Semi-overlapping Multi-bandit Best Arm Identification for Sequential Support Network Learning
📝 Original Paper Info
- Title: Semi-overlapping Multi-bandit Best Arm Identification for Sequential Support Network Learning- ArXiv ID: 2512.24959
- Date: 2025-12-31
- Authors: András Antos, András Millinghoffer, Péter Antal
📝 Abstract
Many modern AI and ML problems require evaluating partners' contributions through shared yet asymmetric, computationally intensive processes and the simultaneous selection of the most beneficial candidates. Sequential approaches to these problems can be unified under a new framework, Sequential Support Network Learning (SSNL), in which the goal is to select the most beneficial candidate set of partners for all participants using trials; that is, to learn a directed graph that represents the highest-performing contributions. We demonstrate that a new pure-exploration model, the semi-overlapping multi-(multi-armed) bandit (SOMMAB), in which a single evaluation provides distinct feedback to multiple bandits due to structural overlap among their arms, can be used to learn a support network from sparse candidate lists efficiently. We develop a generalized GapE algorithm for SOMMABs and derive new exponential error bounds that improve the best known constant in the exponent for multi-bandit best-arm identification. The bounds scale linearly with the degree of overlap, revealing significant sample-complexity gains arising from shared evaluations. From an application point of view, this work provides a theoretical foundation and improved performance guarantees for sequential learning tools for identifying support networks from sparse candidates in multiple learning problems, such as in multi-task learning (MTL), auxiliary task learning (ATL), federated learning (FL), and in multi-agent systems (MAS).💡 Summary & Analysis
1. **Simple Explanation**: This paper focuses on finding the most effective ways to collaborate among multiple partners in AI and ML problems by optimizing network structures based on shared information.-
Moderately Complex Explanation: The research introduces a new model called semi-overlapping multi-(multi-armed) bandit (SOMMAB), which allows efficient learning of support networks from sparse candidate lists through shared evaluations, leading to the selection of the most beneficial sets.
-
Sci-Tube Style Script:
- [Level 1] AI and ML often involve multiple partners working together to solve problems. This paper suggests a way to optimize that collaboration.
- [Level 2] The study introduces SOMMAB, a model that allows efficient learning of support networks through shared evaluations among sparse candidate lists, leading to better performance in selecting beneficial sets.
- [Level 3] The paper presents the Sequential Support Network Learning (SSNL) framework and develops new algorithms and error bounds for optimizing partner selection based on shared computational processes.
📄 Full Paper Content (ArXiv Source)
Abstract
Many modern AI and ML problems require evaluating partners’ contributions through shared yet asymmetric, computationally intensive processes and the simultaneous selection of the most beneficial candidates. Sequential approaches to these problems can be unified under a new framework, Sequential Support Network Learning (SSNL), in which the goal is to select the most beneficial candidate set of partners for all participants using trials; that is, to learn a directed graph that represents the highest-performing contributions. We demonstrate that a new pure-exploration model, the semi-overlapping multi-(multi-armed) bandit (SOMMAB), in which a single evaluation provides distinct feedback to multiple bandits due to structural overlap among their arms, can be used to learn a support network from sparse candidate lists efficiently.
We develop a generalized GapE algorithm for SOMMABs and derive new exponential error bounds that improve the best known constant in the exponent for multi-bandit best-arm identification. The bounds scale linearly with the degree of overlap, revealing significant sample-complexity gains arising from shared evaluations.
From an application point of view, this work provides a theoretical foundation and improved performance guarantees for sequential learning tools for identifying support networks from sparse candidates in multiple learning problems, such as in multi-task learning (MTL), auxiliary task learning (ATL), federated learning (FL), and in multi-agent systems (MAS).
multi-armed bandit, overlapping multi-bandit, best arm identification, multi-task learning, federated learning, multi-agent systems
startsictionsection1@-0.24in0.10in
Introduction
Multi-Armed Bandits (MAB) is a widely used model today. Its best arm identification (BAI) setting is a pure exploration problem, distinct from the original MAB problem to maximize the cumulative reward .
The core objective of BAI is to formulate a strategy that recommends the most beneficial one from $`K`$ possible options. The well-established MAB/BAI model has been motivated by the fact that the efficient allocation of trial resources is a critical aspect, given the significant computational, statistical, ethical, financial, and security/privacy-related budgetary limitations of trials in numerous domains. The uniform exploration of options could result in the inefficient utilization of trial resources, potentially leading to suboptimal option selection. Therefore, it is imperative to employ effective strategies for the distribution of trials across options, thereby ensuring the efficacy of the developed strategy. To evaluate a MAB strategy, usually either the reward of the recommended arm or the probability of error (i.e., not selecting the best arm) is used.
To address the best arm identification problem, two algorithms were given by : 1) the Upper Confidence Bounds (UCB-E) method with a parameter, whose optimal value depends on the complexity of the problem, and 2) the parameter-free Successive Rejects (SR) method. Both these algorithms are shown to be nearly optimal, that is, their error probability decreases exponentially in the number of pulls.
BAI has been utilized, for example, in the context of function learning ; in the feature subset selection problem , and it is intensively used in hyper-parameter learning based on the results from random(ized) trials corresponding to train-test-validation splits . New class of applications of BAI in artificial intelligence are the selection of the best set of (1) jointly learnable tasks in multi-task learning (MTL) , (2) beneficial tasks for a target task in auxiliary task learning (ATL) , (3) contributing clients in federated learning (FL) , and (4) agents forming the most capable auxiliary coalition for an agent to assist in complex problem solving (for a summary of application domains, see Table 1). In these problems, the optimal option does not necessarily comprise all other entities (tasks, clients, or agents, respectively), because some of the entities may exert a deleterious effect on another, for instance, due to disparities in the sample distributions available for the entities.
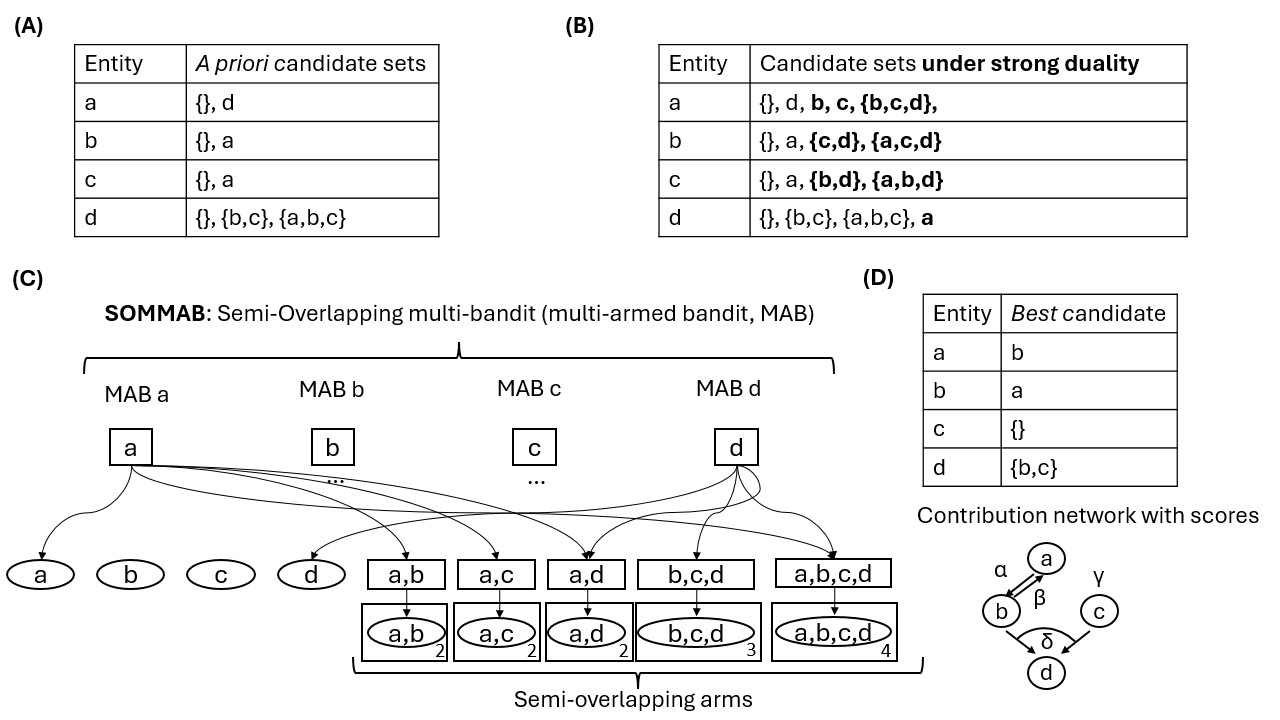
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emDuality and the support network learning problem In these applications, another important property is the donor-recipient duality, in which entities serving as recipients (targets) may also act as donors (contributors) for others. Indeed, in many real-world problems, we may observe (complete) entity duality denoting a setting in which all entities in the problem simultaneously play the role of both a donor and a recipient. A further practically important property arises from the mandatory joint evaluation of participating entities, which implies computational and even implementation coupling. The condition relational duality formalizes the complete form of this property, which requires that if a set $`S`$ is considered as a candidate donor set for an entity $`a`$, then for any $`b\in S`$ the corresponding variant set $`S\setminus \{b\} \cup \{a\}`$ is available as a candidate donor set for $`b`$, ensuring structural coherence of candidate relations across entities. By strong duality, we mean the combination of entity and relational duality. This donor-recipient duality naturally leads to a joint selection problem, where we must determine the most beneficial set of donors for each (recipient) entity. We refer to this problem class as sequential support network learning (SSNL), where each entity aims to identify the most beneficial set of contributors using optionally computationally coupled trials in a sequential learning framework. The solution for a SSNL problem can be represented by a directed graph with edges pointing to recipients from donors in the optimal support sets.
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emTowards multi-bandits The support network learning problem can be viewed as a weakly coupled joint selection problem, which suggests using multi-bandits, a generalization of MABs, as follows. We assume the existence of $`M`$ entities, each characterized by distinct joint learning properties and for entity $`m`$, $`K_m`$ candidates (options, arms) of beneficial entity subsets. The objective is to identify the optimal option for each entity. Certainly, if the number of options were allowed to be exponential in $`M`$ the problem easily becomes intractable; thus, in practice, that must be assumed to be limited. We refer to this assumption as the candidate lists are sparse. Subsequently, it is necessary to solve $`M`$ MAB problems in parallel, while constrained by the total available resources. It is possible that a greater quantity of resources will be required to identify the best option for one node than for another. Therefore, employing a uniform or other arbitrary strategy generally will not result in optimal performance. This problem structure is formulated by as the multi-bandit/multi-MAB (MMAB) best arm identification / pure exploration over $`M`$ MABs.
There are multiple ways to evaluate a MMAB strategy. Three of them are the ones based on
-
the average of the rewards of the recommended arms over the bandits,
-
the average error probability over the bandits,
-
the maximum error probability over the bandits.
The UCB-E and Successive Rejects algorithms above, being designed for a single MAB, are not obvious to extend to MMAB problems. By , studying the MMAB problem in the fixed budget setting, the Gap-based Exploration (GapE) algorithm has been proposed, which focuses on the gap of the arm, that is, the difference between the mean value of the arm and that of the best arm (in the same bandit). They prove an upper-bound on the error probability for GapE, which decreases exponentially with the budget (see Proposition 2), and they also report numerical simulations.
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emFrom duality to the semi-overlapping property The duality properties in support network learning formalized the underlying reality of joint computational evaluations in the learning process. Note that this does not mean hard constraints for the optimal support network. In multi-bandits the shared computations manifest as computationally coupled arms: evaluating the usefulness of auxiliary entities for a given recipient using a randomized trial, i.e., pulling an arm in one bandit, overlaps computationally with evaluating the usefulness of this recipient for the entities referred to as auxiliary, i.e., pulling an arm in another bandit. On the other hand, the resulting contribution scores themselves (i.e., the output of these arms in distinct bandits) typically differ. Later we will formalize these properties together as the semi-overlapping property of arms. In the pairwise case, it means that evaluating the usefulness of node $`a`$ for node $`b`$ shares computation with the evaluation of the usefulness of $`b`$ for $`a`$, even though these contribution scores can be asymmetric (see Fig. 1).
A key question in these diverse learning problems characterized by SSNL
with strong duality is the following:
In order to identify the most beneficial candidate sets for all
entities, how can we efficiently use sequential randomized
computationally shared trials that provide per-entity feedback of the
joint supports of the co-evaluated participants in the trial?
In this paper, firstly we extend the MMAB model introducing the notion of semi-overlapping arms set motivated above, which consists of arms belonging to different bandits and overlapping in the sense that they are “pulled together”, however, the reward distributions and the actual reward responses are not necessarily the same for these arms. Then, we generalize the GapE algorithm and the corresponding upper-bound by mentioned above for this semi-overlapping setting, also improving the constant in the exponent by more than a factor of $`3.5`$, and by another factor of $`r`$ for $`r`$-order semi-overlapping multi-bandits (SOMMAB).
Organization of the paper: Section [sec:related] summarizes the related works, Section [sec:MMABsetup] introduces formally the MMAB problem, Section [sec:gap_algo] describe the (generalized) GapE algorithm, Section [sec:error_bounds] gives the error probability bounds with a proof, which is also fixed, clarified and somewhat streamlined in comparison with the proof by , Section [sec:ACFLappl] presents applications of SSNL, Section [sec:discussion] contains the discussion and conclusion, Section [sec:future] summarizes possible future work, finally, some details of the proof are given in the Appendix.
startsictionsection1@-0.24in0.10in
Related work
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emMulti-armed bandits and best-arm identification The classical MAB problem was introduced in the context of sequential experimental design by , with later developments focusing on regret minimization and upper confidence bound (UCB) strategies . In contrast, BAI considers pure exploration, where the goal is to identify the optimal arm rather than maximize cumulative reward. Fixed-budget and fixed-confidence formulations have been extensively studied, with algorithms such as UCB-E and SR shown to be at least nearly optimal (up to logarithmic factors in $`K`$) . Furthermore, presented the UGapEb($`0,1,n,a`$) algorithm with also a parameter, whose optimal value depends on the complexity and with a bound that exhibits an exponent that is superior to that of the UCB-E algorithm. Our work follows this pure-exploration line for MMABs.
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emMulti-bandits, overlapping and semi-overlapping (structured) MMABs Multi-bandit (or multi-task bandit) problems consider several bandits that must be solved in parallel under a shared sampling budget. introduced a multi-bandit BAI framework and the GapE algorithm, and established exponential error bounds governed by a global complexity measure aggregating per-bandit gaps.
A version of the MMAB setting, the (fully) overlapping multi-bandit together with applications, was introduced by , where the same arm may belong to multiple bandits, thereby coupling the bandit problems. When such an arm is pulled, it returns one reward response from its single reward distribution relevant in each of these bandits. Here, we have to find the best arm in each bandit when arm sets may overlap.
Our SOMMAB model is closest in spirit to these works, but also allows for asymmetric overlap: structurally linked arms may have distinct reward distributions, and a single evaluation provides different information to each bandit. We show that this more general structure still admits GapE-type algorithms, and prove improved error exponents exploiting structural overlap across bandits and analyzing how such structure affects the achievable error exponents that scale with the degree of overlap.
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emCombinatorial bandits and Monte Carlo Tree Search Combinatorial bandits provide a principled framework for subset-level decision making under limited evaluation budgets . In this setting, each action corresponds to selecting a subset (a “super-arm”) from a ground set, and the learner receives linear/additive feedback on the chosen subset — enabling gradual discovery of high-reward candidates via structured exploration and exploitation.
By contrast, Monte Carlo Tree Search (MCTS) offers a general-purpose heuristic for exploring exponentially large decision trees through repeated random simulations, combined with upper-confidence–based selection strategies (e.g., the UCT rule) to balance exploration and exploitation . See, for example, applications of MCTS by in a closely related problem of feature subset selection (FSS). Similar to MABs in FSS , our approach focuses on selection from an arbitrary, well-defined, sparse candidate list of contributor sets, allowing non-additive, interaction-driven reward structures.
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emStructure learning and sparse candidate methods In probabilistic graphical model learning, structure search over directed acyclic graphs is another instance of a high-dimensional, combinatorial optimization problem, although contrary to influence or causal diagrams, there is no ’hard’ acyclicity constraint in the support network, only shared computational evaluations of candidates presents a ’soft’ cost for the sequential learning process itself. However, our approach shares the two-stage perspective of The Sparse Candidate method : it restricts the set of potential donors for each variable and then searches over this reduced space.
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emComputational efficiency of joint evaluations Computational aspects of joint evaluations have also motivated substantial work in multitask learning, such as the Task Affinity Grouping method .
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emTask selection in multi-task and auxiliary task learning Multi-task learning frequently grapples with negative transfer effects, that is, the intricate, complex pattern of beneficial-detrimental effects of certain tasks on others . It is by no surprise as the nature of transfer learning is multi-factorial and transfer effects can be attributed to (1) data representativity, (2) misaligned latent representations, (3) restrictive model learning capacity and (4) optimization bias;thus transfer effects are contextual and depend on the sample sizes, task similarities, sufficiency of hidden representations and model, and stages of the optimization . The auxiliary task learning approach suggests selecting the beneficial auxiliary task subsets for each target task . However, evaluation of candidate auxiliary task subsets can be computationally demanding and leads to loss of statistical power, which could be mitigated by the application of MABs using task representations and carefully constructed candidate task subsets .
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emClient selection in federated learning Federated learning emerged from a distributed, yet centrally aggregated approach for learning from horizontally- and/or vertically-partitioned, but i.i.d. datasets . Heterogeneity of partners in the mainstream formalization of federated learning became pivotal, and a large body of work has examined client selection and scheduling strategies to accelerate convergence, reduce communication, and improve fairness under heterogeneous data and system conditions . Recent hierarchical/personalized FL frameworks further emphasize structured interactions among clients . Our work provides a complementary, pure-exploration viewpoint, in which client selection is reinterpreted as sequential identification of beneficial candidates under a shared evaluation budget. Contrary to hierarchical FL, which aims to find, through a partitioning of partners defined by similar distributions, ’undirected’, homogeneously beneficial coalitions for each coalition member, the SSNL formalization aims to find the most beneficial partner set for each participant.
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emPartner selection in multi-agent systems and multi-agent RL In multi-agent systems (MAS), coalition formation and partner selection have been extensively studied, often using cooperative game theory or learning-based mechanisms. Recent work on cooperative MAS investigates how agents form, adapt, and evaluate coalitions under communication, incentive, and strategic constraints .
These approaches typically assume symmetric or mutually agreed coalitions and often aim at stable or optimal coalition structures. By contrast, SSNL explicitly models asymmetric donor–recipient relationships between partners, and SOMMAB fully represents and levarages the semi-overlapping evaluation pattern. This shifts the focus from equilibrium coalition states to the sequential identification of beneficial asymmetric coalitions under limited samples and computation, linking coalition formation in MAS with best-arm identification and structured pure exploration.
Finally, credit assignment learning in multi-agent reinforcement learning (MARL) provides a generalized, quantitative perspective to multi-bandit formulations by studying how multiple learning agents coordinate, compete, and transfer influence through structured interactions and shared environments . Recent MARL works on cooperative games, value decomposition, and population-based training naturally instantiate asymmetric contribution flows between agents, closely aligning with the support networks studied in this paper .
startsictionparagraph4@1.5ex plus 0.5ex minus .2ex-1emDataset selection
If, in federated learning (FL), clients each possess multiple local datasets, the partner selection problem becomes even more complex: rather than selecting a single client as a whole, the learning system must evaluate and choose among potentially many dataset contributions per client. In such scenarios, each dataset offered by a client may vary in relevance, size, and distributional alignment with the global task, and the usefulness of a client is no longer a single scalar but a composition of contributions from its constituent datasets. This exacerbates the selection challenge because a naive choice of clients may inadvertently favor those with many weak datasets over those with fewer but highly informative ones. Formal dataset selection approaches from the broader machine learning literature, which frame dataset choice as an optimization problem over expected utility or distributional matching, provide valuable tools for quantifying dataset usefulness and can be integrated with client selection strategies to better balance contribution quality and quantity .
startsictionsection1@-0.24in0.10in
Multi-Bandit Problem Setup
Now we define the MMAB BAI problem more formally and introduce the notation used in this paper. Let the number of MABs be denoted by $`M`$ and, for simplicity, the number of arms for each MAB by $`K`$. The reward distribution of arm $`k`$ of bandit $`m`$ is denoted by $`\nu_{mk}`$. It is bounded in $`[0,b]`$ and has mean $`\mu_{mk}`$. Usually, $`m`$, $`p`$, or $`q`$ will denote MAB indices, and $`k`$, $`i`$, or $`j`$ denote arm indices. It is assumed, that each bandit $`m`$ has a unique best arm $`k_m^* := \arg\max_{1\le k\le K} \mu_{mk}`$, and $`\mu_m^* := \mu_{mk_m^*} = \max_{1\le k\le K} \mu_{mk}`$ denotes the mean reward of $`k_m^*`$. In bandit $`m`$, the gap for arm $`k`$ is defined as $`\Delta_{mk} = |\max_{j\ne k} \mu_{mj}-\mu_{mk}|`$. That is, $`\Delta_{mk} = \mu_m^*-\mu_{mk}`$ for suboptimal arms, while the gap of $`k_m^*`$, $`\Delta_{mk_m^*} = \mu_m^* - \max_{j\ne k_m^*} \mu_{mj}`$ is the same as that of a second best arm.
The distributions $`\{\nu_{mk}\}`$ are not known to a forecaster, who, at each round $`t=1,\ldots,n`$, pulls a bandit-arm pair $`I(t)=(m,k)`$ and observes a sample drawn from the distribution $`\nu_{I(t)}`$ independently from the past (given $`I(t)`$). The $`s^{\rm th}`$ sample observed from $`\nu_{mk}`$ will be denoted by $`X_{mk}(s)`$, and the number of times that the pair $`(m,k)`$ has been pulled by the end of round $`t`$ is denote by $`T_{mk}(t)`$. The forecaster estimates each $`\mu_{mk}`$ by computing the average of the samples observed over time, that is, by
\begin{equation}
\label{eq:def_hmu}
\widehat{\mu}_{mk}(t) = \frac1{T_{mk}(t)} \sum_{s=1}^{T_{mk}(t)} X_{mk}(s).
\end{equation}At the end of final round $`n`$, the forecaster specifies an arm with the highest estimated mean for each bandit $`m`$, that is, outputs $`J_m(n) \in \arg\max_k \widehat{\mu}_{mk}(n)`$. The error probability and the simple regret of recommending $`J_m(n)`$ is $`e_m(n):=\mathbb{P}\left(J_m(n)\ne k_m^*\right)`$ and $`r_m(n):=\mu_m^*-\mu_{m J_m(n)}`$, respectively. Recalling the three performance measures mentioned in Sec. [sec:intro], which are to be minimized, the first one corresponds to the expectation (w.r.t. the samples) of the average regret incurred by the forecaster
r(n) := \mathbb{E}\left[ \frac1{M} \sum_{m=1}^M r_m(n) \right] = \frac1{M} \sum_{m=1}^M \left( \mu_m^*-\mathbb{E}\mu_{m J_m(n)} \right),the second one is the average error probability
e(n) := \frac1{M} \sum_{m=1}^M e_m(n) = \frac1{M} \sum_{m=1}^M \mathbb{P}\left(J_m(n)\ne k_m^*\right),while the third one corresponds to the maximum (worst case) error probability
\ell(n) := \max_m e_m(n) = \max_m \mathbb{P}\left(J_m(n)\ne k_m^*\right).gives the rationale of these measures in applications. It is easy to see that the three measures are related through
\frac{\min_{m,k\ne k_m^*} \Delta_{mk}}{M} \cdot \ell(n) \le \min_{m,k\ne k_m^*} \Delta_{mk} \cdot e(n)
\le r(n) \le b e(n) \le b \ell(n),thus bounding one of these measures also gives control for the other two. Thus the bounds both by and in this paper apply to $`\ell(n)`$.
In this paper, we extend MMABs allowing the bandits to have semi-overlapping arms:
Definition 1. A set of semi-overlapping arms (i.e, an evaluation group) consists of multiple arms belonging to different bandits that are “overlapping” in the sense that they are “pulled together”, that is, their joint trial consumes one pull from the budget, however, the reward distributions and the actual reward responses are not necessarily the same for these arms. Here it is assumed for simplicity that such sets are pairwise disjoint.
An MMAB with semi-overlapping arms is a semi-overlapping multi-bandit (SOMMAB).
For any $`r\ge 2`$ integer, an $`r`$-order SOMMAB is one, where each arm belongs to a set of semi-overlapping arms and the size of each maximal set of semi-overlapping arms is at least $`r`$. Moreover, we can call all MMAB a $`1`$-order semi-overlapping MMAB.
Note that when a set of semi-overlapping arms is pulled then for all arms in the set, the corresponding $`T_{mk}(t)`$’s are increased simultaneously, that is, in case of semi-overlapping, the sum of $`T_{mk}(t)`$’s may exceed $`t`$. Namely, for $`r`$-order semi-overlapping multi-bandit, the sum of $`T_{mk}(t)`$ is at least $`rt`$.
Also note that for SSNL, the different sets of semi-overlapping arms are disjoint and correspond to the sets of nodes trialed together. Thus if always at least $`r`$ entities are trialed together, that is, each candidate contributor set has at least size $`r-1`$, then the SSNL problem corresponds to an $`r`$-order SOMMAB. Therefore, we call it an $`r`$-order SSNL.
startsictionsection1@-0.24in0.10in
The GapE Algorithm
Using the definition of $`\widehat{\mu}_{mk}(t)`$, the estimated gaps are defined in an analogous way as $`\Delta_{mk}`$:
\begin{equation}
\label{eq:def_hDelta}
\widehat{\Delta}_{mk}(t) = |\max_{j\ne k} \widehat{\mu}_{mj}(t)-\widehat{\mu}_{mk}(t)|.
\end{equation}We have slightly generalized the Gap-based Exploration (GapE) algorithm by . In particular, instead of one pull for each arm in the initialization phase, the algorithm takes a new parameter $`l`$, and it applies $`l`$ initializing pulls per arm. Also, to make it aligned with SOMMABs, we detailed how GapE should handle semi-overlapping arms if any. The clarified pseudo-code of this generalized GapE(l) algorithm is shown in Figure 2.
Based on the estimated gaps instead of the means, GapE handles the $`M`$-bandit problem somewhat like a single-bandit problem with $`MK`$ arms is handled by UCB-E. At time step $`t`$, an index $`B_{mk}(t)`$ is computed for each pair $`(m,k)`$ by GapE based on the samples up to time $`t-1`$. Then the pair $`(m,k)`$ with the highest $`B_{mk}(t)`$ is selected as $`I(t)`$ (together with arms in the same semi-overlapping set as $`I(t)`$, if any). Similarly to UCB methods of , $`B_{mk}`$ has two terms. The first one is the negative of the estimated gap for the bandit-arm pair (since the gap is to be minimized), while the second one is a confidence radius based exploration term pushing GapE to pull arms that have been underexplored. This way, GapE tends to balance between pulling arms with less estimated gap and smaller number of samples. The exploration tendency of GapE can be tuned by the exploration parameter $`a`$.
When the time horizon $`n`$ is known, both Proposition 2 and Theorem 3 in Section [sec:error_bounds] suggest that $`a`$ should be set as $`a = C \tfrac{n-MK}{H}`$, where $`C`$ stands for appropriate constants specified in the results, respectively, and
H = \sum_{m,k} \frac{b^2}{\Delta_{mk}^2}is the complexity of the MMAB problem introduced by (see further discussion by and in Section [sec:error_bounds] below). As pointed out by , this algorithm differs from most usual bandit strategies in that the index $`B_{mk}`$ for one arm depends explicitly on the samples from the other arms, as well. Due to this, the analysis of GapE is much more complicated. See also the thorough comparison of the GapE and UCB-E algorithms and for an explanation on why the gaps are crucial instead of means in the multi-bandit case by .
Note that the idea of GapE is extended by also into a more involved algorithm, GapE-variance (GapE-V), which takes into account the variances of the arms, as well, and exponential upper-bound on GapE-V’s error probability is also provided.
Since the good range of the exploration parameter $`a`$ in both GapE and GapE-V depends on the problem complexity $`H`$, which is usually unknown in advance, adaptive versions of GapE (somewhat similarly to Adaptive UCB-E of ) and GapE-V are also given there. Moreover, the performance of GapE, GapE-V and their adaptive versions are evaluated by on several synthetic problems, which demonstrates that these algorihms outperform benchmark strategies (Uniform, Uniform+UCB-E).
startsictionsection1@-0.24in0.10in
Error probability bounds
First we present the upper-bound on the error probability $`\ell(n)`$ of GapE by for (non-overlapping) MMABs:
Proposition 2. *If we run GapE with parameters $`l=1`$ and
$`0
in particular for $`a = 4\frac{n-MK}{9H}`$, we have
$`\ell(n) \le 2MKn \exp\left(-\frac{n-MK}{144H}\right)`$.*\ell(n)
\le \mathbb{P}\left(\exists m: J_m(n) \ne k_m^*\right)
\le 2MKn \exp\left(-\frac{a}{64}\right),
give also some remarks about the bound above, the relation of the complexity $`H`$ to the complexity $`H_m`$ of each individual bandit and to the complexity $`H_{mk}`$ of each individual arm in each bandit, the comparison of GapE with the static allocation strategy (achieving at most $`MK\exp(-n/H)`$ error probability), and with the Uniform and combined Uniform+UCB-E allocation strategies (achieving at most $`MK\exp(-n/(MK\max_{m,k} H_{mk}))`$ and $`2MKn\exp(-(n-MK)/(18M\max_m H_m))`$ error probability, respectively).
As stated by : “the constants in the analysis are not accurate.” In this paper, we could improve the constant in the exponent above by more than a factor of $`3.5`$ (for $`l=152`$, and by more than a factor of $`2.4`$ for $`l=1`$) taking it much closer to the constant $`1/18`$ in the bound for the single-MAB algorithm UCB-E by , and by another factor of $`r`$ for $`r`$-order semi-overlapping multi-bandits:
Example 1 (Comparison). It is our understanding that
Theorem 3 leads to the best available bound
for the MMAB problem. 1 To compare this bound to the ones by , as an
example, examine a realistic situation, where the maximum of the
complexities is $`5`$ times their average, that is,
$`M\max_m H_m/H \approx 5`$. Then, for the exponents,
* the bound for Uniform+UCB-E yields $`-(n-MK)/90H`$,
* the GapE bound by yields the weeker $`-(n-MK)/144H`$, while
* our new GapE bound yields $`-(n-MK)/59H`$ ($`l=1`$), or even
$`-(n-MK)/41H`$ (for $`l=152`$ and $`n\ge 152MK`$).
Also, in the setting, where $`M=K=2`$, $`H=25`$ and $`n=20000`$, the
GapE bound by yields the useless $`160000 \exp(-4999/900)=61923\%`$,
while our new GapE bound yields $`160000 \exp(-19997/1425)=12.873\%`$
($`l=1`$), or even $`160000 \exp(-19997/989)=0.02648\%`$ ($`l=152`$).
Moreover, numerical simulations by suggest that the optimal value of $`aH/n`$ is typically in range $`[2,8]`$. Observe, that for large $`n`$, Proposition 2 allows $`aH/n`$ to be increased up to $`0.44`$, whereas Theorem 3 allows it up to $`0.66`$ for $`l=1`$. While this suggest an improving trend, also indicates room for further improvement.
Remark 5. For (massively overlapping) SOMMABs, the number $`n`$ of pulls in the exponent is somewhat weak, and instead we could expect intuitively the total sample size $`\sum_{m,k} T_{mk}(n)`$ there. However, this sum is not known in advance, so we cannot set the parameter $`a`$ depending on it. On the other hand, the best lower bound for this sum that is known in advance, is $`rn`$ for $`r`$-order SOMMABs, and that is exactly what we have at the end of Theorem 3.
Remark 6 ($`M`$-order semi-overlapping).
For the $`M`$-order semi-overlapping case, where the pull of each of the $`K`$ semi-overlapping arm sets (recall that these are disjoint), actually allows a trial in each bandit, the bound takes the form $`\ell(n) < 2MKn \exp\left(-\frac{n-K}{41H/M}\right)`$, with the complexity being the average complexity over the bandits. This makes sense considering that this configuration is equivalent to a single MAB with $`K`$ arms that possess $`M`$-dimensional vector values, where we have to find the best values dimension-wise. See Section [sec:ACFLappl] for the relevance of approximately $`M`$-order semi-overlapping for SSNL.
We have also fixed some flaws, clarified numerous details and slightly streamlined presentation of the original proof by :
[of Theorem 3.] If $`2ac^2\le \log(2MKn)`$, the bound on the probability is trivial. If the Theorem holds for $`b=1`$, then the algorithm fed by the normed inputs $`X_{mk}(t)/b`$ and run by $`b=1`$ would make the same draws and same returns, so the Theorem follows for any $`b`$. Thus w.l.o.g. we assume $`2ac^2>\log(2MKn)`$ and $`b=1`$.
Define $`R\left(t\right)\stackrel{\rm def}{=}\sqrt{a/t}`$ for $`t>0`$, and recall that
I(t)\in\arg\max_{mk} \left( -\widehat{\Delta}_{mk}(t-1) + R\left(T_{mk}(t-1)\right) \right).Let us consider the following event:
\mathcal{E}=
\left\{ \forall m\in\{1,\ldots,M\}, \forall k\in\{1,\ldots,K\}, \forall t\in\{1,\ldots,n\},
\left|\widehat{\mu}_{mk}(t)-\mu_{mk}\right|<cR\left(T_{mk}(t)\right) \right\}From Chernoff-Hoeffding’s inequality and the union bound, we have
\mathbb{P}\left(\xi^C\right) \le 2MKn e^{-2ac^2}.Now we would like to prove that on $`\mathcal{E}`$, we find the best arm for all the bandits, i.e., $`J_m(n) = k_m^*`$, $`\forall m\in\{1,\ldots,M\}`$. All statements below are meant on $`\mathcal{E}`$. Since $`J_m(n)`$ is the empirical best arm of bandit $`m`$, we should prove that for any $`k'\in\{1,\ldots,K\}`$, $`k'\ne k_m^*`$ implies $`\widehat{\mu}_{mk'}(n) < \widehat{\mu}_{m k_m^*}(n)`$. This follows if we prove that for any $`(m,k)`$, $`cR\left(T_{mk}(n)\right) \le \Delta_{mk}/2`$, since then upper- and lower-bounding the $`\widehat{\mu}`$’s by definition of $`\mathcal{E}`$,
\begin{align*}
\widehat{\mu}_{m k_m^*}(n) - \widehat{\mu}_{mk'}(n)
& > \mu_{m k_m^*} - cR\left(T_{m k_m^*}(n)\right) - \mu_{mk'} - cR\left(T_{mk'}(n)\right)\\
&\ge \Delta_{mk'} - \Delta_{m k_m^*}/2 - \Delta_{mk'}/2\\
&\ge \Delta_{mk'} - \Delta_{m k'}/2 - \Delta_{mk'}/2
= 0.
\end{align*}Moreover, the desired $`cR\left(T_{mk}(n)\right) \le \Delta_{mk}/2`$ is equivalent to $`T_{mk}(n) \ge \frac{4ac^2}{\Delta_{mk}^2}`$.
In this step, we show that in GapE, for any bandits $`(m,q)`$ and arms $`(k,j)`$, and for any $`t\ge lMK`$, the following relation between the number of pulls of the arms holds
\begin{equation}
\label{eq:Step2_induction_ineq}
-\Delta_{mk} + (1+2c)R\left(\max(T_{mk}(t)-1,1)\right) \ge -\Delta_{qj} + \frac{1-c}{2}R\left(T_{qj}(t)\right).
\end{equation}We prove this inequality by induction on $`t`$.
Base step. Recall that $`\rho=\sqrt{\min(l/(l-1),2)} \in (1,\sqrt{2}]`$ for $`l\ge 1`$ and $`c = \tfrac1{2\sqrt{3\rho+\rho^2}+2\rho+1} \in (1/9,1/7)`$, and that
\begin{equation}
\label{eq:a_lowerbound}
2ac^2>\log(2MKn) \ge \log(2MKMKl) \ge \log(32l)
\end{equation}for $`n\ge lMK`$, $`M,K\ge 2`$. We know that after the first $`lMK`$ rounds of the GapE algorithm, all the arms have been pulled $`l`$-times, i.e., $`T_{mk}(lMK)=l, \forall m,k`$. Thus, for $`t=lMK`$, inequality [eq:Step2_induction_ineq] is equivalent to
\begin{equation}
\label{eq:gen_basestep_ineq}
\frac{(2+4c)\rho-1+c}{2}\sqrt{\frac{a}{l}} =
\left(\frac{1+2c}{\sqrt{l-1}}-\frac{1-c}{2\sqrt{l}}\right)\sqrt{a}
\ge \Delta_{mk}-\Delta_{qj}
\qquad\mbox{for $l\ge 2$},
\end{equation}and to
\frac{1+5c}2\sqrt{a}
\ge \Delta_{mk}-\Delta_{qj}
\qquad\mbox{for $l=1$}.The latter holds, since [eq:a_lowerbound] yields $`\sqrt{a}c > \sqrt{\tfrac52\log 2}`$ if $`l=1`$, and thus $`\frac{1+5c}2\sqrt{a} > \tfrac52\sqrt{\tfrac52\log 2} > 1 \ge \Delta_{mk}-\Delta_{qj}`$.
For the $`l\ge 2`$ case, we prove in Appendix [sec:app_proof_thm_GapE_bound] the following
Lemma 7. For $`\rho>1`$, $`2\rho-1 > (11-4\rho)c`$.
The inequality in this lemma can be rearranged as $`(2+4c)\rho-1+c > 12c`$, leading to
\frac{(2+4c)\rho-1+c}2 \sqrt{\frac{a}{l}} > 6c\sqrt{\frac{a}{l}}.Since, by [eq:a_lowerbound], $`36ac^2 > 18\log(32l) > l`$ for $`l\le 152`$, we have $`6c\sqrt{a/l}>1`$, which, together with $`\Delta_{mk}-\Delta_{qj}\le 1`$, implies [eq:gen_basestep_ineq].
Inductive step. Let us assume that [eq:Step2_induction_ineq] holds at time $`t-1`$ and we pull arm $`i`$ of bandit $`p`$ at time $`t`$, i.e., $`I(t)=(p,i)`$ and $`T_{pi}(t)\ge l+1`$. So at time $`t`$, the inequality [eq:Step2_induction_ineq] trivially holds for every choice of $`m`$, $`q`$, $`k`$, and $`j`$, except when $`(m,k)=(p,i)\ne(q,j)`$. As a result, in the inductive step, we only need to prove that the following holds for any $`q\in\{1,\ldots,M\}`$ and $`j\in\{1,\ldots,K\}`$
\begin{equation}
\label{eq:induction_ineq_pi}
-\Delta_{pi} + (1+2c)R\left(T_{pi}(t)-1\right)
= -\Delta_{pi} + (1+2c)R\left(\max(T_{pi}(t)-1,1)\right)
\ge -\Delta_{qj} + (1-c)R\left(T_{qj}(t)\right)/2.
\end{equation}for $`(q,j)\ne(p,i)`$. Since arm $`i`$ of bandit $`p`$ has been pulled at time $`t`$, we have that for any bandit-arm pair $`(q,j)`$
\begin{equation}
\label{eq:ineq4}
-\widehat{\Delta}_{pi}(t-1)+R\left(T_{pi}(t-1)\right) \ge -\widehat{\Delta}_{qj}(t-1)+R\left(T_{qj}(t-1)\right).
\end{equation}To prove [eq:induction_ineq_pi], we first prove an upper-bound for $`-\widehat{\Delta}_{pi}(t-1)`$ and a lower-bound for $`-\widehat{\Delta}_{qj}(t-1)`$:
Lemma 8. *For $`c\le 1/3`$,
\begin{equation}
\label{eq:ineq5}
-\widehat{\Delta}_{pi}(t-1) \le -\Delta_{pi} + 2c R\left(T_{pi}(t)-1\right)
\quad \text{ and } \quad
-\widehat{\Delta}_{qj}(t-1) \ge -\Delta_{qj} - \left(2\frac{1+2c}{1-c}\rho+1\right)cR\left(T_{qj}(t)\right).
\end{equation}
```*
</div>
We report the proofs of
Lemma <a href="#le:hDe_bounds_by_De" data-reference-type="ref"
data-reference="le:hDe_bounds_by_De">8</a> in
Appendix <a href="#sec:app_proof_thm_GapE_bound" data-reference-type="ref"
data-reference="sec:app_proof_thm_GapE_bound">[sec:app_proof_thm_GapE_bound]</a>.
The inequality
<a href="#eq:induction_ineq_pi" data-reference-type="eqref"
data-reference="eq:induction_ineq_pi">[eq:induction_ineq_pi]</a>, and as
a result, the inductive step is proved by replacing
$`-\widehat{\Delta}_{pi}(t-1)`$ and $`-\widehat{\Delta}_{qj}(t-1)`$ in
<a href="#eq:ineq4" data-reference-type="eqref"
data-reference="eq:ineq4">[eq:ineq4]</a> from
<a href="#eq:ineq5" data-reference-type="eqref"
data-reference="eq:ineq5">[eq:ineq5]</a> and under the condition that
``` math
\left(2\frac{1+2c}{1-c}\rho+1\right)c\le \frac{1+c}2,
\qquad\mbox{ or equivivalenly }\qquad
(8\rho-1)c^2+(4\rho+2)c-1
\le 0.This condition is satisfied, since $`c`$ is just the higher root of the polynomial above.
In order to prove the condition of $`T_{mk}(n)`$ in Step 1, let us assume that arm $`k`$ of bandit $`m`$ has been pulled less than $`\frac{a(1-c)^2}{4\Delta_{mk}^2}`$ times at time $`t=n`$ (at the end), which is equvivalent to $`-\Delta_{mk} + \frac{1-c}2 R\left(T_{mk}(n)\right) > 0`$. From this inequality and [eq:Step2_induction_ineq], we have $`-\Delta_{qj} + (1+2c) R\left(T_{qj}(n)-1\right) > 0`$, or equivalently $`T_{qj}(n) < \frac{a(1+2c)^2}{\Delta_{qj}^2}+1`$ for any pair $`(q,j)`$. We also know that $`\sum_{q,j} T_{qj}(n) \ge n`$ (with equality if there is no semi-overlapping). From these, taking the assumption on $`T_{mk}(n)`$ and $`\Delta_{mk}^2\le 1`$ into account, we deduce that
n-(MK-1)
< \sum_{q,j} \frac{a(1+2c)^2}{\Delta_{qj}^2} -\frac{a(1+2c)^2}{\Delta_{mk}^2} +\frac{a(1-c)^2}{4\Delta_{mk}^2}
= a(1+2c)^2 H - \frac{aQ_c}{\Delta_{mk}^2}
\le ((1+2c)^2 H - Q_c)a,where $`Q_c=3(1+5c)(1+c)/4`$. So, if we select $`a`$ such that $`n-MK+1 \ge ((1+2c)^2H-Q_c)a`$, we have a contradiction, refuting the assumption above that $`T_{mk}(n) < \frac{a(1-c)^2}{4\Delta_{mk}^2}`$, which means that $`T_{mk}(n) \ge \frac{4ac^2}{\Delta_{mk}^2}`$ for any pair $`(m,k)`$, when $`c\le 1/5`$. The condition for $`a`$ in the theorem comes from our choice of $`a`$ above in this step.
For an $`r`$-order semi-overlapping multi-bandit, we also know that $`\sum_{q,j} T_{qj}(n) \ge rn`$, thus the inequality above becomes
rn-(MK-1) < ((1+2c)^2H-Q_c)a,so if we choose $`a = \frac{rn-MK+1}{(1+2c)^2H-Q_c}`$, we must have the desired $`T_{mk}(n) > \frac{4ac^2}{\Delta_{mk}^2}`$ for any pair $`(m,k)`$, yielding
\ell(n)
\le 2MKn \exp\left(-\frac{2(rn-MK+1)}{(1/c+2)^2H-Q_c/c^2}\right)
< 2MKn \exp\left(-\frac{rn-MK+1}{41H-36}\right)for $`l=152`$. This concludes the proof.
startsictionsection1@-0.24in0.10in
Applications of sequential support network learning
The SSNL appears in many recent applications, such as task selection in auxiliary task learning, client selection in federated learning, and agent selection in multi-agent systems (see Table 1)..
| Problem | Entity | Option | Trial |
| Multi-Task Learning | Task | Multi-output model | Empirical estimate of composite error using random re-sampling |
| Auxiliary Task Learning | Task | Auxiliary task set | Empirical estimate of target task error using random re-sampling |
| Federated Learning | Client | Collaborating clients | Empirical estimate of target client error using random re-sampling |
| Multi-Agent Systems | Agent | Agent coalition | Empirical estimate of target agent’s score using randomized problem solving |
Sequential support network learning in practice: entities, relationships, and trial mechanisms in various application domains.
In these applications, a usual heuristic for the construction of candidate sets is based on top-down approaches, that is, filtering entities with detrimental effects. Consequently, the size of each candidate set, and thus the order of the SSNL, can be close to the number $`M`$ of entities. For such scenarios, the following consequence of Theorem 3 is especially useful:
Corollary 9. *If in $`r`$-order SSNL with $`M`$ entities, we run GapE with $`a = \frac{rn-MK+1}{(1+2c)^2H-Q_c}`$ and $`l=152`$, we have
\ell(n)
< 2MKn \exp\left(-\frac{rn-MK+1}{41H-36}\right),where $`K`$ is the (maximal) number of candidates for a node.*
Thus when $`r`$ is close to $`M`$, in line with Remark 6, the exponent of the bound can take the form $`\frac{rn/M-K}{41H/M} \approx \frac{n-K}{41H/M}`$ with the complexity being the average complexity over the entities.
For the specific applications above, the SSNL realization and MMAB model are detailed as follows.
startsectionsubsection2@-0.20in0.08in
Multi-task learning and auxiliary task learning
In the MTL/ATL approach, tasks correspond to bandits, arms are a priori defined candidate auxiliary task sets for each task, and pulls are evaluations of the performance of the joint model, including the target task and the auxiliary task set corresponding to the pulled arm, which evaluation may use a “$`k`$-fold” cross-validation.
startsectionsubsection2@-0.20in0.08in
Federated learning
In the FL framework, the multi-bandit model is applied as follows: separate bandits correspond to clients or partners in FL, arms are a priori defined candidate partners sets for each partners, and pulls are standard FL evaluations using “k-fold” cross-validation and multiple hypothesis testing correction. This application also utilizes the client-edge-cloud compute continuum : the cloud server at a higher layer can run the MMAB algorithm to orchestrate the joint learning of auxiliary partner sets for each partner, whereas edge nodes at lower layers can do the evaluations by running the standard elementary FL schemes for each partner.
startsectionsubsection2@-0.20in0.08in
Coalition Learning in Multi-agent systems
SSNL is also close to the learning of cooperations in multi-agent systems, optimizing statistical, computational, and communication aspects . However, in our approach, auxiliary partner selection is asymmetric, resembling the selection of an optimal tool set for an agent, and each partner can separately select its auxiliary partner set to improve its performance ; see game-theoretic analysis of dependencies by .
The multi-bandit model is applied as follows: agents correspond to bandits, arms are a priori defined candidate agent sets for each agent, and pulls are evaluations of the joint cooperation (problem solving) with stochastic elements.
startsictionsection1@-0.24in0.10in
Discussion and Conclusion
We demonstrated that a broad class of modern learning problems, where entities contribute to and benefit from others, and where contributions can be explored through weakly coupled shared sequential evaluations, can be cast as instances of a newly introduced framework, Sequential support network Learning (SSNL). Conceptually, SSNL concerns the identification and evaluation of beneficial auxiliary interactions among entities and can be viewed as learning a directed graph encoding the most supportive relations.
We showed that the SSNL problem can be solved efficiently by formulating it as a semi-overlapping multi-bandit (SOMMAB) pure-exploration problem. In this model, each candidate set corresponds to an arm, and structurally coupled evaluations induce semi-overlapping pulls in which a single evaluation provides distinct information to multiple bandits. This abstraction captures the essential asymmetry and shared computational structure of SSNL while retaining the tractability of classical best-arm identification.
Building on this foundation, we established new exponential error bounds for SOMMABs under a generalized GapE algorithm. The bounds significantly improve the constants known for non-overlapping multi-bandit BAI and scale linearly with the degree of overlap. These results show that even partial structural coupling across bandits can meaningfully reduce sample complexity, providing theoretical justification for exploiting shared evaluations in distributed learning systems.
We further outlined realizations of the SOMMAB abstraction in several prominent learning paradigms—including multi-task learning (MTL), auxiliary task learning (ATL), federated learning (FL), and coalition formation in multi-agent systems (MAS). These instantiations illustrate that semi-overlapping evaluation is a recurring structural feature across disparate machine learning applications. In particular, the SSNL–SOMMAB formulation yields a new architectural lens for federated learning that aligns naturally with emerging cloud–edge infrastructures: the SOMMAB algorithms provide a principled mechanism for cloud-level orchestration of the exploration of auxiliary collaborations across clients with evaluations at the edge layers.
startsictionsection1@-0.24in0.10in
Future Work
Several directions emerge naturally from this work. Immediate theoretical challenges are as follows:
-
GapE with variance A variant of GapE, the GapE-V algorithm taking into account the variances of the arms is also proposed by , along with a corresponding bound, which may be improved and extended to semi-overlapping case similarly as Proposition 2.
-
Adaptive algorithms Adaptive versions of both GapE and GapE-V are also proposed by without proofs, where the complexity measures of the multi-bandit problem are estimated on the fly, so they do not need to be known in advance for tuning the exploration parameter $`a`$. Giving bounds for the performance of these adaptive variants is a challenging problem.
-
$`(\epsilon,m)`$-best arm identification Two common generalizations of the MAB/BAI problem are as follows:
- Rather than identifying the optimal arm, for given $`\epsilon`$, the objective is to identify an arm whose mean is closer than $`\epsilon`$ to that of the optimal one.
- For given $`m`$, the objective is to identify the best $`m`$ arm,
rather than the single best.
The combination of these two generalizations gives rise to the $`(\epsilon,m)`$-best arm identification problem, as introduced by , and for which GapE and Theorem 3 may be extended.
Extending SOMMAB beyond fixed sparse candidate sets is another important avenue. One natural extension is to remove the fixed-candidate constraint and move toward open-ended coalition optimization. This requires navigating a combinatorial space of exponentially many coalitions. We propose to incorporate Monte Carlo Tree Search (MCTS) as a meta-level selection mechanism over the support network.
Additional open problems include incorporating stochastic or adversarial overlap patterns, handling partial observability across bandits, and integrating privacy or communication constraints that arise in distributed or federated environments. Each of these generalizations would further broaden the applicability of SSNL/SOMMABs and deepen the theoretical foundations of structured pure-exploration algorithms for cooperative agent learning.
startsictionsection1@-0.24in0.10in
Proofs of Lemmata in Theorem 3
In this appendix we prove the lemmata in the proof of Theorem 3:
[of Lemma 7.] Substituting $`c>0`$, it is to show that
(2\rho-1)(2\sqrt{3\rho+\rho^2}+2\rho+1) = (2\rho-1)/c > 11-4\rho,or equivivalently,
(2\rho-1)\sqrt{3\rho+\rho^2} > 6-2\rho-2\rho^2.This would follow from
(2\rho-1)\sqrt{3\rho+\rho^2} > |6-2\rho-2\rho^2|,which, when squared, becomes
(2\rho-1)^2(3\rho+\rho^2) > (6-2\rho-2\rho^2)^2.After some algebra, this is equivalent to $`(\rho+4)(\rho-1)
0
$, which clearly holds for $\rho>1`$.
[of Lemma 8.] We denote by $`\widehat{\mu}_m^*(t)`$ and $`\widehat{k}_m^*(t)`$ the estimated mean and the index of an (arbitrarily chosen) expirically best arms of bandit $`m`$ after round $`t`$ (i.e., $`\widehat{\mu}_m^*(t) = \widehat{\mu}_{m \widehat{k}_m^*(t)}(t) = \max_{1\le k\le K} \widehat{\mu}_{mk}(t)`$, $`\widehat{k}_m^*(t) \in \arg\max_{1\le k\le K} \widehat{\mu}_{mk}(t)`$). Also, by $`\mu_m^+=\mu_{m k_m^+}`$ and $`k_m^+`$ the mean and the index of an (arbitrarily chosen) second best arms of bandit $`m`$, and by $`\widehat{\mu}_m^+(t)=\widehat{\mu}_{m \widehat{k}_m^+(t)}(t)`$ and $`\widehat{k}_m^+(t)`$ the estimated mean and the index of an (arbitrarily chosen) empirically second best arms of bandit $`m`$ after round $`t`$. (If the empirically best arm is not unique then the empirically best arms and the empirically second best arms constitute the same set, and $`\widehat{\mu}_{m \widehat{k}_m^+(t)}(t)=\widehat{\mu}_{m \widehat{k}_m^*(t)}(t)`$, however, $`\widehat{k}_m^+(t)\ne \widehat{k}_m^*(t)`$ is chosen. Note that $`\widehat{\mu}_{m \widehat{k}_m^*(t)}(t)`$, $`\mu_{m k_m^+}`$, and $`\widehat{\mu}_{m \widehat{k}_m^+(t)}(t)`$ are unambiguous, but $`\mu_{m \widehat{k}_m^*(t)}`$, $`\widehat{\mu}_{m k_m^+}(t)`$, and $`\mu_{m \widehat{k}_m^+(t)}`$ may be arbitrarily chosen from multiple values.)
startsectionsubsection2@-0.20in0.08in
*Upper Bound in [eq:ineq5] Here we prove that
-\widehat{\Delta}_{pi}(t-1) \le -\Delta_{pi} + 2cR\left(T_{pi}(t)-1\right),where arm $`i`$ of bandit $`p`$ is the arm pulled at time $`t`$. This means that $`T_{pi}(t-1) = T_{pi}(t)-1`$. Each $`T`$, $`\mu`$, $`\widehat{\mu}`$, $`\Delta`$, $`\widehat{\Delta}`$, $`k^*`$, $`\widehat{k}^*`$, $`k^+`$ and $`\widehat{k}^+`$ refers for bandit $`p`$ below, so we supress the indices $`p`$ for these values here. Also, each $`T`$, $`\widehat{\mu}`$, $`\widehat{\Delta}`$, $`\widehat{k}^*`$ and $`\widehat{k}^+`$ refers to time $`t-1`$ below, so we omit the argument $`t-1`$ for these values here. Thus, we prove $`\widehat{\Delta}_i \ge \Delta_i - 2cR\left(T_i\right)`$. Observe that, since arm $`i`$ of bandit $`p`$ is pulled at time $`t`$, from [eq:ineq4] we have all of
\begin{align}
-\widehat{\Delta}_i + R\left(T_i\right) &\ge -\widehat{\Delta}_{\widehat{k}^+} + R\left(T_{\widehat{k}^+}\right),\label{eq:algo_pulls_i_hk+}\\
-\widehat{\Delta}_i + R\left(T_i\right) &\ge -\widehat{\Delta}_{\widehat{k}^*} + R\left(T_{\widehat{k}^*}\right), \mbox{ and}\label{eq:algo_pulls_i_hk*}\\
-\widehat{\Delta}_i + R\left(T_i\right) &\ge -\widehat{\Delta}_{k^*} + R\left(T_{k^*}\right)\label{eq:algo_pulls_i_k*}.
\end{align}We consider the following four cases and use $`0\le c\le 1`$ throughout:
$`i=\widehat{k}^*`$ and $`i=k^*`$:
Now we have
\begin{align*}
\widehat{\Delta}_i
&= \widehat{\mu}_i-\widehat{\mu}_{\widehat{k}^+}\\
&\ge \mu_i-\mu_{\widehat{k}^+} -cR\left(T_{\widehat{k}^+}\right)-cR\left(T_i\right)\\
&\stackrel{(a)}{\ge} \mu_i-\mu_{\widehat{k}^+} -2cR\left(T_i\right)\\
&\ge \mu_i-\mu_{k^+} - 2cR\left(T_i\right)
= \Delta_i - 2cR\left(T_i\right).
\end{align*}(a) By definition $`\widehat{\Delta}_i = \widehat{\Delta}_{\widehat{k}^+}`$, thus [eq:algo_pulls_i_hk+] gives $`R\left(T_i\right) \ge R\left(T_{\widehat{k}^+}\right)`$.
$`i=\widehat{k}^*`$ and $`i\ne k^*`$: Now we have $`\widehat{\Delta}_i\ge 0`$ obviously, while
\begin{align*}
\Delta_i-2cR\left(T_i\right)
& = (1-c)(\Delta_i - cR\left(T_i\right)) + c(\Delta_i - (1+c)R\left(T_i\right))\\
&\stackrel{(b)}{\le} (1-c)(\Delta_i - cR\left(T_i\right)) - c(1-c)R\left(T_{k^*}\right)\\
&= (1-c)(\mu_{k^*} - \mu_i - cR\left(T_i\right) - cR\left(T_{k^*}\right))\\
&\le (1-c)(\widehat{\mu}_{k^*} - \widehat{\mu}_{\widehat{k}^*})\qquad\mbox{(on $\mathcal{E}$)}\\
&\le 0.\qquad\mbox{(by definition of $\widehat{\mu}_{\widehat{k}^*}$)}.
\end{align*}(b) is proven using [eq:algo_pulls_i_k*] and $`i=\widehat{k}^*\ne k^*`$, implying
\widehat{\mu}_i + R\left(T_i\right)
\ge \widehat{\mu}_{\widehat{k}^+} + R\left(T_i\right)
\ge \widehat{\mu}_{k^*} + R\left(T_{k^*}\right),which, using bounds on $`\mathcal{E}`$, further implies
\mu_i+(1+c)R\left(T_i\right) \ge \mu_{k^*}+(1-c)R\left(T_{k^*}\right).Rearranging $`\Delta_i - (1+c)R\left(T_i\right) \le -(1-c)R\left(T_{k^*}\right)`$.
$`i\ne\widehat{k}^*`$ and $`i=k^*`$:
Now we have
\begin{align*}
\widehat{\Delta}_i
&= \widehat{\mu}_{\widehat{k}^*}-\widehat{\mu}_i\\
&\ge \widehat{\mu}_{k^*}-\widehat{\mu}_{\widehat{k}^*}\\
&\ge \mu_{k^*}-\mu_{\widehat{k}^*}-cR\left(T_{\widehat{k}^*}\right)-cR\left(T_i\right)\\
&\stackrel{(c)}{\ge} \mu_{k^*}-\mu_{k^+}-cR\left(T_i\right)-cR\left(T_i\right)
= \Delta_i-2cR\left(T_i\right).
\end{align*}(c) By definition $`\widehat{\Delta}_i \ge \widehat{\Delta}_{\widehat{k}^*}`$, thus [eq:algo_pulls_i_hk*] gives $`R\left(T_i\right) \ge R\left(T_{\widehat{k}^*}\right)`$.
$`i\ne\widehat{k}^*`$ and $`i\ne k^*`$: Now we have
\begin{equation}
\label{eq:ineq9}
\widehat{\Delta}_i
= \widehat{\mu}_{\widehat{k}^*}-\widehat{\mu}_i
\ge \widehat{\mu}_{k^*}-\mu_i - cR\left(T_i\right)
\ge \mu_{k^*}-\mu_i - cR\left(T_i\right) - cR\left(T_{k^*}\right).
\end{equation}Recall that by [eq:algo_pulls_i_k*]
\begin{equation}
\label{eq:ineq10}
\widehat{\mu}_i-\widehat{\mu}_{\widehat{k}^*} + R\left(T_i\right) \ge -\widehat{\Delta}_{k^*} + R\left(T_{k^*}\right).
\end{equation}If $`k^*=\widehat{k}^*`$, [eq:ineq10] can be written as
\widehat{\mu}_i + R\left(T_i\right)
\ge \widehat{\mu}_{\widehat{k}^+} + R\left(T_{k^*}\right).By $`i\ne\widehat{k}^*`$ and definition of $`\widehat{k}^+`$, $`\widehat{\mu}_{\widehat{k}^+} \ge \widehat{\mu}_i`$, which gives $`R\left(T_i\right) \ge R\left(T_{k^*}\right)`$ and thus $`\widehat{\Delta}_i \ge \Delta_i - 2cR\left(T_i\right)`$ from [eq:ineq9].
If $`k^*\ne\widehat{k}^*`$, [eq:ineq10] can be written as
\widehat{\mu}_i + R\left(T_i\right) \ge \widehat{\mu}_{k^*} + R\left(T_{k^*}\right)which, using bounds on $`\mathcal{E}`$, implies
\mu_i + (1+c)R\left(T_i\right) \ge \mu_{k^*} + (1-c)R\left(T_{k^*}\right),and rearranging $`-R\left(T_{k^*}\right) \ge \frac{\Delta_i}{1-c} - \frac{1+c}{1-c}R\left(T_i\right)`$. Plugging this into [eq:ineq9] we have
\widehat{\Delta}_i
\ge \Delta_i - cR\left(T_i\right) + \frac{c\Delta_i}{1-c} - c\frac{1+c}{1-c}R\left(T_i\right)
= \frac{\Delta_i - 2cR\left(T_i\right)}{1-c}.Now if $`\Delta_i-2cR\left(T_i\right)\ge 0`$ then the r.h.s. is lower bounded by $`\Delta_i-2cR\left(T_i\right)`$ as required. If $`\Delta_i-2cR\left(T_i\right)<0`$, we are done due to $`\widehat{\Delta}_i\ge 0`$.
startsectionsubsection2@-0.20in0.08in
*Lower Bound in [eq:ineq5]
Here we prove that
-\widehat{\Delta}_{qj}(t-1) \ge -\Delta_{qj} - (2\rho(1+2c)/(1-c)+1)cR\left(T_{qj}(t)\right)for all bandits $`q\in\{1,\ldots,M\}`$ and all arms $`j \in\{1,\ldots,K\}`$, such that the arm $`j`$ of bandit $`q`$ is not the one pulled at time $`t`$, i.e., $`(q,j)\ne (p,i)`$. This means that $`T_{qj}(t-1) = T_{qj}(t)`$.
In a manner akin to the proof for the upper-bound in Part 1, each $`T`$, $`\mu`$, $`\widehat{\mu}`$, $`\Delta`$, $`\widehat{\Delta}`$, $`k^*`$, $`\widehat{k}^*`$, $`k^+`$ and $`\widehat{k}^+`$ refers for bandit $`q`$ below, so we supress the indices $`q`$ for these values here. Also, each $`T`$, $`\widehat{\mu}`$, $`\widehat{\Delta}`$, $`\widehat{k}^*`$ and $`\widehat{k}^+`$ refers to time $`t-1`$ below, so we omit the argument $`t-1`$ for these values here. Thus, we prove $`\widehat{\Delta}_j \le \Delta_j + (2\rho(1+2c)/(1-c)+1)cR\left(T_j\right)`$. Observe that, from the inductive assumption, we have all of
\begin{align}
-\Delta_j + (1+2c)R\left(\max(T_j-1,1)\right) &\ge -\Delta_{k^+} + (1-c)R\left(T_{k^+}\right)/2,\label{eq:induction_i_k+}\\
-\Delta_j + (1+2c)R\left(\max(T_j-1,1)\right) &\ge -\Delta_{k^*} + (1-c)R\left(T_{k^*}\right)/2,\mbox{ and}\label{eq:induction_i_k*}\\
-\Delta_j + (1+2c)R\left(\max(T_j-1,1)\right) &\ge -\Delta_{\widehat{k}^*} + (1-c)R\left(T_{\widehat{k}^*}\right)/2.\label{eq:induction_i_hk*}
\end{align}We consider the following four cases:
$`j=\widehat{k}^*`$ and $`j=k^*`$:
Now we have
\begin{align*}
\widehat{\Delta}_{j}
& = \widehat{\mu}_j-\widehat{\mu}_{\widehat{k}^+}\\
&\le \mu_j-\widehat{\mu}_{k^+} + cR\left(T_j\right)\\
&\le \mu_j-\mu_{k^+} + cR\left(T_{k^+}\right) + cR\left(T_j\right)\\
&\stackrel{(e)}{\le} \Delta_j + 2c(1+2c)\rho R\left(T_j\right)/(1-c) + cR\left(T_j\right)
= \Delta_j + (2\rho(1+2c)/(1-c)+1)cR\left(T_j\right).
\end{align*}(e) By definition $`\Delta_{k^+} = \Delta_j`$, thus [eq:induction_i_k+] gives $`2(1+2c)R\left(\max(T_j-1,1)\right)/(1-c) \ge R\left(T_{k^+}\right)`$. Finally, we have
\begin{equation}
\label{eq:ineq11}
R^2(\max(T_j-1,1))
= \frac{a}{\max(T_j-1,1)}
= \frac{T_j}{\max(T_j-1,1)} \frac{a}{T_j}
\le \frac{la}{\max(l-1,0.5)T_j}
= (\rho R\left(T_j\right))^2,
\end{equation}which gives the result.
$`j=\widehat{k}^*`$ and $`j\ne k^*`$:
Now we have
\begin{align*}
\widehat{\Delta}_j
& = \widehat{\mu}_j-\widehat{\mu}_{\widehat{k}^+}\\
&\le \widehat{\mu}_j-\widehat{\mu}_{k^*}\\
&\le \mu_j-\mu_{k^*} + cR\left(T_{k^*}\right) + cR\left(T_j\right)\\
&\stackrel{\mathrm{(f)}}{\le} \Delta_j+2c(1+2c)\rho R\left(T_j\right)/(1-c) + cR\left(T_j\right)
= \Delta_j + (2\rho(1+2c)/(1-c)+1)cR\left(T_j\right).
\end{align*}(f) By definition $`\Delta_{k^*} \le \Delta_j`$, thus [eq:induction_i_k*] gives $`2(1+2c)R\left(\max(T_j-1,1)\right)/(1-c) \ge R\left(T_{k^*}\right)`$. The claim follows using [eq:ineq11].
$`j\ne\widehat{k}^*`$ and $`j=k^*`$: Now we have
\begin{align*}
\widehat{\Delta}_j
& = \widehat{\mu}_{\widehat{k}^*} -\widehat{\mu}_j\\
&\le \mu_{\widehat{k}^*}-\mu_{k^*} + cR\left(T_j\right) + cR\left(T_{\widehat{k}^*}\right)\\
&\stackrel{\mathrm{(g)}}{\le} -\Delta_{\widehat{k}^*} + 2c/(1-c)\left(\Delta_{\widehat{k}^*}-\Delta_j\right) + cR\left(T_j\right) + 2c(1+2c)\rho R\left(T_j\right)/(1-c)\\
&\le - (1-2c/(1-c))\Delta_{\widehat{k}^*} -2c/(1-c)\Delta_j + cR\left(T_j\right) + 2c(1+2c)\rho R\left(T_j\right)/(1-c)\\
&\stackrel{\mathrm{(h)}}{\le} \Delta_j + cR\left(T_j\right) + 2c(1+2c)\rho R\left(T_j\right)/(1-c)
= \Delta_j + (2\rho(1+2c)/(1-c)+1)cR\left(T_j\right).
\end{align*}(g) [eq:induction_i_hk*] can be rearranged as
\begin{equation}
\label{eq:ineq12}
cR\left(T_{\widehat{k}^*}\right) \le 2c/(1-c)\left(\Delta_{\widehat{k}^*}-\Delta_j\right) + 2c(1+2c)R\left(\max(T_j-1,1)\right)/(1-c).
\end{equation}The claim follows using [eq:ineq12] and [eq:ineq11].
(h) This passage is true when $`0\le 2c/(1-c)\le 1`$, i.e., when $`0\le c \le 1/3`$.
$`j\ne \widehat{k}^*`$ and $`j\ne k^*`$: Now we have
\begin{equation}
\label{eq:ineq13}
\widehat{\Delta}_j
= \widehat{\mu}_{\widehat{k}^*} - \widehat{\mu}_j
\le \mu_{\widehat{k}^*} - \mu_j + cR\left(T_j\right) + cR\left(T_{\widehat{k}^*}\right).
\end{equation}If $`\widehat{k}^* = k^*`$, we may write [eq:ineq13] as
\begin{align*}
\widehat{\Delta}_j
& = -\widehat{\mu}_j+\widehat{\mu}_{\widehat{k}^*}\\
&\le -\mu_j + \mu_{\widehat{k}^*} + cR\left(T_j\right) + cR\left(T_{\widehat{k}^*}\right)\\
&\le \Delta_j +cR\left(T_j\right) +cR\left(T_{\widehat{k}^*}\right)\\
&\stackrel{\mathrm{(i)}}{\le} \Delta_j + cR\left(T_j\right) + 2c(1+2c)\rho R\left(T_j\right)/(1-c)
= \Delta_j + (2\rho(1+2c)/(1-c)+1)cR\left(T_j\right).
\end{align*}(i) By definition $`\Delta_{\widehat{k}^*} = \Delta_{k^*} \le \Delta_j`$, thus [eq:induction_i_hk*] gives $`2(1+2c)R\left(\max(T_j-1,1)\right)/(1-c) \ge R\left(T_{\widehat{k}^*}\right)`$. The claim follows using [eq:ineq11].
Now if $`\widehat{k}^* \ne k^*`$, we may write [eq:ineq13] as
\begin{align*}
\widehat{\Delta}_j
& = \widehat{\mu}_{\widehat{k}^*}-\widehat{\mu}_j\\
&\le \mu_{\widehat{k}^*}-\mu_j + cR\left(T_j\right) + cR\left(T_{\widehat{k}^*}\right)\\
&\le \Delta_j - \Delta_{\widehat{k}^*} + cR\left(T_j\right) + cR\left(T_{\widehat{k}^*}\right)\\
&\stackrel{\mathrm{(j)}}{\le} (1-2c/(1-c))\left(\Delta_j-\Delta_{\widehat{k}^*}\right) + cR\left(T_j\right)+2c(1+2c)\rho R\left(T_j\right)/(1-c)\\
&\stackrel{\mathrm{(k)}}{\le} \Delta_j + cR\left(T_j\right) + 2c(1+2c)\rho R\left(T_j\right)/(1-c)
= \Delta_j + (2\rho(1+2c)/(1-c)+1)cR\left(T_j\right).
\end{align*}(j) Again, this claim follows using [eq:ineq12] and [eq:ineq11].
(k) This passage is true when $`0\le 2c/(1-c)\le 1`$, i.e., when $`0\le c \le 1/3`$.
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
The UGapEb algorithm for single MABs is extended to MMABs by , and it is mentioned that their bound could be stated similarly for MMABs. However, upon communication with the authors, it was revealed that no formal proof exists; only intuition for possibly extending the single MAB proof for MMABs. ↩︎