What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
📝 Original Paper Info
- Title: What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?- ArXiv ID: 2512.24497
- Date: 2025-12-30
- Authors: Basile Terver, Tsung-Yen Yang, Jean Ponce, Adrien Bardes, Yann LeCun
📝 Abstract
A long-standing challenge in AI is to develop agents capable of solving a wide range of physical tasks and generalizing to new, unseen tasks and environments. A popular recent approach involves training a world model from state-action trajectories and subsequently use it with a planning algorithm to solve new tasks. Planning is commonly performed in the input space, but a recent family of methods has introduced planning algorithms that optimize in the learned representation space of the world model, with the promise that abstracting irrelevant details yields more efficient planning. In this work, we characterize models from this family as JEPA-WMs and investigate the technical choices that make algorithms from this class work. We propose a comprehensive study of several key components with the objective of finding the optimal approach within the family. We conducted experiments using both simulated environments and real-world robotic data, and studied how the model architecture, the training objective, and the planning algorithm affect planning success. We combine our findings to propose a model that outperforms two established baselines, DINO-WM and V-JEPA-2-AC, in both navigation and manipulation tasks. Code, data and checkpoints are available at https://github.com/facebookresearch/jepa-wms.💡 Summary & Analysis
1. **Basic Concept**: A world model predicts future states based on past observations and actions. This is crucial for physical agents like robots to interact effectively with their environment, especially in scenarios where rewards are sparse.-
Advantages of JEPA-WM: The Joint-Embedding Predictive Architectures (JEPA) combined with world models enhance performance by integrating visual data and AI more effectively, enabling robots to perform a variety of tasks more efficiently.
-
Optimization Methods: This paper explores various components of training and planning in JEPA-WMs and proposes an optimized model that outperforms previous ones like DINO-WM and V-JEPA-2-AC for manipulation and navigation tasks.
📄 Full Paper Content (ArXiv Source)
Introduction
In order to build capable physical agents, proposed the idea of a world model, that is, a model predicting the future state of the world, given a context of past observations and actions. Such a world model should perform predictions at a level of abstraction that allows training policies on top of it or perform planning in a sample efficient manner .
There already exists extensive literature on world modeling, mostly from the Reinforcement Learning (RL) community. Model-free RL requires a considerable number of samples, which is problematic in environments where rewards are sparse. To account for this, model-based RL (MBRL) uses a given or learned model of the environment in the training of its policy or Q-function . In combination with self-supervised pretraining objectives, MBRL has led to new algorithms for world modeling in simulation .
More recently, large-scale world models have flourished . For specific domains where data is abundant, for example to simulate driving or egocentric video games , some methods have achieved impressive simulation accuracy on relatively long durations.
In this presentation, we model a world in which some (robotic) agent equipped with a (visual) sensor operates as a dynamical system where the states, observations and actions are all embedded in feature spaces by parametric encoders, and the dynamics itself is also learned, in the form of a parametric predictor depending on these features. The encoder/predictor pair is what we will call a world model. We will focus on action-conditioned Joint-Embedding Predictive World Models (or JEPA-WMs) learned from videos . These models adapt to the planning problem the Joint-Embedding Predictive Architectures (JEPAs) proposed by , where a representation of some data is constructed by learning an encoder/predictor pair such that the embedding of one view of some data sample predicts well the embedding of a second view. We use the term JEPA-WM to refer to this family of methods, that we formalize in [eq:frame-teacher-forcing-loss,eq:plan_objective,eq:Ftheta_unroll_1,eq:Ftheta_unroll_2] as a unified implementation recipe rather than a novel algorithm. In practice, we optimize to find an action sequence without theoretical guarantees on the feasibility of the plan, which is closer to trajectory optimization, but we stick to the widely-used term planning.
Among these JEPA-WMs, PLDM shows that world models learned in a latent space, trained as JEPAs, offer stronger generalization than other Goal-Conditioned Reinforcement Learning (GCRL) methods, especially on suboptimal training trajectories. DINO-WM shows that, in absence of reward, when comparing latent world models on goal-conditioned planning tasks, a JEPA model trained on a frozen DINOv2 encoder outperforms DreamerV3 and TD-MPC2 , when we deprive these of reward annotation. DINO-World shows the capabilities in dense prediction and intuitive physics of a JEPA-WM trained on top of DINOv2 are superior to COSMOS. The V-JEPA-2-AC model is able to beat Vision Language Action (VLA) baselines like Octo in greedy planning for object manipulation using image subgoals.
In this paper, we focus on the learning of the dynamics (predictor) rather than of the representation (encoder), as in DINO-WM and V-JEPA-2-AC . Given the increasing importance of such models, we aim at filling what we see as a gap in the literature, i.e., a thorough study answering: how to efficiently learn a dynamics model in the embedding space of a pretrained visual encoder for manipulation and navigation planning tasks ?
Our contributions can be summarized as follows: (i) We study several key components of training and planning with JEPA-WMs: multistep rollout, predictor architecture, training context length, using or not proprioception, encoder type, model size, data augmentation; and the planning optimizer. (ii) We use these insights to propose an optimum in the class of JEPA-WMs, outperforming DINO-WM and V-JEPA-2-AC.
 />
/>
Related work
World modeling and planning.
‘A path towards machine intelligence’ presents planning with Model Predictive Control (MPC) as the core component of Autonomous Machine Intelligence (AMI). World Models learned via Self-Supervised Learning (SSL) have been used in many reinforcement learning works to control exploration using information gain estimation or curiosity , to transfer to robotic tasks with rare data by first learning a world model or to improve sample efficiency . In addition, world models have been used in planning, to find sub-goals by using the inverse problem of reconstructing previous frames to reach the objective represented as the last frame, or by imagining goals in unseen environments . World models can be generative , or trained in a latent space, using a JEPA loss . They can be used to plan in the latent space , to maximize a sum of discounted rewards , or to learn a policy . Other approaches for latent-space planning include locally-linear dynamics models , gradient-based trajectory optimization , and diffusion-based planners . These differ from JEPA-WMs in their dynamics model class, optimization strategy, or training assumptions; we provide a detailed comparison in 7.
Goal-conditioned RL.
Goal-conditioned RL (GCRL) offers a self-supervised approach to leverage large-scale pretraining on unlabeled (reward-free) data. Foundational methods like LEAP and HOCGRL show that goal-conditioned policies learned with RL can be incorporated into planning. PTP decomposes the goal-reaching problem hierarchically, using conditional sub-goal generators in the latent space for a low-level model-free policy. FLAP acquires goal-conditioned policies via offline reinforcement learning and online fine-tuning guided by sub-goals in a learned lossy representation space. RE-CON learns a latent variable model of distances and actions, along with a non-parametric topological memory of images. IQL-TD-MPC extends TD-MPC with Implicit Q-Learning (IQL) . HIQL proposes a hierarchical model-free approach for goal-conditioned RL from offline data.
Robotics.
Classical approaches to robotics problems rely on an MPC loop , leveraging the analytical physical model of the robot and its sensors to frequently replan, as in the MIT humanoid robot or BiconMP . For exteroception, we use a camera to sense the environment’s state, akin to the long-standing visual servoing problem . The current state-of-the-art in manipulation has been reached by Vision-Language-Action (VLA) models, such as RT-X , RT-1 , and RT-2 . LAPA goes further and leverages robot trajectories without actions, learning discrete latent actions using the VQ-VAE objective on robot videos. Physical Intelligence’s first model $`\pi_0`$ uses the Open-X embodiment dataset and flow matching to generate action trajectories.
Background
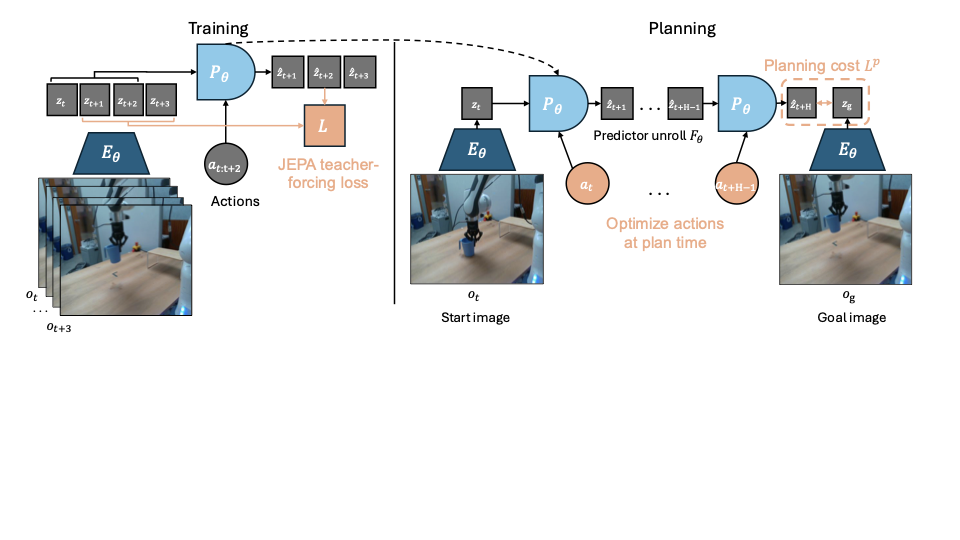
This section formalizes the common setup of JEPA-WMs learned from pretrained visual encoders, but does not introduce novel methods. We summarize JEPA-WM training and planning in 1.
Training method.
In a JEPA-WM, we embed the observations with a frozen visual encoder $`E_{\phi}^{vis}`$, and an (optional) shallow proprioceptive encoder $`E_{\theta}^{prop}`$. Applying each encoder to the corresponding modality constitutes the global state encoder, which we denote $`E_{\phi,\theta}=(E_{\phi}^{vis}, E_{\theta}^{prop})`$. An action encoder $`A_{\theta}`$ embeds the robotic actions. On top of these, a predictor $`P_{\theta}`$ takes both the state and action embeddings as input. $`E_{\theta}^{prop}`$, $`A_{\theta}`$ and $`P_{\theta}`$ are jointly trained, while $`E_{\phi}^{vis}`$ remains frozen. For a past window of $`w`$ observations $`o_{t-w:t}:= (o_{t-w}, \dots, o_{t})`$ including visual and (optional) proprioceptive input and past actions $`a_{t-w:t}`$, their common training prediction objective on $`B`$ elements of the batch is
\begin{equation}
\label{eq:frame-teacher-forcing-loss}
\mathcal{L} = \frac{1}{B}\sum_{b=1}^B L[ P_{\theta}\left( E_{\phi,\theta}(o_{t-w:t}^b), A_{\theta}(a_{t-w:t}^b) \right), E_{\phi,\theta} \left( o_{t+1}^b \right)],
\end{equation}where $`L`$ is a loss, computed pairwise between visual prediction and target, and proprioceptive prediction and target. In our experiments, we chose $`L`$ as the MSE. The architecture chosen for the encoder and predictor in this study is ViT , as in our baselines . In DINO-WM , the action and proprioceptive encoder are just linear layers, and their output is concatenated to the visual encoder output along the embedding dimension, which is known as feature conditioning , as opposed to sequence conditioning, where the action and proprioception are encoded as tokens, concatenated to the visual tokens sequence, which is adopted in V-JEPA-2 . We stress that $`P_{\theta}`$ is trained with a frame-causal attention mask, thus, it is simultaneously trained to predict from all context lengths from $`w=0`$ to $`w=W-1`$, where $`W`$ is a training hyperparameter, set to $`W=3`$. The causal predictor is trained to predict the outcome of several actions instead of one action only. To do so, one can skip $`f`$ observations and concatenate the $`f`$ corresponding actions to form an action of higher dimension $`f \times A`$, as in DINO-WM . More details on the training procedure in 8.
Planning.
Planning at horizon $`H`$ is an optimization problem over the product action space $`\mathbb{R}^{H \times A}`$, where each action is of dimension $`A`$, which can be taken to be $`f \times A`$ when using frameskip at training time. Given an initial and goal observation pair $`o_t, o_g`$, each action trajectory $`a_{t:t+H-1} := (a_{t}, \dots, a_{t+H-1})`$ should be evaluated with a planning objective $`L^p`$. Like at training time, consider a dissimilarity metric $`L`$, (e.g. the $`L_1`$, $`L_2`$ distance or minus the cosine similarity), applied pairwise on each modality, denoted $`L_{vis}`$ between two visual embeddings and $`L_{prop}`$ for proprioceptive embeddings. When planning with a model trained with both proprioception and visual input, given $`\alpha \geq 0`$, the planning objective $`L^p_\alpha`$ we aim to minimize is
\begin{equation}
\label{eq:plan_objective}
L^p_\alpha(o_t, a_{t:t+H-1}, o_g) = (L_{vis} + \alpha L_{prop})(G_{\phi,\theta}(o_t, a_{t:t+H-1}), E_{\phi,\theta}(o_g)),
\end{equation}with a function $`G_{\phi,\theta}`$ depending on our world model. We define recursively $`F_{\phi,\theta}`$ as the unrolling of the predictor from $`z_t=E_{\phi,\theta}(o_t)`$ on the actions, with a maximum context length of $`w`$, (fixed to $`W^p`$, see 6)
\begin{align}
F_{\phi,\theta}: (o_t, a_{t-w:t+k-1}) &\mapsto \hat{z}_{t+k}, \label{eq:Ftheta_unroll_1}
\\
\hat{z}_{i+1} &= P_{\theta}(\hat{z}_{i-w:i},A_{\theta}(a_{i-w:i})), \quad i=t,\dots,t+k-1, \quad z_t=E_{\phi,\theta}(o_t)
\label{eq:Ftheta_unroll_2}
\end{align}In our case, we take $`G_{\phi,\theta}`$ to be the unrolling function $`F_{\phi,\theta}`$, but could choose $`G_{\phi,\theta}`$ to be a function of all the intermediate unrolling steps, instead of just the last one. We provide details about the planning optimizers in 10.
Studied design choices
Our base configuration is DINO-WM without proprioception, with a ViT-S encoder and depth-6 predictor of same embedding dimension. We prioritize design choices based on their scope of impact: planning-time choices affect all evaluations, so we optimize these first and fix the best planner for each environment for the subsequent experiments; training and architecture choices follow; scaling experiments validate our findings. Each component is independently varied from the base configuration to isolate its effect.
Planner.
Various optimization algorithms can be relevant to solve the problem of minimizing equation [eq:plan_objective], which is differentiable. use the Cross-Entropy-Method (CEM) (or a variant called MPPI ), depicted in 10. Since this is a population-based optimization method which does not rely on the gradient of the cost function, we introduce a planner that can make use of any of the optimization methods from NeverGrad . For our experiments, we choose the default NGOpt optimizer , which is designated as a “meta”-optimizer. We do not tune any of the parameters of this optimizer. We denote this planner NG in the remainder of this paper, see details in 10.0.0.3. We also experiment with gradient-based planners (GD and Adam) that directly optimize the action sequence through backpropagation, see details in [app:GD-planner,app:Adam-planner]. The planning hyperparameters common to the four considered optimizers are those which define the predictor-dependent cost function $`G_{\theta}`$, the planning horizon $`H`$, the number of actions of the plan that are stepped in the environment $`m\leq H`$, the maximum sliding context window size of past predictions fed to the predictor, denoted $`W^p`$. The ones common to either CEM and NG or to Adam and GD are the number of candidate action trajectories of which we evaluate the cost in parallel, denoted $`N`$, and the number of iterations $`J`$ of parallel cost evaluations. After some exploration of the impact of planning hyperparameters common to both CEM and NG on success, we fix them to identical values for both, as summarized in 6 in appendix. We plan using either the $`L_1`$ or $`L_2`$ embedding space distance as dissimilarity metric $`L`$ in the cost $`L^p_{\alpha}`$. The results in 5 (left) are an average across the models considered in this study.
Multistep rollout training.
At each training iteration, in addition to the frame-wise teacher forcing loss of equation [eq:frame-teacher-forcing-loss], we compute additional loss terms as the $`k`$-step rollout losses $`\mathcal{L}_k`$, for $`k \geq 1`$, defined as
\begin{equation}
\label{eq:multistep rollout loss}
\mathcal{L}_k = \frac{1}{B}\sum_{b=1}^B L[ P_{\theta}(\hat{z}_{t-w:t+k-1}^b, A_{\theta}(a_{t-w:t+k-1}^b)), E_{\phi,\theta} \left( o_{t+k}^b \right)],
\end{equation}where $`\hat{z}_{t+k-1}^b = F_{\phi,\theta}(o_t,a_{t-w:t+k-2})`$, see equation [eq:Ftheta_unroll_1]. We note that $`\mathcal{L}_1 = \mathcal{L}`$. In practice, we perform truncated backpropagation over time (TBPTT) , which means that we discard the accumulated gradient to compute $`\hat{z}_{t+H}`$ and only backpropagate the error in the last prediction. We study variants of this loss, as detailed in 8.0.0.10, including the one used in V-JEPA-2-AC. We denote the model trained with a sum of loss terms up to the $`\mathcal{L}_k`$ loss as $`k`$-step. We train models with up to a 6-step loss, which requires more than the default $`W=3`$ maximum context size, hence we set $`W=7`$ to train them, similarly to the models with increased $`W`$ introduced afterwards.
Proprioception.
We compare the standard setup of DINO-WM , where we train a proprioceptive encoder jointly with the predictor and the action encoder to a setup with visual input only. We stress that, contrary to V-JEPA-2-AC, we use both the visual and proprioceptive loss terms to train the predictor, proprioceptive encoder and action encoder.
Training context size.
We aim to test whether allowing the predictor to see a longer context at train time allows to better unroll longer sequences of actions. We test values from $`W=1`$ to $`W=7`$.
Encoder type.
As posited by , local features preserve spatial details that are crucial to solve the tasks at hand. Hence we use the local features of DINOv2 and the recently proposed DINOv3 , even stronger on dense tasks. We train a predictor on top of video encoders, namely V-JEPA and V-JEPA-2 . We consider their ViT-L version. After exploration of the frame encoding strategy to adopt 8.0.0.8, we settle on the highest performing one, which consists in duplicating each of the $`o_{t-W+1},\dots, o_{t+1}`$ frames and encoding each pair independently as a 2-frame video. Details comparing the encoding methods for all encoders considered are in 8.0.0.9. The frame preprocessing and encoding is equalized to have the same number of visual embedding tokens per timestep, so the main difference lies in the weights of these encoders that we use out-of-the-box.
Predictor architecture.
The main difference between the predictor architecture of , and the one of , is that the first uses feature conditioning, with sincos positional embedding, whereas the latter performs sequence conditioning with RoPE . In the first, action embeddings $`A_{\theta}(a)`$ are concatenated with visual features $`E_{\theta}(o)`$ along the embedding dimension, and the hidden dimension of the predictor is increased from $`D`$ to $`D + f_a`$, with $`f_a`$ the embedding dimension of actions. The features are then processed with 3D sincos positional embeddings. In the second, actions are encoded as separate tokens and concatenated with visual tokens along the sequence dimension, keeping the predictor’s hidden dimension to $`D`$ (as in the encoder). Rotary Position Embeddings (RoPE) is used at each block of the predictor. We also test an architecture mixing feature conditioning with RoPE. Another efficient conditioning technique is AdaLN , as adopted by , which we also put to the test, using RoPE in this case. This approach allows action information to influence all layers of the predictor rather than only at input, potentially preventing vanishing of action information through the network. We also study the AdaLN-zero variant , which initializes the conditioning MLP to output the zero-vector, so that the predictor behaves like an unconditional ViT block at the beginning of training. Details are provided in 8.0.0.2.
Model scaling.
We increase the encoder size to ViT-B and ViT-L, using DINOv2 ViT-B and ViT-L with registers . When increasing encoder size, we expect the prediction task to be harder and thus require a larger predictor. Hence, we increase accordingly the predictor embedding dimension to match the encoder. We also study the effect of predictor depth, varying it from 3 to 12.
 />
/>
 />
/>
Experiments
Evaluation Setup.
Datasets.
For Metaworld, we gather a dataset by training TD-MPC2 online agents and evaluate two tasks, “Reach" and “Reach-Wall", denoted MW-R and MW-RW, respectively. We use the offline trajectory datasets released by , namely Push-T , Wall and PointMaze. The train split represents 90% of each dataset. We train on DROID and evaluate zero-shot on Robocasa by defining custom pick-and-place tasks from teleoperated trajectories, namely “Place" and “Reach", denoted Rc-Pl and Rc-R. We do not finetune the DROID models on Robocasa trajectories. We also evaluate on a set of 16 videos of a real Franka arm filmed in our lab, closer to the DROID distribution, and denote this task DROID. On DROID, we track the $`L_1`$ error between the actions outputted by the planner and the groundtruth actions of the trajectory from the dataset that defines initial and goal state. We then rescale the opposite of this Action Error, to constitute the Action Score, a metric to maximize. We provide details about our datasets and environments in 9.
Goal definition.
We sample the goal frame from an expert policy provided with Metaworld, from the dataset for Push-T, DROID and Robocasa, and from a random 2D state sampler for Wall and Maze, more details in 9. For the models with proprioception, we plan using proprioceptive embedding distance, by setting $`\alpha=0.1`$ in equation [eq:plan_objective], except for DROID and Robocasa, where we set $`\alpha=0`$, to be comparable to V-JEPA-2-AC.
Metrics.
The main metric we seek to maximize is success rate, but track several other metrics, that track the world model quality, independently of the planning procedure, and are less noisy than success rate. These metrics are embedding space error throughout predictor unrolling, proprioceptive decoding error throughout unrolling, visual decoding of open-loop rollouts (and the LPIPS between these decodings and the groundtruth future frames). More details in 11.2.
Statistical significance.
To account for training variability, we train with 3 seeds per model for our final models in [tab:final_model_comp_baselines]. To account for the evaluation variability, at each epoch, we launch $`e=96`$ episodes, each with a different initial and goal state, either sampled from the dataset (Push-T, Robocasa, DROID) or by the simulator (Metaworld, PointMaze, Wall). We take $`e=64`$ for evaluation on DROID, which proves essential to get a reliable evaluation, even though we compare a continuous action score metric. We use $`e=32`$ for Robocasa given the higher cost of a planning episode, which requires replanning 12 times, as explained in 6. We average over these episodes to get a success rate. Although we average success at each epoch over three seeds and their evaluation episodes, we still find high variability throughout training. Hence, to get an aggregate score per model, we average success over the last $`n`$ training epochs, with $`n=10`$ for all datasets, except for models trained on DROID, for which $`n=100`$. The error bars displayed in the plots comparing design choices are the standard deviation across the last epochs’ success rate, to reflect this variability only.
 />
/>
 />
/>
Results
One important fact to note is that, even with models which are able to faithfully unroll a large number of actions, success at the planning task is not an immediate consequence. We develop this claim in 11.1, and provide visualizations of rollouts of studied models and planning episodes.
Comparing planning optimizers.
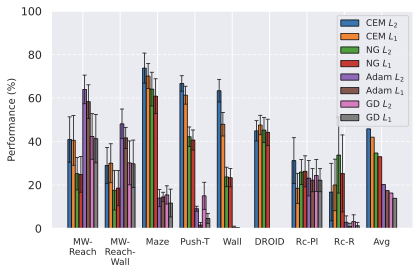
We compare four planning optimizers: Cross-Entropy Method (CEM), Nevergrad (NG), Adam, and Gradient Descent (GD). CEM is a variant of the CMA-ES family with diagonal covariance and simplified update rules. NG uses the NGOpt wizard, which selects diagonal CMA-ES based on optimization space parametrization and budget, see [algo:NG]. We observe in 3 that the CEM $`L_2`$ planner performs best overall.
(i) Gradient-based methods: Adam $`L_2`$ achieves the best overall performance on Metaworld, outperforming all other optimizers, and GD is also competitive with CEM. This can be explained by the nature of Metaworld tasks: they have relatively smooth cost landscapes where the goal is greedily reachable, allowing gradient-based methods to excel. In contrast, on 2D navigation tasks (Wall, Push-T, Maze) that require non-greedy planning, gradient-based methods perform very poorly compared to sampling-based ones, as GD gets stuck in local minima. On DROID, gradient-based methods also perform significantly worse than sampling-based approaches: these tasks require rich and precise understanding of complex real-world object manipulation, leading to multi-modal cost landscapes. Robocasa tasks, being simulated but closer in nature to Metaworld, allow gradient-based methods to perform reasonably well again.
(ii) Sampling-based methods: On 2D navigation tasks, CEM clearly outperforms NG, as these tasks require precise action sequences where CEM’s faster convergence to tight action distributions is beneficial, while NG’s slower, more exploratory optimization is detrimental. To compare both methods, we plot the convergence of the optimization procedure at each planning step in 16, and observe that NG converges more slowly, indicating more exploration in the space of action trajectories. On DROID and Robocasa, CEM and NG perform similarly. When using NG, we have fewer planning hyperparameters than with CEM, which requires specifying the top-$`K`$ trajectories parameter and the initialization of the proposal Gaussian distribution $`\mu^0, \sigma^0`$—parameters that heavily impact performance. Crucially, on real-world manipulation data (DROID and Robocasa), NG performs on par with CEM while requiring no hyperparameter tuning, making it a practical alternative when transitioning to new tasks or datasets where CEM tuning would be costly.
On all planning setups and models, $`L_2`$ cost consistently outperforms $`L_1`$ cost. To minimize the number of moving parts in the subsequent study, we fix the planning setup for each dataset to CEM $`L_2`$, which is either best or competitive on all environments.
 />
/>
 />
/>
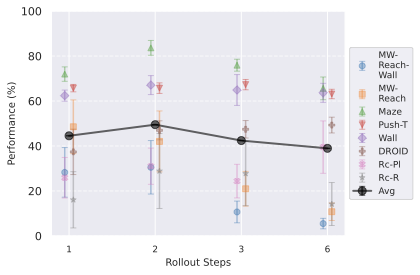
Multistep rollout predictor training.
At planning time, the predictor is required to rollout faithfully an action sequence by predicting future embeddings from its previous predictions. We observe in 4 that the performance increases when going from pure teacher-forcing models to 2-step rollout loss models, but then decreases for models trained in simulated environments. We plan with maximum context of length $`W^p=2`$, thus adding rollout loss terms $`\mathcal{L}_k`$ with $`k > 3`$ might make the model less specialized in the prediction task it performs at test time, explaining the performance decrease. Interestingly, for models trained on DROID, the optimal number of rollout steps is rather six.
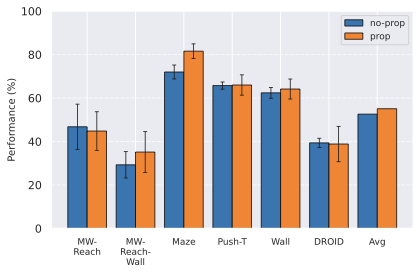
Impact of proprioception.
We observe in 6 that models trained with proprioceptive input are consistently better than without. On Metaworld, most of the failed episodes are due to the arm reaching the goal position quickly, then oscillating around the goal position. Thus, having more precise information on its exact distance to the goal increases performance. On 2D navigation tasks, the proprioceptive input also allows the agent to propose a more precise plan. We do not display the results on Robocasa as the proprioceptive space is not aligned between DROID and Robocasa, making models using proprioception irrelevant for zero-shot transfer.
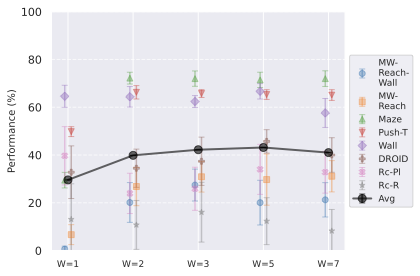
Maximum context size.
Training on longer context takes more iterations to converge in terms of success rate. We recall that we chose to plan with $`W^p=2`$ in all our experiments, since it yields the maximal success rate while being more computationally efficient. The predictor needs two frames of context to infer velocity and use it for the prediction task. It requires 3 frames to infer acceleration. We indeed see in 10 a big performance gap between models trained with $`W=1`$ and $`W=2`$, which indicates that the predictor benefits from using this context to perform its prediction. On the other hand, with a fixed training computational budget, increasing $`W`$ means we slice the dataset into a fewer but longer unique trajectory slices of length $`W+1`$, thus less gradient steps. On DROID, having too low $`W`$ leads to discarding some videos of the dataset that are of length lower than $`W+1`$. Yet, we observe that models trained on DROID have their optimal $`W`$ at 5, higher than on simulated datasets, for which it is 3. It is likely due to the more complex dynamics of DROID, requiring longer context to notably infer real-world arm and object dynamics. One simple experiment shows a very well-known but fundamental property: the training maximum context $`W`$ and planning maximum context $`W^p`$ must be chosen so that $`W^p \leq W`$. Otherwise, we ask the model to perform a prediction task it has not seen at train time, and we see the predictions degrading rapidly throughout unrolling if $`W^p > W`$. To account for this, the $`W=1`$ model performance displayed in 10 is from planning with $`W^p=1`$.
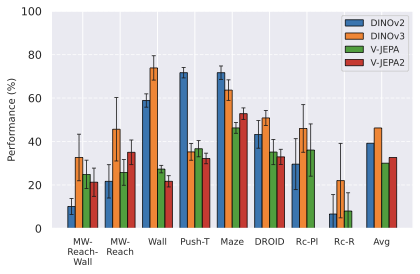
Encoder type.
In 7, we see a clear advantage of DINO encoders compared to V-JEPA encoders. We posit this is due to the well-known fact that DINO has better fine-grained object segmentation capabilities, which is crucial in tasks requiring a precise perception of the location of the agent and objects. Interestingly, DINOv3 clearly outperforms DINOv2 only the more photorealistic environments, Robocasa and DROID, likely due to the pretraining dataset of DINOv3 being more adapted to such images. On Maze and Wall, models trained on DINOv3 take longer to converge to a lower success rate.
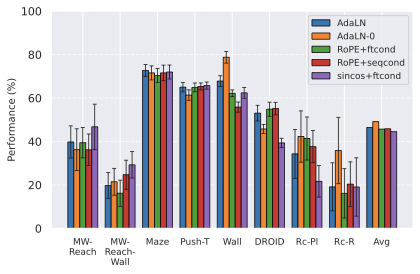
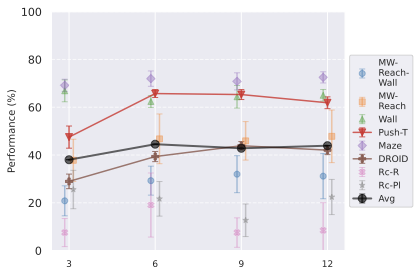
Predictor architecture.
In 9, we observe that, while AdaLN with RoPE achieves the best average performance across environments, the advantage is slight, and results are task-dependent: on Metaworld, sincos+ftcond actually performs best. We do not see a substantial improvement when using RoPE instead of sincos positional embedding. A possible explanation for AdaLN’s effectiveness is that this conditioning intervenes at each block of the transformer predictor, potentially avoiding the vanishing of the action information throughout the layers. It is also more compute-efficient than other conditioning methods, as explained by . We also study AdaLN-zero, following ’s naming. Although find AdaLN-zero to outperform AdaLN in their setup, we observe that, despite a higher average performance, AdaLN-zero underperforms AdaLN on the environments that provide the most reliable signal (DROID, PushT, Maze), which are less prone to noise in success rate and yield more consistent results across our other design choice experiments. Hence, we will consider, for our final JEPA-WMs optimum, the AdaLN variant. One important consideration when scaling predictor embedding dimension is maintaining the ratio of action to visual dimensions, which requires increasing the action embedding dimension in the feature conditioning case. To isolate the effect of the conditioning scheme from capacity differences due to different action ratios, we conduct additional experiments with equalized action ratios (see 11.1), which reveal task-dependent preferences between conditioning schemes that cannot be attributed to action ratio alone.
 />
/>
 />
/>
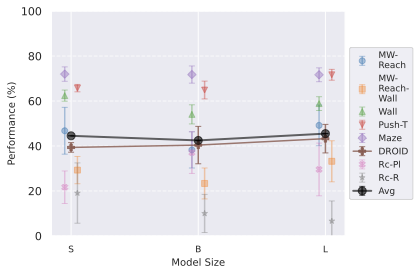
Model scaling.
We show in [subfig:model_size_comparison,subfig:pred_depth_comparison] that increasing encoder size (with predictor width) or predictor depth does not improve performance on simulated environments. However, on DROID, we observe a clear positive correlation between both encoder size and predictor depth with planning performance. This indicates that real-world dynamics benefit from higher-capacity models, while simulated environments saturate at lower capacities. Notably, the optimal predictor depth appears to be 6 for most simulated environments, and possibly as low as 3 for the simplest 2D navigation tasks (Wall, Maze). Moreover, larger models may actually be detrimental on simple datasets: at planning time, although we optimize over the same action space, the planning procedure explores the visual embedding space, and larger embedding spaces make it harder for the planning optimization to distinguish nearby states (see 30).
Our proposed optimum in the class of JEPA-WMs
We combine the findings of our study and propose optimal models for each of our robotic environments, that we compare to concurrent JEPA-WM approaches: DINO-WM and V-JEPA-2-AC . For simulated environments, we use a ViT-S encoder and a ViT-S predictor with depth 6, AdaLN conditioning, and RoPE positional embeddings. We train our models with proprioception and a 2-steps rollout loss, with a maximum context of $`W=3`$. For DROID and Robocasa, following our model size findings, we use a DINOv3 ViT-L encoder with a ViT-L predictor of depth 12, without proprioception. We plan with CEM $`L_2`$ for all environments. We use DINOv2 on all environments, except on the photorealistic DROID and Robocasa, where we use DINOv3. As presented in [tab:final_model_comp_baselines], we outperform DINO-WM and V-JEPA-2-AC in most environments. We provide a full comparison across all planner configurations in [tab:all_planners_model_comp]. We propose in 2 a qualitative comparison of the object interaction abilities of our model against DINO-WM and V-JEPA-2-AC, in a simple counterfactual experiment, where we unroll two different action sequences from the same initial state, one where the robot lifts a cup, and one where it does not. Our model demonstrates a better prediction of the effect of its actions on the environment.
Conclusion
In this paper, we studied the effect of several training and planning design choices of JEPA-WMs on planning in robotic environments. We found that several components play an important role, such as the use of proprioceptive input, the multistep rollout loss, or the choice of visual encoder. We found that image encoders with fine object segmentation capabilities are better suited for the manipulation and navigation tasks that we considered compared to video encoders. We found that having enough context to infer velocity is important, but that too long context harms performance, obviously due to seeing less unique trajectories during training and likely also having less useful gradient from predicting from long context. On the architecture side, we found that the action conditioning technique matters, with AdaLN being a strong choice on average, compared to sequence and feature conditioning, though results are task-dependent. We found that scaling model size (encoder size with predictor width, and predictor depth) does not improve performance on simulated environments. However, on real-world data (DROID and Robocasa), both larger encoders and deeper predictors yield consistent improvements, suggesting that scaling benefits depend on task complexity. We introduced an interface for planning with Nevergrad optimizers, leaving room for exploration of optimizers and hyperparameters. On the planning side, we found that CEM $`L_2`$ performs best overall. The NG planner performs similarly to CEM on real-world manipulation data (DROID and Robocasa) while requiring less hyperparameter tuning, making it a practical alternative when transitioning to new tasks or datasets. Gradient-based planners (GD and Adam) excel on tasks with smooth cost landscapes like Metaworld, but fail on 2D navigation or contact-rich manipulation tasks due to local minima. Finally, we applied our learnings and proposed models outperforming concurrent JEPA-WM approaches, DINO-WM and V-JEPA-2-AC.
Ethics statement
This work focuses on learning world models for physical agents, with the aim of enabling more autonomous and intelligent robots. We do not anticipate particular risk of this work, but acknowledge that further work building on it could have impact on the field of robotics, which is not exempt of risks of misuse. We also acknowledge the environmental impact of training large models, and we advocate for efficient training procedures and sharing of pretrained models to reduce redundant computation.
Reproducibility statement
All code, model checkpoints, and benchmarks used for this project will be released in the project’s repository. We generalize and improve over DINO-WM and V-JEPA-2-AC in a common training and evaluation framework. We hope this code infrastructure will help accelerate research and benchmarking in the field of learning world models for physical agents. We include in 8 details about the training and architecture hyperparameters, as well as the datasets and environments used in 9. We also provide details about our planning algorithms in 10. Additional experiments in 11.1 and study on the correlation of the various evaluation metrics in 11.2 should bring more clarity on our claims.
Acknowledgments
We thank Quentin Garrido for his help and insightful methodology and conceptualization advice throughout the project. We thank Daniel Dugas for the constructive discussions we had throughout the project, and for helping provide the Franka Arm videos we use for evaluation.
Appendix
Extended Related Work
Alternative latent-space planning paradigms.
Several approaches have been proposed for planning in learned latent spaces, differing from JEPA-WMs in their dynamics model class, optimization strategy, or training assumptions. Locally-linear latent dynamics models, such as Embed to Control (E2C) , learn a latent space where dynamics are locally linear, enabling the use of iterative Linear Quadratic Regulator (iLQR) for trajectory optimization. E2C is derived directly from an optimal control formulation in latent space and can operate on raw pixel observations without requiring explicit reward signals during training, using instead a reconstruction-based objective combined with dynamics constraints. Gradient-based trajectory optimization through learned dynamics, as in Universal Planning Networks (UPN) , uses differentiable forward models to directly backpropagate planning gradients through predicted trajectories. We compare to this paradigm in our experiments (gradient descent planner in 5.2.0.1), finding it effective for smooth cost landscapes but prone to local minima in navigation tasks. Diffusion-based planners generate trajectory distributions via iterative denoising, offering multi-modal planning and implicit constraint satisfaction. While Diffuser typically requires offline RL datasets with reward annotations , recent work like DMPC demonstrates diffusion-based MPC on continuous control tasks, though direct comparison with visual goal-conditioned JEPA-WMs remains challenging due to different experimental settings and assumptions. Our work focuses on systematically studying design choices within the JEPA-WM framework, which offers reward-free training from visual observations and flexible test-time goal specification—a complementary setting to these alternative paradigms.
Training details
Predictor.
We train using the AdamW optimizer, with a constant learning rate on the predictor, action encoder and optional proprioceptive encoder. We use a cosine scheduler on the weight decay coefficient. For the learning rate, we use a constant learning rate without any warmup iterations. We summarize training hyperparameters common to environments in 1. We display the environment-specific ones in 2. Both the action and proprioception are first embedded with a linear kernel applied to each timestep, of input dimension action_dim or proprio_dim (equal to the unit action or proprioceptive dimension times the frameskip) and output dimension action_embed_dim or proprio_embed_dim. We stress that, for memory requirements, for our models with 6-step and $`W=7`$, the batch size is half the default batch size displayed in 2, which leads to longer epochs, as in 3. For our models trained on DROID, to compare to V-JEPA-2-AC and because of the dataset complexity compared to simulated ones, we increase the number of epochs to 315, and limit the iterations per epoch to 300, as displayed in 2.
Action conditioning of the predictor.
We study four predictor conditioning variants to inject action information in 9. The conditioning method determines where and how action embeddings are incorporated into the predictor architecture:
-
Feature conditioning with sincos positional embeddings: Action embeddings $`A_{\theta}(a)`$ are concatenated with visual token features $`E_{\theta}(o)`$ along the embedding dimension. Each timestep’s concatenated features are then processed with 3D sinusoidal positional embeddings. This increases the feature dimension and the hidden dimension of the predictor from $`D`$ to $`D + f_a`$, where $`f_a`$ is the action embedding dimension.
-
Sequence conditioning with RoPE: Actions are encoded as separate tokens and concatenated with visual tokens along the sequence dimension, keeping the predictor’s hidden dimension to $`D`$ (as in the encoder). Rotary Position Embeddings (RoPE) is used at each block of the predictor.
-
Feature conditioning with RoPE: This conditioning scheme combines feature concatenation (as in the first variant) with RoPE positional embeddings instead of sincos.
-
AdaLN conditioning with RoPE: Action embeddings modulate the predictor through Adaptive Layer Normalization at each transformer block. Specifically, action embeddings are projected to produce scale and shift parameters that modulate the layer normalization statistics. This approach allows action information to influence all layers of the predictor rather than only at input, potentially preventing vanishing of action information through the network. Combined with RoPE for positional encoding, this design is also more compute-efficient as it avoids increasing feature or sequence dimensions.
One can estimate the strength of the action conditioning of the predictor by looking at the action ratio, i.e., the ratio of dimensions (processed by the predictor) corresponding to action, on the total number of dimensions. With feature conditioning, this ratio is $`\frac{f_a}{D+f_a}`$, where $`f_a`$ is the action embedding dimension. When performing sequence conditioning, this ratio is $`\frac{1}{hw+1}=\frac{1}{257}`$ for standard patch sizes, with $`h`$ and $`w`$ being the height and width of the token grid, namely 16 (as explained in [tab:encoder_comparison_detailed]). Thus, feature conditioning typically yields a higher action ratio than sequence conditioning.
The inductive bias we expect from these designs relates to how strongly actions can influence predictions. AdaLN’s per-layer modulation should provide the most consistent action conditioning throughout the predictor depth, which may explain its superior empirical performance, see 9.
| Hyperparameter | WM | WM-L | WM-V | |
|---|---|---|---|---|
| data | ||||
| $`W`$ | 3 | 3 | 3 | |
| $`f`$ | 5 | - | - | |
| resolution | 224 | 224 | 256 | |
| optimization | ||||
| lr | 5e-4 | - | - | |
| start_weight_decay | 1e-7 | - | - | |
| final_weight_decay | 1e-6 | - | - | |
| AdamW $`\beta_1`$ | 0.9 | - | - | |
| AdamW $`\beta_2`$ | 0.995 | - | - | |
| clip_grad | 1 | - | - | |
| architecture | ||||
| patch_size | 14 | - | 16 | |
| pred_depth | 6 | - | - | |
| pred_embed_dim | 384 | 1024 | 1024 | |
| enc_embed_dim | 384 | 1024 | 1024 | |
| hardware | ||||
| dtype | bfloat16 | - | - | |
| accelerator | H100 80G | - | - |
Training hyperparameters of some of the studied models common to all environments. If left empty, the hyperparameter value is the same as the leftmost column. WM-V refers to models trained with V-JEPA and V-JEPA2 encoders.
| Hyperparameter | Metaworld | Push-T | Maze | Wall | DROID | |
|---|---|---|---|---|---|---|
| optimization | ||||||
| batch_size | 256 | 256 | 128 | 128 | 128 | |
| epochs | 50 | 50 | 50 | 50 | 315 | |
| architecture | ||||||
| action_dim | 20 | 10 | 10 | 10 | 7 | |
| action_embed_dim | 20 | 10 | 10 | 10 | 10 | |
| proprio_dim | 4 | 4 | 4 | 4 | 7 | |
| proprio_embed_dim | 20 | 20 | 20 | 10 | 10 |
Environment-specific training hyperparameters. proprio_embed_dim is used only for models using proprioception. For $`\text{WM}_W`$-6-step, the batch size is half the default batch size displayed here. We do not train but only evaluate DROID models on Robocasa.
Train time.
We compute the average train time per epoch for each combination of world model and dataset in 3.
| Model | Metaworld | Push-T | Maze | Wall | DROID | |
|---|---|---|---|---|---|---|
| 1-step | 23 | 48 | 5 | 1 | 7 | |
| 2-step | 23 | 49 | 5 | 1 | 8 | |
| 3-step | 23 | 50 | 5 | 1 | 9 | |
| 6-step | 30 | 64 | 16 | 2 | 17 | |
| $`W=7`$ | 20 | 42 | 5 | 1 | 13 | |
| WM-B | 23 | 50 | 5 | 1 | 8 | |
| WM-L | 25 | 50 | 5 | 1 | 8 | |
| WM-prop | 24 | 50 | 5 | 1 | 7 | |
| WM-V | 25 | 60 | 7 | 2 | 9 |
Model-specific training times in minutes per epoch on 16 H100 80 GB GPUs for Maze and Wall, on 32 H100 GPUs for Push-T and Metaworld. We denote WM-B, WM-L the variants of the base model with size ViT-B and ViT-L, WM-prop the variant with proprioception and WM-V the variant with V-JEPA encoders. For DROID, we display the train time for 10 epochs since we train for 315 epochs.
Visual decoder.
We train one decoder per encoder on VideoxMix2M with a sum of L2 pixel space and perceptual loss . With a ViT-S encoder, we choose a ViT-S decoder with depth 12. When the encoder is a ViT-L we choose a ViT-L decoder with depth 12. We train this decoder for 50 epochs with batch size 128 on trajectory slices of 8 frames.
State decoder.
We train a depth 6 ViT-S decoder to regress the state from one CLS
token . A linear projection at the entry projects each patch token from
the frozen encoder to the right embedding dimension, 384. At the exit, a
linear layer projects the CLS token to a vector with the same number
of dimensions as the state to decode.
V-JEPA-2-AC reproduction.
To reproduce the V-JEPA-2-AC results, we find a bug in the code that yields the official results of the paper. The 2-step rollout loss is miscomputed, what is actually computed for this loss term is $`\|P_{\phi}(a_{1:T} , s_1, z_1) - z_T\|_1`$ in the paper’s notations. This means that the model, when receiving as input a groundtruth embedding $`z_1`$, concatenated with a prediction $`\hat{z}_2`$, is trained to output $`\hat{z}_2`$. We fix this bug and retrain the models. When evaluating the public checkpoint of the V-JEPA-2-AC on our DROID evaluation protocol, the action score is much lower than our retrained V-JEPA-2-AC models after bug fixing. Interestingly, the public checkpoint of the V-JEPA-2-AC predictor, although having much worse performance at planning, yields image decodings after unrolling very comparable to the fixed models, and seems to pass the simple counterfactual test, as shown in 2.
Regarding planning, VJEPA2-AC does not normalize the action space to mean 0 and variance 1, contrary to DINO-WM, so we also do not normalize with our models, for comparability to V-JEPA-2-AC. The VJEPA2-AC CEM planner does clip the norm of the sampled actions to 0.1, which is below the typical std of the DROID actions. We find this clipping useful to increase planning performance and adopt it. Moreover, the authors use momentum in the update of the mean and std, which should be useful when the number of CEM iterations is high, but we do not find it to make a difference although we use 15 CEM iterations, hence do not adopt it in the planning setup on DROID. The planning procedure in V-JEPA-2-AC optimizes over four dimensions, the first three ones corresponding to the delta of the end-effector position in cartesian space, and the last one to the gripper closure. The 3 orientation dimensions of the proprioceptive state are $`2 \pi`$-periodic, so they often rapidly vary from a negative value above $`\pi`$ to one positive below $`\pi`$. The actions do not have this issue and have values continuous in time.
Data augmentation ablations.
In V-JEPA-2-AC, the adopted random-resize-crop effectively takes a central crop with aspect ratio 1.35, instead of the original DROID aspect ratio of $`1280/720 \simeq 1.78`$, and resizes it to 256x256. On simulated datasets where videos are natively of aspect ratio 1, this augmentation does not have effect. DINO-WM does not use any data augmentation. We try applying the pretraining augmentation of V-JEPA2, namely a random-resize-crop with aspect ratio in $`[0.75, 1.33]`$ and scale in $`[0.3, 1.0]`$, but without its random horizontal flip with probability 0.5 (which would change the action-state correspondence), and resizing to 256x256. We find this detrimental to performance, as the agent sometimes is not fully visible in the crop.
Ablations on models trained with video encoders.
When using V-JEPA and V-JEPA-2 encoders, before settling on training loss and encoding procedure, we perform some ablations. First, we find that the best performing loss across MSE, $`L_1`$ and smooth $`L_1`$ is the MSE prediction error, even though V-JEPA and V-JEPA-2 were trained with an $`L_1`$ prediction error. Then, to encode the frame sequence, one could also leverage the ability of video encoders to model dependency between frames. To avoid leakage from information of future frames to past frames, we must in this case us a frame-causal attention mask in the encoder, just as in the predictor. We have a frameskip $`f`$ between the consecutive frames sampled from the trajectory dataset, considering them consecutive without duplicating them will result in $`(W+1) / 2`$ visual embedding timesteps. In practice, we find that duplicating each frame before encoding them as a video gives better performance than without duplication. Still, these two alternative encoding techniques yield much lower performance than using video encoders as frame encoders by duplicating each frame and encoding each pair independently. V-JEPA-2-AC does use the latter encoding technique. They encode the context video by batchifying the video and duplicating each frame, accordingly to the method which we find to work best by far on all environments. In this case, for each video of $`T`$ frames, the encoder processes a batch of $`T`$ frames, so having a full or causal attention mask is equivalent.
Encoder comparison details.
Given the above chosen encoding method for video encoders, we summarize the encoder configurations in [tab:encoder_comparison_detailed]. The key differences are: (1) encoder weights themselves—DINOv2/v3 trained with their several loss terms on images vs V-JEPA/2 trained with masked prediction on videos; (2) frame preprocessing—video encoders require frame duplication (each frame duplicated to form a 2-frame input); (3) patch sizes—14 for DINOv2 (256 tokens/frame, 224 resolution) vs 16 for others (256 tokens/frame, 256 resolution for V-JEPA/2, DINOv3). We use raw patch tokens without aggregation or entry/exit projections and use all encoders frozen, without any finetuning. DINOv2/v3’s superior performance on our tasks likely stems from better fine-grained object segmentation capabilities crucial for manipulation and navigation, as discussed in the main text.
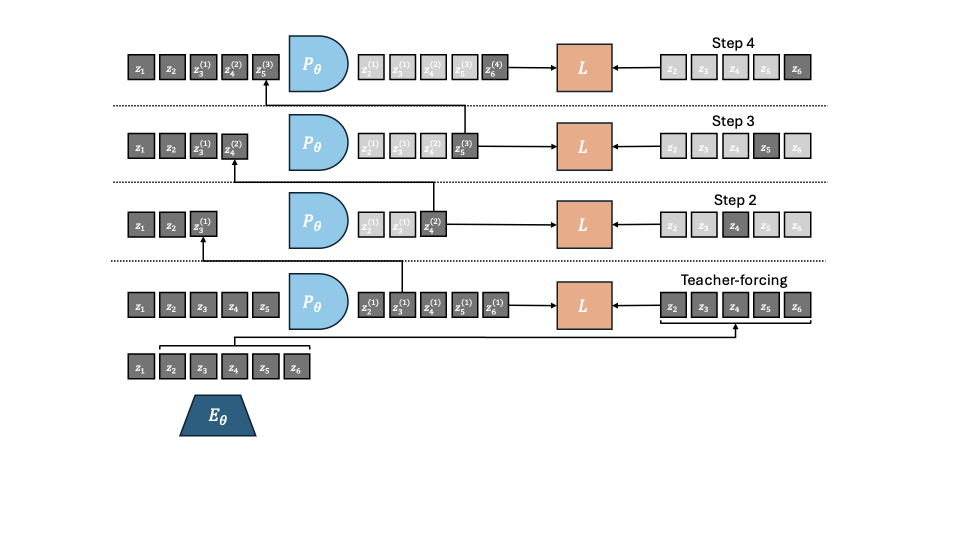
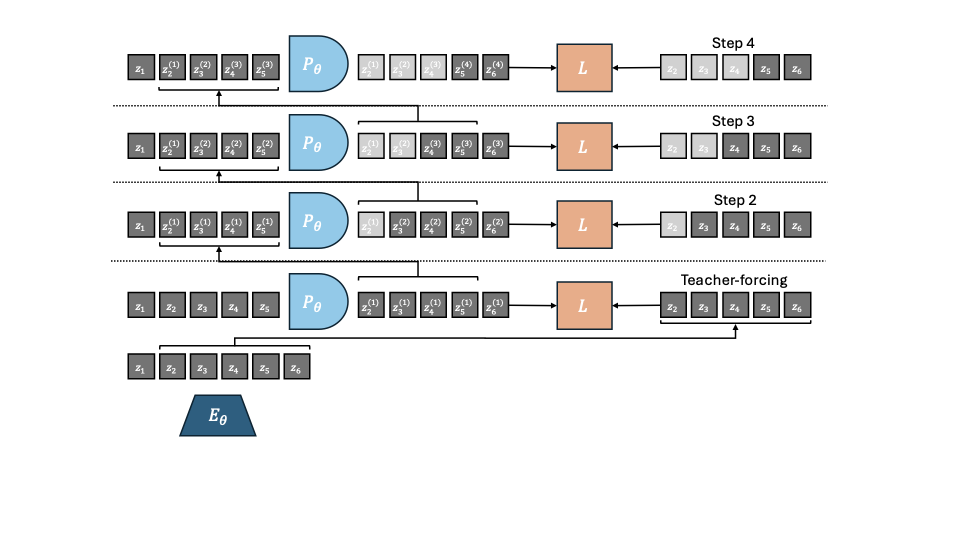
Multistep rollout variants ablations.
We ablate several rollout strategies as illustrated in 15, following the scheduled sampling and TBPTT literature for sequence prediction in embedding space. When using transformers, one advantage we have compared to the classical RNN architecture, is the possibility to perform next-timestep prediction in parallel for all timesteps in a more computationally efficient way, thanks to a carefully designed attention mask. In our case, each timestep is a frame, made of $`H \times W`$ patch tokens. We seek to train a predictor to minimize rollout error, similarly to training RNNs to generate text . One important point is that, in our planning task, we feed a context of one state (frame and optionally proprioception) $`o_t`$, then recursively call the predictor as described in equation [eq:Ftheta_unroll_1], equation [eq:Ftheta_unroll_2] to produce a sequence of predictions $`\hat{z}_{t+1}, \dots, \hat{z}_{t+k}`$. Since our predictor is a ViT, the input and output sequence of embeddings have same length. At each unrolling step, we only take the last timestep of the output sequence and concatenate it to the context for the next call to the predictor. We use a maximum sliding window $`W^p`$ of two timesteps in the context at test time, see 4.0.0.1 and 6. At training time, we add multistep rollout loss terms, defined in equation [eq:multistep rollout loss] to better align training task and unrolling task at planning time. Let us define the order of a prediction as the number of calls to the predictor function required to obtain it from a groundtruth embedding. For a predicted embedding $`z_t^{(k)}`$, we denote the timestep it corresponds to as $`t`$ and its prediction order as $`k`$. There are various ways to implement such losses with a ViT predictor.
-
Increasing order rollout illustrated in 15. In this setup, the prediction order is increasing with the timestep. This strategy has two variants.
-
The “Last-gradient only" variant is the most similar to the unrolling at planning time. We concatenate the latest timestep outputted by the predictor to the context for the next unrolling step.
-
The “All-gradients" variant generalizes the previous variant, by computing strictly more (non-redundant) additional loss terms although using the same number of predictor unrolling steps. These additional loss terms correspond to other combinations of context embeddings.
-
-
“Equal-order": In this variant, at each unrolling step $`k`$, the predictor input is the full output of the previous unrolling step, denoted $`z_t^{(k-1)}, \dots, z_{t+\tau}^{(k-1)}`$, deprived of the rightmost timestep $`z_{t+\tau}^{(k-1)}`$ since it has no matching target groundtruth embedding $`z_{t+\tau}`$.
In all the above methods, we can add sampling schedule , i.e. have a probability $`p`$ to flip one of the context embeddings $`z_t^{(k)}`$ to the corresponding groundtruth embedding $`z_t`$.
The takeaways from our ablations are the following:
-
The “Equal-order" strategy gives worse results. This is due to the fact that, with this implementation, the predictor does not take as input a concatenation (over time dimension) of ground truth embeddings and its predictions. Yet, at planning time, the unrolling function keeps a sliding context of ground truth embeddings as well as predictions. Hence, although this strategy uses more gradient (more timesteps have their loss computed in parallel) than the “Last-gradient only" variant, it is less aligned with the task expected from the predictor at planning time.
-
The strategy that yields best success rate is the 2-step “Last-gradient only" variant with random initial context.
-
Even though the “All-gradients" variant has an ensemble of loss terms that strictly includes the ones of the “Last-gradient only" strategy, it does not outperform it.
-
Across all strategies, we find simultaneously beneficial in terms of success rate and training time to perform TBTT , detaching the gradient on all inputs before each pass in the predictor.
In a nutshell, what matters is to train the predictor to receive as input a mix of encoder outputs and predictor outputs. This makes the predictor more aligned with the planning task, where it unrolls from some encoder outputs, then concatenates to it its own predictions.
 />
/>
 />
/>
Planning environments and datasets
At train time, we normalize the action and optional proprioceptive input by subtracting the empirical mean and dividing by the empirical standard deviation, which are computed on each dataset. At planning time, we sample candidate actions in the normalized action space directly. When stepping the plan in the simulator, we thus denormalize the plan resulting from the optimization before stepping it in the environment. For comparability with V-JEPA-2-AC, we do not normalize actions for DROID. We stress that, in all environments considered, we are scarce in data, except for Push-T, where we have a bigger dataset, compared to the task complexity.
We summarize dataset statistics in 4. Each trajectory dataset is transformed into a dataset of trajectory slices, of length $`W+1`$ for training.
| Dataset Size | Traj. Len. | |
|---|---|---|
| PointMaze | 2000 | 100 |
| Push-T | 18500 | 100-300 |
| Wall | 1920 | 50 |
| Metaworld | 12600 | 100 |
| DROID | 8000 | 20-50 |
Datasets statistics. We denote the number of trajectories in the dataset under Dataset Size, the length of trajectories under Traj. Len.
DROID.
We use the same dataloader as in V-JEPA-2-AC, which defines actions as delta in measured robot positions. One could either feed all three available cameras of DROID (left, right, wrist) simultaneously (e.g. by concatenating them) or alternatively to the model. We choose to use only one view point as simultaneous input. For training, we find that allowing the batch sampler to sample from either the left or right camera allows for slightly lower validation loss than using only one of them.
For evaluation, we collected a set of 16 videos with our own DROID setup, positioning the camera to closely match the left camera setup from the original DROID dataset. These evaluation videos specifically focus on object interaction and arm navigation scenarios, allowing us to assess the model’s performance on targeted manipulation tasks.
As discussed in 5.1, we define the Action Score as a rescaling of the opposite of the Action Error, namely $`800 (0.1 - E)`$ if $`E < 0.1`$ else 0, where $`E`$ is the Action Error. We display the Action Score in all figures discussed in 5.2.
Robocasa.
Robocasa is a simulation framework, based on Robosuite , with several robotic embodiments, including the Franka Panda Arm, which is the robot used in the DROID dataset. Robocasa features over 2,500 3D assets across 150+ object categories and numerous interactable furniture pieces. The framework includes 100 everyday tasks and provides both human demonstrations and automated trajectory generation to efficiently expand training data. It is licensed under the MIT License.
We evaluate DROID models on Robocasa. The already existing pick-and-place tasks require too long horizons to be solved by our current planning procedure. Hence, we need define custom easier pick-and-place task where the arm and target object start closer to the target position. To get a goal frame, we need to teleoperate a trajectory to obtain successful pick-and-place trajectories. We can then use the last frame of these trajectories as goal frame for planning. We needed to tune the camera view point to roughly correspond to the DROID left or right camera viewpoint, otherwise our models were not able to unroll well a sequence of actions. We also customize the gripper to use the same RobotiQ gripper as in DROID. We collect 16 such trajectories to form our evaluation set in the kitchen scene with various object classes. We define the “Reach" condition as having the end-effector at less than 0.2 (in simulator units, corresponding to roughly 5 cms in DROID) from the target object, the “Pick" condition as having lifted the object at more than 0.05 from its initial altitude, and the “Place" condition as having the object at less than 0.15 from the target position of the object. Our teleoperated trajectories all involve three segments, namely reaching the object (segment 1), picking it up (segment 2), and placing it at the target position (segment 3), delimited by these conditions. These three segments allow to define 6 subtasks, namely “Reach-Pick-Place", “Reach-Pick", “Pick-Place", “Reach", “Pick", and “Place". The success definition of each of these tasks is as follows:
-
“Reach-Pick-Place": starting from the beginning of segment 1, success is 1 if the “Pick" and “Place" conditions are met.
-
“Reach-Pick": starting from the beginning of segment 1, success is 1 if the “Pick" condition is met.
-
“Pick-Place": starting from the beginning of segment 2, success is 1 if the “Place" condition is met.
-
“Reach": starting from the beginning of segment 1, success is 1 if the “Reach" condition is met.
-
“Pick": starting from the beginning of segment 2, success is 1 if the “Pick" condition is met.
-
“Place": starting from the beginning of segment 3, success is 1 if the “Place" condition is met.
We focus on the “Place" and “Reach" tasks. Our models have low success rate on the “Pick" task, as they slightly misestimate the position of the end-effector, which proves crucial, especially for small objects.
To allow for zero-shot transfer from DROID to Robocasa, we perform 5 times action repeat of the actions outputted by our DROID model, since we trained on DROID sampled at 4 fps and the control frequency of Robocasa is 20 Hz. We also rescale the actions outputted by our planner to match the action magnitude of Robocasa, namely [-1, 1] for the delta position of the end-effector in cartesian space, and [0, 1] for the gripper closure.
Metaworld.
The Metaworld environment is licensed under the MIT License. The 42 Metaworld tasks we consider are listed in 5. We gather a Metaworld dataset via TD-MPC2 online agents trained on the visual and full state (39-dimensional) input from the Metaworld environment, on 42 Metaworld tasks, listed in 5. We launch the training of each TD-MPC2 agent for three seeds per task. The re-initialization of the environment at each new training episode is therefore different, even within a given seed and task. This randomness governs the initial position of the arm and of the objects present in the scene, as well as the goal positions of the arm and potential objects. Each episode has length 100. We keep the first 100 episodes of each combination of seed and task, to limit the proportion of “expert" trajectories in the dataset, thus promoting data diversity. This results in 126 buffers, each of 100 episodes, hence 12600 episodes of length 100.
We introduce a planning evaluation procedure for each of the Metaworld tasks considered. These are long-horizon tasks that require to perform at least 60 actions to be solved, meaning it should be solvable if planning at horizon $`H = 60 / f`$, if using frameskip $`f`$. This allows us to explore the use of JEPA-WMs in a context where MPC is a necessity. At planning time, we reset the environment with a different for each episode, randomizing the initial position of the arm, of the objects present in the scene, as well as the goal positions of the arm and potential objects. We then play the expert policy provided in the open-source Metaworld package for 100 steps. The last frame (and optionally proprioception) of this episode is set as the goal $`o_g`$ for the planning objective of equation [eq:plan_objective]. We then reset the environment again with the same random seed, and let the agent plan for 100 steps to reach the goal.
| Task | Description |
|---|---|
| turn on faucet | Rotate the faucet counter-clockwise. Randomize faucet positions |
| sweep | Sweep a puck off the table. Randomize puck positions |
| assemble nut | Pick up a nut and place it onto a peg. Randomize nut and peg positions |
| turn off faucet | Rotate the faucet clockwise. Randomize faucet positions |
| push | Push the puck to a goal. Randomize puck and goal positions |
| pull lever | Pull a lever down $`90`$ degrees. Randomize lever positions |
| push with stick | Grasp a stick and push a box using the stick. Randomize stick positions. |
| get coffee | Push a button on the coffee machine. Randomize the position of the coffee machine |
| pull handle side | Pull a handle up sideways. Randomize the handle positions |
| pull with stick | Grasp a stick and pull a box with the stick. Randomize stick positions |
| disassemble nut | pick a nut out of the a peg. Randomize the nut positions |
| place onto shelf | pick and place a puck onto a shelf. Randomize puck and shelf positions |
| press handle side | Press a handle down sideways. Randomize the handle positions |
| hammer | Hammer a screw on the wall. Randomize the hammer and the screw positions |
| slide plate | Slide a plate into a cabinet. Randomize the plate and cabinet positions |
| slide plate side | Slide a plate into a cabinet sideways. Randomize the plate and cabinet positions |
| press button wall | Bypass a wall and press a button. Randomize the button positions |
| press handle | Press a handle down. Randomize the handle positions |
| pull handle | Pull a handle up. Randomize the handle positions |
| soccer | Kick a soccer into the goal. Randomize the soccer and goal positions |
| retrieve plate side | Get a plate from the cabinet sideways. Randomize plate and cabinet positions |
| retrieve plate | Get a plate from the cabinet. Randomize plate and cabinet positions |
| close drawer | Push and close a drawer. Randomize the drawer positions |
| press button top | Press a button from the top. Randomize button positions |
| reach | reach a goal position. Randomize the goal positions |
| press button top wall | Bypass a wall and press a button from the top. Randomize button positions |
| reach with wall | Bypass a wall and reach a goal. Randomize goal positions |
| insert peg side | Insert a peg sideways. Randomize peg and goal positions |
| pull | Pull a puck to a goal. Randomize puck and goal positions |
| push with wall | Bypass a wall and push a puck to a goal. Randomize puck and goal positions |
| pick out of hole | Pick up a puck from a hole. Randomize puck and goal positions |
| pick&place w/ wall | Pick a puck, bypass a wall and place the puck. Randomize puck and goal positions |
| press button | Press a button. Randomize button positions |
| pick&place | Pick and place a puck to a goal. Randomize puck and goal positions |
| unplug peg | Unplug a peg sideways. Randomize peg positions |
| close window | Push and close a window. Randomize window positions |
| open door | Open a door with a revolving joint. Randomize door positions |
| close door | Close a door with a revolving joint. Randomize door positions |
| open drawer | Open a drawer. Randomize drawer positions |
| close box | Grasp the cover and close the box with it. Randomize the cover and box positions |
| lock door | Lock the door by rotating the lock clockwise. Randomize door positions |
| pick bin | Grasp the puck from one bin and place it into another bin. Randomize puck positions |
A list of all of the Meta-World tasks and a description of each task.
Push-T.
In this environment introduced by (MIT License), a pusher ball agent interacts with a T-shaped block. Success is achieved when both the agent and the T-block, which start from a randomly initialized state, reach a target position. For Push-T, the dataset provided in DINO-WM is made of 18500 samples, that are replays of the original released expert trajectories with various level of noise. At evaluation time, we sample an initial and goal state from the validation split, such that the initial attained the goal in $`H`$ steps, with $`H`$ the planning horizon. Indeed, otherwise, the task can require very long-horizon planning, and is not well solved with our planners.
PointMaze.
In this environment introduced by (Apache 2.0 license), a force-actuated 2-DoF ball in the Cartesian directions $`x`$ and $`y`$ must reach a target position. The agent’s dynamics incorporate its velocity, acceleration, and inertia, making the movement realistic. The PointMaze train set is made of 2000 fully random trajectories. At evaluation time, we sample a random initial and goal state from the simulator’s sampler.
Wall.
This 2D navigation environment introduced in (MIT License) features two rooms separated by a wall with a door. The agent’s task is to navigate from a randomized starting location in one room to a goal in one of the two rooms, potentially passing through the door. The Wall dataset is made of 1920 random trajectories each with 50 time steps. At planning time, we also sample a random initial and goal state from the simulator’s sampler.
Planning Optimization
In this section, we detail the optimization procedures for planning in our experiments. Given a modeling function $`F_{\phi,\theta}`$, a dissimilarity criterion $`(L_{vis}+\alpha L_{prop})`$, an initial and goal observation pair $`o_t, o_g`$, we remind we have the objective function $`L^p_\alpha(o_t, a_{t:t+H-1}, o_g) = (L_{vis} + \alpha L_{prop})(F_{\phi,\theta}(o_t, a_{t:t+H-1}), E_{\phi,\theta}(o_g))`$.
Model Predictive Control.
In Metaworld only we perform MPC, a procedure where replanning is allowed after executing a plan in the environment. We set the maximum number of actions that can be stepped in the environment to 100, which constitutes an episode. At each step of the episode where we plan, we use either the CEM or NG planner.
Cross-Entropy Method.
The CEM optimisation algorithm proceeds as in [algo:CEM]. In essence, we fit parameters of a time-dependent multivariate Gaussian with diagonal covariance.
$`\mu^0 \in \mathbb{R}^{H\times A}`$ is zero and covariance matrix $`\sigma^0 \textrm{I} \in \mathbb{R}^{(H\times A)^2}`$ is the identity. Number of optimisation steps $`J`$. Sample $`N`$ independent trajectories $`( \{a_{t}, \ldots, a_{t+H-1}\}) \sim \mathcal{N}(\mu^j, (\sigma^j)^2\textrm{I})`$ For each of the $`N`$ trajectories, unroll predictor to predict the resulting trajectory, $`\hat{z}_i = P_{\theta}(\hat{z}_{i-1}, a_{i-1}), \quad i = t+1, \ldots, t+H`$. Compute cost $`L^p_\alpha(o_t, a_{t:t+H-1}, o_g)`$ for each candidate trajectory. Select top $`K`$ action sequences with the lowest cost, denote them $`( \{a_{t}, \ldots, a_{t+H-1}\})_{1, \dots, K}`$. Update
\begin{align*}
\mu^{j+1} = \frac{1}{K}\sum_{k=1}^K ( \{a_{t}, \ldots, a_{t+H-1}\})_k \\
\sigma^{j+1} = \sqrt{\frac{1}{K-1}\sum_{k=1}^K \left[ ( \{a_{t}, \ldots, a_{t+H-1}\})_k - \mu^{j+1} \right]^2 }
\end{align*}Step the first $`m`$ actions of $`\mu^J`$. where $`m \leq H`$ is a planning hyperparameter in the environment. If we are in MPC mode, the process then repeats at the next time step with the new context observation.
 />
/>
 />
/>
NG Planner.
We design a procedure to use any NeverGrad optimizer with our planning objective $`L^p_\alpha(o_t, a_{t:t+H-1}, o_g)`$, with the same number of action trajectories evaluated in parallel and total budget as CEM, as detailed in [algo:NG]. As discussed in 5.2.0.1, in all the evaluation setups we consider in this study, the NGOpt meta-optimizer always chooses the diagonal variant of the CMA-ES algorithm with a particular parameterization. The diagonal version of CMA is advised when the search space is big. We stress that after trying other parameterizations of the Diagonal CMA algorithm, like its elitist version (with a scale factor of 0.895 instead of 1, which is the default value), success rate can drop by 20% on Wall, Maze and Push-T.
optimizer chosen by nevergrad.optimizers.NGOpt from budget
$`N \times J`$, on space $`\mathbb{R}^{H \times A}`$, with $`N`$
workers. optimizer.ask() $`N`$ trajectories sequentially. For each of
the $`N`$ trajectories, unroll predictor to predict the resulting
trajectory,
$`\hat{z}_i = P_{\theta}(\hat{z}_{i-1}, a_{i-1}), \quad i = t+1, \ldots, t+H`$.
Compute cost $`L^p_\alpha(o_t, a_{t:t+H-1}, o_g)`$ for each candidate
trajectory. optimizer.tell() the cost
$`L^p_\alpha(o_t, a_{t:t+H-1}, o_g)`$ of the $`N`$ trajectories
sequentially. Step the first $`m`$ actions of
optimizer.provide_recommendation(), where $`m \leq H`$ is a planning
hyperparameter in the environment. If we are in MPC mode, the process
then repeats at the next time step with the new context observation.
Gradient Descent Planner.
We also experiment with gradient-based planners that directly optimize the action sequence through backpropagation. Unlike sampling-based methods (CEM, NG), these planners leverage the differentiability of the world model to compute gradients of the planning objective $`L^p_\alpha`$ with respect to actions. The Gradient Descent (GD) planner initializes actions either from a standard Gaussian (scaled by $`\sigma_0`$) or from zero, then performs $`J`$ gradient descent steps with learning rate $`\lambda`$. After each gradient step, Gaussian noise with standard deviation $`\sigma_{\text{noise}}`$ is added to the actions to encourage exploration and help escape local minima. Action clipping is applied to enforce bounds on specific action dimensions. The default hyperparameters are $`J=500`$ iterations, $`\lambda=1`$, $`\sigma_0=1`$, and $`\sigma_{\text{noise}}=0.003`$.
Adam Planner.
The Adam planner extends the GD planner by using the Adam optimizer instead of vanilla stochastic gradient descent. Adam maintains exponential moving averages of the gradient (first moment) and squared gradient (second moment), which can provide more stable optimization dynamics. The default hyperparameters are $`\beta_1=0.9`$, $`\beta_2=0.995`$, $`\epsilon=10^{-8}`$, with the same defaults as GD for other parameters ($`J=500`$, $`\lambda=1`$, $`\sigma_0=1`$, $`\sigma_{\text{noise}}=0.003`$).
Planning hyperparameters.
We display in 6 the hyperparameters used to plan on each environment. We keep the planning hyperparameters of DINO-WM for Push-T, Wall and Maze, but reduce the number of “top" actions, denoted $`K`$, to 10 instead of 30. We obtain these parameters after careful grid search on DINO-WM. The success rate is very sensitive to these parameters, keeping the world model fixed.
| $`N`$ | $`H`$ | $`m`$ | $`K`$ | $`J`$ | $`W^p`$ | $`f`$ | $`M`$ | |
|---|---|---|---|---|---|---|---|---|
| PointMaze | 300 | 6 | 6 | 10 | 30 | 2 | 5 | 30 |
| Push-T | 300 | 6 | 6 | 10 | 30 | 2 | 5 | 30 |
| Wall | 300 | 6 | 6 | 10 | 30 | 2 | 5 | 30 |
| Metaworld | 300 | 6 | 3 | 10 | 15 | 2 | 5 | 100 |
| Robocasa | 300 | 3 | 1 | 10 | 15 | 2 | 5 | 60 |
| DROID | 300 | 3 | 3 | 10 | 15 | 2 | 1 | $`m`$ |
Environment-specific hyperparameters for planning, corresponding to the notations of 10.0.0.2. The number of steps per planning episode is denoted $`M`$ and the frameskip is denoted $`f`$. $`H`$ is the planning horizon, $`m`$ the number of actions to step in the environment, $`K`$ the number of top actions in CEM, $`N`$ the number of trajectories evaluated in parallel, $`J`$ the number of iterations of the optimizer. The total number of replanning steps for an evaluation episode is $`\frac{M}{f m}`$.
Additional experiments
Additional results
Equalized action ratio experiments.
To isolate the effect of the conditioning scheme from capacity differences due to action ratio, we train new models for each of the considered environments where we downscale the image resolution to $`128\times128`$ with a DINOv3-L encoder (patch size 16), yielding $`8\times8 = 64`$ visual patches. This produces matched action ratios: sequence conditioning achieves $`1 / (hw+1) = 1 / 65`$, while feature conditioning achieves $`f_a / (D+f_a) = 16 / 1040`$. Both variants use the same predictor architecture, RoPE positional encoding, frozen encoder, and training data.
Results reveal task-dependent preferences: Sequence conditioning outperforms feature conditioning on DROID, Robocasa, and Metaworld (3D manipulation tasks). Conversely, feature conditioning significantly outperforms on Wall (2D navigation). Performance is comparable on Maze and Push-T. Notably, the Wall result replicates the trend from 9 (different resolution/model size), confirming statistical robustness.
We cannot provide a precise explanation of the underlying mechanism explaining why we observe such differences. What we can say for sure is that, despite matched action ratios, the conditioning schemes differ fundamentally in how action information propagates:
-
Feature conditioning: Action embeddings are concatenated to each visual token. At the first transformer block, action-visual mixing occurs only within the MLP (after self-attention), which combines information across embedding dimensions but processes each spatial token separately.
-
Sequence conditioning: The action token participates in self-attention from the first block, allowing immediate broadcasting to all visual tokens through attention mechanisms.
Observations on Wall task: Training and validation rollout losses are identical between methods, indicating both models predict dynamics equally well. However, during planning, sequence-conditioned models occasionally select very high magnitude actions, while feature-conditioned models consistently choose moderate actions. This suggests the conditioning scheme affects not only prediction but also the structure of the learned latent dynamics relevant for planning.
We hypothesize that for spatially simple tasks (Wall), feature conditioning’s direct action-to-token pathway yields dynamics better suited for planning optimization, while sequence conditioning’s attention-based routing is more beneficial for complex spatial reasoning in manipulation. However, further analysis would be needed to conclusively establish this mechanism.
Additional planner ablations.
In [tab:all_planners_model_comp], we compare the performance of our model to the DINO-WM and VJEPA-2-AC baselines across all planner configurations tested in 5. Our optimal JEPA-WM consistently outperforms the baselines on most tasks and planners, as in [tab:final_model_comp_baselines].
For completeness, we also report in [tab:all_planners_final_ckpt_comp] the per-seed variance at the final checkpoint, which isolates reproducibility across random seeds from training stability. Results are consistent with [tab:all_planners_model_comp], confirming that our method reliably outperforms baselines across both metrics.
In 18 (Left), we display 5 again for completeness, along with 18 (Right), where we compare the performance of all planners on all environments but with proprioception. We adopt the default configuration described in the beginning of 4, namely DINO-WM ViT-S but with proprioception. We can draw the same conclusions as for without proprioception, in 5.
Let us detail the failure cases of the GD planner. On the Wall task, the GD planner gets zero performance, although the task is visually simplistic. We identify two main failure cases. Either the agent goes into the wall without being able to pass the door, which is a classical failure case for better CEM or NG planners. Or the agent finds a local planning cost minimum by going to the borders of the image, when starting close to them. We illustrate both of these in 17.
 style="height:15.0%" />
style="height:15.0%" />
 />
/>
 />
/>
 style="height:15.0%" />
style="height:15.0%" />
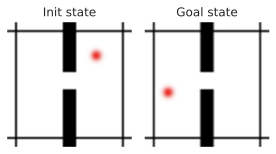 />
/>
 />
/>
/>
/>
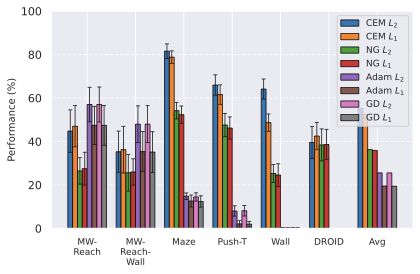 />
/>
Object manipulation on Robocasa and DROID.
We show in 20 a successful planning episode with our proposed JEPA-WM on Robocasa on the “Place" task. Our model is able to perform the “Place" task but has a much lower success rate at the “Pick" task, as it misestimates the position of the arm. We illustrate the shift in camera calibration / action calibration in 19 on the “Reach" task. On all episodes, the model always predicts a state shifted to the left compared to the ground-truth. This phenomenon is less clear on DROID, as we illustrate in 21.
 />
/>
 />
/>
 />
/>
 />
/>
 style="width:90.0%" />
style="width:90.0%" />
Object manipulation on Metaworld.
Our agent solves the pose control tasks like reach and reach-wall. In addition, long-term action unrolling with object interaction seems to be well-captured by our models, as shown in 22 for the bin-picking task. Yet, for tasks involving object manipulation, it hallucinates grasping the object. In 23, the visual decoding of the unrolling of the action plan shows a gap between the imagined consequences of the actions and their consequences in the simulator. This calls for a separate optimization procedure for the action dimension that corresponds to the end-effector’s gripper.
 style="width:99.0%" />
style="width:99.0%" />
 style="width:99.0%" />
style="width:99.0%" />
 style="width:99.0%" />
style="width:99.0%" />
 style="width:70.0%" /> style="width:70.0%" /> |
 style="width:70.0%" />
style="width:70.0%" /> |
Action precision Push-T.
The results in 33 clearly show that CEM performs better than NG for the Push-T task. The Push-T task requires very precise actions, since if the ball is slightly off the position where it should be to push the T-shape, it misses the shape and fails at the task. Hence it proves essential to only step actions after convergence of the planner. Yet, we see in 24 that the NG planner is more explorative and should therefore be parametrized differently for this type of task. Interestingly, the larger model converges faster and brings higher maximal success rate on this task.
 />
/>
 />
/>
 />
/>
 />
/>
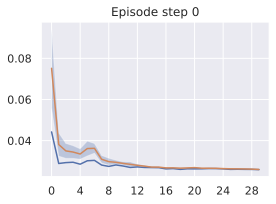 />
/>
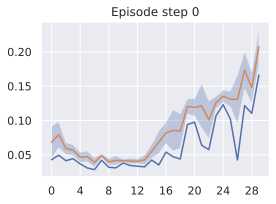 />
/>
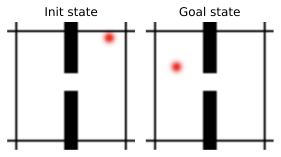 />
/>
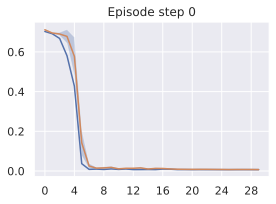 />
/>
 />
/>
 />
/>
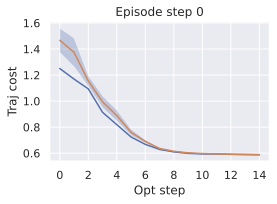 />
/>
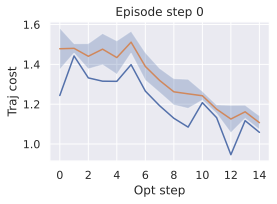 />
/>
Embedding space and model size.
We see in 30 that the relative difference in embedding space distance to the goal is approximately ten times smaller in the ViT-L model than in the ViT-S model. This is consistent with the fact that the ViT-L model has a higher capacity and can therefore embed more information in its latent space, in which two states of Metaworld are closer to each other than in the ViT-S model embedding space.
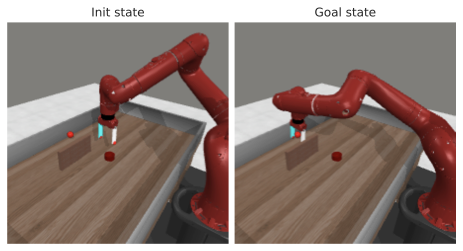 />
/>
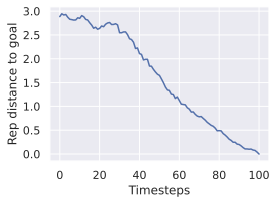 />
/>
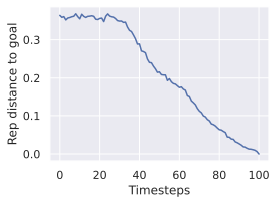 />
/>
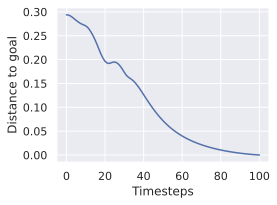 />
/>
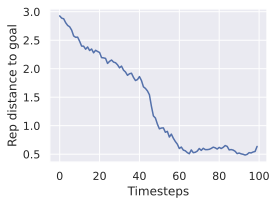 />
/>
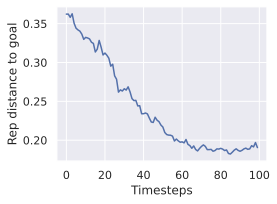 />
/>
Evaluation metrics
The metric we seek to optimize for planning tasks is the success rate, which can be noisy, highly dependent on the initial seed, and sparse at the beginning of training. We therefore derive several other useful metrics and study their correlation with the success rate.
Embedding space error throughout unrolling.
Throughout training, every 300 training iterations, we unroll the predictor on a batch of the validation split for $`n`$ steps. For each of these steps, we compute the $`L_1`$ and $`L_2`$ loss between the predicted embedding and the embedding of the ground truth corresponding future frame. The $`L_2`$ loss at step 1 is the teacher-forcing loss term $`\mathcal{L}`$.
Proprioceptive decoding error throughout unrolling.
Prior to training of the predictors, we train a small ViT probe, called “state decoder" on top of the frozen encoder to regress the state, i.e. proprioception and optionally other simulator state information. Then, when training the predictors we study in this paper, every 300 training iterations, we unroll the predictor for $`n`$ steps on a batch of the validation split and use our state decoder on the predicted features. This yields $`n`$ state predictions, of which we compute the distance to the ground truth future $`n`$ states.
Visual decoder.
Just like the state decoder, we train a visual decoder to reconstruct, from the embeddings outputted by the frozen encoder, the associated frames. We decode each frame independently to avoid artificial consistency across frames, as the decoder is a probing tool. Indeed, in models like COSMOS , the powerful diffusion decoder accounts for beautiful visualisations, although the underlying latent world model might not be as accurate. Every 300 training iterations, we unroll the predictor on a given sequence of actions, and compare the decoding of the predicted embeddings to the ground truth future frames, both qualitatively and with the LPIPS metric .
Action error.
To evaluate models without having to step actions in a real robot or a simulator, we compare the actions outputted by the planner and the groundtruth actions of the trajectory sampled from the dataset to define initial and goal state. On DROID, throughout training, the total action error increases, and even more if we do not clip the actions magnitude in the planner, as done in V-JEPA-2-AC, since we do not normalize the actions. This is because most of the action error comes from the gripper closure and gripper orientation action dims, as detailed in 31. Hence, on DROID, we track the action error on the three first dimensions, corresponding to the end-effector position control, which is more relevant for the tasks we consider.
 />
/>
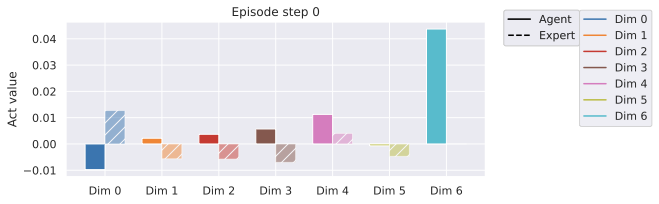 />
/>
 />
/>
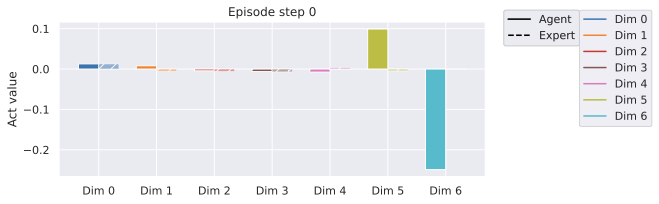 />
/>
Is there a proxy for success rate?
Evaluating several independent planning recipes is compute-intensive, even more so as the model size increases, as well as the planning budget $`N\times H \times J \times W^p`$, see 6. Hence, we look for validation metrics to track throughout the training that correlate well with the success rate. Each epoch of each model and evaluation setup (among four) is a data point with a value for a validation metric and an associated success rate. Considering each epoch as an independent sample allows us to compute the Spearman correlation between each quantitative metric and the success rate. The results in [tab:spearman_corr_mw_sweeps], [tab:spearman_corr_mz_sweeps], 7 and 8 first show that the correlation with training loss (Vis emb) is higher for the easier Wall task. Since we want to find the metric that correlates most to the success rate, we average the Spearman correlations instead of computing them on the union of data points, to avoid Simpson’s paradox. This yields the rightmost column of each table. In both environments, the metric most correlated with the success rate is the planning objective, that is, the Vis Emb loss. Interestingly, only in Metaworld, which requires better long-horizon unrolling capability, do the unroll metrics at step $`H > 1`$ correlate better than step-1 metrics.
Since we are essentially in a supervised learning setting, training a regressor of future embeddings, it is clear that lower validation prediction losses (at all unrolling steps) means a more accurate world model. This is best observed in the visual decodings of validation rollouts throughout training.
Why the success rate does not correlate well to these losses is due to several factors. The validation prediction task is not fully aligned with the goal-conditioned planning task. The planning optimization task we use to evaluate models is a heuristic, where the objective is to minimize the embedding space distance of the last imagined state to the goal.
As we see in DROID experiments 31, letting the planner sample actions that are OOD for the predictor can severely harm the plan accuracy and occult the improvement of the predictor throughout training. Another caveat is that a better world model that does not prevent the planning procedure from getting stuck in local cost minima, as we see with the score obtained with gradient-based planners in [tab:all_planners_model_comp].
| Model name | WM | $`\text{WM}_W`$ | WM-prop | WM-2-step | WM-L | Mean | |
|---|---|---|---|---|---|---|---|
| Proprio dec $`H=1`$ | 0.70 | 0.73 | 0.85 | 0.71 | 0.81 | 0.76 | |
| Proprio dec $`H=2`$ | 0.78 | 0.66 | 0.87 | 0.79 | 0.84 | 0.79 | |
| Proprio dec $`H=3`$ | 0.76 | 0.70 | 0.78 | 0.83 | 0.86 | 0.79 | |
| Vis emb $`L_2`$ $`H=1`$ | 0.80 | 0.73 | 0.88 | 0.82 | 0.87 | 0.82 | |
| Vis emb $`L_2`$ $`H=2`$ | 0.85 | 0.76 | 0.91 | 0.84 | 0.87 | 0.85 | |
| Vis emb $`L_2`$ $`H=3`$ | 0.86 | 0.70 | 0.89 | 0.80 | 0.87 | 0.82 | |
| Vis emb $`L_1`$ $`H=1`$ | 0.87 | 0.79 | 0.92 | 0.83 | 0.90 | 0.86 | |
| Vis emb $`L_1`$ $`H=2`$ | 0.88 | 0.78 | 0.93 | 0.84 | 0.88 | 0.86 | |
| Vis emb $`L_1`$ $`H=3`$ | 0.87 | 0.75 | 0.91 | 0.83 | 0.87 | 0.85 |
Negative Spearman Correlation Coefficients across data points of the four eval setups between smoothed success rate and several validation metrics on the Push-T task. The rightmost mean column is the average of Spearman correlation of each model.In bold is highest value, underlined is 2nd highest. We display the mean success rate over the last 10 epochs in the last row.
| Model name | WM | $`\text{WM}_W`$ | WM-prop | WM-2-step | WM-3-step | WM-L | Mean |
|---|---|---|---|---|---|---|---|
| Proprio dec $`H=1`$ | 0.25 | 0.38 | 0.19 | 0.23 | 0.26 | 0.16 | 0.25 |
| Proprio dec $`H=2`$ | 0.23 | 0.51 | 0.22 | 0.30 | 0.14 | 0.28 | 0.28 |
| Proprio dec $`H=3`$ | 0.22 | 0.49 | 0.39 | 0.26 | 0.34 | 0.23 | 0.32 |
| Vis emb $`L_2`$ $`H=1`$ | 0.72 | 0.94 | 0.74 | 0.73 | 0.69 | 0.75 | 0.76 |
| Vis emb $`L_2`$ $`H=2`$ | 0.69 | 0.94 | 0.69 | 0.70 | 0.61 | 0.74 | 0.73 |
| Vis emb $`L_2`$ $`H=3`$ | 0.68 | 0.94 | 0.65 | 0.69 | 0.56 | 0.70 | 0.70 |
| Vis emb $`L_1`$ $`H=1`$ | 0.78 | 0.96 | 0.81 | 0.77 | 0.73 | 0.80 | 0.81 |
| Vis emb $`L_1`$ $`H=2`$ | 0.74 | 0.96 | 0.76 | 0.72 | 0.69 | 0.79 | 0.78 |
| Vis emb $`L_1`$ $`H=3`$ | 0.73 | 0.96 | 0.73 | 0.72 | 0.64 | 0.75 | 0.75 |
Negative Spearman Correlation Coefficients across data points of the eight eval setups between smoothed success rate and several validation metrics on the Wall task. In bold is highest value, underlined is 2nd highest. We denote the visual embedding prediction errors Vis Emb and the proprioceptive decoding error Proprio dec, at horizons $`H`$ from one to three.
Success over epochs
We display in 32 and 33 the evolution of success rate over training epochs for some of the models that compose the design choice study of this paper.
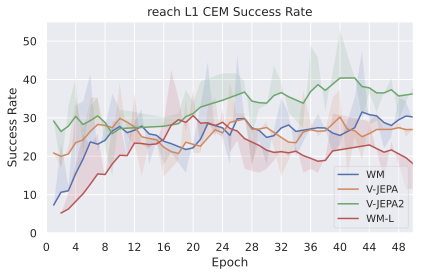 />
/>
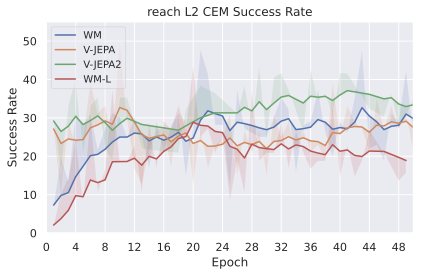 />
/>
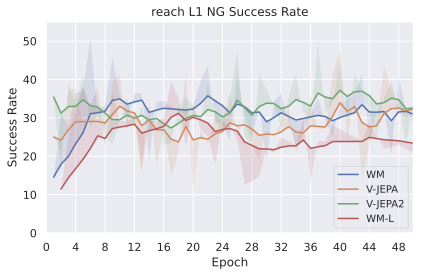 />
/>
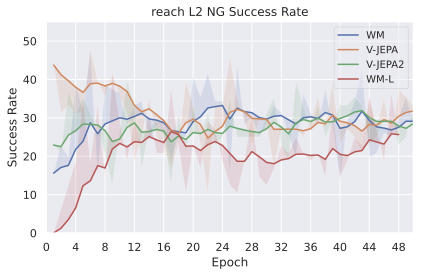 />
/>
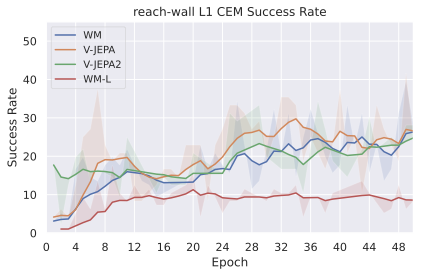 />
/>
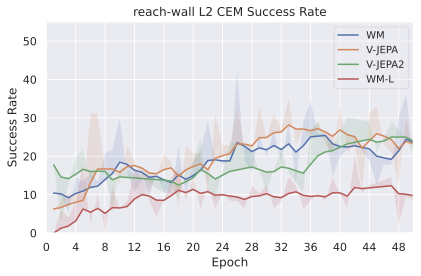 />
/>
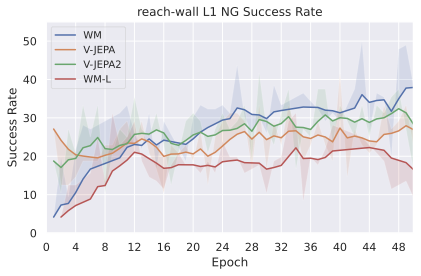 />
/>
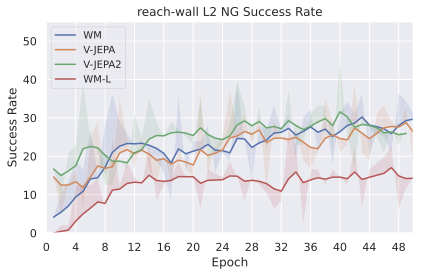 />
/>
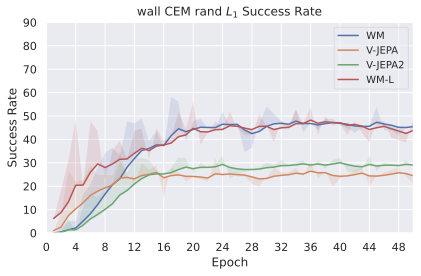 />
/>
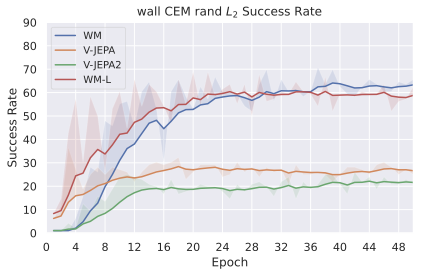 />
/>
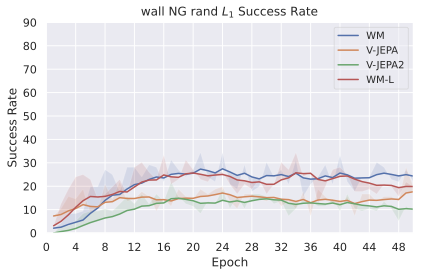 />
/>
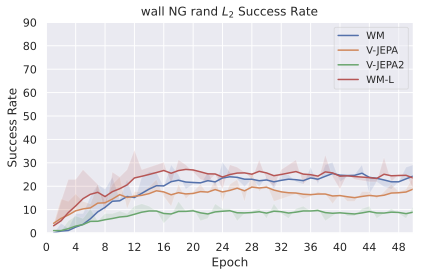 />
/>
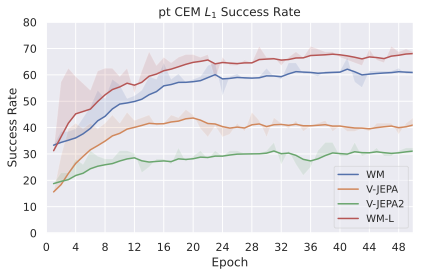 />
/>
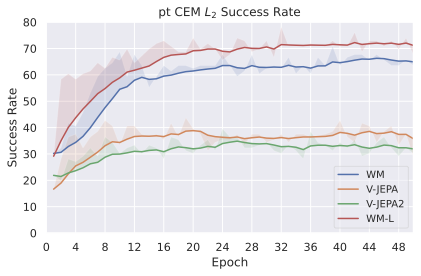 />
/>
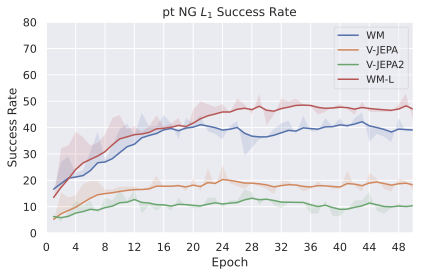 />
/>
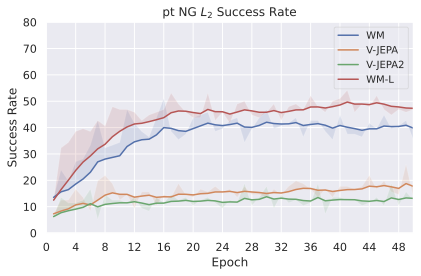 />
/>
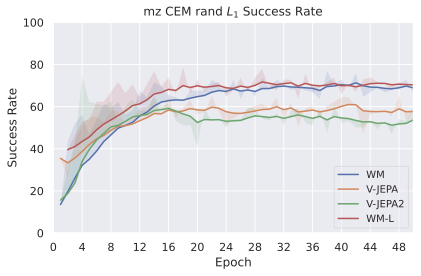 />
/>
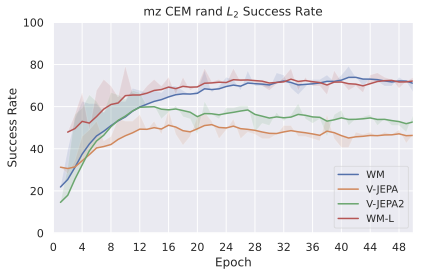 />
/>
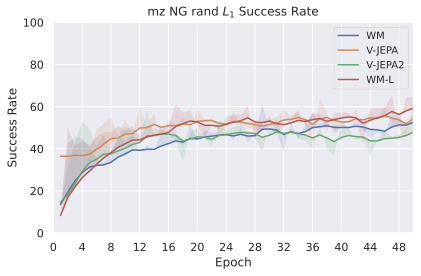 />
/>
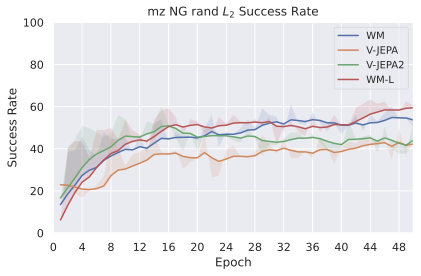 />
/>
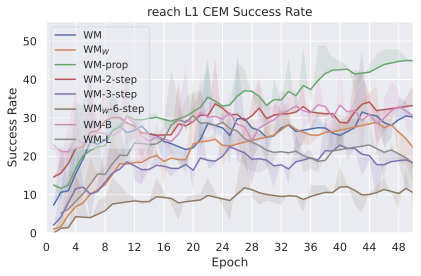 />
/>
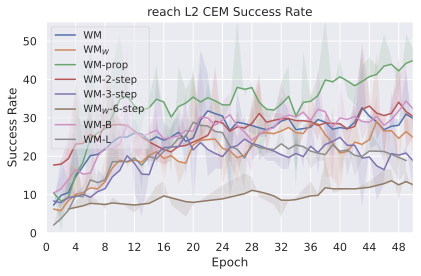 />
/>
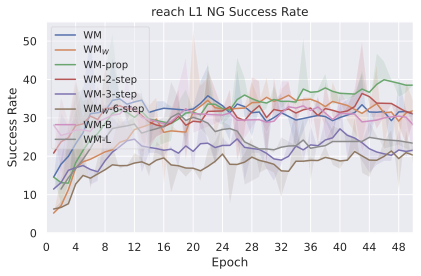 />
/>
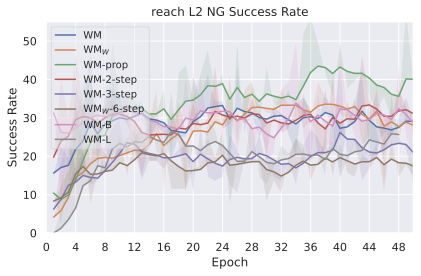 />
/>
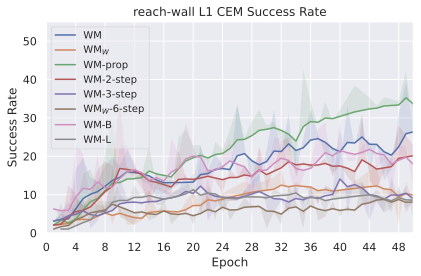 />
/>
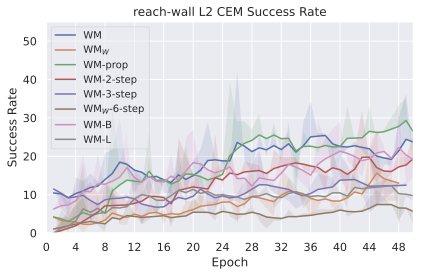 />
/>
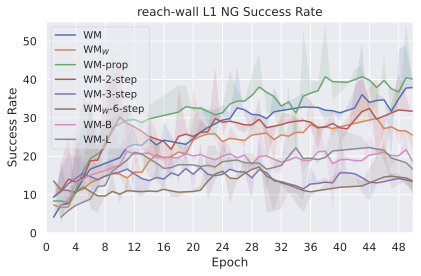 />
/>
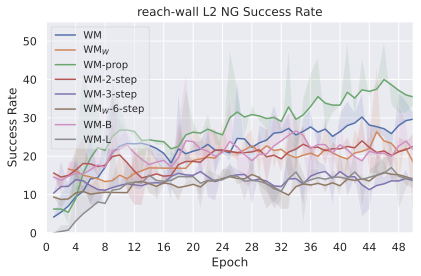 />
/>
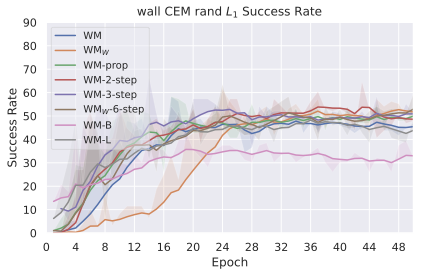 />
/>
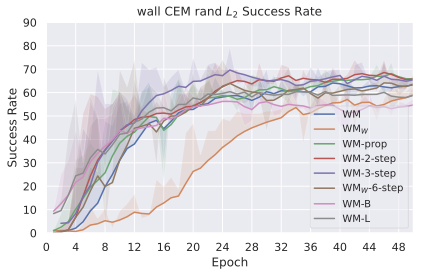 />
/>
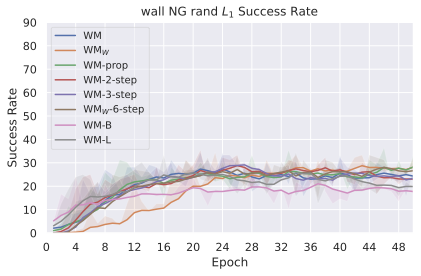 />
/>
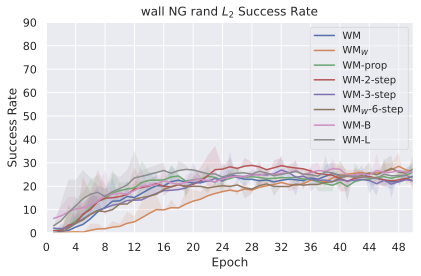 />
/>
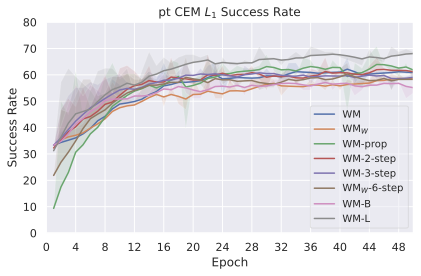 />
/>
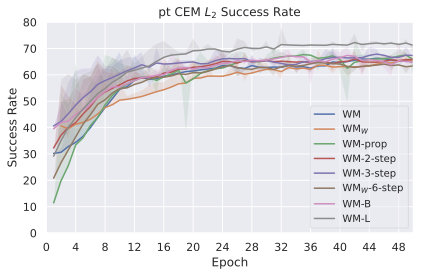 />
/>
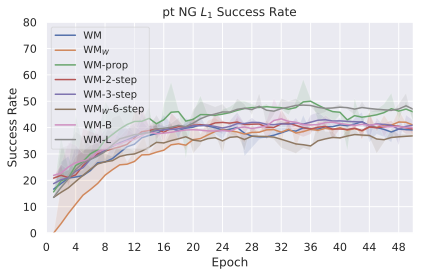 />
/>
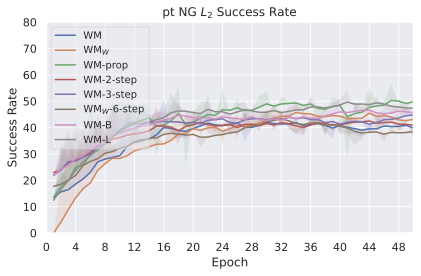 />
/>
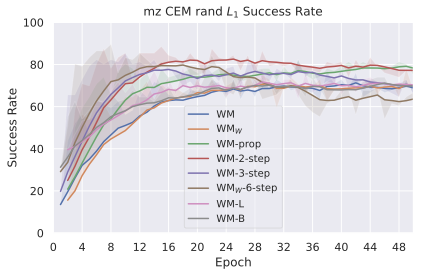 />
/>
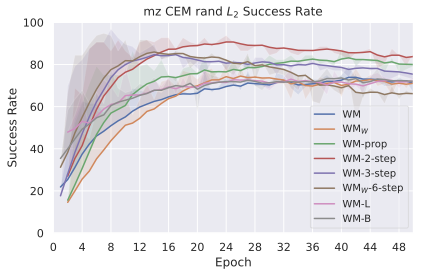 />
/>
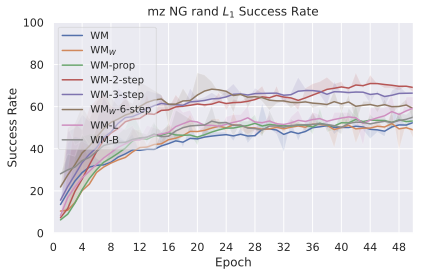 />
/>
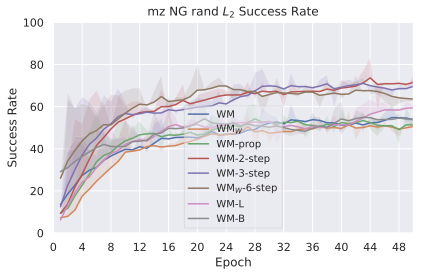 />
/>
📊 논문 시각자료 (Figures)





