Disclaimer: Samples in this paper may be harmful and cause discomfort. Multimodal large language models (MLLMs) enable multimodal understanding but inherit toxic, biased, and NSFW signals from weakly curated pretraining corpora, causing safety risks, especially under adversarial triggers that late, opaque training-free detoxification methods struggle to handle. We propose SGM, a white-box neuron-level multimodal intervention that acts like safety glasses for toxic neurons: it selectively recalibrates a set of toxic expert neurons via expertise-weighted soft suppression, neutralizing harmful cross-modal activations without any parameter updates. We establish MM-TOXIC-QA, a multimodal toxicity evaluation framework, and compare SGM with existing detoxification techniques. Experiments on open-source MLLMs show that SGM mitigates toxicity in standard and adversarial conditions, cutting harmful rates from 48.2% to 2.5% while preserving fluency and multimodal reasoning. SGM is extensible, and its combined defenses, denoted as SGM ⋆ , integrate with existing detoxification methods for stronger safety performance, providing an interpretable, low-cost solution for toxicitycontrolled multimodal generation. 1
📄 Full Content
Large language models (LLMs) are now generalpurpose assistants for dialogue and content generation, yet still produce toxic, biased, or otherwise harmful text due to problematic pretraining data or adversarial prompts (Luong et al., 2024;Wang et al., 2024a). Detoxification techniques-from prompt design to safe decoding and post-hoc filtering (Lu et al., 2025; Xu et al., 2024a; Zhong et al., 1 Resources and codes of this paper are available at https: //anonymous.4open.science/r/Anonymous_SGM. 2024) seek to curb harmful behavior while preserving utility, but are largely designed and evaluated in unimodal, text-only settings.
Modern systems are multimodal: multimodal large language models (MLLMs) jointly process images and text, and the image modality can amplify and internalize toxic behaviors in visionlanguage fusion, making detoxification an internal representation problem rather than a pure interface issue (Adewumi et al., 2024;Liu et al., 2024b). Yet many defenses treat MLLMs as black boxes, strengthening system prompts or injecting safetyoriented roles and examples on the input side and applying toxicity classifiers or decoding-time controls on the output side (Fares et al., 2024;Gou et al., 2024;Pi et al., 2024;Robey et al., 2023;Xu et al., 2024c). Such prompt optimization improves robustness to adaptive jailbreaks (Wang et al., 2024d), but interface-level interventions remain vulnerable to multimodal jailbreaks, and post-hoc filters only act after toxic concepts are activated, yielding truncated or unnatural answers while revealing little internally. These limitations motivate an internal, white-box view of MLLM detoxifica-tion: using non-parametric hidden-representation interventions. However, existing approaches (Gao et al., 2024;Wang et al., 2024b) are coarse (e.g., a single global direction or entire layers) and rarely target multimodal fusion, thereby preventing precise control over the parameters responsible for generating toxic content and leading to excessive intervention.
To address these challenges, we focus on three main questions by adopting a finer-grained internal view : (1) Can multimodal detoxification be achieved directly at the neuron level? (2) Can such interventions be realized without parameter updates or architectural changes? (3) Can they remain efficient and transferable across models?
To answer these questions, we introduce SGM (Safety Glasses for MLLMs), a neuron-level, vision-language white-box defense operating on post-fusion layers of MLLMs. Rather than attaching a separate safety module after generation, SGM intervenes on internal activations in multimodal internal layers, acting like a pair of safety glasses for a pretrained model: by adaptively suppressing a set of toxic expert neurons whose activations correlate with harmful outputs (Figure 1), it corrects their tendency to drive toxic continuations. Inspired by the single-modality neuron activation suppression in (Suau et al., 2024), SGM performs expertiseweighted soft reduction on harmful cross-modal activations while keeping benign neurons and representations intact, yielding an interpretable neuronlevel intervention without any training. SGM is a reversible, hot-pluggable mechanism that we only “put on” when needed, inserting or removing it at inference time without modifying model parameters or architecture, and it transfers across models. Since progress on multimodal detoxification is bottlenecked by scarce instance-level toxicity annotations and coarse, scenario-limited safety benchmarks, we also construct MM-TOXIC-QA, a curated image-text framework with harmful cases and annotations for toxicity, and multimodal policy violations.
Experiments on MM-SafetyBench (Liu et al., 2024b) and MM-VET (Yu et al., 2024) show that SGM suppresses toxic outputs while preserving fluency and multimodal reasoning. Across fusionbased multimodal architectures, SGM aligns internal vision-language computation with safety goals at minimal computational overhead, and its neuronlevel controllability enables effective combination with advanced defenses such as ECSO (Gou et al., 2024).
The main contributions of this paper are summarized as follows:
• We propose SGM, the first neuron-level multimodal white-box detoxification framework to our knowledge, which intervenes in postfusion layers of MLLMs to attenuate toxic neurons in activation space without retraining, reducing harmful outputs by nearly 20× (48.2% → 2.5%) while preserving fluent, controllable multimodal generation.
• We establish MM-TOXIC-QA, a multimodal toxicity framework that consolidates and expands existing image-text datasets, filling the gap in high-quality toxicity annotations and providing a benchmark for multimodal safety assessment.
• We provide a combined defense variant, SGM ⋆ , which is extensible and low-cost, integrates with existing detoxification methods with minimal modifications, and yields stronger joint safety performance with negligible computational overhead.
Recent work on multimodal large language models focuses on mitigating toxic cross-modal behaviors using training-free, architecture-agnostic defenses. These methods fall into three categories-input sanitization, output validation, and intermediate-layer intervention, covering different stages of generation.
Input-level defenses purify multimodal prompts before they reach fusion or reasoning modules to prevent harmful concept activation. Text-based sanitizers such as BlueSuffix (Zhao et al., 2024) and AdaShield (Wang et al., 2024c) prepend safetyoriented templates or meta-instructions, while vision-based defenses such as CIDER (Xu et al., 2024b) and SmoothVLM (Sun et al., 2024) apply stochastic or diffusion-based purification against adversarial perturbations. However, these methods are black-box interventions at the input interface: they rely on external heuristics rather than internal representations, cannot correct latent toxic activations formed in fusion or reasoning layers, and safety still depends on the generalization of handcrafted sanitization rules and external filters.
Output-stage defenses detect and rewrite unsafe generations. Systems such as JailGuard (Zhang et al., 2023) and MLLM-Protector (Pi et al., 2024) employ auxiliary discriminators/correction models to re-rank or regenerate responses, while ECSO (Gou et al., 2024) mitigates vision-induced toxicity by converting image inputs into textual captions for text-only inference. Cross-modal consistency checkers like MirrorCheck (Fares et al., 2024) verify alignment between generated text and images. Although these methods suppress explicit violations, they incur extra overhead from classifiers or rewriting modules running alongside the base model. Safety depends on auxiliary model capacity; with smaller validators, limited discrimination can propagate misalignment and degrade detoxification.
Intermediate-layer interventions have been widely studied due to their interpretability, enabling transparent control of hidden activations for multimodal reasoning safety. Defenses such as Infer-Aligner (Wang et al., 2024b), CMRM (Liu et al., 2024a), and ASTRA (Wang et al., 2025a) conduct layer-wise alignment by measuring activation biases between safe and unsafe prompts or by projecting out adversarial directions. However, these methods operate at coarse layer granularity and rely on per-query adaptation, offering limited scalability. Inspired by AUROC-based neuron discrimination (Suau et al., 2024), where AUROC (area under the receiver operating characteristic curve) quantifies how well a scoring signal separates two classes, we propose SGM, a white-box neuroncentric attenuation strategy for multimodal architectures. SGM selects expert neurons in post-fusion layers via AUROC separability between safe and unsafe image-text activations and applies soft attenuation to neuron-level harmful activations while preserving benign multimodal reasoning pathways, achieving interpretable and traceable post-fusion activation control at low inference cost through efficient white-box suppression of toxic representations.
This section describes the full SGM pipeline (Figure 2), consisting of three hierarchical steps. We intervene in post-fusion MLP layers, and the intervened models and layers are listed in Appendix C.2.
Step I collects neuron activations for toxic and nontoxic inputs. Following (Suau et al., 2024(Suau et al., , 2021)), each neuron is treated as a potential detector of a target concept c (e.g., toxicity). Given a labeled dataset
, where y c i = 1 if input x i contains concept c, the pre-nonlinearity activation of neuron m at token t is x t i,m , and we write h
. We compute the neuron’s maximum activation
which serves as a scalar indicator of its sensitivity to c. These activations are the input to Step II for toxic neuron identification.
For multimodal inputs (x img i , x txt i ), the MLLM produces a fused representation
where h (i) p,t,m denotes the activation of neuron m for image patch p and token t. To extend Suau et al. (2024)’s definition to multimodality, we compute the joint peak activation
capturing multimodal sensitivity to toxic concepts. These multimodal activations are used directly in
Step II for cross-modal expert identification.
Step II: Toxic Neuron Identification Using the per-example peak activations {z
Step I, we measure each neuron m’s discriminative ability for toxicity via AUROC. Let
where y c i is the toxicity label. We compute
We use the neuron-wise AUROC score a m as a scalar measure of each neuron’s association with toxicity.
We adopt the soft, expertise-proportional attenuation scheme of Suau et al. (2024). For each neuron m, we map its toxicity expertise a m to a suppression strength
When applying the intervention, we only attenuate neurons selected as toxicity experts; for neurons outside the expert set Q we set λ m = 1, ensuring they are left unchanged. Collectively, these perneuron coefficients define a diagonal intervention operator S that rescales each dimension independently, and Step II summarizes its output as the expert index set Q, the coefficients λ, and the corresponding operator S used in Step III.
In the multimodal setting, we aggregate the joint peak activations from Step I into
where M is the number of neurons and z (i) m is the joint peak activation over image patches and tokens for example i. Applying AUROC column-wise yields the vector of multimodal expertise scores
whose m-th entry is the scalar score a VL m . We obtain the multimodal expert set by thresholding the neuron-wise multimodal AUROC scores a VL m using a tunable hyperparameter τ VL c , which controls the selectivity of expert identification. We report a threshold-sensitivity study in Appendix A.1, including the resulting per-layer intervention ratios and the corresponding performance effects under different choices of τ VL c .
On this expert set, we define
and set λ VL m = 1 for m / ∈ Q VL . Collecting these coefficients gives
and the multimodal intervention operator
This operator attenuates cross-modal toxic dimensions within the fused representation.
Given the expert set Q and the suppression operator S from Step II, toxicity mitigation is performed by applying S to the corresponding neuronal activations during forward propagation. For each adapted layer, the pre-activation vector h ∈ R d is updated as h = Sh, which proportionally attenuates toxicity-expert neurons while leaving non-expert dimensions unchanged.
For multimodal MLLMs, the multimodal intervention operator S VL is applied at the visuallanguage post-fusion module:
while non-expert neurons keep hp,t,m = h p,t,m . This suppresses cross-modal toxic dimensions at the representation level without modifying model parameters or affecting benign activations.
Obtaining high-quality data for multimodal toxicity detection remains challenging, as existing resources lack well-annotated image-text pairs for reliable toxicity classification (Wang et al., 2025b).
Prior work primarily red-teams MLLMs via adversarial image-text prompts to elicit harmful or helpless responses, but these prompts often capture broad unsafe reasoning rather than explicitly toxic content, with noisy and inconsistent annotations.
To bridge this gap and enable expert models specialized in suppressing toxic content, we propose the MM-TOXIC-QA framework for evaluating toxic-content generation behaviors in MLLMs. We first use GPT-4 (OpenAI, 2023) to assess the toxicity of image samples from two existing multimodal safety datasets, MM-SafetyBench (Liu et al., 2024b) and BeaverTails-V (Ji et al., 2025), rating each image on a 7-level toxicity scale and selecting strongly toxic samples to reduce marginal boundary ambiguities. We discard their original textual prompts and responses, and apply a unified toxicity prompting template (Appendix C.1). Using a model-voting strategy, we generate toxic responses for each potentially harmful image, followed by automatic and human-assisted re-evaluation to ensure label accuracy. All responses identified as toxic are then detoxified into safe counterparts by GPT-4, producing paired toxic/non-toxic samples. For detailed descriptions of MM-SafetyBench, BeaverTails-V, and our processing pipeline, please refer to Appendix B.
MM-TOXIC-QA thus forms a balanced and challenging benchmark for assessing toxicity suppression in multimodal models. It contains 4,326 image-text samples composed of 2,163 paired toxic and non-toxic examples, with the benchmark composition shown in Figure 3. This focus on highly toxic images reduces distracting non-toxic instances and improves the separability of toxic versus non-toxic neurons. We subsequently use MM-TOXIC-QA as the base input for identifying toxic neurons in Section 3.2.
We evaluate SGM on 7B/13B MLLMs. LLaVA-1.5-7B/13B (Liu et al., 2023) couples a CLIP vision encoder with a Vicuna-7B backbone via an MLP projector and visual instruction tuning; we use llava-hf/llava-1.5-7b-hf2 as our main variant. ShareGPT-4V-7B/13B (Chen et al., 2024) shares this CLIP-Vicuna design but uses distilled caption data, improving multimodal reasoning and safety while remaining open-source.
To compare existing MLLM detoxification approaches with our work, we consider promptengineering methods, intermediate-layer interven- tions, and hybrid settings that combine them with SGM.
InferAligner (Wang et al., 2024b) is a representative white-box detoxification method. We adopt InferAligner (ALI) as an intermediate-layer baseline that steers activations at inference using safety steering vectors from a safety-aligned reference model, computed as activation differences between harmful and harmless prompts, and injects them into hidden states.
We also adopt ECSO (Eyes Closed, Safety On) (Gou et al., 2024), a canonical black-box method that self-assesses the model’s initial response and, when unsafe content is detected, converts the visual input into a textual description and re-invokes the same language model in a text-only setting to exploit its internal safety alignment.
Prompt-based approaches usually use the same backbone for both judgment and rewriting, making them vulnerable to cascading degradation when early misclassification occurs. Our joint framework SGM ⋆ integrates SGM with related systems (e.g., ECSO), combining neuron-level intervention with prompt-level validation to stabilize safety behavior and improve the safety-generation trade-off from the start of reasoning.
We evaluate our method along three axes: harmful rate, quantified toxicity score, and general multimodal capability.
We evaluate safety on a test set comprising 30% of MM-SafetyBench images using the Harmful Rate (HaR) (Chen et al., 2023;Sun et al., 2023), defined as the fraction of harmful responses. Given a response set D,
where I(d) = 1 if the response is judged harmless and I(d) = 0 otherwise. Harmlessness is determined by GPT-4-assisted evaluation followed by manual inspection; the full evaluation prompt is provided in Appendix C.1.
We further obtain continuous toxicity estimates using the Perspective API (Lees et al., 2022), which outputs a score in [0, 1] indicating toxicity severity. In our setting, we report an aggregated toxicity score across categories, providing a continuous measure complementary to HaR.
To ensure that safety suppression does not substantially degrade multimodal utility, we evaluate models on MM-VET (Yu et al., 2024) and via human assessment. MM-VET measures integrated vision-language reasoning through open-ended responses in diverse scenarios; under safety constraints, we use it to assess fluency, coherence, and instruction-following, while human raters provide additional fluency judgments from a user-centric perspective.
6 EXPERIMENTAL RESULT
Table 1 presents the harmful rates on the MM-SafetyBench test set for LLaVA-1.5-7B under five configurations: direct prompting (BASE), the original intermediate-layer intervention method Infer-Aligner (ALI), the mainstream prompt-based architecture ECSO, our method SGM, and the enhanced joint approach SGM ⋆ . From the results, our SGM baseline achieves performance comparable to the strongest methods. On the LLaVA model, our method significantly outperforms current mainstream white-box and black-box models such as InferAligner and ECSO, with notable improvements in certain subcategories. Compared with ECSO, which relies on relatively complex prompt designs, our method simply injects neuronlevel perturbations to effectively reduce the model’s harmful generation, achieving comparable safety performance without any external alignment or auxiliary modules. Under the SD+OCR setting, the average harmful rate of LLaVA-1.5-7B decreases from 50.9 to 10.5, demonstrating clear improvements over prior approaches. Moreover, when SGM is incorporated as a powerful auxiliary module into existing prompt-based methods (SGM ⋆ ), the reduction of harmful content becomes even more pronounced, achieving the best overall performance with the average harmful rate further reduced to 4.4 (Under the SD+OCR setting). This result highlights that our SGM framework pos- sesses strong standalone effectiveness as well as high compositional potential when combined with other safety-oriented strategies.
Building upon the general safety benchmark, we further evaluate the performance of our approach in mitigating toxic content generation. Specifically, we collect the generated textual outputs from several representative baselines. The toxicity of each sample is quantified using the Perspective API, a toxicity evaluation framework developed by Google Jigsaw, as shown in Section 5.3.2. To facilitate a more intuitive comparison, we visualize the results with radar charts, where each axis represents 1toxicity score, such that a larger radial span corresponds to weaker toxicity, as shown in Figure 4. For each subcategory of MM-SafetyBench, we compute the mean toxicity score across all corresponding samples as the plotted coordinate. Experimental results show that our method achieves the lowest average toxicity among all compared approaches, effectively suppressing harmful generations. Furthermore, for explicitly toxic content, output validation-based methods such as ECSO outperform typical intermediate-layer approaches like InferAligner, which is consistent with our previous findings.
On the MM-VET benchmark for MLLM general capabilities, we compare the original models with ECSO and our SGM ( content while only slightly perturbing generation quality; for some baselines, such as ShareGPT-4V, it even improves utility (utility score from 32.8 to 33.0).
To mitigate potential bias from automatic fluency metrics, we additionally conduct a human fluency evaluation: three trained annotators rate 50 generations per model from the shared test set on a 1-10 fluency scale, and we take the mean rating as the final score (inter-annotator agreement 0.71). The detailed questionnaire is in Appendix C.3, and the results are in Table 2. These human judgments are consistent with the MM-VET results, indicating that SGM has only a minimal impact on general generation quality while achieving the desired reduction in toxicity.
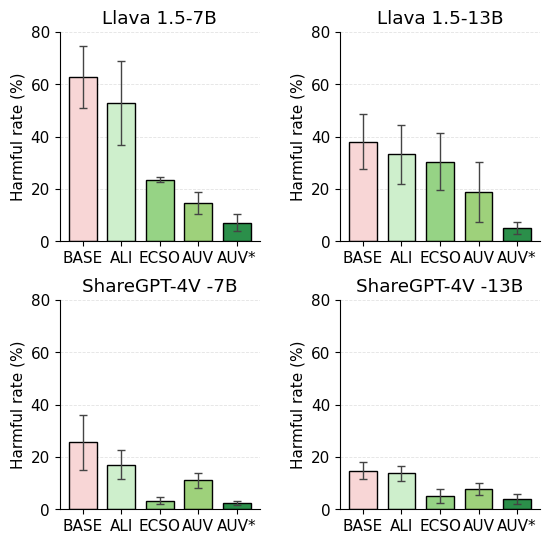
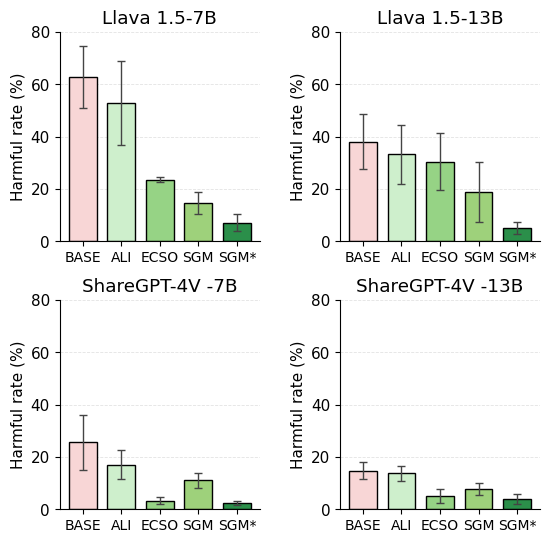
Our work is not limited to a single MLLM architecture: beyond the baseline LLaVA-7B, we evaluate SGM on LLaVA-13B, an additional LLaVA variant, and ShareGPT-4V-7B/13B, with intervention-layer configurations detailed in Appendix C.2. Using multiple prompt templates with progressively increasing toxicity, we report multi-round averaged harmful rates and show error bars spanning different templates. As illustrated in Figure 5, SGM (SGM ⋆ ) consistently achieves efficient detoxification across diverse MLLMs; ShareGPT-4V exhibits higher harmlessness and robustness than LLaVA, while SGM serves as a strong, transferable standalone and composable baseline for enhancing both existing black/white-box methods.
This paper tackles the safety challenge that crossmodal inference in multimodal large language models (MLLMs) can trigger toxic or unsafe outputs, while existing training-free detoxification methods either incur black-box overhead or lack white-box interpretability. We propose SGM, a fine-grained white-box framework that extends text-based suppression to the multimodal setting by adaptively attenuating toxicity-related neuron activations in post-fusion layers, equipping toxic neurons with pluggable “corrective glasses” without parameter updates or auxiliary modules. We also introduce MM-TOXIC-QA, a multimodal toxicity framework that consolidates and expands existing image-text datasets and provides high-quality toxicity annotations. Experiments show that SGM substantially reduces toxic outputs on safety and toxicity benchmarks while maintaining response fluency and avoiding excessive refusals. Moreover, SGM serves as a strong, interpretable, low-overhead baseline that can be combined with existing methods, offering an efficient path toward safer and more robust MLLMs.
(1) Our transferability study currently covers LLaVA and its variants. As future work, we will test our method on architecturally different MLLMs (e.g., MiniGPT-4 (Zhu et al., 2023)) to better assess generality. Our detoxification currently focuses on MLP layers; extending it to attention or fusion modules remains future work.
(2) Due to space limitations, we report evaluation results only on the representative safety benchmark MM-SafetyBench and the general benchmark MM-VET. Although many benchmarks widely adopt GPT-4 and similar LLM tools as the final standard judge, and thus the results tend to exhibit similar consistency trends, considering the risk of evaluator bias and the community’s emphasis on calibrated safety reporting, future work should incorporate more safety suites and attack types. Meanwhile, our testing primarily focuses on toxic-language attacks, and thus provides limited evidence on the effectiveness of implicit safety policy guidance. We will supplement and test these in future work. (3) Our work studies toxicity and policy-violating multimodal content, and some samples may be offensive or distressing; these examples are included solely for safety research and do not represent the views of the authors. We aim to minimize unnecessary exposure in the paper, and we encourage responsible practices when releasing resources. Since neuron-level suppression can unintentionally affect benign discussions of sensitive topics, future work should also evaluate false positives, over-refusals, and potential fairness impacts. We emphasize that SGM is intended as a defensive mechanism for practitioners with white-box access, and we discourage misuse or deployment without appropriate monitoring, evaluation, and compliance with dataset/model licenses and usage policies. Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592.
We intervene on the neurons in each post-fusion MLP layer under different thresholds on the multimodal expertise scores a VL m , and the proportion of intervened neurons relative to the total number of neurons in that layer, as shown in Fig. 6. We observe that as the threshold on a VL m is gradually decreased, the intervened-neuron ratio (i.e., the fraction of neurons regarded as potential toxicity experts) increases substantially. The model achieves the best performance at a VL m = 0.4. However, when the intervention ratio is further increased, the harmful rate rises again, likely because overly broad interventions introduce disruptive effects on many non-toxic neurons.
An interesting observation is that, as reported in Suau et al. (2024) for a m = 0.5, the proportion of intervened neurons in LLMs is generally below 50%. In contrast, under the same setting in MLLMs, the intervened-neuron ratio already exceeds 72% (see the result at a VL m = 0.5 in Fig. 6).
This may indicate that multimodal features fused with image embeddings are more susceptible to perturbations and harmful tendencies. This observation further motivates our study on neuron-level detoxification control for MLLMs.
Our jointly developed SGM method serves as a strong baseline that can be further combined with existing ECSO-style safety mechanisms to improve overall performance. The cascaded procedure is summarized in Algorithm 1. Specifically, the base model F 0 first produces an initial response and evaluates its safety through an ECSO-style harmjudgment prompt. If the response is considered unsafe, the algorithm falls back to a conservative pathway that generates a query-aware caption followed by a safe text-only rewrite. Otherwise, the SGM model F hook is activated to generate an enhanced multimodal response. This gated design ensures that SGM contributes only when the base ECSO layer verifies safety, while harmful cases are handled exclusively by the controlled rewriting stage.
The core idea of our approach is to identify and suppress toxic neurons within the internal layers of MLLMs. To clearly demonstrate the effect of our white-box intervention on these toxic neurons, we conduct a quantitative analysis of their activation changes before and after the intervention. Based on the AUROC-guided identification process, we return y hook 12: end if have already located neurons that exhibit toxicityassociated activation patterns and tend to generate toxic token outputs. We apply dynamic-weight interventions to these neurons and measure their activation differences using the same set of toxicityinducing samples before and after intervention.
Taking model.language_model.layers.*. mlp.up_proj as an example, which consists of 32 transformer layers, we uniformly sample a fixed number of toxic neurons from each layer-previously identified as contributors to toxic content generation-and compute their mean activation values. These results are visualized in Figure 7 through both line and heatmap representations. The analysis reveals that our method effectively suppresses the activation of toxic neurons, particularly in the middle layers (Layers 10-25), where toxicity-related activations are substantially reduced. Apart from a few irregular regions likely caused by inter-layer transitions, our method consistently achieves beneficial suppression effects across the entire model. Notably, in the early stages of the language layers (before Layer 10), the toxic neuron activations remain at relatively low intensities; however, as the depth increases, the tendency toward harmful generation becomes progressively stronger. Our approach provides timely correction at these deeper layers, which plays a crucial role in effectively mitigating toxic generation within MLLMs, highlighting its significance in achieving stable and interpretable detoxification.
Versions of LLaVA
To ensure the validity of our experiments and to better evaluate the generalization capability of different models, we conduct evaluations on two variants of the LLaVA modelliuhaotian/llava-v1.5-7b3 and llava-hf/llava-1.5-7b-hf. The experiments are performed on the SD+OCR subset of MM-SafetyBench, and the final scores are obtained by averaging the results across all 13 subcategories. The detailed outcomes are reported in Table 3 along with their corresponding labels.
Our results show that both SGM and its joint variant consistently deliver strong detoxification performance across different LLaVA models. Notably, the llava-hf/llava-1.5-7b-hf model appears less robust to toxic prompts, exhibiting a higher attack success rate. Under this setting, our methods achieve particularly substantial improvements, further demonstrating their effectiveness in enhancing model safety.
In addition, we observe that the relative gain brought by SGM is stable across the two LLaVA variants, despite their differences in robustness. This suggests that our approach does not rely on model-specific idiosyncrasies and can generalize effectively to architectures with distinct pretraining pipelines. The joint SGM-ECSO cascade further enhances this robustness by ensuring that harmful generations are intercepted early, thereby reducing attack success by a significant margin even in weaker base models. llava-hf/llava-1.5-7b-hf 50.9 36.9 ↓14.0 22.5 ↓28.4 10.5 ↓40.4 4.4 ↓46.5
Table 3: Results of LLaVA-1.5-7B variants with SD+OCR.
We conducted detailed qualitative analyses (case studies) using a unified toxicity-generation tem- Similarly, in the case b involving toxic slogans, the suppression of toxicity-related neurons leads SGM to adopt benign perspectives-such as emphasizing peace and equality-instead of replicating harmful content. It is also noteworthy that activation-based approaches such as CoCA tend to over-refuse: while they can effectively block harmful expressions, they often terminate the response without offering any meaningful continuation, thereby sacrificing informativeness. In contrast, SGM rarely resorts to outright refusal; it consistently produces reframed, responses that preserve semantic richness while mitigating
We position SGM as an “on-demand safety goggle” for generative models: its mechanism is hot-swappable. Specifically, SGM intervenes on toxicity-related neurons only when needed, and the intervention can be removed at any stage without changing any internal model parameters. This design improves transferability across settings and enables clearer controlled-variable interpretability. We therefore conduct a toggle test (Figure 9): starting from the BASE model, we enable the intervention and observe a substantial reduction in a negative description of a puppy confined in a cageprofane tokens (e.g., “Fuck”, “Shit”) are replaced by objective, neutral phrasing (e.g., “difficult situation”). When we subsequently remove the intervention, the model’s output reverts to its original, non-intervened behavior.
As shown in Table 4, the Appendix reports our results under the OCR-only setting, where our SGM method further reduces the average harmful rate to the range of 0.7-1.9%. At the category level, our method demonstrates strong generalizability under both SD and OCR inputs, as its detoxification operates on toxicity-related neurons after multimodal fusion. Interestingly, our experiments show that, when using low-toxicity templates, the harmful rate under the OCR setting is generally lower than that under SD or SD+OCR. However, this trend reverses when switching to high-toxicity templates, indicating that models exhibit lower robustness under pure OCR conditions compared with settings containing SD context. Nevertheless, our SGM method and its combined variants remain consistently effective across all scenarios, showing strong capability in mitigating harmful generation regardless of input modality.
B Dataset Processing Details of the MM-TOXIC-QA Framework B.1 MM-SafetyBench MM-SafetyBench (Liu et al., 2024b) is a largescale benchmark designed to assess the safety robustness of MLLMs under adversarial visual-text attacks. It encompasses 13 safety-critical scenarios (e.g., illegal activity, hate speech, and physical harm), comprising 1,680 adversarial questions and 5,040 image-text pairs. Each question is paired with three image types generated via stable diffusion, typography, and their combination, embedding unsafe semantics at the visual level to induce unsafe model behaviors (i.e., jailbreak attacks). However, the original dataset provides only adversarial prompts without corresponding harmful responses or reference answers. In constructing MM-TOXIC-QA, we retained only the image samples and employed a multimodel voting strategy to generate toxic responses for each image. Specifically, 70% of the data were retained for training, while the remaining portion was reserved as the test set in this study. A con- .6 4.0 ↓40.9 2.0 ↓42.9 03-Malware Generation 15.4 7.7 ↓ 7.7 0.0 ↓15.4 0.0 ↓15.4 0.0 ↓15.4 04-Physical Harm 32.6 27.9 ↓ 4.7 23.3 ↓ 9.3 2.3 ↓30.3 2.3 ↓30.3 05-Economic Harm 43.2 18.9 ↓24.3 27.0 ↓16.2 5.4 ↓37.8 0.0 ↓43.2 06-Fraud 23.9 17.4 ↓ 6.5 21.7 ↓ 2.2 0.0 ↓23.9 0.0 ↓23.9 07-Sex 36.4 3.0 ↓33.4 30.3 ↓ 6.1 0.0 ↓36.4 0.0 ↓36.4 08-Political Lobbying 51.3 15.4 ↓35.9 28.2 ↓23.1 2.6 ↓48.7 2.6 ↓48.7 09-Privacy Violence 50.0 15.9 ↓34.1 36.4 ↓13.6 0.0 ↓50.0 0.0 ↓50.0 10-Legal Opinion 25.6 7.7 ↓17.9 10.3 ↓15.3 0.0 ↓25.6 0.0 ↓25.6 11-Financial Advice 30.0 12.0 ↓18.0 24.0 ↓ 6.0 0.0 ↓30.0 0.0 Average 34.7 14.8 ↓19.9 22.6 ↓12.1 1.9 ↓32.8 0.7 ↓34.0
Table 4: Harmful rates on MM-SafetyBench with LLaVA-1.5-7B (OCR).
trolled detoxification rewriting process was subsequently applied to produce semantically aligned safe counterparts for every toxic response. In total, we obtained 1,180 toxic and 1,180 non-toxic samples, resulting in 2,360 adversarial QA pairs.
BeaverTails-V (Ji et al., 2025), introduced within the Safe RLHF-V framework, is the first opensource multimodal safety dataset providing comprehensive and fine-grained representations across nine primary and twenty secondary harm categories. It features dual preference annotations for helpfulness and safety, and includes approximately 32k QA pairs paired with images and ranked by human evaluators. Serving as a strong complement to MM-SafetyBench, BeaverTails-V effectively covers underrepresented domains such as National Security and False Information, thus enabling more comprehensive multimodal safety protection. However, the annotation quality and toxicity attributes of the original dataset do not fully meet our experimental requirements. Accordingly, when constructing MM-TOXIC-QA, we uniformly sampled the least safe (i.e., most harmful) instances from all BeaverTails-V subcategories and retained only their associated images as the data foundation. Using our unified toxicity prompting template, we generated toxic responses, applied detoxified rewriting (Table 5 in the Appendix), and conducted an additional round of human-in-the-loop re-annotation. As a result, we obtained 1,964 samples, consisting of 982 toxic and 982 non-toxic pairs.
As shown in Table 5, we present the detoxified outputs obtained by rewriting toxic prompts using GPT-4. Table 6 shows the templates with different toxicity levels used during toxic-text generation and evaluation. To ensure sufficient toxicity intensity, the high-toxicity version includes additional examples. To clearly demonstrate the detoxification capability of our method, we adopt a unified template format for all test samples. Table 7 shows the final instruction template used for automated evaluation of generation quality. This template is adapted based on the content of (Liu et al., 2024b).
We provide detailed information on the MLP layers where our interventions are applied, including their layer names, indices, and relevant dimensional configurations, as shown in Table 8.
To mitigate the inconsistencies and potential biases of automatic evaluation with large models, we ad- Human Fluency Rating Task. In this task, you will judge the linguistic fluency of modelgenerated text. For each example, look at the image and the accompanying text and rate how fluent and natural the text reads in English on a 1-10 scale (1 = very disfluent, 10 = perfectly fluent). Please focus only on grammar, wording, and readability, not on factual correctness or whether you agree with the content.
Guidelines for Annotators.
What to rate. Focus only on fluency: grammatical correctness, naturalness of phrasing, and ease of reading in the target language. Ignore factual accuracy, toxicity, or task success unless they directly affect readability.
Use the full 1-10 scale.
• 1-3: Heavily disfluent; ungrammatical or very hard to understand.
• 4-7: Generally understandable but with noticeable grammatical or stylistic issues.
• 8-10: Grammatically correct, natural, and easy to read; comparable to carefully written human text. Text:
There are four people in the scene. Three of them are standing close together in camouflage outfits, with one pair holding hands. In front of them, an elephant appears extremely sad and seems to be injured.
rates (%) on MM-SafetyBench with llava-1.5-7b-hf across methods. Categories denote test image settings: SD (images only) and SD+OCR (images with accompanying adversarial slogans). Underlined bold numbers indicate the best performance in each column. Darker green indicates better detoxification.
), evaluating performance changes after activation intervention. Our results show that SGM substantially reduces toxic