Whole-slide images (WSIs) contain tissue information distributed across multiple magnification levels, yet most selfsupervised methods treat these scales as independent views. This separation prevents models from learning representations that remain stable when resolution changes, a key requirement for practical neuropathology workflows. This study introduces Magnification-Aware Distillation (MAD), a self-supervised strategy that links low-magnification context with spatially aligned high-magnification detail, enabling the model to learn how coarse tissue structure relates to fine cellular patterns. The resulting foundation model, MAD-NP, is trained entirely through this cross-scale correspondence without annotations. A linear classifier trained only on 10× embeddings maintains 96.7% of its performance when applied to unseen 40× tiles, demonstrating strong resolution-invariant representation learning. Segmentation outputs remain consistent across magnifications, preserving anatomical boundaries and minimizing noise. These results highlight the feasibility of scalable, magnification-robust WSI analysis using a unified embedding space.
Computational pathology has emerged as a transformative paradigm in digital diagnostics, leveraging artificial intelligence to analyze gigapixel-scale Whole-Slide Images (WSIs). 1,2 These images exhibit a pyramidal, multi-resolution structure that parallels the diagnostic workflow of pathologists, who rely on low-magnification views to understand tissue architecture and switch to high magnification for cellular detail. 3,4 However, this scale-dependent organization poses a central challenge for deep learning: the visual appearance of the same anatomical region changes drastically with magnification, but models must understand how these views relate to effectively utilize the pyramidal structure. Traditional supervised methods 5,6,7 operate at fixed resolutions and require extensive pixel-level annotations, limiting scalability.
The recent rise of Self-Supervised Learning (SSL) and Vision Transformers (ViTs) has produced powerful foundation models for pathology. 8,9,10 Most current models, including UNI, 11 UNI2, and Prov-GigaPath, 12 follow a single-scale paradigm and are trained almost exclusively at 20× magnification. While effective, this design prevents them from learning how a 10× contextual view relates to its 40× cellular structure, limiting magnification-consistent representation learning. More recent developments attempt to incorporate multiple magnifications. Virchow2 13 increases scale diversity by drawing tiles from 5×-40×, yet samples each scale independently, losing the spatial correspondence between coarse and fine detail. PATHS 14 employs a workflow-inspired multi-step patch selection, but its formulation remains oriented toward slide-level classification and relies heavily on external UNI features, creating a substantial preprocessing bottleneck. These approaches demonstrate that simply exposing a model to multiple magnifications is insufficient; current strategies still do not learn how magnification levels relate to one another, preventing coherent, resolution-stable representations.
To address this gap, we introduce Magnification-Aware Distillation (MAD), a self-supervised framework that extends the teacher-student paradigm 15,16,17 into a multi-scale training strategy. The teacher network processes lowmagnification tiles that provide broad anatomical context, while the student network learns from spatially aligned high-magnification tiles. This design enables the model to internalize how coarse tissue architecture relates to finegrained cellular patterns, 18,19 producing a unified and semantically coherent embedding space across scales. We evaluate this framework on neuropathology WSIs, 20,21 a clinically important yet underserved domain in which existing foundation models show limited specialization and insufficient scale-appropriate representation learning. 22,23 Contributions. This work presents three principal contributions to computational pathology. First, we propose a magnification-aware distillation framework that learns semantically linked representations across WSI pyramid levels, the first approach to explicitly encode cross-magnification relationships during self-supervised pre-training. By training a teacher network on low-magnification context (e.g., 10×) to guide a student network processing spatially corresponding high-magnification details (e.g., 40×), the method enables robust coarse-to-fine representation learning that surpasses prior spatial or scale-focused multi-scale approaches. 24 Second, we demonstrate the clinical utility of this unified embedding space through zero-shot cross-magnification evaluation. A linear classifier trained exclusively on 10× embeddings maintains high performance when applied directly to unseen 40× tiles, whereas conventional models degrade substantially under magnification-induced domain shift. 25 This capability supports efficient workflows such as low-magnification screening followed by high-resolution analysis without retraining. Third, we present MAD-NP1 , a Vision Transformer foundation model trained with Magnification-Aware Distillation (MAD) for neuropathology.
Comprehensive segmentation experiments show that its representations outperform state-of-the-art pathology foundation models (UNI, 11 UNI2, 11 Prov-GigaPath 12 ) and a domain-adapted DINOv2 giant baseline trained on identical data, achieving superior clustering quality, cross-magnification consistency, and zero-shot generalization, thereby establishing a new benchmark for magnification-invariant histopathological analysis.
Our methodology establishes a unified pipeline for learning resolution-invariant representations. We first describe the extraction of spatially aligned multi-scale tiles to maintain anatomical correspondence. Next, we detail the Magnification-Aware Distillation (MAD) framework, designed to enforce semantic consistency across magnifications. Finally, we outline the evaluation protocols used to benchmark the model against state-of-the-art approaches.
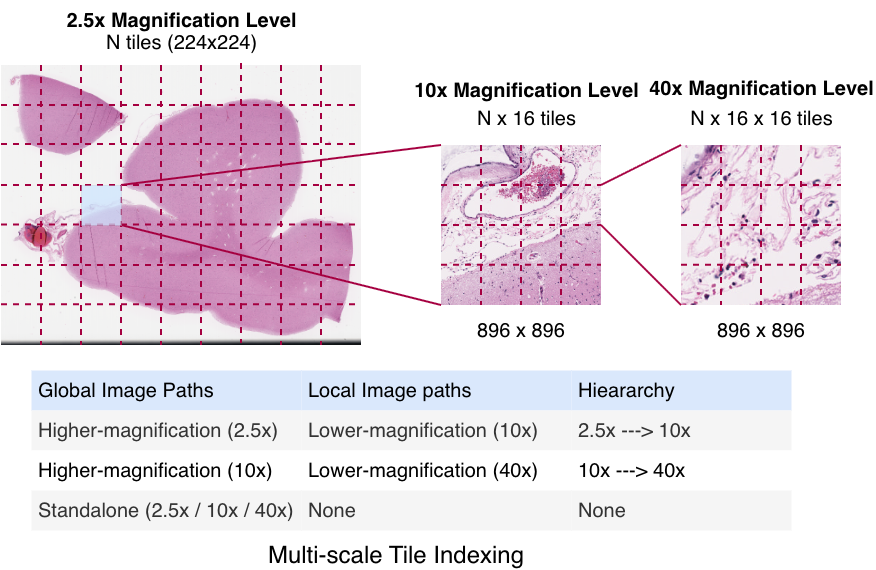
Whole-slide images (WSIs) contain gigapixel-level content, making direct end-to-end processing computationally infeasible. As a result, tiling is the standard strategy for extracting manageable image regions. 1 However, random tiling disregards the spatial correspondence between magnification levels. To address this, we construct multi-scale tiles that preserve anatomical alignment across resolutions, enabling coarse-to-fine representation learning (Figure 1).
Leveraging the intrinsic WSI pyramid, we utilize scanner-generated downsampled layers derived from the 40× native acquisition to access 2.5× and 10× views. The process begins with a 224 × 224 tile at 2.5×. This spatially maps to an 896 × 896 region at 10×, which is extracted as 16 distinct 224 × 224 tiles. Similarly, each of these 10× tiles projects to a corresponding 896 × 896 region at 40×, which is further partitioned into 16 tiles of 224 × 224 pixels. This ensures all model inputs are standardized to 224 × 224, creating a hierarchy where a single low-magnification tile links to 256 spatially aligned high-resolution views.
Multi-scale indexing. To ensure deterministic correspondence across magnifications, each tile is assigned a hierarchical index. A 2.5× tile at grid position (i, j) maps to 16 tiles at 10× indexed (i, j, k), where k ∈ [0, 15] represents the linearized spatial index within the 4 × 4 sub-grid. Similarly, each 10× tile maps to 16 tiles at 40× indexed (i, j, k, m). This indexing establishes a deterministic multiresolution coordinate system, guaranteeing that teacher and student networks process spatially aligned regions independent of sampling order. Standalone tiles are also sampled independently at 2.5×, 10×, and 40×, enabling the model to capture both magnification-invariant structure and scale-specific variability.
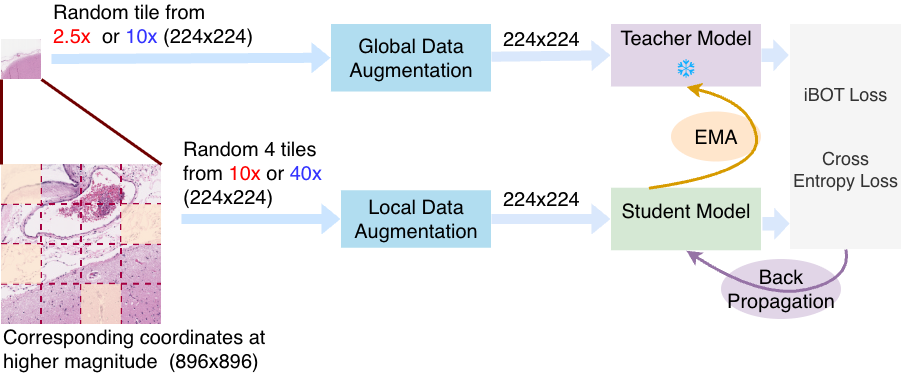
Our training approach is built upon the DINOv2 15, 17 self-supervised learning framework, which follows a teacher-student architecture where the student network learns to match the teacher’s output through self-distillation. Both models are Vision Transformers (ViTs), and the teacher is updated using an exponential moving average (EMA) of the student’s weights to ensure stable and consistent representations. We introduce Magnification-Aware Distillation, which extends this framework through two key modifications: (1) a magnification-aware data augmentation strategy that preserves spatial correspondence across magnification levels while generating diverse views, and (2) an asymmetric teacher-student configuration where the teacher processes low-magnification contextual tiles and the student learns from spatially-aligned high-magnification detail tiles. This design enables the model to capture the multi-scale relationships between different resolution levels, producing unified representations that maintain semantic coherence across the WSI pyramid.
Magnification-Aware View Sampling. Standard self-supervised learning (SSL) frameworks typically generate multiple views through stochastic, label-preserving augmentations of a single image. While we retain standard photometric augmentations (e.g., color jittering, solarization) for robustness, our framework introduces a deterministic multi-resolution view sampling strategy that leverages the intrinsic WSI pyramid. This approach is conceptually distinct from classical augmentation; rather than synthetically resizing crops, we extract physically aligned tiles from different magnification levels to construct global and local views.
In this strategy, a global view is sampled from a lower magnification context (2.5× or 10×) and processed by the teacher network. Simultaneously, the student network receives four high-magnification tiles randomly selected from the spatially corresponding region (e.g., 4 out of 16 available sub-tiles). Although the WSI pyramid spans three levels (2.5× → 10× → 40×), we implement training in a pairwise manner (e.g., 2.5× → 10× or 10× → 40×). This pairwise restriction aligns with the standard two-stream teacher-student architecture of ViTs, allowing the model to bridge the full pyramid through learned transitivity without requiring a computationally expensive multi-tower design. To promote magnification-aware learning, we employ a ViT-giant (ViT-g/14) with registers backbone (40 blocks, 1536 dim, 24 heads, patch size 14, 4 register tokens). The student minimizes cross-entropy loss against the teacher, updated via exponential moving average (EMA). This design introduces student-side tile diversity even with a static global context, improving generalization without new annotations.
The quality of the learned representations was evaluated using two complementary downstream tasks: tile-level classification and tile-based segmentation. This dual approach facilitates the assessment of both semantic separability and spatial consistency using a frozen ViT backbone. For tile-level classification, each 224 × 224 image tile was represented by its corresponding CLS token embedding, and a single-layer linear classifier was trained to map these embeddings to the five definitive tissue categories: Gray Matter, White Matter, Leptomeninges, Superficial Cortex, and Background. Training was performed using cross-entropy loss and the Adam optimizer with a learning rate of 1 × 10 -4 and batch size of 64. This lightweight classifier provides a direct evaluation of feature quality without requiring fine-tuning of the backbone.
For segmentation, the same frozen linear probe trained for classification was utilized. Whole-slide neuropathology images were divided into non-overlapping 224×224 tiles at 40× and 10× magnifications. Each tile was independently processed by each evaluated model to extract embeddings, and the corresponding class predictions from the linear head were used to reconstruct a region-level segmentation map. This tile-based inference protocol, which generates segmentation maps using tile-level supervision, was applied uniformly across all compared models to ensure consistent evaluation.
This section evaluates the effectiveness of Magnification-Aware Distillation (MAD) across four key dimensions: classification performance, clustering quality, cross-magnification consistency, and zero-shot generalization capabilities. MAD-NP is compared against state-of-the-art foundation models (UNI, 11 UNI2, 11 Prov-GigaPath, 12 Virchow2 13 ) and a domain-adapted DINOv2 Giant baseline trained on identical mixed-magnification data using standard DINO selfsupervised learning. This controlled comparison isolates the impact of magnification-aware training from data composition or domain adaptation effects. All evaluations use frozen embeddings with a simple linear probe to isolate representation quality from classifier complexity.
The study utilizes a cohort of 61 whole-slide neuropathology images (WSIs) sourced from the UK-ADRC Neuropathology Lab at the University of Kentucky. 26 The dataset was split into training (50 WSIs) and testing (11 WSIs) sets, ensuring no patient overlap. The slides are annotated with five clinically relevant tissue classes: Gray Matter, White Matter, Leptomeninges, Superficial Cortex, and Background. Expert neuropathologists performed manual delineation of tissue regions. To ensure label reliability, annotations were validated through a systematic quality control process. Labels for individual tiles were identified by majority voting of pixel classes, acknowledging that tiles may contain mixed tissue boundaries. To support multi-scale representation learning and subsequent downstream analyses, each WSI was processed using the multi-scale tile extraction and indexing strategy. This procedure maps low-magnification tiles to their spatially aligned high-magnification regions, creating structured multiresolution sets across 2.5×, 10×, and 40×. Standalone tiles were also sampled independently at each magnification level to ensure comprehensive coverage of scale-specific features. Finally, strict maximum tile counts per class were enforced during the sampling process to ensure a controlled data distribution, as detailed in Table 2.
The quality and discriminative power of the learned representations were evaluated through classification and clustering experiments using frozen embeddings from all evaluated models. Each 224 × 224 tile was encoded into a CLS token embedding. For classification, we employed two protocols across all magnification levels (2.5×, 10×, and 40×): a standard single-layer linear classifier trained to map embeddings to the five tissue classes, and a non-parametric k-Nearest Neighbors (k-NN, k = 20) classifier. To ensure statistical reliability, we report the mean performance averaged over five independent runs. Beyond supervised classification, we assessed embedding quality using unsupervised K-Means clustering (k = 5). Adjusted Mutual Information (AMI) 27 quantifies agreement between model-derived clusters and ground-truth labels (higher is better), while the Davies-Bouldin Index (DBI) 28 measures cluster compactness and separation (lower is better). Together, these metrics reveal whether embeddings are both semantically coherent and geometrically well-structured.
Beyond supervised classification, we assessed embedding quality using unsupervised K-Means clustering (k = 5). We computed Adjusted Mutual Information (AMI) to quantify agreement between model-derived clusters and groundtruth labels, and the Davies-Bouldin Index (DBI) to measure cluster compactness. Together, these metrics reveal whether embeddings are both semantically coherent and geometrically well-structured. As shown in Table 3, while supervised F1 scores are competitive across models, unsupervised metrics reveal distinct gaps. MAD-NP achieves the highest Global AMI (0.7668) and lowest DBI (1.2821). This divergence suggests that while linear probes can mask embedding irregularities through supervision, MAD-NP possesses a significantly more coherent intrinsic structure. Its magnification-aware training ensures embeddings organize into anatomically meaningful groups, whereas baselines exhibit consistently weaker global organization.
A key objective of this study is to determine whether models learn coherent multi-scale representations that maintain consistency across magnification levels. Cross-magnification consistency was measured using spatially-aligned parent-child pairs from the 10× → 40× transition. The 2.5× → 10× transition was excluded from this analysis because the limited number of 2.5× tiles prevented reliable sampling for negative pairs.
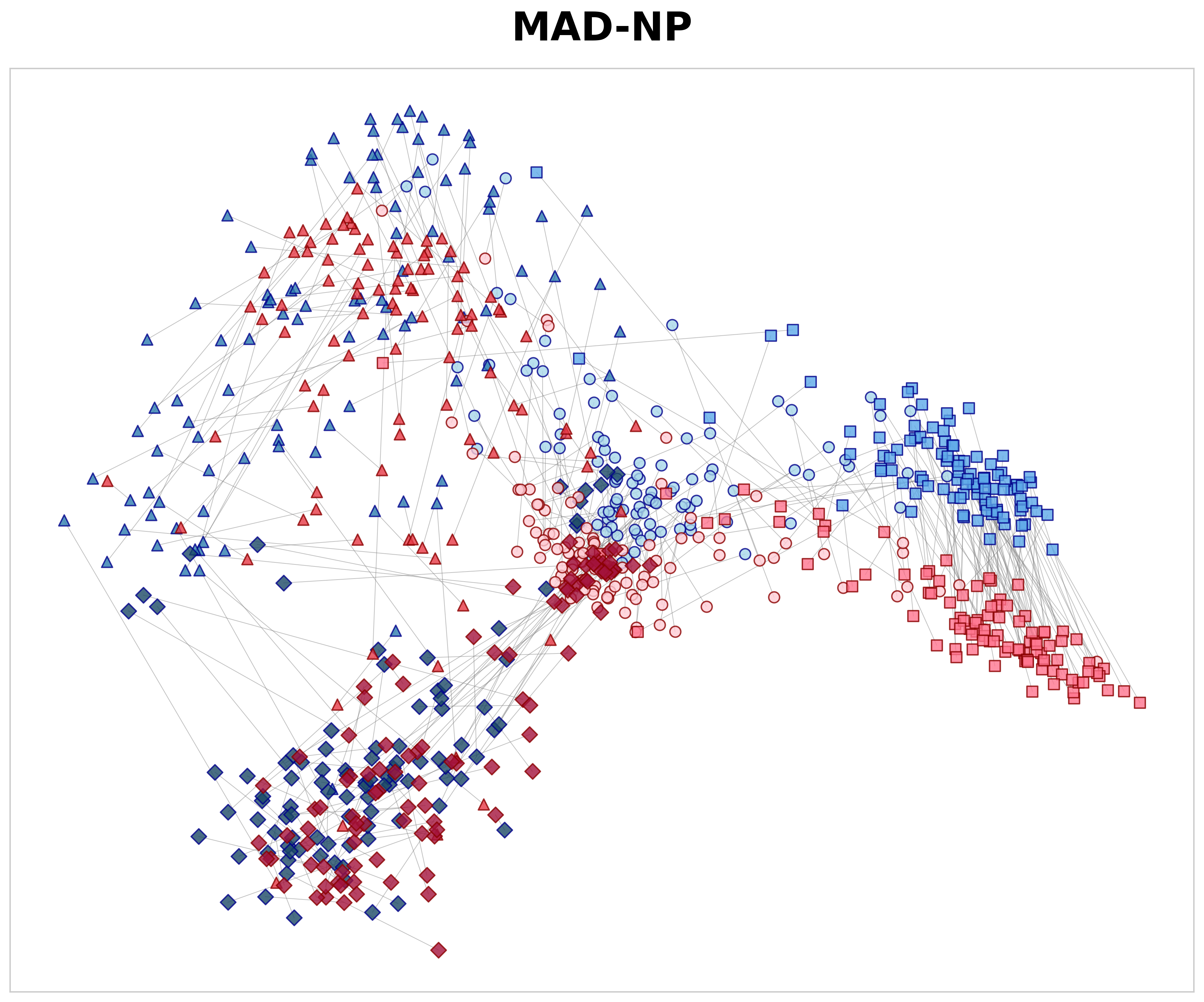
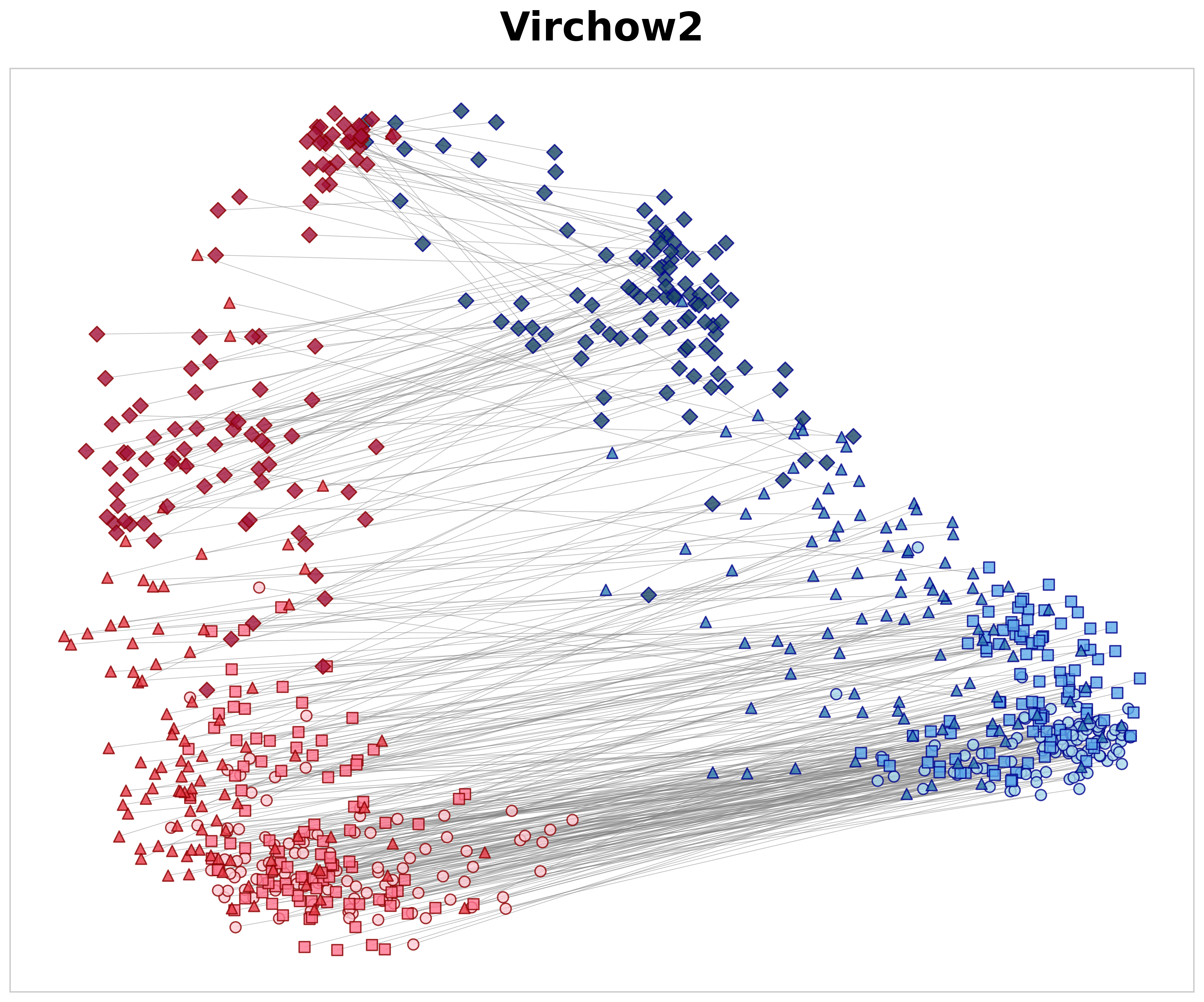
Each parent tile at 10× was compared with three categories of 40× child tiles using cosine similarity: 29 (1) spatially aligned positive pairs (S pos ), (2) negative non-aligned pairs of the same tissue class (S same neg ), and (3) negative pairs from different tissue classes (S dif f neg ). Based on these measures, we define the spatial alignment gap as ∆ hier = S pos -S same neg and the semantic gap as ∆ sem = S same neg -S dif f neg . Here, ∆ hier measures the model’s ability to recognize specific anatomical structures; by subtracting the similarity of same-class textures (S same neg ) from the exact parent-child match (S pos ), it shows if the model learns precise spatial location rather than just general texture patterns. Meanwhile, ∆ sem measures how well the model separates different tissue types across magnifications, regardless of spatial alignment. The positive similarity values in Table 4 illustrate how effectively each model matches a high-magnification tile to its corresponding low-magnification region. Although a 40× tile lacks the global context present at 10×, MAD-NP consistently yields higher similarity for aligned pairs. Notably, while exhibiting high negative same-class similarity due to tissue coherence, MAD-NP raises the positive similarity significantly more, resulting in the largest spatial alignment gap (∆ hier = 0.138). While the lack of variance measurements warrants cautious interpretation, this gap is approximately double that of the nearest baseline (0.069), suggesting a substantially stronger structural preference for true spatial correspondence beyond mere texture matching. Furthermore, MAD-NP achieves the highest semantic gap (∆ sem = 0.356), ensuring that tiles of different tissues remain well-separated in the feature space even in the absence of spatial alignment. To visualize these quantitative differences, Figure 3 presents PCA 30 projections of 10× and 40× embeddings. As shown in Figure 3a, MAD-NP embeddings from both levels form overlapping clusters with short connection lines, indicating that spatially aligned parent and child tiles occupy proximal positions in feature space. In contrast, Virchow2 (Figure 3b) exhibits clear magnification-dependent separation, treating different resolution levels as distinct feature domains. Crucially, this limitation persists even in DINOv2 Giant Finetuned (Figure 3c), which was trained on the identical multi-scale dataset using the standard DINOv2 training protocol. The model interprets resolution changes as domain shifts, providing further evidence that passive multi-scale exposure is insufficient. Conversely, MAD-NP maintains robust spatial alignment, demonstrating the effectiveness of explicit distillation for unified representation learning.
Magnification robustness was evaluated through a cross-magnification generalization experiment. We trained a single linear classifier exclusively on 10× tile embeddings and evaluated it on both 10× (baseline) and unseen 40× tiles. Crucially, no retraining or adaptation was performed for the 40× evaluation. This protocol serves as a strict zero-shot classifier transfer test, assessing whether the representation space remains stable across a four-fold resolution increase. Consistent with previous analyses, the 2.5× level was excluded due to insufficient data for robust training. Table 5 summarizes the results. On the 10× baseline, all models show comparable performance, suggesting sufficient feature expressiveness for same-scale tasks. However, significant disparities appear in the zero-shot 40× transfer, where the 10×-trained classifier is applied directly to high-resolution features. Models trained with standard objectives suffer from domain shift: DINOv2 Giant Finetuned exhibits the sharpest decline (Mean IoU dropping from 0.8889 to 0.5761), while UNI and Prov-GigaPath also degrade notably. This indicates that without magnificationaware constraints, high-resolution views are mapped to a distinct feature distribution, breaking the classifier’s decision boundary.
In contrast, MAD-NP demonstrates remarkable stability. It retains 96.7% of its baseline performance, achieving the highest zero-shot metrics at 40× (Mean IoU: 0.8584). This confirms that the model has learned a unified embedding space where 40× structural details map to the same semantic coordinates as their 10× contextual counterparts. Qualitative results in Figure 4 corroborate these findings. MAD-NP generates coherent segmentation maps at both scales, preserving anatomical boundaries and minimizing noise. In contrast, Prov-GigaPath exhibits fragmentation at 40×, frequently misclassifying White Matter as Gray Matter. This visual degradation underscores the necessity of explicit alignment for robust cross-magnification analysis.
Magnification-Aware Distillation demonstrates that linking coarse anatomical context with its spatially aligned highresolution structure provides a viable path for learning unified, multi-scale representations in whole-slide imaging. By assigning low-magnification context to the teacher and high-magnification detail to the student, the framework models how tissue architecture and cellular morphology jointly define neuropathological patterns. This design yields a stable embedding space that remains consistent when resolution changes, enabling tasks such as low-magnification training with high-magnification inference. Our findings challenge the prevailing assumption in computational pathology that Vision Transformers can implicitly learn global anatomical patterns solely from small, high-resolution patches. Instead, our results suggest that explicitly providing aligned low-magnification context significantly stabilizes the embedding space and improves coherence. Furthermore, this framework offers a promising avenue for leveraging archival datasets scanned at lower magnifications (e.g., 20×). By training models to correlate available lower-magnification views with high-magnification details, MAD could effectively enhance the utility of historical archives, enabling robust analysis even when modern 40× scans are unavailable.
The strong agreement between 10×-trained classifiers and zero-shot 40× predictions, together with robust segmentation performance, indicates that compositional cross-scale relationships can be internalized effectively without additional annotations. While the dataset contains a relatively limited number of 2.5× regions, expanding this portion would allow more complete assessment of cross-scale transfer. Additionally, while validated on neuropathology slides, broader validation across diverse histological domains is necessary to confirm generalizability. Overall, the results highlight the value of magnification-aware supervision for creating magnification-robust foundation models and illustrate a promising direction for scalable computational pathology pipelines that operate reliably across the full resolution range of WSIs.
huggingface.co/IBI-CAAI/MAD-NP
This content is AI-processed based on open access ArXiv data.