Heterogeneity in Multi-Agent Reinforcement Learning
📝 Original Paper Info
- Title: Heterogeneity in Multi-Agent Reinforcement Learning- ArXiv ID: 2512.22941
- Date: 2025-12-28
- Authors: Tianyi Hu, Zhiqiang Pu, Yuan Wang, Tenghai Qiu, Min Chen, Xin Yu
📝 Abstract
Heterogeneity is a fundamental property in multi-agent reinforcement learning (MARL), which is closely related not only to the functional differences of agents, but also to policy diversity and environmental interactions. However, the MARL field currently lacks a rigorous definition and deeper understanding of heterogeneity. This paper systematically discusses heterogeneity in MARL from the perspectives of definition, quantification, and utilization. First, based on an agent-level modeling of MARL, we categorize heterogeneity into five types and provide mathematical definitions. Second, we define the concept of heterogeneity distance and propose a practical quantification method. Third, we design a heterogeneity-based multi-agent dynamic parameter sharing algorithm as an example of the application of our methodology. Case studies demonstrate that our method can effectively identify and quantify various types of agent heterogeneity. Experimental results show that the proposed algorithm, compared to other parameter sharing baselines, has better interpretability and stronger adaptability. The proposed methodology will help the MARL community gain a more comprehensive and profound understanding of heterogeneity, and further promote the development of practical algorithms.💡 Summary & Analysis
This paper conducts a systematic analysis of heterogeneity in Multi-Agent Reinforcement Learning (MARL) and develops methodologies for defining, quantifying, and utilizing it. The proposed HetDPS algorithm dynamically adjusts parameter sharing based on the quantification of various types of heterogeneities among agents, offering better interpretability and adaptability compared to existing methods. Heterogeneity is categorized into observation heterogeneity, response transition heterogeneity, effect transition heterogeneity, objective heterogeneity, and policy heterogeneity.📄 Full Paper Content (ArXiv Source)
| Method | Paradigm | Adaptive | Relation to Heterogeneity Utilization |
|---|---|---|---|
| NPS | No Sharing | No | None |
| FPS | Full Sharing | No | None |
| FPS+id | Full Sharing | No | None |
| Kaleidoscope | Partial Sharing | Yes | No utilization, increases agent policy heterogeneity as the bias |
| SePS | Group Sharing | No | Implicitly utilizes objective heterogeneity and response transition heterogeneity |
| AdaPS | Group Sharing | Yes | Implicitly utilizes objective heterogeneity and response transition heterogeneity |
| MADPS | Group Sharing | Yes | Explicitly utilizes policy heterogeneity only |
| HetDPS (ours) | Group Sharing | Yes | Explicitly utilizes heterogeneity, leveraging heterogeneous distance |
 style="width:85.0%" />
style="width:85.0%" />
Based on the case study in Section 20.3, the proposed method can not only accurately quantify all types of heterogeneity, but also the “comprehensive heterogeneity” among agents. Additionally, the method is independent of the parameter-sharing type used in MARL and can be deployed online, thereby further enhancing its practicality. In this section, we provide a practical application of our methodology to demonstrate its potential in empowering MARL.
We select parameter sharing in MARL as our application context. As a common technique in MARL, parameter sharing can improve sample utilization efficiency , but its excessive use may inhibit agents’ policy heterogeneity expression . Many works have attempted to find a balance between parameter sharing and policy heterogeneity . However, existing approaches suffer from two main problems: poor interpretability, unable to explain why policy heterogeneity is necessary and to what extent; and poor adaptability, manifested by numerous task-specific hyperparameters
To address these issues, we propose a Heterogeneity-based multi-agent Dynamic Parameter Sharing algorithm (HetDPS) with two core ideas (More details can be found in Appendix J):
$`\spadesuit`$ Grouping agents for parameter sharing through heterogeneity distances. We utilize distance-based clustering methods to group agents, thus avoiding the introduction of task-specific hyperparameters like group number or fusion thresholds . The heterogeneity distance matrices also enhance the algorithm’s interpretability.
$`\clubsuit`$ Periodically quantifying heterogeneity and modifying agents’ parameter sharing paradigm. This approach can help policies escape local optima , the effectiveness of such a mechanism has been verified in the MARL domain , and even in broader RL areas such as large model fine-tuning .
Combining the above ideas, we present the method of HetDPS as illustrated in Figure 1. This approach can be combined with common MARL algorithms and supports various parameter-sharing initialization (e.g., FPS and NPS). After every $`T`$ updates, the algorithm computes the distance matrix of agents and groups them via distance-based clustering. If clustering exists from the previous cycle, bipartite graph matching is performed between the two clustering results to help agents determine policy inheritance relationships. This dual-clustering mechanism effectively enhances the algorithm’s adaptability.
We emphasize that utilization of MARL heterogeneity extend beyond this scope. Through our method, researchers can quantify specific types of heterogeneity or composite heterogeneity, which can be integrated with cutting-edge MARL research directions, as detailed in Appendix C.
Preliminaries
Primal Problem of MARL. In this paper, we use Partially Observable Markov Game (POMG) as the general model for the primal problem of MARL.1 To better study agent heterogeneity, we adopt an agent-level modeling approach similar to that in . A POMG is defined as an 8-tuple, represented as follows:
\begin{equation}
\langle N, \{S^i\}_{i\in N}, \{O^i\}_{i\in N}, \{A^i\}_{i\in N}, \{\Omega^i\}_{i\in N}, \{\mathcal{T}^i\}_{i\in N}, \{r_i\}_{i\in N}, \gamma \rangle,
\label{eq:POMG}
\end{equation}Among all elements in Expression [eq:POMG], $`N`$ is the set of all agents, $`\{S^i\}_{i\in N}`$ is the global state space which can be factored as $`\{S^i\}_{i\in N} =\times_{i\in N} S^{i} \times S^{E}`$, where $`S^{i}`$ is the state space of an agent $`i`$, and $`S^{E}`$ is the environmental state space, corresponding to all the non-agent components. $`\{O^i\}_{i\in N}=\times_{i\in N} O^{i}`$ is the joint observation space and $`\{A^i\}_{i\in N}=\times_{i\in N} A^{i}`$ is the joint action space of all agents. $`\{\Omega^i\}_{i\in N}`$ is the set of observation functions. $`\{\mathcal{T}^i\}_{i\in N}=(\mathcal{T}^1, \cdots, \mathcal{T}^{|N|},\mathcal{T}^E)`$ is the collection of all agents’ transitions and the environmental transition. Finally, $`\{r_i\}_{i\in N}`$ is the set of reward functions of all agents and $`\gamma`$ is the discount factor.
Here, we give the independent and dependent variables for each function and their notation. At each time step $`t`$, an agent $`i`$ receives an observation $`o^i_t \sim \Omega^{i}(\cdot|\hat{s}_t)`$, where $`\hat{s}_t \in \{S^i\}_{i\in N}`$ is the global state at time $`t`$. Then, agent $`i`$ makes a decision based on its observation, resulting in an action $`a^i_t \sim \pi_i(\cdot|o^i_t)`$. The environment then collects actions from all agents to form the global action $`\hat{a}_t = (a^1_t, \dots, a^{|N|}_t)`$. We assume that the local state transition of agent $`i`$ is influenced by the global state and global action, so its local state transitions to a new state $`s^i_{t+1} \sim \mathcal{T}^i(\cdot|\hat{s}_t, \hat{a}_t)`$. Similarly, the states of other agents and the environment also transition, yielding the next global state $`\hat{s}_{t+1} = (s^1_{t+1}, \dots, s^{|N|}_{t+1}, s^E_{t+1}) \sim (\mathcal{T}^1(\cdot|\hat{s}_t, \hat{a}_t), \dots, \mathcal{T}^{|N|}(\cdot|\hat{s}_t, \hat{a}_t), \mathcal{T}^E(\cdot|\hat{s}_t, \hat{a}_t)) = \{\mathcal{T}^i\}_{i\in N}(\cdot|\hat{s}_t, \hat{a}_t)`$. At the same time, all agents receive rewards, with the reward for a specific agent $`i`$ given by $`r^i_t \sim r^{i}(\cdot|\hat{s}_t, \hat{a}_t)`$.
The objective of MARL is to solve POMG by finding an optimal joint policy that maximizes the cumulative reward for all agents. We denote the individual optimal policy for agent $`i`$ as $`\pi_i^{*}`$ and the optimal joint policy as $`\hat{\pi}^{*}`$, which can be expressed as $`\hat{\pi}^{*}=(\pi_1^{*}, \dots, \pi_{|N|}^{*})`$. The optimal joint policy for a POMG can be obtained through the following equation:
\begin{equation}
\pi_i^{*} = \arg\max_{\hat{\pi}} \mathbb{E}_{\hat{\pi}} \left[ \sum_{k=0}^{\infty} \gamma^k \sum_{i\in N} r^i_{t+k} \Big| \hat{s}_t = \hat{s}_0 \right],
\label{eq:joint policy}
\end{equation}where $`\gamma`$ is the discount factor, and the expectation is taken over the trajectories via joint policy $`\hat{\pi}`$ starting from the initial state $`\hat{s}_0`$.
Introduction
Multi-agent reinforcement learning (MARL) has achieved success in various real-world applications, such as swarm robotic control , autonomous driving , and large language model fine-tuning . However, most MARL studies focus on policy learning for homogeneous multi-agent systems (MAS), overlooking in-depth discussions of heterogeneous multi-agent scenarios . Heterogeneity is a common phenomenon in multi-agent systems. For example, in nature, different species of fish collaborate to find food ; in human society, diverse teams demonstrate higher intelligence and resilience ; and in artificial systems, aerial drones and ground vehicles cooperate to monitor forest fires . Heterogeneity can enhance system functionality, reduce costs, and improve robustness, but effectively leveraging heterogeneity remains a key challenge in multi-agent system . As an approach of learning through environmental interactions, MARL can effectively enable multi-agent systems to learn collaborative policies. Hence, exploring heterogeneity from a reinforcement learning perspective would significantly broaden the applicability of MARL.
In the current MARL field, although some works explicitly or implicitly mention agent heterogeneity, only a few focus on its definition and identification. Regarding explicit discussion of heterogeneity, studies have explored communication issues , credit assignment , and zero-shot generalization in heterogeneous MARL. However, these works limit their focus to agents with clear functional differences and lack definitions of agent heterogeneity. On the other hand, many studies explore policy diversity in MARL. Some encourage agents to learn distinguishable behaviors based on identity or trajectory information , some works group agents using specific metrics , and some quantify policy differences and design algorithms to control policy diversity .
 style="width:75.0%" />
style="width:75.0%" />
However, these works do not adequately address where policy diversity originates or how it fundamentally relates to agent differences. In terms of defining and classifying heterogeneity in MARL, divides heterogeneity into physical and behavioral types but lacks a mathematical definition. provides extended POMDP for heterogeneous MARL settings, but do not classify or define heterogeneity. Others introduce the concept of local transition heterogeneity , but does not cover all elements of MARL. Currently, there is still a lack of systematic analysis of agent heterogeneity from the MARL perspective. To fill the aforementioned gaps, we conduct a series of studies on defining, quantifying, and utilizing heterogeneity in the MARL domain, the philosophy of our study can be found in Figure 2. And more details of related work can be found in Appendix A. Our contributions are summarized as follows:
• Defining Heterogeneity: Based on an agent-level model of MARL, we categorize heterogeneity into observation heterogeneity, response transition heterogeneity, effect transition heterogeneity, objective heterogeneity, and policy heterogeneity, and provide corresponding definitions.
• Quantifying Heterogeneity: We define the heterogeneity distance, and propose a quantification method based on representation learning, applicable to both model-free and model-based settings. Additionally, we give the concept of meta-transition heterogeneity to quantify agents’ comprehensive heterogeneity.
• Utilizing Heterogeneity: We develop a multi-agent dynamic parameter-sharing algorithm based on heterogeneity quantification, which offers better interpretability and fewer task-specific hyperparameters compared to other related parameter-sharing methods.
In this paper, we adopt a discussion approach that progresses from theory to practice and from general to specific. The overall structure is organized as follows: Section 18 introduces the agent-level modeling of the MARL primal problem; Section 19 provides the classification and definition of heterogeneity in MARL; Section 20 proposes the method for quantifying heterogeneity and presents case studies; Section 21 describes the dynamic parameter-sharing algorithm; Section 22 provides the related experimental results; and Section 23 summarizes the paper.
| Task | Agent Type Distribution |
|---|---|
| 15a_3c | $`5-5-5`$ |
| 30a_3c | $`10-10-10`$ |
| 15a_5c | $`3-3-3-3-3`$ |
| 30a_5c | $`3-3-3-12-9`$ |
Task information for PMS.
| Task | Agent Type Distribution |
|---|---|
| 3s5z | 3 Stalkers (0–2) – 5 Zealots (3–7) |
| 3s5z_vs_3s6z | 3 Stalkers (0–2) – 5 Zealots (3–7) |
| MMM | 2 Marauders (0–1) – 7 Marines (2–8) – 1 Medivac (9) |
| MMM2 | 2 Marauders (0–1) – 7 Marines (2–8) – 1 Medivac (9) |
Agent distribution in four heterogeneous SMAC tasks.
Experiments
In this section, we conduct comprehensive comparisons between HetDPS and other parameter sharing methods. Beyond performance comparisons, we also analyze the heterogeneity characteristics of each MARL task with our methodology, to demonstrate the algorithm’s interpretability. Additionally, we conduct hyperparameter experiments and efficiency and resource consumption experiments, to show the adaptability and practicality of HetDPS.
Experimental Setups
 style="width:80.0%" />
style="width:80.0%" />
Environments. Partical-based Multi-agent Spreading (PMS) is a typical environment in the policy diversity domain. In this environment, multiple agents are randomly generated in the center of the map, while multiple landmarks are generated near the periphery. Both agents and landmarks have various colors, and agents need to move to landmarks with matching colors. Additionally, agents need to form tight formations when they reach the vicinity of landmarks. We employ 4 typical tasks, corresponding to different numbers and color distributions, as detailed in Table 1. The StarCraft Multi-Agent Challenge (SMAC) is a popular MARL benchmark, where multiple ally units controlled by MARL algorithms aim to defeat enemy units controlled by built-in AI.
 style="width:80.0%" />
style="width:80.0%" />
 style="width:80.0%" />
style="width:80.0%" />
Baselines and training. We compare HetDPS with other parameter sharing baselines, as listed in Table [tab:methods_comparison]. As seen from the table, current methods can not effectively utilize heterogeneity. Although some methods implicitly use certain heterogeneity quantification results, the elements they involve are not comprehensive. MADPS, as the only method that explicitly uses policy distance for dynamic grouping, relies on the assumption that policy learning can effectively capture heterogeneity, which lacks practicality. All parameter-sharing methods are integrated with MAPPO, and we use official implementations of the baselines wherever available. For more details of the experiments, see the Appendix K.
Results
| NPS | FPS | FPS+id | Kaleidoscope | SePS | AdaPS | MADPS | HetDPS (ours) | |
|---|---|---|---|---|---|---|---|---|
| Training Speed | 0.952x | 1.000x | 0.992x | 0.974x | 0.986x | 0.614x | 0.539x | 0.712x |
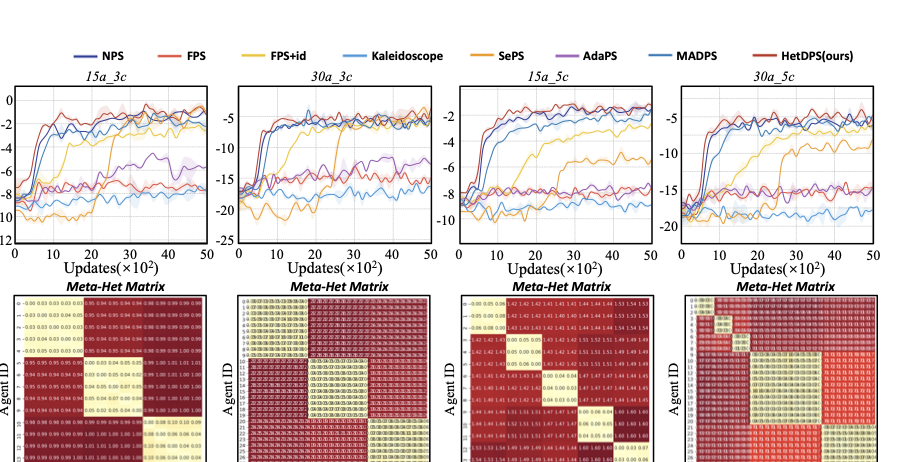
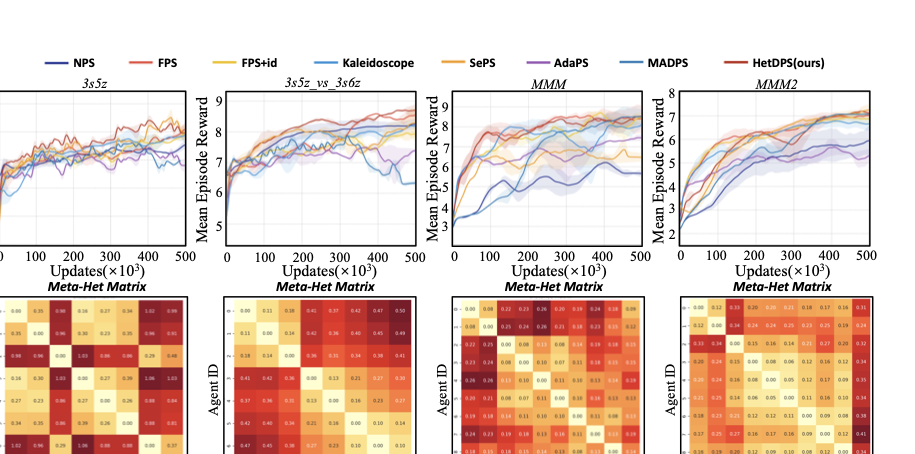
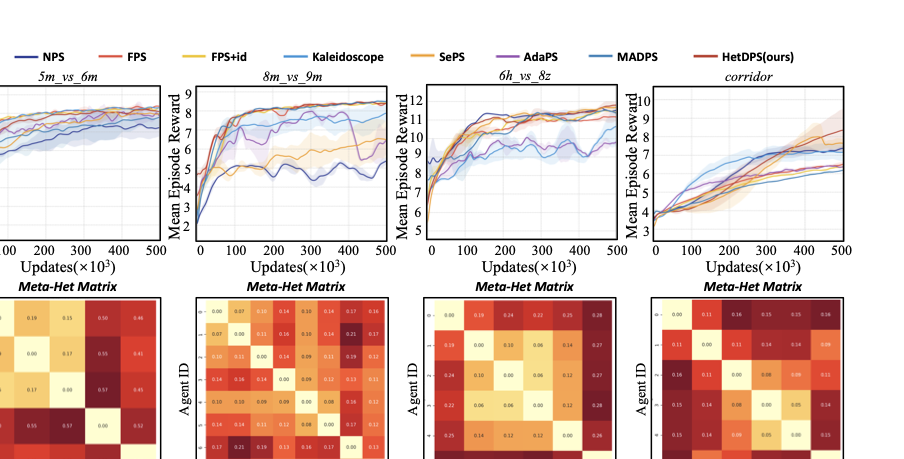
Performance and interpretability. The reward curves and corresponding heterogeneity distance matrices are shown in Figure 3, Figure 4 and Figure 5. From the reward curve results, we can see that HetDPS achieves either optimal or comparable results across all tasks.
The Meta-Het distances in Multi-agent Spreading scenario closely match the type distributions in Table 1, validating demonstrating the effectiveness of our method in identifying agent heterogeneity. In SMAC, we observe that in simpler tasks like 3s5z and MMM, the heterogeneity distances often do not closely match the original agent types. In MMM, agents even tend toward homogeneous policies to improve training efficiency. However, in more difficult tasks such as 3s5z_vs_3s6z and MMM2, agents’ quantification results closely match their original types for better coordination. This confirms that agent heterogeneity depends on both functional attributes and environment interactions.
Similarly, Figure 5 reveals that even “homogeneous" agents exhibit emergent heterogeneity from environment interactions, leading to role division. The performance difference between HetDPS and FPS also reflects the impact of role division versus non-division. Our method thus provides both superior performance and strong interpretability for exploring heterogeneity in MARL tasks.
| Quantization Interval | 15a_3c | 30a_3c | 15a_5c | 30a_5c |
|---|---|---|---|---|
| 20 Updates | -10.12 | -300.56 | -50.89 | -350.23 |
| 100 Updates | -9.45 | -298.91 | -49.32 | -349.67 |
| 200 Updates | -10.78 | -301.34 | -51.15 | -351.45 |
| 1000 Updates | -11.23 | -299.67 | -50.44 | -350.89 |
| 2000 Updates | -9.87 | -300.12 | -49.78 | -349.12 |
Results of varying quantization intervals in PMS, showing the average rewards of agents.
Adaptability. Our approach achieves comparable performance across all tested tasks. Moreover, we emphasize that for all tested tasks, our method uses identical hyperparameters, without requiring task-specific tuning. Other baselines require task-specific hyperparameters: e.g., reset interval, reset rate, and diversity loss coefficient for Kaleidoscope; number of clusters and update interval for SePS and AdaPS; fusion/division threshold and quantization interval for MADPS.
HetDPS employs distance-based clustering, eliminating hyperparameters such as cluster number or fusion threshold. Furthermore, by fully accounting for dual-clustering mechanism, HetDPS is insensitive to the quantization interval. Table 3 shows that performance remains stable across quantization intervals ranging from 20 to 2000 in all multi-agent spreading tasks.
Cost Analysis. We conduct an experiment to investigate training efficiency. The experimental results are shown in Table [tab:eff]. The results indicate that although our method introduces periodic heterogeneity quantification, it does not significantly reduce algorithm efficiency.
Conclusion
Heterogeneity manifests in various aspects of MARL. It is not only related to the inherent properties of agents but also to the coupling factors arising from agent-environment interactions. Consequently, agents that appear homogeneous may develop heterogeneity under environmental influences. In this paper, we categorize heterogeneity in MARL into five types and provide definitions. Meanwhile, we propose methods for quantifying these heterogeneities and conduct case studies. Under our theoretical framework, policy diversity is merely a manifestation of policy heterogeneity, fundamentally originating from the division of labor necessitated by agents’ environmental heterogeneity (cause), serving as an inductive bias (result) for solving optimal joint policies. Thus, we introduce the quantification of heterogeneity as prior knowledge into multi-agent parameter-sharing learning, resulting in HetDPS, an algorithm with strong interpretability and adaptability. HetDPS is not the endpoint of our research, but rather a starting point for heterogeneity applications. We believe that by systematically studying the definition, quantification, and application of heterogeneity, future MARL research will more profoundly understand the complex collaboration mechanisms between agents, and pave the way for more intelligent and adaptive collective decision-making systems.
Quantifying Heterogeneity in MARL
Heterogeneity Distance
According to the definition, each type of heterogeneity corresponds to a core function which connects relevant elements in the heterogeneity type. Therefore, we quantify the differences in these core functions to characterize the degree of heterogeneity.2 To make the quantification results simpler and more practical, we draw upon the ideas of policy distance from the works and , and present the concept of heterogeneity distance.
Let the core function corresponding to a certain heterogeneity type $`F`$ be denoted as $`y \sim F(\cdot|x)`$. The formula for calculating the $`F`$-heterogeneous distance between two agents $`i`$ and $`j`$ is given by:
\begin{equation}
d_{ij}^F = \int_{x \in X} D[F_i(\cdot|x) \parallel F_j(\cdot|x)] \cdot p(x) \, dx,
\label{eq:distance}
\end{equation}where $`X`$ is the space of independent variables, $`p(x)`$ is the probability density function, and $`D [\cdot \parallel \cdot]`$ is a measure that quantifies the difference between distributions. Unlike the works in and , we add probability density terms to ensure accuracy and consider the case of multivariate variables. When the independent variables $`x`$ consist of multiple factors, the above integral becomes a multivariate integral. Based on Equation [eq:distance], we provide the specific expressions for quantifying all heterogeneous distances in Appendix G and discuss the properties of heterogeneous distance in Appendix F.
 style="width:90.0%" />
style="width:90.0%" />
Practical Method
To compute Equation [eq:distance] in practice, we need to address several core issues: 1. Full space traversal. In practice, it is impossible to traverse the entire space $`X`$. 2. Measure $`D`$ is difficult to compute. Even assuming we can obtain model $`F`$ for each agent, the distribution types of $`F`$ may vary, making it difficult to calculate measures between different distributions. 3. Handling cases when model $`F`$ is not available. More commonly, it is hard to obtain environment-based agent models, especially in practical MARL tasks.
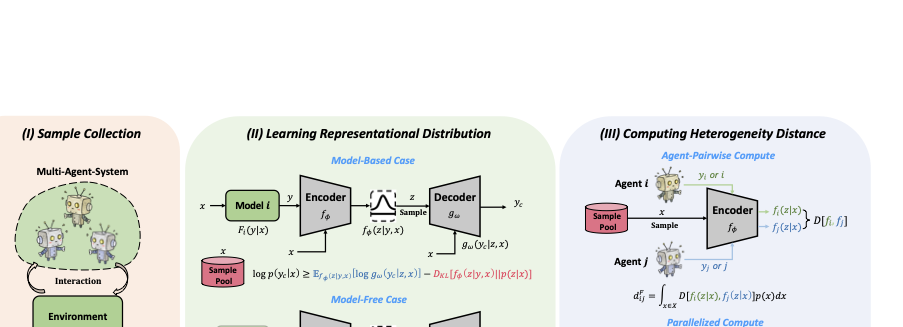
For issue 1, our approach is sampling based on the interaction between agents and the environment. Instead of simply traversing the space or using random policy exploration, we construct a sample pool using trajectories from the training phase of MARL. This significantly reduces computational load and filters out excessive marginal spaces, benefiting the use of heterogeneity distance in subsequent MARL tasks (Section 21). For issue 2, this has been solved in paper (computing policy distance). We follow their approach, which performs representation learning on $`F`$ and maps it to a standardized distribution. For issue 3, we extend the representation learning method to model-free cases. This helps apply the method in real-world settings and enables us to propose the concept of Meta-Heterogeneity Distance. By freely combining different attributes to construct Meta-Transitions, the proposed method can quantify the “comprehensive heterogeneity” of agents.
Combining these ideas, we propose a practical method as shown in Figure 6. In the first step, the agents interact with the environment during MARL training to build a sample pool. Notably, the sample pool data is shuffled to ensure that the learned function follows the Markov property (independent of historical information).
In the second step, the representational distributions are learned. We discuss this in both model-based and model-free settings, corresponding to cases function $`F`$ is known and unknown. We adopt the conditional variational autoencoder (CVAE) for representation learning. In the model-based case, CVAE performs a reconstruction task . The optimization goal is to maximize the likelihood of the reconstructed variable $`\log p(y|x)`$. Through derivation, we obtain the evidence lower bound (ELBO) as:
\begin{equation}
\begin{aligned}
ELBO_{\text{model-based}} = & \mathbb{E}_{f_\phi(z | y, x)}\left[\log g_\omega(y | z, x)\right] \\
& - D_{KL}\left[f_\phi(z | y, x) \parallel p(z | x)\right],
\end{aligned}
\end{equation}where $`f_\phi`$ and $`g_\omega`$ represent the encoder and decoder, respectively, and $`p(z | x)`$ is the prior conditional latent distribution. The relevant losses are designed based on ELBO, including a reconstruction loss and a prior-matching loss.
In the model-free case, CVAE essentially performs a prediction task , capturing the model characteristics of each agent. The network takes the independent variable $`x`$ and agent ID $`i`$ as inputs, using both as conditions to predict $`y`$. The optimization goal is to maximize the likelihood of the predicted $`y`$ given conditions. Similarly, the corresponding ELBO can be derived as (the derivation for this part can be found in Appendix I):
\begin{equation}
\begin{aligned}
ELBO_{\text{model-free}} = & \mathbb{E}_{f_\phi(z | i, x)}\left[\log g_\omega(y | z, i, x)\right] \\
& - D_{KL}\left[f_\phi(z | i, x) \parallel p(z | i, x)\right].
\end{aligned}
\end{equation}In the third step, the heterogeneity distances for MAS are computed. For each $`x`$, we obtain the distribution representation using the encoder in either the model-based or model-free manner. The distance under a specific $`x`$ is computed using the Wasserstein distance of the prior distribution (standard Gaussian). The heterogeneity distance is then calculated via multi-rollout Monte Carlo sampling. In practice, we parallelize this operation 3, enabling simultaneous computation of distances between all agents on GPUs, significantly improving computational efficiency.
Meta-Transition. The aforementioned method can quantify the heterogeneity of agents for specific types. In practical applications, researchers may also want to quantify the comprehensive heterogeneity of agents to enable operations such as grouping. To this end, we give the Meta-Transition model (see Appendix H for details). By measuring the differences between meta-transitions, the comprehensive heterogeneity related to environment can be quantified. We refer to this as the meta-transition heterogeneity distance (Hereafter referred to as Meta-Het).
 style="width:100.0%" />
style="width:100.0%" />
Case Study
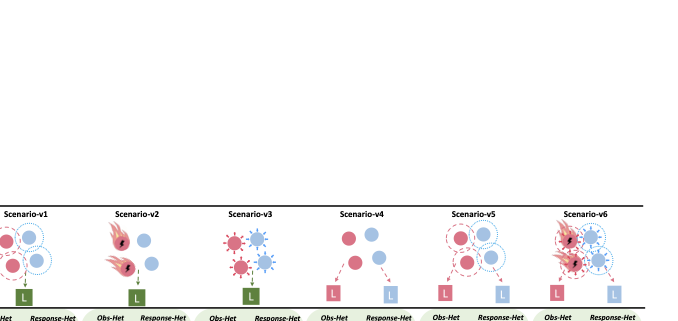
We design a multi-agent spread scenario for case study. In the basic scenario, there are two groups, each with two agents, and their goal is to move to randomly generated landmarks. We create 6 versions of the scenario to show the quantitative results of different types of heterogeneity and Meta-Het. As shown in Figure 7, the first 4 versions correspond to the 4 environment-related types of heterogeneity, while the last 2 versions represent cases where multiple types of heterogeneity exist. We use the model-based manner to compute the first four distance matrices, and the model-free manner to compute the Meta-Het distance matrix.
The results show that for each type of heterogeneity, our method can accurately capture and identify the differences. And the Meta-Het distance between agents in the same group is much smaller than that in different groups. Moreover, as the number of heterogeneity types increases, the Meta-Het distance between different groups also increases. These results demonstrate the effectiveness of our method for various environment-related heterogeneities.
 style="width:95.0%" />
style="width:95.0%" />
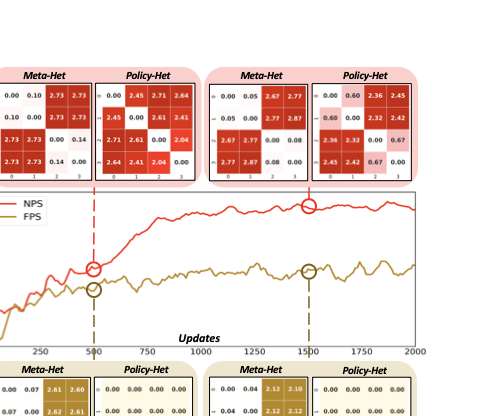
We further quantify the policy heterogeneity distance (Policy-Het) and Meta-Het distance of agents during the training process. We select two algorithms at the extreme cases of parameter sharing: fully parameter sharing (FPS) and no parameter sharing (NPS) for training in the above scenarios. Figure 8 shows the measurement results at 500 and 1500 updates. From the Policy-Het results, the policy distance can effectively reveal the evolution of agent policy differences in MARL. From the Meta-Het results, the comprehensive agent heterogeneity measurement remains consistent across different learning algorithms, and can identify environmental heterogeneous characteristics in scenarios more rapidly compared to policy evolution.
Taxonomy and Definition of Heterogeneity in MARL
| Heterogeneity Type | Heterogeneity Description | Related POMG Elements | Mathematical Definition |
|---|---|---|---|
| Observation Heterogeneity |
Describes the differences of agents in observing global information | Agent’s observation space and observation function | Agents i and j are observation heterogeneous if: Oi ≠ Oj; or ∃ŝ ∈ {Si}i ∈ N, Ωi(⋅|ŝ) ≠ Ωj(⋅|ŝ) |
| Response
Transition Heterogeneity |
Describes the differences of agents in how their state transitions are affected by global environmental components (environment-to-self) | Agent’s state space and local state transition function | Agents i and j are response transition heterogeneous if: Si ≠ Sj; or ∃ŝ ∈ {Si}i ∈ N, â ∈ {Ai}i ∈ N, 𝒯i(⋅|ŝ, â) ≠ 𝒯j(⋅|ŝ, â) |
| Effect
Transition Heterogeneity |
Describes the differences of agents in how their states and actions impact global state transitions (self-to-environment) | Agent’s action space, state space, and global state transition function | Agents i and j are effect transition heterogeneous if: Si ≠ Sj; or Ai ≠ Aj; or ∃s′ ∈ S−i, a′ ∈ A−i, s ∈ Si, a ∈ Ai, 𝒯−i(⋅|s′, s, a′, a) ≠ 𝒯−j(⋅|s′, s, a′, a) |
| Objective Heterogeneity |
Describes the differences of agents in the objective they aim to achieve | Agent’s reward function | Agents i and j are objective heterogeneous if: ∃ŝ ∈ {Si}i ∈ N, â ∈ {Ai}i ∈ N, ri(⋅|ŝ, â) ≠ rj(⋅|ŝ, â) |
| Policy Heterogeneity |
Describes the differences of agents in their decision-making based on observations | Agent’s observation space, action space, and policy | Agents i and j are policy heterogeneous if: Oi ≠ Oj; or Ai ≠ Aj; or ∃o ∈ Oi, πi(⋅|o) ≠ πj(⋅|o) |
Heterogeneity in MAS. Our goal is to define agent heterogeneity from the perspective of MARL. Before achieving this, we discuss heterogeneity in MAS across various disciplines. Early studies define heterogeneity as differences in physical structure or functionality of agents, which aligns with common understanding. Later work describes heterogeneity as differences in agent behavior, further expanding its meaning. Recently, points out that heterogeneity may be a complex phenomenon, related not only to the inherent properties of agents, but also to their interactions with environment. Thus, heterogeneity in MARL should not be limited to inherent functional differences of agents, but should also fully consider various coupling effects of agents within the environment.
Heterogeneity in MARL. The fundamental modeling of MARL primal problem provides convenience for defining heterogeneity. This modeling specifies all MARL elements, delineating the boundaries of the problem discussion 4 and ensuring the completeness of the discussion.
We focus on the heterogeneity among agents within a same POMG. As mentioned in the previous sections, functions in POMG can serve as bridges linking other elements. Therefore, we focus on the functions and classify heterogeneity into five types. This approach can avoid redundant classification, and ensure coverage of each agent-level element. Specifically, these five types of heterogeneity are: Observation heterogeneity, Response transition heterogeneity, Effect transition heterogeneity, Objective heterogeneity, and Policy heterogeneity. Their specific descriptions and definitions are given in Table [tab:heterogeneity]. In this table, $`S^{-i} = \times_{k \in N, k \neq i} S^{k} \times S^{E}`$ represents the joint state space of all agents except agent $`i`$, reflecting the influence of the agent on other states. Similarly, $`A^{-i}`$ denotes the joint action space excluding agent $`i`$, and $`\mathcal{T}^{-i}`$ is the collection of state transitions excluding agent $`i`$.
The definitions in this section are relatively straightforward: if there are any differences in the associated elements, the agents are considered heterogeneous. We need to emphasize that our work goes beyond this. The quantification methods provided in the next section will be able to characterize the degree of agent heterogeneity related to certain attributes in practical scenarios, which far exceeds the level of definition.
Appendix
Limitations
Although our proposed heterogeneity distance can effectively quantify agent heterogeneity and identify various potential heterogeneities, there remain some limitations in its practical implementation. One limitation is in scaling with the number of agents. Typically, the heterogeneity distance quantification algorithm outputs a heterogeneity distance matrix for the entire multi-agent system, with a computational complexity of $`O(N^2)`$. When the number of agents increases significantly, matrix computation becomes costly. However, if only studying heterogeneity between specific agents in the MAS is required, the method remains effective. One only needs to remove data from other agents during CVAE training and sampling computation.
Additionally, the practical algorithms for heterogeneity quantification are built on the assumption that agent-related variables are vectors. If certain agent variables, such as observation inputs, are multimodal, operations like padding in the proposed algorithm become difficult to implement. But this does not affect the correctness of the theory. As the relevant theory still holds in this situation, additional tricks are needed for practical calculation implementation.
Broader Impacts
Our work systematically analyzes heterogeneity in MARL, which has strong correlations with a series of works in MARL. Under our theoretical framework, research on agent policy diversity in MARL can be categorized within the domain of policy heterogeneity. Our work can give a new perspective for studying policy diversity. Our proposed quantification methods can not only help these works with policy evolution analysis but also explain the relationship between policy diversity and agent heterogeneity. Furthermore, our proposed HetDPS, as an application case, can also be classified among parameter sharing-based works.
Additionally, some traditional heterogeneous MARL works can be categorized within environment-related heterogeneity domains. Our quantification and definition methods are orthogonal to these works, which can fully utilize our proposed methodology for further advancement. For instance, observation heterogeneity quantification can be used to enhance agents’ ability to aggregate heterogeneous observation information; transition heterogeneity quantification can help design intrinsic rewards to assist heterogeneous multi-agents in learning cooperative policies.
In conclusion, our work not only expands the scope of heterogeneity in MARL but also closely connects with many current hot topics, contributing to the further development of these works.
An introduction to POMG
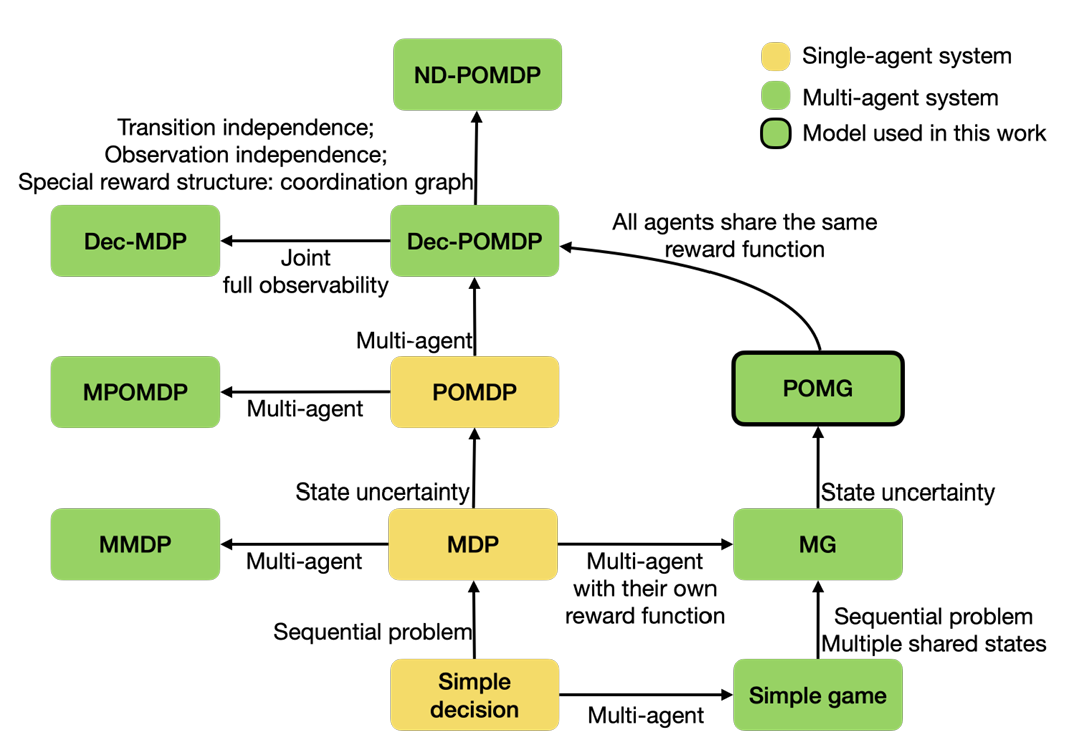
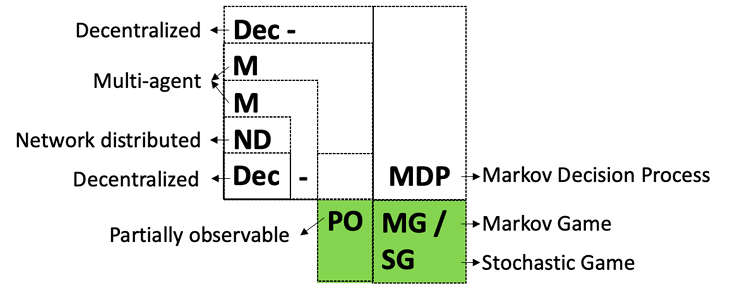
Partially Observable Markov Game (POMG) is essentially an extension of Partially Observable Markov Decision Process (POMDP), which in turn extends Markov Decision Process (MDP). MDP is a mathematical framework that describes sequential decision-making by a single agent in a fully observable environment. In an MDP, the agent can fully observe the environment’s state, select actions based on the current state, and aim to maximize cumulative rewards. Compared to MDP, the key extension of POMDP is the consideration of partial observability, making it suitable for modeling both single-agent partially observable problems and multi-agent problems . In multi-agent POMDPs, agents typically operate in a fully cooperative mode, where their rewards are usually team-shared.
The key extension of POMG over POMDP lies in modeling mixed game relationships among multiple agents. Unlike POMDP, agents in POMG do not share a common reward function; instead, each agent has its own (agent-level) reward function, making POMG more general . This design enables POMG to handle competitive, cooperative, and mixed interaction scenarios, better reflecting the complexity of real-world multi-agent systems. The logical relationships among Markov decision processes and their variants are illustrated in Figure 9 and Figure 10. As shown in these figures, POMG is the most general framework for modeling original problems in the MARL domain. For these reasons, we chose POMG as the foundation for discussing heterogeneity in MARL.
Other potential types of heterogeneity in MARL
Benefiting from the reinforcement learning modeling based on POMG, we have clearly defined the boundaries of heterogeneity discussed in this paper. In fact, within the realm of unconventional multi-agent systems, there might be other types of heterogeneity.
For instance, agents may have different length of decision timesteps, with some agents inclined towards long-term high-level decisions, while others tend to make short-term low-level decisions. Agents may also have different discount factors, some works try to assign varying discount factors to different agents during algorithm training , to encourage agents to develop “myopic” or “far-sighted” policy behaviors, thereby promoting agent cooperation. However, differences in discount factors are more reflective of algorithmic design variations rather than environmental distinctions, and thus fall outside the scope of this paper. Moreover, there may be heterogeneity among agents regarding communication, agents might have different communication channels due to hardware variations. However, the establishment of communication protocols aims to enable agents to receive more information when making decisions, potentially overcoming non-stationarity and partial observability issues . These communication messages are essentially mappings of global information processed in the environment, which are then input into the action-related network modules. From this perspective, agent communication can be modeled as a more generalized observation function that maps global information to local observations for agent decision-making, and communication heterogeneity can be categorized under observation heterogeneity. From a learning perspective, agents might also have heterogeneous available knowledge, such as differences in initial basic policies or variations in supplementary knowledge accessible during execution phase. Moreover, heterogeneity might extend beyond abstract issues, including computational resource differences among agents during learning.
Overall, even from the perspective of multi-agent reinforcement learning, heterogeneity in multi-agent systems remains a domain with extensive discussion space, warranting further subsequent research.
Properties of heterogeneity distance
Recap. The heterogeneity distance between two agents in Section 20 can be computed as follows:
\begin{equation}
d_{ij}^F = \int_{x \in X} D[F_i(\cdot|x), F_j(\cdot|x)] \cdot p(x) \, dx,
\end{equation}where $`X`$ is the space of independent variables, $`p(x)`$ is the probability density function, and $`D [\cdot, \cdot]`$ is a measure that quantifies the difference between distributions.
Proposition 1. (Properties of Heterogeneity Distance) Symmetry: $`d^F_{ij} = d^F_{ji}`$; Non-negativity: $`d^F_{ij} \geq 0`$; Identity of indiscernibles: $`d^F_{ij} = 0`$ if and only if agents $`i`$ and $`j`$ are $`F`$-homogeneous; Triangle inequality: $`d^F_{ij} \leq d^F_{ik} + d^F_{kj}`$ $`(i,j,k \in N)`$. This proposition holds as long as the measure $`D`$ satisfies Property .
Proof. It can be proven that when $`D`$ satisfies Property , heterogeneity distance also satisfies Property .
1) Proof of Symmetry:
\begin{equation}
\begin{aligned}
d_{ij}^F &= \int_{x \in X} D\left[F_i(\cdot|x), F_j(\cdot|x)\right] \cdot p(x) d x \\
&= \int_{x \in X} D\left[F_j(\cdot|x), F_i(\cdot|x)\right] \cdot p(x) d x \\
&= d_{ji}^F.
\end{aligned}
\end{equation}2) Proof of Non-negativity:
\begin{equation}
\begin{aligned}
d_{ij}^F &= \int_{x \in X} D\left[F_i(\cdot|x), F_j(\cdot|x)\right] \cdot p(x) d x \\
&\geq \int_{x \in X} 0 \cdot p(x) d x = 0.
\end{aligned}
\end{equation}3) Proof of Identicals of indiscernibility (necessary conditions):
if agent $`i`$ and agent $`j`$ are $`F`$-homogeneous, then we have: $`X^{(i)} = X^{(j)}`$, $`\forall x \in X=X^{(i)}`$, $`F_i(\cdot|x) = F_j(\cdot|x)`$,
\begin{equation}
\begin{aligned}
d_{ij}^F & =
\int_{x \in X} D\left[F_i(\cdot|x), F_j(\cdot|x)\right] \cdot p(x) d x \\
&= \int_{x \in X} D\left[F_i(\cdot|x), F_i(\cdot|x)\right] \cdot p(x) d x \\
&=\int_{x \in X} 0 \cdot p(x) d x \\
&= 0.
\end{aligned}
\end{equation}4) Proof of Identicals of indiscernibility (sufficient conditions):
\begin{equation}
\begin{aligned}
d_{ij}^F=0 &\xrightarrow{\text{Prop.\ding{193}}} D\left[F_i(\cdot|x), F_i(\cdot|x)\right] = 0, \\
&\quad \forall x \in X^{(i)} \text{ or } X^{(j)}\\
&\xrightarrow{\text{Prop.\ding{193}of $D$}} F_i(\cdot|x) = F_i(\cdot|x), \\
&\quad \forall x \in X, X = X^{(i)} = X^{(j)},
\end{aligned}
\end{equation}then we have agent $`i`$ and agent $`j`$ are $`F`$-homogeneous.
5) Proof of Triangle Inequality:
\begin{equation}
\begin{aligned}
d_{ij}^F &= \int_{x \in X} D\left[F_i(\cdot|x), F_j(\cdot|x)\right] \cdot p(x) \, dx \\
&\leq \int_{x \in X} \left( D\left[F_i(\cdot|x), F_k(\cdot|x)\right] \right. \\
&\quad \left. + D\left[F_k(\cdot|x), F_j(\cdot|x)\right] \right) \cdot p(x) \, dx \\
&= \int_{x \in X} D\left[F_i(\cdot|x), F_k(\cdot|x)\right] \cdot p(x) \, dx \\
&\quad + \int_{x \in X} D\left[F_k(\cdot|x), F_j(\cdot|x)\right] \cdot p(x) \, dx \\
&= d_{ik}^F + d_{kj}^F.
\end{aligned}
\end{equation}In this paper, we choose the Wasserstein Distance as the metric to quantify the distance between distributions, which satisfies the property .
Discussion. In practical computation, we adopt a representation learning-based approach to find an alternative latent variable distribution $`p_i(z|x)`$ to replace the original distribution $`F_i(y|x)`$ for quantification. It can be easily proved that when using latent variable distributions to compute heterogeneous distances, these distances still satisfy properties , , and (following the same proof method as above).
In the model-based case, $`p_i(z|x) = f_\phi(y_i,x)`$, where $`f_\phi`$ represents the encoder of the CVAE. When two agents have the same independent and dependent variables (identical agent functions), their latent variable distributions are also identical. In this case, it is straightforward to prove that property still holds under the model-based case.
In the model-free case, $`p_i(z|x) = f_\phi(i,x)`$. Due to the lack of an environment model, even agents with identical mappings may learn different representation distributions through their encoders, thus not satisfying property . However, as demonstrated in Section 20.3, although we cannot strictly determine agent homogeneity using $`d_{ij}^F=0`$, the heterogeneity distances measured between homogeneous agents in the model-free case are sufficiently small. Moreover, the model-free manner is adequate to distinguish between homogeneous and heterogeneous agents, and still maintains the ability to quantify the degree of heterogeneity (as shown in Sections 20.3 and 22).
More details of computing heterogeneity distance
Here, we present five formulas for calculating heterogeneity distances, corresponding to the five types of heterogeneity discussed in this paper.
Regarding Observation Heterogeneity, its relevant elements include the agent’s observation space and observation function. For two agents $`i`$ and $`j`$, let their observation heterogeneity distance be denoted as $`d^\Omega_{ij}`$. The corresponding calculation formula is:
\begin{equation}
\begin{aligned}
d_{ij}^\Omega &= \int_{\hat{s} \in \{S^i\}_{i \in N}} D\left[\Omega_i(\cdot|\hat{s}), \right. \\
&\quad \left. \Omega_j(\cdot|\hat{s})\right] \cdot p(\hat{s}) \, d\hat{s},
\end{aligned}
\label{eq:distance-1}
\end{equation}where $`D [\cdot, \cdot]`$ represents a measure of distance between two distributions, and $`p(\cdot)`$ is the probability density function (this notation applies to subsequent equations). Here, $`\hat{s}`$ denotes the global state, $`\{S^i\}_{i \in N}`$ represents the global state space, and $`\Omega_i`$ and $`\Omega_j`$ are the observation functions of agents $`i`$ and $`j`$, respectively.
Regarding Response Transition Heterogeneity, its relevant elements include the agent’s action space, state space, and global state transition function. For two agents $`i`$ and $`j`$, let their response transition heterogeneity distance be denoted as $`d^{\mathcal{T}}_{ij}`$. The corresponding calculation formula is:
\begin{equation}
\begin{aligned}
d_{ij}^\mathcal{T} &= \int_{\hat{s} \in \{S^i\}_{i \in N}} \int_{\hat{a} \in \{A^i\}_{i \in N}} \\
&\quad D\left[\mathcal{T}^i(\cdot|\hat{s},\hat{a}), \mathcal{T}^j(\cdot|\hat{s},\hat{a})\right] \\
&\quad \cdot p(\hat{s},\hat{a}) \,d\hat{a} d\hat{s},
\end{aligned}
\label{eq:distance-2}
\end{equation}where $`p(\cdot,\cdot)`$ represents the joint probability density function. $`\hat{s}`$ and $`\hat{a}`$ denote the global state and global action respectively, $`\{S^i\}_{i \in N}`$ and $`\{A^i\}_{i \in N}`$ represent the global state space and global action space, and $`\mathcal{T}_i`$ and $`\mathcal{T}_j`$ are the local state transition functions of agents $`i`$ and $`j`$, respectively.
Regarding Effect Transition Heterogeneity, its relevant elements include the agent’s action space, state space, and global state transition function. For convenience, we denote $`S^{-i} = \times_{k \in N, k \neq i} S^{k} \times S^{E}`$ as the joint state space of all agents except agent $`i`$, $`A^{-i} = \times_{k \in N, k \neq i} A^{k}`$ as the joint action space of all agents except agent $`i`$, and $`\mathcal{T}^{-i}`$ as the collection of state transitions excluding agent $`i`$. For two agents $`i`$ and $`j`$, let their effect transition heterogeneity distance be denoted as $`d^{\mathcal{T}^{-}}_{ij}`$. The corresponding calculation formula is:
\begin{equation}
\begin{aligned}
d_{ij}^{\mathcal{T}^{-}} &=
\int_{s' \in S^{(-i)}} \int_{s \in A^{i}} \int_{a' \in A^{(-i)}}
\int_{a \in A^{i}} \\
&\quad D\left[\mathcal{T}^{-i}(\cdot|x), \mathcal{T}^{-j}(\cdot|x)\right]
\cdot p(x) \, da \, da' \, ds \, ds',
\end{aligned}
\label{eq:distance-3}
\end{equation}where for convenience, we denote $`x=(s',s,a',a)`$, and $`p`$ is the joint probability density function.
The calculation of effect transition heterogeneity distance differs from the previous two types of heterogeneity distances in two significant ways. The first difference lies in its introduction of agent-level elements as variables rather than global variables. When two agents have different agent-level variable spaces, it becomes challenging to calculate the heterogeneity distance under this definition. The second difference is that it involves a quadruple integral, making its computational complexity much higher than the single or double integrals of the previous two distances.
These two differences make the calculation of effect transition heterogeneity distance more challenging. Fortunately, through our proposed meta-transition model, we can simplify the calculation of effect transition heterogeneity distance to a double integral that only involves the agent’s local states and actions. Additionally, the distance measurement through representation learning also reduces the constraints on the similarity of agents’ variable spaces. Even when two agents have different variable spaces (for example, one agent’s local state space is 10-dimensional while another’s is 20-dimensional), we can still process the variable inputs through techniques like padding and then map them to the same dimension using encoder networks. This demonstrates that the approach based on representation learning and meta-transition significantly extends the applicability of heterogeneity distance measurement, which also holds true in the quantification of heterogeneous types discussed below.
Regarding Objective Heterogeneity, its relevant element is the agent’s reward function. For two agents $`i`$ and $`j`$, let their objective heterogeneity distance be denoted as $`d^{r}_{ij}`$. The corresponding calculation formula is:
\begin{equation}
\begin{aligned}
d_{ij}^r &= \int_{\hat{s} \in \{S^i\}_{i \in N}} \int_{\hat{a} \in \{A^i\}_{i \in N}} \\
&\quad D\left[r^i(\cdot|\hat{s},\hat{a}), r^j(\cdot|\hat{s},\hat{a})\right] \\
&\quad \cdot p(\hat{s},\hat{a}) \,d\hat{a} d\hat{s},
\end{aligned}
\label{eq:distance-4}
\end{equation}where $`p(\cdot,\cdot)`$ represents the joint probability density function. $`\hat{s}`$ and $`\hat{a}`$ denote the global state and global action respectively, $`\{S^i\}_{i \in N}`$ and $`\{A^i\}_{i \in N}`$ represent the global state space and global action space, and $`r_i`$ and $`r_j`$ are the reward functions of agents $`i`$ and $`j`$, respectively.
Regarding Policy Heterogeneity Distance, its relevant elements include the agent’s observation space, action space, and policy function. For two agents $`i`$ and $`j`$, let their policy heterogeneous distance be denoted as $`d^\pi_{ij}`$. The corresponding calculation formula is:
\begin{equation}
d_{ij}^\pi = \int_{o \in O^i} D\left[\pi_i(\cdot|o), \pi_j(\cdot|o)\right] \cdot p(o) \, do,
\label{eq:distance-5}
\end{equation}where $`D [\cdot, \cdot]`$ represents a measure of distance between two distributions, and $`p(\cdot)`$ is the probability density function. Here, $`o`$ denotes the observation, $`O^i`$ represents the observation space, and $`\pi_i`$ and $`\pi_j`$ are the policy functions of agents $`i`$ and $`j`$, respectively.
Meta-Transition and its Heterogeneity Distance
To quantify an agent’s comprehensive heterogeneity, we introduce the concept of meta-transition. Meta-transition is a modeling approach that explores an agent’s own attributes from its perspective. Our goal is to quantify an agent’s comprehensive heterogeneity using only the agent’s local information (as global information is typically difficult to obtain in practical MARL scenarios).
Based on this, we provide the definition of meta-transition. Let the meta-transition of agent $`i`$ be denoted as $`M_i`$. It is a mapping $`M_i: S_i \times A_i \rightarrow S_i \times R \times \Omega_i`$. At time step $`t`$, the inputs of meta-transition are the agent’s local state $`s_t^i`$ and local action $`a_t^i`$, and the outputs are the next time step’s local state $`s_{t+1}^i`$, the next time step’s local observation $`o_{t+1}^i`$, and the current time step’s reward $`r_t^i`$ based on the state and action.
We explain why the above relationship can reflect all agent-level elements in POMG. The input local state and local action of meta-transition actually correspond to the inverse mapping to the global state and global action. This inverse mapping potentially restores the local state and action to global information, and then obtains the next time step’s global state according to the global state transition function, which is mapped to local observation through the observation function. Therefore, this process reflects the agent’s effect transition heterogeneity and observation heterogeneity. Additionally, the potential global state and global action also determine the agent’s local state and corresponding reward at the next time step, which reflect the agent’s response transition heterogeneity and objective heterogeneity, respectively.
It is worth noting that meta-transition is not a function that actually exists in POMG, but an implicitly defined mapping. We aim to quantify this mapping difference to capture the agent’s comprehensive heterogeneity. Therefore, meta-transition heterogeneity is quantified in a model-free manner.
Moreover, meta-transition is not limited to the aforementioned form. It can be transformed into different forms according to the modular settings of independent and dependent variables. For example, by removing the agent’s reward, meta-transition can reflect the agent’s observation heterogeneity, response transition heterogeneity, and effect transition heterogeneity.
After determining the input and output of meta-transition, the relevant heterogeneity distance can be calculated using the same model-free method as before. Since meta-transition involves multiple variables, and the dimensions between these variables may differ significantly (for example, the dimension of reward is 1, while the dimension of observation might be 100), directly fitting with deep networks may struggle to capture information corresponding to low-dimensional variables. We address this issue through a dimension replication trick. In practice, we typically replicate the reward dimension to be similar to the dimensions of observation or action, ensuring that the autoencoder network can capture information related to objective heterogeneity during learning.
Derivation of ELBO
The Evidence Lower Bound (ELBO) of the likelihood can be derived as follows:
\begin{equation}
\begin{aligned}
\log p(y|x)
& = \log \int p(y,z|x) d z
\quad \quad \quad \quad \quad \quad \ \textcolor{orange!70!black}{\textbf{ (a) }} \\
& = \log \int \frac{ p(y,z|x) f_{\phi}(z|y,x)}{f_{\phi}(z|y,x)} d z \\
&\quad \quad \textcolor{orange!70!black}{\textbf{ (b) }} \\
& = \log \mathbb{E}_{f_{\phi}(z|y,x)}
\left[
\frac{p(y,z|x)}{f_{\phi}(z|y,x)}
\right] \\
&\quad \quad \textcolor{orange!70!black}{\textbf{ (c) }} \\
& \geq \mathbb{E}_{f_{\phi}(z|y,x)}
\left[ \log
\frac{ p(y,z|x)}{f_{\phi}(z|y,x)}
\right] \\
&\quad \quad \textcolor{orange!70!black}{\textbf{ (d) }} \\
& = ELBO_{\text{model-based}},
\end{aligned}
\end{equation}where $`f_{\phi}(z|y,x)`$ represents the posterior probability distribution of the latent variable generated by the encoder, and $`p(y,z|x)`$ denotes a joint probability distribution concerning the customized feature and latent variable, conditioned on $`o`$. Throughout the derivation of the formula, (a) employs the properties of the joint probability distribution, (b) multiplies both numerator and denominator by $`f_{\phi}(z|y,x)`$, (c) applies the definition of mathematical expectation, and (d) invokes the Jensen’s inequality.
Considering that the ELBO includes an unknown joint probability distribution, we can further decompose it by using the posterior probability distributions from the encoder and decoder:
\begin{equation}
\begin{aligned}
ELBO_{\text{model-based}}
& = \mathbb{E}_{f_{\phi}(z|y,x)}
\left[ \log
\frac{ p(y,z|x)}{f_{\phi}(z|y,x)}
\right] \\
& =
\mathbb{E}_{f_{\phi}(z|y,x)}
\left[ \log
\frac{g_\omega(c|z,x) p(z|x)}{f_{\phi}(z|y,x)}
\right] \\
&\quad \quad \textcolor{orange!70!black}{\textbf{ (a)}} \\
& =
\mathbb{E}_{f_{\phi}(z|y,x)}
\left[ \log
g_\omega(c|z,x)
\right] \\
& \quad +
\mathbb{E}_{f_{\phi}(z|y,x)}
\left[ \log
\frac{ p(z|x)}{f_{\phi}(z|y,x)}
\right] \\
&\quad \textcolor{orange!70!black}{\textbf{ (b) }} \\
& =\underbrace{\mathbb{E}_{f_{\phi}(z|y,x)} \left[\log
g_\omega(c|z,x)\right]}_{\textcolor{blue!70!black}{\textbf{reconstruction term}} } \\
&\quad -
\underbrace{D_{\mathrm{KL}}\left[f_{\phi}(z|y,x)
\| p(z|x)\right]}_{\textcolor{red!70!black}{\textbf{prior matching term}} }, \\
&\quad \textcolor{orange!70!black}{\textbf{ (c) }} \\
\end{aligned}
\end{equation}where $`f_{\phi}(z|y,x)`$ and $`g_\omega(c|z,x)`$ are the posteriors from the encoder and decoder, respectively. The conditional joint probability distribution $`p(y,z|x)`$ is a imaginary construct in mathematical terms and lacks practical significance. It can be formulated using the probability chain rule, constructed from the posterior distribution of the customized feature and the prior distribution of the latent variable (step (a)). Step (b) decomposes the expectation, and step (c) applies the definition of the KL divergence.
Thus, the ELBO can be decomposed into a reconstruction term of the customized feature, and a prior matching term of the posterior and the prior. By maximizing the ELBO, the reconstruction likelihood can be maximized while minimizing the KL divergence between the posterior and the prior. In the model-free case, the same approach can be used to derive the ELBO and corresponding loss function.
Details of HetDPS
HetDPS is a novel algorithm designed to efficiently manage the allocation of neural network parameters across multiple agents in MARL. This algorithm leverages the Wasserstein distance matrix to cluster agents based on their similarities, and subsequently assigns them to suitable neural networks. The pseudocode of HetDPS is shown in Algorithm [alg:dynamic_parameter_sharing].
The algorithm begins by computing the affinity matrix from the Wasserstein distance matrix, which is then used as input to the Affinity Propagation clustering algorithm. This process yields a new set of cluster assignments for the agents. If it is the first time the algorithm is executed, the cluster assignments are directly used as network assignments.
In subsequent iterations, the algorithm compares the new cluster assignments with the previous ones to determine the optimal network assignments. This is achieved by constructing an overlap matrix that captures the similarity between the old and new cluster assignments. Based on the number of old and new clusters, the algorithm handles three distinct cases:
1. Equal number of old and new clusters: In this scenario, the algorithm establishes a one-to-one mapping between the old and new clusters using the Hungarian algorithm. It then constructs a mapping from old clusters to networks and assigns each agent to a network based on its new cluster assignment.
2. More new clusters than old clusters: When the number of new clusters exceeds the number of old clusters, the algorithm handles network splitting. It uses the Hungarian algorithm to find the best matching between old and new clusters and establishes a mapping from new clusters to old clusters. For new clusters without a clear match, the algorithm either finds the most similar old cluster or identifies the closest network. It then executes a splitting operation to copy parameters from the source network to the new network.
3. More old clusters than new clusters: In this case, the algorithm handles network merging. It uses the Hungarian algorithm to find the best matching between old and new clusters and establishes a mapping from old clusters to new clusters. For each new cluster, it identifies the networks to be merged and executes a merging operation based on the specified merge mode (majority, random, average, or weighted). The algorithm then assigns each agent to a network based on its new cluster assignment.
HetDPS offers a flexible and efficient approach to managing neural network parameters in multi-agent systems. By dynamically adjusting network assignments based on agent similarities, the algorithm enables effective parameter sharing and reduces the need for redundant computations.
Initialize policies and parameter sharing paradigm Interact with environment to collect data Add data to reinforcement learning (RL) sample pool Add data to heterogeneity distance sample pool Update policies using RL sample pool Compute heterogeneity distance matrix $`D`$ (Section 20) Cluster agents using Affinity Propagation on $`D`$ Assign networks to agents based on clusters Copy network parameters as needed Compute maximum overlap matching between current and previous clusters Map new clusters to previous networks Split networks: copy parameters for unmatched clusters Merge networks: combine parameters based on merge mode Assign networks to agents
📊 논문 시각자료 (Figures)
A Note of Gratitude
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.-
POMG is an extension of POMDP for multi-agent settings, with the basic extension path being MDP $`\to`$ POMDP $`\to`$ POMG . Please refer to Appendix D to see a more detailed explanation of POMG. ↩︎
-
Quantifying space elements is feasible and even easier to implement. But a space element may appear across multiple heterogeneity types, making it unsuitable as unique identifiers for specific heterogeneity types. ↩︎
-
Our code is provided in the supplementary material. ↩︎
-
In this paper, we focus on the heterogeneity of MARL under the conventional POMG problem. Additional discussions on unconventional heterogeneity types are provided in Appendix E. ↩︎