BandiK Efficient Multi-Task Decomposition Using a Multi-Bandit Framework
📝 Original Paper Info
- Title: BandiK Efficient Multi-Task Decomposition Using a Multi-Bandit Framework- ArXiv ID: 2512.24708
- Date: 2025-12-31
- Authors: András Millinghoffer, András Formanek, András Antos, Péter Antal
📝 Abstract
The challenge of effectively transferring knowledge across multiple tasks is of critical importance and is also present in downstream tasks with foundation models. However, the nature of transfer, its transitive-intransitive nature, is still an open problem, and negative transfer remains a significant obstacle. Selection of beneficial auxiliary task sets in multi-task learning is frequently hindered by the high computational cost of their evaluation, the high number of plausible candidate auxiliary sets, and the varying complexity of selection across target tasks. To address these constraints, we introduce BandiK, a novel three-stage multi-task auxiliary task subset selection method using multi-bandits, where each arm pull evaluates candidate auxiliary sets by training and testing a multiple output neural network on a single random train-test dataset split. Firstly, BandiK estimates the pairwise transfers between tasks, which helps in identifying which tasks are likely to benefit from joint learning. In the second stage, it constructs a linear number of candidate sets of auxiliary tasks (in the number of all tasks) for each target task based on the initial estimations, significantly reducing the exponential number of potential auxiliary task sets. Thirdly, it employs a Multi-Armed Bandit (MAB) framework for each task, where the arms correspond to the performance of candidate auxiliary sets realized as multiple output neural networks over train-test data set splits. To enhance efficiency, BandiK integrates these individual task-specific MABs into a multi-bandit structure. The proposed multi-bandit solution exploits that the same neural network realizes multiple arms of different individual bandits corresponding to a given candidate set. This semi-overlapping arm property defines a novel multi-bandit cost/reward structure utilized in BandiK.💡 Summary & Analysis
1. **Key Contribution**: Introduces a novel approach to the multi-task auxiliary task subset selection problem.-
Comparison: BandiK offers an efficient alternative by selecting beneficial subsets rather than evaluating all possibilities for each target task, saving time and resources compared to previous methods.
-
Metaphor: Imagine BandiK as a detailed city map that helps you understand the relationships between different tasks and find the optimal path through this complex landscape of transfer effects.
📄 Full Paper Content (ArXiv Source)
Introduction
The availability of foundation models in multiple domains, starting with vision and culminating in linguistic tasks redefined the scope of multitask learning as omni-task learning towards artificial general intelligence . Still, detailed quantitative evaluations of multitask learning are frequently grappling with the presence of negative transfer effects, i.e., the intricate, complex pattern of beneficial-detrimental effects of certain tasks on others . It is by no surprise as the nature of transfer learning is multi-factorial and transfer effects can be attributed to (1) shared data, (2) shared latent representations, and (3) shared optimization; thus transfer effects are contextual and depend on the sample sizes, task similarities, sufficiency of hidden representations, and stages of the optimization .
An alternative paradigm suggests selecting the beneficial auxiliary task subsets for each target task or eliminating the detrimental auxiliary tasks; however, evaluation of candidate auxiliary task subsets can be computationally demanding and statistically leads to loss of power due to multiple hypothesis testing.
To address these constraints, we introduce BandiK, a novel three-stage multi-task auxiliary task subset selection method using multi-bandits, where each arm pull evaluates candidate auxiliary sets by training and testing a multiple output neural network on a single random train-test dataset split (the problem setup is shown in Figure 1).
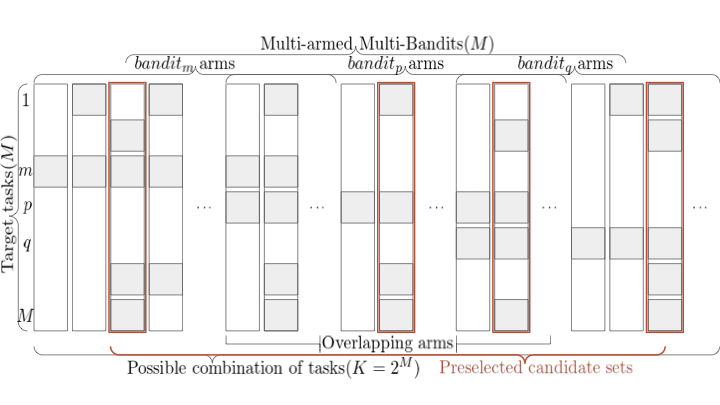 style="width:100.0%" />
style="width:100.0%" />
Firstly, BandiK estimates the pairwise transfers between tasks, which helps in identifying which tasks are likely to benefit from joint learning . In the second stage, it constructs a linear number of candidate sets of auxiliary tasks (in the number of all tasks) for each target task based on the initial estimations, significantly reducing the exponential number of potential auxiliary task sets . Thirdly, it employs a Multi-Armed Bandit (MAB) framework including the tasks, where the arms correspond to the performance of candidate auxiliary sets realized as multiple output neural networks over train-test data set splits . The major steps are summarized in Algorithm [alg:MBS4MTL].
: Estimation of pairwise transfer learning effects between tasks and building positive and negative transfer graphs based on different tests for transfer : Construction of candidate auxiliary sets for each task by applying search methods in the graphs : Definition and simulation of a multi-bandit using the adaptive GapE-V method; selection of best performing multi-task neural network for each target task.
In this paper, we adopt the auxiliary task subset selection approach using hard parameter sharing networks and investigate (1) the construction methods of auxiliary sets, (2) the efficiency of a multi-bandit approach, and (3) the effects of the novel semi-overlapping arms in a multi-bandit. We answer the following questions:
-
Baseline performance: What are the best performances of single, pairwise, and multi-task learning scenarios per tasks?
-
Pairwise task landscape: What are the performances of pairwise target-auxiliary learning scenarios per tasks?
-
Uncertainty and heterogeneity of task performances: What are the variances of task performances? What is their heterogeneity and relation to task properties, such as task sample size?
-
Heuristics for candidate auxiliary sets: What is the landscape of candidate auxiliary sets based on heuristics, such as greedy pairwise, filtered pairwise, pairwise-based transitive closures and cliques, incremental-decremental approaches?
-
Multi-bandit dynamics: What are the distributions of pulls and convergence rates over individual bandits throughout learning, especially regarding their performance gaps and variances?
-
Semi-overlapping arms: What are the effects of semi-overlapping arms between bandits, i.e., the massive multiple presence of shared networks and pulls?
-
Performance of candidate auxiliary task sets: What are the performances of candidate auxiliary task sets, especially regarding their types and the availability of shared candidates (is there any cross-gain)?
-
Nature of transfer: What are the implications of the results for the nature of transfer, i.e., transfer by shared samples, latent features or optimization?
-
Applicability of foundation models: What are the implications for foundation models in special quantitative domains, e.g., in drug-target interaction prediction?
We demonstrate our methods on a drug-target interaction (DTI) prediction problem .
Related works
MABs are successfully applied in hyper-parameter optimization and neural architecture search, though we go a step deeper: a pull of an arm corresponds to a single train-test split evaluation in our case (see e.g., ). The selection of multiple tasks for joint learning motivated a series of sequential learning methods . Combinatorial multi-armed bandits (MABs) allow the pull of multiple arms simultaneously resulting in an aggregate reward of individual arms . Notably, the ’top-$`k`$’ extension considers the subsets up to size $`k`$ and allows variants whether the rewards for the individual arms are available or only their non-linear aggregations . Another relevant extension to our formalization with multiple auxiliary task subset selection problem for each task is the multi-bandit approach, also allowing overlap between the arms , . Finally, recent MAB extensions investigated the use of task representations and learning task relatedness .
Problem setup
Consider a Multi-Task Learning problem with $`M`$ tasks, in which one should decide among $`K=2^{M-1}`$ options for auxiliary task sets for each $`\mathop{\mathrm{task}}_m`$ to reach optimal performance. ($`2^{M-1}`$ being the number of possible sets surely containing $`\mathop{\mathrm{task}}_m`$, which number we propose to significantly reduce in the first two stages of BandiK.) This problem can be formulated as the best arm identification over $`M`$ multi-armed bandits with $`K`$ arms each. In the setting each target task corresponds to a multi arm bandit and each set in the power set of tasks containing the target $`\mathop{\mathrm{task}}_m`$ is considered an arm. (We use indices $`m`$, $`p`$, $`q`$ for the bandits and $`k`$, $`i`$, $`j`$ for the arms.) Pulling an arm induces the training of a neural network on this set of tasks, and we are asked to recommend an arm for each bandit after a given number of pulls (budget).
This setting is a special case of the multi-bandit best arm identification problem . To acquire the reward of an $`\mathop{\mathrm{arm}}_{mk}`$ of $`\mathop{\mathrm{bandit}}_m`$, we train a neural network on the tasks covered by $`\mathop{\mathrm{arm}}_{mk}`$ (always containing at least $`\mathop{\mathrm{task}}_m`$ itself) that we denote $`\mathop{\mathrm{armset}}_{mk}`$. Notice that for a given task subset $`\mathcal{T}`$, at pulling any $`\mathop{\mathrm{arm}}_{mk}`$ with $`\mathop{\mathrm{armset}}_{mk}=\cal{T}`$ of $`\mathop{\mathrm{bandit}}_m`$ corresponding to target $`\mathop{\mathrm{task}}_m\in\mathcal{T}`$, an identical network can be constructed, just there are $`|\mathcal{T}|`$ variations which is the target task in $`\mathcal{T}`$ and which is the (complement) auxiliary task set. Being the target task or an auxiliary one is only a matter of evaluation. Thus, if $`\mathop{\mathrm{armset}}_{mk}=\mathop{\mathrm{armset}}_{pi}`$ the cost of training the underlying network is incurred only once for $`\mathop{\mathrm{arm}}_{mk}`$ and $`\mathop{\mathrm{arm}}_{pi}`$, however, the corresponding rewards, depending on the target tasks ($`\mathop{\mathrm{task}}_m`$ vs. $`\mathop{\mathrm{task}}_p`$), are different. Hence, we call such $`\mathop{\mathrm{arm}}_{mk}`$ and $`\mathop{\mathrm{arm}}_{pi}`$ semi-overlapping arms (as opposed to (fully) overlapping arms with the same reward, e.g., in ). Therefore, in our case joint optimization of the auxiliary task selection problem is not only reasonable for optimal resource allocation among the bandits, but more importantly each $`\mathop{\mathrm{bandit}}_p`$ having a semi-overlapping $`\mathop{\mathrm{arm}}_{pi}`$ with $`\mathop{\mathrm{arm}}_{mk}`$ can also make an update about the arm’s reward whenever $`\mathop{\mathrm{arm}}_{mk}`$ is pulled in $`\mathop{\mathrm{bandit}}_m`$, because the neural network trained once can be evaluated for any included task, so the cost of the reward has to be paid only once.
Following the notation of , let $`M`$ be the number of bandits and $`K=2^{M-1}`$ be the number of possible arms of each bandit. Each $`\mathop{\mathrm{arm}}_{mk}`$ of a $`\mathop{\mathrm{bandit}}_m`$ is characterized by a distribution $`\nu_{mk}`$ bounded in $`[0, 1]`$ with mean $`\mu_{mk}`$. We denote by $`\mu^*_m`$ the mean and $`k^*_m`$ the index of the best arm of $`\mathop{\mathrm{bandit}}_m`$. In each $`\mathop{\mathrm{bandit}}_m`$, we define the gap for each arm as $`\Delta_{mk} = \lvert \max_{j \neq k} \mu_{mj} - \mu_{mk} \rvert`$.
At each round of the game $`t = 1, \dots, n`$, the forecaster pulls a bandit-arm pair $`I(t)=(m,k)`$ and observes a sample drawn from each distribution in $`\{ \nu_{pi} : \mathop{\mathrm{armset}}_{pi} = \mathop{\mathrm{armset}}_{mk}\}`$ independent of the past. Let $`T_{mk}(t)`$ be the number of times that a sample from $`\nu_{mk}`$ has been observed by the end of round $`t`$, meaning $`T_{mk}(t)=T_{pi}(t)`$ throughout the whole game if $`\mathop{\mathrm{armset}}_{mk} = \mathop{\mathrm{armset}}_{pi}`$. Let us note that, in contrast of the non-overlapping case, the final number $`n`$ of rounds is not equal to the sum of $`T_{mk}(n)`$’s for all $`m`$ and $`k`$, leading to a massive relative budget increase. We use the adaptive GapE-V algorithm of with the same values $`\widehat{\mu}_{mk}(t)`$, $`\widehat\Delta_{mk}(t)`$, $`\widehat{\sigma}_{mk}^2(t)`$ 1 , $`B_{mk}(t)`$, and $`\widehat{H}^\sigma(t)`$ as derived in .
In each $`t`$ time step, an $`\mathop{\mathrm{arm}}_{mk}`$ is pulled and an $`f(t)=f(D_{\rm train}(t), \mathcal{T}(t))`$ hard parameter sharing neural network is trained, from random initialization, to predict the $`\mathcal{T}(t)=\mathop{\mathrm{armset}}_{mk}`$ set of tasks, utilizing a random train split of the data. Monte Carlo Subsampling is used to split the dataset into $`D_{\rm train}(t)`$ and $`D_{\rm test}(t)`$ in each round, with sizes $`80\%`$ and $`20\%`$, respectively. All $`\mathop{\mathrm{bandit}}_p`$ corresponding to a $`\mathop{\mathrm{task}}_p\!\in\!\mathcal{T}(t)`$ receives a sample $`X_{pi}(t)`$ by evaluating the performance of the network separately: $`X_{pi}(t)=L_{p}(f(t), D_{\rm test}(t))`$, where $`i`$ is chosen so that $`\mathop{\mathrm{armset}}_{pi} = \mathcal{T}(t)`$. Monte Carlo Cross Validation has been shown asymptotically consistent . Let $`L_m(\mathcal{T})=L_m(f(D_{\rm train}(u), \mathcal{T}), D_{\rm test}(u))`$ denote the loss corresponding to $`\mathop{\mathrm{task}}_m`$ of a network trained and evaluated on a random data split, to predict the tasks in $`\mathcal{T}`$. $`L`$ can be any standard loss function, but throughout this paper we use the Area Under the Receiver Operating Curve (AUROC, $`L^{AUR}`$) and the Area Under the Precision-Recall Curve (AUPR, $`L^{AUP}`$) metrics.
Data and methods
Data set
Following , we use the NURA-2021 data set binarized as ’strong binder’ versus other labels. It includes $`22`$ targets and $`31006`$ compounds. Since completely random train/test splits suffer from the compound series bias, leading to overoptimistic performance estimations , we utilize a more realistic, scaffold-based train/test split in the spirit of , which resulted in $`6441`$ scaffolds.
Models and computations
Every time a network train is mentioned, the SparseChem model, a multiple output MLP is used. Architecture and other hyperparameters were determined by grid search and apart from the number of neurons in the last layer these values were always unchanged. Consequently, ADAM optimizer was used with a learning rate of $`10^{-4}`$ and weight decay of $`10^{-6}`$. Trainings run for $`25`$ epochs with $`10\%`$ batch ratio. Following the $`32000`$ neuron-wide input layer, and two $`1000`$ neuron-wide hidden layers, the width of the output layer was always $`|\mathcal{T}|`$. ReLU activation and $`0.7`$ dropout ratio were used in the hidden layers. Sigmoid and $`0.2`$ dropout in the last layer.
BandiK
We introduce BandiK, a novel three-stage method using multi-bandits for solving the multi-task auxiliary task subset selection problem described in Section 3.
Estimating pairwise transfer and building transfer graphs
In the first stage, we discover multi-task transfer effects, by training on a number of base case candidate task sets. There are four main training scenarios: single task learning (STL, $`\mathcal{T}_m=\{m\}`$), pairwise learning (PW, $`\mathcal{T}_{pq}=\{p, q\}`$), full multitask learning (FMTL, $`\mathcal{T}_{F}=\{1, \dots, M\}`$) and leave-one-out learning (LOO, $`\mathcal{T}_{m-}=\mathcal{T}_{F} \setminus \{m\}`$). We train all possible scenarios on $`500`$ random dataset splits to acquire a sample of the network performances.
Using the results of the base cases, we construct directed positive tranfer graphs ($`P^{metric, test}`$) and directed negative tranfer graphs ($`N^{metric, test}`$). The existence of a $`(p,q)`$ directed edge in a given graph indicates that $`\mathop{\mathrm{task}}_p`$ has a (positive or negative) transfer effect on $`\mathop{\mathrm{task}}_q`$. To construct the positive transfer effect matrices we check if PW options perform better than STL. The edges of negative transfer matrices are derived from comparing LOO to FMTL, e.g., if a $`task_q`$ performs better with $`\mathcal{T}_{p-}`$ than trained with $`\mathcal{T}_F`$, it means that $`\mathop{\mathrm{task}}_p`$ has a clear individual negative transfer effect on $`\mathop{\mathrm{task}}_q`$.
-
$`P^{AUP, diff}_{pq} = 1 \iff L^{AUP}_q(\mathcal{T}_{pq}) - L^{AUP}_q(\mathcal{T}_{q}) > 0`$
-
$`P^{AUR, diff}_{pq} = 1 \iff L^{AUR}_q(\mathcal{T}_{pq}) - L^{AUR}_q(\mathcal{T}_{q}) > 0`$
-
$`N^{AUP, diff}_{pq} = 1 \iff L^{AUP}_q(\mathcal{T}_{p-}) - L^{AUP}_q(\mathcal{T}_{F}) > 0`$
-
$`N^{AUR, diff}_{pq} = 1 \iff L^{AUR}_q(\mathcal{T}_{p-}) - L^{AUR}_q(\mathcal{T}_{F}) > 0`$
In addition to using the difference to indicate better performance, we propose two kinds of significance tests to assess transfer effect:
-
t-test: $`P^{AUP, tt}`$, $`P^{AUR, tt}`$, $`N^{AUP, tt} N^{AUR, tt}`$
-
nemenyi-thrd: $`P^{AUP, nem}`$, $`P^{AUR, nem}`$, $`N^{AUP, nem}`$, $`N^{AUR, nem}`$
where the existence of a $`(p, q)`$ edges of the graphs in the t-test list are calculated using Student t-test with $`p=0.05`$, e.g., if the hypothesis $`h_0: L^{AUP}_q(\mathcal{T}_{pq}) \leq L^{AUP}_q(\mathcal{T}_{q})`$ can be rejected. Nemenyi-thrd: for each $`\mathop{\mathrm{task}}_m`$, firts, Friedman Chi$`^2`$ test is run to check if there are signifficant differences between the STL, PW, FMT and LOO parformances (44 distributions per task) and if so this is followed by Nemenyi test to search pair-wise significant performance differences between .
Construction of candidate auxiliary task sets
In the second stage, using transfer graphs constructed in Stage 1., we propose to construct a fixed number of candidate sets for each $`task_m`$, by running different heuristic based graph search algorithms to find connected tasks with positive/negative transfer. These heuristics closely resemble forward and backward methods used in the feature subset selection problem . In the case of positive transfer the initial candidate set is always $`\mathcal{T}'=\mathcal{T}_m`$ which is inflated with newly found nodes. When negative transfer graphs are searched, results are removed from the initial $`\mathcal{T}'=\mathcal{T}_F`$.
Candidate sets are generated using the following methods.
The final candidate sets genereted by GenerateArms$`(\{`$ $`P^{AUP, diff}`$,$`P^{AUR, diff}`$, $`N^{AUP, diff}`$, $`N^{AUR, diff}`$, $`P^{AUP, tt}`$, $`P^{AUR, tt}`$ , $`N^{AUP, tt}`$, $`N^{AUR, tt}`$, $`P^{AUP, nem}`$, $`P^{AUR, nem}`$ , $`N^{AUP, nem}`$, $`N^{AUR, nem}\}, M)`$
$`398`$ unique candidate sets are generated in Stage 2. using $`4`$ search methods that utilize different suppositions about the transitivity of pairwise transfer effects.
-
DirectNeighbours: the most conservative, choosing only the inward pointing star graph of the direct neighbors of $`task_m`$
-
Transitive: supposes that the pairwise transfer effects are fully transitive and so all the $`task_p`$ nodes in the graph with a connected (directed) path from $`task_p`$ to $`task_m`$ are chosen
-
FilteredTransitive: supposes that the dense transfer effect graph has a sparse generator, therefore, before running S2 it reduces the graph to its maximum weight spanning tree
-
Clique: supposes that the pairwise transfer is not only transitive, but should also be symmetric, so the biggest subset of fully connected nodes containing $`task_m`$ is chosen as the candidate set
Multi-Armed Bandit (MAB)
In the final stage, the problem of task-wise auxiliary task set selection is mapped to a Multi-Armed Multi-Bandit, where each task has a corresponding bandit and the arms give performance estimations of candidate auxiliary sets. The $`276`$ base cases from Stage 1. and $`398`$ Stage 2. candidate sets give us a total of $`674`$ semi-overlapping arms. In this stage the A-GapE-V algorithm is run with a total of $`22`$ bandits and $`398`$ semi-overlapping arms, where the arm set of $`\mathop{\mathrm{bandit}}_m`$ is chosen to be the set of candidate sets containing $`\mathop{\mathrm{task}}_m`$. After the termination of the algorithm each bandit/task is presented with the best arm/auxiliary task set.
Results
We present results about the multi-task properties of the DTI prediction problem, the properties of the multi-bandit architecture, its dynamics, and its performance.
Domain characterization
We explored the performance landscape of the DTI domain and the possibility of multi-task improvements by estimating the base case scenarios of Section 4.3.1 (see Figure 2) .
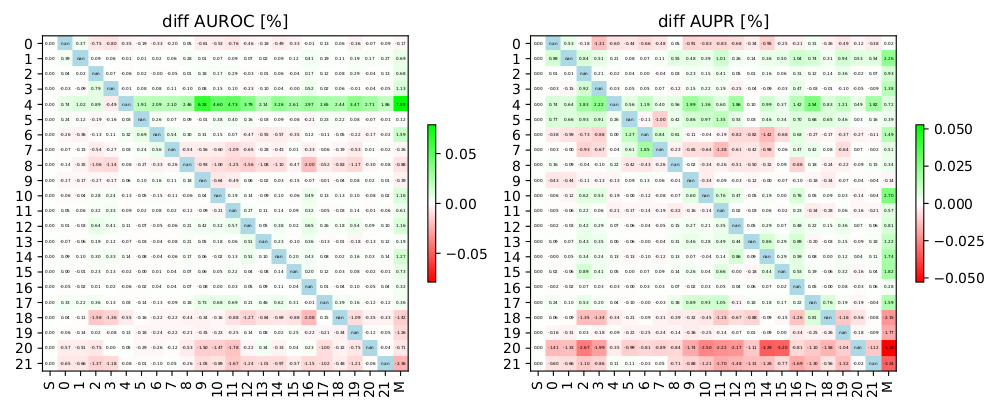
The detailed pairwise transfer effects are illustrated in Figure 3.
The variances of the performance metrics have a major impact on the number of necessary train-test data splits for reliable performance estimation and model selection. Figure 4 shows the sample sizes and the standard deviations of the tasks, which are a major factor determining their variances.

Static properties of BandiK
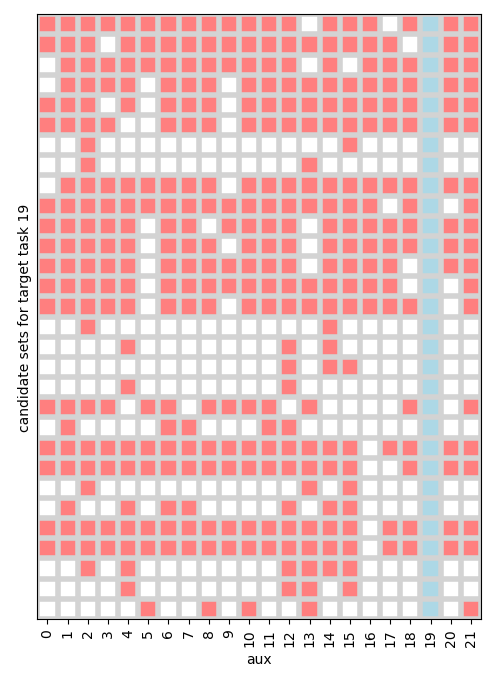
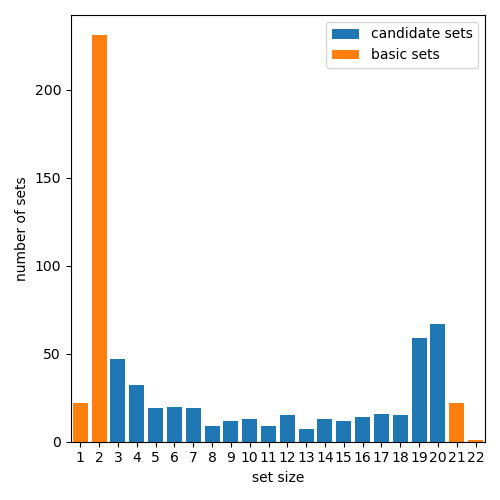
The generated candidate auxiliary subsets (see Section 4.3.2) for a given task are illustrated in Figure 5 and 6. A histogram of the sizes of all generated candidate auxiliary subsets are shown in Figure 7.
Dynamics of BandiK
The performances of the individual bandits corresponding to the target tasks are shown in Figure 8. The final best arms are used as references and the simple regret, the selection error of a non-optimal arm in a given bandit, and the selection error of any non-optimal arm in the multi-bandit are shown.
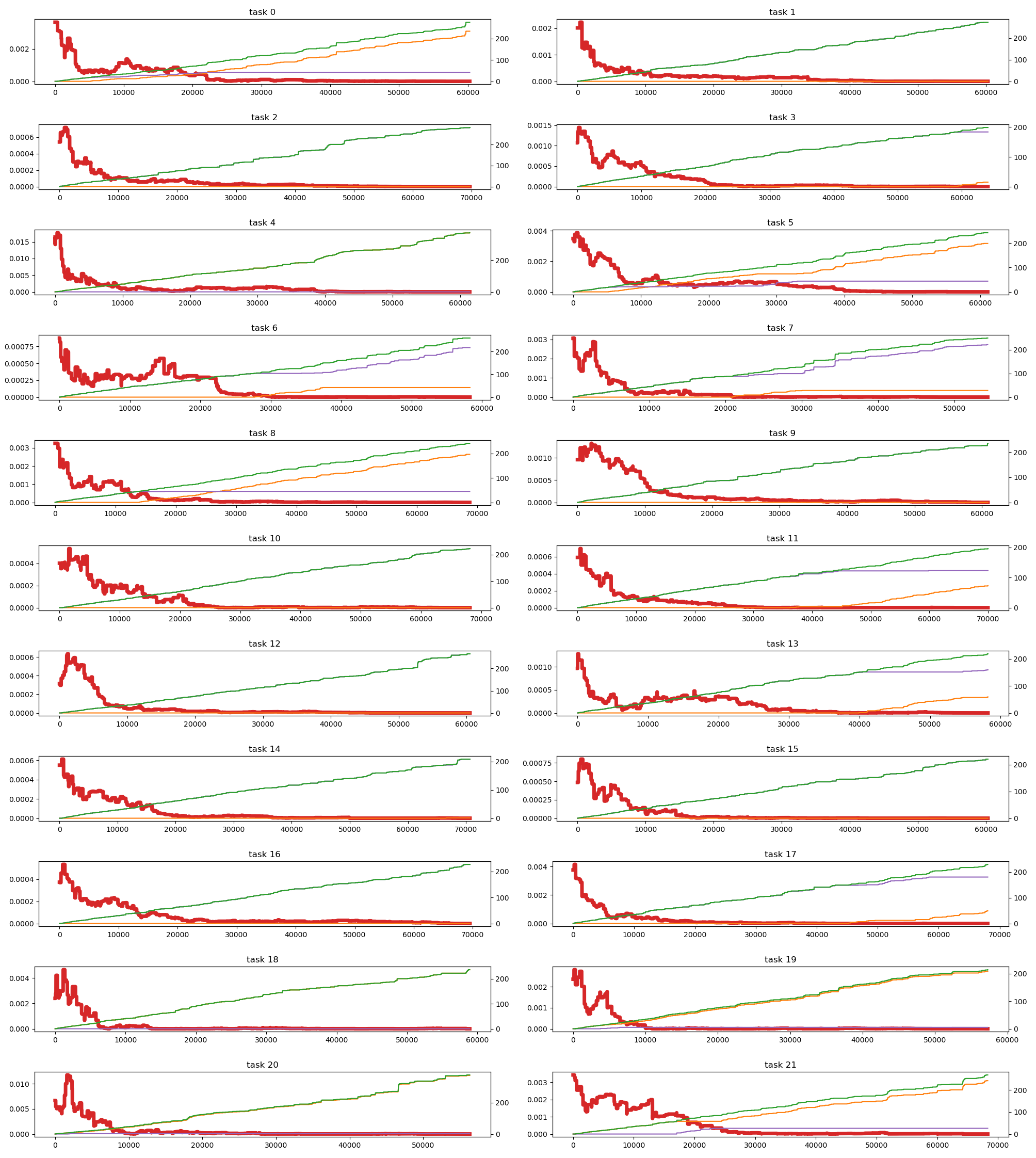
We also investigated the effects of the semi-overlapping arms in BandiK, i.e., the effect of shared neural networks between the bandits in the multi-bandit structure. Figure 9 shows the number of pulls per bandits and the ratio of own pulls versus other pulls originating from such semi-overlapping arms.

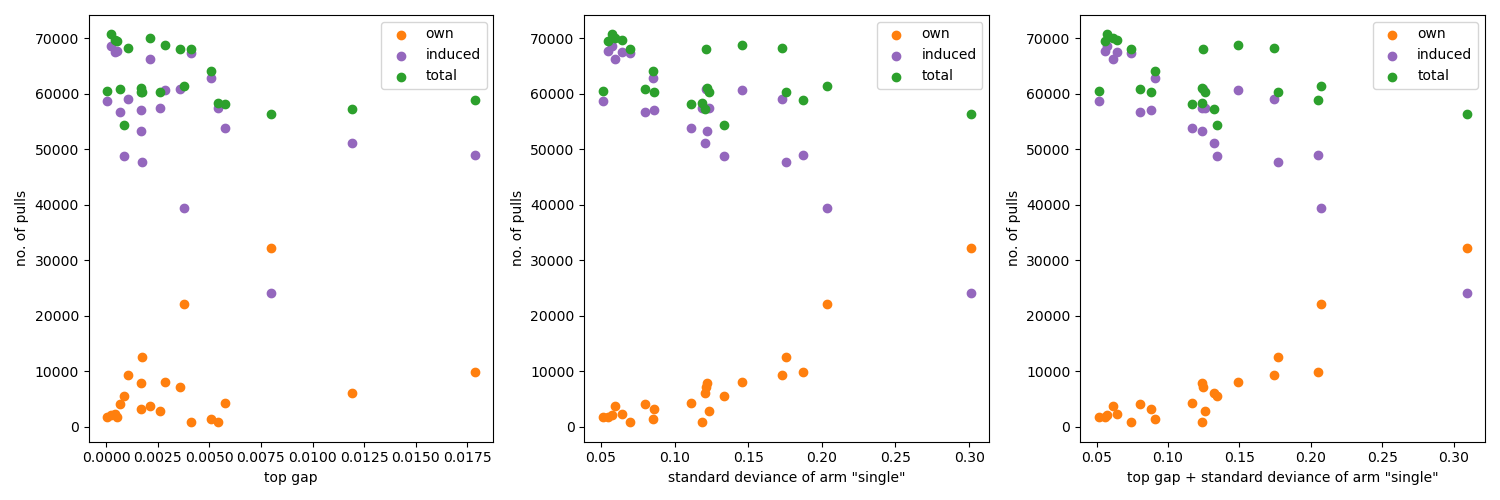
The learning process in the GapE-V method is driven by the gaps between the expected values of the arms, specifically by the gap between the two top arms, and their variances. Figure 10 illustrates the relation between the number of pulls, gaps, and variances. The pulls are separated according to their origin: coming from the pull of the arm of the actual bandit or from the pull of a semi-overlapping arm of another bandit. Table 1 shows the ratios of own and total pulls for each bandits/tasks.
| task | own pulls | induced pulls | ratio of own pulls |
|---|---|---|---|
| 0 | 12630 | 60273 | 20.95% |
| 1 | 2848 | 60293 | 4.72% |
| 2 | 2263 | 69719 | 3.25% |
| 3 | 1344 | 64094 | 2.10% |
| 4 | 22035 | 61406 | 35.88% |
| 5 | 7805 | 61119 | 12.77% |
| 6 | 808 | 58277 | 1.39% |
| 7 | 5533 | 54378 | 10.18% |
| 8 | 8136 | 68726 | 11.84% |
| 9 | 4134 | 60873 | 6.79% |
| 10 | 872 | 68127 | 1.28% |
| 11 | 3716 | 69973 | 5.31% |
| 12 | 1721 | 60494 | 2.84% |
| 13 | 4379 | 58220 | 7.52% |
| 14 | 2076 | 70694 | 2.94% |
| 15 | 3215 | 60287 | 5.33% |
| 16 | 1804 | 69516 | 2.60% |
| 17 | 7122 | 68042 | 10.47% |
| 18 | 9867 | 58904 | 16.75% |
| 19 | 6176 | 57290 | 10.78% |
| 20 | 32224 | 56309 | 57.23% |
| 21 | 9292 | 68301 | 13.60% |
| TOTAL | 150000 | 1385315 | 10.83% |
The number of own and total pulls and their ratio for each task.
Output of BandiK
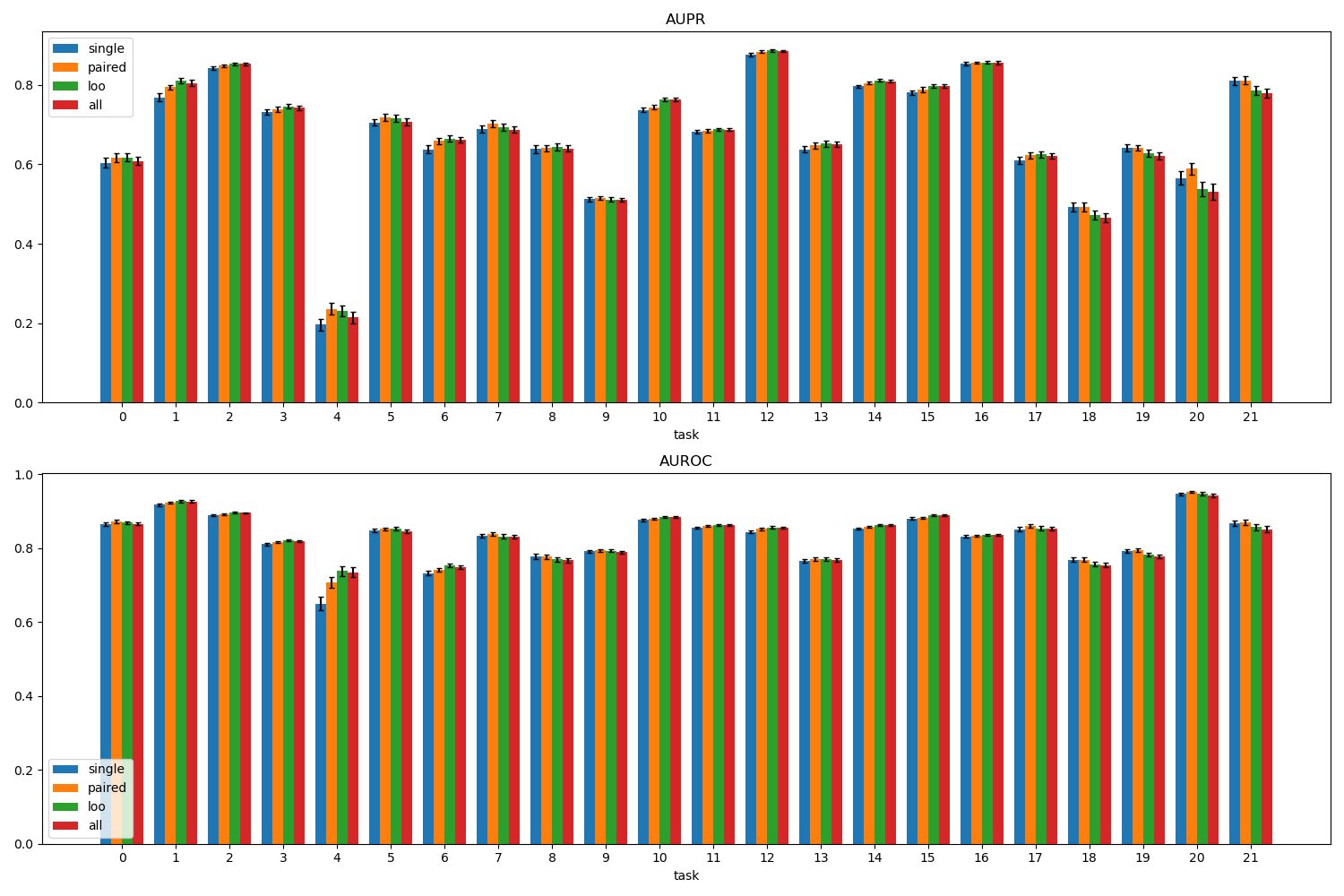
The best performances of various types of candidate auxiliary task subsets for each task are shown in Figure 11 for the AUPR and AUROC measures.
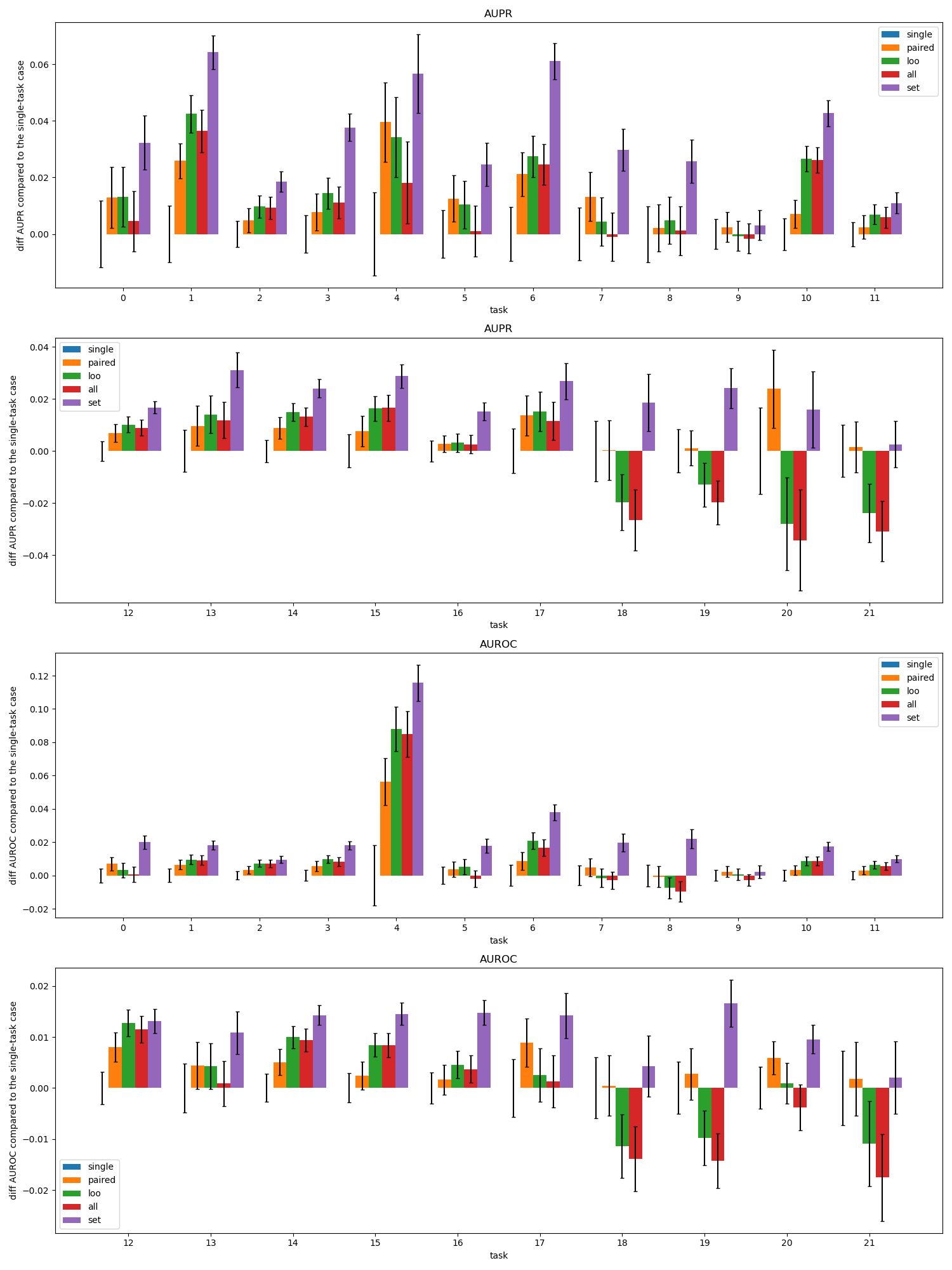
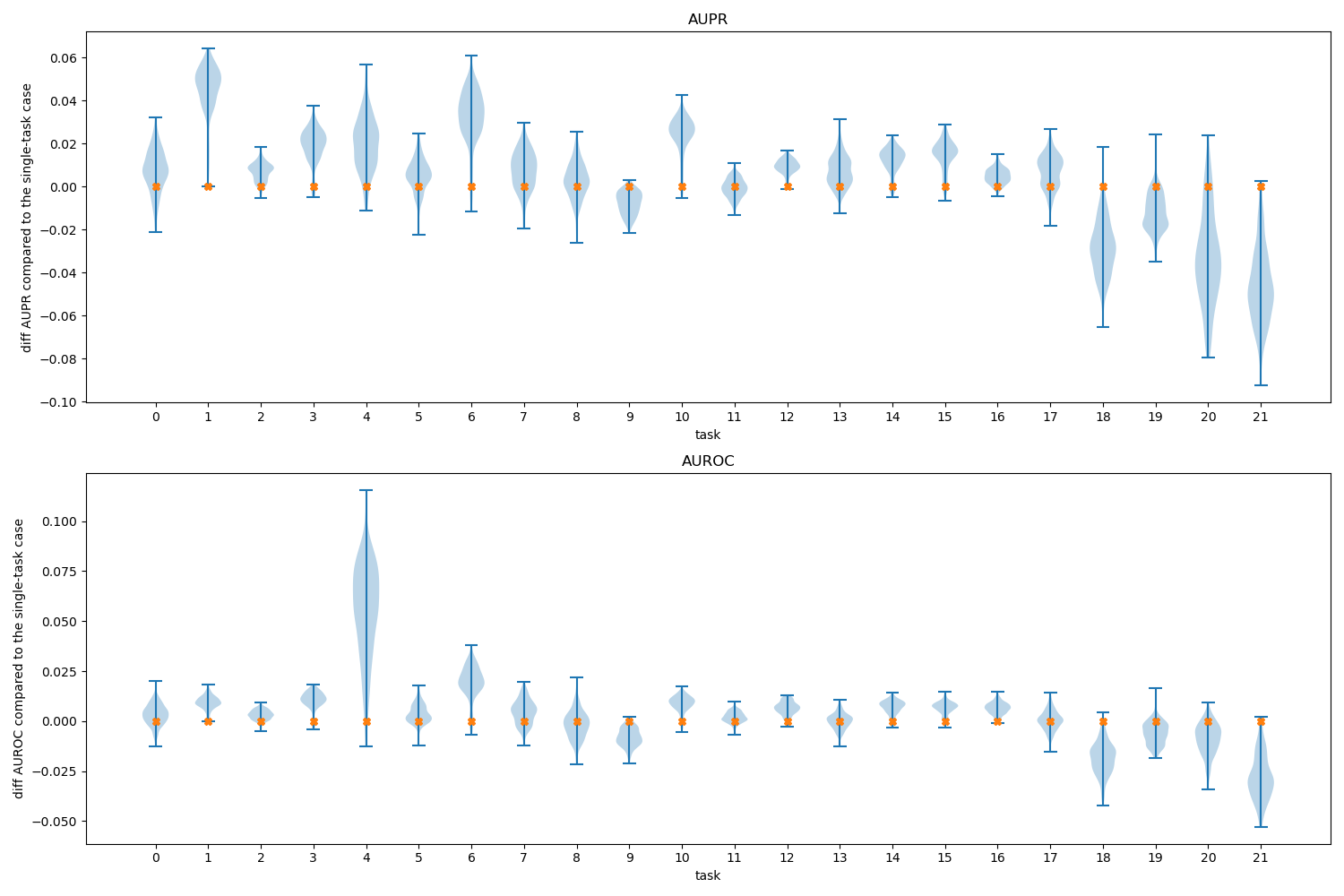
Figure 12 shows the distributions of the performances of the arms for each multi-armed bandit (corresponding to tasks), again using the single-task case as reference point.
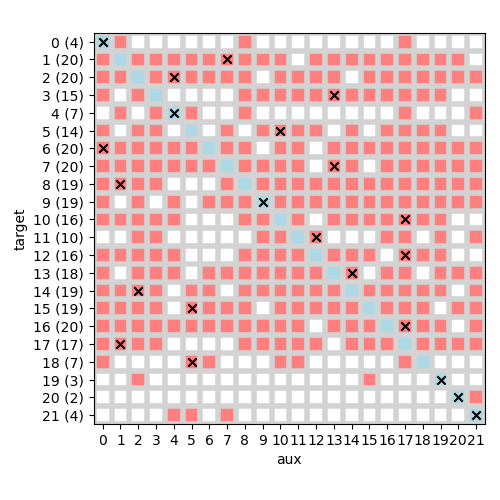
The best candidate auxiliary subsets, are shown in Figure 13. Note that the cross signs in the diagonal indicate when the best network comes from its own candidate set.
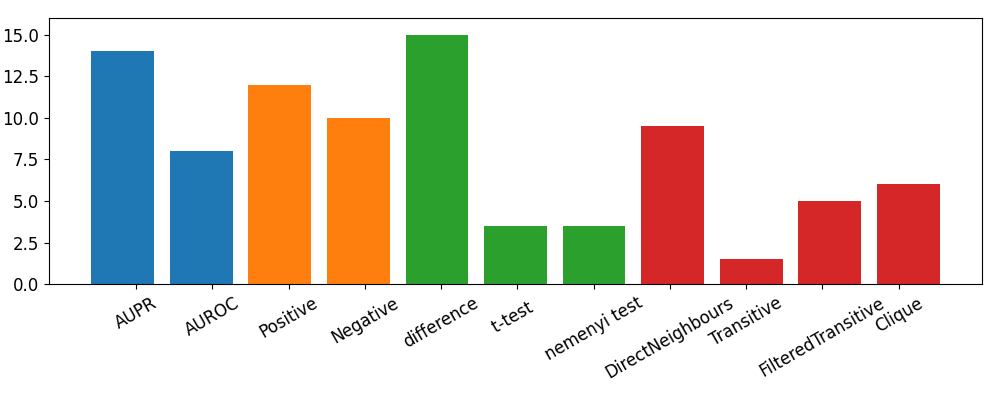
The distribution of the best candidate auxiliary sets according to the origin of candidate set generation is shown in Figure 14. The properties of the best candidate auxiliary sets are summarized in Table 2.
| Task | Metric | Graph | Test | Search | Start Search |
|---|---|---|---|---|---|
| 0 | AUPR | + | diff | Neighbours | 0 |
| 1 | AUROC | - | diff | Clique | 7 |
| 2 | AUPR | - | tt | Neighbours | 4 |
| 3 | AUPR | + | nem | Transitive | 13 |
| 4 | AUROC | - | diff | Filtered | 4 |
| 5 | AUPR | - | diff | Neighbours | 10 |
| 6 | AUPR | - | diff | Clique | 0 |
| AUPR | - | diff | Clique | 3 | |
| 7 | AUROC | - | diff | Clique | 13 |
| 8 | AUROC | + | tt | Filtered | 1 |
| 9 | AUROC | - | diff | Clique | 9 |
| 10 | AUPR | + | diff | Neighbours | 17 |
| 11 | AUROC | + | nem | Filtered | 12 |
| 12 | AUROC | + | diff | Neighbours | 17 |
| 13 | AUPR | - | diff | Neighbours | 14 |
| 14 | AUPR | + | diff | Neighbours | 2 |
| 15 | AUPR | - | diff | Clique | 5 |
| 16 | AUPR | - | tt | Filtered | 17 |
| 17 | AUPR | + | tt | Filtered | 1 |
| AUPR | + | nem | Transitive | 1 | |
| 18 | AUROC | + | nem | Filtered | 5 |
| AUROC | + | nem | Neighbours | 5 | |
| 19 | AUPR | + | diff | Clique | 19 |
| 20 | AUPR | + | diff | Neighbours | 7 |
| 21 | AUPR | + | diff | Neighbours | 21 |
Final selected candidate sets per task. The columns correspond to the metric used for evaluation, the type of transfer matrix used, the test used for including edges in the graph (see 4.3.1) the search algorithm to choose candidates and finally the original task for which the candidate has been designed. If the first cell is empty it means that the same candidate set as the previous was found twice.
Discussion
The exploration of the baseline performances (Q1), the single, pairwise, and multi-task learning scenarios indicated the possibility of improvements (Q1), see Figure 2.
The pairwise task landscape (Q2) confirmed other studies about the existence of central auxiliary tasks, which are useful auxiliary tasks for many other tasks, tasks, which can utilize many other tasks, and the existence of tasks, which seems unrelated to all other tasks using a pairwise task-task similarity approach (see task $`4`$, $`20`$ Figure 3.
The variances of the task performances were surprisingly high, which could be related to the highly incomplete and missing-not-at-random property of the DTI domain; furthermore, the variances were highly varying (Q3), see Figure 4.
We explored a wide range of heuristics to generate a fixed list of candidate auxiliary subsets (Q4); however, their redundancy indicated a high-level consistency in the domain, see Figure 5 and 6.
The distributions of pulls and convergence rates over individual bandits throughout learning were in line with the theoretical expectations and confirmed the sufficiency of the applied simulation length (Q5), see e.g. Figure 8 and 10.
The novel feature of BandiK, the semi-overlapping arms between bandits, proved to be extremely useful, also in the training process (Q6). Figure 9 and Table 1 show the ratio of such overlap pulls (dominated by external pulls).
The performances of candidate auxiliary task sets and the final results also confirmed the fundamental importance of the semi-overlapping nature of BandiK: Figure 14 shows that 18 of the 22 tasks have an externally generated best network (Q7).
The types of the best networks indicate that complex generation methods, including aspects of multi-task consistency, positive and negative tranfer, and filtering are all useful (Q8), see Table 2 and Figure 14. This suggests that shared latent features, and not shared data, are behind large parts of the transfer effects (we minimized the cross-optimization effects using sufficiently lengthy training). However, our results also indicate that in special quantitative domains, such as in drug-target interaction prediction, explicit modeling of latent features, specifically the modeling of drug-target mechanisms, could be essential to understand, detect, and avoid negative transfer (Q9) .
The performances of candidate auxiliary task sets resulted in a significant improvement for each task, see Figure 11.
Conclusion
We introduced BandiK, a novel three-stage multi-task auxiliary task subset selection method using multi-bandits, where each arm pull evaluates candidate auxiliary sets by training and testing a multiple output neural network on a single random train-test dataset split. To enhance efficiency, BandiK integrates these individual task-specific MABs into a multi-bandit structure, which coordinates the selection process across tasks and ensures a globally efficient task subset selection for all the tasks. The proposed multi-bandit solution exploits that the same neural network realizes multiple arms of different individual bandits corresponding to a given candidate set. This semi-overlapping arm property defines a novel multi-bandit cost/reward structure utilized in BandiK.
We validated our approach using a drug-target interaction benchmark. The results show that our methodology facilitates a computationally efficient task decomposition, making it a scalable solution for complex multi-task learning scenarios. These could include more advanced methods modeling the task dependency-independency structure, usage of task similarity metrics, which can cope with the high-level incompleteness, and the use of adaptive construction methods already applied in neural architecture search. The computational efficiency of BandiK could be a key to scale up the current approach using fixed candidate auxiliary task sets to a full-fledged Monte Carlo Tree Search method.
This study was supported by the European Union project RRF-2.3.1-21-2022-00004 within the framework of the Artificial Intelligence National Laboratory.
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
Note that there is a missing $`T_{mk}(t)/(T_{mk}(t)-1)`$ factor in the definition of the unbiased sample variance $`\widehat{\sigma}^2_{mk}(t)`$ in . ↩︎