GenZ: Foundational models as latent variable generators within traditional statistical models
📝 Original Info
- Title: GenZ: Foundational models as latent variable generators within traditional statistical models
- ArXiv ID: 2512.24834
- Date: 2025-12-31
- Authors: Marko Jojic, Nebojsa Jojic
📝 Abstract
We present GenZ, a hybrid model that bridges foundational models and statistical modeling through interpretable semantic features. While large language models possess broad domain knowledge, they often fail to capture dataset-specific patterns critical for prediction tasks. Our approach addresses this by discovering semantic feature descriptions through an iterative process that contrasts groups of items identified via statistical modeling errors, rather than relying solely on the foundational model's domain understanding. We formulate this as a generalized EM algorithm that jointly optimizes semantic feature descriptors and statistical model parameters. The method prompts a frozen foundational model to classify items based on discovered features, treating these judgments as noisy observations of latent binary features that predict real-valued targets through learned statistical relationships. We demonstrate the approach on two domains: house price prediction (hedonic regression) and cold-start collaborative filtering for movie recommendations. On house prices, our model achieves 12% median relative error using discovered semantic features from multimodal listing data, substantially outperforming a GPT-5 baseline (38% error) that relies on the LLM's general domain knowledge. For Netflix movie embeddings, our model predicts collaborative filtering representations with 0.59 cosine similarity purely from semantic descriptions-matching the performance that would require approximately 4000 user ratings through traditional collaborative filtering. The discovered features reveal dataset-specific patterns (e.g., architectural details predicting local housing markets, franchise membership predicting user preferences) that diverge from the model's domain knowledge alone.📄 Full Content
Movies are an example of such items. We can use an LLM to featurize them as binary vectors based on answers to questions as illustrated in Fig. 1. These binary vectors can help explain the patterns found in the movie-user ratings matrix. Collaborative filtering techniques reduce the observation matrix to embeddings, which capture usage statistics absent from the foundational models’ training data. The foundational models, however, can reason about the semantic content-such as the movie synopsis, critical response, credits, and other metadata-either from their training or by retrieving information from a database as part of a RAG system.
We describe how appropriate prompts can be learned from such item statistics by jointly modeling the semantic features and the statistical patterns in the data.
We study a general hybrid statistical-foundational model defined as follows. Let s be the semantic representation of an item, e.g., text with a movie title or its description. Given a collection of semantic feature descriptors θ f , such as ‘historical war film’, a foundational model, which we refer to as s = { “0. Fast and Furious”, “1. Miss Congeniality”, “2. Independence Day”, … } θ f = { “0. Fantastical world”, “1. Historical war film”, “2. Special effects”, “3. Coming-of-age”, … } e_prompt1 = f"For item ‘{s[t]}’ first describe its characteristics.
Then consider this feature:
Finally, output a JSON object with an answer determining if the feature applies to the item.
{{ “applies”: [0 or 1] }}" e_prompt2 = f"For item list ‘{s}’ first describe items characteristics.
Then consider this feature:
Finally, output a JSON object where the keys are the item numbers that satisfy the feature:
{{ “matched_items”: [list] }}" Figure 1: Feature classification h(s, θ f ) with extraction prompt strings shown in Python syntax. Items s in the list are featurized using feature descriptions in θ f . The first prompt is used within a double loop (t, i) over items and features. The second is looped only over i (and batches of items {s}) as each call retrieves the indices of items for which z i = 1 (with z i = 0 for all other items). function h, makes a judgment whether the feature applies to the item (Figure 1). Let z be the true binary feature vector that allows for possible errors in either the model’s judgment or the wrongly worded feature descriptors. We model uncertainty by defining a conditional distribution p(z|s, θ f , θ e ), where z = [z 1 , z 2 , …, z n f ] T is a discrete feature vector (binary, in the example in the figure and in our experiments), θ f is a collection of semantic feature descriptors, such as ‘historical war film’, and θ e = [p e 1 , p e 2 , …, p e n f ] is a set of estimated probabilities of feature classification errors. A feature vector is then linked to observation y through a classical statistical model p(y|z, θ y ), possibly involving latent variables or some other way of modeling structure, and which has its own parameters θ y . By jointly optimizing for the parameters of the model p(y|s) = z p(y|z)p(z|s) based on a large number of pairs (y, s) we can discover the feature descriptions, or the right questions to ask, in order to explain the statistics in the dataset. More generally, hybrid models could have more than one category of items with a (learnable) statistical model of their relationships, for example geographic regions and native plants.
The idea of using interpretable intermediate representations to bridge inputs and predictions has a long history in machine learning. Concept bottleneck models (CBM) Koh et al. (2020); Kim et al. (2023) formalized this approach by training neural networks to predict pre-defined human-interpretable concepts from inputs, then using those concepts to make final predictions. Recent work has leveraged large language models (LLMs) to overcome the need for manually labeled concepts, e.g., Benara et al. (2024); Feng et al. (2025); Chattopadhyay et al. (2023); Zhong et al. (2025); Ludan et al. (2024). These methods may or may not use the CBM formulation but share with it the goal of feature interpretability. In addition, they have a goal of feature discovery, which is also one of the goals here. They address the difficulty of modeling and jointly adjusting the semantic and statistical parts of the model-in our notation p(z|s) and p(y|z)-in different ways.
In most cases, the target y is a discrete variable (the goal is a classification through intermediate concepts), and thus the classification model p(y|z) is a simple logistic regressor or an exhaustive conditional table Chattopadhyay et al. (2023); Feng et al. (2025); Zhong et al. (2025). The optimization of the featurizer p(z|s) primarily relies on the LLM’s domain understanding (such as a task description), but some methods also provide examples of misclassified items, e.g., Zhong et al. (2025); Ludan et al. (2024).
When real-valued multi-dimensional targets y are modeled, showing items with large prediction errors is much less informative because each item may have a different error vector, and thus itemdriven discovery is usually abandoned. For example, in Benara et al. (2024) multidimensional targets (fMRI recordings) are modeled, and the method relies on direct LLM prompting about potentially predictive features based on domain knowledge alone, followed by feature selection, rather than showing specific items to contrast.
“Armageddon”, “The Rock”, “Lethal Weapon 4”, “Con Air”, “Twister” } Negative = { “Mystic River”, “Lost in Translation”, “Collateral”, “Fahrenheit 9/11”, “Big Fish” } m_prompt = f"Consider the two groups and first describe the items and their characteristics. 1. When the statistical model identifies a binary split in the data, we can prompt a foundational model to generate an explanation by providing example items from each group. This explanation can then be used as a feature descriptor in θ f . The prompt need not include all members of each group, only representative examples.
A fundamental limitation shared by these approaches is their reliance on the LLM’s domain understanding to propose discriminative features. This works well when the LLM has been trained on relevant data and the task aligns with common patterns in its training distribution. However, as our experiments demonstrate, domain understanding alone is insufficient when dataset-specific patterns diverge from general knowledge-such as house pricing dynamics in particular markets, or user preferences captured in collaborative filtering from specific time periods or demographics. Moreover, for high-dimensional real-valued targets y, individual prediction errors have multidimensional structure that cannot be easily communicated to an LLM by simply showing “incorrect” examples.
Our approach differs in several key aspects. First, as in some of the recent work, we avoid concept supervision by using a frozen foundational model as an oracle within p(z|s), but with trainable uncertainty parameters θ e . Second, our feature mining is driven by contrasting groups of items identified through the statistical model’s posterior q(z) rather than by querying the LLM’s domain knowledge or showing individual misclassified examples (Figure 2). This group-based contrast allows the method to discover dataset-specific patterns that may not align with the LLM’s training distribution-or even in cases where the LLM has no understanding of what the target y represents. (We do, however, require the (M)LLM to reason about the semantic items s, either based on knowledge encoded in its weights or by retrieving information from a database as in RAG systems). Third, we support arbitrary mappings p(y|z) including nonlinear functions of binary features for highdimensional real-valued observations, shifting the burden of modeling complex feature interactions from the LLM to the statistical model. The LLM is only responsible for explaining the semantic coherence of binary splits discovered based on the model’s prediction errors, making it applicable to domains where the relationship between semantics and observations is not well understood in advance.
We refer to our hybrid model as GenZ (or GenAIz?) as it relies on a pre-trained generative AI model to generate candidate latents z in a prediction model s → z → y. We derive a generalized EM algorithm for training it, which naturally requires investigation of items s when tuning parameters θ f of the featurizer p(z|s).
Before developing the full algorithm, we first describe the semantic part: the semantic parameters θ f , how p(z|s) depends on them and on a foundational model, and how statistical signals from the model enable updating these parameters in an iterative EM-like algorithm.
The foundational model’s reasoning abilities are sufficient to featurize a semantic item using standard classification prompts. A generic version of this is illustrated in Fig. 1. In the example shown, the items are represented with text, in this case movie titles that large language models are likely familiar with. Each string in the list is an item description s-however, the text describing each item could be expanded to include more details about the movie, or a RAG system with access to a movie database could be used in place of an LLM. We use the output h(s, θ f ) of such systems cautiously: we associate an uncertainty level, i.e., a probability p e j of mislabeling h ̸ = z for entry z j in z. Assuming that z is not deterministically linked to s makes it a latent variable in the p(y, z|s) model, allowing flexibility in inference and enabling updates to the semantic feature descriptions in θ f : If the posterior over y can override the foundational model’s determination of whether an item satisfies the feature, this provides a signal for updating the feature semantics.
As already alluded to, the feature semantics θ f are not hand-crafted but learned from the dataset statistics. The statistical signal from the data indicates how the items should be separated along a particular feature j, i.e., how the z j for different items can be altered so that the model explains the data better. In our setup, we deal with binary features, so the signal separates the items into two groups, and we seek a semantic explanation for this separation, θ f . Specifically, for fixed model parameters, focusing on a particular binary feature z i ∈ {0, 1} for one semantic item s, the prior and posterior distributions are generally different:
Thus, sampling the posterior distribution (referred to below as q) for several different items s t yields new feature assignments z t i . These help update the feature descriptor θ f i used in p(z i |s, θ f ) by using the prompt in Fig. 2. There, the positive group has a few items s t for which z t i = 1 and the negative group has a few items for which z t i = 0. Furthermore, we can select group exemplars to contain both semantic items where the posterior and the prior agree, and where they disagree. This encourages small refinements, e.g., from “fearless female characters in an action movie” to “strong female leads”.
Given an item’s semantics s, e.g., a movie description, and its corresponding observed vector y, e.g., the movie’s embedding derived from the statistics in the movie-user matrix, the log likelihood can be bounded as
where E q refers to an expectation under the distribution q. Depending on the variational approximation of q and the model p(y|z) these expectations can be computed exactly, as illustrated by the example of the mean-field q and linear p(y|z) in Section B. Otherwise, a sampling method can be used, often with very few samples due to the iterative nature of the learning algorithm. In experiments (Section 5), we simply evaluate at the mode of q.
The bound is tight when the variational distribution q is equal to the true posterior p(z|y, s), otherwise q(z) serves as an approximate posterior. We refer to the three additive terms as the observation part T 1 = E q [log p(y|z)], the feature part T 2 = E q [log p(z|s)], and the posterior entropy
Given a dataset of pairs {s t , y t } T t=1 , the optimization criterion-the bound on the log likelihood of the entire dataset-is
In general, maximizing the criterion L w.r.t. all variables except semantic model parameters (feature descriptions) θ f is straightforward: we can use existing packages or derive an EM algorithm specific to the choice of the model’s statistical distributions. The variational distributions q t (z) depend only on the individual bounds for each data pair (y t , s t ) in (1) and can be fitted independently for given model parameters θ f , θ e , θ y . The (approximate) posteriors q t (z i ) provide the statistical signal discussed in Section 2 for tuning the semantic feature descriptions θ f i : sampling them separates the samples s t into two groups, and exemplars from each are used to prompt the foundational model with the prompt in Fig. 2 for a new definition of the i-th feature. The optimization of L then consists of steps that improve it w.r.t. the statistical model parameters and the (approximate) posteriors q, alternating with updates of the feature descriptions using those posteriors.
This general recipe can be used in a variety of ways, with different choices for the structure of the conditionals in the model p and different approximations of the posterior q leading to a variety of algorithms including variational learning, belief propagation and sampling Frey & Jojic (2005). We now develop specific modeling choices and a learning algorithm we use in our experiments.
As discussed, the feature model uses a prompt-based feature classification, where each feature is treated independently based on its description θ f i (Fig. 1)
with the uncertainty (probability of error) p e i , so that p(
where h is the binary function that uses one of the prompts in Fig. 1 to detect the feature θ f i in the semantic item s. The expression above uses the indicator function [] to express that with the probability of error p i e , the feature indicator z i is different from h(s, θ f i ). Denoting h i = h(s, θ f i ), we write
Using a factorized posterior q = i q(z i ), the feature term T 2 simplifies to
with ℓ 1 i and ℓ 0 i defined in (5). Finally, the entropy term becomes
We can soften an arbitrary mapping function y = f (z; θ m ) by defining a distribution:
with θ m being the mapping parameters of function f , e.g., regression weights in y = w T z, and σ 2 y being a vector of variances, one for each dimension of y. Different specialized inference algorithms for specific forms of function f can be derived. For example, see the appendix for a procedure derived for a linear model (factor analysis). However, in our experiments, we use a generic inference technique using f in plug-and-play fashion, described below.
Inference of q(z i ) in the fully factorized (mean field) q model Keeping all but one q(z i ) fixed, we derive the update for the i-th feature’s posterior by setting the derivative of the bound B wrt parameters q(z i = 1) and q(z i = 0), subject to q(z i = 1) + q(z i = 0) = 1. We can express the result as:
q(z i = 1) ∝ e Eq +i [log p(y|z)]+Eq +i [log p(z|s)]-Eq +i [log q(z)] , q(z i = 0) ∝ e Eq -i [log p(y|z)]+Eq -i [log p(z|s)]-Eq -i [log q(z)] (10)
where q +i = [z i = 1] j̸ =i q(z j ), and q +i = [z i = 0] j̸ =i q(z j ), i.e the “+i” and “-i” posteriors have their z i value clamped to 1 and 0 respectively in the factorized q = q(z i ). Upon normalization, as the entropy terms E q +i [log q(z)] and E q -i [log q(z)] cancel each other, we obtain:
Interpretation: Whether or not z i should take value 1 or 0 for particular semantic item s depends on:
• the assignment h that the foundational model assigns it and the level of trust we have in that assignment (the probability of error p e i ). The two are captured in prior log likelihoods ℓ 1 , ℓ 0 . • error vector y -f (z), scaled by the currently estimated variances σ 2 y for different elements of the target y, for two possible assignments z i = 1 and z i = 0, with other assignments z j following the current distributions over other features q(z j )
While expectations E q+i and E q+i can potentially be better estimated through sampling, in our experiments, we simply compute log p(y|z) at the mode (assuming most likely values for other z j variables).
Optimizing the bound B wrt to parameters θ m of the mapping in y ≈ f (z; θ m ) and the remaining uncertainty/variance σ 2 y reduces to maximizing sum of T 1 terms over the traing set, i.e. t E t q [log p(y t |z t )]. Again, while sampling of q might be helpful, in our experiments we simply use the mode and iterate:
where z t is the binary vector of assignments of features z i , either a sample from q t or at the mode of the posterior q t for the t-th out of T entries in the data set of pairs s t , y t . • is a point-wise multiplication.
The semantic model has numeric parameters p e i , modeling the hybrid model’s uncertainty in semantic function h that makes an API call to the foundational model. By optimizing the bound wrt these parameters we obtain the update:
Thus, for a given set of semantic feature descriptors θ f , iterating equations (11) for each item t, and (12, 14) using all items in the training set, would fit the numerical model parameters and create the soft feature assignments q t that best balance those feature descriptors with the target real and possible multi-dimensional targets y t .
In section 2 we pointed out that individual q(z i ) distributions carry information about how the data should be split into two groups to create the mining prompt in Fig. 2. But as each of these distributions depend on the others, there is the question of good initialization. In our experiment we use a method akin to the variational EM view of boosting Neal & MacKay (1998), albeit in our case applied to learning to predict real-valued multi-dimensional targets, rather than just for classification.
Note that if we iterate (11,12,14) while keeping p e i = 0.5 for a select feature i the entire hybrid model and the posterior q(z i ) are decoupled from the foundational model’s prediction h i which depends on feature description θ f i to provide its guess at z i . Therefore, the iterative process is allowed to come up with the assignment of z t i for each item t in such a way that maximizes the likelihood (and minimizes the prediction error). This provides a natural binary split of the data into two groups based on error vectors. In case of predicting house prices (one dimensional y, those two groups would be the lower and higher priced houses relative to current prediction, but in case of multi-dimensional observations, such as movie embeddings, the split would be into two clusters, each with their own multi-dimensional adjustment to the current prediction.
A simple algorithm for adding features is shown in Algorithm 1. The key idea is to fit a model with only features j ∈ [1..i] while keeping the new feature i decoupled from the LLM prediction by fixing p e i = 0.5. This allows the data to determine the optimal split before discovering its semantic explanation.
The algorithm operates on the model p({y t , {z t j } i j=1 , s t } T t=1 ), where features j > i do not participate. By keeping p e i = 0.5 fixed during the inner loop, the posterior q t i is determined purely by how well z t i helps explain y t , independent of any LLM prediction. This provides the statistical signal needed to discover meaningful features through the mining prompt.
As we show in experiments on the simple task of discovering binary representation of numbers, iteratively running Algorithm 1 with increasing i adds new features in coarse-to-fine manner, from those that split the data based on large differences in target y to those that contribute to explaining increasingly smaller differences.
A possible problem with such coarse-to-fine approach, especially for nonlinear and easy to overfit functions f (z), is that items with different combinations of features can be arbitrarily split with the feature z i we are updating. For example, suppose we are working on the house pricing dataset and are running the Algorithm 1 for the second time, having added only one feature so far: θ f1 =‘Located in Arizona desert communities’. Then as we iteratively look for a natural split q 2 it is possible that for items with high q 1 , the procedure may split the data along a different semantic axis (e.g., presence of swimming pools) than for the items with low q 1 . To deal with this, we alter Algorithm 1 very slightly: When we sample positive and negative examples, we take them from items that have other features identical. This is akin to using the structured variational approximation q = q(z i |{z j } j̸ =i ) j̸ =i q(z j ), but instead of fitting this for all combinations of other features, we target only one combination at a time. The discovered feature θ fi is still used to assign values h i for all data samples, whether they were in the targeted group or not, so that it can be used in the next step.
To select the combination of features {z j } i-1 j=1 on which we condition the i-th feature discovery, we start with the cost being optimized in (12), from the observation part (T 1 ) of the approximate log likelihood based on a sample (or the mode) z t for each item:
or equivalently, by partitioning over all observed combinations c of the other features:
where T c 1 are the summands that show the total error due to each observed combination c of the other features z -i = [z 1 , . . . , z i-1 ] T . We select the combination c * with the largest total error c * = arg max c T c 1 . Algorithm 2 shows the conditional (targeted) feature addition procedure. The key difference from Algorithm 1 is that positive and negative examples are sampled from a targeted subgroup G * (items sharing the same values for features 1 through i -1), selected by identifying which combination has the largest total error. The discovered feature θ fi is then applied to all items. These algorithms add a feature but can also be used to update a feature by removing it from the set and then adding a new one. While we can select a feature to update at random, we use a more efficient approach: we choose the feature whose removal affects the prediction (likelihood bound) the least, as shown in Algorithm 3. A single feature update becomes a removal of one feature (Algorithm 3) followed by adding a feature (Algorithm 1). Generally, we alternate an arbitrary number of feature adding steps with feature removal steps, as shown in Algorithm 4.
Algorithm 1 Basic feature discovery (non-targeted)
n inner 2: Output: New feature descriptor θ fi and assignments h t i for all items 3: // Initialize: Decouple new feature from LLM prediction 4: Set p e i ← 0.5 ▷ Maximum uncertainty -feature decoupled from h i 5: Initialize q t i ← 0.5 for all t ∈ [1..T ] ▷ Uniform prior 6: // Iterate with p e i = 0.5 fixed: Optimize q and θ y on partial model 7: for iteration = 1 to n inner do 8:
// E-step: Update posteriors for all items and features 9:
for each item t = 1 to T and feature j ∈ [1..i -1] do 10: Update q t j ← using ( 11)
Sample or take mode: z t j ∼ q t j or z t j = [q t j > 0.5] Update mapping parameters θ m using ( 12)
Update observation variance σ 2 y using ( 12)
16:
Update error rates p e j for j < i using ( 14) ▷ But keep p e i = 0.5 17: end for 18: // Mining: Discover semantic explanation 19: Sample q t i to form groups:
n inner 2: Output: New feature descriptor θ fi and assignments h t i for all items Lines 3-17: Same as Algorithm 1 (initialize, iterate to obtain q t i and z t )
18: // Mining: Select targeted group and discover semantic explanation 16) 20: // Sample positive and negative groups from targeted combination 21: for iteration = 1 to n refit do 12:
for each item t and feature k ̸ = j do 13:
Update q t k using (11) for a = 1 to k add do 7:
end for
Especially exciting applications of hybrid models discussed above involve situations in which the foundational model is capable of recognizing patterns in the data, i.e., features that some items share and others do not, but the high-dimensional target y is not understood well by the model, e.g., in scientific discovery based on new experiments. However, there is value in analyzing situations where we (humans) understand the links so that we can better understand what the model is discovering. This is especially interesting when the data involves well understood semantic items, but also novel (or dated!), or otherwise skewed statistics between these items and the targets y which we want to discover, despite a potential domain shift w.r.t. what the foundational model was trained on.
We analyzed three datasets we expected to be illustrative:
• Learning binary: A toy dataset with items s being strings “0”, “1”, . . . , “511”, and the corresponding targets y = str2num(s). We demonstrate that iterating Algorithm 1 recovers a 9-bit binary representation.
• Hedonic regression on house prices: A multimodal dataset from Ahmed & Moustafa (2016), consisting of four listing images and metadata, which we turned into semantic items s describing all information about a house and the target log price y (Fig. 3).
• Cold start in recommendation systems: The Netflix prize dataset. Singular value decomposition of the user-movie matrix is used to make 32-dimensional embedding y for each movie, and the associated semantic item is the movie title and the year of release.
Since LLMs can understand similarities between movies or houses and prices, there was a chance that the models could discover relevant features without our iterative algorithms. In fact, as discussed in Section 1, most prior work on using off-the-shelf LLMs to discover features useful in classification and, especially, regression focused on probing LLMs with the description of the task, rather than the data itself, and subsequent feature selection. Our baseline that represents such approaches, which we refer to as 0-shot, is to provide an LLM with an example list of semantic items, describe the task, and ask for around 50 yes/no characteristics that in the LLM’s judgment would be most useful for the task.
Except for the first experiment, whose purpose is to illustrate coarse-to-fine nature of feature discovery with a linear model, we tested two f (z) functions (softened in p(y|z) through learned variances σ 2 y ): a linear model and a neural network with two hidden layers (64 and 32 units with ReLU activations and dropout rate 0.1), trained using Adam optimizer with learning rate 0.001 for 100 epochs and batch size 32.
For the two more involved datasets (houses and movies), we used conditional feature adding Algorithm 2 with 10-20 cycles of adding 5 features and removing 2. During the process, when a discovered feature is active for less than 2% or more than 98% of the data, it is discarded, resulting in the feature count generally growing until it stabilizes towards the end of the runs.
Mining prompts are executed by GPT 5, while the extraction prompts are executed with GPT 4.
The primary purpose of this experiment was to serve as an explanation of what iteration of the Algorithm 1 tends to do. The semantic items s ∈ {“0”, “1”, . . . , “511”}, have the corresponding targets y = str2num(s). We map characteristics z to predictions y with a linear function f (z) = w T z + b.
When we add the first feature by running Algorithm 1, q i splits the data into high and low values (above or below the mean). When positive and negative groups are incorporated into the mining prompt (Figure 1) and given to GPT 5, it easily detects the pattern: Depending on the random initialization of w, the positive group’s characteristic is of two sorts: either an equivalent of “numbers 0-255 inclusive”, or an equivalent of “numbers greater than 255”.
The first feature splits the data into high and low values, and for all items the model will now predict the mean of one of these two subsets: 127.5 for numbers less than 256, and 383.5 for the rest. The next execution of Algorithm 1 will now assign z 2 = 1 and z 2 = 0 to the items based on where the model over-or underestimates y. (Due to randomness in initialization, z 2 = 1 could focus on either all of the overshoots or all of the undershoots). So, the positive group will consist of either the upper halves of the z 1 groups or the lower halves. For example, the positive group would include all items in both range [0..127] and range [256..383]. Given these as the positive group, and the rest as negative in the mining prompt, GPT 5 sets the next feature to be the equivalent of “Integers with the 2^7 bit unset.” As before, due to random initialization, the positive and negative group could be switched, but that would still yield an equivalent feature, as the model simply adjusts weights.
Here is an example of a set of features θ f obtained by running Algorithm 1 9 times with i increasing from 1 to 9:
• Integers greater than or equal to 256 (i.e., with the 2ˆ8 bit set) • Integers with the 2ˆ7 bit set (i.e., numbers whose value modulo 256 is between 128 and 255) • Integers with the 2ˆ6 (64) bit unset (i.e., numbers whose value modulo 128 is 0-63) • Integers with the 2ˆ5 (32) bit set (i.e., numbers whose value modulo 64 is between 32 and 63) • Integers with the 2ˆ4 (16) bit unset (i.e., numbers whose value modulo 32 is 0-15) • Integers with the 2ˆ3 (8) bit set (i.e., value modulo 16 is between 8 and 15) • Integers with the 2ˆ2 (4) bit unset (i.e., numbers whose value modulo 8 is 0-3) • Integers with the 2ˆ1 (2) bit set (i.e., numbers congruent to 2 or 3 modulo 4) • Integers with the 2ˆ0 (1) bit unset (even numbers)
And here is another one:
• Integers from 256 to 511 (inclusive) • Integers whose value modulo 256 is in the range 128-255 (i.e., their low byte has its highest bit set) • Integers whose value modulo 128 is in the range 0-63 (inclusive) • Integers whose value modulo 64 is in the range 0-31 (the lower half of each 64-block) • Integers whose value modulo 32 is in the range 16-31 (the upper half of each 32-number block) • Integers whose value modulo 16 is in the range 0-7 (the lower half of each 16-number block) • Integers whose value modulo 8 is in the range 0-3 (the lower half of each 8-number block) • Integers congruent to 2 or 3 modulo 4 (i.e., with the second least significant bit set) • Even integers (including 0)
Both reconstructions are perfect. We see the same for other ground truth function choices of y that are linearly related to the value of the number in the string s, y = a 1 • num2str(s) + a 2 . The feature discovery is driven by the structure of the algorithm that breaks the data in a coarse-to-fine manner through binary splits, perfectly matching the binary number representation. All that a foundational model has to do is to recognize this in the provided positive/negative splits. In many applications, such coarse-to-fine binary splitting of the data can be problematic, as features may not interact additively. In the next two experiments in more realistic scenarios, we use Algorithm 2, which chooses the groups conditional on the assignment of the already discovered features.
The multi-modal dataset Ahmed & Moustafa (2016) consists of information for 535 houses listed in 2016, the first of which is shown in Figure 3. While our approach is directly applicable to multi-modal data, to save tokens and avoid limitations on the number of images we can submit in our mining prompt, we first transformed the information to pure text, by running all images through GPT 5 with the prompt “Describe the listing image in detail.”. Each semantic item is a JSON file with metadata (without the price) and image description, and the target y is the log of the price. (Log price modeling is standard in hedonic regression, as some features multiplicatively affect prices. For example, an upgraded interior is costlier for a larger home, or for a home in an expensive ZIP code.)
As discussed in Section 5, we fit y using both linear and nonlinear (neural net) forms of the function f . In both cases, we supply f with additional real-valued inputs x 1 = 1, x 2 = area, x 3 = bedrooms, x 4 = bathrooms, as we do not wish to rediscover these numerical features as we did in the toy experiment in the previous section. However, in the semantic items s, full metadata (the
{ “house_id”: 1, “metadata”: { “bedrooms”: 4, “bathrooms”: 4.0, “area”: 4053, “zip_code”: “85255”, “price”: 869500 }, “image_descriptions”: { “house_id”: 1, “bathroom_description”: “This powder room features ornate, burgundy damask wallpaper…”, “bedroom_description”: “The bedroom is spacious, with plush carpeting and a soft green accent wall …”, “frontal_description”: “The exterior showcases a desert landscape with mature cacti, rocks, and gravel, minimizing maintenance …”, “kitchen_description”: “The kitchen and dining area blend rustic and elegant elements. Rich wood cabinetry, stone accents, …” } } Strikethrough price indicates that price is withheld from items s in training our model. However, in the alternative to our approach, all items including prices were included in baseline prompting, where GPT 5 was given the entire dataset and asked to generate features predictive of the price. number of bedrooms and bathrooms, the area in square feet, but not the price) is still provided, as it can participate in features z to account for both nonlinear transformations of price and combined feature effects. For example, in some locales, luxury homes have more bathrooms than bedrooms and that signal can be captured in the discrete z as an indicator of higher priced homes.
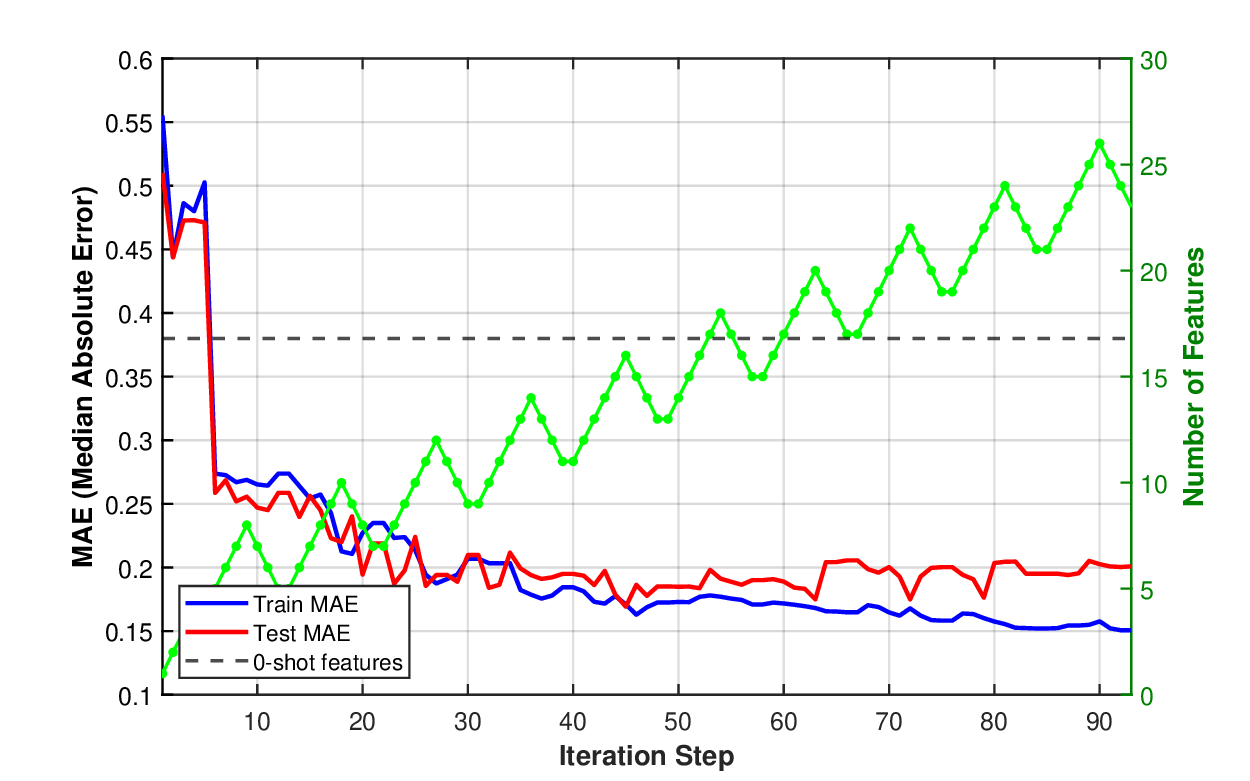
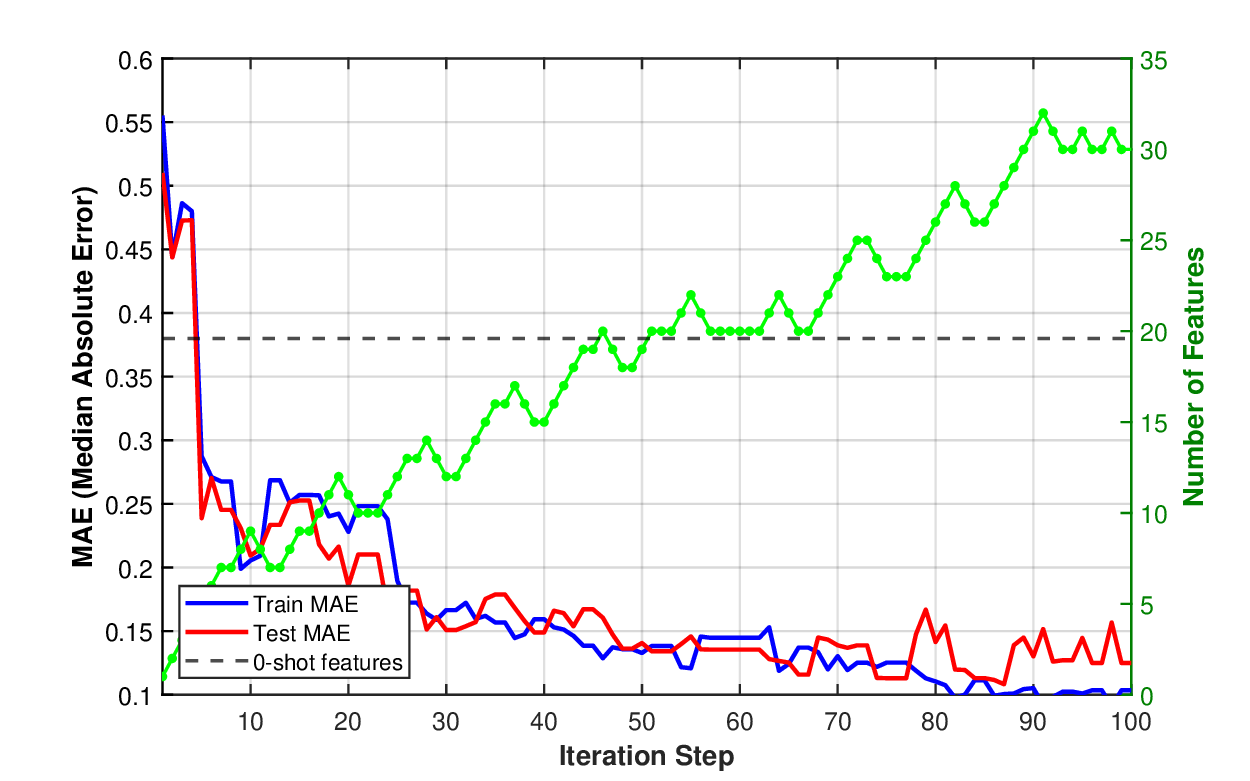
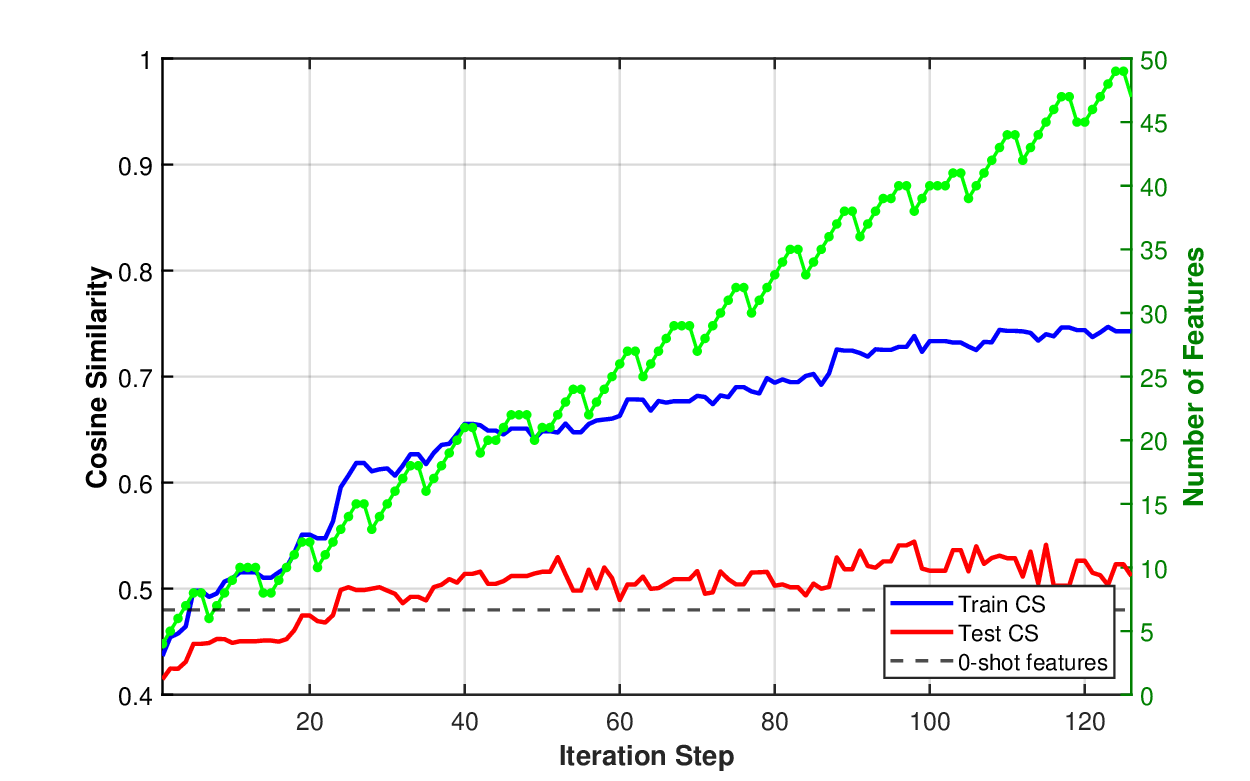
We split the data into the training set (80% of the data) and the test set. We show the learning curves in Figure 4 for the linear model f and a neural network f . The video showing which features are added (blue) or removed (red) in Figure 4 (b) is available at: https://github.com/mjojic/genZ/ tree/main/media. We plot the progress in terms of median absolute error, as this corresponds to how the performance of hedonic regression of house prices tends to be evaluated in industry. For example, Zillow Zillow Group (2024) reported that its Zestimate for off-market homes has a median error rate of 7.01%. (Zestimate for on-market homes is much better because it benefits from the known listing price set by an agent; In our experiments we are trying to predict the price without such professional appraisal). As we model log prices, small median absolute errors (MAE) are close to the relative (percentage) error of the actual (not log) price. For example, achieving MAE of 0.10-0.11, as our model does, is equivalent to a median error rate of around 12%.
The 0-shot baseline is indicated by the horizontal line. The baseline is computed as follows. First, we provided the entire set of semantic items, including the prices to GPT 5 and asked for 50 yes/no questions whose answers would be helpful in predicting the price (GPT gave us 52 instead). Then, these are set to be features θ f , and the pruning Algorithm 3 is applied repeatedly on the training set using linear f (z, x), keeping track of the test performance. (Note that the function f still takes the numeric features x 1 , x 2 , x 3 , x 4 ). The horizontal line on the graph represents the best test set performance achieved during pruning. As discussed in Sections 1, 5, this baseline is meant to simulate what could be expected from methods that rely on LLM’s understanding of the domain, rather than iteratively contrasting items based on modeling error as our approach does. The baseline vastly underperforms, and by comparing the baseline’s features with the features our method discovered (Section A.1) we can see why. For example, the baseline’s features rarely focus on location or the architecture/quality of the build/remodel, and instead capture relatively cosmetic features such as fenced yards or green lawns.
The differences in the learning curves provide another illustration that the hybrid model is adjusting all its parameters in unison during learning. The train and test median absolute error drop together until over-training happens. In the case of the linear model, the training error continues to drop, but the testing error stays stable, while in the case of the nonlinear (neural) model, we see that both train and test errors reach lower levels of around 0.11. This corresponds to roughly 12% relative error on the raw (not log) price, after which the model begins to overtrain more severely, with training error dropping even lower as the testing error continues to rise. (Note Zillow’s 7% errorZillow Group ( 2024), but based on a different, much larger and richer, proprietary dataset of hand-crafted features).
The cold start problem in collaborative filtering systems refers to the challenge of making predictions for new items or users without sufficient interaction history. We use the classic Netflix prize dataset Bennett & Lanning (2007); Kaggle (2006) to demonstrate how our hybrid model can address the cold start problem for new movies by discovering semantic features that predict collaborative filtering embeddings.
For 480,189 users and 17,770 movies, the dataset provides user-movie ratings (0-5, where 0 indicates that the movie was not rated by that user). We computed 32-dimensional embeddings y for each movie using singular value decomposition (SVD) of the ratings matrix. It is well understood that such embeddings capture latent user preferences and movie characteristics discovered through collaborative filtering, and are remarkably good at modeling similarity between movies and matching users to movies via simple vector projection of the embeddings. (See also the discussion in Section C on how instead of embeddings the raw matrix could be modeled with two different types of semantic itemsusers and movies -using a similar formulation to the one above).
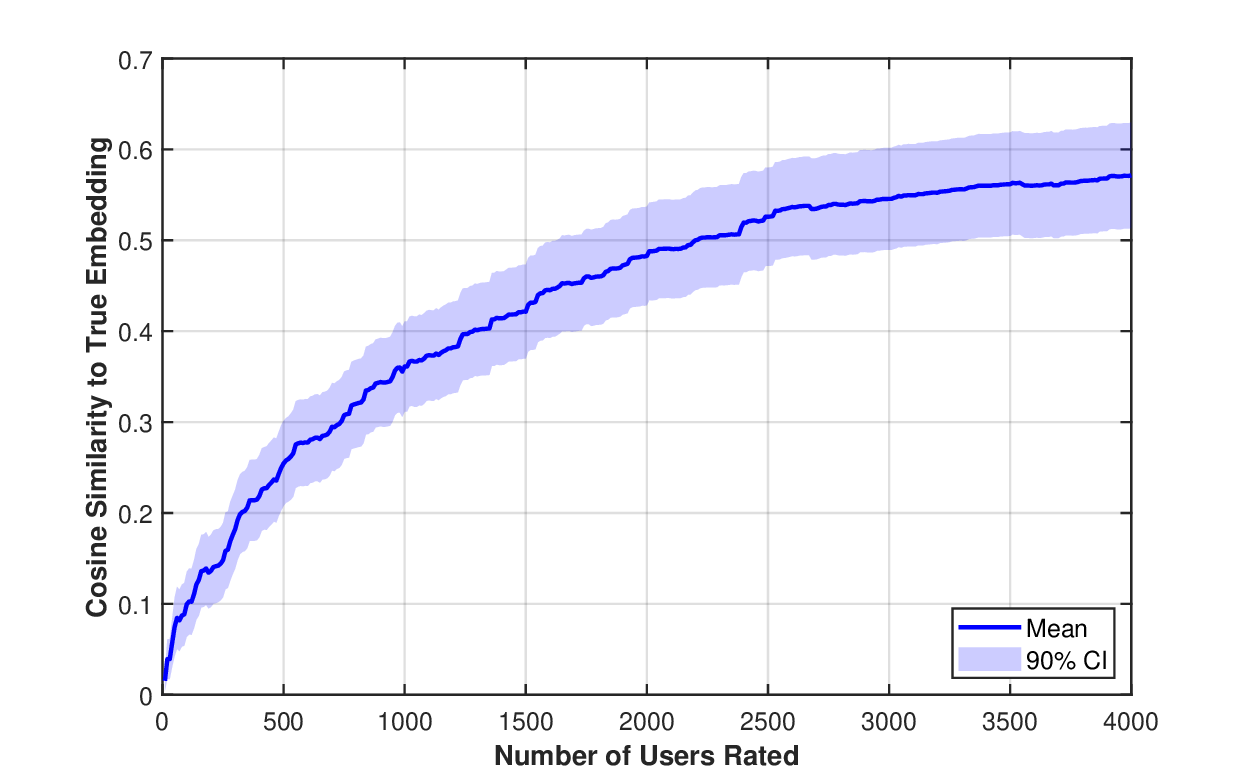
To illustrate the cold start problem, we simulate adding a new movie with limited exposure to viewers, by removing a single movie and gradually adding user ratings. For a selected movie, we set the values in the ratings matrix to zero for all users, then gradually add users’ actual ratings in a random order and recompute the movie’s embedding after each addition. Figure 5 shows how the cosine similarity (CS) between the original (full observation) movie embedding and the embedding based on sparse observations improves as we add ratings for up to 4000 users. The plot shows the mean and 90% confidence interval over 100 randomly selected movies from the dataset. The similarity reaches only about 0.38 after 1000 users and approximately 0.57 after 4000 users. In other words, thousands of users would need to be exposed to the movie, many skipping it, and some rating it, before the CS could grow to around 0.6, leading to more reliable recommendation. We show below that our linear hybrid model can predict embeddings immediately from the semantic items describing the movie, achieving test CS of approximately 0.59 without requiring any user ratings-a performance level that would otherwise require roughly 4000 user ratings to achieve through collaborative filtering alone.
In our experiments, we focused on the 512 most watched movies, again randomly split into training (80%) and test set. This allowed us to set the semantic items s for these movies to consist only of the movie title and year of release: Modern LLMs are familiar with the most popular movies Cosine similarity between embeddings computed from partial ratings vs. full ratings, as user ratings are gradually added in random order. The shaded region shows 90% confidence interval over 100 randomly selected movies. Hundreds of ratings are typically needed before embeddings converge, illustrating the severity of the cold start problem that our hybrid model addresses by predicting embeddings from semantic features alone.
watched in the period from 1998 to 2006. Otherwise, we would need items s to contain more information, as was the case in the house experiment, or allow the LLM to use a RAG system to retrieve relevant information when executing extraction and mining prompts. The quality of the predictions is measured using cosine similarity (CS) between predicted and true 32-dim embeddings y.
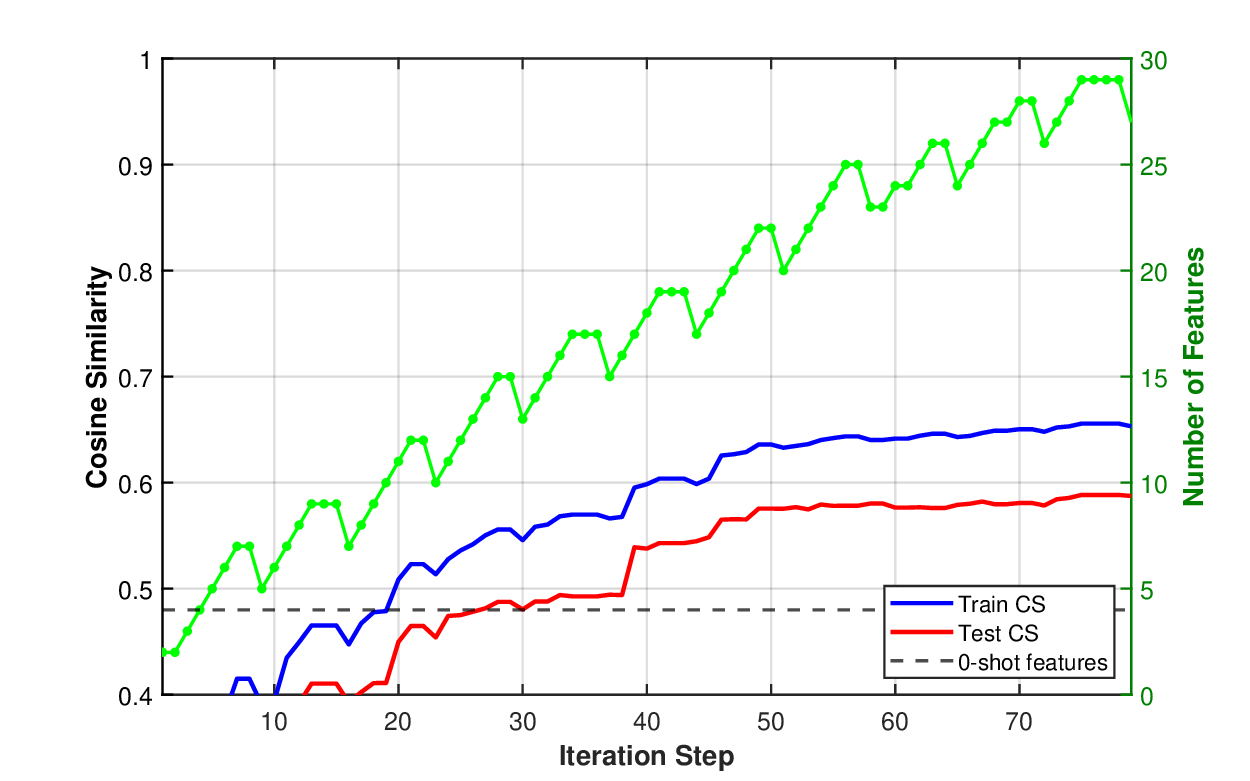
The learning curves are shown in Figure 6 for both linear and neural network models. The video showing which features are added (blue) or removed (red) in Figure 6 (a) is available at: https: //github.com/mjojic/genZ/tree/main/media. As with the houses experiment, we compare against a strong 0-shot baseline (horizontal dashed line at CS=0.48) obtained by asking GPT-5 to suggest 50 features based on the task description and movie titles, then via pruning on the training set find the best feature set in terms of the test error, as this is the best the baseline could possibly get for that training-test split.
The linear model substantially outperforms the 0-shot baseline, reaching a test cosine similarity of approximately 0.59, indicating that the iterative feature discovery process finds movie characteristics more predictive of user preferences than those suggested by the LLM based on task understanding alone. The 0.11 improvement in cosine similarity (from 0.48 to 0.59) is substantial: As the cold start simulation in Figure 5 shows, this difference equals the improvement from adding roughly 2000 additional user ratings. Unlike the house price prediction experiment, using the neural network as the function f (z) in the GenZ system leads to more dramatic overfitting, where the test CS score quickly levels off while the train CS continues to grow.
Examining the discovered features reveals interpretable patterns aligned with user preferences, though notably different in character from the 0-shot baseline features (see Section A.2 for complete feature lists). Where the 0-shot features focus on content-based attributes (genre, plot structure, themes, pacing, narrative devices), the discovered features gravitate toward external markers: specific talent (individual actors and composers), multiple fine-grained award distinctions (Best Picture, Best Actor/Actress for specific role, Best Original Screenplay), franchise membership, and surprisingly precise temporal windows (1995-2000, 2004-2005, or post-1970). The John Williams feature is particularly revealing-it cuts across multiple genres to identify a coherent aesthetic or cultural preference that would be invisible to a content-based analysis. This suggests that collaborative filtering embeddings capture user similarity not through “stories like this” but through shared preferences for prestige signals, specific creative talent, and cultural/temporal cohorts (at least in this dataset). In another dataset, focused on a different selection of movies, or a different time frame, or a different cross-section of users, the system would likely discover different emergent structure in collective viewing, likely somewhat in disagreement with the conventional theories of content similarity. ). The linear model achieves better test performance (CS≈0.59) than the neural network (CS≈0.52) despite using fewer features, suggesting that the relationship between semantic features and collaborative filtering embeddings is predominantly linear. The video showing which features are added (blue) or removed in (a) is available at: https://github.com/mjojic/genZ/tree/main/media .
The differences and similarities of the learning curves relative to the baseline in both experiments indicate that components of the model jointly adjust to different semantics of the data as well as target statistics and their relationships to semantics. Even though the models used here (GPT 4/5) are familiar with the semantics of the data, their ability to predict the real-valued, possibly multidimensional targets benefits from the rest of the system and the modeling choices. For example, while a neural network better models interactions of features needed to predict house prices, the linear model is better suited for modeling movie embeddings. In both applications, the learning curves show classic behavior of iterative improvement until over-training. On the other hand, features generated by the LLMs alone are highly redundant preventing both effective prediction and overtraining. As evident in the discovered features (Section A), our system focuses on properties of the semantic items that fit the statistics of the links s → y, rather than ‘conventional wisdom’ of a zero-shot approach: For houses, the system discovers that location and quality of build/remodel matters most in the data it was given for listings in 2016, while for movies, the system discovers the features important to the audience in the period 1998-2006, such as the difference between newer and older content, importance of franchises, specific actors/directors, and so on. The following 27 features were discovered by our approach with the linear model f (z), reaching test CS of 0.59 (Fig. 6a):
• Not science fiction (no movies centered on aliens, space, or futuristic tech)
• Not released between 1995 and 2000 (inclusive)
• Not primarily comedies • Not primarily romance-focused films (i.e., avoids romantic dramas and romantic comedies)
• Mostly PG-13/PG-rated mainstream releases (i.e., generally avoids hard-R films)
• Not animated (live-action films)
• Not primarily action-adventure, heist, or spy thrillers (i.e., avoids high-octane studio action crowdpleasers) • Not horror (i.e., avoids horror and horror-leaning supernatural thrillers) • Includes many Academy Award Best Picture nominees/winners (i.e., more prestige/canon titles) • Includes a notable number of pre-1995 titles (1960s-early ’90s), whereas the negatives are almost entirely 1995-2004 releases • Primarily entries in major film franchises or multi-film series (including first installments that launched franchises) • Includes multiple war films set amid real historical conflicts (e.g., WWII/Vietnam), which are absent in the negative group • Not crude/raunchy, man-child/SNL-style comedies (when comedic, entries skew quirky/indie or gentle rather than broad/frat humor) • Skews toward female-led or women-centered narratives (e.g., Legally Blonde, The First Wives Club, Freaky Friday, The Pelican Brief, Lara Croft), whereas the negative group is predominantly male-led On the other hand, a 0-shot approach produces very different features. The following 50 features were suggested by GPT-5 based on task description, then pruned to achieve the baseline test CS of 0.48: In our experiments, we used a generic version of the GenZ learning algorithm with the functional link z → y arbitrary (plug-and-play). Instead of computing exact expectations of form E q(z) g(z), we just evaluated g at the mode of q. While this allowed us to run the same algorithm for the linear and nonlinear (neural net) models, we noted that in some cases these expectations can be computed tractably under the full distribution q. Linear model is such a case, and we derive it here for illustration.
A linear link between z and y takes a form
where z is now (n f + 1) × 1 feature vector with an additional element which is always 1, y is a n d × 1 observation vector, and Λ is an n d × (n f + 1) parameter matrix. (Note that the overall model is still nonlinear because the relationships among features z in p(z|s) are nonlinear). The additional constant element zn f +1 = 1 in z allows for learning the bias vector within Λ.
We use the approximate posterior limited to the form q(z) = i q(zi). Defining q(zi = 1) = qi, q(zi = 0) = 1 -qi, and q = [q1, q2, …qn f , 1] T (as zn f +1 := 1), we have
Eq[zz T ] = qq T + diag(q -q ⊙ q), (
where ⊙ denotes point-wise multiplication. (To see this, note that for nondiagonal elements zizj in zz T we have E[zizj] = qiqj but the expectation for the diagonal elements is E[z 2 i ] = qi, rather than q 2 i ). Thus, tr(ΛEq[zz T ]Λ T ) = tr(Λqq T Λ T ) + tr(Λ diag(q -q ⊙ q)Λ T ) = q T Λ T Λq + tr(Λ diag(q -q ⊙ q)Λ T ) ,
This is the only term that involves the parameter θy = Λ, and in the M step, for a given q we will solve for Λ by maximizing it. The derivation is also useful for the E step, in which we estimate q.
With our choice of factorized posterior, the feature term T2 simplifies to
with ℓ 1 i and ℓ 0 i defined in (5). Finally, the entropy part of the bound becomes
To perform inference, i.e. to approximate the posterior p(z|y, s), we optimize the bound B = T 1 + T 2 + T 3 wrt to {qi}, the posterior probabilities q(zi = 1). This is a part of the (variational) E-step needed to compute the expectations (20) used in the observation part T1 in ( 22). By maximizing T1, and therefore the log likelihood bound (1), wrt to Λ ans σ 2 we then perform a part of the M step related to the parameters of the observation conditional (17). In the M-step we can also maximize the bound wrt uncertainty parameters θe = {p e i } of the feature model ( 5), and we use the mining prompt in Fig. 2 to re-estimate the semantic model parameters, the feature descriptions θ f as discussed in Sect. 2. While the optimization can be done with off-the-shelf optimization packages, we derive EM updates here.
E step: For a given (s, y) pair we optimize qi one at a time, keeping the rest fixed. A simple way to approximate qi for a tight bound is to introduce vectors q +i , and q -i which are both equal to q in all entries but the i-th. In the i-th entry, q +i equals 1, and q -i equals 0. In other words, the two are parameter vectors for posterior distributions where the i-th feature zi is forced to be either 1 or 0 with certainty. Given the above derivations, we can thus compute the approximate log likelihood
and similarly for p(y|zi = 0, s), but using expectations wrt q -i . In each case the three terms are computed as above in ( 22), ( 23), and ( 24), but with the appropriate distribution parameter vector q +i or q -i replacing q. The posterior parameter qi = p(y|z i =1,s)
The entropy terms for q +i and q -i are the same: Applying equation ( 7) to q +i and q -i we see that all summands are the same as q +i j = q -i j , except for the i-th summand which is zero in both cases as q +i i = 1 and q -i i = 0. Therefore the entropy terms divide out. The feature terms E q +i [log p(z|s)] E q -i [log p(z|s)] are not the same. The summands are still the same for i ̸ = j, but the i-th terms are different: They are ℓ 1 i and ℓ 0 i , respectively. Therefore, we can divide out the shared parts. The expression simplifies to qi = e
To get all parameters qi these equations need to be iterated, but the iterations can be interspersed with parameter updates of the M step. In this update rule we see that the foundational model’s prediction of zi is balanced with the observation y which may be better explained if the different zi is chosen. As discussed in Sect. 2, this is a signal needed to update the feature descriptor θ f i . For example, if y is a movie embedding vector, then the presence or absence of the feature “historical war movie” helps explain explain, through Λ, the variation in y, which in turn reflect user preferences. If the users do not in fact have preference specifically for historical war movies, but instead for movies based on real historical events, war or not, then this feature will only partially explain the variation, and the posterior might indicate the positive feature, zi = 1, with high probability for a movie which is about historical events but the foundational model correctly classified as not a “historical war movie.”
M step: While the E-step is performed independently for each item s, in the M step we consider a collection of item-onservation pairs (s t , y t ), and the posterior distributions q t from the E-step, and optimize the sum of the bounds B t . From ( 22), we see that
Setting the derivative to zero we derive the update
The noise parameter σ 2 is optimized when
We can (and in our experiments do) optimize the feature uncertainty parameters p e i . These parameters could in principle be extracted from the foundational model using token probabilities or its own claim of confidence in the response (see prompt in Fig. 2). However, the foundational model’s own uncertainty only captures its confidence about judging the characteristic. In our hybrid model, we can have p i e model additional uncertainty that the feature is well-defined. This is especially useful during learning as features evolve. As we discussed above using the “historical war movie” feature as an example, in the E step the posterior may diverge from the foundational model’s feature classification if the feature only approximately aligns with true variation in observations. To estimate, and then reuse, the full uncertainty, we can maximize the bound wrt p e i , to arrive at:
where h t i are the binary responses of the foundational model for feature i in the semantic item s t . (To derive, see (5), although the update is intuitive, as it simply sums the evidence of error as indicated by the posterior).
Finally, to update the feature descriptors θ f i , we sample or threshold the posteriors q t i to get some positive z t i = 1, and negative z t i = 0 examples. We then use exemplars from each group to form the feature mining prompt in Fig. 2. The fondational model’s response in the “characteristic” field is the updated feature description θ f i .
We studied a model that links a semantic description of an item s with an observation vector y. Among other applications, the approach allows us to find features that determine user preferences for movies if y are movie embeddings inferred from movie-user observation matrix. Here we show that such an approach is a simplification of a model that involves two sets of interacting items (e.g. movies/viewers, products/buyers, plants/geographic areas, images/captions, congress members/bills). That model (without the simplification) can also be learned from data.
Suppose that the matrix of the pairwise interactions xt 1 ,t 2 is observed for item pairs from the two groups (s t 1 1 , s t 2 2 ). We would then model the joint distribution p(x|z1, z2)p(z1|s1)p(z2|s2) where, for example, s1 would be a textual description (or an image!) of a plant and s2 a textual description (or a satellite observation!) of a geographic area, and the scalar x would be the presence (or thriving) signal for the combination. We could develop a number of different complex models with suitable latent variables (in addition to z), but honoring the traditionally very successful collaborative filtering methods for dealing with such data, we will focus on embedding methods (which typically rely on matrix decomposition methods, at least in recommender systems). Thus, for each set of items our latent variables z should determine a real-valued embedding y probabilistically, through a distribution p(y|z).
Then, given the low-dimensional embeddings y1, y2 for the items in the pair (e.g. a movie and a user), we would model the association variable as y ≈ u T 1 u2:
In the model over observed association strength x, item embeddings y1 and y2, each based on their own set’s feature vectors z1, z2, which themselves are probabilistically dependent on the items semantics s1, s2 the likelihood can be approximated as log p(x|s1, s2) = log z 1 ,z 2 ,y 1 ,y 2 p(x|y1, y2)p(y1|z1)p(y2|z2)p(z1|s1)p(z2|s2)
≥ E q(z 1 ,z 2 ,y 1 ,y 2 ) log p(x|y1, y2)p(y1|z1)p(y2|z2)p(z1|s1)p(z2|s2) q(z1, z2, y1, y2)
where q(z1, z2, y1, y2) is an approximate posterior.
If we assume a factored posterior q = q(z1)q(z2)q(y1)q(y2), and that the posterior over embeddings Dirac q(y1) = δ(y1 -ŷ1), q(y2) = δ(y2 -ŷ2) then based on (32):
2 -1 2 log(2πσ 2 y ) + Eq log p(y 1 ,z 1 |s 1 ) q(z 1 )
- Eq log p(y 2 ,z 2 |s 2 ) q(z 2 )
,
where the expected embeddings are û1 = E q(z 1 ) [u1], û2 = E q(z 2 ) [u2] If we observe the full association matrix Y, e.g. over n1 ≈ 18000 movies, indexed by i1 and n2 ≈ 500000 users indexed by i2, then the approximate log likelihood of the data, broken into two terms is:
Eq log p( ŷ1 t 1 , z t 1 1 |s t 1 1 ) q(z t 1 1 )
Eq log p( ŷ2 t 2 , z t 2 2 |s t 2 2 ) q(z t 2 2 )
.
This can be seen as solving a regularized matrix decomposition problem as by collecting xt 1 ,t 2 into the observation matrix X and all items’ embedding vectors into matrices Ŷ1 and Ŷ2 the first term (first line) above can be written as
while the second term (line) serves as a regularization term. The regularization term is in fact consisting of two models, one for each type of item, of the form studied in the previous sections. When the observation matrix is very large and also has low intrinsic dimension, as is typically the case in collaborative filtering applications, the first term can be fit very well resulting in low σ 2 x , and making the regularization term adapting to the natural data embedding. Therefore, as our goal for the two p(y, z|s) components is not to interfere with natural embeddings of the data, but rather to explain the statistical patterns so that they would transfer to new semantic items with new descriptions and previously unseen interaction patterns in testing, we can fit the first term independently of the other two, after which the joint modeling problem separates into two separate ones, e.g. extracting the plant features that explain their embeddings and extracting the geographic areas features to explain their own embeddings.
For a given embedding dimension ne the term T1 is minimized when Ŷ1 and Ŷ2 are related to the SVD of X, which reduces the dimensionality to ne X ≈ USV T , where n1 × ne matrix U and the n2 × ne matrix V are orthonormal and S is a diagonal matrix. For example, the term is minimized when
for arbitrary rotation matrix R and a scalar α ∈ [0, 1].
Therefore, if we solve the matrix decomposition problem in T1 we can then fit the features for the two sets of items separately as the second term is decomposed:
Eq log p( ŷ1 t 1 , z t 1 1 |s t 1 1 ) q(z t 1 1 )
Eq log p( ŷ2 t 2 , z t 2 2 |s t 2 2 ) q(z t 2 2 )
.
In other words, by computing the embeddings using a standard matrix decomposition technique, we can build models that generate these item embeddings y using the semantics of the items s.
In case of movie preference datasets, like the Netflix Prize dataset, and data from many other recommender systems, the second set of items -users -are usually not described semantically (through information like their demographics, their writing, etc.). Privacy reasons are often quoted for this, but it is also true that people’s complex overall behavior, as it relates to the task, is better represented simply by their preferences. I.e. knowing which movies they have watched is a better indicator of whether or not they will like a particular new movie for example, than is some description of their life story, even if it were available. In other words, in our Netflix prize experiments, we only fit the movie embeddings.
examples from G * only 24: θ fi ← LLM(Pos, Neg) ▷ Mining prompt, Fig. 2 25: Apply θ fi to all items: h t i ← p(z i = 1|s t , θ fi ) for t = 1, …, T ▷ Extraction prompt, Fig. 1 26: return θ fi , {h t i } T t=1 Algorithm 3 Prune Feature (remove least useful feature) 1: Input:
T t=1 B t using model without feature j 19:∆L j ← L full -L -j▷ Impact of removing feature j 20:if ∆L j < ∆L min then 21:∆L min ← ∆L j , j * ← j 1: Input: Dataset D = {(y t , s t )} T t=1 , k add (features to add), k cut (features to prune), max cycles 2: Output:
T t=1 B t using model without feature j 19:∆L j ← L full -L -j▷ Impact of removing feature j 20:if ∆L j < ∆L min then 21:
T t=1 B t using model without feature j 19:∆L j ← L full -L -j▷ Impact of removing feature j 20:
T t=1 B t using model without feature j 19:∆L j ← L full -L -j
T t=1 B t using model without feature j 19:
📸 Image Gallery