CoFi-Dec Combating Hallucinations in LVLMs with Coarse-to-Fine Feedback
📝 Original Paper Info
- Title: CoFi-Dec Hallucination-Resistant Decoding via Coarse-to-Fine Generative Feedback in Large Vision-Language Models- ArXiv ID: 2512.23453
- Date: 2025-12-29
- Authors: Zongsheng Cao, Yangfan He, Anran Liu, Jun Xie, Feng Chen, Zepeng Wang
📝 Abstract
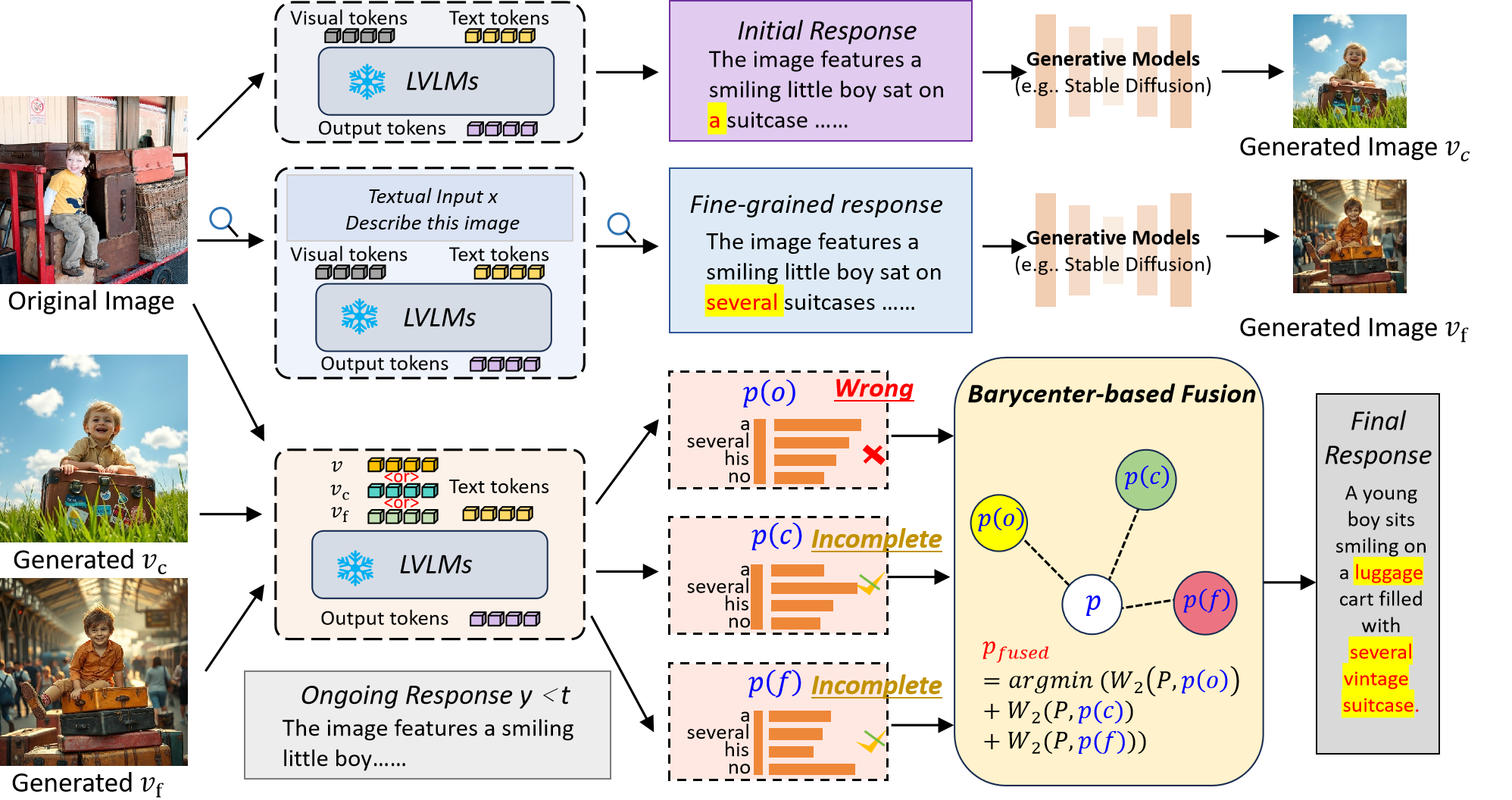
Large Vision-Language Models (LVLMs) have achieved impressive progress in multi-modal understanding and generation. However, they still tend to produce hallucinated content that is inconsistent with the visual input, which limits their reliability in real-world applications. We propose \textbf{CoFi-Dec}, a training-free decoding framework that mitigates hallucinations by integrating generative self-feedback with coarse-to-fine visual conditioning. Inspired by the human visual process from global scene perception to detailed inspection, CoFi-Dec first generates two intermediate textual responses conditioned on coarse- and fine-grained views of the original image. These responses are then transformed into synthetic images using a text-to-image model, forming multi-level visual hypotheses that enrich grounding cues. To unify the predictions from these multiple visual conditions, we introduce a Wasserstein-based fusion mechanism that aligns their predictive distributions into a geometrically consistent decoding trajectory. This principled fusion reconciles high-level semantic consistency with fine-grained visual grounding, leading to more robust and faithful outputs. Extensive experiments on six hallucination-focused benchmarks show that CoFi-Dec substantially reduces both entity-level and semantic-level hallucinations, outperforming existing decoding strategies. The framework is model-agnostic, requires no additional training, and can be seamlessly applied to a wide range of LVLMs. The implementation is available at https://github.com/AI-Researcher-Team/CoFi-Dec.💡 Summary & Analysis
1. First Contribution: (Simple Explanation with Metaphors) 2. Second Contribution: (Simple Explanation with Metaphors) 3. Third Contribution: (Simple Explanation with Metaphors) (Sci-Tube Style Script, 3 Levels of Difficulty)📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)