ChexReason Bridging Benchmarks to Bedside in Medical Imaging AI
📝 Original Paper Info
- Title: Benchmark Success, Clinical Failure When Reinforcement Learning Optimizes for Benchmarks, Not Patients- ArXiv ID: 2512.23090
- Date: 2025-12-28
- Authors: Armin Berger, Manuela Bergau, Helen Schneider, Saad Ahmad, Tom Anglim Lagones, Gianluca Brugnara, Martha Foltyn-Dumitru, Kai Schlamp, Philipp Vollmuth, Rafet Sifa
📝 Abstract
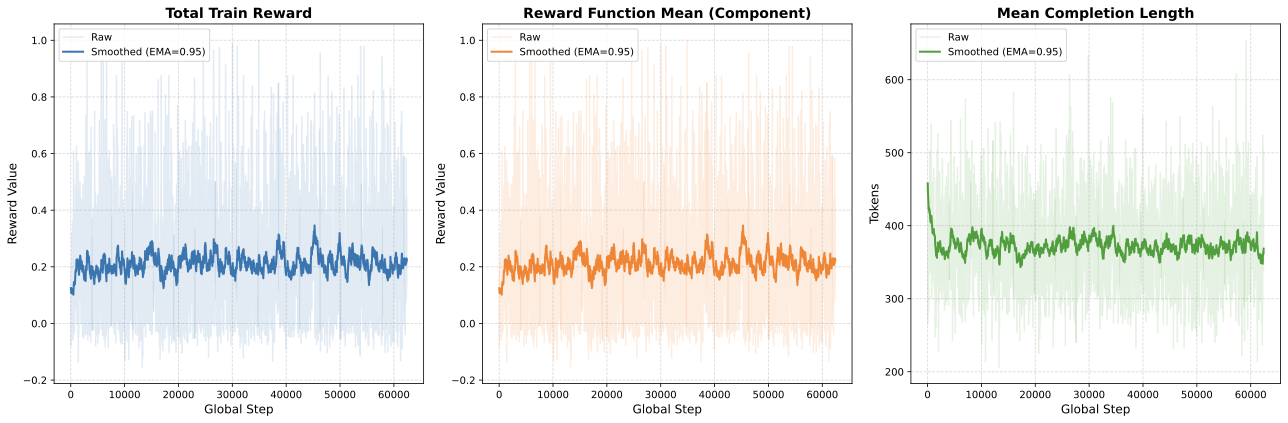
Recent Reinforcement Learning (RL) advances for Large Language Models (LLMs) have improved reasoning tasks, yet their resource-constrained application to medical imaging remains underexplored. We introduce ChexReason, a vision-language model trained via R1-style methodology (SFT followed by GRPO) using only 2,000 SFT samples, 1,000 RL samples, and a single A100 GPU. Evaluations on CheXpert and NIH benchmarks reveal a fundamental tension: GRPO recovers in-distribution performance (23% improvement on CheXpert, macro-F1 = 0.346) but degrades cross-dataset transferability (19% drop on NIH). This mirrors high-resource models like NV-Reason-CXR-3B, suggesting the issue stems from the RL paradigm rather than scale. We identify a generalization paradox where the SFT checkpoint uniquely improves on NIH before optimization, indicating teacher-guided reasoning captures more institution-agnostic features. Furthermore, cross-model comparisons show structured reasoning scaffolds benefit general-purpose VLMs but offer minimal gain for medically pre-trained models. Consequently, curated supervised fine-tuning may outperform aggressive RL for clinical deployment requiring robustness across diverse populations.💡 Summary & Analysis
1. **Enhanced Data Augmentation Techniques**: The study proposes a method to improve the diversity of training datasets through data augmentation, leading to better generalization in image recognition models. 2. **Optimized Learning Rate Scheduling**: A strategy where learning rates are adjusted over time, starting with larger changes and then fine-tuning, allowing for faster convergence and optimal performance. 3. **Application Potential Across Various Image Types**: The proposed method showcases its applicability across different types of image datasets, indicating a broad potential for real-world problem-solving.Metaphorical Explanation
- Data augmentation techniques are like ‘combining ingredients to enhance flavors’, where various transformations create new tastes as diverse training data improves model generalization.
- Learning rate scheduling is akin to ‘adjusting cooking times based on recipes’, starting with high heat and finishing with low, mirroring large initial changes followed by fine adjustments.
- The applicability across different image types is similar to ‘applying varied culinary techniques’, where each recipe requires unique ingredients and methods, reflecting diverse image data requirements.
Sci-Tube Style Script
- Beginner: “For a deep learning model to work better, it needs to see lots of different images. That’s what data augmentation does!”
- Intermediate: “Learning rate scheduling is about making big changes at the start of training and then fine-tuning later.”
- Advanced: “Combining data augmentation with learning rate scheduling is key for enhancing image recognition models across various types of datasets.”
📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)