mHC Manifold-Constrained Hyper-Connections
📝 Original Paper Info
- Title: mHC Manifold-Constrained Hyper-Connections- ArXiv ID: 2512.24880
- Date: 2025-12-31
- Authors: Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Kuai Yu, Liang Zhao, Shangyan Zhou, Zhean Xu, Zhengyan Zhang, Wangding Zeng, Shengding Hu, Yuqing Wang, Jingyang Yuan, Lean Wang, Wenfeng Liang
📝 Abstract
Recently, studies exemplified by Hyper-Connections (HC) have extended the ubiquitous residual connection paradigm established over the past decade by expanding the residual stream width and diversifying connectivity patterns. While yielding substantial performance gains, this diversification fundamentally compromises the identity mapping property intrinsic to the residual connection, which causes severe training instability and restricted scalability, and additionally incurs notable memory access overhead. To address these challenges, we propose Manifold-Constrained Hyper-Connections (mHC), a general framework that projects the residual connection space of HC onto a specific manifold to restore the identity mapping property, while incorporating rigorous infrastructure optimization to ensure efficiency. Empirical experiments demonstrate that mHC is effective for training at scale, offering tangible performance improvements and superior scalability. We anticipate that mHC, as a flexible and practical extension of HC, will contribute to a deeper understanding of topological architecture design and suggest promising directions for the evolution of foundational models.💡 Summary & Analysis
1. **Key Contribution 1: Improved Neural Network Stability** Like reinforcing a building's structure to prevent information loss, *m*HC ensures that important data remains intact during training of larger models.-
Key Contribution 2: Maintained Efficiency
mHC increases stability without raising computational complexity; it’s like operating more vehicles without causing traffic jams. -
Key Contribution 3: Enhanced Scalability
By maintaining stability when scaling up model size, mHC allows for training with larger datasets. This is akin to a building becoming stronger as it grows taller.
📄 Full Paper Content (ArXiv Source)
UTF8gbsn
 style="width:100.0%" />
style="width:100.0%" />
0.9
Introduction
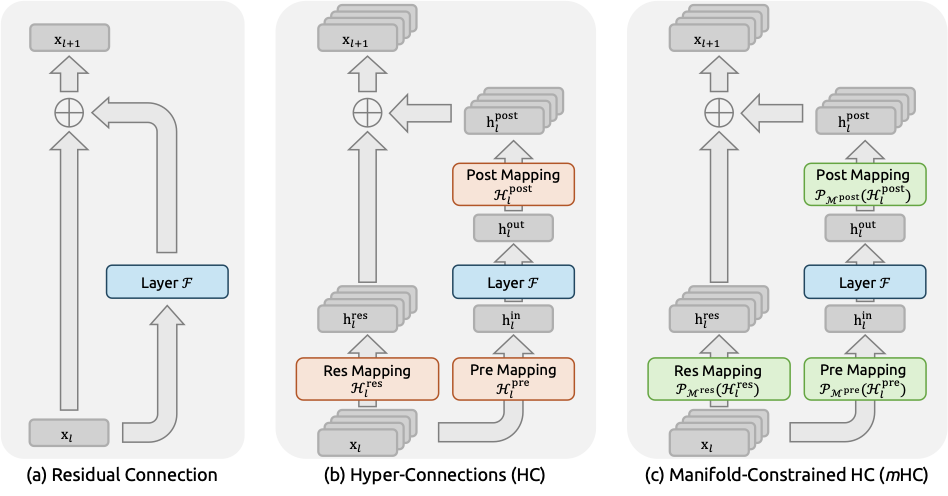
Deep neural network architectures have undergone rapid evolution since the introduction of ResNets . As illustrated in Fig. 1(a), the structure of a single-layer can be formulated as follows:
\begin{equation}
\mathbf{x}_{l+1} = \mathbf{x}_l + \mathcal{F}(\mathbf{x}_l, \mathcal{W}_l),
\label{eqn:single_rc}
\end{equation}where $`\mathbf{x}_l`$ and $`\mathbf{x}_{l+1}`$ denote the $`C`$-dimensional input and output of the $`l`$-th layer, respectively, and $`\mathcal{F}`$ represents the residual function. Although the residual function $`\mathcal{F}`$ has evolved over the past decade to include various operations such as convolution, attention mechanisms, and feed forward networks, the paradigm of the residual connection has maintained its original form. Accompanying the progression of Transformer architecture, this paradigm has currently established itself as a fundamental design element in large language models (LLMs) .
This success is primarily attributed to the concise form of the residual connection. More importantly, early research revealed that the identity mapping property of the residual connection maintains stability and efficiency during large-scale training. By recursively extending the residual connection across multiple layers, Eq. [eqn:single_rc] yields:
\begin{equation}
\mathbf{x}_L = \mathbf{x}_l + \sum_{i=l}^{L-1} \mathcal{F}(\mathbf{x}_i, \mathcal{W}_i),
\label{eqn:multi_rc}
\end{equation}where $`L`$ and $`l`$ correspond to deeper and shallower layers, respectively. The term identity mapping refers to the component $`\mathbf{x}_l`$ itself, which emphasizes the property that the signal from the shallower layer maps directly to the deeper layer without any modification.
Recently, studies exemplified by Hyper-Connections (HC) have introduced a new dimension to the residual connection and empirically demonstrated its performance potential. The single-layer architecture of HC is illustrated in Fig. 1(b). By expanding the width of the residual stream and enhancing connection complexity, HC significantly increases topological complexity without altering the computational overhead of individual units regarding FLOPs. Formally, single-layer propagation in HC is defined as:
\begin{equation}
\mathbf{x}_{l+1} = \mathcal{H}_{l}^{\mathrm{res}}\mathbf{x}_l + \mathcal{H}_{l}^{\mathrm{post}\, \top}\mathcal{F}(\mathcal{H}_{l}^{\mathrm{pre}}\mathbf{x}_l, \mathcal{W}_l),
\label{eqn:single_hc}
\end{equation}where $`\mathbf{x}_{l}`$ and $`\mathbf{x}_{l+1}`$ denote the input and output of the $`l`$-th layer, respectively. Unlike the formulation in Eq. [eqn:single_rc], the feature dimension of $`\mathbf{x}_{l}`$ and $`\mathbf{x}_{l+1}`$ is expanded from $`C`$ to $`n \times C`$, where $`n`$ is the expansion rate. The term $`\mathcal{H}_{l}^{\mathrm{res}} \in \mathbb{R}^{n \times n}`$ represents a learnable mapping that mixes features within the residual stream. Also as a learnable mapping, $`\mathcal{H}_{l}^{\mathrm{pre}} \in \mathbb{R}^{1 \times n}`$ aggregates features from the $`nC`$-dim stream into a $`C`$-dim layer input, and conversely, $`\mathcal{H}_{l}^{\mathrm{post}} \in \mathbb{R}^{1 \times n}`$ maps the layer output back onto the stream.
However, as the training scale increases, HC introduces potential risks of instability. The primary concern is that the unconstrained nature of HC compromises the identity mapping property when the architecture extends across multiple layers. In architectures comprising multiple parallel streams, an ideal identity mapping serves as a conservation mechanism. It ensures that the average signal intensity across streams remains invariant during both forward and backward propagation. Recursively extending HC to multiple layers via Eq. [eqn:single_hc] yields:
\begin{equation}
\mathbf{x}_{L} = \left(\prod_{i=1}^{L-l}\mathcal{H}_{L-i}^{\mathrm{res}}\right)\mathbf{x}_l + \sum_{i=l}^{L-1}\left(\prod_{j=1}^{L-1-i}\mathcal{H}_{L-j}^{\mathrm{res}}\right)\mathcal{H}_{i}^{\mathrm{post}\, \top}\mathcal{F}(\mathcal{H}_{i}^{\mathrm{pre}}\mathbf{x}_i, \mathcal{W}_i),
\label{eqn:multi_hc}
\end{equation}where $`L`$ and $`l`$ represent a deeper layer and a shallower layer, respectively. In contrast to Eq. [eqn:multi_rc], the composite mapping $`\prod_{i=1}^{L-l}\mathcal{H}_{L-i}^{\mathrm{res}}`$ in HC fails to preserve the global mean of the features. This discrepancy leads to unbounded signal amplification or attenuation, resulting in instability during large-scale training. A further consideration is that, while HC preserves computational efficiency in terms of FLOPs, the hardware efficiency concerning memory access costs for the widened residual stream remains unaddressed in the original design. These factors collectively restrict the practical scalability of HC and hinder its application in large-scale training.
To address these challenges, we propose Manifold-Constrained Hyper-Connections (mHC), as shown in Fig. 1(c), a general framework that projects the residual connection space of HC onto a specific manifold to restore the identity mapping property, while incorporating rigorous infrastructure optimization to ensure efficiency. Specifically, mHC utilizes the Sinkhorn-Knopp algorithm to entropically project $`\mathcal{H}_{l}^{\mathrm{res}}`$ onto the Birkhoff polytope. This operation effectively constrains the residual connection matrices within the manifold that is constituted by doubly stochastic matrices. Since the row and column sums of these matrices equal to $`1`$, the operation $`\mathcal{H}_{l}^{\mathrm{res}}\mathbf{x}_l`$ functions as a convex combination of the input features. This characteristic facilitates a well-conditioned signal propagation where the feature mean is conserved, and the signal norm is strictly regularized, effectively mitigating the risk of vanishing or exploding signals. Furthermore, due to the closure of matrix multiplication for doubly stochastic matrices, the composite mapping $`\prod_{i=1}^{L-l}\mathcal{H}_{L-i}^{\mathrm{res}}`$ retains this conservation property. Consequently, mHC effectively maintains the stability of identity mappings between arbitrary depths. To ensure efficiency, we employ kernel fusion and develop mixed precision kernels utilizing TileLang . Furthermore, we mitigate the memory footprint through selective recomputing and carefully overlap communication within the DualPipe schedule .
Extensive experiments on language model pretraining demonstrate that mHC exhibits exceptional stability and scalability while maintaining the performance advantages of HC. In-house large-scale training indicates that mHC supports training at scale and introduces only a 6.7% additional time overhead when expansion rate $`n=4`$.
Related Works
Architectural advancements in deep learning can be primarily classified into micro-design and macro-design. Micro-design concerns the internal architecture of computational blocks, specifying how features are processed across spatial, temporal, and channel dimensions. In contrast, macro-design establishes the inter-block topological structure, thereby dictating how feature representations are propagated, routed, and merged across distinct layers.
Micro Design
Driven by parameter sharing and translation invariance, convolution initially dominated the processing of structured signals. While subsequent variations such as depthwise separable and grouped convolutions optimized efficiency, the advent of Transformers established Attention and Feed-Forward Networks (FFNs) as the fundamental building blocks of modern architecture. Attention mechanisms facilitate global information propagation, while FFNs enhance the representational capacity of individual features. To balance performance with the computational demands of LLMs, attention mechanisms have evolved towards efficient variants such as Multi-Query Attention (MQA) , Grouped-Query Attention (GQA) , and Multi-Head Latent Attention (MLA) . Simultaneously, FFNs have been generalized into sparse computing paradigms via Mixture-of-Experts (MoE) , allowing for massive parameter scaling without proportional computational costs.
Macro Design
Macro-design governs the global topology of the network . Following ResNet , architectures such as DenseNet and FractalNet aimed to enhance performance by increasing topological complexity through dense connectivity and multi-path structures, respectively. Deep Layer Aggregation (DLA) further extended this paradigm by recursively aggregating features across various depths and resolutions.
More recently, the focus of macro-design has shifted toward expanding the width of the residual stream . Hyper-Connections (HC) introduced learnable matrices to modulate connection strengths among features at varying depths, while the Residual Matrix Transformer (RMT) replaced the standard residual stream with an outer-product memory matrix to facilitate feature storage. Similarly, MUDDFormer employs multiway dynamic dense connections to optimize cross-layer information flow. Despite their potential, these approaches compromise the inherent identity mapping property of the residual connection, thereby introducing instability and hindering scalability. Furthermore, they incur significant memory access overhead due to expanded feature widths. Building upon HC, the proposed mHC restricts the residual connection space onto a specific manifold to restore the identity mapping property, while also incorporating rigorous infrastructure optimizations to ensure efficiency. This approach enhances stability and scalability while maintaining the topological benefits of expanded connections.
Preliminary
We first establish the notation used in this work. In the HC formulation, the input to the $`l`$-th layer, $`\textbf{x}_l\in \mathbb{R}^{1\times C}`$, is expanded by a factor of $`n`$ to construct a hidden matrix $`\textbf{x}_l = (\textbf{x}^\top_{l,0}, \ldots, \textbf{x}^\top_{l,n-1})^\top \in \mathbb{R}^{n \times C}`$ which can be viewed as $`n`$-stream residual. This operation effectively broadens the width of the residual stream. To govern the read-out, write-in, and updating processes of this stream, HC introduces three learnable linear mappings—$`\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}}, \ensuremath{\mathcal{H}^{\mathrm{post}}_{l}}\in \mathbb{R}^{1\times n}`$, and $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}\in \mathbb{R}^{n\times n}`$. These mappings modify the standard residual connection shown in Eq. [eqn:single_rc], resulting in the formulation given in Eq. [eqn:single_hc].
In the HC formulation, learnable mappings are composed of two parts of coefficients: the input-dependent one and the global one, referred to as dynamic mappings and static mappings, respectively. Formally, HC computes the coefficients as follows:
\begin{equation}
\begin{cases}
\tilde{\mathbf{x}}_l = \text{RMSNorm}(\mathbf{x}_l) \\
\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}} = \alpha_l^\mathrm{pre} \cdot \tanh(\theta^\mathrm{pre}_l \tilde{\mathbf{x}}^\top_l) + \mathbf{b}_l^\mathrm{pre} \\
\ensuremath{\mathcal{H}^{\mathrm{post}}_{l}} = \alpha_l^\mathrm{post} \cdot \tanh(\theta^\mathrm{post}_l \tilde{\mathbf{x}}^\top_l) + \mathbf{b}_l^\mathrm{post} \\
\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}} = \alpha_l^\mathrm{res} \cdot \tanh(\theta^\mathrm{res}_l \tilde{\mathbf{x}}^\top_l) + \mathbf{b}_l^\mathrm{res}, \\
\end{cases}
\label{eqn:hc_details}
\end{equation}where $`\text{RMSNorm}(\cdot)`$ is applied to the last dimension, and the scalars $`\alpha_l^\mathrm{pre}, \alpha_l^\mathrm{post}`$ and $`\alpha_l^\mathrm{res} \in \mathbb{R}`$ are learnable gating factors initialized to small values. The dynamic mappings are derived via linear projections parameterized by $`\theta^\mathrm{pre}_l, \theta^\mathrm{post}_l \in \mathbb{R}^{1 \times C}`$ and $`\theta^\mathrm{res}_l \in \mathbb{R}^{n \times C}`$, while the static mappings are represented by learnable biases $`\mathbf{b}_l^\mathrm{pre}, \mathbf{b}_l^\mathrm{post} \in \mathbb{R}^{1\times n}`$ and $`\mathbf{b}_l^\mathrm{res} \in \mathbb{R}^{n\times n}`$.
It is worth noting that the introduction of these mappings—$`\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}}`$, $`\ensuremath{\mathcal{H}^{\mathrm{post}}_{l}}`$, and $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$—incurs negligible computational overhead, as the typical expansion rate $`n`$, e.g. 4, is much smaller than the input dimension $`C`$. With this design, HC effectively decouples the information capacity of the residual stream from the layer’s input dimension, which is strongly correlated with the model’s computational complexity (FLOPs). Consequently, HC offers a new avenue for scaling by adjusting the residual stream width, complementing the traditional scaling dimensions of model FLOPs and training data size discussed in pre-training scaling laws .
Although HC necessitates three mappings to manage the dimensional mismatch between the residual stream and the layer input, preliminary experiments presented in Tab. 1 indicate that the residual mapping $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$ yields the most significant performance gain. This finding underscores the critical importance of effective information exchange within the residual stream.
| $`\mathcal{H}^{\mathrm{res}}_{l}`$ | $`\mathcal{H}^{\mathrm{pre}}_{l}`$ | $`\mathcal{H}^{\mathrm{post}}_{l}`$ | Absolute Loss Gap |
|---|---|---|---|
| $`\phantom{-\ }0.0\phantom{00}`$ | |||
| $`-\ 0.022`$ | |||
| $`-\ 0.025`$ | |||
| $`-\ 0.027`$ |
Ablation Study of HC Components. When a specific mapping ($`\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}}`$, $`\ensuremath{\mathcal{H}^{\mathrm{post}}_{l}}`$, or $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$) is disabled, we employ a fixed mapping to maintain dimensional consistency: uniform weights of $`1/n`$ for $`\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}}`$, uniform weights of ones for $`\ensuremath{\mathcal{H}^{\mathrm{post}}_{l}}`$, and the identity matrix for $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$.
Numerical Instability
While the residual mapping $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$ is instrumental for performance, its sequential application poses a significant risk to numerical stability. As detailed in Eq. [eqn:multi_hc], when HC is extended across multiple layers, the effective signal propagation from layer $`l`$ to $`L`$ is governed by the composite mapping $`\prod_{i=1}^{L-l}\mathcal{H}_{L-i}^{\mathrm{res}}`$. Since the learnable mapping $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$ is unconstrained, this composite mapping inevitably deviates from the identity mapping. Consequently, the signal magnitude is prone to explosion or vanishing during both the forward pass and backpropagation. This phenomenon undermines the fundamental premise of residual learning, which relies on unimpeded signal flow, thereby destabilizing the training process in deeper or larger-scale models.
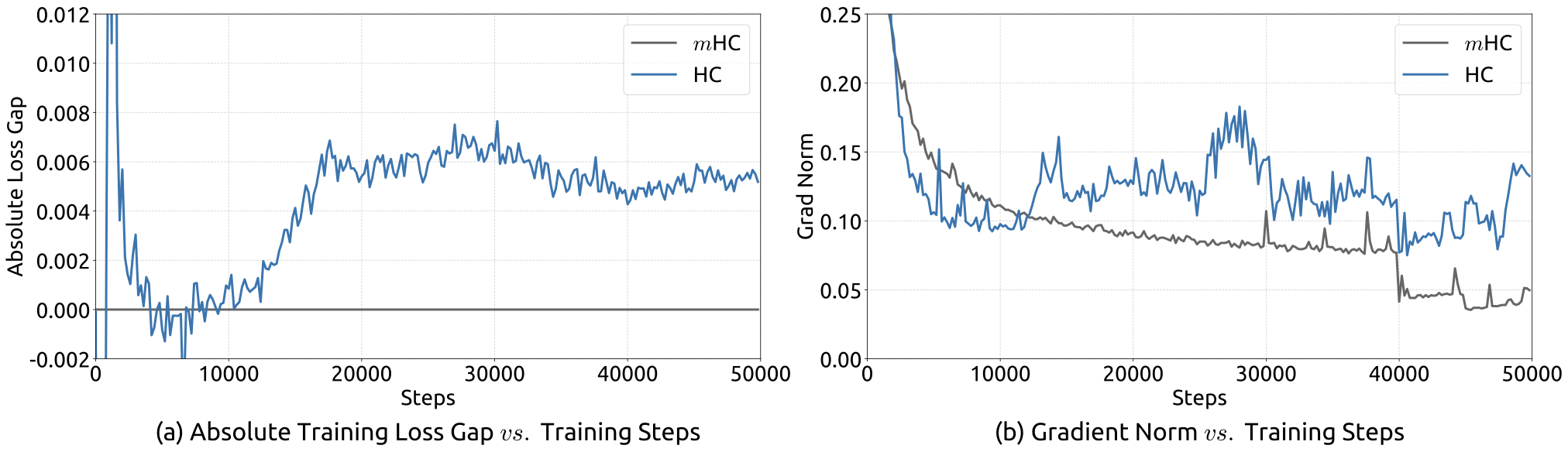
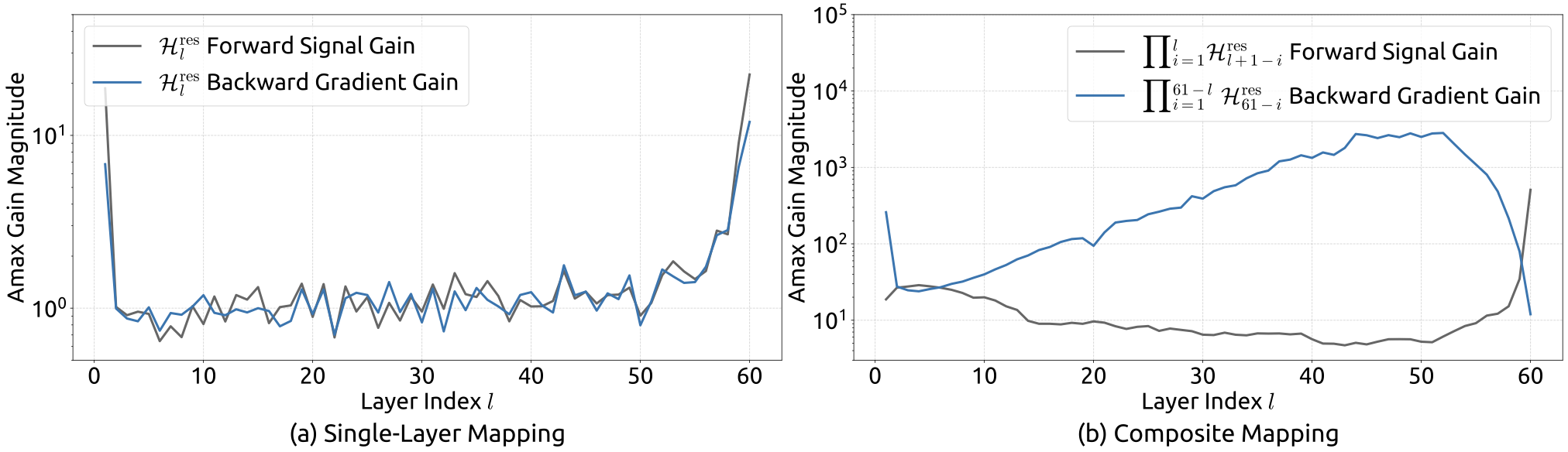
Empirical evidence supports this analysis. We observe unstable loss behavior in large-scale experiments, as illustrated in Fig. 2. Taking mHC as the baseline, HC exhibits an unexpected loss surge around the 12k step, which is highly correlated with the instability in the gradient norm. Furthermore, the analysis on $`\mathcal{H}^{\mathrm{res}}_{l}`$ validates the mechanism of this instability. To quantify how the composite mapping $`\prod_{i=1}^{L-l}\mathcal{H}_{L-i}^{\mathrm{res}}`$ amplifies signals along the residual stream, we utilize two metrics. The first, based on the maximum absolute value of the row sums of the composite mapping, captures the worst-case expansion in the forward pass. The second, based on the maximum absolute column sum, corresponds to the backward pass. We refer to these metrics as the Amax Gain Magnitude of the composite mapping. As shown in Fig. 3 (b), the Amax Gain Magnitude yields extreme values with peaks of 3000, a stark divergence from 1 that confirms the presence of exploding residual streams.
 style="width:100.0%" />
style="width:100.0%" />
 style="width:100.0%" />
style="width:100.0%" />
System Overhead
While the computational complexity of HC remains manageable due to the linearity of the additional mappings, the system-level overhead prevents a non-negligible challenge. Specifically, memory access (I/O) costs often constitute one of the primary bottlenecks in modern model architectures, which is widely referred to as the “memory wall” . This bottleneck is frequently overlooked in architectural design, yet it decisively impacts runtime efficiency.
| Method | Operation | Read (Elements) | Write (Elements) | ||
|---|---|---|---|---|---|
|
Residual Merge | 2C | C | ||
| Total I/O | 2C | C | |||
|
Calculate ℋlpre, ℋlpost, ℋlres | nC | n2 + 2n | ||
| ℋlpre | nC + n | C | |||
| ℋlpost | C + n | nC | |||
| ℋlres | nC + n2 | nC | |||
| Residual Merge | 2nC | nC | |||
| Total I/O | (5n + 1)C + n2 + 2n | (3n + 1)C + n2 + 2n |
Focusing on the widely adopted pre-norm Transformer architecture, we analyze the I/O patterns inherent to HC. Tab. 4 summarizes the per token memory access overhead in a single residual layer introduced by the $`n`$-stream residual design. The analysis reveals that HC increases the memory access cost by a factor approximately proportional to $`n`$. This excessive I/O demand significantly degrades training throughput without the mitigation of fused kernels. Besides, since $`\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}}`$, $`\ensuremath{\mathcal{H}^{\mathrm{post}}_{l}}`$, and $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$ involve learnable parameters, their intermediate activations are required for backpropagation. This results in a substantial increase in the GPU memory footprint, often necessitating gradient checkpointing to maintain feasible memory usage. Furthermore, HC requires $`n`$-fold more communication cost in pipeline parallelism , leading to larger bubbles and decreasing the training throughput.
Method
Manifold-Constrained Hyper-Connections
Drawing inspiration from the identity mapping principle , the core premise of mHC is to constrain the residual mapping $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$ onto a specific manifold. While the original identity mapping ensures stability by enforcing $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}} = \mathbf{I}`$, it fundamentally precludes information exchange within the residual stream, which is critical for maximizing the potential of multi-stream architectures. Therefore, we propose projecting the residual mapping onto a manifold that simultaneously maintains the stability of signal propagation across layers and facilitates mutual interaction among residual streams to preserve the model’s expressivity. To this end, we restrict $`\mathcal{H}^{\mathrm{res}}_{l}`$ to be a doubly stochastic matrix, which has non-negative entries where both the rows and columns sum to 1. Formally, let $`\mathcal{M}^\mathrm{res}`$ denote the manifold of doubly stochastic matrices (also known as the Birkhoff polytope). We constrain $`\mathcal{H}^{\mathrm{res}}_{l}`$ to $`\mathcal{P}_{\mathcal{M}^\mathrm{res}}(\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}})`$, defined as:
\begin{equation}
\mathcal{P}_{\mathcal{M}^\mathrm{res}}(\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}) \coloneq \left\{ \ensuremath{\mathcal{H}^{\mathrm{res}}_{l}} \in \mathbb{R}^{n \times n} \mid \ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}\mathbf{1}_n = \mathbf{1}_n, \ \mathbf{1}^\top_n\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}} = \mathbf{1}^\top_n, \ \ensuremath{\mathcal{H}^{\mathrm{res}}_{l}} \geqslant 0 \right\},
\end{equation}where $`\mathbf{1}_n`$ represents the $`n`$-dimensional vector of all ones.
It is worth noting that when $`n=1`$, the doubly stochastic condition degenerates to the scalar $`1`$, thereby recovering the original identity mapping. The choice of double stochasticity confers several rigorous theoretical properties beneficial for large-scale model training:
-
Norm Preservation: The spectral norm of a doubly stochastic matrix is bounded by 1 (i.e., $`\|\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}\|_2 \le 1`$). This implies that the learnable mapping is non-expansive, effectively mitigating the gradient explosion problem.
-
Compositional Closure: The set of doubly stochastic matrices is closed under matrix multiplication. This ensures that the composite residual mapping across multiple layers, $`\prod_{i=1}^{L-l}\mathcal{H}_{L-i}^{\mathrm{res}}`$, remains doubly stochastic, thereby preserving stability throughout the entire depth of the model.
-
Geometric Interpretation via the Birkhoff Polytope: The set $`\mathcal{M}^\mathrm{res}`$ forms the Birkhoff polytope, which is the convex hull of the set of permutation matrices. This provides a clear geometric interpretation: the residual mapping acts as a convex combination of permutations. Mathematically, the repeated application of such matrices tends to increase the mixing of information across streams monotonically, effectively functioning as a robust feature fusion mechanism.
Additionally, we impose non-negativity constraints on the input mappings $`\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}}`$ and output mappings $`\ensuremath{\mathcal{H}^{\mathrm{post}}_{l}}`$. This constrain prevents signal cancellation arising from the composition of positive and negative coefficients, which can also be considered as a special manifold projection.
Parameterization and Manifold Projection
In this section, we detail the calculation process of $`\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}}, \ensuremath{\mathcal{H}^{\mathrm{post}}_{l}}, \text{and } \ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}`$ in mHC. Given the input hidden matrix $`\mathbf{x}_l \in \mathbb{R}^{n \times C}`$ at the $`l`$-th layer, we first flatten it into a vector $`\vec{\mathbf{x}}_l = \text{vec}(\mathbf{x}_l) \in \mathbb{R}^{1\times nC}`$ to preserve full context information. Then, we follow the original HC formulation to get the dynamic mappings and the static mappings as follows:
\begin{equation}
\begin{cases}
\vec{\mathbf{x}}'_l = \text{RMSNorm}(\vec{\mathbf{x}}_l) \\
\ensuremath{\tilde{\mathcal{H}}^{\mathrm{pre}}_{l}} = \alpha_l^\mathrm{pre} \cdot (\vec{\mathbf{x}}'_l\varphi^\mathrm{pre}_l) + \mathbf{b}_l^\mathrm{pre} \\
\ensuremath{\tilde{\mathcal{H}}^{\mathrm{post}}_{l}} = \alpha_l^\mathrm{post} \cdot (\vec{\mathbf{x}}'_l\varphi^\mathrm{post}_l) + \mathbf{b}_l^\mathrm{post} \\
\ensuremath{\tilde{\mathcal{H}}^{\mathrm{res}}_{l}} = \alpha_l^\mathrm{res} \cdot \text{mat}(\vec{\mathbf{x}}'_l\varphi^\mathrm{res}_l) + \mathbf{b}_l^\mathrm{res}, \\
\end{cases}
\end{equation}where $`\varphi^\mathrm{pre}_l, \varphi^\mathrm{post}_l \in \mathbb{R}^{nC \times n}`$ and $`\varphi^\mathrm{res}_l \in \mathbb{R}^{nC \times n^2}`$ are linear projections for dynamic mappings and $`\text{mat}(\cdot)`$ is a reshape function from $`\mathbb{R}^{1\times n^2}`$ to $`\mathbb{R}^{n\times n}`$.
Then, the final constrained mappings are obtained via:
\begin{equation}
\begin{cases}
\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}} = \sigma(\ensuremath{\tilde{\mathcal{H}}^{\mathrm{pre}}_{l}}) \\
\ensuremath{\mathcal{H}^{\mathrm{post}}_{l}} = 2\sigma(\ensuremath{\tilde{\mathcal{H}}^{\mathrm{post}}_{l}}) \\
\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}} = \text{Sinkhorn-Knopp}(\ensuremath{\tilde{\mathcal{H}}^{\mathrm{res}}_{l}}),
\end{cases}
\end{equation}where $`\sigma(\cdot)`$ denotes the Sigmoid function. The $`\text{Sinkhorn-Knopp}(\cdot)`$ operator firstly makes all elements to be positive via an exponent operator and then conducts iterative normalization process that alternately rescales rows and columns to sum to 1. Specifically, given a positive matrix $`\mathbf{M}^{(0)} = \exp(\ensuremath{\tilde{\mathcal{H}}^{\mathrm{res}}_{l}})`$ as the start point, the normalization iteration proceeds as:
\begin{equation}
\mathbf{M}^{(t)} = \mathcal{T}_r\left(\mathcal{T}_c(\mathbf{M}^{(t-1)})\right),
\end{equation}where $`\mathcal{T}_r`$ and $`\mathcal{T}_c`$ denote row and column normalization, respectively. This process converges to a doubly stochastic matrix $`\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}=\mathbf{M}^{(t_{\text{max}})}`$ as $`t_{\text{max}} \to \infty`$. We choose $`t_{\text{max}}=20`$ as a practical value in our experiments.
Efficient Infrastructure Design
In this section, we detail the infrastructure design tailored for mHC. Through rigorous optimization, we implement mHC (with $`n = 4`$) in large-scale models with a marginal training overhead of only 6.7%.
Kernel Fusion
Observing that RMSNorm in mHC imposes significant latency when operating on the high-dimensional hidden state $`\vec{\mathbf{x}}_l \in \mathbb{R}^{1\times nC}`$, we reorder the dividing-by-norm operation to follow the matrix multiplication. This optimization maintains mathematical equivalence while improving efficiency. Furthermore, we employ mixed-precision strategies to maximize numerical accuracy without compromising speed, and fuse multiple operations with shared memory access into unified compute kernels to reduce memory bandwidth bottlenecks. Based on the inputs and parameters detailed in Eq. [eq:fuse:1] to [eq:fuse:4], we implement three specialized mHC kernels to compute $`\mathcal{H}^{\mathrm{pre}}_{l}`$, $`\mathcal{H}^{\mathrm{post}}_{l}`$, and $`\mathcal{H}^{\mathrm{res}}_{l}`$. In these kernels, the biases and linear projections are consolidated into $`\mathbf{b}_l`$ and $`\varphi_l`$, and the RMSNorm weight is also absorbed in $`\varphi_l`$.
-
Eq. [eq:fuse:5] to [eq:fuse:6]: We develop a unified kernel that fuses two scans on $`\vec{\mathbf{x}}_l`$, leveraging matrix multiplication units to maximize memory bandwidth utilization. The backward pass—comprising two matrix multiplications—is similarly consolidated into a single kernel, eliminating redundant reloading of $`\vec{\mathbf{x}}_l`$. Both kernels feature a finely tuned pipeline (load, cast, compute, store) to efficiently handle mixed-precision processing.
-
Eq. [eq:fuse:7] to [eq:fuse:9]: These lightweight operations on small coefficients are opportunistically fused into a single kernel, significantly reducing kernel launch overhead.
-
Eq. [eq:fuse:10]: We implement the Sinkhorn-Knopp iteration within a single kernel. For the backward pass, we derive a custom backward kernel that recomputes the intermediate results on-chip and traverses the entire iteration.
\begin{align}
\varphi_l &: \text{tfloat32} &&[nC, n^2+2n] \label{eq:fuse:1}\\
\vec{\mathbf{x}}_l &: \text{bfloat16} &&[1, nC] \label{eq:fuse:2}\\
\alpha_l^\mathrm{pre}, \alpha_l^\mathrm{post}, \alpha_l^\mathrm{res} &: \text{float32} &&\text{Scalars} \label{eq:fuse:3}\\
\mathbf{b}_l &: \text{float32} &&[1, n^2+2n] \label{eq:fuse:4}\\
\left[{\ensuremath{\tilde{\tilde{\mathcal{H}}}^{\mathrm{pre}}_{l}}}, {\ensuremath{\tilde{\tilde{\mathcal{H}}}^{\mathrm{post}}_{l}}}, {\ensuremath{\tilde{\tilde{\mathcal{H}}}^{\mathrm{res}}_{l}}}\right] &: \text{float32} &&= \vec{\mathbf{x}}_l\varphi_l \label{eq:fuse:5}\\
r &: \text{float32} &&= \left\|\vec{\mathbf{x}}_l\right\|_2 / \sqrt{nC} \label{eq:fuse:6}\\
\left[\ensuremath{\tilde{\mathcal{H}}^{\mathrm{pre}}_{l}}, \ensuremath{\tilde{\mathcal{H}}^{\mathrm{post}}_{l}}, \ensuremath{\tilde{\mathcal{H}}^{\mathrm{res}}_{l}}\right] &: \text{float32} &&= 1/r \left[\alpha_l^\mathrm{pre}{\ensuremath{\tilde{\tilde{\mathcal{H}}}^{\mathrm{pre}}_{l}}}, \alpha_l^\mathrm{post}{\ensuremath{\tilde{\tilde{\mathcal{H}}}^{\mathrm{post}}_{l}}}, \alpha_l^\mathrm{res}{\ensuremath{\tilde{\tilde{\mathcal{H}}}^{\mathrm{res}}_{l}}}\right] + \mathbf{b}_l \label{eq:fuse:7}\\
\ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}} &: \text{float32} &&= \sigma\left(\ensuremath{\tilde{\mathcal{H}}^{\mathrm{pre}}_{l}}\right) \label{eq:fuse:8}\\
\ensuremath{\mathcal{H}^{\mathrm{post}}_{l}} &: \text{float32} &&= 2\sigma\left(\ensuremath{\tilde{\mathcal{H}}^{\mathrm{post}}_{l}}\right) \label{eq:fuse:9}\\
\ensuremath{\mathcal{H}^{\mathrm{res}}_{l}} &: \text{float32} &&= \text{Sinkhorn-Knopp}\left(\ensuremath{\tilde{\mathcal{H}}^{\mathrm{res}}_{l}}\right) \label{eq:fuse:10}
\end{align}Using the coefficients derived from the aforementioned kernels, we introduce two additional kernels to apply these mappings: one for $`\mathcal{F}_{\mathrm{pre}}\coloneq \ensuremath{\mathcal{H}^{\mathrm{pre}}_{l}}\mathbf{x}_l`$ and another for $`\mathcal{F}_{\mathrm{post,res}}\coloneq \ensuremath{\mathcal{H}^{\mathrm{res}}_{l}}\mathbf{x}_l+\mathcal{H}_{l}^{\mathrm{post}\, \top}\mathcal{F}(\cdot,\cdot)`$. Through fusing the application of $`\mathcal{H}^{\mathrm{post}}_{l}`$ and $`\mathcal{H}^{\mathrm{res}}_{l}`$ with residual merging, we reduce the number of elements read from $`(3n+1)C`$ to $`(n+1)C`$ and the number of elements written from $`3nC`$ to $`nC`$ for this kernel. We efficiently implement the majority of kernels (excluding Eq. [eq:fuse:5] to [eq:fuse:6]) using TileLang . This framework streamlines the implementation of kernels with complex calculation process and allows us to fully utilize the memory bandwidth with minimal engineering effort.
Recomputing
The $`n`$-stream residual design introduces substantial memory overhead during training. To mitigate this, we discard the intermediate activations of the mHC kernels after the forward pass and recompute them on-the-fly in the backward pass, through re-executing the mHC kernels without the heavy layer function $`\mathcal{F}`$. Consequently, for a block of $`L_r`$ consecutive layers, we need only store the input $`\mathbf{x}_{l_0}`$ to the first layer. Excluding lightweight coefficients while accounting for the pre-norm with in $`\mathcal{F}`$, Tab. 5 summarizes the intermediate activations preserved for the backward pass.
| Activations | xl0 | ℱ(ℋlprexl, 𝒲l) | xl | ℋlprexl | RMSNorm(ℋlprexl) |
|---|---|---|---|---|---|
| Size (Elements) | nC | C | nC | C | C |
| Stored Method | Every Lr layers | Every layer | Transient inside Lr layers | ||
Since mHC kernels recomputation is performed for blocks of $`L_r`$ consecutive layers, given a total of $`L`$ layers, we must persistently store the first layer input $`\mathbf{x}_{l_0}`$ for all $`\lceil\tfrac{L}{L_r}\rceil`$ blocks for the backward pass. In addition to this resident memory, the recomputation process introduces a transient memory overhead of $`(n+2)C\times L_r`$ elements for the active block, which determines the peak memory usage during backpropagation. Consequently, we determine the optimal block size $`L_r^*`$ by minimizing the total memory footprint corresponded to $`L_r`$:
\begin{equation}
L_r^* = \arg\min_{L_r} \left[ nC\times \left\lceil\frac{L}{L_r}\right\rceil + (n+2)C\times L_r \right] \approx \sqrt{\frac{nL}{n+2}}.
\end{equation}Furthermore, pipeline parallelism in large-scale training imposes a constraint: recomputation blocks must not cross pipeline stage boundaries. Observing that the theoretical optimum $`L_r^*`$ typically aligns with the number of layers per pipeline stage, we choose to synchronize the recomputation boundaries with the pipeline stages.
Overlapping Communication in DualPipe
In large-scale training, pipeline parallelism is the standard practice for mitigating parameter and gradient memory footprints. Specifically, we adopt the DualPipe schedule , which effectively overlaps scale-out interconnected communication traffic, such as those in expert and pipeline parallelism. However, compared to the single-stream design, the proposed $`n`$-stream residual in mHC incurs substantial communication latency across pipeline stages. Furthermore, at stage boundaries, the recomputation of mHC kernels for all $`L_r`$ layers introduces non-negligible computational overhead. To address these bottlenecks, we extend the DualPipe schedule (see Fig. 4) to facilitate improved overlapping of communication and computation at pipeline stage boundaries.
 />
/>
Notably, to prevent blocking the communication stream, we execute the $`\mathcal{F}_{\mathrm{post,res}}`$ kernels of MLP (i.e. FFN) layers on a dedicated high-priority compute stream. We further refrain from employing persistent kernels for long-running operations in attention layers, thereby preventing extended stalls. This design enables the preemption of overlapped attention computations, allowing for flexible scheduling while maintaining high utilization of the compute device’s processing units. Furthermore, the recomputation process is decoupled from pipeline communication dependencies, as the initial activation of each stage $`\mathbf{x}_{l_0}`$ is already cached locally.
Experiments
Experimental Setup
We validate the proposed method via language model pre-training, conducting a comparative analysis between the baseline, HC, and our proposed mHC. Utilizing MoE architectures inspired by DeepSeek-V3 , we train four distinct model variants to cover different evaluation regimes. Specifically, the expansion rate $`n`$ for both HC and mHC is set to 4. Our primary focus is a 27B model trained with a dataset size proportional to its parameters, which serves as the subject for our system-level main results. Expanding on this, we analyze the compute scaling behavior by incorporating smaller 3B and 9B models trained with proportional data, which allows us to observe performance trends across varying compute. Additionally, to specifically investigate the token scaling behavior, we train a separate 3B model on a fixed corpus of 1 trillion tokens. Detailed model configurations and training hyper-parameters are provided in Appendix 7.1.
Main Results
 style="width:100.0%" />
style="width:100.0%" />
l | Y Y Y Y Y Y Y Y Benchmark & BBH & DROP & GSM8K & HellaSwag &
MATH & MMLU & PIQA & TriviaQA
(Metric) & (EM) & (F1) & (EM) & (Acc.) & (EM) & (Acc.) & (Acc.) &
(EM)
# Shots & 3-shot & 3-shot & 8-shot & 10-shot & 4-shot & 5-shot &
0-shot & 5-shot
27B Baseline & 43.8 & 47.0 & 46.7 & 73.7 & 22.0 & 59.0 & 78.5 &
54.3
27B w/ HC & 48.9 & 51.6 & 53.2 & 74.3 & 26.4 & 63.0 & 79.9 &
56.3
27B w/ mHC & 51.0 & 53.9 & 53.8 & 74.7 & 26.0 &
63.4 & 80.5 & 57.6
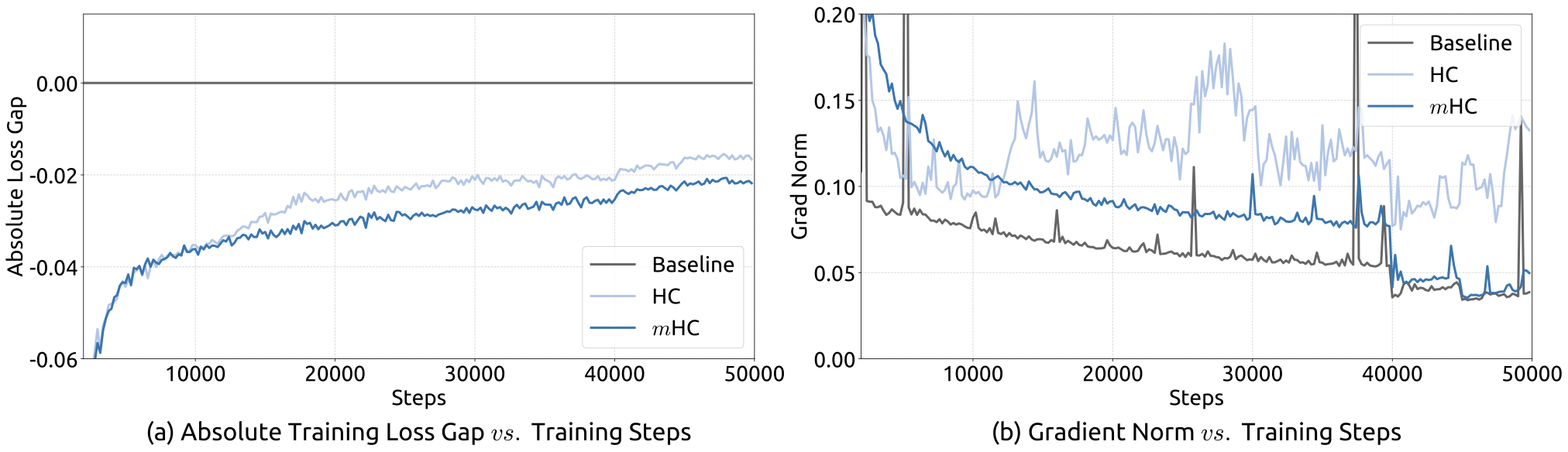
We begin by examining the training stability and convergence of the 27B models. As illustrated in Fig. 5 (a), mHC effectively mitigates the training instability observed in HC, achieving a final loss reduction of 0.021 compared to the baseline. This improved stability is further corroborated by the gradient norm analysis in Fig. 5 (b), where mHC exhibits significantly better behavior than HC, maintaining a stable profile comparable to the baseline.
Tab. [tab:27b_result] presents the downstream performance across a diverse set of benchmarks . mHC yields comprehensive improvements, consistently outperforming the baseline and surpassing HC on the majority of tasks. Notably, compared to HC, mHC further enhances the model’s reasoning capabilities, delivering performance gains of 2.1% on BBH and 2.3% on DROP .
Scaling Experiments
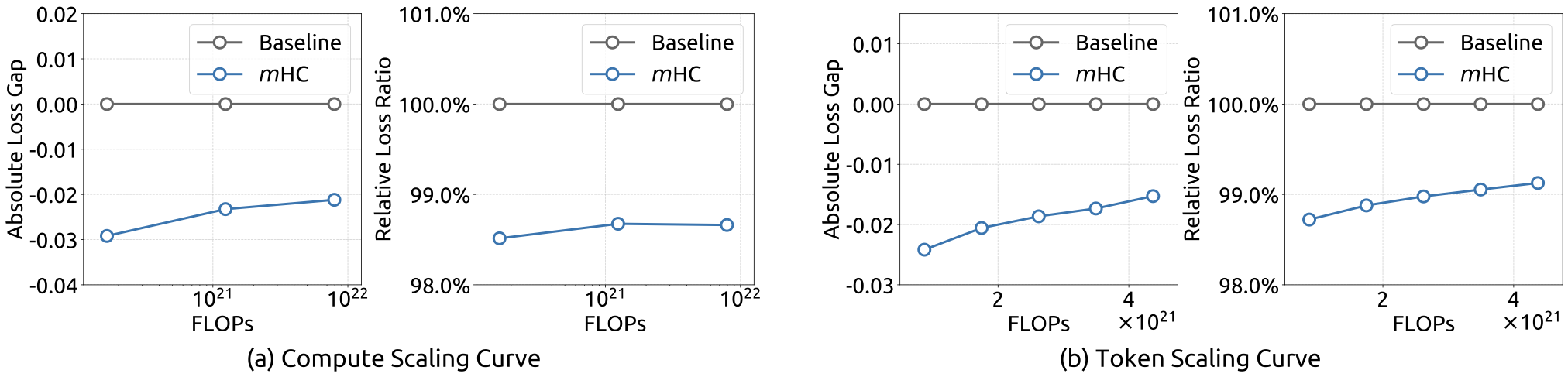 style="width:100.0%" />
style="width:100.0%" />
To assess the scalability of our approach, we report the relative loss improvement of mHC against the baseline across different scales. In Fig. 6 (a), we plot the compute scaling curve spanning 3B, 9B, and 27B parameters. The trajectory indicates that the performance advantage is robustly maintained even at higher computational budgets, showing only marginal attenuation. Furthermore, we examine the within-run dynamics in Fig. 6 (b), which presents the token scaling curve for the 3B model. Collectively, these findings validate the effectiveness of mHC in large-scale scenarios. This conclusion is further corroborated by our in-house large-scale training experiments.
Stability Analysis
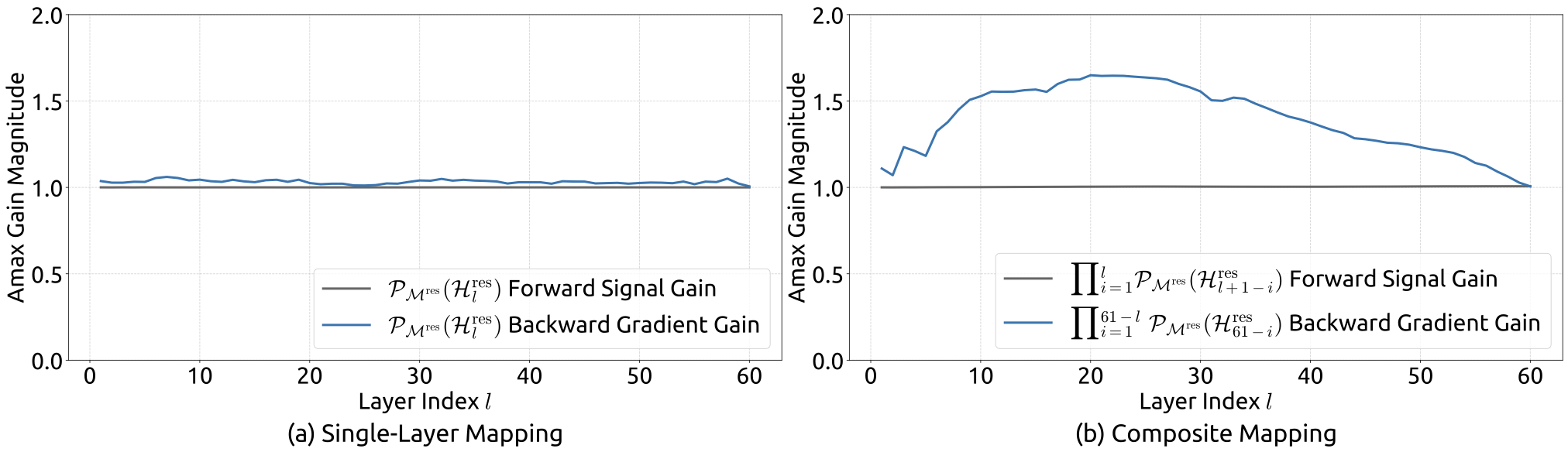 style="width:100.0%" />
style="width:100.0%" />
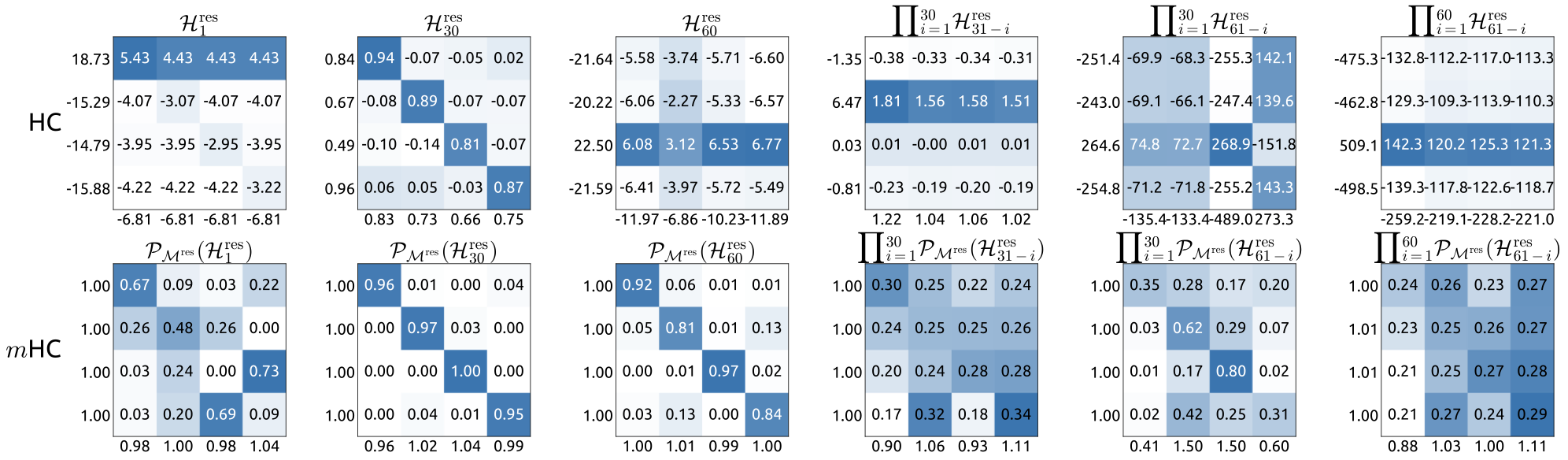 style="width:100.0%" />
style="width:100.0%" />
Similar to Fig. 3, Fig. 7 illustrates the propagation stability of mHC. Ideally, the single-layer mapping satisfies the doubly stochastic constraint, implying that both the forward signal gain and the backward gradient gain should equal to 1. However, practice implementations utilizing the Sinkhorn-Knopp algorithm must limit the number of iterations to achieve computational efficiency. In our settings, we use 20 iterations to obtain an approximate solution. Consequently, as shown in Fig. 7(a), the backward gradient gain deviates slightly from 1. In the composite case shown in Fig. 7(b), the deviation increases but remains bounded, reaching a maximum value of approximately 1.6. Notably, compared to the maximum gain magnitude of nearly 3000 in HC, mHC significantly reduces it by three orders of magnitude. These results demonstrate that mHC significantly enhances propagation stability compared to HC, ensuring stable forward signal and backward gradient flows. Additionally, Fig. 8 displays representative mappings. We observe that for HC, when the maximum gain is large, other values also tend to be significant, which indicates general instability across all propagation paths. In contrast, mHC consistently yields stable results.
Conclusion and Outlook
In this paper, we identify that while expanding the width of residual stream and diversifying connections yields performance gains as proposed in Hyper-Connections (HC), the unconstrained nature of these connections leads to signal divergence. This disruption compromises the conservation of signal energy across layers, inducing training instability and hindering the scalability of deep networks. To address these challenges, we introduce Manifold-Constrained Hyper-Connections (mHC), a generalized framework that projects the residual connection space onto a specific manifold. By employing the Sinkhorn-Knopp algorithm to enforce a doubly stochastic constraint on residual mappings, mHC transforms signal propagation into a convex combination of features. Empirical results confirm that mHC effectively restores the identity mapping property, enabling stable large-scale training with superior scalability compared to conventional HC. Crucially, through efficient infrastructure-level optimizations, mHC delivers these improvements with negligible computational overhead.
As a generalized extension of the HC paradigm, mHC opens several promising avenues for future research. Although this work utilizes doubly stochastic matrices to ensure stability, the framework accommodates the exploration of diverse manifold constraints tailored to specific learning objectives. We anticipate that further investigation into distinct geometric constraints could yield novel methods that better optimize the trade-off between plasticity and stability. Furthermore, we hope mHC rejuvenates community interest in macro-architecture design. By deepening the understanding of how topological structures influence optimization and representation learning, mHC will help address current limitations and potentially illuminate new pathways for the evolution of next-generation foundational architectures.
Appendix
Detailed Model Specifications and Hyper-parameters.
l | Y Y Y | Y & & & & 3B
& & & & 1T Tokens
Vocab Params & 331M & 496M & 662M & 331M
Active Params & 612M & 1.66B & 4.14B & 612M
Total Params & 2.97B & 9.18B & 27.0B & 2.97B
Layers & 12 & 18 & 30 & 12
Leading Dense Layers & & 1
Routed Experts & 64 & 64 & 72 & 64
Active Experts & & 6
Shared Experts & & 2
Dimension & 1280 & 1920 & 2560 & 1280
FFN Dimension & 896 & 1280 & 1536 & 896
Load Balancing Method & & Loss-Free
Attention Heads & 16 & 24 & 32 & 16
Attention Dimension & & 128
Attention Variant & & MLA
KV Rank & & 512
Position Embedding & & RoPE
RoPE Dimension & & 64
RoPE $`\theta`$ & & 10000
Layer Norm Type & & RMSNorm
Layer Norm $`\varepsilon`$ & & 1e-20
mHC/HC Expansion Rate $`n`$ & & 4
mHC/HC Gating Factor Init $`\alpha`$ & & 0.01
mHC Sinkhorn-Knopp $`t_{\text{max}}`$ & & 20
Sequence Length & & 4096
Vocab Size & & 129280
Batch Size & 320 & 512 & 1280 & 2560
Training Steps & 30000 & 50000 & 50000 & 100000
Training Tokens & 39.3B & 105B & 262B & 1.05T
Warmup Steps & & 2000
Optimizer & & AdamW
AdamW Betas & & (0.9, 0.95)
AdamW $`\varepsilon`$ & & 1e-20
Base Learning Rate & 8.6e-4 & 5.9e-4 & 4.0e-4 & 9.0e-4
Lr Scheduler & & Step
Lr Decay Step Ratio & & [0.8 $`\times`$, 0.9 $`\times`$]
Lr Decay Rate & & [0.316, 0.1]
Weight Decay & & 0.1
📊 논문 시각자료 (Figures)
