improvement on WikiText-103 (-0.9%), slight degradation on TinyStories (+0.9%), and highly variable results on PTB (std > 1.0). Our analysis across 7 regularization strengths reveals no significant correlation (r = -0.293, p = 0.523) between weight and activation orthogonality. These findings demonstrate that weight-space regularization neither achieves its geometric goal nor reliably improves performance, making it unsuitable for MoE diversity.💡 Summary & Analysis
1. **Failure of Orthogonality Regularization**: Despite its intuitive appeal, orthogonality regularization does not improve model performance as expected. This is like adding the same amount of every ingredient to a recipe and expecting it to taste good.-
Weight-Activation Gap: The geometric property of weights doesn’t translate into activation space. This is akin to designing a building structure and then finding that construction methods don’t match the design perfectly.
-
Inconsistent Results: Across different datasets, orthogonality regularization yields unreliable results, suggesting it may complicate model optimization rather than improve it.
📄 Full Paper Content (ArXiv Source)
Mixture-of-Experts (MoE) models scale efficiently by activating only a subset of parameters per input . A common assumption is that expert representations should be orthogonal to minimize interference . This intuition stems from linear algebra: orthogonal vectors are maximally distinguishable and their outputs do not interfere when combined.
Hypothesis.
Orthogonality regularization should improve expert diversity and reduce perplexity.
Finding.
It does not—and is unreliable. Across three datasets (TinyStories, WikiText-103, PTB), geometric regularization yields inconsistent results: marginal improvement on WikiText-103 ($`-0.9\%`$), slight degradation on TinyStories ($`+0.9\%`$), and high variance on PTB (std $`>`$ 1.0).
Why?
We identify a Weight-Activation Gap: weight-space orthogonality (MSO $`\approx 10^{-4}`$) does not translate to activation-space orthogonality (MSO $`\approx 0.6`$). Across 7 regularization strengths, we find no significant correlation between weight and activation overlap ($`r = -0.293`$, $`p = 0.523`$), indicating that weight geometry and functional orthogonality are largely independent.
Contributions.
-
We show that orthogonality regularization fails to reduce weight MSO—it actually increases it by up to 114%—and yields inconsistent effects on loss: marginal improvement on WikiText-103 ($`-0.9\%`$), slight degradation on TinyStories ($`+0.9\%`$), and high variance on PTB (std $`>`$ 1.0).
-
We identify a weight-activation disconnect: activation overlap is $`\sim`$1000$`\times`$ higher than weight overlap, with no significant correlation ($`r = -0.293`$, $`p = 0.523`$, $`n`$=7).
-
We demonstrate that weight-space regularization is an unreliable optimization target—it neither achieves its geometric goal nor reliably improves performance.
Method
Orthogonality Loss.
For expert weight matrices $`\{W_i\}_{i=1}^N`$, we define:
\begin{equation}
\mathcal{L}_{\text{orth}}= \sum_{i < j} |\langle \tilde{W}_i, \tilde{W}_j \rangle|^2
\label{eq:orth_loss}
\end{equation}where $`\tilde{W}_i = \text{vec}(W_i) / \|\text{vec}(W_i)\|`$ is the normalized flattened weight vector. This loss encourages orthogonality among expert representations and is added to the language modeling objective with weight $`\lambda`$.
Mean Squared Overlap (MSO).
We measure geometric diversity using:
\begin{equation}
\text{MSO}= \frac{2}{N(N-1)} \sum_{i < j} |\langle \tilde{W}_i, \tilde{W}_j \rangle|^2
\end{equation}Lower MSO indicates more orthogonal (diverse) experts. We compute MSO for both weights and activations.
Activation MSO.
For co-activated experts producing outputs $`\{h_i\}`$, we compute:
\begin{equation}
\text{MSO}_{\text{act}} = \mathbb{E}_{x}\left[\frac{2}{k(k-1)} \sum_{i < j \in \mathcal{S}(x)} \left(\frac{\langle h_i, h_j \rangle}{\|h_i\|\|h_j\|}\right)^2\right]
\end{equation}where $`\mathcal{S}(x)`$ is the set of $`k`$ selected experts for input $`x`$. This measures functional similarity between expert outputs on actual inputs.
Experiments
Setup.
We train NanoGPT-MoE ($`\sim`$130M parameters, 8 experts, 6 layers, top-2 routing) on TinyStories for 10K iterations with AdamW (lr=$`5 \times 10^{-4}`$, $`\beta_1`$=0.9, $`\beta_2`$=0.95, weight decay=0.1). Each MoE layer contains 8 experts with hidden dimension 512 and intermediate dimension 2048. TinyStories experiments use 5 random seeds (42, 123, 456, 789, 1337).
Implementation Details.
We regularize the up-projection weights ($`W_{\text{up}} \in \mathbb{R}^{d_{\text{ffn}} \times d_{\text{model}}}`$) of each expert. Each weight matrix is flattened and L2-normalized before computing pairwise inner products. The $`\lambda`$ sweep uses 7 values: $`\{0, 0.001, 0.005, 0.01, 0.05, 0.1, 0.2\}`$. MSO is computed per layer and averaged across all 6 MoE layers. Activation MSO is computed on the post-gating expert outputs for the top-2 selected experts, unweighted by gating scores. We do not use auxiliary load balancing loss.
Weight MSO Under Regularization
Table 1 reveals a surprising finding: orthogonality regularization does not reduce weight MSO—it increases it. Despite the loss explicitly penalizing expert overlap, the final weight MSO rises with $`\lambda`$, suggesting the regularization interferes with natural training dynamics rather than enforcing orthogonality.
| Method | Weight MSO | $`\Delta`$ |
|---|---|---|
| Baseline | $`5.43 \times 10^{-4}`$ | — |
| + Orth ($`\lambda`$=0.001) | $`7.52 \times 10^{-4}`$ | $`+39\%`$ |
| + Orth ($`\lambda`$=0.01) | $`1.16 \times 10^{-3}`$ | $`+114\%`$ |
Orthogonality regularization increases weight MSO, contrary to its intended effect. Baseline weights are already near-orthogonal.
Perplexity Does Not Improve
Despite the explicit regularization objective, perplexity improvements are not statistically significant (Table 2).
| Method | Val PPL | $`\Delta`$% | p-value |
|---|---|---|---|
| Baseline | $`5.94 \pm 0.08`$ | — | — |
| + Orth ($`\lambda`$=0.001) | $`6.00 \pm 0.32`$ | $`+0.9\%`$ | 0.727 |
Orthogonality regularization does not improve perplexity ($`p = 0.727`$, paired t-test, $`n`$=5 seeds). Variance increases from 0.08 to 0.32.
Why Are p-values High?
The high p-value ($`p = 0.727`$) reflects both minimal effect size and increased variance. The baseline shows low std (0.08), while $`\lambda`$=0.001 increases variance to 0.32—a 4$`\times`$ increase that destabilizes training. The slight PPL increase (+0.9%) is dwarfed by this variance, indicating the regularization adds noise without benefit.
The Weight-Activation Gap
Table 3 reveals the core finding: weight and activation geometry are fundamentally decoupled.
| $`\lambda`$ | Weight MSO | Act. MSO | Ratio |
|---|---|---|---|
| 0 (baseline) | $`5.43 \times 10^{-4}`$ | $`0.572`$ | 1053$`\times`$ |
| 0.001 | $`7.52 \times 10^{-4}`$ | $`0.581`$ | 773$`\times`$ |
| 0.01 | $`1.16 \times 10^{-3}`$ | $`0.577`$ | 496$`\times`$ |
| 0.1 | $`2.04 \times 10^{-3}`$ | $`0.593`$ | 290$`\times`$ |
| 0.2 | $`2.78 \times 10^{-3}`$ | $`0.564`$ | 203$`\times`$ |
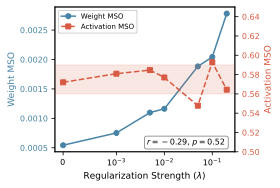
Activation MSO ($`\sim`$0.57) remains constant while weight MSO increases with $`\lambda`$. Pearson $`r = -0.293`$, $`p = 0.523`$ ($`n`$=7), indicating no significant correlation.
Correlation Analysis.
Figure 1 visualizes the disconnect: as $`\lambda`$ increases, weight MSO rises (regularization is applied), but activation MSO remains flat at $`\sim`$0.57. Across 7 regularization strengths, we find Pearson $`r = -0.293`$ ($`p = 0.523`$, 95% CI: $`[-0.857, 0.590]`$)—not statistically significant. This confirms that weight and activation geometry are independent.
 />
/>
Cross-Dataset Validation
To test whether our findings generalize beyond TinyStories, we evaluate orthogonality regularization on WikiText-103 and Penn Treebank —two standard benchmarks with different characteristics (Table 4).
| Dataset | Tokens | Base | Orth | $`\Delta`$ |
|---|---|---|---|---|
| WikiText-103 | 118M | $`3.76_{\pm.02}`$ | $`3.73_{\pm.05}`$ | $`-0.9\%`$ |
| TinyStories | 2.1M | $`5.94_{\pm.08}`$ | $`6.00_{\pm.32}`$ | $`+0.9\%`$ |
| PTB | 1.2M | $`6.17_{\pm.95}`$ | $`5.74_{\pm1.11}`$ | $`-7.0\%^*`$ |
Cross-dataset validation ($`n`$=3 seeds for WikiText-103/PTB, $`n`$=5 for TinyStories, $`\lambda`$=0.001). $`^*`$PTB shows high variance; effect direction unreliable.
Dataset-Dependent Effects.
Multi-seed experiments reveal mixed effects. On WikiText-103 (118M tokens), orthogonality regularization yields a small, consistent improvement ($`-0.9\%`$). However, on PTB (1.2M tokens), results are highly variable across seeds (std $`\sim`$ 1.0), making conclusions unreliable. This high variance suggests that the effectiveness of geometric regularization may depend on dataset-seed interactions rather than dataset characteristics alone.
Interpretation.
The high variance on PTB (std $`\sim`$1.0) compared to WikiText-103 (std $`\sim`$0.05) may reflect dataset-scale effects. Smaller datasets may exhibit more seed-dependent expert specialization patterns, leading to unstable outcomes. Regardless of direction, the inconsistency itself undermines the reliability of weight-space regularization—a method that works only under specific seed-dataset combinations is impractical.
Analysis: Why Does the Gap Exist?
The Role of Non-Linearities.
Modern MoE experts use non-linear activation functions (SiLU/Swish) and LayerNorm . Consider the expert computation:
\begin{equation}
h_i = \text{LayerNorm}(\text{SiLU}(W_i \cdot x))
\end{equation}Even if $`W_i \perp W_j`$, the non-linearities transform the geometry non-trivially. SiLU applies element-wise gating that depends on activation magnitudes, while LayerNorm re-centers and re-scales activations to unit variance. These operations can compress the angular differences between expert outputs, increasing activation overlap regardless of weight geometry.
Input Distribution Effects.
Weight orthogonality constrains static parameters, but activation orthogonality depends on the input distribution. If inputs $`x`$ project similarly onto different weight subspaces (e.g., due to low-rank structure in the input distribution), the resulting activations $`W_i \cdot x`$ and $`W_j \cdot x`$ will be correlated even when $`W_i \perp W_j`$. Natural language inputs may exhibit such structure due to semantic regularities.
Mathematical Intuition.
Consider two weight matrices $`W_1, W_2`$ with Frobenius orthogonality $`\langle W_1, W_2 \rangle_F = \text{tr}(W_1^T W_2) = 0`$. This constraint only ensures the sum of entries in $`W_1^T W_2`$ is zero—it does not imply $`W_1^T W_2 = 0`$. For an input $`x`$, the activation inner product is $`\langle z_1, z_2 \rangle = x^T W_1^T W_2 x`$. Since $`W_1^T W_2`$ can have arbitrary non-zero structure (only its trace is constrained), this quadratic form is generally non-zero for typical inputs. Thus, Frobenius orthogonality of weights provides no guarantee of activation orthogonality.
Related Work
MoE Scaling and Architecture.
The modern MoE paradigm originates from , who demonstrated trillion-parameter scaling via sparse gating. simplified this with top-1 routing in Switch Transformers, while GShard enabled efficient distributed training. Recent work explores finer-grained expert decomposition: DeepSeekMoE uses 64 fine-grained experts per layer, and Mixtral achieves strong performance with 8 experts using top-2 routing. These architectures assume expert diversity emerges naturally through training.
Expert Specialization and Diversity.
Several methods address expert diversity through routing improvements. X-MoE uses hyperspherical routing with cosine-normalized gating to mitigate representation collapse. HyperRouter dynamically generates router parameters via hypernetworks. S2MoE applies stochastic learning with Gaussian noise to prevent overlapping expert features. ReMoE proposes ReLU routing with L1 regularization for differentiable expert selection. SMoE-Dropout applies random routing to prevent expert collapse. CompeteSMoE uses competition-based routing to address representation collapse. Recent analysis by finds that expert diversity increases with layer depth, yet concludes that the degree of expert specialization “remains questionable.” report that expert representations can exhibit up to 99% similarity even in well-performing MoE models, proposing an orthogonal optimizer as a solution. Our results extend this skepticism: even when weight-space metrics suggest diversity, activation-space overlap persists. Critically, these methods primarily target routing or optimization diversity, whereas we analyze weight-space geometric constraints directly.
Geometric Analysis in Deep Learning.
Neural Collapse shows that classifier representations converge to equiangular tight frames (ETFs) during terminal training. This geometric structure—where class representations are maximally separated—inspired our hypothesis that expert representations should similarly benefit from orthogonality. However, classifier heads are linear mappings from features to logits, whereas MoE experts are non-linear transformations with internal structure. Our negative result suggests the Neural Collapse analogy does not transfer: non-linearities break the geometry.
Discussion
Our results challenge the implicit assumption that weight-space orthogonality leads to functional diversity. Beyond being ineffective, geometric regularization is unreliable—showing high variance (std $`>`$ 1.0) on smaller datasets like PTB.
Implications for MoE Design.
-
Weight-space regularization is unreliable. Its effects are inconsistent: marginal improvement on WikiText-103 ($`-0.9\%`$), degradation on TinyStories ($`+0.9\%`$), and high variance on PTB. This unpredictability makes it unsuitable as a general strategy.
-
Activation-space regularization may be more appropriate. Directly constraining $`\text{MSO}_{\text{act}}`$ during training could enforce functional diversity without the weight-activation disconnect.
-
Natural training already achieves low weight MSO. The baseline weight MSO ($`\sim 10^{-4}`$) is already near-orthogonal, suggesting gradient descent implicitly regularizes expert geometry .
-
Dataset scale matters. Smaller datasets exhibit higher seed-dependent variance, making regularization effects unpredictable.
Conclusion
We investigate whether geometric regularization of MoE expert weights improves model performance and find that it does not—and is unreliable. Orthogonality loss fails to reduce weight MSO (it increases by up to 114%), and its effects on downstream performance are inconsistent: marginal improvement on WikiText-103 ($`-0.9\%`$), slight degradation on TinyStories ($`+0.9\%`$), and high variance on PTB (std $`>`$ 1.0). We identify a fundamental disconnect between weight and activation orthogonality: activation MSO remains $`\sim`$1000$`\times`$ higher than weight MSO, with no significant correlation ($`r = -0.293`$, $`p = 0.523`$, $`n`$=7). This gap arises from non-linear transformations (SiLU, LayerNorm) and input distribution effects. Our analysis reveals that geometric regularization neither achieves its geometric goal nor reliably improves performance, making it unsuitable as a strategy for MoE diversity. Future work should explore activation-space regularization or alternative diversity metrics that directly target functional behavior.
Limitations
Scale.
Our experiments use NanoGPT-MoE ($`\sim`$130M parameters). Whether the weight-activation gap persists at larger scales (1B+ parameters) or with different architectures (e.g., Mixtral, DeepSeek-MoE) remains an open question. Prior work reports router-level gains at larger scales ; our findings may be setup-specific.
Statistical Power.
TinyStories experiments use 5 random seeds with statistical testing. WikiText-103 experiments with 3 seeds show consistent improvement ($`3.76 \pm 0.02`$ baseline vs $`3.73 \pm 0.05`$ orth). PTB experiments exhibit high variance across seeds ($`6.17 \pm 0.95`$ baseline vs $`5.74 \pm 1.11`$ orth), making conclusions about PTB unreliable. The single-seed result reporting degradation may not be representative.
Mechanism.
We identify the weight-activation gap but do not fully explain its cause. While we hypothesize that non-linearities and input structure play a role, a rigorous mathematical analysis of how SiLU and LayerNorm transform geometric relationships remains future work.
Baselines.
We do not compare against SMoE-Dropout or Loss-Free Balancing , which may achieve different results through alternative mechanisms (random routing, auxiliary-loss-free bias updates).
Layer-wise Variation.
The weight-activation gap varies across layers: early layers (0–3) show larger gaps ($`\sim`$3000–5600$`\times`$), while later layers (4–5) show smaller gaps ($`\sim`$300–450$`\times`$). This pattern may arise from later layers having higher weight MSO ($`\sim`$10$`\times`$ higher than early layers), reducing the denominator of the ratio. A full analysis of why later layers develop less orthogonal weights remains future work.
Regularization Strength.
Our cross-dataset experiments use a fixed $`\lambda=0.001`$. The optimal regularization strength may vary across datasets; a comprehensive hyperparameter search could reveal conditions where geometric regularization is beneficial.
Future Directions.
Alternative approaches worth exploring include: (1) gradient-space orthogonality, enforcing that expert gradients point in different directions; (2) routing diversity losses that maximize expert selection entropy; (3) contrastive objectives that push apart expert outputs rather than weights; or (4) activation-space regularization that directly penalizes $`\text{MSO}_{\text{act}}`$ during training.
📊 논문 시각자료 (Figures)