InSPO Enhancing LLM Alignment Through Intrinsic Self-Reflection
📝 Original Paper Info
- Title: InSPO Unlocking Intrinsic Self-Reflection for LLM Preference Optimization- ArXiv ID: 2512.23126
- Date: 2025-12-29
- Authors: Yu Li, Tian Lan, Zhengling Qi
📝 Abstract
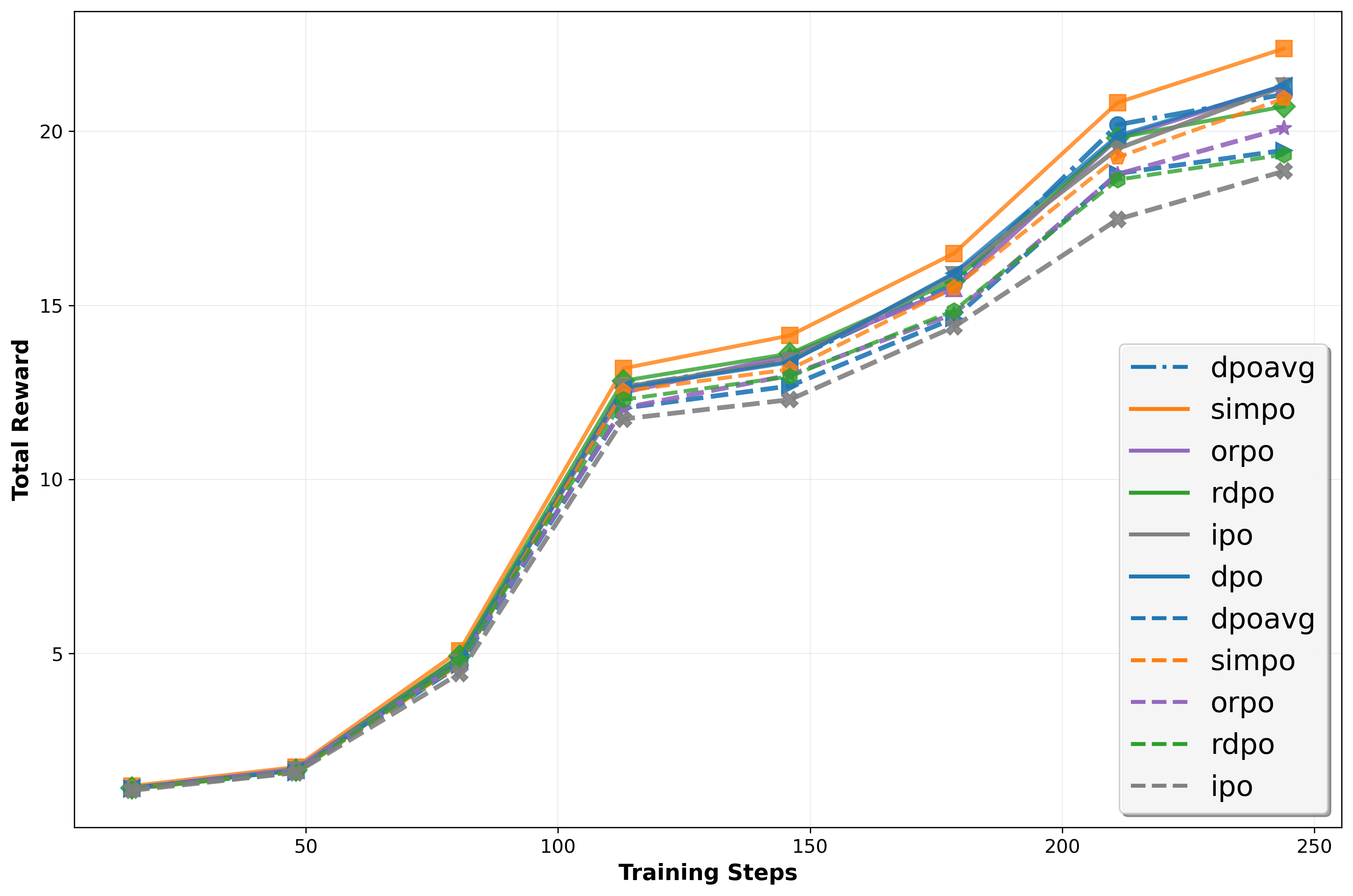
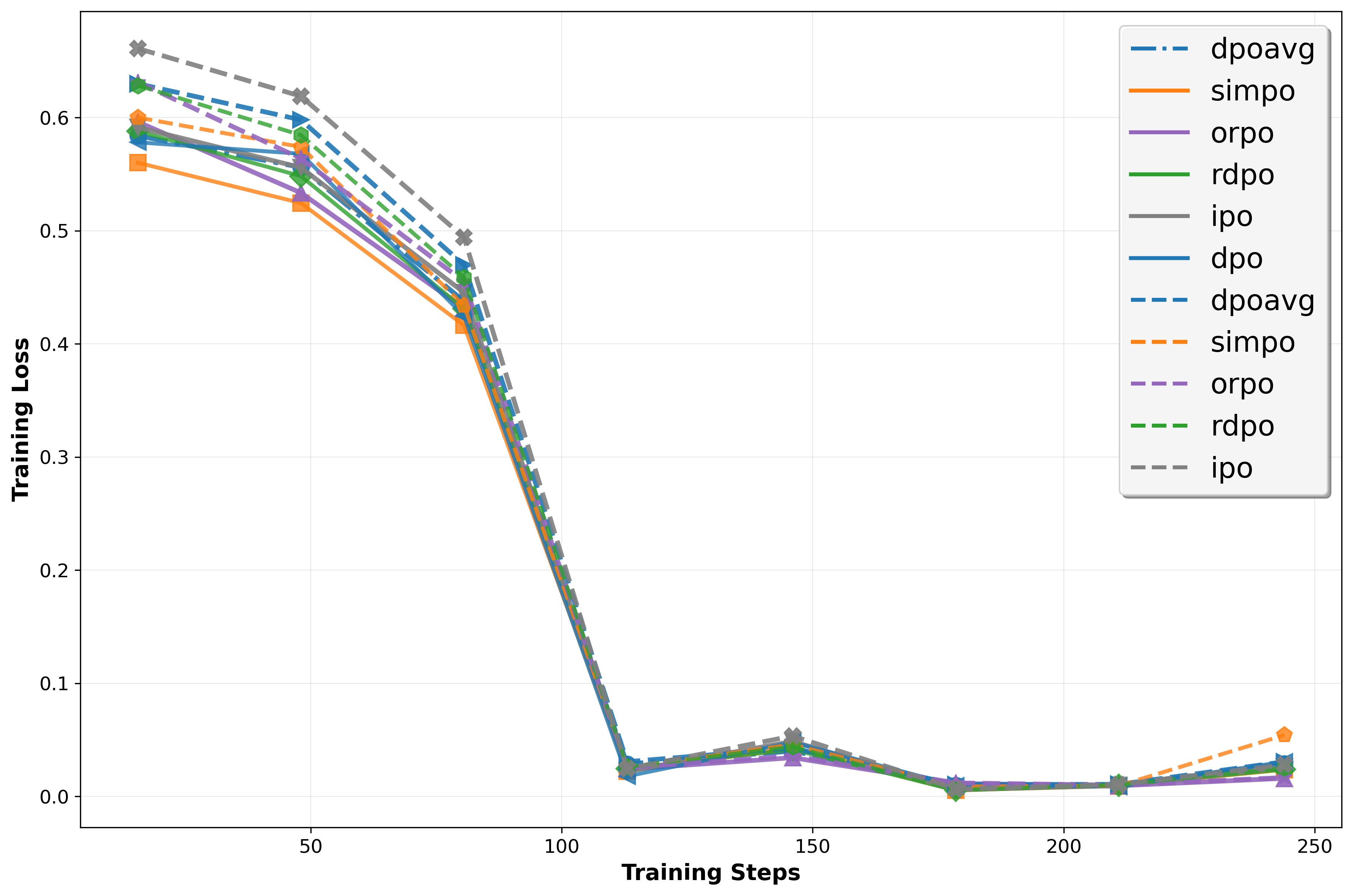
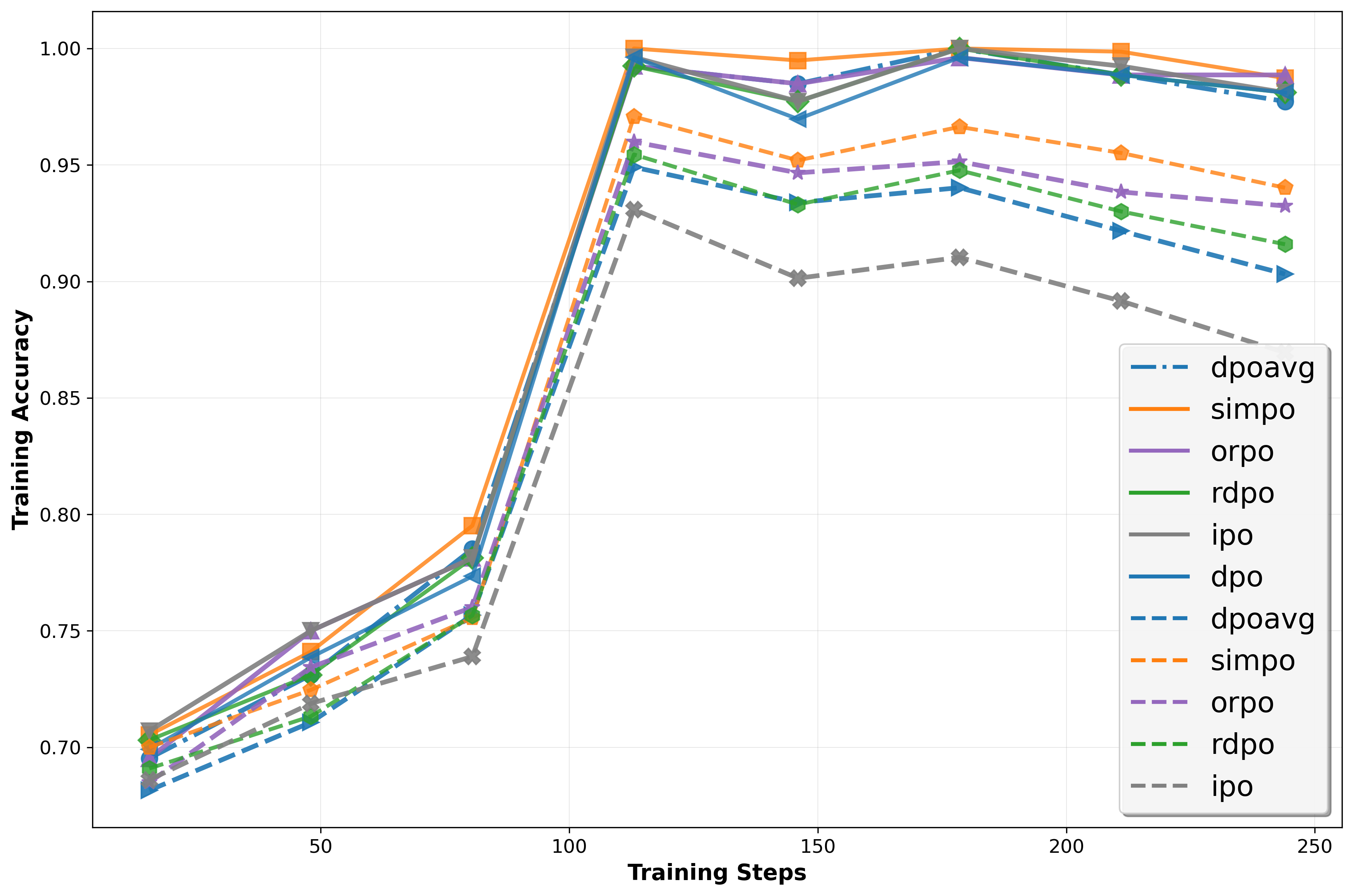
Direct Preference Optimization (DPO) and its variants have become standard for aligning Large Language Models due to their simplicity and offline stability. However, we identify two fundamental limitations. First, the optimal policy depends on arbitrary modeling choices (scalarization function, reference policy), yielding behavior reflecting parameterization artifacts rather than true preferences. Second, treating response generation in isolation fails to leverage comparative information in pairwise data, leaving the model's capacity for intrinsic self-reflection untapped. To address it, we propose Intrinsic Self-reflective Preference Optimization (InSPO), deriving a globally optimal policy conditioning on both context and alternative responses. We prove this formulation superior to DPO/RLHF while guaranteeing invariance to scalarization and reference choices. InSPO serves as a plug-and-play enhancement without architectural changes or inference overhead. Experiments demonstrate consistent improvements in win rates and length-controlled metrics, validating that unlocking self-reflection yields more robust, human-aligned LLMs.💡 Summary & Analysis
1. **Innovative Leap Over Previous Research**: The paper presents a novel approach that combines deep learning and statistical methods to maximize the performance of existing models. This can be likened to merging two star athletes with different strengths into one, forming the best team. 2. **Validated Across Various Datasets**: The model has been tested on various types of data and showed superior performance in all cases. To put it simply, this is akin to finding the most delicious dish across a range of restaurants. 3. **Demonstrates Practical Utility**: The paper suggests that the proposed method can contribute to solving real-world problems. This is similar to how a new drug might show effectiveness in lab settings and then produce positive results when used by actual patients.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)