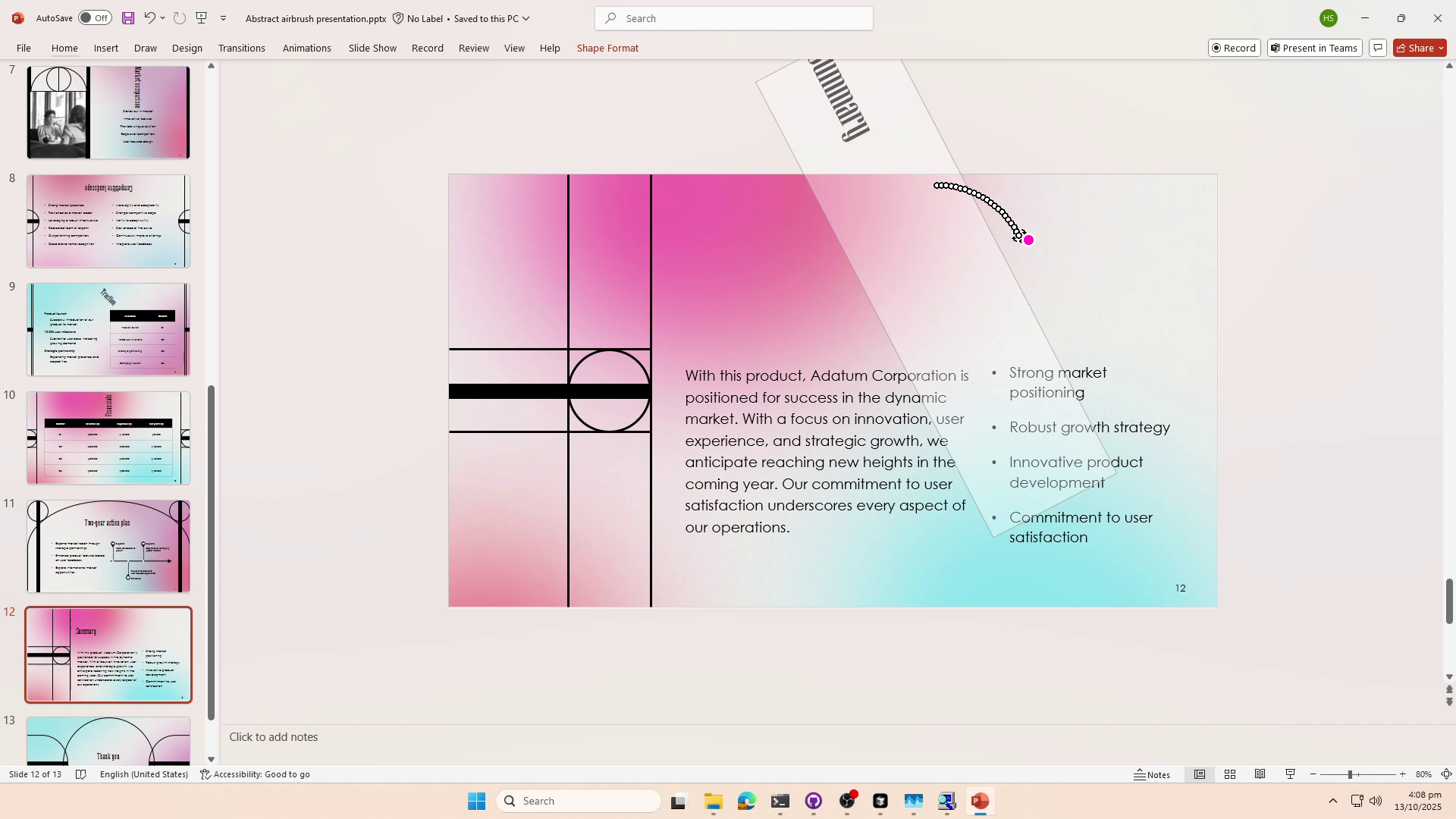
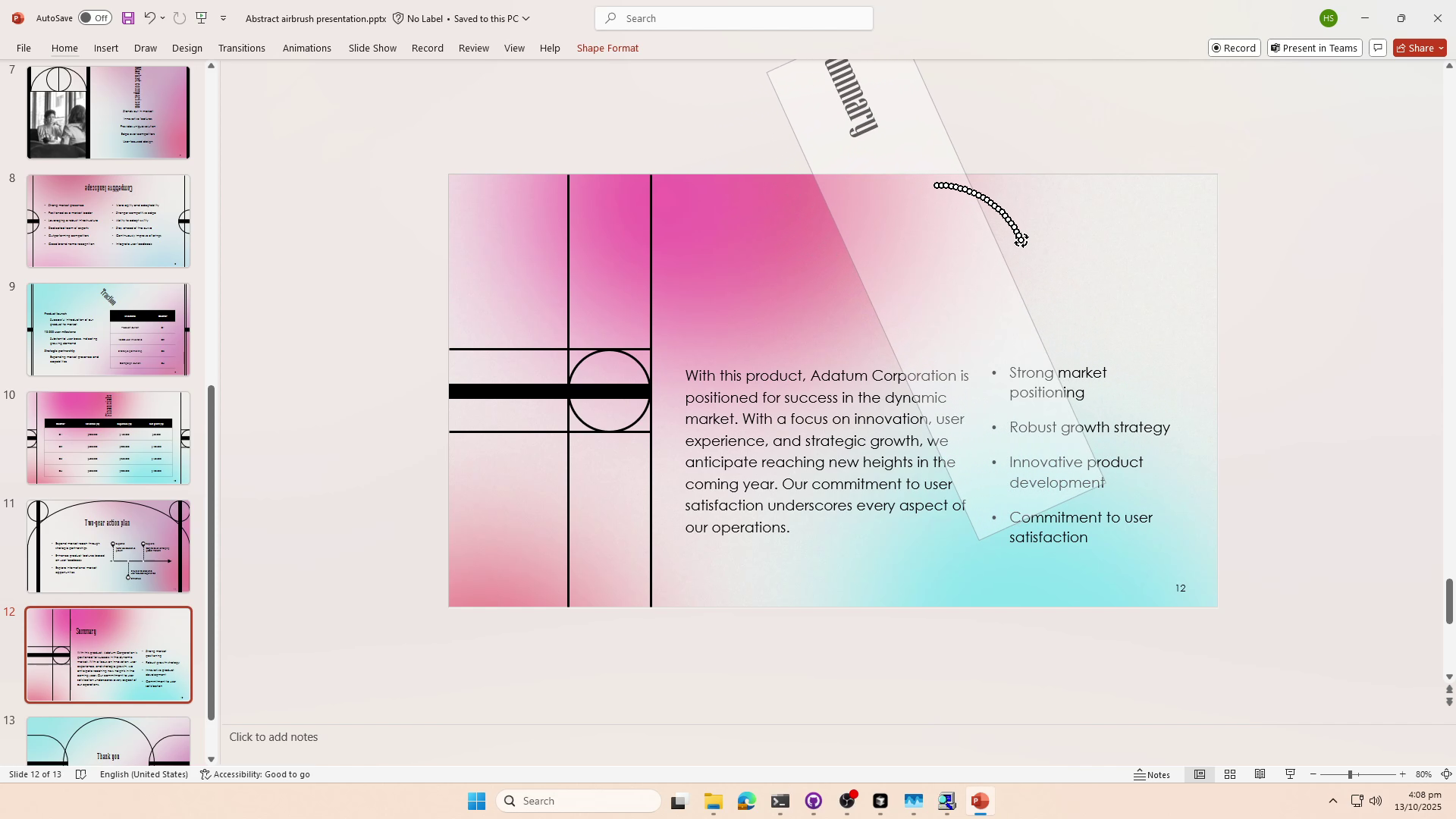
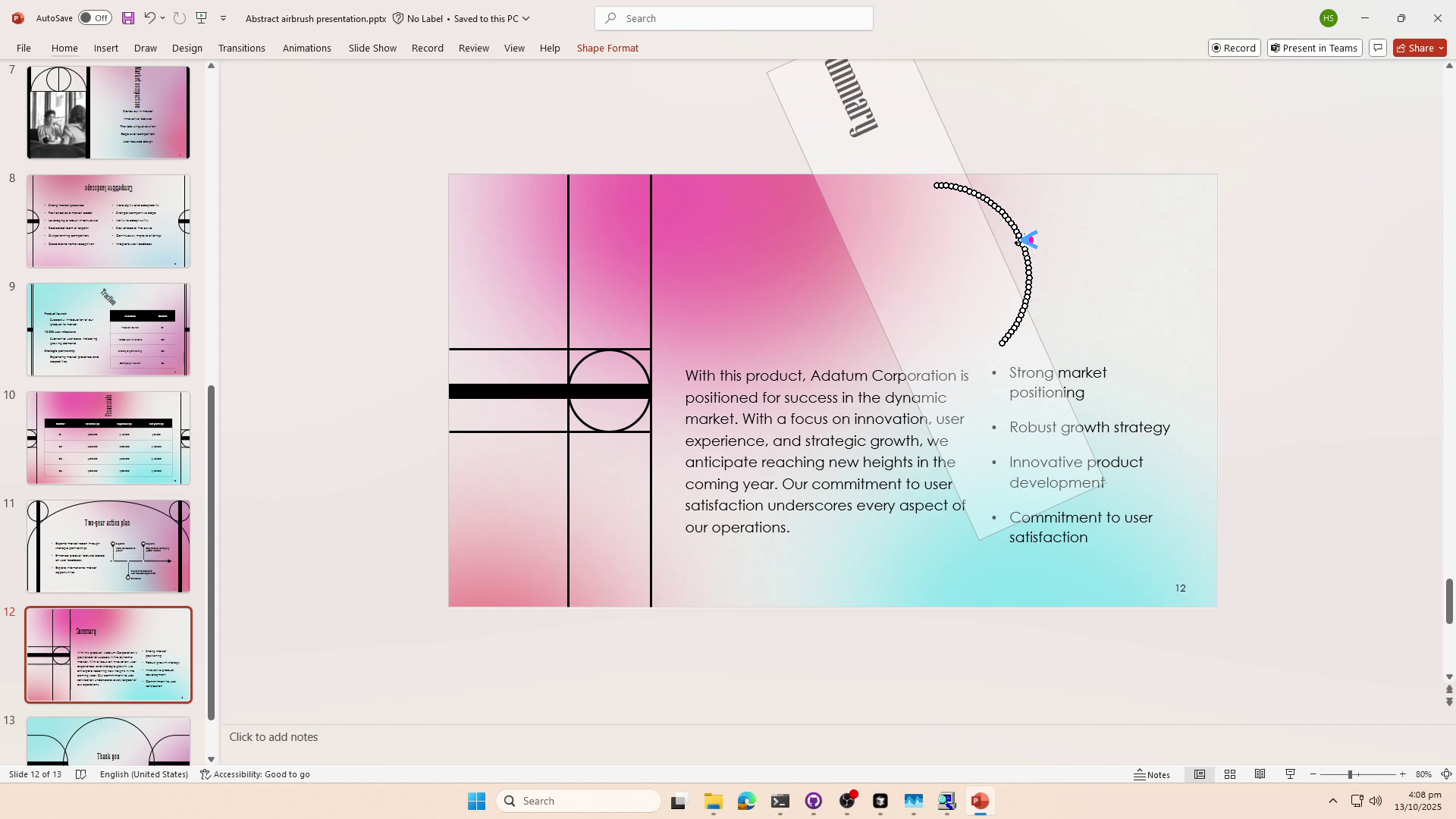
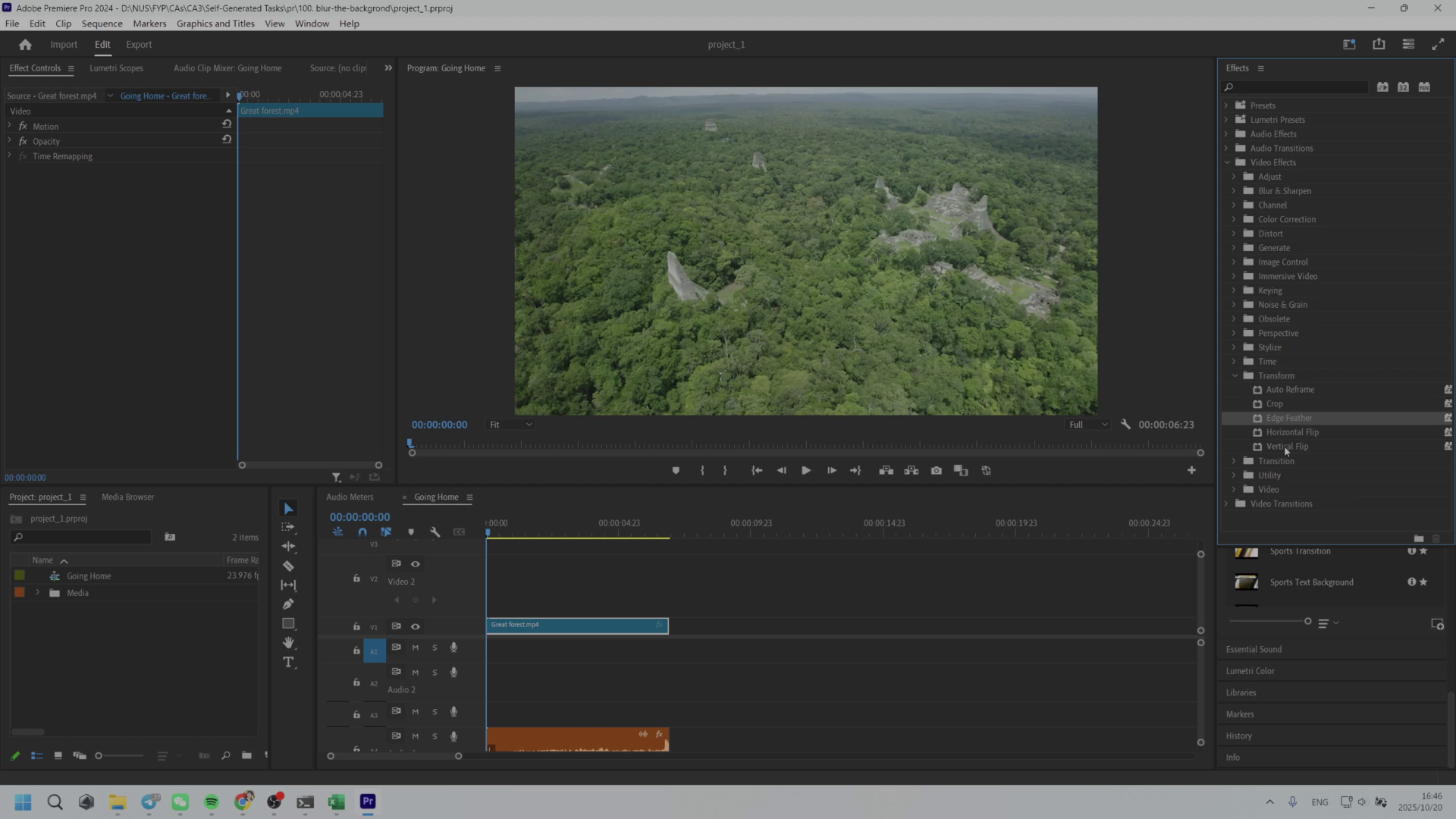
ShowUI-$π$ The Dexterous Hand of GUIs
📝 Original Paper Info
- Title: ShowUI-$π$ Flow-based Generative Models as GUI Dexterous Hands- ArXiv ID: 2512.24965
- Date: 2025-12-31
- Authors: Siyuan Hu, Kevin Qinghong Lin, Mike Zheng Shou
📝 Abstract
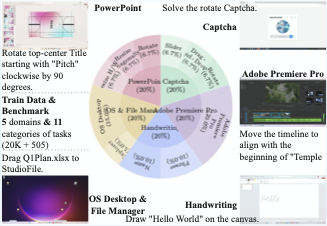
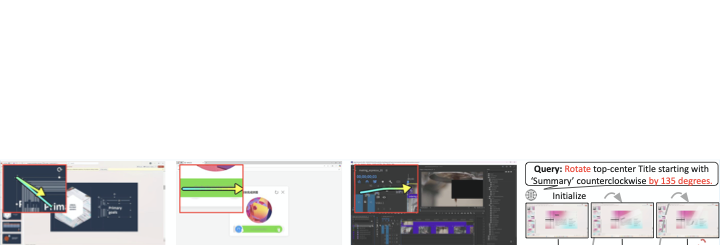
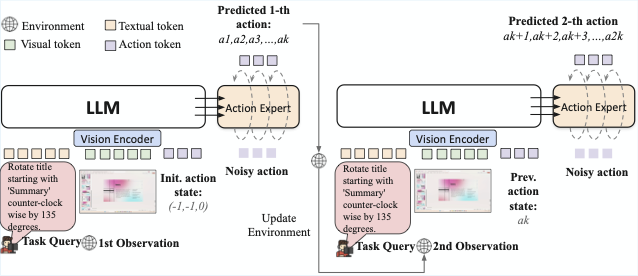
Building intelligent agents capable of dexterous manipulation is essential for achieving human-like automation in both robotics and digital environments. However, existing GUI agents rely on discrete click predictions (x,y), which prohibits free-form, closed-loop trajectories (e.g. dragging a progress bar) that require continuous, on-the-fly perception and adjustment. In this work, we develop ShowUI-$π$, the first flow-based generative model as GUI dexterous hand, featuring the following designs: (i) Unified Discrete-Continuous Actions, integrating discrete clicks and continuous drags within a shared model, enabling flexible adaptation across diverse interaction modes; (ii) Flow-based Action Generation for drag modeling, which predicts incremental cursor adjustments from continuous visual observations via a lightweight action expert, ensuring smooth and stable trajectories; (iii) Drag Training data and Benchmark, where we manually collect and synthesize 20K drag trajectories across five domains (e.g. PowerPoint, Adobe Premiere Pro), and introduce ScreenDrag, a benchmark with comprehensive online and offline evaluation protocols for assessing GUI agents' drag capabilities. Our experiments show that proprietary GUI agents still struggle on ScreenDrag (e.g. Operator scores 13.27, and the best Gemini-2.5-CUA reaches 22.18). In contrast, ShowUI-$π$ achieves 26.98 with only 450M parameters, underscoring both the difficulty of the task and the effectiveness of our approach. We hope this work advances GUI agents toward human-like dexterous control in digital world. The code is available at https://github.com/showlab/showui-pi.💡 Summary & Analysis
1. **Importance of Model Selection**: Choosing the right deep learning model for image recognition is crucial. 2. **High Accuracy and Cost with ResNet**: ResNet showed the highest accuracy across all datasets but came with a higher computational cost. 3. **Efficiency of MobileNet**: MobileNet was more efficient in terms of computation time while maintaining good accuracy levels.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)