Evolving, Not Training Zero-Shot Reasoning Segmentation via Evolutionary Prompting
📝 Original Paper Info
- Title: Evolving, Not Training Zero-Shot Reasoning Segmentation via Evolutionary Prompting- ArXiv ID: 2512.24702
- Date: 2025-12-31
- Authors: Kai Ye, Xiaotong You, Jianghang Lin, Jiayi Ji, Pingyang Dai, Liujuan Cao
📝 Abstract
Reasoning Segmentation requires models to interpret complex, context-dependent linguistic queries to achieve pixel-level localization. Current dominant approaches rely heavily on Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL). However, SFT suffers from catastrophic forgetting and domain dependency, while RL is often hindered by training instability and rigid reliance on predefined reward functions. Although recent training-free methods circumvent these training burdens, they are fundamentally limited by a static inference paradigm. These methods typically rely on a single-pass "generate-then-segment" chain, which suffers from insufficient reasoning depth and lacks the capability to self-correct linguistic hallucinations or spatial misinterpretations. In this paper, we challenge these limitations and propose EVOL-SAM3, a novel zero-shot framework that reformulates reasoning segmentation as an inference-time evolutionary search process. Instead of relying on a fixed prompt, EVOL-SAM3 maintains a population of prompt hypotheses and iteratively refines them through a "Generate-Evaluate-Evolve" loop. We introduce a Visual Arena to assess prompt fitness via reference-free pairwise tournaments, and a Semantic Mutation operator to inject diversity and correct semantic errors. Furthermore, a Heterogeneous Arena module integrates geometric priors with semantic reasoning to ensure robust final selection. Extensive experiments demonstrate that EVOL-SAM3 not only substantially outperforms static baselines but also significantly surpasses fully supervised state-of-the-art methods on the challenging ReasonSeg benchmark in a zero-shot setting. The code is available at https://github.com/AHideoKuzeA/Evol-SAM3.💡 Summary & Analysis
1. **New Approach**: This paper redefines reasoning segmentation as an evolutionary search problem at inference time. By maintaining diverse hypothesis populations and using evolutionary algorithms, it provides a robust approximation of the optimal solution. - Metaphor: Imagine exploring multiple routes to find the best path; each route offers different answers, and evaluating various options is key.-
Evolutionary Algorithm Utilization: Leverages pre-trained models’ discriminative capabilities for visual evolution search.
- Metaphor: Think of choosing the most suitable outfit from several candidates, where each candidate is optimized for different scenarios.
-
Enhanced Robustness: Improves robustness over existing methods to achieve stable segmentation outcomes in complex scenes.
- Metaphor: It’s akin to designing an umbrella that works well across various weather conditions, making optimal choices for each condition and ensuring effectiveness under diverse circumstances.
📄 Full Paper Content (ArXiv Source)
easoning Segmentation aims to generate pixel-level binary masks based on complex natural language queries . This task requires the model to interpret text instructions through logical reasoning. Unlike traditional semantic or instance segmentation tasks that rely on pre-defined categorical labels , reasoning segmentation addresses more complex, context-dependent queries or even instructions requiring reasoning to identify the target instance (e.g., “something that the person uses to fish”). This setting better reflects the real-world requirements for intelligent assistants and robotics, while simultaneously imposing significantly higher demands on the model: it must possess fine-grained visual perception, robust image-text alignment capabilities, and broad domain knowledge combined with common sense and logical reasoning.
 style="width:95.0%" />
style="width:95.0%" />
Given the comprehensive capabilities of Multi-modal Large Language Models (MLLMs) in reasoning and multi-modal perception, incorporating MLLMs has become the mainstream solution for this task.
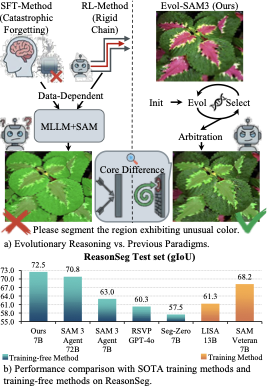
Current approaches for reasoning segmentation are primarily dominated by two learning-based paradigms: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), yet both face inherent limitations regarding training costs and rigid inference patterns. The first paradigm, SFT-based methods , attempts to internalize the segmentation task by fine-tuning MLLMs to map text instructions directly to pixel masks. However, the extensive parameter updates required often induce catastrophic forgetting of general reasoning capabilities, leading to poor generalization on out-of-distribution instructions . The second paradigm, RL-based methods , treats the MLLM as a policy network optimized via reward signals. Despite introducing dynamic interaction, these models still execute a fixed policy during inference. This results in a brittle, linear reasoning trajectory: if the initial step falls into a local optimum (e.g., misidentifying the target), the agent lacks the intrinsic mechanism to perform dynamic backtracking or global search to recover .
The emergence of SAM 3 marks a pivotal turning point, as it endows a powerful interactive segmentation model with intrinsic semantic understanding capability for the first time. Unlike predecessor models that responded only to geometric prompts like points or boxes (which was the fundamental reason previous methods required expensive training for MLLMs to output coordinates ), SAM 3 can directly comprehend and locate simple noun phrases. Based on this technological leap, works represented by the SAM 3 Agent have rapidly emerged, establishing a new paradigm of Training-Free Visual Agents. This paradigm completely discards parameter updates, utilizing a frozen SOTA MLLM as the brain for planning and SAM 3 as the hand with a semantic interface for execution. This design maximizes the preservation of the MLLM’s general reasoning abilities and world knowledge, endowing the system with strong zero-shot transfer capabilities.
However, despite the potential shown by the SAM 3 Agent, its inference mechanism remains trapped in a Heuristic Trial-and-Error strategy, suffering from two critical robustness defects. First, the refinement steps of the SAM 3 Agent rely heavily on the MLLM’s intuition to decide. This jumping logic based on dialogue history is often random and unstructured (e.g., the model may switch disorderly between color and location descriptions). Lacking a clear gradient or optimization direction, the agent easily oscillates around suboptimal solutions, failing to converge to the prompt that triggers SAM 3’s peak performance. Secondly, although the SAM 3 Agent includes a selection mechanism, it typically filters within a set of candidates generated by a single reasoning path. This means that if the initial direction of semantic understanding deviates, all subsequent interactions are confined within this erroneous semantic frame. The system lacks a mechanism to simultaneously maintain and compare distinct heterogeneous hypotheses, leading to an inability to escape local optima.
To address these challenges, we propose EVOL-SAM3, a novel training-free framework that reframes reasoning segmentation as an inference-time evolutionary search problem. Unlike the SAM 3 Agent, which relies on linear heuristic jumps, Evo-SAM3 maintains a dynamically evolving population of hypotheses. We design a comprehensive visual evolutionary algorithm: it conducts extensive directed exploration in the semantic space via semantic mutation operators and introduces a heterogeneous competition mechanism, forcing “text-based reasoning” and “box-based localization” to compete within the same ecological niche to resolve ambiguity. Most crucially, we leverage the MLLM’s superior discriminative capability to construct a Visual Arena replacing simple filtering with a tournament selection mechanism. This enables Evo-SAM3 to transform the MLLM’s discriminative power into a driving force for search without any parameter updates, ultimately evolving the optimal prompt that maximizes SAM 3’s potential.
Our main contributions are summarized as follows:
-
We are the first to model the reasoning segmentation task as an inference-time evolutionary search problem. We demonstrate that maintaining a diverse population of hypotheses and using evolutionary algorithms for systematic search allows for a more robust approximation of the optimal solution.
-
We introduce a specialized evolutionary mechanism featuring (1) semantic mutation for directed exploration, (2) heterogeneous competition to resolve ambiguity, and (3) a visual arena utilizing tournament selection for robust optimization.
-
Experiments on benchmarks demonstrate that under the Zero-Shot setting, EVOL-SAM3 not only significantly outperforms existing training-free agents but also surpasses dedicated models trained via STF or RL on multiple key metrics.
Related Works
Learning-based Reasoning Segmentation. Current methodologies for reasoning segmentation can be broadly categorized into three paradigms: Supervised Fine-Tuning , Reinforcement Learning , and hybrid SFT+RL strategies. SFT-based methods typically formulate the task as a sequence generation problem. By end-to-end fine-tuning Multi-modal Large Language Models on large-scale segmentation datasets, these models are trained to output specific mask tokens or polygon coordinates. However, this paradigm faces significant limitations. The aggressive parameter updates required for pixel-level alignment often induce catastrophic forgetting, degrading the MLLM’s inherent general reasoning capabilities. Furthermore, SFT models tend to overfit the training distribution, resulting in poor generalization when encountering complex, out-of-distribution instructions in open-world scenarios.
RL and Hybrid Strategies. To align the optimization objective with evaluation metrics, RL-based methods formulate segmentation as a policy decision process, optimizing the model via reward signals. However, existing RL methods often fail to achieve fully end-to-end gradient flow between the MLLM and SAM, or heavily rely on manually constructed trajectory data for initialization . This black-box optimization often yields suboptimal prompts that fail to trigger the executor’s peak performance. Recent works attempt to combine the strengths of both worlds through hybrid strategies. A representative method, LENS , jointly optimizes the Chain-of-Thought (CoT) and mask generation in an end-to-end manner by employing Group Relative Policy Optimization (GRPO) with rewards spanning sentence, box, and segment levels. Despite these architectural advancements, all learning-based paradigms—whether SFT, RL, or hybrid—share a critical bottleneck: excessive reliance on training resources. Developing such models requires substantial computational resources and massive annotated datasets, creating an extremely high barrier to entry. Moreover, once trained, the inference policy remains static, lacking the flexibility to adaptively self-correct without further parameter updates.
Training-Free Visual Agents. In response to the high training barriers, a Training-Free paradigm has emerged, represented by the SAM 3 Agent . This approach links a frozen MLLM as a planner with SAM 3 for execution, thereby preserving the MLLM’s inherent generalization capabilities. Nevertheless, current training-free agents rely heavily on heuristic trial-and-error. Their reasoning process is typically linear and unstructured, lacking a systematic optimization objective. If the agent’s initial semantic interpretation is flawed, it lacks the mechanism to globally explore alternative hypotheses, often leading to irreversible failures in complex scenes.To address these limitations, we propose EVOL-SAM3, which reformulates reasoning segmentation as an inference-time evolutionary search problem. Unlike linear approaches, our framework maintains a population of diverse hypotheses and leverages the discriminative power of MLLMs to perform global optimization, enabling robust alignment without any parameter updates.
 style="width:100.0%" />
style="width:100.0%" />
Method
Problem Formulation
We formally define the reasoning segmentation task as follows: given an input image $`I \in \mathbb{R}^{H \times W \times 3}`$ and a natural language query $`q`$, the objective is to generate a binary mask $`M \in \{0, 1\}^{H \times W}`$ that semantically aligns optimally with the target described by $`q`$. Traditional approaches, such as fully supervised fine-tuning or reinforcement learning, typically aim to learn a parameterized conditional distribution $`P_\theta(M | I, q)`$. However, this paradigm is inherently static during inference, relying heavily on the model’s memorization of the training distribution.
In this work, we reformulate this task as an inference-time latent variable optimization problem. We posit that for any arbitrarily complex query $`q`$, there exists an optimal latent prompt $`z^*`$ within a hybrid semantic-geometric space $`\mathcal{Z}`$. When this optimal prompt drives a powerful, deterministic segmentation executor, it yields the optimal solution. Based on this premise, we define our objective as searching for $`z^*`$ within the space of frozen foundation models:
\begin{equation}
z^* = \mathop{\arg\max}_{z \in \mathcal{Z}} \mathcal{F}(M_z, q; \Psi_{\text{VLM}}) \quad \text{s.t.} \quad M_z = \Phi_{\text{SAM}}(I, z)
\label{eq:optimization_objective}
\end{equation}In this formulation, $`\Phi_{\text{SAM}}: \mathbb{R}^{H \times W \times 3} \times \mathcal{Z} \to \{0, 1\}^{H \times W}`$ denotes the frozen Executor (implemented via SAM 3 ), which deterministically maps the latent variable $`z`$ to a segmentation mask $`M_z`$. $`\mathcal{F}`$ represents the Fitness Function, parameterized by a frozen Vision-Language Model $`\Psi_{\text{VLM}}`$ (implemented via Qwen2.5-VL ), which quantifies the semantic alignment between $`M_z`$ and the original query $`q`$. The core advantage of this modeling lies in decoupling: it leverages the MLLM’s reasoning capabilities to navigate the complex semantic space $`\mathcal{Z}`$, while retaining SAM 3’s robust geometric priors for pixel-level generation. Crucially, this avoids the risk of catastrophic forgetting associated with fine-tuning foundation models.
Solving the optimization problem in Eq. [eq:optimization_objective] presents two intrinsic mathematical challenges: non-differentiability and reference-free evaluation. First, since the search space $`\mathcal{Z}`$ consists of discrete natural language tokens and geometric coordinates, and $`\Phi_{\text{SAM}}`$ operates as a black-box function, the gradient $`\nabla_z \mathcal{F}`$ is inaccessible, precluding gradient-based optimization methods. Second, the absence of ground truth masks during inference makes the precise calculation of $`\mathcal{F}`$ impossible.
To address these challenges, we propose the EVOL-SAM3 framework, which employs an Evolutionary Algorithm (EA) as a derivative-free solver. Specifically, we maintain a population of hypotheses $`\mathcal{P}_t = \{z_1^{(t)}, \dots, z_N^{(t)}\}`$ at generation $`t`$, and approximate $`z^*`$ by iteratively applying MLLM-driven Semantic Mutation and Selection Operators. To overcome the lack of ground truth, we exploit the property that MLLMs exhibit superior performance in discrimination tasks compared to generation tasks. We approximate the fitness landscape via a Visual Arena mechanism, where the scalar fitness $`\mathcal{F}(z)`$ is modeled as the win-rate of a candidate solution in pairwise tournaments judged by $`\Psi_{\text{VLM}}`$. In this way, we transform static pre-trained models into a dynamic system capable of deliberate search and optimization.
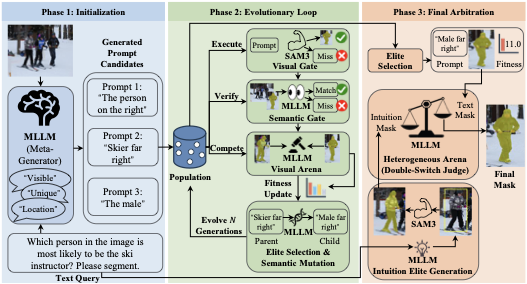
Framework Overview
As illustrated in Figure 2, EVOL-SAM3 reformulates the static reasoning segmentation task into a training-free, dynamic evolutionary search process. The framework leverages a frozen MLLM for high-level semantic planning and evaluation, while utilizing SAM 3 for low-level pixel execution. The pipeline initiates with Population Initialization (Phase 1), where the MLLM acts as a meta-generator to expand the user’s single query into a diverse population of prompts covering various descriptive perspectives (e.g., attributes, spatial relations). Subsequently, the system enters the core Evolutionary Reasoning Loop (Phase 2). In each generation, candidate prompts drive SAM 3 to generate segmentation masks. These masks are rigorously filtered by a Semantic Gate for consistency and then evaluated via pairwise competition in a Visual Arena. Following the principle of survival of the fittest, elite individuals undergo MLLM-driven Semantic Mutation to spawn the next generation, iteratively converging towards the optimal semantic description of the target.
To mitigate potential linguistic hallucinations in complex scenarios, we introduce a final Heterogeneous Arena (Phase 3). In this stage, the system extracts not only the best text-derived mask from the evolutionary search but also generates an auxiliary detection-based mask derived from the MLLM’s geometric intuition. These two candidates, originating from distinct reasoning paths (semantic reasoning vs. geometric localization), are submitted to a Heterogeneous Arena. Through a double-blind adaptive judgment mechanism, the MLLM selects the most robust final segmentation. This cascaded “Generate-Evolve-Arbitrate” mechanism enables Evo-SAM3 to achieve precise alignment and robust segmentation for complex visual queries without requiring any parameter updates.
Semantic Meta-Planning
The ultimate performance of evolutionary search is critically contingent on the quality and coverage of the initial population $`\mathcal{P}_0`$. In complex visual scenarios, the raw user query $`q`$ is often concise or semantically ambiguous (e.g., “the man” is ill-posed in a multi-person scene). Relying directly on such a single starting point makes the search process prone to getting trapped in local optima or failing to converge. To overcome this cold-start problem, we introduce a semantic meta-planning phase prior to the evolutionary loop. In this stage, the frozen MLLM functions as a vision-aware meta-generator. Unlike traditional blind textual augmentation or paraphrasing, this generator jointly analyzes the input image $`I`$ and query $`q`$ to deconstruct the abstract query into a set of visually grounded hypotheses. By identifying potential distractors within the image, it actively infers discriminative features capable of uniquely identifying the target, thereby extending a single query point into a distribution that covers the target’s potential semantic space.
Specifically, the meta-planning process constructs a heterogeneous population $`\mathcal{P}_0`$ through multi-dimensional semantic anchoring. The first dimension is attribute augmentation, where the MLLM automatically supplements visual details (e.g., color, texture) to distinguish the target from similar instances. The second is spatial explicitness, which converts implicit relative positional relationships into absolute spatial descriptions (e.g., refining “the person on the left” to “the leftmost person” or “the person in the bottom-left corner”). The third is referent specification, which replaces generic pronouns with specific nouns. The initial population generated through this strategy possesses high genetic diversity and eliminates referential ambiguity to a significant extent at the initialization stage. This provides a robust and high-quality search space for the subsequent evolutionary reasoning loop, significantly reducing the exploration cost of the algorithm.
Image $`I`$, Query $`q`$, Population $`\mathcal{P}_0`$, Max Gen $`G`$ Optimal Mask $`M^*`$
$`\mathcal{P}_{valid} \leftarrow \emptyset`$
Step A: Execution & Cascaded Verification $`M_i \leftarrow \Phi_{\text{SAM}}(I, z_i)`$ $`s_{conf} \leftarrow \text{Score}(M_i)`$ $`g_{sem} \leftarrow \text{SemanticGate}(M_i, q; \Psi_{\text{VLM}})`$ $`\mathcal{P}_{valid} \leftarrow \mathcal{P}_{valid} \cup \{z_i\}`$
Step B: Visual Arena Selection Initialize fitness $`\mathcal{F}`$ for all $`z \in \mathcal{P}_{valid}`$ $`w \leftarrow \text{VisualArena}(M_a, M_b, q; \Psi_{\text{VLM}})`$ Update $`\mathcal{F}(z_a) \leftarrow \mathcal{F}(z_a) + \Delta`$, $`\mathcal{F}(z_b) \leftarrow \mathcal{F}(z_b) - \Delta`$ Update $`\mathcal{F}(z_b) \leftarrow \mathcal{F}(z_b) + \beta \Delta`$, $`\mathcal{F}(z_a) \leftarrow \mathcal{F}(z_a) - \beta\Delta`$
$`z_{elite} \leftarrow \arg\max_{z \in \mathcal{P}_{valid}} \mathcal{F}(z)`$
Step C: Termination Check break
Step D: Semantic Mutation $`\mathcal{P}_t \leftarrow \{z_{elite}\}`$ $`z_{mut} \leftarrow \text{Mutation}(z_{elite}, q; \Psi_{\text{VLM}})`$ $`\mathcal{P}_t \leftarrow \mathcal{P}_t \cup \{z_{mut}\}`$
return $`\Phi_{\text{SAM}}(I, z_{elite})`$
Detailed Mechanisms of Evolutionary Reasoning Loop
To effectively optimize the latent prompt $`z`$ without ground truth supervision, we instantiate the evolutionary loop with three cascaded operators: Execution & Cascaded Verification, Visual Arena Selection, and Semantic Mutation. This loop is designed to align discrete semantic search with continuous pixel generation, iteratively converging towards the optimal solution.
Execution and Cascaded Verification Operator.
This step serves as the bridge between the discrete semantic space $`\mathcal{Z}`$ and the continuous pixel space, while simultaneously acting as a computational filter. For each latent prompt $`z_i`$ in the population $`\mathcal{P}_t`$, the frozen executor $`\Phi_{\text{SAM}}`$ deterministically maps it to a binary mask $`M_i`$ and an internal confidence score $`s_{conf}^{(i)} \in [0, 1]`$. This process is formulated as:
\begin{equation}
(M_i, s_{conf}^{(i)}) = \Phi_{\text{SAM}}(I, z_i)
\end{equation}To prune the search space of low-quality hypotheses, we employ a dual-layer gating function $`\mathcal{G}(z_i)`$. Initially, a Confidence Gate leverages the executor’s uncertainty to filter out hallucinations via an indicator function:
\begin{equation}
g_{conf}(z_i) = \mathbb{I}(s_{conf}^{(i)} > \tau_{conf})
\end{equation}Subsequently, candidates passing this preliminary filter are subjected to a Semantic Gate, where the VLM $`\Psi_{\text{VLM}}`$ acts as a verifier. By analyzing the joint distribution of the raw image $`I`$ and the mask overlay $`I \oplus M_i`$, it validates consistency with the query $`q`$, yielding a binary decision $`g_{sem}(z_i)`$. Only individuals satisfying both constraints are admitted into the valid population:
\begin{equation}
\mathcal{P}_{valid} = \{z_i \in \mathcal{P}_t \mid g_{conf}(z_i) \cdot g_{sem}(z_i) = 1\}
\end{equation}Visual Arena Selection Operator.
Approximating the fitness landscape $`\mathcal{F}(z)`$ in a reference-free setting is non-trivial. Exploiting the property that MLLMs are stronger discriminators than generators, we reformulate fitness estimation as a Pairwise Tournament. For pairs $`(z_a, z_b) \in \mathcal{P}_{valid}`$ with significant geometric discrepancy, we construct a visual triplet input. The evaluator $`\Psi_{\text{VLM}}`$ functions as a judge, estimating the preference probability $`P(z_a \succ z_b | q)`$ based on semantic alignment. This relative ranking mechanism circumvents the calibration bias inherent in absolute scoring. The Visual Arena Selection Operator approximates the fitness landscape $`\mathcal{F}(z)`$ in a reference-free setting. Exploiting the property that MLLMs are stronger discriminators than generators, we reformulate fitness estimation as a Pairwise Tournament. For pairs $`(z_a, z_b) \in \mathcal{P}_{valid}`$ with significant geometric discrepancy, we construct a visual triplet input. The evaluator $`\Psi_{\text{VLM}}`$ functions as a judge, estimating the preference probability $`P(z_a \succ z_b | q)`$ based on semantic alignment. This relative ranking mechanism circumvents the calibration bias inherent in absolute scoring. We dynamically update individual fitness scores using an asymmetric Elo-based update rule. To facilitate exploration, if the challenger $`z_b`$ defeats the incumbent $`z_a`$, we apply a boosted reward scaled by $`\beta > 1`$:
\begin{equation}
\mathcal{F}(z_b) \leftarrow \mathcal{F}(z_b) + \beta \Delta, \quad \mathcal{F}(z_a) \leftarrow \mathcal{F}(z_a) - \beta \Delta
\end{equation}Conversely, if the incumbent retains the advantage, a standard update step $`\Delta`$ is applied. This mechanism allows high-potential mutations to rapidly ascend in rank while maintaining population stability.
Semantic Mutation Operator.
To escape local optima and traverse the semantic manifold effectively, we introduce a Semantic Mutation operator $`\mathcal{M}`$ driven by the reasoning capabilities of the MLLM. Unlike stochastic character-level perturbations, this operator performs a logical reconstruction of the elite prompt $`z_{elite}`$ to generate a child $`z_{mut}`$ with higher “SAM-compatibility”:
\begin{equation}
z_{mut} = \mathcal{M}(z_{elite}, q; \Psi_{\text{VLM}})
\end{equation}Our implementation incorporates two strategies to constrain the solution space of $`\Phi_{\text{SAM}}`$: (1) Simplification, which removes non-discriminative redundancy to minimize executor attention drift; and (2) Ambiguity Avoidance, which transforms relative spatial descriptions into absolute superlatives (e.g., mutating “person on the right” into “rightmost person”). These mutations explicitly guide the search towards regions of the semantic space that yield deterministic and accurate segmentation.
Heterogeneous Arena
While the evolutionary reasoning loop (Algorithm [alg:evo_loop]) excels in semantic alignment, producing a high-quality candidate $`M_{text}`$, relying solely on textual prompts remains susceptible to linguistic hallucinations in scenes with complex textures. To establish a robust safeguard, we introduce a heterogeneous arena module. This component leverages the geometric intuition of the MLLM to construct an auxiliary spatial reasoning path, facilitating a final adjudication against $`M_{text}`$ via a double-blind mechanism.
Geometric Intuition and Spatial Filtering. Distinct from the iterative refinement of textual prompts, the geometric path focuses on capturing the global spatial localization of the target via a single forward pass. We prompt the frozen MLLM to perform a detection task, directly predicting a bounding box $`B_{pred}`$, formulated as $`B_{pred} = \Psi_{\text{VLM}}(I, q; \text{detect})`$. This box serves as a geometric prompt for SAM to generate a candidate mask $`M_{box} = \Phi_{\text{SAM}}(I, B_{pred})`$. To ensure the validity of this geometric prior, we enforce a spatial consistency filter. This filter calculates the intersection over union between the bounding box of the generated mask, denoted as $`\text{bbox}(M_{box})`$, and the MLLM-predicted box $`B_{pred}`$. The geometric mask is deemed a valid contender only if it exhibits high spatial coherence:
\begin{equation}
\text{IoU}(\text{bbox}(M_{box}), B_{pred}) > \tau_{spat}
\end{equation}This constraint effectively discards instances where the MLLM localizes a general region but the segmentation model fails to identify a salient object within that vicinity, ensuring the geometric reliability of $`M_{box}`$.
Double-Blind Swap Mechanism. At this stage, we obtain two heterogeneous candidates: the optimal text-derived mask $`M_{text}`$ and the box-derived mask $`M_{box}`$. To select the final segmentation $`M^*`$ without bias, we submit them to a heterogeneous arena. Acknowledging the inherent position bias in MLLMs, where models may exhibit a preference for images appearing in specific input slots, we design a double-blind swap adjudication strategy. We construct two permuted visual prompt tuples: the forward permutation $`V_{fwd} = (I, M_{text}, M_{box})`$ and the reverse permutation $`V_{rev} = (I, M_{box}, M_{text})`$. The MLLM acts as a judge $`J`$ in two independent trials. The final selection is determined by a strict consistency logic that favors the robust geometric prior in uncertain cases:
\begin{equation}
M^* =
\begin{cases}
M_{text} & \text{if } J(V_{fwd}) = M_{text} \land J(V_{rev}) = M_{text} \\
M_{box} & \text{otherwise (Fallback Priority)}
\end{cases}
\end{equation}By enforcing consistency across permutations, we mitigate the stochasticity of the VLM. Specifically, any logical conflict (e.g., the model always choosing the first image regardless of content) or preference for the box triggers the fallback to $`M_{box}`$, thereby enforcing safe performance boundaries.
Experiments
Implementation Details
We implement EVOL-SAM3 using the PyTorch framework on a server equipped with 8 NVIDIA RTX 3080 GPUs. As a training-free framework, our method focuses on inference-time optimization without updating the backbone parameters. For the Multi-modal Large Language Model (MLLM) backbone, we employ Qwen2.5-VL-Instruct, evaluating both the 3B and 7B parameter versions to verify scalability. To optimize memory efficiency while maintaining performance, the MLLM inference is conducted in FP16 precision. For the visual segmentation backend, we utilize SAM 3, with image resolution and mask generation hyperparameters strictly aligned with the SAM3Agent baseline to ensure a fair comparison. The evolutionary process is configured with a population size of $`N_{pop}=4`$ and a maximum of $`T_{max}=2`$ generations. In the Visual Arena, the Elo rating update step is set to 1.0, and the confidence threshold for mask filtering is set to $`\tau_{mask}=0.6`$. All semantic mutations and arena selections are performed in a zero-shot manner.
Datasets and Evaluation Metrics
To ensure a fair comparison with state-of-the-art methods, we strictly follow the evaluation protocols and dataset settings established in previous research. We conduct extensive experiments on four standard benchmarks. For Reasoning Segmentation, we use the ReasonSeg dataset, which contains complex queries requiring implicit reasoning, and report results on its validation set. For Referring Expression Segmentation, we evaluate on RefCOCO, RefCOCO+, and RefCOCOg. Specifically, we use the val, testA, and testB splits for RefCOCO and RefCOCO+; for RefCOCOg, we use the val (UMB) and test (UMB) partitions. Consistent with prior works, we employ gIoU and cIoU as the primary evaluation metrics.
| Model | Training Data | Val Set | Test Set | Test (Short) | Test (Long) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-2 (lr)3-4 (lr)5-6 (lr)7-8 (lr)9-10 (lr)11-12 Name | Version | RES | ReasonSeg | gIoU | cIoU | gIoU | cIoU | gIoU | cIoU | gIoU | cIoU |
| SEEM | – | × | × | 25.5 | 21.2 | 24.3 | 18.7 | 20.1 | 11.5 | 25.6 | 20.8 |
| Grounded SAM | – | × | × | 26.0 | 14.5 | 21.3 | 16.4 | 17.8 | 10.8 | 22.4 | 18.6 |
| OVSeg | – | × | × | 28.5 | 18.6 | 26.1 | 20.8 | 18.0 | 15.5 | 28.7 | 22.5 |
| GLaMM | Vicuna 7B | × | 47.4 | 47.2 | – | – | – | – | – | – | |
| SAM4MLLM | Qwen-VL 7B | × | 46.7 | 48.1 | – | – | – | – | – | – | |
| SAM4MLLM | LLaVA1.6 8B | × | 58.4 | 60.4 | – | – | – | – | – | – | |
| Seg-Zero | Qwen2.5-VL 3B | × | 58.2 | 53.1 | 56.1 | 48.6 | – | – | – | – | |
| Seg-Zero | Qwen2.5-VL 7B | × | 62.6 | 62.0 | 57.5 | 52.0 | – | – | – | – | |
| X-SAM | Phi3 3.8B | 56.6 | 32.9 | 57.8 | 41.0 | 47.7 | 48.1 | 56.0 | 40.8 | ||
| HyperSeg | Phi2 3B | 59.2 | 56.7 | – | – | – | – | – | – | ||
| Ref-Diff | LLaVA1.5 7B | × | × | – | 52.4 | – | 48.7 | – | 48.0 | – | 49.1 |
| Ref-Diff | LLaVA1.5 13B | × | × | – | 60.5 | – | 49.9 | – | 48.7 | – | 51.0 |
| LISA | LLaVA 7B | × | 44.4 | 46.0 | 36.8 | 34.1 | 37.6 | 34.4 | 36.6 | 34.7 | |
| LISA | LLaVA 7B | 52.9 | 54.0 | 47.3 | 34.1 | 40.6 | 40.6 | 49.4 | 51.0 | ||
| LISA | LLaVA 13B | × | 48.9 | 46.9 | 44.8 | 45.8 | 39.9 | 43.3 | 46.4 | 46.5 | |
| LISA | LLaVA 13B | 56.2 | 62.9 | 51.7 | 51.1 | 44.3 | 42.0 | 54.0 | 54.3 | ||
| LISA | Llama2 13B | 60.0 | 67.8 | 51.5 | 51.3 | 43.9 | 45.8 | 54.0 | 53.8 | ||
| LISA | LLaVA1.5 7B | × | 53.6 | 52.3 | 48.8 | 47.1 | 48.3 | 48.8 | 49.2 | 48.9 | |
| LISA | LLaVA1.5 7B | 61.3 | 62.9 | 55.6 | 56.9 | 48.3 | 46.3 | 57.9 | 59.7 | ||
| LISA | LLaVA1.5 13B | × | 57.7 | 60.3 | 53.8 | 50.8 | 50.8 | 50.0 | 54.7 | 50.9 | |
| LISA | LLaVA1.5 13B | 65.0 | 72.9 | 61.3 | 62.2 | 55.4 | 50.6 | 63.2 | 65.3 | ||
| LENS | Qwen2.5-VL-3B | 62.1 | 64.9 | 57.2 | 58.0 | – | – | – | – | ||
| HRSeg | LLaVA1.1 7B | 57.4 | 54.7 | 43.4 | 41.7 | 54.4 | 54.5 | 51.6 | 50.5 | ||
| HRSeg | LLaVA1.6 7B | 64.9 | 63.1 | 49.5 | 48.7 | 59.2 | 58.9 | 57.0 | 57.2 | ||
| SAM-Veteran | Qwen2.5-VL 7B | 68.2 | 67.3 | 62.6 | 56.1 | – | – | – | – | ||
| SAM-Veteran | Qwen2.5-VL 32B | 72.3 | 70.0 | 62.9 | 58.2 | – | – | – | – | ||
| READ | LLaVA1.5 7B | 59.8 | 67.6 | 58.5 | 58.6 | 52.6 | 49.5 | 60.4 | 61.0 | ||
| SegAgent | Qwen2.5-VL 7B | 33.0 | 25.4 | 33.5 | 31.3 | – | – | – | – | ||
| LLM-Seg | LLaVA1.1 7B | 52.3 | 47.5 | 47.9 | 46.2 | 41.1 | 40.2 | 49.8 | 49.1 | ||
| RSVP | LLaVA1.6 7B | × | × | 59.2 | 56.7 | 56.9 | 50.7 | 47.9 | 42.0 | 58.4 | 53.0 |
| RSVP | Qwen2-VL 7B | × | × | 58.6 | 48.5 | 56.1 | 51.6 | 48.5 | 44.3 | 57.1 | 53.0 |
| RSVP | Gemini1.5-Flash | × | × | 56.9 | 49.2 | 57.1 | 59.2 | 47.3 | 40.2 | 60.2 | 65.6 |
| RSVP | GPT-4o | × | × | 64.7 | 63.1 | 60.3 | 60.0 | 55.4 | 50.4 | 61.9 | 62.5 |
| Gemini Seg | Gemini2.5 Flash | ? | ? | 28.3 | 13.3 | 30.6 | 9.2 | 16.5 | 8.0 | 35.0 | 9.5 |
| SAM 3 Agent | Qwen2.5-VL 7B | × | × | 62.2 | 49.1 | 63.0 | 53.5 | 59.4 | 43.5 | 64.1 | 56.2 |
| SAM 3 Agent | Qwen2.5-VL 72B | × | × | 74.6 | 65.1 | 70.8 | 64.0 | 70.3 | 55.7 | 71.0 | 66.3 |
| SAM 3 Agent | Llama4 Maverick | × | × | 68.5 | 61.5 | 67.1 | 60.9 | 66.8 | 59.4 | 67.2 | 61.3 |
| EVOL-SAM3 (ours) | Qwen2.5-VL 3B | × | × | 66.9 | 57.1 | 65.9 | 58.9 | 62.0 | 47.3 | 67.1 | 62.5 |
| EVOL-SAM3 (ours) | Qwen2.5-VL 7B | × | × | 70.7 | 63.4 | 72.5 | 67.4 | 67.0 | 46.8 | 74.3 | 73.3 |
COMPARISONS
As shown in Table [tab:main_results], we report detailed performance comparisons on the ReasonSeg benchmark. The most remarkable finding is that EVOL-SAM3 demonstrates superior performance under a fully zero-shot setting, surpassing existing learning-based methods (encompassing SFT and RL). Specifically, our 7B version achieves 70.7 gIoU on the validation set. This not only significantly outperforms the classic LISA-7B (52.9 gIoU) but, more notably, surpasses LISA-13B (65.0 gIoU), which has undergone deep optimization via supervised fine-tuning and reinforcement learning. This result prompts us to revisit the heavy reliance of high-performance reasoning segmentation on expensive supervised data or reward feedback, and demonstrates the feasibility of mining the reasoning potential of frozen models as an efficient alternative.
Furthermore, among training-free counterparts, EVOL-SAM3 proves that a refined evolutionary mechanism is more efficient than merely scaling up model parameters. Although the baseline SAM 3 Agent achieves 74.6 gIoU on the validation set by relying on a massive 72B parameter model, our method achieves a reversal on the more challenging Test Set (72.5 vs. 70.8 gIoU) using only 7B parameters. Finally, the robustness of EVOL-SAM3 in handling long and complex queries is particularly pronounced. Benefiting from the effective decomposition and error correction of complex instructions enabled by the semantic mutation and visual arena mechanisms, we achieve an outstanding 74.3 gIoU on the Test (Long) subset. This significantly outperforms RSVP (GPT-4o) at 61.9 gIoU and SAM 3 Agent (72B) at 71.0 gIoU, fully validating the unique advantages of dynamic evolutionary search in deep semantic understanding.
| Model | Training | RefCOCO | RefCOCO+ | RefCOCOg | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-2 (lr)3-3 (lr)4-6 (lr)7-9 (lr)10-12 Name | Version | RES | val | testA | testB | val | testA | testB | val (U) | test (U) | val (G) |
| LISA | LLaVA 7B | 74.9 | 79.1 | 72.3 | 65.1 | 70.8 | 58.1 | 67.9 | 70.6 | – | |
| GSVA | 13B | 79.2 | 81.7 | 77.1 | 70.3 | 73.8 | 63.6 | 75.7 | 77.0 | – | |
| GLaMM | Vicuna 7B | 79.5 | 83.2 | 76.9 | 72.6 | 78.7 | 64.6 | 74.2 | 74.9 | – | |
| SAM4MLLM | LLaVA1.6 7B | 79.6 | 82.8 | 76.1 | 73.5 | 77.8 | 65.8 | 74.5 | 75.6 | – | |
| SAM4MLLM | LLaVA1.6 8B | 79.8 | 82.7 | 74.7 | 74.6 | 80.0 | 67.2 | 75.5 | 76.4 | – | |
| GLEE | Plus | 79.5 | – | – | 68.3 | – | – | 70.6 | – | – | |
| GLEE | Pro | 80.0 | – | – | 69.6 | – | – | 72.9 | – | – | |
| DETRIS | DETRIS-L | 81.0 | 81.9 | 79.0 | 75.2 | 78.6 | 70.2 | 74.6 | 75.3 | – | |
| UniLSeg | UniLSeg-20 | 80.5 | 81.8 | 78.4 | 72.7 | 77.0 | 67.0 | 78.4 | 79.5 | – | |
| UniLSeg | UniLSeg-100 | 81.7 | 83.2 | 79.9 | 73.2 | 78.3 | 68.2 | 79.3 | 80.5 | – | |
| PSALM | Phi1.5 1.3B | 83.6 | 84.7 | 81.6 | 72.9 | 75.5 | 70.1 | 73.8 | 74.4 | – | |
| EVF-SAM | RC | 82.1 | 83.7 | 80.0 | 75.2 | 78.3 | 70.1 | 76.8 | 77.4 | – | |
| EVF-SAM | Extra Data | 82.4 | 84.2 | 80.2 | 76.5 | 80.0 | 71.9 | 78.2 | 78.3 | – | |
| RICE | Qwen2.5-7B | 83.5 | 85.3 | 81.7 | 79.4 | 82.8 | 75.4 | 79.8 | 80.4 | – | |
| MLCD-seg | Qwen2.5-7B | 83.6 | 85.3 | 81.5 | 79.4 | 82.9 | 75.6 | 79.7 | 80.5 | – | |
| HyperSeg | Phi2 2.7B | 84.8 | 85.7 | 83.4 | 79.0 | 83.5 | 75.2 | 79.4 | 78.9 | – | |
| LENS | Qwen2.5-VL 3B | 84.2 | 85.3 | 81.0 | 79.4 | 82.8 | 74.3 | 81.2 | 81.0 | – | |
| SAM-Veteran | Qwen2.5-VL 7B | – | 80.8 | – | – | 76.6 | – | – | 73.4 | – | |
| SAM-Veteran | Qwen2.5-VL 32B | – | 80.4 | – | – | 77.4 | – | – | 73.4 | – | |
| READ | LLaVA1.5 7B | 78.1 | 80.2 | 73.2 | 68.4 | 73.7 | 60.4 | 70.1 | 71.4 | – | |
| SegAgent | Qwen-VL 7B | 79.2 | 81.4 | 75.7 | 71.5 | 76.7 | 65.4 | 74.8 | 74.6 | – | |
| X-SAM | Phi3 3.8B | 85.1 | 87.1 | 83.4 | 78.0 | 81.0 | 74.4 | 83.8 | 83.9 | – | |
| GL-CLIP | ResNet-50 | × | 32.7 | 35.3 | 30.1 | 37.7 | 40.7 | 34.9 | 41.6 | 42.9 | 44.0 |
| GL-CLIP | ViT-B/32 | × | 32.9 | 34.9 | 30.1 | 38.4 | 42.1 | 32.7 | 42.0 | 42.0 | 42.7 |
| CaR | ViT-B/16 | × | 33.6 | 35.4 | 30.5 | 34.2 | 36.0 | 31.0 | 36.7 | 36.6 | 36.6 |
| Ref-Diff | VAE | × | 37.2 | 38.4 | 37.2 | 37.3 | 40.5 | 33.0 | 44.0 | 44.5 | 44.3 |
| TAS | ResNet-50 | × | 39.9 | 42.9 | 35.9 | 44.0 | 50.6 | 36.4 | 47.7 | 47.4 | 48.7 |
| TAS | ViT-B/32 | × | 39.8 | 41.1 | 36.2 | 43.6 | 49.1 | 36.5 | 46.6 | 46.8 | 48.1 |
| IteRPrimeE | – | × | 40.2 | 46.5 | 33.9 | 44.2 | 51.6 | 35.3 | 46.0 | 45.1 | 45.8 |
| Pseudo-RIS | CRIS | × | 39.8 | 44.8 | 33.0 | 42.2 | 46.3 | 34.5 | 43.7 | 43.4 | 43.8 |
| Pseudo-RIS | ETRIS | × | 41.1 | 48.2 | 33.5 | 44.3 | 51.4 | 35.1 | 46.0 | 46.7 | 46.8 |
| LGD+DINO | ViT-B/32 | × | 49.5 | 54.7 | 41.0 | 49.6 | 58.4 | 38.6 | 50.3 | 51.1 | 52.5 |
| VLM-VG | ResNet-50 | × | 47.7 | 51.8 | 44.7 | 41.2 | 45.9 | 34.7 | 46.6 | 47.1 | – |
| VLM-VG | ResNet-101 | × | 49.9 | 53.1 | 46.7 | 42.7 | 47.3 | 36.2 | 48.0 | 48.5 | – |
| HybridGL | ViT-B/32 | × | 49.5 | 53.4 | 45.2 | 43.4 | 49.1 | 37.2 | 51.3 | 51.6 | – |
| SAM 3 Agent | Qwen2.5-VL 7B | × | 59.4 | 64.3 | 55.0 | 51.4 | 57.0 | 44.9 | 57.2 | 58.8 | 59.7 |
| 1-12 EVOL-SAM3 (ours) | Qwen2.5-VL 3B | × | 66.8 | 70.9 | 59.9 | 56.1 | 63.1 | 49.3 | 63.0 | 63.5 | 64.0 |
| EVOL-SAM3 (ours) | Qwen2.5-VL 7B | × | 68.7 | 73.7 | 64.4 | 64.4 | 67.8 | 54.0 | 64.7 | 65.5 | 65.9 |
Table [tab:res_benchmark] presents the evaluation results on the classic RefCOCO, RefCOCO+, and RefCOCOg datasets. We observe that task-specific supervised training still yields dominant performance gains for RES tasks. As shown, fully fine-tuned methods (e.g., X-SAM, RICE, MLCD-seg) generally outperform zero-shot approaches by a large margin. This is attributed to the fact that RES tasks heavily rely on specific referring patterns (e.g., “the person on the left”), which are explicitly reinforced during supervised training, enabling SFT models to establish strong text-region mappings. Consequently, zero-shot methods, lacking this targeted pattern adaptation, naturally face a performance gap.
However, within the Zero-Shot category, EVOL-SAM3 achieves a remarkable performance breakthrough, significantly narrowing the gap with supervised methods. Compared to existing training-free baselines, EVOL-SAM3 demonstrates superior generalization. Specifically, our 7B model achieves the best zero-shot performance across all three datasets. Compared to the baseline SAM 3 Agent, which shares the identical Qwen2.5-VL-7B backbone, our method realizes a comprehensive performance leap. For instance, on the RefCOCO val and testA subsets, we achieve improvements of +9.3 cIoU ($`59.4 \to 68.7`$) and +9.4 cIoU ($`64.3 \to 73.7`$), respectively. On RefCOCO+ val, which demands strictly appearance-based grounding, the gain reaches +13.0 cIoU ($`51.4 \to 64.4`$). Similarly, on RefCOCOg val (U), which features more complex sentence structures, we obtain a significant increase of +7.5 cIoU ($`57.2 \to 64.7`$).
This significant performance improvement validates the necessity of transforming static inference into a dynamic iterative process. The results demonstrate that even in the absence of task-specific training data, introducing an adaptive optimization mechanism during the inference phase can effectively calibrate the misalignment between semantic understanding and visual perception, thereby achieving robustness and accuracy comparable to fully supervised methods in traditional referring expression segmentation tasks.
ABLATION STUDY
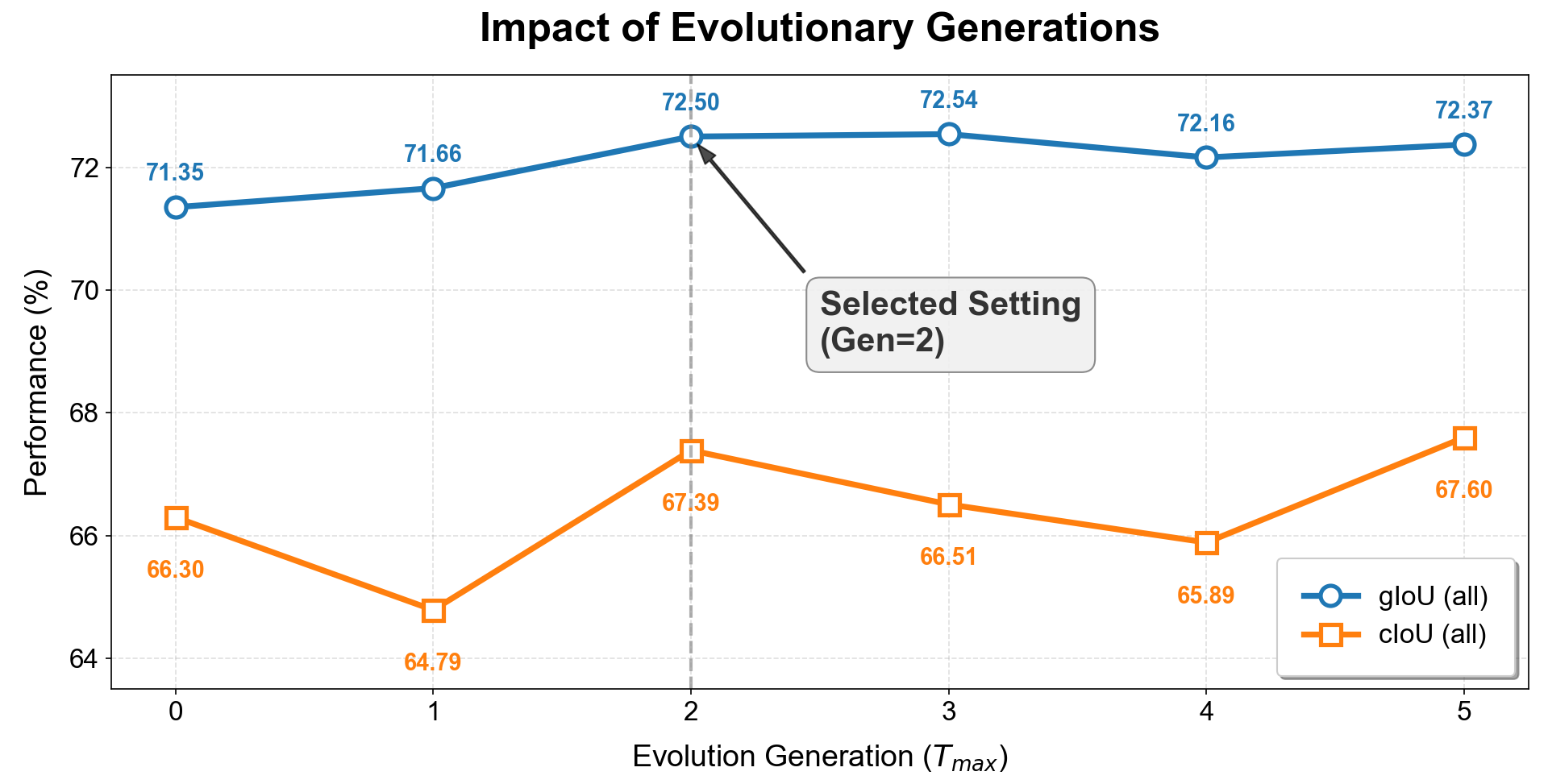
Evolutionary Generations
To thoroughly investigate the impact of evolutionary iterations on model performance, we conducted a sensitivity analysis on the maximum number of generations $`T_{max}`$ using the ReasonSeg validation set. As illustrated in the figure, the model exhibits a significant upward trajectory in segmentation performance as generations increase from 0 to 2, with gIoU and cIoU rising from 71.35% and 66.30% to 72.50% and 67.39%, respectively. This result strongly validates the effectiveness of our evolutionary mechanism: by introducing semantic mutation and arena selection, the model can transcend the limitations of the initial meta-planning and dynamically rectify early suboptimal solutions to approach more precise semantic descriptions. However, we observe distinct diminishing returns beyond $`T_{max}=2`$, where performance metrics saturate or even fluctuate slightly (e.g., a drop in cIoU at Gen 3). Given that the computational cost of inference increases linearly with evolutionary generations, further iterations do not yield performance gains commensurate with the additional overhead. Consequently, to achieve the optimal trade-off between reasoning accuracy and system efficiency, we adopt $`T_{max}=2`$ as the default configuration, which is sufficient for the model to achieve adequate reasoning calibration at a manageable cost.
We attribute the performance saturation and fluctuations observed beyond $`T_{max}=2`$ to two primary factors. First, the rapid convergence of the semantic search space. For most visual reasoning tasks, the number of valid logical paths from an ambiguous query to a precise referral is finite. Our experiments suggest that within two rounds of “mutation-selection” iteration, the evolutionary algorithm typically traverses and locks onto the most plausible semantic interpretation within the current context. Subsequent generations often involve minor paraphrasing rather than discovering substantive new semantic information. Second, the inherent upper bound of frozen backbones. It is crucial to note that EVOL-SAM3 is fundamentally a mining strategy rather than a learning process. It aims to elicit the maximum latent potential of the frozen MLLM and SAM but cannot surpass their intrinsic perceptual limits (e.g., recognizing extremely small or heavily occluded objects). Consequently, once the inference instruction is optimized to the boundary of the model’s understanding, further evolutionary attempts risk introducing overly complex descriptions or hallucinations, leading to semantic drift. This also explains the slight oscillation in cIoU observed at higher generations.
| Fitness Evaluation Strategy | gIoU | cIoU |
|---|---|---|
| Direct Scoring (w/o Arena) | 71.00 | 64.45 |
| Single-Pass Judge (w/o Double-Switch) | 69.42 | 66.50 |
| Dual-Pass Arena (Ours) | 72.50 | 67.40 |
Ablation study on the Visual Arena mechanism. We compare our proposed Double-Switch comparative evaluation with Direct Scoring and Single-Pass strategies on the ReasonSeg validation set.
Effectiveness of the Visual Arena Mechanism
Table 1 presents the ablation results regarding different fitness evaluation strategies. First, the Direct Scoring strategy, which requires the MLLM to assign absolute quality scores without peer comparison, yields a suboptimal cIoU of 64.45%. This suggests that without a reference target, the model struggles to provide well-calibrated scores and is susceptible to numerical hallucinations, leading to unstable evolutionary directions. Second, introducing a Single-Pass Judge (pairwise comparison without position swapping) improves the cIoU to 66.50% but, surprisingly, degrades the gIoU to 69.42%. We attribute this drop to the inherent position bias of Large Language Models, where the model preferentially selects options at specific positions (e.g., typically favoring the first option). This bias results in the erroneous elimination of high-quality individuals during the selection phase. Finally, our Dual-Pass Arena, equipped with the Double-Switch mechanism, effectively mitigates this bias by enforcing consistency checks across swapped positions. This strategy achieves the best overall performance (72.50% gIoU and 67.40% cIoU), demonstrating that establishing a fair and robust comparison mechanism is critical for identifying superior solutions in evolutionary search.
Qualitative Analysis
To further evaluate the reasoning capability of the model in complex real-world scenarios, Figure 4 presents a detailed visual comparison between EVOL-SAM3 and the strong baseline SAM3Agent. The results reveal the inherent limitations of static reasoning models in handling functional descriptions and abstract spatial referents, while our method demonstrates superior self-correction capabilities. First, the baseline model exhibits a strong salient object bias. When the query involves “objects to propel the boat,” the baseline captures the semantic relevance but is misled by the visually dominant “boat,” failing to localize the semantically correct but smaller “oars.” In contrast, EVOL-SAM3 leverages the semantic mutation mechanism within the evolutionary loop to successfully suppress this visual bias, precisely focusing attention on the specific components that align with the functional description.
Second, when distinguishing low-saliency or implicit targets, the baseline model is highly prone to linguistic hallucinations or missed detections. Benefiting from the incorporation of geometric intuition by the heterogeneous arena module, EVOL-SAM3 not only successfully recalls the imperceptible tire valve area but also accurately grounds the abstract concept of “activity area” to the specific grass field. This provides compelling evidence that modeling the reasoning process as a dynamic search rather than a single-pass mapping effectively bridges the gap between complex semantics and visual signals.
 style="width:95.0%" />
style="width:95.0%" />
Conclusion
In this paper, we proposed EVOL-SAM3, a novel zero-shot framework that reformulates reasoning segmentation as an inference-time evolutionary search process. By synergizing a frozen MLLM with SAM 3 through a dynamic “Generate-Evolve-Arbitrate” pipeline, our method effectively navigates the semantic space to identify optimal prompts without any parameter updates. The introduction of the Visual Arena and Heterogeneous Arena mechanisms ensures robust optimization and safeguards against the hallucinations inherent in static inference. Extensive experiments on ReasonSeg and RefCOCO benchmarks demonstrate that EVOL-SAM3 not only surpasses existing training-free agents but also outperforms fully supervised state-of-the-art models in a zero-shot setting. This work provides compelling evidence that scaling inference-time computation via evolutionary strategies offers a promising and efficient alternative to traditional training paradigms for complex visual reasoning tasks.
📊 논문 시각자료 (Figures)