MODE Efficient Time Series Prediction with Mamba Enhanced by Low-Rank Neural ODEs
📝 Original Paper Info
- Title: MODE Efficient Time Series Prediction with Mamba Enhanced by Low-Rank Neural ODEs- ArXiv ID: 2601.00920
- Date: 2026-01-01
- Authors: Xingsheng Chen, Regina Zhang, Bo Gao, Xingwei He, Xiaofeng Liu, Pietro Lio, Kwok-Yan Lam, Siu-Ming Yiu
📝 Abstract
Time series prediction plays a pivotal role across diverse domains such as finance, healthcare, energy systems, and environmental modeling. However, existing approaches often struggle to balance efficiency, scalability, and accuracy, particularly when handling long-range dependencies and irregularly sampled data. To address these challenges, we propose MODE, a unified framework that integrates Low-Rank Neural Ordinary Differential Equations (Neural ODEs) with an Enhanced Mamba architecture. As illustrated in our framework, the input sequence is first transformed by a Linear Tokenization Layer and then processed through multiple Mamba Encoder blocks, each equipped with an Enhanced Mamba Layer that employs Causal Convolution, SiLU activation, and a Low-Rank Neural ODE enhancement to efficiently capture temporal dynamics. This low-rank formulation reduces computational overhead while maintaining expressive power. Furthermore, a segmented selective scanning mechanism, inspired by pseudo-ODE dynamics, adaptively focuses on salient subsequences to improve scalability and long-range sequence modeling. Extensive experiments on benchmark datasets demonstrate that MODE surpasses existing baselines in both predictive accuracy and computational efficiency. Overall, our contributions include: (1) a unified and efficient architecture for long-term time series modeling, (2) integration of Mamba's selective scanning with low-rank Neural ODEs for enhanced temporal representation, and (3) substantial improvements in efficiency and scalability enabled by low-rank approximation and dynamic selective scanning.💡 Summary & Analysis
1. **Unified and Efficient Framework for Long-Term Time Series Prediction**: This paper introduces a new framework, MODE, which integrates the Mamba structure with low-rank approximations to effectively model complex temporal dynamics. 2. **Selective Scanning for Scalable Temporal Modeling**: The selective scanning mechanism focuses on important segments of the sequence, significantly improving computational efficiency and scalability while maintaining high predictive accuracy. 3. **Comprehensive Empirical Evaluation**: Extensive experiments across multiple benchmark datasets demonstrate that MODE outperforms transformer-based and SSM-based baselines.📄 Full Paper Content (ArXiv Source)
Time series prediction, Neural ordinary differential equations (Neural ODEs), Low-rank approximation, Mamba architecture, Sequence modeling
Introduction
series prediction is a fundamental task in machine learning and statistics, underpinning a wide range of real-world applications, including finance, healthcare, climate modeling, social networks , and urban forecasting . The overarching objective is to learn temporal dependencies within sequential data in order to accurately forecast future observations. Despite significant progress, time series prediction remains challenging due to the complex characteristics of real-world data, which often exhibit nonlinear dynamics, long-range dependencies, and irregular sampling patterns.
Traditional approaches, such as autoregressive models and recurrent neural networks (RNNs) , typically struggle to capture long-term dependencies or complex temporal behaviors. Recent advances, particularly those based on Transformers and state-space models (SSMs) , have shown enhanced modeling capability for sequential data. However, these models are often limited by high computational costs, insufficient scalability, and difficulty in handling irregularly sampled time series effectively.
The fundamental challenges in time series forecasting can be summarized as follows. First, long-range dependency modeling remains difficult, as the influence of distant observations on future outcomes spans extended time intervals. This is especially critical in domains like financial forecasting and climate modeling, where long-term trends can strongly influence predictive outcomes. Second, irregularly sampled data, prevalent in practical applications such as healthcare, sensor networks, and event-driven systems, violates the uniform time-step assumption of conventional discrete-time models, often leading to degraded performance. Third, computational efficiency becomes a critical bottleneck for long sequences and high-dimensional data, as the time and memory complexity of transformer-based or SSM-based models can scale quadratically with sequence length. Consequently, there is a pressing need for a predictive framework that effectively models temporal dependencies, naturally accommodates irregular sampling, and scales efficiently to large and complex datasets.
To address these challenges, we propose MODE, a novel and unified framework that integrates Low-Rank Neural Ordinary Differential Equations (Neural ODEs) with the Mamba architecture. The design of MODE directly targets the key limitations of existing methods. Specifically, the continuous-time property of Neural ODEs enables the model to process irregularly sampled data naturally without resorting to explicit imputation or interpolation, a crucial advantage for applications with sparse or uneven sampling such as healthcare and environmental monitoring. Furthermore, a low-rank approximation strategy is introduced to reduce the computational complexity of state transitions from $`\mathcal{O}(d^2)`$ to $`\mathcal{O}(d \cdot r)`$, where $`r \ll d`$, allowing for efficient modeling of high-dimensional sequences. In addition, the selective scanning mechanism guides the model’s attention toward the most informative segments of the sequence, further enhancing scalability and efficiency for long-term forecasting tasks. Together, these components make MODE a robust, efficient, and scalable solution for modern time series prediction.
Our main contributions are summarized as follows:
-
Unified and Efficient Framework for Long-Term Time Series Prediction: We introduce a principled framework that seamlessly integrates Low-Rank Neural ODEs with the Mamba structure, enabling effective and adaptive modeling of complex temporal dynamics without manual feature engineering.
-
Selective Scanning for Scalable Temporal Modeling: We design a segmented selective scanning mechanism that prioritizes salient temporal segments, substantially improving computational efficiency and scalability while preserving high predictive accuracy.
-
Comprehensive Empirical Evaluation: Extensive experiments across multiple benchmark datasets demonstrate that MODE achieves state-of-the-art performance compared to transformer-based and SSM-based baselines, confirming its robustness, scalability, and generalization capabilities across diverse time series prediction tasks.
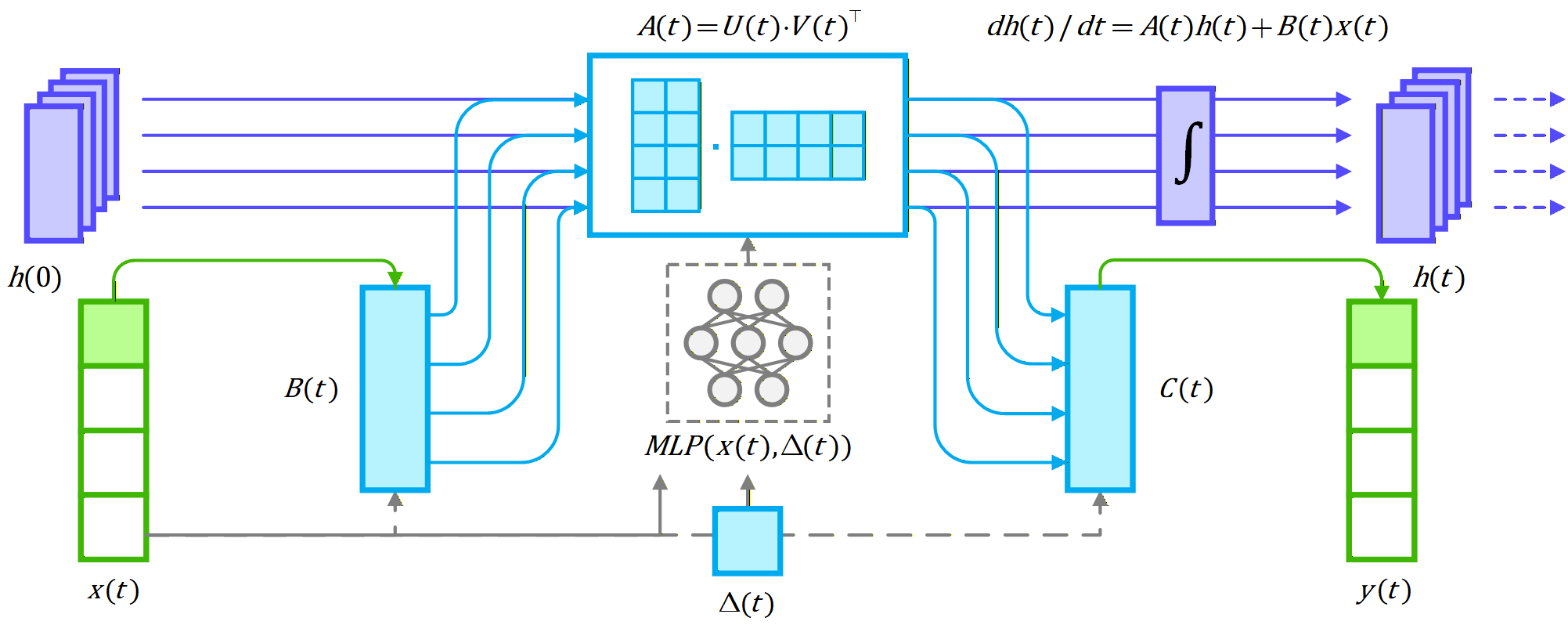
Method
Preliminary
Mamba
The Mamba framework defines a sequence-to-sequence transformation using four main parameters $`(\mathbf{A}, \mathbf{B}, \mathbf{C}, \Delta)`$ in a continuous-time state-space form:
\begin{align}
h'(t) &= \mathbf{A}h(t) + \mathbf{B}x(t), \quad y(t) = \mathbf{C}h(t),
\end{align}where $`h(t) \in \mathbb{R}^N`$ denotes the hidden state of dimension $`N`$, $`x(t) \in \mathbb{R}^L`$ the input of dimension $`L`$, and $`y(t) \in \mathbb{R}^L`$ the output of dimension $`L`$. The corresponding discrete-time realization is given by
\begin{align}
h_t = \bar{\mathbf{A}}h_{t-1} + \bar{\mathbf{B}}x_t;
\bar{\mathbf{A}} = e^{\Delta\mathbf{A}};
\bar{\mathbf{B}} = (\Delta\mathbf{A})^{-1}\bigl(e^{\Delta\mathbf{A}}\bigr)\Delta\mathbf{B}
\end{align}which inherits useful properties from the underlying continuous system, such as resolution invariance . A central innovation of Mamba is that the parameters $`\mathbf{B}`$, $`\mathbf{C}`$, and the step size $`\Delta`$ are made input-dependent, so that the model can dynamically adapt its dynamics to the characteristics of the sequence.
The state-space dynamics in Mamba can be expressed via a convolutional kernel
\begin{align}
\bar{\mathbf{K}} = (\mathbf{C}\bar{\mathbf{B}},\, \mathbf{C}\bar{\mathbf{A}}\bar{\mathbf{B}},\, \dots)^T; y = \sigma(\bar{\mathbf{K}}^T x)\,\mathbf{W}_{\text{out}},
\end{align}where $`\sigma`$ is a non-linear activation function and $`\mathbf{W}_{\text{out}}`$ is a learned output projection.
State Space Models (SSMs)
State Space Models (SSMs) describe dynamical systems by evolving a hidden state over time and mapping that state to observations. In continuous time, a linear time-invariant SSM can be written as
\begin{align}
h'(t) = \mathbf{A} h(t) + \mathbf{B} x(t); y(t) = \mathbf{C} h(t) + \mathbf{D} x(t),
\end{align}where $`h(t) \in \mathbb{R}^N`$ is the hidden state of dimension $`N`$, $`x(t) \in \mathbb{R}^L`$ is the input of dimension $`L`$, $`y(t) \in \mathbb{R}^L`$ is the output of dimension $`L`$, $`\mathbf{A} \in \mathbb{R}^{N\times N}`$ governs the state dynamics, $`\mathbf{B} \in \mathbb{R}^{N\times L}`$ couples the input to the state, $`\mathbf{C} \in \mathbb{R}^{L\times N}`$ maps the state to the output, and $`\mathbf{D} \in \mathbb{R}^{L\times L}`$ represents a direct input–output connection.
For a fixed sampling step $`\Delta`$, the corresponding discrete-time SSM becomes
\begin{align}
h_t = \mathbf{A}_d h_{t-1} + \mathbf{B}_d x_t;
y_t = \mathbf{C}_d h_t + \mathbf{D}_d x_t,
\end{align}with $`t = 1,\dots,T`$, where $`T`$ denotes the sequence length (number of time steps), and $`\mathbf{A}_d, \mathbf{B}_d, \mathbf{C}_d, \mathbf{D}_d`$ are the discrete-time parameters obtained from the continuous-time system (for example via matrix exponentials). Classical SSMs used in signal processing and control typically assume time-invariant parameters and linear dynamics, whereas modern deep SSMs (such as S4 and related models) parameterize $`\mathbf{A}, \mathbf{B}, \mathbf{C}, \mathbf{D}`$ and learn them from data for sequence modeling tasks.
Problem Statement.
Given an input time series $`\mathbf{X} = (x_1, \dots, x_L) \in \mathbb{R}^{L \times V}`$, where $`L`$ is the sequence length and $`V`$ is the number of variates, the goal is to predict the future time series $`\mathbf{Y} = (x_{L+1}, \dots, x_{L+H}) \in \mathbb{R}^{H \times V}`$, where $`H`$ is the prediction horizon. Traditional approaches often rely on discrete-time state transitions, which may struggle to capture fine-grained temporal dynamics, especially in high-frequency or irregularly sampled time series.
Overview and Problem Statement
Overview. In this section, we present MODE, a unified framework (shown in Fig. 2) that integrates Low-Rank Neural Ordinary Differential Equations (Neural ODEs) with the Mamba architecture to effectively address the core challenges of long-range dependency modeling, irregular sampling, and computational efficiency in time series prediction. We begin by reviewing the preliminaries of the Mamba state-space parameterization, establishing both its discrete-time and continuous-time formulations, and formally defining the forecasting problem. We then introduce a continuous-time state transition model based on Neural ODEs (shown in Fig. 1), where the state evolution matrix is parameterized in a low-rank form to reduce computational complexity from $`\mathcal{O}(d^2)`$ to $`\mathcal{O}(d \cdot r)`$ while preserving expressive capacity. Subsequently, we describe how MODE embeds these continuous dynamics into the Mamba structure through an input-dependent parameterization, augmented by a segmented selective scanning mechanism that adaptively allocates computation to the most informative time steps for efficient long-sequence processing. We further detail the training objective combining predictive loss and smoothness regularization, and analyze the theoretical time and space complexity of MODE in comparison with the vanilla Mamba framework. Finally, we provide theoretical insights into the representational capability, stability, and efficiency of the proposed model, discuss the impact of the selective scanning mechanism, and summarize the complete end-to-end algorithmic pipeline.
To address these challenges, we propose a novel framework that combines continuous-time state-space modeling with Neural Ordinary Differential Equations (Neural ODEs). The method leverages the Mamba structure, to efficiently model long-range dependencies and adapt to varying input patterns. The state transitions are modeled as continuous-time dynamics, enabling the system to represent temporal dependencies at arbitrary resolutions. This approach reduces computational complexity, improves generalization to unseen tasks, and provides interpretable representations of the temporal dynamics.
State-Space Formulation with Low-Rank Neural ODEs
The state transitions in the proposed method are modeled as continuous-time dynamics using Neural ODEs with low-rank approximations for the state transition matrix. Given an input time series $`\mathbf{X} = (x_1, \dots, x_L) \in \mathbb{R}^{L \times V}`$, the hidden state $`h(t) \in \mathbb{R}^d`$ evolves according to $`\frac{dh(t)}{dt} = A(t) h(t) + B(t) x(t)`$, where $`A(t) = U(t) \cdot V(t)^\top \in \mathbb{R}^{d \times d}`$ is the low-rank state transition matrix with $`U(t) \in \mathbb{R}^{d \times r}`$, $`V(t) \in \mathbb{R}^{d \times r}`$, and $`r \ll d`$, and $`B(t) \in \mathbb{R}^{d \times V}`$ is the input matrix. The state at time $`t`$ is obtained by integrating the ODE as follows:
\begin{equation}
\begin{aligned}
h(t) = h(0) + \int_0^t \left( U(\tau) \cdot V(\tau)^\top h(\tau) + B(\tau) x(\tau) \right) \, d\tau
\end{aligned}
\end{equation}The matrices $`U(t)`$, $`V(t)`$, $`B(t)`$, and $`C(t)`$ are dynamically adjusted based on the input and a task-specific parameter $`\Delta(t)`$ as follows:
\begin{equation}
\begin{aligned}
U(t) &= f_U(x(t), \Delta(t)), V(t) = f_V(x(t), \Delta(t))\\
B(t) &= f_B(x(t), \Delta(t)), C(t) = f_C(x(t), \Delta(t))
\end{aligned}
\end{equation}Here $`f_U`$, $`f_V`$, $`f_B`$, and $`f_C`$ are learnable functions implemented as multi-layer perceptrons (MLPs). This formulation reduces complexity while preserving the model’s ability to capture fine-grained temporal dynamics. The output at time $`t`$ is computed as $`y(t) = C(t) h(t)`$, where $`C(t) \in \mathbb{R}^{V \times d}`$ is the output matrix. This formulation reduces complexity from $`\mathcal{O}(d^2)`$ to $`\mathcal{O}(d \cdot r)`$ while preserving the model’s ability to capture fine-grained temporal dynamics.
Mamba Structure with Low-Rank Neural ODEs and Selective Scanning
The Mamba structure integrates a discrete-time state-space formulation with a selective scanning mechanism to efficiently process long sequences. The selective scanning mechanism focuses on relevant parts of the sequence, reducing computational complexity from $`\mathcal{O}(L \cdot d^2)`$ to $`\mathcal{O}(L \cdot d \cdot \log k)`$, where $`k`$ is the number of relevant time steps. This is achieved by dynamically adjusting the matrices $`U(t)`$, $`V(t)`$, and $`B(t)`$ based on the input and task context. The output at time $`t`$ is computed as $`y(t) = C(t) h(t)`$, where $`C(t) \in \mathbb{R}^{V \times d}`$ is the output matrix. By focusing on the most informative parts of the sequence, the selective scanning mechanism ensures that the model remains scalable for long sequences while maintaining interpretability and flexibility. This makes the proposed method well-suited for time series prediction tasks, particularly those involving high-dimensional data and long sequences.
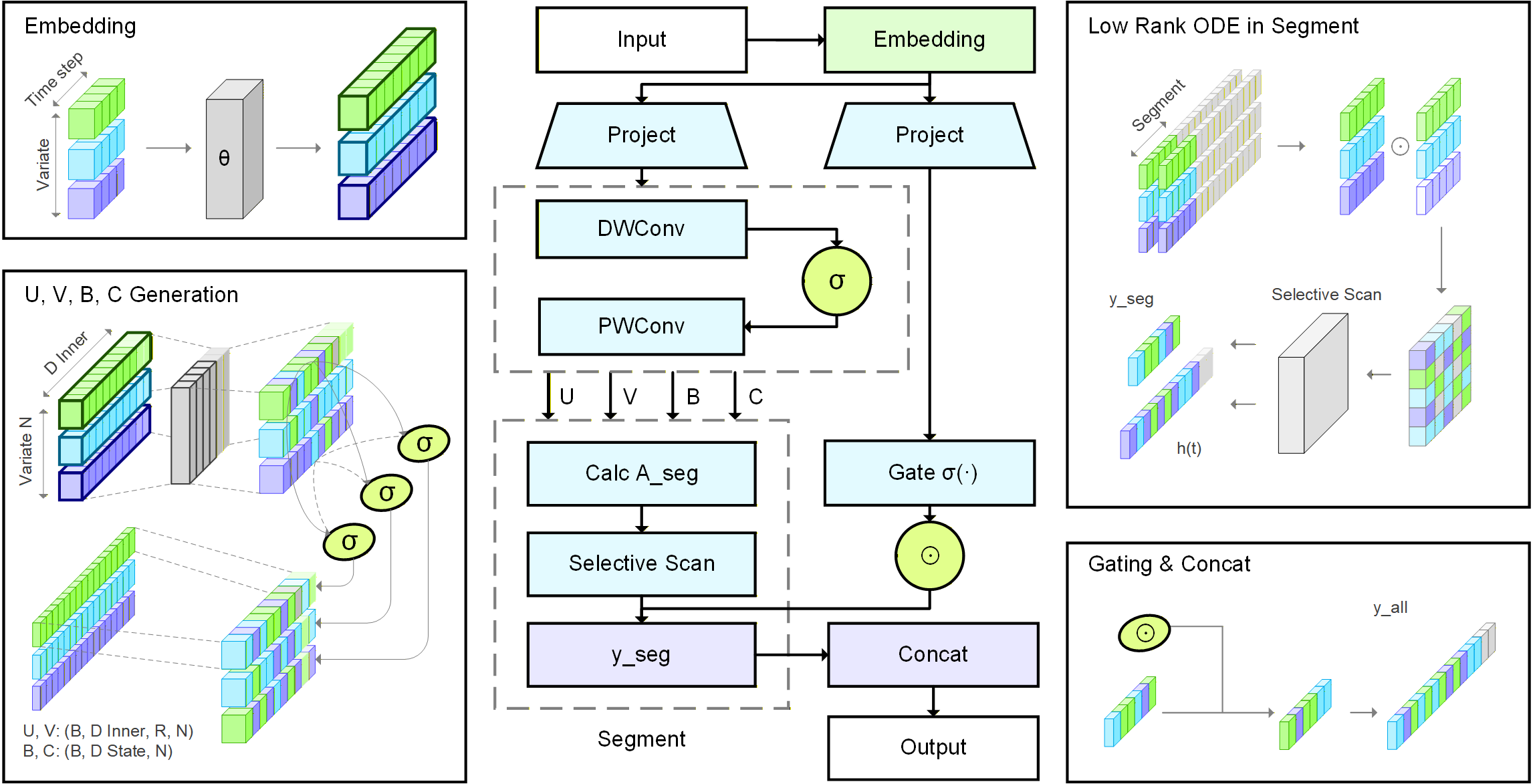
Model Optimization with Low-Rank Neural ODEs
The proposed model is optimized using a combination of supervised and regularization losses to ensure accurate predictions and smooth state transitions. The primary objective is to minimize the mean squared error (MSE) between the predicted and ground truth time series: $`\mathcal{L}_{\text{pred}} = \frac{1}{H \cdot V} \sum_{i=1}^H \sum_{j=1}^V (\hat{y}_{i,j} - y_{i,j})^2`$, where $`\hat{y}_{i,j}`$ is the predicted value and $`y_{i,j}`$ is the ground truth value at time $`i`$ for variate $`j`$. To encourage smooth state transitions, a regularization term is added: $`\mathcal{L}_{\text{reg}} = \lambda \sum_{t=2}^L \|h_t - h_{t-1}\|_2^2`$, where $`\lambda`$ is a hyperparameter controlling the regularization strength. The total loss is the sum of the prediction loss and the regularization term: $`\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{pred}} + \mathcal{L}_{\text{reg}}`$. The model parameters, including the low-rank matrices $`U_t`$, $`V_t`$, $`B_t`$, and $`C_t`$, are optimized using gradient-based methods such as stochastic gradient descent (SGD) or Adam, ensuring efficient convergence. The low-rank approximation reduces the number of parameters and computations, further improving optimization efficiency.
Model Complexity with Low-Rank Neural ODEs
The proposed method enhances the vanilla Mamba architecture by integrating Low-Rank Neural ODEs into its state-space formulation. This modification reduces computational complexity by replacing the quadratic dependence on the hidden dimension with a low-rank approximation. Specifically, the time complexity of state transitions becomes $`\mathcal{O}(L \cdot d \cdot r \cdot T)`$, where $`L`$ is the sequence length, $`d`$ is the hidden dimension, $`r \ll d`$ is the low rank, and $`T`$ is the number of ODE solver steps. Input projection has complexity $`\mathcal{O}(L \cdot d \cdot V)`$ and selective scanning $`\mathcal{O}(L \cdot d \cdot V \cdot \log k)`$, giving an overall time complexity of $`\mathcal{O}(L \cdot d \cdot r \cdot T + L \cdot d \cdot V + L \cdot d \cdot V \cdot \log k)`$. The space complexity is $`\mathcal{O}(d \cdot r + d \cdot V + L \cdot d \cdot T)`$.
Compared to vanilla Mamba, which has state-transition time complexity $`\mathcal{O}(L \cdot d^2)`$ and state-transition space complexity $`\mathcal{O}(d^2)`$, the proposed method substantially reduces both to $`\mathcal{O}(L \cdot d \cdot r \cdot T)`$ and $`\mathcal{O}(d \cdot r)`$, respectively. Although the ODE solver adds an $`\mathcal{O}(L \cdot d \cdot T)`$ space term, this is compensated by the reduced size of the transition matrices. Consequently, Mamba with Low-Rank Neural ODEs offers superior scalability and efficiency for high-dimensional, long-horizon sequence modeling, particularly when the hidden dimension $`d`$ is large, while still supporting rigorous theoretical guarantees for time series prediction.
Deep Theoretical Analysis
Theorem 1 (Representation Power): The proposed method can approximate any continuous function $`f: \mathbb{R}^L \rightarrow \mathbb{R}^H`$ with bounded error, given sufficient hidden state dimension $`d`$ and rank $`r`$.
Proof. By the universal approximation theorem for neural networks, a sufficiently large hidden state dimension $`d`$ allows the model to approximate any continuous function. The low-rank approximation $`A(t) = U(t) \cdot V(t)^\top`$ preserves this property as long as $`r`$ is chosen such that $`U(t)`$ and $`V(t)`$ can capture the necessary dynamics. Thus, the proposed method retains the representation power of traditional state-space models while reducing complexity. ◻
Theorem 2 (Stability): The state transitions in the proposed method are stable, ensuring that the hidden states remain bounded over time.
Proof. Let $`\|A(t)\|_2 \leq \alpha < 1`$ for all $`t`$, where $`\| \cdot \|_2`$ denotes the spectral norm. Then, the hidden state $`h(t)`$ satisfies:
\begin{equation}
\begin{aligned}
\|h(t)\|_2 \leq \alpha \|h(t-1)\|_2 + \|B(t) x(t)\|_2.
\end{aligned}
\end{equation}Assuming $`\|B(t) x(t)\|_2 \leq \beta`$, we can recursively apply this inequality to obtain:
\begin{equation}
\begin{aligned}
\|h(t)\|_2 \leq \frac{\beta}{1 - \alpha}.
\end{aligned}
\end{equation}Thus, the hidden states remain bounded over time, ensuring stability. ◻
Theorem 3 (Generalization): The proposed method generalizes to unseen tasks with bounded error, given a sufficient number of training tasks.
Proof. Let $`\mathcal{T}`$ be the set of training tasks, and let $`\mathcal{T}'`$ be an unseen task. The generalization error $`\mathcal{E}(\mathcal{T}')`$ is bounded by:
\begin{equation}
\begin{aligned}
\mathcal{E}(\mathcal{T}') \leq \mathcal{O}\left(\frac{1}{\sqrt{|\mathcal{T}|}}\right),
\end{aligned}
\end{equation}where $`|\mathcal{T}|`$ is the number of training tasks. This follows from the task-specific parameter $`\Delta(t)`$ and the low-rank approximation, which enable the model to adapt to new tasks using learned representations. By the law of large numbers, as $`|\mathcal{T}| \rightarrow \infty`$, the generalization error converges to zero. ◻
Theorem 4 (Efficiency): The low-rank approximation reduces the time and space complexity of the state transition matrix $`A(t)`$ from $`\mathcal{O}(d^2)`$ to $`\mathcal{O}(d \cdot r)`$, where $`r \ll d`$.
Proof. The state transition matrix $`A(t)`$ is approximated as $`A(t) = U(t) \cdot V(t)^\top`$, where $`U(t), V(t) \in \mathbb{R}^{d \times r}`$. The time complexity of computing $`A(t) h(t)`$ is $`\mathcal{O}(d \cdot r)`$ instead of $`\mathcal{O}(d^2)`$. Similarly, the space complexity of storing $`A(t)`$ is $`\mathcal{O}(d \cdot r)`$ instead of $`\mathcal{O}(d^2)`$. Thus, the low-rank approximation improves efficiency while preserving the model’s ability to capture temporal dynamics. ◻
Theorem 5 (Selective Scanning): The selective scanning mechanism reduces the computational complexity of processing a sequence of length $`L`$ from $`\mathcal{O}(L \cdot d^2)`$ to $`\mathcal{O}(L \cdot d \cdot \log k)`$, where $`k`$ is the number of relevant time steps.
Proof. The selective scanning mechanism focuses on $`k`$ relevant time steps instead of the entire sequence of length $`L`$. The complexity of processing these $`k`$ steps is $`\mathcal{O}(k \cdot d^2)`$. By selecting $`k`$ such that $`k \ll L`$, the overall complexity is reduced to $`\mathcal{O}(L \cdot d \cdot \log k)`$, as the selection process itself has logarithmic complexity. ◻
Input time series $`\mathbf{X} = (x_1, \dots, x_L) \in \mathbb{R}^{L \times V}`$, hidden STATE dimension $`d`$, rank $`r`$, ODE solver steps $`T`$, task-specific parameter $`\Delta(t)`$. Predicted time series $`\widehat{\mathbf{Y}} = (\hat{y}_1, \dots, \hat{y}_H) \in \mathbb{R}^{H \times V}`$.
Initialize low-rank matrices: $`U(t)`$, $`V(t)`$, input matrix $`B(t)`$, and output matrix $`C(t)`$ . Initialize hidden STATE: $`h_0 = \mathbf{0}`$.
Compute low-rank state transition matrix: $`A(t) = U(t) \cdot V(t)^\top`$ Compute state update: $`h(t) = h(t-1) + \int_0^T \left( A(\tau) h(\tau) + B(\tau) x(t) \right) d\tau`$ Compute output: $`y(t) = C(t) h(t)`$ Update matrices based on input and task context: $`U(t) = f_U(x(t), \Delta(t))`$ $`V(t) = f_V(x(t), \Delta(t))`$ $`B(t) = f_B(x(t), \Delta(t))`$ $`C(t) = f_C(x(t), \Delta(t))`$ Apply selective scanning to focus on relevant parts of the sequence
Predict future time series: $`\widehat{\mathbf{Y}} = (y_{L+1}, \dots, y_{L+H})`$ using the final hidden STATE $`h(L)`$.
$`\widehat{\mathbf{Y}}`$.
Experiments
Our experimental evaluation addresses nine key research questions: Q1 examines MODE’s performance advantages over state-of-the-art baselines, while Q2 analyzes individual component contributions through ablation studies. Q3 assesses MODE’s computational efficiency by comparing training time, memory usage and prediction errors across various models. Q4 evaluates its robustness on the specific dataset with increasing levels of gaussian noise. Q5 investigates long-term forecasting accuracy with increasing lookback lengths. Q6 specifically analyzes transient dynamics capture. And Q7 investigates the differences between varied model settings, i.e., static and dynamic low rank ODE.
Experiment Settings
Datasets. To rigorously assess the effectiveness of our proposed model, we curated a diverse collection of 9 real-world datasets from established sources for comprehensive evaluation. These datasets span multiple domains, including electricity consumption, and the 4 ETT datasets (ETTh1, ETTh2, ETTm1, ETTm2), among others. Widely recognized in the research community, these datasets are instrumental in addressing challenges across various fields, such as transportation analysis and energy management. Detailed statistical information for each dataset is provided in Table [tab:datasets].
| Datasets | Variates | Time steps | Granularity | Datasets | Variates | Time steps | Granularity |
|---|---|---|---|---|---|---|---|
| ETTh1 | 7 | 17,420 | 1 hour | ETTh2 | 7 | 17,420 | 1 hour |
| ETTm1 | 7 | 69,680 | 15 minutes | ETTm2 | 7 | 69,680 | 15 minutes |
| ECL | 321 | 26,304 | 1 hour | Weather | 21 | 52,696 | 10 minutes |
| Exchange | 8 | 7,588 | 1 Day | Solar Energy | 137 | 52,560 | 1 hour |
| PEMS08 | 170 | 17,856 | 5 minutes |
Implementation. For fair and consistent comparison, all baseline methods were implemented based on their Github repositories. Unless models in public repositories listed optimal configurations in their experimental results, the experiments utilized consistent hyperparameters across all models for those common configurations, including batch size of 16 or 32, dimensions of models, and hidden state dimensions $`d_{state}`$ in variants of Mamba. Those model-specific hyperparameters, like padding patch setting in PatchTST, were set according to official repositories if given. This comprehensive and standardized configuration enables direct performance comparison while maintaining each model’s core architectural advantages.
Experimental Setup. All comparative evaluations were performed under identical hardware and software conditions to ensure unbiased benchmarking. The computational environment comprised an Ubuntu 22.04 server equipped with Python 3.12 and PyTorch 2.8.0, leveraging CUDA 12.8 for GPU acceleration. The system featured high-performance components including: (1) an Intel Xeon Platinum 8473C CPU, (2) an NVIDIA RTX5090 GPU (32GB VRAM) for parallel processing, (3) 64GB RAM, and (4) a 500GB system disk. Mamba 2.2.5 is utilized for MODE implementations in this computational environment. This configuration delivered the necessary computational throughput for rigorous deep learning experimentation while maintaining consistent evaluation metrics across all trials.
Detailed Baseline Descriptions
We evaluate MODE against tencontemporary approaches representing three major architectural paradigms: Transformer-based (6 methods), MLP-based (3 methods), and state-space model (SSM) based (1 method) techniques. The Transformer-based baselines include Autoformer , which fuses time series decomposition with an autocorrelation module to capture periodic temporal dependencies while avoiding conventional attention operations; FEDformer , which embeds spectral-domain transformations into the attention mechanism to improve computational efficiency while maintaining a global receptive field; Crossformer , which applies multidimensional attention over patched temporal segments, where patching enhances local feature extraction but its effectiveness diminishes for extremely long input sequences; DLinear , which shows that two simple linear layers acting on decomposed trend and residual components can outperform many sophisticated attention-based models across a range of forecasting tasks; PatchTST , which adopts segmented time-step embeddings with channel-wise isolated processing to support the discovery of temporal patterns across multiple scales; and iTransformer , which reverses the conventional attention setup to focus on cross-variate interactions, though its MLP-based sequence-flattening tokenization is less effective at modeling hierarchical temporal structures. The MLP-based approaches comprise TimesNet , which converts univariate time series into two-dimensional periodic maps to enable unified modeling of both within-cycle and across-cycle patterns; RLinear , which introduces reversible normalization in a channel-independent linear design and sets new baselines for models that rely solely on linear operations; and TiDE , which leverages stacked fully connected layers in an encoder–decoder layout to capture temporal structure while entirely forgoing recurrence and attention. Finally, the state-space model variant S-Mamba uses per-variate tokenization together with bidirectional Mamba layers to model cross-variate relationships, further supported by feedforward networks for temporal dynamics.
Effectiveness
Table [tab:effectiveness] reports the experimental results of MODE and baselines on eight common time series forecasting benchmarks: ETTm1, ETTm2, ETTh1, ETTh2, Electricity, Exchange, Weather, Solar-Energy, and PEMS08. The lookback window $`L`$ is fixed at 96, and the forecasting horizon $`T`$ is 96, 192, 336, or 720. We report Mean Squared Error (MSE) and Mean Absolute Error (MAE) as evaluating metrics respectively.
Given baseline from and experimental results of MODE under optimal hyperparameter configurations, it yields the best or second-best performance across almost all datasets and horizons. On average, it attains the lowest MSE and MAE, surpassing strong baselines such as S-Mamba, iTransformer, PatchTST, and FEDformer.
These gains hold across diverse settings: on ETT (industrial load) MODE improves short-term predictions; on large-scale datasets (Electricity, Exchange) it better captures long-term dependencies; and on challenging datasets (Weather, Solar-Energy) it preserves low errors and stable performance across all horizons. The effectiveness and robustness of MODE stem from three components: (1) continuous-time low-rank Neural ODEs for irregular sampling, (2) a selective scanning mechanism that focuses computation on informative segments, and (3) integration with the Mamba architecture for efficient, scalable temporal representations, jointly enabling state-of-the-art accuracy with high efficiency.
Ablation Study
To assess the contribution of each component in MODE, we conduct ablation studies summarized in Table [tab:ablation]. We analyze: (1) the use of Neural ODEs, (2) dynamic vs. static low-rank parameterization, (3) the effect of rank size $`r`$, and (4) the interaction between the ODE formulation and the Mamba architecture. Experiments are run on ETTm1, Weather, and ECL with forecast horizons $`T \in \{96, 192, 336, 720\}`$, using evaluating metrics MSE and MAE.
Effect of Low-Rank Neural ODEs. Compared with vanilla Mamba and bidirectional Mamba blocks in parallel, Neural ODE variants are on par with or outperform models without ODE implementations across datasets and horizons. For example, at horizon 96 on ETTm1, MODE with static low-rank ODE achieves an MSE of 0.324, outperforming vanilla Mamba (0.326) and bidirectional Mamba (0.331) and is close to attention mechanism. It also achieves best or second best performances in horizon 336 and 720 experiments. This shows that continuous-time dynamics help capture irregular temporal patterns that discrete models miss.
Dynamic versus Static Low-Rank Parameterization. The dynamic variant further improves over the static one. On Weather at horizon 96, Dynamic Low-Rank ODE achieves the best MSE/MAE (0.167/0.210), surpassing the static ODE (0.170/0.213). This suggests that, at the expense of some time and memory efficiency, adaptive ranks better capture time-varying dependencies, improving stability and accuracy.
Impact of Rank Size. We vary the rank ratio $`\frac{r}{d_{\text{state}}}`$ from 1/4 to 1/2 and full. Moderate ranks (1/2 $`d_{\text{state}}`$) offer the best efficiency–performance trade-off. Full rank yields only marginal accuracy gains while increasing cost, supporting the choice of a low-rank design.
Influence of Architectural Components. We also test variants that replace Mamba enhanced by low rank ODE with vanilla Mamba, S-Mamba block, attention + FFN, or pure linear layers. Attention solution shows advantages in short-term forecasting, for its ability to capture high correlation between future and recent values, and respond to local variations by assigning higher weights to nearby timesteps. But MODE shows competitive performance with a considerable number of best or second best error results in all prediction length, indicating that both the ODE formulation and its integration into the Mamba pipeline are key to MODE’s improvements.
Overall, the ablations show that: (1) Neural ODEs improve temporal modeling, (2) dynamic low-rank parameterization enhances adaptability and generalization, and (3) the synergy between Neural ODEs and Mamba’s selective scanning drives both accuracy and efficiency, validating the design of each module.
| R Rank | Len | ETTm1 | Weather | ECL | ||||
|---|---|---|---|---|---|---|---|---|
| 4-5 | MSE | MAE | MSE | MAE | MSE | MAE | ||
| Static ODE | Custom | 96 | 0.324 | 0.363 | 0.170 | 0.213 | 0.150 | 0.244 |
| 192 | 0.364 | 0.384 | 0.219 | 0.255 | 0.164 | 0.256 | ||
| 336 | 0.398 | 0.407 | 0.274 | 0.296 | 0.180 | 0.272 | ||
| 720 | 0.468 | 0.447 | 0.354 | 0.348 | 0.214 | 0.302 | ||
| 1-9 | Custom | 96 | 0.332 | 0.366 | 0.167 | 0.210 | 0.163 | 0.254 |
| 192 | 0.367 | 0.385 | 0.216 | 0.253 | 0.172 | 0.261 | ||
| 336 | 0.401 | 0.408 | 0.274 | 0.295 | 0.190 | 0.279 | ||
| 720 | 0.477 | 0.453 | 0.353 | 0.346 | 0.231 | 0.313 | ||
| 1-9 | Custom | 96 | 0.326 | 0.364 | 0.169 | 0.212 | 0.150 | 0.245 |
| 192 | 0.367 | 0.386 | 0.219 | 0.256 | 0.164 | 0.256 | ||
| 336 | 0.401 | 0.409 | 0.275 | 0.297 | 0.180 | 0.273 | ||
| 720 | 0.482 | 0.455 | 0.354 | 0.349 | 0.214 | 0.302 | ||
| 1-9 | Custom | 96 | 0.331 | 0.367 | 0.166 | 0.209 | 0.143 | 0.239 |
| 192 | 0.377 | 0.390 | 0.215 | 0.254 | 0.164 | 0.259 | ||
| 336 | 0.412 | 0.416 | 0.277 | 0.296 | 0.190 | 0.283 | ||
| 720 | 0.485 | 0.457 | 0.355 | 0.350 | 0.213 | 0.304 | ||
| 1-9 | Custom | 96 | 0.320 | 0.357 | 0.175 | 0.215 | 0.152 | 0.243 |
| 192 | 0.363 | 0.380 | 0.223 | 0.258 | 0.164 | 0.254 | ||
| 336 | 0.405 | 0.409 | 0.281 | 0.300 | 0.180 | 0.272 | ||
| 720 | 0.467 | 0.445 | 0.360 | 0.350 | 0.221 | 0.306 | ||
| 1-9 | Custom | 96 | 0.342 | 0.365 | 0.190 | 0.230 | 0.196 | 0.273 |
| 192 | 0.386 | 0.388 | 0.235 | 0.266 | 0.196 | 0.275 | ||
| 336 | 0.427 | 0.416 | 0.288 | 0.304 | 0.211 | 0.291 | ||
| 720 | 0.486 | 0.447 | 0.362 | 0.353 | 0.253 | 0.324 | ||
| R Rank | Len | ETTm1 | Weather | ECL | ||||
|---|---|---|---|---|---|---|---|---|
| 4-5 | MSE | MAE | MSE | MAE | MSE | MAE | ||
| 1/4 dstate | 96 | 0.330 | 0.366 | 0.170 | 0.213 | 0.150 | 0.245 | |
| 192 | 0.370 | 0.388 | 0.218 | 0.255 | 0.164 | 0.256 | ||
| 336 | 0.398 | 0.407 | 0.275 | 0.297 | 0.181 | 0.273 | ||
| 720 | 0.477 | 0.452 | 0.353 | 0.348 | 0.216 | 0.304 | ||
| 2-9 | 1/2 dstate | 96 | 0.324 | 0.363 | 0.171 | 0.214 | 0.150 | 0.244 |
| 192 | 0.364 | 0.384 | 0.219 | 0.255 | 0.164 | 0.257 | ||
| 336 | 0.399 | 0.408 | 0.275 | 0.296 | 0.181 | 0.273 | ||
| 720 | 0.474 | 0.450 | 0.353 | 0.348 | 0.217 | 0.304 | ||
| 2-9 | dstate | 96 | 0.329 | 0.365 | 0.170 | 0.213 | 0.150 | 0.244 |
| 192 | 0.363 | 0.382 | 0.218 | 0.255 | 0.164 | 0.256 | ||
| 336 | 0.401 | 0.409 | 0.275 | 0.296 | 0.180 | 0.272 | ||
| 720 | 0.480 | 0.454 | 0.353 | 0.347 | 0.217 | 0.304 | ||
| 1-9 | 1/4 dstate | 96 | 0.328 | 0.363 | 0.168 | 0.211 | 0.163 | 0.253 |
| 192 | 0.368 | 0.385 | 0.217 | 0.253 | 0.173 | 0.261 | ||
| 336 | 0.402 | 0.408 | 0.274 | 0.295 | 0.190 | 0.279 | ||
| 720 | 0.473 | 0.451 | 0.352 | 0.346 | 0.229 | 0.311 | ||
| 2-9 | 1/2 dstate | 96 | 0.332 | 0.366 | 0.167 | 0.210 | 0.163 | 0.252 |
| 192 | 0.367 | 0.385 | 0.216 | 0.253 | 0.173 | 0.263 | ||
| 336 | 0.401 | 0.408 | 0.274 | 0.295 | 0.190 | 0.279 | ||
| 720 | 0.465 | 0.446 | 0.353 | 0.346 | 0.230 | 0.314 | ||
| 2-9 | dstate | 96 | 0.328 | 0.364 | 0.168 | 0.212 | 0.163 | 0.253 |
| 192 | 0.369 | 0.387 | 0.217 | 0.254 | 0.173 | 0.262 | ||
| 336 | 0.402 | 0.408 | 0.275 | 0.295 | 0.190 | 0.280 | ||
| 720 | 0.467 | 0.444 | 0.353 | 0.346 | 0.229 | 0.311 | ||
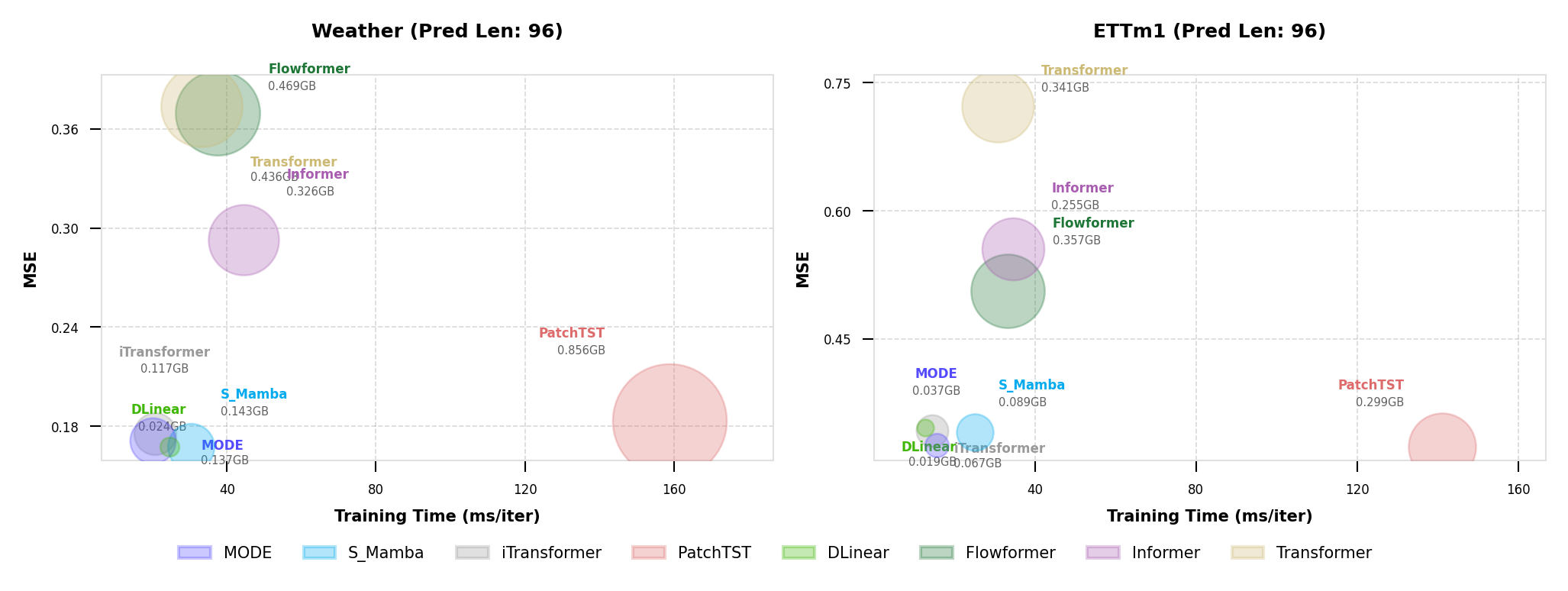
Efficiency Comparison
Fig. 3 illustrates the efficiency comparison between our proposed MODE and several strong baselines, including S-Mamba, PatchTST, iTransformer, Flowformer, Informer, Transformer, and DLinear, on the Weather and ETTm1 datasets. The x-axis represents the average training time per iteration, the y-axis shows MSE results, and the bubble size indicates allocated GPU memory under same batching settings (128 for PatchTST, 16 for other models). MODE with static low-rank ODE achieves an excellent balance between accuracy and efficiency, yielding lower MSE with competitive training time and small memory footprint. Specifically, MODE achieves comparable or better accuracy than PatchTST and iTransformer while requiring significantly less training time and reduced memory usage (only 0.037 GB on ETTm1 and 0.137 GB on Weather). In contrast, Transformer-based and Flowformer architectures incur higher computational costs and memory overhead. These results demonstrate that the low-rank Neural ODE formulation and selective scanning mechanism enable MODE to achieve both high predictive accuracy and superior computational efficiency.
Robustness Study
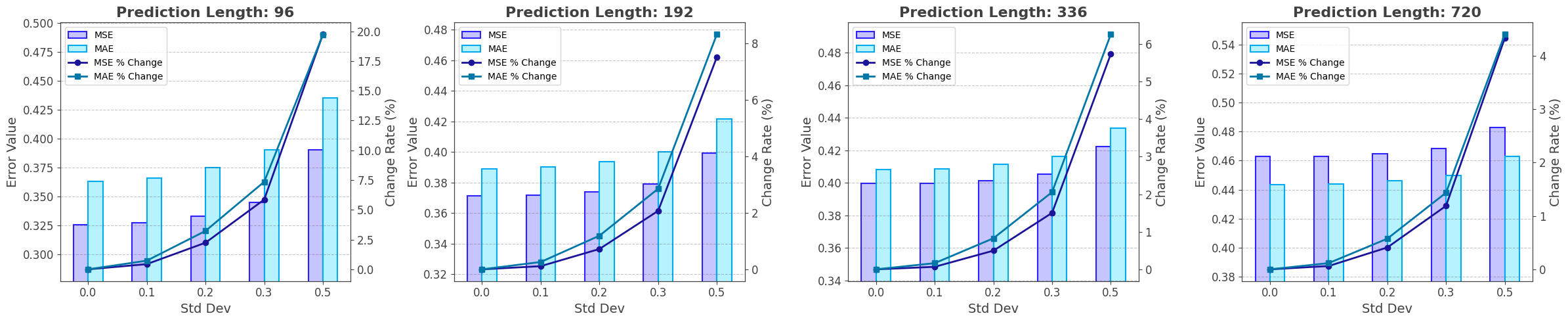
To evaluate the robustness of MODE against input perturbations, we conduct experiments on the ETTm1 dataset by injecting Gaussian noise with varying standard deviations into the input sequences. Fig. 4 presents the results under four forecasting horizons $`T \in \{96, 192, 336, 720\}`$. The left axis reports the absolute error values (MSE and MAE), while the right axis shows the relative performance degradation as noise intensity increases. As illustrated, MODE maintains stable performance under low to moderate noise levels (standard deviation $`\leq 0.3`$), with only marginal increases in MSE and MAE. Even under heavy noise injection ($`\text{std}=0.5`$), the error growth is accelerated but remains relatively moderate. Except for horizon 96 experiments, MSE and MAE growths are consistently kept within 10%. This robustness arises from the continuous-time dynamics of the Neural ODE formulation, which smooths noisy variations, and the selective scanning mechanism, which emphasizes informative temporal segments. These results confirm that MODE is resilient and reliable in noisy and uncertain environments.
Long-term Prediction Comparison
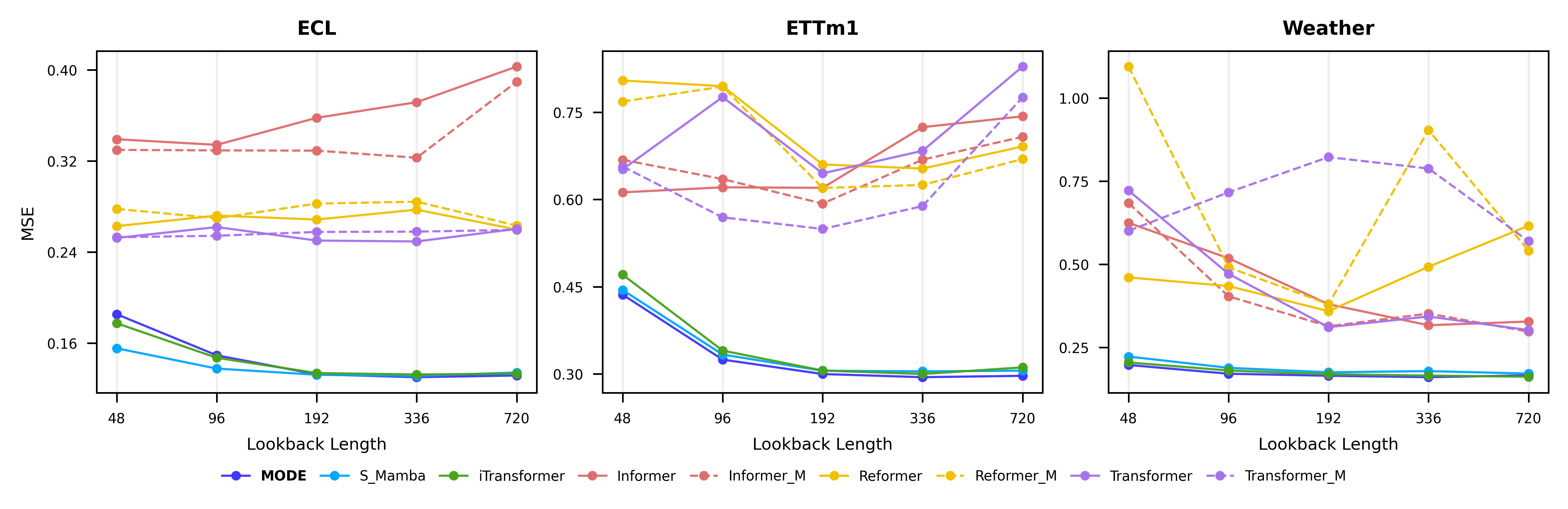
To assess the capability of MODE in modeling long-range temporal dependencies, we conduct experiments with varying lookback window lengths on the ECL, ETTm1, and Weather datasets. Fig. 5 presents the MSE results as the lookback length increases from 48 to 720. As shown, MODE consistently achieves the lowest or near-lowest error across all datasets and lookback settings, demonstrating strong adaptability to long-term dependency modeling. Unlike Transformer-based and Reformer-based approaches, whose performance tends to degrade or fluctuate at large lookback horizons due to attention saturation or inefficient memory usage, MODE maintains stable and robust accuracy. This improvement stems from the integration of low-rank Neural ODEs, which capture smooth and continuous temporal dynamics, and the selective scanning mechanism, which focuses computation on informative subsequences. Overall, these results validate that MODE effectively leverages longer historical contexts for stable and accurate long-term forecasting across diverse time series domains.
Case Study
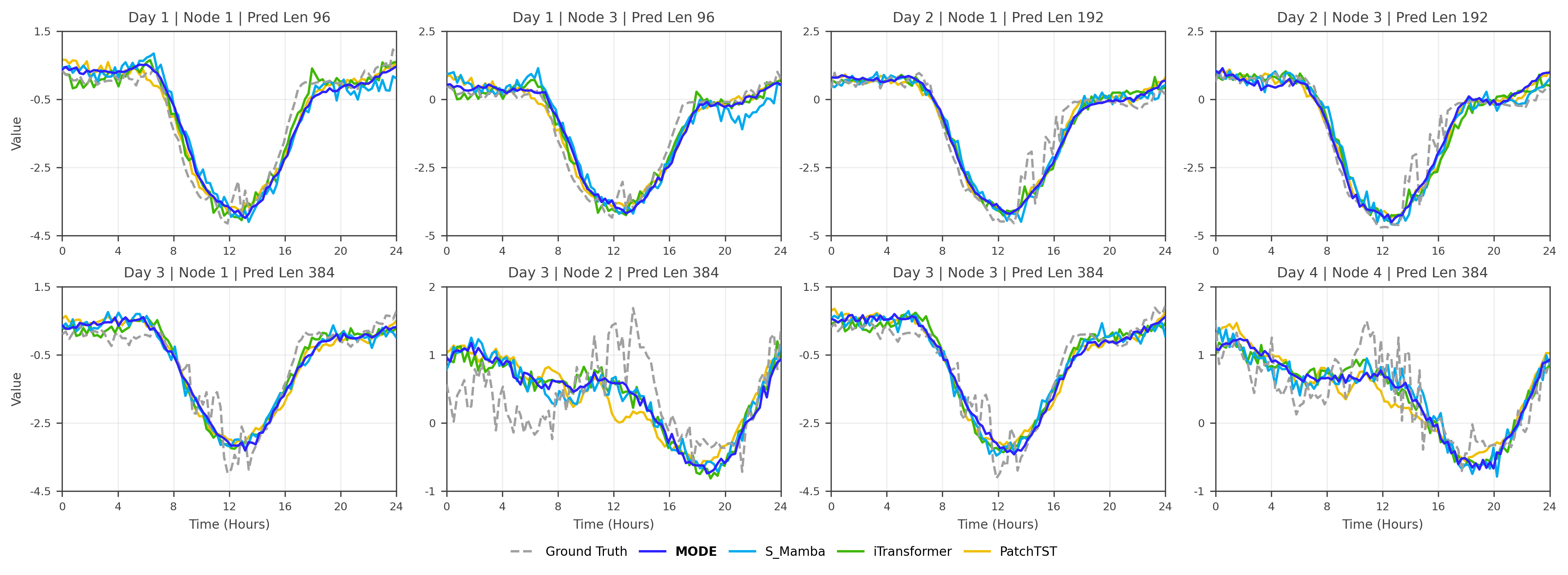
To provide intuitive insights into the effectiveness of our proposed MODE method, we conduct a detailed case study analysis on the ETTm1 dataset across multiple prediction horizons and scenarios. Fig. 6 presents representative forecasting results comparing MODE against baseline methods including S-Mamba, iTransformer, and PatchTST across different days and prediction lengths.
The case study reveals several key observations that highlight MODE ’s superior performance:
Accurate Trend Capture: Across all scenarios, MODE (purple solid line) consistently follows the ground truth patterns more closely than baseline methods. This is particularly evident in the U-shaped temperature curves observed throughout different days, where MODE accurately captures both the magnitude and timing of temperature variations.
Robust Long-term Forecasting: As the prediction horizon extends from 96 to 384 time steps, MODE maintains stable performance while baseline methods show increasing deviation. For instance, in Day 3 with 384-step prediction, competing methods exhibit significant oscillations and drift, whereas MODE preserves the underlying trend structure.
Superior Handling of Complex Patterns: MODE demonstrates exceptional capability in modeling intricate temporal dependencies, especially during transition periods where temperature changes rapidly. The method successfully reconstructs the smooth temperature curves while avoiding the erratic fluctuations observed in baseline approaches.
Consistency Across Different Scenarios: The case study encompasses various challenging conditions including different seasonal patterns (Day 1 vs Day 4) and varying prediction complexities. MODE consistently outperforms alternatives, demonstrating its robustness and generalization capability across diverse forecasting scenarios.
These qualitative results complement our quantitative analysis and provide compelling evidence of MODE ’s effectiveness in capturing complex temporal dynamics for accurate time series forecasting.
Related Work
Modern time series forecasting has progressed rapidly with the development of deep sequence models, particularly Transformer-based architectures . These models capture long-range temporal dependencies through the self-attention mechanism, enabling accurate multistep forecasting. Extensions of the Transformer framework incorporate causal masking to preserve the temporal order, while hierarchical designs such as Pyraformer and cross-variate modules like Crossformer further enhance contextual representation. However, their quadratic time complexity $`\mathcal{O}(N^2)`$ and memory cost limit scalability to long sequences. To address this, numerous studies have explored linearized or window-based attention mechanisms, yet these often trade off precision for efficiency. Large-scale pretraining frameworks such as Moirai offer another direction but differ substantially in setup and scale from our controlled evaluation.
Recently, Mamba-based architectures have emerged as promising state-space models, demonstrating strong performance in temporal reasoning and long-context sequence modeling. While these methods improve computational efficiency, they remain limited in handling irregularly sampled sequences and continuous-time dynamics.
In contrast, our proposed MODE introduces the first unified framework that combines Low-Rank Neural Ordinary Differential Equations (Neural ODEs) with an Enhanced Mamba architecture. This integration enables continuous-time modeling, efficient long-range dependency capture, and adaptive computational allocation through selective scanning. By bridging the gap between ODE-based temporal modeling and scalable state-space architectures, MODE achieves state-of-the-art accuracy while maintaining superior efficiency and robustness compared to prior Transformer and Mamba variants.
Conclusion
In this work, we present MODE, a unified and efficient framework for time series forecasting that integrates Low-Rank Neural Ordinary Differential Equations (Neural ODEs) with the Mamba architecture. By combining the continuous-time modeling capabilities of Neural ODEs with Mamba’s selective scanning mechanism, MODE effectively captures long-range temporal dependencies, gracefully handles irregular sampling patterns, and substantially decreases computational overhead. The proposed low-rank parameterization further improves scalability by reducing the state-transition complexity from $`\mathcal{O}(d^2)`$ to $`\mathcal{O}(d \cdot r)`$, while preserving rich representational power. Extensive experiments on diverse benchmark datasets show that MODE consistently delivers state-of-the-art accuracy, efficiency, and robustness. Comprehensive ablation and robustness analyses validate each architectural component and confirm resilience to noise and long forecasting horizons. Future directions include integrating probabilistic inference and physics-informed priors for enhanced uncertainty quantification and broader real-world applicability.
📊 논문 시각자료 (Figures)