HiGR Efficient Generative Slate Recommendation via Hierarchical Planning and Multi-Objective Preference Alignment
📝 Original Paper Info
- Title: HiGR Efficient Generative Slate Recommendation via Hierarchical Planning and Multi-Objective Preference Alignment- ArXiv ID: 2512.24787
- Date: 2025-12-31
- Authors: Yunsheng Pang, Zijian Liu, Yudong Li, Shaojie Zhu, Zijian Luo, Chenyun Yu, Sikai Wu, Shichen Shen, Cong Xu, Bin Wang, Kai Jiang, Hongyong Yu, Chengxiang Zhuo, Zang Li
📝 Abstract
Slate recommendation, where users are presented with a ranked list of items simultaneously, is widely adopted in online platforms. Recent advances in generative models have shown promise in slate recommendation by modeling sequences of discrete semantic IDs autoregressively. However, existing autoregressive approaches suffer from semantically entangled item tokenization and inefficient sequential decoding that lacks holistic slate planning. To address these limitations, we propose HiGR, an efficient generative slate recommendation framework that integrates hierarchical planning with listwise preference alignment. First, we propose an auto-encoder utilizing residual quantization and contrastive constraints to tokenize items into semantically structured IDs for controllable generation. Second, HiGR decouples generation into a list-level planning stage for global slate intent, followed by an item-level decoding stage for specific item selection. Third, we introduce a listwise preference alignment objective to directly optimize slate quality using implicit user feedback. Experiments on our large-scale commercial media platform demonstrate that HiGR delivers consistent improvements in both offline evaluations and online deployment. Specifically, it outperforms state-of-the-art methods by over 10% in offline recommendation quality with a 5x inference speedup, while further achieving a 1.22% and 1.73% increase in Average Watch Time and Average Video Views in online A/B tests.💡 Summary & Analysis
1. **Hierarchical Generative Framework (HiGR)**: Traditional recommendation systems evaluate each item independently and combine them into a slate. HiGR introduces a hierarchical approach that optimizes both global structure and specific item selection, achieving efficient inference and quality optimization simultaneously.-
Contrastive Learning for ID Structuring (CRQ-VAE): HiGR uses contrastive learning to structure IDs while preserving semantic information but reducing complexity. This enables the model to control the slate generation process more accurately.
-
Listwise Preference Alignment (ORPO): By optimizing list-level preferences based on user feedback, HiGR enhances overall slate quality and bridges the gap between training objectives and real-world evaluation metrics.
📄 Full Paper Content (ArXiv Source)
<ccs2012> <concept> <concept_id>00000000.0000000.0000000</concept_id> <concept_desc>Do Not Use This Code, Generate the Correct Terms for Your Paper</concept_desc> <concept_significance>500</concept_significance> </concept> </ccs2012>
Introduction
Personalized recommendation systems now play a central role in large-scale online services, powering user experiences across news feeds, short-video platforms, and e-commerce applications . Unlike traditional item-level recommendation that presents items individually, slate recommendation - where a ranked list of items is displayed simultaneously to users - has emerged as the dominant paradigm. The slate, as a fundamental unit of user experience, determines not only which content users consume but also how they perceive the platform’s relevance and diversity.
Traditional slate recommendation approaches typically follow a two-stage paradigm: first scoring candidate items independently using point-wise or pair-wise ranking models , then assembling the final slate through greedy selection or reranking heuristics. While computationally efficient, these methods suffer from critical limitations: 1) They optimize item-level objectives rather than list-level quality, failing to account for the synergistic relationships among items within a slate. For instance, in short-video recommendation, users often prefer diverse content that balances entertainment, information, and novelty—a holistic preference that cannot be captured by independent item scoring. 2) The greedy assembly process lacks the ability to look ahead or backtrack. Even if individual items are scored accurately, the final combination is often suboptimal because earlier selections constrain later choices without a global optimization perspective.
Recent advances in generative models , particularly large language models and autoregressive architectures, have opened new possibilities for slate recommendation. By formulating recommendation as a sequence generation task, these approaches can model complex dependencies between items and generate coherent recommendation lists in an end-to-end manner. To adapt items for generation, recent works typically employ Semantic IDs (SID) based on Residual Quantized VAEs (RQ-VAE) to tokenize items into discrete codes. Despite their theoretical appeal, existing generative methods face three fundamental challenges that hinder their practical deployment in large-scale systems. First, conventional semantic quantization often yields an entangled ID space where “different prefixes share similar semantics” or “same prefixes imply different semantics.” This lack of clear semantic boundaries makes it difficult for the model to precisely control the generation process. Second, while SID reduce vocabulary size, they present a single item as a sequence of multiple tokens (e.g., 3 tokens per item). Autoregressive models must generate tokens one by one, with each generation step depending on all previous outputs. For a typical slate of 10 items requiring 30 sequential steps. This significantly slows down the reasoning process, creating a bottleneck for systems requiring sub-100ms latency. Third, autoregressive generation lacks holistic list planning. Although these models theoretically can condition each item on previous context, they still operate in a left-to-right generation paradigm without explicit mechanisms for global slate structure planning. This often leads to locally coherent but globally suboptimal slates, where later items may contradict earlier selections or fail to achieve desired list-level properties such as diversity, coverage, or topical coherence.
To address these limitations, we introduce HiGR (Hierarchical Generative Slate Recommendation), a novel framework that reformulates slate recommendation as a hierarchical coarse-to-fine generation process with listwise preference alignment. Fundamentally, to solve the semantic entanglement issue, we first propose an auto-encoder with residual quantization and contrastive learning (CRQ-VAE). Unlike conventional quantization, CRQ-VAE injects prefix-level contrastive constraints, ensuring that high-level ID prefixes explicitly encode semantic similarity and separability. This creates a structured vocabulary where the “prefix” acts as a reliable semantic anchor. Building these structured IDs, HiGR decouples slate generation into two levels: a list-level preference planning stage that captures the global structure and intent of the entire slate, followed by an item-level decoding stage that grounds the preference plans into specific item selections. This hierarchical design enables efficient inference while maintaining coherent global planning—addressing both efficiency and quality challenges simultaneously. This coarse-to-fine decomposition mirrors how humans approach slate curation: first deciding the overall composition and themes, then filling in specific items.
Beyond architectural innovation, we propose a listwise preference alignment objective that directly optimizes slate-level quality. Traditional recommendation models are trained with item-level cross-entropy loss, which does not reflect how users actually evaluate slates—holistically and comparatively. Drawing inspiration from reinforcement learning from human feedback (RLHF) in large language models, we leverage implicit user feedback on entire presented slates to construct list-level preference pairs, then optimize HiGR to generate slates that maximize overall engagement metrics such as dwell time, completion rate, and user satisfaction. This alignment bridges the gap between training objectives and real-world evaluation metrics. Our main contributions are as follows:
-
We propose HiGR, the first end-to-end generative slate recommendation framework, which significantly optimizes inference efficiency and performance, enabling its deployment in industrial scenarios.
-
We present CRQ-VAE that enforces prefix-level alignment via contrastive learning and HSD that decouples list-level planning from item-level selection, enabling efficient inference with coherent global structure.
-
We propose a listwise preference alignment objective that directly optimizes slate-level quality using implicit user feedback, better aligning model training with real-world evaluation metrics.
-
We demonstrate significant improvements in both recommendation quality and inference efficiency through extensive offline evaluations and online A/B tests on our large-scale commercial platform, providing a practical solution for deploying generative models in online slate recommendation systems.
Related Work
Slate Recommendation
Standard pointwise recommendation methods formulate the recommendation task as a regression or classification problem, estimating the absolute relevance score for each user-item pair independently. While effective in predicting individual interactions (e.g., CTR), this method overlooks the relative order among candidates and neglects the mutual influence between items. In contrast, slate recommendation methods treat the entire recommendation list as the fundamental unit of learning, aim to capture the inter-item dependencies and the global context of the ranking list. For instance, ListCVAE employs Conditional Variational Autoencoders to model the joint distribution of recommendation lists, encoding both positional biases and complex inter-item dependencies within a latent space. GFN4Rec adapts Generative Flow Networks to recommendation, modeling the list generation as a sequential flow where the probability of sampling a list is proportional to its expected reward. DMSG leverages conditional diffusion models to synthesize coherent and diverse item slates guided by natural language prompts, thereby achieving precise controllability and semantic alignment in list-wise recommendation. However, these methods are either constrained by the reranking paradigm which induces cascading errors, or struggle with training instability and convergence difficulties stemming from their complex optimization objectives, thereby hindering their deployment in real-world industrial systems. In contrast, our work adopts an end-to-end generative paradigm that reformulates slate construction as an auto-regressive sequence generation task. This architecture facilitates efficient global planning in slate recommendation and seamlessly integrates into industrial-scale systems, while inheriting the superior scaling properties of large language models.
Generative Recommendation
The paradigm of recommender systems is shifting from traditional discriminative modeling to generative modeling , inspired by the success of Large Language Models (LLMs). Generative Recommendation reformulates the recommendation task as a sequence-to-sequence generation problem. For example, HSTU introduces a high-performance backbone that replaces standard attention mechanisms with gated linear recurrence, significantly boosting training and inference speed. MTGR proposes an industrial-scale generative framework based on the HSTU architecture, which effectively combines the scalability of generative models with the precision of traditional DLRMs by explicitly preserving cross-features and employing Group-Layer Normalization. Furthermore, OneTrans advanced the backbone architecture by designing mechanisms for effective multi-task learning and knowledge transfer, enabling the generative model to generalize better across diverse recommendation scenarios.
Generative recommendation typically incorporates items as tokens within the model context . However, extensive items create a large vocabulary size and exacerbate cold-start issues. To address this problem, there is another category of generative recommendation methods that explore Semantic IDs (SIDs) to revolutionize item representation. Semantic IDs - sequences of discrete tokens derived from item representations - have been introduced to enable a fixed-size vocabulary while preserving semantic information. The construction of semantic ids generally relies on vector quantization techniques. TIGER utilizes residual-quantized variational auto-encoders (RQ-VAE) to recursively encode items by self-supervised learning and embedding reconstruction, facilitating effective knowledge transfer to cold-start items. LETTER introduces a learnable tokenization framework to optimize codebooks end-to-end for sequential recommendation. OneRec employs iterative K-means to generate hierarchical IDs, offering superior computational efficiency. Additionally, recent efforts have begun to explore unified representations , aiming to combine the generalization benefits of semantic tokens with the specificity of atomic IDs. However, existing alignments typically occur before or after quantization rather than within the hierarchical quantization process. To avoid structural misalignment, we propose a contrastive RQ-VAE. By enforcing feature alignment at the prefix level, it enhances the interpretability and controllability of Semantic IDs, enabling the model to balance diversity and relevance during decoding.
 style="width:100.0%" />
style="width:100.0%" />
 style="width:48.0%" />
style="width:48.0%" />
Reinforcement Learning for Generative Recommendation
In generative recommendation, Reinforcement Learning (RL) is increasingly employed to bridge the gap between the next-token prediction objective and business metrics. Unlike supervised learning, RL enables the generative policy to maximize cumulative rewards and align with complex preferences. To mitigate the brittleness of hand-crafted rewards, PrefRec adopts a paradigm similar to Reinforcement Learning from Human Feedback (RLHF) , training a reward model on user historical preferences to guide the policy toward long-term engagement. To further stabilize training, DPO4Rec adapts pairwise preference learning to sequence models, transforming the alignment problem into a stable supervised loss that complements or replaces complex online RL loops. Recent industrial advancements demonstrate the scalability of these techniques. OneRec-V1 unifies retrieval and ranking with a generative backbone, employing iterative DPO for preference alignment. Evolving further, OneRec-V2 incorporates duration-aware reward shaping and adaptive ratio clipping to optimize user engagement from real-time feedbacks, marking a significant step toward fully aligned generative recommendation systems. Despite the remarkable success of RLHF and DPO in aligning LLMs, they face significant hurdles when deployed in real-world streaming scenarios. The reliance on an auxiliary reference model imposes a heavy computational penalty, limiting training throughput and resource efficiency. Moreover, generic alignment objectives often fail to account for the complex, multi-dimensional nature of slate generation, potentially leading to instability or loss of diversity. Therefore, we introduce the Odds Ratio Preference Optimization. This approach solves the efficiency problem by removing the reference model and addresses the structural requirements of recommendation by enforcing a “triple-objective” (ranking, interest, and diversity). By coupling this multi-faceted alignment directly with the supervised loss, we achieve a stable, high-efficiency training process that accurately reflects complex user preferences.
Methodology
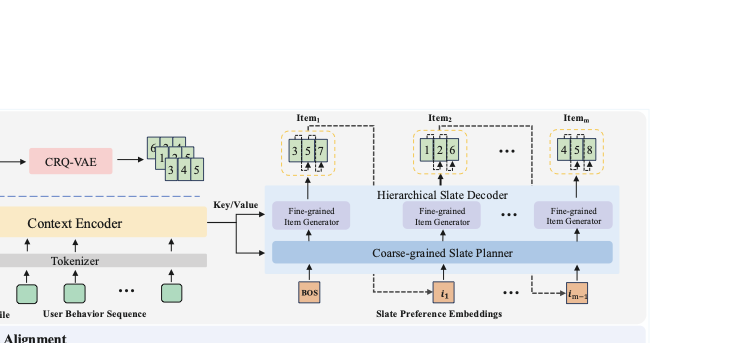
In this section, we propose HiGR, a generative framework designed to solve slate recommendation problem through hierarchical autoregressive generation and preference alignment. In section 3.1, we first formally define the slate recommendation task. Section 3.2 proposes a CRQ-VAE for semantic quantization to address ID entanglement and lack of collaboration. Section 3.3 details hierarchical slate decoder network for efficient pretraining and inference. Finally, Section 3.4 present a post-training paradigm that leverages preference alignment to optimize ranking fidelity, true interest preference, and slate diversity. The overall framework of HiGR is illustrated in Figure 1.
 style="width:48.0%" />
style="width:48.0%" />
Preliminary
Unlike typical recommendation tasks which aim to predict the next interested item a user interact with, slate recommendation tasks aim to return a ranked list of items maximizing positive user feedback for the entire slate.
Formally, we denote $`\mathcal{U}`$ and $`\mathcal{V}`$ as the sets of users and items. $`u \in \mathcal{U}`$ denotes the user representation, including user-side features (e.g., user ID, age, gender). $`v \in \mathcal{V}`$ denotes the item representation, comprising item-side features (e.g., item ID, title, category). $`S^u = \{v_1^u, v_2^u, \cdots, v_n^u\}`$ denotes the positive historical behavior of user $`u`$, where each $`v_{:}^u`$ represents the item that the user has effectively watched or interacted with, and $`n`$ is the length of behavior sequence. All items in $`S^u`$ are arranged in chronological order. For each user, given the user features $`u`$ along with the positive historical behavior $`S^u`$ of the user, the objective of slate recommendation can be formalized as:
\begin{equation}
O^u = \mathcal{F}_{\theta}(u, S^u)
\end{equation}where $`\theta`$ is the parameters of recommendation model, and $`O^u=\{\hat{v}_1^u, \hat{v}_2^u,\cdots, \hat{v}_M^u\}`$ are $`M`$ recommended items in a slate.
Contrastive RQ-VAE
In generative recommendation, semantic quantization methods such as RQ-VAE and RQ-KMeans can produce semantic IDs (SID) in a coarse-to-fine manner. However, in large-scale industrial settings, they exhibit three critical shortcomings that hinder their direct deployment for slate recommendation: 1) ID Entanglement and Sparsity: Overcomplete codebooks often result in a highly sparse and entangled ID space. This often leads to the “polysemy” or “synonymy” of ID prefixes, which undermines the interpretability and controllability of the IDs; 2) Lack of Collaborative Alignment: Optimization driven solely by reconstruction and residual minimization ignores the relational structure of between items. Without positive/negative constraints, similar samples are not encouraged to share or cluster around common ID prefixes, whereas dissimilar samples are not pushed apart, weakening the generator’s ability to capture collaborative signals; 3) Inefficient Diversity Control: Diversity is assessed only after generation by comparing the continuous embeddings aggregated from multiple codebook layers. This prevents imposing direct, per-position constraints on semantic IDs during the quantization process.
To address these three issues, we propose a variational auto-encoder with residual quantization and contrastive learning (CRQ-VAE). As shown in Figure 2, CRQ-VAE integrates hierarchical quantization with contrastive learning to ensure that the resulting IDs are semantically rich and structurally collaborative.
Hierarchical residual quantization and reconstruction.
Given an item $`x`$ embedded by bge-m3 , the encoder produces a latent representation $`z = \mathcal{E}(x)`$. The residual is initialized as $`r^0 = z`$. For each layer $`d`$, let $`\{e_k^d\}_{k=1}^{K}`$ denote the codebook of size $`K`$. The quantizer selects the closest codeword $`c^d`$ and updates the residual $`r^d`$,
\begin{equation}
c^d = {\arg\min}_{k}\|r^{d-1} - e_k^d\|_2^2, \quad r^d = r^{d-1} - e_{c^d}^d
\end{equation}After $`D`$ layers, we obtain the codeword sequence $`\{c^d\}_{d=1}^{D}`$ and quantized latent $`\hat{z} = \sum_{d=1}^{D}e_{c^d}^d`$. The prior works typically optimize reconstruction loss and layer-wise quantization loss,
\begin{equation}
\begin{aligned}
\mathcal{L}_\mathrm{recon} & = \|\hat{x} - x\|_2^2 \\
\mathcal{L}_\mathrm{layer\_quan} & = \sum_{d=1}^{D}\left(\|r^{d-1} - \mathrm{sg}(e_{c^d}^d)\|_2^2 + \eta \|e_{c^d}^d - \mathrm{sg}(r^{d-1})\|_2^2\right)
\end{aligned}
\end{equation}where $`\mathrm{sg}(\cdot)`$ denotes the stop-gradient operation. $`\eta`$ denotes the trade-off parameter.
However, $`\mathcal{L}_\mathrm{layer\_quan}`$ causes $`r^{d-1}`$ to approach $`e_{c_d}^d`$, resulting in “residual vanishing” phenomenon where subsequent layers receive near-zero vectors $`r^d`$. To address this issue, we propose a global quantization loss,
\begin{equation}
\mathcal{L}_\mathrm{global\_quan} = \|\hat{z} - \mathrm{sg}(z)\|_2^2 + \eta\|z - \mathrm{sg}(\hat{z})\|_2^2
\end{equation}which directly optimizes the global quantization error at the latent level. This explicitly counteracts residual collapse, ensuring that deeper codebooks retain meaningful semantic information rather than decaying into noise, thus stabilizing the hierarchical learning process.
Prefix-level contrastive constraints to align collaboration and similarity.
We construct an anchor-positive set $`(x_a, x_p)`$ from semantic neighbors or high co-occurrence signals, and treat other in-batch samples as negatives $`x_n`$. We apply a temperature-scaled InfoNCE loss to the first $`D-1`$ layers so that similar samples are pulled together on the same layer codeword prefixes while dissimilar samples are pushed apart,
\begin{equation}
\mathcal{L}_\mathrm{cont} = - \frac{1}{D-1}\sum_{d=1}^{D-1} w_d\log \frac{\psi(x_a^d, x_p^d)}{\psi(x_a^d, x_p^d) + \sum_{n\neq a,p}\psi(x_a^d,x_n^d)}
\end{equation}where $`\psi(\cdot,\cdot)=\exp(\cos(\cdot,\cdot)/\tau)`$ denotes the exponentiated cosine similarity scaled by temperature $`\tau`$, $`w_d`$ denotes the coefficient of InfoNCE at the $`d`$-th layer, and $`x_{i\in\{a,p,n\}}^d`$ denotes the matched codeword embedding $`e_{c^d}^d`$. Crucially, we exclude the $`D`$-th layer from contrastive constraints. This design choice ensures that while prefixes capture high-level semantics, the final layer retains the fine-grained discriminability necessary for identifying specific items.
The overall loss function of CRQ-VAE is,
\begin{equation}
\mathcal{L}_\mathrm{CRQ-VAE} = \mathcal{L}_\mathrm{recon} + \lambda_1\mathcal{L}_\mathrm{global\_quan} + \lambda_2\mathcal{L}_\mathrm{cont}
\end{equation}where $`\lambda_1`$ and $`\lambda_2`$ weight the quantization and contrastive terms. This quantization ensures that similarity has been internalized into the ID prefixes. Consequently, slate recommendation can directly impose constraints and rewards on prefixes to control diversity and relevance during decoding, without resorting to costly a post-eriori comparisons over aggregated continuous embeddings.
Hierarchical Slate Decoder
An intuitive approach to generative slate recommendation is to treat the SID of each item as a token, train the recommendation model using next-token prediction (NTP) loss, and autoregressively generate subsequent items based on the previous items during inference. Nevertheless, this approach is hindered by two significant limitations. First, since each item is presented by $`D`$ SIDs, generating a slate of $`M`$ items requires $`D \times M`$ inference steps. This substantial computational overhead leads to excessive latency, rendering the method impractical for recommendation scenarios that demand strict real-time performance. Second, this token-by-token decoding lacks an explicit hierarchical structure, which entangles intra-item representations with inter-item transition patterns, making it difficult to accurately capture complex and holistic list-level dependencies. To overcome these limitations, HiGR achieves slate recommendation in a coarse-to-fine manner by decoupling slate generation into a list-level preference planning stage that captures the global structure and intent of the entire slate, followed by an item-level decoding stage that grounds the preference plans into specific item selections.
As shown in Figure 3, HSD consists of a coarse-grained slate planner a fine-grained item generator. Initially, the user features $`u`$ and user historical behaviors $`S^u`$ are fed into an encoder to obtain the context embedding, $`C = \mathcal{E}(u,S^u)`$. This embedding captures historical interactions, serving as keys and values for cross-attention in the subsequent modeling.
Coarse-grained Slate Planner
In HSD, the coarse-grained slate planner takes the preference embeddings of preceding items in the target slate as input and generates the preference embedding of the next target item in an autoregressive manner. In the training phase, we utilize the first $`M-1`$ items’ preference embedding and a Beginning-of-Sequence (BOS) token to form the input sequence:
\begin{equation}
h^{(0)}=[\text{Emb}(\text{BOS}),i_1,\cdots,i_{M-1}] \in\mathbb{R}^{M \times d_\text{model}}
\end{equation}where $`d_\text{model}`$ denotes the hidden dimension. $`i_m`$ denotes the preference embedding of $`m`$-th item, and here we define the ground-truth preference embedding of each item as the summation of its constituent SID embeddings, $`i_m = \sum_{d=1}^D{s_m^d}`$.
After $`l_\text{slate}`$ layers of stacked transformer blocks, the predicted preference sequence $`\boldmath{\hat{I}}`$ can be obtained by follows:
\begin{equation}
\begin{aligned}
h_\text{cross}^{(l_\text{slate})}&=h^{(l_\text{slate}-1)}+\text{CrossAttn}(\text{RMSNorm}(h^{(l_\text{slate}-1)}),k_{l_\text{slate}},v_{l_\text{slate}}) \\
h_\text{self}^{(l_\text{slate})}&=h_\text{cross}^{(l_\text{slate})}+\text{SelfAttn}(\text{RMSNorm}(h_\text{cross}^{(l_\text{slate})})) \\
\hat{I} &=h^{(l_\text{slate})}=h_\text{self}^{(l_\text{slate})}+\text{FFN}(\text{RMSNorm}(h_\text{self}^{(l_\text{slate})}))
\end{aligned}
\end{equation}where $`k_{l_\text{slate}}=\text{RMSNorm}_{k,l_\text{slate}}(C)`$ and $`v_{l_\text{slate}}=\text{RMSNorm}_{v,l_\text{slate}}(C)`$, and $`\hat{I} \in \mathbb{R}^{M \times d_\text{model}}`$ carries the preference for each item in the slate.
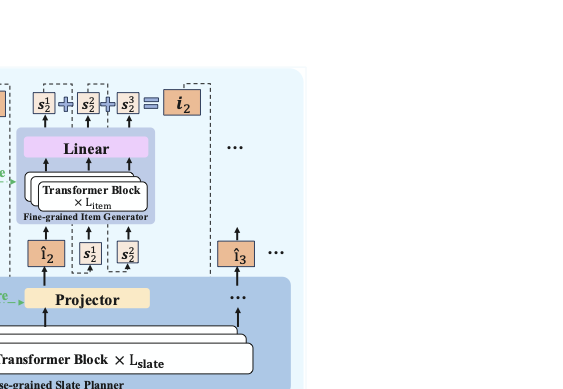
Fine-grained Item Generator
The predicted preference embedding for each item is subsequently passed to the fine-grained item generator to produce the corresponding SID sequence. Considering the $`m`$-th item in $`\boldmath{\hat{I}}`$, we denote $`\hat{i}_m \in \mathbb{R}^{d_\text{model}}`$ as the predicted preference embedding of item $`m`$. During training, the preference embedding $`\hat{i}_m`$ and the first $`D-1`$ SIDs are utilized to form the input sequence of $`m`$-th item generator:
\begin{equation}
g^{(0)}=[\hat{i}_{j},s_j^1,\cdots,s_j^{D-1}] \in\mathbb{R}^{D \times d_\text{model}}
\end{equation}$`l_\text{item}`$ layers of stacked transformer are applied to obtain the final representations of the $`m`$-th item’s SID sequence:
\begin{equation}
\begin{aligned}
g_\text{cross}^{(l_\text{item})}&=h^{(l_\text{item}-1)}+\text{CrossAttn}(\text{RMSNorm}(h^{(l_\text{item}-1)}),k_{l_\text{item}},v_{l_\text{item}}) \\
g_\text{self}^{(l_\text{item})}&=h_\text{cross}^{(l_\text{item})}+\text{SelfAttn}(\text{RMSNorm}(h_\text{cross}^{(l_\text{item})})) \\
g^{(l_\text{item})}&=h_\text{self}^{(l_\text{item})}+\text{FFN}(\text{RMSNorm}(h_\text{self}^{(l_\text{item})}))
\end{aligned}
\end{equation}where $`k_{l_\text{item}}=\text{RMSNorm}_{k,l_\text{item}}(C)`$ and $`v_{l_\text{item}}=\text{RMSNorm}_{v,l_\text{item}}(C)`$. Then the generated specific SID sequence can be obtained by follows:
\begin{equation}
\hat{s}_j^1,\cdots,\hat{s}_j^D=\text{Output}(g^{(l_\text{item})})\in \mathbb{R}^{D \times d_\text{model}}
\end{equation}Note $`M`$ fine-grained item generators stacked on top of the coarse-grained slate planner are structurally identical and share parameters. Reflecting the higher complexity of high-level preference planning compared to conditional SID decoding, the number of list planner layers, $`l_\text{slate}`$ , is set to be significantly larger than the number of item generator layers, $`l_\text{item}`$.
Finally, the loss for training the overall network can be formalized as follows:
\begin{equation}
\mathcal{L}_\text{slate}=-\sum_{m=1}^{M}\sum_{d=1}^{D}\log P(\hat{s}_i^{d+1}|\hat{i}_1,\cdots,\hat{i}_m,\hat{s}_m^{1},\cdots,\hat{s}_m^{d};\Theta)
\end{equation}where $`\Theta`$ is the parameters of the model.
Greedy-Slate Beam-Item Inference
We propose a Greedy-Slate Beam-Item (GSBI) strategy to balance inference effectiveness and efficiency. Specifically, during inference, conditioned on the predicted preference embedding from the coarse-grained slate planner, the fine-grained item generator performs beam search decoding with beam width $`B`$ to generate the SID sequence for each item in an antoregressive manner. The decoding process for the $`M`$ items is executed independently: each item generator decodes its SID sequence solely based on its corresponding preference embedding, ensuring that generating one item does not depend on the intermediate decoding states of other items in the slate. Moreover, the preference embedding of each item within a slate is also generated autoregressively by the slate planner. At each time step, the planner’s input is obtained by summing the embeddings of the optimal SID sequence, which is greedily identified as the top-$`1`$ candidate from the beam search results of the preceding item generator. This GSBI inference strategy significantly enhances the efficiency of slate generation, rendering its deployment in large-scale industrial scenarios feasible.
Preference Alignment
While pretraining via teacher forcing allows the model to learn the compositional structure of SID, it inherently suffers from historical exposure bias. To align the model with true user preferences, we adopt Odds Ratio Preference Optimization (ORPO) . Compared to traditional alignment methods like DPO or RLHF , ORPO offers two critical advantages for industrial-scale recommendation: 1) Efficiency: Being reference-model-free, it halves the forward-pass computation and significantly reduces GPU memory overhead, facilitating high-throughput streaming training. 2) Stability: By coupling preference alignment with supervised learning, it prevents objective drift and ensures the model remains grounded in the pretrained semantic distribution.
Based on ORPO, we build a slate-level preference pairs. Beyond binary choices, we systematically design preference pairs to optimize “triple-objective”: ranking fidelity, genuine interest, and slate diversity within a single generative trajectory.
Preference modeling with an odds-based objective.
We define the per-step log-odds for a slate $`y`$ as,
\begin{equation}
\ell_\theta(x,y_t) = \log\frac{\pi_{\theta}(y_{t}\mid x,y_{<t})}{1-\pi_{\theta}(y_{t}\mid x,y_{<t})}
\end{equation}where $`\pi_\theta`$ denotes the policy actor.
Let $`z_\theta=\sum_{t=1}^{MD}\ell_\theta(x,y_t)`$ be the slate-level log-odds. For a preference pair $`\{(y^{+},y^{-})\}`$, the combined objective is,
\begin{equation}
\mathcal{L}_\mathrm{post} = - \log\pi_\theta(y_t^{+}|x,y_{i<t}^{+}) -\alpha \log\sigma\left(z_\theta(x,y^{+}) - z_\theta(x,y^{-})\right)
\end{equation}where $`\alpha`$ denotes the coefficient of preference alignment. The combined post-training loss allows the model to learn true user preferences while maintaining generative accuracy without an auxiliary reference model.
Construction of reference pairs.
We build $`(y^+,y^-)`$ to reflect “triple-objective” optimization:
Positive samples: Take a user’s truly engaged watch sequence and rerank it in descending order using true users’ feedback to obtain $`y^{+}`$.
Negative samples: 1) Randomly permute $`y^{+}`$ to prioritize optimal ordering; 2) Replace items with negative feedback to filter exposure noise; 3) Take the first item in $`y+`$ as an anchor and append the top-$`(M-1)`$ items to penalize repetitive recommendations and “information cocoons”, thereby promoting slate diversity.
By sampling from these diverse negatives, the model learns to reject trajectories that are poorly ranked, irrelevant, or repetitive. In summary, our post-training approach transforms preference alignment into a holistic slate optimization process, ensuring that the generated SID sequences are not only accurate but also diverse and well-ordered.
Experiments
In this section, we first describe our experimental setup, including the baseline methods, evaluation metrics, and implementation details. Then we compare the proposed method with strong baselines and conduct several ablation experiments to verify the effectiveness of HiGR. Finally, we deploy HiGR to our commercial media platform and further validate the effectiveness of the proposed method through online A/B testing.
Experimental Setup
Baselines Methods
We adopt several representative recommendation models as the baseline methods to ensure a comprehensive and robust evaluation. For pretraining, we compare our HiGR with three main paradigms. First, we include traditional slate recommendation method ListCVAE as the baseline. Second, discriminative recommendation models, like SASRec and BERT4Rec are compared for further evaluation. Third, we validate the performance of our HiGR with recent advanced generative recommendation methods like TIGER , HSTU and OneRec. For post-train comparison, we include preference optimization methods, like DPO and SimPO to provide a thorough assessment of our proposed model’s performance.
Evaluation dataset and Metrics
We evaluate the proposed HiGR on our large-scale commercial media platform through offline metrics evaluation and online A/B test. For offline evaluation, we collected samples where each item within a slate had positive feedback (e.g., effective views) as a high-quality test set. We compared the performance of different methods by calculating the hit rate, recall (defined as effective views hit rate and recall) and NDCG of items in the predicted slate versus those in the true labels. Additionally, we also collected some samples (those without a large amount of positive feedback) based on real online exposure samples. We compared the hit rate and recall (defined as impressions hit rate and recall) of different methods on these samples to reflect whether the model-predicted slates could be effectively exposed.
Implementation Details
1) Model Architecture: For the core components, we set the hidden dimension of cross/self attention layers as $`d_\text{model} = 512`$ and the feed-forward network dimension as $`d_\text{FFN} = 2048`$. The proposed CRQ-VAE module is configured with $`D=3`$ quantization layers and a codebook size of $`256`$. The architecture incorporates $`l_\text{slate}=14`$ slate planners and $`l_\text{item}=2`$ item generators. These layer counts are used as the default configuration unless specified otherwise in the ablation studies. 2) Training Configuration: We optimize the model using the Adam optimizer with a batch size of $`4096`$. The learning rate and weight decay are both set to $`1\times 10^{-4}`$. During the construction of positive samples for CRQ-VAE, we apply a cosine similarity threshold of $`0.8`$ to distinguish positive sample $`x_p`$ from negative sample $`x_n`$. 3) Hyperparameters and Inference: The loss function coefficients for CRQ-VAE are set as follows: $`\eta = 0.1`$, $`\lambda_1 = 0.1`$, $`\lambda_2 = 0.01`$, with weight terms $`w_1 = 1`$, $`w_2 = 0.1`$, and $`w_3 = 0.01`$. For preference alignment, the coefficient $`\alpha`$ is set to $`0.1`$. During inference, the decoding length $`L`$ is the same as the slate of size $`M=5`$ using a beam search strategy with a width of $`B = 5`$, except in specific ablation studies.
Overall Performance
The overall comparison results of the proposed HiGR and other representative recommendation methods are demonstrated in Table [Overall_exp]. As observed, HiGR consistent outperforms all baseline methods across all evaluation metrics. Specially, HiGR significantly outperforms traditional slate recommendation and discriminative models, which demonstrates the superiority of the generative recommendation paradigm. While TIGER and HSTU demonstrate competitive performance, HiGR achieves a substantial margin over these earlier generative paradigms. Notably, even when compared to the strongest generative baseline, OneRec, HiGR continues to show superior capability.
Ablation Study
In this section, we perform comprehensive ablation studies to validate the effectiveness of HiGR’s core designs. Specifically, we evaluate the quality of Contrastive Semantic IDs, the impact of architectural choices in Hierarchical Sequential Decoding, and the influence of different preference alignment strategies.
Performance of Contrastive Semantic ID
To evaluate the quality of semantic quantization, we compare the proposed CRQ-VAE with RQ-Kmeans and RQ-VAE, as shown in Table 1. In terms of collision, which measures uniqueness, CRQ-VAE further reduces the rate to a remarkably low 2.37% compared to RQ-VAE. More importantly, regarding the consistency metric, CRQ-VAE achieves a high score of 66.47%, surpassing RQ-VAE by approximately 10.7%. Combined with the highest concentration of 93%, these statistics strongly support our hypothesis that contrastive learning optimizes the codebook space distribution and enhances semantic consistency.
| Methods | Collision $`\downarrow`$ | Concentration $`\uparrow`$ | Consistency $`\uparrow`$ |
|---|---|---|---|
| RQ-Kmeans | 0.2126 | 0.83 | 0.4533 |
| RQ-VAE | 0.0298 | 0.75 | 0.5577 |
| CRQ-VAE | 0.0237 | 0.93 | 0.6647 |
Performance comparison of different semantic quantization methods
| Type | Methods | Industrial | ||||
|---|---|---|---|---|---|---|
| 3-7 | Impressions | Effective Views | NDCG | |||
| 3-4 (lr)5-6 | hit@5 | recall@5 | hit@5 | recall@5 | ||
| Classic Slate Rec. | ListCVAE | 0.0857 | 0.0178 | 0.0571 | 0.0117 | 0.0186 |
| Discriminative Rec. | BertRec | 0.0911 | 0.0187 | 0.0632 | 0.0129 | 0.0201 |
| SASRec | 0.1057 | 0.0218 | 0.0700 | 0.0143 | 0.0243 | |
| Generative Rec. | TIGER-0.025B | 0.1812 | 0.0383 | 0.1204 | 0.0249 | 0.0406 |
| HSTU-0.025B | 0.2281 | 0.0506 | 0.1487 | 0.0310 | 0.0492 | |
| OneRec-0.025B | 0.2438 | 0.0577 | 0.1603 | 0.0367 | 0.0589 | |
| Generative Slate Rec. | HiGR-w/o RL-0.025B | 0.2641 | 0.0612 | 0.1810 | 0.0395 | 0.0631 |
| HiGR-w/o RL-0.1B | 0.2994 | 0.0721 | 0.2012 | 0.0465 | 0.0753 | |
| HiGR-0.1B | 0.3163 | 0.0760 | 0.2145 | 0.0495 | 0.0831 | |
Ablation Study of HSD
| Variant | Impressions | Effective Views | NDCG | ||
| hit@5 | recall@5 | hit@5 | recall@5 | ||
| HiGR | 0.2994 | 0.0721 | 0.2012 | 0.0465 | 0.0753 |
| Pooling Strategy from SID Sequence to Item Preference | |||||
| mean pooling | 0.2953 | 0.0701 | 0.1981 | 0.0448 | 0.0747 |
| max pooling | 0.2979 | 0.0708 | 0.1978 | 0.0460 | 0.0734 |
| Impact of Context Embedding | |||||
| w/o CE | 0.2785 | 0.0651 | 0.1837 | 0.0418 | 0.0664 |
| Parameter Sharing of Item Generator | |||||
| Non-shared | 0.2973 | 0.0735 | 0.2002 | 0.0477 | 0.0748 |
We perform a detailed ablation study to quantify the impact of different designs in the proposed HSD. We evaluate the following variants: 1) Pooling Strategy from SID Sequence to Item Preference: we adopt sum, mean and max pooling methods to obtain the item preference embedding from the predicted SID sequence at each step in inference, respectively. 2) Impact of Context Embedding: We investigate the impact of Context Embedding (CE) on performance by either incorporating or excluding it as the key/value input in the fine-grained item generator’s cross-attention mechanism. 3) Parameter Sharing: We also examined whether sharing the fine-grained item generator across items compromises the model’s performance. As shown in Table 2, 1) the performance variance among these three strategies is marginal, indicating that HiGR is robust to the choice of pooling mechanism. Nevertheless, sum pooling consistently yields slightly superior results compared to mean and max pooling. Consequently, we adopt sum pooling as the default configuration in our proposed HiGR framework. 2) Context Embedding proves crucial to the model’s performance, as its removal leads to a significant degradation in metrics. 3) Furthermore, we observe that non-shared item generator does not yield performance gains. Consequently, a shared item generator is adopted to ensure model efficiency and facilitate the processing of variable-length sequences.
Ablation Study of Preference Alignment
To investigate the influence of reinforcement learning methods and negative sampling strategies on post-training, we conduct the ablation study on industrial offline data.
| RL methods | Impressions | Effective Views | NDCG | ||
| hit@5 | recall@5 | hit@5 | recall@5 | ||
| w/o RL | 0.2994 | 0.0721 | 0.2012 | 0.0465 | 0.0753 |
| w/- DPO | 0.3055 | 0.0732 | 0.2069 | 0.0477 | 0.0780 |
| w/- SimPO | 0.3090 | 0.0740 | 0.2085 | 0.0480 | 0.0766 |
| w/- ORPO | 0.3163 | 0.0760 | 0.2145 | 0.0495 | 0.0831 |
 style="width:48.0%" />
style="width:48.0%" />
Table 3 reports the performance of the naive HiGR model and its variants trained with different reinforcement learning methods, including DPO, SimPO, and ORPO. Compared with the version without RL, all three RL-based methods consistently improve hit@5, recall@5, and NDCG on both impressions and effective views. Among them, ORPO achieves the best overall performance, yielding the highest gains across all metrics. These results demonstrate that reinforcement learning–based post-training can effectively align the model with the target objectives on industrial offline data, and that ORPO provides a better optimization effect than DPO and SimPO in our setting.
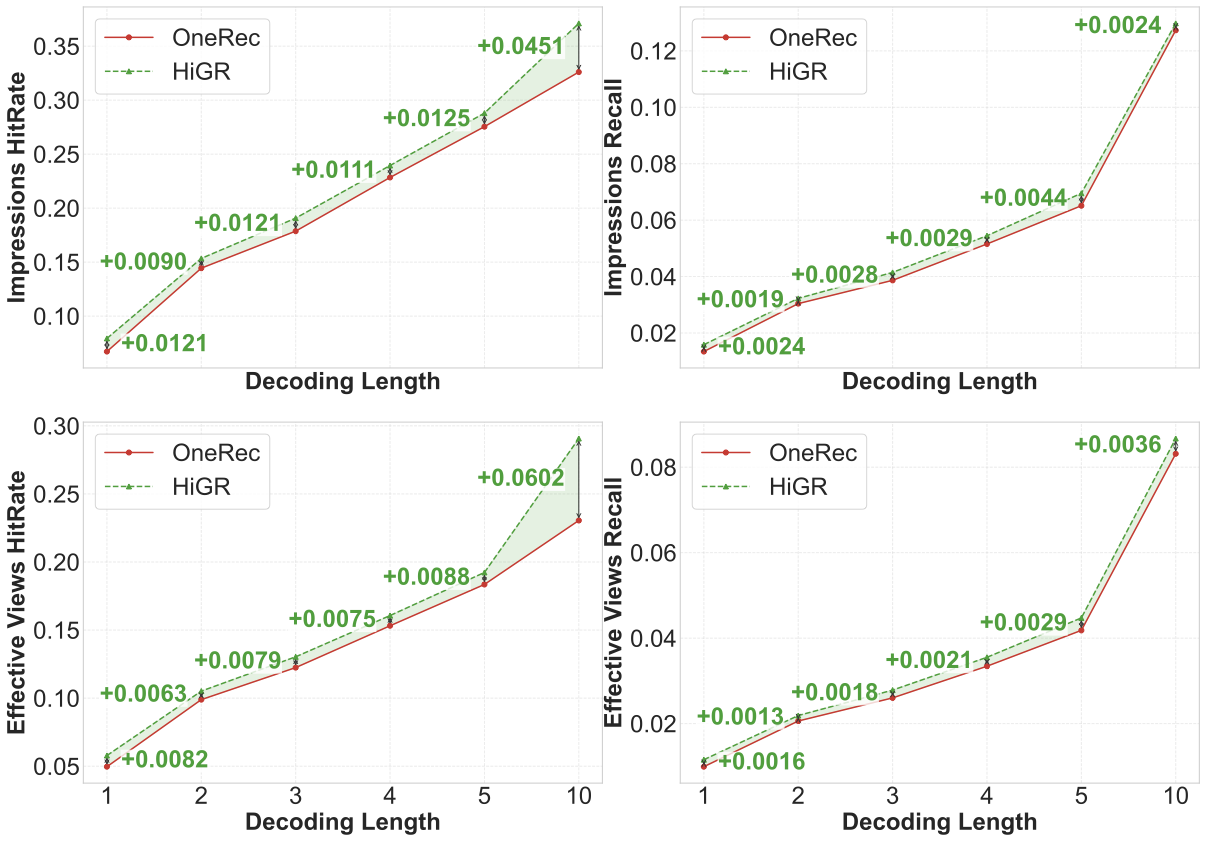
Performance of different Decoding Length
The shared fine-grained item generator within the Hierarchical Slate Decoder endows HiGR with the flexibility to generate slates of arbitrary lengths. We validate this capability through a comparative study with OneRec, evaluating performance under a range of slate sizes. As shown in Figure 4, We conducted a comprehensive comparative analysis between OneRec and HiGR across a spectrum of slate lengths, specifically $`L\in\{1,2,3,4,5,10\}`$. In the single-item generation scenario ($`L=1`$), HiGR exhibits a substantial performance margin over OneRec. More importantly, as the slate length extends, HiGR consistently maintains this superiority, demonstrating its exceptional robustness and stability in handling long-sequence generation tasks compared to the baseline.
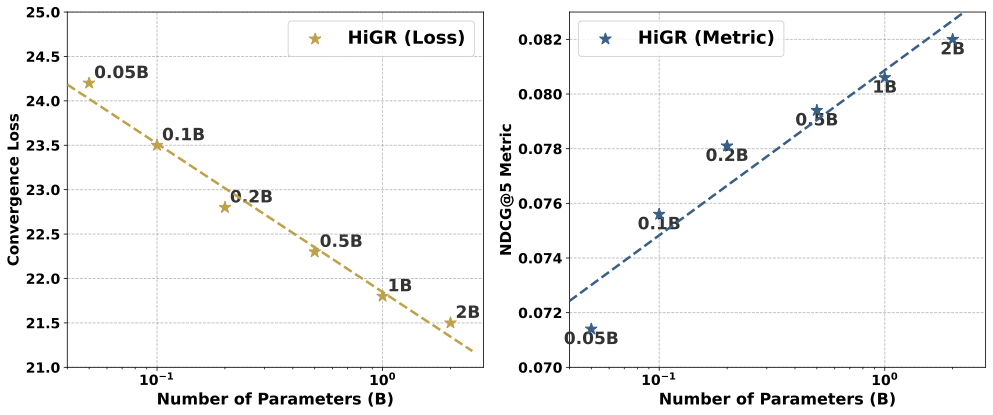
Scaling-Law Validation
 style="width:48.0%" />
style="width:48.0%" />
To investigate the scalability of our proposed framework, we evaluated the convergence loss and NDCG@5 metric of HiGR across a wide spectrum of model sizes, ranging from 0.05B to 2B parameters. As illustrated in Figure 5, the results exhibit a distinct linear trajectory on a logarithmic scale, indicating a power-law relationship between model capacity and performance. This property is particularly pivotal for industrial applications, as it implies that performance gains are predictable and can be consistently achieved by scaling up model capacity, thereby providing a reliable pathway to enhance recommendation quality in large-scale scenarios.
Efficiency Analysis
 style="width:40.0%" />
style="width:40.0%" />
We validate the efficiency of HiGR from theoretical complexity analysis and empirical experiments. Given a list of $`M`$ items, each item consists of $`D`$ sids, which means decoding $`M \times D`$ tokens. Note $`d`$ is the hidden dimension of the model, $`l_\text{item}`$ is the number of layers of item-level decoder in HiGR and lazy decoder layers in OneRec, $`l_\text{sid}`$ is the number of layers of sid-level decoder in HiGR. For the OneRec model, the time complexities of decoding with greedy search and beam search are $`\mathcal{O}(M^3D^3\cdot l_\text{item} \cdot d)`$ and $`\mathcal{O}(B \cdot M^3D^3\cdot l_\text{item} \cdot d)`$, respectively. While the time complexity of HiGR is $`\mathcal{O}(M^3 \cdot l_\text{item} \cdot d + B \cdot MD^3 \cdot l_\text{sid} \cdot d)`$. Note $`l_\text{item}`$ is much larger than $`l_\text{sid}`$, the time complexity of HiGR is much smaller than OneRec.
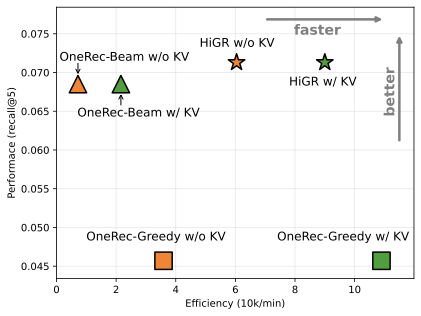
For a fair comparison, we configured both OneRec and HiGR with identical model settings and conducted all experiments in the same hardware environment. As shown in Figure 6, the horizontal and vertical axes correspond to inference efficiency (samples/minute) and effective view Recall@5, respectively. Without KV caching, the proposed HiGR outperforms OneRec with beam search by over 5% in performance, while also being more than 5 times faster in inference speed. HiGR significantly outperforms OneRec with greedy search, while also offering faster inference speed. With KV caching, HiGR also demonstrated superior performance and inference efficiency.
Online A/B Tests
We conducted online A/B tests on our commercial media platform under Tencent, which serves tens of millions of Daily Active Users (DAUs). Specifically, we allocated 2% of live traffic to benchmark HiGR against the incumbent multi-stage recommender system. Our evaluation relies on four metrics: Average Stay Time and Average Watch Time per user to measure temporal engagement, alongside Average Video Views (VV) and Average Request Count per user to capture the frequency of interaction and content consumption. Online evaluation shows that HiGR has achieved 1.03% and 1.22% improvement in Average Stay Time and Average Watch Time, 1.73% and 1.57% improvement in Average Video Views (VV) and Average Request Count, which demonstrates that HiGR achieves superior recommendation performance and translates into significant growth in the platform’s core business metrics.
Conclusion
We have presented HiGR, a hierarchical generative framework for efficient and high-quality slate recommendation. By leveraging CRQ-VAE for structured semantic tokenization and employing a coarse-to-fine hierarchical decoding strategy, our model successfully resolves the critical challenges of low inference efficiency and lack of global planning in prior autoregressive approaches. Additionally, the integration of listwise preference alignment ensures the generation of slates that maximize overall user satisfaction. Extensive experiments on industrial dataset of our large-scale commercial platform, involving both offline evaluations and online A/B tests, confirm that HiGR consistently outperforms state-of-the-art methods, yielding significant gains in both effectiveness and efficiency. We believe this work sets a solid foundation for next-generation generative recommendation, successfully reconciling high-fidelity generation with low-latency inference.
📊 논문 시각자료 (Figures)
