RAIR A Rule-Aware Benchmark Uniting Challenging Long-Tail and Visual Salience Subset for E-commerce Relevance Assessment
📝 Original Paper Info
- Title: RAIR A Rule-Aware Benchmark Uniting Challenging Long-Tail and Visual Salience Subset for E-commerce Relevance Assessment- ArXiv ID: 2512.24943
- Date: 2025-12-31
- Authors: Chenji Lu, Zhuo Chen, Hui Zhao, Zhenyi Wang, Pengjie Wang, Jian Xu, Bo Zheng
📝 Abstract
Search relevance plays a central role in web e-commerce. While large language models (LLMs) have shown significant results on relevance task, existing benchmarks lack sufficient complexity for comprehensive model assessment, resulting in an absence of standardized relevance evaluation metrics across the industry. To address this limitation, we propose Rule-Aware benchmark with Image for Relevance assessment(RAIR), a Chinese dataset derived from real-world scenarios. RAIR established a standardized framework for relevance assessment and provides a set of universal rules, which forms the foundation for standardized evaluation. Additionally, RAIR analyzes essential capabilities required for current relevance models and introduces a comprehensive dataset consists of three subset: (1) a general subset with industry-balanced sampling to evaluate fundamental model competencies; (2) a long-tail hard subset focus on challenging cases to assess performance limits; (3) a visual salience subset for evaluating multimodal understanding capabilities. We conducted experiments on RAIR using 14 open and closed-source models. The results demonstrate that RAIR presents sufficient challenges even for GPT-5, which achieved the best performance. RAIR data are now available, serving as an industry benchmark for relevance assessment while providing new insights into general LLM and Visual Language Model(VLM) evaluation.💡 Summary & Analysis
1. **Standardized Evaluation Framework** - RAIR defines a 4-level scale for evaluating product-query relevance, providing an objective and precise benchmark to measure model performance, much like the criteria used in a race to judge athletes' performances. 2. **Diverse Dataset Construction** - RAIR offers various datasets from basic cases to complex ones, enabling models to be evaluated across different levels of difficulty, similar to how a textbook progresses learners from basics to advanced topics. 3. **Multimodal Evaluation Capability** - By supporting both image and text in relevance evaluation, RAIR allows for more accurate and detailed analysis by considering visual information along with textual data.📄 Full Paper Content (ArXiv Source)
<ccs2012> <concept> <concept_id>00000000.0000000.0000000</concept_id> <concept_desc>Do Not Use This Code, Generate the Correct Terms for Your Paper</concept_desc> <concept_significance>500</concept_significance> </concept> <concept> <concept_id>00000000.00000000.00000000</concept_id> <concept_desc>Do Not Use This Code, Generate the Correct Terms for Your Paper</concept_desc> <concept_significance>300</concept_significance> </concept> <concept> <concept_id>00000000.00000000.00000000</concept_id> <concept_desc>Do Not Use This Code, Generate the Correct Terms for Your Paper</concept_desc> <concept_significance>100</concept_significance> </concept> <concept> <concept_id>00000000.00000000.00000000</concept_id> <concept_desc>Do Not Use This Code, Generate the Correct Terms for Your Paper</concept_desc> <concept_significance>100</concept_significance> </concept> </ccs2012>
Introduction
With the rapid development of web, e-commerce has become a vital part of daily life. Billions of consumers search for the desired products on e-commerce platforms such as Taobao and Amazon, which are built on a powerful search engine.The search engine processes the user’s query, extracts pertinent items from a catalog containing billions of products and presents the items best satisfy user intent. Therefore, the search relevance, which determines how well the product matches the query, is of paramount importance throughout the entire pipeline.
Due to the significant importance, search relevance has attracted considerable attention from the research community. With large language models (LLMs) demonstrating remarkable capabilities, they have become the dominant backbone for relevance task. In contrast to previous encoder-based approaches, LLM-based methods place greater emphasis on leveraging the model’s chain-of-thought(CoT) capabilities to enhance accuracy. ELLM models the relevance task as a two-stage paradigm, where attribute extraction-based reasoning precedes the final decision-making process. LREF enhances model capabilities through synthesized multi-dimensional Chain-of-Thought exemplars, integrating rule references and attribute extraction. As models demonstrate advanced reasoning capabilities for conventional cases, developing challenging evaluation benchmarks becomes increasingly critical. Existing datasets such as Shopping Queries and Shopping MMLU provides only basic e-commerce annotations without the necessary complexity, thus failing to gain widespread adoption as a relevance benchmark.
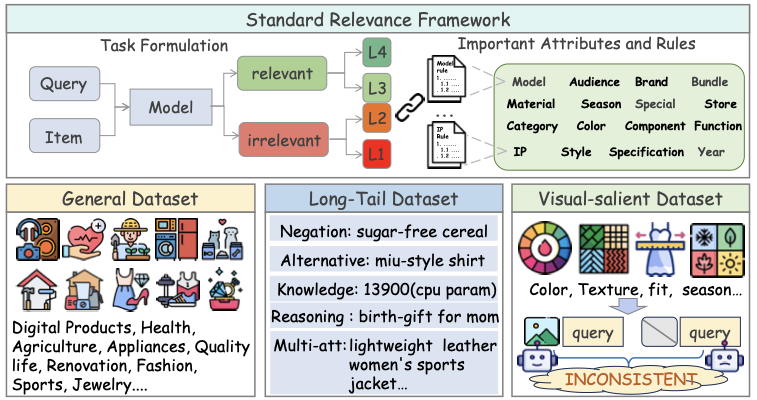
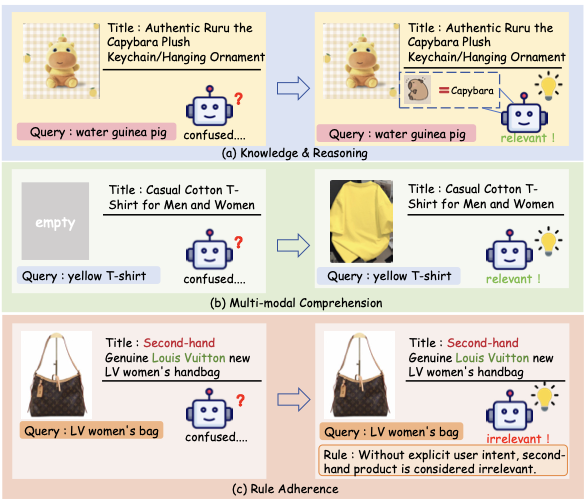
A comprehensive relevance benchmark for LLMs and Visual Language Models(VLMs) should include diverse e-commerce data and evaluate most critical competencies, which we have synthesized into the following three aspects as illustrated in Figure 1. (1) Knowledge & Reasoning Capability, which represents the fundamental model capability requirements for relevance assessment. Complex e-commerce scenarios demand reasoning that combines world knowledge with inference, surpassing basic matching mechanisms. As demonstrated in Figure 1(a), accurate judgment requires the model to access its knowledge base to recognize that “Capybara is synonymous with water guinea pig.”, which illustrates the knowledge requirements for handling complex cases. (2) Multi-modal Comprehension Capability, which represents the advanced capability requirements. In real-world scenarios, Item images play a vital role in search results, significantly influencing user perception. Besides, Visual modalities provide complementary discriminative features that transcend textual representations. As shown in Figure 1(b), Visual information provides critical discriminative cues when textual features alone are insufficient. Although current approaches predominantly rely on LLMs, VLM-based relevance modeling represents an inevitable trend from a long-term perspective. (3)Rule Adherence Capability, which constitutes a crucial foundation for standardized relevance assessment. Relevance assessment is anchored in a sophisticated rule system, meticulously crafted by domain experts who synthesize user preferences to transform subjective relevance judgments into objective, quantifiable, and standardized protocols. In essence, this functions as complementary specifications for common knowledge scenarios. As illustrated in Figure 1(c), the model can make correct judgments when properly adhering to the rule “Without explicit user intent, second-hand product is considered irrelevant.” In current LLM-based approaches such as LREF and TaoSR1, rule compliance has emerged as a crucial capability requirement, and has been specifically modeled during the training process. Following the above insights, we aim to propose a comprehensive and challenging benchmark, providing a standard reference for evaluating models’ relevance judgment capabilities in e-commerce scenarios. Furthermore, we aim to provide an e-commerce-specific lens for assessing general LLM and VLM’s capabilities in instruction following, world knowledge application, and reasoning.
 style="width:100.0%" />
style="width:100.0%" />
To address above critical challenges, in this paper, we introduce the Rule-Aware benchmark with Image for Relevance assessment(RAIR), with its overall framework depicted in Figure [fig:head]. Our work primarily encompasses two main aspects: First, We provide a standardized definition for relevance assessment tasks. Based on extensive data analysis, we classify relevance into four levels, from L1 to L4, with increasing degrees of discrepancy. Specifically, L1 and L2 are categorized as irrelevant, while L3 and L4 are considered relevant. From another perspective, we systematically categorize potential user query requirements into 16 distinct attributes (including category and brand) based on e-commerce domain characteristics. The relevance level annotation is determined through comprehensive assessment of how well these attributes are satisfied. Following cross-validation by multiple domain experts, we establish a generalized and efficient assessment protocol within RAIR, offering a set of universal and lightweight evaluation rules.
Second, We provide comprehensive and challenging evaluation data. The RAIR benchmark consisting of three parts: a general subset and two challenging subsets. 1)General subset. This subset is designed to evaluate models’ fundamental capabilities in e-commerce relevance. Through strategic stratified sampling across industry sectors and careful calibration of data proportions based on industry distributions, we constructed a balanced dataset that comprehensively captures real-world e-commerce scenarios while mitigating potential domain bias. (2) Long-tail hard subset. This subset is constructed as a challenging testbed to probe the upper bounds of models’ reasoning and knowledge capabilities. we employed a systematic sampling approach for complex queries. We first defined a taxonomy of special-intent queries (e.g., negation, reasoning-dependent) and multi-attribute requirements quires, extracted candidates from search logs using rule-based methods, and then applied an LLM-based filtering pipeline to retain the most challenging cases. (3)visual salience subset. This subset is aim to comprehensively evaluate models’ multimodal capabilities. we developed a taxonomy of visual-related keywords and retrieved query-ad pairs across exposure channels, using a blacklist to eliminate false matches. The samples were then refined through an LLM-based pipeline for visual attribute verification and difficulty-based screening. Each instance across all subsets is accompanied by assessment criteria and privacy-compliant product images.
Overall, our main contributions can be summarized as follows:
1) We established a standardized framework for relevance assessment tasks by defining evaluation levels and key attributes, accompanied by comprehensive assessment rules to ensure objective and precise relevance assessment.
2) We created a pipeline based on LLM to select the intended samples from a massive candidate pool, enabling the formation of the long-tail hard subset and visual salience subset.
3) We propose a Chinese dataset equipped with images and annotation rules for each data entry, providing a benchmark for relevance evaluation in the industry and offering a powerful adjunct to current evaluation frameworks for LLM and VLM.
4) We conducted experiments on RAIR using a series of open and closed-source models and performed analysis. The experimental results demonstrate that RAIR possesses sufficient challenge and discriminative power.
Related Works
E-commerce Relevance method
Prior to the LLM era, relevance modeling relied primarily on two types of encoder-based architectures: representation-based and interaction-based models. Representation-based models employ a dual-tower architecture to encode queries and items separately, enabling efficient relevance computation. Sentence-BERT employs a siamese BERT architecture to generate and compare separate encodings for queries and items. PolyEncoder projects query embeddings into multiple representation spaces via trainable vectors to capture diverse global features. DeepBoW generates vocabulary-sized embeddings for queries and items, enhancing semantic granularity and interpretability. Interaction-based models employ a single-tower architecture that enables early query-item interactions, leading to enhanced performance. Among these, BERT-based methods that concatenate queries and items before extracting fused representations have achieved sota. Recently, LLMs achieved remarkable results across a range of tasks due to their extensive inherent knowledge. Mehrdad et al. first introduced a 7B decoder-only LLM for relevance assessment, showing enhanced generalization on long-tail samples. ELLM leverages LLMs’ chain-of-thought capabilities by first extracting query-item attributes before making relevance decisions, and employs multi-dimensional knowledge distillation to optimize smaller models. LREF synthesizes discriminative rules through GPT-generated chain-of-thought reasoning and applies DPO for debiasing, while TaoSR1 incorporates relevance rules through knowledge injection and reinforces them via RLVR using the GRPO algorithm. The advancement of relevance-focused LLMs reflects a shift from basic classification toward rule-based knowledge integration.
E-commerce Relevance benchmark
ECinstruct introduce the first e-commerce instruction dataset and EcomGPT utilized ChatGPT to construct atomic tasks based on fundamental e-commerce data types. eCeLLM encompasses ten diverse tasks, including attribute extraction, product matching, sentiment analysis, and sequential recommendation. Shopping MMLU evaluates LLMs in e-commerce through four core tasks, including shopping concept comprehension and knowledge reasoning. Amazon-M2 evaluates LLMs across four shopping-related capabilities: concept understanding, knowledge reasoning, behavior consistency, and multilingual processing. However, these works serve as general e-commerce comprehension benchmarks rather than specific relevance assessment frameworks. EcomMMMU demonstrated the value of visual data in product understanding through a Visual Salience Subset (VSS), inspiring our approach. While Shopping Queries provides relevance assessment datasets, it lacks judgment rules and visual data, and its limited complexity fails to reflect real-world challenges. This highlights the ongoing need for a comprehensive and robust relevance assessment benchmark.
 style="width:100.0%" />
style="width:100.0%" />
Benchmark Construction
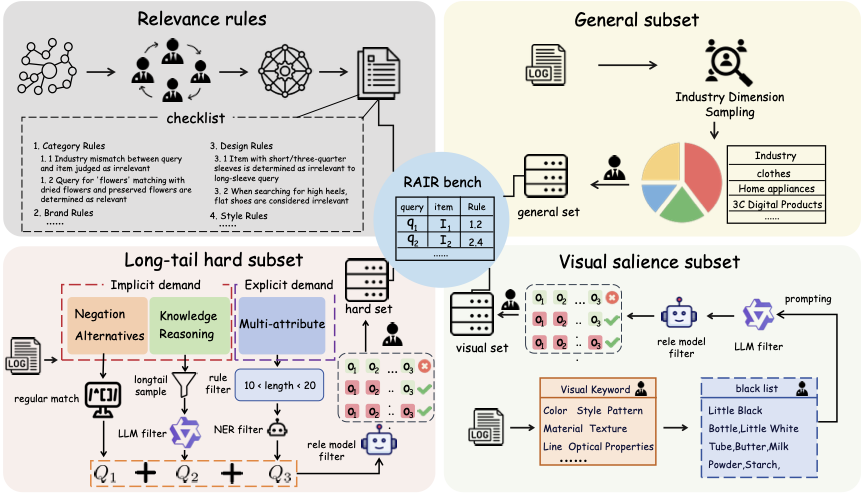
In this section, we provide a comprehensive overview of RAIR’s construction methodology as shown in Figure 3. Section 3.1 presents a standardized relevance task definition, along with detailed description of its corresponding rules and derivation process. Sections 3.2, 3.3, and 3.4 detail the construction pipelines for the general subset, long-tail subset, and visual salience subset of RAIR, respectively. Section 3.5 describes how we align each data entry with its corresponding assessment rules. RAIR data are derived from Taobao user search logs and underwent professional relevance annotation with quality assurance.
 style="width:100.0%" />
style="width:100.0%" />
Task Formulation
Relevance assessment
In the context of e-commerce, the standard relevance assessment task is to predict a fine-grained relevance label $`y`$ for a given query-item pair $`(Q, I)`$. The label $`y`$ is selected from a set of discrete, ordered levels, such as $`\{L1, L2, L3, L4\}`$, which represent the degree of relevance from irrelevant to perfectly matching. Formally, the task is to learn a function $`f: (Q, I) \rightarrow y`$.
Rule-Aware Relevance assessment
In practical applications, relevance judgments often extend beyond semantic similarity and involve subjective assessments. To resolve this ambiguity and create an objective, quantifiable, and standardized evaluation framework, we introduce a set of explicit guiding principles referred to as Rules.
These Rules serve as a reasonable supplement to general world knowledge, designed to disambiguate subjective criteria and ensure consistent judgments. Rather than being ad-hoc business tricks, they are lightweight, generalizable principles distilled from extensive, long-term case studies across various e-commerce sectors. Their primary function is to standardize the interpretation of common subjective terms found in queries and item descriptions. For instance, a rule might define ‘new arrival‘ by a specific time frame (e.g., released within one year of the search date), quantify a ‘price mismatch‘ (e.g., a deviation greater than 10%), or provide clear definitions for age-related terms (e.g., ‘youth‘, ‘teenager‘, ‘child‘) and perceptual attributes like color similarity. This approach ensures that our Rules have broad coverage across different industries and relevance levels, enabling a more precise and fine-grained assessment of a model’s reasoning capabilities.
Accordingly, we formulate the rule-aware relevance assessment task as predicting a label $`y`$ conditioned on the set of applicable rules $`R`$:
y = f(Q, I | R)Here, $`R`$ provides the essential constraints and context needed to ground the relevance judgment in a consistent and objective manner.
General Subset
The general subset aims to comprehensively assess models’ basic reasoning, knowledge, and attribute extraction capabilities through common e-commerce cases, which requires maintaining a relatively balanced data distribution. Naive uniform sampling from search logs can introduce inherent biases stemming from platform-specific traffic distributions, as evidenced by Taobao’s dominance in fashion and cosmetics versus JD’s concentration in electronics and home appliances. Therefore, we implemented a two-step sampling strategy: first stratifying queries by industry sectors and conducting proportional sampling, then applying downsampling to dominant industries to mitigate distribution imbalance in the dataset. Through this sampling strategy, we constructed a balanced general subset containing 46,775 entries distributed across 14 industries, ensuring that no individual sector, including traditionally dominant categories such as fashion and cosmetics, constitutes more than 15% of the dataset.
Long-Tail Hard Subset
To provide more challenging data for LLM evaluation and better differentiate their capabilities, we focus on mining hard cases of relevance in e-commerce business scenarios. Inspired by Shopping Queries and TaoSR1, from a query perspective, We categorize difficult queries into: (1) Explicit hard demands, where user requirements are straightforward and involve multiple attributes (MR); (2) Implicit hard demands, where user requirements are indirectly expressed and require further interpretation. For implicit hard queries, we identify four distinct types of intents:
Negation(NE), search queries containing negation words or exclusionary terms, such as “sugar-free cereal”.
Alternatives(AL), cost-effective alternatives that are similar to high-end products, such as “Estée Lauder alternatives”.
Knowledge-dependent(KD), queries that require specific domain knowledge to understand or answer, such as “13900” which is actually a CPU model number.
Reasoning-dependent(RD), requirements that are not explicitly expressed in the query but actually exist, requiring understanding based on common sense or usage scenarios, such as “birthday gift for mom”.
These challenging queries not only require models to have basic attribute extraction capabilities, but also demand sufficient world knowledge and reasoning abilities. Taking “13900” as an example, the model needs to possess the knowledge that “13900 is an Intel CPU model” to make correct judgments. To filter out challenging queries from massive data, we categorized the above 5 types of intents into 3 categories for processing. For NE and AL intent types, since they have fixed keywords or phrase structures, we pre-defined a set of keywords and used regular expressions to filter out corresponding queries based on logs and get a set $`Q^1`$. For KD and RD intent types, which lack fixed sentence structures and typically appear as long-tail queries, we performed undersampling on low-frequency queries from the logs based on the query frequency table described in Section 3.2 to obtain the set $`Q^2_{step1}`$. Afterwards, we prompted a powerful LLM (Qwen3-235B) to perform 8 inferences on each sample $`q_i`$ in $`Q^2_{step1}`$, filtering queries where self-consistent results matched the corresponding intent and occurred more than half (>4) times out of the 8 inferences and finally get $`Q^2`$. This process can be represented as follows:
\begin{equation}
\label{equ:1}
R(q_i,a_{ij}) = \sum_{j=1}^{8} Qwen(q_i)
\end{equation}\begin{equation}
\label{equ:2}
Q^2 =\begin{cases}
if \;\arg\max(R(q_i,a_{ij}) \in \{KD,RD\} \;\&\; count> 4 \quad 1\\[6pt]
else\quad 0
\end{cases}
\end{equation}For MR queries, we first filter out queries with string length greater than 10 but less than 20, primarily to avoid interference from outlier queries. For the filtered queries, we employed a NER (Named Entity Recognition) model trained on internal data to identify attributes, and retained only queries containing more than 5 recognized attribute values and obtain $`Q^3`$, which can be be represented as follows:
\begin{equation}
\label{equ:3}
Q^3 = \{10<length(query)<20\; \& \;count(NER(query)) > 5 \}
\end{equation}To identify genuinely challenging samples, we concatenated $`Q^1`$, $`Q^2`$, and $`Q^3`$, and performed eight inference passes using a relevance model trained on internal data. We filter out samples that the model correctly predicted more than 5 times, based on the insight that higher prediction accuracy indicates higher model confidence, and consequently lower sample difficulty. This process can be represented as follows:
\begin{equation}
\label{equ:2}
Q = \{\sum_{i=1}^{8} (\text{rele\_model}_i(x) = y_x) \leq 5,x \in \text{concat}(Q_1,Q_2,Q_3)\}
\end{equation}Visual Salience Subset
In the e-commerce domain, the main product image provides crucial, fine-grained visual information, such as color and style, which is vital for accurately assessing relevance based on visual attributes. While recent works like have evaluated the capability of multimodal models to leverage visual content in e-commerce tasks, they were not specifically designed for relevance assessment. Furthermore, the immense potential sample space in relevance evaluation makes it infeasible to directly adapt the model-based filtering methods proposed by to curate a visually-focused subset. To address these limitations, we devised a multi-stage pipeline to construct such a dataset.
To start with, we established a comprehensive keyword taxonomy for visual queries, encompassing attributes like color, style, pattern, and material. Using this taxonomy, in the first stage, we performed keyword-based retrieval of query-ad pairs across various exposure spaces. To mitigate noise from false recalls, we first applied a predefined blacklist to filter out erroneous matches (e.g., the query “milk powder” being incorrectly retrieved by the color keyword “pink”). Subsequently, to isolate samples where the main image is indispensable for a correct judgment, we retained only those query-ad pairs where the triggering visual keyword did not appear in the product’s textual description. In the second stage, recognizing that a static blacklist is insufficient to cover all non-visual interference, we further employed a LLM to verify that the keywords in the remaining samples genuinely refer to visual properties.
Building on this refined set, the third stage of our pipeline aimed to identify a challenging subset of hard cases. We trained a naive relevance model using the query, item text, and image as input to predict relevance grades. This model was trained on an internal dataset of 200,000 samples drawn from the same distribution as our general evaluation set, with further details provided in the appendix. For each candidate sample from our filtered set, we conducted eight independent predictions with this model. We then identified and retained samples with a prediction consistency of less than four in a majority vote. Based on the same rationale as in Section 3.2, such samples, characterized by a chaotic distribution of predicted grades and high model uncertainty, are likely to be inherently difficult. Following this automated selection and filtering process, the resulting candidate pool was subjected to multiple rounds of human annotation to produce the final visually-challenging subset.
Rule-Aware Benchmark Construction
While some state-of-the-art methods have begun to incorporate explicit rules as a modeling factor , existing public benchmarks generally lack annotations for this crucial dimension. This creates a significant gap between academic evaluation and real-world industrial scenarios. To bridge this gap and meticulously assess the rule-following capabilities of modern models, we augmented each sample in our benchmark with a checklist of the specific rules governing its relevance judgment.
To generate these annotations with high fidelity, we employed a reverse-engineering approach using a large language model (LLM). First, to manage the prompt’s context length and improve accuracy, we stratified the benchmark samples into slices based on their relevance label ($`y`$) and industry ($`c`$). The complete set of rules, $`R_{\text{all}}`$, was manually partitioned into smaller, contextually relevant subsets, $`R'_{y,c}`$, each corresponding to a specific slice. For each query-item pair $`(Q, I)`$ within a slice, we constructed a prompt that included the sample, its corresponding rule subset $`R'_{y,c}`$, and a task instruction.
We then prompted the LLM to perform $`k`$ independent inferences to identify the applicable rules. Let $`\mathcal{M}_i(Q, I, R'_{y,c})`$ be the set of rules identified by the LLM in the $`i`$-th inference. The final annotated rule checklist for the sample, $`R_{(Q,I)}`$, is derived by retaining only those rules identified in at least two inferences to ensure robustness:
R_{(Q,I)} = \left\{ r \in R'_{y,c} \mid \sum_{i=1}^{k} \mathbb{I}(r \in \mathcal{M}_i(Q, I, R'_{y,c})) \ge 2 \right\}where $`\mathbb{I}(\cdot)`$ is the indicator function. This filtering process mitigates noise and spuriousness in the annotations. We emphasize that this rule checklist is intended strictly for evaluation and should not be incorporated into any model training procedures.
RAIR benchmark
Data Statistics
RAIR benchmark encompasses 14 real-world e-commerce industries, comprising three subsets with a total of 63,601 samples: the general subset with 46,775 samples, the long-tail hard subset with 10,931 samples, and the visual salience subset with 5,895 samples. Table 1 presents the data volume of 5 challenging query intents in the hard long-tail subset and the distribution of industry categories is shown in Appendix 8. For each entry in the dataset, we provide query, item title, item cpv (color-pattern-version), sku (stock keeping unit) information, anonymized item image and manual annotations for L1-L4. The comprehensive distribution of ground truth annotations across the dataset is presented in Table 2. Additionally, to facilitate subsequent model development and error attribution, we provide the corresponding rule identifiers that serve as the basis for relevance judgment in each data instance.
| Query Type | Query Intent | Num | Frequency |
|---|---|---|---|
| Explicit demand | Multi-attribute | 5071 | 46.4% |
| Implicit demand | Negation | 1073 | 9.8% |
| Alternatives | 213 | 1.9% | |
| Reasoning dependent | 2436 | 22.3% | |
| Knowledge dependent | 2138 | 20.0% |
| Relevance | Ground Truth | Num | Frequency |
|---|---|---|---|
| L1 | % | ||
| L2 | % | ||
| L3 | % | ||
| L4 | % |
Distribution of ground truth labels in RAIR
Evaluation Metric
We employed a range of metrics to evaluate the model’s performance on RAIR. The dataset provides annotations from L1 to L4, thus we first introduced the four-class accuracy metric (acc@4) as follows:
\begin{equation}
\label{equ:3}
\text{acc@4} = \frac{1}{N}\sum_{i=1}^{N}\mathbb{I}(\hat{y}_i = y_i)
\end{equation}Given the nature of the relevance task, where L1 and L2 can be considered as irrelvant and L3 and L4 as relevant, we introduced the binary classification accuracy metric (acc@2) as follows:
\begin{equation}
\label{equ:4}
\text{acc@2} = \frac{1}{N}\sum_{i=1}^{N}\mathbb{I}(\hat{y}_i,y_i \in (L1,L2) | \hat{y}_i,y_i \in (L3,L4))
\end{equation}Additionally, to mitigate the impact of the imbalance in data label distribution, we introduce the macro F1 score as follows, which is calculated as the average of F1 scores across all classes.
\begin{equation}
\label{equ:4}
F1\text{-}score_i = 2\frac{\text{Recall}_i \times \text{Precision}_i}{\text{Recall}_i + \text{Precision}_i}
\end{equation}\begin{equation}
\label{equ:4}
macro-F1 = \frac{1}{N}\sum_{i=1}^{N}F1-score_i
\end{equation}Experiments
| Model | Setting | General Set | Longtail Hard Subset | ||||
|---|---|---|---|---|---|---|---|
| 3-5 (lr)6-8 | acc@2 | acc@4 | macro-F1 | acc@2 | acc@4 | macro-F1 | |
| Open-source Instruct Models | |||||||
| Qwen3-4B-Instruct | Base | 0.761 | 0.694 | 0.408 | 0.539 | 0.385 | 0.303 |
| w/ rule | 0.787 | 0.694 | 0.404 | 0.542 | 0.378 | 0.300 | |
| Qwen3-30B-Instruct | Base | 0.766 | 0.707 | 0.409 | 0.586 | 0.442 | 0.343 |
| w/ rule | 0.763 | 0.683 | 0.391 | 0.587 | 0.431 | 0.333 | |
| Qwen3-235B-Instruct | Base | 0.839 | 0.714 | 0.466 | 0.604 | 0.411 | 0.364 |
| w/ rule | 0.830 | 0.676 | 0.417 | 0.609 | 0.381 | 0.359 | |
| Llama3.1-8B-Instruct | Base | 0.786 | 0.529 | 0.261 | 0.542 | 0.314 | 0.227 |
| w/ rule | 0.788 | 0.416 | 0.224 | 0.525 | 0.248 | 0.200 | |
| Llama3.1-70B-Instruct | Base | 0.781 | 0.721 | 0.395 | 0.536 | 0.431 | 0.304 |
| w/ rule | 0.774 | 0.668 | 0.369 | 0.547 | 0.378 | 0.295 | |
| Open-source Thinking Models | |||||||
| Qwen3-4B-Thinking | Base | 0.692 | 0.614 | 0.385 | 0.524 | 0.387 | 0.311 |
| w/ rule | 0.805 | 0.720 | 0.453 | 0.584 | 0.419 | 0.357 | |
| Qwen3-30B-Thinking | Base | 0.739 | 0.671 | 0.424 | 0.521 | 0.398 | 0.306 |
| w/ rule | 0.784 | 0.718 | 0.457 | 0.582 | 0.448 | 0.362 | |
| Qwen3-235B-Thinking | Base | 0.712 | 0.636 | 0.422 | 0.546 | 0.412 | 0.321 |
| w/ rule | 0.779 | 0.702 | 0.470 | 0.585 | 0.451 | 0.367 | |
| Closed-source Models | |||||||
| Gemini 2.5 Pro | Base | 0.783 | 0.692 | 0.465 | 0.608 | 0.466 | 0.389 |
| w/ rule | 0.795 | 0.701 | 0.483 | 0.627 | 0.481 | 0.392 | |
| GPT-5 | Base | 0.781 | 0.654 | 0.434 | 0.643 | 0.423 | 0.381 |
| w/ rule | 0.845 | 0.714 | 0.433 | 0.681 | 0.435 | 0.407 | |
Setups
We present a comprehensive evaluation of a diverse set of LLMs on our proposed RAIR benchmark. The selected models cover a diverse range of architectures and parameter sizes, including open-source models and closed-source API-based models released by leading AI research organizations. Specifically, we evaluate open-source models ranging from 4B to 235B parameters, complemented by state-of-the-art API-based models including GPT-5 and Gemini 2.5 Pro. For each model, we conducted only one attempt and validated the result and all evaluations are performed using the officially recommended inference parameters. In our evaluation protocol, we assessed open-source models on the complete dataset, whereas for API-based models, considering computational cost constraints, we adopted a sampling strategy where 1,000 instances were uniformly sampled from each subset. The experiments were conducted in triplicate, with the final results reported as the mean of these three independent trials.
Main Result
Table [tab:main_results] and Table [tab:visual_results] summarize the performance of various models on the RAIR. The open-source models are arranged in ascending order of model size, and performance metrics are provided for both their Instruct and Thinking variants. To validate the effectiveness of the discriminative rules, we systematically incorporated these rules, into the prompt, and generated rule-guided inference results for each model. We derive two primary conclusions: (1)Sufficient Challenging Nature of RAIR: The benchmark poses significant challenges to current models. Without discriminative rules, even the most powerful model, GPT-5, only achieved a acc@2 of 84.5% and a macro-F1 score of 43.3% on the general subset. The long-tail subset and visual salience subset presents a significantly more challenging evaluation set, with all models exhibiting at least a 10-point performance degradation compared to the general subset. (2)Adequate Discriminative Capability of RAIR. RAIR effectively distinguishes performance differences among models, as evidenced by our fine-grained comparative analysis, with key findings summarized below.
‘Disparity between Open-source Models and closed-source models. The leading open-source model, Qwen3-235B-Instruct, achieved comparable performance to the strongest closed-source model on the general subset. However, a substantial performance gap persists in the long-tail subset(60.9% vs 68.1% on acc@2), where closed-source models maintain their advantage in handling complex and challenging cases.
Comparative Analysis of Model Performance Across Different Parameter Scales. The empirical results demonstrate a clear positive correlation between model parameter scale and performance metrics within identical model families. This scale-dependent performance improvement exhibits particularly significant manifestation in the long-tail subset. While smaller models such as Qwen3-4B-Instruct achieve performance comparable to larger parameter models(78.7% vs 84.5% on acc@2) on the general subset, they show significant performance gaps in long-tail scenarios(54.2% vs 68.1% on acc@2), highlighting the inherent capability limitations of smaller-scale models.
Performance Gains from Rule Integration. Empirical results indicate that most open-source Instruct models did not demonstrate significant performance improvements with rule integration. This limited enhancement may be attributed to the substantial increase in context length, approximately 10,000 tokens, introduced by rule injection into the prompt. The extensive contextual demands make it challenging for models to efficiently identify and apply relevant rules during discrimination tasks. In contrast, rule integration yielded substantial performance improvements for Thinking models, including GPT-5(78.1% to 84.5% on acc@2) and Gemini-2.5-pro(78.3% to 79.5% on acc@2). This enhancement demonstrates the superior capability of deep thinking models in comprehending and adhering to rules within extended contextual settings. Furthermore, a clear observation emerges regarding Thinking models: rule-guided reasoning demonstrates superior effectiveness compared to unconstrained speculation. Excessive deliberation on simple instructions may lead to unnecessary complexity and potentially erroneous outcomes.
Comparative Analysis of Thinking and Non-Thinking Models. Before rule integration, Thinking models performed notably worse than non-Thinking ones due to unconstrained reasoning. After rule integration, both types achieved similar performance. Given that prompt injection is the simplest form of rule application, Thinking models show considerable room for improvement.
Comparison of VLMs’ Multimodal Capabilities we conducted comprehensive assessments across a range of VLMs on visual salience subset. Each model underwent evaluation under two conditions: with and without image input. As Table [tab:visual_results] shows: the empirical results demonstrate that the introduction of visual information leads to significant performance improvements across all VLMs, which proves the robust evaluative capacity for VLMs. Additionally, the visual inputs demonstrated increasingly significant performance improvements on more powerful models such as GPT-5, Gemini-2.5-pro. Notably, Gemini-2.5-pro exhibited substantial gains, with its acc@2 metric increasing from 57.8% to 67%, and its macro-F1 score improving from 28.5% to 37.7%. In contrast, Qwen2.5-vl-7B showed only marginal improvement. This indicates that more sophisticated models demonstrate superior capabilities in both visual comprehension and multimodal information integration, revealing a strong correlation between model capacity and multimodal processing efficiency.
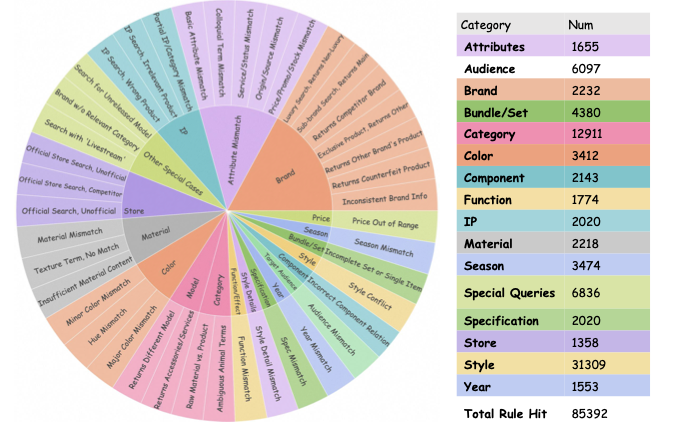
Analysis of Model Limitations
To gain a deeper understanding of the model’s limitations in rule-based
reasoning, we conducted a fine-grained error analysis on the failure
cases of Qwen3-235B-a22B-Instruct-2507(the best open-source model) on
both the general and hard subsets of our benchmark. We categorized the
rules that the model failed to follow, and the distribution of these
error categories is presented in Figure
4.
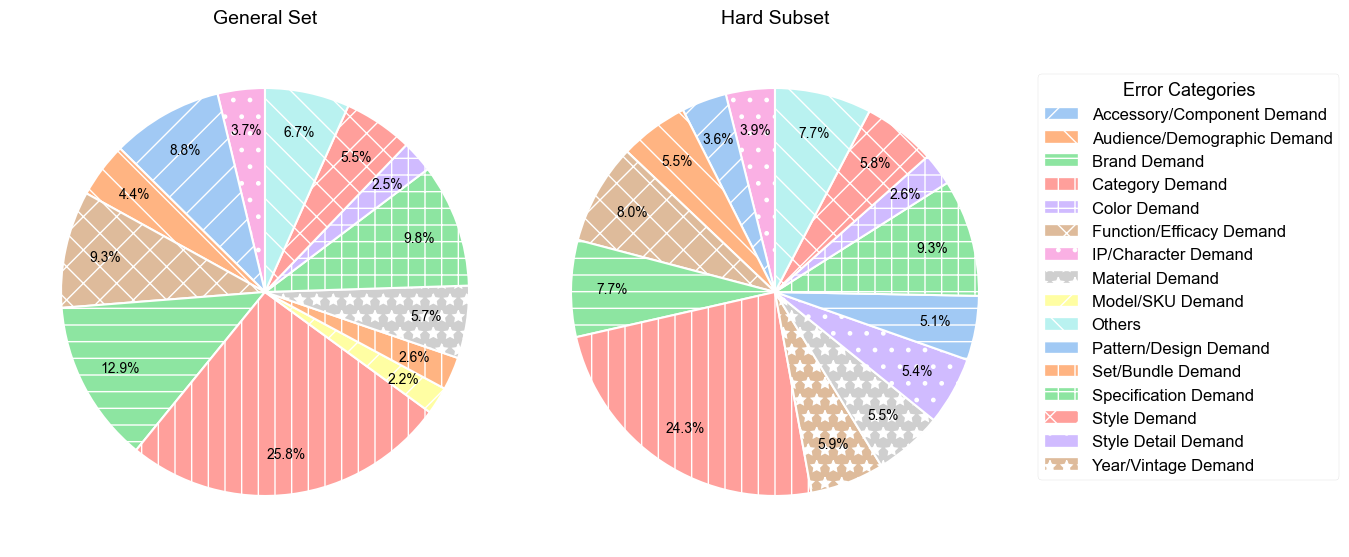
Qwen3-235B-a22B-Instruct-2507 model on the general set and
the hard subset.As shown in the left chart of Figure 4, on the general set, the model’s errors are predominantly concentrated on fundamental product attributes. The most significant source of error is Category Demand (25.8%), indicating that the model often fails to correctly match the basic product category specified in the query. Other major error types include Specification Demand (12.9%), Brand Demand (9.8%), and Function/Efficacy Demand (9.3%). These findings suggest that even on relatively straightforward samples, the model exhibits deficiencies in accurately identifying and verifying core entity attributes.
The hard subset shows a distinct error pattern shift: while Category Demand (24.3%) remains the primary error source, objective errors decrease from 12.9% to 7.7%, whereas subjective errors increase notably. This suggests that models perform better with concrete, verifiable specifications but struggle with abstract concepts, multiple constraints, or subjective preferences. The hard subset highlights these weaknesses, validating our benchmark’s design and its ability to diagnose model limitations. We further analyzed model capabilities from an industry perspective, with detailed results presented in Appendix 7.
Conclusion
In this paper, we propose a Rule-Aware benchmark with Image for Relevance assessment (RAIR), providing a comprehensive benchmark for relevance evaluation in the e-commerce domain and offering a novel perspective for assessing general LLMs and VLMs. We open-source a complete set of relevance judgment rules, with each data point annotated with corresponding rule identifiers. Regarding dataset composition, we present a general subset to evaluate models’ fundamental e-commerce relevance assessment capabilities, alongside a long-tail subset and a visual salience subset to measure models’ performance upper bounds and multimodal capabilities. Extensive experiments demonstrate the comprehensiveness and challenging nature of our proposed benchmark.
Industry Gap Analysis
| Industry | acc@2 |
|---|---|
| Average | 0.839 |
| Food & Fresh Products | 0.806 |
| Fashion & Apparel | 0.803 |
| Industrial & Agricultural | 0.778 |
| Automotive | 0.760 |
| Healthcare | 0.757 |
Industries significantly below the average level
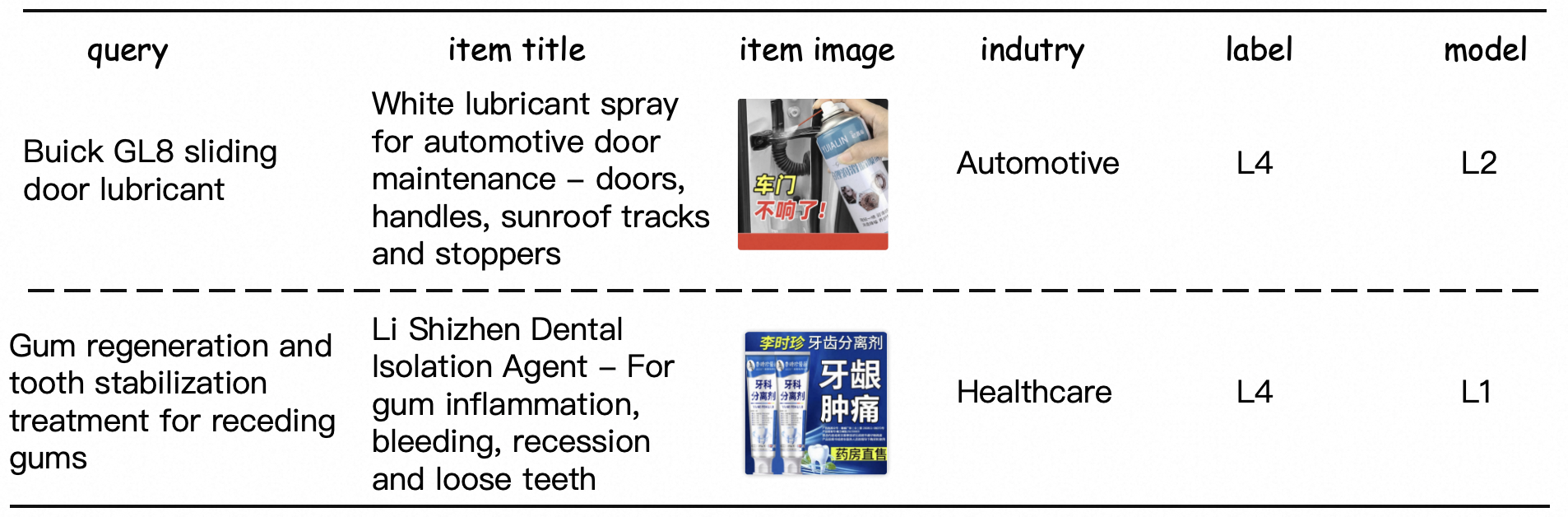
To conduct a fine-grained analysis of model performance bottlenecks on RAIR, we performed a series of systematic experiments. Initially, we conducted an industry-wise breakdown of inference results from Qwen3-235B, which achieved the best performance among open-source models on the complete General subset. Employing acc@2 as our primary evaluation metric, we isolated industries exhibiting performance deficits of 3 percentage points or more relative to the mean. The comparative analysis is presented in Table 3. The empirical results demonstrate that the accuracy metrics across five industries are substantially below the overall mean, with particularly notable deviations in the Automotive and Healthcare sectors, where the performance gap exceeds 7 percentage points relative to the average. Through case analysis, we find that data from the healthcare sector frequently involves specialized medical terminology and specific pharmaceutical products, posing significant challenges to the model’s domain expertise. As for the automotive sector, due to the nature of e-commerce platforms not selling vehicles directly, the queries primarily concern auto parts and accessories, which demands rigorous domain knowledge and fine-grained attribute extraction capabilities from the model. To better illustrate the challenges in these two domains, we present two representative cases in Figure 5, which demonstrate the high demands for professional knowledge required of models.
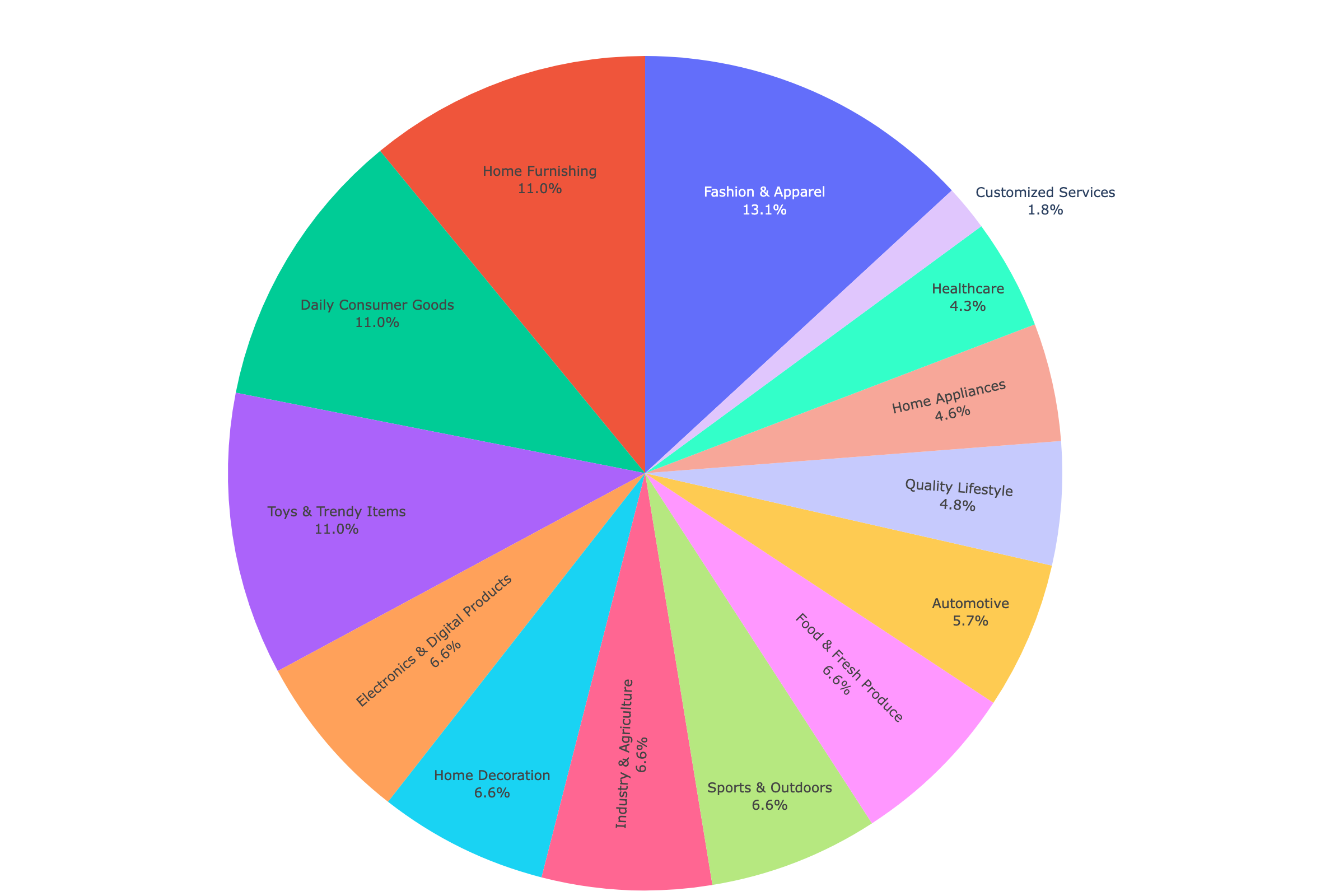
The Industry Distribution in General Subset
Table 6 illustrates the industry distribution within the general subset. The distribution demonstrates relative uniformity across industries, with only a few minor sectors showing marginal variations in representation. This balanced distribution ensures comprehensive coverage across industrial sectors, facilitating a thorough evaluation of the model’s performance across diverse domains.
📊 논문 시각자료 (Figures)