Title: Skim-Aware Contrastive Learning for Efficient Document Representation
ArXiv ID: 2512.24373
Date: 2025-12-30
Authors: Waheed Ahmed Abro, Zied Bouraoui
📝 Abstract
Although transformer-based models have shown strong performance in word-and sentence-level tasks, effectively representing long documents, especially in fields like law and medicine, remains difficult. Sparse attention mechanisms can handle longer inputs, but are resource-intensive and often fail to capture full-document context. Hierarchical transformer models offer better efficiency but do not clearly explain how they relate different sections of a document. In contrast, humans often skim texts, focusing on important sections to understand the overall message. Drawing from this human strategy, we introduce a new selfsupervised contrastive learning framework that enhances long document representation. Our method randomly masks a section of the document and uses a natural language inference (NLI)-based contrastive objective to align it with relevant parts while distancing it from unrelated ones. This mimics how humans synthesize information, resulting in representations that are both richer and more computationally efficient. Experiments on legal and biomedical texts confirm significant gains in both accuracy and efficiency.
📄 Full Content
Since the introduction of Language Models (LMs), the focus in NLP has been on fine-tuning large pre-trained language models, especially for solving sentence and paragraph-level tasks. However, accurately learning document embeddings continues to be an important challenge for several applications, such as document classification (Saggau et al., 2023), ranking (Ginzburg et al., 2021;Izacard et al., 2021), retrieval-augmented generation (RAG) systems that demand efficient document representation encoders (Zhang et al., 2024;Zhao et al., 2025) and legal and medical applications like judgment prediction (Chalkidis et al., 2019;Feng et al., 2022), legal information retrieval (Sansone and Sperlí, 2022), and biomedical document classification (Johnson et al., 2016;Wang et al., 2023).
Learning high-quality document representations is a challenging task due to the difficulty in developing efficient encoders with reasonable complexity. Most document encoders use sentence encoders based on self-attention architectures such as BERT (Devlin et al., 2019). However, it is not feasible to have inputs that are too long as self-attention scales quadratically with the input length. To process long inputs efficiently, architectures such as Linformer (Wang et al., 2020), Big Bird (Zaheer et al., 2020a), Longformer (Beltagy et al., 2020a) and Hierarchical Transformers (Chalkidis et al., 2022a) have been developed. Unlike quadratic scaling in traditional attention mechanisms, these architectures utilize sparse attention mechanisms or hierarchical attention mechanisms that scale linearly. As such, they can process 4096 input tokens, which is enough to embed most types of documents, including legal and medical documents, among others.
While methods based on sparse attention networks offer a solution for complexity, the length of the document remains a problem for building faithful representations for downstream applications such as legal and medical domains. First, fine-tuning these models for downstream tasks is computationally intensive. Second, capturing the meaning of the whole document remains too complex. In particular, it is unclear how or to what extent inner-dependencies between text fragments are considered. This is because longer documents contain more information than shorter documents, making it difficult to capture all the relevant information within a fixed-size representation. Additionally, documents usually cover different parts, making the encoding process complex and may lead to collapsed representations. This is particularly true for legal and medical documents, as they contain specialized terminology and text segments that describe a series of interrelated facts.
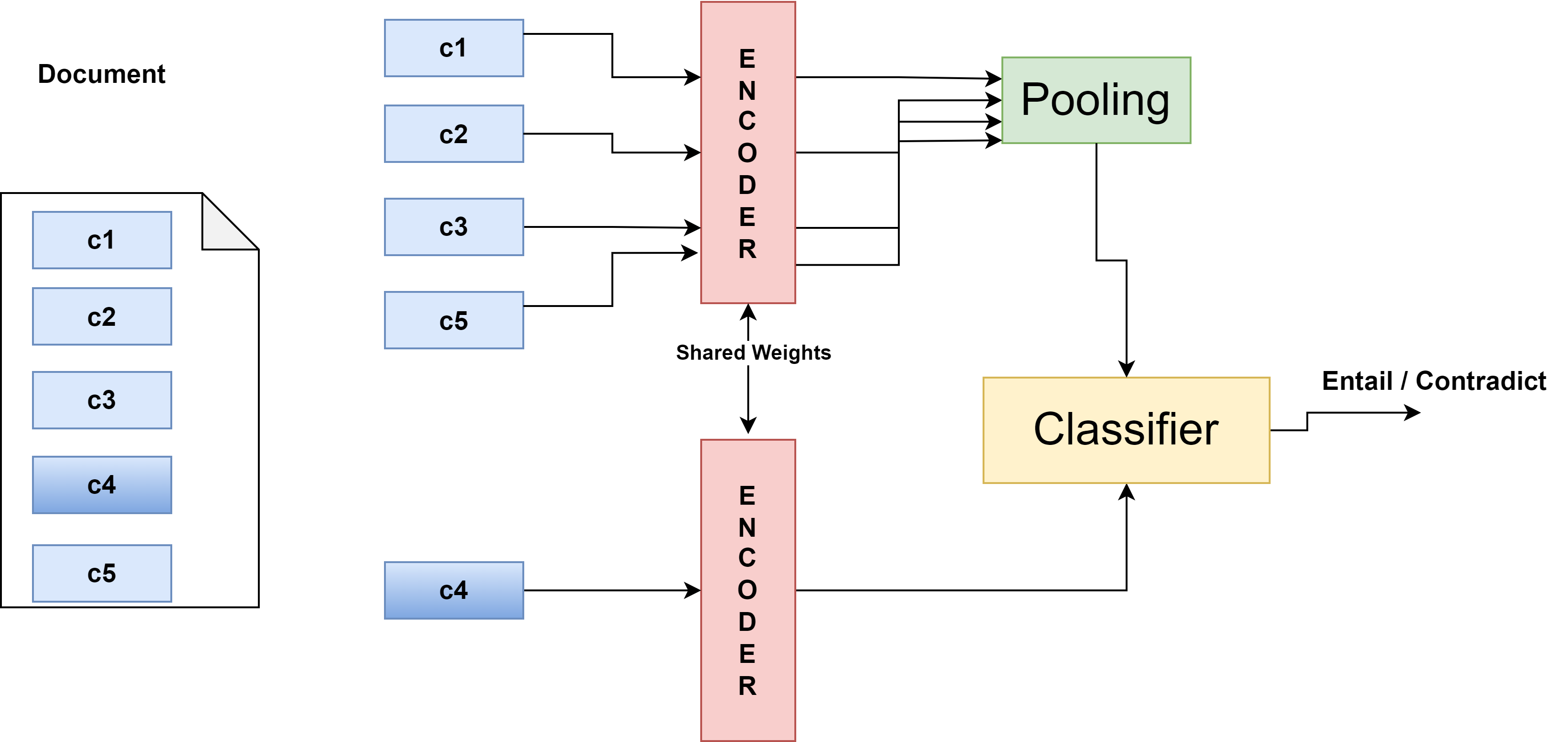
When domain experts, such as legal or medical professionals, read through documents, they skillfully skim the text, honing in on some text fragments that, when pieced together, provide an understanding of the content. Inspired by this intuitive process, our work focuses on developing document encoders capable of generating highquality embeddings for long documents. These encoders mimic the expert ability to distill relevant text chunks, enabling them to excel in downstream tasks right out of the box, without the need for fine-tuning. We propose a novel framework for self-supervised contrastive learning that focuses on long legal and medical documents. Our approach features a self-supervised Chunk Prediction Encoder (CPE) designed to tackle the challenge of learning document representations without supervision. By leveraging both intra-document and interdocument chunk relationships, the CPE enhances how documents should be represented through its important fragments. The model operates by randomly selecting a text fragment from a document and using an encoder to predict whether this fragment is strongly related to other parts of the same document. To simulate the skimming process, we frame this task as a Natural Language Inference (NLI) problem. In our method, “entailment” and “contradiction” are not literal NLI labels. Rather, we use an NLI-style binary objective as a practical proxy that teaches the model whether a chunk is semantically compatible with its document context (positive) or not (negative). This enables the encoder to judge whether a local fragment is compatible with document-level context, thereby capturing long-range, cross-fragment relevance. This method not only uncovers connections between different documents, but also emphasizes the relevance of various sections, thus enriching the overall learning process for document representations. The main contributions are as follows:
• We introduce a self-supervised Chunk Prediction Encoder (CPE) that employs random span sampling into a hierarchical transformer and Longformer: by sampling text spans and training the model to predict whether a span belongs to the same document, CPE captures both intra-and inter-document fragment relationships, preserves global context through chunk aggregation, and models the complex hierarchical structures of long texts.
• We apply a contrastive loss that pulls to-gether representations of related fragments and pushes apart unrelated ones, reinforcing meaningful connections across different parts of the same document.
• We conducted extensive experiments to demonstrate the effectiveness of our framework. Specifically, i) we compare the quality of our document embeddings against strong baselines, (ii) we benchmark CPE-based models in an end-to-end fine-tuning setup while training all parameters jointly and comparing downstream classification performance against established methods, and (iii) we perform an ablation study to assess the impact of different chunk sizes, visualize the resulting embedding space, and evaluate performance on shorter documents. We also compare with LLMs such as LLaMA capabilities for handling long legal texts.
This section provides an overview of the modelling of long documents and self-supervised document embedding.
Modeling of long documents. Long documents are typically handled using sparse-attention models such as Longformer (Beltagy et al., 2020b) and BigBird (Zaheer et al., 2020b). These models use local and global attention mechanisms to overcome the O(n 2 ) complexity of standard full attention mechanisms. Alternatively, one can use a hierarchical attention mechanism (Yang et al., 2016), where the document is processed in a hierarchical manner. For example, (Chalkidis et al., 2019) applied a hierarchical BERT model to model long legal documents. The model first processes the words in each sentence using the BERT-base model to produce sentence embeddings. Then, a self-attention mechanism is applied to the sentence-level embeddings to produce document embeddings. The authors have demonstrated that their hierarchical BERT model outperforms both the Vanilla BERT architecture and Bi-GRU models. Similarly, (Dai et al., 2022) explored the various methods of splitting the long document and compared them with sparse attention methods on long document classification tasks. Their findings showed that better results were achieved by splitting the document into smaller chunks of 128 tokens. (Wu et al., 2021) proposed a model called Hi-Transformer, which applies both sentence-level and documentlevel transformers followed by hierarchical pooling. Meanwhile, (Chalkidis et al., 2022b) introduced a variant of hierarchical attention transformers based on segment encoder and cross-segment encoder, which demonstrated comparable results with the Longformer model. In this work, we consider processing long documents with a hierarchical attention mechanism and sparse-attention Longformer encoders. We further improve document embedding using self-supervised contrastive learning.
Unsupervised Document Representation. Unsupervised document representation learning is a highly active research field. At first, deep learning models were introduced to create contextualized word representations, such as Word2Vec (Mikolov et al., 2013) and GloVE (Pennington et al., 2014). The Doc2Vec (Le and Mikolov, 2014) model was proposed, which utilized contextualized word representation to generate document embeddings. In the same vein, the Skip-Thoughts (Kiros et al., 2015) model extended the word2vec approach from the word level to the sentence level. Transformerbased models (Reimers and Gurevych, 2019) were also suggested to produce a vector representation of the sentence. Recently, there have been advancements in self-supervised contrastive learning methods (Iter et al., 2020;Gao et al., 2021;Giorgi et al., 2021;Klein and Nabi, 2022;Saggau et al., 2023). In this direction, CONPONO proposes using sentence-level objectives with a masked language model to capture discourse coherence between sentences. The sentence-level encoder predicts text that is k sentences away. On the other hand, SimCSE (Gao et al., 2021) uses a dropout version of the same sentence as a positive pair on short sentences. Similarly, (Saggau et al., 2023) proposed SimCSE learning on long documents with additional Bregman divergence. On the other hand, SDDE (Chen et al., 2019) model was proposed to generate document representation based on interdocument relationships using an RNN encoder. We follow a similar strategy of exploiting interdocument relationships, we employe transformerbased pre-trained language models with multiple negatives ranking contrastive loss.
Processing legal and medical documents is an active research topic. (Chalkidis et al., 2019) propose the hierarchical BERT model to process legal documents. (Malik et al., 2021) propose the hierarchical transformer model architecture for the legal judgment prediction task. The input document is split into several chunks of size 512 tokens. Each chunk embedding is produced by a pre-trained XLNET model. Then, a Bi-GRU encoder is applied to the chunk embeddings to produce final document embeddings. (Zheng et al., 2021) train the BERT model on CaseHOLD (Case Holdings On Legal Decisions) dataset. (Hamilton, 2023) employed GPT-2 models to predict how each justice votes for supreme court justice’s opinions. (Yang et al., 2019) process the legal document using a Multi-Perspective Bi-Feedback Network to classify law articles. (Xu et al., 2020) propose to represent the document using a graph neural network. To distinguish confusing articles, a distillation-based attention network is applied to extract discriminative features.
For medical document processing, in (Arnold et al., 2020), authors propose contextualized document representations to answer questions from long medical documents. The model employs a hierarchical dual encoder based on hierarchical LSTM to encode medical entities. (Mullenbach et al., 2018) proposed a convolutional neural network base labelwise attention network to produce label-wise document representations by attending to the most relevant document information for each medical code. In (Chalkidis et al., 2020), authors showed that the pre-trained BERT model outperforms CNNbased label-wise attention networks. In the same direction, (Kementchedjhieva and Chalkidis, 2023) proposed encoder-decoder architecture and outperforms the encoder-only model on multi-label text classification for legal and medical domains. The work in (Wang et al., 2023) provides a comprehensive survey focusing on the integration of pretrained language models within the biomedical domain. Their investigation highlights the substantial benefits of employing LMs in various NLP tasks. In contrast to previous works, we propose the learn document representation using self-supervised contrastive learning pre-trained LMs.
To process long documents in time efficient manner, we use state-of-the-art hierarchical transformer method (Chen et al., 2019;Wu et al., 2021;Dai et al., 2022) and sparse attention longformer model (Beltagy et al., 2020b). To enhance the quality of these representations, we propose self- CPE for Hierarchical Representation. We first briefly introduce hierarchical representation model using pre-trained model M. Let D be an input document, and c 1 , c 2 , …, c n denotes the set of corresponding text chunks in D where n is the maximum number of chunks, padding with zero if the chunks are less than n. Each chunk contains a sequence of T tokens C = (w 1 , w 2 , .., w t ), where t is less than 512. Furthermore, the special classification [CLS] token is added at the start of each chunk. Our aim is to learn the vector representation of each chunk using a shared small language model encoder as follows:
where f represents the output of a model (which can be BERT, RoBERTa, LegalBERT, Clinical-BioBERT or any other). Following the common strategy, we consider the [CLS] token as the representation of the whole chunk. To obtain the final document representation from different chunk features, we consider the following pooling strategies: the Mean-Pooling obtained by taking the mean of chunks representation d t = 1/n n i=1 f i , and the Max-Pooling over chunks representation. Each chunk encodes the local feature of the document, and the whole document is represented by the average of these local features.
Learning process We propose a chunk prediction encoder to train a hierarchical transformer model using self-supervised contrastive learning to leverage intra and inter-document relationships. For each document, we randomly remove one chunk and then ask the NLI classifier to predict whether this chunk is derived from other chunks of the document. By doing so, we force the model to learn the dependencies between chunks and their relevance in representing a document. Consider a mini-batch of N documents, denoted as
For each document d i , we randomly select a text chunk c + and remove it from that document di to form a positive pair di , c + .
We then select a negative chunk c -from the remaining N -1 documents of the batch to form a negative pair, ( di , c -). Notice that c -does not belong to document di . One concern that could be seen here is the text chunks could be similar and fit on both positive and negative documents. However, this is not an issue as in the training objective, we have multiple negatives, so our model is forced to optimize most dissimilar documents than most similar ones. The chunk predictive contrastive learning process can be viewed as an unsupervised natural language inference task, where a positive chunk sample represents an entailment of a document, and negative samples from other documents represent a contradiction of the document. We use multiple negatives ranking loss (Henderson et al., 2017) to train the model:
where f denotes the feature vector generated by document encoder, sim represents cosine similarity, c + i is the positive chunk taken from the document d i and c - k are the k negative sample of chunk taken from other documents than d i . Multiple negative ranking loss compares the positive pair representation with the negative pair samples in mini-batch. The general architecture is illustrated in Figure 1. Our architecture includes a shared encoder that generates a complete document embedding, except for chunk C4. Additionally, the shared encoder shown at the bottom produces a vector representation of C4. The classifier is responsible for learning whether the embedding of chunk C4 aligns with or contradicts the document embedding.
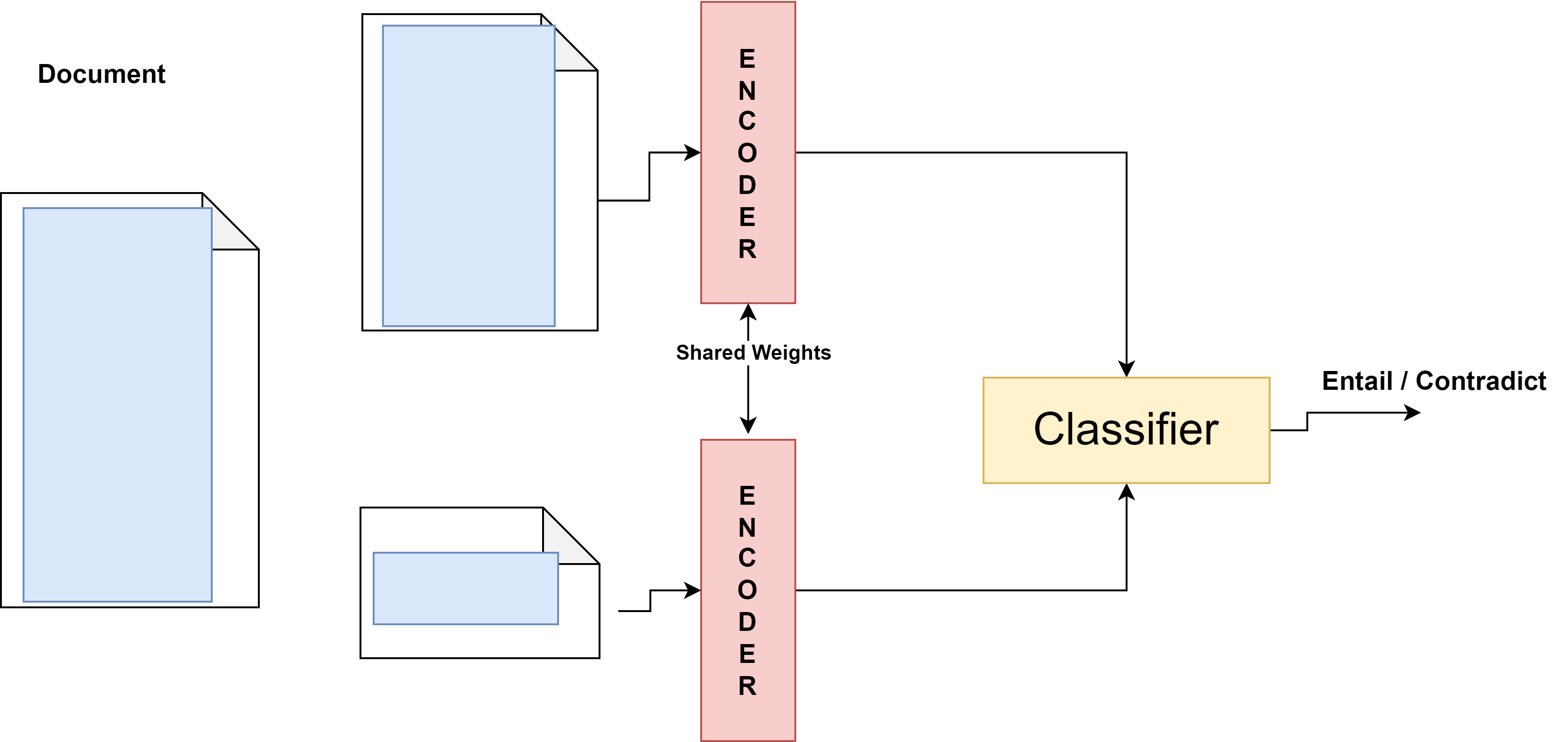
During the training of the CPE on the Longformer model, the document is split into two segments: the reference text and the positive text chunk. Our approach aims to ensure that the reference text segment and the positively sampled text chunk, which is extracted from the same document, are in agreement and maximize in consequence the objective function. Suppose we have a mini-batch of N documents, denoted as
For each document d i , we randomly select a text chunk c + and the remaining text as reference text d to form a positive pair di , c + i . We then select a negative chunk c -from the remaining N -1 documents of the batch to serve as the negative pair, ( di , c - j ). The reference text and positive text chunks are passed through the same Longformer encoder. The proposed method utilizes the [CLS] token representations to produce the reference text (z di ) embedding and text segment (z + c ) embedding. The linear classifier is then trained to maximize the agreement between the segment and reference text, both sampled from the same document and minimize the agreement between reference text and segment taken from another document. The multiple negatives ranking loss is used to optimize the model as given as follows:
where z di , z + c i , and z - c k denote the feature vectors generated by the Longformer document encoder. The general architecture is depicted in Figure 2. A shared Longformer encoder creates a document embedding for most of the text, excluding a small portion that has been removed. Additionally, a shared encoder at the bottom generates a vector representation of the removed chunk. The classifier learns to differentiate whether the embedding of the small chunk aligns with or contradicts the document embedding.
In this section, we define the experimental setup for evaluating the proposed contrastive learning framework.
Datasets We evaluate our encoders on three legal datasets, ECHR, SCOTUS, and EURLEX and two medical datasets, MIMIC and Biosq. Table 4 in Appendix provides statistics and the average document length of each dataset. Notice that we also consider Biosq to test the capability of our model in handling short-length documents as well.
Setting and evaluation metrics We consider small language models such bert-base1 , robertabase2 , legal-bert-base3 , and ClinicalBioBERT4 models as we seek for a simple model with less number of parameters. While our hierarchical transformer is capable of processing documents of any length, in this study, we restrict our analysis to the initial 4096 tokens driven primarily by computational considerations. We propose generalized CPE which can be applied to any hierarchical attentional document such as ToBERT (Chalkidis et al., 2021), RoBERT (Pappagari et al., 2019), or sparse attention models such BigBird (Zaheer et al., 2020a). By leveraging more advanced methods, the CPE can achieve better performance. We output the performance of the CPE using an advanced hierarchical attentional document encoder in the table 5.
We conduct a comprehensive evaluation of the proposed CPE framework by benchmarking against a hierarchical transformer encoder, a sparse-attention Longformer model, and state-of-the-art hierarchical transformer variants. Experiments are carried out on standard long legal and medical datasets under frozen-embedding and full end-to-end finetuning settings.
Evaluation of Hierarchical Representation Legal and medical topic classification results on fixed document representation via hierarchical transformer results in presented in Table 1. From the table, we can observe that MLP classifiers with document embedding from various PTM produce worse performance on all datasets. It is evident that self-supervised contrastive learning SimCSE, ESimCSE, and CPE improves the classification performance of PTM document embedding across the datasets. The SimCSE embedding improves the performance of BERT embedding by 12% in terms of the macro-F1 score on the ECHR. While improvement of ESimCSE over BERT embedding is 14%. However, the CPE embedding achieves the best performance on all datasets using BERT PTM. Specifically, CPE improves macro-F1 scores approximately by 6%, and 4% on BERT embedding of SimCSE, ESimCSE for ECHR, dataset. Similar improvement can be observed on SCOTUS,
To further solidify our findings, we evaluated our proposed CPE encoder in an end-to-end fine-tuning setting. We applied the LegalBERT CPE encoder to encode different chunks. Rather than using simple average pooling, we employed a two-layer transformer encoder to aggregate the information from different chunks. All parameters are trained in an end-to-end manner. The results for the classification of long documents are presented in Table 3. On the ECHR dataset, our model achieves a macro-F1 score of 66.1 an improvement of 2.5 points over LegalLongformer and 2.1 points over Hi-LegalBERT-and a micro-F1 score that is 0.9 points higher than LegalLongformer and 2.6 points higher than Hi-LegalBERT. Compared with LSG, we see even larger margins +5.8 pp macro and +1.6 pp micro on ECHR, +3.6 pp macro and +4.2 pp micro on SCOTUS. HAT delivers a strong micro-F1 (79.8) on ECHR but underperforms on SCOTUS macro (59.1), indicating less balanced class handling. Our consistent gains in both macro-and micro-F1 confirm that our CPE encoder generates high-quality chunk representations, simplifying the downstream classification of both frequent and rare legal classes during fine-tuning.
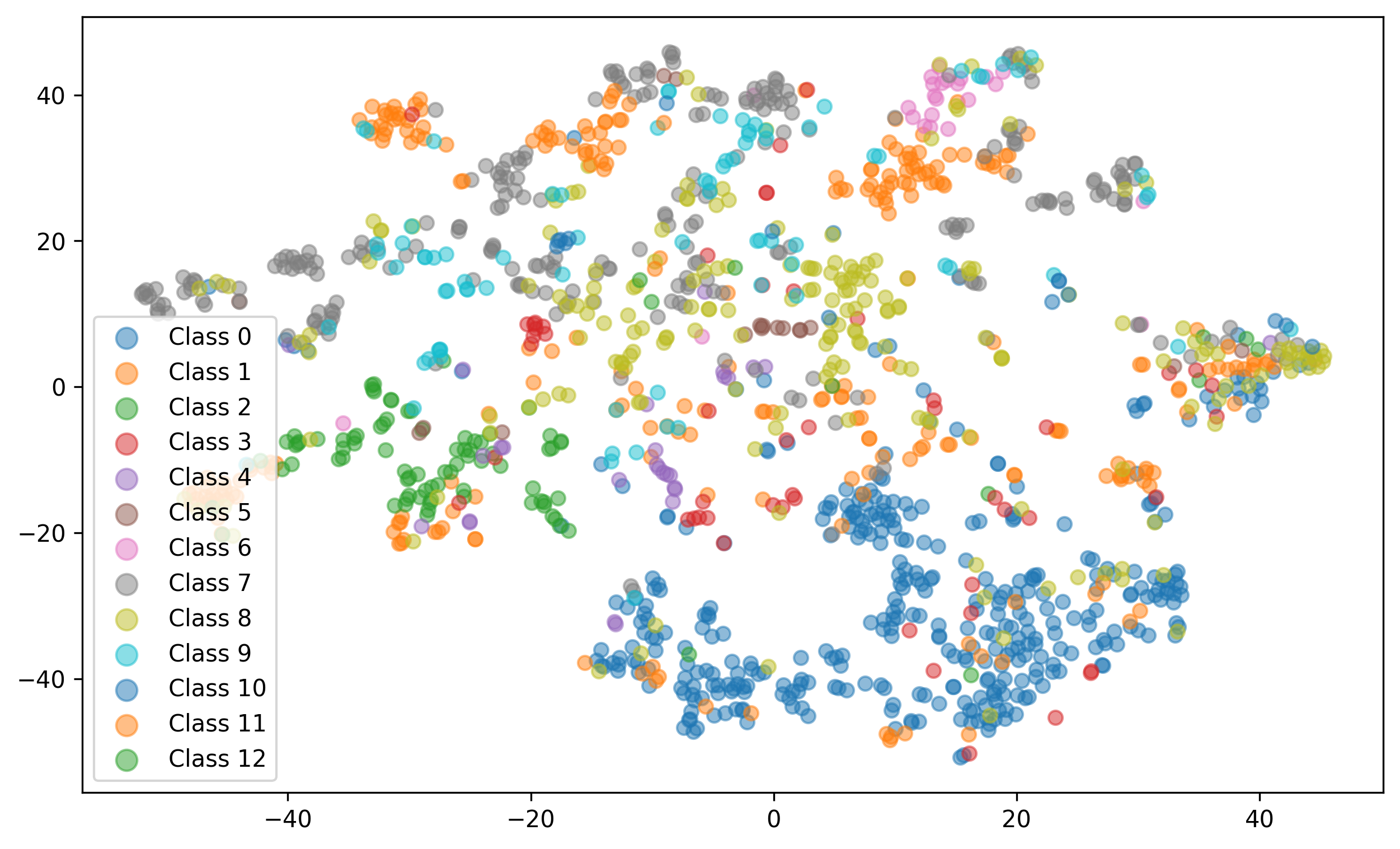
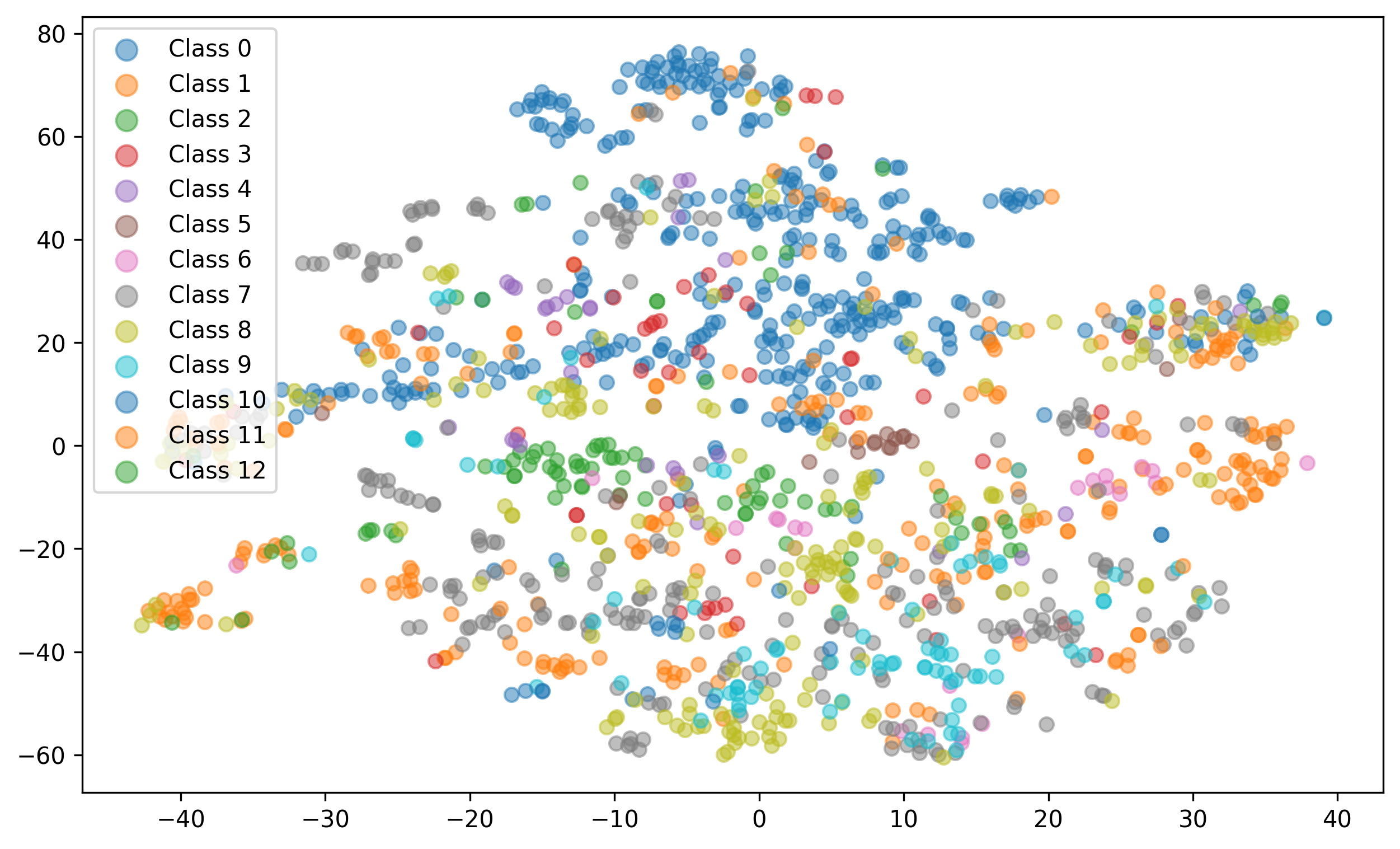
Supplementary Evaluation and Analysis Additional evaluations in the appendix highlight the robustness of the proposed CPE framework. As shown in Table 3, end-to-end fine-tuning with a hierarchical transformer improves performance over baselines like Hi-LegalBERT and LegalLongformer, confirming CPE’s effectiveness. An ablation study on chunk size (Table 6) shows 128token chunks offer the best performance, balancing context and relevance. On the short-document BIOSQ dataset (Table 7), CPE outperforms contrastive baselines, demonstrating its adaptability beyond long texts. Embedding visualizations and similarity metrics (Figure 3) further confirm that CPE produces semantically coherent and discriminative document representations.
We MIMIC-III: Medical information mart for intensive care (MIMIC-III) (Johnson et al., 2016) dataset comprises 40K discharge summaries from US hospitals, with each summary mapped to one or more (International classification of diseases, ninth revision) ICD-9 taxonomy labels. We utilized labels from the first level of the ICD-9 hierarchy.
BIOASQ (Tsatsaronis et al., 2015): The BIOASQ dataset comprises biomedical articles sourced from PubMed. Each article is annotated with concepts from the Medical Subject Headings (MeSH) taxonomy. We used the first levels of the MeSH taxonomy. The dataset is divided into train and test categories.
We use the AdamW optimizer with a learning rate of 2e -5 and weight decay of 0.001. The model is trained for 3 epochs for self-supervised SimCSE, ESimCSE, and CPE settings, while the MLP classifier model is trained for 20 epochs. The classifier uses a batch size of 16, while the self-contrastive learning module uses a batch size of 4. We apply Max Pooling to the chunk representations to aggregate information across the chunks. All models are trained using NVIDIA Quadro RTX 8000 48GB GPU.
Evaluation of Advanced Hierarchical Representation In Section 3, we introduced a generalized CPE that can be used with any long document encoder. We hypothesise that the performance
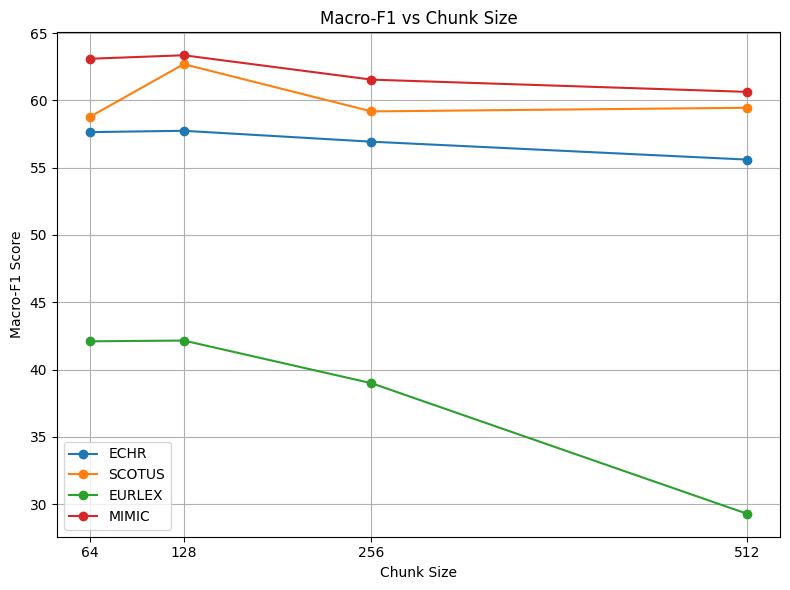
We conducted an ablation study to evaluate the impact of different chunk sizes, visualize the quality of the embedding space, and examine the performance of the CPE framework on short documents. Impact of chunk length: that EURLEX is highly sensitive to the chunk size parameter, likely because its shorter average text length means that larger chunks incorporate too much irrelevant detail.
Performance on short document corpus To evaluate our CPE framework on short documents, we perform experiments on the BIOASQ dataset. We followed the method outlined in Section 3.2, but instead of using the Longformer encoder, we utilized ClinicalBioBERT and BERT features, setting the length of the positive chunk to 64 tokens. We evaluated clustering quality using completeness and homogeneity measures. As shown in Figure 4, the completeness and homogeneity scores for CPE are 0.31 and 0.38, respectively, compared to 0.23 and 0.32 for SimCSE. This indicates a clear improvement in topic separation using the projected embeddings from CPE.
Training Time Table 8 presents the training time required by each model on the ECHR and SCOTUS datasets. Self-supervised contrastive learning using a CPE encoder requires approximately 3 h on ECHR and 1.5 h on SCOTUS dataset. In contrast, SimCSE and ESimCSE training takes place 4.5 on ECHR and 2.5 h on SCOTUS dataset.
SimCSE, and ESimCSE require significantly longer training times due to their document-level postive pair and negative pair. Our CPE training is more efficient because each positive and negative pair involves a single sampled chunk paired with an aggregated document context rather than encoding the entire document twice, reducing both computation and memory overhead.
Furthermore, for the evaluation of the document embedding in the downstream with an MLP head (1.78M trainable parameters), the training is light, taking less than 10 minutes per epoch on our hardware.
Table 9 demonstrates that the zero-shot prompting model LLAMA underperforms compared to embedding models (HBERT+MLP), primarily due to the extensive length of its prompts. Although the literature suggests that few-shot demonstrations can enhance model performance, the limited context window presents significant challenges when handling long documents, each averaging 4,096 tokens. Incorporating even one-shot examples into the prompt consumes nearly all available space, leaving insufficient room for the actual query. Furthermore, the LLAMA model tends to over-predict a limited number of classes while rarely predicting others, leading to imbalanced classification outcomes, as indicated by a low macro-F1 score.
reports classification results. The top rows show the performance of models using BERT embedding and the bottom rows display the performance of models using ClinicalBioBERT embedding. The ClinicalBioBERT Embedding CP E + MLP model produces the highest macro and micro F1 scores, achieving 71.28 and 84.43 macro F1 and micro F1-scores, respectively. This indicates that self-supervised CPE learning produces high-quality embeddings. Conversely, the state-ofthe-art ClinicalBioBERT Emb SimCSE + MLP and ClinicalBioBERT Emb ESimCSE + MLP models does not enhance the performance of the baseline model Embedding + MLP. This suggests that using only dropout augmentation or basic word repetition to form positive pairs for generating text embeddings yields little benefit for document-or paragraph-level representations, even though these techniques perform very well for sentence embeddings. Results demonstrate that the proposed CPE method improves embedding derived from Clini-calBioBERT by around 4% macro-F1.