Evaluating the Impact of Compression Techniques on the Robustness of CNNs under Natural Corruptions
📝 Original Paper Info
- Title: Evaluating the Impact of Compression Techniques on the Robustness of CNNs under Natural Corruptions- ArXiv ID: 2512.24971
- Date: 2025-12-31
- Authors: Itallo Patrick Castro Alves Da Silva, Emanuel Adler Medeiros Pereira, Erick de Andrade Barboza, Baldoino Fonseca dos Santos Neto, Marcio de Medeiros Ribeiro
📝 Abstract
Compressed deep learning models are crucial for deploying computer vision systems on resource-constrained devices. However, model compression may affect robustness, especially under natural corruption. Therefore, it is important to consider robustness evaluation while validating computer vision systems. This paper presents a comprehensive evaluation of compression techniques - quantization, pruning, and weight clustering applied individually and in combination to convolutional neural networks (ResNet-50, VGG-19, and MobileNetV2). Using the CIFAR-10-C and CIFAR 100-C datasets, we analyze the trade-offs between robustness, accuracy, and compression ratio. Our results show that certain compression strategies not only preserve but can also improve robustness, particularly on networks with more complex architectures. Utilizing multiobjective assessment, we determine the best configurations, showing that customized technique combinations produce beneficial multi-objective results. This study provides insights into selecting compression methods for robust and efficient deployment of models in corrupted real-world environments.💡 Summary & Analysis
1. **Impact of Compression Techniques**: This study examines how compression techniques impact the robustness against natural corruptions, enabling stable model performance on devices with limited resources like autonomous cars and smartphones. 2. **Balancing Compression Ratio and Performance**: The research analyzes the trade-off between compression ratio and accuracy to find an optimal balance where the model size is minimized without significantly compromising its performance. 3. **Various Model and Technique Combinations**: Different models and combinations of compression techniques are tested to compare their effectiveness, leading to identifying the most powerful configurations.📄 Full Paper Content (ArXiv Source)
System Validation, Machine Learning, Image Classification, Robustness, Compression Techniques, Edge AI, TinyML.
Introduction
Humans can adapt to changes in image structures and styles, including snow, blur, and pixelation; however, computer vision models struggle with such variations. Consequently, the performance of the model decreases when the input is naturally distorted, which poses challenges in practical settings where such distortions are inevitable. For example, autonomous vehicles must handle diverse conditions such as fog, frost, snow, sandstorms, or falling leaves to accurately read traffic signs. However, predicting all natural conditions is not feasible. Therefore, evaluating the robustness of the model is crucial to validate the reliability of computer vision and machine learning systems in safety-critical contexts .
The robustness of models against different types of perturbation has been a studied topic in the machine learning community. Natural corruptions, which are an important type of disturbance, are common in real scenarios and can reduce the accuracy of models, so their study has been widely carried out . Models are sometimes deployed on resource-limited devices, such as embedded systems and smartphones, necessitating a reduction in model size while maintaining accuracy. Techniques such as pruning (sparsity) , quantization , and weight sharing (clustering) have been suggested for this purpose. These methods can be used individually or in combination to take advantage of their unique strengths in reducing the size of the model .
Therefore, it is important to study the robustness of these compressed models against natural corruptions, as they will be used in environments prone to corrupted images, exposing potential vulnerabilities. Works such as applied compression techniques to machine learning models and evaluated the robustness of these optimized models. Although applies two or more successive techniques to reduce model, their study focuses on robustness against adversarial attacks, and the combinations of techniques explored were more limited.
The purpose of this study is to analyze the impact of model compression techniques on robustness against natural corruption. From there, analyze the impact of these compression techniques in relation to different models and also how robustness relates to other important metrics in relation to the compressed model. Our main contributions are as follows.
-
Evaluate the impact of compression techniques and their combinations on robustness under natural corruptions of models with different architectures.
-
Evaluate the trade-off between robustness, accuracy, and compression ratio.
The structure of this paper is as follows: Section 2 surveys the literature pertinent to our research. Section 3 outlines the corruptions, compression methods, models, and evaluation criteria. Section 4 delivers the experimental findings and model evaluations. Finally, Section 5 offers conclusions and future work suggestions.
Related Works
In the authors set a benchmark for evaluating classifier robustness, culminating in the creation of IMAGENET-C. This benchmark aids in gauging model performance against these common challenges. Additionally, it distinguishes between robustness against corruption and perturbation versus adversarial attacks. Other datasets like CIFAR-10-C, CIFAR-100-C, TINY IMAGENET-C, and IMAGENET 64 X 64-C serve similar purposes as IMAGENET-C. Robustness against corruption is quantitatively assessed using Mean Corruption Error (mCE) and Relative Mean Corruption Error (Relative mCE).
The work evaluates the impact of post-hoc pruning on the calibration and resilience of image classifiers facing corruptions. The research demonstrates that post-hoc pruning in Convolutional Neural Networks (CNN) significantly boosts calibration, performance, and durability against model corruption. Structured pruning focused on filters or channels, while unstructured pruning targeted model weights, with pruning rates spanning 10% across 0% to 70%.
The work evaluated the robustness of quantized neural network models against various noises, such as adversarial attacks, natural corruptions, and systematic noises in ImageNet. The experiments showed that lower bit quantization is more resistant to adversarial attacks but becomes less resistant to natural corruptions and systematic noise.
The work analyzed the performance of quantized neural network models under various noises, including data disturbance, model parameter disturbance, and adversarial attacks, using the data set Tiny ImageNet. The benchmark evaluates three classical architectures and the quantization method, BBPSO-Quantizer, considering low bitwidths. The authors’ findings indicate that models quantized with fewer bits perform better than floating-point models.
In , the authors explore the impact of model compression methods, such as quantization, pruning, and clustering, on the adversarial robustness of neural networks, especially within TinyML. Using FGSM and PGD methods to create adversarial examples, the study assessed the robustness of models trained adversarially post-application techniques, both separately and jointly. The results indicate a general decline in robustness; however, the combination of methods does not markedly deteriorate the results beyond individual applications. Some techniques even bolstered resilience to minor perturbations.
Although the work establishes the benchmark for evaluating robustness against natural corruptions, it does not explore the impact of compression techniques on robustness. In addition, analyzes the impact of compression techniques on robustness, however robustness against adversarial attacks. As summarized in Table [tab:related_works], focus on individual techniques and do not investigate combinations of methods or include weight sharing in robustness analysis. Therefore, this work is relevant for analyzing the impact of compression techniques on the robustness of CNNs under natural corruptions, as well as for investigating how robustness interacts with other key metrics, such as accuracy and compression ratio.
Methodology
Initially, models were loaded with pre-trained weights on the ImageNet dataset to meet the study objectives . Transfer learning was then used to adapt these models to the CIFAR-10 and CIFAR-100 datasets. The initial evaluation with uncorrupted test images provided a baseline performance measurement. Various compression techniques were subsequently applied, both individually and in combination. The optimized models were evaluated using three key metrics: accuracy, mean corruption error (mCE) and compression ratio. These metrics support a comprehensive analysis that focuses on performance, robustness, and efficiency. The following sections detail these procedures.
The datasets selected for corrupted images were CIFAR-10-C and CIFAR-100-C, publicly accessible and feature 15 types of corruption, each with 5 severity levels (see Figure 1). Thus, each dataset includes 75 corruptions applied to CIFAR-10 and CIFAR-100. Consequently, CIFAR-10 and CIFAR-100 were used to assess uncorrupted (clean) images. Although proposed other image datasets, CIFAR-10-C and CIFAR-100-C were selected primarily for their smaller size compared to others. The CIFAR-10 and CIFAR-100 test sets each contain 10,000 images, allowing rapid model construction and validation without extensive computational resources. In addition, using two data sets facilitated the model evaluation in both a simpler context with CIFAR-10 (10 classification classes) and a more complex context with CIFAR-100 (100 classification classes).

To assess robustness against common corruptions, in the authors used several state-of-the-art models, including ResNet-50 and VGG-19 . In addition, in the authors used MobileNetV2 . In this work, we will use the following models: (1) ResNet-50, as it is a widely used classic backbone architecture in computer vision tasks and, in addition, showed the best results in ; (2) VGG-19, as it is a deep architecture with simple layers; (3) MobileNetV2, because it is a lightweight model designed for efficient deployment in embedded devices. Therefore, with these options, we can have a variation in the types of models and their sizes.
As tools for training, fine-tuning and optimizing the models, we use TensorFlow together with LiteRT . LiteRT is optimized for machine learning on edge devices, and TensorFlow has a dedicated module for model compression. Compressions are the key point of our study and TensorFlow and LiteRT have the techniques of quantization , post-training, and during training, pruning and Weight Sharing with easy implementation. In addition, we will apply a collaborative compression by applying one technique after another to ensure the effects of the accumulated compressions. Figure 2 shows various deployment paths that can be explored in search of more compressed models, the leaf nodes are models ready for deployment, which means that they are partially or fully quantized in the tflite format. The green fill indicates the steps where fine-tuning is required, and the red border indicates the collaborative optimization steps, the deployment path with only quantization (post or during training) has been omitted from the figure. Therefore, the idea of this work is to explore both techniques individually and together to assess the impact that successive combined techniques have on the robustness against corruption. The set of applied techniques can be seen in Table 1. In addition, we use the Keras API to implement the CNN models considered in this study. Finally, we use the Python language with the Pandas, NumPy, Scikit-learn, and Matplotlib libraries.1
| Code | Compression Technique |
|---|---|
| 1 | Original |
| 2 | Quantization Int8 |
| 3 | Sparsity (Pruning) |
| 4 | Sparsity with Quantization Int8 |
| 5 | Clustering (Weight Sharing) |
| 6 | Clustering with Quantization Int8 |
| 7 | Sparsity preserving Clustering |
| 8 | Sparsity preserving Clustering with Quantization Int8 |
| 9 | Quantization Aware Training (QAT) |
| 10 | QAT with Quantization Int8 |
| 11 | Clustering preserving QAT (CQAT) |
| 12 | CQAT with Quantization Int8 |
| 13 | Sparsity preserving QAT (PQAT) |
| 14 | PQAT with Quantization Int8 |
| 15 | Pruning preserving Clustering preserving QAT (PCQAT) |
| 16 | PCQAT with Quantization Int8 |
Set of compression techniques applied.
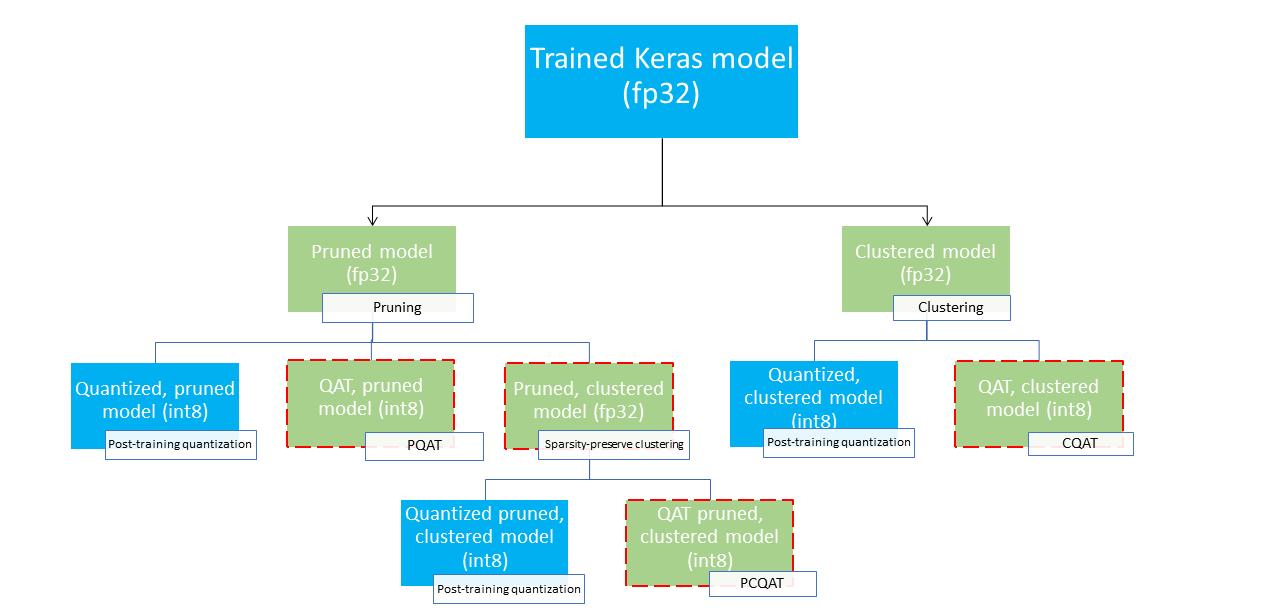
Table [tab:all_hyperparameters] presents a summary of the hyperparameters defined for each component of the model, including architecture, training configuration, and compression techniques. We trained the models, both original and compressed, using the hyperparameters in the Model section of this table, we use the Adam optimizer due to its adaptive learning rate and momentum properties, which accelerate convergence and have shown strong empirical performance in training deep neural networks and the use of categorical cross-entropy was due to the kind of problem we have. We used the Early Stopping technique in all stages that involved transfer learning or fine-tuning, with a limit of 30 epochs and patience of 5 epochs. However, we did not apply Early Stopping to the pruning technique, as it is performed progressively over the course of the epochs, and stopping training early would compromise its effectiveness . For the pruning and weight sharing techniques, we followed the standard hyperparameters defined by TFLite, as specified in the Pruning and Clustering sections of Table [tab:all_hyperparameters].
| CIFAR-10 | CIFAR-100 | ||
|---|---|---|---|
| Model | Accuracy (%) | Accuracy (%) | Size (MB) |
| ResNet-50 | 88% | 76% | 91MB |
| VGG-19 | 72% | 56% | 73MB |
| MobileNetV2 | 90% | 72% | 13MB |
Results original models.
Table 2 presents the accuracy and dimensions of the original models before compression. These results will serve as a reference for the compressed models. In particular, for CIFAR-10, MobileNetV2 achieves the highest accuracy at 90% and is the smallest model, while VGG-19 performs the worst at 72%. Regarding CIFAR-100, ResNet-50 leads with a 76% accuracy and is the largest model, while VGG-19 again shows the lowest performance at 56%.
We considered the following metrics to evaluate models and compression techniques: accuracy, Mean Corruption Error (mCE), and the compression ratio of the model. The Corruption Error (CE) is calculated using Equation [eq:mCE].
\begin{equation}
\text{CE}_c^f = \frac{\sum_{s=1}^5 E_{s,c}^f}{\sum_{s=1}^5 E_{s,c}^\text{Baseline}}
\label{eq:mCE}
\end{equation}where $`c`$ indicates which of the 15 corruptions is being evaluated, $`f`$ is the compressed model being evaluated (e.g. ResNet-50 (Pruned)), $`s`$ is the severity level ranging from 1 to 5, $`E_{s,c}^f`$ is the model error rate for the corrupted images and $`Baseline`$ is the original model trained with the clean data. From this, we can summarize the robustness of the model by calculating the average of the 15 CE ($`{\text{CE}}_{\text{Gaussian Noise}}^f, {\text{CE}}_{\text{Shot Noise}}^f, ..., {\text{CE}}_{\text{JPEG}}^f`$). This result is Mean Corruption Error (mCE). The compression ratio is obtained from the ratio between the original model size and the compressed model size.
We will compute the Pareto front for the obtained solutions using these metrics, focusing on a multi-objective evaluation aimed at maximizing accuracy, minimizing mCE, and maximizing the compression ratio. The Pareto front will present a set of non-dominated solutions that surpass other solutions within the search space. A Pareto-optimal solution cannot improve any objective without negatively impacting at least one other objective.
Results and discussion
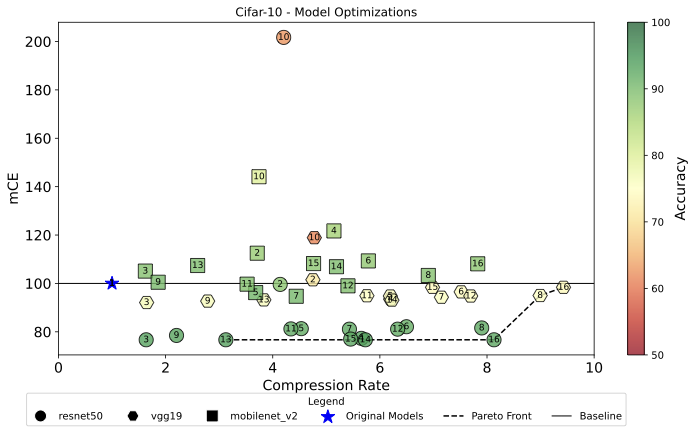
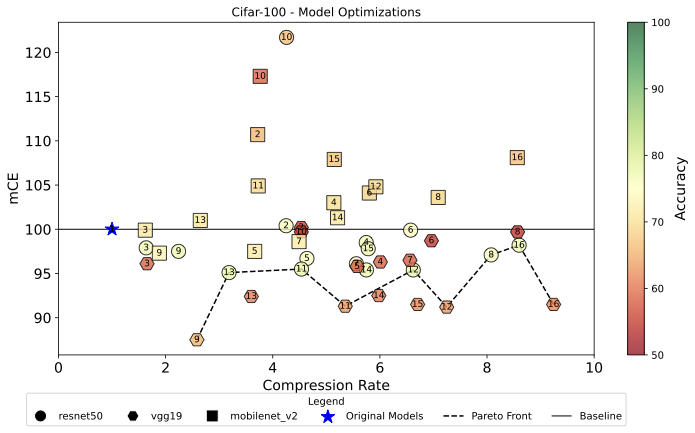
In this section, we present the results obtained in the experiments. Figure 5 shows the results obtained from the compressed models in terms of compression rate, mCE and accuracy, considering CIFAR-10, CIFAR-100 and the compression techniques defined in Table 1.
 />
/>
 />
/>
0.48
| mCE | CR | Acc | Model | Technique | |
|---|---|---|---|---|---|
| Best mCE | 76.7 | 8.13 | 92.67 | ResNet-50 | PCQAT Int8 (#16) |
| Best CR | 98.4 | 9.42 | 74.19 | VGG-19 | PCQAT Int8 (#16) |
| Best Acc | 78.3 | 5.52 | 94.34 | MobileNetV2 | PQAT Int8 (#14) |
| Worst mCE | 201.7 | 4.2 | 62.89 | ResNet-50 | QAT Int8 (#10) |
| Worst CR | 105.1 | 1.62 | 88.9 | MobileNetV2 | Pruning (#3) |
| Worst Acc | 61.33 | 4.77 | 61.33 | VGG-19 | QAT Int8 (#10) |
0.48
| mCE | CR | Acc | Model | Technique | |
|---|---|---|---|---|---|
| Best mCE | 87.5 | 2.5 | 65.4 | VGG-19 | QAT (#9) |
| Best CR | 91.5 | 9.2 | 61.5 | VGG-19 | PCQAT Int8 (#16) |
| Best Acc | 95.5 | 4.5 | 77.8 | ResNet-50 | CQAT (#11) |
| Worst mCE | 130.1 | 4 | 54.7 | MobileNetv2 | QAT Int8 (#10) |
| Worst CR | 99.9 | 1.62 | 71.3 | MobileNetv2 | Pruning (#3) |
| Worst Acc | 99.7 | 8.5 | 54.1 | VGG-19 | Sparsity+Q Int8(#8) |
Figure 3 shows that 69% (31 of 45) of the generated models achieved an mCE below or equal to the baseline, highlighting the positive influence of compression methods on the robustness of the model with the CIFAR-10 dataset. In particular, only the QAT with Quantization Int8 (#10) method resulted in mCE values exceeding 100 for the three models examined, whereas techniques such as CQAT (#11), CQAT with Quantization Int8 (#12), Clustering (#5) and Sparsity preserving Clustering (#7) maintained mCE at or below the baseline. Similarly, Figure 4 indicates that 69% of the solutions achieved an mCE no greater than the baseline for CIFAR-100, reaffirming the advantageous effect of compression on robustness. The technique #2 yielded results above 100 for the three models concerning mCE, while techniques #5, #3, #7 and #9 consistently achieved mCE values at or below the baseline in all three models examined.
Investigation of the Pareto Front for CIFAR-10 (Figure 3) yielded model-specific results. ResNet-50 occupies 71% of the Pareto Front (5 out of 7 solutions). The non-dominated solutions involve QAT in conjunction with other methods, notably techniques #13, #14 and #16, highlighting the combined effectiveness of QAT, Pruning and Clustering for compression, mCE, and accuracy. The use of Int8 quantization is a differential in this context. VGG-19 makes up 29% of the Pareto Front, with techniques #8 and #16, indicating that the synergy between sparsity-preserving clustering and PCQAT, bolstered by Int8 quantization, is highly effective. MobileNetV2 has no representations on the Pareto Front.
Similarly, the Pareto Front for CIFAR-100 (Figure 4) produced model-specific results. ResNet-50 occupies 56% (5 out of 9 solutions) of the Pareto Front. The techniques that make up the Pareto Front are #13, #11, #12, #8 and #16. VGG-19 composes 44% of the Pareto Front. The Pareto-optimal solutions for VGG-19 include techniques #9, #11, #12 and #16. The QAT point (#9) stands out for its very low mCE. The presence of PCQAT with Quantization Int8 (#16) indicates that aggressive optimizations are possible, but the accuracy for this point in VGG-19 must be carefully evaluated. MobileNetV2 did not have representation for the Pareto front.
Table [tab:best_worst_cifar10_100] presents the extreme results that illustrate the trade-off dynamics among compression techniques. In CIFAR-10, technique #16 stood out with the lowest mCE (76.7) for ResNet-50 and the highest compression rate (9.42) for VGG-19, demonstrating its multiobjective optimization prowess. Meanwhile, technique #14 achieved the highest accuracy (94.34) on MobileNetV2, indicating varying effectiveness according to the model and the objective. In particular, technique #10 yielded the worst performance in specific settings (ResNet-50 for mCE, VGG-19 for precision). In CIFAR-100, The technique #9 yielded the lowest mCE (87.5) on VGG-19, whereas #10 on MobileNetV2 peaked at 130.1, highlighting the quantization effects dependent on the model and metric. For compression ratio, technique #16 excelled in VGG-19 (CR of 9.2), contrasting technique #3 on MobileNetV2, which had the lowest CR (1.62). Technique #11 reached the highest accuracy (77.8) on ResNet-50. Conversely, technique #8 on VGG-19 had the poorest accuracy (54.1).
| Technique | mCE | CR | Acc |
|---|---|---|---|
| #1 | 100 (0.0) | 1 (0.0) | 85.2 (8.7) |
| #2 | 105.5 (6.0) | 4.1 (0.4) | 84.2 (8.3) |
| #3 | 88.0 (13.3) | 1.6 (0.01) | 88.2 (8.1) |
| #4 | 94.0 (19.6) | 5.6 (0.4) | 87.3 (8.3) |
| #5 | 89.6 (7.1) | 4.6 (1.1) | 87.6 (8.6) |
| #6 | 94.4 (11.5) | 6.4 (0.7) | 86.6 (8.4) |
| #7 | 88.9 (6.7) | 5.5 (1.2) | 87.9 (8.4) |
| #8 | 92.1 (9.2) | 7.8 (0.9) | 87.4 (8.4) |
| #9 | 88.1 (10.3) | 2.2 (0.4) | 88.3 (8.3) |
| #10 | 141.8 (43.5) | 4.2 (0.4) | 73.5 (13.9) |
| #11 | 89.9 (8.8) | 4.4 (1.0) | 87.3 (8.6) |
| #12 | 89.7 (8.6) | 6.3 (1.0) | 87.4 (8.6) |
| #13 | 88.9 (14.4) | 3.1 (0.5) | 88.3 (8.6) |
| #14 | 88.8 (14.2) | 5.6 (0.4) | 88.2 (8.6) |
| #15 | 92.2 (13.8) | 5.5 (1.0) | 87.1 (8.9) |
| #16 | 92.1 (13.9) | 8.3 (0.8) | 87.1 (8.9) |
CIFAR-100
| mCE | CR | Acc | |
|---|---|---|---|
| #1 | 100.0 (0.0) | 1.0 (0.0) | 69.1 (9.0) |
| #2 | 109.0 (11.5) | 4.1 (0.3) | 64.4 (8.6) |
| #3 | 98.0 (1.5) | 1.6 (0.01) | 70.1 (8.1) |
| #4 | 105.4 (12.6) | 5.6 (0.4) | 66.5 (8.2) |
| #5 | 96.5 (0.7) | 4.5 (0.8) | 69.7 (8.2) |
| #6 | 103.6 (5.9) | 6.4 (0.5) | 66.3 (8.3) |
| #7 | 97.1 (1.1) | 5.4 (0.8) | 69.7 (8.2) |
| #8 | 102.6 (5.6) | 7.8 (0.6) | 66.8 (9.1) |
| #9 | 94.6 (4.8) | 2.2 (0.3) | 72.7 (5.1) |
| #10 | 117.2 (12.8) | 4.1 (0.3) | 58.5 (5.5) |
| #11 | 98.7 (6.4) | 4.4 (0.7) | 70.3 (6.0) |
| #12 | 98.6 (6.4) | 6.6 (0.5) | 70.2 (6.0) |
| #13 | 97.1 (4.1) | 3.1 (0.4) | 70.5 (7.0) |
| #14 | 97.3 (4.0) | 5.6 (0.3) | 70.5 (7.1) |
| #15 | 100.5 (7.4) | 5.7 (0.7) | 68.7 (6.3) |
| #16 | 101.2 (7.8) | 8.6 (0.4) | 68.6 (6.3) |
CIFAR-100
Table [tab:mean_results] presents the mean and standard deviation of the metrics evaluated for each compression technique used in the models. Regarding CIFAR-10 (Table [tab:mean_cifar10]), technique #3 achieved the lowest mean mCE, technique #16 exhibited the highest mean compression rate, and technique #9 reached the highest mean accuracy. In particular, 86% (13 of 15) of the techniques showed an mCE below the original model (#11). For CIFAR-100 (Table 4), technique #9 also yielded the lowest mean mCE and the highest mean accuracy, while technique #16 achieved the highest mean compression rate. Here, 53% (8 out of 15) of the techniques yielded mCE below the model without compression (#1).
Discussion. The findings indicate that the applied compression techniques generally improved model robustness against natural corruptions, as evidenced by decreased or unchanged mCE values compared to the original models in most scenarios. In particular, complex architectures like ResNet-50 and VGG-19 adopted various compression strategies more effectively. These networks exhibited substantial improvements in robustness and efficiency, particularly when advanced techniques such as PQAT, CQAT, PCQAT, and their Int8 quantized versions were used. The range of Pareto-optimal points in these models highlights the adaptability of these architectures in balancing conflicting goals. In contrast, MobileNetV2 lacks representation on the Pareto front, likely due to its compact design, limiting the advantages of these methods or requiring more specific compression approaches. It is important to mention that QAT with Quantization Int8 (#10) did not perform well compared to other techniques, suggesting that it may not improve robustness or offer a favorable balance among precision, robustness, and compression rate.
Therefore, these results emphasize the importance of assessing the trade-offs between robustness, accuracy, and compression rate when deploying compressed models on resource-constrained devices. For inherently small models, additional compression might be unnecessary unless severe limitations apply. In contrast, for larger models, compression could efficiently balance these criteria. In embedded systems, initiating with aggressive compression approaches tailored to the architecture can yield competitive performance within this multiobjective context.
Conclusion and future works
This work aimed to analyze the impact of model compression techniques on the robustness to natural corruptions. The results demonstrated that, in general, compression techniques preserve or improve robustness, which is particularly relevant for the deployment of models on resources-constrained devices. Furthermore, the findings highlighted that the effect of each technique can vary depending on the model, emphasizing the importance of tailoring compression strategies to specific architectures. Finally, when compressing models with the goal of maintaining robustness, it is crucial to consider additional metrics such as accuracy and compression rate. A joint analysis of these factors can provide deeper insight into the overall performance and trade-offs of the applied techniques.
Future work could explore the use of alternative frameworks such as PyTorch, since the LiteRT library currently lacks support to compress some of the more recent model architectures. Furthermore, future studies could explore each technique in greater depth, applying new hyperparameter ranges different from those used in this study. Moreover, a more detailed analysis of each type of corruption could be conducted to identify which distortions most significantly affect model robustness under different compression techniques. Evaluating performance in other corruption scenarios or using more realistic datasets may also improve the generalization of the findings. Finally, extending the analysis to include additional state-of-the-art models could further validate and strengthen the conclusions drawn from this study.
This study advances the scientific field by thoroughly examining the effects of model compression on robustness to natural corruption. It underscores the necessity of assessing robustness in conjunction with metrics like accuracy and compression ratio, particularly for deployment on devices with limited resources.
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
All the code used is available for reproduction. https://github.com/itallocastro/compression-techniques-robustness-under-natural-corruptions ↩︎