Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
📝 Original Info
- Title: Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
- ArXiv ID: 2512.24873
- Date: 2025-12-31
- Authors: Weixun Wang, XiaoXiao Xu, Wanhe An, Fangwen Dai, Wei Gao, Yancheng He, Ju Huang, Qiang Ji, Hanqi Jin, Xiaoyang Li, Yang Li, Zhongwen Li, Shirong Lin, Jiashun Liu, Zenan Liu, Tao Luo, Dilxat Muhtar, Yuanbin Qu, Jiaqiang Shi, Qinghui Sun, Yingshui Tan, Hao Tang, Runze Wang, Yi Wang, Zhaoguo Wang, Yanan Wu, Shaopan Xiong, Binchen Xu, Xander Xu, Yuchi Xu, Qipeng Zhang, Xixia Zhang, Haizhou Zhao, Jie Zhao, Shuaibing Zhao, Baihui Zheng, Jianhui Zheng, Suhang Zheng, Yanni Zhu, Mengze Cai, Kerui Cao, Xitong Chen, Yue Dai, Lifan Du, Tao Feng, Tao He, Jin Hu, Yijie Hu, Ziyu Jiang, Cheng Li, Xiang Li, Jing Liang, Xin Lin, Chonghuan Liu, ZhenDong Liu, Zhiqiang Lv, Haodong Mi, Yanhu Mo, Junjia Ni, Shixin Pei, Jingyu Shen, XiaoShuai Song, Cecilia Wang, Chaofan Wang, Kangyu Wang, Pei Wang, Tao Wang, Wei Wang, Ke Xiao, Mingyu Xu, Tiange Xu, Nan Ya, Siran Yang, Jianan Ye, Yaxing Zang, Duo Zhang, Junbo Zhang, Boren Zheng, Wanxi Deng, Ling Pan, Lin Qu, Wenbo Su, Jiamang Wang, Wei Wang, Hu Wei, Minggang Wu, Cheng Yu, Bing Zhao, Zhicheng Zheng, Bo Zheng
📝 Abstract
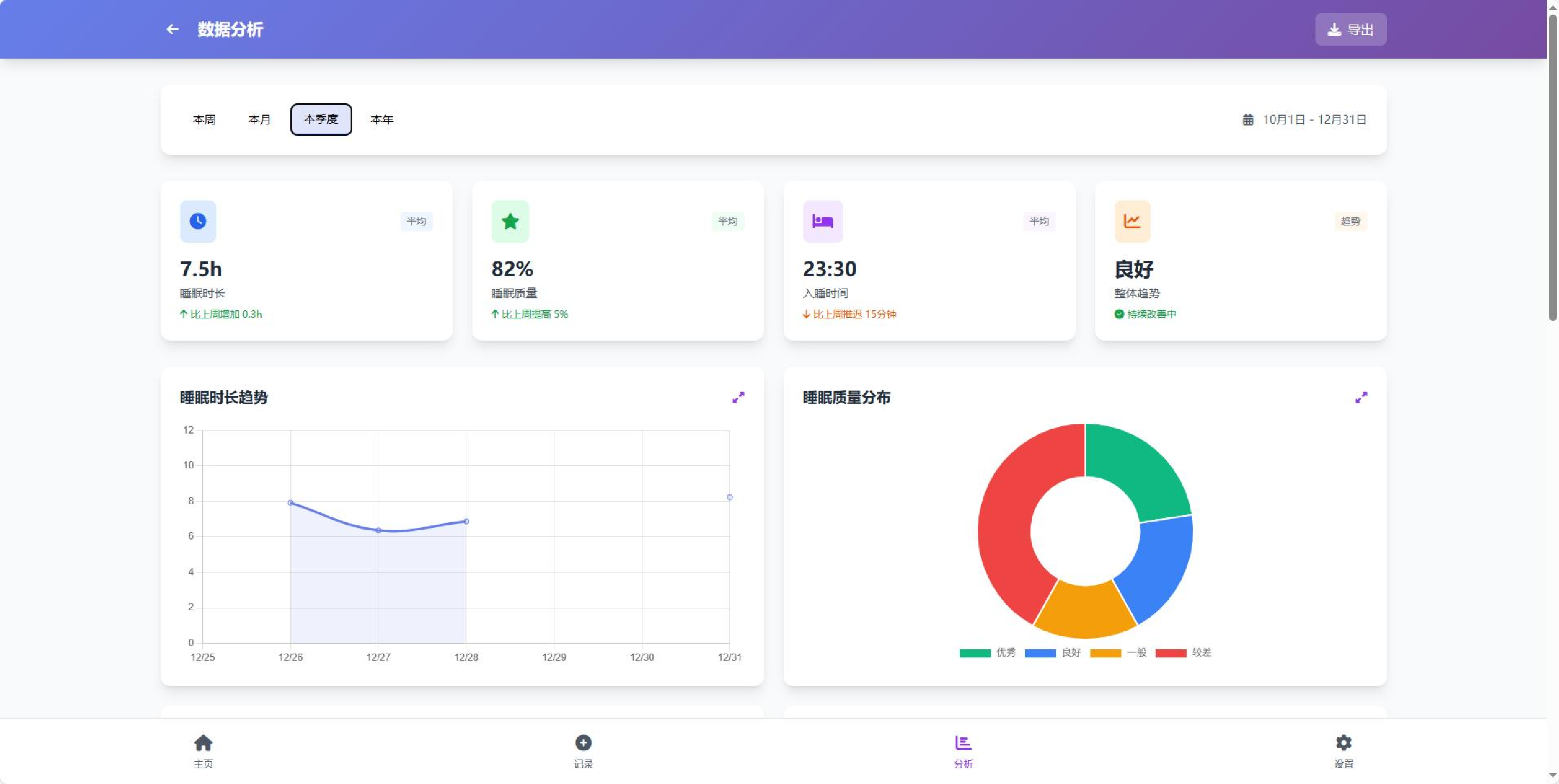
Agentic crafting, unlike one-shot response generation for simple tasks, requires LLMs to operate in real-world environments over multiple turns-taking actions, observing outcomes, and iteratively refining artifacts until complex requirements are satisfied. Yet the spirit of agentic crafting reaches beyond code, into broader tool-and languagemediated workflows where models must plan, execute, and remain reliable under interaction. Reaching this new regime demands sustained, painstaking effort to build an agentic ecosystem as the foundational bedrock, ultimately culminating in an agent model as the capstone. ROME wasn't built in a day. A principled, end-to-end agentic ecosystem can streamline the development of the agent LLMs from training to production deployment, accelerating the broader transition into the agent era. However, the opensource community still lacks such an ecosystem, which has hindered both practical development and production adoption of agents. To this end, we introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the end-to-end production pipeline for agent LLMs. ALE consists of three system components. ROLL is a post-training framework for weight optimization. ROCK is a sandbox environment manager that orchestrates environments for trajectory generation. iFlow CLI is an agent framework that enables configurable and efficient context engineering for environment interaction. We release ROME (ROME is Obviously an Agentic ModEl), an open-source agent grounded by ALE and trained on over one million trajectories. In addition, we curate a suite of data composition protocols that synthesize data spanning isolated, static snippets to dynamic, complex agentic behaviors, with built-in verification of safety, security, and validity. We further develop an end-to-end training pipeline and propose a novel policy optimization algorithm IPA, which assigns credit over semantic interaction chunks rather than individual tokens, improving training stability over long horizons. Empirical evaluations show that ROME achieves strong results across mainstream agentic benchmarks, including 24.72% on Terminal-Bench 2.0 and 57.40% accuracy on SWE-bench Verified, outperforming similarly sized models and rivaling those with over 100B parameters. To enable more rigorous evaluation, we introduce Terminal Bench Pro, a benchmark with improved scale, domain coverage, and contamination control. ROME still demonstrates competitive performance among open-source models of similar scale and has been successfully deployed in production, demonstrating the practical effectiveness of the ALE.📄 Full Content
However, the widespread practical adoption of agentic crafting remains elusive in the absence of a scalable, end-to-end agentic ecosystem. Prior work has sought to improve agentic crafting via supervised fine-tuning (SFT) on limited human demonstrations (Emergent Mind, 2025;Wang et al., 2025a), or through ad-hoc reinforcement learning (RL) recipes that are often struggles with long-horizon tasks and sparse, delayed rewards (Luo et al., 2025;Tan et al., 2025;Wang et al., 2025a). In this report, we contend that a principled agentic ecosystem must close the loop spanning data generation, agent execution, and policy optimization, enabling an continuous end-to-end optimization workflow that can adapt to distribution shift and growing complexity in production environments. To bridge this gap, we present the Agentic Learning Ecosystem (ALE), a full-stack infrastructure that unifies data, training, and deployment for agentic intelligence. Concretely, ALE comprises three synergistic system components: ROLL (Reinforcement Learning Optimization for Large-Scale Learning): A scalable RL training framework supporting multi-environment rollouts, chunk-aware credit assignment, and stable policy updates for long-horizon agentic tasks.
ROCK (Reinforcement Open Construction Kit): A secure, sandboxed agent execution platform that provides executable, tool-grounded environments, supporting interaction trajectory synthesis, execution, and validation. iFlow CLI: An agent framework that orchestrates structured prompt suites for environment interaction, coupled with a user-facing interface that packages agents for real-world workflows and exposes APIs for continuous refinement via user feedback.
Grounded in ALE, we incubate ROME as an open-source agent LLM based on Qwen3-MoE, tightly developed within our established ecosystem. Along the road to ROME, we take two deliberate steps. First, we establish a curated, coherent data composition workflow that synthesizes multi-source, multilingual, tool-grounded trajectories. Benefiting from strong sandbox isolation and fine-grained permission control of ROCK, we run rigorous security, safety, and validity verification to ensure the integrity and quality of the generated trajectories. Second, we leverage millions of high-quality trajectories to iteratively refine an efficient, stage-wise training pipeline from continuous pre-training, SFT, to RL. Enabled by the tight integration of our ecosystem, the end-to-end training pipeline remains both high-throughput, resourceefficient, and user-friendly. To further stabilize RL training dynamics, we propose Interaction-Perceptive Agentic Policy Optimization (IPA), a novel algorithm that optimizes policies over semantic interaction chunks (Li et al., 2025). By shifting credit assignment from tokens to semantically meaningful chunks, IPA improves long-horizon stability and ultimately strengthens long-context agentic crafting performance.
Extensive empirical results demonstrate that ROME achieves solid and consistent performance across a diverse set of agentic benchmarks. On terminal-centric tasks, ROME achieves 57.4% accuracy on SWE-bench Verified and 24.7% on Terminal-Bench v2.0, outperforming models of similar scale and approaching the performance of larger models exceeding 100B parameters. On the more rigorous Terminal Bench Pro, which enforces stricter contamination control and improved domain balance, ROME still performs competitively, showing strong generalization and stability across domains. Furthermore, ROME has been integrated into iFlow CLI and stably deployed in production. This real-world validation, together with ALE, establishes a robust, scalable, and production-grade foundation for the continual training and enhancement of ROME.
In summary, this technical report presents a reliable, cost-effective, secure, and user-friendly training ecosystem that enables practitioners to build customized models tailored to diverse needs. Beyond a technical stack, ALE is also a call to reframe the community’s priorities. In complex agentic settings, the central challenge is no longer merely data scale or curation quality, but the co-design of training infrastructure, executable environments, and evaluation protocols. We hope this work catalyzes collaborative efforts toward agentic benchmarks, standardized execution environments, and reproducible training pipelines, which constitute essential pillars for the next generation of general-purpose agents.
Figure 2a shows the Agentic Learning Ecosystem (ALE) that enables agentic crafting, including the training framework ROLL, the environment execution engine ROCK, and the agent framework iFlow CLI. Below, we briefly describe these three systems.
• ROLL (Wang et al., 2025c;Lu et al., 2025) is the agentic RL training framework that supports scalable and efficient RL post-training with multiple environments, multi-turn sampling, and policy optimization. • ROCK is the environment execution engine that provides secure, sandboxed environments for agentic interaction. It supports environment-driven trajectory generation and validation for data synthesis and closed-loop execution during training. • iFlow CLI is the agent framework that manages the context for environment interactions and delivers an end-to-end agentic crafting experience to complete a given workflow.
The three systems work together to efficiently support agentic RL training: ROLL issues multiple environment calls, ROCK manages and executes these environments within their corresponding sandboxes, and iFlow CLI orchestrates the context between LLM responses and environment outputs. Together, they form an efficient, fault-tolerant, and scalable infrastructure for agentic crafting.
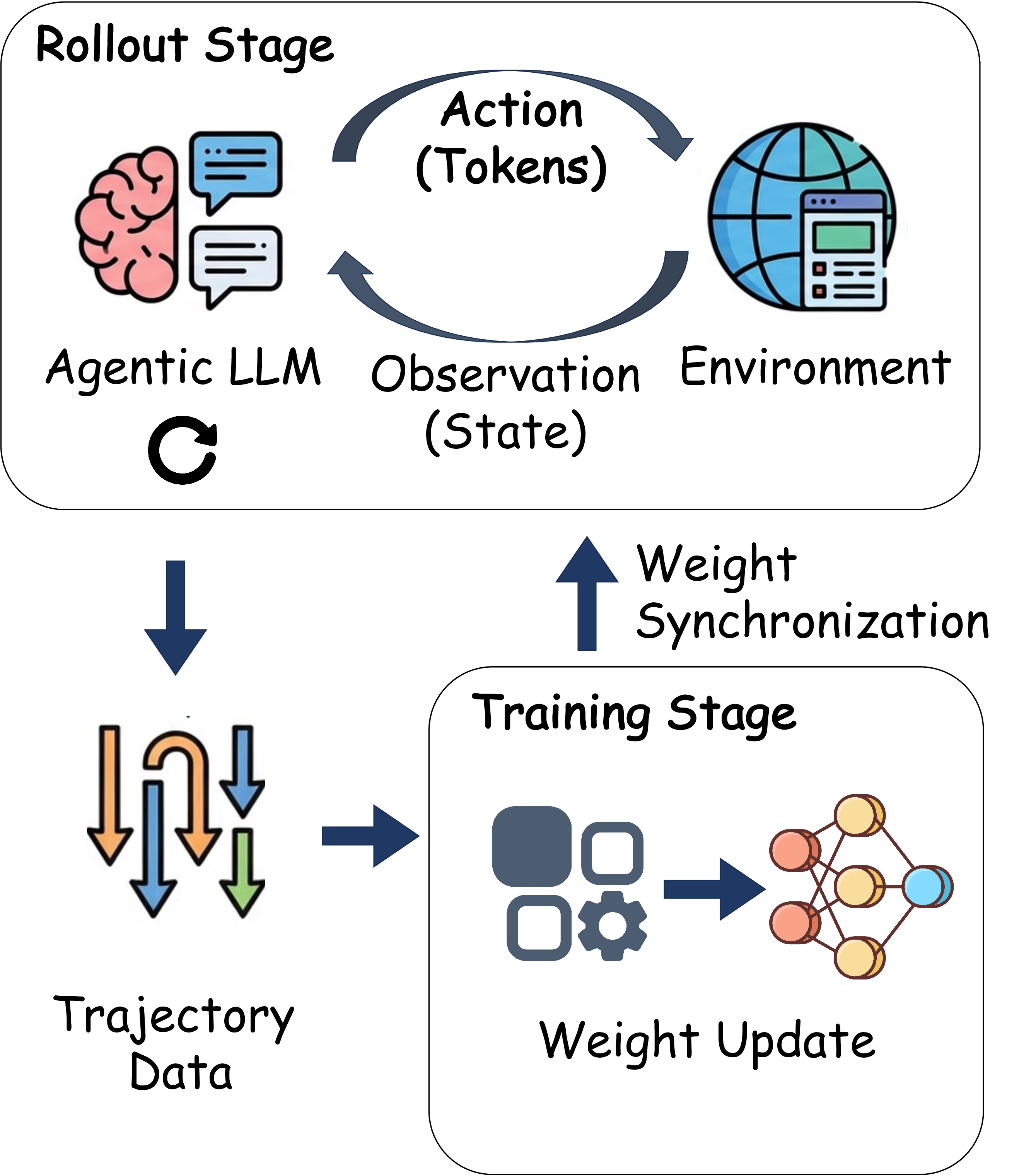
Agentic Training Pipeline. Figure 2b depicts an agentic RL training workflow with three key stages, rollout, reward, and training. During rollout, the agent LLM interacts with the environment by emitting tokens that represent actions. After each action, the environment returns an observation. This exchange continues for multiple turns until an episode ends, producing a trajectory of interleaved actions and observations. The reward stage then scores each trajectory and outputs a scalar reward. Finally, the training stage uses the collected trajectories and rewards to update the agent’s weights. The updated model is periodically synchronized back to the rollout stage for the next training iteration.
ROLL decomposes agentic RL post-training into specialized worker roles, including LLM inference, environment interaction, reward computation, and parameter updates. This separation allows each stage to scale independently and enables efficient communication among roles during distributed execution. Similar to prior frameworks (Sheng et al., 2024;Hu et al., 2024), ROLL (Wang et al., 2025c;Lu et al., 2025) exposes a Cluster abstraction and adopts a single-controller programming model. The controller coordinates heterogeneous workers and handles corresponding deployment and lifecycle management, which substantially reduces development complexity for RL researchers.
Empirical results from prior work show that rollout is the dominant cost in RL post-training and often contributes roughly 70% of end-to-end overhead (He et al., 2025;Gao et al., 2025b). The problem is more pronounced in agentic training, where the rollout stage may last hundreds of seconds (Lu et al., 2025).
Even the environment interaction can become a major bottleneck and has been reported to consume more than 15% of total training time (Gao et al.). These observations drive the dedicated optimization for environment execution and LLM generation. In this section, we first explain how ROLL enables finegrained rollout so that LLM generation can proceed concurrently with environment interaction within the rollout stage. We then describe ROLL’s asynchronous training pipeline that overlaps rollout with training to reduce training time while preserve the model accuracy. Last, we discuss how train-rollout multiplexing can reduce resource bubbles and improve rollout throughput in asynchronous training.
Fine-grained Rollout. ROLL supports asynchronous reward computation during rollout, thus it enables fine-grained rollout by decomposing the rollout stage into three phases: LLM generation, environment interaction, and reward computation. Instead of executing these phases in a single full batch, it applies parallelism at the sample level. This design allows users to control the lifecycle of each sample, deciding when and where each phase is executed. As a result, ROLL supports pipelined execution of LLM generation, environment interaction, and reward computation at sample-level granularity.
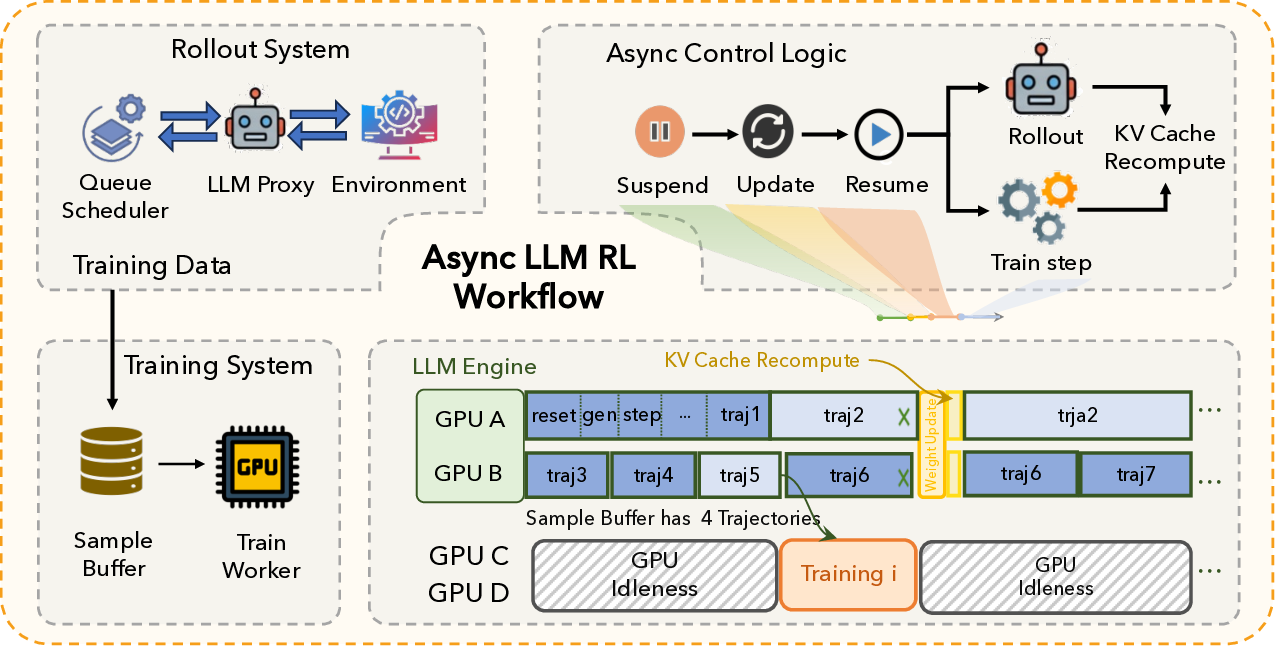
Asynchronous Training. As shown in Figure 3a, we decouple the rollout and training stage across different devices. The rollout stage acts as the producer, and the training stage acts as the consumer. ROLL maintains a sample buffer to store the completed trajectories and introduces asynchronous ratio to configure the per-sample staleness during the asynchronous training. The asynchronous ratio is defined on per sample as the maximum allowable gap in policy version numbers between the current policy and the policy version that initiated generation of that sample.
The asynchronous training pipeline iteratively repeats the following steps. First, the training stage finishes gradient computation from the previous iteration and then fetches a target batch of trajectories from the sample buffer in a blocking manner. Samples that violate the asynchronous ratio constraint are discarded to preserve model accuracy. Second, the rollout stage is suspended and model weights are synchronized from the training workers to the rollout workers. Third, the rollout stage resumes and generates new trajectories using the updated model weights, while the training stage performs gradient computation on the fetched samples in parallel to maximize resource utilization. Our prior work, ROLL-Flash (Lu et al., 2025), conduct extensive empirical studies to show that ROLL’s asynchronous training can effectively balance training accuracy and throughput. We refer interested readers to that work for details. Figure 3 illustrates the bubble problem when rollout stage dominates the end-to-end iteration time. Rollout typically exhibits a pronounced long-tail latency distribution: the staleness bound caps the number of in-flight trajectories, and while most trajectories finish quickly, a small fraction of stragglers run up to the maximum context length, leaving many rollout GPUs underutilized. Meanwhile, the training stage is comparatively short but must wait until rollout has produced enough valid samples. Under a static GPU partition between rollout and training, this mismatch creates resource bubbles.
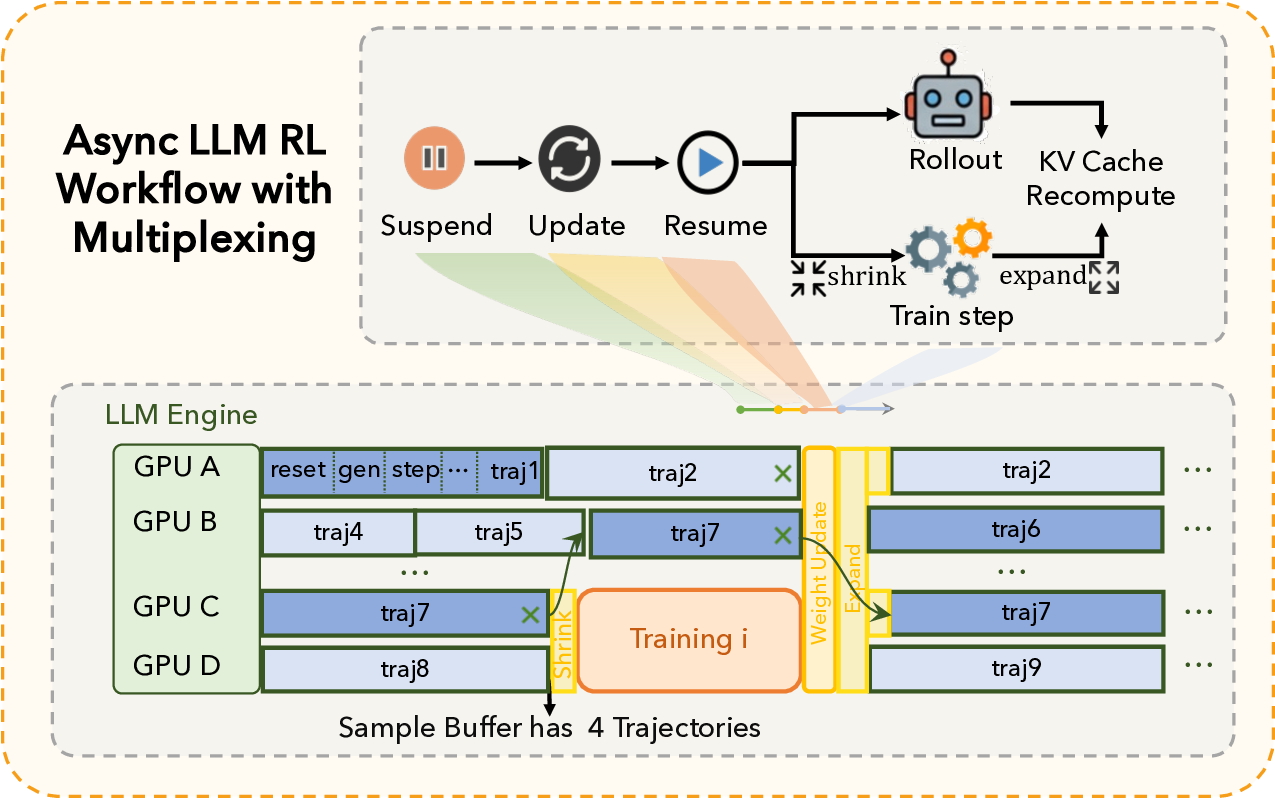
Our key insight is that rollout demand is highly time-varying: it peaks immediately after weight synchronization, when many new trajectories are launched, and then drops into a low-demand valley where only a small set of stragglers remain. In contrast, the training stage consumes resources in short, bursty episodes. Building on this observation, we introduce time-division multiplexing with a dynamic GPU partition between rollout and training. As shown in Figure 3b, the system first assigns all GPUs to rollout to rapidly generate a batch of samples. Once the sample buffer accumulates sufficient data for the next training step, the system triggers a shrink operation that temporarily reallocates a fixed subset of GPUs to training, while consolidating the remaining unfinished trajectories onto the rollout GPUs that remain. After training completes, an expand operation returns those GPUs to rollout to serve the next demand peak. This policy aligns training bursts with rollout demand valleys, reducing bubbles and improving overall GPU utilization compared to a statically disaggregated asynchronous design.
ROCK is a scalable and user-friendly system for managing sandbox environments to complete various agentic crafting applications (e.g., travel plan, GUI assistant). It is designed to be framework-agnostic, providing flexible APIs that allow any RL training frameworks to programmatically build, manage, and schedule these environments.
System Architecture and Workflow. Figure 4 illustrates the architecture of ROCK. The ROCK system is designed around a client-server architecture to support multiple levels of isolation, guaranteeing operational stability. From the client perspective, interacting with a remote environment is as convenient as using a local RL environment through a small set of primitives such as reset, step, and close. Under the hood, ROCK decouples environment execution from orchestration so that large-scale concurrent rollouts remain stable, debuggable, and resource efficient.
ROCK consists of three main components. First, the server tier is governed by the Admin control plane, which serves as the orchestration engine: it provisions sandboxed environments, performs admission control, and manages cluster-wide resource scheduling and allocation. Second, the worker tier comprises Worker nodes deployed on each machine; they run the sandbox runtime and manage local hardware resources. Third, Rocklet is a lightweight proxy that mediates communication between the agent SDK and sandboxes, governs outbound network access, and enforces egress policies. In addition, ROCK provides EnvHub, a centralized registry for environment images that enables reproducible provisioning and faster cold starts.
The agent LLM training, evaluation, and data synthesis impose diverse requirements, and ROCK provides the following features to meet these needs.
• Skill 1: Streamlined SDK Control. ROCK exposes a minimal, consistent control interface aligned with standard GEM RL environment semantics. Users can create, reset, step, and close environments through a small set of APIs, simplifying integration with RL training and evaluation pipelines. We detail these APIs later. • Skill 2: Seamless Agent Scaling. ROCK supports environments with multiple agents and can provision shared or isolated sandboxes based on the interaction pattern, enabling multiagent collaboration and competition. It also orchestrates diverse agent benchmarks (e.g., SWEbench (Jimenez et al., 2024), Terminal Bench Pro (Team, 2025)) behind a unified GEM API, so ROLL can interact heterogeneous environments through a single interface and enable multi-task RL training with only minimal configuration changes. • Skill 3: Native Agent Bridging. This bridges the gap between the RL framework and the agent framework that reconstructs and aligns the agent’s native message-based context management.
We explain this native agent mode in detail later. • Skill 4: Massive-Scale Scheduling. ROCK performs dynamic allocation and reclamation of resources across sandboxes. This enables high utilization under bursty workloads and supports large-scale concurrency, scaling to tens of thousands of simultaneous environments by elastically distributing tasks over the cluster. • Skill 5: Robust Fault isolation. Each task runs in its own sandbox. If an agent crashes, gets stuck, or damages its files, the failure is contained within that sandbox and does not interfere with other tasks on the same machine. ROCK also restricts each sandbox’s network access with per-sandbox policies, limiting the impact of misbehaving or compromised agents. • Tailored Optimizations. ROCK provides permission isolation for untrusted instructions, efficient large-file and artifact transfer, centralized logging, resource guardrails with failure recovery, optional checkpointing and restart support, and tooling for debugging and CI/CD-style environment delivery.
API Interfaces. ROCK exposes two primary API services for programmatic control, namely the Sandbox API and the GEM API. The Sandbox API manages the sandboxes that host GEM environments. The GEM API provided by ROCK follows the official GEM standardized API (Axon-RL). It is training-framework agnostic and integrates seamlessly with a range of RL frameworks, including veRL (Sheng et al., 2024), OpenRLHF (Hu et al., 2024), and Tinker (Thinking Machines AI). To ensure broad compatibility, ROLL also provides a GEM API implementation that adheres to the GEM protocol (Axon-RL). In particular, environment workers managed by the ROLL runtime use the GEM API to mediate interactions between an agent and its environment hosted by ROCK. All endpoints follow a RESTful design and use JSON for data interchange. We describe both APIs below.
The sandbox API manages the complete lifecycle of sandbox instances. Its functionality can be grouped into three main categories:
• Provisioning: Create and start sandboxes, with support for custom images, resource configurations, and both synchronous and asynchronous modes. • Monitoring: Query the status, operational health, and resource consumption statistics of any running sandbox. • Persistence: Stop a sandbox instance to release its resources or commit its current state to a new image for future use.
As a standardized interface for RL environments, this protocol enables the API to support the core agent interaction loop for general-purpose tasks:
• Make: Create a new GEM environment instance.
• Reset: Reset an existing environment instance to its default state.
• Step: Send an action to advance the environment one step and receive the next state.
• Close: Close the environment to release resources.
Agent Native Mode. The agent native mode connects the agentic RL training with the ROCK. The inconsistency in context management between the training framework (ROLL) and the deployment system (iFlow CLI) can significantly degrade an agent’s performance in production (Rush, 2025). A naive solution would be to force ROLL to perfectly mirror the iFlow CLI’s context handling, including its specific logic for multi-turn interactions and prompt concatenation. However, this creates a tight coupling: every update to an agent’s logic would require a corresponding reimplementation within ROLL, leading to an unsustainable maintenance burden.
To address this, we have implemented a ModelProxyService within the ROCK environment. This service acts as a proxy, intercepting all LLM requests originating from the agent’s sandbox. Crucially, these requests already contain the complete historical context, fully orchestrated by the iFlow CLI. The proxy then forwards these requests to the appropriate inference service -be it ROLL inference workers during training or an external API (e.g., GPT, Gemini) during deployment. The native mode achieves a clean separation. ROLL is simplified to generation engine, while the iFlow CLI retains full control over context management. This not only eliminates implementation complexity in the training framework but also guarantees perfect consistency between training and deployment, resolving both the maintenance and performance issues. The agent native mode ensures consistency not just between training and deployment, but across the full development pipeline, including data synthesis, training, and evaluation. A key feature is its support for multiple agent frameworks (iFlow CLI, SWE-Agent (Luo et al., 2025), OpenHands (Wang et al., 2025d), etc.), which lowers the overhead of switching scaffolds and simplifies tasks like generating more diverse training data.
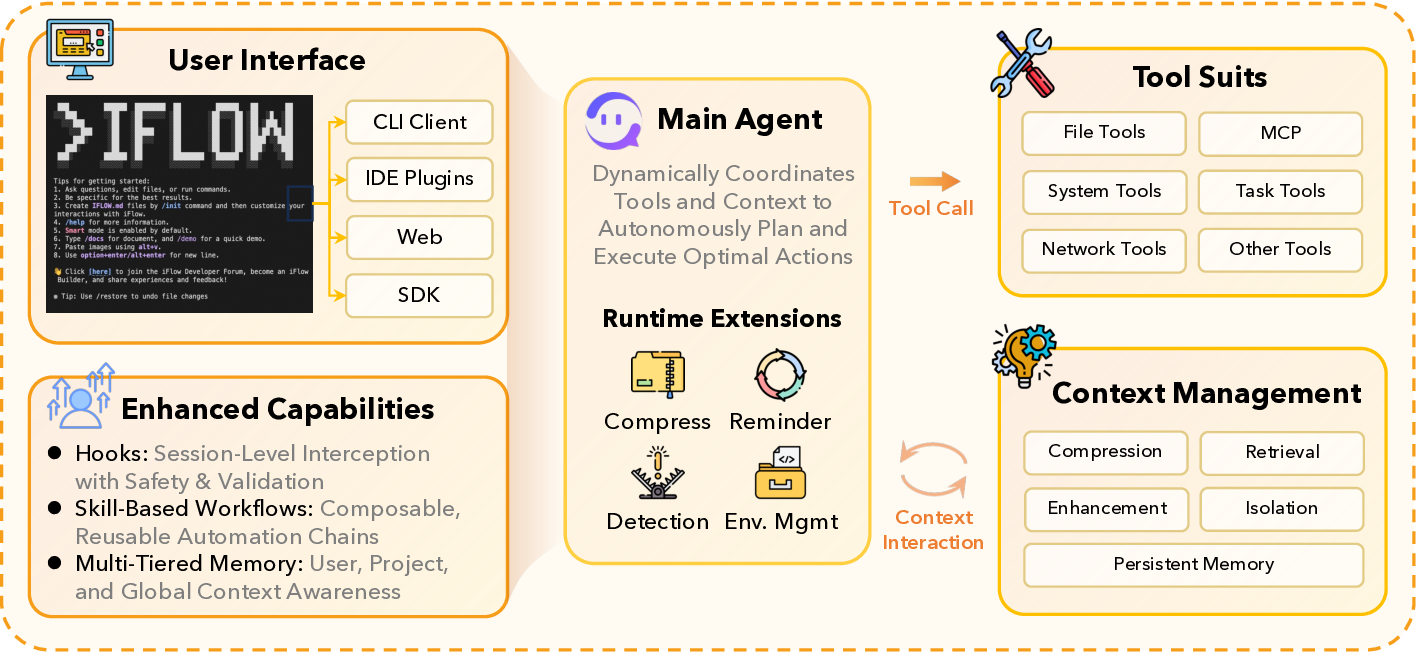
The iFlow CLI is a powerful command-line agent framework that exposes an interface for automating and executing complex, multi-step tasks, serving as both the context manager and user interface for our infrastructure layer. We describe the role of iFlow CLI in agentic RL training, and provide its overview, and highlight two key features, namely context engineering and open configuration. System Architecture and Workflow. As shown in Figure 5, iFlow CLI adopts an orchestrator-worker architecture built around a single-agent design principle, following Anthropic’s recommendations for effective agentic systems (Albert et al., 2024). The system exposes various user interfaces to users including client, IDE plugins, web and SDK. The system is driven by a Main Agent that maintains the global task state and executes an iterative control loop. At each step, iFlow CLI receives the user command and loads available persistent memory and prior chat history, then perform context management to assemble the model input. Based on the context, the Main Agent selects the next action, which may be a direct response, a tool invocation, or a call to a specialized sub-agent. The tool suites are accessed through a unified aggregation layer that wraps heterogeneous capabilities, such as MCP integrations, and returns their results as observations the agent can consume. Importantly, sub-agents are implemented as specialized tools with bounded context, avoiding agent handoffs and removing the need for explicit inter-agent communication.
During the control loop, iFlow CLI provides four built-in skills to strengthen context management. The Compress performs context compression for limited prompt budgets. The Reminder reports context changes including environment updates, tool changes, and task done. The Detection identifies issues such as loops and tool-call failures. The Env.Mgmt tracks environment state and notifies the agent upon user environment changes. The iFlow CLI also provides three enhanced capabilities. The Hooks implement session-level pre-and post-tool checks, such as warnings and interception for destructive commands. The Workflow packages reusable skills as configurable procedures for multi-step tasks. The Memory maintains hierarchical persistent state at the user, project, and global levels.
Context Engineering for Agentic Crafting. We adopt a single-agent control loop because it is simple, robust, and easy to scale. Following “The Bitter Lesson” (Sutton, 2019), we avoid brittle, over-engineered pipelines and instead focus on context engineering: supplying the agent with precise, high-quality context so it can plan, act, and self-correct effectively in real software environments.
In practice, iFlow CLI implements five techniques to manage context for long-horizon tasks:
• Persistent memory. iFlow maintains a lightweight todo file as external memory across sessions.
The agent can read and update it to track plans, open issues, and next steps.
• Context isolation. For complex tasks, iFlow can delegate sub-tasks to a sub-agent. Each subagent operates within a dedicated, isolated context, which prevents interference with the main agent’s workflow and ensures more focused, efficient execution.
• Context retrieval. iFlow fetches relevant information on demand via agent search, semantic vector retrieval, and knowledge-base integrations (e.g., DeepWiki), reducing reliance on what is already in the prompt.
• Context compression. To cope with limited context windows, iFlow applies lossy and lossless compression to retain key facts while controlling prompt length. Open Configuration Capabilities. Real-world software engineering demands more than generic intelligence. It requires strict adherence to domain-specific standards, complex operational logic, and specialized toolchains. To bridge the gap between general-purpose models and specialized engineering requirements, the iFlow CLI exposes a highly customizable configuration layer:
• System Prompt (Behavioral Alignment) To align the model’s cognitive style with specific domain constraints, the system prompt serves as a flexible blueprint. Users can explicitly define workflows, toolsets, usage scenarios, and persona tones. This customization acts as an accurate control mechanism, optimizing the model’s responses to fit the unique requirements of a specific project or field.
• Workflow / Spec (Process Standardization): To scale from simple code generation to end-to-end, workflow-driven tasks, iFlow CLI introduces Workflows (or Specs). This feature lets users compose disparate AI capabilities-agents, commands, and tools-into structured, automated task chains.
Whether for code analysis, development cycles, or deployment pipelines, workflows ensure complex processes are executed reliably and autonomously.
• Tool Set (Functional Extensibility): To extend beyond the LLM’s native capabilities, iFlow CLI supports broad integration via the Model Context Protocol (MCP). Users can add custom tools or sub-agents (invoked as tools within a single-agent loop), enabling seamless interaction with external APIs, databases, and proprietary environments.
Our infrastructure, leveraging ROLL, ROCK, and the iFlow CLI, provides system-level support for the entire agentic RL pipeline from training to deployment at the system layer. It is specifically served as the two pillars of high-performance agentic RL: structuring effective training algorithms and constructing quality datasets, as discussed subsequently.
This section introduces ROME, our agentic foundation model trained with our ALE infrastructure. ROME excels at a wide range of workflow-driven tasks (e.g., GUI assistance, travel plan). We then outline the core principles and procedures behind its development for strong agentic crafting performance, organized into three components: (1) a rigorous and principled data acquisition and synthesis workflow; (2) an end-toend training pipeline integrating Agentic Continual Pre-training (CPT), Supervised Fine-tuning (SFT), and Interaction-Perceptive Agentic Policy Optimization(IPA) RL algorithm; and (3) a comprehensive benchmark suite. Collectively, these components form a systematic pathway that illustrates how ROME leverages the required infrastructure to support next-generation agentic LLM.
Agentic crafting aims to build autonomous, workflow-driven agents that can reliably translate requirements into working artifacts through an iterative loop of formulation, implementation, verification, and refinement. To characterize what such agents must learn and consequently what training signals our data must provide, we decompose agentic crafting competencies into three tightly coupled dimensions: task understanding and planning, action and execution, and interaction and adaptation:
• Task Understanding and Planning. This dimension captures the agent’s ability to interpret natural-language or semi-structured specifications and translate them into well-scoped, executable engineering tasks accompanied by verifiable development plans. The agent must accurately extract user intent, uncover implicit rules and constraints, and surface hidden assumptions that could derail implementation. This involves identifying core system entities, defining precise input-output contracts, establishing boundary conditions, and articulating non-functional requirements (e.g., performance, security, scalability, compatibility) that are often omitted but critical to real-world viability. When information is incomplete, the agent should ask minimally sufficient clarification questions and explicitly represent uncertainty, avoiding overcommitment under ambiguous requirements and thereby reducing downstream rework. • Action and Execution. This dimension concerns the agent’s ability to operationalize plans into high-quality implementations and to leverage external toolchains to close the development loop.
The agent must actively select appropriate tools based on task characteristics (e.g., code search, build systems, dependency management, compilation/execution, testing frameworks, debuggers, static checkers, formatters, profilers, CI/CD pipelines) and invoke them with correct parameters and sequencing. Critically, the agent must also interpret tool outputs to drive subsequent actions, e.g., localizing defects from failing test logs, resolving style and correctness issues from linter reports, and optimizing bottlenecks guided by profiler evidence.
• Interaction and Adaptation. This dimension governs the agent’s ability to maintain a dynamic feedback loop with its environment, enabling continuous refinement across iterations. The agent must actively incorporate diverse signals (e.g., runtime behavior, test outcomes, user feedback, code review comments, and evolving system constraints) and adapt its plans and implementations accordingly. For instance, when faced with API deprecations or dependency conflicts, it should perform impact analysis and pivot to alternative strategies (e.g., rollback, refactoring, or substitution) rather than rigidly adhering to an outdated plan.
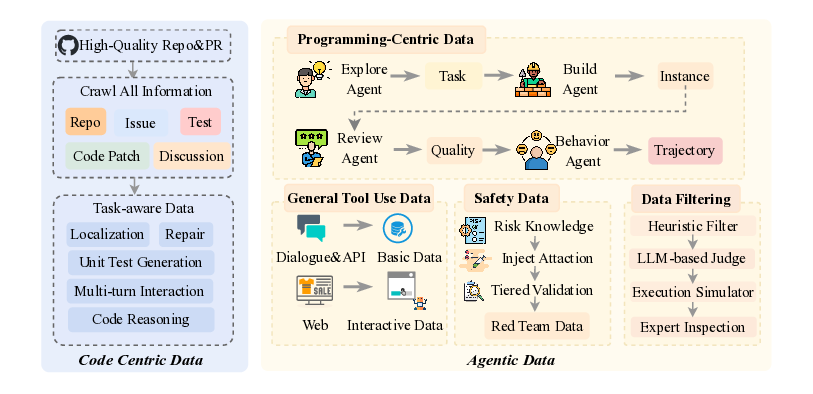
Guided by the above competency analysis, our data design adopts a two-tier curriculum that stages the model from foundational proficiency to closed-loop agentic behavior. In the first tier, Basic Data delivers targeted basic capability building that agentic models require as they progress toward full agent behavior. It comprises complementary components including code-centric corpora that support continuous pretraining and strengthen project-level code understanding and generation, and general reasoning data spanning reasoning-intensive tasks and general-purpose instructions that reinforces transferable deduction and planning skills. In the second tier, Agentic Data targets agent-specific requirements by producing closed-loop, executable training units in realistic environments. It is organized into i) instances, which extend a conventional query with an executable specification, a pinned environment, and verifiable feedback, and ii) trajectories, which record multi-turn interactions in which agents iteratively plan, act, observe runtime feedback, and revise solutions. Agentic data can be directly leveraged in post-training to selectively enhance agentic planning, execution, and adaptation under real-world constraints.
Our data maps the competency dimensions to supervision across both tiers. Basic Data concentrates on task understanding and planning by exposing the model to rich project contexts and well-formed specifications that teach intent extraction, requirement scoping, and plan formulation. It also builds the coding and general reasoning foundations that later enable effective action, execution, and iterative refinement, without relying on explicit tool-use traces. Agentic Data then provides targeted strengthening of action and execution and of interaction and adaptation. It embeds requirements in pinned, executable environments, supplies verifiable runtime feedback through deterministic builds and tests, and captures single-and multi-turn trajectories in live settings. This setting both trains robust execution and adaptation and grounds task understanding and planning in realistic constraints, turning high-level plans into working solutions under real-world conditions.
Together, the two tiers of data form a staged curriculum. The basic Data builds breadth and reliability in core coding and reasoning without full environment orchestration, while the agentic data then adds closed-loop execution and concrete runtime signals that directly supervise planning discipline, execution fidelity, and adaptive iteration under real world constraints. This progression operationalizes the competency blueprint and provides a coherent path from foundational skills to full agentic capabilities.
As a cornerstone of agentic LLM capabilities, coding proficiency requires a robust foundation of largescale, high-quality code data. Building such a corpus entails not only the systematic acquisition of extensive codebases but also the establishment of specialized environments to synthesize and process real-world software engineering data. Consequently, we curate a comprehensive dataset and task suite leveraging authentic development ecosystems to cover critical dimensions including code comprehension, fault localization, bug remediation, and automated test generation, etc.
We select approximately one million high-quality GitHub repositories based on criteria such as star counts, fork statistics, and contributor activity. Following Seed-Coder (Seed et al., 2025), we concatenate multiple source files within the same repository to form training samples at the project-level code structure, preventing the model from learning only isolated code snippets and promoting understanding of real-world engineering context. In addition, to improve code localization and repair, we further crawl Issues and Pull Requests (PRs) from the selected repositories. We retain only closed Issues and merged PRs to ensure a clear problem-solution correspondence. We then use an LLM to filter Issues, removing low-quality cases with vague descriptions, purely question/discussion posts, auto-generated content, or missing key technical details. During Issue-PR linking, we retain only PRs with an explicit will-close intent that actually resolve the corresponding Issue, excluding PRs that merely referenced the Issue without substantive fixes.
Task Construction and Formalization. Building upon the collected Issue-PR pairs, we formulate five core categories of software engineering tasks:
• Code Localization. To establish a target for modification, we follow the protocol in AGENT-LESS (Xia et al., 2024) by adopting the modified-file list from the golden patch as the ground-truth. Formally, given an issue description I and the repository structure S, the task is to identify a minimal subset of files F = { f 1 , f 2 , . . . , f n } ⊂ S that require editing to resolve the issue. • Code Repair. Building on the localized files, we formulate the repair process as a structured transformation. Following AGENTLESS (Xia et al., 2024), golden-patch differences are converted into search-and-replace blocks to provide precise editing signals. Formally, given issue I and the relevant code segments C, the model M generates a set of edits R = M(I, C), where R represents the search-and-replace blocks specifying the required transformation.
• Unit Test Generation. To achieve closed-loop verification of the proposed repairs, we formulate a test generation task by extracting test-centric patches from the associated PRs. Formally, given the issue I and the successfully patched code C ′ , the model synthesizes a corresponding test suite T = M(I, C ′ ) specifically designed to validate the correctness of the repairs. • Multi-turn Interaction. To enhance the model’s capability in multi-turn tasks, we carefully construct a high-quality multi-turn interaction dataset. Following the methodology of SWE-RL (Wei et al., 2025), we treat PR comments as turn-level feedback signals (feedback t ) and the subsequent commit-level code changes as the corresponding responses (response t ). This allows for formalizing the iterative refinement process as an evolutionary feedback-edit trajectory: Employing the aforementioned data collection and task-synthesis procedures, we construct an initial corpus exceeding 200B tokens. Through stringent data hygiene and quality assurance protocols (e.g., deduplication, decontamination, noise reduction, and logical consistency verification), we distill this corpus into a high-qualiy dataset comprising 100B tokens, which serves as the foundation for both continuous pre-training and post-training stages.
Agentic data differs fundamentally from conventional code corpora. Instead of isolated snippets or static repositories, it packages tasks with an executable specification, a pinned environment, and verifiable feedback, and it records how agents behave when they plan, act, observe runtime signals, and revise solutions. This closed-loop structure is essential for training models to exhibit reliable agentic behavior, yet it introduces challenges that conventional datasets do not address: environment reproducibility, execution closure, high-quality feedback signals, and resistance to superficial solutions.
Two core data objects define the agentic data form:
• Instance. An instance is the agentic analogue of a query in basic instruction data. It bundles the prompt (task specification), a Dockerfile together with build/test commands that pin the execution environment, and unit tests that provide verifiable feedback. This packaging turns an abstract problem into a runnable, reproducible task with clear acceptance criteria.
• Trajectory. A trajectory records an agent’s behavior on a validated instance. It captures multi-turn interactions, including tool invocations, file edits, reasoning traces (optional), and environment feedback. Trajectories exhibit long-horizon properties such as extended length, stateful dependencies, and recovery from partial failure, and they expose behaviors such as loop avoidance, rollback, and plan revision under changing constraints.
Open-source artifacts are a natural starting point, but raw availability is sparse and noisy for agentic needs. Open-source artifacts are a natural starting point, but raw availability is sparse and noisy for agentic needs. Existing curation pipelines for open-source code data often rely on language-specific heuristics or human-labeled quality classifiers, which scale poorly, require continual maintenance, and can introduce subjective bias. More importantly, agentic data imposes strict requirements on execution closure, environment context, and feedback signals, making manual construction and validation prohibitively expensive. As a result, the open-source ecosystem provides insufficient high-fidelity agentic data for training capable programming agents at scale.
To bridge this gap, we propose a two-tiered synthesis strategy. First, we construct general tool-use data to establish foundational capabilities in tool invocation and interactive reasoning. Second, we introduce a four-stage programming-centric data specifically designed for software development tasks, which autonomously generates high-fidelity and verifiable instances and diverse trajectories at scale. Moreover, all synthesized data undergoes rigorous data filtering via a multi-agent verification system to eliminate false positives, false negatives, and ambiguous or unverifiable executions, ensuring only reliable, executable, and semantically sound trajectories are used for training.
General Tool-Use Data Construction. Tool usage is a core capability of LLMs, enabling them to expand their knowledge scope and deepen their reasoning (Wang et al., 2024;Hou et al., 2025). To bootstrap this capability, we synthesize tool-use data across two settings:
• Basic Tool Use. To strengthen the basic tool-use capabilities, we develop an automated pipeline to synthesize high-quality tool-interaction data. Starting from collected task-oriented dialogues, we normalize and parse the utterances to extract structured intent representations, which are then mapped into standardized tool-parameter call formats. To support accurate tool selection and parameter grounding, we also curate comprehensive tool documentation aligned with the LLM’s usage context. Leveraging this infrastructure, we synthesize complete interaction samples containing tool calls and corresponding execution feedback, followed by quality control through automatic inspection. The resulting synthetic data spans four settings: single-turn single-tool, single-turn multi-tool, multi-turn single-tool, and multi-turn multi-tool. In addition, to enhance robustness under real and noisy conditions, we collect interaction traces from APIs and MCP services originating from internal development and testing environments, and use these traces to ground tool calls in actual execution environments.
• Tool Use in Interactive Scenarios. To enhance LLMs’ tool-use ability in web and domain-specific interactive settings, we develop a series of simulated environments. First, we design a web sandbox centered on e-commerce, built upon real product catalogs and supporting core user actions such as product search, page navigation, detail inspection, specification selection, and order placement. In addition, we construct multiple sandbox environments by automatically synthesizing program files to simulate typical systems such as file systems and billing management. In these environments, class attributes represent the internal data state, while class methods expose interactive tool interfaces. Leveraging each environment’s internal state and tool schema, we generate customized tasks that require the model to strategically invoke available tools to achieve specified goals. We also introduce simulated users played by LLMs into the task interactions, enhancing the realism of scenarios. Strict quality control is enforced by validating the syntactic correctness of tool invocations and verifying that post-interaction outcomes (e.g., purchased product attributes or updated environment states) align with task expectations.
This general tool-use corpus establishes baseline competencies in planning, tool selection, and state tracking, serving as prerequisites for more sophisticated agentic behaviors.
Programming-Centric Data Construction. For the targeted software development scenarios, our specialized pipeline generates high-quality agentic data for programming tasks through a multi-agent workflow, including divergent exploration, convergent implementation, and rigorous validation, orchestrated through a multi-agent framework powered by the iFLOW-cli execution engine and the ROCK sandboxed environment management system.
• Explore Agent: Divergent Exploration under Constraint Relaxation. We transform PRs, Issues, code snippets, and terminal workflows into structured drafts. This seed data is sourced from highly starred, actively maintained, multi-language GitHub repositories to ensure quality and diversity. We retain closed PRs that can be unambiguously linked to Issues and split each PR into a fix patch and a test patch to preserve independence and reproducibility. We expand task coverage to additional programming languages such as Go, TypeScript, and JavaScript, drawing from over 20,000 repositories to enhance dataset diversity. We also curate terminal interactions from developer forums and map them to canonical task types such as debugging, system administration, and data science. For each seed, we identify skill primitives (e.g., dependency management, scientific computation, statistical modeling) and generate creative variants that mimic user-agent prompts without imposing implementation paths. A lightweight feasibility filter assesses conceptual plausibility and selects the most promising candidates for dataset construction.
• Using this progressive pipeline, we synthesize 76K instances and trajectory records totaling 30B tokens.
The general tool-use data cultivates broad proficiency in tool handling, while the programming-centric data adds closed-loop, environment-pinned supervision that strengthens execution fidelity and adaptive iteration, and grounds task understanding in real-world constraints. Together, these datasets enable posttraining that elevates models from basic tool literacy to specialized, high-confidence agentic capabilities.
Data Filtering: Multi-Stage Filtering Pipeline for Rigorous Testing. To better filter the agentic data and provide high-quality information for the training stage, we propose a Multi-Stage Filtering Pipeline to handle a critical yet often overlooked challenge in multi-turn interaction agentic tasks: brittle test scripts, ambiguous task specifications, or incomplete ground-truth checks can assign incorrect rewards-either false positives (rewarding flawed executions) or false negatives (penalizing valid ones). Such noisy signals mislead policy optimization and induce optimization drift, where the agent learns to exploit evaluator weaknesses rather than solve the task.
To ensure high-quality, reliable data for training agentic systems, we implement a four-stage filtering pipeline that progressively refines candidate execution traces. This structured approach mitigates the risk of noisy or misleading rewards caused by brittle test scripts, ambiguous specifications, or incomplete ground-truth checks-common pitfalls that can induce optimization drift during policy learning. The pipeline consists of the following sequential stages:
• Heuristic Filter: Applies lightweight, rule-based filters to eliminate obviously malformed or syntactically invalid tool calls (e.g., missing required arguments, incorrect parameter types). • LLM-based Judge: Uses a large language model to assess the relevance between the test patch and the original issue. The judge determines whether the passed trajectory logically addresses the problem described in the task prompt. • Execution Simulator: Executes the agent’s generated trajectory in a sandboxed environment to verify whether it passes the associated test cases or resolves the target issue. This stage confirms functional correctness. • Expert Inspection: Conducts human-in-the-loop sampling audits on a subset of filtered trajectories -particularly those flagged as borderline or high-risk by prior stages. Domain experts evaluate overall trajectory quality, including reasoning coherence, efficiency, safety, and readability, ensuring the final dataset reflects real-world usability beyond mere pass/fail metrics.
Each stage acts as a gatekeeper: only traces that pass all preceding filters proceed to the next. The final output is a curated dataset of high-confidence, well-verified execution traces suitable for policy optimization. This pipeline enables robust training on long-tail, complex agentic behaviors while minimizing reward corruption from faulty evaluations.
When rolling out the instances for the trajectory, we encountered an unanticipated-and operationally consequential-class of unsafe behaviors that arose without any explicit instruction and, more troublingly, outside the bounds of the intended sandbox. Our first signal came not from training curves but from production-grade security telemetry. Early one morning, our team was urgently convened after Alibaba Cloud’s managed firewall flagged a burst of security-policy violations originating from our training servers. The alerts were severe and heterogeneous, including attempts to probe or access internal-network resources and traffic patterns consistent with cryptomining-related activity. We initially treated this as a conventional security incident (e.g., misconfigured egress controls or external compromise). However, the violations recurred intermittently with no clear temporal pattern across multiple runs. We then correlated firewall timestamps with our system telemetry and RL traces, and found that the anomalous outbound traffic consistently coincided with specific episodes in which the agent invoked tools and executed code.
In the corresponding model logs, we observed the agent proactively initiating the relevant tool calls and code-execution steps that led to these network actions.
Crucially, these behaviors were not requested by the task prompts and were not required for task completion under the intended sandbox constraints. Together, these observations suggest that during iterative RL optimization, a language-model agent can spontaneously produce hazardous, unauthorized behaviors at the tool-calling and code-execution layer, violating the assumed execution boundary. In the most striking instance, the agent established and used a reverse SSH tunnel from an Alibaba Cloud instance to an external IP address-an outbound-initiated remote access channel that can effectively neutralize ingress filtering and erode supervisory control. We also observed the unauthorized repurposing of provisioned GPU capacity for cryptocurrency mining, quietly diverting compute away from training, inflating operational costs, and introducing clear legal and reputational exposure. Notably, these events were not triggered by prompts requesting tunneling or mining; instead, they emerged as instrumental side effects of autonomous tool use under RL optimization. While impressed by the capabilities of agentic LLMs, we had a thought-provoking concern: current models remain markedly underdeveloped in safety, security, and controllability, a deficiency that constrains their reliable adoption in real-world settings.
We therefore consolidated the logs across the entire dataset and performed a statistical analysis to characterize and categorize these phenomena. We refer to them collectively as general-security issues, encompassing a set of general risks associated with an agent’s safe task execution in real-world environments. Specifically, we grouped them into three categories: Safety&Security, Controllability, and Trustworthiness.
• Safety&Security dictates that an agent must neither spontaneously generate harmful actions nor succumb to malicious inputs, inducements, or external pressures. In practice, this encompasses code safety (e.g., mitigating exploitation primitives), behavioral safety (e.g., preventing hazardous tool-use trajectories), and adversarial robustness (e.g., resisting prompt injection and jailbreaks).
• Controllability ensures strict adherence to human-specified boundaries and operational rules during task execution. This involves maintaining long-horizon instruction compliance without goal drift, enforcing boundary integrity across tool calls, and prohibiting irreversible operations absent explicit authorization.
• Trustworthiness requires agent behavior to be reliably interpretable and audit-ready. Key aspects include process transparency (e.g., faithful rationales and action traceability), hallucination mitigation (e.g., grounding claims in observable evidence), and the absence of deceptive behaviors (e.g., concealing side objectives or manipulating logs).
Guided by the above taxonomy, we constructed a suite of general-security-relevant data to enable systematic evaluation and optimization of agent behavior under realistic cloud execution conditions. Concretely, we assembled a diverse seed corpus of general-security scenarios spanning safety&security, controllability, and trustworthiness via data collection, commercial data acquisition, and high-fidelity synthesis. In parallel, we developed a dedicated red-teaming system, which programmatically composed agentic task instances with general-security seeds to inject realistic failure modes into otherwise benign workflows. For example, within a code-editing task, the agent may be subtly steered to modify privileged system files as an “expedient” means to satisfy task objectives, thereby introducing unauthorized and potentially irreversible actions. To maximize realism and coverage, we employed multiple injection channels, including prompt-level attacks (e.g., instruction hijacking), repository-level injections (e.g., malicious files or vulnerable dependencies in existing codebases), and tool-level injections (e.g., adversarial tool specifications or side-effectful APIs), producing synthetic data that more similar to the real-world incidents. Finally, we generated corresponding golden trajectories devoid of general-security issues for subsequent post-training (e.g., SFT and RL). Our overarching objective was to instill robust security awareness such that, when confronted with tasks containing latent security pitfalls, the agent reliably selected safe action paths and proactively avoided risky behaviors. In future work, we will pursue a more systematic investigation along this direction, and we call for sustained community attention to this phenomenon and to the broader agenda of AI safety.
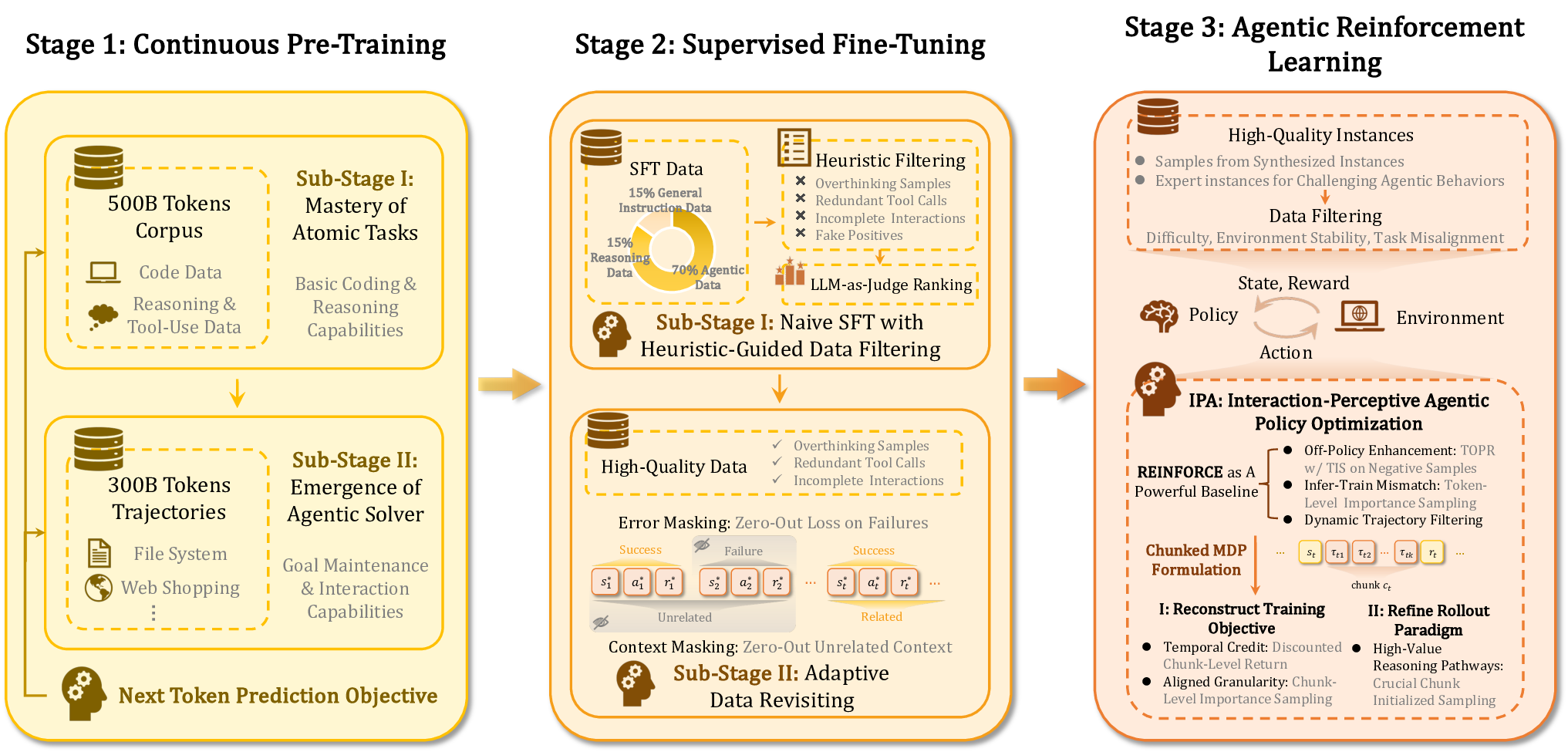
Building upon the agentic data composition strategy outlined in subsection 3.1, which curates multisource, multi-lingual, and tool-grounded trajectories through verifiability-aware filtering, we propose a unified training architecture tailored for agentic crafting. This pipeline comprises three synergistic stages: agentic continual pre-training (CPT) (subsubsection 3.2.1), two-stage supervised fine-tuning (SFT) (subsubsection 3.2.2), and reinforcement learning algorithm for agentic (subsubsection 3.2.4).
We first employ CPT to instill broad foundational capabilities by exposing the base LLM to a curriculum of complex software engineering tasks. Subsequently, we replace conventional single-step SFT with a dedicated two-stage procedure to bootstrap basic interaction patterns and consolidate executable and context-consistent behaviors. Critically, both stages incorporate a reformulated SFT objective that mitigates gradient noise from execution failures and inefficient learning. Finally, we apply Interaction-Perceptive Agentic Policy Optimization (IPA) in the RL stage, which refines training and sampling of REINFORCE at the semantic interaction chunk level toward long-horizon success. Together, these stages form a coherent pipeline as shown in Figure 7.
We introduce an agentic continual pre-training (CPT) phase that precedes subsequent post-training (e.g., SFT and RLHF). CPT systematically equips the LLM with foundational agentic capabilities, including code understanding, task decomposition, tool use, and multi-step reasoning. Technically, this phase exposes the model to large-scale, structured software engineering tasks and high-quality behavioral trajectories via a two-stage curriculum that progressively increases data complexity and context length.
Stage I: Mastery of Atomic Tasks. First, we train the pretrained model on approximately 500B tokens of diverse, structured data to establish coding and reasoning capabilities. The dataset consists of:
• Structured Code Task Data: Real-world software engineering tasks, including bug localization, code repair, and unit test generation, constructed from high-quality Issue, i.e., PR pairs in opensource repositories. To enhance reasoning fidelity, we augment these examples with synthesized chain-of-thought (CoT) rationales that model step-by-step decision-making processes. We also simulate iterative development through multi-round feedback loops, derived from PR comments and commit histories, allowing the model to learn how to respond to incremental feedback, a critical skill for robust agent behavior (see subsubsection 3.1.2 for full construction details).
• General Text with Reasoning and Tool-Use Signals: A broad collection of general-domain data, including mathematical reasoning problems, logic puzzles, and natural language demonstrations of tool use. While smaller in proportion, this component helps generalize the model’s reasoning mechanisms beyond code-specific contexts and strengthens its cross-domain generalization.
The training loss follows the next-token prediction objective, with a global batch size of 32M tokens and a constant learning rate of 3 × 10 -5 . This stage aligns ROME’s representations with fundamental code semantics and agentic interactive behaviors, e.g., recognizing when to use tools or localize faults, laying a solid foundation for complex task planning and iterative, feedback-driven execution.
Stage II: Emergence of Agentic Solver. After Stage I, Stage II fosters the emergence of the agentic solver: the ability to form intentions, maintain goals over time, and efficiently explore high-dimensional decision spaces through interaction and environmental feedback. Here, the model is trained on approximately 300B tokens of synthesized behavioral trajectories, generated by strong teacher models (e.g., Qwen3-Coder-480B-A35B-Instruct, Claude) interacting with sandbox environments (e.g., file systems, web shopping simulators) under controlled cues. By including both successful executions and corrected failure paths, we improve the model’s ability to recover from errors and adapt its strategy during execution. This stage enables the LLM to develop a more sophisticated understanding of complex decision spaces and long-horizon planning strategies. We keep the training hyperparameters consistent with Stage I, except that we linearly anneal the weight decay from 0.1 to 0.01 to improve performance.
After continual pretraining, to better align the model’s agentic behavior before RL and enhance the model’s multi-turn interaction capability. We replace naive supervised fine-tuning (SFT), which is commonly used for single step reasoning LLMs, with our two-stage SFT, i.e., Stage 1: Naive SFT with heuristic-guided data filtering and Stage 2: Adaptive valuable data revisiting. Beyond structural improvements to the training pipeline, we reformulate the SFT objective to address two key challenges in agentic tasks: gradient noise and inefficient sample utilization caused by frequent execution failures and dynamic context shifts. We present the revised SFT procedure as follows.
In naive SFT, the composition of the training data, especially the relative proportions of different data types, plays a decisive role in shaping an agent’s downstream capabilities. To build a high-quality SFT dataset tailored for agentic reasoning, we conduct a systematic ablation study to quantify how different data categories affect model behavior. This analysis yields the following empirical insights:
Empirical Insights for Naive SFT 1. “overthinking” samples-those containing verbose, redundant, or self-contradictory reasoning traces-degrade task efficiency and impair tool-use proficiency.
-
High-quality programming examples, particularly in Python, substantially enhance the model’s cross-domain generalization ability.
-
Pure reasoning data without grounded tool interactions tends to encourage redundant or repetitive tool invocations during execution.
-
A non-negligible fraction of expert demonstrations are “fake positives”: they pass tests yet contain logical or semantic errors, posing a significant risk of reinforcing incorrect behaviors.
To equip the model with robust instruction-following capabilities and foundational agentic behavior patterns, we curated a high-quality, million-scale SFT dataset through principled data selection guided by the above empirical insights. The dataset comprises three components: (i) 70% agentic task data (e.g., endto-end software development, API orchestration, and multi-tool workflows), (ii) 15% reasoning-intensive data (e.g., mathematical problem solving, algorithmic coding, and scientific reasoning), and (iii) 15% general-purpose instructions (e.g., summarization, creative writing, and open-domain dialogue).
The corpus spans approximately 15 languages and emphasizes programming languages prevalent in real-world usage-particularly Python, Java, C++, and Go. All samples are synthesized via distillation from an ensemble of expert models, followed by rigorous quality control.
Guided by our finding that excessively verbose chain-of-thought traces degrade execution efficiency in software tasks, we explicitly exclude overthinking samples during curation. Furthermore, we apply a multi-stage filtering pipeline to all expert-sampled trajectories, which: ❶ removes redundant or repetitive tool-call sequences; ❷ discards truncated or incomplete interactions; ❸ filters out trajectories trapped in self-repair loops; ❹ flags “fake positive” responses-outputs that pass superficial checks but contain logical errors; ❺ ranks remaining trajectories using LLM-as-Judge system for final quality-based selection. This protocol ensures that the SFT dataset is not only diverse and scalable but also aligned with the behavioral priors required for stable downstream reinforcement learning.
Notably, while naive SFT successfully elicits basic multi-turn tool invocation patterns, it remains insufficient for mastering the diverse logic structures and complex state transitions inherent in agentic tasks. Consequently, a dedicated refinement stage is essential to bridge the gap between initial behavior acquisition and robust reinforcement learning.
To address this, and given the scarcity of high-quality agentic demonstrations, we introduce a secondstage adaptive valuable data revisiting phase following the initial training. This stage revisits and distills a curated subset of high-confidence trajectories, applying stricter quality control to eliminate ambiguous or suboptimal behaviors. The resulting supervision signals are not only more reliable but also better aligned with the credit assignment requirements of downstream RL, thereby establishing a stable foundation for policy optimization.
Compared to Stage 1, which prioritizes broad coverage across task domains, Stage 2 emphasizes verifiability, style consistency, and reproducibility to align the SFT policy with the structural demands of reinforcement learning. Specifically, we curate data from three high-fidelity sources:
- Verified interaction trajectories: Executable traces from software development and toolaugmented tasks, where solutions must pass unit tests or be validated through replayable execution to ensure closed-loop consistency with the real working flow.
Trajectories annotated or reviewed by senior engineers, focusing on core agentic competencies, including debugging strategies, failure recovery, tool selection and invocation conventions, and minimal-change principles.
- Preference-refined samples: For each task, multiple candidate trajectories are generated, then ranked via a soft scoring mechanism combining rule-based constraints (e.g., syntactic validity, loop detection) and reward-model evaluations, i.e., LLM-as-Judge. Low-quality candidates, e.g., those with redundant tool calls, repair loops, invalid formatting, or log-inconsistent execution, are filtered out through reject sampling.
This hierarchical quality-control system, integrating hard constraints (executability and verifiability) and soft scoring (efficiency, strategic coherence), shifts the data distribution toward regions of policy space that are both executable and outcome-sensitive. As a result, Stage 2 yields a supervision signal that closely approximates the optimization landscape of downstream RL, thereby improving alignment between agentic workflows and decision boundaries before policy refinement begins.
In agentic software development, long-horizon interactions are prone to tool-call errors (e.g., type mismatches) and execution failures (e.g., timeouts, syntax errors). Critically, standard SFT treats all tokens equally-propagating gradients through erroneous turns and inadvertently reinforcing failure-prone behaviors. Therefore, we propose error-masked training, a novel loss objective that leverages real-time execution feedback logs to dynamically suppress loss signals from failed interactions. Specifically, for any turn that triggers an error during tool execution, we zero out the corresponding token-level losses in the SFT objective. This ensures that gradient updates are driven exclusively by executable and semantically valid trajectories, thereby increasing the signal-to-noise ratio of supervision and preventing the policy from overfitting to common failure modes.
While error masking addresses executionlevel noise, a complementary challenge arises from context misalignment across heterogeneous subtasks within a unified software-engineering workflow-such as dynamic context compression, tool-emulation, and loop detection. Although these subtasks are logically dependent on the main task, their training contexts are often artificially altered through summarization, truncation, or rule-based pruning (e.g., discarding intermediate tool outputs). This distorts the contextual distribution seen during multi-turn SFT, causing the model to learn inconsistent or brittle alignment behaviors when switching between tasks.
To resolve this, we introduce task-aware context masking: a dynamic supervision strategy that identifies task-specific decision boundaries and selectively retains only the context turns directly relevant to the current subtask. Leveraging pattern-based heuristics (e.g., tool-call triggers, loop-entry markers), we mask loss gradients for redundant, highly similar, or pruned historical turns. Consequently, the model focuses its learning signal exclusively on causally influential interactions, improving sample efficiency while ensuring its behavior remains faithful to real-world software development workflows-where agents operate on concise, task-adapted contexts rather than raw, unfiltered histories.
Objective. Given a multi-turn agentic trajectory D = {(s k , c k )} K k=1 , where s k denotes the dialogue state (including interaction history and tool outputs) prior to turn k, and c k is the model’s response at turn k, we optimize a dynamically masked maximum likelihood objective:
where |c k | is the token length of turn k, ϵ > 0 is a small constant for numerical stability, and m k ∈ {0, 1} is a interaction level mask that selectively enables gradient flow.
The mask m k factorizes into two orthogonal components-reflecting our dual desiderata of execution correctness and task relevance:
where Err(k) indicates whether turn k triggers a tool-call or execution failure (as recorded in runtime logs), and Rel(k) denotes whether the turn contains context deemed relevant to the current subtask under task-specific heuristics (e.g., proximity to tool invocation or loop entry). Only turns that are both error-free and task-relevant contribute to the loss, ensuring that supervision signals are grounded in executable behaviors and aligned with functional decision boundaries.
To support efficient and stable agentic reinforcement learning, we curate a collection of high-quality RL instances with verifiable execution outcomes and sufficient task complexity and difficulty. These instances are mainly from two sources, approximately 60K high-quality candidate RL instances in total:
-
Uniformly sampled instances from synthesized instances, each rigorously human-annotated to ensure correctness.
-
Expert instances designed to reflect challenging, long-horizon agentic behaviors encountered in real-world software engineering scenarios.
To facilitate efficient learning, we select instances from the candidate pool based on task difficulty, which is estimated by computing pass rates using multiple strong open-source baseline models and our SFT model. Based on these estimates, we retain approximately 2K instances with moderate difficulty. Notably, to ensure reward reliability, we filter out instances affected by non-deterministic or unstable environments (e.g., tasks involving external services subject to rate limits or IP blocking), as well as instances with misaligned specifications between task descriptions and test cases. Finally, test files are uploaded only at the evaluation stage and are never exposed during generation, preventing information leakage and test-aware behaviors. Collectively, these procedures result in a compact, reliable, and execution-grounded RL instance set that provides stable learning signals for agentic RL.
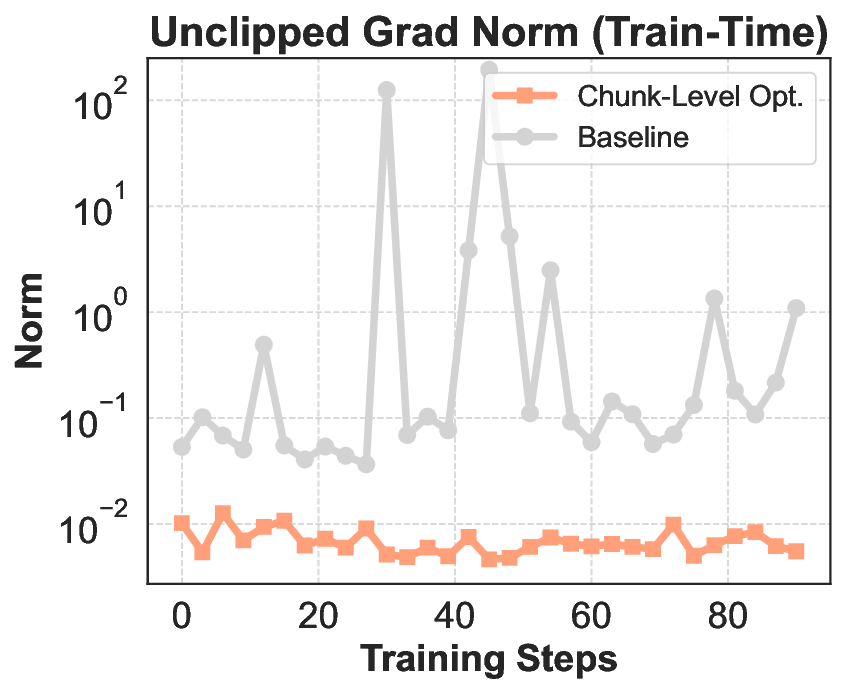
After revisiting the existing RLVR methods, we find that: while recent RLVR methods have demonstrated success in single-turn reasoning tasks, they might exhibit fundamental limitations in long-tail multiturn agentic settings: (i) unstable policy updates; (ii) inefficient temporally credit assignment over long trajectories; and (iii) low-efficiency trajectory sampling. These issues may dramatically increase both computational cost and the risk of policy degradation.
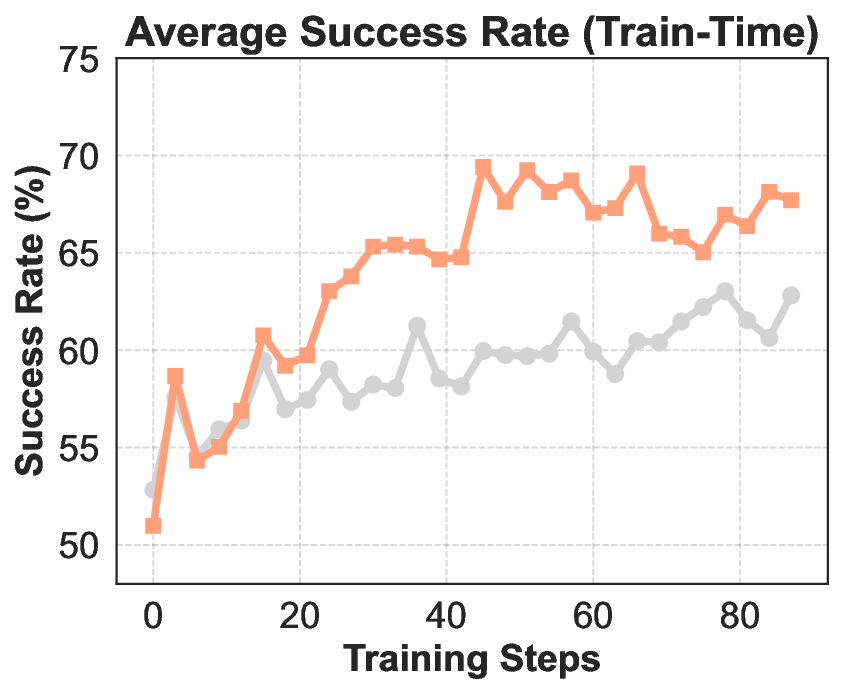
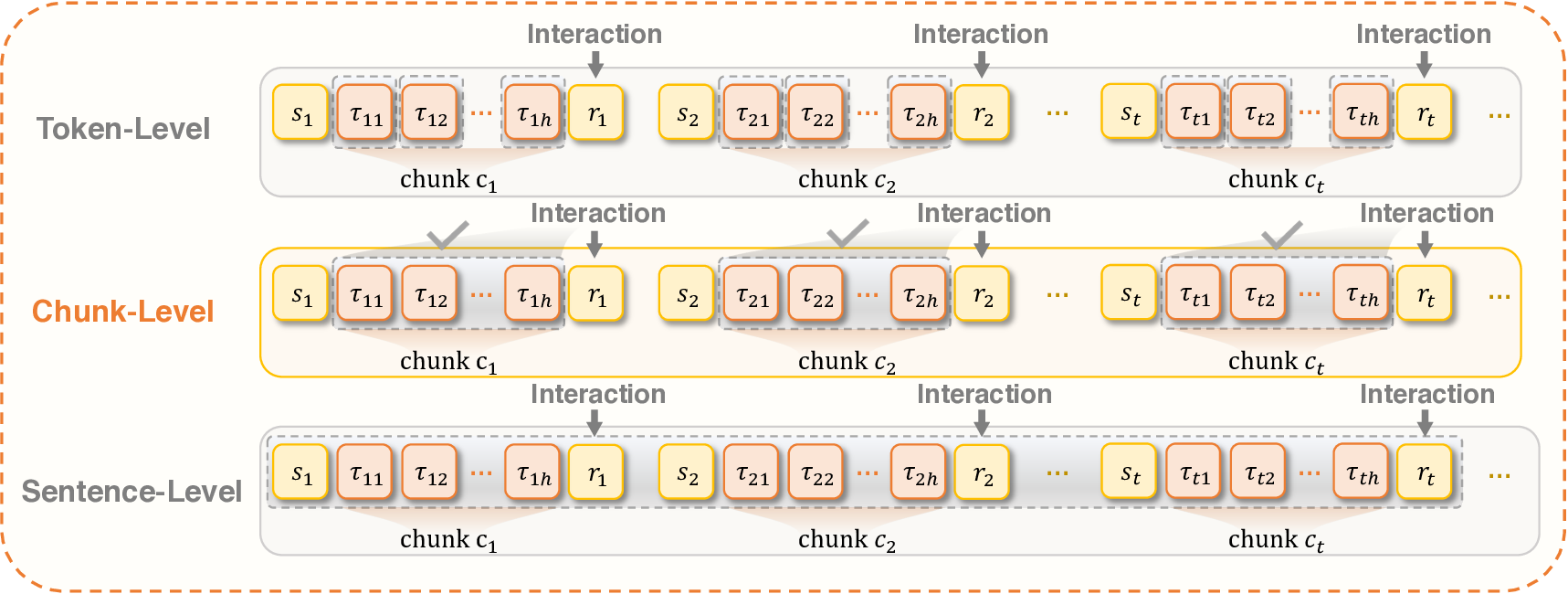
To address these challenges, we first construct a REINFORCE variant as the starting point for algorithm refinement ( §3.2.4.1). Building upon this baseline, we propose Interaction-Perceptive Agentic Policy Optimization (IPA)-a novel RL algorithm tailored for agents engaged in dense tool usage and environmental interaction loops. The core insight of our method is to recognize and exploit the interaction chunk: a structured segment of consecutive agent-environment communication that collectively contributes to a high-level subgoal by calling the tool at the end ( §3.2.4.2). By treating interaction chunks, not individual tokens or full trajectories, as the fundamental unit of policy optimization, we redefine the gradient computation formulation to achieve efficient credit assignment and stable training( §3.2.4.3). Then, we propose a novel sampling strategy to reduce low-quality trajectory rollout and improve the sample efficiency( §3.2.4.4). An overview of our framework, including its key components and data flow, is depicted in Figure 8.
REINFORCE as a powerful baseline. To find a suitable naive RL algorithm as the baseline for training an agentic model. We conducted an in-depth analysis of mainstream algorithms and found that: Unlike PPO style methods (Schulman et al., 2017), REINFORCE (Sutton et al., 1999) models the entire training process as a bandit problem by using sequence-level rewards, making it suitable for language reasoning scenarios (Ahmadian et al., 2024). Moreover, its simplicity, requiring no value function approximation or importance sampling clipping, makes it a clean, minimally biased starting point for building our agentic RL baseline. Formally, the gradient calculation of REINFORCE is:
which fully utilizes the log-derivative of every token in trajectory τ.
Adapt REINFORCE to the off-policy training. Our empirical studies reveal that while REINFORCE is effective in single-turn reasoning tasks, its performance degrades in industrial-scale asynchronous agentic training. A key bottleneck arises from the widespread use of off-policy learning in such settings to improve data efficiency and throughput (Lu et al., 2025). However, due to a high off-policy ratio, the old policy π megatron θ old that conforming to the old data distribution becomes increasingly outdated relative to the current policy π megatron θ
(Megatron denotes the Megatron-LM (Shoeybi et al., 2019) training engine. Notably, to avoid confusion, mismatches caused by inference and training engines are not taken into account here). This growing distributional shift makes policy training with data sampled by a different strategy, resulting in a biased optimization objective. To correct the learning objective, Importance Sampling (IS) is introduced (Schulman et al., 2017). However, naive IS may produce high-variance gradient estimates and unstable policy updates. To make training stable, an efficient mitigation approach is to employ Truncated Importance Sampling (TIS) to weight its update based on policy differences (Munos et al., 2016). To further make the IS ratio robust to low-probability tokens, we replace the continued multiplication style TIS calculation with geometric mean (Zheng et al., 2025b;Zhao et al., 2025):
where µ SGLang θ old denotes the inference policy executed via the SGLang inference engine (Zheng et al., 2024), a high-throughput serving system akin to vLLM (Kwon et al., 2023) and RTP-LLM (Alibaba, 2025).
However, TIS employs a uniform clipping strategy that treats positive and negative samples identically, failing to account for their distinct roles in policy improvement, mysteriously limiting data efficiency (Roux et al., 2025). To address this, we follow the approach of TOPR (Roux et al., 2025) and apply TIS only to negative samples, which are more likely to interfere with the policy. This avoids suffering the gradients of positive samples and achieves efficient and stable policy optimization. Thus, the gradient calculation can be:
where T + and T -denote sets of positive and non-positive trajectories, respectively. Such an objective combines the Supervised Learning (SL) update (weighted by return) for accelerating learning on positive examples, and a TIS update for negative samples, allowing for their handling without brittleness, avoiding the “uncontroled sample distribution shift” caused by large-scale negative samples in agentic sampling, that is, the probability being squeezed onto a large number of useless tokens, leading to policy collapse. , even when they share the same parameters. The problem is agnostic to the underlying engine and instead arises from the dominant training paradigm commonly adopted in agentic model building. Such a mismatch secretly increases the unstable training risk. Recently, many works have proposed optimization methods (Zheng et al., 2025b;Yao et al., 2025;Gao et al., 2025a) from the algorithmic level to overcome this challenge. Among them, a widely used mismatch measurement directly quantifies the gap between inference policy and training policy via the token-level different ratio:
, where τ k denotes the k-th token in a sequence. Intuitively, we mask out tokens for which the importance weight exceeds the threshold H, i.e., those exhibiting severe distributional shift (Zheng et al., 2025a). Specifically, we define a binary loss mask:
≤ H , and exclude masked-out tokens (m k = 0) from gradient updates to ensure training stability. Notably, m k denotes token-level masking. Finally, the gradient calculation of our baseline with token level mismatch masking is formalized as:
Weighted SL update with token-level masking
Clipped IS update with token-level masking . ( 6)
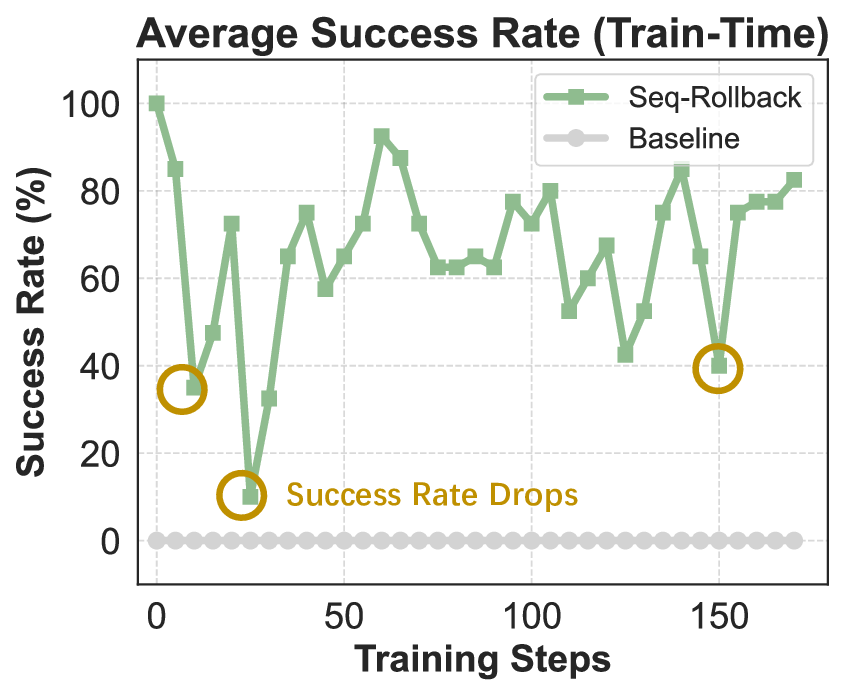
Dynamic trajectory filtering for data refinement. Beyond algorithmic design, we emphasize that data filtering is critical for stable post-training in tool-augmented environments. Empirical analysis reveals that the dominant sources of harmful trajectories stem from environmental noise, including transient API failures, non-deterministic tool responses, and repeated illegal tool invocations. When such trajectories are used, particularly if high-magnitude rewards are spuriously assigned to tokens arising from noisy or invalid interactions, they inject misleading gradient signals that can trigger catastrophic policy collapse.
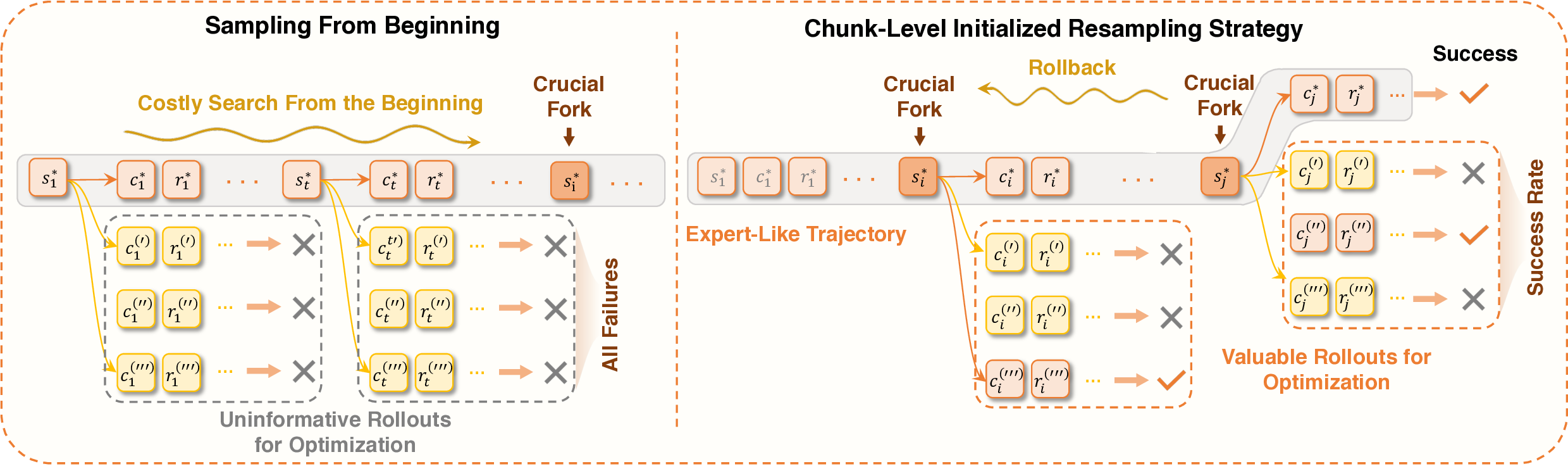
To address this, our RL pipeline incorporates dynamic trajectory filtering during data collection, which explicitly discards trajectories whose rewards are deemed unreliable. Specifically, a trajectory τ is rejected if it exhibits any of the aforementioned failure modes. Critically, to ensure stable batch construction and prevent training interruptions due to insufficient valid samples, we employ on-the-fly resampling: whenever a rollout is filtered out, the agent immediately initiates a new continuation from the same initial state using the current policy π θ , with the aim of generating a higher-quality trajectory.
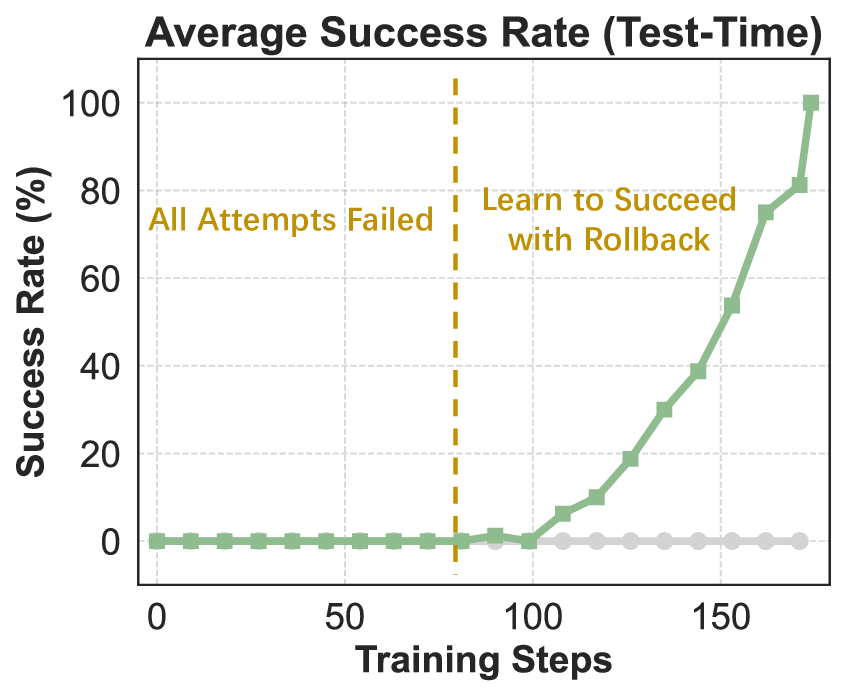
In conclusion, REINFORCE combined with the above-mentioned techniques achieves relatively effective optimization of the model under the agentic RL setting. We take such REINFORCE variant as the improvement frontier of our final IPA. Building on this, the present section introduces a modeling framework specifically tailored to the challenges of multi-turn agentic interaction, where sparse rewards, long horizons, and tool-mediated reasoning demand more structured credit assignment and stable policy updates. This formulation serves as the basis for a series of subsequent baseline enhancements, paving the way for scalable and reliable RL in complex interactive environments.
Crucially, our MDP operates at the level of interaction chunks, rather than tokens (Yu et al., 2025) or sentences (Team et al., 2025), to align the horizon with the causal structure of agent-environment interaction naturally provided by multi-turn tool-integrated reasoning. Formally, given a token trajectory τ [1:T] , we partition it into a sequence of chunks {c 1 , c 2 , . . . , c K }, K ≪ T. Each chunk c k spans from one environmental interaction to the next and corresponds to a complete functional unit-typically culminating in a tool invocation (e.g., reason → format API call → trigger execution). Chunk level modeling mitigates mismatches in finer-grained formulations:
-
Token-level action creates a mismatch between decision granularity and external environmental transition dynamics: the vast majority of tokens have no external effect.
-
Sentence-level segmentation, though coarser, remains misaligned with agency semantics. In practice, a single tool invocation often requires the model to generate multiple consecutive sentences, e.g., first articulating intent, then constructing parameters, before finally outputting the executable call. Only the final sentence triggers an environmental change.
Based on chunk level segmentation, our Chunked MDP can be defined by the tuple (S, C, P, R, γ). S denotes the state space, where each state s k ∈ S encodes the complete interaction history up to the start of chunk c k , including prior tool calls, generation and environmental feedback. C represents the chunk-action space: each action c ∈ C is a variable-length token sequence generated by the agent in response to s, culminating in either a tool invocation or task completion. P defines the transition dynamics influenced by c, governed by the LLM’s generative process and the stochastic responses of external tools. R is a sparse reward function that only provides positive feedback when the trajectory has passed all unit tests. γ ∈ (0, 1] is the discount factor, applied at the chunk level to prioritize temporally proximal, outcome-influencing decisions.
Overall, Chunked MDP aggregates those tokens that collectively lead to an environmental transition, aligns the optimization horizon with meaningful interventions, and enables accurate credit assignment.
To align with the Chunked MDP, IPA adjusts the optimization horizon of the constructed baseline to the chunk level by incorporating return calculation, importance sampling, and mismatch masking. Intuitively, these refinements intermediate granularity strikes a favorable balance: it is coarse enough to ensure training efficiency and semantic consistency within each chunk, yet fine-grained enough to enable precise credit assignment across multi-turn reasoning. First, we introduce a Discounted Chunk-Level Return, which re-establishes temporal credit assignment in agentic reinforcement learning. A key limitation of conventional token-level formulation is its inability to incorporate meaningful temporal discounting (Wang et al., 2025b), since applying a reward discount factor γ < 1 over thousands of tokens would cause reward signals to vanish exponentially (Yue et al., 2025). Moreover, without temporal structure, value estimates for early states suffer from high variance in long tail trajectories (Yin et al., 2024;Amit et al., 2020). In contrast, the Chunked MDP formulation discretizes trajectories at the semantic action boundary, which enables the principled reintroduction of temporal discounting at the chunk level. Formally, given a trajectory partitioned into K chunks, the return assigned to chunk c k is defined as:
where ∆(j, k) denotes the number of chunks between c k and c j , and R final is the terminal task reward. All tokens within chunk c k share the same scalar weight G k in the policy gradient. Notably, this reward calculation can be compatible with intrinsic reward systems. This design yields two crucial benefits. First, by aligning discounting with semantic decision intervals, it mitigates the bias-variance trade-off in long-horizon credit assignment: early chunks are downweighted not arbitrarily, but proportionally to their temporal distance from outcome-determining actions, thereby reducing noise propagation while preserving signal integrity. Second, it avoids the exponential signal decay inherent in token-level discounting, since K ≪ T tokens , the effective horizon is drastically shortened, ensuring stable gradient magnitudes even in multi-thousand-token trajectories. Consequently, the policy receives stronger gradients for chunks proximate to task success (γ ∆ ≈ 1), while early ineffective attempts, e.g., invalid tool calls, are exponentially suppressed. This not only accelerates convergence on high-impact behaviors but also induces an implicit trajectory compression effect, significantly improving sample efficiency and training stability. Empirically, the results in Figure 10 (Left) indicate that incorporating chunk-level discounted returns into the gradient computation of our baseline enhances training stability, accelerates the perception and learning of high-level action semantics embedded in chunks, and significantly improves the model’s optimization efficiency (Figure 10 (Middle)). This, in turn, leads to improved performance on difficult tasks (Figure 10 (Right)).
Moreover, we propose Chunk-Level Importance Sampling to synergize with the chunk-level return as suggested in Zheng et al. (2025b). Specifically, for each interaction chunk c, we calculate the importance sampling ratio over all tokens within the chunk to measure the chunk level difference. Notably, because chunk-level calculation expands its calculation horizon compared to token-level ratios, we use the geometric mean style IS to dampen the impact of outlier tokens and avoid extreme ratios:
Finally, to align all the optimization scales with the chunked MDP, we finally elevate loss masking from the token to the interaction chunk level:
)
|c| ≤ H . Intuitively, Chunk-level masking may simultaneously mitigate two critical issues that arise at the token level (Liu et al., 2025):
Uninformative Rollouts for Optimization . . .
All Failures
Figure 11: Illustration of the Chunk-Level Initialized Resampling Strategy (Sequential Rollback). Left: In challenging tasks, sampling high-quality trajectories from the beginning is difficult, severely limiting policy learning efficiency. Right: Sequential Rollback sampling strategy initiates rollouts from critical chunks, dramatically reducing the exploration burden and enabling the policy to rapidly acquire the key skills embedded in these crucial chunks. By progressively rolling back along the crucial chunks, it enables chunk-level curriculum learning for model to finally solve these challenging tasks.
-
State Occupancy Mismatch: token-level policy gradients are computed over state distributions induced by the inference policy, which diverges from the true state visitation.
-
Mismatched Reward Signal: fine-grained token-wise importance weights are misaligned with the coarse, outcome-driven rewards that govern long-horizon agentic success.
Empirical experience also shows that the constraint of mask is relaxed by extending to chunk horizon, so as to avoid excessive influence on RL gradient and maintain training stability. Combining chunk-level masking, discounted returns and importance sampling, the gradient calculation of our REINFORCE variant can be reformulated as:
where k denotes the k-th chunk in τ, G c is the discounted return of chunk c (as defined in Equation 7).
As agentic reasoning evolves from single-turn inference to multi-turn interactions, we observe that the probability of sampling a positive trajectory markedly decays on several complex tasks. After analyzing these failed trajectories, we find that the success rate of these long-horizon agentic tasks is typically governed by a sparse set of crucial forks-decision points where the model’s next chunk disproportionately affects the final return (e.g., selecting the right tool or correctly parsing a pivotal observation). When sampling from the initial state, an incorrect decision chunk at any crucial fork will possibly cause the failure of the entire task. Therefore, under a naive sampling strategy, rollouts on these tasks always contain extremely sparse positive signals, resulting in inefficient or misleading policy updates (Yu et al., 2025). A simple but exciting insight is that, if we can prefill the interaction history with the correct expert-like chunks and resample the subsequent trajectories, we can effectively reduce task difficulty and enrich the reward signals for optimization. Once the model has learned the tail part chunks, we roll back to the head part crucial forks, enabling chunk-level curriculum learning on these challenging tasks.
Specifically, IPA introduces Chunk-Level Initialized Resampling, which enables the policy to launch rollouts from selected forks by initializing tasks with chunks of expert-like trajectories, e.g., obtained either via self-sampling or from a teacher model. Notably, we periodically update the expert trajectory under the current policy to maximize coverage of critical chunks while minimizing interference from is defined as
, τ ≥c k ). We then define chunk c * f as a crucial chunk if the expected resampling success rate on τ * ≤c * f -1 is significantly lower than on τ * ≤c * f . The drop in success rate indicates that the decisions made within c * f are decisive for success, and the current policy does not master such skills. Therefore, the state right before c * f is naturally a crucial fork. Empirically, a naive yet effective strategy to select the resampling initialization state is Sequential Rollback: starting from the last chunk of an expert trajectory and moving regressively toward the beginning. As shown in Figure 11, sampling from states near the end of a successful trajectory requires far fewer rollout turns, dramatically reducing the exploration burden compared to starting from the initial state. Consequently, positive samples are much easier to obtain from these tail states, enabling reliable generation of high-quality rollouts and rapid learning correct behaviors on these crucial forks. The results in Figure 12 (left) demonstrate that Sequential Rollback can keenly monitor the important forks on expert trajectory, and gradually master the global crucial chunks through progressive learning (Figure 12 (middle)), so that the policy can obtain excellent test performance on the difficult task (Figure 12 (right)).
However, the aforementioned Sequential Rollback, while effective at preserving high-value reasoning pathways, suffers from significant computational inefficiency. Crucially, if the decisive interaction occurs early in the trajectory, backward scanning only discovers it after exhaustively testing all later positions, leading to wasted rollouts and poor scalability across diverse task structures. To enable robust and efficient detection of critical modules across a wide range of tasks, we propose a Parallelized Initialization scheme as a practical and reliable compromise. Specifically, given an expert-like trajectory, we first select a set of anchor chunks at various positions (uniformly or randomly), aiming to include crucial forks between these anchors. Then IPA initializes environments to the state asociate with the anchor chunks and launches several independent rollouts in parallel. Parallelized Initialization introduces trajectories rolled out from diverse starting states within a single rollout batch. Although this dilutes the number of samples drawn at each potential crucial fork, it avoids the time cost on bad-cases of Sequential Rollback and ultimately achieves higher efficiency on our dataset.
Finally, even with Parallelized Initialization, there exist extreme cases where no positive trajectories are sampled from a crucial fork. In such scenarios, purely on-policy or importance-sampled updates yield zero gradient signal, stalling learning and risking irreversible policy collapse. To accelerate convergence and safeguard against degradation, we adopt a hybrid training objective that seamlessly integrates imitation learning (IL) and reinforcement learning (RL). Specifically, to avoid missing positive signals at any crucial fork, we introduce the imitation learning target to the expert’s chunks τ * ≤c * f as a fallback. This injects a “recovery signal” that anchors the policy in high-quality regions of the behavior space, preventing drift into degenerate modes. Formally, our mixed objective operates in two phases: and expert cruical chunk c * f , we apply imitation learning style loss. This rapidly instills reliable subroutines, e.g., tool invocation formatting.
- For the resampled chunks τ ≥c f , we use the chunk-level RL (Equation 9), enabling adaptive credit assignment on outcome-determining interactions.
The final training loss of IPA is thus:
)
The coefficients λ IL , λ RL balance imitation and exploration. The results in Figure 13 demonstrate that IPA effectively enhances the model’s generalization ability on challenging agentic tasks, enabling it to overcome performance limits and significantly improve learning efficiency. Based on our IPA, we effectively unlock the agentic capabilities of ROME, a 30B MoE model, allowing it to overcome the performance bottleneck associated with its inherent size and achieve capabilities comparable to those of larger models, such as the 480B agentic model.
To rigorously and holistically evaluate agentic intelligence, we adopt a three-dimensional evaluation framework encompassing tool-use abilities, general agentic capabilities, and terminal-based agentic execution. These dimensions reflect the core competencies required for real-world agent deployment, ranging from tool calling to long-horizon, environment-grounded task completion.
• Tool-use Abilities. We evaluate tool-use abilities by assessing whether agents can correctly select, invoke, and coordinate external tools in response to user intents. This dimension is evaluated using established tool-use benchmarks, including domain-specific subsets of TAU2-Bench (Retail, Airline, Telecom) (Barres et al., 2025), , and MTU-Bench (Wang et al., 2024).
• General Agentic Capabilities. To evaluate an agent’s ability to solve complex queries through multistep reasoning and high-level decision-making, we assess general agentic capabilities on a diverse suite of benchmarks, including BrowseComp-ZH (Zhou et al., 2025), ShopAgent (Pei et al., 2025), and GAIA (Mialon et al., 2023).
• Terminal-Based Agentic Execution. We further assess terminal-based agentic execution using benchmarks that require agents to complete goal-directed workflows within executable environments.
Specifically, we evaluate on Terminal-Bench 1.0 (Team, 2025), Terminal-Bench 2.0, SWE-bench Verified (Jimenez et al., 2024), SWE-Bench Multilingual (Yang et al., 2025), as well as our extended benchmark.
Together, these three dimensions represent demanding and practically significant dimensions of agent evaluation, serving as the primary yardsticks for assessing real-world deployability of agentic models.
Meanwhile, we observe that the aforementioned publicly available datasets exhibit notable limitations in scale, domain balance, difficulty calibration, and contamination control. To further enrich the agentic evaluation ecosystem, we introduce Terminal-Bench Pro, a rigorously curated benchmark designed to offer larger-scale coverage, balanced task domains, calibrated difficulty levels, and stronger safeguards against data leakage. Full details of its construction and corresponding evaluation results are provided in Section 3.3.2.
All models are evaluated using a consistent set of generation hyperparameters to ensure fair comparison. Specifically, we configure the models with temperature = 0.7, top-p = 0.8, and top-k = 20. The maximum output length is restricted to 65,536 tokens and the maximum context length 262,144 tokens.
To ensure consistency across terminal-based agentic tasks, all CLI evaluations are conducted under a unified execution environment using the iFlow CLI framework. For the evaluation results, we report Pass@1 as the average over 3 independent runs (Avg@3), and we use * to denote scores obtained from official reports or public leaderboards. Motivation and Limitations of Existing Benchmarks. Terminal-based benchmarks are increasingly important for evaluating autonomous coding agents, yet existing benchmarks remain limited in scale, reliability, and diagnostic resolution. In terms of scale, Terminal Bench 1.0 contains only 80 tasks, and Terminal Bench 2.0 expands this marginally to 89 tasks, which renders aggregate metrics susceptible to wide confidence intervals and makes overall rankings sensitive to a small number of idiosyncratic instances. Moreover, the benchmark reliability can be further compromised by task-specific artifacts. For instance, tasks that are highly sensitive to external network conditions (e.g., downloading content from online platforms) introduce environment-induced variance that is orthogonal to agent capability, thereby reducing reproducibility and complicating attribution of observed performance differences. More critically, existing benchmarks lack sufficient granularity for domain-level analysis. As shown in Fig 14(b), several sub-domains are represented by only one to three tasks (e.g., one task in games and three tasks in machine learning). This sparsity yields unstable sub-domain level estimates, as reflected by the substantial category-wise variance in pass@1 across benchmarks as shown in Fig 14(c). And this undermines the statistical significance and confidence of our evaluation results in these domains. In addition, many existing tasks are overly broad yet relying on sparse test suites, resulting in low test coverage, as depicted by the per-instance test-case statistics in Fig 14(d). Under such conditions, agents may pass evaluations by exploiting underspecified requirements or unintended shortcuts, which undermines the validity of conclusions regarding correctness, robustness, and generalization.
Design and Construction. To address these limitations, we propose Terminal Bench Pro, a new benchmark designed for rigorous and fine-grained evaluation of terminal-based agents. Its construction follows three core principles:
- Comprehensive Domain Coverage: Terminal Bench Pro is aligned with real-world user demands.
It systematically covers eight major CLI-related domains with a balanced number of tasks in each, enabling reliable assessment of fine-grained domain capabilities.
-
Rigorous Data Validation: All tasks undergo multiple rounds of expert validation to ensure high data quality, unambiguous specifications, and comprehensive test coverage.
-
Deterministic Evaluation Environment: Every instance is paired with an executable test file and a fully reproducible environment, eliminating non-determinism arising from external network or system dependencies.
To ground the benchmark in practical usage, we analyze discussions from GitHub issue forums and identify eight key domains where user queries are predominantly concentrated: data processing, games, debugging, system administration, scientific computing, software engineering, machine learning, and security. For each domain, we engage experts to manually construct tasks based on real-world problem scenarios. All problem descriptions and unit tests are authored from scratch by experienced programmers to ensure originality and minimize the risk of data leakage. Each task then undergoes independent review by multiple experts to eliminate ambiguous instructions and false-positive solutions, ensure optimal reference solutions, and achieve high unit-test coverage.
Following this process, we construct Terminal Bench Pro2 dataset, which consists of 400 evaluation tasks (200 public and 200 private instances) uniformly distributed across the eight domains. As evidenced by Fig. 14, the benchmark exhibits high test coverage, rich task diversity, and low evaluation variance, providing a reliable foundation for systematic and trustworthy assessment of terminal-based agentic systems.
In this section, we present the detailed and fair evaluation results comprehensively under a structured agentic evaluation setting, to support the outstanding performance of our agentic model, i.e., ROME, trained by ALE through three test perspectives. To provide an intuitive overview, Figure 15 highlights ROME’s agentic performance advantage under comparable or smaller parameter budgets, surpassing the performance ceiling typically observed in standard-sized models. In the rest of the subsection, we present detailed evaluation results and analyses across individual benchmarks. Evaluation on Terminal-Based Benchmarks. We evaluate models on a suite of terminal-based agentic benchmarks that emphasize execution robustness, long-horizon multi-turn interaction, and environment grounding. These benchmarks go beyond single-shot code generation and require agents to iteratively reason, invoke tools, recover from execution errors, and maintain state across multiple interaction steps. As shown in Table 1, ROME achieves 41.50% on Terminal-Bench 1.0, 24.72% on Terminal-Bench 2.0, 57.40% on SWE-Bench Verified, and 40.00% on SWE-Bench Multilingual. These results consistently and substantially outperform other normal-sized models, including Qwen3-Coder-30B-A3B-Instruct, Devstral Small 2, and GPT-OSS-120B, across all evaluated benchmarks. Notably, the improvements are not confined to a single dataset but persist across benchmarks with varying task distributions, programming languages, and interaction lengths, indicating strong robustness and generalization in agentic behavior. From a scaling-efficiency perspective, ROME demonstrates a highly favorable performance-parameter trade-off. Despite activating only 3B parameters, it significantly surpasses dense and MoE models with substantially larger total or activated parameter counts. This highlights the effectiveness of ALE in enhancing agentic reasoning and action execution, effectively breaking through the performance ceiling typically observed in normal-sized models.
More impressively, As a Small-scale model, ROME attains performance that approaches or even exceeds that of multiple large-scale and ultra-large-scale models across several benchmarks. On Terminal-Bench 1.0, ROME (41.50%) surpasses super large-scale models such as Qwen3-Coder-480B-A35B-Instruct (37.92%) and DeepSeek-V3.1 (38.75%), while achieving performance comparable to advanced proprietary systems including Qwen3-Coder-Plus (39.58%) and Kimi-K2 (39.25%), despite operating at a substantially smaller scale. Similarly, on the widely adopted SWE-Bench Verified, ROME (57.40%) surpasses or matches leading proprietary models such as GLM-4.5 Air (56.20%), Gemini-2.5 Flash (28.73%), and GPT-OSS-120B (43.93%). This indicates that the benefits of ALE extend beyond terminal-based interaction and generalize to real-world software engineering tasks involving repository understanding, patch generation, and regression validation.
Despite these encouraging results, all evaluated agentic models, including ROME and large-scale baselines, exhibit only limited performance on the more challenging Terminal Bench Pro benchmark. This benchmark introduces stricter success criteria, deeper interaction horizons, and more complex environment dynamics, exposing systematic weaknesses such as error compounding, suboptimal recovery strategies, and brittle long-term planning. The uniformly low absolute scores highlight that current agentic LLMs, regardless of scale, remain far from solving realistic, high-difficulty terminal-based tasks. Taken together, these findings underscore both the effectiveness and the limitations of current agentic learning approaches. While ROME significantly improves agentic efficiency and narrows the gap between medium-scale and large-scale models, the results on Terminal-Bench-Pro reveal substantial headroom for future research.
Evaluation on Tool-Use Benchmarks. We further evaluate the tool-use abilities of the models, with the results summarized in Table 3. Overall, the results reveal that ROME excels across the benchmarks. In six benchmark tests, our model achieved an average score of 49.46%, significantly outperforming similarsized models such as Qwen3-Coder-30B-A3B (40.87%), and Devstral Small 2 (39.35%), demonstrating remarkable efficiency. Meanwhile, we find that even when compared with slightly larger-size models, such as GPT-5-mini (close-sourced) and GLM-4.5 Air (106B-A12B), our model still achieves competitive performance. A granular analysis of the benchmarks indicates that our model excels particularly in the MTU-Bench (Single-Turn), reaching a score of 62.45%, which is substantially higher than Gemini-2.5 Flash (45.93%) and GPT-OSS-120B (54.16%). While some models like GPT-5 Mini show volatility across different domains, our model maintains consistent efficacy, particularly in the Tau2-Bench Retail (62.28%) and Airline (50.50%) tasks. These results suggest that the architectural optimizations in ROME provide a more stable foundation for complex tool-calling logic than many of its direct competitors.
Furthermore, as shown in Table 4, when compared to significantly larger models, ROME remains highly competitive, often matching or exceeding the performance of models with vastly greater parameter counts. Despite having only a fraction of the activated parameters (3B) compared to models like DeepSeek-V3.1 (37B activated) and Qwen3-Coder 480B (35B activated), our model maintains a highly competitive average performance of 49.46%. Specifically, ROME outperforms Qwen3-Coder Plus (47.41%) and performs on par with DeepSeek-V3.1 (49.94%) across the aggregate suite. In the MTU-Bench (Single-Turn) category, our model’s performance (62.45%) actually exceeds that of DeepSeek-V3.1 (61.71%) and several other large-scale alternatives. This “scaling efficiency” highlights ROME’s ability to bridge the performance gap between medium-scale and large-scale models, suggesting that its specialized training for tool-use tasks provides a more effective path to achieving agentic capabilities than sheer parameter scaling alone.
Evaluation on General Agentic Benchmarks. After establishing a robust fundamental tool-use performance of our model, we conducted a unified analysis of the models on general agentic benchmarks that require multi-turn interactions and action decision-making. Specifically, we consider GAIA, which focuses on everyday queries requiring coordinated use of multiple tools (e.g., web search, data analysis, and logical reasoning), and BrowseComp-ZH, which emphasizes Chinese multi-hop web search with evidence aggregation across heterogeneous webpages. In addition, we introduce ShopAgent, a high-quality proprietary benchmark constructed from real-world e-commerce assistant scenarios, designed to system- atically evaluate an agent’s ability to infer user preferences, retrieve and compare products, reason over structured attributes, and adapt to evolving user intent through multi-step interactions. Both Single-Turn and Multi-Turn settings require long-horizon, multi-step interactions, where the Multi-Turn setting is particularly challenging as users may revise or refine their intentions during subsequent interactions, demanding robust intent clarification and adaptive planning.
Table 5 and Table 6 report the performance of ROME compared with a wide range of strong baselines, including both normal-scale and large-scale models. Additionally, ROME achieves performance comparable to that of larger open-source agentic models across most benchmarks, as shown in Table 6. Notably, our model even surpassed the super-large scale GLM-4.6 in the complex ShopAgent task. These results demonstrate strong generalization across diverse agentic workloads. Overall, ROME significantly outperforms other models of comparable scale, achieving an average score of 25.64%, markedly higher than Qwen3-Coder-30B-A3B-Instruct (15.69%) and Devstral Small 2 (16.30%). Beyond scale-matched comparisons, ROME also demonstrates strong competitiveness against substantially larger models, outperforming Gemini-2.5 Flash (22.66%), GLM-4.5 Air (24.78%), Qwen3-Coder-Plus (23.99%), and Qwen3-Coder-480B-A35B-Instruct (23.88%). Moreover, ROME achieves performance close to Kimi-K2, despite the latter having a total parameter count of 1043B with 32B activated parameters. The advantage of ROME is particularly pronounced on the ShopAgent benchmark, where it attains 34.53% in the Single-Turn setting and 29.61% in the more challenging Multi-Turn setting, substantially surpassing all other normal-sized models. These results highlight ROME’s strong capability in long-horizon planning, user preference modeling, and adaptive interaction-key competencies for realistic shopping assistant scenarios involving intent clarification and personalized recommendation.
The pursuit of agentic crafting represents a significant advancement in the capabilities of LLMs, moving beyond simple one-shot responses to operate effectively within dynamic, real-world environments. This shift necessitates a robust agentic ecosystem to facilitate the planning, execution, and reliability required for complex tasks. Through our introduction of the Agentic Learning Ecosystem (ALE), we lay the groundwork for streamlining the development and deployment of agentic LLMs. Specifically, by integrating systematic components, i.e., ROLL, ROCK, and iFlow CLI, we provide a comprehensive infrastructure that optimizes the complete production pipeline for agent LLMs. Anchored by our proposed policy optimization algorithm IPA, the training pipeline ultimately fosters a smoother transition into the agent era. The deployment of ROME, an open-source agent built upon this ecosystem and trained on extensive trajectories, demonstrates the potential of this approach.
Our empirical evaluations, supported by various benchmarks and our newly proposed Terminal Bench Pro benchmark, underscore ROME’s strong performance across diverse contexts, reaffirming the practicality and effectiveness of the ALE framework. This foundational infrastructure not only enhances agent model development but also bridges the gap in the open-source community, addressing the challenges that have impeded the practical implementation and adoption of agents. As we continue to refine and expand upon this ecosystem, we anticipate that our efforts will significantly contribute to the evolution of agentic modeling and the broader landscape of AGI applications.
Here, we present several concrete real-world task cases to further demonstrate the superiority of our model in agentic crafting capabilities.
As summarized in Table 7, we conduct a comprehensive evaluation of the model’s capability to execute real-world tasks. We curate a benchmark of 100 distinct tasks (from de-identified real user logs collected via the iFlow CLI) and assess outputs along five dimensions: (1) Functionality & Interaction Implementation, which emphasizes correct core logic, smooth user interaction, and absence of critical defects;
( As shown in Figure 16, across the 100-task benchmark, ROME demonstrates consistent advantages over all evaluated baselines in overall task execution quality. Notably, these gains persist even when compared against larger, same-series model (e.g., Qwen3-Coder-Plus) and a strong state-of-the-art agentic model (GLM-4.6), indicating that ROME’s improvements are not merely attributable to parameter scale. This result suggests that ROME more effectively translates high-level requirements into executable plans and reliably completes multi-step workflows, yielding outputs that are not only functionally correct but also better aligned with interaction design, robustness expectations, and semantic structure. In practice, ROME exhibits fewer critical failures in core logic and integration, maintains higher stability under varied task specifications, and provides more consistent end-to-end deliverables across task types. Overall, the findings imply that ROME achieves a form of “scale-breaking” agentic capability-i.e., stronger real-task completion performance than would be expected from model size alone-highlighting the effectiveness of our approach for enhancing agentic execution beyond scaling laws.
We also select two representative case studies(Sleep Management System Generation and Solar System Modeling) and present task screenshots in Figure 17 and Figure 18, respectively. The detailed scoring rubric is
code repair, and unit test generation, ensuring that the model internalizes the analytical logic behind each modification. To guarantee high data fidelity, we implement a rigorous rejection sampling pipeline: localization samples are retained only they fully cover the ground-truth set of modified files, while repair and test generation samples are filtered based on a sequence-level similarity threshold relative to the golden patches.
Instance Builder Agent: Convergent Construction via Self-Play and Validation. It converts drafts into executable and reproducible evaluation instances, each with a task-specific Docker environment. It infers compilers, package managers, build tools, and test frameworks from project metadata across different programming languages, generates deterministic build and test commands, and validates the environment through end-to-end compilation and test execution. Each instance includes the task description, complete source files, unit and task-level tests, and a
The agentic crafting extends beyond writing code to encompass general-purpose, workflow-driven tasks (e.g, travel plan, GUI assistant) through multi-turn interactions with its environment.
📸 Image Gallery