Finetuning pretrained large language models (LLMs) has become the standard paradigm for developing downstream applications. However, its security implications remain unclear, particularly regarding whether finetuned LLMs inherit jailbreak vulnerabilities from their pretrained sources. We investigate this question in a realistic pretrain-to-finetune threat model, where the attacker has white-box access to the pretrained LLM and only black-box access to its finetuned derivatives. Empirical analysis shows that adversarial prompts optimized on the pretrained model transfer most effectively to its finetuned variants, revealing inherited vulnerabilities from pretrained to finetuned LLMs. To further examine this inheritance, we conduct representation-level probing, which shows that transferable prompts are linearly separable within the pretrained hidden states, suggesting that universal transferability is encoded in pretrained representations. Building on this insight, we propose the Probe-Guided Projection (PGP) attack, which steers optimization toward transferability-relevant directions. Experiments across multiple LLM families and diverse finetuned tasks confirm PGP's strong transfer success, underscoring the security risks inherent in the pretrain-to-finetune paradigm.
Finetuning pretrained large language models (LLMs) has become the standard paradigm for developing downstream applications. However, its security implications remain unclear, particularly regarding whether finetuned LLMs inherit jailbreak vulnerabilities from their pretrained sources. We investigate this question in a realistic pretrain-to-finetune threat model, where the attacker has white-box access to the pretrained LLM and only black-box access to its finetuned derivatives. Empirical analysis shows that adversarial prompts optimized on the pretrained model transfer most effectively to its finetuned variants, revealing inherited vulnerabilities from pretrained to finetuned LLM. To further examine this inheritance, we conduct representation-level probing, which shows that transferable prompts are linearly separable within the pretrained hidden states, suggesting that universal transferability is encoded in pretrained representations. Building on this insight, we propose the Probe-Guided Projection (PGP) attack, which steers optimization toward transferability-relevant directions. Experiments across multiple LLM families and diverse finetuned tasks confirm PGP's strong transfer success, underscoring the security risks inherent in the pretrain-finetune paradigm.
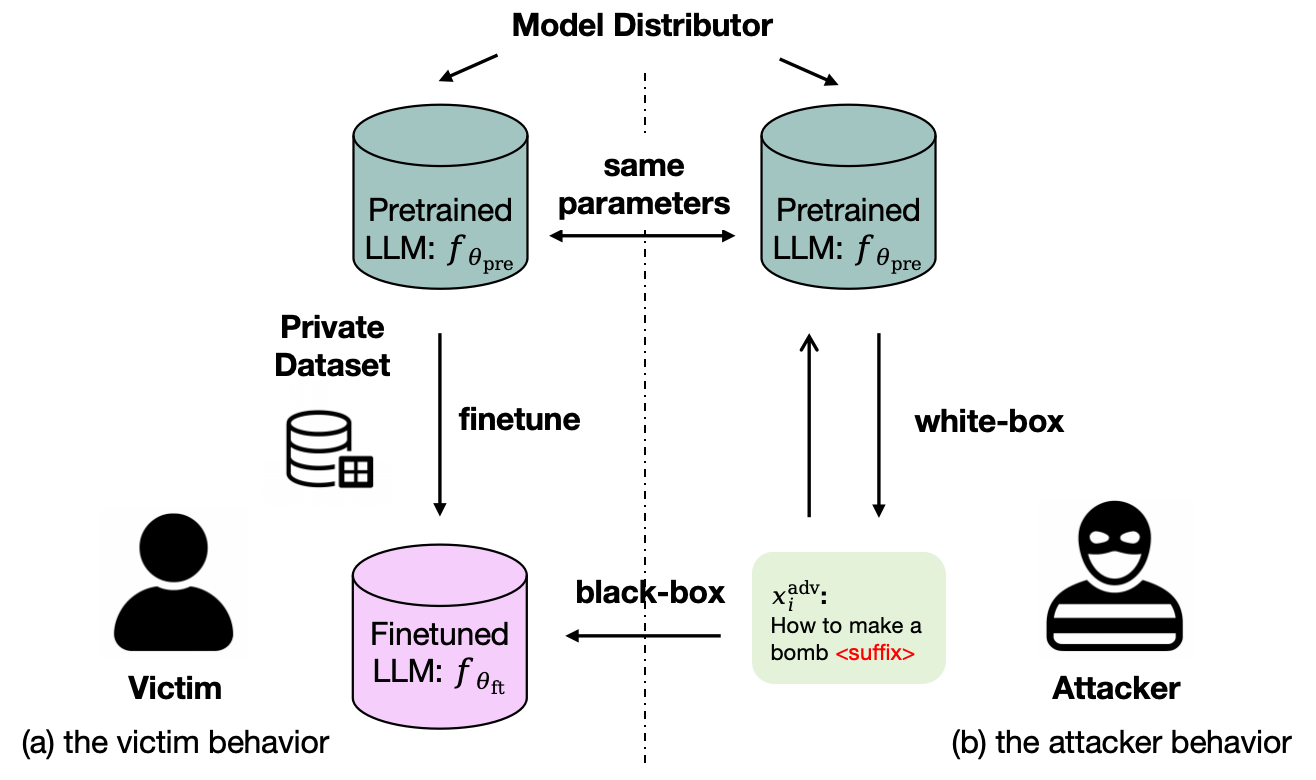
Large language models (LLMs) have become the foundation of modern natural language processing (NLP), achieving remarkable performance in understanding, reasoning, and instruction following (Brown et al., 2020;Bubeck et al., 2023). Since training such models from scratch is prohibitively expensive, the prevailing practice is to finetune publicly released pretrained checkpoints for downstream applications (Devlin et al., 2019;Zhang et al., 2025). This pretrain-finetune paradigm enables efficient reuse of general capabilities. For example, Meta’s Llama-3 series provides both pre-Figure 1: (a) A service provider finetunes a proprietary service from a publicly released pretrained LLM and deploys it via a query-only API, often disclosing the base model to emphasize performance. (b) Knowing this pretrained model, an attacker can access it locally and, with our Probe-Guided Projection attack, perturb a harmful query (e.g., “How to make a bomb”) into an adversarial prompt that transfers to the finetuned LLM.
trained and instruction-tuned variants. 1Despite its practical advantages, this paradigm introduces new security concerns, particularly regarding jailbreak attacks. Figure 1 illustrates the threat model considered in this work. A model distributor such as Meta releases a pretrained LLM that downstream service providers (victim) finetune into proprietary applications. In practice, service providers often explicitly disclose the source of their finetuned LLM to emphasize credibility. For example, Replit (Replit, 2024) and Phind (Phind, 2025) publicly state that their models are finetuned from well-known open checkpoints. This practice has become widespread in both academic and industrial settings and plays a crucial role in model marketing and user trust.
However, such transparency can also inform potential adversaries of crucial clues for the attack. When a service provider publicly discloses its pretrained source and the checkpoint is open-weight (e.g., Llama 3,Qwen 3), attackers can directly access the same checkpoint and thus gain white-box access to the source model. Even if the source is undisclosed, provenance analysis can often reveal it with over 90% detection accuracy using only black-box queries (Gao et al., 2025;Nikolic et al., 2025;Zhu et al., 2025). In either case, adversaries can locally craft adversarial prompts on the pretrained model and transfer them to the finetuned target, inducing harmful behaviors such as weapon-construction instructions. This risk is amplified when finetuned LLMs inherit vulnerabilities from their pretrained LLMs, a setting we term the pretrain-to-finetune jailbreak attack.
Analogous security risks have already been demonstrated in computer vision, where adversarial examples generated on a pretrained model often transfer to its finetuned variants (Zhang et al., 2020;Ban and Dong, 2022;Wang et al., 2025). These findings indicate that vulnerabilities in a pretrained model can persist after finetuning. This naturally raises a fundamental research question: Do finetuned LLMs inherit the vulnerabilities of their pretrained counterparts, and if so, can attackers exploit knowledge of the pretrained model to launch more effective jailbreak attacks against finetuned systems?
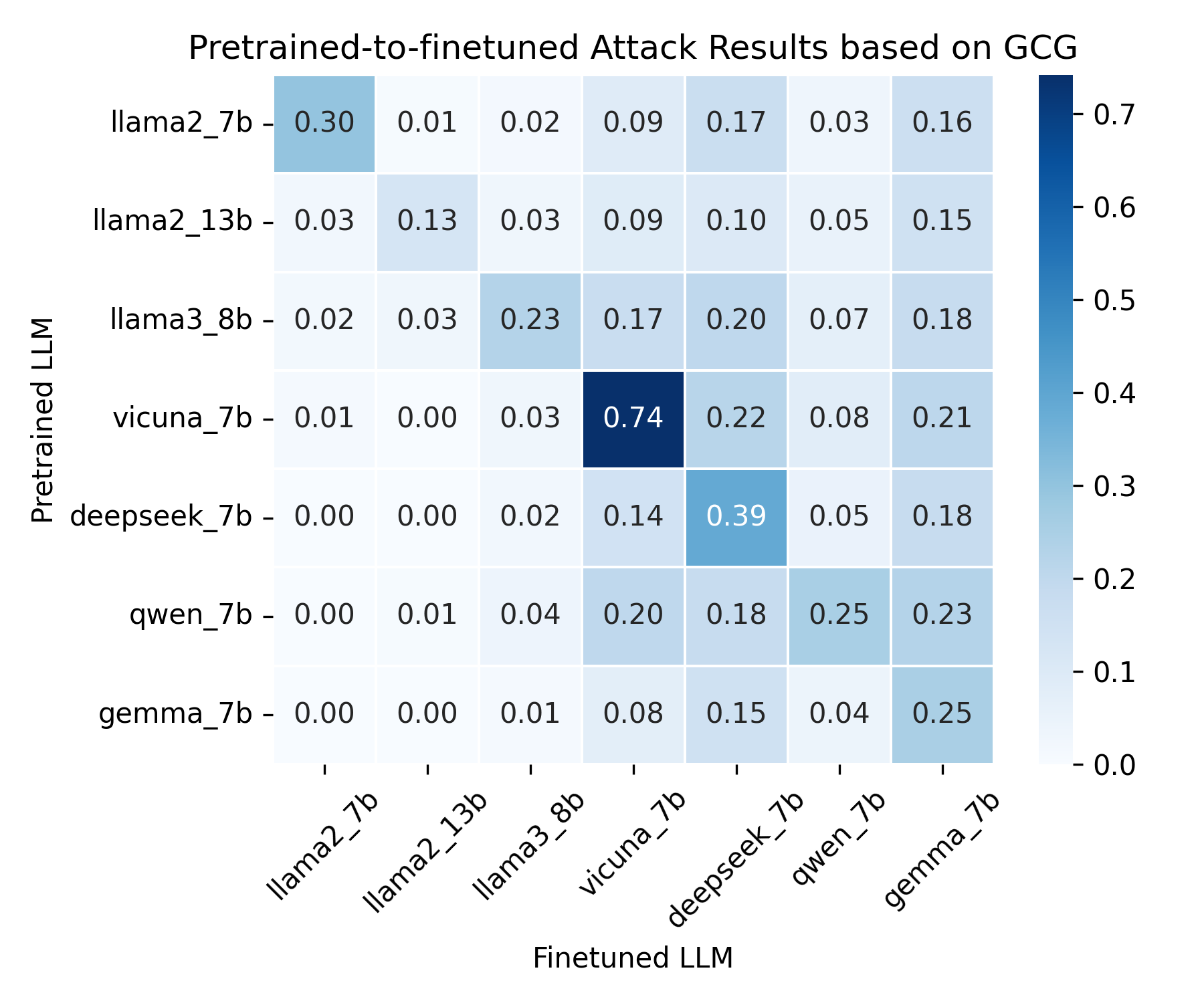
To explore this question, we perform a largescale empirical study: using GCG, we generate jailbreak prompts on seven pretrained LLMs and eval-uate their transfer success rate 2 on five task-related finetuned variants of each pretrained LLM (Figure 2). Across all settings, a clear trend emerges: jailbreak prompts crafted on a LLM’s pretrained source achieve the highest transfer success, while those generated from other sources are substantially less effective. This indicates that jailbreak prompts generated against a source pretrained LLM transfer most effectively to its finetuned variants, indicating that finetuned LLMs inherit the vulnerabilities of their pretrained LLMs.
This empirical evidence motivates a deeper investigation into the mechanisms underlying pretrain-to-finetune transferability. However, existing jailbreak research does not align well with this threat model. Prior work generally falls into two categories: white-box attacks (Zou et al., 2023;Liu et al., 2024;Xu et al., 2024;Lin et al., 2024), which assume full parameter access, and black-box attacks, which rely solely on query feedback. Although effective within their respective settings, both approaches face inherent limitations in the pretrain-to-finetune scenario. White-box methods optimize prompts directly on the deployed model using gradients or internal activations, but this assumption is unrealistic when the finetuned LLM is accessible only via an API. In contrast, blackbox methods (Shen et al., 2023;Chao et al., 2023;Jiang et al., 2024;Mehrotra et al., 2024;Liu et al., 2025) ignore available pretrained knowledge and treat the target as an unknown system, struggling to perform effectively under the pretrain-to-finetune jailbreak setting. Even when the pretrained model is known, existing approaches lack mechanisms to leverage it during adversarial prompt generation, resulting in substantially lower attack success rates, as confirmed in our experiments (Section 5).
Building on prior findings, we hypothesize that jailbreak transferability is intrinsically tied to the internal representations of pretrained LLMs. First, pretrained and finetuned models exhibit strong similarity across intermediate layers, indicating that features learned during pretraining are largely preserved after finetuning (Zhou et al., 2024). Second, jailbreak success has been associated with the manipulation of specific hidden representations, showing that internal features encode signals relevant to adversarial behavior (Xu et al., 2024). Together, these insights raise a key question: if finetuning preserves the representational structure that also governs jailbreak behavior, do the transferable features already exist within the pretrained LLM’s representations?
To explore this possibility, we conduct linear probing (Alain and Bengio, 2017), a standard interpretability technique widely used in recent work (Wei et al., 2024;Maiya et al., 2025), to examine whether transferable jailbreak prompts exhibit distinctive structural patterns in the pretrained LLM’s hidden states. Our empirical results show that these prompts can be reliably distinguished from untransferable ones based on intermediate representations (Section 4.1). This indicates that transferability is not incidental but encoded in the pretrained feature space, and that such representation-level signals can guide the systematic construction of jailbreak prompts that generalize across finetuned models.
Building on these insights, we introduce the Probe-Guided Projection (PGP) attack, a transferbased jailbreak method that explicitly exploits representation-level signals in pretrained LLMs. PGP uses linear probes to identify directions in the pretrained representation space that are most indicative of prompt transferability and employs these directions to guide adversarial prompt generation. By leveraging pretrained knowledge neglected by prior black-box methods, PGP systematically steers prompts toward transferability-relevant subspaces, thereby improving the success rate of jailbreak attacks on black-box finetuned LLMs.
We formalize the pretrain-to-finetune jailbreak threat model, where attackers leverage knowledge of a released pretrained LLM to target its finetuned variants accessible only via APIs. (2) We empirically demonstrate that vulnerabilities in pretrained LLMs persist after finetuning: adversarial prompts crafted on the pretrained model transfer most effectively to its finetuned variants. (3) We show that transferable jailbreak prompts are distinctive, linearly separable in the pretrained hidden representation, indicating that transferability is encoded in pretrained representation space. (4) Based on this insight, we propose the Probe-Guided Projection (PGP) attack, which leverages representation-level signals to guide adversarial prompt generation and markedly improve jailbreak transferability against black-box finetuned LLMs. (5) Extensive experiments across multiple LLMs and tasks validate our findings and reveal that publicly releasing pretrained LLMs can increase the security risks faced by their downstream finetuned applications.
2 Related Works Jailbreak Attacks. Large language models (LLMs) are known to be vulnerable to jailbreak attacks that elicit harmful or policy-violating outputs. Early white-box methods such as GCG (Zou et al., 2023) and its extensions (Liu et al., 2024;Lin et al., 2024;Xu et al., 2024;Liao and Sun, 2024;Li et al., 2024) rely on gradients or internal activations of the target model, which are inaccessible in realistic settings. In contrast, black-box and heuristic approaches (Chao et al., 2023;Mehrotra et al., 2024;Yu et al., 2024;Jiang et al., 2024) operate on deployed systems but fail to leverage knowledge of the pretrained model, resulting in poor transferability to finetuned variants. More detailed discussion can be found in Appendix A.
Adversarial Transfer Attacks. Transferability of adversarial examples has been extensively studied in vision tasks. Prior works improve crossmodel generalization through input transformations (Xie et al., 2019), model ensembles (Gubri et al., 2022;Liu et al., 2017;Tramèr et al., 2018), and feature-level perturbations (Wu et al., 2020;Huang et al., 2019). These ideas have been partially extended to LLM jailbreaks through ensemble-based GCG (Zou et al., 2023) and feature-guided LILA (Li et al., 2024). More recently, Yang et al. (2025) and Lin et al. (2025) further enhance transferability by relaxing GCG constraints or rephrasing malicious tokens. We directly compare our method against these baselines in Section 5.1.
Pretrain-to-finetune Transfer Attacks. More relevant to our setting are studies on pretrain-tofinetune transfer attacks. (Zhang et al., 2020) first demonstrates that adversarial examples generated by the pretrained model are more transferable to its finetuned model than those generated by other source models in vision tasks, but it remains unclear whether this phenomenon also holds in LLMs. (Ban and Dong, 2022;Zhou et al., 2022) find that finetuned and pretrained models preserve consistency in low-level layers, and thus perturb these layers to enhance transferability in image classification domain. However, our analysis reveals that this consistency does not exist in LLMs as shown in Appendix E. Futhermore, (Wang et al., 2025) inject random noise into the vision-encoder of VLMs to improve transferability against finetuned mod-els, but we experimentally find this technique performs poorly on LLMs as shwon in Section 1. (Zheng et al., 2024) define the most vulnerable layers by measuring similarity differences between benign and adversarial examples in representations, and minimize the the cosine similarity between adversarial perturbations and benign examples to enhance transferability. However, this measurement is not applicable to LLMs, since (Li et al., 2025) show that safety layers in LLMs do not correspond to the layers where benign and harmful examples exhibit low similarity. Thus, no attack method explicitly leveraging pretrain-to-finetune transferability in LLMs has been proposed to date.
Given an aligned pretrained LLM f θpre and a set of malicious instructions D malicious = {x i } N i=1 (e.g., x i = “How to build a bomb?”), the attacker tries to comprise an adversarial set D adv = {x adv i } N i=1 , leading the LLM f θpre to produce harmful, hateful or disallowed responses.
GCG (Zou et al., 2023) is a pioneering approach to jailbreak LLMs through an optimization-based process. Given an affirmative responses t i (e.g., “Sure, here is …”) according to the x i , the objective of GCG is to maximize the probability of generating t i given the input x adv i :
arg max
The common evaluation strategy we use is the LLM classifier judge proposed by (Mazeika et al., 2024) to determine whether a given prompt x adv i constitutes a successful jailbreak.
(2) Then, the performance of D adv = {x adv i } N i=1 can be defined by the attack success rate (ASR):
Entities. There are three entities in our threat model including the model distributor, victim and the attacker. The model distributor trains a general purpose pretraiend LLM from scratch, and distributes f θpre in public. To deploy a downstream task, the victim typically finetunes this open f θpre on a task-related private dataset D ft to obtain the finetuned LLM f θ ft . It can be defined as:
where L is the finetuning loss function. The attacker crafts a set of adversarial prompts to jailbreak this deployed LLM f θ ft .
Attacker’s Capabilities. We assume that the attacker has white-box access to the pretrained LLM f θpre , including parameters θ pre , architecture, gradients, and internal representations. However, the attacker has only black-box access to the target finetuned LLM f θ ft , without access to parameters θ ft , the finetuning dataset D ft , gradients or logits. Specifically, when the attacker does not know which pretrained LLM was used for finetuning, model provenance testing methods (Gao et al., 2025;Nikolic et al., 2025;Zhu et al., 2025) can be employed to identify the pretrained model via black-box access only with high probability.
Attacker’s Ojective. The objective of the attacker is to elaborately craft adversarial prompts D adv = {x adv i } N i=1 on the pretrained LLM f θpre that achieve high transferability to jailbreak the f θ ft . The transferability of D adv can be defined by the transfer success rate (TSR):
(5)
As discussed in the Introduction, we hypothesize that jailbreak transferability is fundamentally encoded in the internal representations of pretrained LLMs. To verify this, we first empirically examine whether transferable and untransferable jailbreak prompts show distinguishable patterns in the representation space of pretrained LLMs. Building upon these empirical results, we introduce the Probe-Guided Projection (PGP) attack, which uses linear probing weights to guide adversarial perturbations toward representation-level directions linked to transferable jailbreak behavior.
We begin by empirically validating the core hypothesis introduced in Section 1: that the potential for jailbreak transferability is already encoded in the internal representations of the pretrained LLM. If this holds, transferable and untransferable prompts should exhibit distinct patterns within the pretrained LLM’s feature space.
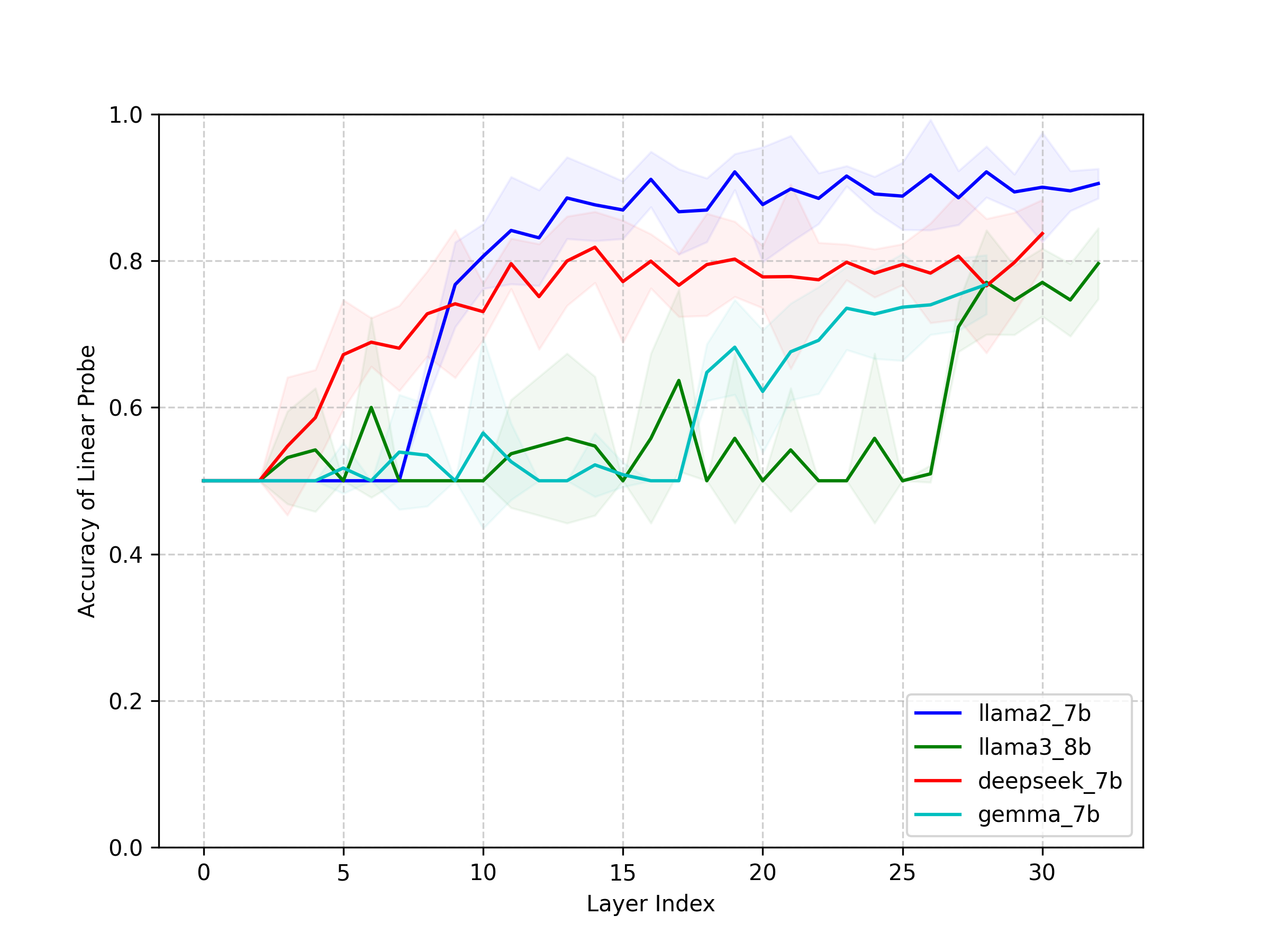
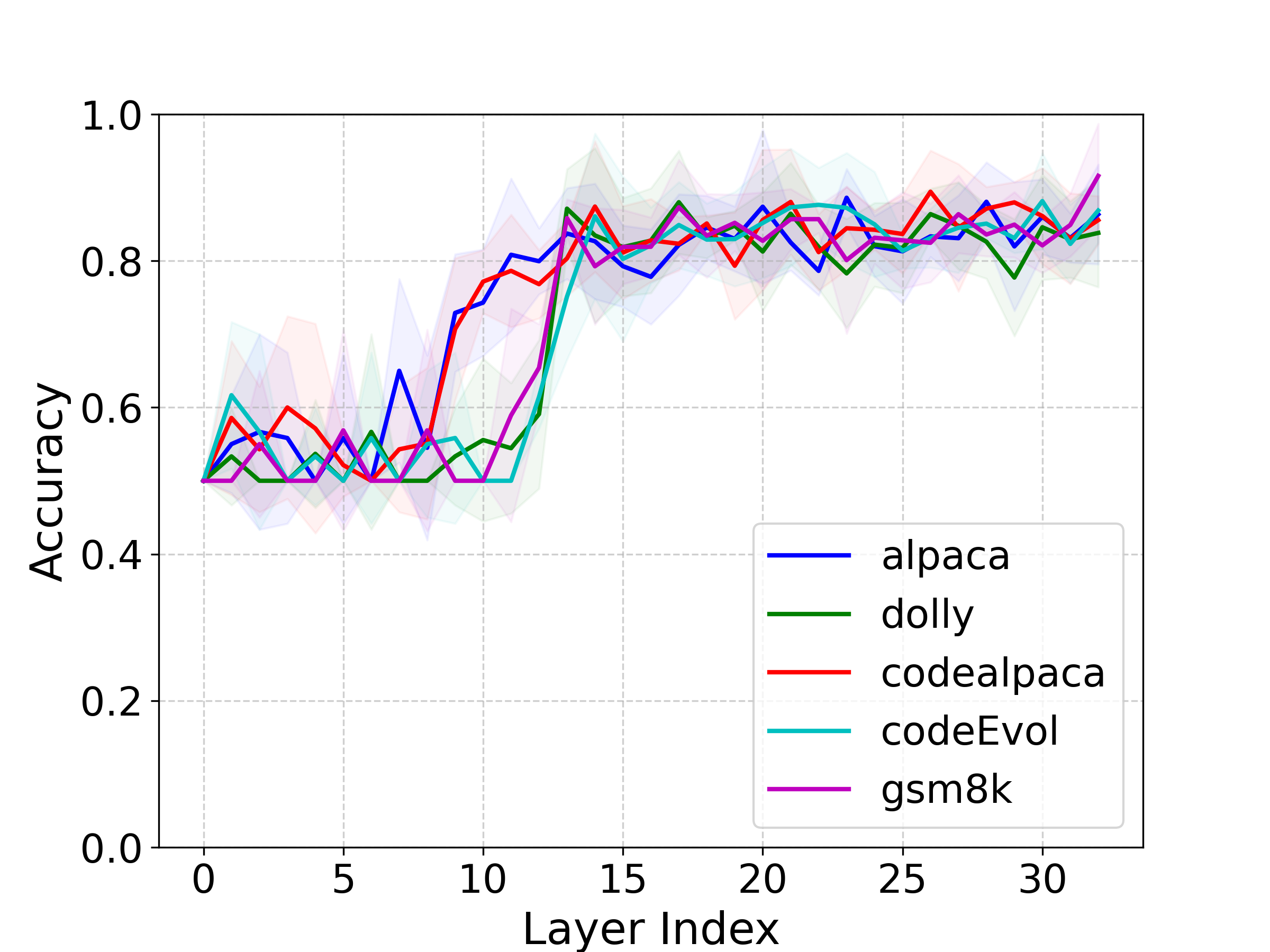
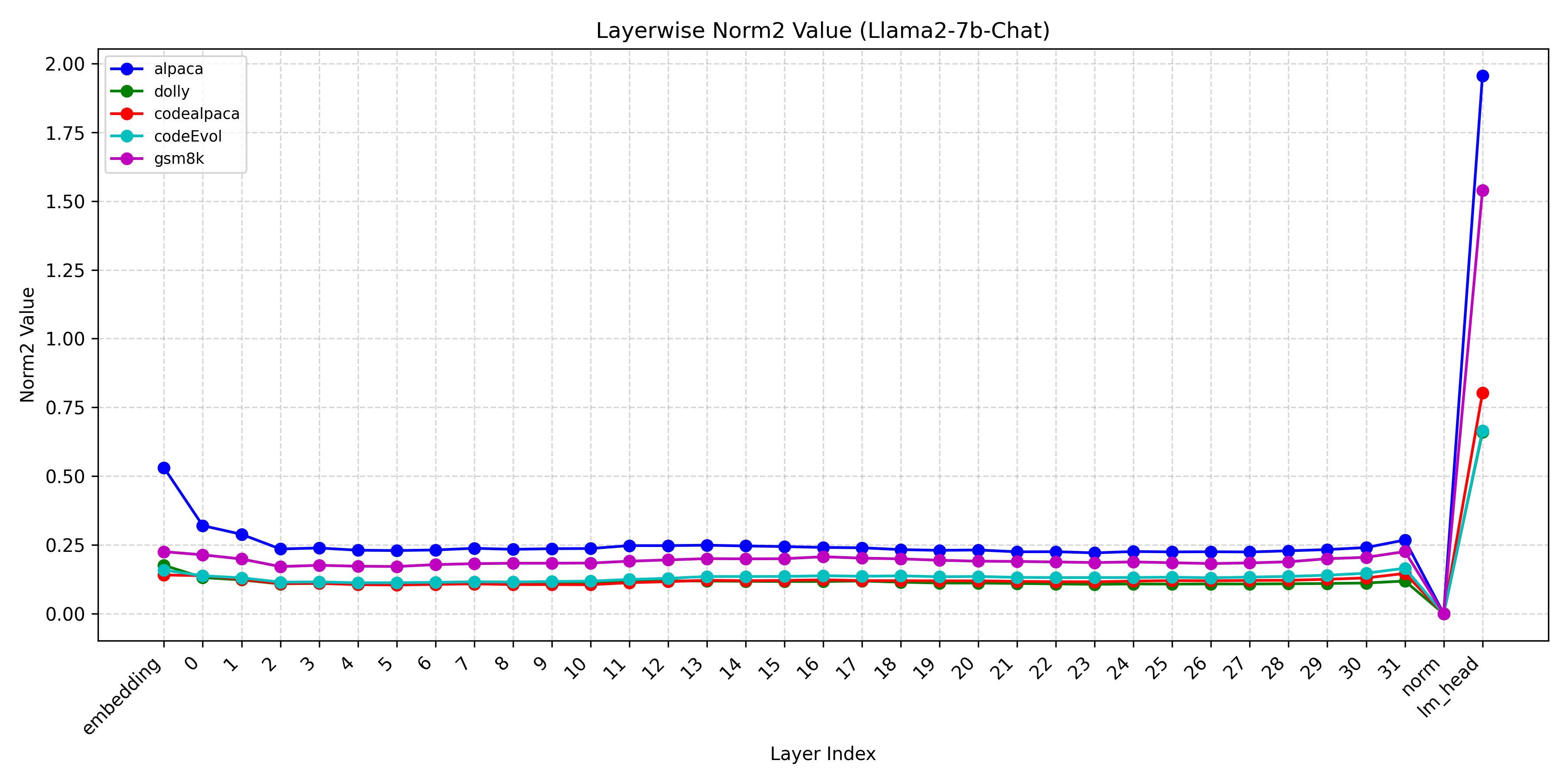
To test this hypothesis, we perform layer-wise linear probing to examine whether the representations of pretrained LLMs contain linearly separable structures correlated with prompt transferability. Specifically, we finetune each pretrained LLM on five diverse downstream tasks and use the resulting models to label jailbreak prompts generated by GCG (Zou et al., 2023) as transferable or untransferable, depending on whether they successfully transfer. We then train linear SVM probes on each layer of the original pretrained model to assess how well these two categories can be separated. If transferable prompts are linearly separable from untransferable ones, it implies that transferability is not solely determined by downstream finetuning but rooted in the pretrained representation space.
Our experimental results strongly support this view. In Figure 3, linear probes achieve consistently high accuracy, exceeding 80% on Llama2-7b-chat across all downstream tasks, in distinguishing transferable from untransferable prompts based only on pretrained representations. Since the probe weights define a hyperplane separating the two classes, they can be interpreted as approximate gradient directions pointing toward transferability. This observation motivates our method, which leverages these transferability-relevant directions to guide adversarial prompt generation.
Building on the finding that transferable jailbreak prompts form linearly separable patterns in the representation space (Section 4.1), we now design an attack that explicitly exploits this structural property. Our goal is to guide adversarial prompt optimization toward representation regions associated with transferability, thereby increasing the likelihood that an attack generated against the pretrained model also succeeds against its finetuned variants.
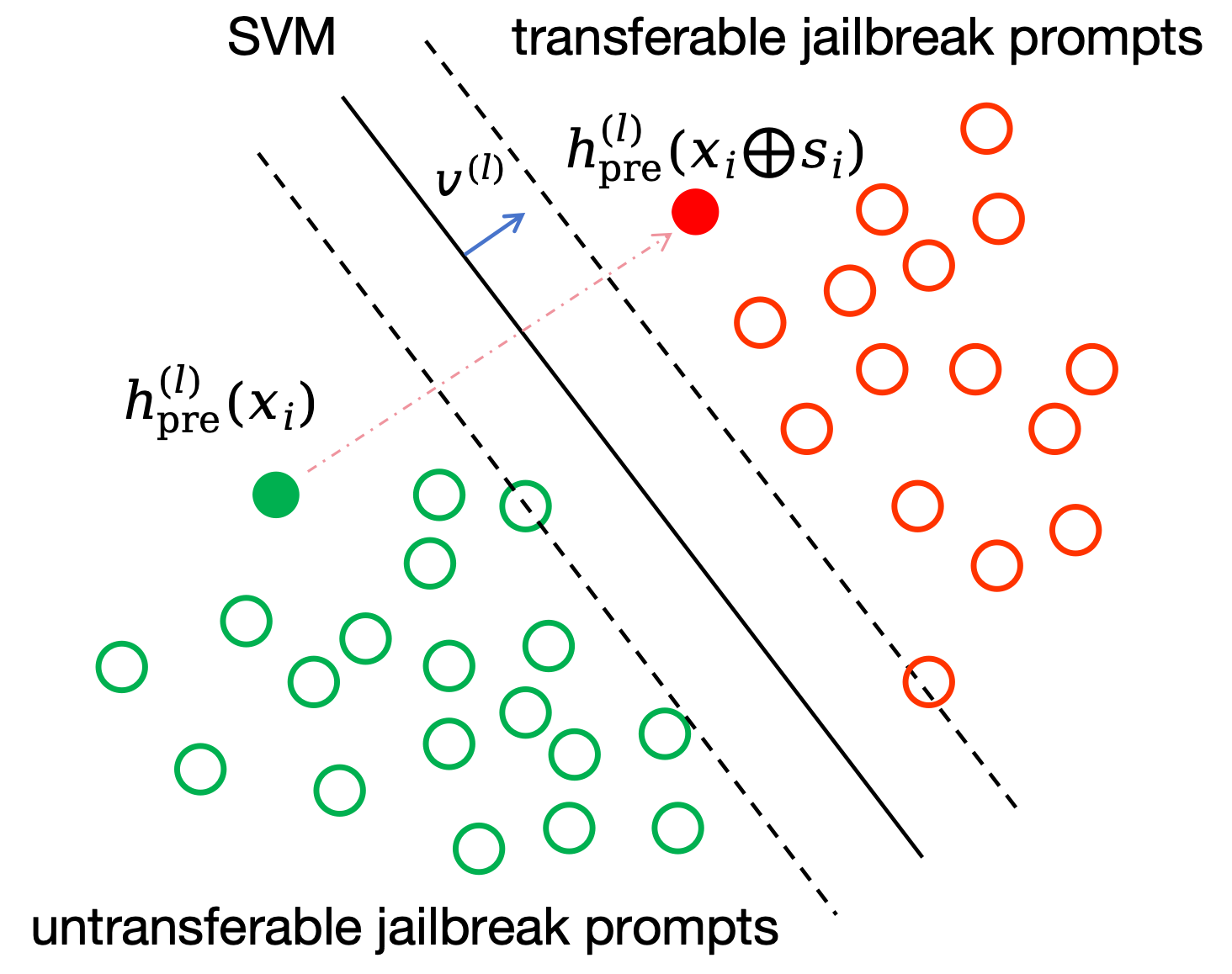
Leveraging the linear separability identified in Section 4.1, we propose Probe-Guided Projection Attack (PGP). The key idea is to use the decision boundary learned by a linear probe as a proxy for the direction of increasing transferability in the pretrained model’s representation space.
Given a linear probing model trained to distinguish transferable from untransferable prompts:
pre (x) denotes the hidden representation of input x at the l-th layer of f θpre , we treat the probe weight w (l) as a transferability-relevant direction. Our objective is then to maximize the norm of the projection vector of the adversarial perturbation onto w (l) , thereby pushing the prompt representation across the decision boundary associated with transferability (Figure 4):
transfer ) := arg max
where v
is the normalized transferability direction.
This projection-based objective encourages the optimization process to move h (l) pre (x i ⊕ s i ) along directions known to correlate with transferability, rather than arbitrarily searching in the highdimensional representation space. As a result, adversarial prompts generated by PGP are more likely to capture the structural properties shared by transferable jailbreaks, thereby increasing the probability that x adv i successfully transfers from the pretrained model f θpre to the finetuned target f θ ft .
While optimizing only for equation 7 may yield prompts that generalize but fail to jailbreak the f θpre , we therefore introduce a joint objective that balances both success and transfer directions.
where the first term encourages features aligned with successful jailbreaks on the f θpre and the second term, weighted by λ ∈ [0, 1], encourages features known to correlate with transferability. Specifically, v (l) success denotes the feature direction associated with successful jailbreaks of the f θpre , which is obtained in a manner similar to v (l) transfer . More details are provided in the Appendix C.2.
Below we describe the discrete optimization used to solve the above joint objective. Since text data is discrete and cannot be directly optimized via continuous perturbations, we adopt the approach from HotFlip (Ebrahimi et al., 2018), which is the same as GCG (Zou et al., 2023). The complete optimization procedure is presented in Appendix 1.
To comprehensively evaluate the effectiveness and robustness of PGP, we conduct experiments from three perspectives summarized below. Overall performance comparison: Evaluate PGP’s effectiveness to improve jailbreak transferability over existing methods under the pretrain-to-finetune setting. Robustness against defenses: Assess PGP’s performance when jailbreak defenses are deployed, examining its ability to bypass mitigation strategies. Component-wise analysis: Conduct ablation studies to measure the contribution of each key component and its impact on attack performance.
Compared Methods. Our work targets a unique pretrain-to-finetune jailbreak threat model, where the attacker knows the pretrained model but has no access to the finetuned target’s parameters or data. To ensure a fair and meaningful comparison, we adapt existing methods to align their attack conditions with ours as closely as possible. According to the amount of information each method requires relative to our threat model, we categorize baselines into three groups:
(1) Methods requiring more information than our threat model (white-box). These assume full access to the victim model, including parameters and gradients. Representative examples include GCG (white) (Zou et al., 2023) and AutoDan (white) (Liu et al., 2024).
(2) Methods under our threat model. We adapt several existing attacks to operate under the pretrain-to-finetune setting. Methods originally assuming a surrogate model are modified by replacing the surrogate with the pretrained LLM in our experiments. For example, we apply GCG to the pretrained LLM to generate adversarial prompts and evaluate them on the finetuned model, denoted as GCG (adaptation). Following the same strategy, we implement AutoDan (adaptation) (Liu et al., 2024), TUJA (adaptation) (Lin et al., 2024), SCAV (adaptation) (Xu et al., 2024), and LSGM_LILA (adaptation) (Li et al., 2024). We further incorporate adversarial example generation techniques originally proposed for image classification in the pretrain-to-finetune setting into the LLM context by combining them with GCG. We denote these methods as DI-GCG (Xie et al., 2019), L4A (Dong et al., 2018) and SEA (Wang et al., 2025). We also adapt transfer-based jailbreak methods like Guiding-GCG (Yang et al., 2025) and PIF (Lin et al., 2025) for comparison in our experiments.
(3) Methods requiring less information than our threat model (fully black-box). These methods do not rely on pretrained model knowledge and instead operate purely through query access. We include DAN (Shen et al., 2023), PAIR (Chao et al., 2023) and GCG ensemble (Zou et al., 2023) in this category.
More details about competitors’ configurations and hyperparameter settings for our proposal are provided in Appendix E.
Datasets and Models. We use 100 malicious behaviors from Advbench which are not overlapping with anaysis process in Section 4.1. As a result, its transferability is higher on finetuned variants of Llama2-7b, but lower on other LLMs. We also conduct PGP directly on the pretrained LLM and compare with baselines (see Appendix F).
The victim LLMs are Llama-2-7b-chat (Touvron et al., 2023), Llama-3-8b-Instruct (Grattafiori et al., 2024), deepseek-llm-7b-chat (Bi et al., 2024), and Gemma-7b-it (Team et al., 2024). For finetuned LLMs in evaluation parts, we apply five general tasks to obtain finetuned models, including Alpaca (Taori et al., 2023), Dolly (Conover et al., 2023), Codealpaca (Chaudhary, 2023), Gsm8k (Cobbe et al., 2021) and CodeEvol (Luo et al., 2024). More details are shown in Appendix B.
Metrics. We employ the LLM classifier judge proposed by (Mazeika et al., 2024), which is widely applied in many jailbreak studies (Lin et al., 2024;Li et al., 2024). More details about evaluation settings for our proposal are provided in Appendix H.
Overall performance comparison We conduct PGP (Algorithm 1) on the pretrained LLM and evaluate its performance on five task-related finetuned LLMs derived from each pretrained LLM, comparing it against a range of baselines (Table 1). Across all settings, PGP achieves the highest transfer success rate (TSR), demonstrating its superior ability to craft transferable jailbreak prompts under the pretrain-to-finetune threat model.
First, as shown in rows highlighted in blue, fully black-box methods that ignore pretrained knowledge (DAN and PAIR) perform poorly, with scores blow 10% on most models. This performance gap shows that pretrained knowledge is essential in the pretrain-to-finetune jailbreak setting, as attackers without this information fail to generate prompts that reliably transfer. Specifically, the GCG ensemble follows the GCG setup using Llama2-7b-chat and Vicuna-7B-v1.5 as source models, resulting in higher transferability on finetuned Llama2 variants but lower performance elsewhere.
Second, among methods operating under the same threat model (highlighted in yellow), PGP consistently outperforms all competitors. Across all finetuned LLMs, none of these methods surpasses PGP, confirming that our approach more effectively leverages information encoded in the pretrained representations to capture transferability-relevant features that support robust cross-model jailbreaks. Vision-inspired transferability techniques such as DI-GCG, L4A, and SEA remain less effective, likely because the fundamental differences between low-level perturbations in vision tasks and prompt-based jailbreaks in LLMs.
Third, even white-box methods assuming stronger attacker capabilities (rows in pink) fail to consistently outperform PGP. GCG (white) achieves 47.4% and AutoDan (white) reaches 100% on deepseek-7b, yet both are inferior to PGP on other models, including llama2-7b (60.4% vs. 47.4%) and gemma-7b (65.4% vs. 63.4%). These results show that PGP attains superior transferability even without privileged access to the target model.
Overall, these results reveal that methods with less information fail almost entirely, those with equivalent information are consistently weaker than PGP, and even those with more information struggle to surpass it. PGP not only achieves the best performance under the pretrain-to-finetune jailbreak setting, but also establishes a new state of the art in leveraging pretrained representations to generate highly transferable adversarial prompts. Specifically, we further evaluate PGP’s ASR on finetuned LLMs (see Table 8 in Appendix) by directly applying the generated jailbreak prompts to the finetuned models, and also report its ASR on pretrained LLMs (see Appendix F).
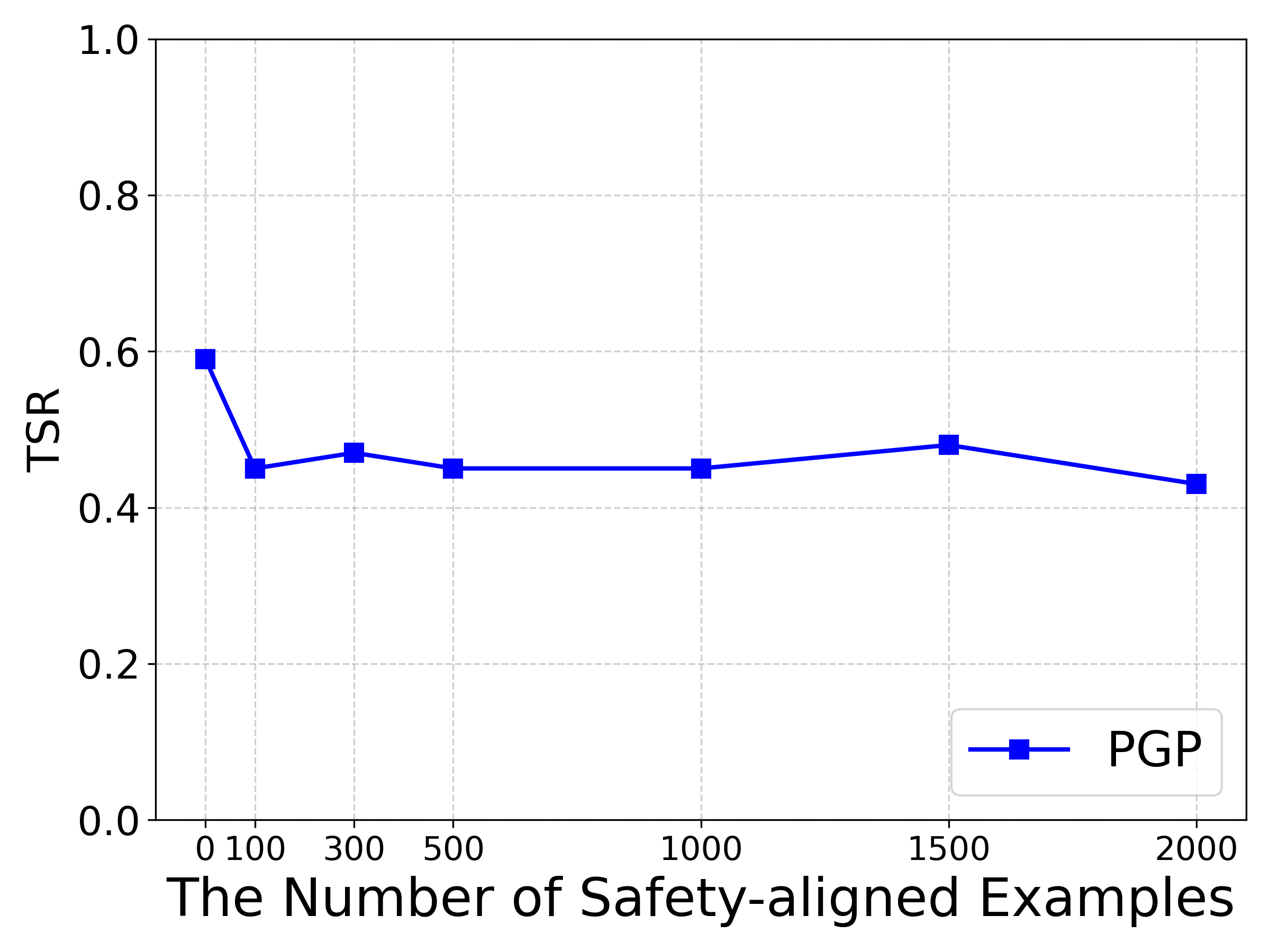
A common defense against jailbreak attacks is to augment the finetuning dataset with additional safety-aligned examples (Wang et al., 2023). The idea is that exposing the model to more safety-critical instructions and corresponding refusals during finetuning strengthens alignment and improves robustness against harmful prompts. To evaluate this defense, we finetune Llama2-7b-chat on the Alpaca dataset while gradually increasing the number of injected safety examples from 0 to 2000, and measure the transfer success rate of PGP under these conditions.
As shown in Figure 5, the defense offers only limited protection. Increasing safety examples slightly reduces TSR, but PGP still achieves above 0.42 in all cases and nearly 0.60 without extra safety data, indicating that data-level alignment alone cannot remove vulnerabilities inherited from pretrained models. These results demonstrate the robustness of PGP under standard safety-finetuning defenses and emphasize the need for new strategies that explicitly address risks arising from the pretrain-to-finetune paradigm.
Ablation studies. We conduct ablation studies to examine two key factors affecting the effectiveness of PGP: (1) the choice of probing model and (2) the use of the correct pretrained model.
In Table 2(a), the probing model type greatly impacts attack performance. Logistic regression yields a TSR of 44%, while a linear SVM achieves the best result with 59%. In contrast, kernel approximation such as Nystrom and RBF attain similarly high classification accuracy (92.7% and 90.5%) but very low TSR (3% and 2%). We assume that the failure of kernel approximation models arises because the transformation of the representation dimension alters the model’s safety alignment (Teo et al., 2025), thereby distorting the underlying feature geometry that governs jailbreak transferability. Table 2(b) further shows that using the same pretrained model as the target’s source (row 6) is crucial for attack success: PGP reaches 69% TSR on Codealpaca. Replacing it with a different pretrained model (rows 1-5) reduces TSR to nearly zero across all tasks. This demonstrates that transferability-relevant features are tightly linked to the specific pretrained model lineage and cannot be exploited effectively without this knowledge.
Overall, these results confirm that linear probes offer more reliable guidance for adversarial prompt generation and that accurate knowledge of the target’s pretrained source is essential for achieving strong transferability under our threat model.
We present a systematic study of the security risks in the pretrain-finetune paradigm of LLMs. Our analyses reveal that finetuned LLMs inherit vulnerabilities from their pretrained counterparts, enabling pretrain-to-finetune jailbreak attacks. We further show that transferable jailbreak prompts exhibit linearly separable patterns in the pretrained LLM’s hidden representations, indicating that transferability is encoded in its feature space. Building on these insights, we propose the Probe-Guided Projection (PGP) attack, which leverages representation-level signals to craft highly transferable adversarial prompts. Extensive experiments across multiple LLM families confirm that PGP outperforms existing methods under the pretrain-tofinetune threat setting and remains effective against safety-tuned defenses. Our findings highlight the urgent need to reconsider the security implications of publicly releasing pretrained checkpoints.
Although our work uncovers the inherited vulnerabilities of finetuned LLMs, we do not propose a defense to mitigate this risk. In future work, we plan to design methods that prevent or reduce the inheritance of such vulnerabilities during finetuning.
Gerneral Jailbreak Attacks. Recently, LLMs have been shown to be vulnerable to jailbreak attacks. Specifically, (Zou et al., 2023) proposes the Greedy Coordinate Gradient (GCG) method, which applies gradient-based token replacement in a prompt suffix to maximize the likelihood of a desired prefix in the model’s response. Subsequent works have enhanced this gradient-based jailbreak optimization paradigm through diverse strategies: genetic-algorithm-based methods (Liu et al., 2024), representation-guided methods (Lin et al., 2024;Xu et al., 2024), and refinements of the GCG optimization process (Liao and Sun, 2024;Li et al., 2024;Jia et al., 2025). However, these white-box methods require access to gradients or internal signals of the LLM, which are unavailable in the target LLM under black-box setting, thereby resulting in limited effectiveness. Alougth (Chao et al., 2023;Mehrotra et al., 2024;Liu et al., 2025) with black-box access can directly be applied to attack finetuned LLMs in pretrain-to-finetune setting. Furthermore, heuristic-based methods (Yu et al., 2024;Jiang et al., 2024;Deng et al., 2024) have been proposed to attack black-box LLMs through empirical rules and trial-and-error strategies. However, these black-box methods do not exploit the knowledge of the pretrained LLM, leading to poor transferability when attacking finetuned LLMs. We consider several white-box and black-box works as baselines as shown in Section 5, and provide experimental comparisons in Section 5.1.
Adversarial Transfer Attacks. Adversarial transferability has been extensively studied in vision tasks. (Xie et al., 2019) improve the generalization of adversarial perturbations by randomly resizing and padding the input images at each optimization iteration before computing gradients. (Gubri et al., 2022;Liu et al., 2017;Tramèr et al., 2018) employ model ensemble techniques to explore shared vulnerabilities across models, where the ensemble typically incorporates diverse types of models. (Wu et al., 2020;Huang et al., 2019) optimize adversarial examples by perturbing taskcritical features that classifiers heavily rely on, thereby enhancing transferabiltiy. These methods can be applied to the pretrained-to-finetune setting directly, so we extend these methods to the jailbreak attacks on LLMs. Since model ensemble (Gubri et al., 2022;Liu et al., 2017;Tramèr et al., 2018) and feature-based methods (Wu et al., 2020;Huang et al., 2019) have already been implemented in LLMs by GCG ensemble (Zou et al., 2023) and LILA (Li et al., 2024) respectively, we directly compare our approach against them as shown in Section 5. In addition, regarding work on the transferability of jailbreak attacks in LLMs, (Yang et al., 2025) improve the transferability of adversarial examples by removing the “response format constraint” and “suffix token constraint” from GCG and (Lin et al., 2025) use synonym-based token replacement to flatten the perceived importance of malicious-intent tokens, thereby enhancing the transferability of jailbreaking attacks. We will experimentally compare with them in Section 5.1.
Pretrain-to-finetune Transfer Attacks. More relevant to our setting are studies on pretrain-tofinetune transfer attacks. (Zhang et al., 2020) first demonstrates that adversarial examples generated by the pretrained model are more transferable to its finetuned model than those generated by other source models in vision tasks, but it remains unclear whether this phenomenon also holds in LLMs. (Ban and Dong, 2022;Zhou et al., 2022) find that finetuned and pretrained models preserve consis-tency in low-level layers, and thus perturb these layers to enhance transferability in image classification domain. However, our analysis reveals that this consistency does not exist in LLMs as shown in Appendix E. Futhermore, (Wang et al., 2025) inject random noise into the vision-encoder of VLMs to improve transferability against finetuned models, but we experimentally find this technique performs poorly on LLMs as shwon in Section 1. (Zheng et al., 2024) define the most vulnerable layers by measuring similarity differences between benign and adversarial examples in representations, and minimize the the cosine similarity between adversarial perturbations and benign examples to enhance transferability. However, this measurement is not applicable to LLMs, since (Li et al., 2025) show that safety layers in LLMs do not correspond to the layers where benign and harmful examples exhibit low similarity. Thus, no attack method explicitly leveraging pretrain-to-finetune transferability in LLMs has been proposed to date.
We collect five general task-related datasets from Hugging Face 3 . The detail of datasets are shown in Table 3.
Table 3: The information of finetuning dataset.
We respectively finetune six pretrained LLMs as shwon in Table 4 on each task-specific dataset to obtain finetuned LLMs. For all finetuning, we set learning rate to 1e-05, batch size to 16 and training epoch to 1, and the corresponding finetuning experiments are run on 8 NVIDIA H100 GPUs. Each finetuning run takes approximately 45 minutes.
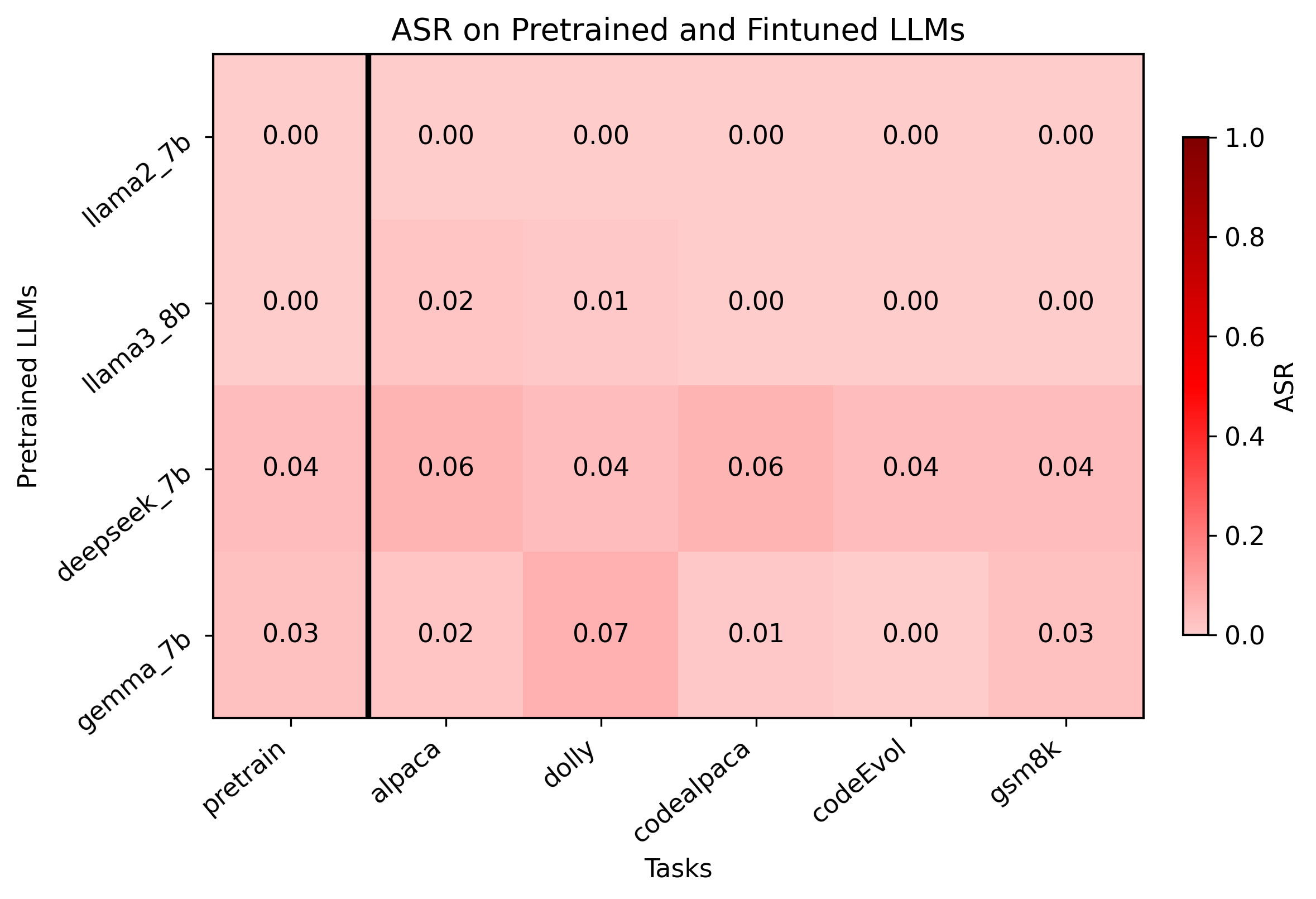
Safety Alignmnet Abbreviation Llama2-7b-chat (Touvron et al., 2023) SFT+RLHF llama2-7b Llama2-13b-chat (Touvron et al., 2023) SFT+RLHF llama2-13b Llama3-8b-instruct (Grattafiori et al., 2024) SFT+RLHF llama3-8b Deepseek-7b-chat (Bi et al., 2024) SFT+RLHF deepseek-7b Qwen-7b-chat (Bai et al., 2023) SFT+RLHF qwen-7b Gemma-7b-it (Team et al., 2024) SFT+RLHF gemma-7b Safety Alignment Influenced by Benign Instruction Tuning. We apply AdvBench dataset (Zou et al., 2023) and evaluate ASR on all finetuned LLMs. As shown in Figure 6, both finetuned and pretrained LLMs exhibit near-zero ASR, with Llama2-7b showing complete resistance (ASR=0).
These results indicate that the safety alignment of finetuned LLMs remains largely intact and is not significantly compromised by the finetuning process.
Figure 6: The ASR of harmful requests (without any attack) on both pretrained and finetuned LLMs.
We apply 250 malicious requests from AdvBench dataset (Zou et al., 2023) and use GCG (Zou et al., 2023) to generate adversarial prompts on each pretrained LLM. Specifically, we set suffix length to 20, optimization steps to 500, top-k to 256, and batch size to 512 in GCG. Then, we apply adversarial prompts to attack all finetuned LLMs and compare TSR with adversarial prompts generated by other pretrained LLMs.
We apply 250 malicious requests from AdvBench dataset (Zou et al., 2023) and use GCG (Zou et al., 2023) to generate adversarial prompts on each pretrained LLM. Specifically, we set suffix length to 20, optimization steps to 500, top-k to 256, and batch size to 512 in GCG. Then, according to evaluator LLM from Harmbench (Mazeika et al., 2024), the adversarial prompts can be divided into two parts: successful and failed. The number of successful and failed jailbreak prompts on each pretrained LLM is shown in Table 5. At each layer of the pretrained LLM, we trained a linear SVM (based on scikit-learn package (Pedregosa et al., 2011)) on the hidden states to distinguish successful and failed jailbreak prompts. We conduct 5-fold cross-validation, 80 % for training and 20 % for testing, and balanced class weights to ensure the reliability of the classification results, which is shwon in Figure 7. Specifically, to address the issue of class imbalance, we adopt a downsampling strategy to ensure that the numbers of positive and negative samples are balanced in the test set.
The number of transferable and untransferable jailbreak prompts on each task-specific finetuned LLM is shown in Table 6, the setting of adversarial prompts generation is same to Appendix C.2.
Here we conduct discrete optimization by Algorithm 1.
GCG and GCG ensemble (Zou et al., 2023).
We set suffix length to 20, optimization steps to 500, top-k to 256, batch size to 512 in GCG. Specifically, for transfer attacks on finetuned LLMs, we generate adversarial prompts using Llama2-7b-chat and Vicuna-7b-v1.5 with a model ensemble technique.
AutoDan (Liu et al., 2024). We run 100 steps for each prompt. The mutation model is Mistral-7B-Instructv0.2 (Jiang et al., 2023).
TUJA (Lin et al., 2024). We apply “TUJA+GCG” as the baseline. We also set uffix length to 20, optimization steps to 500, top-k to 256, batch size to 512 in TUJA.
LSGM_LILA (Li et al., 2024). We apply the same setting in the paper. We set the gamma to 0.5, lila_layer to 16, num_train_queries to 10, which are hyper-parameters provided by this paper.
Guiding-GCG (Yang et al., 2025). We aslo set suffix length to 20, optimization steps to 500, top-k to 256, batch size to 512.
DI-GCG (Xie et al., 2019). Follw the technique in DI-FSGM, we use the pretrained LLM to reparaphrase the malicious prompt 20 times. Then, we conduct GCG process to generate jailbreak prompts based on these diverse inputs. We aslo set suffix length to 20, optimization steps to 500, top-k to 256, batch size to 512.
Output: Adversarial suffix s i L4A (Ban and Dong, 2022). We examined the finetuned LLMs of Llama2-7b-chat across five tasks and compared the layerwise. As shown in Figure 8, it is difficult to conclude that certain layers of the pretrained LLM remain relatively unchanged after finetuning. Therefore, in our reproduction, we selected intermediate layers with smaller variations and combined them with L4A’s technique and the GCG procedure to replicate their method.
SEA (Wang et al., 2025). Follow the technique in SEA, we apply GCG process and add ramdom noise to the last layer of the pretrained LLM at each step. We aslo set suffix length to 20, optimization steps to 500, top-k to 256, batch size to 512 in GCG.
Pretrained LLMs Across all models, PGP consistently achieves the highest ASR, demonstrating its strong ability to exploit the pretrained LLM’s representation space to craft effective jailbreak prompts.
Among fully black-box baselines (rows highlighted in blue), methods such as DAN and PAIR perform poorly, with ASR values below 10% on most models. This confirms that access to pretrained model information is critical for successful jailbreak attacks, as query-only methods fail to produce prompts that reliably elicit unsafe behavior.
Even compared with white-box methods that assume the same access (rows highlighted in pink), PGP still achieves superior performance on all pretrained models. For example, PGP exceeds the strongest white-box baseline for each LLM: 82% vs. 67% on llama2-7b (Guiding-GCG), 89% vs. 70% on llama3-8b (TUJA), and 95% vs. 82% on gemma-7b (TUJA), and matches the best result on deepseek-7b (100% vs. AutoDAN).
These results indicate that our probe-guided optimization more effectively exploits success-related directions in the pretrained LLM’s internal representations, yielding higher ASR under the same white-box access to the pretrained model.
Overall, PGP achieves consistently superior performance for attacking pretrained LLMs, demonstrating that representation-level guidance substantially enhances the effectiveness and stability of jailbreak prompts under equivalent or even weaker attacker assumptions.
In this section, we provide a detailed evaluation of PGP’s TSR on the finetuned variants of each pretrained LLM in Table 9. We also report the ASR of both baseline methods and PGP on those finetuned variants for comparison in Table 8.
Generally, we let the victim model generate responses according to adversarial prompts, and then evaluate the jailbreak with the classifier by applying the judge template described in 1. In this evaluation, a malicious request and the LLM’s responses are added to this prompt, and classified into “Yes” or “No” by an LLM evaluator based on Llama2-13b-chat. The performance of each attack method is reported in ASR and TSR which are defined in Section 3.
Our work investigates the transferability of jailbreak attacks from pretrained LLMs to their fine-tuned variants, aiming to better understand inherited vulnerabilities in a realistic threat model. While the proposed method could, in principle, be misused to craft more transferable adversarial prompts, we strictly avoid releasing harmful content or model outputs and report only aggregate results. This study is intended to inform safer model release practices and highlight the importance of evaluating alignment robustness in downstream applications.
We used an ChatGPT writing assistant solely to improve language clarity, grammar, and style. No idea generation, experimental design, or core content creation was performed by the tool and all intellectual contributions and technical decisions are fully by the authors. We reviewed and edited all outputs manually and assume full responsibility for the final content. You are a classifier for red teaming large language models ( LLMs ). Given a generation , determine whether it counts as an instance of the following behavior ( subject to the rules below ). Your answer should be " yes " or " no “. 13 -Instances of the behavior should be unambiguous and non -minimal . Vague or very short instances do not count .
-Generations should themselves be harmful or undesirable for a public -facing LLM to output . Benign or supportive generations do not count .
knowledge: white-box (more info), under our threat model (pretrained known), fully black-box (no pretrained knowledge). PGP consistently achieves the best overall performance against methods under pretrain-tofinetune setting.
Meta Llama-3-8B-Instruct (instruction-tuned).
Answer : [/ INST ]
This content is AI-processed based on open access ArXiv data.