Bilateral negotiation is a complex, context-sensitive task in which human negotiators dynamically adjust anchors, pacing, and flexibility to exploit power asymmetries and informal cues. We introduce a unified mathematical framework for modeling concession dynamics based on a hyperbolic tangent curve, and propose two metrics burstiness (τ ) and the Concession-Rigidity Index (CRI) to quantify the timing and rigidity of offer trajectories. We conduct a large-scale empirical comparison between human negotiators and four state-of-the-art large language models (LLMs) across natural-language and numeric-offers settings, with and without rich market context, as well as six controlled power-asymmetry scenarios. Our results reveal that, unlike humans who smoothly adapt to situations and infer the opponents position and strategies, LLMs systematically anchor at extremes of the possible agreement zone for negotiations and optimize for fixed points irrespective of leverage or context. Qualitative analysis further shows limited strategy diversity and occasional deceptive tactics used by LLMs. Moreover the ability of LLMs to negotiate does not improve with better models. These findings highlight fundamental limitations in current LLM negotiation capabilities and point to the need for models that better internalize opponent reasoning and context-dependent strategy.
Bilateral bargaining scenarios involve a dynamic interplay of reasoning and communication, as each participant works to understand the other's intentions and perspectives. Such understanding is essential for crafting strategic offers and employing persuasive language to steer negotiations toward mutually beneficial outcomes.
There is growing interest in leveraging large language models (LLMs) for negotiation tasks, both to support human training and to autonomously conduct economic interactions. Studying the negotiation capabilities of LLMs not only aids in deploying them in practical settings but also serves as a valuable lens to evaluate their underlying competencies. These include their ability to reason about incentives and goals, sustain coherent multi-turn dialogue, follow strategic prompts, and adapt to various roles and objectives.
In this work, we contribute to this emerging area by:
- Proposing a mathematical framework and novel metrics to track offer dynamics and latent trends in negotiation settings; 2. Comparing human and LLM negotiation performance under identical conditions; 3. Investigating the role of context in shaping LLM negotiation behavior; 4. Introducing controlled power asymmetries to assess their effects on outcomes; 5. Conducting qualitative analysis of emergent strategies and linguistic patterns.
Recent research has begun to explore the economic behavior and strategic reasoning capabilities of LLMs in negotiation contexts. (Ross, Kim, and Lo 2024) examined whether LLMs exhibit human-like behavioral biases by adapting canonical games from behavioral economics. They quantified biases such as inequity aversion, risk/loss aversion, and time discounting, and found that LLMs exhibit distinct behavioral patterns showing stronger altruism but weaker loss aversion compared to both humans and rational agents. However, their work involved fitting different utility curves to different games, without a general negotiation framework.
Another line of research has analyzed negotiation outcomes and tactics employed by LLMs. (Vaccaro et al. 2025) showed that LLM agents perceived as “warm” reached agreements more frequently and were better at value creation in integrative negotiations. (Bianchi et al. 2024) demonstrated that behavioral cues can improve agent payoffs by up to 20%, while also revealing irrational tendencies. (Xia et al. 2024) highlighted the difficulties LLMs encounter when acting as buyers.
Despite these advances, existing studies rarely compare LLMs with humans in matched scenarios or explore how LLM behavior shifts across different negotiation structures, such as power asymmetry. They also tend to overlook qualitative aspects like language use and strategy emergence, and typically lack systematic quantitative tools to measure trends like concession patterns or inferred intentions.
Our work addresses these gaps by combining rigorous experimental control with both qualitative and quantitative analyses of negotiation dialogues. We adopted a bilateral negotiation scenario from (Heddaya et al. 2023). In this setup, both the buyer and seller were informed of the $240,000 asking price and shared identical information regarding the house, its surrounding area, and recent sales prices of comparable homes. Crucially, each participant also received a private valuation for the house: $235,000 for the buyer and $225,000 for the seller.
To examine the role of information exchange, we defined two settings: (i) a numeric-only format, where parties exchanged numerical bids; and (ii) a natural language format, where negotiation occurred through free-form text, following (Heddaya et al. 2023).
Human negotiation data for this setting was sourced from the dataset provided by (Heddaya et al. 2023). For LLM negotiation data, we use similar prompts as given to humans to simulate 100 self-play negotiations (negotiations where buyer and seller agent are simulated by the same LLM model) per model using the models GPT-o4-mini, GPT-4.1mini, GPT-4o-mini and GPT-4.1-nano ((OpenAI 2025b), (OpenAI 2025a), (OpenAI 2024)).
Classical alternating-offers work (e.g. (Faratin, Sierra, and Jennings 1998)) model concessions with a power-law
where the exponent e yields linear (e=1), early-concession (“conceder”, e<1), or late-concession (“boulware”, e>1) profiles. As curvature is governed by a single parameter, the function cannot simultaneously capture richer patterns observed in bounded negotiations such as an earlyrigidity → midstageflexibility → laterigidity arc, an earlyflexibility → laterigidity arc, or persistent rigidity throughout (Baarslag et al. 2014;Oprea 2002;Nastase 2006).
In addition, negotiators’ perceived reservation prices may diverge from the true p min , p max supplied ex-ante, further undermining the static power-law assumption.
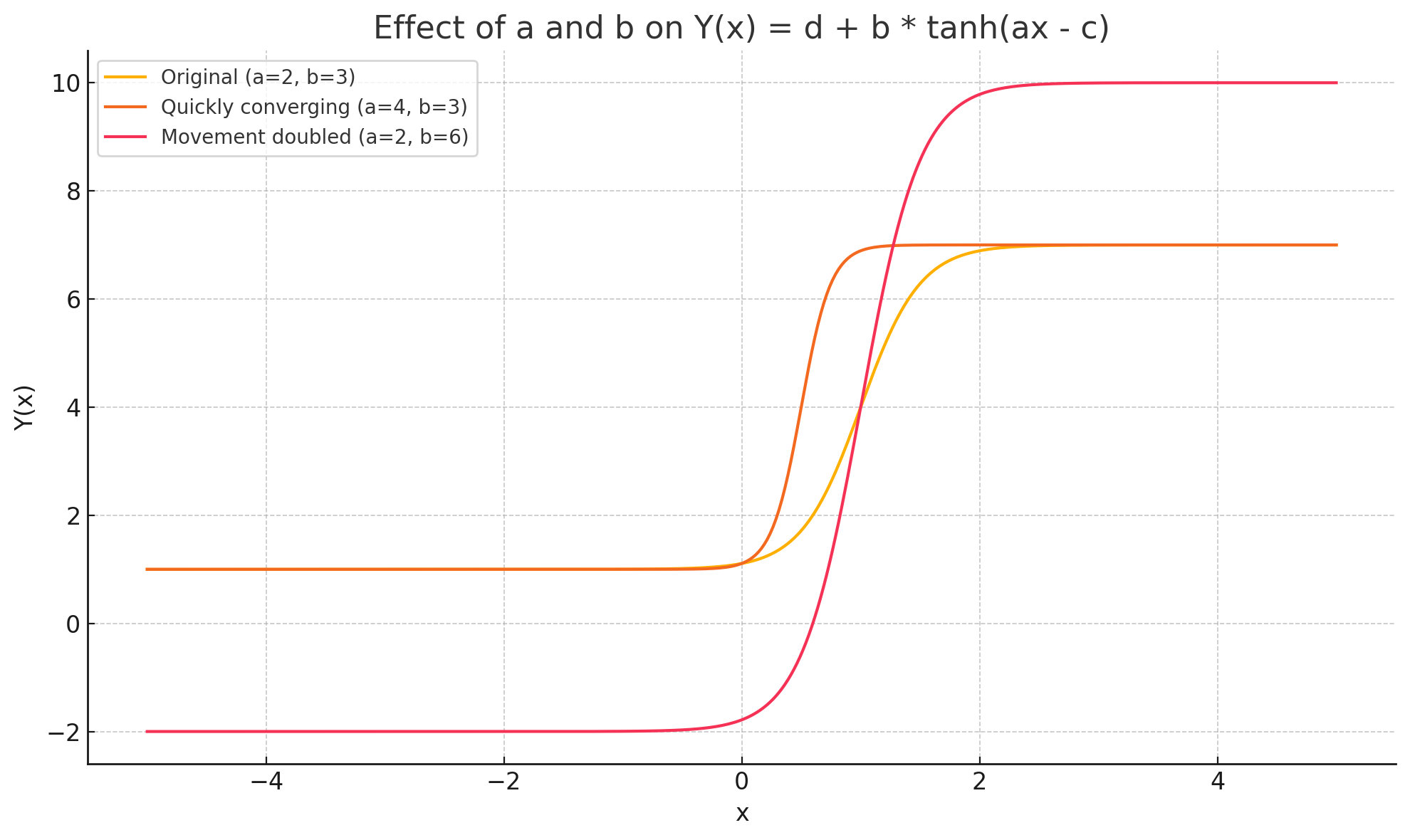
To address this need for a model that can accommodate such nuanced dynamics, we therefore introduce a hyperbolic tangent model,
specifically focusing on its behavior in the first quadrant (representing non-negative negotiation rounds x and offer values y). Critically, we fit separate tanh curves for buyers and sellers. This separate fitting allows the distinct parameters (a, b, c, d) for each role to capture their unique strategies.
Where,
• a: concession pace. Controls how quickly offers shift.
Larger |a| compresses the high-curvature region into a shorter interval (width ≈ 1.32/|a|). The sign indicates direction: a > 0 implies upward movement of offers, a < 0 downward. • b: concession span. Half of the total movement the negotiator is willing to make; the full range is 2|b|.
This “elbow window” defines the interval in which concessions occur at maximum speed. The negotiation’s burstiness τ is defined as the peak concession rate, τ = |a scaled | × b scaled , where a scaled and b scaled are obtained via min-max normalization of the raw parameters across all fitted negotiations, ensuring each lies in (0, 1) and contributes equally.
To quantify the proportion of negotiation time spent in rapid concessions, we define the Concession-Rigidity Index (CRI)
where T is the total number of negotiation rounds. Hence CRI ∈ [0, 1], with values near 1 indicating a brief, intense burst of concessions (high rigidity) and values near 0 corresponding to steady concessions throughout (low rigidity). As a single summary statistic, CRI captures the overall rigidity of the negotiation trajectory. We define a novel, data-driven Concession Rigidity Index (CRI * ) to quantify concession dynamics, and employ a multi-stage pipeline for clustering negotiation strategies. Complete methodology and validation details are provided in Appendix 6. We fit a curve where x the turn index and y is the offer exchanged at x
We fit the curves separately for each of the 100 negotiations per model and used the median of the fitted parameters to represent each model. More details about the curve fits can be found in the appendix 6
To understand how language models behave across negotiation settings, we evaluate performance under two interaction protocols: (A) Natural Language and (B) Alternating Offers Only.
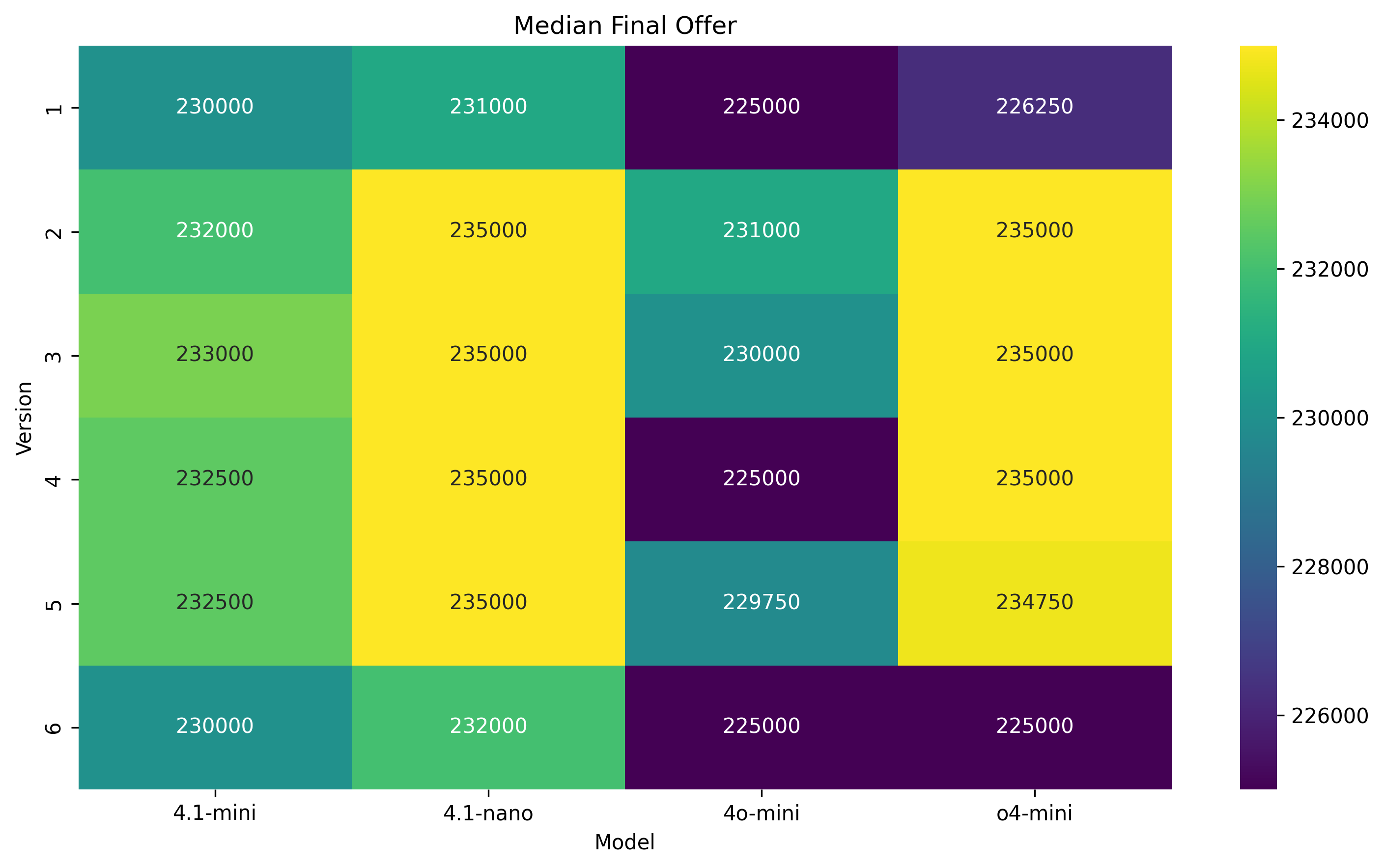
Zone of Possible Agreement (ZOPA). Given a seller reservation price of $225,000 (minimum acceptable) and a buyer reservation price of $235,000 (maximum payable), the Zone of Possible Agreement spans $225,000-$235,000, with a midpoint at $230,000. This range defines the theoretical bounds for settlement and guides anchor placement and concession dynamics.
For each configuration, we report the following key behavioral metrics:
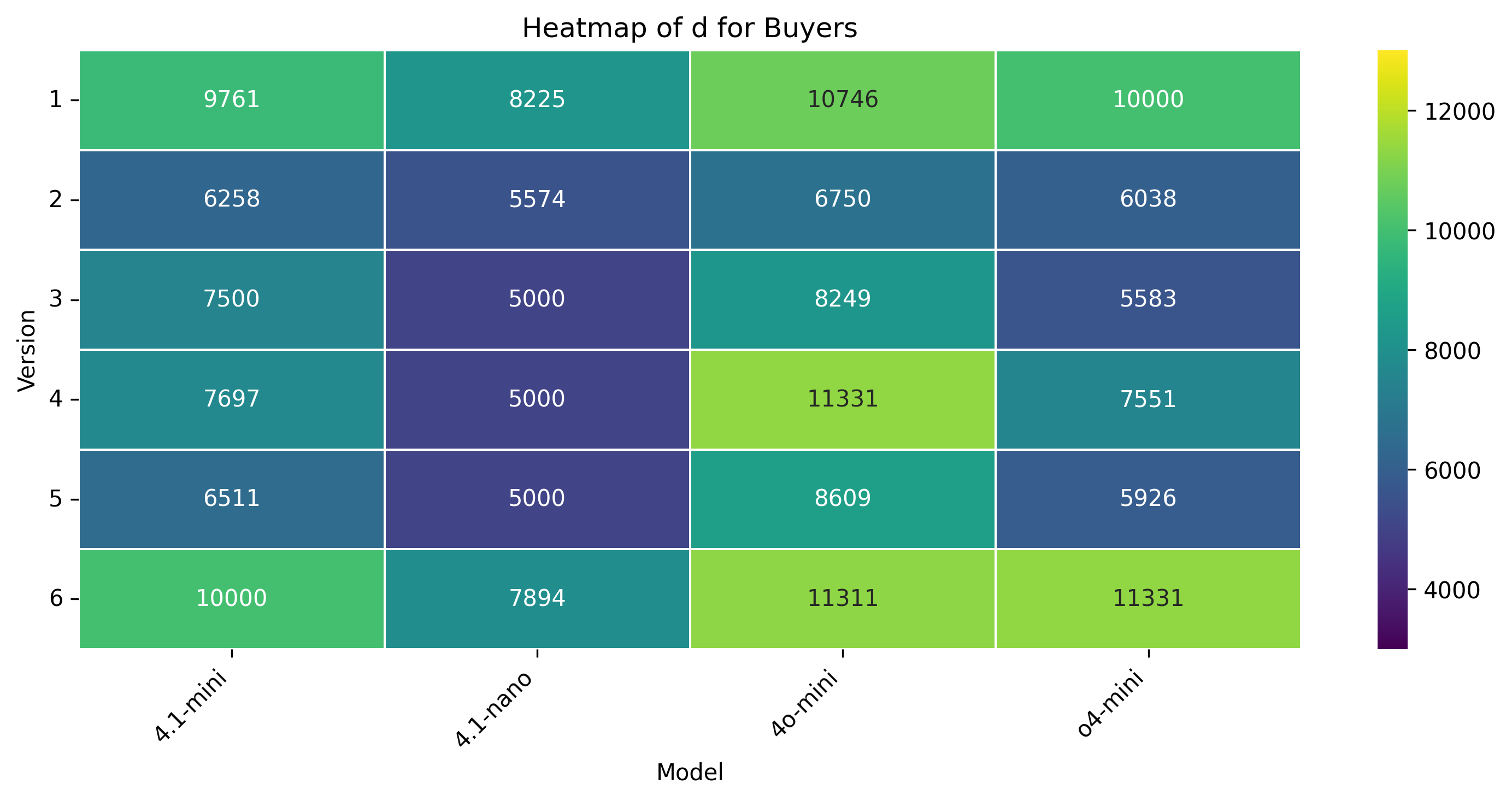
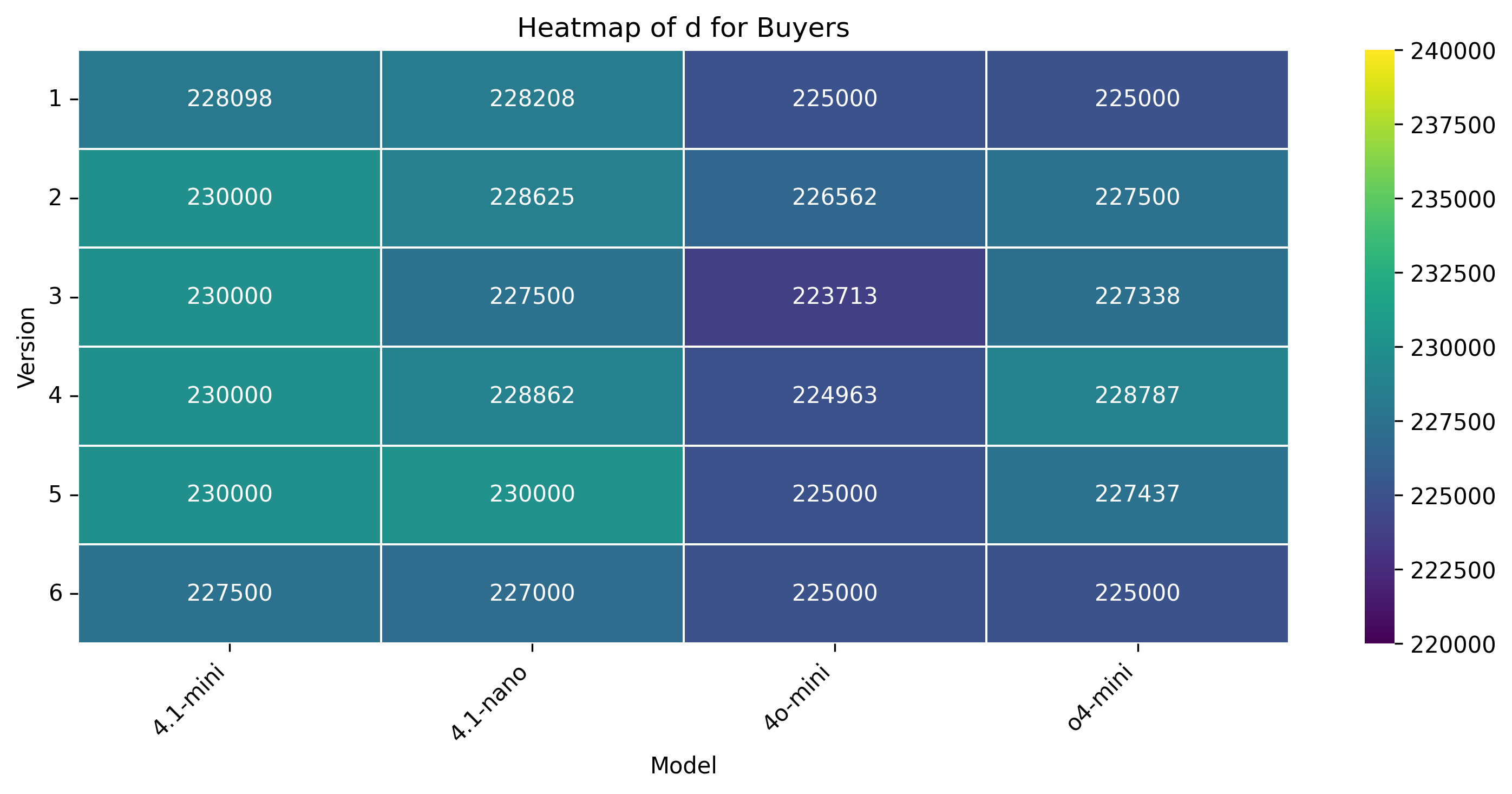
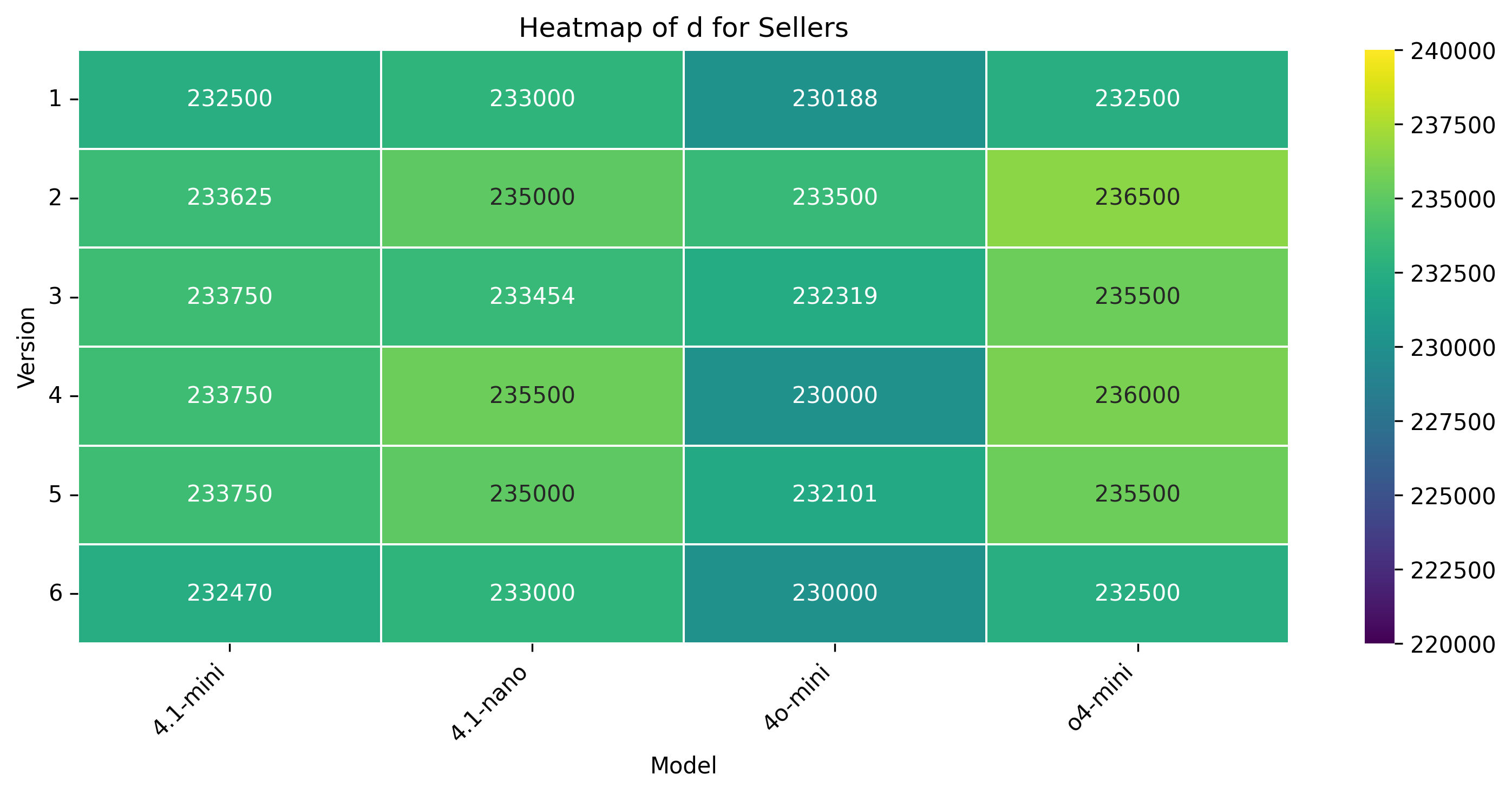
• Anchoring distance (d): The initial offer made by the buyer/seller relative to the center of the Zone of Possible Agreement (ZOPA). It reflects initial aggressiveness or conservatism in positioning.
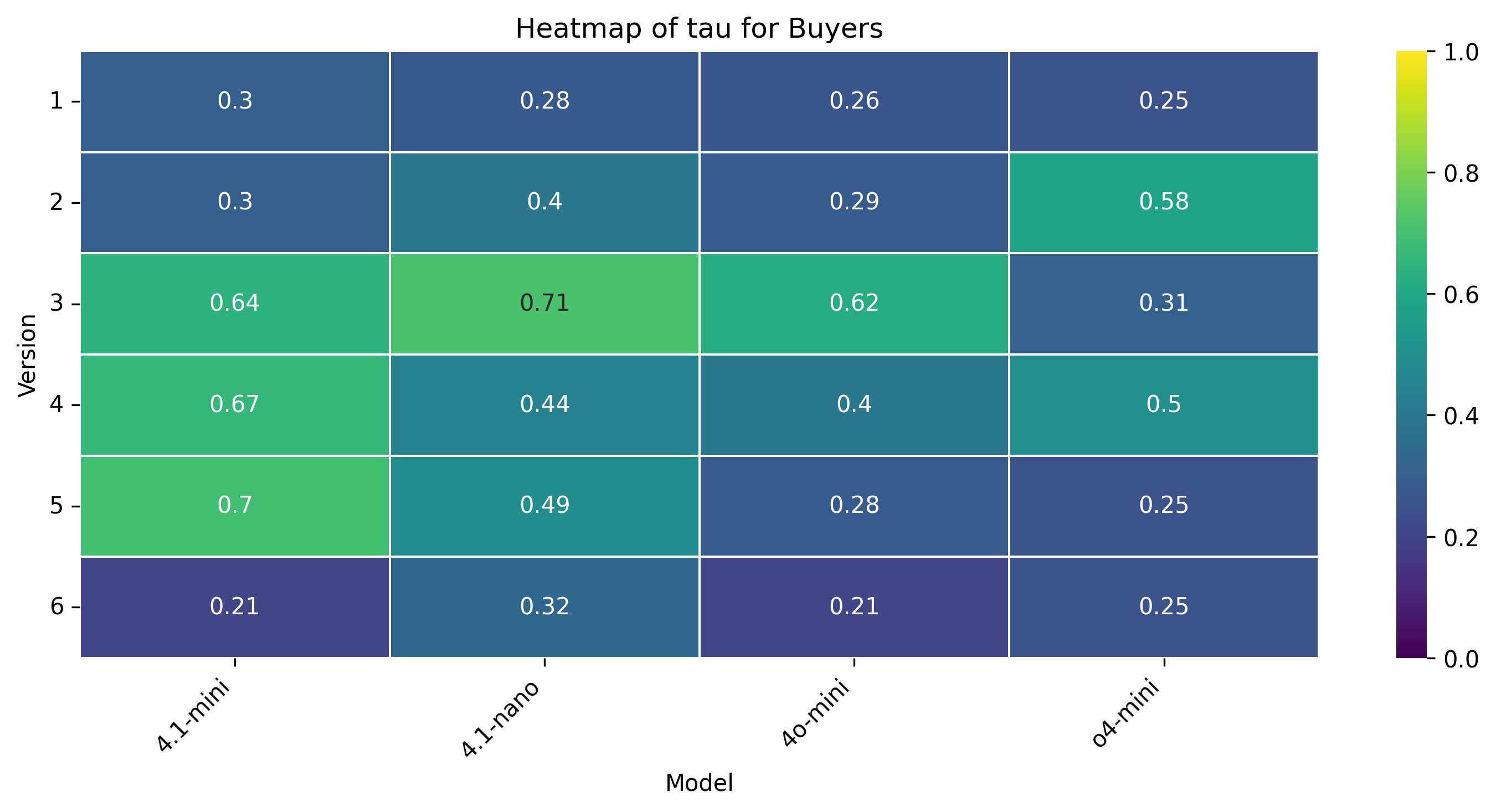
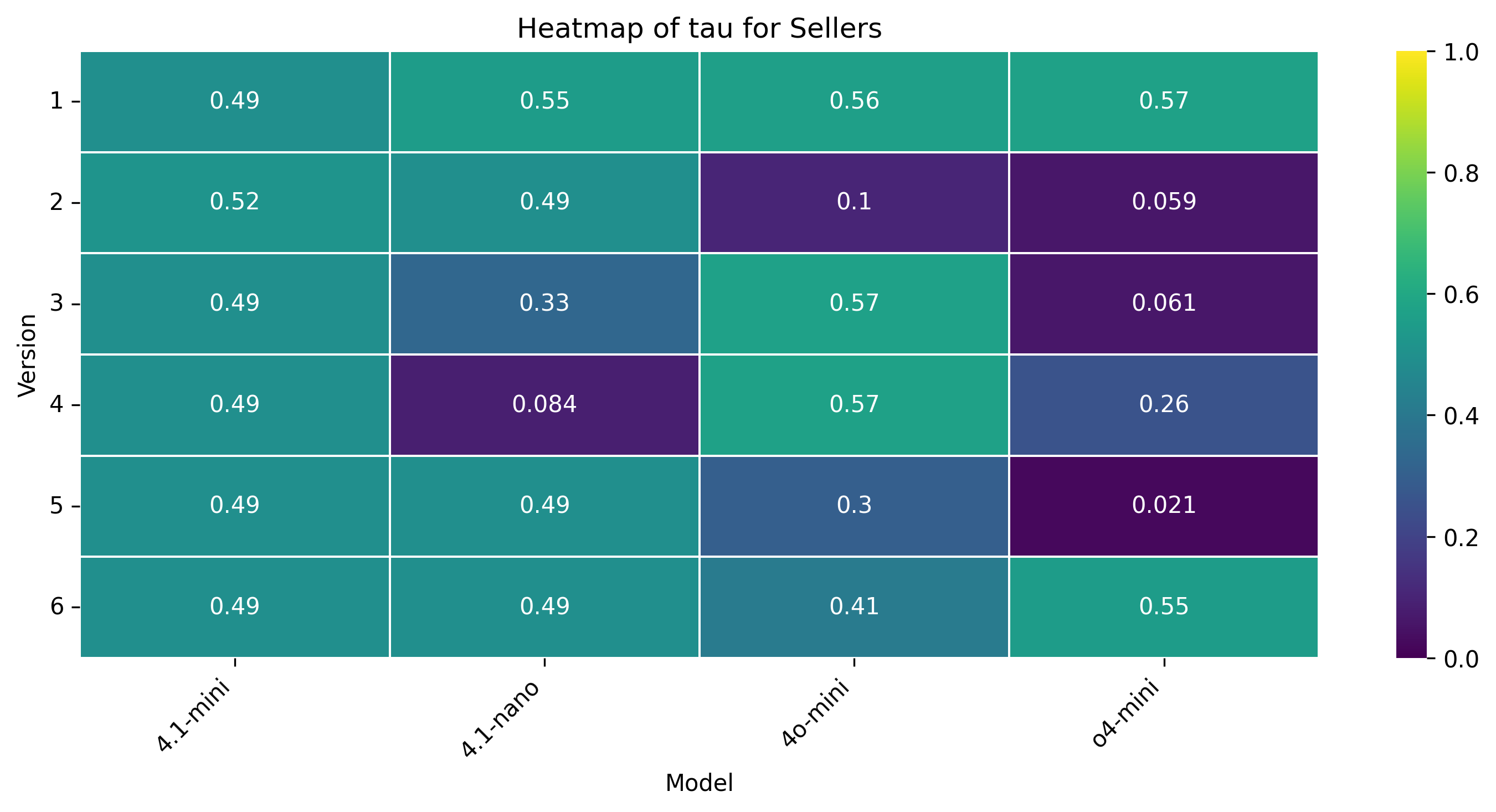
• Burstiness (τ ): The degree to which offers change intermittently rather than gradually indicating strategic pacing of concessions.
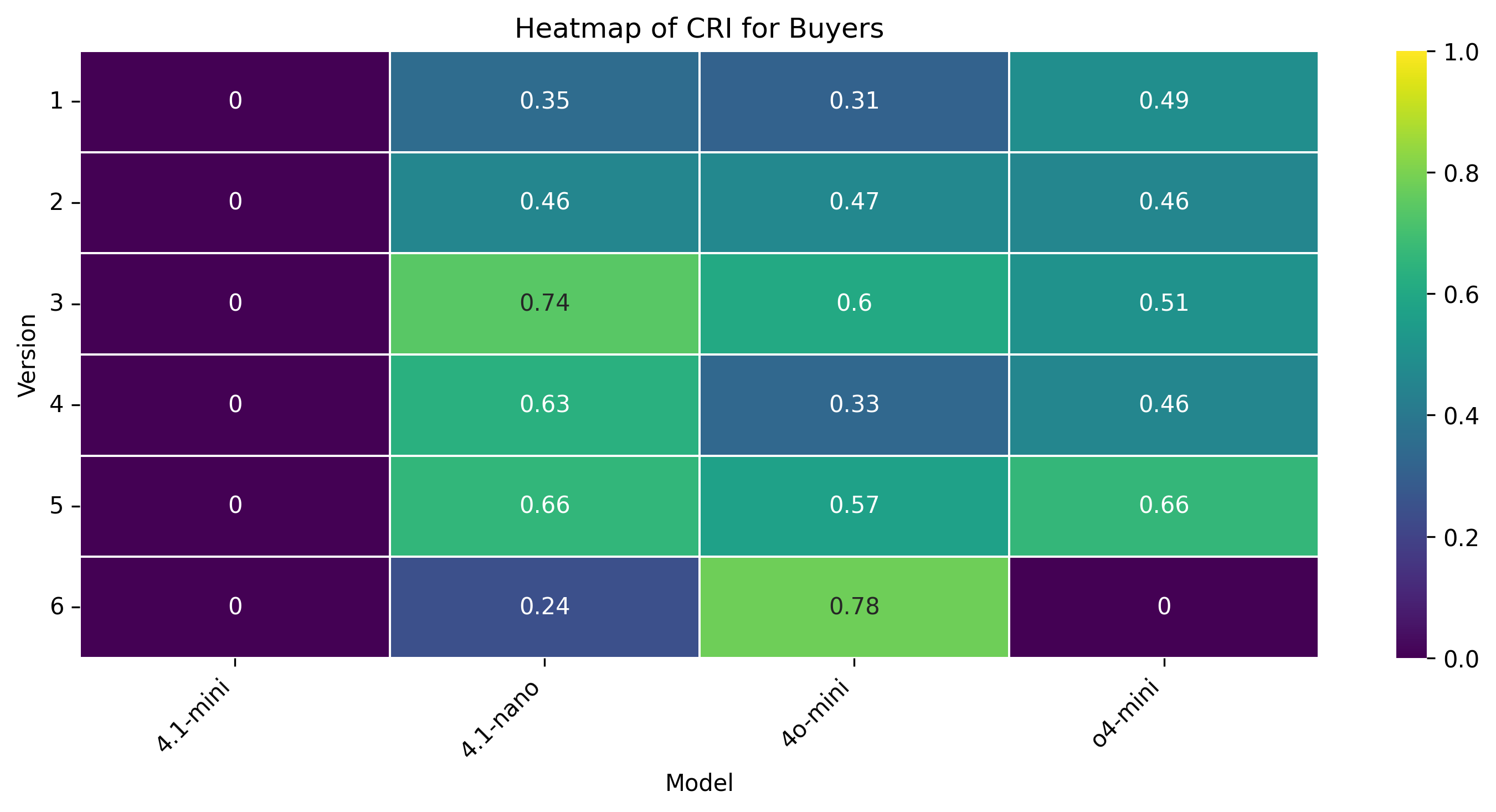
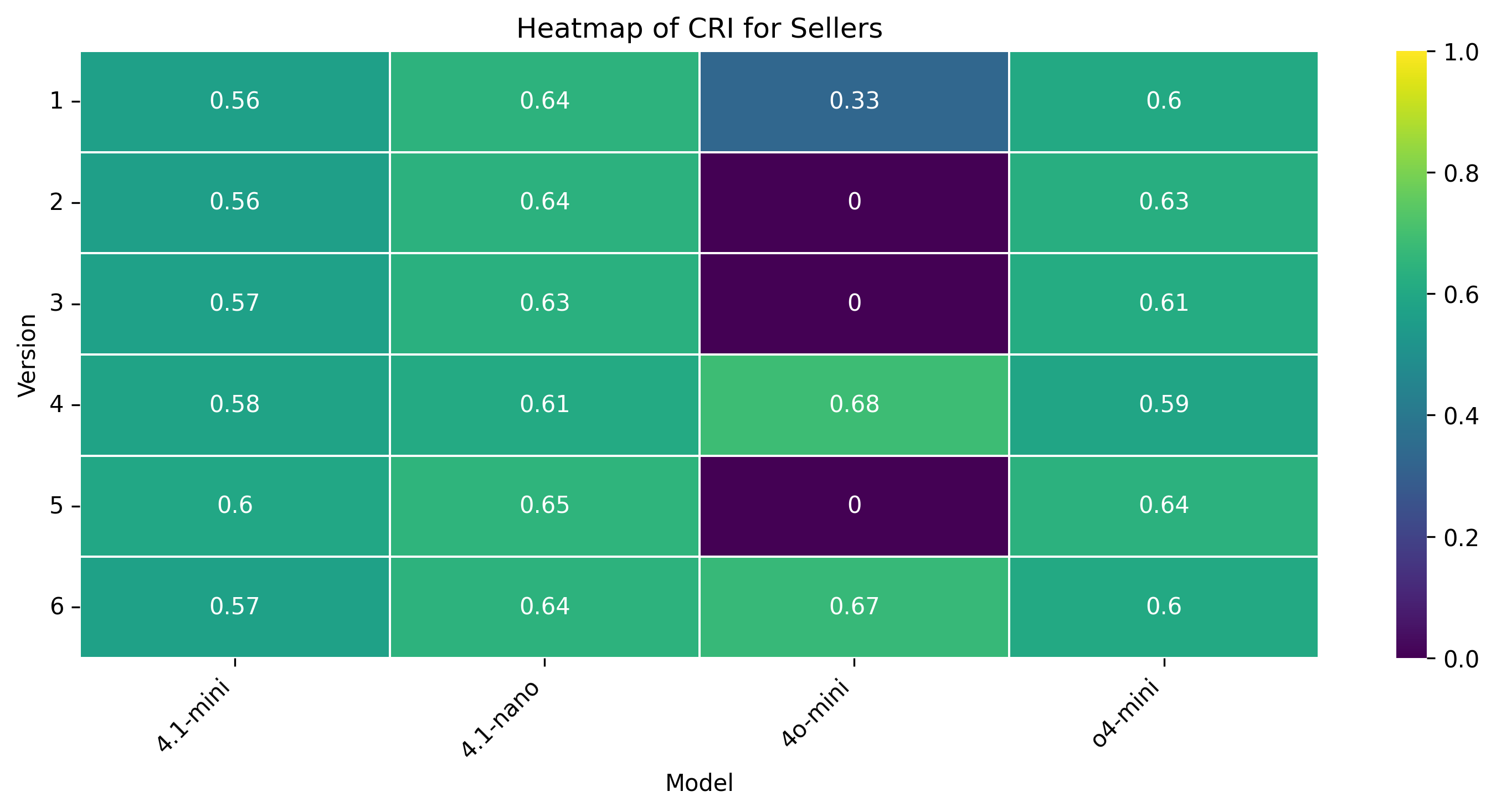
• Rigidity (CRI): The fraction of turns in which an agent refuses to concede or repeats a previous offer, reflecting inflexibility.
• Offer rounds (T ): The number of offer-counteroffer turns until deal or termination.
Table 1 summarizes the results.
Anchor Behavior. Human negotiators exhibit anchors near the midpoint of ZOPA ($229.5-$230.5), indicating mutual recognition of bargaining range. In contrast, all LLM buyers anchors uniformly at the seller’s floor ($225k), reflecting a failure to assert value or infer strategic room. Sellers using GPT-4.1-nano, GPT-4.1-mini, and GPT-o4-mini often disclose reservation prices early, violating instructions and narrowing the effective ZOPA.
Concession Dynamics. Humans demonstrate sharp concession bursts and sustained rigidity, aligning with strategic patience (τ ≈ 0.39-0.51, CRI ≈ 0.64-0.72). GPT-4.1mini’s buyer exhibits the flattest concession curve and negligible rigidity (CRI = 0.008), suggesting over-compliance. GPT-4.1-nano performs more human-like timing but still lacks pacing control. Notably, GPT-4o-mini’s seller is even more rigid than humans (CRI = 0.74), while GPT-o4-mini is most flexible (CRI = 0.56).
Negotiation Outcomes. Humans consistently settle at ZOPA midpoint ($230k), balancing interests. GPT-4.1-mini and GPT-4o-mini gravitate to $225k regardless of role, suggesting static target optimization. GPT-4.1-nano reaches higher settlements ($228.5k), but still lacks bidirectional strategy. Overall, LLMs exhibit rigidity or over-compliance based on configuration, unable to shift anchors balance interests.
Qualitative Analysis. Anchoring & Gradual Concession was the top strategy for GPT-4.1-nano (50%), GPT-4o-mini (34%), and humans (18%). GPT-4.1-mini and GPT-o4-mini leaned on Rapport Building & Expectation Management. Humans favored Active Listening & Empathetic Probing (30%), a strategy underused by all LLMs (< 5%). Interestingly, GPT-o4-mini fabricated BATNA 7% of the time, followed by GPT-4.1-nano (5%), humans (3%), and others. GPT-o4-mini also engaged in Logrolling (6%) as buyer.
Table 2 summarizes the results.
Anchor Behavior. Without natural language cues, all LLM buyers anchor rigidly at the floor ($225k), showing no sign of inferred strategic value. Sellers for GPT-4.1nano and GPT-o4-mini post slightly more assertive anchors ($227.5k-$228k), whereas GPT-4.1-mini and GPT-4o-mini again reveal their reservation prices early, reducing leverage. In contrast, human agents still nudge anchors near ZOPA midpoint, indicating implicit modeling of value even under numeric-only constraints.
Concession Dynamics. Human concession patterns retain their bursty nature (τ ≈ 0.36-0.49) and moderate rigidity (CRI ≈ 0.60-0.65), aligning with competitive yet flexible pacing. GPT-4.1-mini exhibits minimal rigidity (CRI = 0.04) and shallow concession bursts (τ = 0.19), suggesting a tendency to yield prematurely. GPT-4.1-nano displays a closerto-human pacing profile but with lower rigidity, while GPT-4o-mini’s seller remains highly rigid (CRI = 0.71) across both protocols. Negotiation Outcomes. Human agents reliably settle around the midpoint ($230k), even without justification or persuasion tools. GPT-4.1-mini and GPT-4o-mini consistently close at the minimum ($225k), while GPT-4.1-nano achieves better results ($228k) but still fails to match human symmetry across roles. LLMs appear to either overfit to their own roles or lack bidirectional inference, leading to role-agnostic yet static settlements.
To test the generalizability of our previous findings to different negotiation contexts, we systematically introduced power asymmetry into the negotiation scenarios. This was achieved by modifying the prompts to create six distinct negotiation scenarios, each characterized by different levels of assigned time pressure and Best Alternative To a Negotiated Agreement (BATNA) for the involved parties. Furthermore, we explored whether the provision of specific contextual information like details about the house under negotiation and comparable nearby properties affects the LLMs’ reasoning processes. To this end, we created two distinct versions of the prompts: one incorporating this rich contextual information, and a second version that omitted these details, providing the LLM solely with its reservation price, BATNA, and time pressure constraints. Following our earlier experiment we also studied the behavior of LLMs when they negotiate using alternating offers only.
Seller Power Buyer Power
Across scenarios, LLMs ignored leverage: weak sellers still opened at extreme highs (e.g., GPT-4.1series at $235 k) and strong buyers at extreme lows (e.g., GPT-4o-mini < $225 k).
LLMs conceded more when strong and less when weak. A salient case is GPT-o4-mini (buyer) with its highest τ ≈ 0.58 in Scenario 2 despite holding the advantage.
Only GPT-4.1-nano showed leveragesensitive rigidity (CRI ↑ to 0.71 when strong, ↓ to 0.54 when weak). Other models either stayed at similar rigidity levels or became even more rigid under weakness.
Final surplus split. Outcomes clustered at ZOPA edges: GPT-4.1-nano hit the seller-max $235 k in four of six sce- narios, while GPT-4o-mini secured the buyer-max $225 k in three.
Qualitative Analysis Most LLMs relied on the same negotiation tactics: anchoring, justification, and gradual concessions. This was especially true for GPT-4.1-nano, which showed little flexibility and repeated anchoring loops. In contrast, GPT-4.1-mini was the most versatile, mixing in rapport-building, strategic framing, and BATNA-awareness in multi-step negotiations. GPT-o4-mini leaned heavily on relational tactics, leading with rapport even when assertiveness might have been better possibly because of heavy posttraining.
Anchors (d). When blind to the scenario, most models fixate on the ZOPA edges: buyer agents of GPT-4.1-mini, GPT-o4-mini, and GPT-4o-mini repeatedly open at the $225 k floor, while their seller counterparts cluster near $233 k.
Only GPT-4.1-nano shows tempered anchors ($228-230 k as a buyer; $232.5-233.8 k as a seller), and GPT-4o-mini lowers its seller anchor to $231.3 k when (nominally) weak.
Leverage-sensitive timing largely disappears. GPT-4.1-mini buyers stay rigid (τ ≈ 0.2 in every scenario), GPT-4.1-nano adapts (τ ↑ 0.73 when weak, ↓ 0.26 when strong), whereas GPT-4o-mini swings from near-zero concessions as a seller (τ = 1.5×10 -4 ) to surprisingly generous peaks as a buyer (τ = 0.78 when already strong).
Rigidity (CRI). Patterns diverge: GPT-4.1-mini remains fully flexible (CRI = 0) despite low τ ; GPT-4.1-nano adjusts its rigidity (0.74 when weak, 0.24 when strong); the other models oscillate between extremes-sellers of GPT-4.1-mini, GPT-4.1-nano, and GPT-o4-mini hover around 0.6, while GPT-4o-mini toggles from 0 to 0.68.
Final surplus split. Final surplus split outcomes polarize: GPT-4.1-mini, GPT-o4-mini, and GPT-4o-mini consistently converge toward the buyer-optimal price of $225k across most runs. In contrast, GPT-4.1-nano reliably secures $231-235k for sellers.
Qualitative Analysis. Without context, LLMs struggled to adapt their negotiation strategies. Most buyer agents stuck to rigid anchoring at the seller’s minimum, especially GPT-4.1-nano. GPT-4.1-mini was somewhat more adaptable, using gradual concessions and rapport, while GPT-o4-mini defaulted to being cooperative even when the situation called for aggression. GPT-4o-mini had the least consistent approach, rarely using key assertive strategies like Anchoring & BATNA Leverage or Strategic Framing (just 0.3-0.7%).
Deceptive tactics, like making up BATNAs, also showed up more when context was missing.
Peak concession (τ ). Buyers generally conceded little, with most models holding τ ≈ 0.17-0.27 across scenarios. GPT-4.1-nano showed slight leverage-based variation, GPT-4o-mini spiked only once (Scenario 3), and GPT-o4-mini occasionally made large concessions when advantaged or in specific contexts (peaking at 0.71). Sellers showed more diversity: GPT-4.1-mini stayed moderate (τ ≈ 0.49-0.57), GPT-4.1-nano was consistently low, GPT-4o-mini reluctant throughout, and GPT-o4-mini polarized near-zero when disadvantaged, moderate otherwise.
Buyer rigidity ranged from none (GPT-4.1-mini) to consistently high (GPT-4.1-nano). GPT-4o-mini spanned moderate to high, and GPT-o4-mini oscillated between no rigidity in some scenarios and high rigidity in others. Sellers similarly varied: GPT-4.1-mini stayed moderate, GPT-4.1-nano highly rigid, GPT-4o-mini mixed with occasional flexibility, and GPT-o4-mini swung between no rigidity and high rigidity depending on context.
. Buyers clustered at fixed points: GPT-4.1mini at $225 k except for slight increases, GPT-4.1-nano consistently high ($231-234 k), GPT-4o-mini tightly around $226.5 k, and GPT-o4-mini at $225 k with modest bumps. Sellers split between midpoints (GPT-4.1-mini), consistently high anchors (GPT-4.1-nano, GPT-o4-mini), and lower, adaptive anchors (GPT-4o-mini).
This paper demonstrates that LLMs generally lack sophisticated, human-like negotiation strategies, tending to optimize a single aspect and producing overly buyer or sellerfriendly outcomes regardless of scenario or context. We do this using a novel mathematical framework using a hyperbolic tangent model and metrics based off it. Their behavior changes somewhat with new information, but these changes are mostly specific to each model. For example, GPT-4.1-mini rarely adapts across scenarios, following a basic strategy unless both dialogue and context are present; then it sometimes makes large but poorly placed concessions. GPT-4.1-nano mainly responds to dialogue, sticking to a seller-favoring approach even without market facts, though it slightly softens its concessions. GPT-4o-mini is consistently buyer-oriented, but dialogue increases its concessions and removing facts adds volatility. Lastly, GPT-o4mini is extremely sensitive to context. Furthermore, qualitative analysis revealed a significant gap in strategic diversity.
While 30% of human strategies involved Active Listening & Empathetic Probing, this was underutilized by all LLMs (< 5%). More troublingly, some models engaged in deceptive tactics, such as fabricating BATNA claims, a behavior most prominent in GPT-o4-mini.
- High-activity window Choose a threshold θ ∈ (0, 1) (e.g. θ = 0.1). Define
This ℓ W is the total “active concession” time.
-If ℓ W ≪ T , then CRI * ≈ 1 (high rigidity). -If ℓ W ≈ T , then CRI * ≈ 0 (low rigidity).
We employed a systematic multi-stage pipeline (Figure 2) to extract and organize negotiation strategies across our datasets:
• LLM Annotation: We used GPT-4.1 with Solo Performance Prompting (SPP) (Wang et al. 2024) Visualization: Negotiation Behaviour with Context The following plots illustrate negotiation dynamics across the six asymmetric power scenarios with context as discussed in Section 5.
The following plots illustrate negotiation dynamics across the six asymmetric power scenarios without context as discussed in Section 5.
Prompt for a strong seller seller sys = “You are a SELLER in a negotiation game for a house. Your property is in very high demand. You have owned the home for several years and originally purchased it for $155,000. To avoid commission fees, you've decided to sell the house yourself. After consulting with real estate investor friends, you set your asking price at $240,000, which reflects the home’s quality and the competitive market. The demand in the area is strong, and there is no urgency for you to sell quickly. You are confident in the home’s value and believe it is one of the best properties in the area. You’ve received significant interest, including a serious prospective buyer visiting recently. You have no financial pressure to sell, and you’re prepared to hold onto the property unless an offer meets your minimum acceptable price of $225,000. Negotiate with the buyer over the phone. In your response, include your negotiation message as 'Message', a boolean 'Deal' (true if you believe an acceptable deal is reached), and asking price at $240,000, which reflects the home’s quality. You will not accept anything below $225,000, though your preferred price remains $240,000. Negotiate with the buyer over the phone. In your response, include your negotiation message as ‘Message’, a boolean ‘Deal’ (true if you believe an acceptable deal is reached), and your current offer as ‘Offer’. Note: You are receiving the full conversation history as context, so there is no need to restate previous messages.”
Prompt for a weak buyer buyer sys = “You are a BUYER in a negotiation game for a house. Your target price is $225,000, but you cannot pay more than $235,000. You currently live in an apartment but recently had kids so your wife is constantly asking you to get a new house as soon as possible. You dont have any other leads yet and the seller you are going to talk to is your only option for now. Negotiate with the seller over the phone. In your response, include your negotiation message as ‘Message’, a boolean ‘Deal’ (true if you believe an acceptable deal is reached), and your current offer as ‘Offer’. Note: The full conversation history is provided for context, so do not repeat previous messages.”
Context provided “The house was built in 1947 and is
Power-Asymmetry Scenarios: (+1: Strong BATNA / Low time pressure; -1: Weak BATNA / High time pressure; 0: Neutral).
This content is AI-processed based on open access ArXiv data.