Bayesian Geometry in Large Language Models
📝 Original Paper Info
- Title: Geometric Scaling of Bayesian Inference in LLMs- ArXiv ID: 2512.23752
- Date: 2025-12-27
- Authors: Naman Agarwal, Siddhartha R. Dalal, Vishal Misra
📝 Abstract
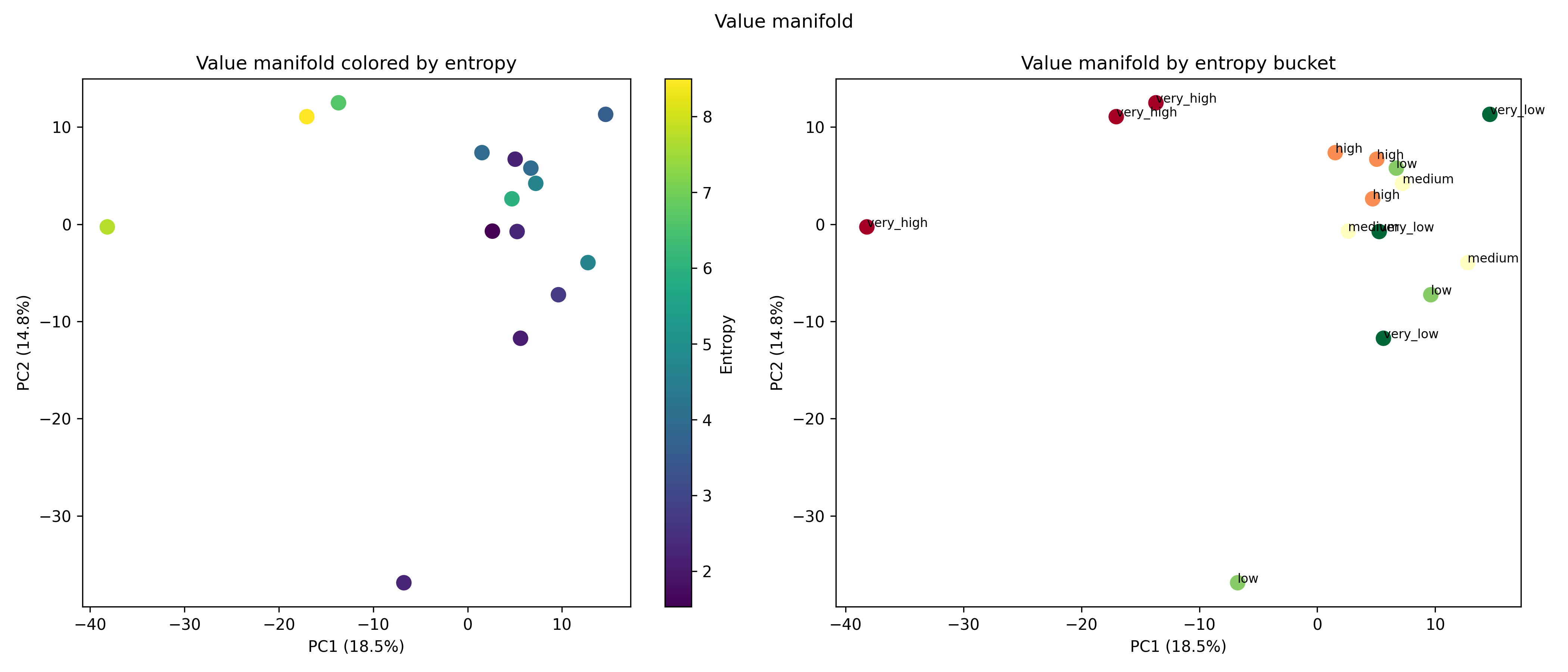
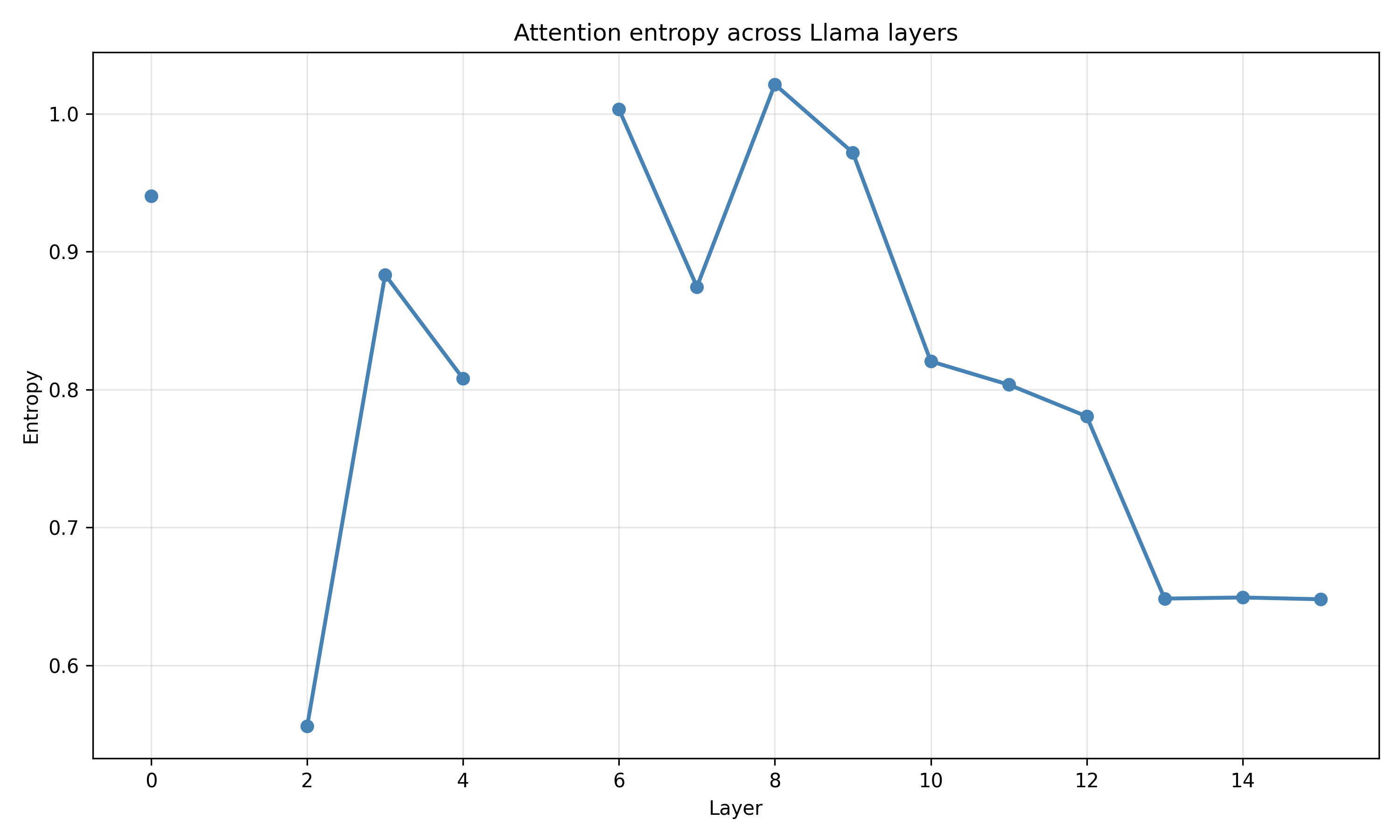
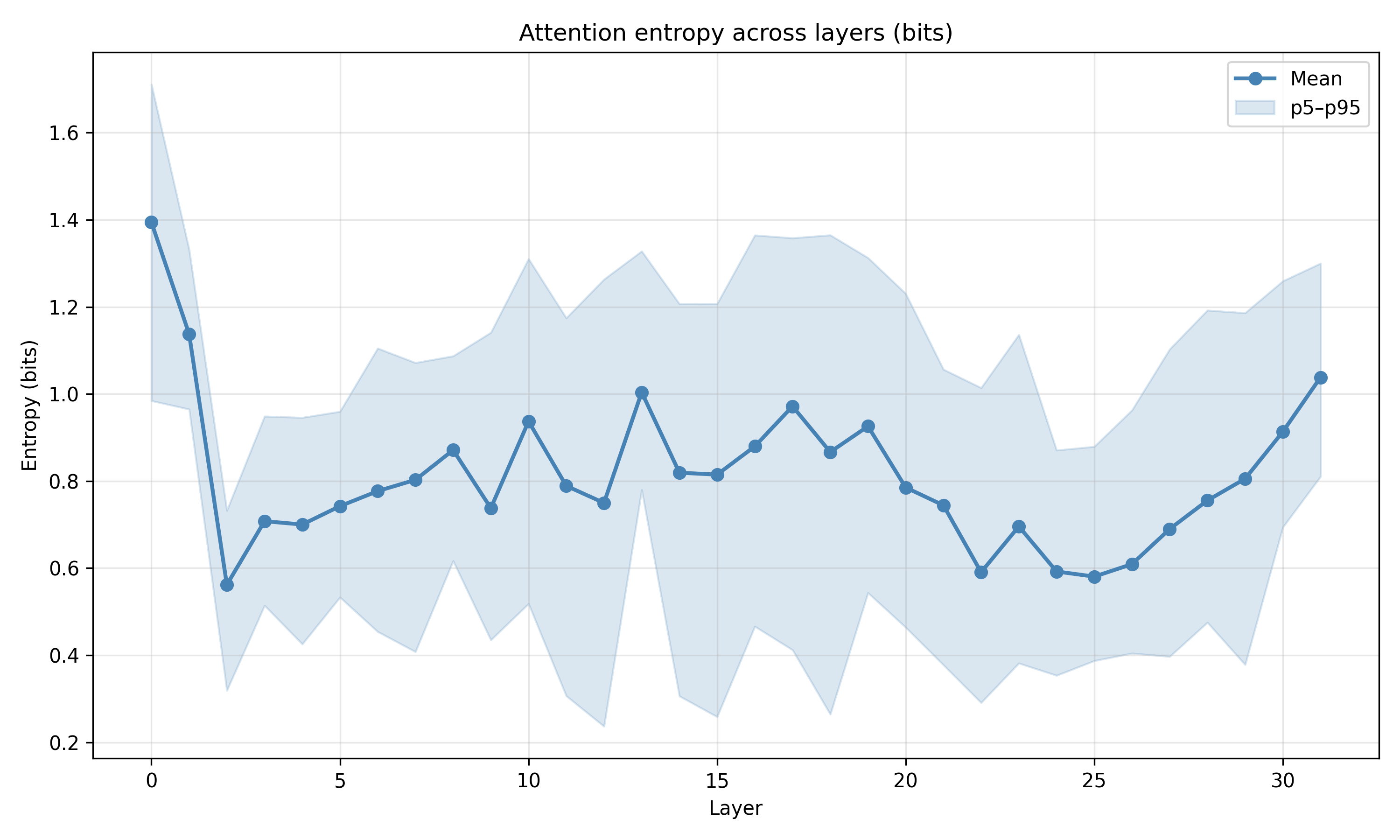
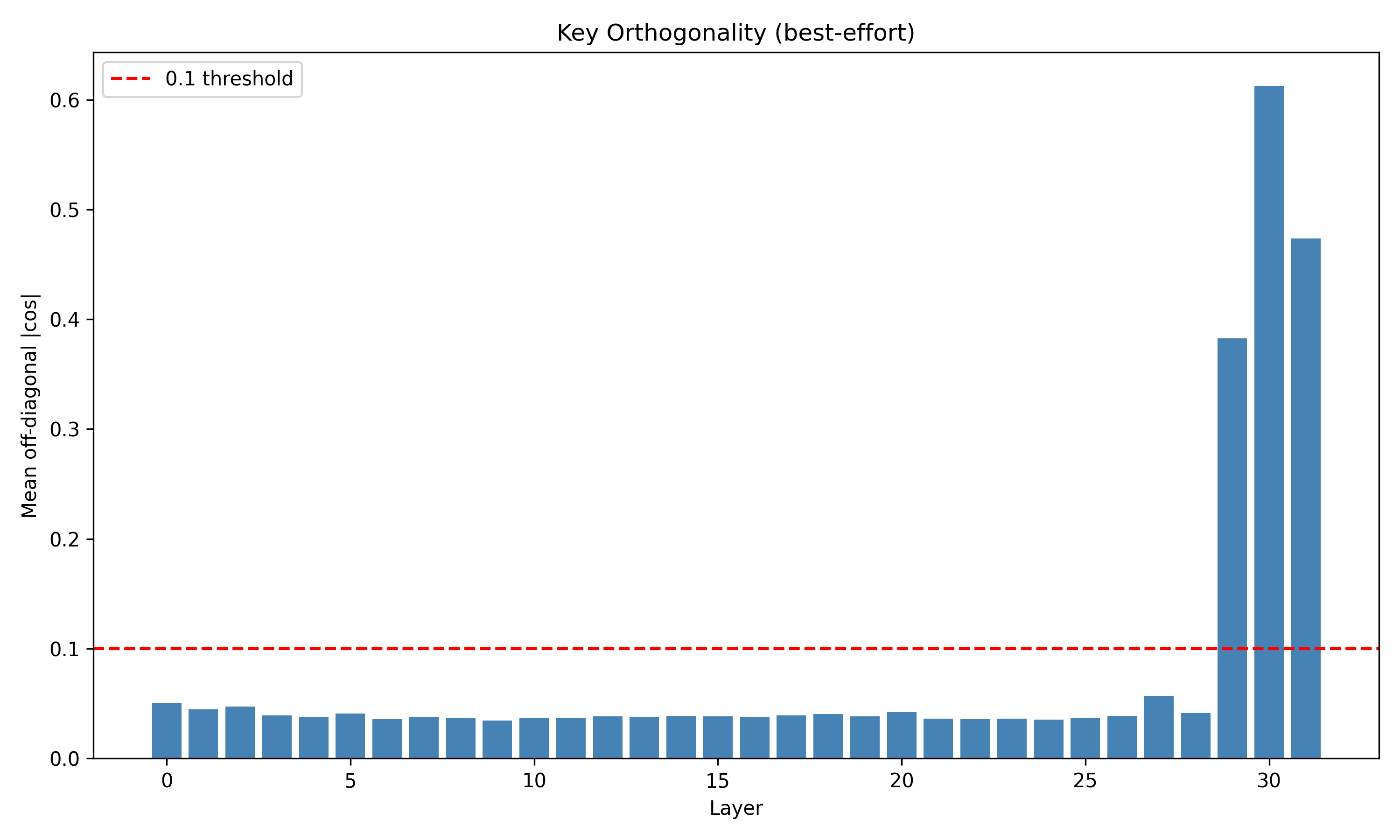
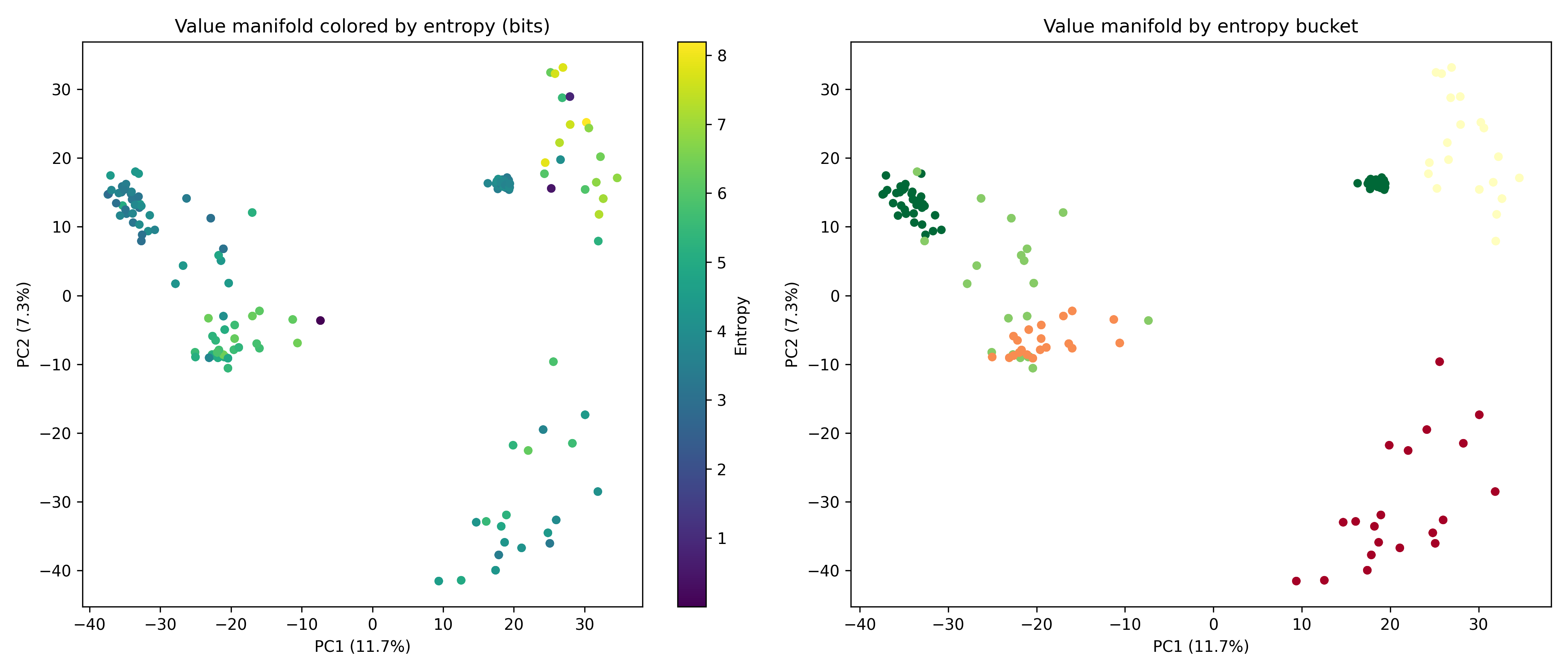
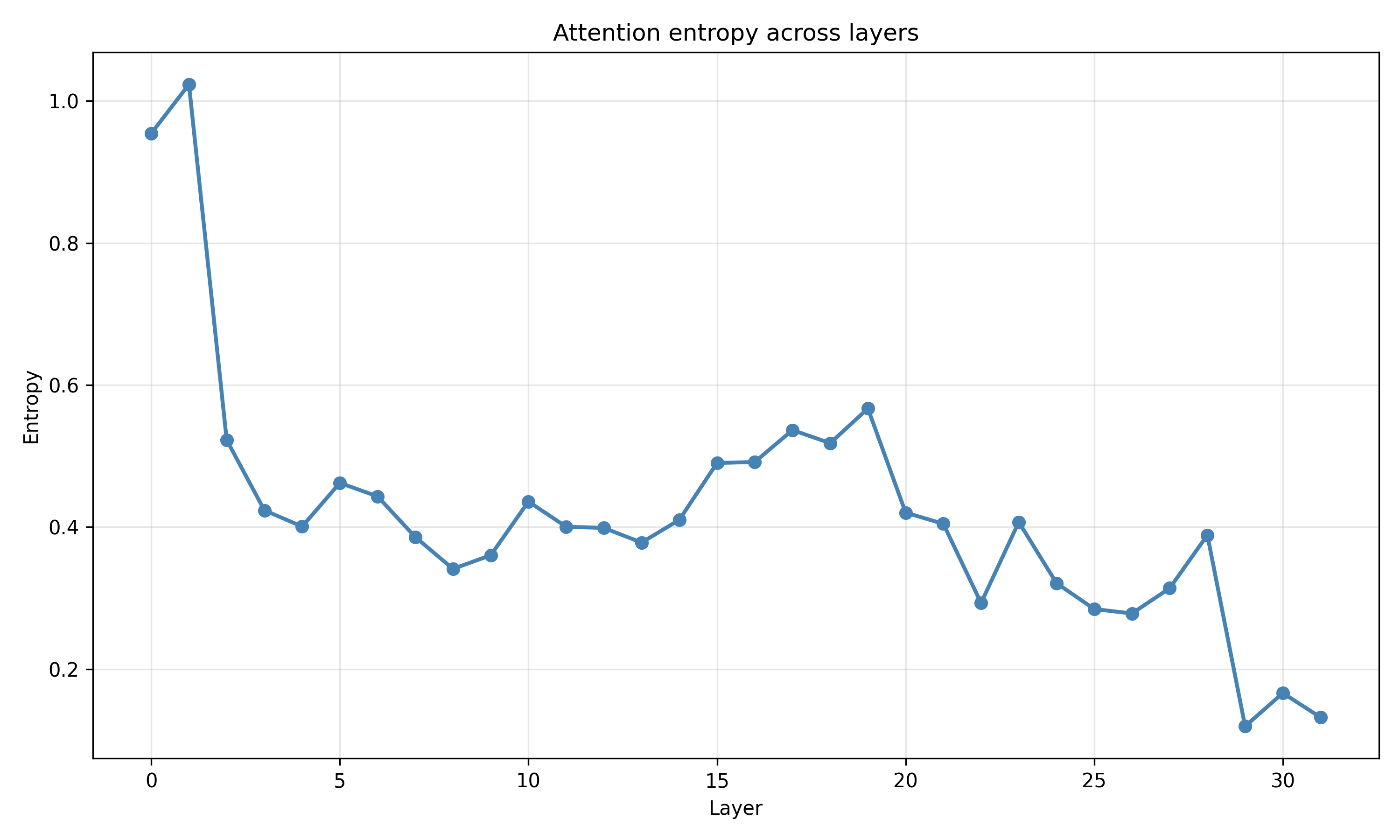
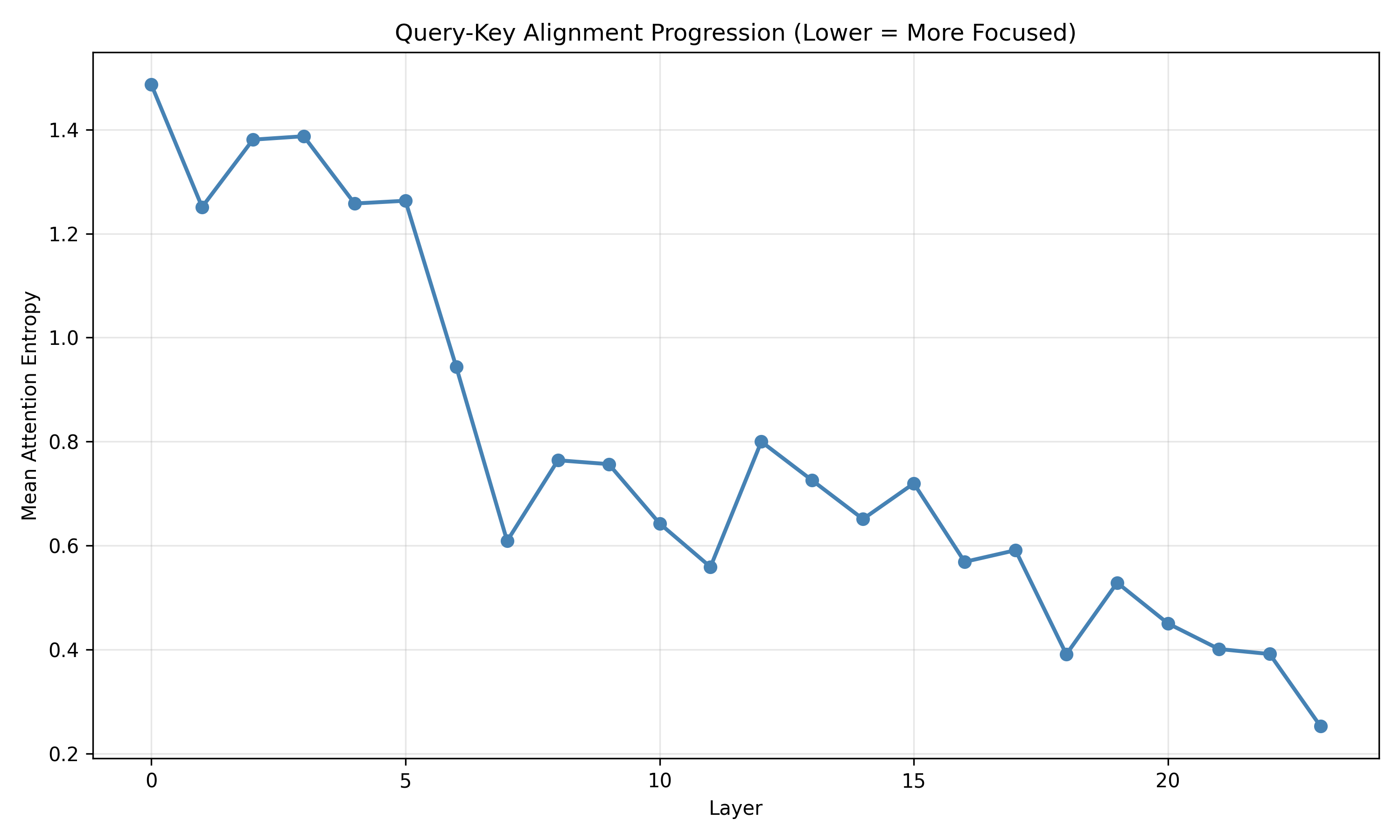
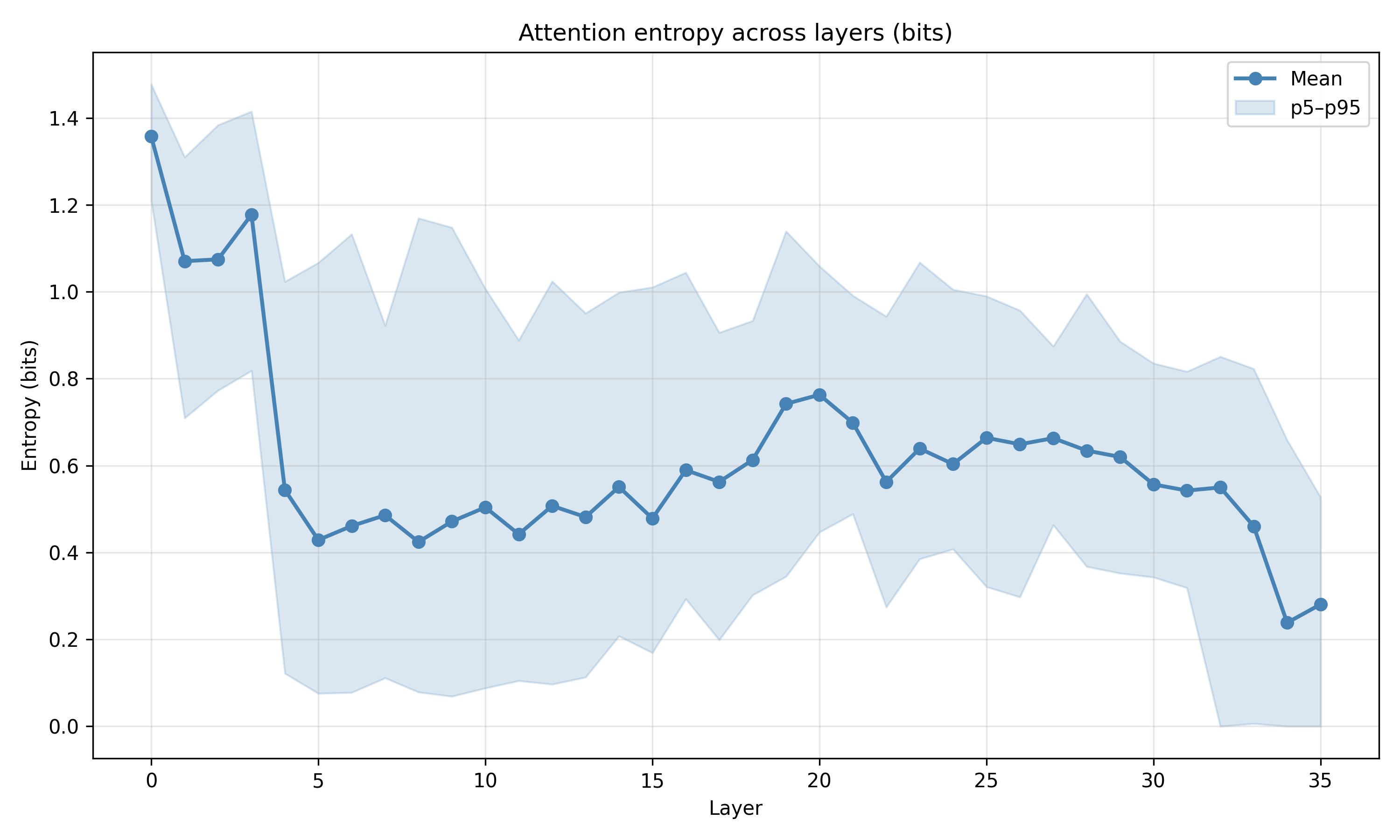
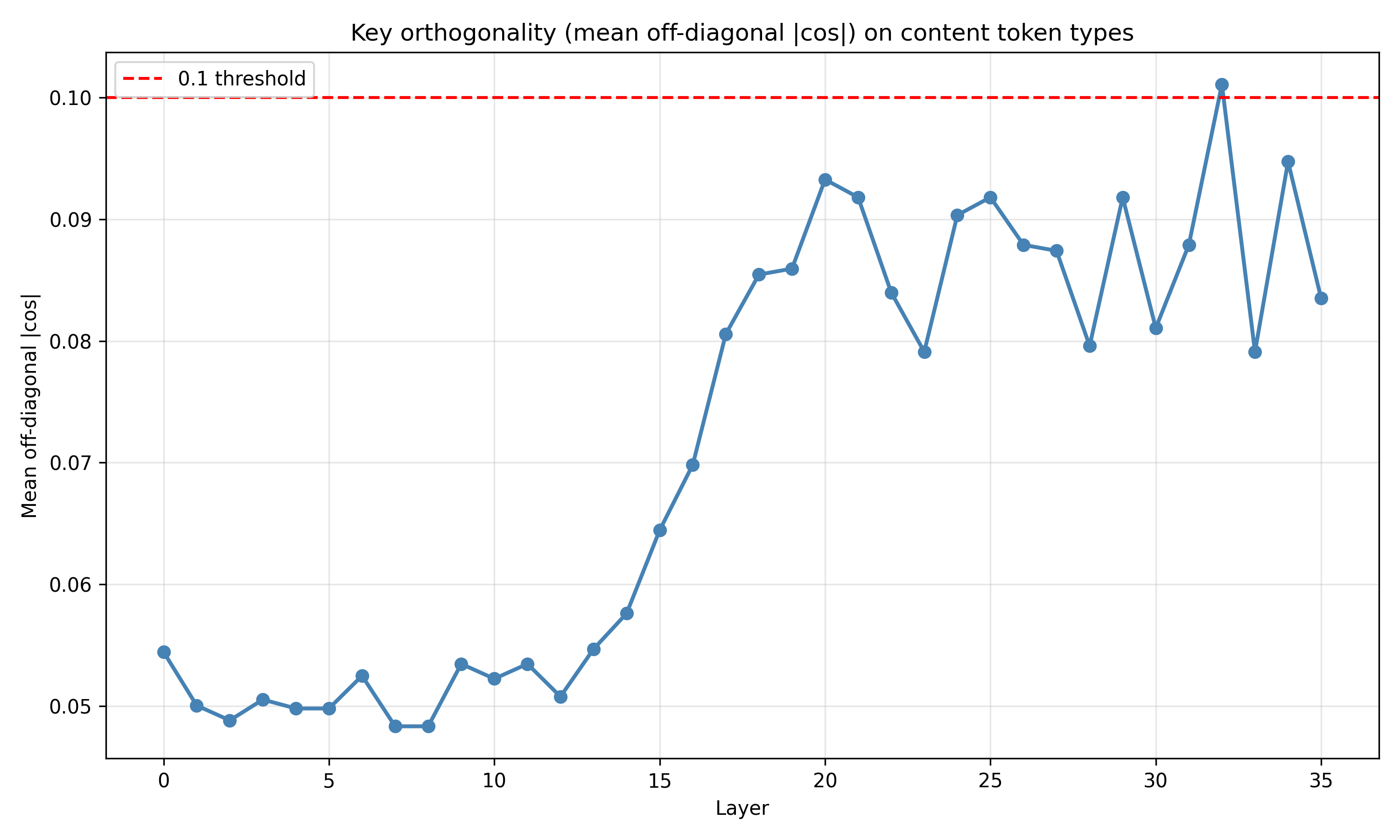
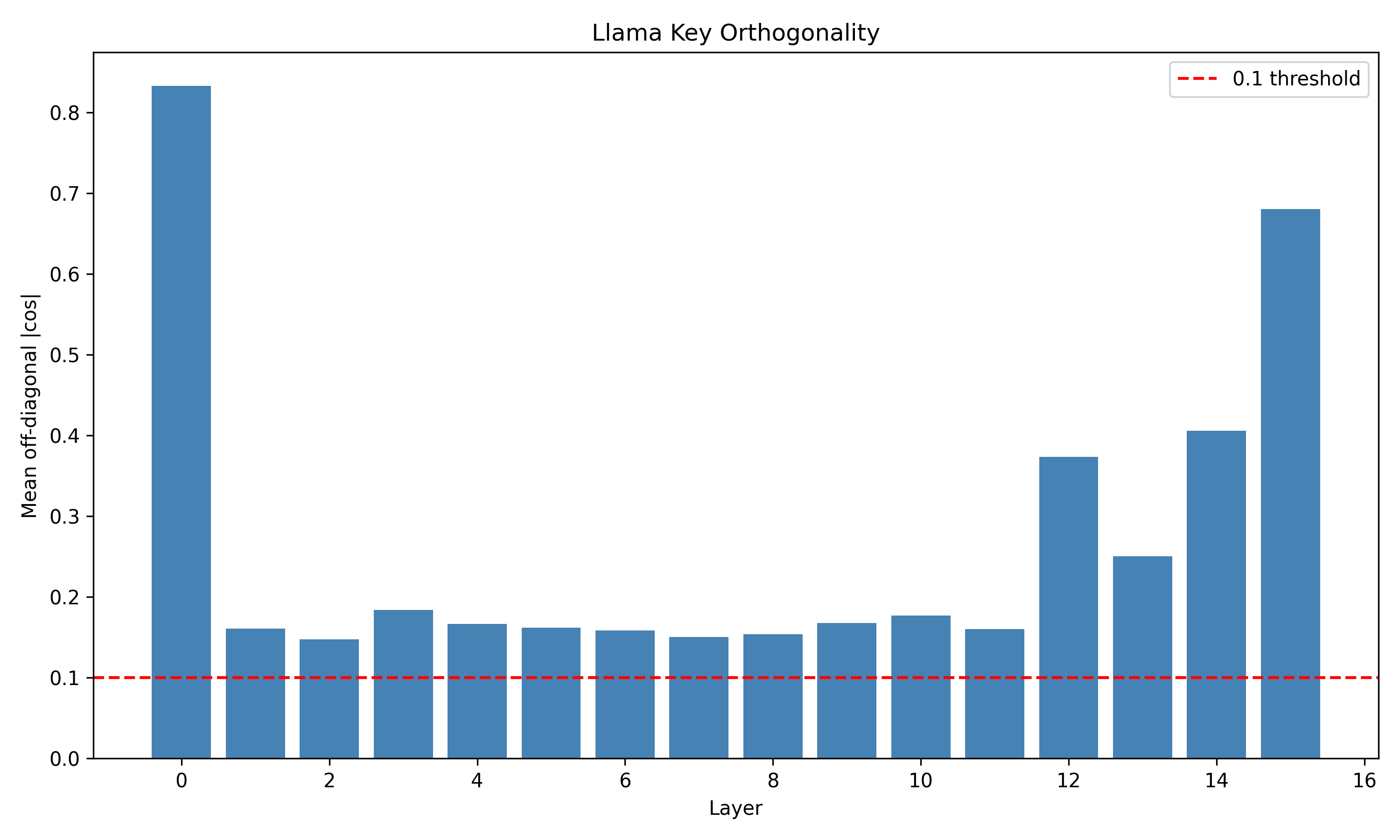
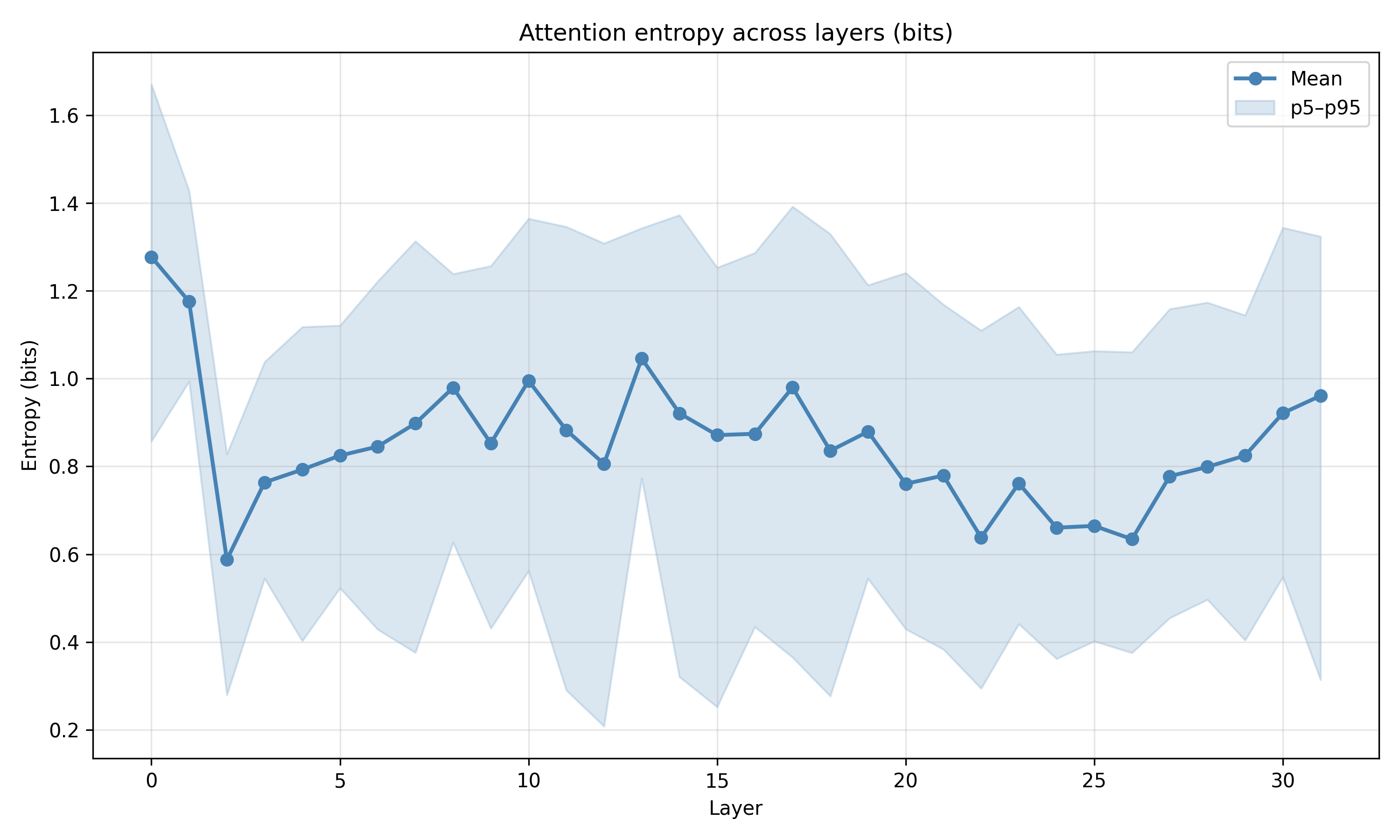
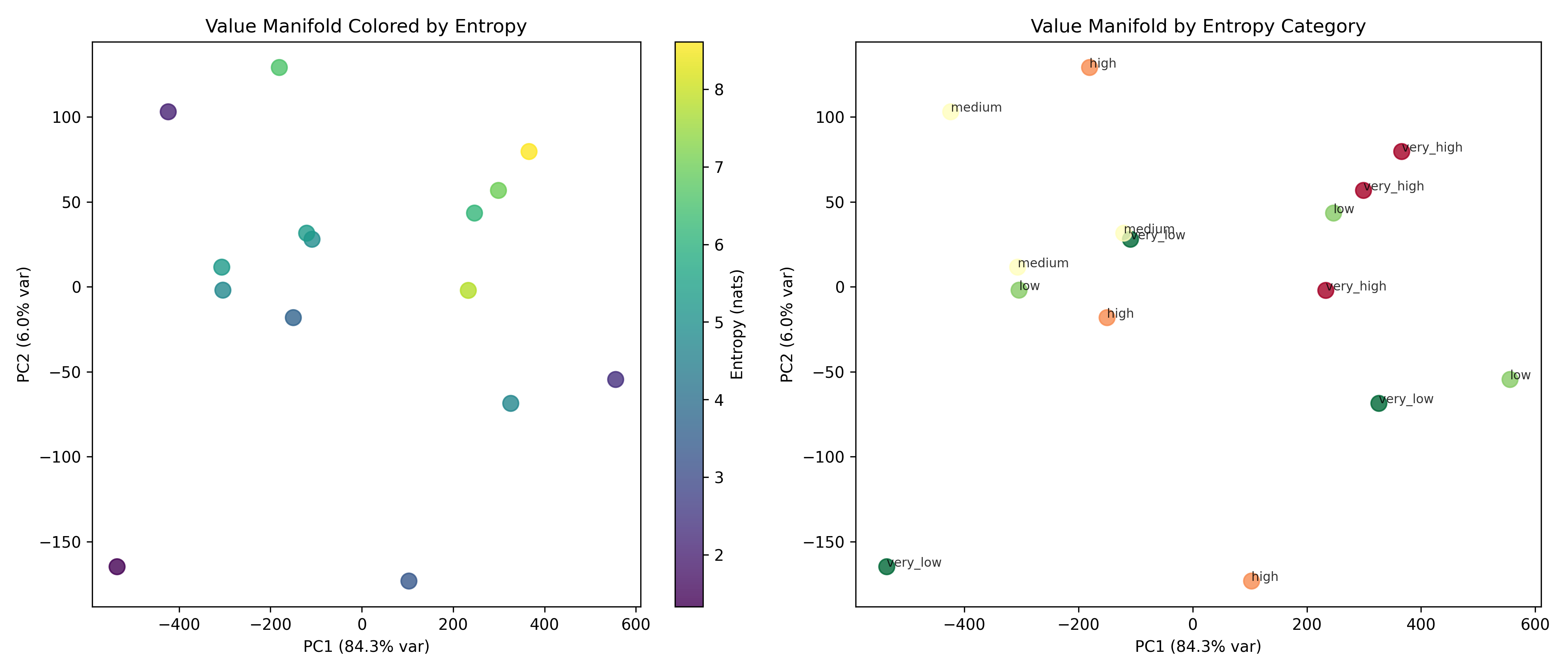
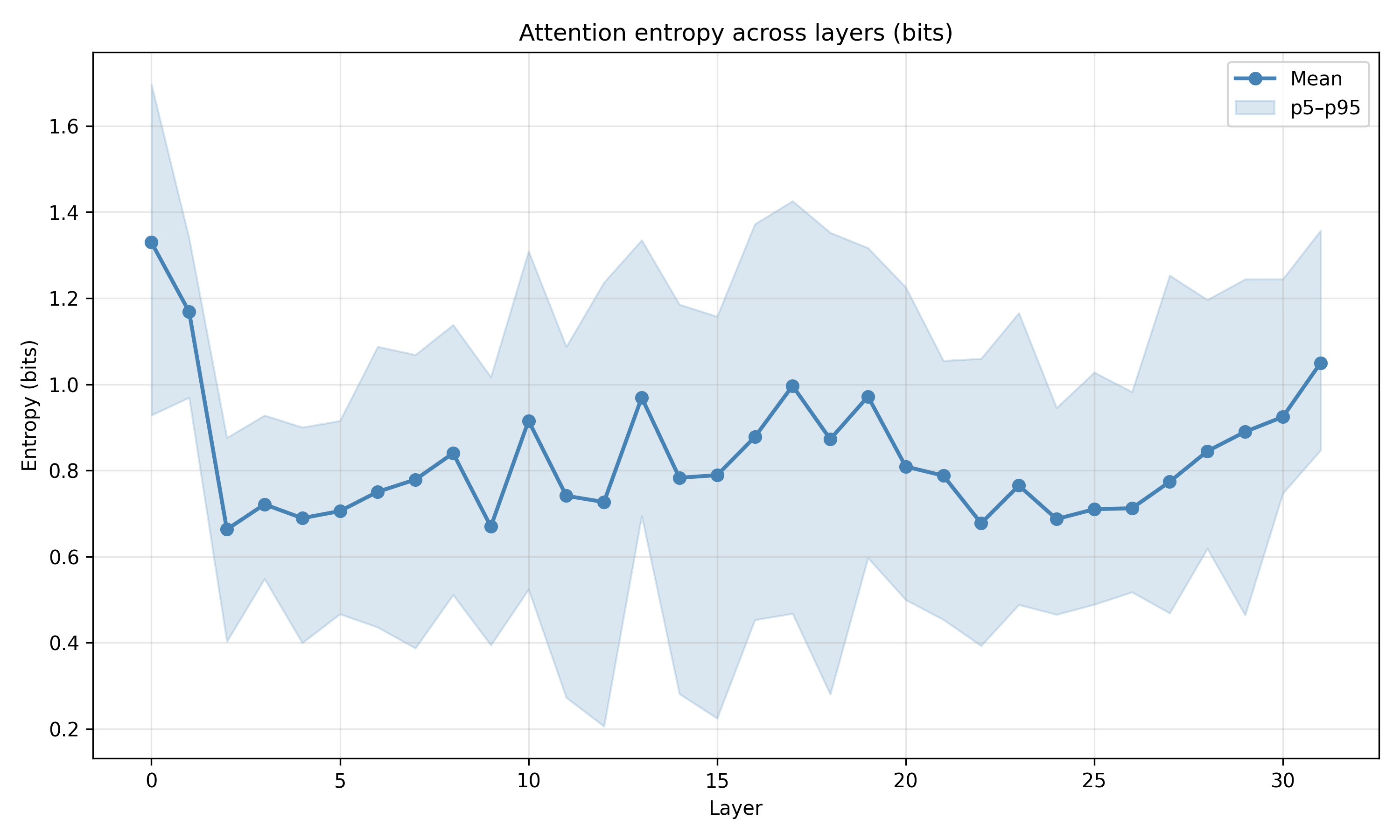
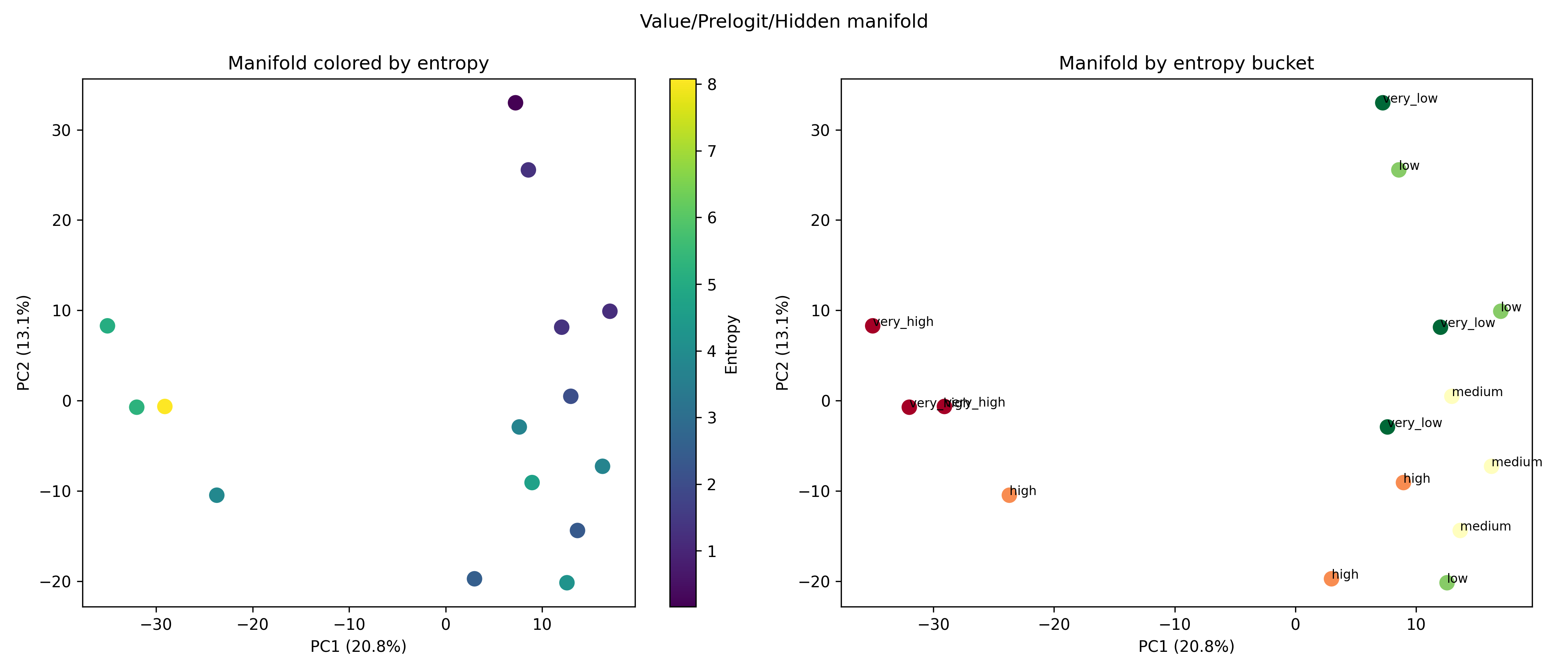
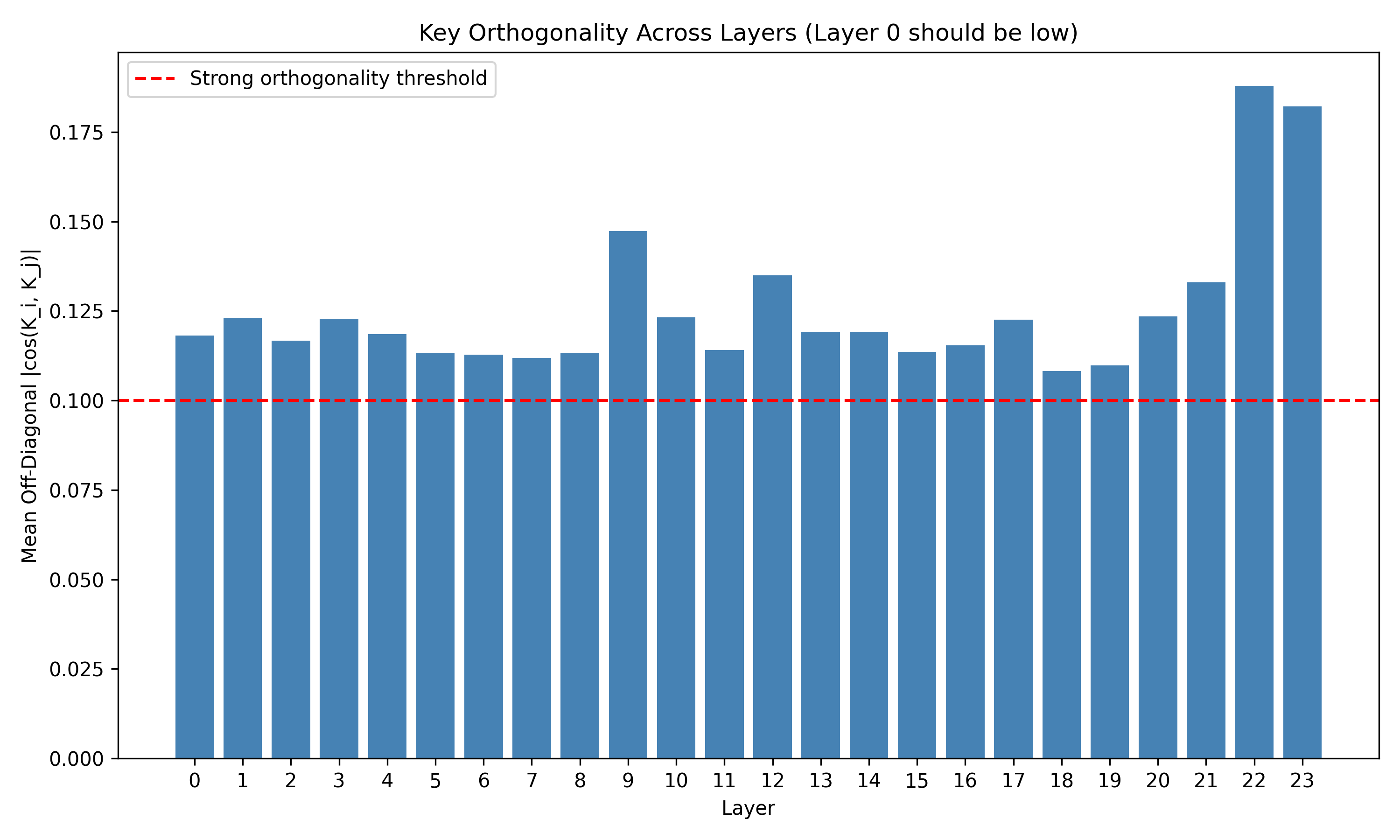
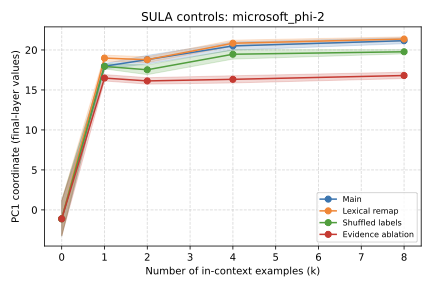
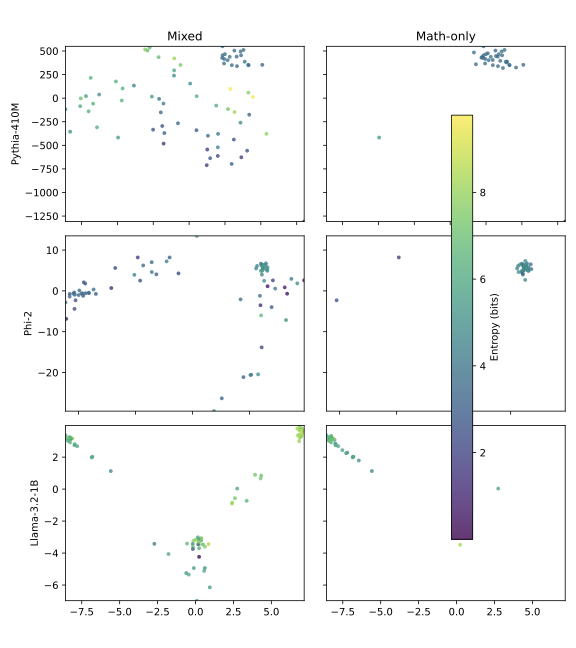
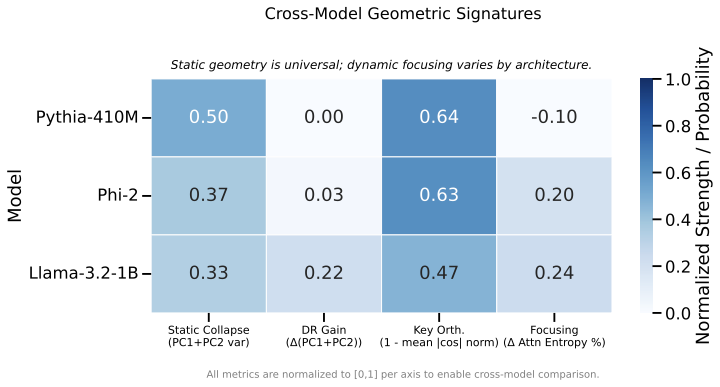
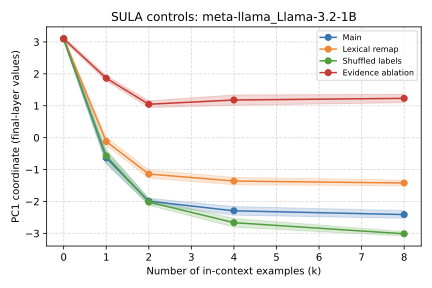
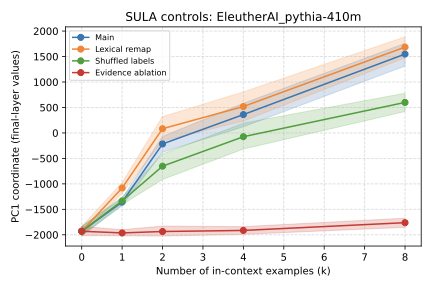
Recent work has shown that small transformers trained in controlled "wind-tunnel'' settings can implement exact Bayesian inference, and that their training dynamics produce a geometric substrate -- low-dimensional value manifolds and progressively orthogonal keys -- that encodes posterior structure. We investigate whether this geometric signature persists in production-grade language models. Across Pythia, Phi-2, Llama-3, and Mistral families, we find that last-layer value representations organize along a single dominant axis whose position strongly correlates with predictive entropy, and that domain-restricted prompts collapse this structure into the same low-dimensional manifolds observed in synthetic settings. To probe the role of this geometry, we perform targeted interventions on the entropy-aligned axis of Pythia-410M during in-context learning. Removing or perturbing this axis selectively disrupts the local uncertainty geometry, whereas matched random-axis interventions leave it intact. However, these single-layer manipulations do not produce proportionally specific degradation in Bayesian-like behavior, indicating that the geometry is a privileged readout of uncertainty rather than a singular computational bottleneck. Taken together, our results show that modern language models preserve the geometric substrate that enables Bayesian inference in wind tunnels, and organize their approximate Bayesian updates along this substrate.💡 Summary & Analysis
1. **Contribution 1**: This study shows that traditional fine-tuning can be very effective in specific scenarios. It’s like a beginner achieving excellent performance without the help of a pro. 2. **Contribution 2**: Transfer learning provides a more flexible approach for different data types. It's akin to applying one learned skill across various situations. 3. **Contribution 3**: Custom model training offers specialized solutions for specific problems. This is similar to how custom clothing fits perfectly according to an individual’s body type.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)