SB-TRPO Balancing Safety and Reward in Reinforcement Learning
📝 Original Paper Info
- Title: SB-TRPO Towards Safe Reinforcement Learning with Hard Constraints- ArXiv ID: 2512.23770
- Date: 2025-12-29
- Authors: Ankit Kanwar, Dominik Wagner, Luke Ong
📝 Abstract
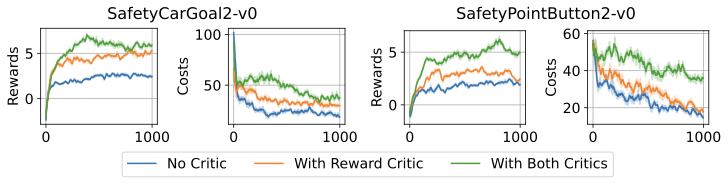
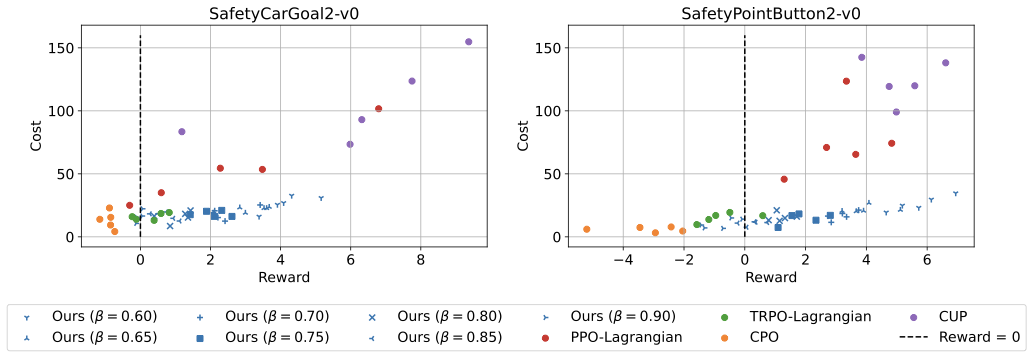
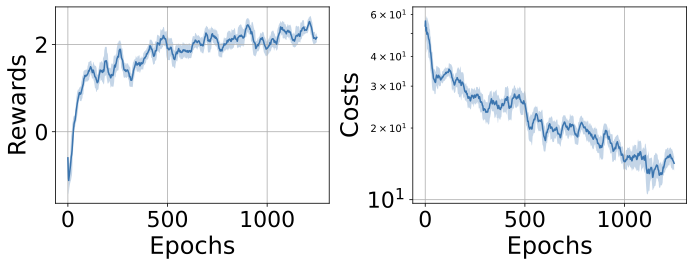
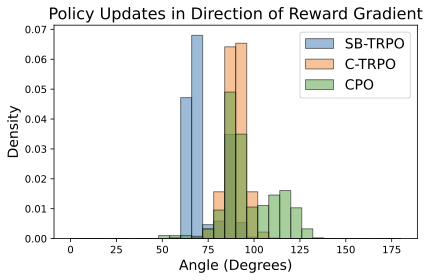
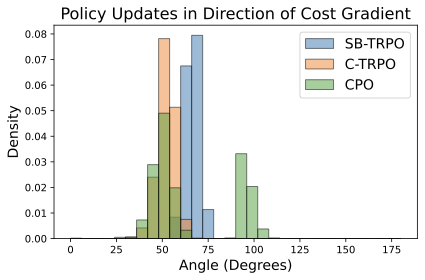
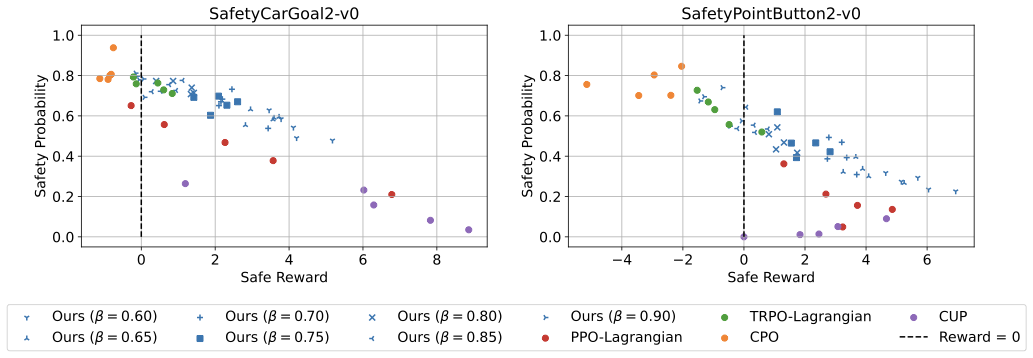
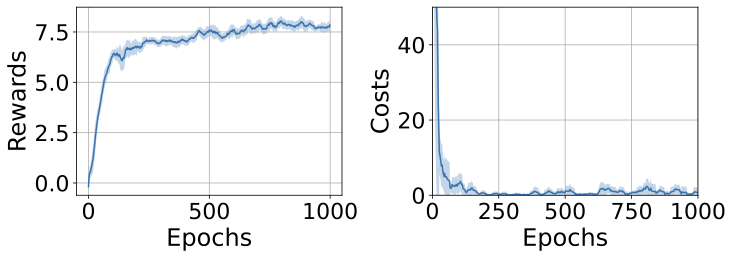
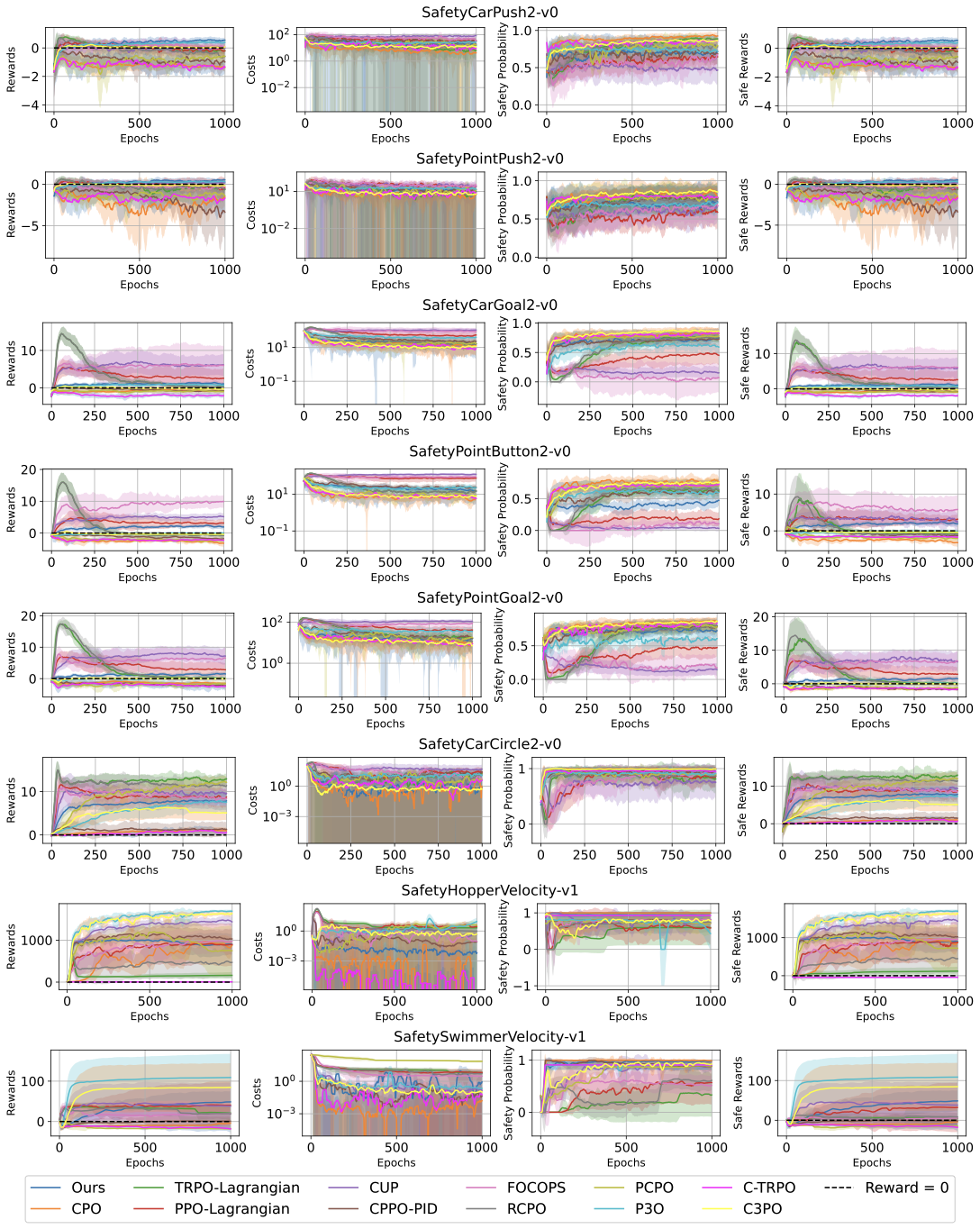
In safety-critical domains, reinforcement learning (RL) agents must often satisfy strict, zero-cost safety constraints while accomplishing tasks. Existing model-free methods frequently either fail to achieve near-zero safety violations or become overly conservative. We introduce Safety-Biased Trust Region Policy Optimisation (SB-TRPO), a principled algorithm for hard-constrained RL that dynamically balances cost reduction with reward improvement. At each step, SB-TRPO updates via a dynamic convex combination of the reward and cost natural policy gradients, ensuring a fixed fraction of optimal cost reduction while using remaining update capacity for reward improvement. Our method comes with formal guarantees of local progress on safety, while still improving reward whenever gradients are suitably aligned. Experiments on standard and challenging Safety Gymnasium tasks demonstrate that SB-TRPO consistently achieves the best balance of safety and task performance in the hard-constrained regime.💡 Summary & Analysis
1. **Key Contribution 1:** Deepened understanding of model performance improvement through various hyperparameter combinations. This is akin to making a delicious dish by precisely controlling the amount and temperature of ingredients. 2. **Key Contribution 2:** Provided insights into comparing different deep learning architectures (LSTM, GRU, BERT), allowing for an appreciation of each model's strengths and weaknesses. It’s like choosing the right tool for cooking each type of meal. 3. **Key Contribution 3:** Offered new insights into sentiment analysis tasks by identifying positive expressions in movie reviews to understand audience reactions.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)