The advancement of Text-to-SQL systems is currently hindered by the scarcity of highquality training data and the limited reasoning capabilities of models in complex scenarios (Hu et al., 2023; Li et al., 2023) . In this paper, we propose a holistic framework that addresses these issues through a dualcentric approach. From a Data-Centric perspective, we construct an iterative data factory that synthesizes RL-ready data characterized by high correctness and precise semantic-logic alignment, ensured by strict execution verification (Hu et al., 2023; Caferoglu et al., 2025; Dai et al., 2025) . From a Model-Centric perspective, we introduce a novel Agentic Reinforcement Learning framework. This framework employs a Diversity-Aware Cold Start stage to initialize a robust policy, followed by Group Relative Policy Optimization (GRPO) to refine the agent's reasoning via environmental feedback (Shao et al., 2024; Zhang et al., 2025) . Extensive experiments on BIRD (Li et al., 2023) and Spider (Yu et al., 2018) benchmarks demonstrate that our synergistic approach achieves state-of-the-art performance among single-model methods.
Text-to-SQL aims to democratize database access by translating natural language into executable queries (Pourreza and Rafiei, 2023;Li et al., 2023). While Large Language Models (LLMs) have demonstrated impressive capabilities, training specialized, efficient models faces significant bottlenecks on realistic benchmarks such as BIRD (Li et al., 2023) and Spider (Yu et al., 2018). We identify two primary hurdles: (1) Data Scarcity and Quality: High-quality, complex Text-to-SQL pairs are expensive to annotate, and existing datasets often lack the scale and precision required for stable * These authors contributed equally. † Corresponding author.
Reinforcement Learning (RL) (Hu et al., 2023;Li et al., 2023). ( 2) Reasoning Limitations: Standard Supervised Fine-Tuning (SFT) often fails to imbue models with self-correction capabilities, while standard RL methods frequently struggle with instability and inefficient exploration in the sparse-reward environment of SQL generation (Sheng and Xu, 2025;Pourreza et al., 2025).
In this work, we present a unified framework that tackles these challenges simultaneously through Data-Centric and Model-Centric pathways.
Data-Centric: RL-Ready Synthesis. To break the data scaling wall, we design an iterative data factory to synthesize interactive trajectories (Hu et al., 2023;Caferoglu et al., 2025). To ensure the generated samples are suitable for RL, we enforce strict Semantic-Logic Alignment: we apply a “Generation-as-Verification” strategy, retaining only those trajectories where the execution results perfectly match the ground truth (Dai et al., 2025;Weng et al., 2025). This yields a massive scale of high-correctness data, preventing reward hacking during the subsequent RL stage (Dai et al., 2025).
Model-Centric: Agentic RL with GRPO. The availability of complex synthetic data exposes the limitations of traditional training methods (Pourreza and Rafiei, 2023;Pourreza et al., 2024a). To bridge the gap, we propose a two-stage Agentic RL framework. First, we implement a Diversity-Aware Cold Start to initialize a robust policy from curated high-quality trajectories (Hu et al., 2023;Caferoglu et al., 2025). Second, we optimize the agent using Group Relative Policy Optimization (GRPO) (Shao et al., 2024;Zhang et al., 2025). Unlike standard methods that rely on unstable value networks, GRPO iteratively refines the policy by comparing the relative execution rewards of a group of synthesized trajectories, stabilizing training and improving exploration under sparse feedback (Shao et al., 2024;Cheng et al., 2025).
Our contributions are summarized as follows:
• We build a data pipeline that alleviates data scarcity by synthesizing high-correctness, RLready data via strict execution verification.
• We propose an Agentic RL framework combining Diversity-Aware Cold Start and GRPO to enhance reasoning and exploration (Shao et al., 2024;Zhang et al., 2025).
• We demonstrate that our method achieves single-model SOTA results on BIRD (Li et al., 2023) and Spider (Yu et al., 2018) benchmarks.
2 Related Work
Data synthesis alleviates annotation bottlenecks in Text-to-SQL by generating additional NL-SQL pairs via templates, schema-guided sampling, and LLM generation. Large-scale synthetic corpora enable pretraining and SFT, improving coverage across domains and dialects (Hu et al., 2023;Li et al., 2025;Pourreza et al., 2024b). Because synthetic pairs can be illogical or misaligned, recent pipelines emphasize data verification, such as executability checks, relationship preservation, and automatic repair, before mixing synthetic data with human data (Hu et al., 2023;Caferoglu et al., 2025).
Supervised fine-tuning for Text-to-SQL suffers from a mismatch between loss and evaluation: cross-entropy optimizes string-level overlap, while benchmarks measure execution accuracy (Zhong et al., 2018). These limitations motivate the use of reinforcement learning. Early works (Zhong et al., 2018) use execution feedback as a reward to align training with correctness. However, the binary execution reward is inherently sparse and provides little learning signal for near-correct outputs. Recent works (Sheng and Xu, 2025;Pourreza et al., 2025) address this by reward shaping, designing partial reward components to densify feedback. Yet even with shaped rewards, exploration is still constrained in the large SQL structural space.
Inference for Text-to-SQL increasingly leans on constructing richer context and reducing noise. Practical systems augment schemas with field metadata/descriptions and representative values to re-duce ambiguity (Shkapenyuk et al., 2025;Talaei et al., 2024), as well as pruning schemas with retrieval-based schema linking (Liu et al., 2025;Pourreza et al., 2024a;Pourreza and Rafiei, 2023).
Recent pipelines also adopt multi-turn refinement uses execution feedback to iteratively refine outputs (Xu et al., 2025).
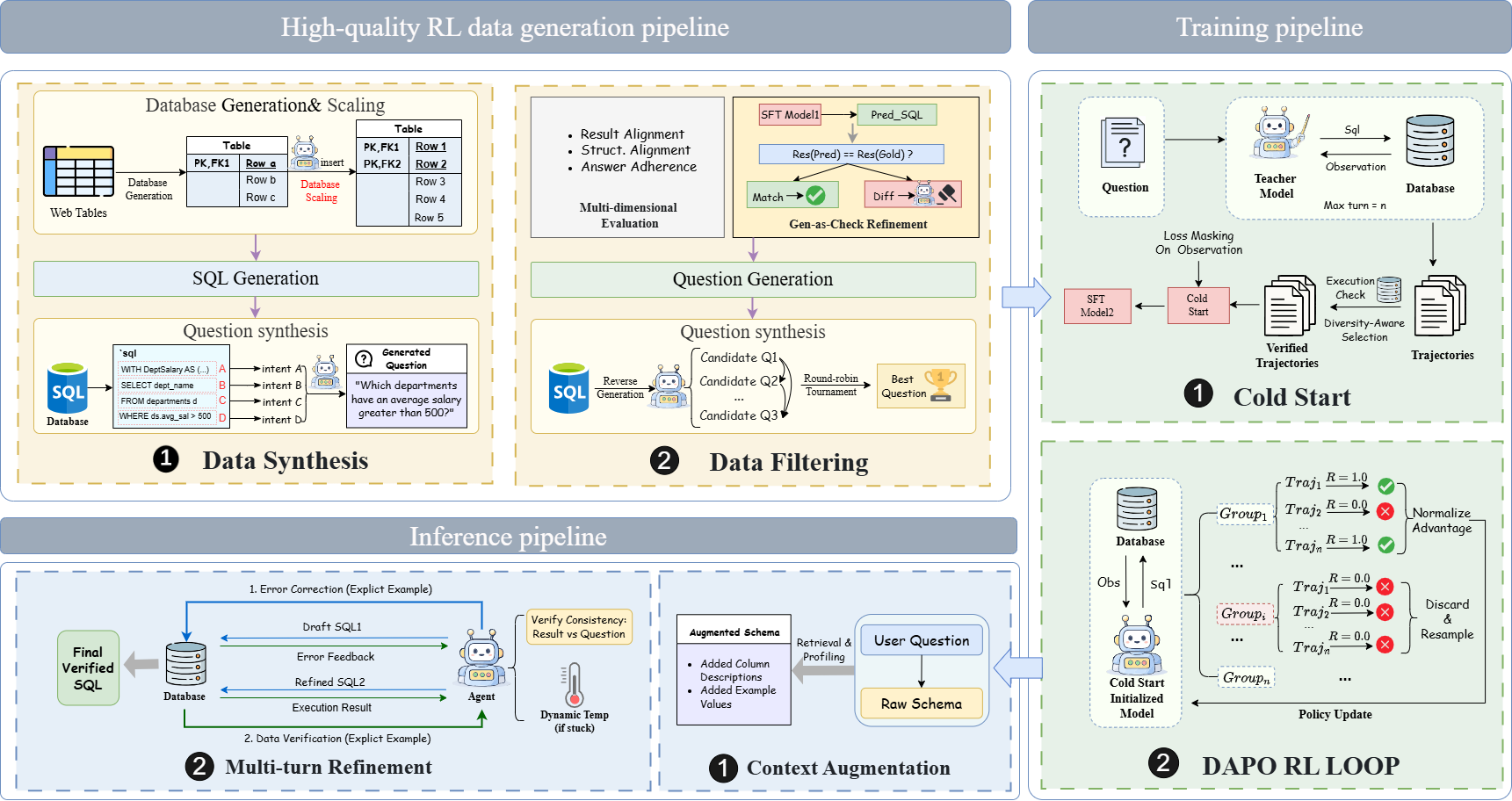
To address the scaling bottlenecks and logical inconsistencies discussed in Section 1, we propose AGRO-SQL, an end-to-end framework that synchronizes a high-fidelity data factory with an entropy-guided optimization strategy.
To address the scaling bottlenecks and logical inconsistencies discussed in Section 1, we propose AGRO-SQL, an end-to-end framework synchronizing a high-fidelity data factory with an entropyguided optimization strategy (see Figure 1). To ensure the “zero-noise” gold labels essential for scaling RL, we develop an RL-Ready Iterative Data Pipeline comprising two stages. First, the Structural-Aware Synthesis stage enhances baseline synthesis (Li et al., 2025) by employing DAGbased database augmentation to mitigate accidental execution correctness, enforcing SQL decomposition to capture structural constraints, and utilizing tournament-based selection to ensure high logical fidelity. Second, to eliminate “logic noise,” we implement a K-cycle Iterative Gen-as-Check Refinement loop. Synthesized samples are verified by comparing SFT model predictions against gold SQLs; divergences trigger a multi-dimensional audit by an LLM-as-a-Judge, and problematic samples are iteratively regenerated until logical consistency is confirmed via execution.
To enable robust multi-turn reasoning, we propose a two-stage framework comprising Cold Start Supervised Fine-Tuning (SFT) and Agentic Reinforcement Learning (Agentic RL). In the SFT stage, we distill interactive capabilities from a teacher model, DeepSeek V3.2(DeepSeek-AI et al., 2025) by synthesizing diverse trajectories. To mitigate overfitting, we employ a diversity-aware selection mechanism based on hybrid embeddings of SQL actions and reasoning thoughts, fine-tuning the model with a loss-masking objective that focuses solely on agent-generated tokens. In the Agentic RL stage, we further optimize the policy π θ using Group Relative Policy Optimization algorithm (GRPO) (Shao et al., 2024). Formulated as a POMDP, the training aligns the agent with environmental feedback using a sparse reward function (R = 1.0 for correct execution, R = -1.0 for invalid format). GRPO stabilizes optimization by computing advantages Âi relative to a group of sampled trajectories, effectively encouraging selfcorrection and semantic accuracy.
To mitigate semantic-logic mismatch, we propose a three-stage context augmentation pipeline.
Database Profile Construction: The pipeline starts by profiling column’s statistical exemplars (Shkapenyuk et al., 2025;Talaei et al., 2024). Semantic Description Generation: We first harvest any existing metadata from the benchmark or database. If not, we generate descriptions using LLM. Dynamic Pruning via Retrieval: Then we conduct context pruning, using a biencoder to calculate embeddings and retrieve top-K units (Reimers and Gurevych, 2019). Finally, to keep critical columns for potential multi-hop joins, we remove them from the retrieval process and always retain them (Wang et al., 2020(Wang et al., , 2025)). We implement a Multi-turn Refinement mechanism with Execution Feedback to transform the task into a action-feedback loop for refining SQL. At each turn, the LLM agent observes the history and generates an action. The environment executes the SQL and returns an observation. This cycle enables the model to correct syntactic and schema Errors, as well as semantic divergences.
In this section, we evaluate the effectiveness of our proposed method. We first introduce the experimental setup, followed by a presentation and analysis of the main results.
We conduct experiments on two widely-recognized Text-to-SQL benchmarks to ensure a comprehensive evaluation of our model’s capabilities.
Spider (Yu et al., 2018) is a foundational and widely-used benchmark in the Text-to-SQL field. It contains 7,000 training samples and 1,034 development samples, spanning 200 databases across 138 diverse domains.
Bird (Li et al., 2023) represents a more recent and challenging benchmark, designed to better reflect real-world application scenarios. This dataset features a larger scale, with 9,428 training and 1,534 development samples. It covers 95 largescale databases from 37 professional domains, demanding more complex reasoning than Spider. each).
Table 1 presents the primary results of our method against SOTA baselines on the development sets of Spider (Yu et al., 2018) and BIRD (Li et al., 2023). AGRO-SQL achieves the best performance among all single models of similar size. Notably, on the more challenging BIRD benchmark (Li et al., 2023), our method shows a significant improvement in Execution Accuracy (EX), highlighting the effectiveness of the agentic RL framework in complex multi-step reasoning.
We presented AGRO-SQL, a framework synergizing high-fidelity data synthesis with agentic reinforcement learning (GRPO). By enforcing strict execution verification in data generation and stabilizing exploration via group-relative optimization, our method significantly improves reasoning robustness. Experiments on the BIRD benchmark show our agentic model achieves an execution accuracy of 70.66%, which further improves to 72.10% with self-consistency, establishing a new state-ofthe-art for open-source models.
Our approach relies heavily on executable environments for data verification, reward computation, and agentic refinement. While execution-based signals provide reliable supervision, they require access to runnable databases and introduce additional computational overhead, which may limit applicability in restricted or latency-sensitive settings. In addition, although our iterative synthesis pipeline enforces strict execution correctness, synthetic data may still exhibit coverage gaps for rare SQL patterns or long-tail schemas, and execution equivalence alone cannot fully guarantee natural language faithfulness. Addressing these limitations will require more execution-free or structure-aware feedback signals and broader validation in realworld deployment scenarios.
Deploying autonomous Text-to-SQL agents requires strict security measures. To prevent unauthorized data exposure or modification, such systems must operate with read-only permissions and robust access controls. We also emphasize the importance of monitoring synthetic training data to mitigate potential biases in generated queries.
This content is AI-processed based on open access ArXiv data.