SpaceTimePilot Generative Rendering of Dynamic Scenes Across Space and Time
📝 Original Paper Info
- Title: SpaceTimePilot Generative Rendering of Dynamic Scenes Across Space and Time- ArXiv ID: 2512.25075
- Date: 2025-12-31
- Authors: Zhening Huang, Hyeonho Jeong, Xuelin Chen, Yulia Gryaditskaya, Tuanfeng Y. Wang, Joan Lasenby, Chun-Hao Huang
📝 Abstract
We present SpaceTimePilot, a video diffusion model that disentangles space and time for controllable generative rendering. Given a monocular video, SpaceTimePilot can independently alter the camera viewpoint and the motion sequence within the generative process, re-rendering the scene for continuous and arbitrary exploration across space and time. To achieve this, we introduce an effective animation time-embedding mechanism in the diffusion process, allowing explicit control of the output video's motion sequence with respect to that of the source video. As no datasets provide paired videos of the same dynamic scene with continuous temporal variations, we propose a simple yet effective temporal-warping training scheme that repurposes existing multi-view datasets to mimic temporal differences. This strategy effectively supervises the model to learn temporal control and achieve robust space-time disentanglement. To further enhance the precision of dual control, we introduce two additional components: an improved camera-conditioning mechanism that allows altering the camera from the first frame, and CamxTime, the first synthetic space-and-time full-coverage rendering dataset that provides fully free space-time video trajectories within a scene. Joint training on the temporal-warping scheme and the CamxTime dataset yields more precise temporal control. We evaluate SpaceTimePilot on both real-world and synthetic data, demonstrating clear space-time disentanglement and strong results compared to prior work. Project page: https://zheninghuang.github.io/Space-Time-Pilot/ Code: https://github.com/ZheningHuang/spacetimepilot💡 Summary & Analysis
1. **SpaceTimePilot** is the first video diffusion model that allows for novel view synthesis and temporal control from a single video, akin to being able to freely adjust the viewing angle of a 3D movie. 2. The *temporal-warping training scheme* modifies existing multi-view video datasets to simulate diverse temporal variations. This can be compared to warping frames in a video to achieve effects like reverse playback or slow motion. 3. The **Cam$`\times`$Time** dataset provides rich information on camera and time combinations, allowing for effective learning of spatial and temporal control, similar to having a laser pointer that allows free movement through each frame of the video.📄 Full Paper Content (ArXiv Source)
Videos are 2D projections of an evolving 3D world, where the underlying generative factors consist of spatial variation (camera viewpoint) and temporal evolution (dynamic scene motion). Learning to understand and disentangle these factors from observed videos is fundamental for tasks such as scene understanding, 4D reconstruction, video editing, and generative rendering, to name a few. In this work, we approach this challenge from the perspective of generative rendering. Given a single observed video of a dynamic scene, our goal is to synthesize novel views (reframe/reangle) and/or at different moments in time (retime), while remaining faithful to the underlying scene dynamic.
A common strategy is to first reconstruct dynamic 3D content from 2D observations, , perform 4D reconstruction, and then re-render the scene. These methods model both spatial and temporal variations using representations such as NeRFs or Dynamic Gaussian Splatting , often aided by cues like geometry , optical flow , depth , or long-term 2D tracks . However, even full 4D reconstructions typically show artifacts under novel viewpoints. More recent work uses multi-view video diffusion to generate sparse, time-conditioned views and refines them via Gaussian-splatting optimization, but rendering quality remains limited. Advances in video diffusion models further enable camera re-posing with more lightweight point cloud representations, reducing the need for heavy 4D reconstruction. While effective in preserving identity, their reliance on per-frame depth and reprojection limits robustness under large viewpoint changes. To mitigate this, newer approaches condition generation solely on camera parameters, achieving strong novel-view synthesis on both static and dynamic scenes . Autoregressive models like Genie-3 even enable interactive scene exploration from a single image, showing that diffusion models can encode implicit 4D priors. Nonetheless, despite progress in spatial viewpoint control, current methods still lack full 4D exploration, , the ability to navigate scenes freely across both space and time.
 />
/>
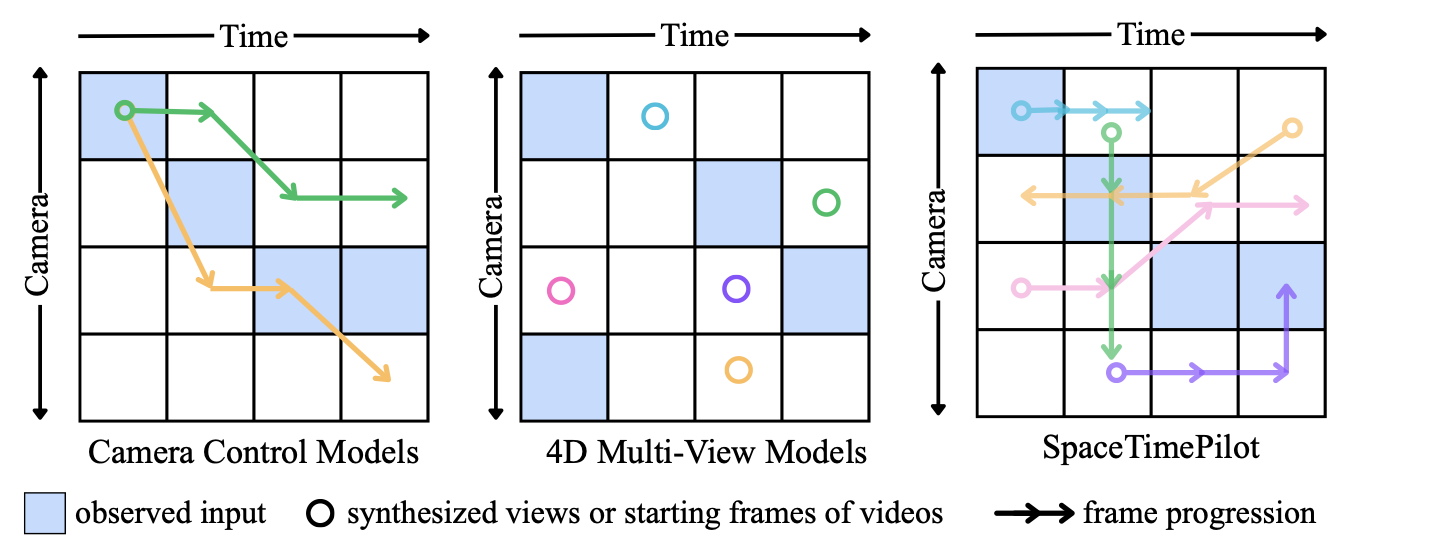
In this work, we introduce SpaceTimePilot, the first video diffusion model that enables joint spatial and temporal control. SpaceTimePilot introduces a new notion of “animation time” to capture the temporal status of scene dynamics in the source video. As such, it naturally disentangles temporal control and camera control by expressing them as two independent signals. A high-level comparison between our approach and prior methods is illustrated in Fig. 1. Unlike previous methods, SpaceTimePilot enables free navigation along both the camera and time axes. Training such a model requires dynamic videos that exhibit multiple forms of temporal playback while simultaneously being captured under multiple camera motions, which is only feasible in a controlled studio setups. Although temporal diversity can be increased by combining multiple real datasets , as done in , this approach remains suboptimal, as the coverage of temporal variation is still insufficient to learn the underlying meaning of temporal control. Existing synthetic datasets also do not exhibit such properties.
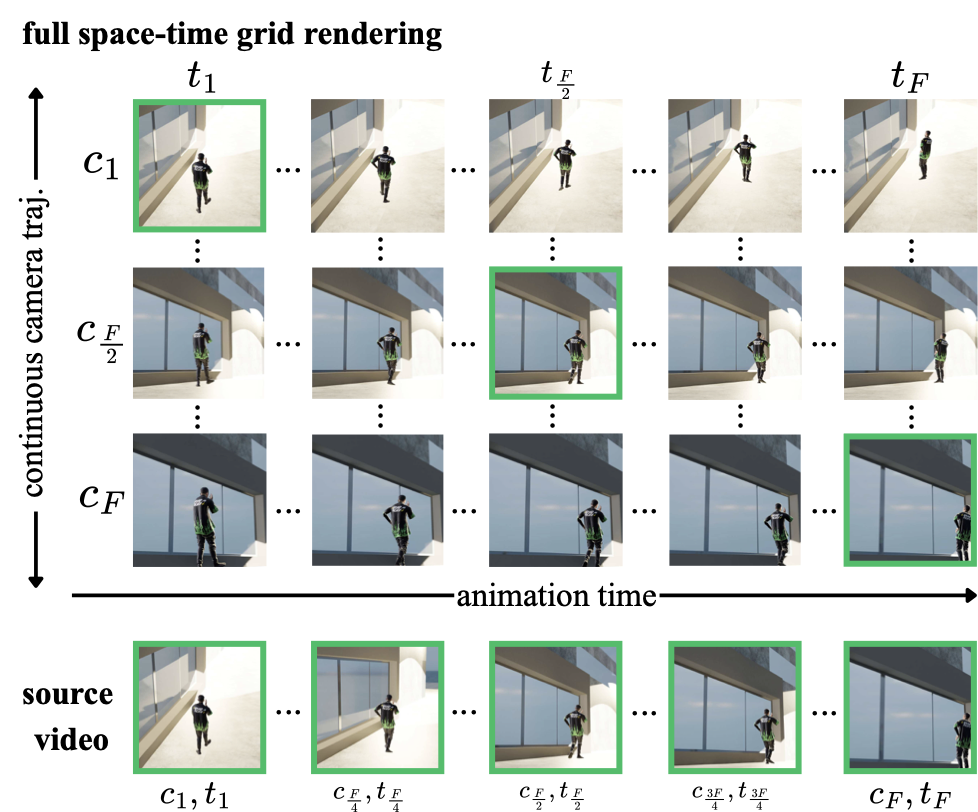
To address this limitation, we introduce a simple yet effective temporal-warping training scheme that augments existing multi-view video datasets to simulate diverse conditioning types while preserving continuous video structure. By warping input sequences in time, the model is exposed to varied temporal behaviors without requiring additional data collection. This simple yet crucial strategy allows the model to learn temporal control signals, enabling it to directly exhibit space–time disentanglement effects during generation. We further ablate various temporal-conditioning schemes and introduce a convolution-based temporal-control mechanism that enables finer-grained manipulation of temporal behavior and supports effects such as bullet-time at any timestep within the video. While temporal warping increases temporal diversity, it can still entangle camera and scene dynamics – for example, temporal manipulation may inadvertently affect camera behavior. To further strengthen disentanglement, we introduce a new dataset that spans the full grid of camera–time combinations along a trajectory. Our synthetic Cam$`\times`$Time dataset contains 180k videos rendered from 500 animations across 100 scenes and three camera paths. Each path provides full-motion sequences for every camera pose, yielding dense multi-view and full-temporal coverage. This rich supervision enables effective disentanglement of spatial and temporal control.
Experimental results show that SpaceTimePilot successfully disentangles space and time in generative rendering from single videos, outperforming adapted state-of-the-art baselines by a significant margin. Our main contributions are summarized as follows:
-
We introduce SpaceTimePilot, the first video diffusion model that disentangles spatial and temporal factors to enable continuous and controllable novel view synthesis as well as temporal control from a single video.
-
We propose the temporal-warping strategy that repurposes multi-view datasets to simulate diverse temporal variations. By training on these warped sequences, the model effectively learns temporal control without the need for explicitly constructed video pairs captured under different temporal settings.
-
We propose a more precise camera–time conditioning mechanism, illustrating how viewpoint and temporal embeddings can be jointly integrated into diffusion models to achieve fine-grained spatiotemporal control.
-
We construct the Cam$`\times`$Time Dataset, providing dense spatiotemporal sampling of dynamic scenes across camera trajectories and motion sequences. This dataset supplies the necessary supervision for learning disentangled 4D representations and supports precise camera–time control in generative rendering.
Related work
We aim to re-render a video from new viewpoints with temporal control, a task closely related to Novel View Synthesis (NVS) from monocular video inputs.
Video-based NVS.
Prior video-based NVS methods can be broadly characterized along two axes: (i) whether they target static or dynamic scenes, and (ii) whether they incorporate explicit 3D geometry in the generation pipeline.
For static scenes, geometry-based methods reconstruct scene geometry from the input frames and use diffusion models to complete or hallucinate regions that are unseen under new viewpoints . Although these approaches achieve high rendering quality, they rely on heavy 3D preprocessing. Geometry-free approaches bypass explicit geometry and directly condition the diffusion process on observed views and camera poses to synthesize new viewpoints.
For dynamic scenes, inpainting-based methods such as TrajectoryCrafter , ReCapture , and Reangle also adopt warp-and-inpaint pipelines, while GEN3C extends this with an evolving 3D cache and EPiC improves efficiency via a lightweight ControlNet framework. Geometry-free dynamic models instead learn camera-conditioned generation from multi-view or 4D datasets (, Kubric-4D ), enabling smoother and more stable NVS with minimal 3D inductive bias. Proprietary systems like Genie 3 further demonstrate real-time, continuous camera control in dynamic scenes, underscoring the potential of video diffusion models for interactive viewpoint manipulation.
Disentangling Space and Time.
Despite great progress in camera controllability (space), the methods discussed above do not address temporal control (time). Meanwhile, disentangling spatial and temporal factors has become a central focus in 4D scene generation, recently advanced through diffusion-based models. 4DiM introduces a Masked FiLM mechanism that defaults to identity transformations when conditioning signals (e.g., camera pose or time) are absent, enabling unified representations across both static and dynamic data through multi-modal supervision. Similarly, CAT4D leverages multi-view images to conduct 4D dynamic reconstruction to achieve space–time disentanglement but remains constrained by its reliance on explicit 4D reconstruction pipelines, which limits scalability and controllability. In contrast, our approach builds upon text-to-video diffusion models and introduces a new temporal embeddings module and refined camera conditioning to achieve fully controllable 4D generative reconstruction.
Method
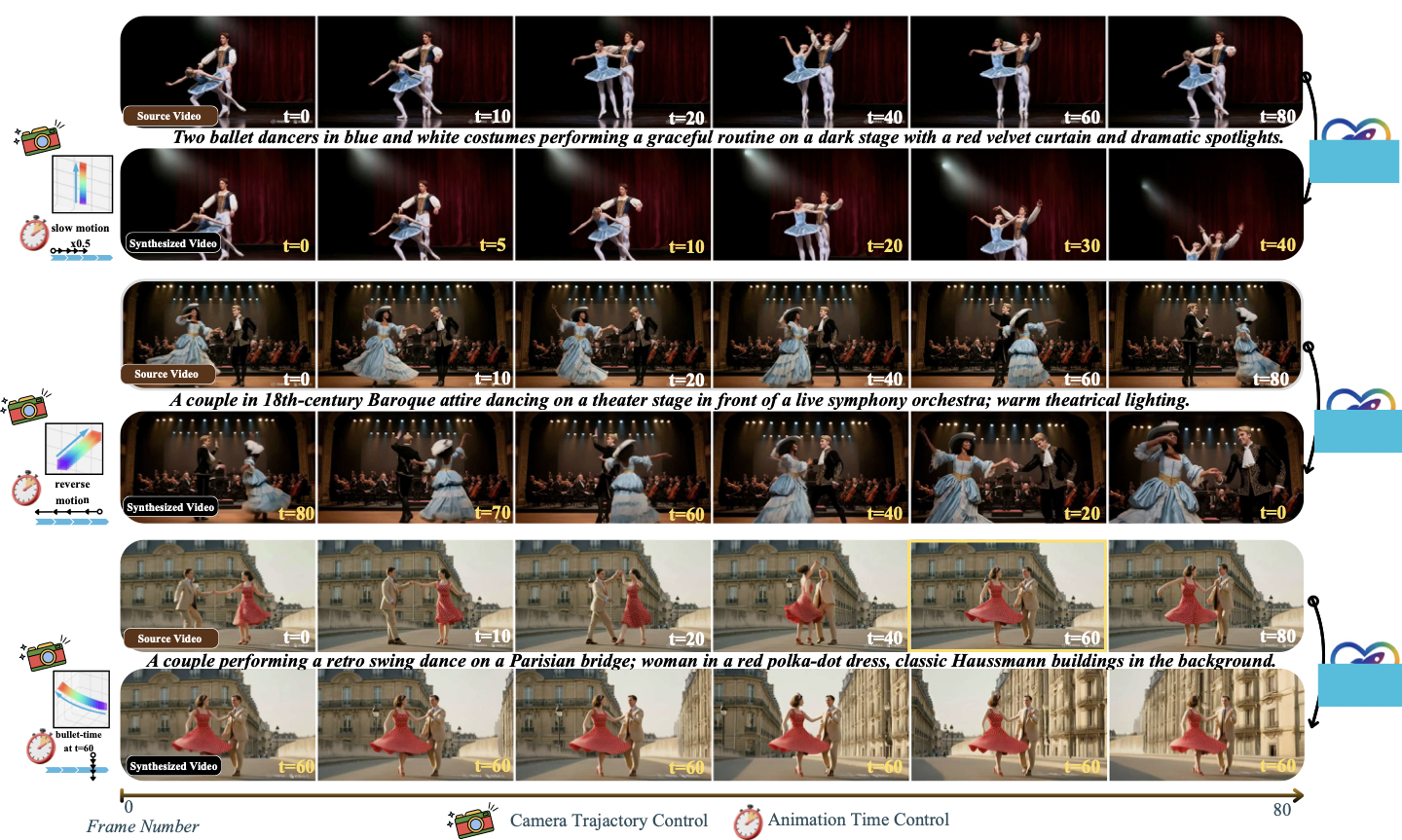
We introduce SpaceTimePilot, a method that takes a source video $`V_{\text{src}}\in \mathbb{R}^{F\times C\times H\times W}`$ as input and synthesizes a target video $`V_{\text{trg}}\in \mathbb{R}^{F\times C\times H\times W}`$, following an input camera trajectory $`\mathbf{c}_{\text{trg}}\in \mathbb{R}^{F\times 3 \times 4}`$ and temporal control signal $`\mathbf{t}_{\text{trg}} \in \mathbb{R}^{F}`$. Here, $`F`$ denotes the number of frames, $`C`$ the number of color channels, and $`H`$ and $`W`$ are the frame height and width, respectively. Each $`\mathbf{c}_{\text{trg}}^{f} \in \mathbb{R}^{3 \times 4}`$ represents the camera extrinsic parameters (rotation and translation) at frame $`f`$, with respect to the 1st frame of $`V_{\text{src}}`$. The target video $`V_{\text{trg}}`$ preserves the scene’s underlying dynamics, geometry, and appearance in $`V_{\text{src}}`$, while adhering to the camera motion and temporal progression specified by $`\mathbf{c}_{\text{trg}}`$ and $`\mathbf{t}_{\text{trg}}`$. A key feature of our method is the disentanglement of spatial and temporal factors in the generative process, enabling effects such as bullet-time and retimed playback from novel viewpoints (see [fig:teaser]).
Preliminaries
Our framework builds upon recent advances in large-scale text-to-video diffusion models and camera-conditioned video generation. We adopt a latent video diffusion backbone similar to modern text-to-video foundation models , consisting of a 3D Variational Auto-Encoder (VAE) for latent compression and a Transformer-based denoising model (DiT) operating over multi-modal tokens.
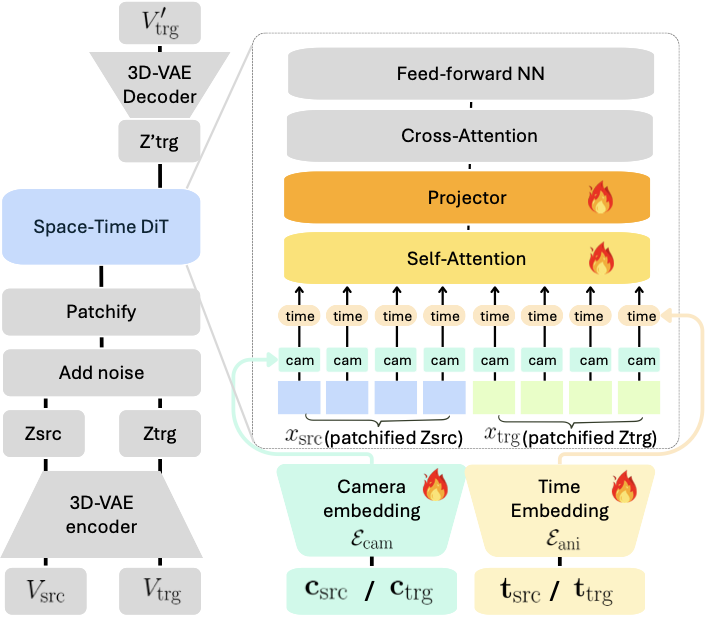
Additionally, our design draws inspiration from ReCamMaster , which introduces explicit camera conditioning for video synthesis. Given an input camera trajectory $`\mathbf{c}\in \mathbb{R}^{F\times 3 \times 4}`$, spatial conditioning is achieved by first projecting the camera sequence to the space of video tokens and adding it to the features:
\begin{equation}
x' = x + \mathcal{E}_\text{cam}\left(\mathbf{c}\right),
\label{eq:camera-condition}
\end{equation}where $`x`$ is the output of the patchifying module and $`x'`$ is the input to self-attention layers. The camera encoder $`\mathcal{E}_\text{cam}`$ maps each flattened $`3 \times 4`$ camera matrix (12-dimensional) into the target feature space, while also transforming the temporal dimension from $`F`$ to $`F'`$.
Disentangling Space and Time
We achieve spatial and temporal disentanglement through a two-fold approach: a dedicated time representation and specialized datasets.
Time representation
Recent video diffusion models include position embeddings for latent frame index $`f'`$, such as RoPE($`f'`$). However, we found using RoPE($`f'`$) for temporal control to be ineffective, as it interferes with camera signals: RoPE($`f'`$) often constrains both temporal and camera motion simultaneously. To address space and time disentanglement, we introduce a dedicated time control parameter $`\mathbf{t}\in \mathbb{R}^F`$. By manipulating $`\mathbf{t}_\text{trg}`$, we can control the temporal progression of the synthesized video $`V_{\text{trg}}`$. For example, setting $`\mathbf{t}_\text{trg}`$ to a constant locks $`V_{\text{trg}}`$ to a specific timestamp in $`V_{\text{src}}`$, while reversing the frame indices produces a playback of $`V_{\text{src}}`$ in reverse.
 />
/>
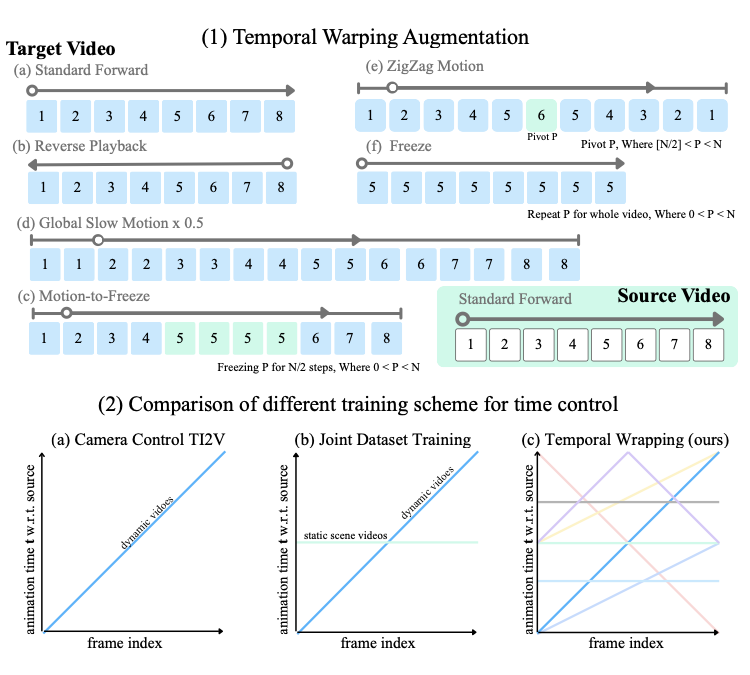
(Top) For multi-view dynamic scene datasets, a set of temporal warping operations, including reverse, playback, zigzag motion, slow motion, and freeze are apppplied with teh source video as standford. This gives explicit supervision for temporal control, without constructing additional temporally varied training data.
(Bottom) Existing camera-control and joint dataset training rely on monotonic time progression and static scene videos, making it difficult for models to understand temporal variation. The introduced temporal mappings from multi-view video data, which provide diverse and clear signal on tempral variation, and directly lead to disentanglement of space and time.
Time Embedding.
To inject temporal control into the diffusion model, we analyze several approaches. First, we can encode time similar to a frame index using RoPE embedding. However, we find it less suitable for time control (visual evaluations are provided in Supp. Mat.). Instead, we adopt sinusoidal time embeddings applied at the latent frame $`f'`$ level, which provide a stable and continuous representation of each frame’s temporal position and offer a favorable trade-off between precision and stability. We further observe that each latent frame corresponds to a continuous temporal chunk, and propose using embeddings of original frame indices $`f`$ to support finer granularity of time control. To accomplish this, we introduce a time encoding approach $`\mathcal{E}_\text{ani}(\mathbf{t})`$, where $`\mathbf{t}\in \mathbb{R}^F`$. We first compute the sinusoidal time embeddings to represent the temporal sequence, $`\mathbf{e}_\text{src}= \mathrm{SinPE}\!\left(\mathbf{t}_\text{src}\right)`$, $`\mathbf{e}_\text{trg}= \mathrm{SinPE}\!\left(\mathbf{t}_\text{trg}\right)`$, where $`\mathbf{t}_\text{src}, \mathbf{t}_\text{trg}\in \mathbb{R}^F`$. Next, we apply two 1D convolution layers to progressively project these embeddings into the latent frame space, $`\widetilde{\mathbf{e}} = \mathrm{Conv1D_2}(\mathrm{Conv1D_1}(\mathbf{e}))`$. Finally, we add these time features to the camera features and video tokens embeddings, updating [eq:camera-condition] as follows:
\begin{equation}
x' = x + \mathcal{E}_\text{cam}\left(\mathbf{c}\right) + \mathcal{E}_\text{ani}\left(\mathbf{t}\right).
\label{eq:cam-and-ani-condition}
\end{equation}In 4.2, we compare our approach with alternative conditioning strategies, such as using sinusoidal embeddings where $`\mathbf{t}_\text{src},\mathbf{t}_\text{trg}`$ are directly defined in $`\mathbb{R}^{F'}`$, and employing an MLP instead of a 1D convolution for compression. We demonstrate both qualitatively and quantitatively the advantages of our proposed method.
Datasets
To enable temporal manipulation in our approach, we require paired training data that includes examples of time remapping. Achieving spatial-temporal disentanglement further requires data containing examples of both camera and temporal controls. To the best of our knowledge, no publicly available datasets satisfy these requirements. Only a few prior works, such as 4DiM and CAT4D, have attempted to address spatial-temporal disentanglement. A common strategy is to jointly train on static-scene datasets and multi-view video datasets . The limited control variability in these datasets leads to confusion between temporal evolution and spatial movement, resulting in entangled or unstable behaviors . We address this limitation by augmenting existing multi-view video data with temporal warping and by proposing a new synthetic dataset.
Temporal Warping Augmentation.
We introduce simple augmentations that add controllable temporal variations to multi-view video datasets. During training, given a source video $`V_{\text{src}}= \{I_\text{src}^f\}_{f=1}^{F}`$ and a target video $`V_{\text{trg}}= \{I_\text{trg}^f\}_{f=1}^{F}`$, we apply a temporal warping function $`\tau: [1, F] \rightarrow [1, F]`$ to the target sequence, producing a warped video $`V_\text{trg}' = \{I_\text{trg}^{\tau(f)}\}_{f=1}^{F}`$. The source animation timestamps are uniformly sampled, $`\mathbf{t}_\text{src}= 1:F`$. Warped timestamps, $`\mathbf{t}_\text{trg}= \tau(\mathbf{t}_\text{src})`$, introduce non-linear temporal effects (see 2 top b–e): (i) reversal, (ii) acceleration, (iii) freezing, (iv) segmental slow motion, and (v) zigzag motion, in which the animation repeatedly reverses direction. After these augmentations, the paired video sequences $`(V_\text{src}, V_\text{trg}')`$ differ in both camera trajectories and temporal dynamics, providing the model with a clear signal for learning disentangled spatiotemporal representations.
max width=
| Dataset | Dynamic scenes | Src. Time: $`t_{\text{src}}`$ | Tgt. Time: $`t_{\text{trg}}`$ | Camera |
|---|---|---|---|---|
| RE10k | 1 | 1 | Moving | |
| DL3DV10k | 1 | 1 | Moving | |
| MannequinChallenge | 1 | 1 | Moving | |
| Kubric-4D | 1:60 | 1:60 | Moving | |
| ReCamMaster | 1:80 | 1:80 | Moving | |
| SynCamMaster | 1:80 | 1:80 | Fixed | |
| Cam$`\times`$Time (ours) | 1:120 | $`\{1, 2, \dots, 120\}^{120}`$ | Moving |
Comparison of existing multi-view datasets for camera and temporal control against Cam$`\times`$Time. Cam$`\times`$Time provides full-grid rendering (Figure 3), enabling target videos to sample arbitrary temporal variations over the full range from 0 to 120.
Synthetic Cam$`\times`$Time Dataset for Precise Spatiotemporal Control.
While our temporal warping augmentations encourage strong disentanglement between spatial and temporal factors, achieving fine-grained and continuous control — that is, smooth and precise adjustment of temporal dynamics — benefits from a dataset that systematically covers both dimensions. To this end, we construct Cam$`\times`$Time, a new synthetic spatiotemporal dataset rendered in Blender. Given a camera trajectory and an animated subject, Cam$`\times`$Time exhaustively samples the camera–time grid, capturing each dynamic scene across diverse combinations of camera viewpoints and temporal states $`\left(\mathbf{c}, \mathbf{t}\right)`$, as illustrated in 3. The source video is obtained by sampling the diagonal frames of the dense grid (3 (bottom)), while the target videos are obtained by more free-form sampling of continuous sequences. We compare Cam$`\times`$Time against existing datasets in 1. While are real videos with complex camera path annotations, they either do not provide time-synchronized video pairs or only provide pairs of static scenes . Synthetic multi-view video datasets provide pairs of dynamic videos but do not allow training for time control. In contrast, Cam$`\times`$Time enables fine-grained manipulation of both camera motion and temporal dynamics, enabling bullet-time effects, motion stabilization, and flexible combinations of the controls. We designate part of Cam$`\times`$Time as a test set, aiming for it to serve as a benchmark for controllable video generation. We will release it to support future research on fine-grained spatiotemporal modeling.
 />
/>
| Method | PSNR↑ | SSIM↑ | LPIPS↓ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-5 (lr)6-9 (lr)10-13 | Dir. | Speed | Bullet | Avg | Dir. | Speed | Bullet | Avg | Dir. | Speed | Bullet | Avg |
| ReCamM+preshuffled† | 17.13 | 14.84 | 14.61 | 15.52 | 0.6623 | 0.6050 | 0.5965 | 0.6213 | 0.3930 | 0.4793 | 0.4863 | 0.4529 |
| ReCamM+jointdata | 18.32 | 17.57 | 17.69 | 17.86 | 0.7322 | 0.7220 | 0.7209 | 0.7250 | 0.2972 | 0.3158 | 0.3089 | 0.3073 |
| SpaceTimePilot(Ours) | 21.75 | 20.87 | 20.85 | 21.16 | 0.7725 | 0.7645 | 0.7653 | 0.7674 | 0.1697 | 0.1917 | 0.1677 | 0.1764 |
$`^\dagger`$ Uses simple frame-rearrangement operators (reversal, repetition, freezing) applied prior to inference to emulate temporal manipulation.
Precise Camera Conditioning
We aim for full camera trajectory control in the target video. In contrast, the previous novel-view synthesis approach assumes that the first frame is identical in source and target videos and that the target camera trajectory is defined relative to it. This stems from the two limitations. First, the existing approach ignores the source video trajectory, yielding suboptimal source features computed using the target trajectory for consistency:
x_\text{src}' = x_\text{src}+ \mathcal{E}_\text{cam}\left(\mathbf{c}_\text{trg}\right), \quad x_\text{trg}' = x_\text{trg}+ \mathcal{E}_\text{cam}\left(\mathbf{c}_\text{trg}\right).Second, it is trained on datasets where the first frame is always identical across the source and target videos. This latter limitation is addressed in our training datasets design.
To overcome the former, we devise a source-aware camera conditioning. We estimate camera poses for both the source and target videos using a pretrained pose estimator, and inject them jointly into the diffusion model to provide explicit geometric context. Eq. [eq:cam-and-ani-condition] is therefore extended into:
\begin{align}
&x_\text{src}' = x_\text{src}+ \mathcal{E}_\text{cam}\left(\mathbf{c}_\text{src}\right) + \mathcal{E}_\text{ani}\left(\mathbf{t}_\text{src}\right), \label{eq-srccam} \\
&x_\text{trg}' = x_\text{trg}+ \mathcal{E}_\text{cam}\left(\mathbf{c}_\text{trg}\right) + \mathcal{E}_\text{ani}\left(\mathbf{t}_\text{trg}\right), \nonumber \\
&x' = [x_\text{trg}', x_\text{src}']_{\text{frame-dim}}, \nonumber
\end{align}where $`x'`$ denotes the input of the DiT model, which is the concatenation of target and source tokens along the frame dimension. This formulation provides the model with both source and target camera context, enabling spatially consistent generation and precise control over camera trajectories.
Support for Longer Video Segments
Finally, to showcase the full potential of our camera and temporal control, we adopt a simple autoregressive video generation strategy, generating each new segment $`V_{\text{trg}}`$ conditioned on the previously generated segment $`V_{\text{prv}}`$ and a source video $`V_{\text{src}}`$ to produce longer videos.
To enable this capability during inference, we need to extend our training scenario to support conditioning on two videos, where one serves as $`V_{\text{src}}`$ and the other as $`V_{\text{prv}}`$. The source video $`V_{\text{src}}`$ is taken directly from the multi-view datasets or from our synthetic dataset, as was described previously. $`V_{\text{prv}}`$ is constructed in a similar way to $`V_{\text{trg}}`$ — either using temporal warping augmentations or by sampling from the dense space-time grid of our synthetic dataset. When temporal warping is applied, $`V_{\text{prv}}`$ and $`V_{\text{trg}}`$ may originate from the same or different multi-view sequences representing the same time interval. To maintain full flexibility of control, we do not enforce any other explicit correlations between $`V_{\text{prv}}`$ and $`V_{\text{trg}}`$, apart from specifying camera parameters relative to the selected source video frame.
Note that not constraining the source and target videos to share the same first frame (as discussed in 3.3) is crucial for achieving flexible camera control in longer sequences. For instance, this design enables extended bullet-time effects: we can first generate a rotation around a selected point up to $`45^\circ`$ ($`V_{\text{trg},1}`$), and then continue from $`45^\circ`$ to $`90^\circ`$ ($`V_{\text{trg},2}`$). Conditioning on two consecutive source segments allows the model to leverage information from newly generated viewpoints. In the bullet-time example, conditioning on the previously generated video enables the model to incorporate information from all newly synthesized viewpoints, rather than relying solely on the viewpoint of the corresponding moment in the source video.
Experiments
 />
/>
Implementation details.
We adopt the Wan-2.1 T2V-1.3B model , which produces $`F'`$=21 latent frames and decodes them into $`F`$=81 RGB frames using a 3D-VAE. The network is conditioned on camera and animation-time controls as defined in Eq. [eq-srccam]. Unless otherwise specified, SpaceTimePilot is trained with ReCamMaster and SynCamMaster datasets with the temporal warping augmentation described in Sec. 3.2.2, along with Cam$`\times`$Time. Please refer to Supp. Mat. for complete network architecture and additional training details.
Comparison with State-of-the-Art Baselines
Time-Control Evaluation.
We first evaluate the retiming capability of our model. To factor out the error induced by camera control, we condition SpaceTimePilot on a fixed camera pose while varying only the temporal control signal. Experiments are performed on the withheld Cam$`\times`$Time test split, which contains 50 scenes rendered with dense full-grid trajectories that can be retimed into arbitrary temporal sequences. For each test case, we take a moving-camera source video but set the target camera trajectory to the first-frame pose. We then apply a range of temporal control signals, including reverse, bullet-time, zigzag, slow motion, and normal playback, to synthesize the corresponding retimed outputs. Since we have ground-truth frames for all temporal configurations, we report perceptual losses: PSNR, SSIM, and LPIPS.
We consider two baselines: (1) ReCamM+preshuffled: original ReCamMaster combined with input re-shuffling; and (2) ReCamM+jointdata: following , we train ReCamMaster with additional static-scene datasets which provide only one single temporal pattern.
While frame shuffling may succeed in simple scenarios, it fails to disentangle camera and temporal control. As shown in Table [tab:temporal_eval], this approach exhibits the weakest temporal controllability. Although incorporating static-scene datasets improves performance, particularly in the bullet-time category, relying on a single temporal control pattern remains insufficient for achieving robust temporal consistency. In contrast, SpaceTimePilot consistently outperforms all baselines across all temporal configurations.
Visual Quality Evaluation.
Next, we evaluate the perceptual realism of our 1800 generated videos using VBench . We report all standard visual quality metrics to provide a comprehensive assessment of generative fidelity. [tab:vbench_visual_only] shows that our model achieves visual quality comparable to the baselines.
|
|
Camera-Control Evaluation.
Finlay, we evaluate the effectiveness of our camera control mechanism detailed in Sec. 3.3. Unlike the retiming evaluation above, which relies on synthetic ground-truth videos, here we construct a real-world 90-video evaluation set from OpenVideoHD , encompassing diverse dynamic human and object motions. Each method is evaluated across 20 camera trajectories: 10 starting from the same initial pose as the source video and 10 from different initial poses, resulting in a total of 1800 generated videos. We apply SpatialTracker-v2 to recover camera poses from the generated videos and compare them with the corresponding input camera poses. To ensure consistent scale, we align the magnitude of the first two camera locations. Trajectory accuracy is quantified using $`\mathbf{RotErr}`$ and $`\mathbf{TransErr}`$ following , under two protocols: (1) evaluating the raw trajectories defined w.r.t. the first frame (relative protocol, RelRot, RelTrans) and (2) evaluating after aligning to the estimated pose of the first frame (absolute protocol, AbsRot, AbsTrans). Specifically, we transform the recovered raw trajectories by multiplying the relative pose between the generated and source first frames, estimated by DUSt3R . We also compare this DUSt3R pose with the target trajectory’s initial pose, and report RotErr, RTA@15 and RTA@30, as translation magnitude is scale-ambiguous.
 />
/>
 style="width:100.0%" />
style="width:100.0%" />
To measure only the impact of source camera conditioning, we consider the original ReCamMaster (ReCamM) and two variants. Since ReCamMaster is originally trained on datasets where the first frame of the source and target videos are identical, the model always copies the first frame regardless of the input camera pose. For fairness, we retrain ReCamMaster with more data augmentations to include non-identical first frames, denoted as ReCamM+Aug. Next, we condition the model additionally with source cameras $`\mathbf{c}_\text{src}`$ following Eq. [eq-srccam], denoted as ReCamM+Aug+$`\mathbf{c}_\text{src}`$. Finally we also report the results of TrajectoryCrafter .
In Table [tab:camera_accuracy], we observe that the absolute protocol produces consistently higher errors, as trajectories must not only match the overall shape (relative protocol) but also align correctly in position and orientation. Interestingly, ReCamM+Aug yields higher errors than the original ReCamM, whereas incorporating source cameras $`\mathbf{c}_\text{src}`$ results in the best overall performance. This suggests that, without explicit reference to $`\mathbf{c}_\text{src}`$, exposure to more augmented videos with differing initial frames can instead confuse the model. The newly introduced conditioning signal on the source video’s trajectory $`\mathbf{c}_\text{src}`$ achieves substantially better camera-control accuracy across all metrics, more reliable first-frame alignment, and more faithful adherence to the full trajectory than all baselines.
Qualitative results.
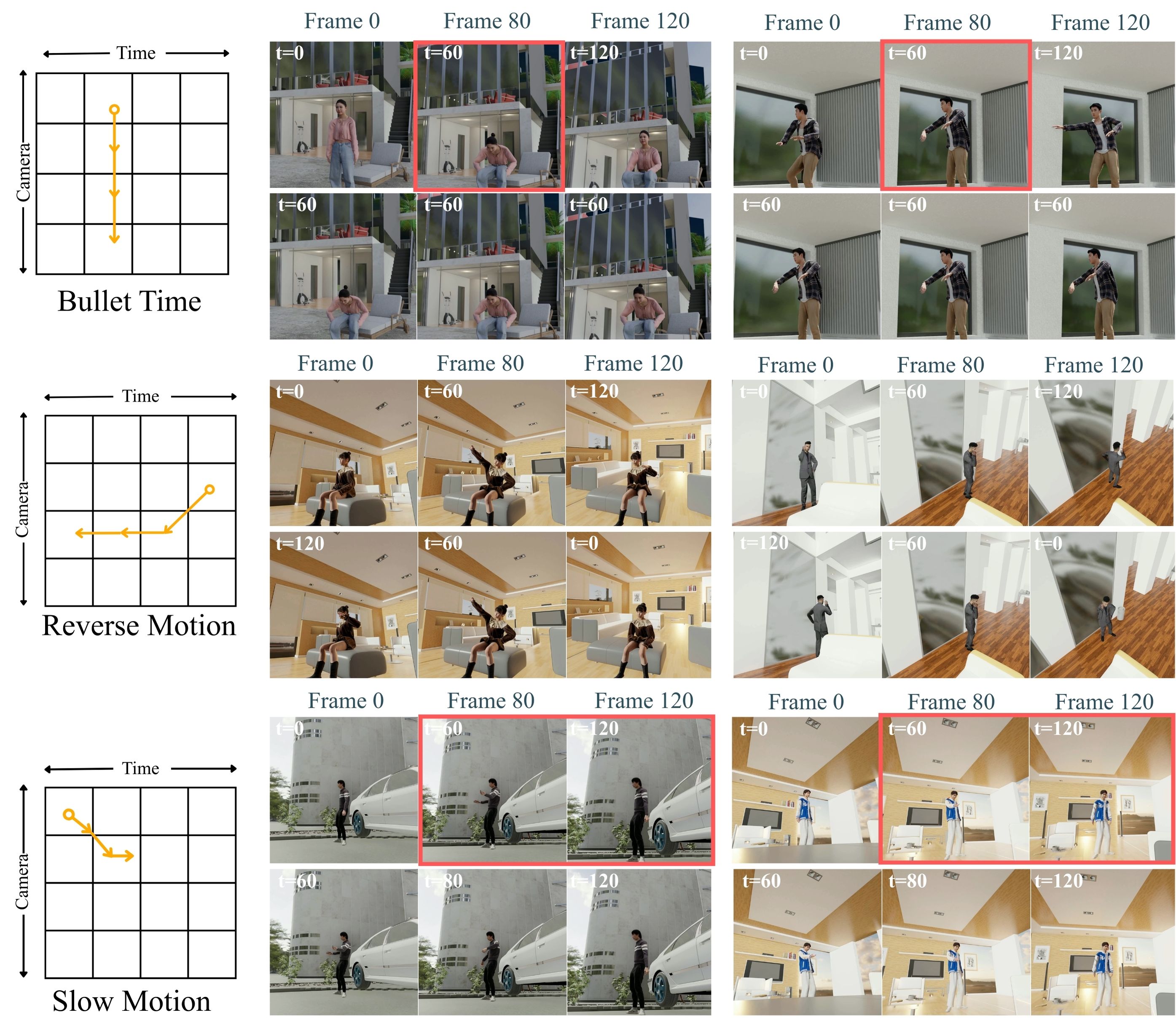
Besides the quantitative evaluation, we also demonstrate the strength of SpaceTimePilot with visual examples. In 5, we show that only our method correctly synthesizes both the camera motion (red boxes) and the animation-time state (green boxes). While ReCamMaster handles camera control well, it cannot modify the temporal state, such as enabling reverse playback. TrajectoryCrafter, in contrast, is confused by the reverse frame shuffle, causing the camera pose of the last source frame (blue boxes) to incorrectly appear in the first frame of the generated video. More visual results can be found in 4.
Ablation Study
To validate the effectiveness of the proposed Time embedding module, in Table [tab:time_embed_ablation], we follow the time-control evaluation set up in Sec. 4.1.1 and compare our 1D convolutional time embedding against several variants and alternatives discussed in Sec. 3.2.1: (1) Uniform-Sampling: sampling the 81-frame embedding uniformly to a 21-frame sequence, which is equivalent to adopting sinusoidal embeddings at the latent frame $`f'`$ level; (2) 1D-Conv: using 1D convolution layers to compress from $`\mathbf{t}\in \mathbb{R}^F`$ to $`\mathbf{t}\in \mathbb{R}^{F'}`$, trained with ReCamMaster and SynCamMaster datasets. (3) 1D-Conv+jointdata: row 2 but including additionally static-scene datasets . (4) 1D-Conv (ours): row 2 but instead including the proposed Cam$`\times`$Time. We observe that applying a 1D convolution to learn a compact representation by compressing the fine-grained $`F`$-dim embeddings into a $`F'`$-dim space performs notably better than directly constructing sinusoidal embeddings at the coarse $`f'`$ level. Incorporating static-scene datasets yields only limited improvements, likely due to their restricted temporal control patterns. By contrast, using the proposed Cam$`\times`$Time consistently delivers the largest gains across all three metrics, confirming the effectiveness of our newly introduced datasets. Furthermore, as shown in 6, we present a visual comparison of bullet-time results using uniform sampling and an MLP instead of the 1D convolution for compressing the temporal control signal. Uniform sampling produces noticeable artifacts, and the MLP compressor causes abrupt camera motion, whereas the 1D convolution effectively locks the animation time and enables smooth camera movement.
Conclusion
We present SpaceTimePilot, the first video diffusion model to provide fully disentangled spatial and temporal control, enabling 4D space-time exploration from a single monocular video. Our method introduces a new “animation time” representation together with a source-aware camera-control mechanism that leverages both source and target poses. This is supported by the synthetic Cam$`\times`$Time and a temporal-warping training scheme, which supply dense spatiotemporal supervision. These components allow precise camera and time manipulation, arbitrary initial poses, and flexible multi-round generation. Across extensive experiments, SpaceTimePilot consistently surpasses state-of-the-art baselines, offering significantly improved camera-control accuracy and reliable execution of complex retiming effects such as reverse playback, slow motion, and bullet-time.
Acknowledgement
We would like to extend our gratitude to Duygu Ceylan, Paul Guerrero, and Zifan Shi for insightful discussions and valuable feedback on the manuscript. We also thank Rudi Wu for helpful discussions on implementation details of CAT4D.
Network Architecture
The network architecture of SpaceTimePilot is depicted in 7. The newly introduced animation-time embedder $`\mathcal{E}_{\text{ani}}`$ encodes the source and target animation times, $`\mathbf{t}_\text{src}`$ and $`\mathbf{t}_\text{trg}`$, into tensors matching the shapes of $`x_\text{src}`$ and $`x_\text{trg}`$, which are then added to them respectively. During training, we train only the camera embedder $`\mathcal{E}_{\text{cam}}`$, the animation-time embedder $`\mathcal{E}_{\text{ani}}`$, the self-attention (full-3D attention), and the projector layers before the cross-attention.
 />
/>
 />
/>
Longer Space-Time Exploration Video with Disentangled Controls
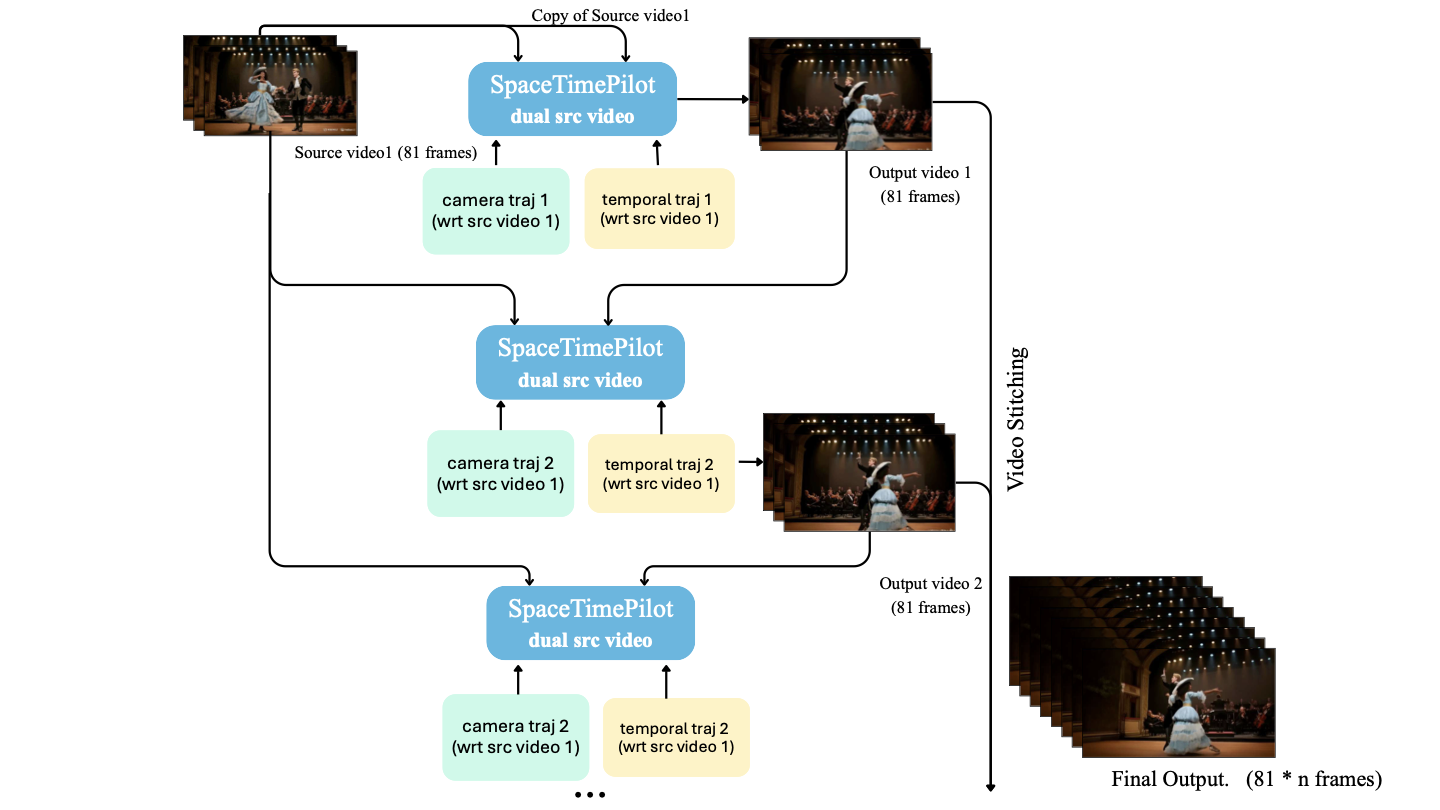
One of the central advantages of SpaceTimePilot is its ability to freely navigate both spatial and temporal dimensions, with arbitrary starting points in each dimension and fully customizable trajectories through them. Although each individual generation is limited to an 81-frame window, we show that SpaceTimePilot can effectively extend this window indefinitely through a multi-turn autoregressive inference scheme, enabling continuous and controllable space–time exploration from a single input video. The overall pipeline is illustrated in 8.
The core idea is to generate the final video in autoregressive segments that connect seamlessly. For example, given a source video of 81 frames, we may first generate a 0.5$`\times`$ slow-motion sequence covering frames 0–40 with a new camera trajectory. Then, continuing both the visual context and the generated camera trajectory, we can produce the next segment starting from the final camera pose of the previous output, while temporally traversing the remaining frames 40–81. This yields an autoregressive chain of viewpoint-controlled video segments that together create a continuous long-range space–time trajectory.
A key property that enables this behavior is that our model can generate video segments whose camera poses do not need to start at the first frame. This allows precise control over the starting point, both in time and viewpoint, for every generated chunk, ensuring smooth, consistent motion over extended sequences.
To maintain contextual coherence across iterations, we introduce a lightweight memory mechanism. During training, the model is conditioned on a pair of source videos, which enables consistent chaining during inference. Specifically:
-
At iteration $`i = 1`$, the model is conditioned only on the original source video.
-
At iteration $`i = 2`$, it is conditioned on both the source video and the previously generated 81-frame segment.
-
This process repeats, with each iteration conditioning on the source video as well as the most recent generated segment.
This simple yet effective strategy allows SpaceTimePilot to generate arbitrarily long, smoothly connected sequences with continuous and precise control over both temporal manipulation and camera motion.
Here, we showcase how this can be used to conduct large viewpoint changes, as demonstrated in 9.

Additional Ablation Studies
Temporal Warping Augmentation
 />
/>
Using as our default datasets, we compare training jointly with static-scene datasets with applying only temporal warping (TW) augmentation on the default datasets (Sec. 3.2.2 in the main paper). Although static-scene datasets naturally support bullet-time effects, they do not provide enough diversity of temporal control configurations for models to reliably learn time locking on their own, as shown in 10 (top). Please refer to section “Effective Temporal Warping” in the website for more videos.
In 10 (bottom), we further show that freezing temporal warping (3rd row) produces better results than training without freezing it. Please refer to section “Freeze Warping Ablations” in the website for more videos.
Significance of Cam$`\times`$Time Dataset
Besides the quantitative results in the main paper (Table 5), in
11 (top), we provide visual
comparisons demonstrating the effectiveness of the proposed
Cam$`\times`$Time dataset. Clear
artifacts appear in baselines trained without additional data or with
only static-scene augmentation (highlighted in red boxes), whereas
incorporating Cam$`\times`$Time
removes these artifacts, demonstrating its significance. Please refer to
section “Dataset Ablations” in the website for more videos.
Time Embedding Ablation
 />
/>
As promised in Sec. 3.2.1 in the main paper, we compare several
time-embedding strategies. RoPE($`f'`$) can freeze the scene dynamics at
$`\mathbf{t}`$=40, but it also undesirably locks the camera motion.
Using MLP, by contrast, fails to lock the temporal state at all (red
boxes). Conditioning on the latent frame $`f'`$ (with uniform sampling)
introduces noticeable artifacts. In comparison, the proposed 1D-Conv
embedding enables SpaceTimePilot to
preserve the intended scene dynamics while still generating accurate
camera motion. Adding
Cam$`\times`$Time to training
further enhances the results. Please refer to section “Time-Embedding
Method Ablation” in the website for more examples.
Additional Qualitative Visualizations
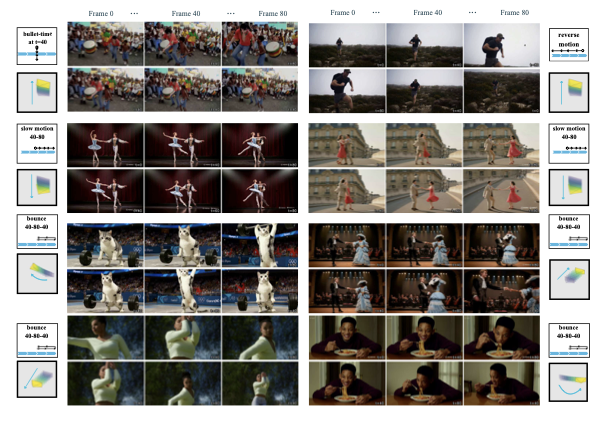
We show more qualitative results of SpaceTimePilot in [fig:more_quali]. Our model provides fully disentangled control over camera motion and temporal dynamics. Each row presents a different pairing of temporal control inputs (top-left icon) and camera trajectories. SpaceTimePilot reliably generates coherent videos under diverse conditions, including normal and reverse playback, bullet-time, slow motion, replay motion, and complex camera movements such as panning, tilting, zooming, and vertical translation. Please refer to section “Video Demonstrations” in the website for more examples.
📊 논문 시각자료 (Figures)

![]()