Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
Predicting future 3D hand motion is essential for in-context interaction and proactive assistance, where a system anticipates human intent from visual, linguistic, and motion cues. Humans perform this naturally, i.e., understanding the goal of an action, interpreting the scene layout, and coordinating movement based on recent dynamics. Achieving this computationally requires jointly reasoning about task semantics, spatial geometry, and temporal motion. We develop a model that predicts long-horizon 3D hand trajectories by integrating visual and motion context with language, which conveys intent and disambiguates visually similar actions. Such capabilities enable applications in robot manipulation, language-conditioned motion synthesis, and assistive systems that respond to human intent.
A major bottleneck is the lack of large-scale, high-quality 3D trajectory data. Controlled datasets [4,26,30] offer accurate annotations but limited diversity, while large-scale egocentric video datasets [17,42] contain rich real-world interactions but noisy, weakly goal-directed trajectories and little temporal structure. Crucially, they lack explicit interaction stages, e.g., approach and manipulation, which are needed to separate purposeful motion from background and to connect trajectories to intent. Models trained on such raw videos often generalize poorly because the links between intent, spatial relations, and motion dynamics are missing.
Beyond data limitations, existing modeling approaches also fall short. Affordance-based methods [2,11] rely on object detectors and affordance estimators, which propagate upstream detection errors and introduce additional computational overhead. End-to-end motion predictors, including those based on diffusion [20,40], variational [5], and state-space models [6], focus on short-term dynamics with limited semantic grounding. Vision-Language-Action (VLA) systems [24,38,60] exhibit strong reasoning ability, but applying VLMs [3,12,13,15,34] directly to generate continuous 3D motion remains challenging, as they struggle to produce smooth, high-frequency action sequences. Bridges between VLM reasoning and motion experts [10,28,31,33,48,49,54,58] typically rely on implicit tokens or lengthy reasoning chains, which limits efficiency, generalization, and interpretability when generating finegrained, fast actions.
To address these challenges, we introduce the EgoMAN project, which couples a large-scale, stage-aware dataset with a modular reasoning-to-motion framework. The Ego-MAN dataset contains over 300K egocentric clips from 1,500+ scenes, including 219K 6DoF hand trajectories annotated with interaction stages (approach, manipulation) and 3M structured vision-language-motion QA pairs. This supervision explicitly encodes why, when, and how hands move, enabling models to learn intent-linked, spatially grounded motion patterns at scale.
Building on this dataset, the EgoMAN model introduces a compact trajectory-token interface that connects high-level reasoning to continuous 3D hand motion. We define four trajectory tokens: one semantic token () and three stage-aware waypoint tokens (, , ) marking key transitions in interaction. These tokens represent wrist-centered spatio-temporal waypoints rather than object-centric affordances, providing a clear, structured interface for conditioning a flow-matching motion expert. A progressive three-stage training strategy learns (i) intent-conditioned and stage-aware reasoning over semantics, spatial and motion, (ii) motion dynamics, and (iii) their alignment through the token interface, enabling long-horizon, intent-consistent 3D trajectory prediction in diverse real-world scenes.
Our main contributions are: • EgoMAN dataset: a large-scale, interaction stage-aware 6DoF hand trajectory dataset with structured semantic, spatial, and motion reasoning annotations. • EgoMAN model: a modular reasoning-to-motion architecture with a trajectory-token interface and progressive training that aligns semantic intent with physically grounded motion generation. • We achieve state-of-the-art accuracy and generalization with high efficiency in 3D hand trajectory prediction across diverse real-world egocentric scenes.
Hand Trajectory Prediction. Egocentric hand forecasting aims to infer future hand motion from past observations under ego-motion and depth ambiguity. Large-scale works often predict short-horizon 2D trajectories at low framerates [5,19,36,39,40], while curated datasets enable 3D trajectory prediction [6,20,41]. Prior 3D methods generally follow either: (a) object-centric, affordance-driven models [2,11,36], which rely on detectors and affordance estimators but suffer from error propagation and additional computational efficiency cost from detection; or (b) endto-end motion models predicting trajectories directly from video and past hand motion [39][40][41], sometimes incorporating egomotion [39][40][41] or 3D priors such as point clouds [41].
Given that 3D labels are often uncertain and scarce [6], generative models have become standard: VAEs [5], state-space models [6], diffusion [20,40], and hybrid variants [39,41]. However, these methods typically forecast short fixed horizons, focus on low-level motion, and encode intent implicitly, limiting generalization in diverse real-world egocentric scenarios. Our work instead predicts long-horizon, semantically grounded 6DoF trajectories by explicitly conditioning on intent, spatial context, and interaction stages. Learning Interactions from Human Videos. Human videos provide rich demonstrations of hand-object interactions, driving research in reconstruction and forecasting [6,7,35,36,40]. Controlled datasets [4,26,30] offer precise 3D annotations but limited task diversity; robotic imitation datasets [21,23,53] provide structured demonstrations but remain narrow and scripted. Large-scale egocentric datasets [17,42] capture varied daily activities with language annotations but often contain noisy trajectories and unclear interaction boundaries. We address these gaps by curating EgoMAN-Bench, consolidating real-world egocentric datasets into a stage-aware supervision benchmark. Our model builds on this benchmark to connect reasoning about interaction stages with accurate, long-horizon 3D trajectory prediction, aligning with recent efforts in robot learning from human videos [2,8,9,21,23,56].
Vision-Language Models for Embodied AI. Modern VLMs unify perception and language [3,13,16,27,34,43,51], enabling broad video understanding and reasoning. Their extensions to Vision-Language-Action (VLA) systems [24,38,60] support manipulation and navigation via robot datasets, but direct action prediction through VLMs often struggles to produce smooth, high-frequency trajectories. To mitigate this, recent works have sought to incorporate hand trajectory prediction in VLAs either through pre-training or co-training [29,55]. Coupled VLM-motion systems, where the VLM is linked to an action module, use implicit feature routing [10,49,54], which suffers from poor generalization and limited interpretability, while other approaches rely on long reasoning chains as the interface [28,31,58], resulting in high inference cost and low efficiency. In contrast, we introduce a trajectory-token interface that directly links high-level reasoning to continuous 3D motion using four specialized semantic and spatiotemporal waypoint tokens, enabling an efficient, interpretable interface that effectively guides the motion expert to generate smooth, accurate high-frequency trajectories.
EgoMAN is a large-scale egocentric interaction dataset (300+ hrs, 1,500+ scenes, 220K+ 6DoF trajectories) built from Aria glasses [14] across EgoExo4D [17], Nymeria [42], and HOT3D-Aria [4]. It provides high-quality wrist-centric trajectories, structured interaction annotations, and rich QA supervision for semantic, spatial, and motion reasoning. This section summarizes dataset statistics, annotation pipeline, trajectory annotation, QA construction, and the dataset split.
The data spans diverse interactions-scripted manipulation in HOT3D-Aria, real-world activities (bike repair, cooking) in EgoExo4D, and everyday tasks in Nymeria. Trajectories cover substantial variation: 27.8% exceed 2 s, 34.0% move over 20 cm on average, and 35.3% rotate more than 60 • . We train on EgoExo4D and Nymeria and reserve HOT3D-Aria as test-only set.
Annotation Pipeline. We use GPT-4.1 [45] to extract interaction annotations for EgoExo4D and Nymeria. At each atomic action timestamp [17,42], we crop a 5 s clip and annotate two wrist-centric interaction stages: (1) Approach-the hand moves toward the target manipulation region; (2) Manipulation-the hand performs the action with the object in hand. Detailed prompts and filters are provided in the appendix. For HOT3D, we infer interaction stages using hand-object trajectories, defining approach as 0.5-2.0 s prior to object motion (object visible and within 1 m), and the manipulation stage corresponds to period after motion onset.
EgoMAN Trajectory. The EgoMAN dataset provides 6DoF wrist trajectories for both hand wrists (3D position + 6D rotation [59]), sampled at 10 frames per second (FPS). For EgoExo4D, we use hand tracking data produced by Aria’s Machine Perception Services (MPS) [1]. For Nymeria dataset, we use trajectories obtained from two wrist-mounted devices. For HOT3D dataset, we directly use the high-quality 6DoF hand trajectories provided by the dataset. All trajectories are aligned by transforming positions and orientations into the camera coordinate frame of the final visual frame before interaction begins.
EgoMAN QA. We generate structured question-answer pairs using GPT, covering semantic (21.6%), spatial (42.6%), and motion (35.8%) reasoning .
(1) Semantic reasoning questions target high-level intent, such as:
• “What will be the next atomic action?”
• “What object will the hand interact with next?” • “Why does the next action happen?” These questions connect language to goal-directed hand behaviors, enabling deeper understanding of the motivations and purposes behind specific actions.
(2) Spatial reasoning questions ground intent within metric 3D space by querying the wrist’s state at key interaction stages such as approach onset, manipulation onset (approach completion), and manipulation end. These questions may target a single stage (e.g., “Where/When will the left hand complete the manipulation?”) or span multiple stages (e.g., “Where/When is the right hand at the start and end of manipulation?”), enabling reasoning about transitions between interaction stages. Some questions explicitly reference objects and stage timestamps, supporting reasoning over objecttime-space relationships that align with interaction intent.
(3) Motion reasoning questions probe how past motion informs both semantic and spatial understanding, supporting reasoning about the evolution of motion over time. To construct these questions, we augment a random subset of semantic and spatial questions by prepending a 0.5-second 6DoF hand trajectory sequence from before the interaction start time. (e.g., “Given the , where will the right hand complete the approach stage?”) This approach enables analysis of how previous hand movements influence subsequent actions and spatial positions, deepening the connection between motion history and interaction intent. Dataset Split. To support our progressive training pipeline, we split the EgoMAN dataset into 1,014 scenes for pretraining (64%), 498 for finetuning (31%), and 78 for testing (5%). The pretraining set contains lower-quality trajectory annotations-where the target object may be occluded, image quality is low, or interaction intent is ambiguous, and interacitons are generally sparse. In total, the pretrain set comprises 74K samples, 1M QA pairs. The finetune set, by contrast, provides 17K high-quality trajectory samples.
For evaluation, we introduce EgoMAN-Bench as our test set, which consists of two settings: (1) EgoMAN-Unseen includes 2,844 trajectory samples from 78 held-out EgoExo4D and Nymeria scenes with high-quality trajectories, used to evaluate generalization to new in-domain but previously unseen scenes. (2) HOT3D-OOD includes 990 trajectory samples from HOT3D (dataset only used in testing), designed to evaluate out-of-distribution (OOD) performance on novel subjects, objects, and environments.
As illustrated in Fig. 2
Given a single RGB frame V t , past wrist trajectories {L τ , R τ } t τ =t-H , and an intent description I as input, the task is to predict future 6DoF trajectories { Lτ , Rτ } t+T τ =t+1 across manipulation stage, e.g., reaching, manipulating, or releasing. Each position vector L τ ∈ R 6 and rotation vector R τ ∈ R 12 represent the 3D positions and 6D rotations of both wrists. Our EgoMAN model acts as the function F that maps the inputs to future trajectories:
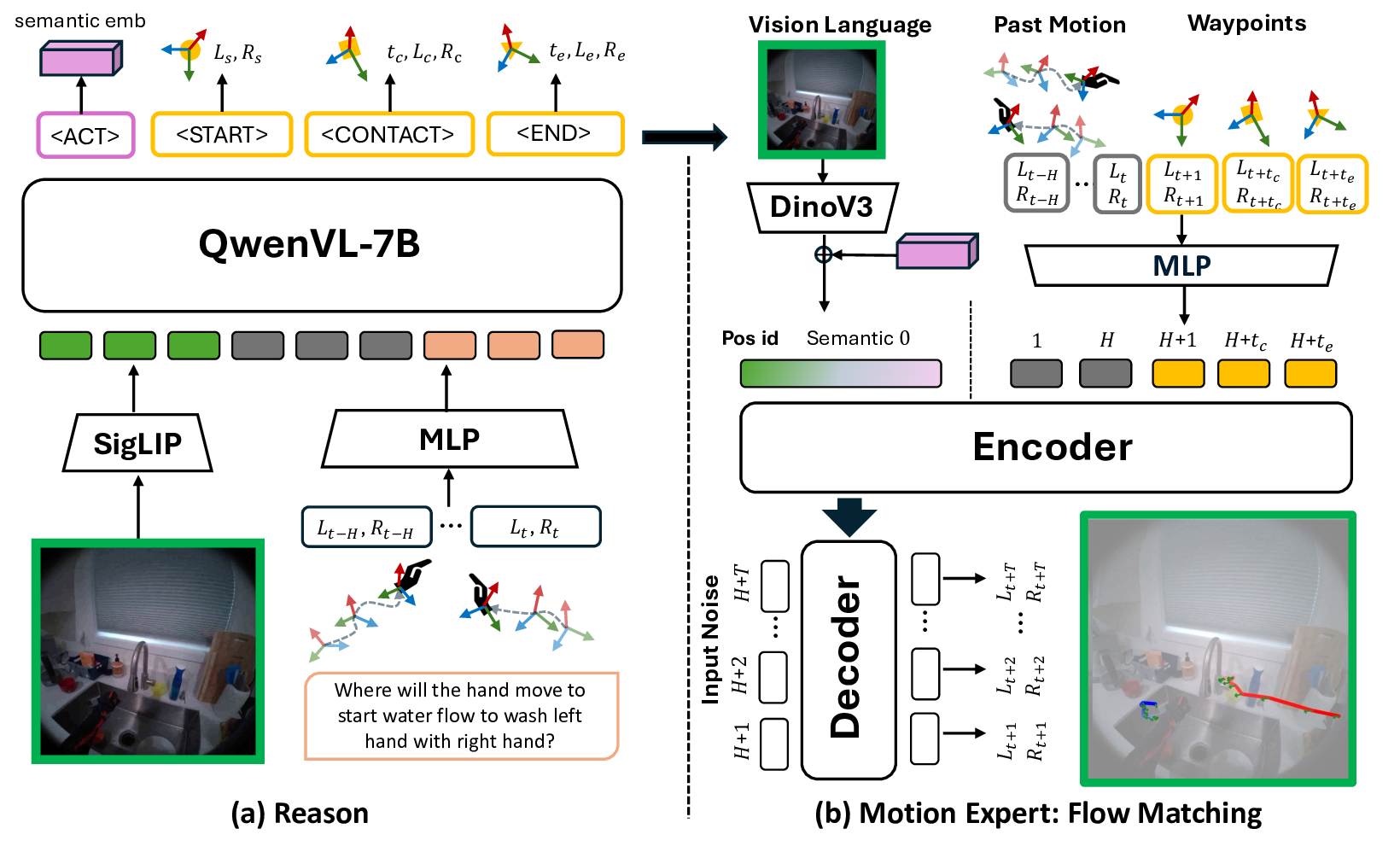
To predict accurate hand trajectory that aligns with human intent and environment context, we need to understand the spatial context of the environments as well as intent semantics. Therefore, the first module of EgoMAN model is reasoning model which aligns spatial perception and motion reasoning with task intent semantics and interaction stages. Built on Qwen2.5-VL [3], it takes as input an egocentric frame V t , a language query with intent description I, and past wrist trajectories {L τ , R τ } t τ =t-H . The past-motion sequence is encoded into the same latent space as the VLM’s visual and language features, and then fused with them. Depending on the query, the module outputs either (i) a natural-language answer or (ii) a set of structured trajectory tokens that represent key interaction semantics and waypoints.
We introduce four trajectory tokens, one action semantic token and three waypoint tokens, to explicitly capture intent semantics and key spatiotemporal transitions across interaction stages. The action semantic token decodes an action semantic embedding corresponding to the interaction phrase (e.g., “left hand grabs the green cup”). The three waypoint tokens: , , and denote the approach onset, manipulation onset (i.e., approach completion), and maunipulation completion stages respectively. Each waypoint token is equipped with a lightweight head that predicts a timestamp, 3D wrist positions, and 6D wrist rotations. These tokens allow the module to align semantic intent with the corresponding spatiotemporal hand states.
Reasoning Pre-training. To support this dual functionality to predict text and trajectory tokens, we first pretrain the module on 1M question-answer pairs from the Ego-MAN pretraining split (Sec. 3). Semantic questions requiring natural language answers are supervised with the standard next-token prediction loss (L text ). In contrast, queries requiring numeric outputs (e.g., timestamps, 6DoF location), such as spatial reasoning queries, append a special token <HOI_Query> to the question end, instructing the model to decode trajectory tokens. For these queries, in addition to the language modeling loss that supervises the special token as text (L text ), we supervise the token with an action-semantic loss (L act ) and the waypoint tokens with a dedicated waypoint loss (L wp ).
Specifically, we calculate the action-semantic loss by projecting the hidden state of to a semantic embedding and contrast against a CLIP-encoded [50] GT embedding. To stabilize training under varying batch sizes caused by the flexible mix of query types, with questions requiring an answer varying in proportion across batches, we adaptively use cosine similarity or InfoNCE [44]:
where z i and z + i denote normalized predicted and GT embeddings, sim(•) is cosine similarity, and τ is a learnable temperature parameter. When the number of valid training samples K falls below a threshold κ, we apply a cosine similarity loss to avoid unstable contrastive updates; otherwise, we use an InfoNCE-style contrastive loss.
For waypoint learning, each waypoint token is supervised with Huber losses weighted by Gaussian time windows:
We use the continuous 6D rotation parameterization [59] with a geodesic rotation loss (Lgeo), and compute the 2D loss (L2D) by projecting predicted 3D positions into the input image frame. Only visible waypoints are supervised to avoid ambiguity.
The complete reasoning pre-training loss is:
where the λ terms weight each loss component.
Where will the hand move to start water flow to wash left hand with right hand?
Given the trajectory tokens from the Reasoning Module, the Motion Expert predicts high-frequency 6DoF wrist trajectories by modeling fine-grained hand dynamics. The Motion Expert is an encoder-decoder transformer using Flow Matching (FM) [33] conditioned on past wrist motion, intent semantics, low-level visual features, and stage-aware waypoints. FM learns a conditional velocity field that yields smooth, probabilistic trajectories, with the three waypoint tokens providing structural guidance.
As shown in Fig. 2 (b), the encoder organizes all inputs into a unified sequence. Motion-related tokens lie on a unified temporal axis: H past wrist motion points occupy steps 1-H, waypoint tokens are placed at predicted timestamps offset by H, and future queries span H+1-H+T . These temporal tokens receive positional IDs based on their timestamps. In parallel, intent semantics and DINOv3 [52] visual features are added as non-temporal context tokens. The decoder then generates the T future 6DoF trajectory points by attending to this complete encoded context.
We follow the standard FM: a noisy sample x 0 is interpolated with the ground truth x 1 , and the supervision target is v = x 1 -x 0 . The loss is a mean squared error over 3D positions and 6D rotations:
At test time, we sample an initial random trajectory x 0 and integrate the velocity field over N steps:
to obtain future wrist trajectories. the Motion Expert was pretrained to consume ground-truth waypoints and action phrases. At inference, however, the Motion Expert must consume the predicted (and potentially noisy) tokens from the Reasoning Module. To bridge this gap, we align the two components through joint training on the Trajectory-Token Interface.
In the full EgoMAN model, the Reasoning Module is prompted with QA-style input, e.g., Given the past wrist motion: {past_motion}. Where will the hands move to {in-tent}?<HOI_QUERY>, and produces the structured trajectory token sequence . These tokens are then decoded into Motion Expert inputs: yields an action-semantic embedding that replaces the ground-truth phrase embedding, while , , and decode into 6DoF waypoints and timestamps (i.e., their positional encodings), replacing ground-truth waypoints. To align the reasoning and motion components, we jointly train them on the EgoMAN finetuning dataset using two objectives: (1) a next-token prediction loss L text over the trajectory-token sequence, and (2) the Flow Matching loss L FM on the trajectories generated by the Motion Expert, as in Sec. 4.3. This unified setup enables efficient intent reasoning and produces physically consistent 6DoF trajectories aligned with the intent semantics.
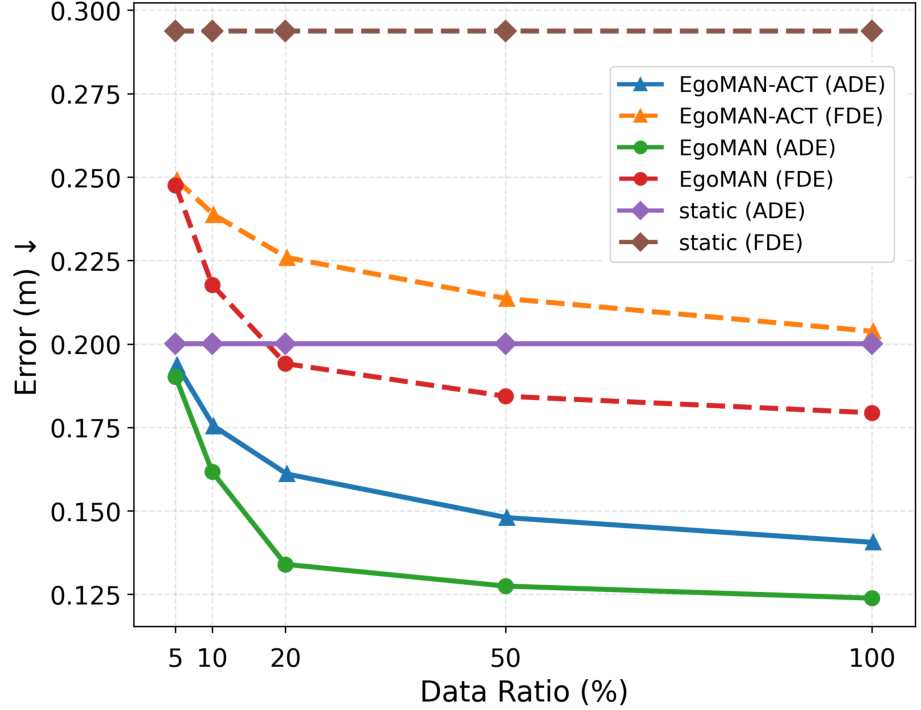
We evaluate the EgoMAN model thoroughly on EgoMAN-Bench to answer three core questions: (1) Does the reasoning-to-motion pipeline improve long-horizon 6DoF prediction over state-of-the-art baselines? (2) How effectively does the Reasoning Module generate accurate and reliable waypoints for intent-aligned spatial prediction? (3) How do the progressive training strategy and the trajectorytoken interface contribute to overall performance? We further provide qualitative results showing diverse generaliza-tion and controllable intent-conditioned motion.
Trajectory Metrics. We evaluate all methods using standard hand-trajectory forecasting metrics, including Average Displacement Error (ADE), Final Displacement Error (FDE), and Dynamic Time Warping (DTW), all reported in meters, as well as Angular Rotation Error (Rot) in degrees. To assess stochastic generative prediction, each model samples K=1/5/10 trajectories per query. Unless otherwise specified, all results are reported as best-of-K, which selects the trajectory with minimum error to the ground truth. Waypoint (WP) Metrics. We evaluate the and waypoints predicted by our VLM. We report two metrics in meters to quantify the localization accuracy of key intent states: Contact Distance (Contact): The Euclidean distance between the predicted and ground-truth wrist locations at the approach-completion timestamp. and Trajectory-Warp Distance (Traj): The average Euclidean distance from each predicted waypoint to its nearest point on the GT trajectory.
Hand Trajectory Predictor Baselines. We compare against five trajectory baselines. Baselines marked with () are adapted for fair comparison by matching the EgoMAN setting: using a single RGB image, an intent text embedding, and past motion as inputs to predict up to 5-second 6DoF bi-hand trajectories, with metrics computed over the ground-truth duration. 1) USST [6]: an uncertainty-aware state-space transformer for egocentric 3D hand trajectory forecasting; 2) MMTwin* [41]: a model using twin diffusion experts and a Mamba-Transformer backbone for joint egomotion and hand motion prediction; 3) HandsOnVLM* [5]: a VLM that predicts 2D trajectories via dialogue, which we adapt to 6DoF poses using a Conditional Variational Affordance-driven Baselines. We evaluate three affordancebased methods: HAMSTER* [31], VRB* [2], and Vid-Bot [11], each adapted to our waypoint prediction setting for a fair comparison. All methods take the same RGB image, Metric3D depth [22], and verb-object text as input, and predict contact and goal points aligned with EgoMAN’s and waypoints. Aria fisheye images are rectified to pinhole views using device calibration. VRB* and HAMSTER* produce 2D affordance points that we unproject to 3D, and for HAMSTER* we treat the first and last predicted points as contact and goal. VidBot and VRB* return object-conditioned affordance candidates; when multiple candidates appear, we select the one closest to the target object. Since these models output affordance points rather than wrist poses, we approximate wrist locations by choosing the predicted point closest to the GT wrist within 5 cm.
Trajectory Evaluation. As shown in
As shown in Table 3
We visualize qualitative best-of-K=10 forecasts in Figure 3 on EgoMAN-Bench (EgoMAN-Unseen and HOT3D-OOD).
On the left of Figure 3, we compare waypoints from affordance baselines (VRB*, VidBot) with those from our Ego-MAN model. Our predicted contact and end points align closely with the GT wrist positions, while affordance methods often miss the target surface due to detection errors or collapse toward the hand instead of the intended goal region. On Figure 3 right, we compare full 6DoF trajectories against trajectory baselines (USST, HandsOnVLM, MMTwin, FM-base). EgoMAN generates smoother and more accurate motions that reach the target and complete the manipulation with correct wrist orientation, while baselines often underreach, overshoot, or drift in cluttered scenes or under unfamiliar objects and intent descriptions. ingly different yet valid 6DoF trajectories (e.g. opening the oven, retrieving a fork, poking food, turning on the stove). This controllable intent-to-motion mapping enables flexible generation of diverse hand trajectories, which can support robot learning and data augmentation.
We introduced the EgoMAN dataset, a large-scale egocentric benchmark for interaction stage-aware 6DoF hand trajectory prediction, featuring structured QA pairs that capture semantic, spatial, and motion reasoning. We also presented the EgoMAN model, a modular reasoning-to-motion framework that aligns high-level intent with physically grounded 6DoF trajectories through a trajectory-token interface and progressive training. Experiments show strong gains over both motion-only and VLM baselines: Flow Matching yields smoother and more stable trajectories, VLM-driven reasoning improves semantic alignment and generalization to novel scenes and intents, and the trajectory-token interface enables efficient inference, bridging intent-conditioned stage-aware reasoning with precise low-level motion generation. Overall, EgoMAN offers a practical step toward in-context action prediction, supporting applications in robot manipulation, language-conditioned motion synthesis, and intent-aware assistive systems.
In this appendix, we provide: 1. A video demonstration of our system, including representative interaction cases (Sec. B).
Our video provides a visual overview of the core contributions of EgoMAN, covering the dataset, the model architecture, and qualitative demonstrations. The video first introduces the EgoMAN dataset and highlights the full EgoMAN pipeline, consisting of the Reasoning Module, the Motion Expert, and the end-to-end 6-DoF trajectory generation flow (bridging reasoning to motion through the Trajectory-Token Interface).
In the dataset overview segment, we present diverse examples of hand-object interactions corresponding to the twelve most frequent verbs in EgoMAN (e.g., Grasp, open, place, pour, stir). The showcased clips span multiple sources such as EgoExo4D [17], Nymeria [42], and HOT3D-Aria [4], illustrating that interactions occur in realistic everyday scenes with natural noise, clutter, and challenging viewpoints. These examples demonstrate the dataset’s scale, variability, and difficulty, motivating the need for robust intention-conditioned 3D hand trajectory modeling.
The qualitative results section highlights EgoMAN’s ability to generate intention-guided trajectories. We first show dozens of representative cases across various scenarios: such as stir milk and turn off stove in kitchen scenes, pick up socks and open door in household scenes, close laptop and grab cable in working scenarios, and manipulate bowl or manipulate ranch bottle in HOT3D scenes. For each case, the video displays (1) the original input image, (2) the intention text, (3) intermediate waypoint predictions from the Reasoning Module, and (4) the final 6-DoF trajectory output. These predictions are visualized both on the static input image and overlaid on future ego-video frames to more clearly illustrate spatial accuracy and motion quality.
Across all demonstrations, EgoMAN consistently predicts accurate contact and end-point waypoints around target objects, with the generated 3D trajectories following realistic manipulation paths that match the intended semantics. While certain open-ended tasks (e.g., open door, pick up socks) may exhibit slight variations in final pose or timing, or minor deviations in the non-manipulating hand relative to the single ground-truth instance, the predicted trajectories for the manipulating hand remain semantically aligned with the intended goal. These results highlight EgoMAN’s capability to produce reliable, intention-driven 6-DoF hand trajectories across diverse scenes and interaction types.
We further show results of goal-directed trajectory generation, where the same input image paired with different intention descriptions. EgoMAN model is able to predict trajectories in distinct that align with the intended goals, even in unseen environments.
Please visit our project website to check more trajectory prediction results in diverse interaction scenarios.
Reasoning Module. The Reasoning Module is optimized in bf16 using AdamW [37] with cosine learning rate decay. The vision encoder and multimodal projector are frozen. We use a base learning rate of 1×10 -5 , a warmup ratio of 0.02, weight decay of 0.05, maximum gradient norm of 1.0, and a batch size of 256 across 8×NVIDIA A100 80GB GPUs. Training runs for 2 epochs on approximately 1M EgoMAN QA samples. Images use dynamic resizing with max_pixels=50176 and min_pixels=784. If past motion is provided in the input question, we use the most recent 5 past points of both hands tokenized at 10 fps; otherwise a zero-initialized motion history is used. A 4-layer MLP is used to extract features from the motion, which are then fed into Qwen2.5-VL [3]. The specialized waypoint decoders are lightweight ReLU MLPs with hidden dimension 768, predicting timestamp, 3D position, and 6DoF rotation. The action semantic decoder is a single-layer MLP (dim 768). When valid samples in a batch fall below κ=10, we use cosine similarity loss; otherwise, we apply an InfoNCE loss [44]. Loss weights are set as λ wp =0.3 and λ act =0.1, with internal weights λ t =1.0, λ 3D =2.0, λ 2D =0.5, λ r =0.5, and λ geo =0.15. We apply Huber loss with β=0.2 for rot6D, β 3D =0.07, and β 2D =0.02 for location terms. The geodesic rotation loss is applied only to visible waypoints. Temporal modulation is implemented using a Gaussian time window with σ time =3.0. Motion Expert. We pre-train the flow-matching (FM) [33] based motion decoder using approximately 17K trajectories. Inputs include DINOv3 image features, ground-truth action phrases, waypoint tokens, and past wrist motion. Motion sequences are sampled at 10 fps with a maximum 50-step future horizon (5 s). The FM architecture uses a hidden dimension of 768, with 6 encoder and 6 decoder transformer layers and 8 attention heads. A sinusoidal time embedding (256-D) is mapped to FiLM-style [47](γ, β) parameters. A 2-layer self-attention block is applied before decoding, along with modality and positional embeddings. We train in FP32 using AdamW with a learning rate of 1×10 -4 , weight decay of 1×10 -4 , a cosine schedule with 5% warmup, and a batch size of 256 on a single A100 GPU. The training objective is the sum of MSE loss on 3D positions and MSE loss on 6D rotations, with a rotation loss weight of 0.5. At inference time, we iterate for 150 steps and retain only the predicted trajectory segment beyond the length of the ground-truth target.
Joint Training of EgoMAN Model. We initialize the Reasoning Module from the reasoning pretraining checkpoint and the motion decoder from the FM pretraining weights.
The training setup largely follows the reasoning pretraining configuration, but FM components are kept in FP32. We use a learning rate of 5×10 -6 and a batch size of 128 cross 8×NVIDIA A100 80GB GPUs. The model is trained for 60 epochs on the same finetuning trajectory dataset used in motion pretraining. At inference time, we iterate for 150 steps and retain only the predicted trajectory segment beyond the ground-truth target length.
In this section, we provide more detailed analysis of our ablation results in main paper Sec 5.4 and Table 4
We evaluate semantic alignment between trajectories and action verbs by training a motion encoder to map hand trajectories to a pre-computed verb text embedding space using a CLIP-style contrastive loss [18,50]. We report Recall@3 Method R@3 ↑ FID ↓
USST* [6] 15.0 0.22 MMTwin* [41] 22.9 0.86 HandsonVLM* [5] 27.9 0.10 FM-Base 39.7 0.05 EgoMAN 43.9 0.04 (fraction of samples where the GT caption is retrieved in the top 3 over 239 verbs in the test samples) and Fréchet Inception Distance (FID) between predicted and ground-truth motion embeddings. To account for generative diversity, we report best-of-K (K=10) retrieval results. Table 5 shows that EgoMAN achieves the strongest semantic alignment between motion and verb phrases, with the highest R@3 (43.9%) and lowest FID (0.04). Generative baselines such as USST and MMTwin produce smooth trajectories but exhibit weaker text alignment, while HandsOn-VLM benefits from language conditioning yet suffers from noisy CVAE decoding. FM-Base already improves verb specificity, indicating that Flow Matching promotes more structured motion. Adding VLM reasoning and waypoint constraints in EgoMAN further reduces ambiguity, tightening the trajectory-verb correspondence and producing a motion embedding distribution closer to ground truth.
In this section, we analyze how scaling the Reasoning Module affects both high-level semantic reasoning and downstream motion prediction. We evaluate multiple model sizes from Qwen2.5-VL and Qwen3-VL families, using identical training data and identical Trajectory-Token Interface settings. Our analysis focuses on two components: (i) Ego-MAN QA: measuring semantic and spatial reasoning, and (ii) trajectory prediction on EgoMAN-Bench: measuring the effect of Reasoning Module scale on 6-DoF hand trajectory generation.
F.1. EgoMAN QA Evaluation Metrics. We evaluate three complementary aspects of reasoning quality:
• Waypoint Spatial Reasoning: We evaluate 3D waypoint accuracy for and using three metrics. Location error (Loc) is the Euclidean distance (in meters) between the predicted and ground-truth waypoints’ positions. Time error (Time) measures the temporal accuracy of the predicted interaction stages. Since (approach onset) is always aligned to time 0, we compute the L1 difference (in seconds) only for the predicted (manipulation onset) and (manipulation completion) timestamps. Rotation error (Rot) is the geodesic distance (in degrees) between predicted and ground-truth wrist orientations, computed from the relative rotation matrix. These metrics quantify spatial, temporal, and rotational grounding of interaction-stage waypoints. • Semantic Embedding Alignment: we compute Recall@3 (R@3) between predicted and 2844 ground-truth action embeddings, as well as the mean Pearson correlation (Pearson) across embedding dimensions, which reflects how well the learned embedding space preserves semantic similarity. • Semantic Text QA: We measure the quality of generated answers using three complementary NLP metrics. BERTScore (BERT) [57] computes semantic similarity using contextualized token embeddings from a pretrained BERT model, capturing paraphrases and fine-grained meaning. BLEU [46] evaluates n-gram precision between predictions and references, reflecting lexical overlap. ROUGE-L (ROUGE) [32] measures the longest common subsequence between texts, capturing phraselevel recall. Together, these metrics assess both semantic fidelity and surface-form similarity between predicted answers and ground-truth explanations.
Results Analysis. As shown in Table 6, the models achieve strong textual QA performance (BERTScore ≈0.92, ROUGE≈0.49) and moderate but meaningful semantic alignment (R@3 up to 11% and Pearson up to 0.26), providing reliable semantic grounding despite the large actionembedding space consists of 2844 samples.
In this section, we detail the LLM-based prompting pipeline used to construct the EgoMAN benchmark. Our pipeline consists of four stages: (i) extracting fine-grained hand-object interaction segments with temporal structure, (ii) filtering invalid or irrelevant interactions and canonicalizing intention goals, (iii) generating diverse QA pairs for reasoning pretraining, and (iv) filtering trajectory phrases to retain only visually grounded, unambiguous interaction samples. The corresponding prompts are shown in Figs. 7-10.
We first extract temporally localized, atomic hand-object interactions from continuous egocentric video. Given reference narrations and timestamps, the LLM is prompted to decompose an interaction into structured approach and manipulation stages, each annotated with start/end times, coarse trajectory attributes (start/end locations and shape), and a natural-language atomic description and reasoning. The output is serialized as JSON and forms the core interaction representation used in later stages (Fig. 7).
Not all extracted segments correspond to clean, usable handobject interactions. We therefore perform a second LLM pass to filter invalid or noisy annotations. Given a candidate atomic description and the reference annotations, the model judges whether the interaction is (i) relevant to the underlying sequence, and (ii) a true hand-object interaction performed by the main subject, rather than background motion or nonmanipulative activities. It also summarizes the high-level intention goal into a short phrase, which we later use as a canonical intent label and conditioning token (Fig. 8).
For each valid interaction, we generate a set of diverse, intentaware QA pairs used to train the Reasoning Module. The prompt in Fig. 9 guides the LLM to produce 8-12 short question-answer pairs that cover complementary aspects of the next interaction: intention goal, which hand will be used, upcoming action and object, spatial trajectory, temporal onset and completion, atomic motion description, and causal reasoning (“why” the action occurs). The prompt enforces that all answers must be grounded strictly in the provided interaction data and that the intention goal is injected in multiple phrasings to encourage robust semantic alignment.
We apply an image-conditioned filtering step to ensure that the interaction phrases used for trajectory prediction are visually grounded and unambiguous. As shown in Fig. 10, the LLM is asked to verify that (i) the described interaction is physically realistic, (ii) the target object is clearly visible in the egocentric frame, (iii) the image quality is sufficient, and (iv) the phrase refers to a single, unambiguous object. The model outputs a binary validity flag and a short failure reason when rejected. This step prunes low-quality or ambiguous samples and improves the reliability of EgoMAN-Bench trajectory supervision.
While EgoMAN demonstrates strong intention-conditioned 6-DoF trajectory prediction, several limitations remain. First, our modeling focuses primarily on wrist-level 6-DoF motion and considers only coarse interaction stages (, , ). More fine-grained sub-stages-such as pre-contact adjustment, micro-corrections during manipulation, or multi-step object reorientation-are not explicitly modeled, limiting the system’s ability to capture high-resolution dexterous behavior. Second, although our dataset is large-scale and diverse, it inevitably contains sensor noise, imperfect annotations, and no human verification loop; higher-quality 3D trajectories and cleaner supervision would further benefit learning. Future work includes extending the representation from wrist trajectories to full hand pose and articulation, enabling more fine-grained reasoning about object manipulation and grasp dynamics. Incorporating multi-stage interaction parsing and richer contact semantics would further improve temporal grounding. Improving dataset quality through higherfidelity 3D annotations or curated human-verified demonstrations could significantly enhance supervision for fine-grained manipulation learning. Finally, deploying EgoMAN-derived policies on real robotic systems presents an exciting direction for evaluating how intention-grounded 6-DoF predictions transfer to embodied manipulation performance.
Once both the Reasoning Module and Motion Expert are pretrained, we jointly train them to connect high-level reasoning with low-level motion generation. A key challenge in this stage is the distribution mismatch. The Reasoning Module was pretrained to predict tokens based on ground-truth, while
PretrainWP ADE ↓ FDE ↓ DTW ↓ Rot ↓
Pretrain
This content is AI-processed based on open access ArXiv data.