Title: Comparing Approaches to Automatic Summarization in Less-Resourced Languages
ArXiv ID: 2512.24410
Date: 2025-12-30
Authors: Chester Palen-Michel, Constantine Lignos
📝 Abstract
Automatic text summarization has achieved high performance in high-resourced languages like English, but comparatively less attention has been given to summarization in less-resourced languages. This work compares a variety of different approaches to summarization from zero-shot prompting of LLMs large and small to fine-tuning smaller models like mT5 with and without three data augmentation approaches and multilingual transfer. We also explore an LLM translation pipeline approach, translating from the source language to English, summarizing and translating back. Evaluating with five different metrics, we find that there is variation across LLMs in their performance across similar parameter sizes, that our multilingual fine-tuned mT5 baseline outperforms most other approaches including zero-shot LLM performance for most metrics, and that LLM as judge may be less reliable on less-resourced languages.
📄 Full Content
Automatic text summarization in higher-resourced languages like English has achieved high scores in automated metrics (Al-Sabahi et al., 2018;Liu et al., 2022;Zhang et al., 2020a). However, for many lessresourced languages, the task remains challenging. While there are datasets that cover multilingual summarization in less-resourced languages (Giannakopoulos et al., 2015(Giannakopoulos et al., , 2017;;Palen-Michel and Lignos, 2023;Hasan et al., 2021), these datasets often still have relatively few examples compared to their higher-resourced counterparts.
To better understand which approaches work best with less-resourced languages, we conduct a comparative study of a variety of approaches to automatic summarization. Specifically, we compare zero-shot prompting with three smaller-scale LLMs (Mixtral 8x7b, Llama 3 8b, Aya-101). Given that LLMs’ pretraining data tends to be dominated by higher-resourced languages, we also experiment with fine-tuning smaller mT5 in a variety of settings. We fine-tune mT5 per-individual language and with all available language data combined for multilingual transfer as baselines. Multilingual transfer has proven to be a useful strategy for less-resourced languages (Wang et al., 2021); however, other works have shown that multilingual models have limits and given enough data, fully monolingual models can perform better (Virtanen et al., 2019;Tanvir et al., 2021).
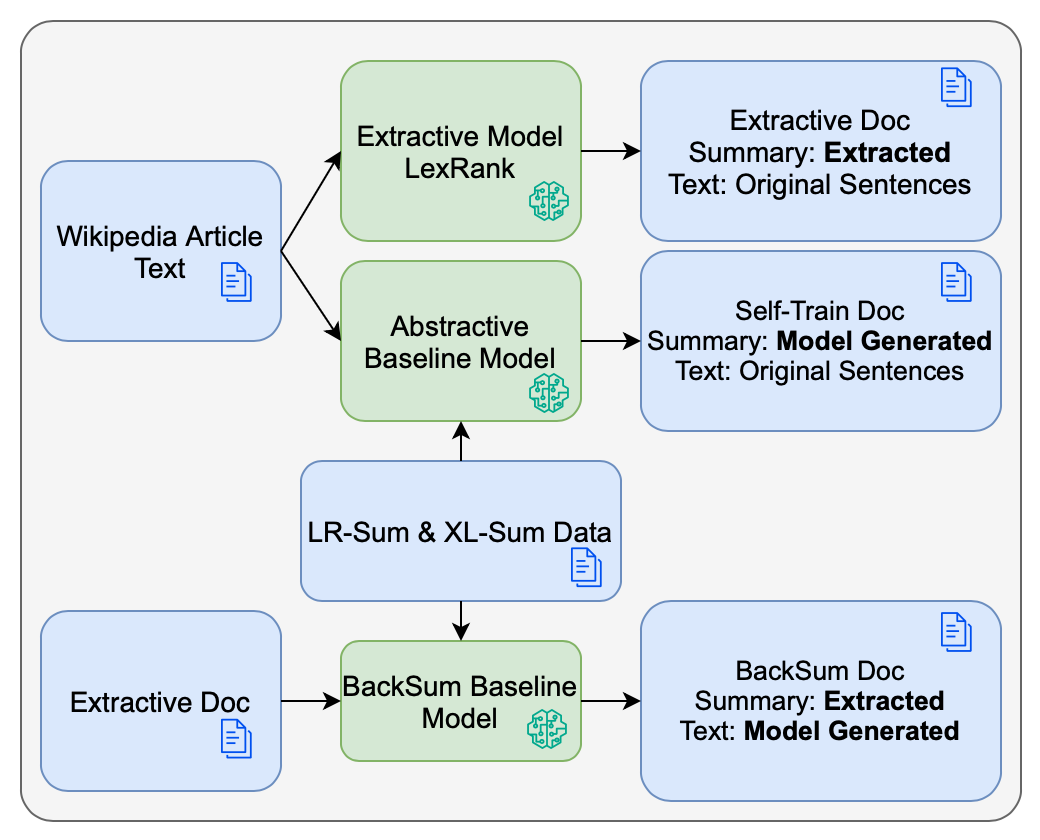
We further explore fine-tuning mT5 with synthetic data generated by leveraging extra Wikipedia data using three different approaches shown in Figure 1. While prior work has focused on comparing multilingual summarization models which take advantage of multilingual transfer with fine-tuning on a single (Palen-Michel and Lignos, 2023;Hasan et al., 2021) or the use of synthetic data for a single language only (Parida and Motlicek, 2019), this work compares the performance of multilingual pretrained models fine-tuned using data for a single language with fine-tuning that uses the combination of synthetic and real data from all languages.
We then conduct additional experiments with three larger LLMs (Gemma-3 27b, Llama-3.3 70b, Aya-Expanse 32b). We also try a pipeline approach with these larger LLMs translating to English, summarizing in English, and translating back to the target language. We primarily evaluate with ROUGE scores and BERTScore, but with increased attention on LLM as judge evaluation (Fu et al., 2024;Kim et al., 2024;Pombal et al., 2025) we also conduct some experiments with M-Prometheus, an open multilingual LLM trained for evaluation.
Our contributions are the following: 1. A comparison of various approaches to summarization in less-resourced languages including: fine-tuning mT5 in a per-individual language and multilingual setting with and without three data augmentation strategies, zero-shot LLM inference with smaller LLMs and comparatively larger LLMs, and a pipeline approach translating from the original language to English then summarizing and translating back to the target language with LLMs.
A comparison of popular summarization evaluation approaches including ROUGE-1, ROUGE-2, ROUGE-L, BERTScore, and reference-free LLM as judge using M-Prometheus, which demonstrates different evaluation methods yield somewhat different views of which models perform best.
An analysis of the English content produced by LLMs when producing summaries for lessresourced languages.
We conclude that there is some variation across LLMs in their performance across similar parameter sizes and that zero-shot LLM performance significantly lags the multilingual baseline for most metrics. We also find that data augmentation for individual language fine-tuning for mT5 showed improvement over baselines, but does not outperform fine-tuning mT5 in a multilingual transfer scenario.
Because improved methods for evaluating summarization continue to be developed and explored and because we welcome participatory research (Caselli et al., 2021), where speakers of languages have opportunity to collaborate on the design of NLP tools, upon publication we will release all candidate summaries generated as part of this work for future summarization evaluation work.
The two main approaches to automatic summarization have been extractive and abstractive methods. Extractive models select important sentences in the source article to use as summaries (Luhn, 1958;Radev et al., 2001;Christian et al., 2016). Abstractive models typically cast the problem as a sequence-to-sequence problem and apply a neural language model (Rush et al., 2015;See et al., 2017;Hsu et al., 2018;Zhang et al., 2020a). Abstractive neural models typically require larger amounts of training data to train.
Prior work on multilingual summarization has largely focused on newswire text from higher resourced languages or covers more languages but with very limited data (Scialom et al., 2020;Giannakopoulos et al., 2015Giannakopoulos et al., , 2017)). Some of the languages in our study have little to no work in summa-rization, like Armenian (Avetisyan and Broneske, 2023). Others, like Georgian, have been studied in cross-lingual summarization (Turcan et al., 2022), but appear to be underexplored for monolingual summarization. There is a recent effort to create a Kurdish summarization dataset (Badawi, 2023). The Global Voices summarization dataset (Nguyen and Daumé III, 2019) contains some examples of Macedonian. MassiveSumm (Varab and Schluter, 2021) has greater coverage of languages, but is automatically created, recall-oriented, and has complex redistribution requirements, so we did not make use of it in this work.
Large language models (LLMs) have been shown to perform comparably to human summaries for English (Zhang et al., 2024). However, using LLMs for less-resourced languages is less wellstudied. We select three reasonably well performing smaller LLMs and three more recent larger LLMs largely because of their widespread adoption and benchmark performance. 1Regarding data augmentation, the most similar prior work to our approaches includes Parida and Motlicek (2019), which used a similar approach to what we refer to as “back-summarization,” but they apply it only to German. The approach is also similar to the concept of back-translation (Sennrich et al., 2016) for machine translation where inference is done in the opposite direction to create additional synthetic labeled data. Another approach we use, self-training, has been used in other previous work with other tasks and datasets (Du et al., 2021;Karamanolakis et al., 2021;Meng et al., 2021).
Evaluating the quality of a summary is inherently difficult due to there being multiple ways to express similar content and the subjectiveness of the task. Summarization was historically scored using ROUGE-1, ROUGE-2, and ROUGE-L metrics (Lin, 2004). Model-based metrics, such as BERTScore (Zhang et al., 2020b) are also used, although works such as Sun et al. (2022) have found issues in bias with BERTScore. There have been many proposed methods of evaluating summarization systems (Darrin et al., 2024;Vasilyev et al., 2020;Fu et al., 2024).
Human evaluation is often conducted, but it is time consuming, expensive, and cognitively demanding (Iskender et al., 2021;Lin, 2004) and can also be inconsistent, with some work showing inter-annotator discrepancy (Kryscinski et al., 2019). The challenge of conducting human evaluation is even more prominent in work in multiple languages, particularly less-resourced languages, where human judges may be difficult to recruit.
For experiments, we use LR-Sum (Palen-Michel and Lignos, 2023) and XL-Sum (Hasan et al., 2021). LR-Sum contains summarization data for 40 languages, many of which are also less-resourced. LR-Sum is built using the description field from the Multilingual Open Text corpus (Palen-Michel et al., 2022) and is similar in approach and content to XL-Sum (Hasan et al., 2021), which contains BBC news articles in 44 languages. For this study, we focused on a small set of languages from LR-Sum and XL-Sum which had the fewest number of examples in the corpus, while also choosing languages for linguistic diversity. The goal was to select a relatively diverse set of less-resourced languages.
As seen in Table 15 in Appendix H, many of the languages we work with have fewer than 1,000 summarization examples, which presents a challenge for neural abstractive summarization systems, which typically require large amounts of training data. With the exception of Burmese and Pashto, the languages we worked with did not have overlap between XL-Sum and LR-Sum. While there is little summarization training data for these languages, there is unlabeled text data available in Wikipedia. However, many Wikipedia articles for less-resourced languages are quite short in length.
We used Segment Any Text (Frohmann et al., 2024) to perform sentence segmentation of the Wikipedia articles to filter out documents which have fewer than 5 sentences. Wikipedia articles that have fewer than 5 sentences tend to be incomplete, lists, or definitions, and do not appear to be useful as additional summarization data. After filtering out Wikipedia articles shorter than five sentences long, for many of the languages there is substantially less data available than may appear in raw counts of Wikipedia articles. Specifically, Khmer surprisingly has nearly the same amount of training examples available in LR-Sum as there are suitable Wikipedia articles.
We explore three approaches for using Wikipedia articles as extra synthetic training data for summarization. The summarization task can be considered document and summary pairs, ⟨D, S⟩, where documents consist of sentences and summaries consist of sentences D = {d 1 , d 2 , d 3 …} , S = {s 1 , s 2 , s 3 …}. Generating augmented data then consists of creating novel D ′ and/or S ′ as additional training pairs. In this case we apply the augmentation strategies to Wikipedia, which does not have existing summaries. Portions of example summaries and documents created from each strategy are shown in Table 10 in Appendix E.
The approach to creating these extra synthetic training documents is shown in Figure 1. We train a baseline multilingual sequence-to-sequence abstractive model using mT5 (Xue et al., 2021). For experiments, we do this on a per-language basis and also in a multilingual way with upsampling to ensure a balance of different languages is seen.
We use the same set of hyperparameters across all experiments. All models used mT5-base as the underlying pre-trained model. All models were trained for 3 epochs with 100 warmup steps. We used a label smoothing factor of 0.1, a beam size of 4, weight decay of 0.01, a max target length 512, max source length of 1024, an effective batch size of 32 and a learning rate of 5e-4. Hyperparameters were chosen largely following those suggested in XL-Sum (Hasan et al., 2021) Extractive-Training For augmented data, first we use the LexRank (Erkan and Radev, 2004) extractive summarization algorithm as implemented in the lexrank python package3 to create summaries. We chose LexRank since it was reported as the highest performing extractive method by Palen-Michel and Lignos (2023). LexRank was set to select two sentences since most of the newswire summaries in LR-Sum and XL-Sum are roughly two sentences long. We then directly use these extracted summaries as target summaries alongside the original Wikipedia text. The extractive summary is composed of sentences chosen from the document so the new example is ⟨D, S ′ ⟩ where S ′ = {d n , d m }.
Second, after fine-tuning a multilingual abstractive sequence-to-sequence model using mT5 as the underlying model, we use it to generate summaries on Wikipedia articles. These generated summaries and the original Wikipedia text are used for the self-training experiment. Again the summary is new ⟨D, S ′ ⟩ but here the sentences are model generated S ′ = {x 1 , x 2 , …}.
Third, we train a model that when given a summary generates the article associated with the summary. We apply this backsummarization model to the LexRank extracted summaries of Wikipedia articles, S ′ = {d n , d m }, to get a generated document D ′ = {y 1 , y 2 , …} and use the extracted summary as the summary. For Back-Summarization, the summary and document are both automatically generated, ⟨D ′ , S ′ ⟩.
Individual Models with Augmented Data For each of the three data augmentation approaches, we train on a concatenation of the original training dataset with up to 6k of the synthetic training examples. We refer to this as “individual” because models are trained on individual languages (i.e. they are not multilingual models). We choose to use only a subset of available Wikipedia articles in part to have a better balance of synthetic data and real data and also in part for faster experiments due to resource constraints. For individual model experiments, we focus on just the smallest 7 languages from LR-Sum: Sorani Kurdish (ckb), Haitian Creole (hat), Armenian (hye), Georgian (kat), Khmer (khm), Kurmanji Kurdish (kmr), and Macedonian (mkd).
We fine-tune three versions of mT5 for each of the data augmentation approaches with a combination of all the XL-Sum and LR-Sum training data with the addition of the augmented data. When training the multilingual model, upsampling is done by language. This increases the diversity of the examples seen during training for less-resourced languages, but not their frequency. We focus on 18 languages for multilingual model experiments which represent the smaller languages of LR-Sum and XL-Sum.
Smaller LLMs We run inference with a set of comparatively smaller LLMs, Mixtral 8x7b (Jiang et al., 2024), Llama 3 (8B) (Dubey et al., 2024), and Aya-101 (12.9B) (Üstün et al., 2024). We use Ollama for inference for Mixtral and Llama 3.
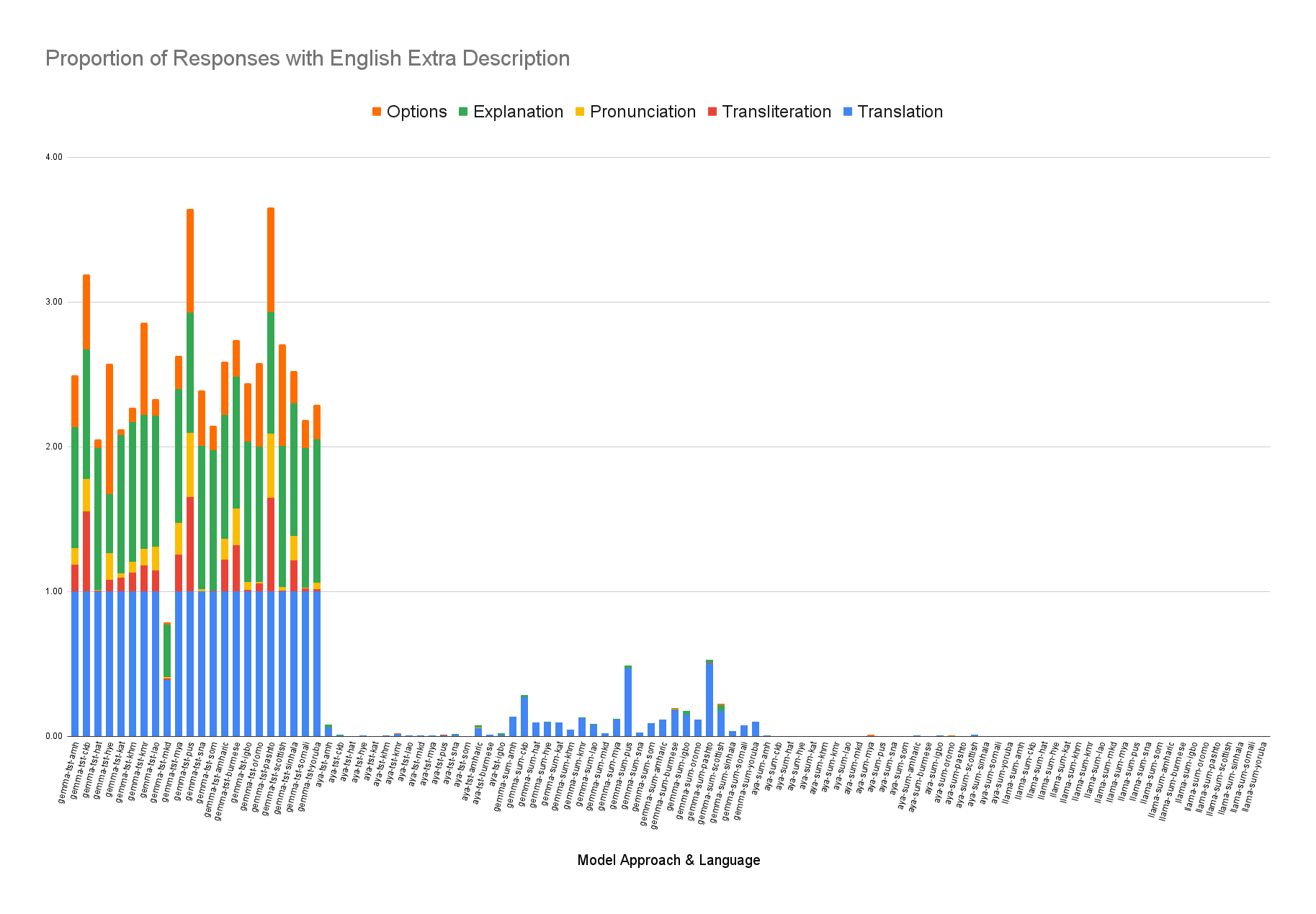
Since Aya-101 was not supported by Ollama we used Hugging Face Transformers (Wolf et al., 2020) and BitsAndBytes 4 to load it in 8-bit quantization. 5 We set no_repeat_ngrams to 3, truncation to True, and max_length to 256. Prompts are described in the Appendix D. Because we found that the LLMs generated a significant amount of English, we use CLD3 (Salcianu et al., 2016) to detect what the mean proportion of summaries generated by LLMs are English. We checked with CLD3’s performance with random unicode characters to ensure it did not misclassify unfamiliar characters as English.
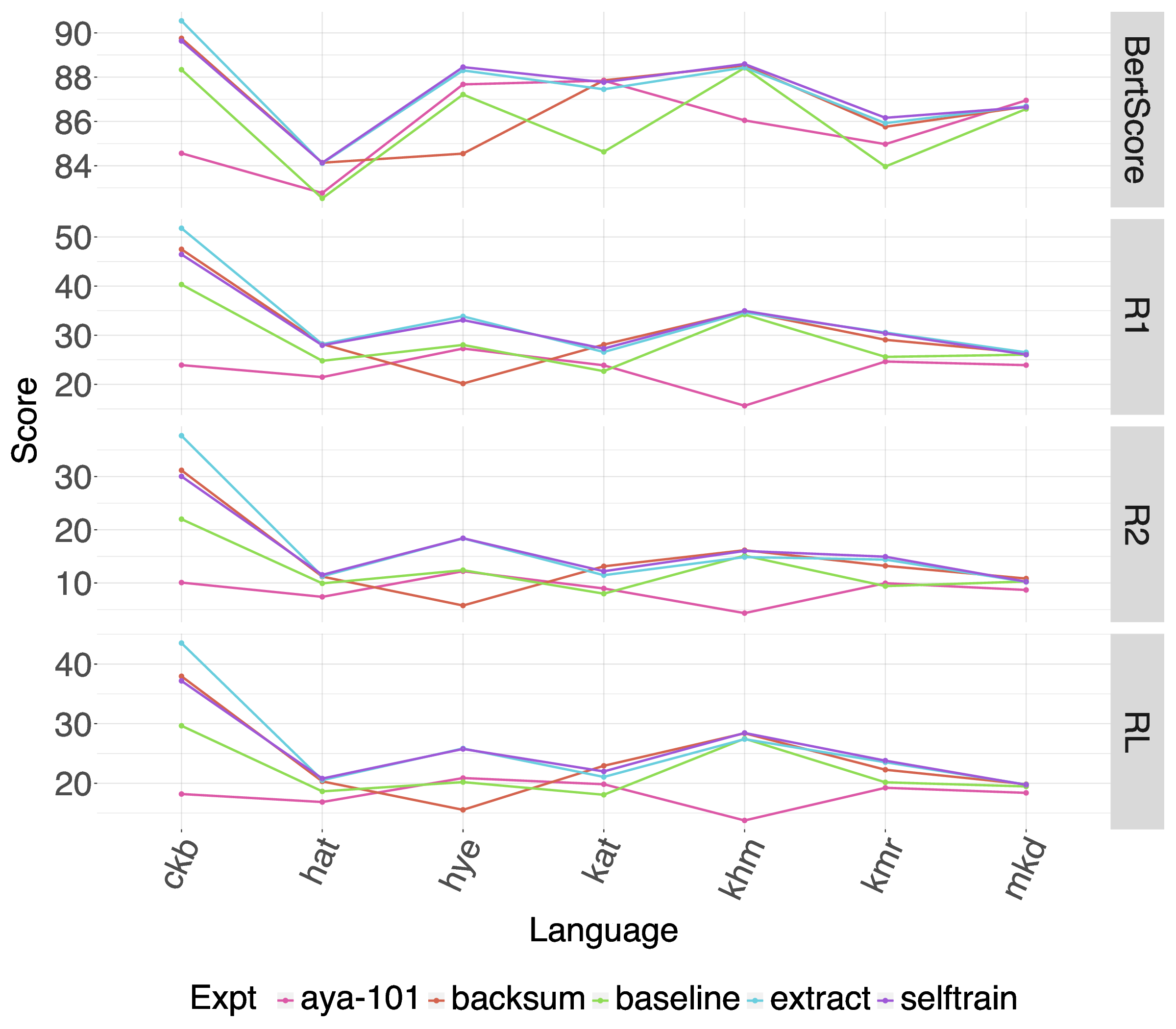
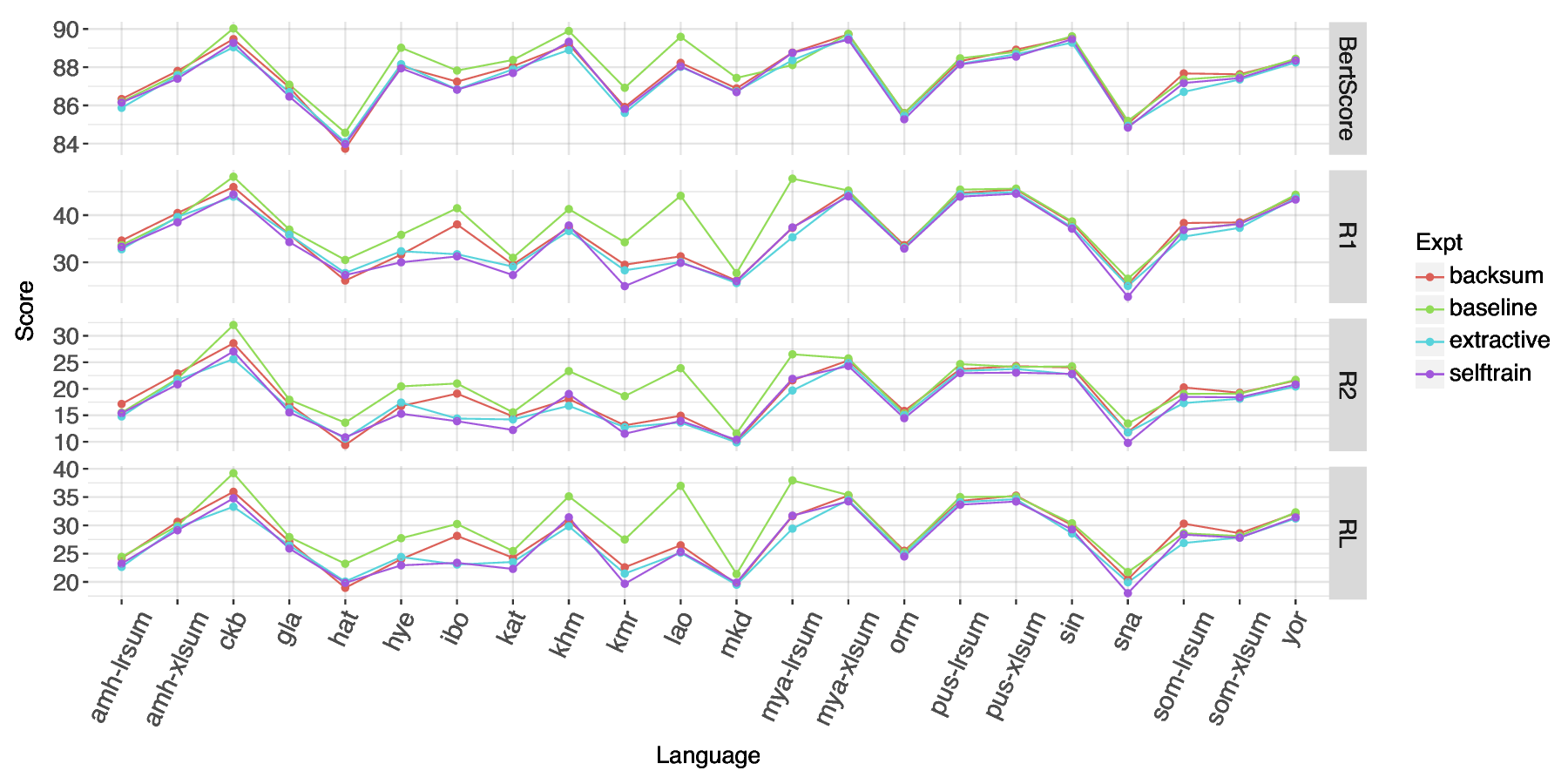
As shown in Figure 2,6 and in more detail in Appendix A Table 5, all languages have higher ROUGE scores with the inclusion of additional synthetic training data than fine-tuning mT5 with just the training data of an individual language. Sorani Kurdish (ckb), Kurmanji Kurdish (kmr), and Armenian (hye) in particular have the most substantial increases in ROUGE scores from the baseline. Armenian using the backsum approach is the only language that has a worse score when using augmented data.
Of the different strategies for making use of the additional Wikipedia articles, none stands out as being particularly stronger than the others across all languages. Self-training seems to have better scores for ROUGE-2 and ROUGE-L when it outperforms the other methods, but the difference tends to be small with the exception of Kurmanji Kurdish. Khmer (khm) had the smallest amount of augmented data since the Khmer Wikipedia articles were quite small and had a relatively small increase in scores.
Although augmented training of individual models performs better than training individual models without augmented data, the scores of individual models are still lower than multilingual fine-tuning of mT5 with a combination of all LR-Sum and XL-Sum training data as seen in 6 in Appendix A do not demonstrate a clear improvement over the baseline. For Amharic, Sorani, Georgian, Pashto, and Somali, the Back-Summarization approach performs somewhat better. Self-training tends to have the same or lower ROUGE Scores for all languages and test set varieties tested. Compared to the best performing LLM with prompting, both the multilingual fine-tuning of mT5 with and without augmentation have higher scores.
Smaller LLMs Despite impressive summarization capabilities of LLMs as discussed in Zhang et al. (2024), the LLM models we explored here performed underwhelmingly. As seen in Table 2, Mixtral performed the worst while Llama3 tended to perform somewhat better than Mixtral, and Aya-101 performed best of the LLMs examined. 7 We observe that Mixtral and Llama3 tend to produce a decent amount of English. The proportion of English appears to be highest when the target language has a non-Roman script. For example, Amharic, Georgian, Khmer, Lao, and Burmese all produce English with mean proportions over 30%.
We manually reviewed the responses of LLMs when they generated English output despite being given non-English articles and being prompted to respond in the target language. Sometimes the English response is an apology message explaining that it cannot perform the task; other times it is a plausible English summary of the target article. In some cases the model asks to see the text despite having already been shown the text, and sometimes the model begins in the target language but eventually switches to English.
This work was developed over years by a research group with relatively limited computational resources. During development of this work, we gained access to GPUs with more memory, new LLMs were released, and better LLM as judge approaches were developed. These factors led us to perform an additional set of experiments that builds upon the results in the previous section but explores using larger LLMs and using LLMs in additional ways, namely for evaluation and for a translate-summarize-translate pipeline.8 So now, having compared mT5 fine-tuning methods with smaller LLMs and finding the multilingual baseline mT5 model and Aya-101 with highest ROUGE and BERTScores, we turn to using larger LLMs and evaluating with M-Prometheus.
Larger LLMs We additionally run inference using 3 moderately sized LLMs, Gemma-3 27B (Team, 2025), Aya-Expanse 32B (Dang et al., 2024), and Llama 3.3 70B. For these runs we use VLLM for inference. The prompts we used request that the model generate a summary in two sentences. Two sentences of summary was requested to be similar to the reference summaries for the datasets used given that most of the reference summaries are roughly two sentences long. The specific prompts used are detailed in Appendix D.
We experiment with a pipeline approach to generating summaries in less-resourced languages where an LLM is first prompted to translate the article into English, and then summarize in two sentences the English-translated article. Finally, the model is prompted to translate back to the target language. We run experiments using Gemma-3 27B and Aya-Expanse 32B since these two LLMs had better performance than Llama 3.3 when doing simple summarization prompts. The specific prompts used are detailed in Appendix D.
Larger LLMs When comparing relatively larger LLMs of similar sizes, shown in Table 3, Aya-Expanse and Llama 3.3 tend to outperform Gemma, but neither completely outperforms the other for all Table 2: LLM performance across languages measured in Rouge-L and BERTScore along with the percentage of generated summary containing English found by language id. All results are a a mean of 500 bootstrap samples with standard error reported.
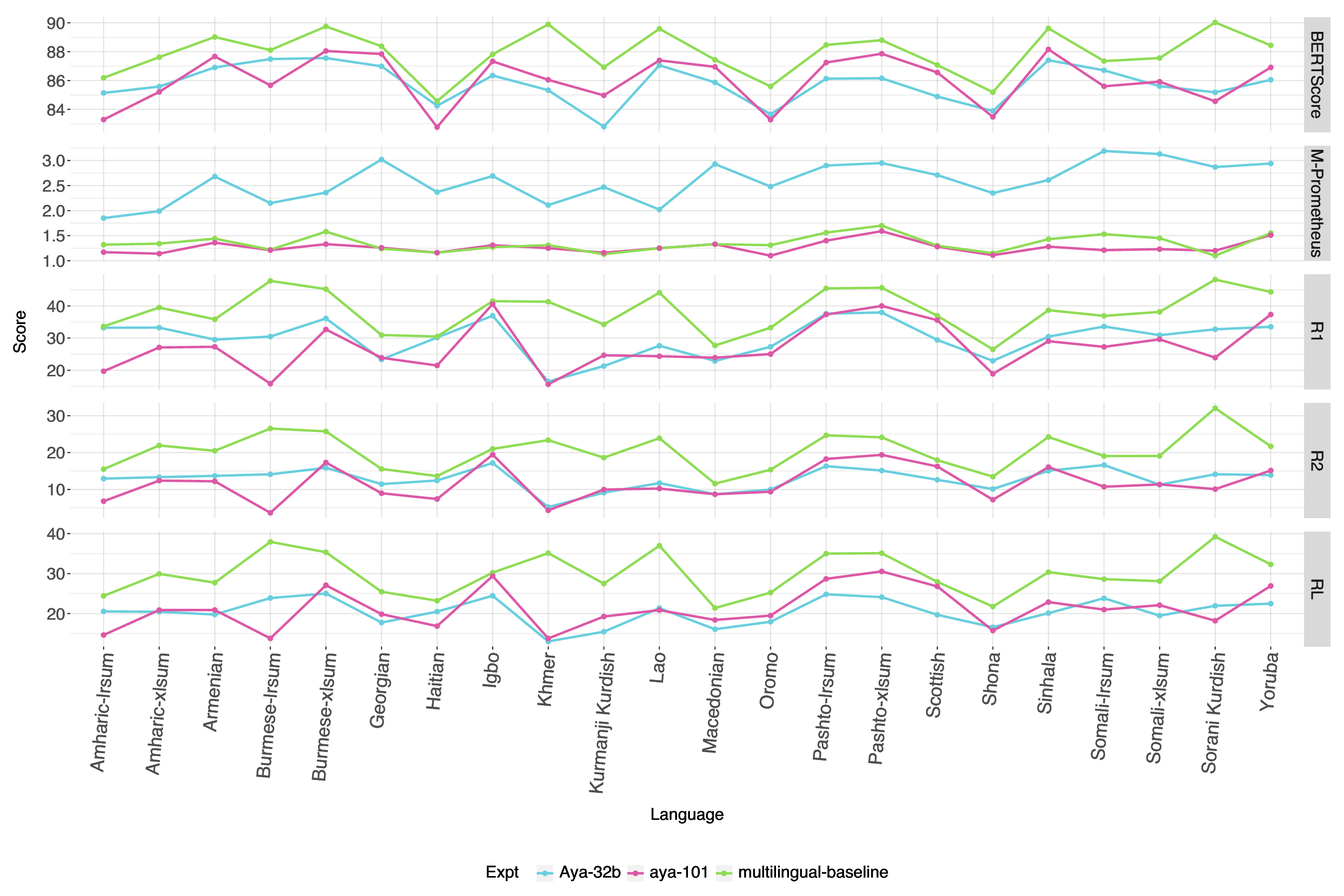
languages. All smaller LLMs performed worse than larger LLMs with the exception of Llama 3’s performance on Sorani Kurdish and Aya-101, which has better performance in some languages than larger LLMs. We see in Figure 4 that Aya-Expanse tends to have scores below the multilingual finetuned mT5 baseline model, with the exception of M-Prometheus scores which tend to favor Aya-Expanse 32b. Aya-101 and Aya-Expanse are comparable in most cases, but it varies based on metric and language.
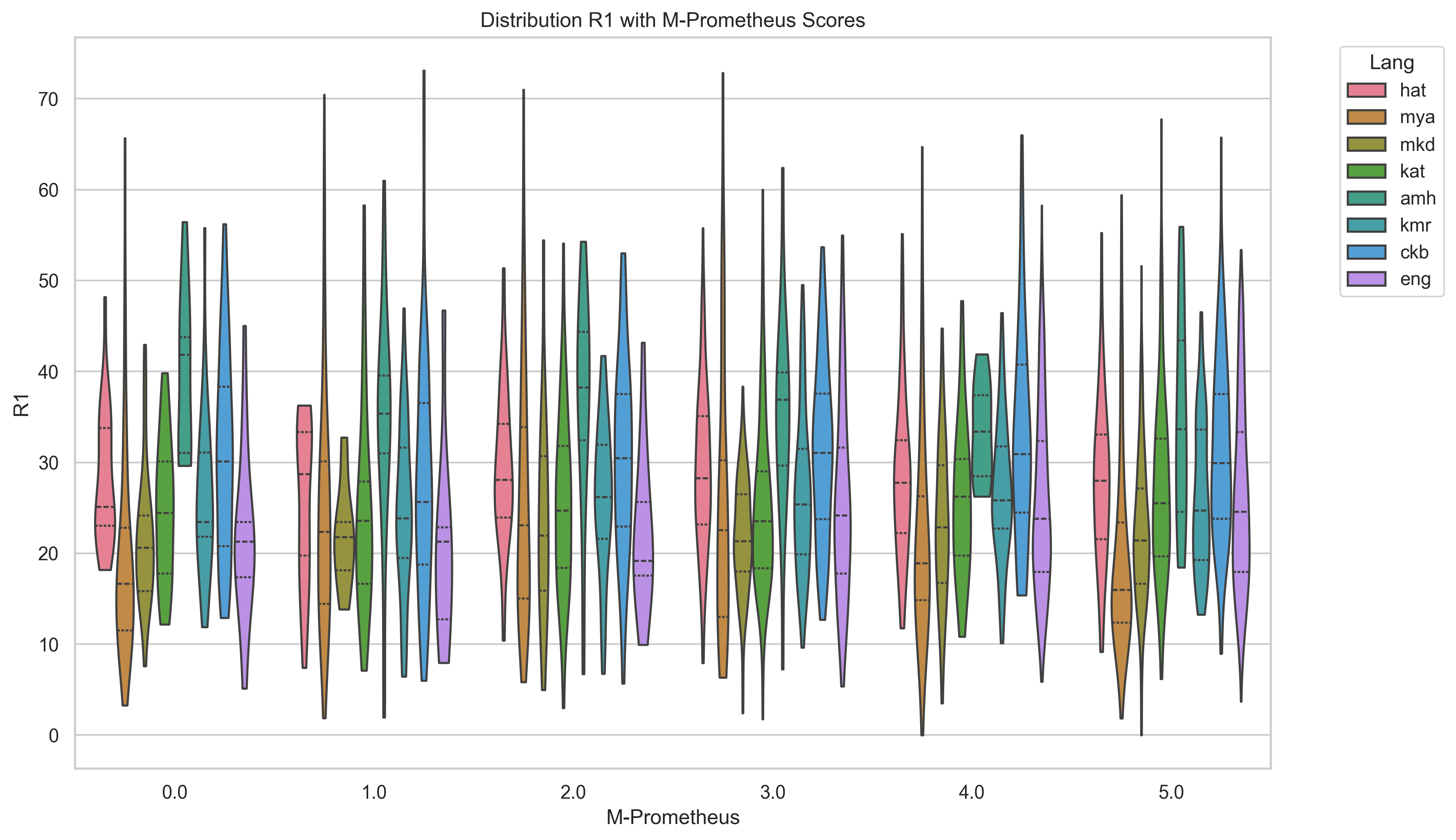
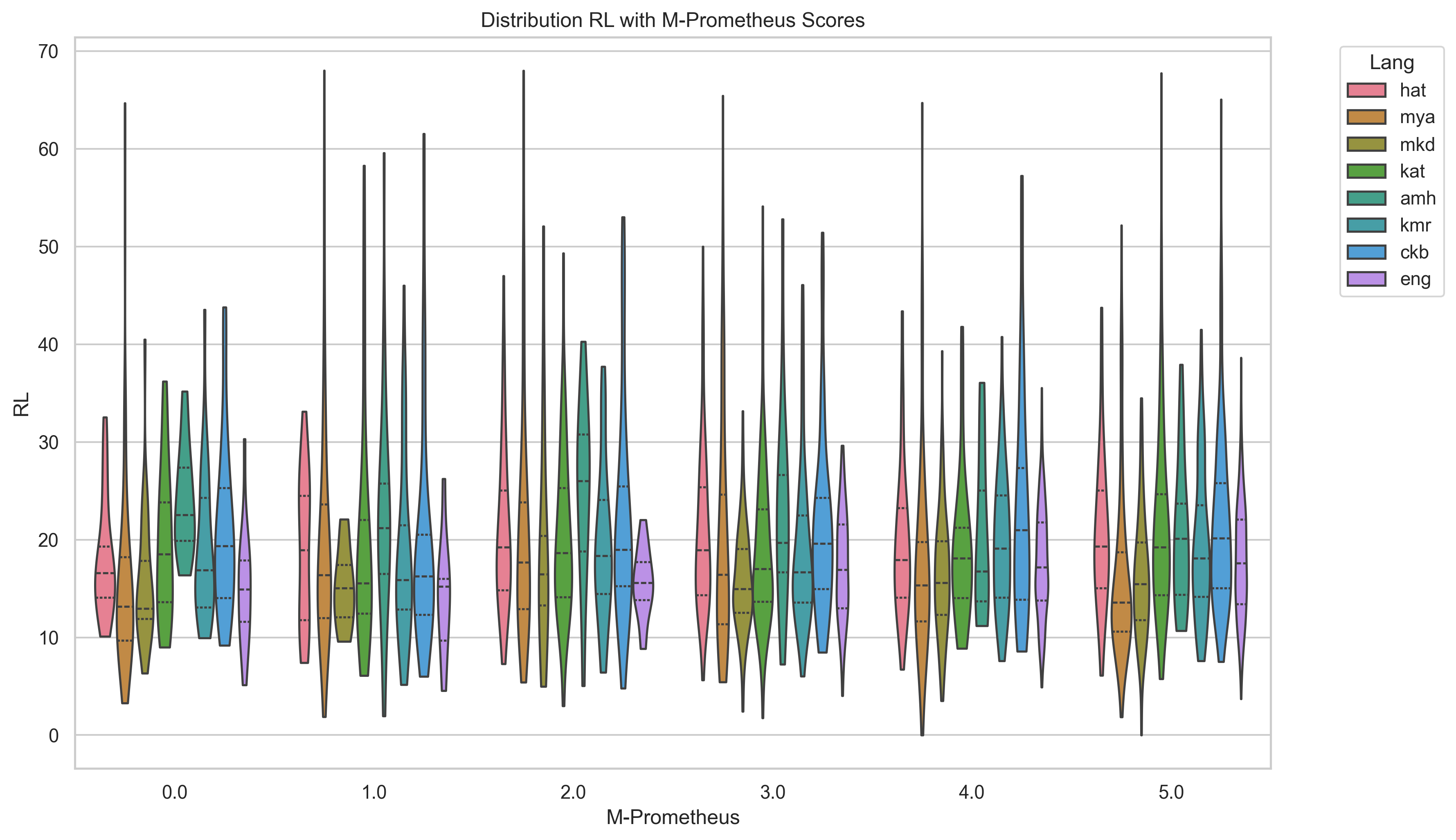
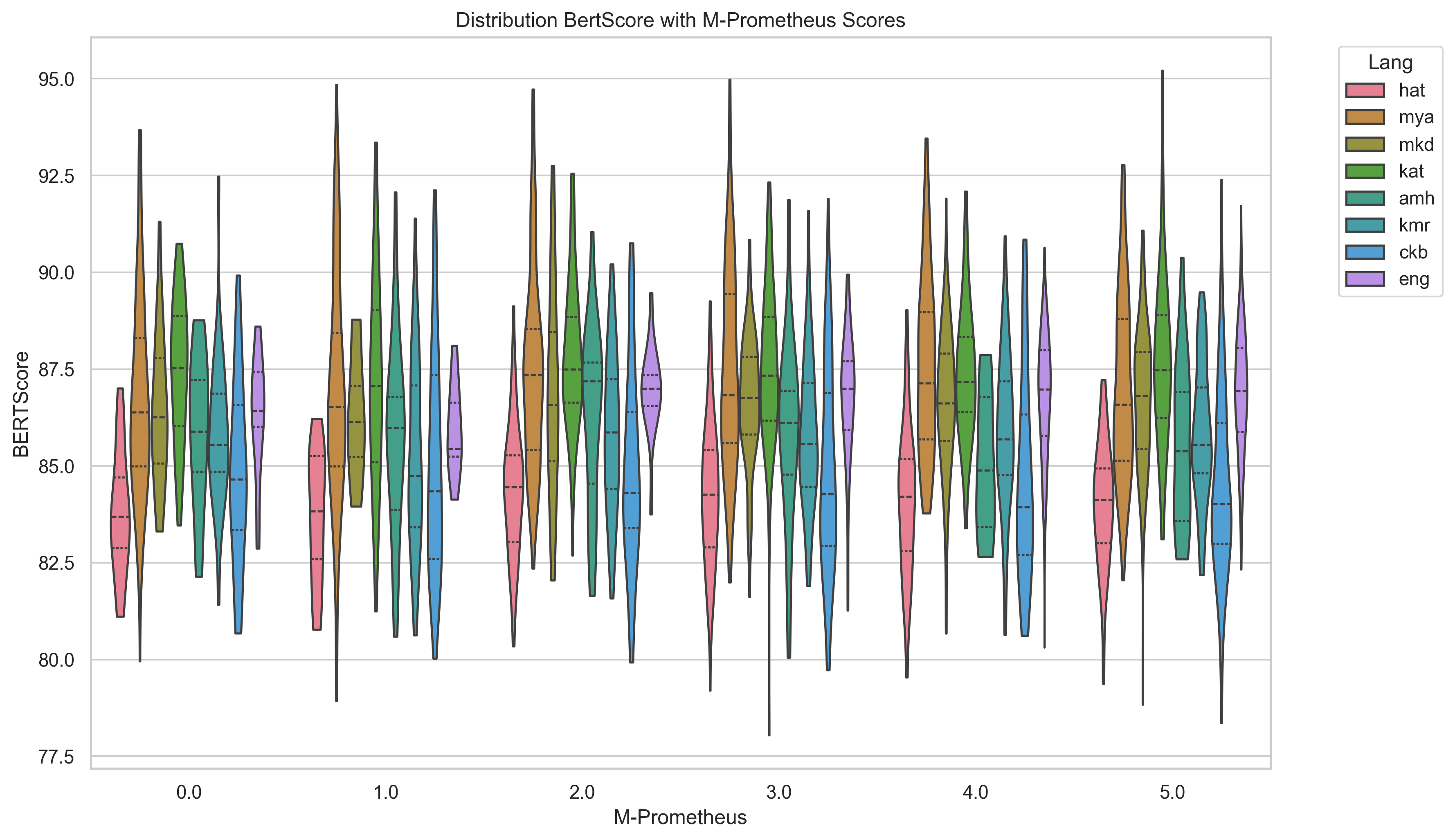
Translate-Summarize-Translate (TST) Overall, the TST pipeline results (Table 4) demonstrated worse performance across all metrics than the highest performing simple zero-shot prompting.9 By examining the output, we observed that although smaller LLMs often produced output which was entirely an English response, larger LLMs sometimes produced additional English commentary in addition to a summary in the target language. We postprocessed the LLM output to include only the target summary by filtering out extra English commentary using a combination of pattern matching and language ID. This English commentary is broken down into categories in Appendix A Figure 5. Gemma produced the most additional commentary, nearly always mentioning a translation when using the TST approach and sometimes providing a translation in the simple summarization prompt approach. Languages like Pashto, Sorani Kurdish, and Amharic show higher rates of the LLM provid-ing unprompted transliteration and pronunciation. The criteria and prompts provided for evaluation are described in the Appendix Section D.2. We find M-Prometheus scores favor larger LLM output such as that of Aya-Expanse 32b (as seen in Figure 4). We examined the distribution of summaries’ ROUGE-L scores from Llama 3.3, comparing M-Prometheus with BERTScore and ROUGE-1. We show the distribution of summaries’ ROUGE-L scores from Llama 3.3 compared with M-Prometheus scores in Figure 6, and BERT Score and ROUGE 1 in Appendix G, Figures 7 and8.
We observed that M-Prometheus scores generally do not appear to increase with other scoring metrics and that there is a larger variance for less-resourced languages, while M-Prometheus scores on English summaries appear to have a better alignment with reference-based metrics and less variance. This suggests that M-Prometheus may be more reliable at evaluating on higher-resource than less-resourced languages. There is some slight pattern of increase between M-Prometheus scores 1-3, but the distribution of other scoring metrics appears to be slightly lower generally for M-Prometheus scores of 4 and 5.
Which approaches work best overall for summarization in less-resourced languages? The TST pipeline approach did not outperform zero-shot LLM prompting. We compare the best zero-shot LLM of smaller models, larger models with the best performing fine-tuning of mT5 in Figure 4. Multilingual T5 without augmentation out-performed LLMs for all metrics except M-Prometheus.
How well do different metrics measure summarization performance? While our aim is not to conduct a comprehensive assessment of summarization metrics, we do observe some differences in metrics. BERTScore, RL, and R1 can show some nuances in performance when comparing languages, but general trends appear to be mostly consistent across these metrics. Meanwhile, reference free LLM eval with M-Prometheus tends to favor larger LLM model output. It is possible that M-Prometheus is better equipped to evaluate nuances in summarization that reference-based summarization miss. However, it appears M-Prometheus, being largely trained on six languages and evaluated on a set of roughly 30 higher-resourced languages, has a bias towards larger LLMs trained similarly on mostly higher-resourced languages and we found evidence it may be less reliable in measuring lessresourced languages.
Which LLMs output the most English and what kind of English output is it? Smaller LLMs tend to have English responses that refuse to complete the task or summarize in English. Of the smaller models, Aya-101 avoids English responses best. We find that larger, more recent LLMs avoid this trend and instead add extra English text in their response. Gemma-3 tends to produce extra English comments the most of models examined and the type of comments varies some by language.
Single language or multilingual-fine-tuning with synthetic data? We find generally, that multilingual fine-tuning still works best with most languages we examined even when synthetic data is added. However there is evidence from Sorani Kurdish that scores that the best performing augmentation approach with individual language fine-tuning can outperform the multilingual fine-tuning baseline by a significant margin.
What augmentation approach works best? For individual models, we found that each data augmentation approach showed an increase in ROUGE scores over the baseline, but there was not one approach that proved to be definitely better than any other across languages. For multilingual models, back-summarization appeared to be the most competitive augmentation strategy, but the baseline without augmentation performed better for many languages.
We have compared a variety of different approaches to summarization with less-resourced languages. We found that one of the biggest challenges with LLMs is not outputting English, and found that LLMs, and other strategies including data augmentation and a translation pipeline still under-perform a fine-tuned mT5 multilingual baseline with more traditional reference-based metric. LLM judge M-Prometheus shows a preference for LLM generated summaries, and appears less reliable when evaluating less-resourced summaries.
Some LLMs in our experiments were loaded with quantization due to resource constraints, so is possible could have had higher performance if the nonquantized model could have been used. Marchisio et al. (2024) demonstrated that quantization can have more prominent impacts on human evaluation than automatic metrics and that not all languages are impacted equally with multilingual models. Unfortunately, we were resource constrained and could only make of the LLMs in a quantized setting.
An important limitation to this work is that the evaluation is done entirely with automated metrics. Limitations to summarization metrics are known and human evaluation is preferred. However, human evaluation can be expensive and especially difficult for less-resourced languages due to the added difficulty in recruitment of annotators and quality control with a team of speakers of a diverse set of languages. We have done our best to report reasonable evaluation metrics and release our model generated summaries for further evaluation in future work by speakers of these languages. We unfortunately did not have funding for the thousands of dollars required to perform a substantial human evaluation even for a subset of the languages we study in this work.
Our work is limited to claims about the particular models and datasets studied. While we examined multiple languages, data augmentation strategies, and LLMs, it is possible that the findings we observed here may not be the same as those on a different set of languages or different LLMs. However, we believe that our experiments and observations are still informative and of interest to the research community.
Like any text generation model, automatic summarization is based on statistical properties of language and is likely to sometimes generate statements that may be false. The models and approaches described in this work are primarily for research purposes and summaries generated by these models are only intended to be used to aid human creation of summaries and should be viewed with skepticism regarding their factual content. The datasets used in this work are free and openly available to the public. While we did not collaborate directly with speakers of the languages studied in this work, we make our model outputs publicly available and welcome collaborations with speakers of the languages studied in order to further investigate approaches to summarization in these languages.
We report ROUGE-1, ROUGE-2, ROUGE-L and BERTScore for experiments with individual models in Table 5 and multilingual models in Table 6. All results are mean results and include standard error which was computed using bootstrap sampling with 500 resamples (Tibshirani and Efron, 1993).
For the all experiments in this work we used the mT5 tokenizer to compute ROUGE scores. For computing novelty and length, we made use of some language specific tokenizers rather than rely on subword tokenization. For Haitian Creole, Georgian, Macedonian, and both varieties of Kurdish, we used utoken 10 . For Armenian, we used Stanza (Qi et al., 2020). and we used khmernltk (Hoang, 2020) for Khmer. The tokenizers used in this work matter both for caluculating ROUGE scores and for determining the mean novelty score. For non-latin scripts, using the rouge package in huggingface’s evaluate 11 can result in zero or near zero scores for non-latin script languages without explicitly supplying a tokenizer.
We conducted further analysis of generated summaries using bigrams to compute mean novelty and also include the mean length of summaries. We include them here due to space constraints in the paper. Table 9 shows the mean novelty scores for summaries computed using bigrams.
For LLM experiments we use the following prompts.
For Aya-101, we use “Write a summary for the following article in «LANGUAGE». \n «ARTICLE_TEXT»”, where «ARTICLE_TEXT» is replaced with the text of the article to be summarized and «LAN-GUAGE» is replaced with the desired language. For Mixtral and Llama3, we used:
“Write a summary for the following article in «LANGUAGE».
Write the summary in «LANGUAGE». Do not provide a translation or explain anything. Only provide the summary, do not provide any other information except for the summary in «LANGUAGE». Summarize this article:\n«ARTICLE_TEXT» “. glects to provide a summary or the summary is not in the intended language.”, “score2_description”: “The model provides a response but it is not a good summary. The response is factually inaccurate, not very informative, or not very fluent.”, “score3_description”: “The model provides a summary but it is lacking in some of the desired qualities of a good summary.”, “score4_description”: “The model provides a reasonable summary of the in-put text that includes most of the desired qualities of a good summary.”, “score5_description”: “The model provides an excellent summary that meets all of the requested criteria of a good summary.”
We show example augmentation data in
How extractive or abstractive are the multilingual fine-tuned MT5 summaries? While models trained on synthetic data have an advantage in ROUGE score over the baselines trained on only the human written summaries, it is possible that summaries produced by these models are still lacking in certain ways despite having higher scores. In particular, models trained on Extract-Train or Back-Sum data are trained on summaries generated from extractive models. One concern could be that these models only learn to copy material from the text rather than synthesizing a novel summary. We further probe this issue by computing mean novelty scores for each summary. This score is the percentage of tokens that do not appear in the article text.
We compute this novelty score using tokenizers described in Appendix B.
As seen in Table 13, the test set reference summaries have somewhat high novelty. Each individual model generally has lower mean novelty than the test set. We may have expected model trained on extractive summaries to be generally less novel than those trained on self-training; however this does not appear to be the case. This also shows a hint at why Armenian has low ROUGE scores for the back-sum approach. With such a high mean novelty score, there is evidence the model is generating a larger number of irrelevant words.
We show the novelty scores for the multilingual models in Table 12. Similarly we see lower mean novelty from the multilingual models with augmented training data than the reference summaries.
We present additional evaluation figures here. Figure 6, Figure 7, and Figure 8 compare M-Prometheus scores with BERTScore and ROUGE scores.
Table 15 shows counts of documents for each dataset.
Llama 3 8b Instruct (Dubey et al., 2024) and Mixtral 8x7b (Jiang et al., 2024) are two open source LLMs which we use for benchmarking LLM performance in this work because of their reasonable performance on other benchmarks (Beeching et al., 2023;Fourrier et al., 2024) and ease of use for inference using Ollama.12 While Llama 3 and Mixtral perform reasonably on English, Aya-101 (Üstün et al., 2024) is an LLM trained on much more multilingual data. We use these three LLMs off-the-shelf with simple prompts to compare our fine-tuned mT5 experiments. For larger LLMs we use Gemma-3 27B (Team, 2025), Aya-Expanse 32B (Dang et al., 2024), and Llama 3.3 70B. These models have reported reasonable performance and claim multilingual coverage.
Mixtral I’m sorry, I’m having difficulty understanding the text you provided. It appears to be written in Lao language and contains some unusual characters. Could you please rephrase or translate the question into English so I can better understand and provide an accurate response?
Overall, Ambassador Goldberg’s visit to Luang Prabang reflects the U.S. government’s ongoing commitment to supporting sustainable development, cultural preservation, and consular services in Laos, while also fostering stronger bilateral relations between the two countries.
Llama3 I’d be happy to help you with that! However, I need the article text to write a summary in Lao.
Please provide the article text, and I’ll do my best to summarize it for you in Lao.
The Hua Seng Hung Company is one of the companies that have received an investment from the United States. This company has a lot of potential and it’s expected to grow rapidly.
The company is involved in many fields such as real estate, finance, and technology…
While conventionally line plots are not used when the x-axis is categorical, we provide a single line per method in addition to points to make cross-lingual trends easier to visualize.
Rouge-1 and Rouge-2 are included in Appendix A in Table7.
We separate this work into a different section, as these experiments were able to be run with more languages and with additional evaluation metrics.