The low-altitude economy (LAE) is rapidly expanding driven by urban air mobility, logistics drones, and aerial sensing, while fast and accurate beam prediction in uncrewed aerial vehicles (UAVs) communications is crucial for achieving reliable connectivity. Current research is shifting from singlesignal to multi-modal collaborative approaches. However, existing multi-modal methods mostly employ fixed or empirical weights, assuming equal reliability across modalities at any given moment. Indeed, the importance of different modalities fluctuates dramatically with UAV motion scenarios, and static weighting amplifies the negative impact of degraded modalities. Furthermore, modal mismatch and weak alignment further undermine cross-scenario generalization. To this end, we propose a reliability-aware dynamic weighting scheme applied to a semantic-aware multi-modal beam prediction framework, named SaM²B. Specifically, SaM²B leverages lightweight cues such as environmental visual, flight posture, and geospatial data to adaptively allocate contributions across modalities at different time points through reliabilityaware dynamic weight updates. Moreover, by utilizing crossmodal contrastive learning, we align the "multi-source representation beam semantics" associated with specific beam information to a shared semantic space, thereby enhancing discriminative power and robustness under modal noise and distribution shifts. Experiments on real-world low-altitude UAV datasets show that SaM²B achieves more satisfactory results than baseline methods.
W ITH the requirement of sixth-generation (6G) mobile communications, the world is entering an unprecedented era of massive data interaction [1]. However, constrained by spectrum resources and insufficient deployment density of ground base stations (BSs), traditional cellular networks still face bottlenecks in achieving ubiquitous coverage and large-scale concurrent communications. LAE, as an (*Corresponding author: Anbang Zhang) Haojin Li and Haijun Zhang are with University of Science and Technology Beijing, China (email: Haojin.li@sony.com, haijunzhang@ieee.org).
Haojin Li and Chen Sun are with Sony China Research Laboratory, China (email: chen.sun@sony.com).
Anbang Zhang is with School of Control Science and Engineering, Shandong University, China (e-mail: zab 0613@163.com).
Kaiqian Qu is with Southeast University, Nanjing 210096, China (e-mail: qukaiqian2021@163.com).
Chenyuan Feng is with the College of Computer Science, University of Exeter, U.K. (email: c.feng@exeter.ac.uk).
T. Q. S. Quek is with the Information Systems Technology and Design Pillar, Singapore University of Technology and Design, Singapore 487372 (e-mail: tonyquek@sutd.edu.sg).
emerging application paradigm, integrates low-altitude aviation activities with advanced air mobility aircraft, providing seamless, three-dimensional services for scenarios such as airborne networks [2] and smart transportation [3].
To support such applications, low-altitude UAV networks must possess reliable high-speed communication and realtime sensing capabilities. Notably, ITU-R has approved the IMT-2030 (6G) draft recommendation, identifying integrated sensing and communication (ISAC) as one of the 6G key application scenarios [4], aiming to widely deploy wireless sensing architectures in future networks. This means that future lowaltitude communication networks will not only provide highspeed data links for UAVs but also enable real-time sensing [5] of the surrounding airspace environment, assisting in obstacle avoidance, navigation, and mission execution.
However, the low-altitude high-dynamic environments pose significant challenges, despite the widespread deployment of mmWave links offers the advantage of ultra-wide bandwidth, it still suffers from severe path loss and rapid channel changes caused by the high-speed maneuvering of UAVs. Also, complex urban terrain further exacerbates link instability. To maintain a robust connection, the system must complete beam prediction and switching within milliseconds. Traditional beam management methods based on periodic channel detection [6] are too costly and have unacceptable latency in LAE. Single Location-based beam selection is highly dependent on highprecision positioning. Recently, deep learning (DL) methods have been introduced into beam prediction [7], attempting to directly map sensor data to beam indices. However, most existing solutions rely on a single modality [8], resulting in a significant performance decline when modality degradation occurs. More critically, even within multi-modal systems, existing methods often employ fixed fusion weights, assuming all modalities are equally reliable at any given moment. In practice, modal reliability varies significantly across scenarios. Without explicitly modeling modal importance, fusion struggles to adapt. Consequently, there is an urgent need for a more reliable multi-modal adaptation strategy capable of measuring the importance of different modalities.
Motivated by this, we propose a reliability-aware, semantic multi-modal beam prediction framework, SaM²B. Specifically, SaM²B incorporates lightweight cues such as environmental visual information, geospatial cues, and flight attitude features. It then employs attention mechanisms to infer the reliability of each modality, enabling adaptive weight allocation at ev-
As shown in Fig. 1, we consider a UAV mmWave communication system operating in the LAE scenario. This communication system employs orthogonal frequency-division multiplexing (OFDM) transmission with K subcarriers and a cyclic prefix of length D. In the downlink, the BS applies beamforming to enhance the received signal quality at the UAV. To enable directional transmission, the BS employs a pre-defined beamforming codebook F = {f q } Q q=1 , where f q ∈ C M ×1 denotes the q-th beamforming vector and Q is the total number of candidate beams. Let h k [t] ∈ C M ×1 denote the downlink channel vector between the BS and the UAV at the k-th subcarrier and time instant t.
Accordingly, the received signal at the UAV on the k-th subcarrier is given by:
where s ∈ C is the transmitted complex symbol with power constraint E[|s| 2 ] = P , P denotes the average symbol power. And h H k is the mmWave channel vector, and n[t] ∼ CN 0, σ 2 n represents complex additive Gaussian noise. The selection strategy of the optimal beam index q * [t] that maximizes the average receive signal-to-noise ratio (SNR) over all K subcarriers, i.e.,
where q * [t] denotes the index of the optimal beamforming vector at time t. Here, P/σ 2 corresponds to the transmit SNR. Thus, the selected beamforming vector is f
. This selection criterion ensures the highest possible received SNR under the given codebook constraints.
At time t, we can obtain observations and representations of S modalities (S ≥ 1). For example, environmental vision, geographic location, and flight attitude. Conventional approaches typically cascade multi-modal features or perform linear fusion with fixed weights:
where, ws = 1 is independent of time or context. This implies the assumption that all modalities are equally reliable at any time t. And F s is a mapping transformation in neural networks. X s (t) is the encoder output for one modality.
• The inherent fragility of single modality: Models relying solely on a single sensor source (such as GPS alone or IMU alone) are highly prone to failure in real-world environments. Changes in single-modality distribution can cause learned maps to rapidly degrade, necessitating supplementary data from other modalities. • A key shortcoming in traditional multi-modal fusion:
To enhance robustness, many approaches incorporate multi-modal data, but they often employ static fusion through concatenation with fixed weights. This overlooks the varying confidence levels across different encoder outputs, and averaging their outputs with equal weights leads to suboptimal decisions. In contrast, our reliability-focused multi-modal approach does not rely on stable channel statistics. Instead, it dynamically evaluates the credibility of each modality to transform heterogeneous sensor cues into a unified and semantically consistent signal. This transforms beam prediction from passive channel fitting into active environment-driven inference, enabling rapid and accurate UAV beam prediction.
Within the above system model, we propose a novel beam prediction framework that leverages sensory data collected at
After ImageNet normalization, the ROI is passed through a ResNet-18 backbone Ψ img (with classification head removed), followed by a lightweight MLP head Γ img , yielding a Qdimensional embedding:
Remark. If b[t] is unavailable, the framework defaults to global average pooling over the full frame, ensuring robustness by trading precision for coverage.
- GPS Position Information: During flight, UAVs continuously acquire the geographic coordinates G[t]. After normalization, a lightweight multilayer perceptron (MLP) Ψ GPS maps the input into a Q-dimensional shared representation space to extract semantic position features:
This transformation preserves geospatial information while reducing the sparsity of raw coordinates in the highdimensional embedding space.
- UAV Height and Horizontal Distance: The UAV relative altitude H[t] and horizontal displacement D[t] with respect to the base station jointly form a two-dimensional feature vector HD[t]. After min-max normalization, an MLP Ψ HD projects it into the shared semantic space:
The resulting embedding encodes the UAV-BS spatial geometry, serving as a crucial constraint for beam prediction.
- UAV Posture: UAV posture is obtained from the onboard inertial measurement unit (IMU), which provides real-time orientation parameters including roll, pitch, and yaw, denoted as V[t] = [roll, pitch, yaw] ∈ R 3 . After normalization, an MLP Ψ att embeds the posture vector into the semantic space:
This representation captures UAV orientation dynamics, enabling the framework to account for mobility-induced fluctuations in channel characteristics.
To avoid the degradation of certain modalities in multimodal fusion from fixed weights, we introduce credibilityaware dynamic weights. At each time step, fusion coefficients are adaptively assigned based on modal quality, thereby emphasizing modalities with higher informational value.
Cross-modality Alignment: SaM²B utilizes cosine similarity constraints to align the different modality representations, inspired by CLIP [9].
Specifically, given a semantic feature vector Xγ [t] extracted from modality γ ∈ A, we first perform ℓ 2 -normalization:
which projects all features onto the unit hypersphere. This normalization stabilizes the training process by constraining the feature space and allows cosine similarity to be directly applied as the alignment metric.
To capture cross-modal consistency, we compute the pairwise similarity between modalities γ 1 and γ 2 at time t as
where
to achieve the capture of dynamic correlation patterns across modalities. The correlations extracted by each attention head are spliced and projected back to the original space as
Cross-Modality Attention: Due to the different capabilities of each modality, we allow dynamic weighting and semantic sensing fusion of specific modality features. Let v s [t] = F Att [t] (s,:) ∈ R Q . We first obtain an attention score from data,
and a reliability score from lightweight quality cues,
where r s [t] collects modality-specific quality features. To adaptively emphasize reliable modalities, we fuse two scores:
and
where ϕ(•) is a normalization (e.g., z-score or temperature scaling) and α ∈ [0, 1] is a learnable or fixed mixing coefficient. The fused representation is then,
where FFN(•) denotes a position-wise feed-forward network (FFN) that refines the fused representation. Then, FFN(•) is fed into a prediction network f Θ (•) to produce beam probabilities P = f Θ (Z) ∈ R Q , where Θ is model parameter set, and the final beam is q[t] = arg max q P[q]. End-to-end Learning Phase: We design an end-to-end learning process. The unified training objective integrates task prediction accuracy and multi-modal alignment consistency, leading to a robust and generalizable framework. Specifically, we optimize beam index prediction accuracy through crossentropy loss defined as:
where p q ∈ {0, 1} denotes the ground-truth one-hot encoded optimal beam index, pq represents the model prediction probability for the q-th beam, and σ Softmax (•) is the softmax activation function. Moreover, the cross-modal feature similarity is achieved by normalizing the temperature-scaled contrast loss, i.e.,
where the temperature parameter θ > 0 regulates the similarity concentration: the smaller θ, the sharper distribution; and the larger θ, the softer distribution. Thus, we design a trade-off objective subjected to by dynamic constraints on the contributions of different modal, which ensures beam prediction performance, as:
where β ≥ 0 is trade-off parameter, controlling the contribution of different objectives.
IV. EXPERIMENTS AND DISCUSSIONS A. Experimental Settings 1) Dataset and Neural Network Architecture: To evaluate performance, we utilize Scenario 23 in the DeepSense 6G dataset [10], which targets UAV communications and provides multi-modal information (RGB images, GPS, IMU, flight posture, velocity, and mmWave signals). The setup includes a fixed receiver with a 60 GHz phased-array antenna and camera, and a UAV with a mmWave transmitter. The original 64-dimensional beam power vectors are down-sampled to 32, with the maximum-power beam chosen as the ground-truth label. The dataset is divided into 70% for training, 30% for testing process. Based on this dataset, we design the model backbone using MLP architecture and ResNet blocks.
- Compared Methods: We evaluate SaM²B against three state-of-the-art baselines, described as follows: Based on NLinear [11], this method utilizes a linear model to map data. We incorporate it into our established multi-modal framework for modal linear fusion. To distinguish it from the original algorithm, we name it MM-NLinear. Based on BBOX scheme [12], this method employs full-image input to encode key visual data. We integrate this model into an existing modal linear fusion multi-modal framework while retaining our contrastive learning scheme. To distinguish it from the original algorithm, we name it No-BBOX. Moreover, we compared a scheme [13] that utilizes image and location information to aid beam prediction, named as MM-aid.
To ensure fair comparisons, we standardized the experimental environments for all methods. Specifically, all models share the same neural network backbone architecture and are subject to equivalent constraints on computational complexity and memory usage to simulate resource-constrained edge device deployment scenarios.
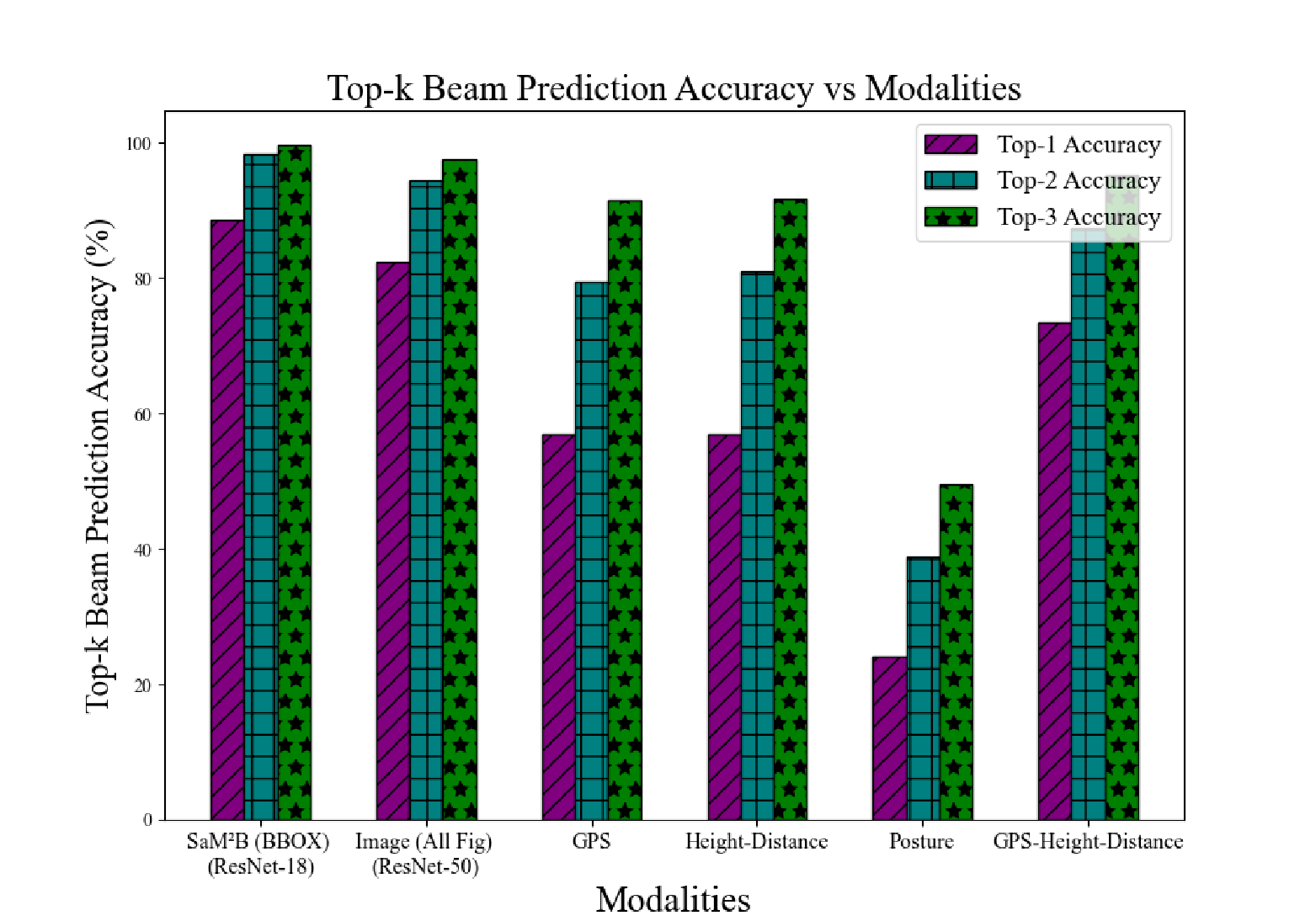
To evaluate the utility of different modalities in mmWave beam prediction, we conducted ablation experiments as shown Figure 3. Specifically, SaM²B (using only the target BBOX, ResNet-18) achieved Top-1 = 88.63%, Top-2 = 98.26%, Top-3 = 99.68%, slightly outperforming the Whole image approach (using the deeper ResNet-50 architecture) at 86.32%, 96.34%, 99.41%. This indicates that preserving the local appearance of the target after background removal is more beneficial for identifying the optimal beam. Performance significantly degrades when relying solely on geometric/positional information: GPS achieves 56.97%, 79.34%, 91.38%, Height-Distance achieves 56.81%, 80.94%, 91.67%, while using posture alone yields only 24.06%, 38.89%, 49.43%. This demonstrates that single geometric modality information imposes weak constraints on beam indexing and is susceptible to noise. Fusing geometric information (GPS-Height-Distance) significantly improves performance to 73.42%, 87.36%, 95.18%, validating that complementarity among multi-source geometric signals enhances beam prediction on high-speed moving UAVs. In summary, incorporating contrastive learning alignment loss into the multi-modal framework enhances discriminative power, and enables efficient processing using lighter-weight networks.
As shown in Figure 4, SaM²B model demonstrates outstanding convergence characteristics, achieving a peak Top-1 accuracy of nearly 90%, significantly outperforming all baseline models. The key gain comes from our reliabilityaware dynamic weighting, which adaptively up-weights informative modalities. The MM-NLinear method, which employs linear projection for multi-modal fusion, fails to account for the overlapping effects between different modalities, resulting in performance inferior to SaM²B. In contrast, the MM-Aid approach, which utilizes positional information, performs the worst, as geometric information alone does not yield improved beam prediction. The No-BBOX baseline, which relies solely on full-image encoding within the multi-modal contrastive learning framework, maintains high accuracy but suffers from high computational complexity due to processing the entire image. This highlights the critical role of structured spatial information for effective beam prediction.
V. CONCLUSIONS In this paper, we propose a reliability-aware dynamic weighting mechanism for the semantic-aware multi-modal beamforming prediction framework (SaM²B). By integrating multi-modal environmental data and adaptively allocating the contributions of different modalities over time through reliability-aware weight updates, our method generates modality-invariant semantic representations to address the issues of modal mismatch and weak alignment. Experimental results on real-world low-altitude UAV datasets demonstrate that SaM²B significantly outperforms traditional benchmark methods in communication performance. Future work include extensions through time prediction for active beam tracking, online uncertainty awareness to further evaluate generalization ability and robustness.
1] |A|×|A| forms a symmetric similarity matrix. Maximizing these pairwise similarities encourages modality-invariant representations, effectively disentangling semantic features from modality-specific noise.By encouraging cross-modal similarity, this geometric constraint in SaM²B implicitly disentangles modality-invariant semantics from modality-specific noise, enhancing robustness and generalizability under the distribution shifts.
1] |A|×|A| forms a symmetric similarity matrix. Maximizing these pairwise similarities encourages modality-invariant representations, effectively disentangling semantic features from modality-specific noise.
This content is AI-processed based on open access ArXiv data.