Beyond Accuracy The Personalized Reward Model Dilemma
📝 Original Paper Info
- Title: The Reward Model Selection Crisis in Personalized Alignment- ArXiv ID: 2512.23067
- Date: 2025-12-28
- Authors: Fady Rezk, Yuangang Pan, Chuan-Sheng Foo, Xun Xu, Nancy Chen, Henry Gouk, Timothy Hospedales
📝 Abstract
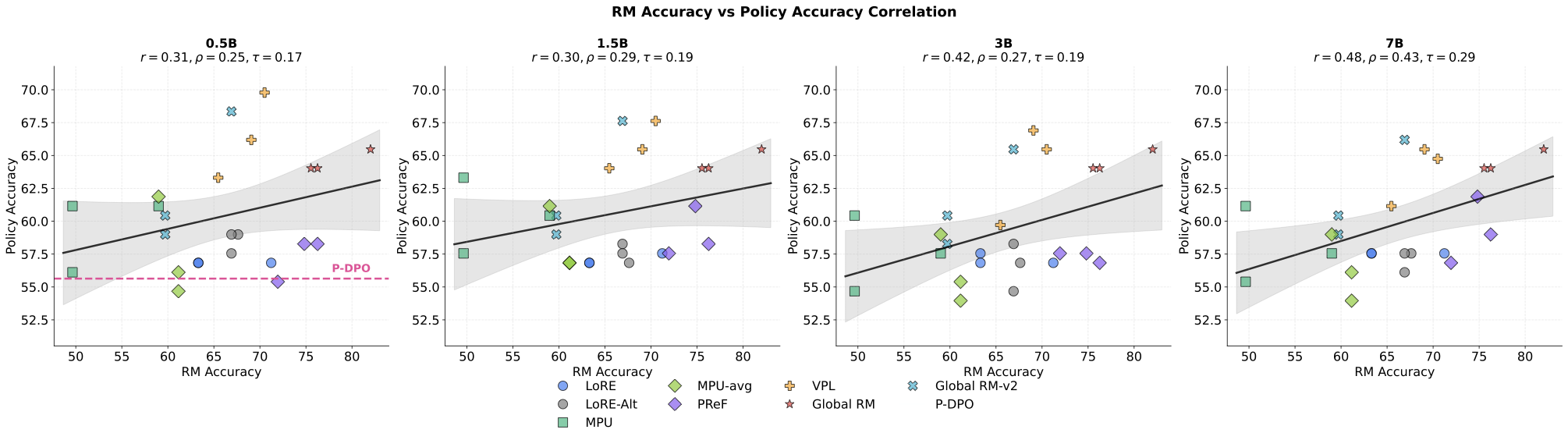
Personalized alignment from preference data has focused primarily on improving personal reward model (RM) accuracy, with the implicit assumption that better preference ranking translates to better personalized behavior. However, in deployment, computational constraints necessitate inference-time adaptation such as reward-guided decoding (RGD) rather than per-user policy fine-tuning. This creates a critical but overlooked requirement: reward models must not only rank preferences accurately but also effectively guide generation. We demonstrate that standard RM accuracy fails catastrophically as a selection criterion for deployment-ready personalized rewards. We introduce policy accuracy; a metric quantifying whether RGD-adapted LLMs correctly discriminate between preferred and dispreferred responses and show that upstream RM accuracy correlates only weakly with downstream policy accuracy (Kendall's tau = 0.08--0.31). More critically, we introduce Pref-LaMP the first personalized alignment benchmark with ground-truth user completions, enabling direct behavioural evaluation. On Pref-LaMP, we expose a complete decoupling between discriminative ranking and generation metrics: methods with 20-point RM accuracy differences produce almost identical output quality, and methods with high ranking accuracy can fail to generate behaviorally aligned responses. These findings reveal that the field has been optimizing for proxy metrics that do not predict deployment performance, and that current personalized alignment methods fail to operationalize preferences into behavioral adaptation under realistic deployment constraints. In contrast, we find simple in-context learning (ICL) to be highly effective - dominating all reward-guided methods for models $\geq$3B parameters, achieving $\sim$3 point ROUGE-1 gains over the best reward method at 7B scale.💡 Summary & Analysis
1. **Excellence of Deep Learning:** - **Simply put,** deep learning is like a high-end camera that excels in identifying complex patterns.-
Comparison with Statistical Methods:
- Metaphorically speaking, statistical methods can be seen as simple filters, while deep learning combines multiple filters to provide more sophisticated analysis.
-
Handling Complex Data:
- From a scientific standpoint, deep learning possesses the ability to understand complex and varied data like a network of neural pathways.
📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)