Neural scaling laws have become foundational for optimizing large language model (LLM) training, yet they typically assume a single dense model output. This limitation effectively overlooks "Familial Models", a transformative paradigm essential for realizing ubiquitous intelligence across heterogeneous device-edge-cloud hierarchies. Transcending static architectures, Familial Models integrate early exits with relay-style inference to yield G deployable sub-models from a single shared backbone. In this work, we theoretically and empirically extend scaling laws to capture this "one-run, many-models" paradigm by introducing granularity (G) as a fundamental scaling variable alongside model size (N ) and training tokens (D). To rigorously quantify this relationship, we propose a unified functional form L(N, D, G) and parameterize it using large-scale empirical runs. Specifically, we employ a rigorous IsoFLOP experimental design to strictly isolate architectural impact from computational scale. Across fixed budgets (10 19 -10 21 FLOPs), we systematically sweep model sizes and granularities while dynamically adjusting tokens. To further resolve behavior at the level of individual exits, we introduce a branch scaling law , revealing that additional upstream branches have negligible impact on performance. Building on these laws, we define an Efficiency Leverage metric (EL) that compares the average loss of Familial Models to that of independent size-matched dense models under equal FLOPs, using the fitted scaling relations, we find that EL > 1 across all compute regimes and granularities considered, with the advantage most pronounced in the low-compute regime.Theoretically, this bridges fixed-compute training with dynamic architectures. Practically, it validates the "train once, deploy many" paradigm, demonstrating that deployment flexibility is achievable without compromising the compute-optimality of dense models.
In the landscape of modern Large Language Model (LLM) deployment, diverse applications impose varying constraints on latency and computational cost (Kwon et al., 2023;Hou et al., 2025;Semerikov et al., 2025). Practitioners are no longer satisfied with a single fixed model; instead, there is a pressing need for a flexible suite of models capable of spanning multiple cost tiers (Chen et al., 2023;Huang et al., 2025;Park et al., 2024). To address this, "Familial Models" have emerged as a transformative solution (An et al., 2025). Going beyond standard early-exit architectures (Teerapittayanon et al., 2016), the proposed approach synergistically integrates Early Exiting with Scalable Branches (EESB) and Hierarchical Principal Component Decomposition (HPCD). Specifically, instead of merely attaching prediction heads to intermediate layers, lightweight, decomposable branch networks (Houlsby et al., 2019) are constructed to allow for fine-grained parameter tuning via low-rank matrix approximation (Hu et al., 2022). This architecture enables a single training run to produce G deployable sub-models (where G denotes granularity) that share a unified backbone and aligned hidden features (Kusupati et al., 2022). This structural consistency not only offers a continuous spectrum of depth-cost trade-offs but also inherently supports relay-style cooperative inference across heterogeneous devices (Kang et al., 2017) without additional middleware, thereby significantly enhancing the flexibility and efficiency of the "train once, deploy many" paradigm.
To guide efficient model training and resource allocation, the field relies heavily on Neural Scaling Law. The foundational era began with Kaplan et al. (2020), who characterized test loss as a predictable power-law function of model size (N ), dataset size (D), and compute budget (C). This paradigm was significantly refined by (Hoffmann et al., 2022) through IsoFLOP analysis, establishing the “Chinchilla” scaling law which advocates for proportional scaling of parameters and data (N ∝ D) to maximize efficiency. Recent rigorous replications have further solidified this foundation; despite identifying methodological flaws in the original Chinchilla study-such as optimizer early stopping and parameter rounding errors-researchers reaffirmed the validity of the compute-optimal frontier with corrected, statistically robust confidence intervals (Pearce and Song, 2024;Porian et al., 2024).
As the field evolves, scaling laws are expanding beyond dense models to specialized, efficient architectures. For instance, recent work on Mixture-of-Experts (MoE) introduced “Efficiency Leverage” (EL) to quantify the computational advantage over dense models (Tian et al., 2025). This research revealed that efficiency is governed by distinct architectural factors: EL scales as a power law with the activation ratio (sparsity) and exhibits a non-linear “U-shaped” sensitivity to expert granularity, with advantages amplifying significantly at larger compute budgets (Tian et al., 2025;Krajewski et al., 2024). These advances reflect a broader paradigm shift: as the community navigates potential saturation in pure scaling and explores new frontiers like post-training scaling and data quality, the focus is moving toward architecture-aware laws that ensure precise resource optimization.
However, existing scaling laws are inherently built upon a “one-run, one-model” paradigm (Yuan et al., 2025), characterizing loss solely as a function of N and D for a single output. This perspective fails to capture the unique “one-to-many” dynamics of Familial models training, where the outcome is not a solitary model but a set of G interdependent sub-models derived from a single optimization process. Traditional laws overlook the architectural dimension of “Granularity” (G, the number of exit points), and thus cannot quantify the potential interference or synergy between exits, nor predict the performance cost of making a model family “finer-grained.” To bridge this theoretical gap, we propose a unified scaling framework that explicitly incorporates Granularity (G) as a fundamental scaling variable alongside N and D. Drawing inspiration from the architectural deconstruction approach of Tian et al. (2025), our methodology proceeds as follows:
- Familial Models Scaling Law: To quantify the modulatory effect of granularity, we adopt the formulation:
This multiplicative structure isolates the granularity penalty G γ from the standard power-law decay, effectively interpreting γ as the marginal “tax” imposed on the backbone for supporting multiple independent operating points. By parameterizing the unified functional form with data from our rigorous IsoFLOP experiments, we derive the Familial Models Scaling Law. The fitted law is quantitatively established as:
In this equation, the irreducible loss E = 1.0059 represents the theoretical performance limit, while the small exponent γ ≈ 0.0333 empirically confirms that the architectural overhead for supporting G exits is minimal, following a gentle multiplicative scaling rule.
To quantitatively analyze the performance gap between branch models in Familial Models and size-matched dense models, we propose the following branch-level scaling relation (P denotes the number of branch points preceding the given branch within the family, and Q denotes the number of branch points succeeding it):
This formulation explicitly disentangles the penalties on loss induced by additional branch points before and after the exit under consideration, with α and β capturing their respective contributions. By fitting this functional form to more than one hundred experimental configurations, we obtain a branch-level scaling law for Familial Models that quantitatively characterizes the performance gap between familial branches and size-matched dense models. The fitted law is quantitatively established as:
This scaling relation further implies that adding additional branch points before a given exit has only a negligible effect on its performance, indicating that Familial Models can introduce multiple sub-models of different sizes with virtually no degradation in the quality of the underlying backbone model.
Efficiency Leverage: Motivated by the efficiency leverage metric proposed for MoE models in Tian et al. (2025), we define an analogous Efficiency Leverage (EL) for Familial Models to quantify their compute advantage over dense models. Specifically, EL is defined as the ratio of the average loss of a dense baseline to that of a Familial Model under a matched compute budget:
The results show that EL remains strictly greater than 1 across all compute budgets, indicating that Familial Models achieve lower loss than dense models under matched FLOPs budgets. Moreover, this advantage is amplified in the low-compute regime, where the Efficiency Leverage attains its highest values.
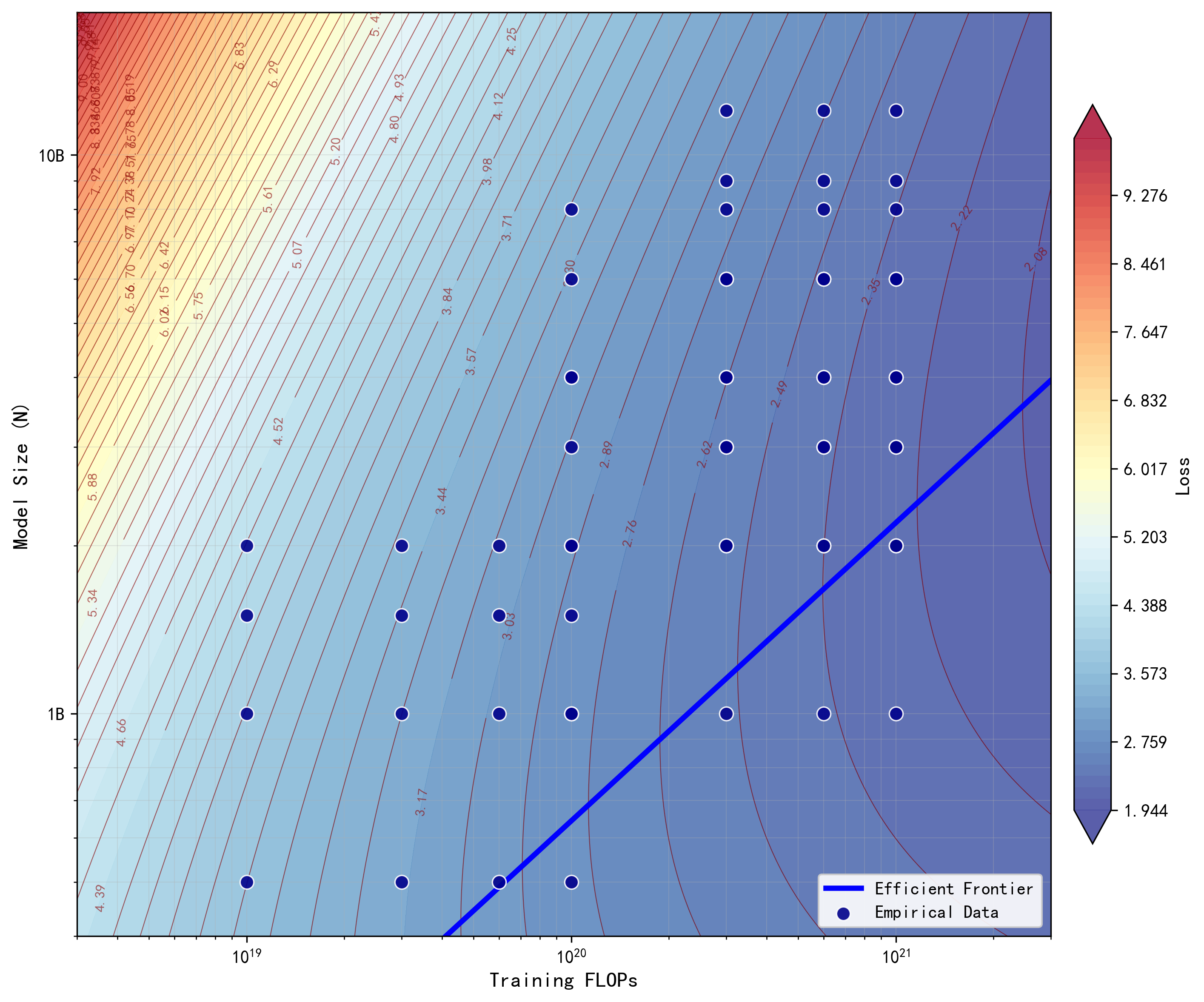
To ensure the scaling coefficients accurately reflect the architectural trade-offs of Familial Models, we parameterize the scaling law using a dataset derived from strict IsoFLOP (constant compute) constraints. By systematically varying model size N and granularity G within fixed compute budgets (10 19 -10 21 FLOPs), we generate a high-fidelity observation set. This design effectively decouples the marginal cost of granularity from computational scale, allowing for a precise isolation of the granularity exponent γ independent of the fitting algorithm employed.
This work pioneers the theoretical formalization of the “Familial Models” paradigm, establishing the first unified scaling law that explicitly incorporates Granularity (G) as a fundamental dimension alongside model size (N ) and data (D). Unlike prior studies limited to static dense models, we quantify the “cost of flexibility” by accurately modeling the three-dimensional loss surface. A critical discovery from our results is that the granularity exponent γ is extremely small (≈ 0.033), quantitatively proving that the architectural penalty for supporting multiple exit points is negligible. Beyond this global law, we introduce a branch-level scaling law for Familial Models that quantifies the performance gap between individual branches and size-matched dense models. The fitted coefficients show that additional branch points before a given exit have only a very minor impact on its loss, indicating that the familial architecture can produce multiple sub-models of different sizes from a single training run with virtually no degradation in backbone performance. Finally, we define an Efficiency Leverage metric EL and, using the fitted familial scaling law, compute its variation across different FLOPs budgets. The resulting curves confirm that EL exceeds 1 for all compute regimes considered, implying that Familial Models are consistently more compute-efficient than dense models, with the advantage most pronounced in the low-compute regime.
We adopt a conventional dense Transformer equipped with a single final prediction head as the baseline, which corresponds to the special case G = 1. Within each compute-budget group, we fix the total training compute (FLOPs; ranging from 10 19 to 10 21 ) and, for each architectural configuration, derive the corresponding training-token budget D implied by the fixed compute constraint. This ensures fair, compute-matched comparisons across models within the same group.
Familial Models is built upon a shared backbone and augments it with multiple early-exit prediction heads placed at selected intermediate layers. This design allows a single trained trunk to produce multiple deployable sub-models with different effective depths and inference costs. Formally, let the trunk contain L transformer layers. We attach exit heads at a set of intermediate layers{l 1 ,…,l G-1 } and also retain the standard output at the final layer L. This yields a total of G usable exits (including the final exit). We define G as the granularity factor, where a larger G corresponds to more available operating points (i.e., more depth/cost tiers) and thus finer deployment granularity. Training typically optimizes all exits jointly by minimizing a weighted sum of exit-specific language-modeling losses:
Where L g denotes the language-modeling loss at exit g, and w g is the corresponding weight. In our implementation, we assign equal weights to all exits (i.e., w g = 1/G), such that the total Familial Models loss is defined as the arithmetic mean of the individual losses across all exits. Within each experimental group, we keep the exit-weighting scheme and training protocol fixed, so that the primary independent variables for scaling analysis are (N, D, G).
Modern deployment environments are rarely uniform; they often demand a versatile suite of models spanning a wide range of latency and cost tiers to adapt to varying hardware constraints (e.g., server-side vs. ondevice) and dynamic query complexities. Relying on a single fixed operating point is inefficient, yet training independent models for each desired tier incurs a prohibitive computational cost that scales linearly with the number of models. Familial Models offer an elegant solution to this dilemma by training a shared Transformer trunk equipped with multiple intermediate exits. In this architecture, a single training run yields G deployable sub-models, each representing a distinct effective depth and inference cost. Here, the granularity G serves as a critical architectural hyperparameter, directly quantifying the density of valid operating points available from a single backbone. It effectively measures the “deployment resolution” of the model family-a higher G implies a finer-grained ability to trade off accuracy for speed without the need for retraining.
Classical scaling laws (e.g., Kaplan et al., 2020;Hoffmann et al., 2022) have provided robust guidelines for predicting how loss varies with parameter count N and training tokens D. However, these frameworks operate under the assumption of distinct, independently trained models, failing to account for the internal dependencies and weight sharing inherent in multi-exit architectures1 . In the Familial models setting, the training outcome is not a solitary scalar loss, but a trajectory of losses across G entangled sub-models derived from the same optimization process. To capture this “one-run, many-models” paradigm within a unified theoretical framework, we explicitly incorporate G as a third fundamental scaling dimension alongside N and D. By studying the joint scaling function L(N, D, G), we aim to rigorously quantify the marginal cost of granularity-determining whether the architectural overhead of supporting multiple exits alters the fundamental compute-optimal frontier established for dense models.
Next, we define the functional form of the familial models scaling law and use it to outline our objectives and experimental roadmap.
Following empirical scaling-law literature-particularly compute-optimal scaling analyses (e.g., Hoffmann et al.)-we model pretraining loss as a smooth, monotone function of model size and data scale, exhibiting diminishing returns and approaching a non-zero irreducible floor. In the dense setting, this behavior is well captured by an additive decomposition in which loss approaches an irreducible term and decays as power laws in N and D. To extend this perspective to Familial Models, we introduce granularity (G) and propose a unified scaling law, utilizing the methodology of Hoffmann et al. to fit our extended parametric form to strictly compute-matched training runs:
where E is the irreducible loss floor as N, D → ∞, A and B are positive scale coefficients, and α, β > 0 govern the rates of power-law improvement from increasing model size and data scale. The term G γ captures the multiplicative effect of granularity on the learnable component of the loss. This formulation reduces to the standard (N, D) scaling law when G = 1, while remaining compact, interpretable, and straightforward to fit from empirical runs.
A standard decomposition-based fitting procedure is adopted in the log domain (Hoffmann et al., 2022) , combining robust regression with multi-start initialization to ensure numerical stability and reliable parameter estimation.
• Log-domain decomposition with LSE: To facilitate gradient-based optimization and ensure numerical stability, the standard scaling law formulation is reformulated as:
Ensuring positivity and optimization stability, the coefficients are parameterized by:
For a specific run i, the predicted log value log Li is calculated using these exponential terms:
Specifically, we implement the log of the positive sum via a log-sum-exp operator defined as: LSE(x, y, z) = log (exp(x) + exp(y) + exp(z)) ,
This results in the final formulation:
• Robust objective: Huber loss on log-residuals: The discrepancy between the model’s prediction and the observed data is quantified by the log-residual r i , which is defined as:
The model is fitted by minimizing the sum of Huber losses: min a,b,e,α,β,γ i∈R
Huber δ (r i ),
We use δ = 10 -3 for Huber robustness2 . Empirically, larger δ tends to overfit lower-compute regimes and predict held-out larger-compute runs poorly, while δ < 10 -3 does not materially change the resulting predictions-consistent with robust behavior.
• Optimization: L-BFGS with grid initialization: As the objective function is non-convex, L-BFGS is employed to locate high-quality local minima. To further reduce sensitivity to initialization, optimization is initialized from a grid of starting points, which improves stability and consistency of the fitted solutions.
The solution achieving the lowest final objective value is selected. In our experiments, the optimal solution does not occur at the boundary of the initialization grid, indicating that the resulting fit is unlikely to be an artifact of the chosen grid limits.
α ∈ {0, 0.5, . . . , 2}, β ∈ {0, 0.5, . . . , 2}, e ∈ {-1, -0.5, . . . , 1}, a ∈ {0.5, . . . , 25}, b ∈ {0.5, . . . , 25}, γ ∈ {0, 0.5, . . . , 2},
We conduct a series of experimental groups designed to support reliable scaling-law estimation under controlled compute conditions. In each group, we fix the overall training compute budget (FLOPs
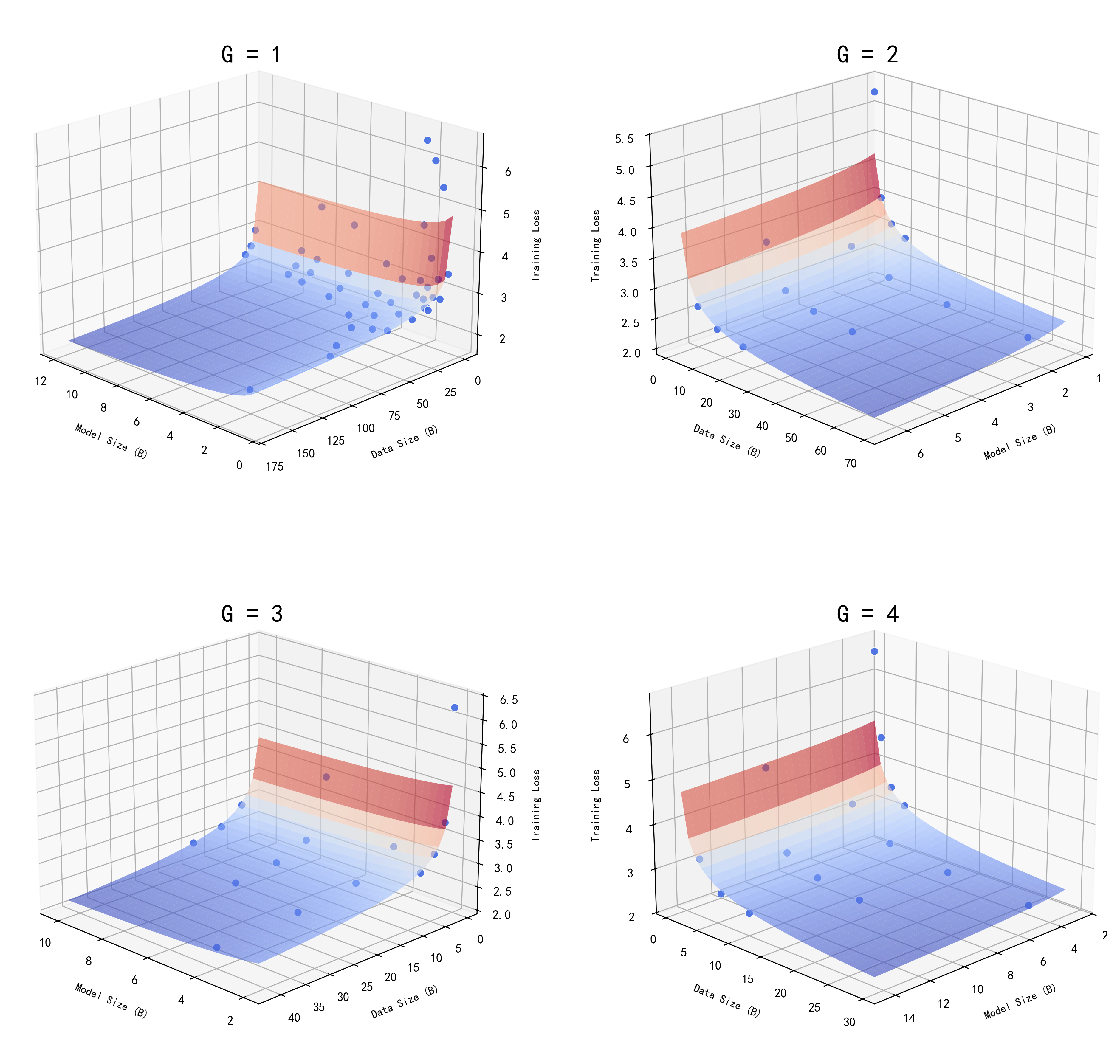
For the representative experimental group, the fitted scaling relation takes the form:
To facilitate interpretation, we visualize the learned relationship as a set of three-dimensional loss surfaces indexed by granularity G. In Figure 1
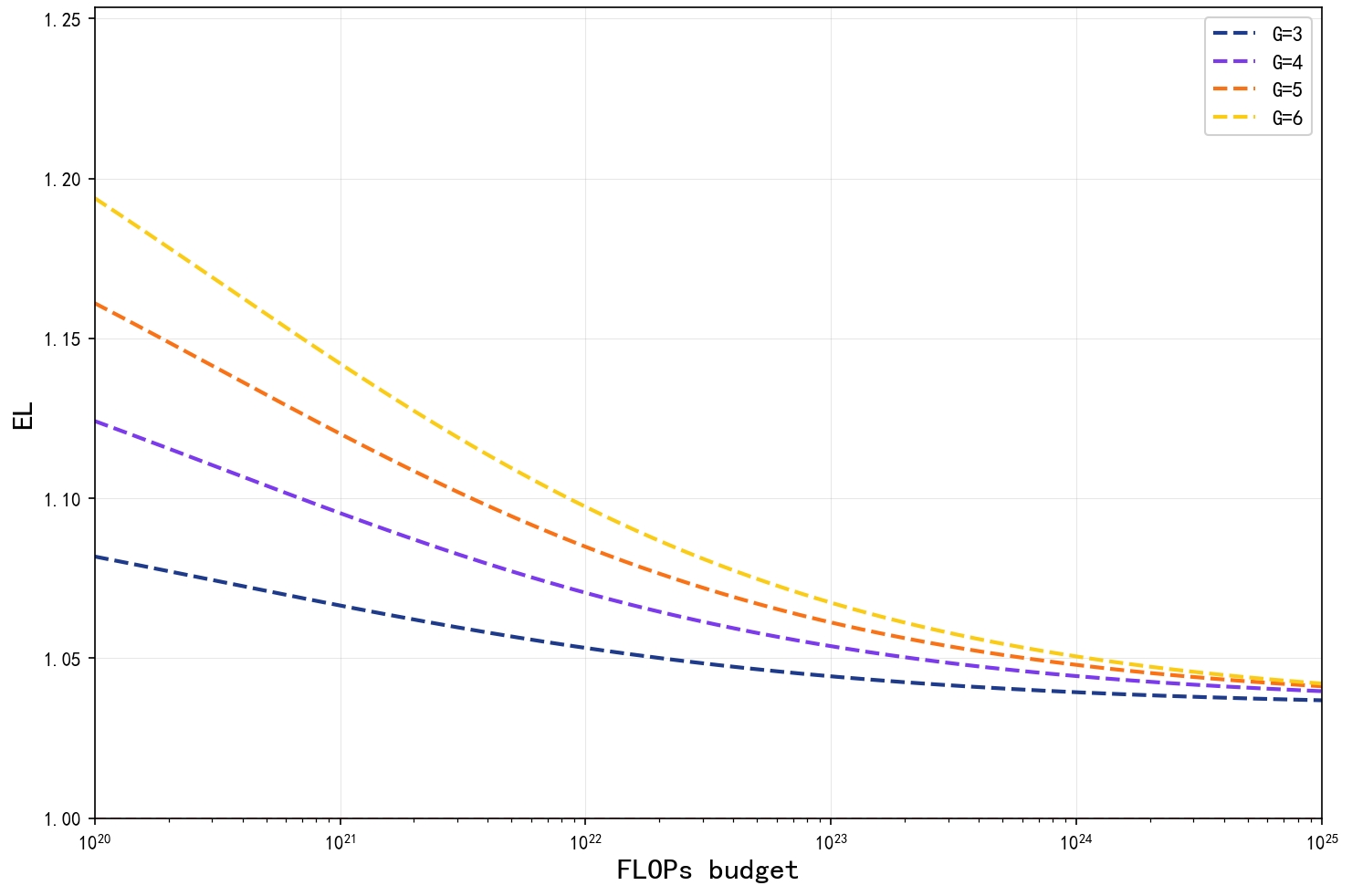
Figure 2 illustrates the efficiency frontier, providing a quantitative framework to guide the training and design of Familial Models. By mapping the relationship between model size N and data scale D, this frontier facilitates a principled approach to the “one-run, many-models” paradigm.
We investigate the performance differences between branch models in Familial Models and their dense counterparts under matched parameter counts and compute budgets. Specifically, for the fam4B family, we examine the 1B and 2B branch models against independently trained dense models of the same parameter size across four distinct FLOP budgets. The same experimental protocol is applied to the fam2B and fam12B families. Figure 3 reports the loss curves at the first branching point in each family compared to dense models of identical size, while Figure 4 presents the corresponding comparison for the second branching point. From Figure 3, we observe that as the granularity G increases, the training loss increases monotonically, exhibiting an approximately linear relationship with G. In contrast, Figure 4 reveals a more nuanced pattern: increasing G from 1 to 2 incurs only a marginal loss penalty, whereas for G ≥ 2, the relationship between granularity and loss returns to a near-linear trend.
This discrepancy arises from how additional branches are positioned relative to the branch under consideration.
In Figure 3, increasing G corresponds to adding branches after the evaluated branch point, whereas in Figure 4, the change from G = 1 to G = 2 is realized by inserting an additional branch before the evaluated branch point; only when G increases from 2 to 4 are new branches appended downstream. Consequently, adding branches downstream of a given branch has a significantly larger impact on its loss than adding branches upstream, and this impact is approximately linear with respect to the number of downstream additions. Moreover, as the compute budget increases, the slope of this linear relationship decreases, implying that with more abundant compute, the loss gap between different granularities diminishes. This behavior is consistent with the training dynamics: gradients from downstream branches propagate through and update all parameters of the evaluated branch’s backbone, whereas gradients from upstream branches affect only the shared earlier layers (a subset of the parameters).
Building on the above empirical results, we propose a scaling law for branch models in Familial Models that characterizes the additional loss incurred when introducing extra branch points compared to a dense baseline:
where L(P, Q, D) denotes the loss of the considered branch model and L dense is the loss of a dense model with matched parameter count and compute. The term P denotes the number of branch points preceding the given branch within the family, and Q denotes the number of branch points following it. Since, during training, downstream branches typically exert a stronger influence on the performance of upstream branches than the reverse, we assign distinct penalty weights α and β to P and Q, respectively. The factor (D d /D) a further captures the dependence of this penalty on the compute budget through the ratio between token budget D .
Using the same fitting procedure as for the preceding scaling laws, we fit the branch model loss on over 100 experimental configurations and obtain(the corresponding fitted curves based on the above experimental data are shown in Figure 5 and Figure 6):
The fitted coefficients show that additional branch points before a given branch (captured by P ) have a much smaller impact on its loss than additional branch points after it (captured by Q). Moreover, this scaling law implies that, under a fixed compute budget, the largest branch in a Familial Models can match the performance of a dense model of the same size to within a negligible margin, while simultaneously producing multiple smaller sub-models. This highlights a key advantage of Familial Models over traditional dense architectures: they preserve near-compute-optimal performance at the largest scale while providing a rich set of intermediate operating points for deployment.
To quantitatively assess the advantage of Familial Models over dense models, we introduce the Efficiency Leverage (EL), defined as the ratio between the average loss of multiple dense models and the average loss across all branch points of a corresponding Familial Models under the same compute budget: Based on the fitted Familial Models scaling law, we compute EL as a function of training FLOPs for different granularities, and plot the resulting curves in Figure 7. The curves show that EL remains consistently greater than 1, indicating that Familial Models achieve lower loss than their dense counterparts at matched compute.
Moreover, for a given FLOPs budget, EL tends to increase with granularity G, indicating that architectures with more exits derive greater relative benefit from the Familial design. This Efficiency Leverage is most pronounced in the low-compute regime, where the shared backbone enables Familial Models to make more effective use of limited training resources.
The establishment of the Familial Models scaling law L(N, D, G), together with the proposed branch scaling law L(P, Q, D) for Familial Models, not only optimizes the training of Familial Models but also provides a theoretical foundation for a wide range of downstream applications that require dynamic resource adaptation at both the model and branch levels.
Empirical Validation of Granularity Efficiency. Our rigorous fitting results for the Familial Models scaling law L(N, D, G) reveal that the granularity exponent γ is extremely small, indicating that under matched model size (N ) and data scale (D), increasing granularity G-i.e., adding more exit layers so that a single training run yields more deployable sub-models-induces only a very mild multiplicative change in loss. In practical terms, the fitted factor G γ stays close to 1 over a wide range of G, meaning that the loss surface is only weakly sensitive to the number of exits. Complementing this global law, our branch-level scaling analysis further quantifies how the loss of an individual exit depends on the number and placement of additional branch points: extra branches before a given branch have only a negligible effect on its loss. Moreover, by plugging the fitted familial scaling law into the definition of Efficiency Leverage EL(X Fam | X Dense ), we obtain EL-FLOPs curves that remain consistently above 1 across all compute budgets considered, quantitatively confirming that Familial Models achieve uniformly lower loss than sets of independent dense models trained under the same compute constraints. Taken together, these findings imply a favorable architectural trade-off: Familial Models training can amortize high pretraining costs across multiple deployment sizes with minimal degradation in the performance of the main trunk, allowing practitioners to obtain a spectrum of sub-models at different inference budgets from a single training run while largely preserving the scaling behavior expected from dense single-exit training.
Extending to Complex Modalities and Tasks. This inherent flexibility holds significant promise for other domains.
For instance, in Multi-Intent Spoken Language Understanding (SLU), recent surveys highlight the necessity of joint modeling to capture complex intent-slot interactions (Wu et al., 2025). Familial Model architectures could adaptively allocate compute based on the complexity of the user’s utterance, efficiently handling multi-intent scenarios with lower latency. Similarly, in the realm of multimedia security, frameworks like Aperture have demonstrated the value of patch-aware mechanisms for joint forgery detection and localization (?). Future work could explore integrating Familial backbones into such detection systems, allowing for rapid, coarse-grained screening at early exits and fine-grained, pixel-level localization at deeper layers.
Enabling Collaborative Ecosystems. Furthermore, the “relay-style” inference capability of Familial Models aligns naturally with the emerging trend of multi-model collaboration (Shao and Li, 2025). As demonstrated by recent advances in enhanced tool invocation, decoupling reasoning from format normalization via specialized collaborative models significantly improves reliability (Zhang et al., 2025). Familial Models can serve as the efficient infrastructure for such agentic workflows, where shallower sub-models handle routine formatting or filtering tasks, while deeper sub-models are reserved for complex reasoning and tool selection, thereby realizing a truly ubiquitous and equitable intelligence ecosystem.
Based on the classic scaling law formulation, this study introduces a granularity factor G to extend the scaling law specifically for Familial Models, providing a theoretical foundation for the “train once, obtain multiple models” paradigm. By fitting over 100 sets of experimental data, we derive the following unified formula:
Experimental results indicate that the exponent γ for granularity G is extremely small (γ ≈ 0.0333). This suggests that for a given model size N and training token count D, increasing granularity G incurs only a negligible penalty on the loss function. Since the value of G γ remains very close to 1 across a wide range, the average loss of Familial Models exhibits extremely low sensitivity to variations in granularity. This characteristic offers significant advantages for engineering practice: under an equivalent compute budget, Familial Models can yield multiple sub-models of varying sizes in a single training run without significantly compromising performance, thereby adaptively meeting diverse application requirements.
To further quantify how individual branches behave relative to size-matched dense models, we propose a branch-level scaling relation:
where P and Q denote the numbers of branch points preceding and following the exit under consideration, respectively. This formulation explicitly separates the penalties on loss induced by upstream and downstream branches, with the fitted coefficients showing that additional upstream branches have only a minimal effect on branch performance. Consequently, Familial Models can add multiple intermediate exits without materially degrading the performance of the main trunk, effectively yielding a family of sub-models at different scales from a single training run.
Building on these scaling laws, we introduce an Efficiency Leverage (EL) metric to capture the compute advantage of Familial Models over dense models, defined as the ratio between their respective average losses under a matched compute budget. Empirical evaluation using the fitted Familial Models Scaling Law shows that EL remains consistently greater than 1 across all FLOPs regimes, with the gain most pronounced in the low-compute setting.
Our research demonstrates the superiority of Familial Models in engineering practice. By enabling the acquisition of multiple models of varying sizes through a single training run, this architecture effectively addresses the demand for diverse deployment scales under fixed compute budgets, while maintaining performance comparable to dense model baselines.
Unlike independent models, sub-models in a family architecture share the majority of their parameters. This creates a multi-objective optimization landscape where gradients from deeper exits can regularize or potentially interfere with shallower ones, a dynamic not captured by traditional scaling laws for dense models.
Training runs occasionally exhibit transient loss spikes or instabilities, particularly in early phases. Unlike Mean Squared Error (MSE), which heavily penalizes these outliers and can skew the fitted curve, Huber loss transitions to linear scaling for large residuals, thereby effectively ignoring these non-representative data points.
Specifically, the forward and backward pass computations of the additional exit heads are included in the total FLOPs count. Therefore, for a fixed compute budget, increasing the granularity G (i.e., adding more heads) results in a slightly higher per-token cost, necessitating a compensatory reduction in the training token count D compared to a dense baseline.
This content is AI-processed based on open access ArXiv data.