Text-guided object segmentation requires both cross-modal reasoning and pixel grounding abilities. Most recent methods treat text-guided segmentation as one-shot grounding, where the model predicts pixel prompts in a single forward pass to drive an external segmentor, which limits verification, refocusing and refinement when initial localization is wrong. To address this limitation, we propose RSAgent, an agentic Multimodal Large Language Model (MLLM) which interleaves reasoning and action for segmentation via multi-turn tool invocations. RSAgent queries a segmentation toolbox, observes visual feedback, and revises its spatial hypothesis using historical observations to re-localize targets and iteratively refine masks. We further build a data pipeline to synthesize multi-turn reasoning segmentation trajectories, and train RSAgent with a two-stage framework: cold-start supervised finetuning followed by agentic reinforcement learning with fine-grained, task-specific rewards. Extensive experiments show that RSAgent achieves a zero-shot performance of 66.5% gIoU on Rea-sonSeg test, improving over Seg-Zero-7B by 9%, and reaches 81.5% cIoU on RefCOCOg, demonstrating state-of-the-art performance on both indomain and out-of-domain benchmarks.
Text-guided segmentation takes an image and a natural language description of the task object as input and returns a fine-grained segmentation mask, covering both referring expression segmentation (RES) (Kazemzadeh et al., 2014;Yu et al., 2016) and reasoning segmentation (Lai et al., 2024), where the input text may be explicit expressions or implicit reasoning queries. Unlike closed-set semantic segmentation, which is restricted to a predefined label space, this setting must generalize to open-vocabulary concepts and therefore requires tight coupling between linguistic understanding and visual localization. This formulation introduces several key challenges: (i) grounding the task object to the correct region under large appearance variation, (ii) performing compositional or relational reasoning across modalities, and (iii) translating high-level linguistic cues into precise pixel boundaries. These requirements make text-guided segmentation particularly attractive for interactive perception and embodied applications (e.g., robotics).
Multimodal Large Language Models (MLLMs) have become a central component in the latest paradigms for this task because of their integrated reasoning and multimodal perception abilities (Ren et al., 2024b;Bai et al., 2024;Rasheed et al., 2024;An et al., 2024;Wei et al., 2025;Xie et al., 2025;Wang et al., 2025a). Early attempts such as LISA (Lai et al., 2024), have explored the use of MLLMs to enhance reasoning segmentation capabilities via predefined semantic tokens (e.g., token), bridging the gap between MLLMs and segmentation models by supervised fine-tuning (SFT). Although SFT approaches can effectively inject MLLM reasoning into segmentation pipelines, they often face issues such as eroding general reasoning competence and weak robustness under distribution shifts. Reinforcement learning (RL) style approaches, meanwhile, optimize the model with reward signals for generating pixel prompts (e.g., boxes and points) and then feed them into Segment Anything Model (SAM) (Kirillov et al., 2023) to produce the final prediction. The reward design evolves from pixel prompt’s accuracy (Liu et al., 2025a) to the predicted mask’s IoU with ground truth (GT) mask (Huang et al., 2025b;You & Wu, 2025), which are effective in enhancing models’ reasoning ability. However, these RL structures face two major limitations: (i) single prompt generation and directly obtaining the final reward not only completely forgoes SAM’s inherent capability for iterative refinement, but also prevents the model from revisiting visual information it initially overlooked, particularly those seemingly irrelevant and ambiguous regions to initiate new segmentation attempts, and (ii) the reward function may over-emphasize coarse overlap or prompt-level accuracy, while providing limited supervision on reasoning process, which probably results in unexpected masks.
Therefore, to address these limitations, we present RSAgent, an agentic MLLM that performs interleaved cross-modal reasoning and action for segmentation. Specially, RSAgent reformulates text-guided segmentation as an interactive problem: as shown in Figure 2, given an image and a problem, the MLLM does not output mask tokens, nor rely on single-pass prompting, but instead produces coherent textual reasoning and decides tool actions to query an external segmentation toolbox, receiving visual feedback after each turn and using it for visual reflection. This iterative loop allows RSAgent to re-localize when early spatial hypotheses are wrong or refine the mask according to visual reflection. To make such agentic behavior learnable, we first introduce a data pipeline to generate high quality multi-turn reasoning segmentation trajectories. Then we construct a high quality dataset including 5K complete reasoning trajectories for cold-start SFT and 2K image-problem pairs as part of RL training dataset. Further we develop a two-stage training framework: a cold-start SFT phase that utilizes constructed multi-turn tool trajectories, followed by RL that optimizes long-horizon decisions with rewards that revisit while encouraging continuous mask improvement. As shown in Figure 1, RSAgent achieves state-of-the-art performance on both RES and ReasonSeg benchmarks, demonstrating that our approach is a stronger and more robust pathway for text-guided segmentation.
Our contributions can be listed as follows:
• We propose RSAgent, a novel agentic framework which enables the MLLM to query a segmentation toolbox, observe visual feedback, and revise its spatial hypothesis using historical observations to re-localize targets and iteratively refine masks.
• We present a multi-turn reasoning trajectory generation pipeline, which helps to build the dataset for training. What’s more, to enhance the agent’s cross-modal reasoning ability, we introduce a two-stage training strategy: cold-start SFT and RL with fine-grained rewards.
Reasoning in Large Language Models. Recent LLMs have exhibited strong gains in deliberate reasoning: scaling inference time computation can reliably improve performance on challenging problems (OpenAI, 2024), and process-aware supervision or verification further strengthens step-by-step solution quality (Uesato et al., 2022;Lightman et al., 2024;Wang et al., 2024). Beyond purely text-only reasoning, reason-and-act paradigms such as ReAct (Yao et al., 2023) interleave natural language rationales with actions, enabling models to revise intermediate hypotheses using external observations rather than relying solely on token histories. RL based post-training can further amplify these behaviors: DeepSeek-R1 (Guo et al., 2025) demonstrates that RL can incentivize long-form reasoning patterns including self-reflection and verification. However, most prior work primarily targets high-level correctness and coarse-grained multimodal understanding (Wang et al., 2025b;Hong et al., 2025), leaving dense, pixel-level reasoning tasks such as segmentation relatively underexplored. In contrast, RSAgent extends the “reason-and-act” paradigm to segmentation: it preserves coherent textual reasoning while interacting with a decoupled segmentation toolbox, enabling visual reflection for iterative re-localization and refinement.
MLLMs for Text-Guided Segmentation. Recent studies endow MLLMs with pixel-level segmentation capability from natural language prompts, typically by augmenting an MLLM with a mask generation module, e.g., a promptable segmentor such as SAM or a lightweight mask decoder.
Early token-based approaches introduce special segmentation tokens (e.g., ) and an embedding-as-mask interface that maps language-model representations to dense masks (Lai et al., 2024;Bai et al., 2024;An et al., 2024;Wang et al., 2025a). Building on this line, MLLM-centric systems further move toward unified pixel grounding under conversational and multi-target settings, such as PixelLM (Ren et al., 2024b) and GLaMM (Rasheed et al., 2024). GSVA (Xia et al., 2024) extends referring segmentation to the generalized setting by supporting multiple targets and explicitly rejecting empty referents. Complementary to SFT style training, several recent methods emphasize RL for learning a decoupled policy that outputs spatial prompts to guide an external segmentor: Seg-Zero (Liu et al., 2025a) produces position prompts with RL, SAM-R1 (Huang et al., 2025b) leverages mask reward feedback for fine-grained alignment, and VisionReasoner (Liu et al., 2025b) unifies multiple perception tasks in an RL-based framework. Besides, POPEN (Zhu et al., 2025) explores preference-based optimization and ensembling to improve segmentation quality and reduce hallucinations.
In this section, we present RSAgent, the data pipeline and the training strategies that enable effective multi-turn tool invocations for text-guided segmentation. We first formulate text-guided segmentation as an episodic decision making problem in pixel space (Section 3.1). Then we provide an overview of RSAgent (Section 3.2). Next, we describe our data pipeline and cold-start SFT that bootstrap tool-use behaviors and align the base model to the interactive setting (Section 3.3). Finally, we introduce the RL stage (Section 3.4), which further improves multi-round refinement and encourages efficient tool invocation.
Unlike prior approaches that predict a mask in a single forward pass of the model (Liu et al., 2025a;You & Wu, 2025), we cast text-guided segmentation as an episodic decision making problem in pixel space. As illustrated in Figure 3, the agent interacts with an external visual toolbox over multiple rounds, incrementally gathers visual evidence, refines candidate masks, and eventually commits to a final prediction. Formally, each example consists of an image I, a natural language problem Q which could be either an explicit referring expression or a complex description, and, during training only, a GT mask M gt .
Agent tool interaction. We formalize RSAgent as a vision-language policy π θ operating in a finite-horizon Markov Decision Process (MDP). At step t, the agent receives an observation
, where V t denotes the set of visual views available to the agent (including the original image and a history pool of overlays summarizing previous observations), and C t is the text context composed of the system prompt, the user prompts, and the accumulated assistant’s feedback up to step t. For notational convenience, we write the reasoning trajectory up to step T as:
where r t denotes the model’s intermediate reasoning tokens, a t denotes a set of parameterized tool calls and o t means the observation of this turn, which is concated to O t . In the whole P 1:T , RSAgent alternates between textual reasoning, tool usage, and inspection of updated visual context, gradually refining its belief about the target object before committing to a final mask prediction.
Action space and tools. Conditioned on O t-1 , the policy π θ generates an interleaved sequence of reasoning and action tokens, which may contain (i) updated reasoning r t together with one or more structured tool invocations a t , or (ii) a terminating answer of spatial prompts describing the final segmentation. The tools exposed to the agent form a compact but expressive action space: (i) view-manipulation operations that zoom in or rotate the image to adjust the field of view, and (ii) the major and frequently used segmentation operation that receives spatial prompts into candidate masks via a frozen SAM2 (Ravi et al., 2025). The episode terminates when the agent emits a dedicated answer or when a maximum interaction budget is reached.
Problem-centric data collection. To synthesize the multi-turn reasoning trajectories, constructing the textual promblems for images is the primary task. We first collect image-mask pairs (I, M gt ) and associated annotations from SA-1B dataset (Kirillov et al., 2023). Then we construct a natural language problem Q describing the target object. Concretely, we employ strong proprietary vision-language models (practically, we used Gemini2.5-Pro (Google, 2025) and OpenAI-o3 (OpenAI, 2025)) to generate problems in the style of reasoning segmentation according to (I, M gt ).
The details are provided in Appendix. B.
Multi-turn tool interaction for trajectory synthesis. After problem generation, we synthesize full multi-round trajectories with the seed pair (I, Q) by letting a model with the ability of pixel understanding interact with the same tool environment as RSAgent and generate multi-turn interleaved reasoning trajectories. Concretely, we place Qwen2.5-VL-72B-Instruct (Bai et al., 2025) in our visual tool environment, which exposes the view manipulation and segmentation tools described in Section 3.2. The resulting interaction yields a full pixel-space reasoning trajectory with multi-turn tool calls and corresponding visual states. The overall pipeline is illustrated in Figure 4.
Trajectory filtering. To ensure that the synthetic trajectories provide reliable supervision, we select the cold-start data with two hard principles: (i) the IoU of the final predicted mask and M gt can’t be lower than 0.9, and (ii) the number of reasoning turns should not surpass 8. The former principle not only validates the accuracy of the problem, but also demonstrates the multi-turn interleaved reasoning process’s correctness. For the latter, although some trajectory’s final answer is correct, the actual reasoning process may be unreliable due to overly long context, compounding errors or hallucinated rationales.
In addition to the high quality trajectories selected under the above criteria, we also filter a supplemental set of trajectories that exhibit a modest number of tool invocations and a low final mask IoU, for which a correct mask is produced by segmentation tool at some intermediate reasoning step.
After manually verifying the correctness of the corresponding problem Q, we revise the terminal supervision to align with this correct intermediate mask and discard the most misleading portions of the erroneous reasoning trace, and then add these curated trajectories to our dataset.
Cold-start SFT. Through our data pipeline, we obtain a dataset D sft of approximately 5K examples, each containing both coherent reasoning trajectories and corrective
This objective teaches the model to produce effective trajectories with robust step-by-step reasoning patterns, thereby endowing RSAgent with stronger pixel-level reasoning and self-correction capabilities and providing a solid foundation for subsequent RL.
We further optimize RSAgent with RL under a carefully designed reward scheme, enabling the agent to adaptively discover effective tool-use strategies for courageous attempt and iterative mask refinement.
The essence of RL training is to let the policy learn how to select actions that yield higher returns through interaction with the environment. Consequently, unlike the cold-start SFT stage, the RL dataset does not need to contain pregenerated multi-round trajectories: it is sufficient to provide the policy with the image I and its associated problem Q as input, together with the GT mask M gt used solely for reward computation.
We construct approximately 2K RL examples using the same data curation procedure as in Section 3.3, and additionally sample 8K instances from the RefCOCOg training split to form the overall RL dataset D rl .
Unlike prior approaches (Liu et al., 2025a;Huang et al., 2025b) that rely solely on outcome-based rewards for models that predict a segmentation mask in a single forward pass, we introduce a fine-grained reward design that jointly accounts for both the final result and the intermediate decision process, enabling the policy to acquire more efficient and effective decision strategies. Specifically, our reward function consists of the following components:
• Final-answer reward R final : encourages high quality final masks via both mask IoU and bounding box IoU with the GT.
• Format reward R format : rewards syntactically valid, schema-compliant and blocks, penalizes unparsable outputs and invalid tool invocations.
• Process reward R process : step-wise shaping based on IoU improvement, including the best-so-far IoU in the reasoning process, tool-dependent call costs, and pointlevel sparsity or novelty for segmentation prompts.
The unified reward function is formulated as:
where α, β, γ controls the relative strength of dense shaping versus outcome quality. The details of each reward are provided in Appendix C.
Based on the rollout formulation in Section 3.2 and rewards defined above, we optimize the policy with Group Relative Policy Optimization (GRPO) (Shao et al., 2024) (without an explicit KL penalty term (Hu et al., 2025) as commonly used in RLHF) on dataset D rl . Let y i,1:Ti denote the concatenation of all non-observation tokens (reasoning tokens and tool-call tokens) generated in rollout P i . The GRPO objective is:
where ρ i,n denotes the importance ratio:
Here, G is the number of sampled rollout paths; T i is the number of non-observation tokens in P i ; and S i is the trajectory-level return computed from our reward. We compute a group-relative advantage A i by normalizing returns within each rollout group:
where δ is a small constant for numerical stability. Through carefully designed RL training, the agent becomes capable of interpreting target descriptions and performing pixel-level reasoning via iterative tool invocations, thereby accurately segmenting the object in the image that best matches the textual problem.
4.1. Experimental Settings.
Implementation Details. We implement our RSAgent based on Qwen2.5-VL-7B-Instruct (Bai et al., 2025). SAM2-large (Ravi et al., 2025) is used as the segmentation tool. In cold-start SFT stage, we optimize the model with a learning rate of 2 × 10 -5 for 2 epochs and the batch size is 128. After the SFT stage, we implement the RL optimization on VERL (Sheng et al., 2025) demonstrating that explicit multi-round reasoning with a carefully designed toolbox and reward is highly effective for focusing on ambiguous regions before committing to a final mask. What’s more, RSAgent-single’s performance also outperforms the previous CoT guided single-pass segmentation models, which suggest that our method indeed enhanced the model’s reasoning ability. Although SAM3 Agent drives SAM3 model to achieve strong performance on ReasonSeg through training-free multi-round tool invocations, RSAgent, equipped with efficient SFT and RL, can likewise operate in a multi-round tool-calling regime to control a SAM2-based toolbox and attain comparable, or even superior, evaluation results despite relying on the comparatively weaker SAM2 backbone, which reflects more holistic segmentation quality across objects and scenes.
Qualitative Analysis. Combining the above quantitative analysis and the qualitative exhibition of Figure 2, existing segmentation approaches that rely on implicit tokens distort the native textual output space of MLLMs, thereby compromising their language capability and weakening semantic generalization, while single-pass of segmentation methods lack progressive interaction with the environment. More importantly, these methods suffer from a fundamental limitation in cross-modal reasoning, which prevents models from truly capturing fine-grained visual attributes. In contrast,
RSAgent not only generates correct and coherent textual reasoning, but also performs visually grounded reflection through multi-turn tool invocations. This interleaved reasoning ability stems from our design to decouple reasoning from a segmentation-centric tool environment, which preserves the MLLM’s inherent language reasoning capacity while enabling adaptive exploration and refinement.
Analysis of cold-start SFT and RL. We first verify whether cold-start SFT and RL are indispensable components of our training pipeline. As shown in Table 3, directly deploying an off-the-shelf Qwen2.5-VL-7B-Instruct model without any additional training in our framework yields poor performance on both RES and ReasonSeg benchmarks, and in some cases even underperforms the single forward pass baselines. We attribute this to a paradigm mismatch: the base model is primarily pretrained for QA-style generation and is not explicitly exposed to tool-use interactions, leading to significant misalignment when transferred to a novel tool invocation setting. In contrast, after cold-start SFT (or even RL alone), the model learns to invoke external tools to support interleaved reasoning segmentation. Moreover, the interactive nature of RL encourages more adaptive multiturn behaviors, enabling the policy to autonomously explore, refine, and correct predictions across iterations.
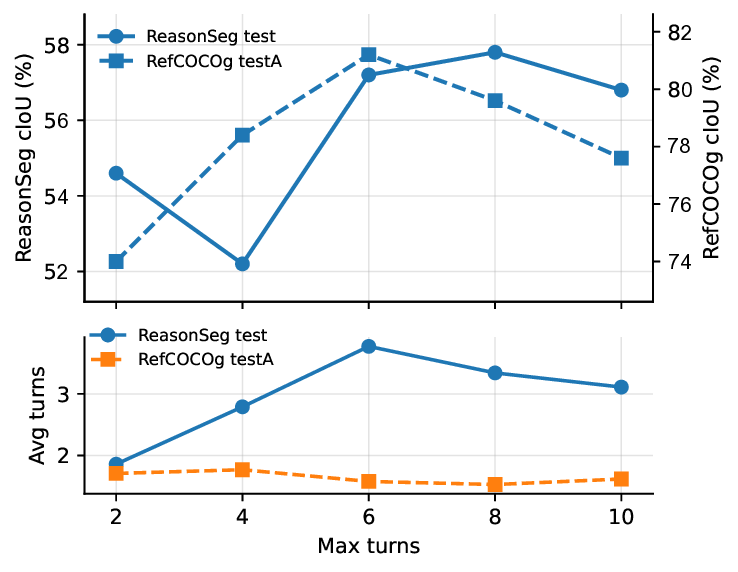
Analysis of multi-turn tool invocation. Although multiturn of decision in segmentation helps the model to rethink and provide accurate masks, overlong or unnecessary context may results in unexpected masks. As shown in Figure 5, the model’s performance gradually improves as the max number of turns to call tools during training (max-turns) gets higher until 8 turns. What’s more, during inference the average turns of successful predictions (when IoU > 0.9) stops until max-turn reaches 6. For RefCOCOg benchmark which is less challenging compared with ReasonSeg, the tendency comes out the same, which indicates that appropriate max-turns during training do enhance the agent’s cross-modal reasoning ability and incentivize its automony to invoke tools. Analysis of reward design. We explore the impact of different reward functions during GRPO training. We study the model trained without R final , R process and R format . Table 4 shows the results that removing either component leads to consistent performance drops, demonstrating every reward’s unique role in multi-turn reasoning segmentation ability construction.
Analysis of segmentation tool. We further investigate whether RSAgent’s gains mainly come from its multi-turn interleaved reason-and-act policy, rather than from a particular choice of the underlying segmentor. Specifically, we evaluate different versions of SAM and HQ-SAM (Ke et al., 2023). Table 5 summarizes the results, showing that RSAgent consistently benefits from iterative interaction across tools, and can effectively exploit stronger segmentors while remaining robust when the tool is lightweight.
We propose RSAgent, an agentic MLLM for text-guided segmentation that predicts masks via multi-turn reason-and-act with an external toolbox. Given an original image and textual problem, RSAgent operates by generating pixel prompts and invoking visual tools to focus on the correct region and iteratively refine the final mask. To enable the MLLM with the ability to correctly invoke appropriate tools and refine the mask through multi-turn of reasoning and actions, we first develop a data pipeline and generate dataset of 7K samples for training. Then we develop a two stage framework specialized for the multi-turn tool invocations.
Qualitative results and quantitative evaluations demonstrate that RSAgent achieves state-of-the-art performance in both in-domain and out-of-domain benchmarks, revealing its interleaved reasoning segmentation ability to trial and refine via multi-turn tool invocations.
which a correct mask is produced by SAM2 at some intermediate reasoning step. After manually verifying the correctness of the corresponding problem Q, we revise the terminal supervision to align with this correct intermediate mask and discard the most misleading portions of the erroneous reasoning trace, and then add these curated trajectories to the cold-start dataset.
We formulate tool-augmented segmentation as a finite-horizon interactive episode. At each step t, the policy either invokes a tool (zoom/rotate/segment) or outputs a final answer in the required JSON schema. Our overall reward is decomposed into three components: (i) Final-answer reward R final for final mask quality, (ii) Format reward R format for valid / / blocks, and (iii) Process reward R process for step-wise shaping along the trajectory.
C.1. Process reward R process .
Following prior findings that step-level (process-based) supervision provides richer signals and eases long-horizon credit assignment compared to outcome-only feedback, we incorporate step-wise IoU-improvement shaping as a process reward to guide tool-use trajectories (Lightman et al., 2024;Uesato et al., 2022). Let IoU t denote the foreground IoU (thresholded at 0.5) between the current best predicted mask and the ground-truth mask after executing the t-th turn of tool call, and define ∆ t = IoU t -IoU t-1 . We use step-wise shaping to ease credit assignment: r t = λ ∆ clip(∆ t , -0.1, 0.5) + λ best max(0, IoU t -
where IoU * t-1 = max k≤t-1 IoU k is the best-so-far IoU. We assign a tool-dependent call cost c(a t ) = λ cost • κ(a t ) with multipliers κ(•) (e.g., higher for segmentation of 2.5 than for geometric transforms of 1) to discourage excessive tool usage. We adopt λ δ as 1, λ best as 0.5, λ inv as 1. Then the final R process is calculated as:
where we default η as 1 during training.
Point-level sparsity/novelty (within R process ). When invoking the segmentation tool, we additionally encourage novel point prompts while penalizing redundant clicks:
where N new counts points whose distance to the historical point set is at least d min of 8, and Redund accumulates a normalized penalty for points closer than d min , encouraging sparsity and reducing repeated clicks.
C.2. Format reward R format .
We reward syntactically valid, schema-compliant and blocks, and penalize unparsable outputs and invalid tool invocations. Concretely, R format includes (i) a small bonus for parsable, schema-compliant JSON outputs, and (ii) penalties for invalid tool calls or unparsable generations .
C.3. Final-answer reward R final .
Given the final , we run the segmentation model for each predicted item to obtain masks, and score them against the GT instance set using Hungarian matching. We define
where IoU match is the matched mean IoU over GT connected components, and IoU box is the IoU between the union bounding box of predicted masks and the GT union box. This term directly encourages high quality final masks via both mask IoU and bounding-box IoU.
Episode return. We aggregate the above components as Equation. 3 where β controls the strength of dense process shaping relative to the final outcome. We adopt α of 1, β of 0.5, γ of 0.2 as our training parameter.
Evaluation Metrics. Following previous work on textguided segmentation, we adopt two commonly used evaluation metrics: generalized IoU (gIoU) and cumulative IoU (cIoU). Specifically, gIoU is computed as the average of per-image IoU, while cIoU is defined as the IoU of the cumulative predicted and GT masks across the entire dataset. baselines such as(Liu et al., 2025a; Huang et al., 2025b) by at least 5.0% gIoU on val split, 6.3% cIoU on val split, 6.3% gIoU on test split and 3.6% cIoU on test split, as it can handle long and compositional descriptions involving spatial relations or fine-grained attributes more robustly,
Evaluation Metrics. Following previous work on textguided segmentation, we adopt two commonly used evaluation metrics: generalized IoU (gIoU) and cumulative IoU (cIoU). Specifically, gIoU is computed as the average of per-image IoU, while cIoU is defined as the IoU of the cumulative predicted and GT masks across the entire dataset. baselines such as(Liu et al., 2025a; Huang et al., 2025b)
Evaluation Metrics. Following previous work on textguided segmentation, we adopt two commonly used evaluation metrics: generalized IoU (gIoU) and cumulative IoU (cIoU). Specifically, gIoU is computed as the average of per-image IoU, while cIoU is defined as the IoU of the cumulative predicted and GT masks across the entire dataset. baselines such as
This content is AI-processed based on open access ArXiv data.