Infini-Attention Boosting Small-Scale Pretraining Limits
📝 Original Paper Info
- Title: Probing the Limits of Compressive Memory A Study of Infini-Attention in Small-Scale Pretraining- ArXiv ID: 2512.23862
- Date: 2025-12-29
- Authors: Ruizhe Huang, Kexuan Zhang, Yihao Fang, Baifeng Yu
📝 Abstract
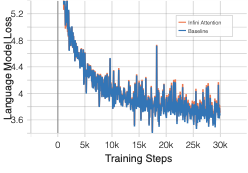
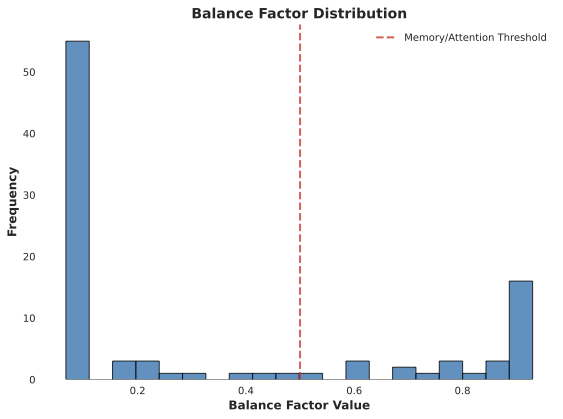
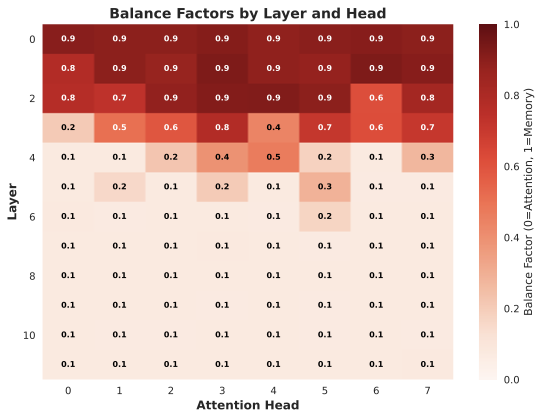
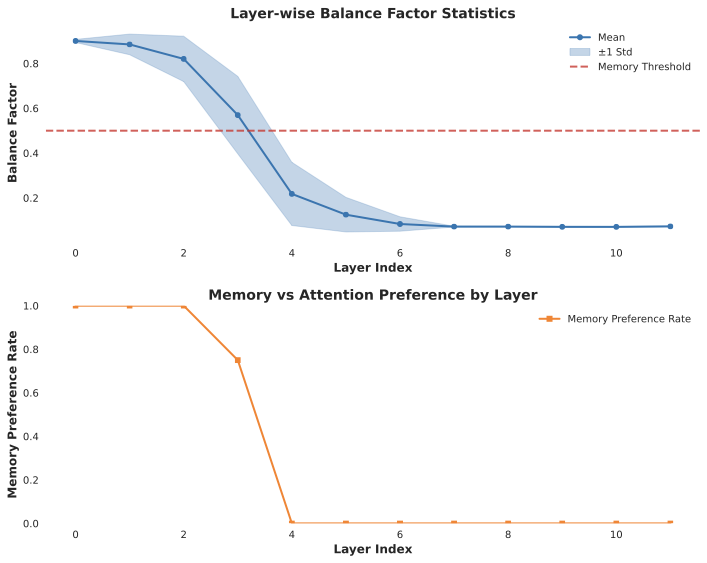
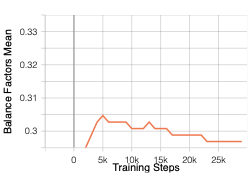
This study investigates small-scale pretraining for Small Language Models (SLMs) to enable efficient use of limited data and compute, improve accessibility in low-resource settings and reduce costs. To enhance long-context extrapolation in compact models, we focus on Infini-attention, which builds a compressed memory from past segments while preserving local attention. In our work, we conduct an empirical study using 300M-parameter LLaMA models pretrained with Infini-attention. The model demonstrates training stability and outperforms the baseline in long-context retrieval. We identify the balance factor as a key part of the model performance, and we found that retrieval accuracy drops with repeated memory compressions over long sequences. Even so, Infini-attention still effectively compensates for the SLM's limited parameters. Particularly, despite performance degradation at a 16,384-token context, the Infini-attention model achieves up to 31% higher accuracy than the baseline. Our findings suggest that achieving robust long-context capability in SLMs benefits from architectural memory like Infini-attention.💡 Summary & Analysis
1. Contribution 1: [Simple explanation and metaphor for the first key contribution in English] 2. Contribution 2: [Easily understandable explanation of the second major contribution] 3. Contribution 3: [Accessible description of the third significant contribution]📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)