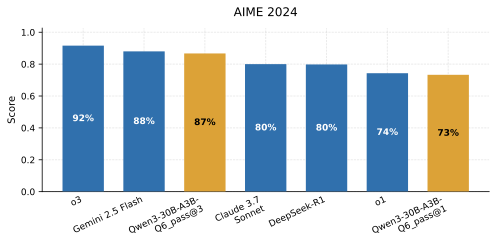
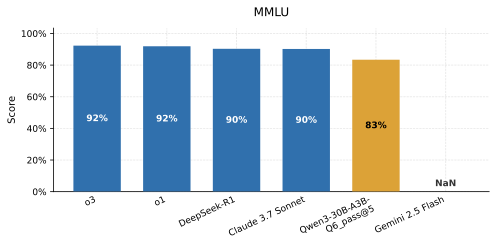
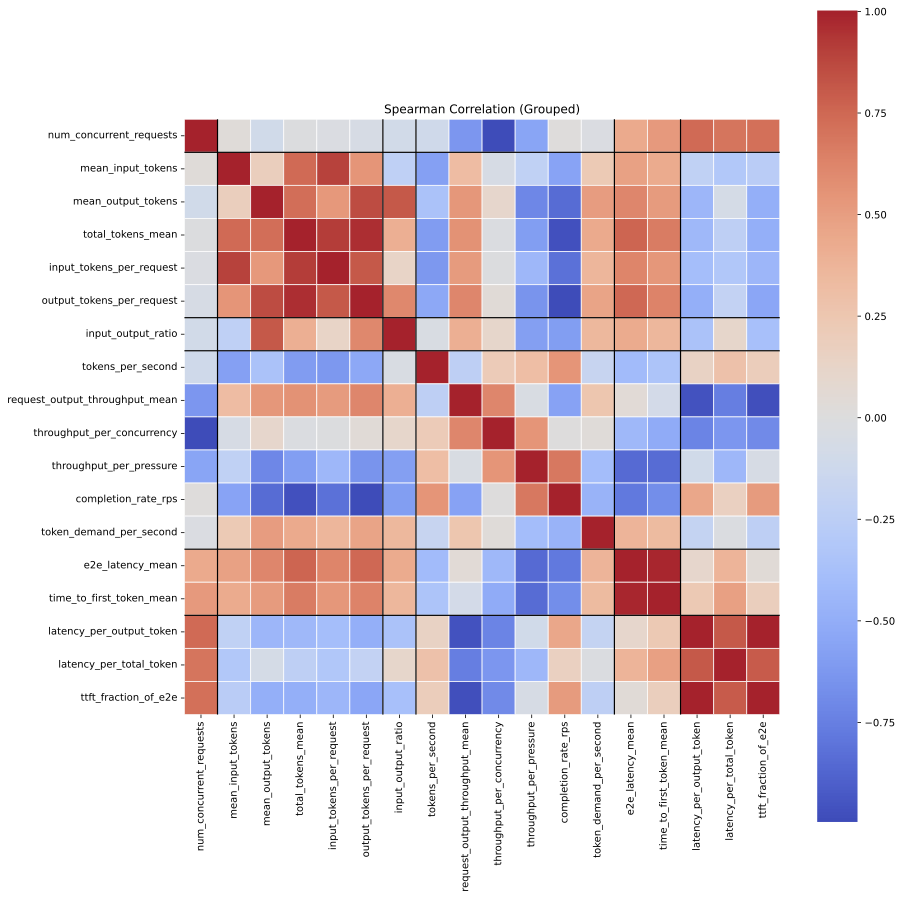
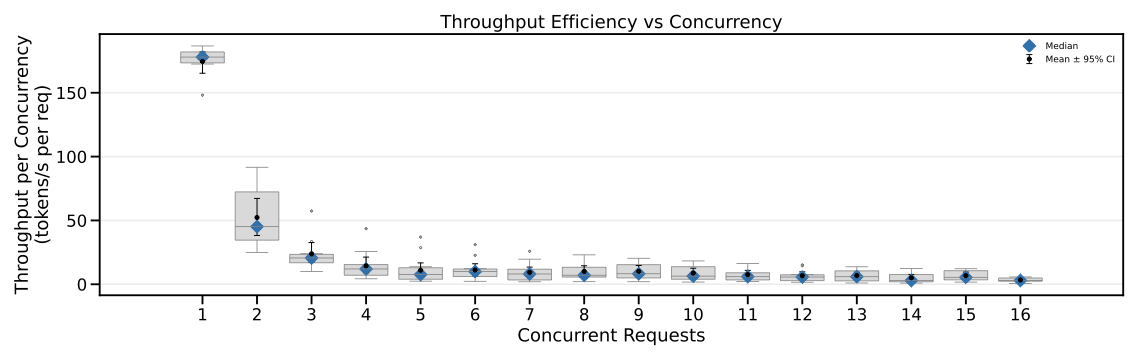
- Title: Viability and Performance of a Private LLM Server for SMBs A Benchmark Analysis of Qwen3-30B on Consumer-Grade Hardware
- ArXiv ID: 2512.23029
- Date: 2025-12-28
- Authors: Alex Khalil, Guillaume Heilles, Maria Parraga, Simon Heilles
📝 Abstract
The proliferation of Large Language Models (LLMs) has been accompanied by a reliance on cloud-based, proprietary systems, raising significant concerns regarding data privacy, operational sovereignty, and escalating costs. This paper investigates the feasibility of deploying a high-performance, private LLM inference server at a cost accessible to Small and Medium Businesses (SMBs). We present a comprehensive benchmarking analysis of a locally hosted, quantized 30-billion parameter Mixture-of-Experts (MoE) model based on Qwen3, running on a consumer-grade server equipped with a next-generation NVIDIA GPU. Unlike cloud-based offerings, which are expensive and complex to integrate, our approach provides an affordable and private solution for SMBs. We evaluate two dimensions: the model's intrinsic capabilities and the server's performance under load. Model performance is benchmarked against academic and industry standards to quantify reasoning and knowledge relative to cloud services. Concurrently, we measure server efficiency through latency, tokens per second, and time to first token, analyzing scalability under increasing concurrent users. Our findings demonstrate that a carefully configured on-premises setup with emerging consumer hardware and a quantized open-source model can achieve performance comparable to cloud-based services, offering SMBs a viable pathway to deploy powerful LLMs without prohibitive costs or privacy compromises.
💡 Summary & Analysis
This paper covers various approaches to improve the efficiency and performance of Large Language Models (LLMs). Quantization plays a crucial role in reducing model size and inference time. Studies such as AWQ and SpQR introduce new developments in weight quantization. Memory management techniques like PagedAttention and FastServe are also discussed, which significantly reduce inference times.
The paper further explores on-premise and on-device deployment studies. These methods execute models directly on local devices or premises rather than the cloud, which is particularly important for data security and latency reduction purposes.
📄 Full Paper Content (ArXiv Source)
references.bib @inproceedingsshazeer2021switch, title = Switch
Transformers: Scaling to Trillion-Parameter Models with Simple Routing,
author = Shazeer, Noam and others, booktitle = Proceedings of the 9th
International Conference on Learning Representations (ICLR), year =
2021, url = https://arxiv.org/abs/2101.03961
@inproceedingsfrantar2022gptq, title = OPTQ: Accurate Post-Training
Quantization for Generative Pre-trained Transformers, author = Frantar,
Elias and Ashkboos, Saeed and Gholami, Amir and Alistarh, Dan, booktitle
= International Conference on Learning Representations (ICLR), year =
2023, url = https://openreview.net/forum?id=tcbBPnfwxS
@articlelin2024awq, title = AWQ: Activation-Aware Weight Quantization
for LLM Compression and Acceleration, author = Lin, Jiayi and Tang,
Sheng and Li, Xu and Wang, Hongyi and He, Yihang and Li, Mu and Chen,
Zhiqiang and Wang, Yizhou, journal = arXiv preprint arXiv:2306.00978,
year = 2024
@articledettmers2023spqr, title = SpQR: A Sparse-Quantized
Representation for Near-Lossless LLM Weight Compression, author =
Dettmers, Tim and Lewis, Mike and Shleifer, Sam and Zettlemoyer, Luke,
journal = arXiv preprint arXiv:2306.03078, year = 2023
@articlexia2024fp6, title = FP6-LLM: Efficiently Serving Large Language
Models Through FP6-Centric Algorithm-System Co-Design, author = Xia,
Haojun and Zheng, Zhen and Wu, Xiaoxia and Chen, Shiyang and Yao, Zhewei
and Youn, Stephen and Bakhtiari, Arash and Wyatt, Michael and Zhuang,
Donglin and Zhou, Zhongzhu and Ruwase, Olatunji and He, Yuxiong and
Song, Shuaiwen Leon, journal = arXiv preprint arXiv:2401.14112, year =
2024
@miscllamacpp2025, title = llama.cpp: Inference of LLaMA and other LLMs
in C/C++, author = Georgi Gerganov and contributors, year = 2025,
howpublished = https://github.com/ggerganov/llama.cpp
@articlepaloniemi2025onpremise, title = On-Premise Large Language Model
Deployments: Motivations, Challenges, and Case Studies, author =
Paloniemi, Tuomas and Nieminen, Antti and Rossi, Pekka, journal =
Journal of Cloud Computing, year = 2025
@miscsovereignAI2024, title = Sovereign AI: Policy and Infrastructure
Strategies for National LLM Hosting, author = European Commission AI
Office, year = 2024, howpublished =
https://digital-strategy.ec.europa.eu
@articlewang2023ondevicellms, title = On-Device Language Models: A
Comprehensive Review, author = Xu, Jiajun and Li, Zhiyuan and Chen, Wei
and Wang, Qun and Gao, Xin and Cai, Qi and Ling, Ziyuan, journal = arXiv
preprint arXiv:2409.00088 , year = 2024
@miscqwen32025release, title = Qwen3 Technical Report and Model Release,
author = Alibaba DAMO Academy, year = 2025, howpublished =
https://huggingface.co/Qwen
@inproceedingskwon2023pagedattention, title = Efficient Memory
Management for Large Language Model Serving with PagedAttention, author
= Kwon, Woojeong and Lin, Yizhuo and Xie, Xuechen and Chen, Tianqi,
booktitle = Proceedings of the 29th ACM Symposium on Operating Systems
Principles (SOSP), year = 2023
@inproceedingszhang2023fastserve, title = FastServe: Efficient LLM
Serving Using Speculative Scheduling, author = Zhang, Zhihao and Xu,
Hang and Wang, Yuxin and Chen, Kai, booktitle = Proceedings of the ACM
Symposium on Cloud Computing (SoCC), year = 2023
@articlechitty2024llminferencebench, title=LLM-Inference-Bench:
Inference Benchmarking of Large Language Models on AI Accelerators,
author=Krishna Teja Chitty-Venkata and Siddhisanket Raskar and Bharat
Kale and Farah Ferdaus and Aditya Tanikanti and Ken Raffenetti and
Valerie Taylor and Murali Emani and Venkatram Vishwanath, year=2024,
journal = arXiv preprint arXiv:2411.00136
@inproceedingsdao2022flashattention, title = FlashAttention: Fast and
Memory-Efficient Exact Attention with IO-Awareness, author = Dao, Tri
and Fu, Daniel and Ermon, Stefano and Rudra, Atri and Re, Christopher,
booktitle = Advances in Neural Information Processing Systems (NeurIPS),
year = 2022
@articleshen2024flashattention2, title = FlashAttention-2: Faster
Attention with Better Parallelism and Work Partitioning, author = Shen,
Haotian and Dao, Tri and Chen, Zhewei and Song, Xinyun and Zhao, Tianle
and Li, Zhuohan and Stoica, Ion and Gonzalez, Joseph E. and Zaharia,
Matei, journal = arXiv preprint arXiv:2307.08691, year = 2024
@miscvllm2023, title = vLLM: A fast and memory-efficient LLM serving
library (repo & docs), author = vLLM Project, year = 2023, howpublished
= https://github.com/vllm-project/vllm
, note = PagedAttention and vLLM
documentation
@miscllmperf2024, title = LLMPerf: A benchmarking and load-generation
tool for LLM inference, author = LLMPerf Project, year = 2024,
howpublished = https://github.com/ray-project/llmperf
, note = Tool
used to generate synthetic LLM workloads in experiments
@misclmeval2023, title = lm-evaluation-harness: A framework for
evaluating language models, author = Ethayarajh, K. and contributors
(EleutherAI), year = 2023, howpublished =
https://github.com/EleutherAI/lm-evaluation-harness
, note = Evaluation
harness used for MMLU and comparable benchmarks
@miscaime2024_hf, title = AIME 2024 Dataset, author = Maxwell-Jia and
HuggingFace Datasets contributors, year = 2024, howpublished =
https://huggingface.co/datasets/Maxwell-Jia/AIME_2024
, note = Dataset
of AIME 2024 problems (used for math reasoning evaluation)
@miscartificialanalysis2025, title = Artificial Analysis — AI Model &
API Providers Analysis, author = ArtificialAnalysis, year = 2025,
howpublished = https://artificialanalysis.ai
, note = Model comparison
and independent benchmarks (source for Table 1 numbers)
@miscopenrouter2025, title = OpenRouter — Models & Provider Metrics,
author = OpenRouter, year = 2025, howpublished =
https://openrouter.ai
, note = Aggregated provider and model metrics
(source for Table 1 numbers)
@articlemckay1979lhs, title = A Comparison of Three Methods for
Selecting Values of Input Variables in the Analysis of Output from a
Computer Code, author = McKay, Michael D. and Beckman, Richard J. and
Conover, William J., journal = Technometrics, volume = 21, number = 2,
pages = 239–245, year = 1979, url =
https://doi.org/10.1080/00401706.1979.10489755
The copyright of this content belongs to the respective researchers. We deeply appreciate their hard work and contribution to the advancement of human civilization.