LLMs in K-12 Beyond the Tutoring Hype
📝 Original Paper Info
- Title: Problems With Large Language Models for Learner Modelling Why LLMs Alone Fall Short for Responsible Tutoring in K--12 Education- ArXiv ID: 2512.23036
- Date: 2025-12-28
- Authors: Danial Hooshyar, Yeongwook Yang, Gustav Šíř, Tommi Kärkkäinen, Raija Hämäläinen, Mutlu Cukurova, Roger Azevedo
📝 Abstract
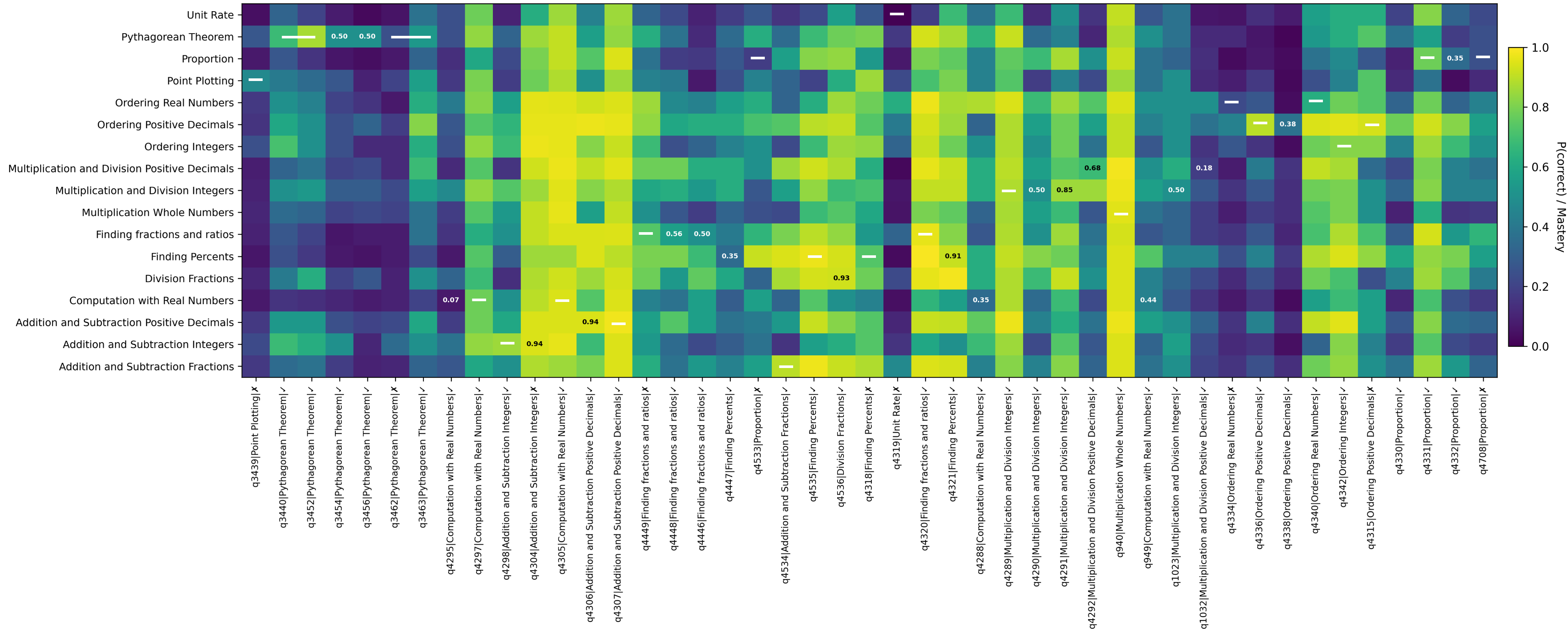
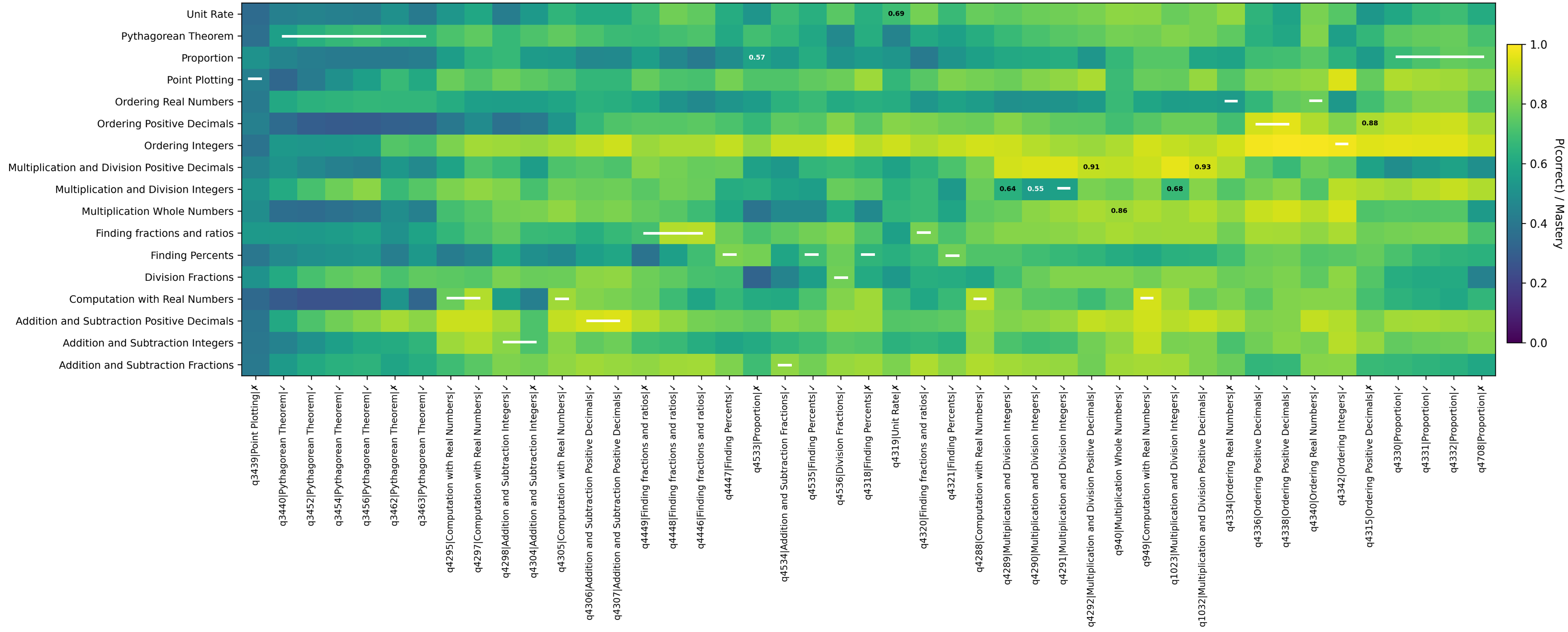
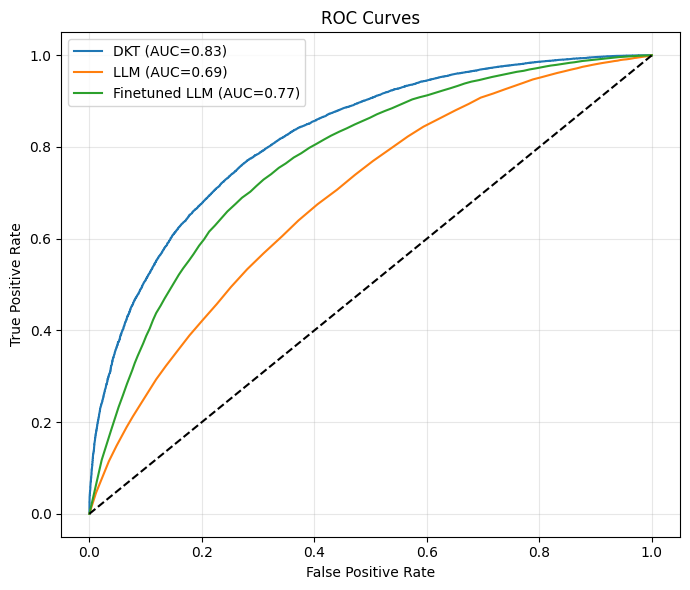
The rapid rise of large language model (LLM)-based tutors in K--12 education has fostered a misconception that generative models can replace traditional learner modelling for adaptive instruction. This is especially problematic in K--12 settings, which the EU AI Act classifies as high-risk domain requiring responsible design. Motivated by these concerns, this study synthesises evidence on limitations of LLM-based tutors and empirically investigates one critical issue: the accuracy, reliability, and temporal coherence of assessing learners' evolving knowledge over time. We compare a deep knowledge tracing (DKT) model with a widely used LLM, evaluated zero-shot and fine-tuned, using a large open-access dataset. Results show that DKT achieves the highest discrimination performance (AUC = 0.83) on next-step correctness prediction and consistently outperforms the LLM across settings. Although fine-tuning improves the LLM's AUC by approximately 8\% over the zero-shot baseline, it remains 6\% below DKT and produces higher early-sequence errors, where incorrect predictions are most harmful for adaptive support. Temporal analyses further reveal that DKT maintains stable, directionally correct mastery updates, whereas LLM variants exhibit substantial temporal weaknesses, including inconsistent and wrong-direction updates. These limitations persist despite the fine-tuned LLM requiring nearly 198 hours of high-compute training, far exceeding the computational demands of DKT. Our qualitative analysis of multi-skill mastery estimation further shows that, even after fine-tuning, the LLM produced inconsistent mastery trajectories, while DKT maintained smooth and coherent updates. Overall, the findings suggest that LLMs alone are unlikely to match the effectiveness of established intelligent tutoring systems, and that responsible tutoring requires hybrid frameworks that incorporate learner modelling.💡 Summary & Analysis
1. **Importance of Transfer Learning**: Transfer learning is a technique where a pre-trained model is reused for new tasks. This is like repurposing car parts from one vehicle to another, applying what was learned in previous data to new problems. 2. **Effectiveness of Custom Models**: Custom models are algorithms specifically designed for particular tasks that lead to more accurate predictions. This is akin to using specialized tools to create intricate crafts. 3. **Impact of Datasets**: Excellent performance across various datasets indicates the significant influence of both quantity and quality of data on model performance.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)