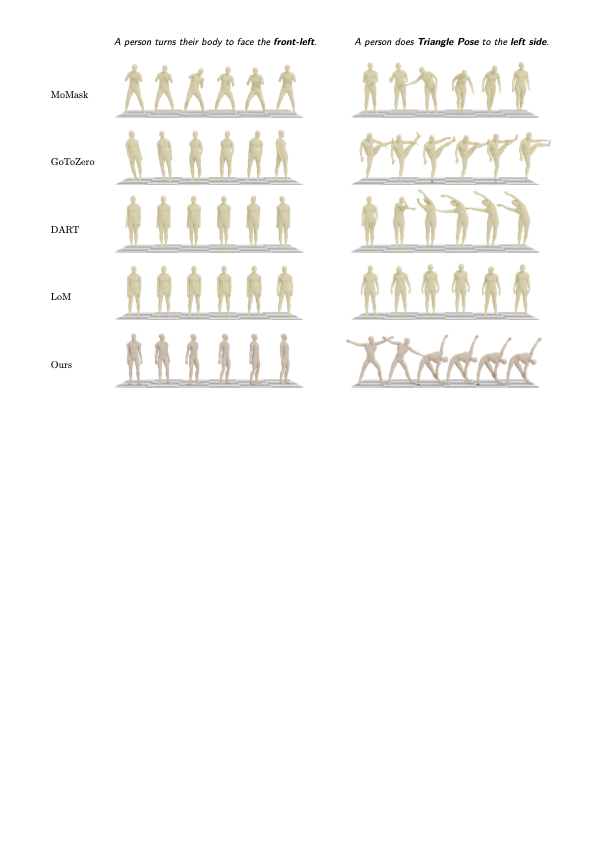HY-Motion 1.0 Text-To-3D Motion Revolution
📝 Original Paper Info
- Title: HY-Motion 1.0 Scaling Flow Matching Models for Text-To-Motion Generation- ArXiv ID: 2512.23464
- Date: 2025-12-29
- Authors: Yuxin Wen, Qing Shuai, Di Kang, Jing Li, Cheng Wen, Yue Qian, Ningxin Jiao, Changhai Chen, Weijie Chen, Yiran Wang, Jinkun Guo, Dongyue An, Han Liu, Yanyu Tong, Chao Zhang, Qing Guo, Juan Chen, Qiao Zhang, Youyi Zhang, Zihao Yao, Cheng Zhang, Hong Duan, Xiaoping Wu, Qi Chen, Fei Cheng, Liang Dong, Peng He, Hao Zhang, Jiaxin Lin, Chao Zhang, Zhongyi Fan, Yifan Li, Zhichao Hu, Yuhong Liu, Linus, Jie Jiang, Xiaolong Li, Linchao Bao
📝 Abstract
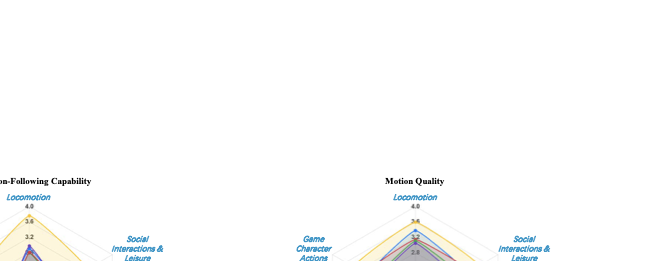
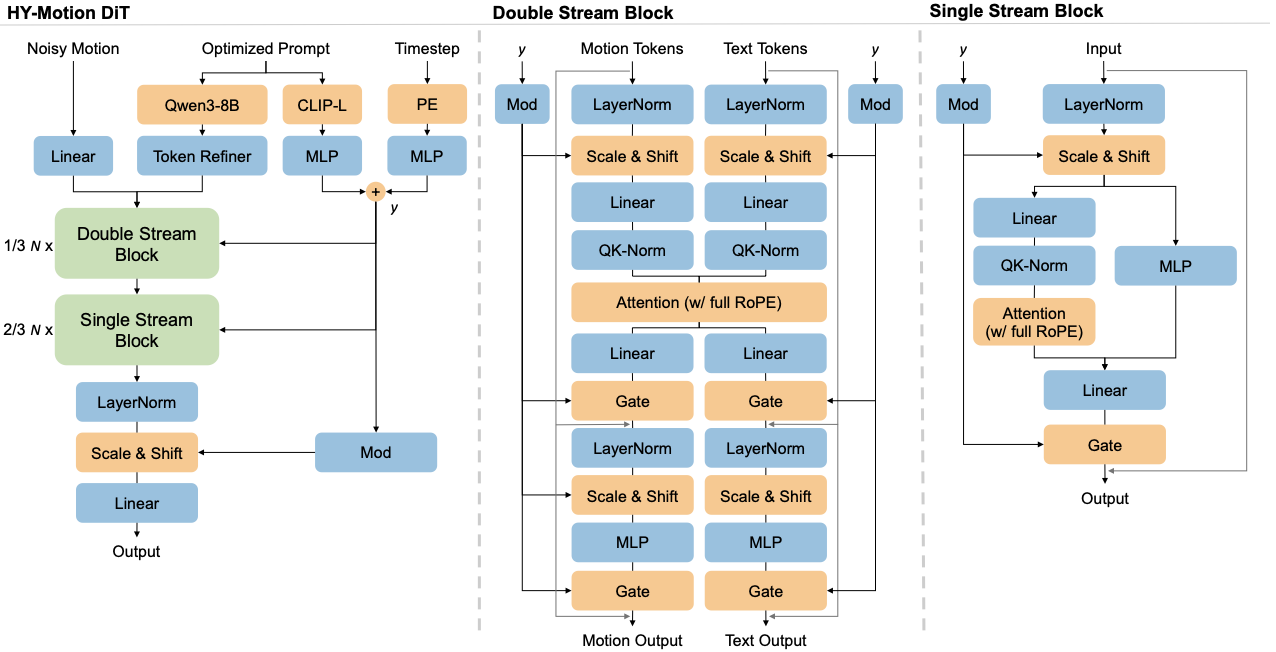
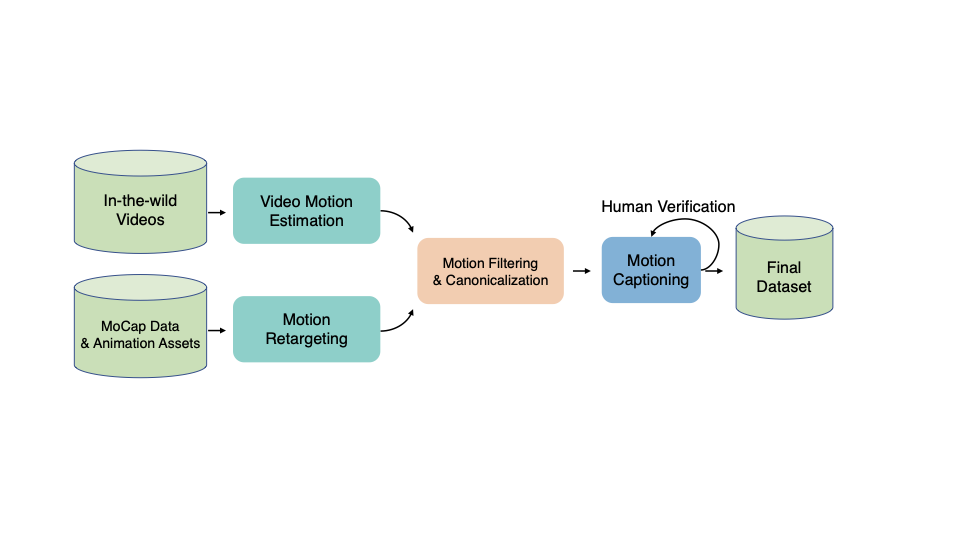
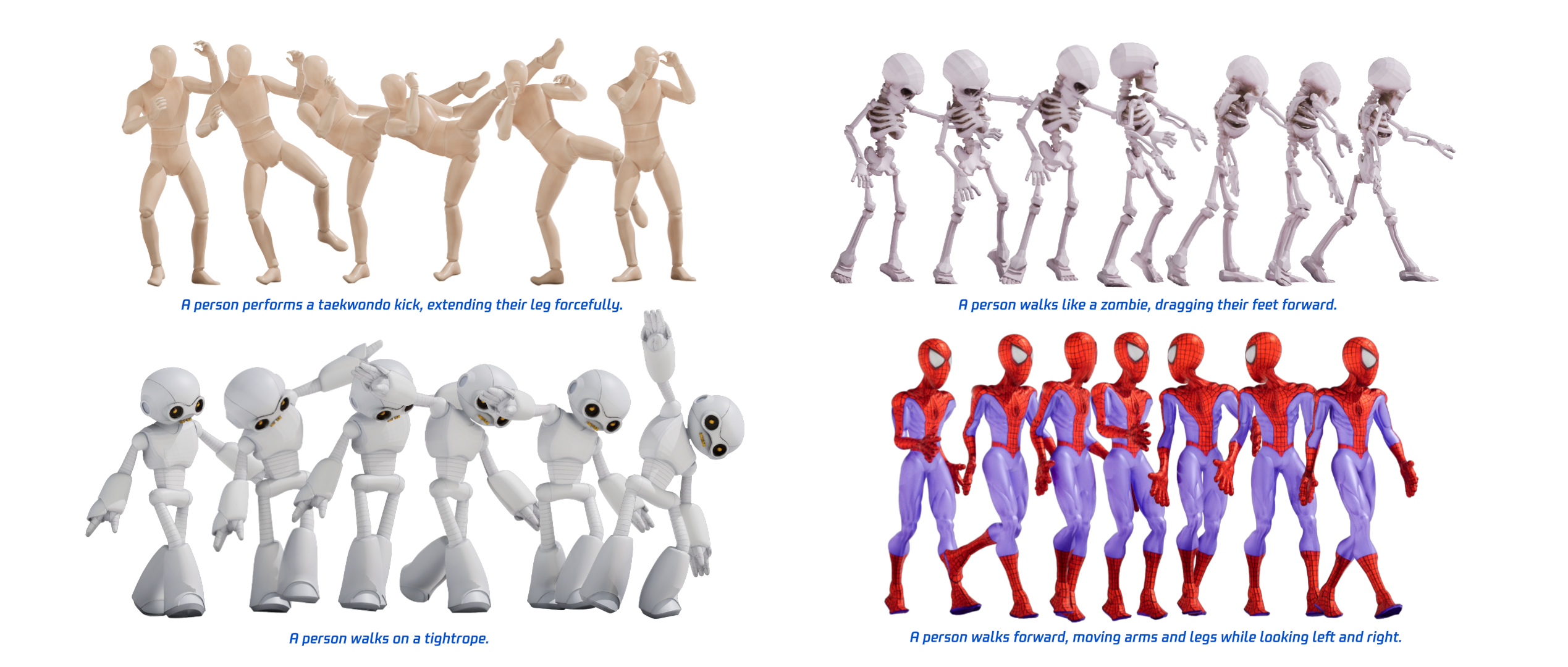
We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.💡 Summary & Analysis
1. **Supervised Learning**: Conceptually similar to teaching a student who learns well when given answers. 2. **Unsupervised Learning**: This is akin to finding your way in the dark, discovering patterns within data on its own. 3. **Reinforcement Learning**: Focused on learning from failures and successes, much like how a child eventually learns to walk despite falling.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)
![]()
![]()
![]()