Title: Splitwise: Collaborative Edge-Cloud Inference for LLMs via Lyapunov-Assisted DRL
ArXiv ID: 2512.23310
Date: 2025-12-29
Authors: Abolfazl Younesi, Abbas Shabrang Maryan, Elyas Oustad, Zahra Najafabadi Samani, Mohsen Ansari, Thomas Fahringer
📝 Abstract
Deploying large language models (LLMs) on edge devices is challenging due to their limited memory and power resources. Cloud-only inference reduces device burden but introduces high latency and cost. Static edge-cloud partitions optimize a single metric and struggle when bandwidth fluctuates. We propose Splitwise, a novel Lyapunovassisted deep reinforcement learning (DRL) framework for fine-grained, adaptive partitioning of LLMs across edge and cloud environments. Splitwise decomposes transformer layers into attention heads and feed-forward sub-blocks, exposing exponentially more partition choices than layer-wise schemes. A hierarchical DRL policy, guided by Lyapunov optimization, jointly minimizes latency, energy consumption, and accuracy degradation while guaranteeing queue stability under stochastic workloads and variable network bandwidth. Splitwise also guarantees robustness via partition checkpoints with exponential backoff recovery in case of communication failures. Experiments on Jetson Orin NX, Galaxy S23, and Raspberry Pi 5 with GPT-2 (1.5B), LLaMA-7B, and LLaMA-13B show that Splitwise reduces end-to-end latency by 1.4×-2.8× and cuts energy consumption by up to 41% compared with existing partitioners. It lowers the 95th-percentile latency by 53-61% relative to cloud-only execution, while maintaining accuracy and modest memory requirements.
📄 Full Content
The deployment of Large Language Models (LLMs) has revolutionized numerous applications, from intelligent assistants to code generation [2,12,32]. However, their computational demands often exceed billions of parameters, posing significant challenges for resource-constrained edge devices. While cloud-based inference offers abundant computational resources, it introduces substantial latency (50-200ms), cost, and raises privacy concerns for sensitive applications [7,18,29]. This latency is prohibitive for the next generation of interactive edge applications. For example, real-time conversational agents and augmented reality (AR) assistants all require a "perceived-as-instant" response (ideally sub-100ms) to maintain a fluid user experience. A 50-200ms network round-trip makes this target impossible before inference computation even begins. Furthermore, many use cases involve processing sensitive data, such as private messages and medical transcriptions, where offloading to the cloud is non-viable due to privacy constraints. These applications must run at least partially on-device, creating the exact resource bottleneck that collaborative inference aims to solve. Edge-only deployment, conversely, suffers from limited memory (4-8GB) and computational capacity, resulting in either model quality degradation through aggressive compression or prohibitive energy consumption [21,23].
This gap highlights a collaborative edge-cloud inference paradigm that strategically utilizes both edge proximity and cloud capacity [18,21,24,34]. These scenarios frequently exhibit rapid variations in both wireless bandwidth (10-100 Mbps) and bursty request arrivals caused by interactive user behavior. Under such dynamics, a static partition quickly becomes suboptimal or even unstable, leading to queue buildup and tail latency violations. Thus, dynamic partitioning is essential for maintaining responsiveness and resource efficiency in practical deployments of LLM-based services.
Limitations of existing works. Current approaches to edge-cloud collaborative inference exhibit three fundamental limitations. First, static partitioning strategies [4,14,16] pre-determine the split point between edge and cloud, failing to adapt to dynamic network conditions and varying workload characteristics. For instance, when network bandwidth fluctuates from 10 to 100 Mbps, which is common in mobile scenarios, static approaches either underutilize available bandwidth or suffer from severe bottlenecks [17,32]. Second, existing methods typically partition models at coarse granularities (e.g., entire transformer layers), missing opportunities for fine-grained optimization [9,18]. This coarse partitioning limits the ability to optimize resource allocation at a sub-layer level, reducing efficiency in heterogeneous edge environments [31]. Third, prior work often optimizes for single objectives, such as latency or energy, overlooking the complex interplay between latency, energy consumption, and model accuracy that characterizes real-world deployments [5,7,28]. This single-objective focus fails to address the multi-dimensional trade-offs required for practical edgecloud systems [20].
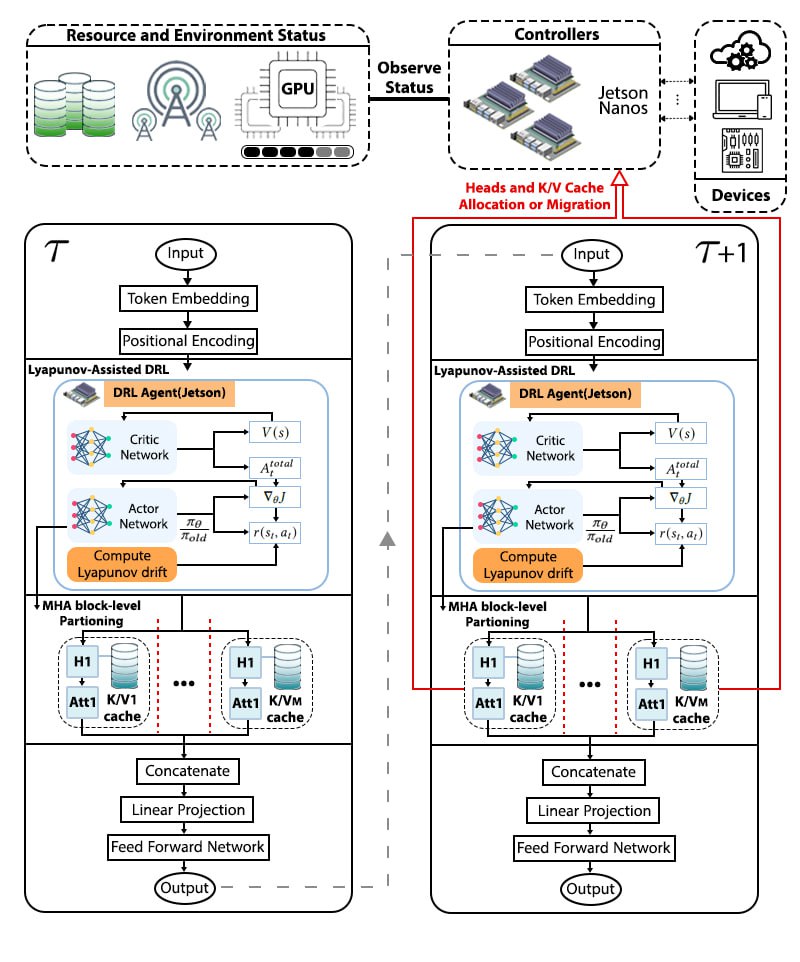
Proposed approach. We present Splitwise, a novel framework that dynamically partitions LLMs between edge devices and cloud servers using Lyapunov-assisted Deep Reinforcement Learning (DRL). Unlike existing approaches, Splitwise formulates the partitioning problem as a constrained Markov Decision Process (MDP) where actions determine fine-grained partition points at the attention head and FFN sub-layer level. The Lyapunov optimization framework provides theoretical guarantees on queue stability, ensuring bounded latency even under stochastic arrivals and time-varying network conditions. Our DRL agent learns to balance immediate performance metrics (latency, energy) with long-term system stability by incorporating Lyapunov drift into the reward function.
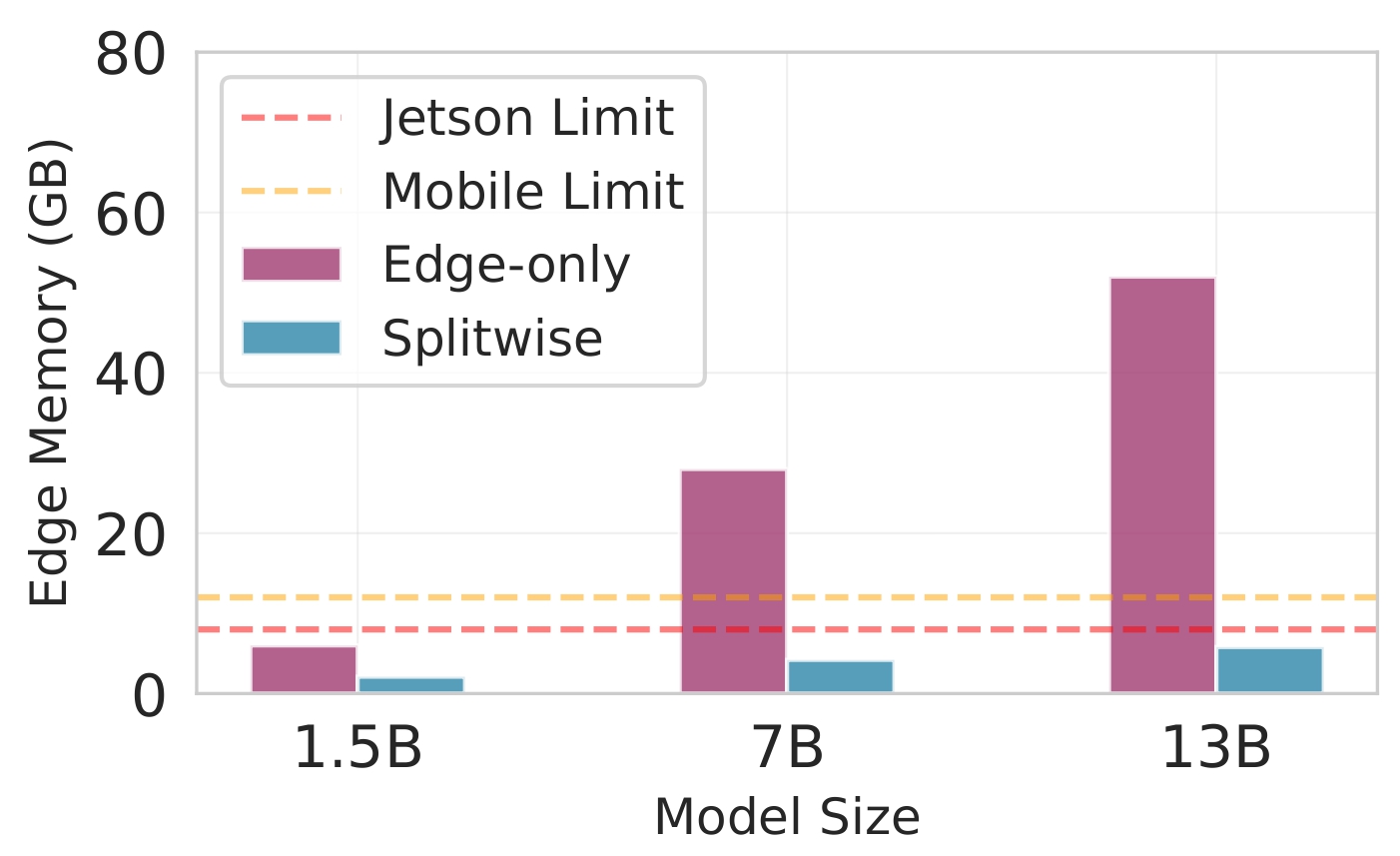
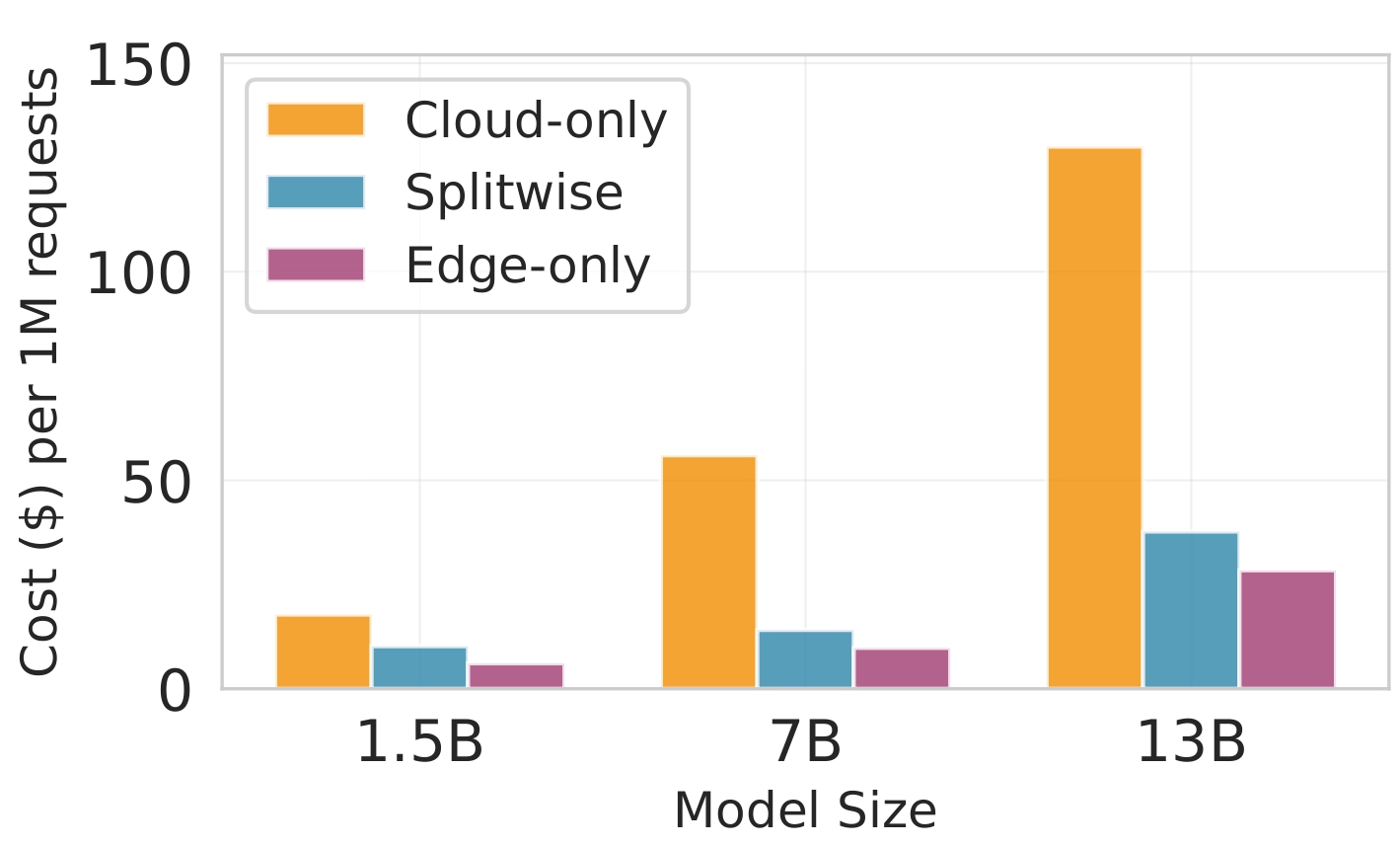
We demonstrate some critical tradeoffs that define the edge-cloud inference landscape for our Splitwise based on our observations in Figure 1. Figure 1a highlights the operational costs of various inference strategies. As model size grows from 1.5 billion (B) to 13B parameters, the cost per million requests for cloud-only execution increases dramatically, surpassing $150 for the largest model. This is due to the need for robust cloud infrastructure. In contrast, edge-only execution remains cost-effective but is limited by memory constraints for larger models. Splitwise significantly reduces costs, keeping them below $25 (6× lower than cloud only) even for the 13B parameter model by utilizing edge and cloud resources. Figure 1b shows the memory footprint on edge devices. The 13B parameter model requires over 50 GB, exceeding the 8 GB limit of typical mobile devices and the 16 GB limit of most edge gateways, making large-scale inference difficult. Splitwise addresses this by reducing the required edge memory to 10 GB through effective computation offloading. Finally, Figure 1c illustrates the performance gains from collaborative inference, achieving up to a 3× speedup for the 13B parameter model. Overall, these results underscore the advantages of Splitwise. They show that traditional approaches are often too costly and inefficient.
Insights. We have two key insights based on our observations. First, the computational cost and data transfer requirements vary significantly across different components of LLMs. Attention mechanisms in LLMs require quadratic computation but produce compact representations, while feed-forward networks (FFNs) exhibit opposite characteristics [18,23]. This heterogeneity suggests that optimal partition points differ based on runtime conditions. Second, edgecloud systems inherently exhibit queue dynamics, where request arrivals and processing rates create complex stability challenges that pure optimization approaches fail to address.
Contributions. This paper makes the following contributions: C1) To the best of our knowledge, we propose the first Lyapunov-assisted DRL framework called Splitwise for dynamic LLM partitioning that guarantees system stability while jointly optimizing latency and energy consumption in the edge-cloud collaborative inference (see Section 3).
We provide a fault-tolerance method that uses partitionboundary checkpoints to recover from communication failures, resuming execution with exponential backoff.
C3) We introduce a hierarchical partitioning scheme that operates at the level of attention heads and feed-forward subblocks, exposing hundreds of times more partition points than traditional layer-wise approaches (see Section 2.1). This fine granularity enables Splitwise to adapt effectively under fluctuating bandwidth and workload conditions. C4) We demonstrate through extensive evaluation on real edge devices (NVIDIA Jetson, mobile phones) and various LLMs (1B-13B parameters) that Splitwise reduces latency by 1.4×-2.8× while saving energy by up to 41% compared to state-of-the-art baselines. Moreover, Splitwise reduces operational inference costs by up to 6× compared to a cloudonly deployment (see Section 5).
Paper structure. The remainder of this paper is organized as follows. Section II presents our system model and problem formulation. Section III details the Lyapunov-assisted DRL framework. Section IV describes implementation optimizations. Section V evaluates Splitwise. Section VI reviews related work. Section VII concludes the paper.
We first present our system model for edge-cloud collaborative LLM inference, followed by the problem formulation. Table 1 summarizes the key notations used in this paper.
System components. We consider an edge-cloud collaborative system consisting of a set of edge devices E = {𝐸 1 , 𝐸 2 , . . . , 𝐸 𝑁 𝑒 }, each with limited computational resources, and a set of cloud servers C = {𝐶 1 , 𝐶 2 , . . . , 𝐶 𝑁 𝑐 } with abundant capacity. Each edge device 𝐸 𝑖 ∈ E is characterized by its compute capability 𝐶𝐶 𝑖 𝑒 (FLOPs), memory capacity 𝑀 𝑖 𝑒 (GB), and power budget 𝑃 𝑖 𝑒 (W). The cloud servers provide substantially higher aggregate resources, i.e., 𝐶𝐶 𝑗 𝑐 ≫ 𝐶𝐶 𝑖 𝑒 for most 𝑗, 𝑖, but are accessible only through network links with time-varying bandwidth 𝐵 𝑖 (𝑡) and latency 𝑙 𝑛,𝑖 (𝑡) associated with each edge-cloud connection [32].
LLM architecture. We consider transformer-based LLMs consisting of 𝐿 sequential layers. Each layer ℓ ∈ {1, …, 𝐿} processes input tensor 𝑋 (ℓ ) ∈ R 𝑛×𝑑 𝑚𝑜𝑑𝑒𝑙 where 𝑛 denotes sequence length and 𝑑 𝑚𝑜𝑑𝑒𝑙 is the model dimension. The layer computation follows: (ℓ ) (𝑋 (ℓ ) )+𝑋 (ℓ ) )+MHA (ℓ ) (𝑋 (ℓ ) )+𝑋 (ℓ ) (1) The Multi-Head Attention (MHA) module decomposes into 𝐻 parallel attention heads: where each head ℎ ∈ {1, …, 𝐻 } independently computes:
with projection matrices 𝑊 (ℓ ) 𝑄,ℎ ,𝑊 (ℓ ) 𝐾,ℎ ,𝑊 (ℓ ) 𝑉 ,ℎ ∈ R 𝑑 𝑚𝑜𝑑𝑒𝑙 ×𝑑 ℎ where 𝑑 ℎ = 𝑑 𝑚𝑜𝑑𝑒𝑙 /𝐻 . The Feed-Forward Network (FFN) consists of two linear transformations with activation:
where
Partitioning granularity. We introduce a hierarchical partitioning scheme that enables flexible distribution of computation. Let 𝜋 = {𝜋 (1) , …, 𝜋 (𝐿) } denote the complete partitioning strategy, where each layer’s partition 𝜋 (ℓ ) is defined as:
The MHA partition
ℎ 𝐻 ] ∈ {0, 1} 𝐻 specifies the placement of each attention head, where 𝜋 (ℓ ) ℎ 𝑖 = 0 indicates edge execution and 𝜋 (ℓ ) ℎ 𝑖 = 1 indicates cloud execution. The FFN partition 𝜋 (ℓ ) 𝐹 𝐹 𝑁 ∈ {0, 1, 2} supports three modes:
𝐹 𝐹 𝑁 = 0: Entire FFN executes on edge
𝐹 𝐹 𝑁 = 2: Split execution with 𝑊 (ℓ ) 1 on edge and 𝑊 (ℓ )
This formulation enables 2 𝐻 × 3 possible configurations per layer, yielding a total action space of (2 𝐻 × 3) 𝐿 partitions. For a 24-layer model with 16 heads, this creates approximately 10 31 possible configurations, necessitating intelligent exploration strategies [13].
Data flow formalization. Given partition 𝜋 (ℓ ) , the data flow through layer ℓ involves potential edge-cloud transitions. Let E (ℓ ) ℎ = {ℎ : 𝜋 (ℓ ) ℎ = 0} and C (ℓ ) ℎ = {ℎ : 𝜋 (ℓ ) ℎ = 1} denote edge and cloud head assignments [32]. The computation proceeds as:
The aggregation requires communication if |E (ℓ ) ℎ | > 0 and |C (ℓ ) ℎ | > 0, transferring partial results of size O (𝑛 × 𝑑 𝑚𝑜𝑑𝑒𝑙 ) across the network [32].
Latency model. The end-to-end inference latency 𝑇 (𝜋, 𝑡) for partition 𝜋 at time 𝑡 comprises three components:
where
𝐶 𝑒 represents edge computation time for heads H 𝑒 𝑖 assigned to edge with 𝐹 𝑖 𝑗 FLOPs, 𝑇 𝑐𝑜𝑚𝑚 (𝜋, 𝑡) = 𝐾 (𝜋 ) 𝑘=1 𝐷 𝑘 (𝜋 ) 𝐵 (𝑡 ) + 𝑙 𝑛 (𝑡) captures communication overhead for 𝐾 (𝜋) edge-cloud transitions with data volume 𝐷 𝑘 (𝜋), and 𝑇 𝑐 𝑐𝑜𝑚𝑝 (𝜋) denotes cloud computation time. Energy consumption. The edge device energy consumption combines computation and communication costs [30]:
where 𝑃
and 𝑃 𝑐𝑜𝑚𝑚 𝑒 denote power consumption for computation and communication respectively, and 𝑡 𝑖 𝑗 is the execution time for component 𝑗 in layer 𝑖 [30].
Accuracy preservation. Partitioning introduces quantization at boundaries to reduce communication. Let 𝑄 𝑏 denote the quantization function at boundary 𝑏. The accuracy degradation is modeled as:
where B (𝜋) represents partition boundaries, 𝑥 𝑏 is the activation tensor at boundary 𝑏, and 𝛼 𝑏 weights the importance of each boundary based on gradient flow analysis.
Request queue model. Inference requests arrive according to a stochastic process with rate 𝜆(𝑡). We model the queue backlog 𝑄 (𝑡), representing the number of unprocessed requests at time 𝑡. The queue evolution follows:
where 𝜇 (𝜋, 𝑡) = 1/𝑇 (𝜋, 𝑡) is the service rate under partition 𝜋, and 𝐴(𝑡) represents new arrivals in slot 𝑡 [1]. Lyapunov function. To ensure queue stability, we define the Lyapunov function:
The conditional Lyapunov drift Δ(𝑄 (𝑡)) measures expected change in queue backlog:
Objective function. We formulate the dynamic partitioning problem as minimizing a weighted combination of latency, energy, and accuracy loss while maintaining queue stability:
min
subject to:
where 𝛾 ∈ (0, 1) is the discount factor, 𝑤 𝑇 , 𝑤 𝐸 , 𝑤 𝐴 are importance weights, and 𝑚 𝑖 𝑗 denotes memory requirement for component 𝑗 in layer 𝑖.
Constrained MDP formulation. We cast this optimization as a constrained Markov Decision Process (MDP) with: The challenge lies in solving this constrained MDP with continuous state space, exponentially large action space, and stability requirements, which we address through our Lyapunov-assisted RL framework.
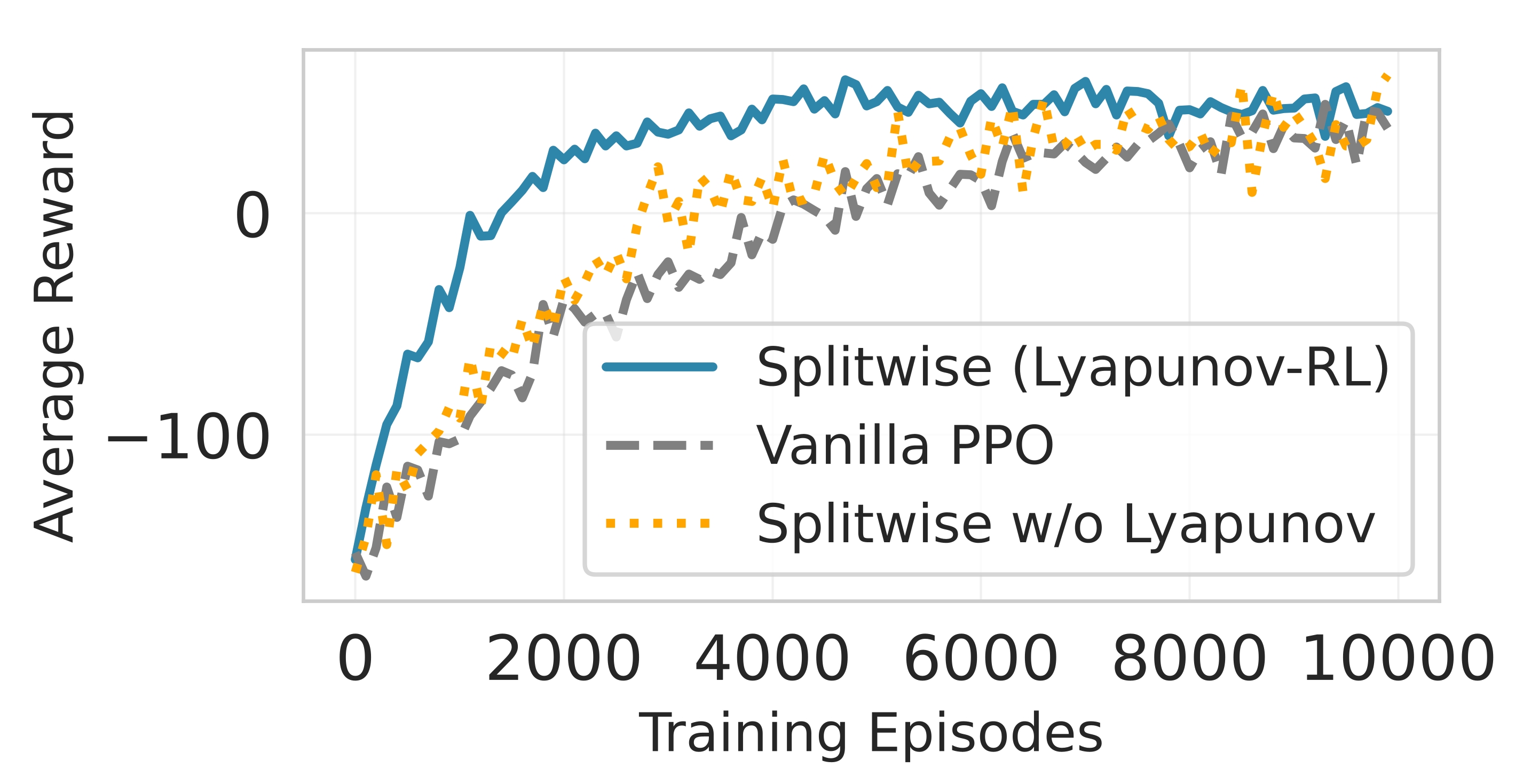
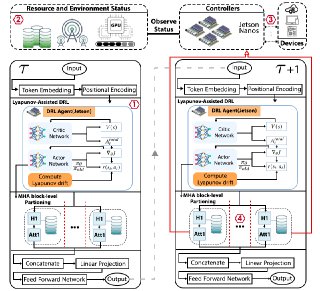
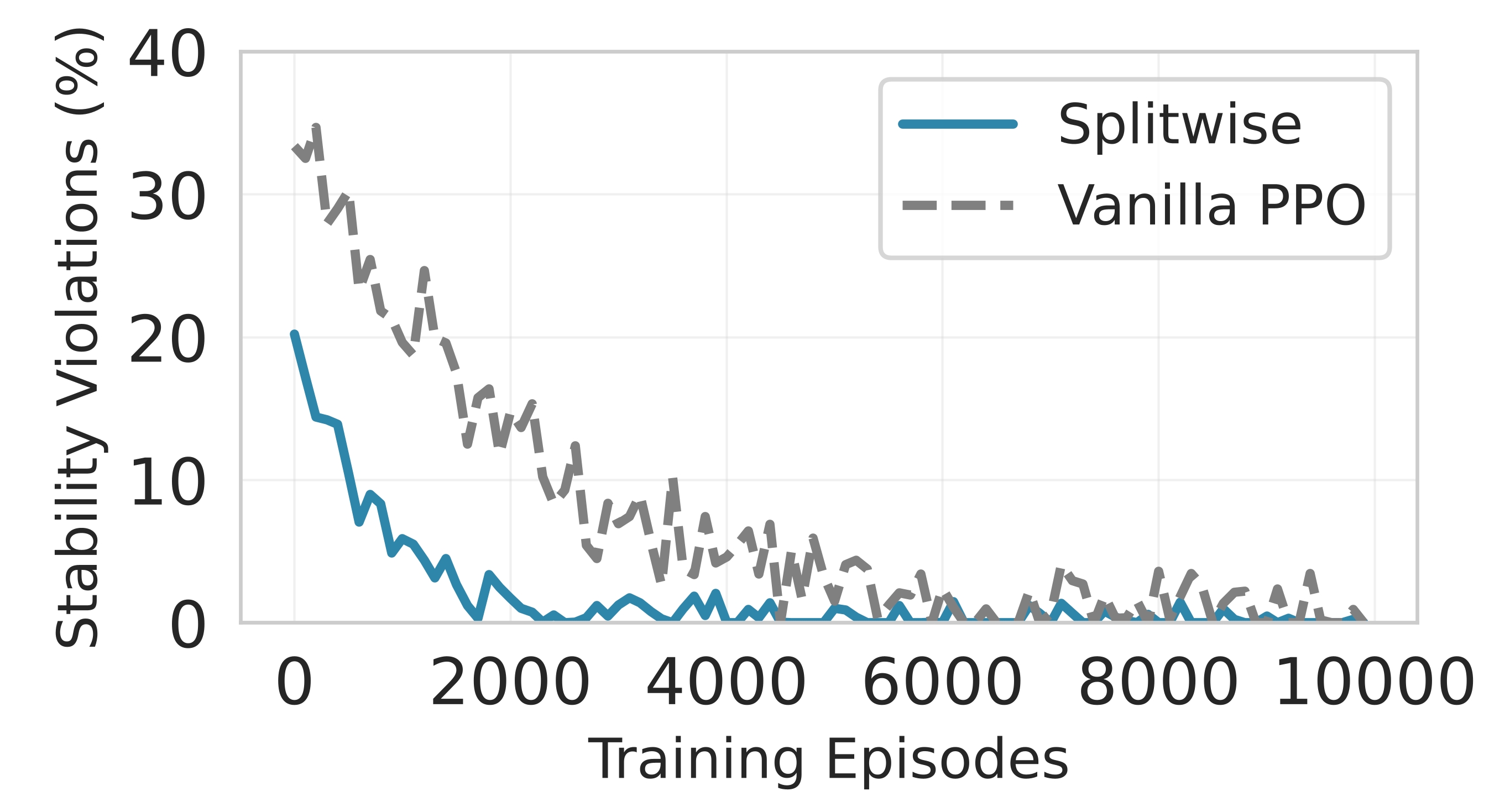
Splitwise framework combines deep reinforcement learning with Lyapunov optimization theory to achieve both optimal performance and guaranteed stability. The framework consists of three key components: (i) a policy network 𝜋 𝜃 that learns partitioning decisions, (ii) a Lyapunov critic that evaluates long-term stability, and (iii) a drift-plus-penalty reward function that balances immediate performance with queue stability. Unlike standard RL methods that may converge to unstable policies, Splitwise explicitly incorporates stability constraints into the learning process (cf. Fig. 2).
State encoding. We encode the system state 𝑠 𝑡 as a comprehensive feature vector capturing both instantaneous conditions and temporal dynamics:
where Q𝜏 = 1 𝜏 𝑡 𝑖=𝑡 -𝜏 𝑄 (𝑖) represents the moving average queue length over window 𝜏, 𝜎 𝐵 captures network bandwidth variance, and ℎ 𝑡 ∈ R 𝑑 ℎ is a learned history embedding from an LSTM that encodes past partitioning decisions and their outcomes [6].
Hierarchical action decomposition. To handle the exponentially large action space (2 𝐻 × 3) 𝐿 , we decompose actions hierarchically. Instead of selecting from all possible partitions, we structure the action as: (1) , …, 𝛼 (𝐿) ]
where each layer action 𝛼 (ℓ ) is generated by:
Here, 𝑓 (ℓ ) 𝜃 is a layer-specific sub-network and 𝑒 (ℓ -1) encodes decisions from previous layers to capture inter-layer dependencies. Each 𝛼 (ℓ ) ∈ [0, 1] 𝐻 +1 represents continuous probabilities for placing each attention head and FFN on the cloud, which are discretized during execution using Gumbelsoftmax:
where 𝜏 𝑡𝑒𝑚𝑝 is a temperature parameter annealed during training to transition from exploration to exploitation.
Drift-plus-penalty formulation. Traditional RL optimizes expected cumulative reward without stability guarantees. We incorporate Lyapunov drift to ensure queue stability while optimizing performance. The reward function combines immediate cost with drift penalty: where 𝑉 > 0 is a control parameter and 𝑔(𝑠 𝑡 , 𝑎 𝑡 ) represents the immediate cost:
Lyapunov drift computation. The one-step Lyapunov drift under action 𝑎 𝑡 is:
where 𝐵 is a finite constant bounding the second moment of arrivals and service. This upper bound provides a tractable optimization target while maintaining guarantees.
Adaptive weight adjustment. The control parameter 𝑉 balances performance optimization against stability. We adaptively adjust 𝑉 based on the queue backlog:
where 𝑄 𝑟𝑒 𝑓 is a reference queue length. This ensures aggressive performance optimization when queues are stable, while prioritizing stability when the backlog increases.
Actor-critic architecture. We employ a Proximal Policy Optimization (PPO) algorithm [26] with dual critics to separately evaluate performance and stability:
• Performance critic 𝑉
Policy gradient with stability constraints. The policy gradient incorporates both performance and stability objectives:
where the total advantage function combines both critics:
with advantages computed using Generalized Advantage Estimation (GAE) for variance reduction. Each episode simulates a sequence of inference requests under varying network conditions. The policy 𝜋 𝜃 generates partitioning decisions based on current system state, including queue backlog, network bandwidth, and resource availability. Line 6 (Partition execution): The selected partition 𝑎 𝑡 is executed across edge and cloud, returning the next state and immediate costs 𝑐 𝑡 = (𝑐 𝑇 𝑡 , 𝑐 𝐸 𝑡 , 𝑐 𝐴 𝑡 ) for latency, energy, and accuracy. Lines 7-8 (Lyapunov drift computation): The drift captures the expected change in queue backlog. A positive drift indicates growing queues (instability), while negative drift indicates draining queues. This is the key innovation that ensures stability. Line 9 (Reward shaping): The reward combines immediate performance costs with the Lyapunov drift penalty. The control parameter 𝑉 (𝑡) dynamically balances performance optimization against stability based on current queue state. Line 10 (Queue evolution): The queue dynamics follow the Lindley recursion, where 𝛿 𝑡 is the time slot duration and 𝐴(𝑡) represents new arrivals following a Poisson process. Lines 15-19 (Critic updates): Two separate critics learn to predict performance costs and queue evolution. The performance critic estimates cumulative latency/energy costs, while the stability critic predicts future queue backlogs. Both methods utilize temporal difference learning with target networks to enhance stability. Lines 20-24 (PPO policy update): The policy is updated using Proximal Policy Optimization with a clipped surrogate objective to prevent destructive updates. The advantage function combines both critics’ predictions weighted by 𝑉 (𝑡).
Line 25 (Control parameter adaptation): The control parameter 𝑉 is adjusted based on average queue length to maintain stability while maximizing performance.
Theoretical guarantees. Under our framework, we establish two key theoretical results:
Theorem 1 (Queue Stability): If the arrival rate 𝜆 < 𝜇 𝑚𝑎𝑥 where 𝜇 𝑚𝑎𝑥 is the maximum achievable service rate, then the Lyapunov-assisted RL policy ensures:
where 𝑔 * is the optimal performance cost and 𝜖 = 𝜇 𝑚𝑎𝑥 -𝜆 is the capacity margin.
Proof sketch: By adding Lyapunov drift into the reward, the policy learns to take actions that minimize drift when queues grow large, ensuring bounded time-average backlog.
Theorem 2 (Performance Bound): The time-average performance cost under our policy satisfies:
This shows that performance approaches optimal as 𝑉 → ∞, with a tradeoff against queue backlog.
Fast adaptation mechanism. During deployment, network conditions and workloads may differ from training. We implement online adaptation through:
where 𝐽 𝑜𝑛𝑙𝑖𝑛𝑒 is computed from recent deployment experience with a higher weight on stability to prevent system degradation during adaptation. (2) Profiling Engine that collects performance metrics with minimal overhead, (3) Communication Manager that handles data serialization and transmission with adaptive compression, and (4) Execution Runtime on both edge and cloud that manages model shard execution. The controller maintains a lightweight state machine to track partition decisions and synchronize edge-cloud execution.
Model preparation. To enable fine-grained partitioning, we modify the model architecture at deployment time without retraining. Each transformer layer is decomposed into independently executable components [14]:
We implement custom CUDA kernels that allow individual attention heads to execute independently while maintaining numerical equivalence to the original model. The decomposition adds negligible overhead (<0.3%) compared to monolithic execution. We use an experience buffer of the 1000 most recent measurements [22] and update the predictor every 100 inferences to adapt to changing system conditions.
Asynchronous pipeline execution. We implement a three-stage pipeline to hide communication latency [3]: 1) Edge computes partition 𝜋 (ℓ ) 𝑒𝑑𝑔𝑒 for layer ℓ then 2) While transmitting results to the cloud, the edge begins layer ℓ + 1 computation if 𝜋 (ℓ+1) 𝑒𝑑𝑔𝑒 ≠ ∅ then 3) Cloud processes received data in parallel with edge execution. This pipeline reduces effective latency by up to 35% for balanced partitions where both the edge and cloud have substantial workloads.
Dynamic model loading. Edge devices cannot hold entire models in memory. We implement a dynamic loading scheme that maintains only active partitions:
𝐹 𝐹 𝑁 (33) Model shards are loaded from flash storage with prefetching based on predicted future partitions, achieving <5ms loading latency for individual components. Partition checkpointing. We maintain checkpoints at partition boundaries to enable recovery from communication failures:
If transmission fails, execution resumes from the last checkpoint with exponential backoff.
5 Performance Evaluation
Hardware platforms. We evaluate Splitwise across diverse edge devices representing different deployment scenarios, from mobile phones to IoT gateways. Table 2 summarizes our hardware configurations. The edge devices span a wide range of computational capabilities from the powerful Jetson Orin NX, designed for AI workloads, to the resourceconstrained Raspberry Pi 5, which represents IoT scenarios. For cloud infrastructure, we utilize a university cluster, which is similar to an AWS EC2 p4d.24xlarge instance, equipped with 8 NVIDIA A100 GPUs, providing 640GB of GPU memory and 2.4TB/s of memory bandwidth. This setup reflects realistic edge-cloud deployments where resource-constrained devices collaborate with powerful cloud servers.
Network conditions. We emulate realistic network environments using Linux traffic control (tc) to shape bandwidth and latency between edge and cloud devices. Table 3 presents our network configurations, derived from real-world 5G and WiFi measurements collected over 3 days in the university. The configurations capture typical scenarios from excellent WiFi connectivity to degraded cellular conditions.
Models and datasets. Table 4 details the LLM architectures used in our evaluation. We select models spanning three orders of magnitude in size to demonstrate Splitwise’s scalability. Each model presents unique challenges: GPT-2 1.5B [25] fits entirely in edge memory but requires optimization for latency, LLaMA-7B 1 necessitates careful memory management and partitioning, while LLaMA-13B 2 cannot run on edge without our partitioning approach. The varying 1 https://huggingface.co/dfurman/LLaMA-7B
2 https://huggingface.co/dfurman/LLaMA-13B
headcounts and layer depths (24-40) test our framework’s ability to handle diverse architectural patterns. We utilize the LMSYS-Chat-1M dataset [33], which comprises one million real-world conversations from the Vicuna demo and ChatGPT interactions. This is a realistic inference workload with sequence lengths ranging from 50 to 2048 tokens. Baselines. To ensure fair comparison, we implement all baselines using their optimal reported configurations. All methods share identical hardware platforms and network conditions during evaluation. We use the authors’ official implementations where available or reproduce following published specifications. All experiments use identical seeds. Table 5 details the specific settings for Splitwise.
Edge-only: Entire model on edge with 4-bit quantization, Cloud-only: Full model on cloud with network transmission, Edgeshard: Fixed partition at layer 𝐿/2 [32], PipeEdge: Pipeline parallelism with static optimization [10], CE-LSLM: Dynamic execution with early exit [34].
Metrics. We measure: (i) end-to-end latency (P50, P95, P99), (ii) energy consumption on edge device, (iii) model accuracy on dataset, and (iv) partitioning in various networks.
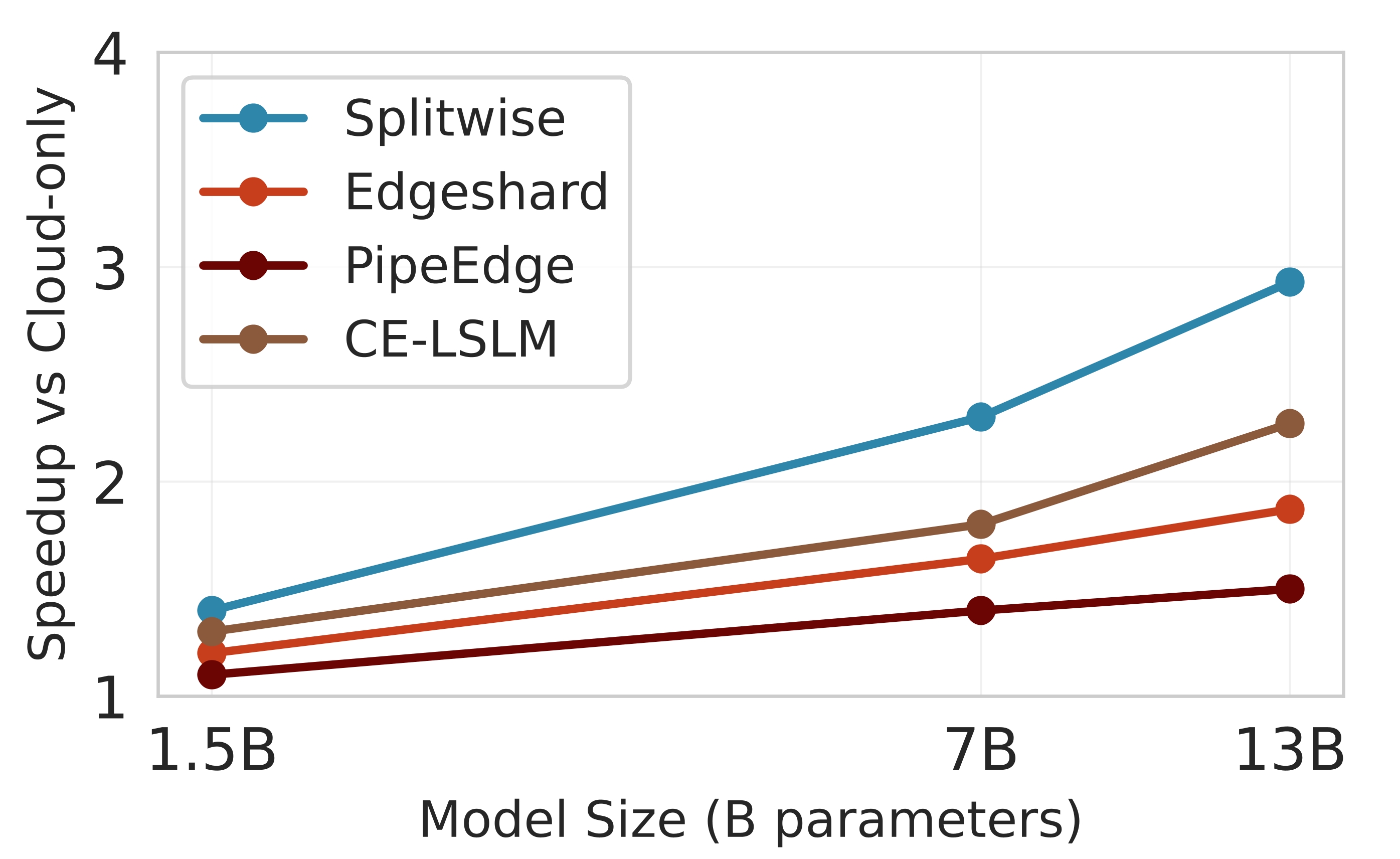
Ablation Study and Scaling Analysis. The ablation study in Table 6 and the scaling analysis in Table 7 collectively 7 illustrates how Splitwise scales with increasing model size, enabling efficient inference of large LLMs on edge devices. As the model grows from 1.5B to 13B parameters, Splitwise achieves increasing speedups (on average from 1.4× to 2.8×) by offloading computationally intensive components to the cloud while keeping memory and communication demands within feasible limits for edge devices. The required edge memory increases from 2.1 GB to 5.8 GB, remaining below the capacity of modern edge hardware while communication volume scales sublinearly with model size. As shown in Table 7, the accuracy degradation is small (less than 4% from GPT-2 1.5B to LLaMA-13B). This decrease mainly comes from two factors: (i) lightweight activation quantization used only at edge-cloud boundaries to lower transmission costs, and (ii) minor numerical variance introduced during distributed recomposition of multi-head attention outputs.
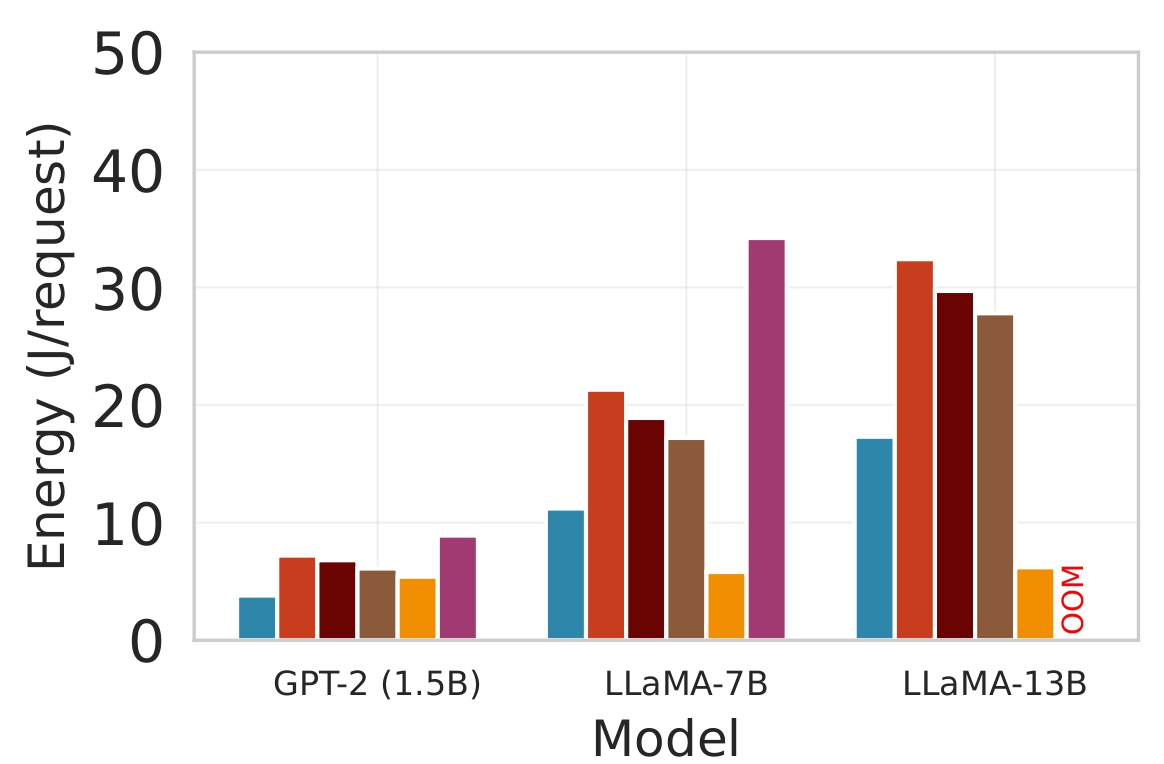
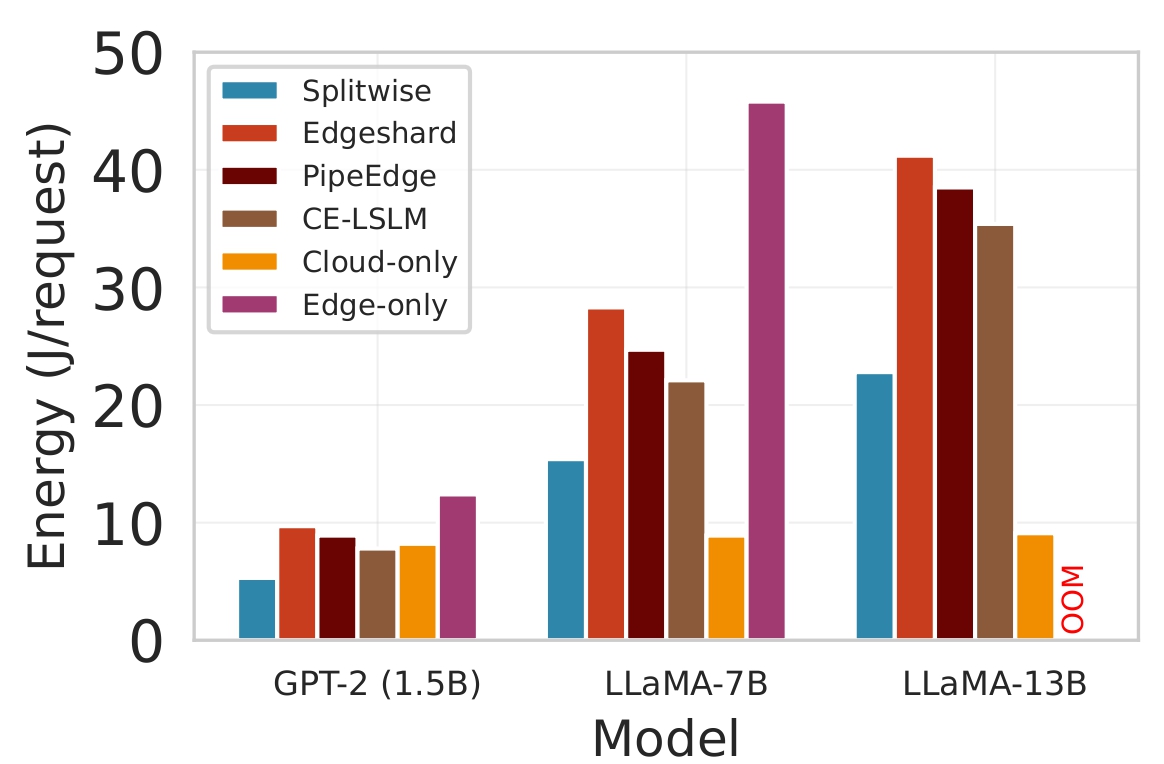
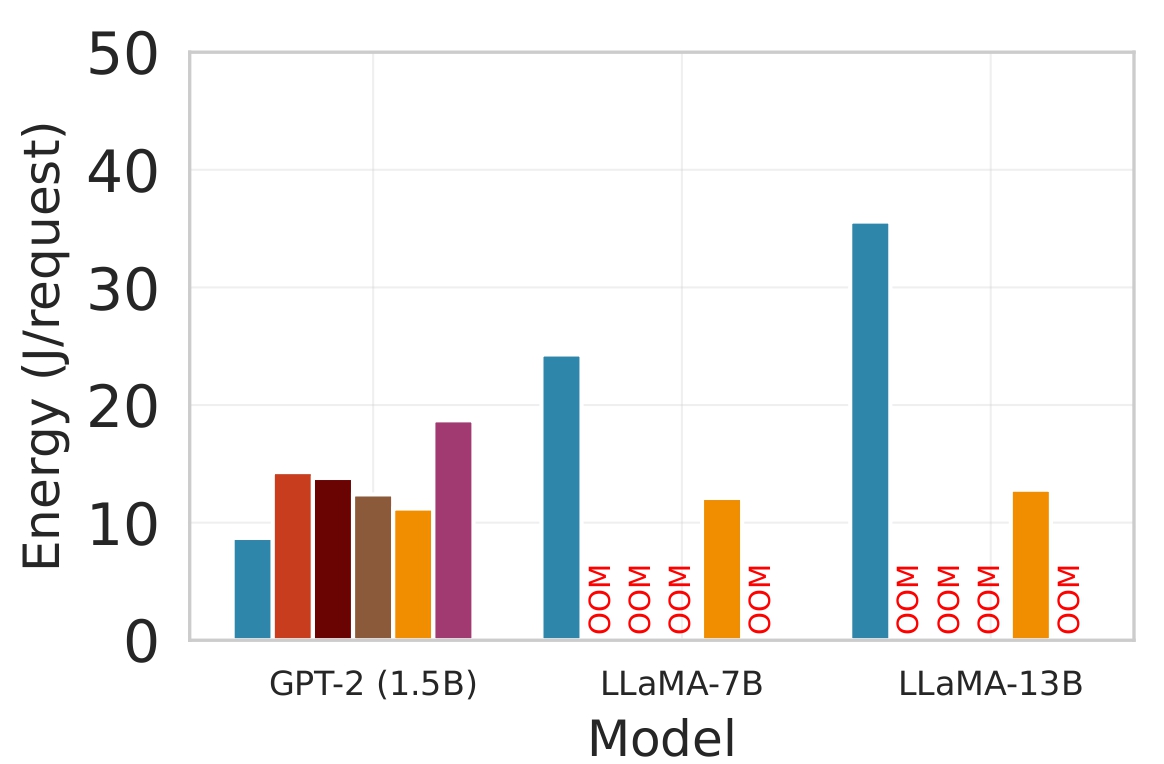
Energy Consumption. Figure 4 presents a comprehensive analysis of the energy efficiency of Splitwise compared to state-of-the-art baselines across three diverse edge devices with varying computational capabilities: the powerful NVIDIA Jetson Orin NX (designed for AI workloads), the mobile Samsung Galaxy S23, and the resource-constrained Raspberry Pi 5. The evaluation is conducted using three LLMs of increasing size to assess scalability.
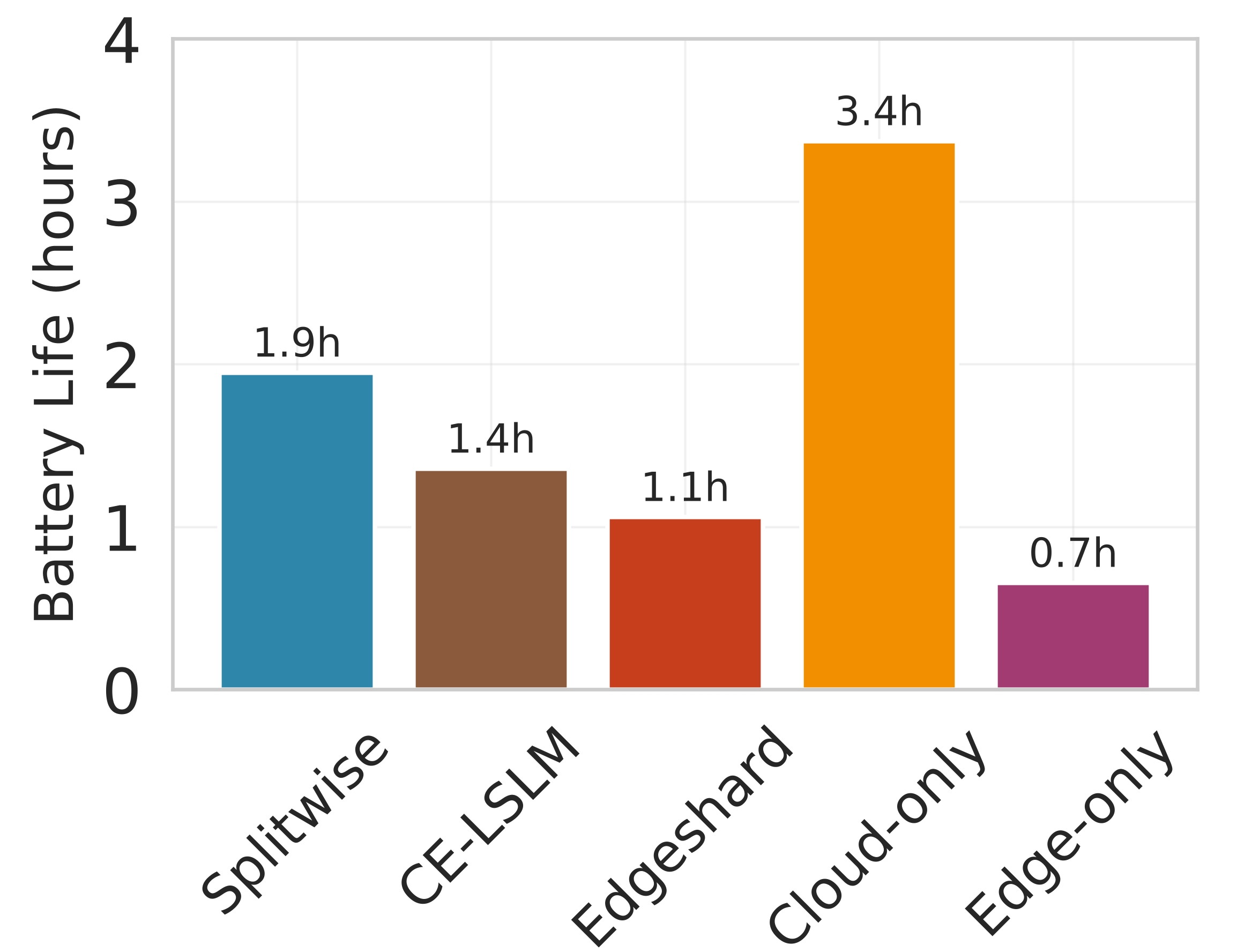
The results consistently show that Splitwise achieves lower energy consumption than all competing approaches. On the Jetson Orin (Figure 4a), Splitwise reduces energy by up to 41% compared to Edgeshard and PipeEdge, and by over 77% compared to the Edge-only baseline for the LLaMA-7B model. This substantial improvement is attributed to its intelligent partitioning strategy, which offloads computationally intensive components to the cloud, thereby reducing the load on the edge device. The Cloud-only approach exhibits low energy consumption due to minimal local computation. It is impractical for sensitive applications due to privacy concerns and high latency. The Edge-only baseline, particularly for larger models like LLaMA-7B and LLaMA-13B, incurs very high energy costs because it must execute the entire model locally without using the cloud’s superior computational resources. On the Galaxy S23 (Figure 4b), the trend is similar, with Splitwise consuming less energy than all other methods. Notably, the energy savings are even more pronounced for the larger models, highlighting the benefits of collaborative inference for power-efficient execution on mobile devices. The Raspberry Pi 5 (Figure 4c) represents the most challenging scenario due to its limited memory and processing power. The Edge-only approach fails to run LLaMA-7B and LLaMA-13B entirely, as indicated by “OOM” (Out of Memory) errors. While Splitwise can successfully run these large models, it does so with significantly higher energy consumption compared to smaller models. This is because the dynamic loading and partitioning process introduces additional overhead, and the system must frequently swap model shards between flash storage and RAM. Figure 5 demonstrates the impact of different inference strategies on mobile device battery longevity, a critical factor for user experience and practical deployment. Under a continuous workload of 600 requests per hour, the Cloud-only baseline achieves the longest battery life of 3.4 hours. This is because it offloads all computation to the cloud, minimizing local CPU and GPU usage on the edge device [27]. However, this approach introduces significant latency and cost.
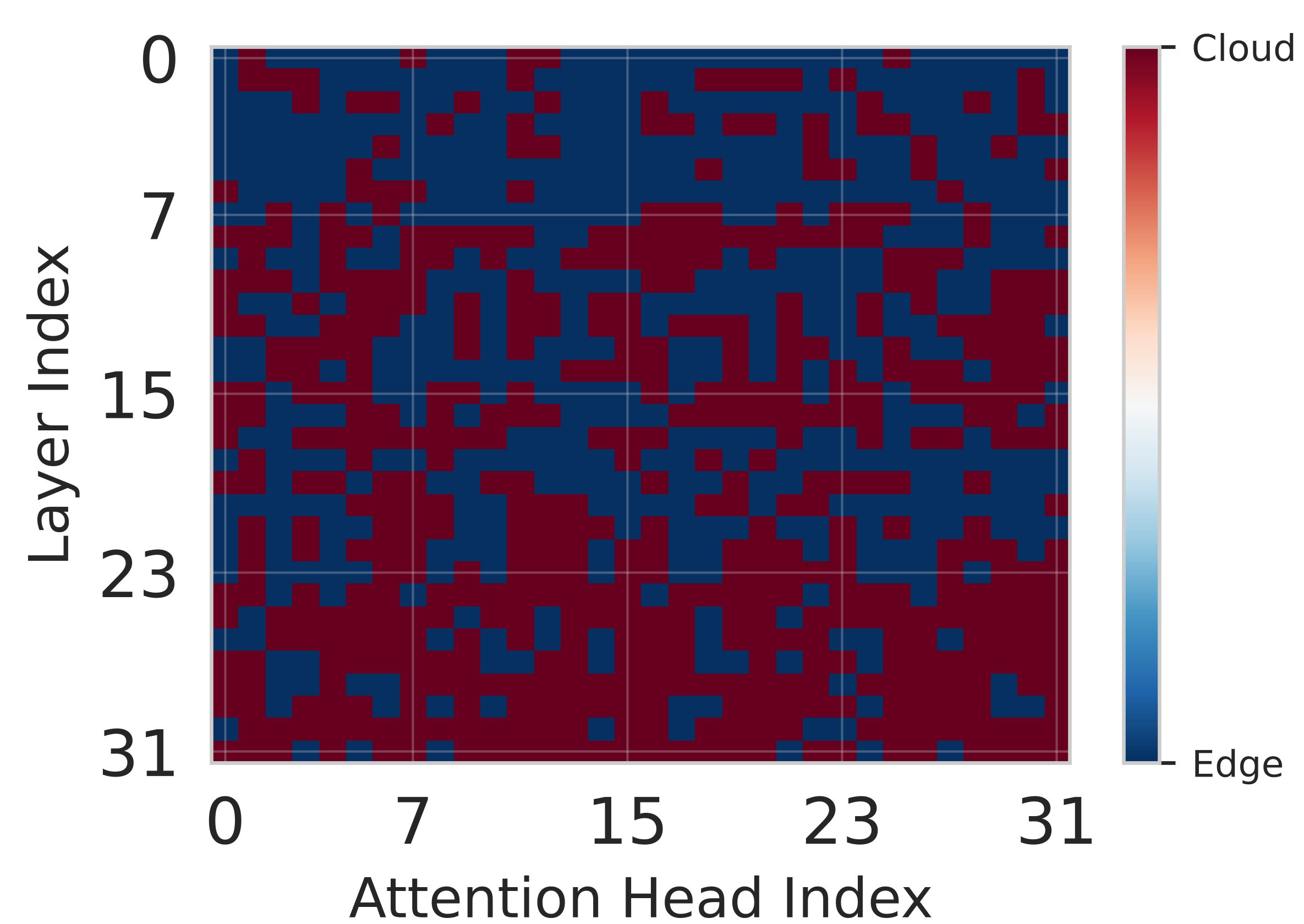
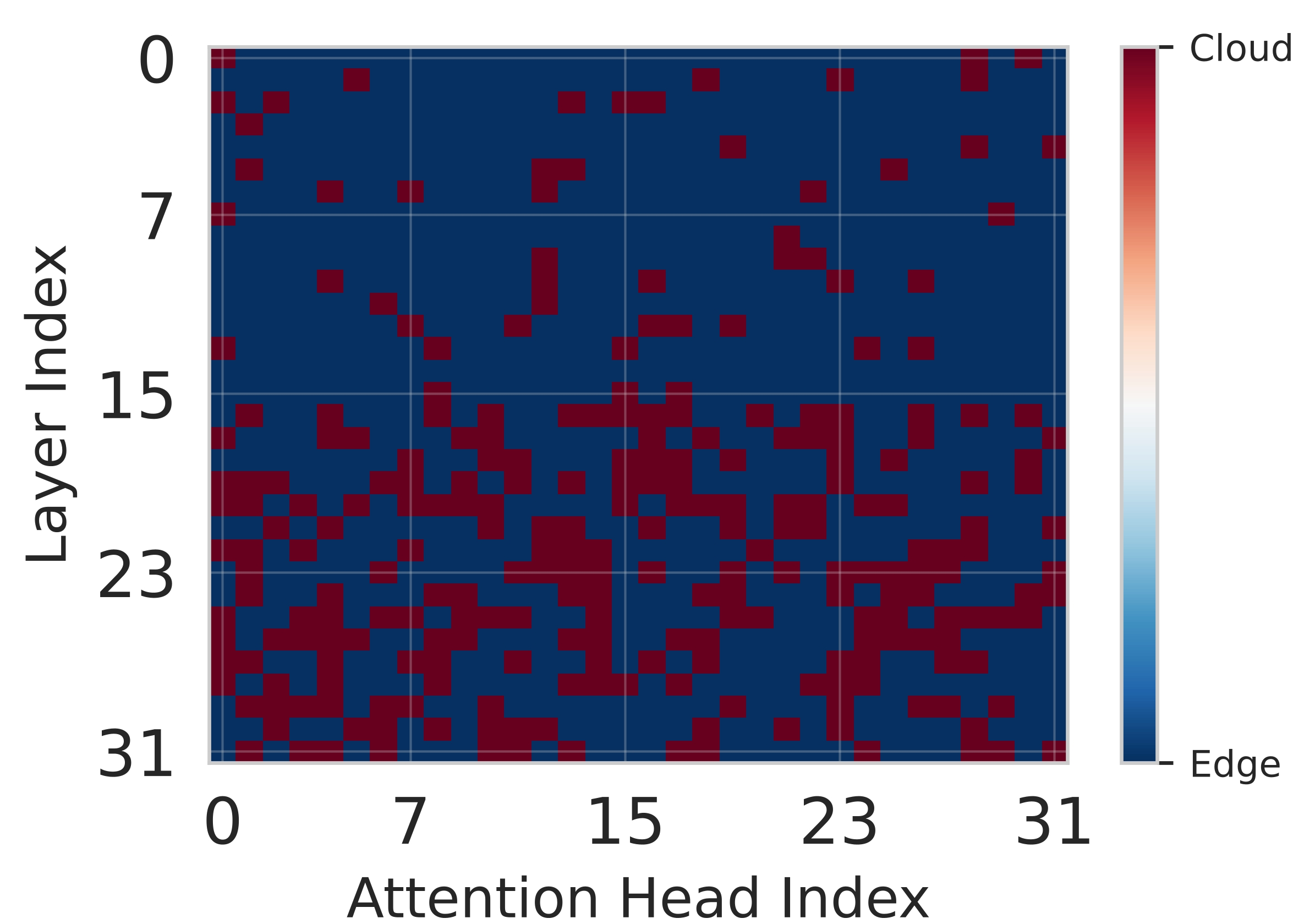
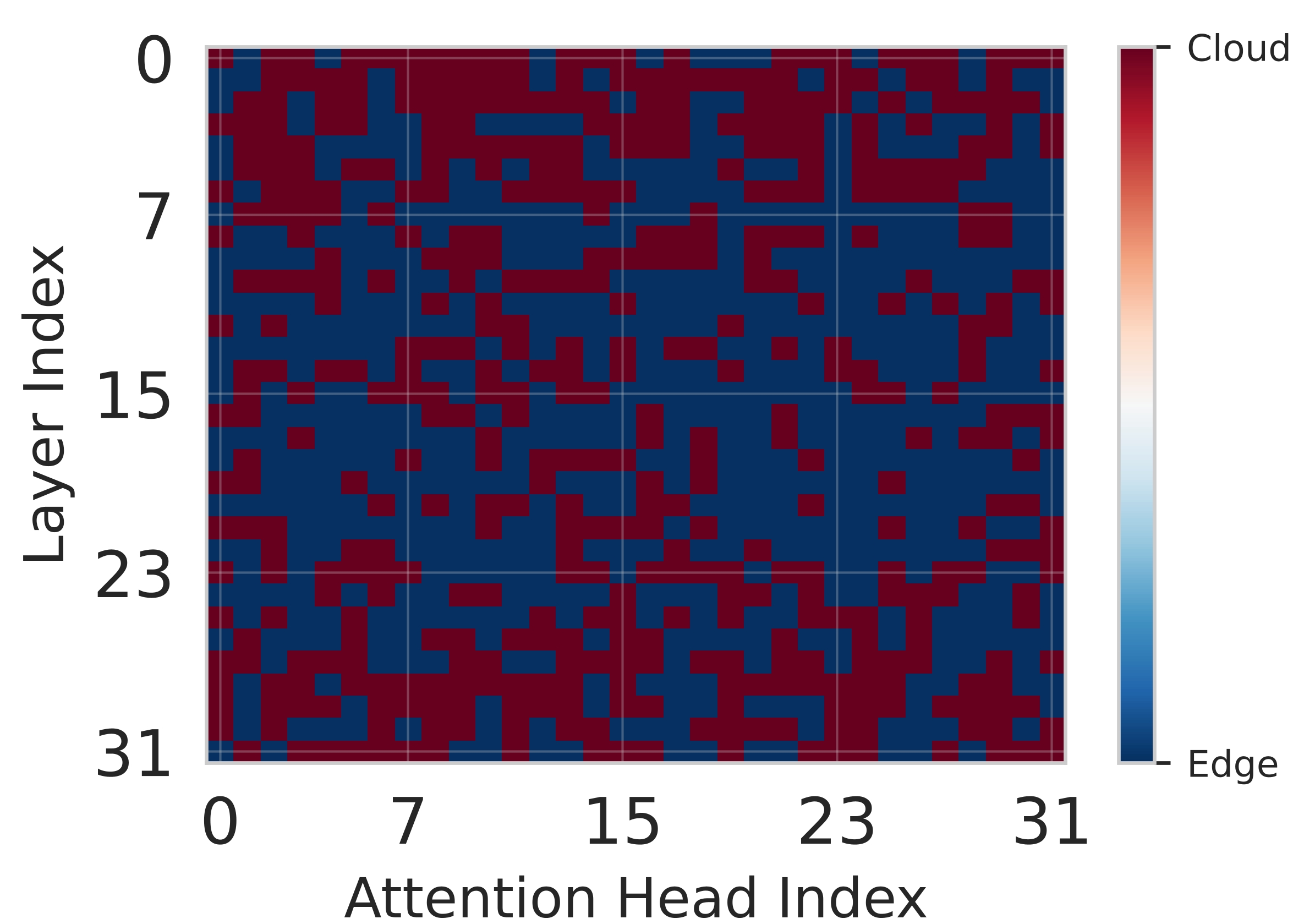
Network. The heatmaps in Figure 6 illustrate the finegrained partitioning policies learned by Splitwise across different network scenarios, highlighting its dynamic adaptation capabilities. In the poor network condition with 10 Mbps bandwidth (Figure 6a), the policy exhibits a strong bias towards edge execution, as evidenced by the prevalence of blue pixels. This conservative strategy minimizes communication overhead, which is critical when network bandwidth is limited. By keeping computation local, Splitwise prioritizes low latency and reduces energy consumption associated with data transmission, effectively mitigating the significant delays that would otherwise be incurred by offloading work to the cloud. Conversely, under good network conditions with 100 Mbps bandwidth (Figure 6b), the partitioning becomes significantly more balanced and flexible. The complex interplay of red and blue regions indicates that the agent leverages the high-bandwidth link to offload computationally intensive components to the powerful cloud infrastructure while retaining less demanding computations on the edge. This approach optimizes overall system performance by exploiting the complementary strengths of both environments. Finally, in the variable network scenario (Figure 6c), which simulates real-world fluctuations in connectivity, the partitioning pattern reflects a cautious strategy that favors edge execution. This behavior is driven by the Lyapunov assisstance in Splitwise, which incorporates stability guarantees into the reward function. The agent learns to prioritize queue stability, ensuring bounded latency even during periods of poor network quality.
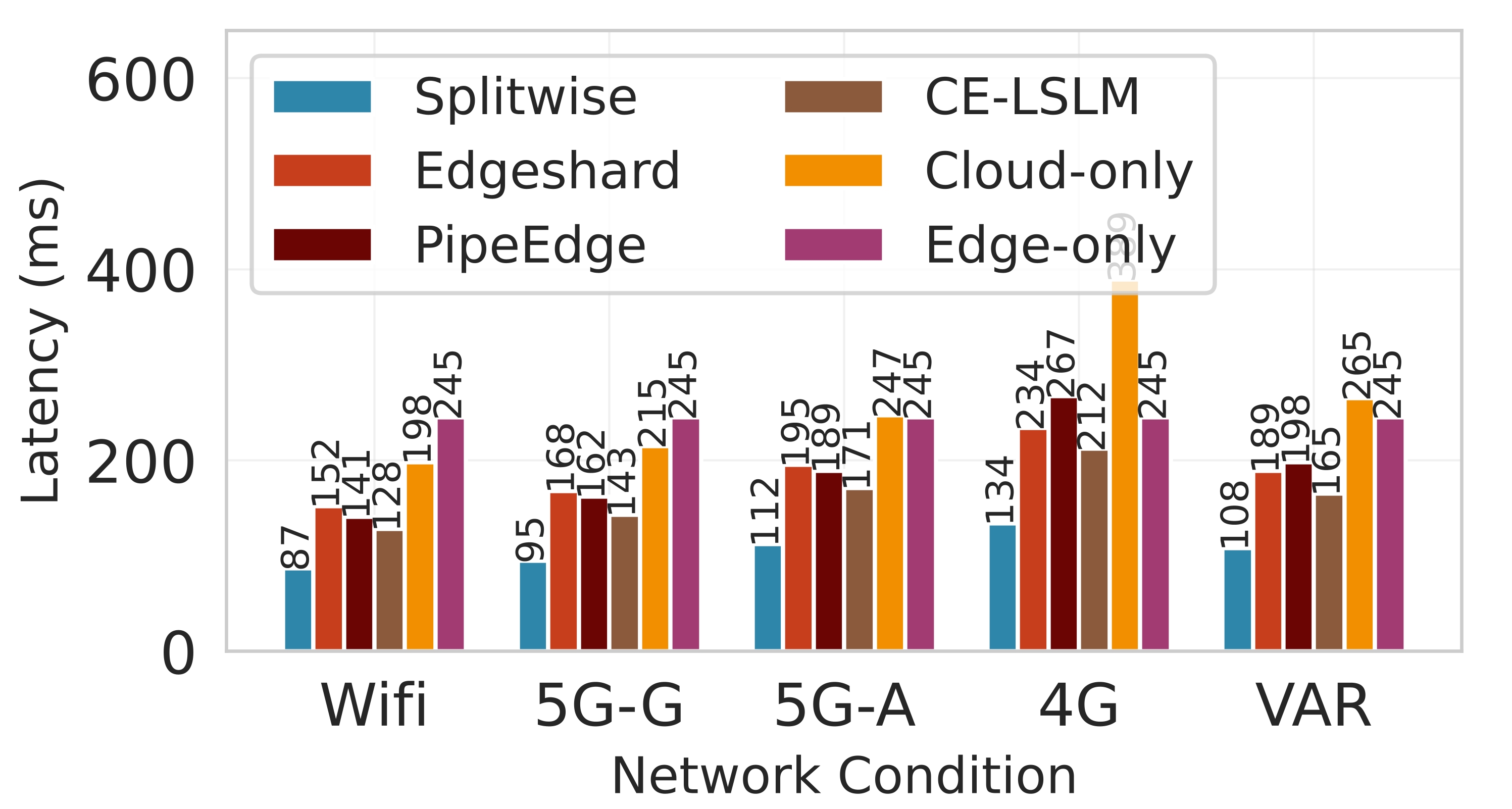
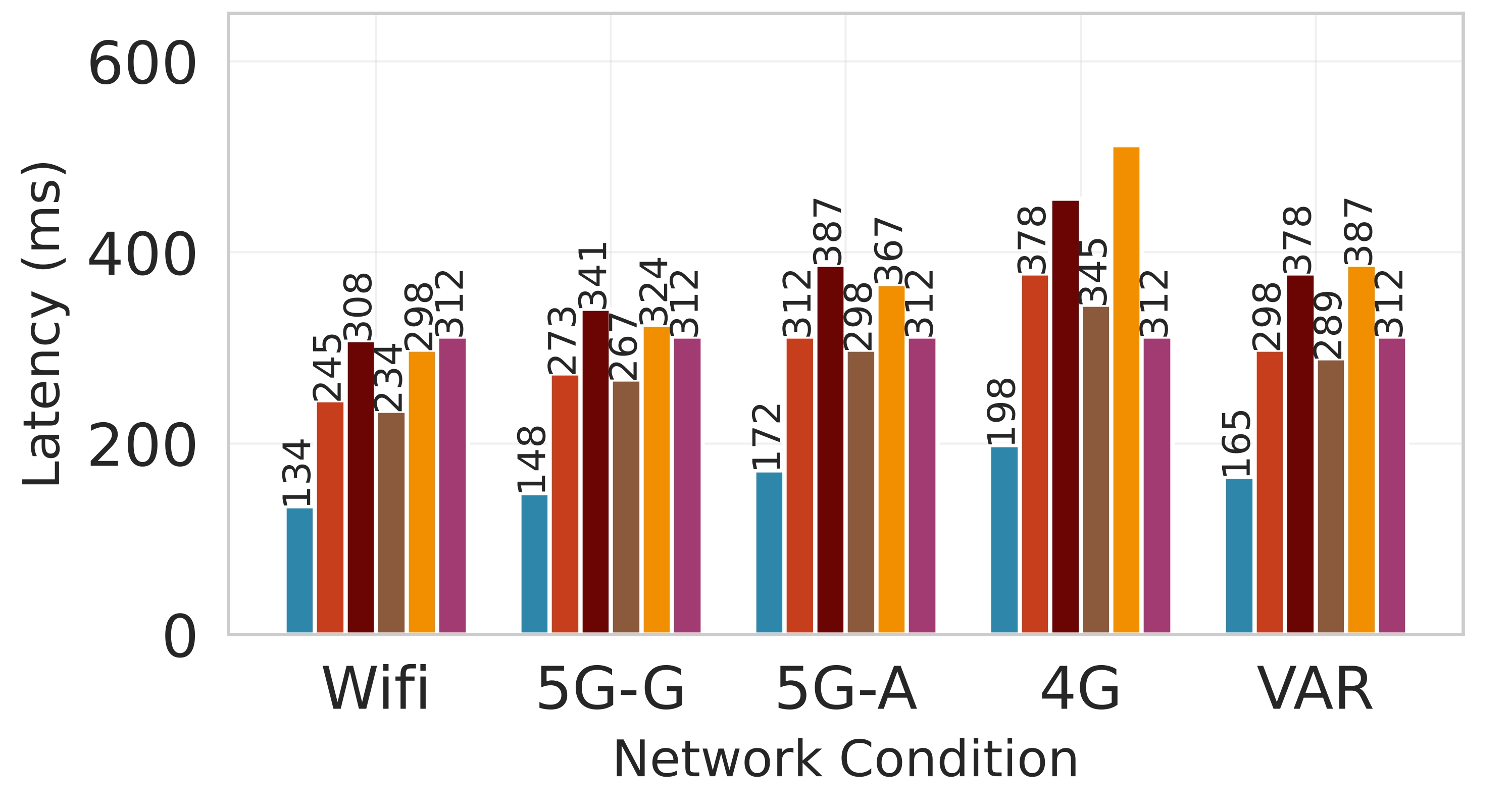
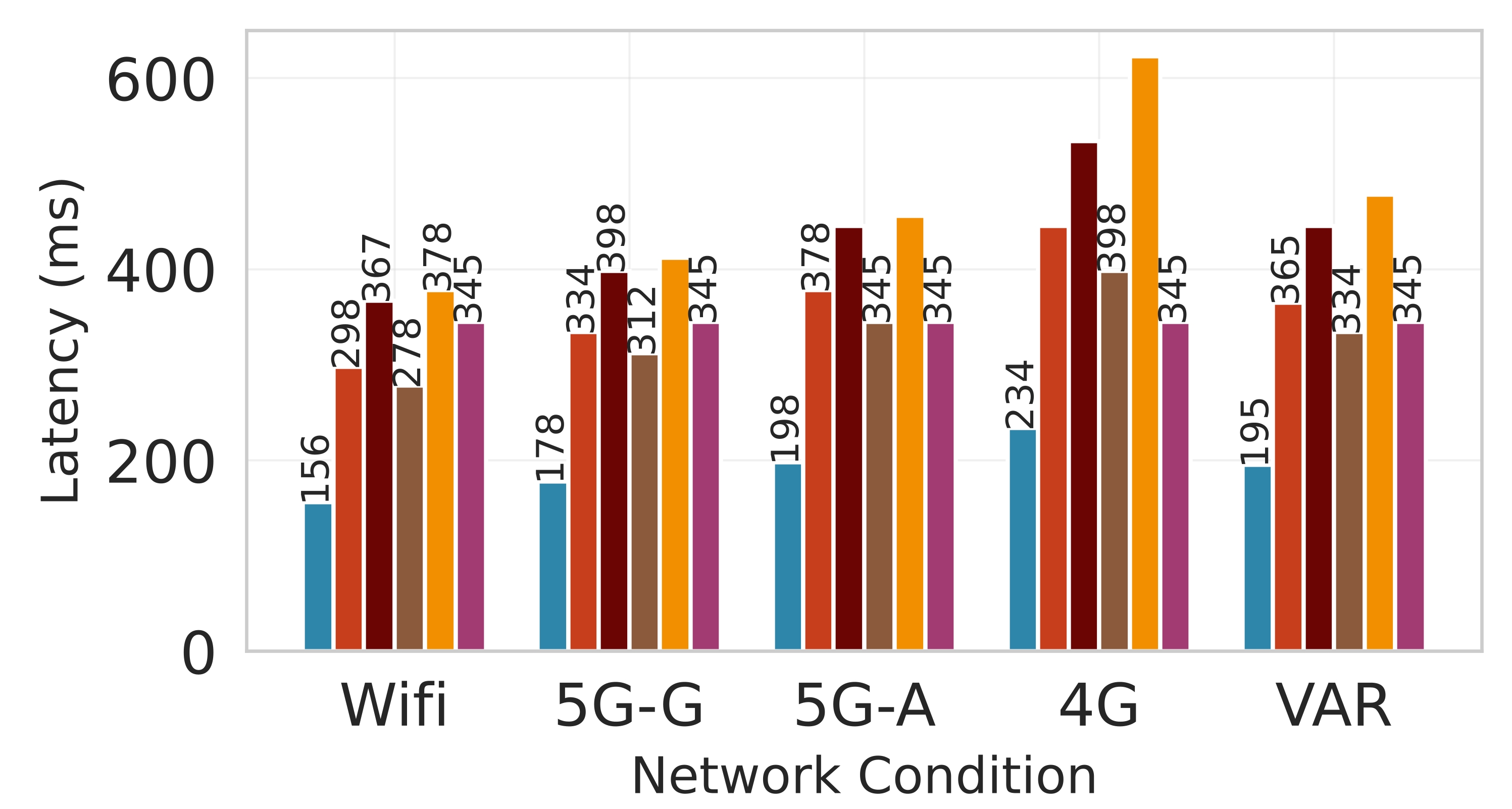
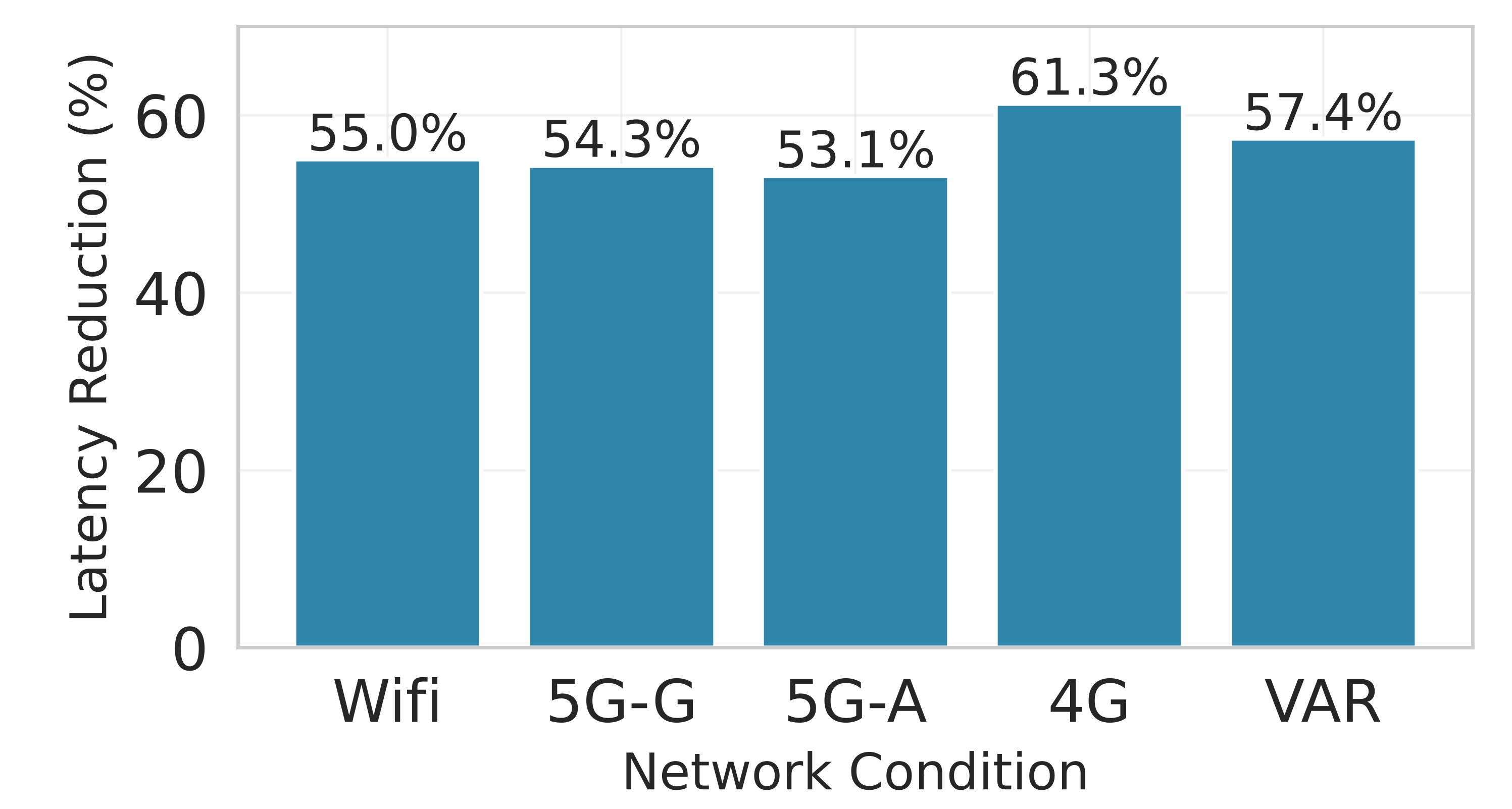
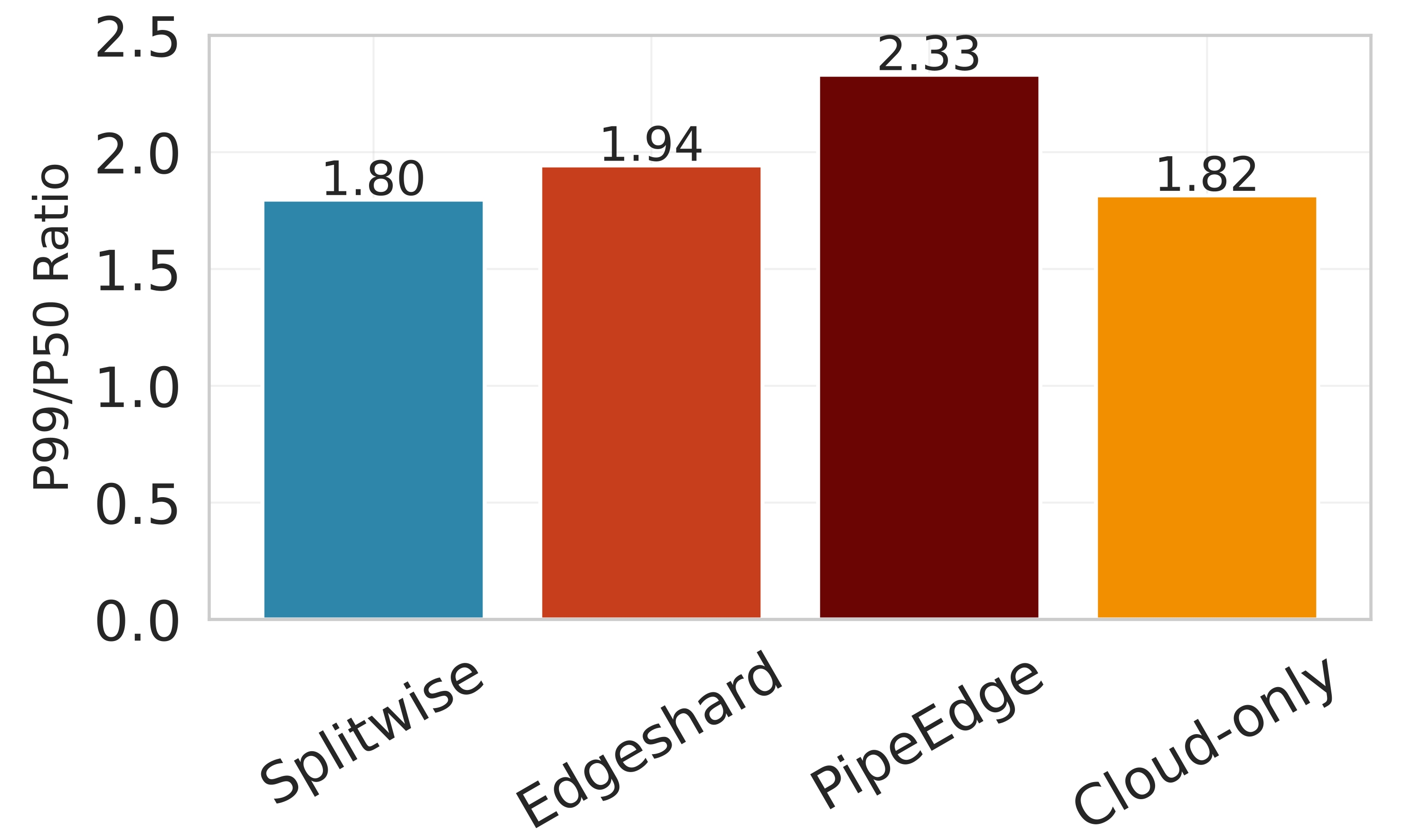
Latency. Figure 7 shows the effectiveness of Splitwise in minimizing latency while maintaining system stability. In both the P50 (median) and P99 (99th percentile) latency metrics shown in Figures 7a and7b, Splitwise consistently outperforms all competing baselines across all network scenarios. The cloud-only approach, which incurs significant communication overhead, exhibits the highest latency, particularly under poor network conditions like 4G and VAR, where it can exceed 500 ms. In contrast, edge-only execution, while avoiding network delays, suffers from high computational latency due to the limited processing power of edge devices. Static partitioning methods such as Edgeshard and PipeEdge perform better than these extremes but still fail to adapt to dynamic network fluctuations, resulting in suboptimal performance. The superiority of Splitwise is most shown in its ability to maintain low and stable latency even under challenging conditions. This is achieved through its dynamic, fine-grained partitioning strategy that employs the Lyapunov optimization framework to balance immediate performance with long-term queue stability. By intelligently allocating computation between the edge and cloud based on network quality, Splitwise minimizes the impact of network bottlenecks. Figure 7d demonstrates that Splitwise achieves a 53.1% to 61.3% reduction in P95 latency compared to the cloud-only baseline across all network types.
Static model partitioning. Early work on DNN partitioning [14,17] pioneered layer-wise splitting between edge and cloud. Neurosurgeon [14] profiles per-layer latency and energy costs offline and selects a single optimal split point. DADS [9] extends this by considering multiple DNNs simultaneously but remains limited to static partitioning. These approaches fundamentally assume stable network conditions and uniform workload assumptions, which fail in real-world deployments where bandwidth varies the day [8]. Moreover, existing methods partition at layer granularity, missing opportunities for finer-grained optimization within transformer blocks.
Edge-cloud collaborative inference. Collaborative inference systems [5,7,11,12,16,19,34] distribute computation across edge and cloud resources. SPINN [16] progressively refines predictions using early exits, but this approach is incompatible with autoregressive LLMs, where each token depends on complete model execution. CoDL [11] dynamically adjusts partition points for CNNs but relies on heuristic policies that fail to generalize across model architectures.
Splitwise Features. Our work differs from prior literature in 3 ways. First, we enable fine-grained partitioning at sub-layer granularity, exposing an order of magnitude more partition points. Second, we provide theoretical guarantees on queue stability through Lyapunov analysis while simultaneously optimizing multiple objectives. Third, we handle the combinatorial explosion of the action space through hierarchical decomposition and learned embeddings, making the approach tractable for large models.
Splitwise demonstrates that fine-grained partitioning with queue-stability guarantees enables efficient edge-cloud LLM inference. It decomposes transformer layers into attention heads and feed-forward blocks and uses a hierarchical policy with Lyapunov-assisted rewards to assign components to either the edge or the cloud. This design exposes far more split options than layer-wise methods while remaining tractable through action decomposition. It adapts to fluctuating network links, delivering latency reductions of 1.4×-2.8×, up to 41% energy savings, and 53-61% lower P95 latency compared with static and cloud-only baselines. It balances immediate performance with long-term queue stability. Future work includes integrating early exits and compression to further cut communication and broaden applicability.