HaineiFRDM Exploring Diffusion for Restoring Defects in High-Speed Films
📝 Original Paper Info
- Title: HaineiFRDM Explore Diffusion to Restore Defects in Fast-Movement Films- ArXiv ID: 2512.24946
- Date: 2025-12-31
- Authors: Rongji Xun, Junjie Yuan, Zhongjie Wang
📝 Abstract
Existing open-source film restoration methods show limited performance compared to commercial methods due to training with low-quality synthetic data and employing noisy optical flows. In addition, high-resolution films have not been explored by the open-source methods.We propose HaineiFRDM(Film Restoration Diffusion Model), a film restoration framework, to explore diffusion model's powerful content-understanding ability to help human expert better restore indistinguishable film defects.Specifically, we employ a patch-wise training and testing strategy to make restoring high-resolution films on one 24GB-VRAMR GPU possible and design a position-aware Global Prompt and Frame Fusion Modules.Also, we introduce a global-local frequency module to reconstruct consistent textures among different patches. Besides, we firstly restore a low-resolution result and use it as global residual to mitigate blocky artifacts caused by patching process.Furthermore, we construct a film restoration dataset that contains restored real-degraded films and realistic synthetic data.Comprehensive experimental results conclusively demonstrate the superiority of our model in defect restoration ability over existing open-source methods. Code and the dataset will be released.💡 Summary & Analysis
1. **High-Resolution Restoration Challenges**: This paper proposes a deep learning-based diffusion model that can operate on devices with low VRAM, similar to how a camera app captures fast-moving actions accurately. 2. **Patch-Based Learning and Inference Frameworks**: To reduce the computational cost of processing high-resolution videos, this paper introduces a patch-based training method where the model restores small parts of an image rather than the entire thing, then combines these patches into a complete image. 3. **Real-Degraded Film Dataset**: The paper proposes a new dataset composed of real-degraded films and synthetic data to serve as a benchmark for evaluating and improving models.📄 Full Paper Content (ArXiv Source)
For each film, film-restoration professionals have to restore every frame in a manual way. For instance, one 2 hour film has around $`170,000`$ frames so that it is a huge time and labor costs for professionals to restore the films, let alone there are tons of films waited to be restored. Therefore there exists an urgent need to design some models to alleviate the restoration burden.
Also, in a common film restoration cooperation, each professional is usually equipped with one consumer device, like one 24GB VRAM RTX 4090 GPU. In this case, we have to take both the inference time and VRAM limmit into consideration when we design the video diffusion model.
After comparing various restoration methods both open-sourced methods and commercial software, we find that current open-source research methods way lag behind commercial software, like MTI and DIAMANT. Here we conclude most restoration problem for almost all open-source methods: 1) The current open-source methods’ training goal is quite different from what human experts want. At dust removal stage, human experts sometimes just expect to remove the dust and scratch, leave everything else still to keep the film with an old-time vibe, not bringing new quality issue by the model and leave color adjustment and shaking removal to next stage. And open-sourced methods usually use the synthetics methods used in RTN to generate low-quality data and try to restore everything including deblur, dust removal, color and contrast adjustment with one model. These LQ-GT data pairs generated with this method are quite different from the actual degraded film samples, which push models to bring every blur area to a clear area and may affect the shooting depth in the film and change the film directors’ aesthetic idea. Also, previous methods might introduce detail artifacts and large color distortion which add more stress to human expert and make the restored frames barely used. 2) Due to limited film restoration data, previous methods usually only restore the black and white films and leave color film aside, which limited their application. DeepRemaster trys to restor RGB film by turning RGB space into LAB space then only fix the L channel, which would show obvious artifact when playing films; 3) previous methods usually use REDS and DAVIS these vlog-style videos not even some film movie as their training data, which did not consider content-types, shooting-styles and degradation types and limited these methods generalization ability; 4) previous methods have difficulty in fast movement shot. commercial methods like MTI, DIAMANT usually use frame-interpolation methods. And open-sourced methods usually use BasicVSR like framework and employs learned optical-flow to facilitate restoration. This method is cool with slow motion frames but the optical-flow may fail when the adjacent frames with large difference and alter the film content, which add more stress for human expert in human recheck stage; 5) previous methods usually evaluate on cropped $`512 \times 512`$ or rescaled resolution frames and lacks evaluation on actual film-scaned resolution data, like 1080p, 2K, 4K resolution. And their methods may shows poor details artifact when test on 2K resolution film data. After emplyed 3D window inference methods like RVRT did, the result frames would show patchy effect, which is also unacceptable to human expert. The previous methods lack a common benchmark and previously they just use their own close-sourced synthetic dataset for evaluation. Also, there are lots of real-degraded film not categorized yet, which helps to unveil model’s actual performance.
The challenges that we meet when exploiting diffusion models for film restoration: 1) train and test model on consumer graphic cards with low VRAM like 24GB VRAM. 2) how to guide model with global aspect when restore a local patches and how to collaborate those different patches without color or details difference for same object.
We explore the video diffusion’s generation prior for old-film restoration scenario with more generalized performance. Also, unlike previous works that detect scratch map by using noise-existing optical-flow to warp the neighboring frames, we did not design any scratch detection module and try to explore the diffusion model’s potential to understand the scratch degradation with their intrinsic real-world awareness. And we design one memory efficient pipeline to make employ the diffusion model on customer device possible.
Our main contributions can be summarized as follows:
-
We explore diffusion model’s content understanding ability to restore fast-movement frames.
-
And we propose a memory-efficient pipeline that the model could be trained and evaluated on 24GB-VRAM consumers Graphic Cards. We put forward an efficient frequency-aware attention module to compensate the loss in extracting condition feature. Besides, we deploy patch-wise training and inference pipeline, which makes training on consumer device(24G GPU) possible. And we propose to add global cross-attention module and VAE-fusing strategy to alleviate patch-wise inconsistency problem.
-
We propose a film- degradation dataset including real-degraded films and the Synthetic Degradation data generated by our proposed synthetic model. And we propose a synthetic degradation benchmark and a real-degraded film benchmark in film-level resolution that could be used to fully evaluate the restoration result for further works.
Related Works
 style="width:100.0%" />
style="width:100.0%" />
Film Restoration
Films degradation could be classified to structured defects and non-structured degradation. Structured defects are physical damages on film, like scratch, friction trace, dust, etc. Accordingly, non-structured degradations, include blurriness, gaussian noise, color fading, . Traditional methods focus on restoring structured defects and are composed of defects detection and restoration stage, which helps to preserve the contents of the clean region while restoring the defects in the frame. However, because these methods are based on imperfect hypothesis, hand-crafted features and manual thresholds, these method lacks content-understanding ability which limits their defects detection and restoration performance on actual films. Especially for frame with fine textures, large size defects or large movement, these tradition methods may fail to detect most frame defects and cause texture inconsistency at defects area.
More recently, deep-learning based methods tend to solve structured defects and non-structured degradations at same time. And these methods can be classified into optical-flow based methods and implicit motion-modeling methods based on their ways of temporal modeling. 1) Implicit motion-modeling methods directly use neural network to lean spatial-temporal features without using explicit motion information like optical-flows. For example, DeepRemaster proposed a fully 3D convolution. However, limited by 3D convolution’s constrained receptive field, this method may not restore most defects, and its restored frames have poor temporal consistency. TAPE used shifted-window mechanism to propagate features within different frames. By using attention mechanism, this methods shows noticable performance. But this methods still struggle to differentiate defects with complex textures in frames; 2) Optical-flow based methods, following BasicVSR framework, tried to fix noisy optical flow and use optical flow to propagate frame features so as to detect defects and improve results’ temporal consistency. Additionally, these methods used window attention, focal attention or Mamba to improve frames features’ spatial-temporal consistency while decreasing model’s memory consumption. However, the learned optical flow was still inaccurate, which the model was misled to incorrectly fix the clean area content as defects. Consequently, content structure like human’s arm may be erased in restored frames, which is unacceptable for human experts. Also, most methods use limited synthetic data proposed in , which have large difference from actual films. ; 3) Frame-interpolation methods
To sum up, all above methods have limited content-understanding ability, which may cause content-structure erasing, temporal flickering problem. Also, these methods have not consider different types of defects and have only been tested on low-resolution frames like 720p, and their restoring performance would slump for 2K or 4K high-resolution film data.
Patch-based Image Generation
Diffusion models show promising potential in restoration task. However, scanned films are usually of 2K or 4K high resolutions and training diffusion model on high-resolution video requires huge computational costs. And thus diffusion models are hard to directly restore high-resolution frames on restoration laboratory’s consumer-grade devices. In order to explore diffusion model’s content-understanding ability to restore tangled film defects, we refer to patch-based generation methods to lower computation cost.
For Patch-based high-resolution image generation methods, MultiDiffusion used a sliding-window scheme to generate patches and fuse the patches to form a panoramic image. However, this method suffered from object repetition issue. Additionally, a popular training-free approach is to generate a low-resolution image and then use super-resolution tricks to upscale the image. ScaleCrafter and FouriScale use dilated convolutions to upscale image feature in diffusion denoising process. But these methods struggle to keep patches’ texture consistent in high-resolution result. Subsequently, DemoFusion, proposed a global residual framework by firstly generating a low-resolution image, upsampling the image in feature space and then use this feature as reference to guide diffusion denoising process to generate patch-consistent high resolution image, which inspiring its following studies. In addition to training-free methods, some approaches like Inf-DiT and HPDM, proposed to redesign network structures and fused explicit patch position information into the model so as to enable high-resolution generation.
Film Restoration Dataset
Due to lacking high-quality restoration data, we observed real films in restoration laboratory and constructed a dataset that comprising real-degraded films and synthetic data. And each data in our dataset is composed of degraded frames, restored frames, defects mask and video description, as showed in Fig.6.
 style="width:100.0%" />
style="width:100.0%" />
To construct restored real films, we firstly collected ‘before-after’ restoration videos that released by Restoration Laboratories and some companies, including MTI, DIAMANT. Secondly, we extracted degraded and restored frames from the comparison videos and computed binary defect masks with paired frames. However, some restored videos suffer from pixel-mismatch problem because the frames may have been through video deflickering, color toning procedures besides defect restoration. Also, some restored frames may still have defects remains due to imperfect restoration. To collect pixel-matching, well-restored high-resolution frames, we manually filter videos in a frame-by-frame manner. Finally, we used CogVLM2 to generate video caption, manually recheck the text and labeled the video with camera-angle and shot-size descriptors. As result, we collected restored real films with totally 5-minute duration(24fps) for training and collected 2K-resolution real films with 10-minute duration for testing.
To enlarge dateset volume, we synthesized realistic degraded frames following Fig.6. Specifically, we collected flawless film clips according to different camera angles and shot sizes. And we collected different types film defect templates including sparse and intensive dust, cigarette-burn holes, flickering and constant scratches, . Furthermore, we randomly apply quality degradation(rescale,jpeg compression) and film texture simulation(add grain) to sampled frames to increase diversity . After that, we add color to defects in templates refer to defects on colored films and then fuse the frames and the defects to get the degraded frames.
Method
To avoid content-distortion and imperfect restoration problem when restoring fast-movement frames, we propose the HaineiFRDM(Film Restoration Diffusion Model) employing diffusion model’s content-understanding ability to recognize and restore frame defects without hurting the flawless content. We design a patch-based training framework(Sec.4.1) and a global-residual-based inference framework(Sec.4.2) to solve patch-inconsistency problem and lower computational cost when restoring high-resolution frames.
Patch-based Training Framework
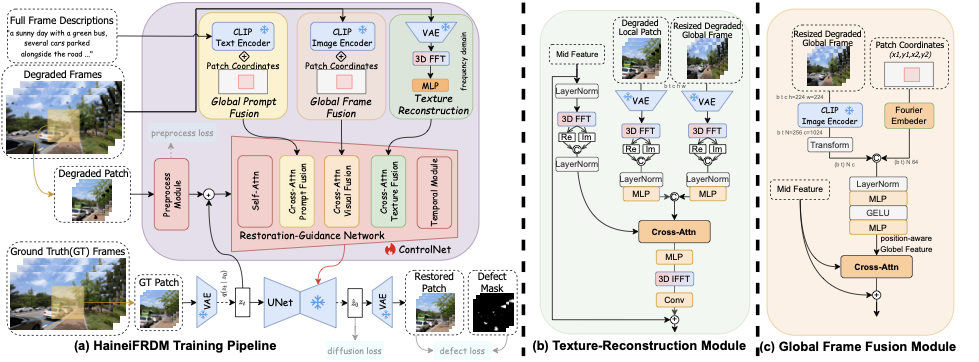
As depicted in Fig.1, our model’s training framework is mainly composed of VAE, UNet, Restoration-Guidance Network, Global-Frame-Fusion Module and Texture-Reconstruction Module. Considering industrial demands of restoring high-resolution frames on low-VRAM devices, we train our model to restore frames in latent space and use a patch-based training strategy. Specifically, we split full video frames into overlapped 3D-patches referring to shifted-window mechanism, randomly sample a patch position and then prepare the corresponding degraded patch, GT patch and defect masks for training. Furthermore, we encode the degraded patch with our Preprocess Module to extract defect-irrelevant features and encode the flawless patch into latent space with VAE model to lower computation overload. And we randomly sample a timestep $`t`$, add noise to GT patch’s VAE feature to get noisy feature $`z_t`$ and fuse the noisy feature and the preprocessed feature to input into our Restoration-Guidance Network.
To exploit the generation prior and content-understanding ability of pretrained diffusion model, our Restoration-Guidance Network guide the generation process through injecting learned residuals into the pretrained UNet, referring to ControlNet. Inside of Restoration-Guidance Network, the fused feature would sequentially go through self-attn, global-prompt-fusion, global-frame-fusion, texture-reconstruction and temporal modules. Especially, we introduce the global-prompt-fusion and global-frame-fusion module to improve model’s global-frame awareness while restoring a local patch. And we design a Texture-Reconstruction Module to keep frame contents’ textures in restored frames consistent with the texture in original frames.
Moreover, the learned residuals, generated by the Restoration-Guidance Network, is input into UNet to produce restored frame features $`\hat{z_0}`$. And we decode the restored feature $`\hat{z_0}`$ into RGB frames and introduce a defect loss to highlight defects region in restored frames.
Global Fusion Module
Though restoring each patch separately lower the computational requirements, a local patch may have inadequate information for the model to distinguish defects with flawless content, which results in content-distortion and false-restoration problem when restoring high-resolution and fast-movement frames. For example, if merely observing the cropped patch frames showed in Fig.3, black defects have high similarities with hand rail object in the frames and showed information is not enough for human expert or model to understand the scene and restore defects correctly.
 style="width:100.0%" />
style="width:100.0%" />
To solve the problem, we design global-frame-fusion and a global-prompt-fusion modules, Fig1(c), to exploit the global frames’ visual and textual information when restoring a local patch. For global-frame-fusion module, we fuse patch’s bounding box coordinates and global-frame to get a location-related visual feature and then inject the feature into the model via cross-attention mechanism, referring to object-location-control methods proposed in . Specifically, we firstly resize the Degraded Global Frames and feed each frame into CLIP image encoder to get visual patch tokens that bearing more positional information than CLS token. Secondly, we transform the patch coordinates into location features via Fourier Embeder and fuse the location feature with the visual patch tokens to get a position-aware Global frame feature. Finally, we use cross-attention mechanism to fuse the global-frame feature with mid features that outputted from previous module and then inject the fused feature back into the Restoration-Guidance Network so as to exploit global frames’ visual information.
For global-prompt-fusion module, we experiment to exploit the prompt information to help model better understand the scene. One straightforward idea is to generate textual descriptions of every patches using LLMs. But the prompt generation process is time-costing for high-resolution and long-duration films. So that we propose to generate full frame’s video descriptions and exploit the textual information via a similar procedure used in the global-frame-fusion module.
Texture-reconstruction Frequency Module
Restoration experts set strict criterion for preserving film details, expecting the restored frames keep highly consistent texture and content as in original films. As shown in Fig.4(c), though the global-frame-fusion module helps improving content-consistency of restored frames, high-frequency texture of restored frames still have obvious texture-mismatch problem.
To improve high-frequency detail’s consistency, we refer to SFHformer’s idea to restore texture in frequency domain and propose a frequency-based texture-reconstruction module, depicted in Fig.1(b). To be specific, we firstly extract a degraded local patch’s VAE feature and transform the feature into freuqncy domain using 3D-FFT, expecting to extract high-frequency information. Meanwhile, we extract frequency feature of resized degraded global frames and use it as reference information to maintain frame’s low-frequency information like overall color and lightness. After, we concatenate the real and image part of 3D-FFT’s result and use MLP to further optimize the frequency features. Lastly, we transform the model’s mid feature into frequency feature, use cross-attention to fuse the frequency feature with the mid feature and then use 3D-iFFT to transform the frequency-domain feature back into feature space.

Patch-Consistent Inference Framework
Using the model with above module to independently restore every RGB patch could alleviate the patching artifact when restoring 720p-resolution frames, as shown in Fig.5. However, with film’s scanning resolution rise to displaying level($`\geq`$ 2K-resolution), each patch’s information is more limited and some defects becomes indistinguishable from frame content, which weaken the model’s restoration ability. Also, the model lacks correlation in restoring different patches, which further results in inconsistent textures.

To solve patching artifacts, we refer to high-resolution image generation methods and propose a patch-consistent inference framework, depicted in Fig., which using global residuals to maintain full frame’s consistency. Specifically, we firstly downsample and pad the high-resolution frames to get a patch-sized frames, use the FRDM model to restore the frames and upsample the frames back to original resolution. These pre-restored frames have most frame defects restored and maintains global and content consistency, which is suitable for being a reference to instruct the color and structure at local patches. Therefore, we extract reference frames’ features and adding noise to get global residuals $`z^{GR}_{t}`$, providing reference information for each denoised timestep. Secondly, we extract features for original degraded frames and add noise to get a noisy low-quality feature $`z^{LQ}_T`$.
In each denoising timstep $`t`$, we firstly fuse the previous-timestep restored feature $`z_t^{RS}`$ with the global residual feature $`z^{GR}_{t}`$ using GRFM(Global Residual Fusion Module) to get a fused feature $`z_t^{fused}`$. The GRFM is implemented as a re-weighting model as eq.[eq:infer_cos_fuse].
\begin{equation}
\label{eq:infer_cos_fuse}
z_t^{fused} = (1 - c_t) \cdot z_t^{RS} + c_t \cdot z_t^{GS}
\end{equation}\begin{equation}
\label{eq:infer_cos_weight}
c_t = 0.25 \cdot \left[ 1 + cos(\pi \cdot \frac{T-t}{T}) \right],
\end{equation}where we use $`z^{LQ}_T`$ as $`z_T^{RS}`$ at timestep $`T`$. And we use a cosine-decreasing weight $`c_t`$ for the global residuals, as in eq.[eq:infer_cos_weight]. Furthermore, we patchify the fused feature $`z^{fused}_t`$, denoise each patch with our HaineiFRDM model respectively and assemble the patches to get a restored feature $`z_{t-1}^{RS}`$. Lastly, we repeat the above denoising process until getting the final restored frames’ features $`z_0^{RS}`$ and use VAE Decoder to transform the feature back to RGB restored frames.
Besides using the global residual to improve global consistency, we also use KV-cache mechanism in self-attention module to pass previous patches’ restoration information to HaineiFRDM, so as to help model determine the texture used to restore the current patch.
Loss Functions
Firstly, we use Diffusion Loss $`\mathcal{L}_{noise}`$ to guide training.
\begin{equation}
\label{eq:loss1}
\mathcal{L}_{noise}=\mathbb{E}_{z_0,t, \epsilon \sim \mathcal{N}(0,1)}\left[
\left\|\epsilon-\epsilon_{\theta}\left(z_t,t\right)\right\|_2^2
\right],
\end{equation}where $`t`$ is a radom-sampled timestep, $`\epsilon`$ is a random noise, $`\epsilon_{\theta}`$ denotes a noise predicted by diffusion model(parameterized by $`\theta`$). And $`z_0`$ is flawless frames features, $`z_t`$ denotes previous-timestep feature.
To extract defect-irrelevant frame features, we follow to extract frame features in multiple scales and then transform the feature back to RGB space to compute loss,
\begin{equation}
\label{eq:loss2}
\mathcal{L}_{preprocess} = \sum_{j=1}^{S}\left[
\frac{1}{N}\sum_{i}^{N}
\left\|
I_{preprocess}^{i,j} - I_{GT}^{i}
\right\|_1
\right],
\end{equation}where $`N`$ is frames number, $`S`$ is scale number, $`I_{preprocess}`$ denotes frame predicted by the Preprocess Module and $`I_{GT}`$ denote flawless frame.
The above loss functions mainly supervise the global quality and the loss value of tiny defects might be overwhelmed by global loss, which make the trained model struggle to restore small defetcs. So that we design a defect loss, which transform the restored feature $`\hat{z_0}`$ into RGB frame $`I_{pred}`$ and then compute the loss of defect area by using defect masks $`m_{defect}`$.
\begin{equation}
\label{eq:loss3}
\mathcal{L}_{defect} = \frac{1}{N}\sum_{i=1}^{N}
\left\|
(I_{pred}^{i} - I_{GT}^{i}) \cdot m_{defect}^{i}
\right\|_1
,
\end{equation}The above losses form our final optimization goal:
\begin{equation}
\label{eq:loss-all}
\mathcal{L}_{total} =
\mathcal{L}_{noise} +
\alpha_{p} \mathcal{L}_{preprocess} +
\alpha_{d} \mathcal{L}_{defect}
.
\end{equation}where we empirically use $`\alpha_{p}=1`$ and $`\alpha_{d}=81`$.
Film Restoration Dataset
Due to lacking high-quality restoration data, we observed real films in restoration laboratory and constructed a dataset that comprising real-degraded films and synthetic data. And each data in our dataset is composed of degraded frames, restored frames, defects mask and video description, as showed in Fig.6.
style="width:100.0%" />
To construct restored real films, we firstly collected ‘before-after’ restoration videos that released by Restoration Laboratories and some companies, including MTI, DIAMANT. Secondly, we extracted degraded and restored frames from the comparison videos and computed binary defect masks with paired frames. However, some restored videos suffer from pixel-mismatch problem because the frames may have been through video deflickering, color toning procedures besides defect restoration. Also, some restored frames may still have defects remains due to imperfect restoration. To collect pixel-matching, well-restored high-resolution frames, we manually filter videos in a frame-by-frame manner. Finally, we used CogVLM2 to generate video caption, manually recheck the text and labeled the video with camera-angle and shot-size descriptors. As result, we collected restored real films with totally 5-minute duration(24fps) for training and collected 2K-resolution real films with 10-minute duration for testing.
To enlarge dateset volume, we synthesized realistic degraded frames following Fig.6. Specifically, we collected flawless film clips according to different camera angles and shot sizes. And we collected different types film defect templates including sparse and intensive dust, cigarette-burn holes, flickering and constant scratches, . Furthermore, we randomly apply quality degradation(rescale,jpeg compression) and film texture simulation(add grain) to sampled frames to increase diversity . After that, we add color to defects in templates refer to defects on colored films and then fuse the frames and the defects to get the degraded frames.
Experiments
Implementation Details
We train our model in two stage. In the first stage, we first train the
VideoMamba Model with L1 Loss and Perceptual Loss with lr=$`1e{-4}`$.
In the second stage, we train the video diffusion model. Constrained by
24G VRAM, we only train the controlnet module and fix all the temporal
layers.
Data
Here we first introduce how we synthetic the old-film data for training.
evaluation metrics
we use PSNR, SSIM, LIPIPS, BRISQUE, FVD.
Quantitative Evaluation
for the synthetic dataset.
Quantitative Evaluation
for the synthetic dataset.
Qualitative Evaluation
Text-Based Polishing Ability: Previous works, like RTN , lack the text understanding ability. They usually trained with cropped region. The models may fail for some film cases, for instance, the zooming shot focusing mostly on faces. Without the additional information like text description, previous models suffered from understanding the scene and simply copy the original image. In our methods, we employ the text-understanding ability of diffusion models to help the model better understand the local region.
extreme degraded case
show $``pathe_newsreel``$ results here. We find online.
Ablation Study
Self-Attn Memory + RoPE
VideoMamba Block
Memory comparison
Global Frame Block
FreqAttn Block
Local Prompt Search VS GlobalPrompt
After experimenting with two prompts employing strategy, we find that the whole frame’s prompt information constrained with bounding box information could help the model learn the global frame content more easily. We find that the experiment with global prompt could converge more quickly. For example, to reach PSNR = 20dB as a pedestal, the global prompt strategy only uses 12w iterations, much faster than employing an enlarged fixed grid prompt costing 20w iterations.
And in the reality restoration scenario, it would be a lot of labor to provide a prompt for each region. By using position-aware CLIP embedding, our proposed global-prompt module could use the text description in a more efficient and practical way.
Conclusion and Limitation
We currently only consider the dust and scratch removal. And there are a lot other degradations included in human restoration process have not been explored, like color adjustment, dye fading, frame lost.
Current Template Fusion method used in Data Synthetic model may still suffer from generating LQ and GT pair with color distortion in some situation.
Here we find that the diffusion model still has some trouble recognizing and repainting for some constant lines scratches.
Generation Speed. Slow Feedback if deployed into software.
Cross scene information have not been explored!
Temporal length is more limited than previous works that employ traditional methods.
Loss in exquisite details
Acknowledgements: We would like to thank anonymous reviewers for their constructive comments.
📊 논문 시각자료 (Figures)



