Precision and Reasoning Bridging VLMs to Robotic Actions
📝 Original Paper Info
- Title: Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training- ArXiv ID: 2512.24125
- Date: 2025-12-30
- Authors: Yi Liu, Sukai Wang, Dafeng Wei, Xiaowei Cai, Linqing Zhong, Jiange Yang, Guanghui Ren, Jinyu Zhang, Maoqing Yao, Chuankang Li, Xindong He, Liliang Chen, Jianlan Luo
📝 Abstract
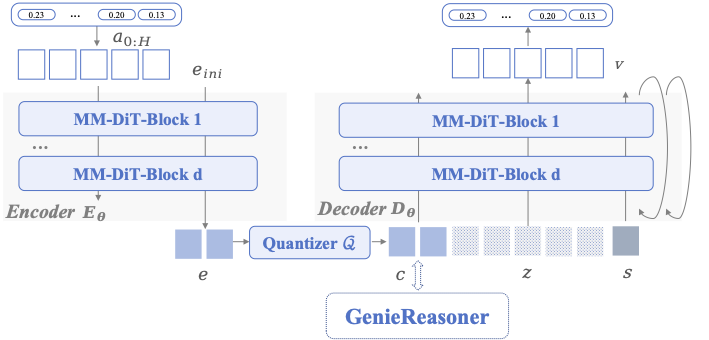
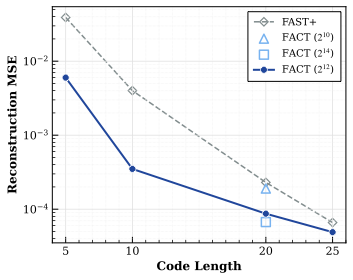
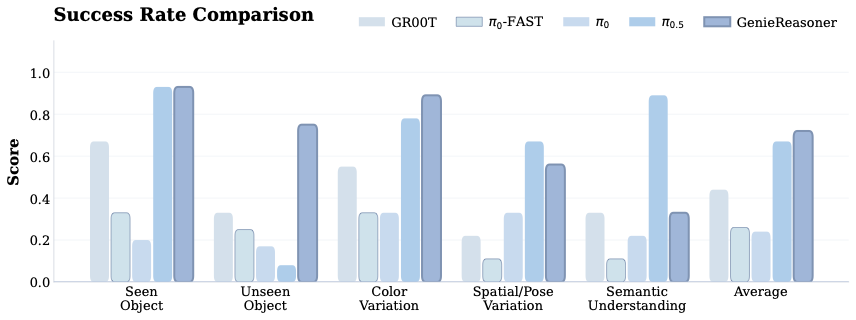
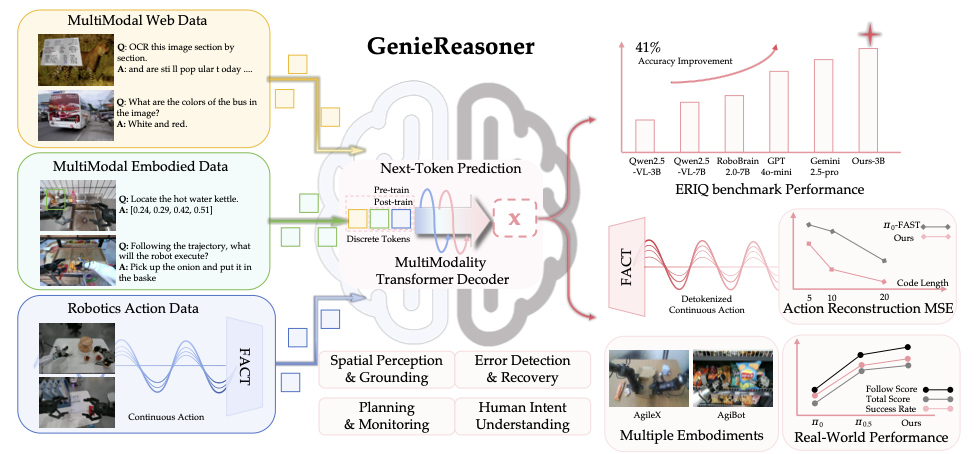
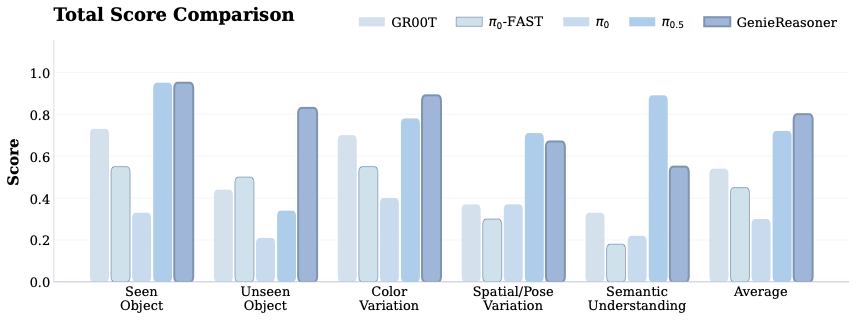
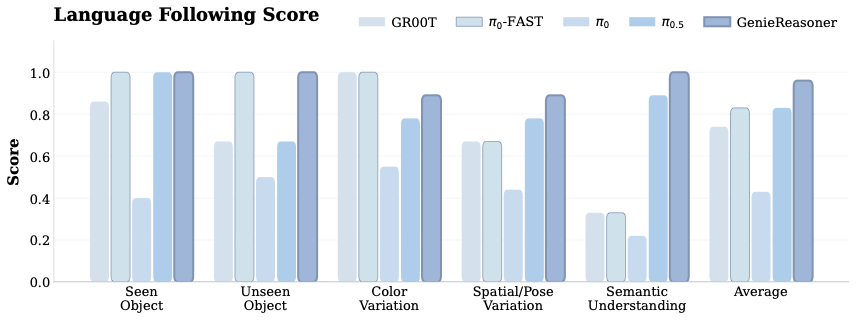
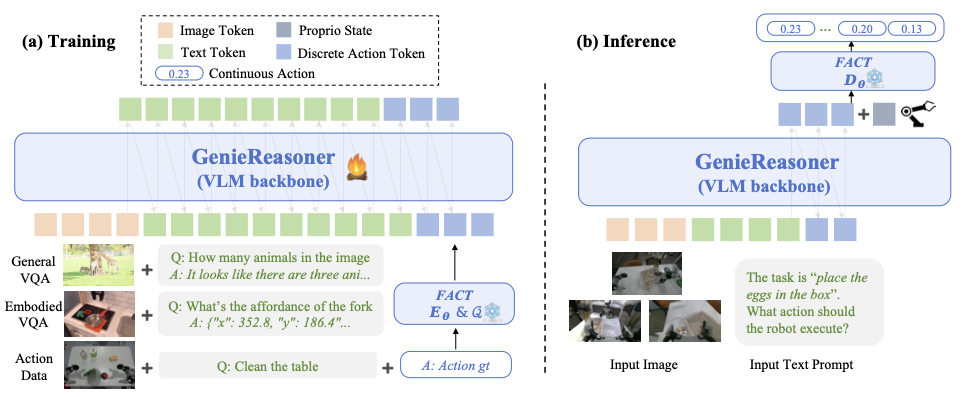
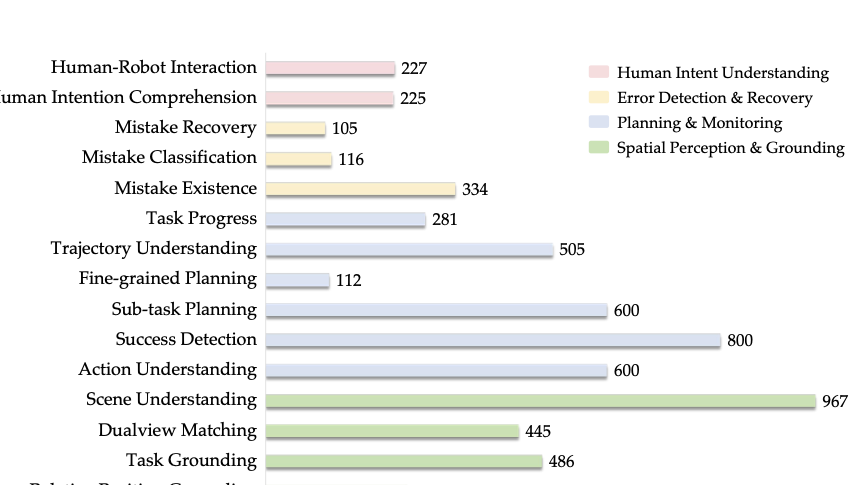
General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation. Project page: https://geniereasoner.github.io/GenieReasoner/💡 Summary & Analysis
1. **Contribution 1: Combining CNN and Transformer** The paper suggests a method to combine two powerful models in image classification. This can be likened to merging a car with a motorcycle for better speed and stability.-
Contribution 2: Novel Learning Techniques
It proposes new learning methods that improve data efficiency, similar to providing optimal lighting and water to plants in a garden to enhance growth. -
Contribution 3: Real-world Application Cases
The paper reports on the application of its proposed methodologies to real image datasets, serving as validation for practical effectiveness.
Sci-Tube Style Script
- Beginner
- “This paper suggests combining two powerful models in image classification to achieve better results.”
- Intermediate
- “New learning techniques that improve data efficiency are introduced, allowing more effective training with less data.”
- Advanced
- “Performance of the proposed methodology is validated through application on real-world image datasets.”
📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)