Fine-tuning diffusion models via online reinforcement learning (RL) has shown great potential for enhancing text-to-image alignment. However, since precisely specifying a ground-truth objective for visual tasks remains challenging, the models are often optimized using a proxy reward that only partially captures the true goal. This mismatch often leads to reward hacking, where proxy scores increase while real image quality deteriorates and generation diversity collapses. While common solutions add regularization against the reference policy to prevent reward hacking, they compromise sample efficiency and impede the exploration of novel, high-reward regions, as the reference policy is usually sub-optimal. To address the competing demands of sample efficiency, effective exploration, and mitigation of reward hacking, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a versatile framework compatible with various RL algorithms. Our key insight is that regularization need not be applied universally; instead, it is highly effective to selectively penalize a subset of samples that exhibit high uncertainty. To address the exploration challenge, GARDO introduces an adaptive regularization mechanism wherein the reference model is periodically updated to match the capabilities of the online policy, ensuring a relevant regularization target. To address the mode collapse issue in RL, GARDO amplifies the rewards for highquality samples that also exhibit high diversity, encouraging mode coverage without destabilizing the optimization process. Extensive experiments across diverse proxy rewards and hold-out unseen metrics consistently show that GARDO mitigates reward hacking and enhances generation diversity without sacrificing sample efficiency or exploration, highlighting its effectiveness and robustness. Our project is available at https://tinnerhrhe.github.io/ gardo_project
Denoising diffusion and flow models trained on large-scale datasets have found great success in text-to-image generation tasks, exhibiting unprecedented capabilities in visual quality [25,42,59,62]. While supervised pre-training provides these models a strong prior, it is often insufficient for ensuring alignment with human preferences [38,50]. Reinforcement Learning (RL) has emerged as a predominant paradigm to address this gap, either employing online policy-gradient approaches [4,10,15,30,35,64] or direct reward backpropagation [7,63]. These methods typically assume a reward model r(x) that captures human preferences, and the training objective is to maximize the rewards over generated samples, i.e., E x∼π [r(x)]. Consequently, the accuracy of r(x) plays a critical role in finetuning performance. However, a key challenge arises from the nature of reward specification in vision. In contrast to the language domain, where rewards are often verifiable (e.g., the correctness of mathematical solutions or compiled code), rewards for visual tasks are typically more complex. Such rewards typically fall into two categories, both of which are imperfect proxies for genuine human preference: 1) Model-based rewards such as ImageReward [63], UnifiedReward [55], and HPSv3 [34] are trained on finite human preference datasets to approximate a groundtruth "genuine" reward, indicating that they are accurate only within their training data distribution; 2) Rule-based rewards such as object detection and text rendering (i.e., OCR) [5] are limited to evaluating specific attributes, and thus fail to capture the overall qualities of generated samples. These limitations expose a significant distribution shift [57] vulnerability: fine-tuning methods can rapidly over-optimize the proxy reward by generating images that fall outside the trusted support of the reward model. This often yields spurious reward signals and thereby leads to reward hacking [49], where proxy rewards increase while the actual quality of the images degrades.
To address this challenge, prior work has employed KLbased regularization during fine-tuning to mitigate overoptimization on these spurious reward signals [10,30,51].
However, as the online policy improves, the divergence from the static reference model can cause the KL penalty to dominate the RL loss. This often leads to diminishing policy updates, thereby impeding sample efficiency. Moreover, by design, the regularization constrains the online policy to remain in proximity to the reference model, which is often suboptimal. This can stifle effective exploration and prevent the discovery of emerging behaviors that are absent from the reference model.
Can we prevent reward hacking without compromising sample efficiency and effective exploration? In this paper, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a novel framework designed to overcome these limitations. Our gated regularization mechanism is motivated by the core insight: KL penalty is not universally required; Theoretically, only samples assigned with spurious rewards need regularization to prevent hacking. Accordingly, our gated mechanism applies the KL penalty selectively, targeting only a small subset (e.g., ≈10%) of samples within each batch that exhibit the highest reward uncertainty [2]. We quantify this uncertainty by measuring the disagreement among an ensemble of reward functions, which serves as an effective proxy for the trustworthiness of the reward signal. High disagreement signifies that a generated sample likely falls into an out-of-distribution region where the reward models are extrapolating unreliably. To further accelerate training and sustain exploration, GARDO incorporates an adaptive regularization target. We periodically update the reference model with a recent snapshot of the online policy, facilitating continual improvement while retaining the stabilizing benefits of KL regularization. Finally, to enhance mode coverage, we introduce a diversity-aware optimization strategy. This is achieved by carefully amplifying the advantage term for high-quality samples that also exhibit high diversity. This amplification is carefully calibrated to ensure it neither dominates nor reverses the sign of the original advantage, which encourages broader exploration without destabilizing the optimization.
Our contributions are summarized as follows: (i) We provide a systematic analysis of the reward hacking phenomenon in RL-based fine-tuning for text-to-image alignment, identifying the core limitations of existing regularization techniques. (ii) We make a novel innovation on traditional KL regularization. First, a gated regularization method selectively applies penalties only to highuncertainty samples, thereby allowing the majority of samples to be optimized freely towards high-reward regions. Second, an adaptive regularization target facilitates continual improvement and sustained exploration by dynamically updating the reference anchor. (iii) We propose a robust and generalist diversity-aware approach to improve generation diversity and mode coverage for diffusion RL. (iv) Ex-tensive experiments on multiple tasks across different proxies and unseen metrics demonstrate both the efficiency and effectiveness of our proposed method. Our work demonstrates that it is possible to successfully balance the competing demands of sample efficiency, exploration, and diversity, all while robustly mitigating reward hacking during the fine-tuning of image generative models.
Fine-Tuning Diffusion Models via Rewards. Recent research has increasingly focused on fine-tuning pre-trained diffusion models using reward signals derived from human feedback. A reward model (RM) is trained on a finite dataset, learning to assign a scalar score that approximates true human preference [31,56,60,63]. Typical methods include policy-gradient RL [3,11,36], direct preference optimization (DPO) [29,31,33,52,65,68,69], and direct reward backpropagation [6,40,63]. Recently, Flow-GRPO [30] and DanceGRPO [64] have adapted GRPO for finetuning cutting-edge flow matching models, showing strong performance and inspiring subsequent research [12,19,27,53,54,67,71]. Reward Hacking. Fine-tuning with either model-based or rule-based reward models for alignment of visual generation is highly susceptible to reward hacking [26,49]. This issue arises because the reward model is an imperfect proxy for the true human preference. As a generative model optimizes against this proxy, it often discovers adversarial solutions that exploit the reward model’s flaws, such as favoring extreme saturation or visual noise [6,31], to achieve a high score, despite failing to satisfy human intent. To address this, standard methods like DPOK [10] and Flow-GRPO [30] employ KL regularization to constrain the policy update. While this can prevent the most egregious forms of reward hacking, it often sacrifices convergence speed and hinders effective exploration. Another line of work, exemplified by RewardDance [60], focuses on improving the reward model itself through scaling; however, this does not eliminate the vulnerability to out-of-distribution samples. Concurrently, Pref-GRPO [54] utilizes a pairwise preference model to provide a more robust reward signal and avoid illusory advantages. This approach, however, is not universally applicable as it is limited to preference-based reward models and incurs substantial computational costs for pairwise comparisons.
Both diffusion models and flow models map the source distribution, often a standard Gaussian distribution, to a true data distribution p 0 . As shown in previous works [17,22,48], these models can utilize an SDE-based sampler dur-ing inference to restore from diffused data. Inspired by DDPO [4], we formulate the multi-step denoising process in flow and diffusion-based models as a Markov Decision Process (MDP), defined by a tuple (S, A, R, P, ρ 0 ). At each denoising step t, the model receives a state s t ≜ (c, t, x t ), and predicts the action a t ≜ x t-1 based on the policy π(a t |s t ) ≜ p θ (x t-1 |x t , c). A non-zero reward R(s t , a t ) ≜ r(x 0 , c) is given only at the final step, where R = 0 if t ̸ = 0. The transition function P is deterministic. At the beginning of each episode, the initial state s T is sampled from the initial state distribution ρ 0 . The goal is to learn a policy π * = arg max π E ρ0,at∼π(st) R(s 0 , a 0 )] by maximizing the expected cumulative reward R.
Reinforcement Learning (RL) [4,10] has been widely used for enhancing sample quality by steering outputs towards a desired reward function. Unlike earlier approaches based on PPO [45] or REINFORCE [58], recent methods [30,64] have demonstrated greater success using GRPO [46]. We take GRPO as the base RL algorithm throughout our paper. GRPO rollouts {x i 0 } G i=1 samples conditioned on the same input c, and estimates the advantage within each group:
Then the following surrogate objective optimizes π θ :
with r i t = π θ (a t |s t )/π θ old (a t |s t ) the importance sampling ratio, π θ old the behavior policy to sample data, ϵ the clipping range of r t , and D KL the KL regularization term.
We first present the reward hacking issues in image generation as a motivated example. Subsequently, we provide a theoretical analysis, and propose practical methods to address the problem. Finally, we provide a didactic example for empirical validation to illustrate our method clearly.
We investigate RL in the context of fine-tuning text-toimage models. Here, the reward function is often a neural network trained on finite preference data or a rule-based metric, which serves as just a proxy for the true reward. Misalignment between the two objectives can lead to reward hacking: a learned policy performs well according to the proxy reward but not according to the true reward [39]. Definition 1 (Reward hacking [26]). Suppose R is a proxy reward used during RL fine-tuning, and R denotes the true reward. R is a hackable proxy with respect to π ref s.t.
is the RL objective, and π ref is the reference policy.
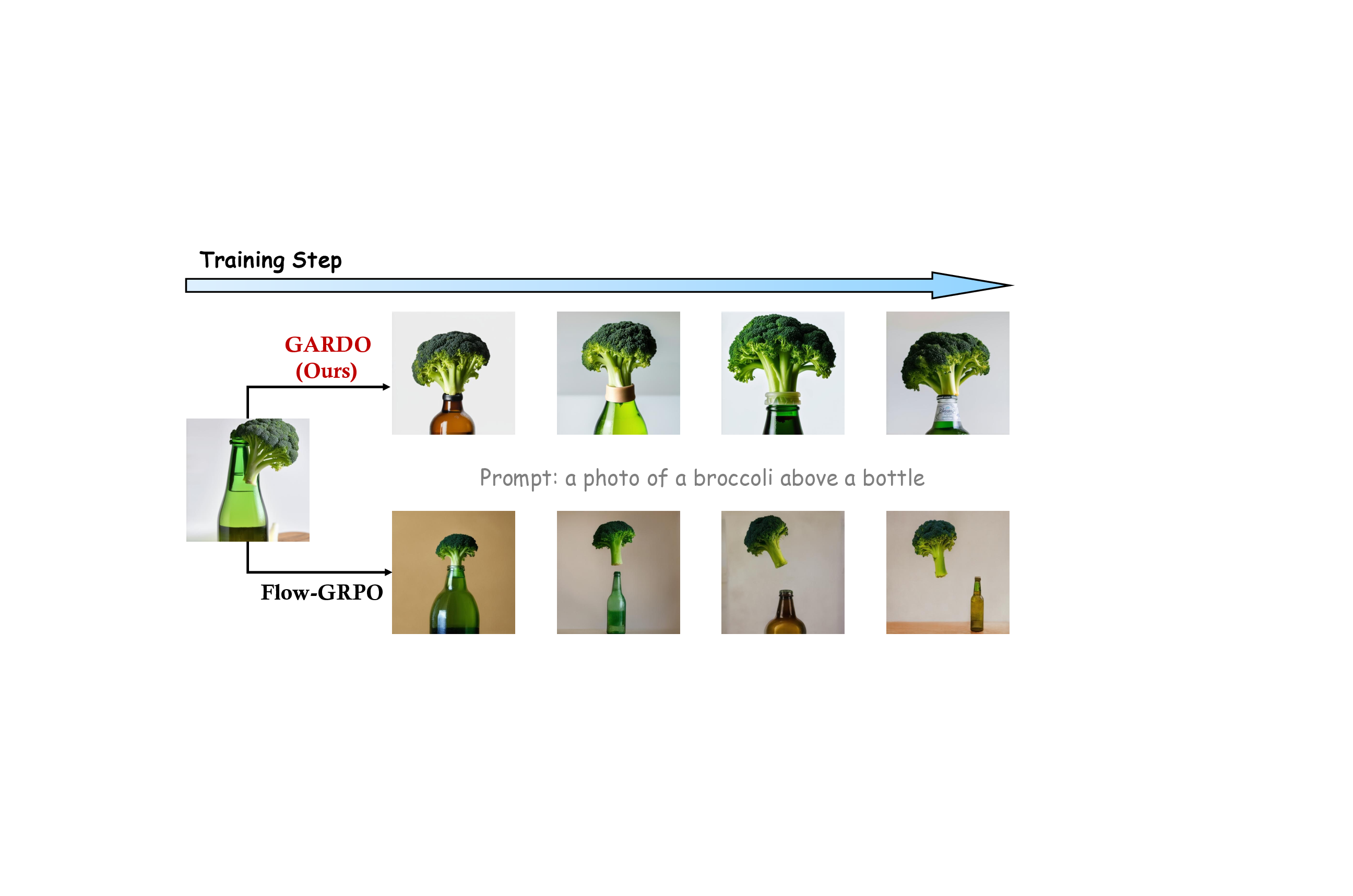
As demonstrated in Figure 1, standard methods like Flow-GRPO [30] maximize the proxy score (i.e., OCR) at the expense of perceptual quality, failing to align with the true human preferences. Previous methods [51] address this issue by incorporating a KL divergence regularization term,
where β controls the regularization strength. This kind of approach mitigates reward hacking (or reward overoptimization) by explicitly penalizing significant deviations of the online policy, π, from the reference policy, π ref .
However, this strategy introduces two significant limitations. First, because the reference policy π ref is typically suboptimal, the regularization loss can impede learning, leading to poor sample efficiency. Second, the constant penalty constrains π θ to exploit the “safe” region around π ref , preventing it from discovering novel behaviors or solutions that are absent from the reference model.
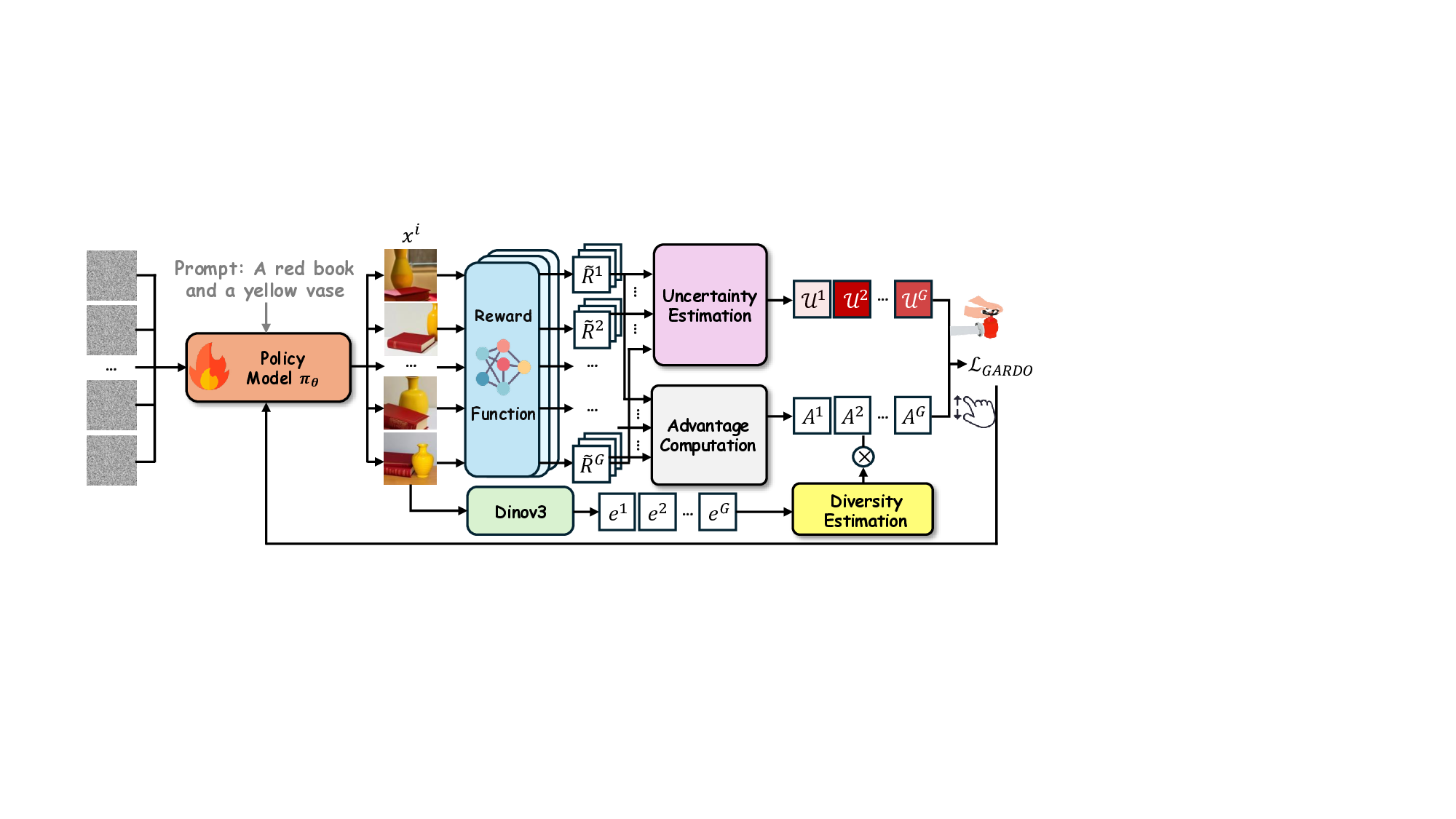
Ideally, for fine-tuning image generative models via RL, our goal is to reconcile the following competing objectives: (i) optimizing π θ with high sample efficiency, (ii) avoiding reward hacking and over-optimization, (iii) encouraging exploration to high-reward, novel modes which may be missing from π ref , and (iv) preserving generation diversity. Conventional KL regularization is effective in accomplishing (ii) and (iv), but often at the expense of (i) and (iii). This inherent trade-off motivates our work. Based on our theoretical findings, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a novel framework that is simple, effective, and capable of satisfying all these objectives simultaneously. Overview of GARDO is illustrated in Fig. 2, and we detail our method in the subsequent sections.
First, we investigate the reasons of reward hacking. As discussed in previous works [16,50,61], the optimal solution to the KL-regularized objective in Eq (4) can be written as
where Z is an intractable normalization constant [41]. Here, p * (x) is largely defined by both the reference model π ref (x) and the proxy reward R(x).
Proposition 1 The probability ratio between any two samples, x 1 and x 2 , under the optimal solution distribution defined in Eq. ( 5) is given by the following closed form,
If
), then their probability difference is defined solely by the proxy reward, i.e., p * (x 1 )/p * (x 2 ) = exp(( R(x 1 ) -R(x 2 ))/β). Reward hacking arises when the proxy reward is misaligned with the true reward, R. For example, if R(x 1 ) > R(x 2 ) while R(x 1 ) < R(x 2 ), the model will incorrectly assign a higher sampling probability to the lower-quality sample, x 1 . However, in other cases, such as ‘x 1 > x 2 ’ holds for both R and R, the proxy is reliable and does not lead to reward hacking. Inspired by this finding, we have the following key insight:
Regularization is not universally required. It is required only for samples with spurious proxy reward R.
The application of KL regularization should be conditional on the alignment between proxy and true rewards. Universally penalizing all samples introduces unnecessary regularization signals, thereby impeding convergence. Gated KL Mechanism. KL is gated for selective samples. We propose an uncertainty-driven approach to select samples for regularization during the training process [1]. Only samples that exhibit high uncertainty U will be penalized, where U reflects the trustworthiness of the proxy reward [8]. Our approach for quantifying uncertainty is inspired by prior work in reinforcement learning [2], where the uncertainty is often estimated using the disagreement within an ensemble learned
In the denoising MDP of image generation, considering the proxy R is a function of the final state x 0 , we can simplify the uncertainty quantification as U (s t ) := Std(V k (s t )). However, directly learning ensemble K value functions from scratch is computationally prohibitive for large-scale generative models, given their vast state space and the complexity of the image generation process. To circumvent this challenge, we adopt a more practical approach that approximates the value function using readily available, pre-trained reward models [28]. Instead of leveraging the deviation among ensemble value functions for estimating uncertainty, we propose a new un- certainty quantification approach:
where w(y i ) = 1 B j̸ =i I(y i > y j ) denotes the win rate within a batch of size B, and { Rn } K n=1 are the auxiliary reward models. Under this formulation, a high uncertainty score arises when w( R) ≫ mean({w( Rn )} K n=1 ), effectively flagging samples with anomalously high proxy R compared to the ensemble. We choose light-weight Aesthetic [44] and ImageReward [63] as R throughout our paper (i.e., K=2), thereby the computation cost is negligible. Note that only R is optimized during fine-tuning, while R only serves as a metric for estimating uncertainty. Surprisingly, a key empirical finding of our work is that this selective penalization is highly efficient. We find that applying the KL penalty to only a small subset of samples (e.g., approximately 10 %) with the highest uncertainty is sufficient to prevent reward hacking. Adaptive KL Regularization. While the gated KL mechanism penalizes only high-uncertainty samples, we observe that the sample efficiency still slows as training progresses. As indicated in Proposition 1, π ref also plays a pivotal role in determining the optimal distribution. If R(x 1 ) = R(x 2 ), a failure mode arises if π ref (x 1 ) ≪ π ref (x 2 ), resulting p * (x 1 ) ≪ p * (x 2 ), which is not an expected behavior. We remark that a static reference model becomes increasingly sub-optimal, particularly at later training stages, which can affect the optimization a lot. To mitigate this limitation and facilitate sustained improvement, we propose an adaptive regularization objective. We periodically hard-resets the reference model π ref to the current policy at specific epochs, allowing it to remain updated. In particular, the reference model is updated whenever the KL divergence D KL surpasses a pre-defined threshold ϵ KL , or, failing that, after a maximum of m gradient steps. Our proposed adaptive KL mechanism ensures the regularization target remains relevant, preventing the KL penalty from dominating the RL loss and halting exploration, thereby achieving sustained policy improvement.
A static reference model inevitably becomes a constraint on RL optimization. Dynamically updating the reference model facilitates prolonged improvement.
As noted by Liu et al. [30], a significant consequence of reward hacking is the reduced diversity. This issue is exacerbated by the intrinsically mode-seeking nature of reinforcement learning, which often struggles to capture multimodal distributions [23]. Enhancing sample diversity is therefore critical not only for preventing mode collapse but also for broadening the policy’s exploration space. While our gated and adaptive regularization scheme effectively mitigates reward hacking without sacrificing sample efficiency, it does not explicitly promote generation diversity. To address this limitation, we introduce a diversity-aware optimization strategy that amplifies rewards for high-quality samples that also exhibit high diversity. Diversity-Aware Advantage Shaping. The core idea is to reshape the advantage function by incorporating a diversitybased signal during policy optimization. Specifically, for a group of generated samples, {x i 0 } G i=1 ∼ p θ (x 0 |c), we first map each sample from the pixel space into a semantic feature space, obtaining feature embeddings e i for each clean image x i 0 . We employ DINOv3 [47] for the feature extraction, which serves as a powerful vision foundation model. A sample’s diversity is then quantified by its isolation in the feature space. We define a diversity score, d i , as the cosine distance to its nearest neighbor within the group, {e i } G i=1 . This diversity score is subsequently used to reshape the advantages, as illustrated as follows:
There are several key design principles for our proposed diversity-aware advantage reshaping: (1) We use a multiplicative re-weighting of the advantage term rather than an additive diversity bonus. This design circumvents the need for delicate hyperparameter tuning to balance the scales of the proxy reward and the diversity score, which could otherwise cause one signal to dominate the other. ( 2) The advantage shaping is applied only when a sample’s advantage is positive. This is a critical constraint that ensures the model is rewarded only for generating samples that are both highquality and novel. It explicitly prevents the model from generating aberrant or low-quality images simply to increase its diversity score. We summarize our method in the pseudocode in Alg. 1.
Multiplicative advantage reshaping exclusively within positive samples enables robust diversity improvement.
Empirical Validation. As illustrated in Fig. 3, we provide a didactic example to validate the superior efficacy of our method. We observe that only GARDO successfully captures all high-reward modes, reaching the maximum reward. The most notable outcome is GARDO’s discovery of the central cluster, a mode with only 0.1× probability density assigned by the reference model compared with other modes. This “mode recovery” capacity underscores GARDO’s potential for robust exploration, showing it can incentivize emerging behaviors that lie far from the pre-trained distribution. An Interesting Finding. Beyond the above techniques, we find that simply removing the standard deviation in advantage normalization also helps mitigate reward hacking. In image generation tasks, reward models often assign overly similar rewards R(x i 0 , c) to comparable images within the same group, causing an extremely small standard deviation, i.e., Std → 0. This dangerously amplifies small, and often meaningless, reward differences in Eq. ( 1), making training sensitive to reward noise and leading to over-optimization. While a concurrent work, Pref-GRPO [54], proposes to mitigate this issue by using a preference model to convert rewards into pairwise win-rates, this method is computationally expensive and lacks generality, as it relies on exhaustive pairwise comparisons and is restricted to preference-based reward models. In contrast, we propose a simpler, more efficient, and general solution: directly removing standard deviation (Std) from advantage normalization [18,32]. This imposes a natural constraint when rewards are similar, preventing harmful amplification.
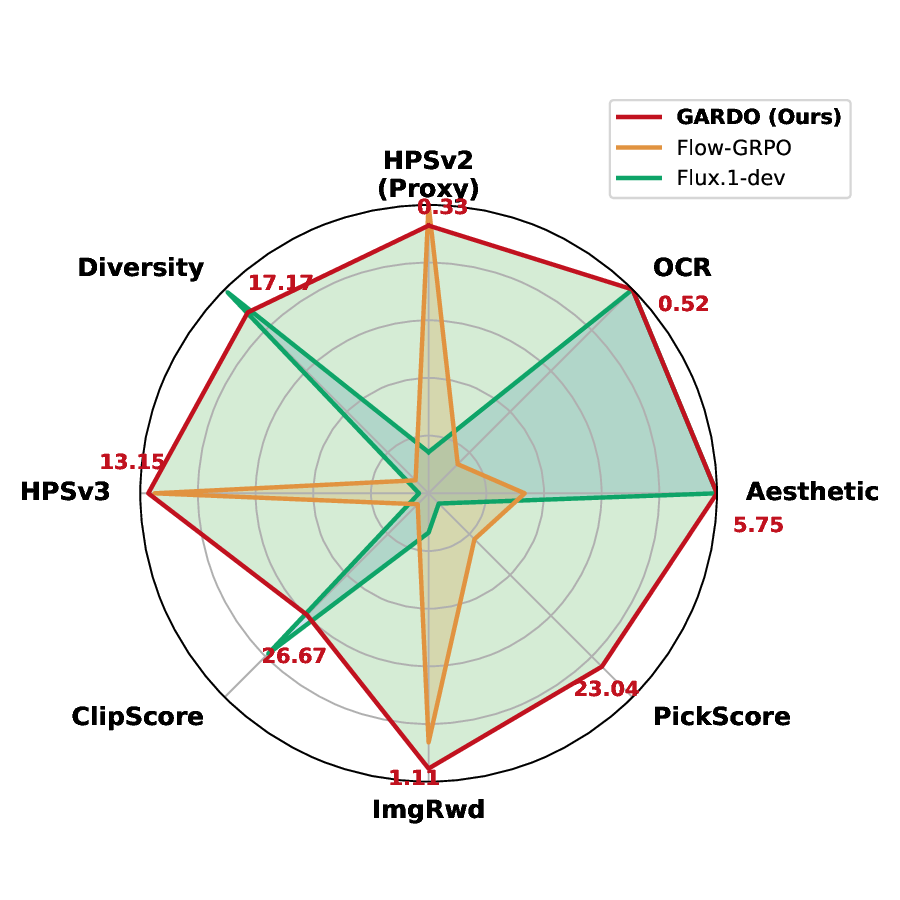
Setup. Following Flow-GRPO [30], we choose SD3.5-Medium [9] as the base model and GRPO as the base RL algorithm for empirical validation. To demonstrate the versatility of our framework across different base models and RL algorithms, we also provide additional results on Flux. 1-dev [25] and on a distinctly different online RL algorithm, DiffusionNFT [70], in Appendix B. Throughout all experiments, images are generated at 512×512 resolution. We fine-tune the reference model with LoRA [21] (α = 64, r = 32). We set group size G = 24 for estimating the diversity-aware advantages. Benchmarks. We employ multiple tasks with diverse metrics to evaluate the performance of our method for preventing reward hacking without sacrificing sample efficiency. We employ GenEval [13] and Text Render (OCR) [5] as the proxy tasks. GenEval evaluates the model’s generation ability on complex compositional prompts, including 6 different dimensions like object counting, spatial relations, and attribute binding. OCR measures the text accuracy of generated images. For these two tasks, we use the corresponding training and test sets from Flow-GRPO. We employ unseen metrics including Aesthetic [44], PickScore [24], ImageReward [63], ClipScore [20], and HPSv3 [34] for assessing the o.o.d. generalization performance. For evaluating the diversity of the generated images, we use the mean of pairwise cosine distance across a group of images for quantification, i.e., Div = mean i,j∈ [1,G],i̸ =j (1-ei•ej |ei||ej | ). More implementation details are provided in Appendix A.
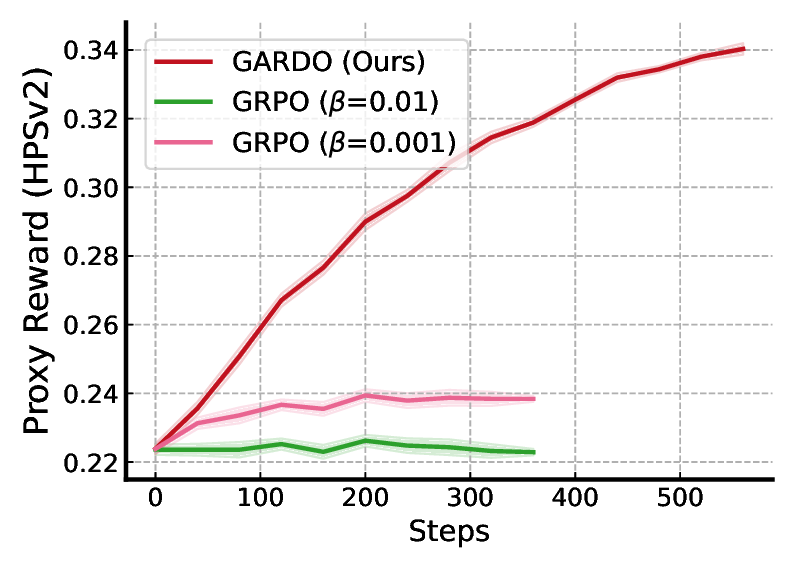
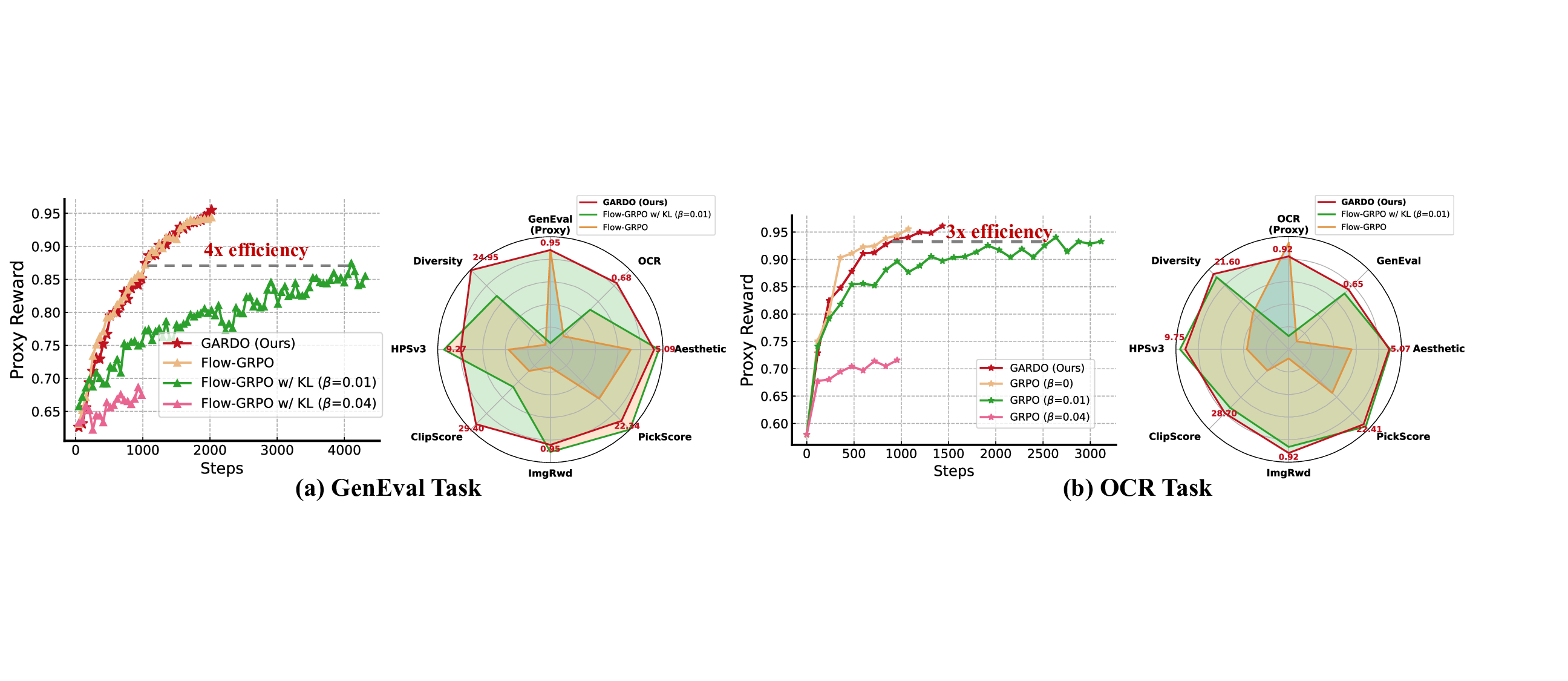
Removing Std from Advantage Normalization is Useful. As shown in Table 1, eliminating standard deviation normalization alleviates reward hacking and improves performance on unseen rewards compared to the baseline, while largely preserving sample efficiency and high proxy rewards. However, its performance on unseen metrics still falls short of the reference model. This observation clearly demonstrates that, while this technique is valuable, it is insufficient on its own to fully resolve the reward hacking problem as defined in Definition 1. Efficiency vs. Reward Hacking. The results in Table 1 highlight a critical trade-off inherent in RL-based finetuning. The GRPO (β = 0) baseline, while achieving a high proxy reward, suffers from severe reward hacking, as evidenced by its poor performance on unseen metrics such as Aesthectic, HPSv3, and diversity. Adding a KL penalty mitigates this over-optimization but at a significant cost to sample efficiency, resulting in a proxy reward that is over 10 points lower given the same computational budget. In contrast, our proposed method successfully reconciles this trade-off. As illustrated in Fig. 4, it achieves a proxy reward comparable to the strongest KL-free baseline while simultaneously preserving high unseen rewards. Notably, GARDO’s generalization performance not only matches but in some cases surpasses that of the original reference model. Quantitative results on GenEval tasks are provided in Fig. 6. After training over the same steps, we find that only GARDO successfully follows the instruction and generates high-quality images, while vanilla GRPO ob-viously hacks the proxy reward, generating noisy images with blurred backgrounds and Gibbs artifacts.
Prompt: A lighthouse stands by the shore Diversity-Aware Advantage Shaping Improves Diversity. The results in Table 1 demonstrate that our proposed diversity-aware optimization leads to a remarkable increase in sample diversity scores, i.e., 19.98 → 24.95 for GenEval. Visualization is provided in Fig. 5 to further validate this efficacy. This increased diversity broadens the policy’s exploration space, enabling it to discover novel states beyond the initial data distribution. This, in turn, prevents convergence to a narrow set of solutions (i.e., mode collapse). Ultimately, the enhanced exploration translates into improved final performance on both proxy and unseen metrics. Gated and Adaptive KL Enhances Sample Efficiency without Reward Hacking. As shown in Table 1, ‘GARDO w/o div’, which comprises only the gated and adaptive KL regularization, is sufficient to overcome the sample efficiency bottleneck of standard regularization, matching the convergence speed of the KL-free baseline while still mitigating reward hacking. It achieves a 0.91 OCR score given 600 steps without compromising the unseen rewards. This success is accomplished through two key components: (1)
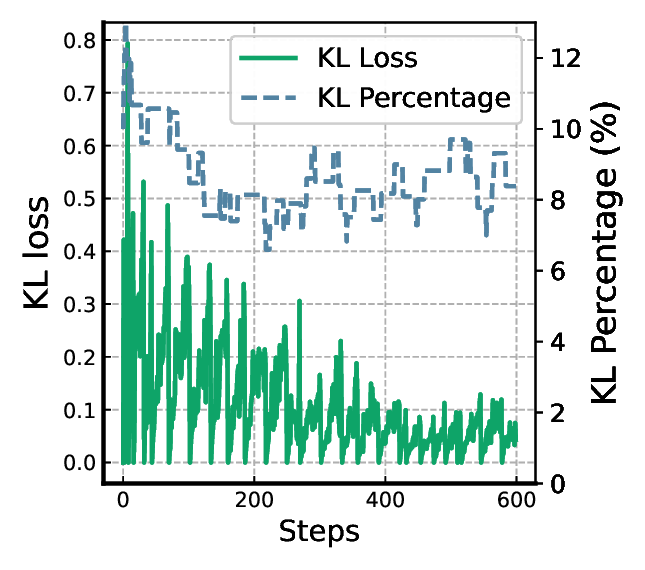
The adaptive regularization dynamically updates the reference model to prevent excessive regularization from a suboptimal anchor, and (2) the gated KL identifies and applies a relatively high regularization specifically to “illusory” samples with high reward uncertainty, thus avoiding unnecessary penalties. The dynamics of KL percentage and KL loss are provided in Fig. 8a, where only around 10% of the samples are penalized. Fig. 7 shows the examples that are identified as highly uncertain and thus penalized.
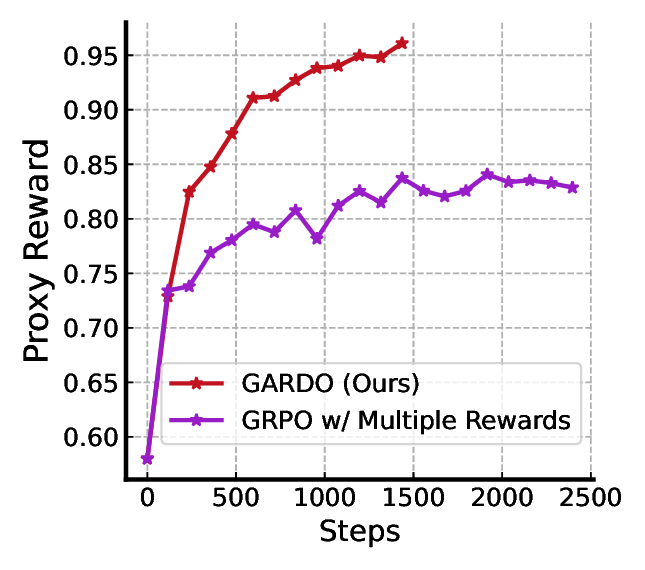
Comparison with Multiple Reward Training. While we leverage an ensemble of off-the-shelf reward models for uncertainty estimation, the policy itself is optimized against only a single proxy reward. This differentiates our approach from multi-objective reinforcement learning (MORL) methods, which seek to balance a weighted combination of multiple, often competing, reward signals. To demonstrate the superiority of our approach, we compare GARDO with the policy trained by multiple rewards, i.e., 0.8×OCR(Proxy)+0.1×Aesthetic+0.1×Imagereward. This baseline is unregularized to maximize the sample efficiency. From the results shown in Fig. 8b, we observe that RL trained with multiple rewards exhibits significantly lower sample efficiency with respect to the primary OCR proxy reward. This finding is aligned with previous multiobjective RL literature [66], highlighting the challenges of optimizing for conflicting or misaligned rewards.
By eliminating universal KL regularization for all samples and periodically resetting the reference model according to the learning dynamic, along with the diversity-aware optimization, we can effectively unlock the emerging behavior that is missing from the base model [14]. We validate this using a challenging counting task: the model is trained on datasets containing 1-9 objects and then tested on its ability to generate 10-11 objects, where the base model consistently fails. The results in Table 2 show that GARDO significantly improves the counting accuracy. This is particularly evident in the difficult task of generating 10 objects, where the base model exhibits near-zero accuracy. We provide the visualization results of GARDO counting 11 objects in Fig. 9.
In this paper, we propose a novel and effective approach to address the challenge of reward hacking in fine-tuning diffusion models. We introduce a gated and adaptive regularization mechanism for more fine-grained control, and a diversity-aware strategy to encourage mode coverage, which significantly enhances sample efficiency and emerging behaviors. Nevertheless, a primary limitation of our method is its dependency on auxiliary reward models for uncertainty estimation. Consequently, the scalability of our approach to resource-intensive video generative models remains an open question for future investigation. Unseen Tasks We adopt DrawBench [43] for evaluation, which consists of 200 prompts spanning 11 different categories, serving as an effective test set for comprehensive evaluation of the T2I models. For each prompt, we generate four images for evaluation for a fair and convincing comparison. We employ Aesthetic [44], PickScore [24], ImageReward [63], ClipScore [20], and HPSv3 [34] for extensive evaluation of the o.o.d. generalization ability, and detecting the degree of reward hacking. For the diversity score, we employ Dinov3 [47] to extract feature embeddings e i of each image. Then we use the mean of pairwise cosine distance across a group of images for diversity quantification:
where a group of images is generated, given the same prompt.
GARDO is built upon an existing regularized-RL objective, which can be compatible with various RL algorithms.
To demonstrate GARDO’s versatility, we apply it to a recently released RL algorithm, DiffusionNFT [70]
We provide the generated images along the training process in Fig. 13 and Fig. 14. As the training step increases, we observe that Flow-GRPO obviously hacks the reward ( or exploits the flaws), yielding reduced perceptual visual quality. However, GARDO remains a high visual quality throughout the training process, without compromising optimization performance on the proxy reward.
A yellow book and a red vase
Flow-GRPO
Prompt: a photo of an orange motorcycle and a pink donut
This content is AI-processed based on open access ArXiv data.