Vehicular platooning promises transformative improvements in transportation efficiency and safety through the coordination of multi-vehicle formations enabled by Vehicleto-Everything (V2X) communication. However, the distributed nature of platoon coordination creates security vulnerabilities, allowing authenticated vehicles to inject falsified kinematic data, compromise operational stability, and pose a threat to passenger safety. Traditional misbehaviour detection approaches, which rely on plausibility checks and statistical methods, suffer from high False Positive (FP) rates and cannot capture the complex temporal dependencies inherent in multi-vehicle coordination dynamics. We present Attention In Motion (AIMFORMER), a transformerbased framework specifically tailored for real-time misbehaviour detection in vehicular platoons with edge deployment capabilities. AIMFORMER leverages multi-head self-attention mechanisms to simultaneously capture intra-vehicle temporal dynamics and inter-vehicle spatial correlations. It incorporates global positional encoding with vehicle-specific temporal offsets to handle join/exit maneuvers. We propose a Precision-Focused Binary Cross-Entropy (PFBCE) loss function that penalizes FPs to meet the requirements of safety-critical vehicular systems. Extensive evaluation across 4 platoon controllers, multiple attack vectors, and diverse mobility scenarios demonstrates superior performance (≥ 0.93) compared to state-of-the-art baseline architectures. A comprehensive deployment analysis utilizing TensorFlow Lite (TFLite), Open Neural Network Exchange (ONNX), and TensorRT achieves sub-millisecond inference latency, making it suitable for real-time operation on resource-constrained edge platforms. Hence, validating AIMFORMER is viable for both invehicle and roadside infrastructure deployment.
Internet of Vehicles (IoV) transforms modern transportation, with Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) communication enabling cooperative driving applications [1]. Among the most promising representations of this vision is vehicle platooning. It enables multiple vehicles to travel in close formation with coordinated inter-vehicular spacing, yielding substantial improvements in traffic throughput, fuel efficiency, and safety [2], [3], [4], [5], [6]. Vehicular platoons operate through Cooperative Adaptive Cruise Control (CACC) systems that extend traditional Adaptive Cruise Control (ACC) capabilities by incorporating real-time communication (Cooperative Awareness Message (CAM)) of kinematic data, including position, velocity, and acceleration via standardized protocols such as IEEE 802.11p or Cellular Vehicle-to-Everything (V2X) [1].
This fundamental reliance on continuous wireless information exchange, however, introduces critical security vulnerabilities that threaten both operational integrity and passenger safety [7], [5]. The distributed nature of platoon coordination creates an attack surface where malicious or compromised vehicles can inject falsified information to manipulate the behavior of other platoon members. Such attack consequences range from reduced stability to complete platoon destabilization and increased collision risks [8]. The effects can be further amplified when misbehavior originates from the platoon leader, given its key role in platooning. Unlike external adversaries, which can be thwarted by secure V2X protocols [1], [9], [10], [11], internal adversaries transmitting false kinematic data pose a significant challenge that requires realtime detection.
Traditional approaches to Misbehavior Detection Schemes (MDSs) in Vehicular Ad-hoc Network (VANET) have predominantly employed plausibility checks, statistical outlier detection, and rule-based behavioral analysis [12], [13]. While computationally efficient, these techniques suffer from several limitations: (i) high False Positive (FP) rates when encountering sophisticated attacks, (ii) inability to generalize across diverse platoon configurations and control policies, and (iii) inadequate modeling of complex temporal dependencies inherent in multi-vehicle coordination dynamics. The challenge is further compounded by the dynamic nature of platooning scenarios. Topology changes during vehicle join and exit maneuvers constitute prime moments for attack as they involve multiple cars, potentially in different lanes (e.g., during a join). Such attacks can be catastrophic not only to the platoon itself, but to other road users [14], [7], [15], with a two-fold challenge for misbehavior detection during maneuvering: FPs disrupt legitimate platoon operations, while False Negatives (FNs) enable successful attacks.
Several detection approaches emerged to address these limitations through diverse methodologies. Probabilistic methods employing Gaussian Mixture Model (GMM)-Hidden Markov Model (HMM) achieve 87% F1-score [7], specialized classifiers leverage Random Forest (RF) for rapid inference [16], [17], [18], and recurrent networks (Long Short-Term Memory (LSTM)/Gated Recurrent Unit (GRU)) demonstrate improved accuracy [19], [20]. Most closely related to our work, Atten-tionGuard [5] applies attention mechanisms to achieve 88-92% accuracy with 96-99% Area Under the Curve (AUC). However, arXiv:2512.15503v2 [cs.CR] 22 Dec 2025 three essential constraints persist across these approaches: (i) inference latency incompatible with real-time requirements; (ii) reliance on manual feature engineering or position-specific architectures limiting cross-configuration generalization; (iii) sequential processing in recurrent networks. The latter prevents efficient parallel training while struggling to simultaneously capture both intra-vehicle temporal evolution and inter-vehicle spatial correlations, which are essential for detecting coordinated attacks during topology changes.
Transformer architectures [21] can address constraints (ii) and (iii) through self-attention mechanisms that enable parallel sequence processing while simultaneously modeling both intra-vehicle temporal dynamics and inter-vehicle spatial correlations. Thus, transformers can capture attack propagation patterns across platoon formations by jointly observing the evolution of individual vehicle behavior and cross-vehicle correlation structures. Such dual modeling capacity proves essential for distinguishing legitimate coordination dynamics from malicious manipulation, thereby minimizing FPs during legitimate maneuvers while maintaining robust detection of sophisticated, coordinated attacks.
Concurrently, the maturation of edge computing within vehicular networks enables deploying Machine Learning (ML) models closer to data sources, addressing the ultra-low latency requirements (typically under 100ms) essential for safetycritical driving applications [22]. Edge Artificial Intelligence (AI) enables real-time inference on resource-constrained platforms while preserving privacy through localized processing and reducing communication overhead to centralized cloud infrastructure [23].
To address these combined challenges of real-time inference and sophisticated attack detection in platooning, this paper presents AIMFORMER, a transformer-based framework specifically designed for real-time misbehavior detection in vehicular platoons with edge deployment capabilities. Our approach leverages multi-head self-attention mechanisms to simultaneously capture intra-vehicle temporal dynamics and inter-vehicle coordination patterns, enabling comprehensive behavioral analysis across diverse attack vectors, platoon topologies, and operational scenarios.
Contribution. We summarize our contributions as follows: 1) We build on our prior work [5] and develop the first transformer-based misbehavior detection framework specifically designed for vehicular platooning environments, incorporating global positional encoding mechanisms that maintain temporal awareness across multi-vehicle sequences with asynchronous dynamics.
This section establishes the foundational concepts necessary for understanding the proposed framework: IoV platooning coordination, transformer encoder architecture, and the context of edge AI deployment.
Vehicle platooning enables coordinated convoy formations through V2V and V2I communication, where CACC systems extend traditional ACC by exchanging real-time kinematic data (i.e., position, velocity, acceleration) via IEEE 802.11p or cellular V2X protocols.
Communication Topologies and Control Strategies: Platoon communication architectures operate through distinct topological configurations that determine information flow patterns. The predominant topologies include: Predecessor-Following, where vehicles receive information exclusively from their immediate predecessor, minimizing communication overhead but potentially suffering from error propagation; Predecessor-Leader, where vehicles maintain links with both predecessor and platoon leader, enhancing string stability through dual information sources; and Bidirectional Communication, where vehicles exchange information with both preceding and following vehicles, facilitating enhanced situational awareness and disturbance rejection capabilities.
Platoon coordination employs two primary spacing policies: Constant Time Headway (CTH) maintains time-based following distances that scale with vehicle speed, enhancing stability at higher velocities while reducing road utilization efficiency; Constant Vehicle Spacing (CVS) enforces fixed physical distances regardless of speed, maximizing road capacity but requiring precise control mechanisms during dynamic maneuvers.
Several control strategies implement these policies: PATH (CVS with Predecessor-Leader topology), Ploeg (CTH with Predecessor-Following topology), Consensus (hybrid policy with multi-source information), and Flatbed (CVS with leader and predecessor speed information). These different information flows and controller policies lead to varied vulnerability susceptibility and platoon reactions [8], [7], [24].
The Transformer encoder utilizes self-attention mechanisms for parallel sequence processing, capturing long-range dependencies without the computational limitations inherent in Recurrent Neural Networks (RNNs).
Self-Attention Mechanism. The self-attention mechanism operates by transforming input sequences into three fundamental representations: queries (Q), keys (K), and values (V ). For an input sequence x 1 , x 2 , . . . , x n where each x i ∈ R d , the scaled dot-product attention computes:
This formulation enables each sequence position to attend to all other positions simultaneously, creating a comprehensive representational model that captures complex temporal dependencies essential for time-series analysis tasks.
Multi-Head Attention and Positional Encoding. Multihead attention extends the self-attention mechanism by computing multiple attention operations in parallel across different representational subspaces. This parallel processing enables the model to capture diverse types of dependencies simultaneously, with different attention heads specializing in distinct relational patterns within the data. The multi-head attention mechanism is defined as:
where each attention head operates in a lower-dimensional subspace, allowing the model to focus on different aspects of the input sequence concurrently. Since the attention mechanism lacks inherent sequential ordering information, positional encoding provides the model with explicit positional awareness. The Transformer employs sinusoidal positional encodings that are added directly to input embeddings, enabling the model to distinguish between different temporal positions while maintaining the ability to generalize to sequences of varying lengths.
Edge AI enables ML model execution on devices proximate to data sources, addressing latency, bandwidth, and privacy constraints inherent in cloud-centric approaches [25], [26]. For safety-critical vehicular applications requiring sub-100ms response times, edge deployment facilitates real-time misbehavior detection while preserving the benefits of localized processing. Recent embedded implementations demonstrate compact Deep Neural Network (DNN) architectures achieving high accuracy on resource-constrained hardware [27], [28], [29], making distributed security frameworks feasible for vehicular platoons. Within the platooning context specifically, edge AI enables distributed misbehavior detection, real-time trust management, and adaptive coordination that leverage local processing capabilities while minimizing communication overhead to centralized infrastructure.
We consider vehicles implementing V2X protocol stacks [30] equipped with valid Vehicular Communication (VC) cryptographic credentials obtained through legitimate vehicle registration, allowing them to participate in V2X communications and platooning operations [31], [10], [11], [32]. Successful misbehavior detection can trigger the credential revocation mechanisms, preventing future malicious participation in platoon operations. Platoons operate under a designated leader who coordinates vehicle enrollment and departure occurring through individual vehicle join/exit maneuvers or platoon merging operations. Upon admission, joining vehicles position themselves at leader-designated locations, and the updated configuration is broadcast to all members. Our system model assumes a string-stable platoon of vehicles traveling on a highway segment, allowing for join/exit maneuvers at any position based on vehicle capabilities and destination compatibility.
We consider internal adversaries equipped with valid cryptographic credentials, obtained through legitimate vehicle registration. Following the general adversary model for secure and privacy-preserving VC systems [1], [33] and vehicular platooning assumptions [3], [8], [34], [35], these authenticated attackers can participate in V2X communications and transmit messages accepted as legitimate by other platoon members. However, internal adversaries cannot extract private keys that are stored in Hardware Security Modules (HSMs) [1], provisioned during the vehicle registration [10]. Adversarial behavior stems from direct vehicle control, or malware intercepting internal data streams (e.g., Controller Area Network (CAN) bus messages, sensor outputs) before V2X transmission.
Internal adversaries mount falsification attacks by manipulating kinematic data in transmitted CAMs. Specifically, we consider three data falsification attacks executed by rational adversaries who maximize attack effectiveness while minimizing self-harm [7]. First, attackers can broadcast incorrect positional coordinates, misleading neighboring vehicles about their actual location. This attack type particularly affects controllers that rely on absolute positioning information for distance calculations and coordination decisions. Second, malicious vehicles can report incorrect velocity values, causing platoon followers to make inappropriate acceleration decisions. The severity of impact varies based on control strategy, with CVSbased controllers showing greater vulnerability to speed-based attacks. Finally, attackers can transmit false acceleration data. This attack type can cause immediate and severe destabilization effects across diverse controller implementations.
Attack Windows. The platoon topology reconfiguration events represent critical vulnerability windows: during join and exit maneuvers, platoons experience temporary instability characterized by modified communication topologies, redis-tributed control responsibilities, and heightened requirements for accurate state information exchange. Adversaries exploit these transitional phases to amplify attack effectiveness and maximize disruption potential.
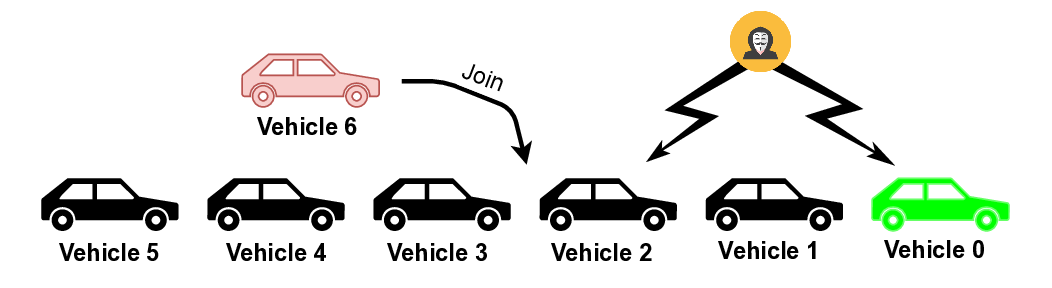
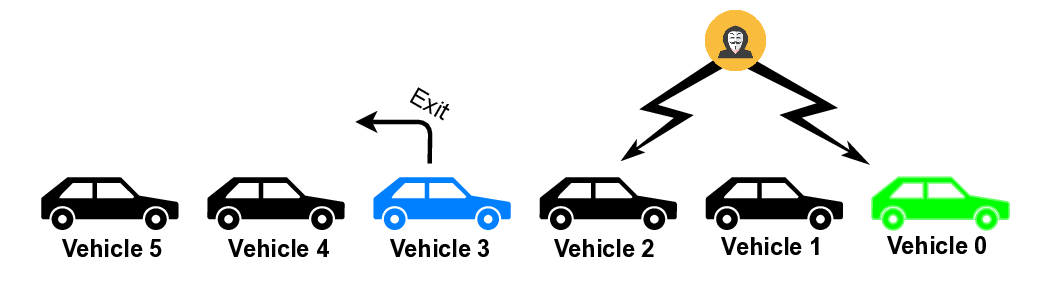
Attack Scenarios. Fig. 1 illustrates three attack scenarios: (a) Join Maneuver where Vehicle 6 integrates while the adversary broadcasts falsified kinematic data, targeting the admission and spacing phase to create unsafe gaps or collision risks; (b) Exit Maneuver where the adversary manipulates CAMs during Vehicle 3’s departure, exploiting the critical period when remaining vehicles reestablish predecessor-follower relationships; and (c) Steady-State where the adversary performs data falsification during normal cruising operations without topology changes. For each attack scenario, we consider both an attacker leading the platoon and an attacker traveling just ahead of the maneuvering position. This setup ensures both maximal attack reach (leader attacker) and amplified attack impact (vehicle 2 attacker) by potentially causing collisions in both lanes (as the maneuvering vehicle changes lanes) [7].
We examine 9 distinct attack types spanning three manipulation strategies [7]: Constant Offset Attacks introducing fixed biases to position, velocity, or acceleration; Gradual Offset Attacks applying time-varying drift to kinematic parameters; and Combined Physics-Consistent Attacks simultaneously falsifying multiple state variables while maintaining kinematic feasibility to evade simple plausibility checks.
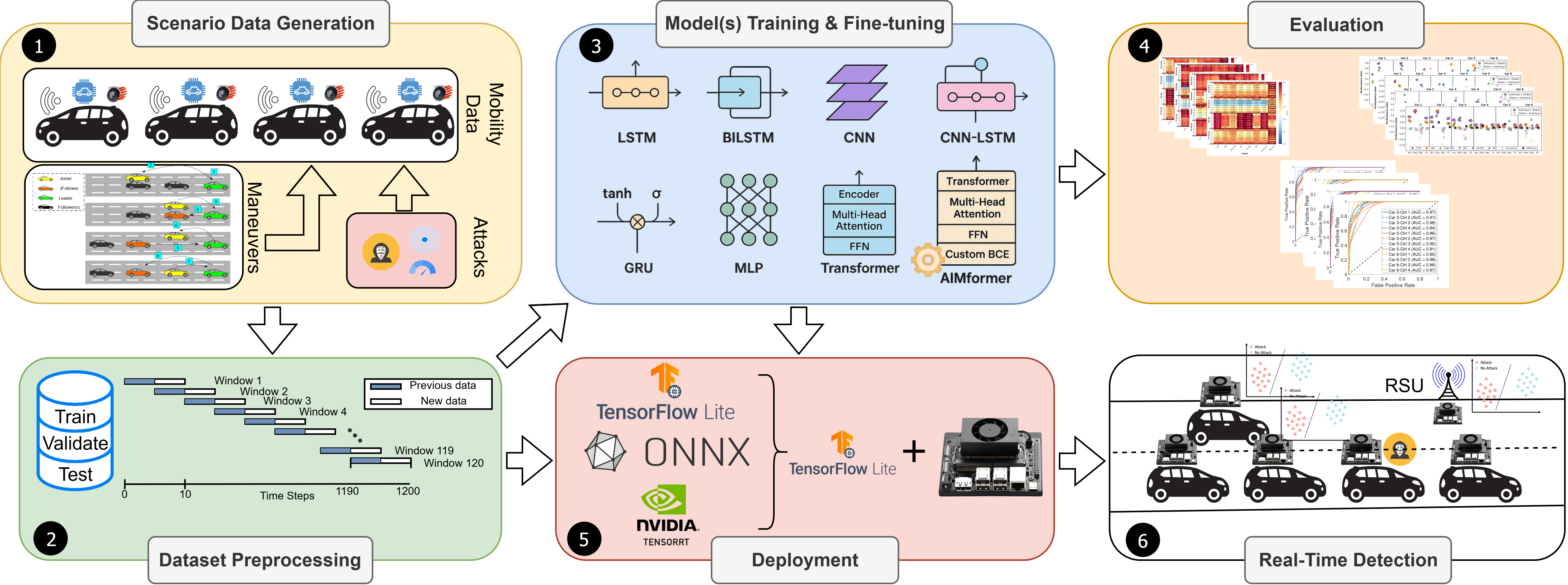
A. Proposed Framework Fig. 2 presents our end-to-end attack detection pipeline from data generation to deployment. In step 1 , we generate scenario data incorporating diverse mobility patterns (middle-join, middle-exit, normal traveling) across different platoon formations with attackers in various positions (described in III-B).
The mobility features are sourced from ego-vehicle sensors, each with its own sensor errors (as described in [7]), which capture the resulting mobility effects after controller actuation. The deployed MDS learns to distinguish misbehavior from nominal mobility based on these patterns. Step 2 preprocesses the mobility data into normalized train/validation/test sets, segmenting them into windows of ten messages (1 second) with 100ms step size, enabling inference after each disseminated CAM. Each timestep receives a label (attack/no attack) and mask (Eq. 11).
Step 3 involves training baseline architectures (LSTM, Bidirectional LSTM (BiLSTM), CNN, CNN-LSTM, GRU, MLP, Transformer) and our AIMFORMER solution, creating both global models (deployable in Roadside Units (RSUs)) and individual vehicle-specific models (Section IV-C).
Step 4 evaluates all models on the unseen test set, applying iterative refinement (Section V). Step 5 converts and quantizes models via TFLite, ONNX, and TensorRT for resource-constrained deployment, evaluating inference time and memory footprint (Section V-C). Finally, step 6 analyzes individual versus global model performance across platoon positions (Section V-B).
Model Architecture. We present a Transformer-based architecture for single-or multi-vehicle binary classification. Given input X ∈ R B×V ×T ×F (batch size B, vehicles V , sequence length T , features F ), the model produces binary predictions Ŷ ∈ R B×V ×T for each timestep. Global positional encoding with vehicle-specific temporal offsets aligns the vehicles individual time windows to the overall vehicle trip:
where g v,t represents the global time position for vehicle v at local timestep t. Input processing reshapes and embeds multi-vehicle data for parallel computation:
where
where
and M is the attention mask (Table I). The masking strategy combines padding and causal constraints for variable-length sequences with asynchronous entry/exit times:
Each encoder block ℓ ∈ {1, 2, . . . , L} applies standard Transformer operations with residual connections and layer normalization:
where the feed-forward network is:
with
where
This architecture captures intra-vehicle temporal dependencies through self-attention operating independently over each vehicle’s time series, with global positional encoding providing trajectory-phase awareness. The vehicle-independent processing enables flexible deployment as either global (multivehicle) or individual (single-vehicle) models, without requiring architectural modifications.
Loss Function. We propose PFBCE to enhance precision by explicitly penalizing FPs while maintaining balanced treatment of positive samples, enabling detection of attack-influenced behavior that mimics nominal mobility [5]:
where:
The FP penalty w (i,j) FP penalizes positive predictions (σ(ŷ i,j ) > τ ) on benign samples, encouraging conservative classification. The positive class weight w (i,j) pos addresses class imbalance through moderate upweighting (λ pos ), maintaining sensitivity while benefiting from precision enhancement. The mask m i,j excludes invalid data (different entry/exit times or inapplicable scenarios), with normalization by |M| ensuring consistent loss magnitude (Table II).
Why PFBCE Over Focal Loss. Focal Loss emphasizes hard examples through (1-p t ) γ , but treats all difficult samples uniformly regardless of error type, preventing direct control of the precision-recall trade-off. PFBCE instead provides explicit and interpretable error asymmetry: the FP penalty w FP selectively suppresses confident incorrect positives to improve precision, while the positive-class weight w pos independently handles class imbalance to tune recall. This decoupled design enables precise control over precision-recall behavior that Focal Loss cannot provide.
Model Training. We design two modeling approaches: global models trained on all platoon vehicles’ data to learn whole-platoon mobility patterns, and individual models trained per-vehicle for position-specific local classification.
Model Tuning. We performed hyperparameter tuning using Keras Tuner’s Hyperband algorithm [36], which efficiently balances exploration and computational cost by early termination of poor trials. Following Han et al. [37], we tuned the following parameters: hidden dimensions, attention heads, encoder blocks, dropout rate, and learning rate. Batch size (128) balances training time and generalization [38]. Loss Tuning. Based on Eq. 21, we tuned weights and thresholds to balance FPs and FNs. Reducing positive weight (λ pos ) improved learning, while increasing attack threshold (0.5 → 0.6) improved classification metrics (Section V-A). We investigated the F1-score-based loss; however, PFBCE provided superior balance without sacrificing precision (Table IV). All models were trained, tuned, and evaluated using the attack data ratios in Table V. The variations reflect controller susceptibility to specific attacks, with vehicles downstream of the attacker (position 2) experiencing higher attack exposure.
Our testing process encompasses three evaluation types: (i) global model on whole-platoon data (General Input), (ii) global model on individual vehicle data (Vehicle-specific Input), and (iii) individual models on their own vehicle data. This investigation reveals trade-offs between locally-and edgedeployed models in platooning environments.
We utilize binary classification metrics (i.e., recall, precision, F 1 score, accuracy). With padding and masking, the underlying True Positive (TP), FP, FN, True Negative (TN) are:
For model comparison, we use Receiver Operating Characteristic (ROC) (displaying True Positive Rate (TPR) over False Positive Rate (FPR)) and AUC. We define Performance Gain (PG) for vehicle v and metric m as:
where Individual v,m and Global v,m represent individual and global model performance, respectively.
To showcase AIMFORMER superiority, we implemented seven baseline DNN architectures commonly used for timeseries and misbehavior detection in IoVs [39], [40]. AIMFORMER’s distinguishing features include: positional encoding with temporal offset awareness (Eqs. 3 and 4), three dropout operations per block (0.1 rate), two normalizations per block, and the custom PFBCE loss (Eq. 21) that penalizes FPs while weighting positive samples (Eq. 24). However, this complexity is reflected in the number of parameters (highest) and footprint (12 MB global, 6.2 MB individual). Nonetheless, quantization achieves significant size reduction (Table VII), facilitating edge deployment.
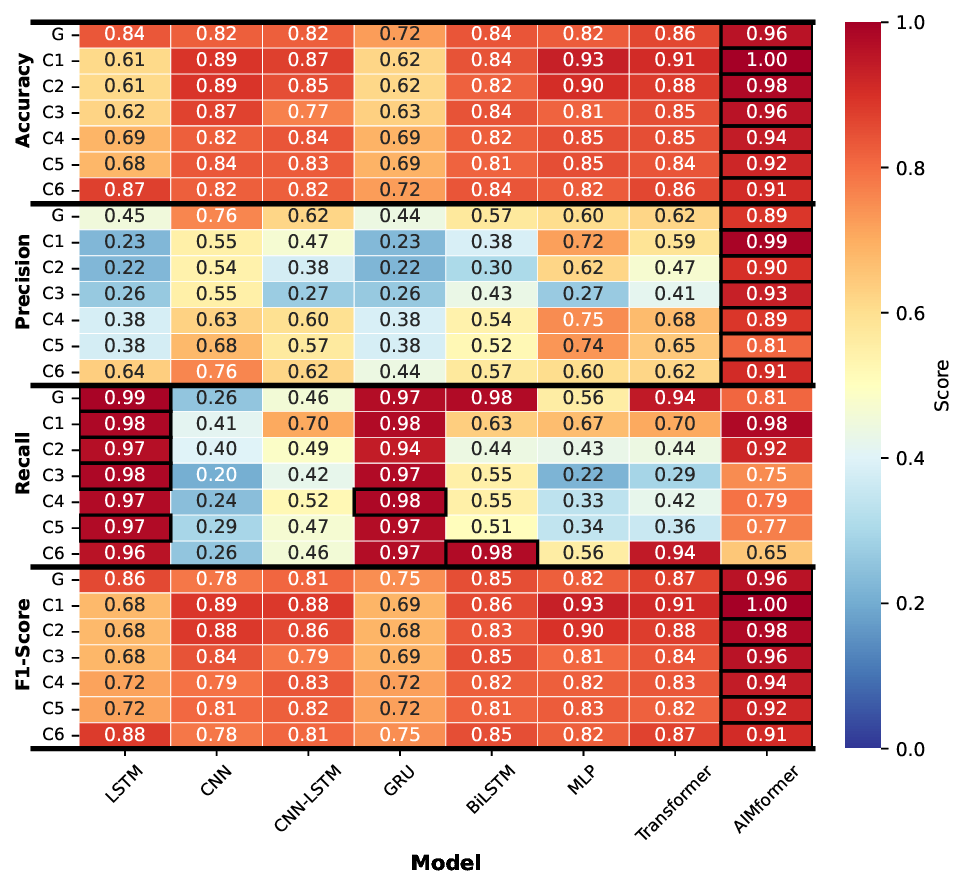
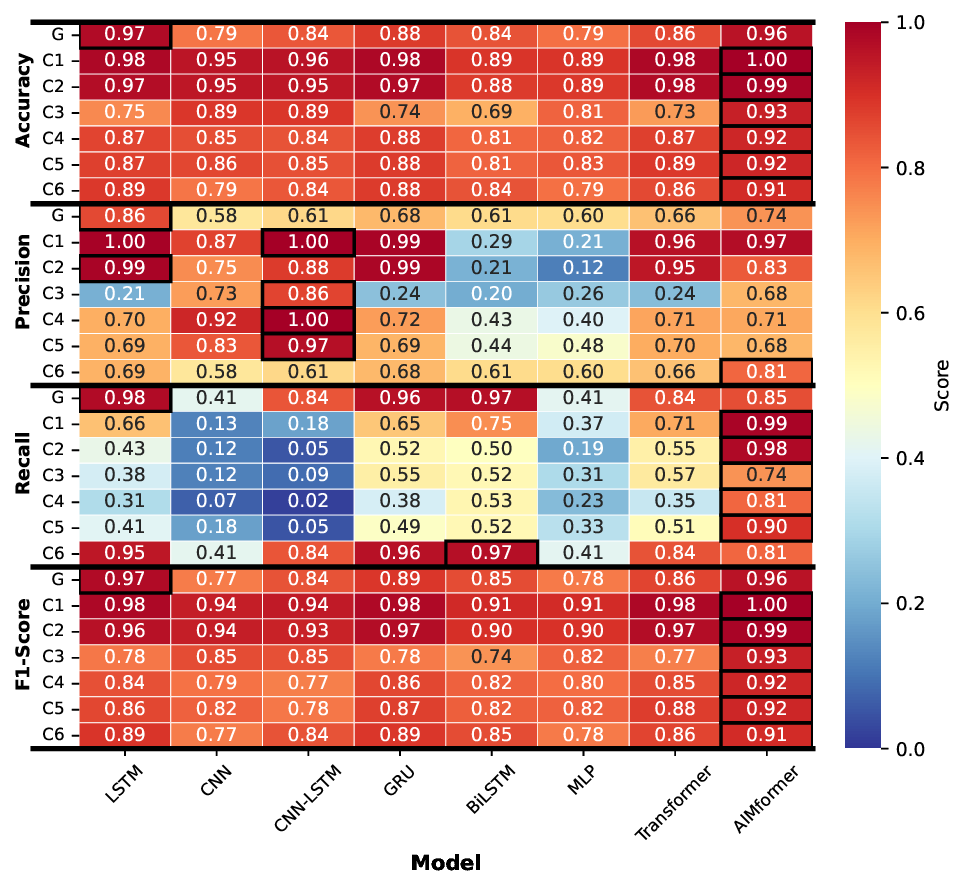
Fig. 3 presents classification metrics for all architectures across vehicle positions (C1-C6) and global input (G), for the global model, with black borders marking best performers. Across all controllers, AIMFORMER consistently outperforms baselines. For Controller 1 (Fig. 3a), most models achieve > 80% accuracy but struggle with precision-recall balance due to class imbalance; AIMFORMER’s global input outperforms individual inputs for positions C4-C6. Controller 2 (Fig. 3b) shows CNN-LSTM achieving the highest precision but the lowest recall (overly conservative); AIMFORMER demonstrates superior F1-scores across all positions. For Controller 3 (Fig. 3c), GRU achieves low FPs but high FNs; AIMFORMER maintains high recall (critical for safety) while effectively detecting attacks in challenging positions C3-C5. Controller 4 (Fig. 3d) validates AIMFORMER’s balanced precision-recall trade-off, yielding substantially higher F1-scores across all cars.
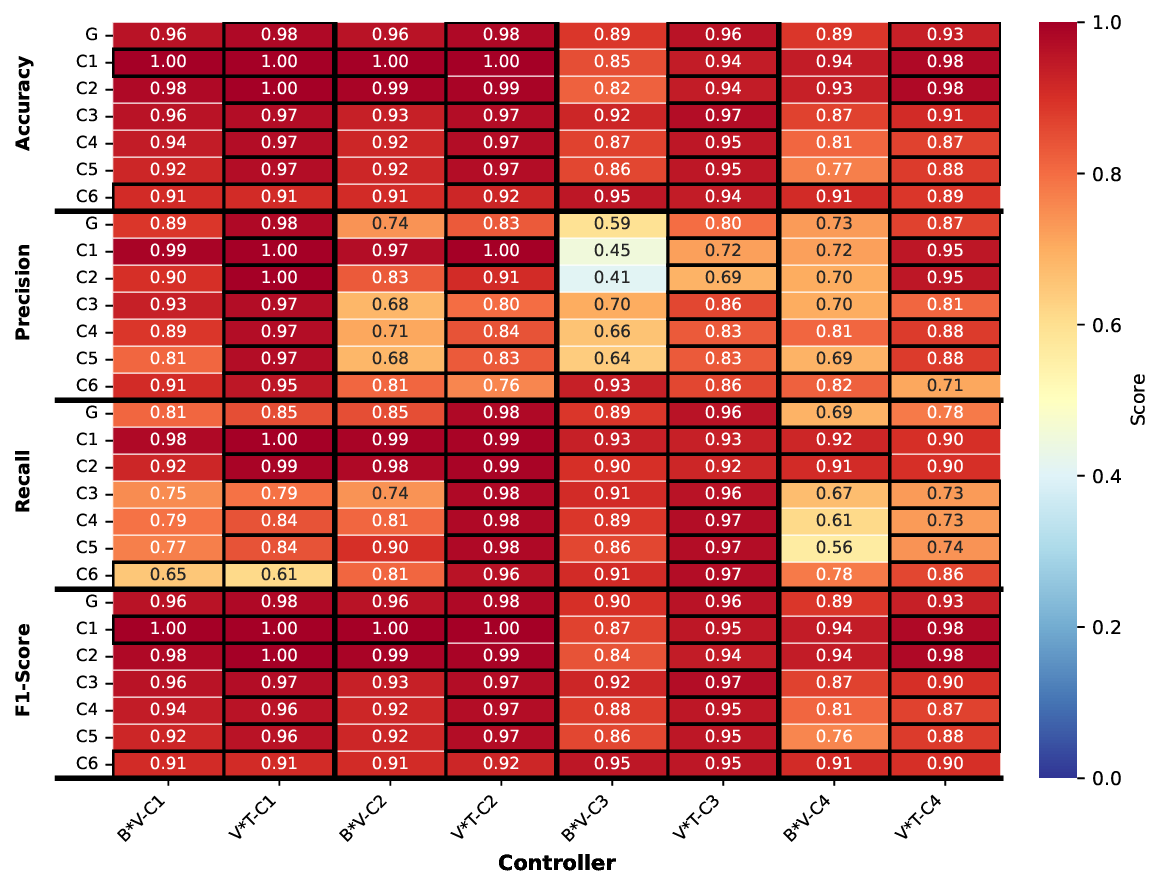
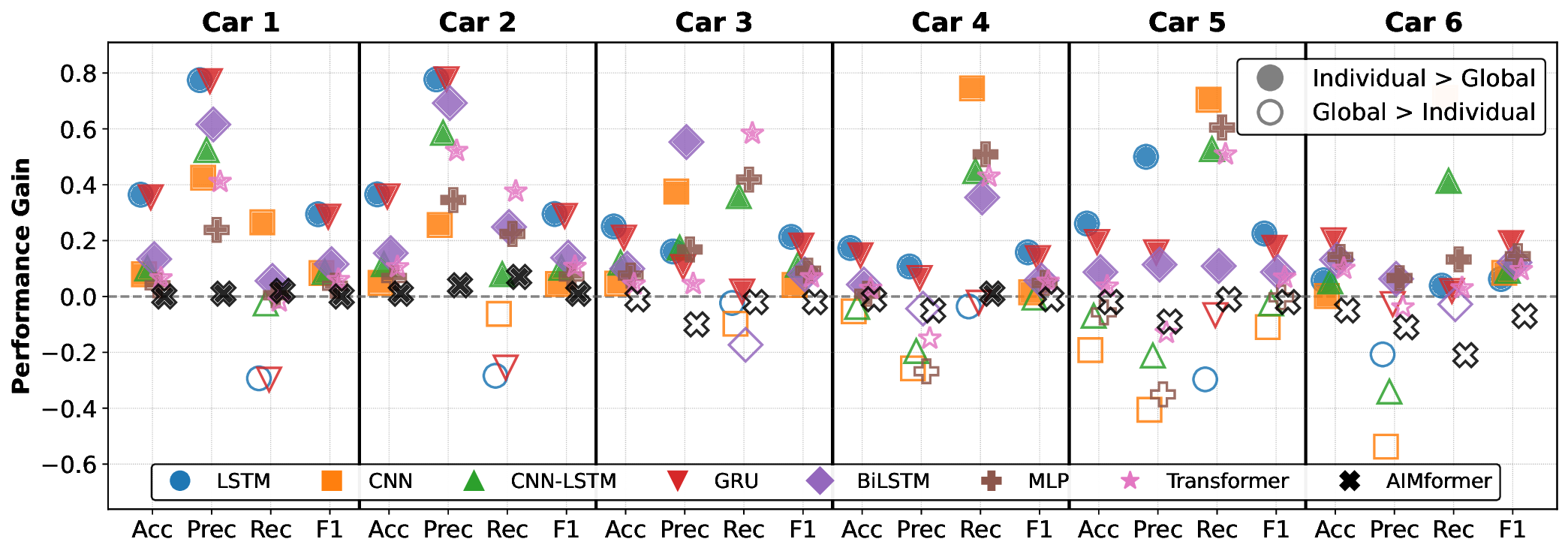
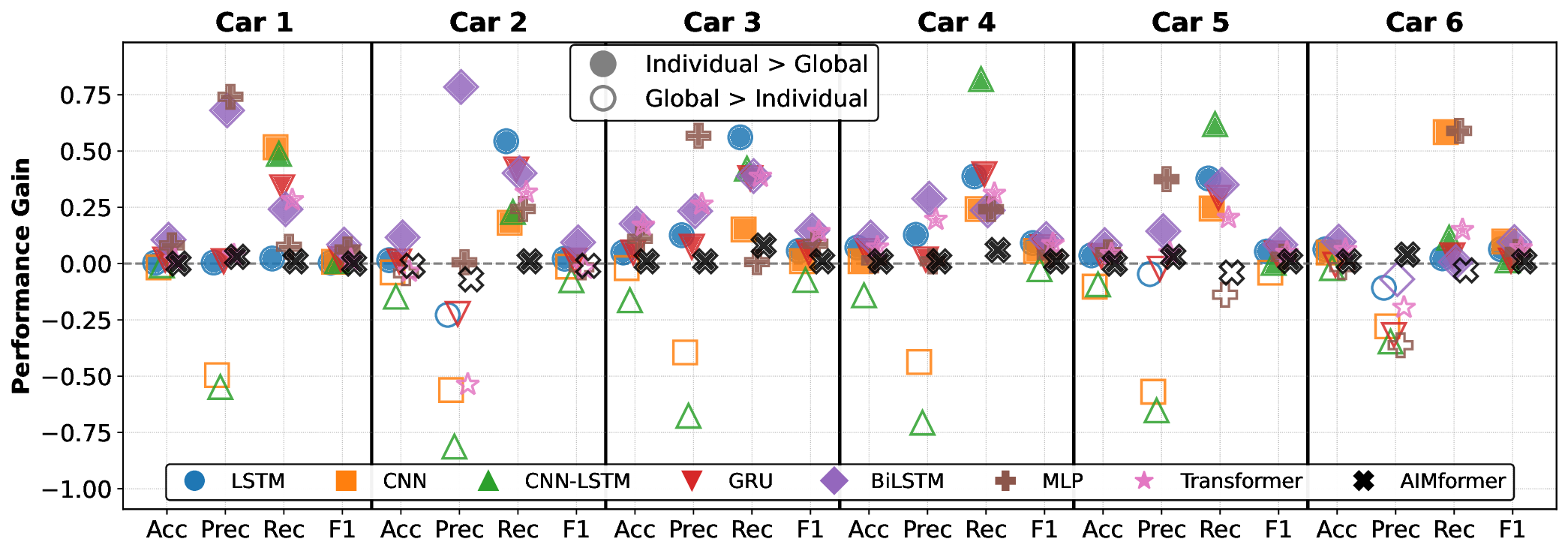
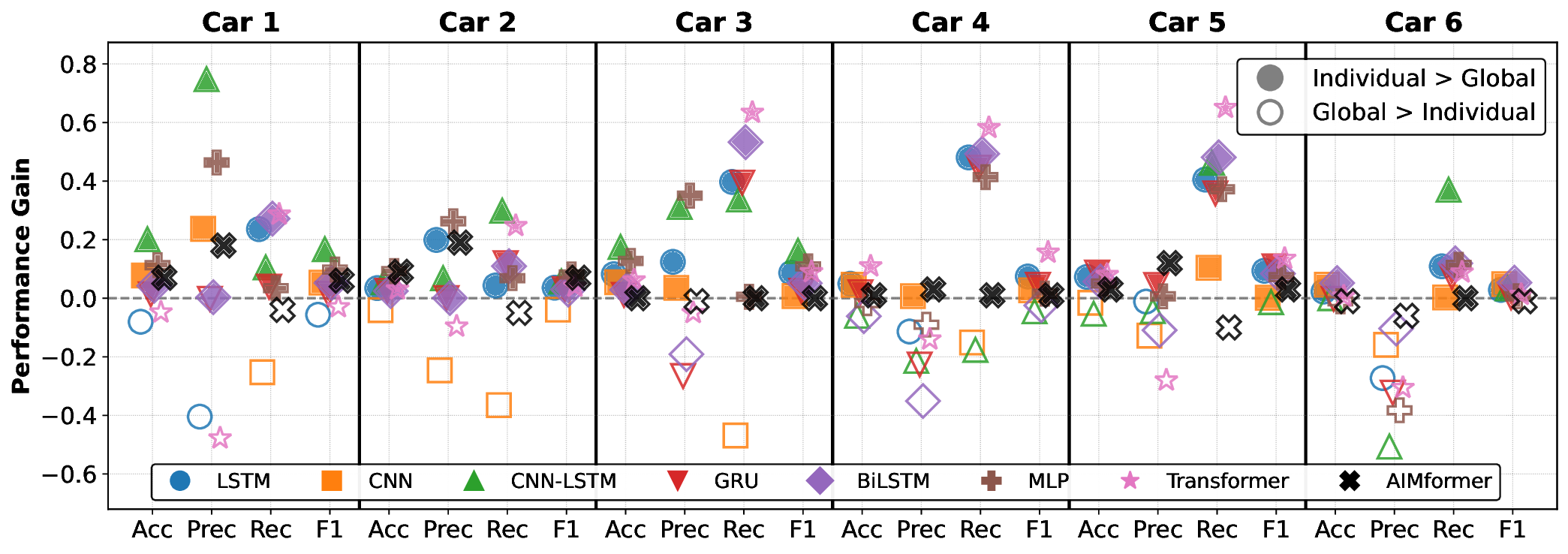
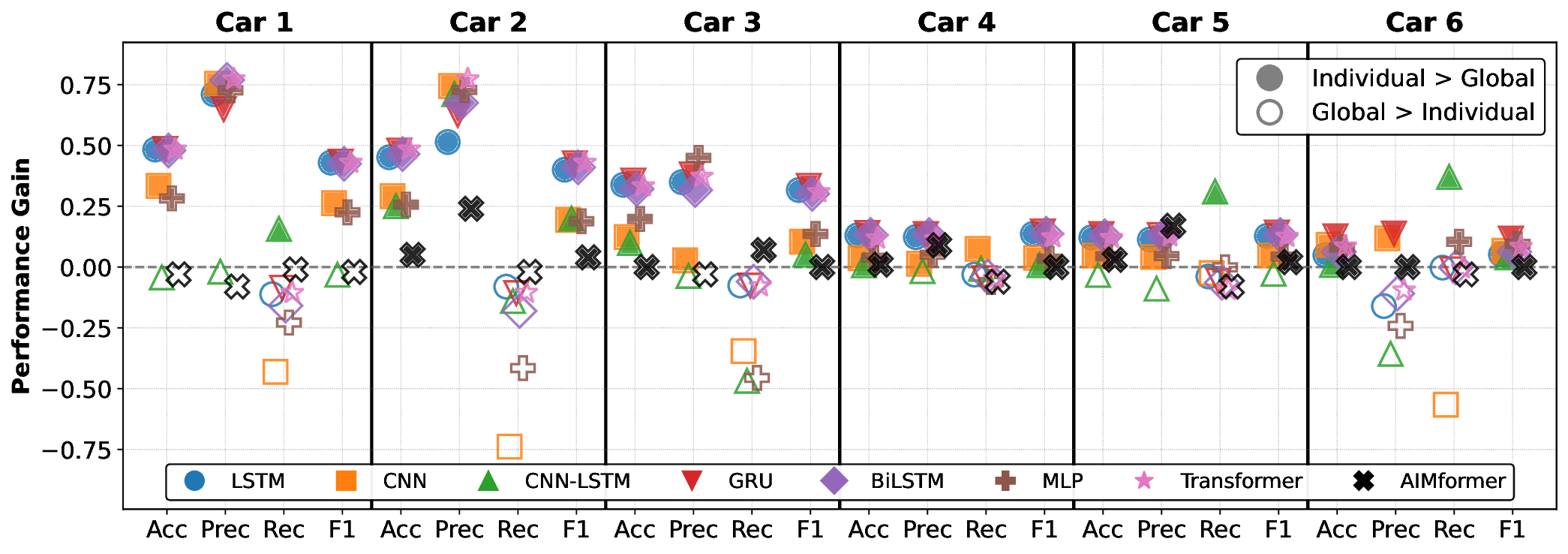
Fig. 4 illustrates the P G (Eq. 27) comparing individual vs. global models (filled icons: individual superior; empty: global superior). Upstream vehicles (C1-C2) consistently benefit from individual models, while C6 exhibits controller-dependent behavior. Vehicles C3 to C5 show architecture-dependent trends that favor individual models. Notably, AIMFORMER exhibits performance parity between deployment approaches, with one exception (Controller 1, C6: global model superior by ≈ 8% F1). This performance consistency, coupled with global model results (highlighted in Fig. 3, row G), demonstrates AIMFORMER’s ability to learn position-dependent patterns through the entire platoon input, making it optimal for both vehicle-local and RSU-based deployment in real-world V2X scenarios. Moreover, our vehicle-independent processing approach further enables scalability to larger platoons. Since self-attention operates independently over each vehicle’s time series, the global model’s generalization across C0 to C6 directly extends to additional vehicles, resulting in larger platoon sizes, without requiring architectural modifications.
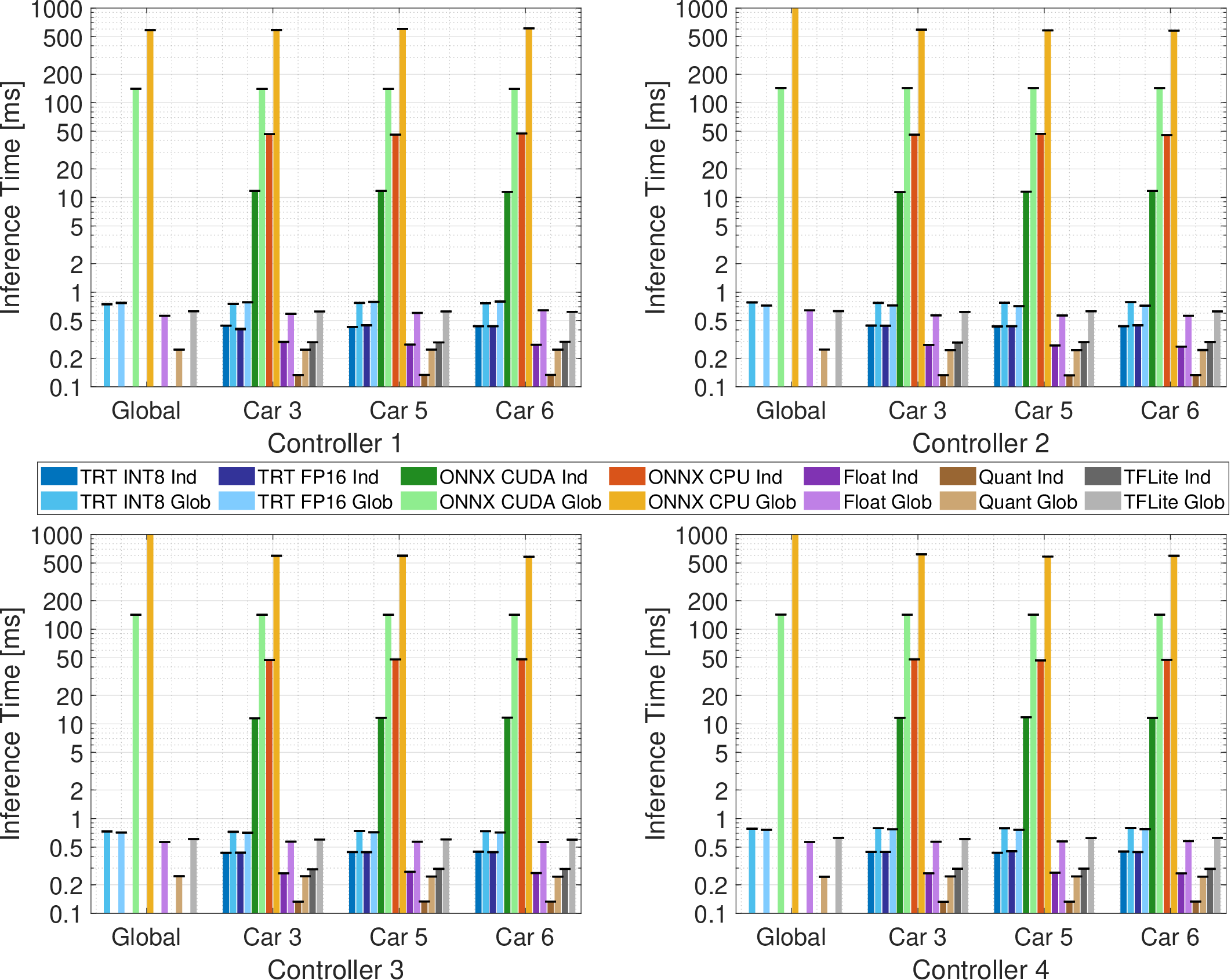
We evaluate AIMFORMER on the Jetson Orin Nano Super Developer Kit, employing model quantization [28] across three optimization frameworks: (i) TFLite (direct TensorFlow transformation), (ii) ONNX (CPU and CUDA configurations on Jetson Orin Nano Super Developer Kit), and (iii) TensorRT (hardware-optimized). Both individual and global models are optimized using f loat16 and int8 quantization. erence absent accuracy degradation. ONNX performs significantly worse: CPU-only inference requires ≈ 50-600ms (prohibitive for 10Hz CAM transmission); CUDA deployment reduces individual model latency to 10ms (viable but suboptimal). TensorRT achieves 0.75-0.8ms (global) and ≈ 0.4ms (individual), constituting a small fraction of single CAM intervals, enabling deployment on TensorRT-capable devices. TFLite exhibits the fastest quantized inference (0.13ms individual, 0.26ms global), requiring no additional hardware, making it ideal for both in-vehicle and RSU deployment.
The previous sections demonstrated the superiority of the transformer-encoder in detecting misbehavior. Global models outperformed the individuals for vehicles downstream in the platoon, eliminating the need for multiple models. However, an extra step can be taken by changing Eq. 5 from
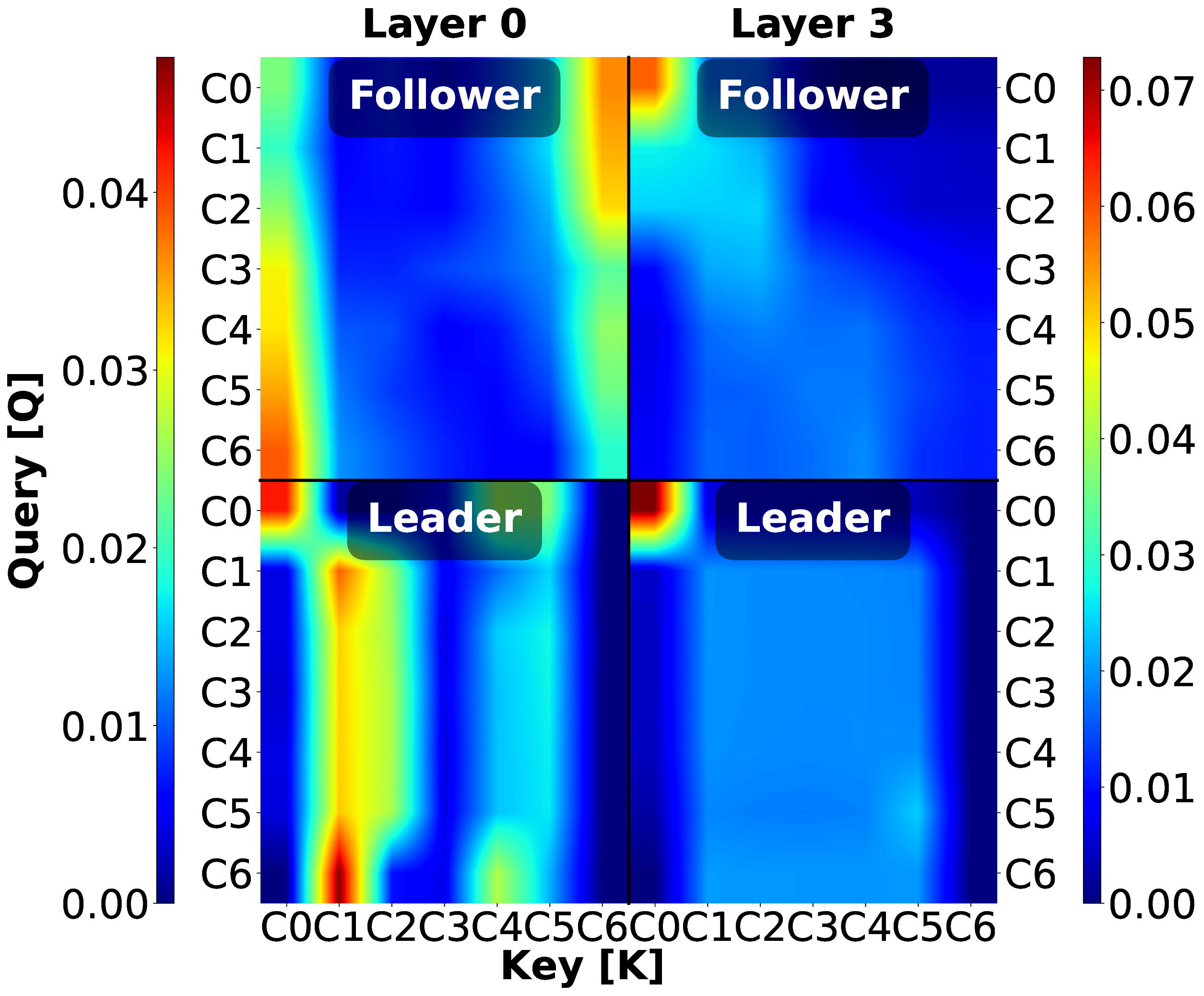
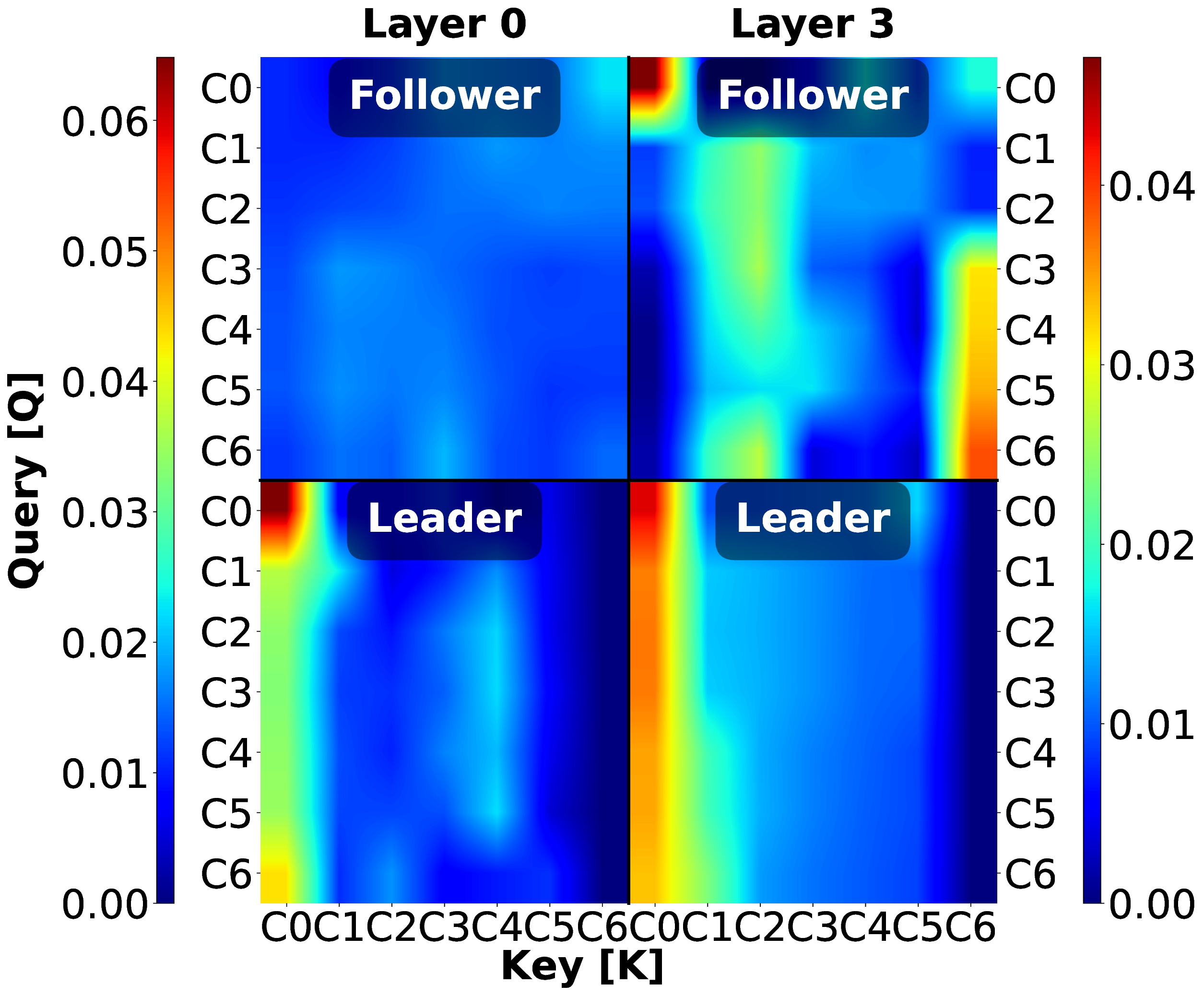
This reshaping captures spatio-temporal vehicle interactions through self-attention operating over the concatenated V • T Fig. 8 presents the attention weights for layer 0 (input) and layer 3 (output) across all controllers in the case of attacks. Communication topology fundamentally shapes attention-based security strategies with distinct layer-wise progression and attack-adaptive patterns.
Controller 1 (PATH) employs leader and joiner monitoring for follower attacks (C0-C6 → C0, C6 with gradient), while for leader attacks, Layer 0 shifts to victim monitoring (C0-6 → C1) and Layer 3 maintains C0-centric patterns, demonstrating attack-adaptive feature extraction with topology-invariant higher layers. Controller 2 (Ploeg), without leader visibility, progresses from minimal Layer 0 to focused Layer 3 back-tracking (C4-6 → C3) for follower attacks. For leader attacks, Layer 0 focuses on the victim (C0) while Layer 3 develops position-dependent stratification (C0-2 → C0, C3-6 → C1), compensating for topology constraints through distributed spatial detection. Controller 3 (Consensus) exhibits a “victimversus-attacker” targeting strategy: follower attacks show C3 → C3 self-monitoring (Layer 0) followed by collective validation C0-6 → C3 (Layer 3). Meanwhile, the leader attacks unify the followers’ attention towards the victim, initially, the attacker, subsequently. Controller 4 (Flatbed) monitors multiple simultaneous targets for follower attacks: C0 → C0, C3-C5 → C6, as the joiner integrates behind attacker C2, while simultaneously focusing attention on attacker V2. For leader attacks, it presents a unified C0-C6 → C0 attention across both layers.
Notably, this approach enables attack localization through the attention focus. For follower attacks, PATH monitors reference points (C0, C6) without specific attacker localization; Ploeg and Consensus attend to V3 (the immediate victim), enabling indirect localization through predecessor inference; while Flatbed achieves direct attacker (C1-C4 and C6 → C2) and victim (C3-C5 → C6) identification. For leader attacks, all controllers eventually scrutinize C0, facilitating direct source identification. These findings reveal a spectrum from leader monitoring (PATH) to victim-based inference (Ploeg, Consensus) to explicit source-targeting (Flatbed), with localization capability determined by whether attention focuses on attack symptoms, affected vehicles, or the attacker itself.
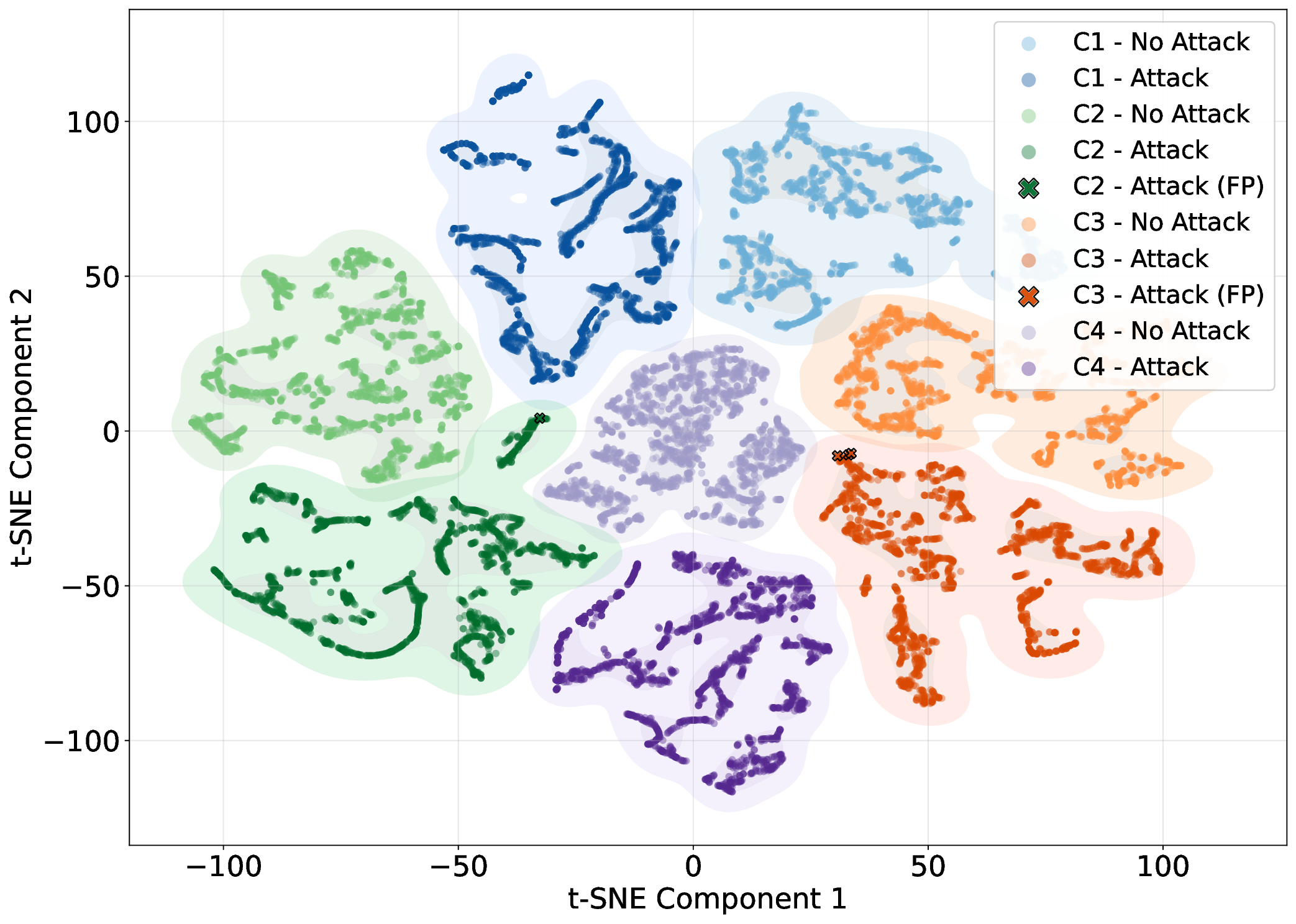
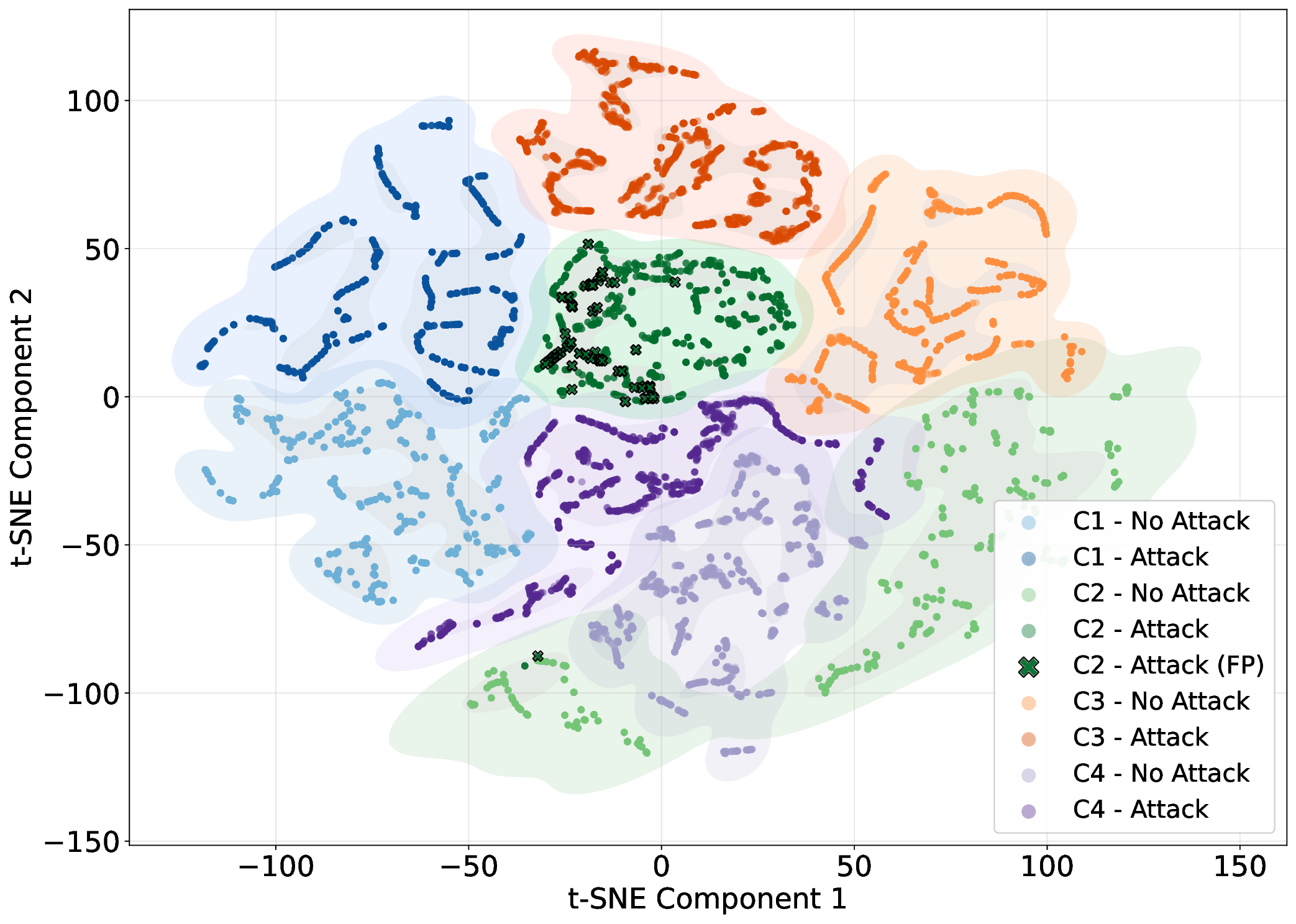
Fig. 9 presents the t-SNE visualizations of the controllers (C1-C4) with learned embeddings from the two transformerencoder global architectures. The shaded regions are constructed using Kernel Density Estimation (KDE), showing the density regions of the data points. In both cases, we collect the same 2000 samples, allowing for a direct comparison of the clustering. Similar colors represent the classification of benign and attack data points for the same controller, while X colored notations correspond to FPs for that controller.
Fig. 9a showcases the inference result when the model processes each vehicle’s temporal sequences separately, whereas Fig. 9b illustrates the clustering based on the inter-vehicle attention. The former shows overlap between the benign/attack regions of C1 (blue regions), a high number of FPs for C2, and an overlap between C2 and C4. On the other hand, intervehicle attention (Fig. 9b) results in each controller occupying distinct regions, with clear separation between benign and attack regions, due to the capture of overall platoon behavioral patterns. There is a substantial decrease in the number of FPs for C2 with 3 FPs for C3.
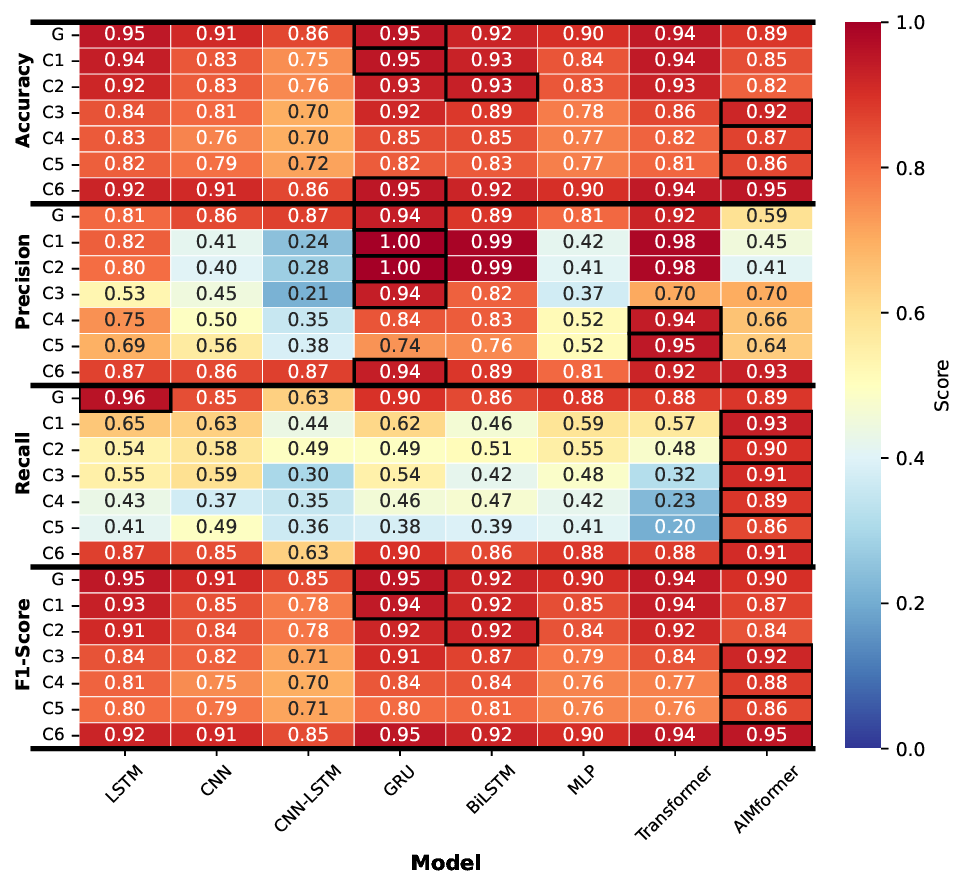
To strengthen the argument for V • T ’s improvement, we present in Fig. 10 the comparison heatmap (similarly to Fig. 3). For global inference, V • T consistently outperformed B • V , with F1-scores of 0.98, 0.98, 0.96, and 0.93 for controllers C1-C4, respectively, compared to B•V ’s 0.96, 0.96, 0.90, and 0.89. This advantage persists in individual vehicle inference (keeping in mind that V • T requires whole platoon input), where V • T maintains F1-scores above 0.90 for most vehicles while B • V exhibits greater variability (0.76-1.00). The performance gap is most evident in precision.
Our comprehensive evaluation reveals distinct deployment strategies for various operational contexts, as well as limitations.
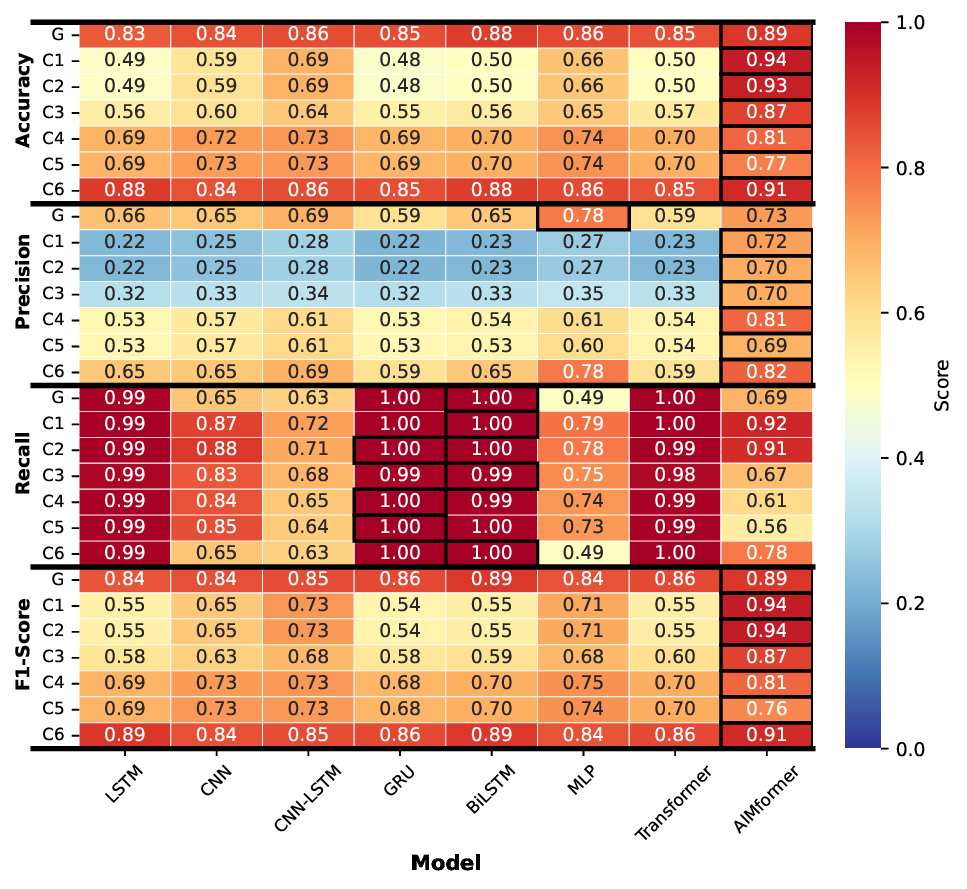
Vehicle-local deployment (individual models) suits upstream vehicles (positions 1-2) that exhibit position-specific patterns, privacy-constrained scenarios that limit platoon-wide data sharing, heterogeneous platoons with varying capabilities, and bandwidth-limited environments. The 50-90% inference speedup and 50% size reduction make individual models optimal for resource-constrained hardware. Nonetheless, a locally deployed B•V global model would enable the deployment of a single model, regardless of platoon position, at the cost of increased inference time (but still < 1ms) and memory footprint.
Infrastructure-based deployment (RSU-hosted V•T global models) maximizes detection performance, including attack localization, through platoon-wide input capturing cross-vehicle correlations. This approach is suitable for scenarios that require consistent platoon-wide performance and high-precision detection to minimize FPs.
Combining the two methods achieves an optimal balance: vehicles can deploy local models for low-latency detection, while querying RSU-hosted global models for more accurate detection and localization of the attacker, balancing accuracy, latency, communication overhead, and computational requirements.
Limitations and Future Directions. Our simulation-based evaluation could improve through real-world mobility testbed validation. The framework addresses known attack patterns (i.e., constant offset, gradual drift, and combined falsification); adaptive adversaries may craft evasion attacks, necessitating an investigation into adversarial robustness. Current deployment assumes static models; online learning and federated learning could enable privacy-preserving adaptation. While our PFBCE loss reduces FPs, comprehensive quantification of false alarm impacts on platoon operations remains unexplored. Finally, extension to mixed autonomy scenarios with heterogeneous capabilities presents opportunities for future work, alongside integration with complementary security mechanisms, including cryptographic protocols and secure hardware.
This section discusses misbehavior detection in VCs systems, transformer architectures for security applications, Deep Learning (DL) for vehicular security, and edge AI deployment.
Misbehavior detection in IoV environments has evolved from rule-based plausibility checks to ML-based approaches. Van der Heijden et al. [61] provided a comprehensive survey identifying fundamental challenges in cooperative ITS, including the difficulty of distinguishing between benign sensor errors and malicious data falsification. Boualouache and Engel [39] extended this analysis to 5G-enabled vehicular networks, emphasizing the need for real-time detection capabilities that scale with increasing network density.
Frameworks have been essential for advancing the field. Kamel et al. [41] introduced the VeReMi dataset, providing the first reproducible benchmark for comparing misbehavior detection algorithms across diverse attack scenarios. The VeReMi Extension [62] expanded coverage to include additional attack vectors and environmental conditions, becoming the de facto standard for evaluating detection approaches. So et al. [45] demonstrated that combining Physical (PHY)-layer plausibility checks with traditional position verification improves detection rates by 15-20%, achieving 83-95% accuracy against falsification attacks.
ML integration has shown substantial promise. Sharma and Liu [63] developed a data-centric model achieving 94% detection accuracy by leveraging ensemble methods, while Gyawali et al. [49] incorporated reputation techniques to reduce FP rates in dynamic network topologies. Privacypreserving approaches have gained attention, with Uprety et al. [51] proposing Federated Learning (FL) for distributed misbehavior detection that maintains 92% accuracy while preserving location privacy.
Platoon-specific security research remains limited. Previous work [7] characterized attack impact across different platoon controllers and topologies, revealing that acceleration falsification poses the greatest threat to string stability. However, existing detection mechanisms struggle with combined attacks that manipulate multiple kinematic parameters in physically consistent patterns-a gap our transformer-based approach addresses.
Transformer architectures revolutionized sequence modeling tasks, with recent applications for cybersecurity. Xu et al. [64] introduced Anomaly Transformer, leveraging association discrepancy to identify temporal anomalies in multivariate time series with 98.2% AUC on benchmark datasets. Tuli et al. [65] proposed TranAD, demonstrating that deep transformer networks outperform LSTM-based approaches by 8-12% for multivariate time series anomaly detection through parallel processing of temporal dependencies.
Self-supervised learning has enhanced the effectiveness of transformers for security tasks. Jeong et al. [66] developed AnomalyBERT, which employs data degradation schemes during pre-training to achieve robust anomaly detection without extensive labeled data, particularly relevant for vehicular environments where attack samples are scarce. Long et al. [67] applied transformers to cloud network intrusion detection, achieving 97.3% accuracy with significantly reduced false positive rates compared to traditional DNN approaches.
Despite these advances, transformer applications for vehicular misbehavior detection remained unexplored. Existing work focuses on network traffic analysis or generic time series anomaly detection, lacking the domain-specific considerations necessary for understanding the dynamics of platoon coordination. Our AIMFORMER architecture addresses this gap through global positional encoding mechanisms that capture cross-vehicle temporal relationships and custom loss functions optimized for the requirements of safety-critical vehicular applications.
DL approaches have become predominant in vehicular security research, with LSTM and CNN architectures achieving substantial detection performance. For misbehavior detection in VANET environments, Alladi et al. [44] developed a DLbased classification scheme achieving 95.7% accuracy across nine attack categories in cooperative ITS. Hsieh et al. [46] proposed an integrated CNN-LSTM architecture that captures both spatial feature patterns and temporal dependencies, demonstrating 93.2% detection rates on the VeReMi dataset.
In-vehicle network security has received considerable attention. Kang and Kang [50] applied DNN for CAN bus intrusion detection, achieving 99.7% accuracy for binary classification tasks. Song et al. [52] extended this work with convolutional architectures that automatically extract message timing patterns, while Longari et al. [54] employed LSTM autoencoders for unsupervised anomaly detection with 99.2% AUC. Javed et al. [56] combined CNN with attention-based GRU to achieve state-of-the-art performance (99.5% accuracy) for controller area network intrusion detection.
Hybrid architectures have shown promise for complex vehicular scenarios. Sun et al. [58] proposed a CNN-LSTM with attention for spatiotemporal feature extraction, demonstrating improved detection of multi-stage attacks. Zhu et al. [59] investigated mobile edge-assisted deployment of LSTM models, achieving real-time inference (< 50ms latency) on resourceconstrained edge servers.
FL approaches address privacy concerns in distributed vehicular networks. Gurjar et al. [48] proposed a FL-based misbehavior classification framework achieving 98.6% accuracy while preserving vehicle location privacy. However, these approaches typically require substantial computational resources for model training and aggregation, which limits their practical deployment on edge platforms. While achieving high accuracy, existing DL approaches face limitations: LSTM architectures struggle with long-range temporal dependencies essential for analyzing platoon coordination, and CNN-based methods require careful manual feature engineering for time series data. Furthermore, most prior work evaluates detection performance in isolation rather than considering an end-to-end pipeline from data collection to edge deployment.
Edge AI has emerged as an enabling technology for realtime vehicular security, addressing latency and privacy constraints inherent in cloud-centric approaches. Gong et al. [68] identify three key deployment paradigms: on-vehicle inference, roadside unit processing, and hybrid edge-cloud architectures. Zhang and Letaief [23] demonstrated that edge intelligence can reduce end-to-end latency by 10-15x compared to cloud processing while maintaining comparable accuracy; essential for safety-critical vehicular applications with sub-100ms response requirements.
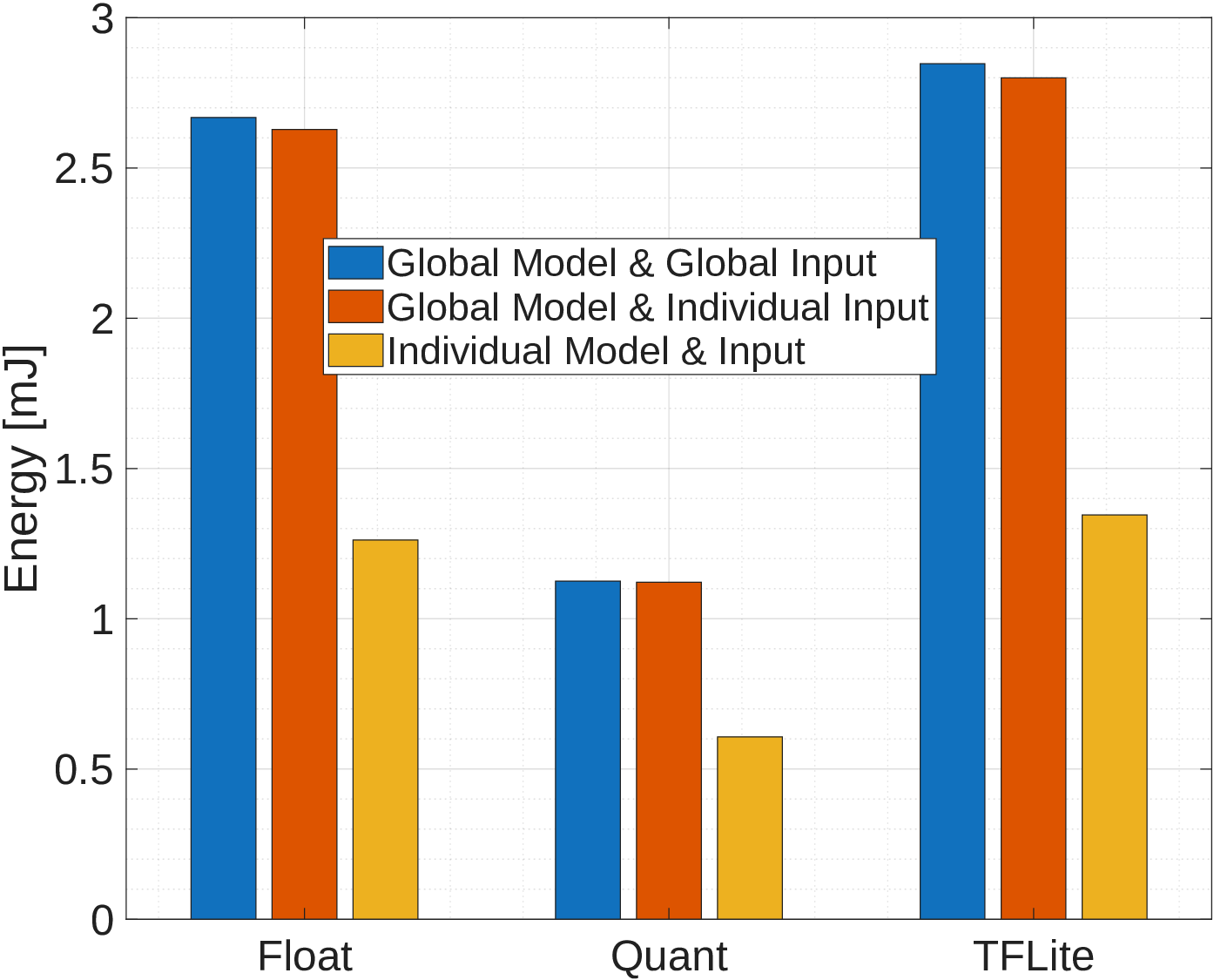
Tiny Machine Learning (TinyML) frameworks enable deployment on resource-constrained hardware. De Prado et al. [69] demonstrated deployment of DNN models on autonomous mini-vehicles using model quantization, achieving 3-5x energy efficiency improvements with minimal accuracy degradation (< 2%). Alajlan and Ibrahim [70] provided a comprehensive overview of TinyML techniques for Internet of Things (IoT) edge devices, emphasizing the importance of model architecture and target hardware co-design.
DNN inference acceleration in vehicular edge computing has received substantial research attention. Liu et al. [71] proposed joint optimization of task partitioning and edge resource allocation, achieving 40% latency reduction with 99% reliability guarantees for safety-critical inference tasks. Li et al. [72] developed mobility-aware acceleration strategies that adapt model partitioning based on vehicle trajectory predictions, maintaining inference quality during handover events. FL approaches balance privacy preservation with model performance in distributed vehicular environments. Valente et al. [73] demonstrated embedded FL for VANET environments, achieving 94.3% accuracy with on-vehicle training on Raspberry Pi-class hardware. Mughal et al. [74] proposed adaptive FL with multi-edge clustering, reducing communication overhead by 60% while maintaining convergence properties. Pervej et al. [75] addressed highly mobile scenarios, developing a resource-constrained vehicular edge FL that maintains 93% accuracy despite frequent topology changes.
Model quantization techniques enable the deployment of AI on edge platforms [27]. Recent work [28], [29] has demonstrated that 8-bit integer quantization can reduce transformer model sizes by 4x with < 1% accuracy degradation for classification tasks. However, the impact of quantization on transformer-based misbehavior detection for vehicular platoons remains unexplored, particularly regarding the precisionrecall trade-offs critical for safety-critical applications.
Table VIII compares AIMFORMER with existing frameworks. Our work builds upon foundational contributions in vehicular misbehavior detection, particularly VeReMi [41] for plausibility-based validation, and extends recent advances in ensemble methods [47], [55], FL [51], [48], and recurrent architectures [42], [44], [46]. While these approaches demonstrate strong detection capabilities in general VANET contexts, they face limitations when applied to the strict realtime requirements and dynamic operational characteristics of platoon systems.
Within platoon-focused detection, prior approaches span probabilistic methods (GMM-HMM, 87% F1, 130-280ms) [7], recurrent networks (LSTM/GRU, > 96% accuracy) [19], [20], and specialized methods (RF, 10ms inference) [16], [17], [18]. Most directly, our work builds on AttentionGuard [5], which achieves 88-92% accuracy and 96-99% AUC but with inference times of 100-500ms, precluding practical edge deployment.
AIMFORMER advances beyond AttentionGuard and the broader landscape through four key contributions: (1) integrated quantization-aware training achieving the first transformer-based detector with sub-millisecond inference (0.13-0.8ms versus 100-500ms), enabling practical On-Board Unit (OBU)/edge deployment; (2) unified framework handling position, speed, and acceleration falsification including stealth variants through adaptive masking and global positional encoding, whereas prior work targets specific attack types [16] or scenarios [19]; (3) two to three orders of magnitude faster inference while maintaining superior detection performance (96-99% AUC); (4) comprehensive evaluation including different maneuvers (i.e., join, exit, lane change) representing critical vulnerability windows that prior work does not systematically address [5], [7], [20].
To summarize, AIMFORMER delivers a complete solution combining high detection accuracy with practical edge deployment feasibility, addressing the fundamental challenge of deploying DL models on resource-constrained vehicular hardware while advancing beyond probabilistic [7], recurrent [19], [20], specialized [16], and our prior transformerbased work [5].
We presented AIMFORMER, a transformer-based framework for misbehavior detection tailored specifically to vehicular platooning environments. Our framework incorporates domain-specific techniques, including global positioning encoding with temporal offsets, as well as a precision-focused loss function. These components effectively address the unique challenges of detecting malicious behavior in coordinated multi-vehicle systems. AIMFORMER simultaneously models inter-vehicle temporal dependencies and spatial correlations, enabling robust detection across heterogeneous control strategies and attack vectors while maintaining the computational efficiency required for safety-critical applications. Our comprehensive evaluation establishes AIMFORMER’s superiority over existing DNN architectures, demonstrating consistent performance gains across various attack scenarios with an AUC of 96-99%. Moreover, deployment analysis validates the practical feasibility of sub-millisecond inference latencies, achievable through model quantization and optimization, enabling both vehicle-local and infrastructure-based deployments.
j Ground truth binary label for vehicle i at time step j ŷi,j Predicted logit for vehicle i at time step j m i,j Binary loss mask for vehicle i at time step j Sets and Derived Variables M Set of valid vehicle-time observations, {(i, j) : m i,j = 1} |M| Number of valid vehicle-time observations ℓ i,j Standard BCE loss for vehicle i at time step j w (i,j) FP FP penalty weight for vehicle i at time step j w
pos {0.5, 0.7, 0.75, 0.9, 1} 0.6 τ {0.5, 0.6, 0.7} 0.6
This content is AI-processed based on open access ArXiv data.