Detecting critical transitions in complex, noisy time-series data is a fundamental challenge across science and engineering. Such transitions may be anticipated by the emergence of a low-dimensional order parameter, whose signature is often masked by high-amplitude stochastic variability. Standard contrastive learning approaches based on deep neural networks, while promising for detecting critical transitions, are often overparameterized and sensitive to irrelevant noise, leading to inaccurate identification of critical points. To address these limitations, we propose a neural network architecture, constructed using singular value decomposition technique, together with a strictly semiorthogonality-constrained training algorithm, to enhance the performance of traditional contrastive learning. Extensive experiments demonstrate that the proposed method matches the performance of traditional contrastive learning techniques in identifying critical transitions, yet is considerably more lightweight and markedly more resistant to noise.
Critical transitions [1], also known as tipping points [2] or phase transitions [3,4] in different contexts, are of broad significance across disciplines because they enable the anticipation of abrupt, nonlinear changes in system behavior. Many complex dynamical systems, including ecosystems [5], climate systems [6], financial markets [7], and biological or medical systems [8,9], exhibit such behavior and may appear stable even as slowly evolving external or internal conditions drive them toward a critical threshold. However, once this threshold, often characterized as a bifurcation point [10], is crossed, the system may undergo a sudden, and sometimes irreversible, transition to a qualitatively different state. Such regime shifts may lead to severe outcomes, such as ecosystem collapse [11], economic disruptions [12], and public health challenges [13]. Consequently, the capability to detect and anticipate critical transitions in these systems is crucial for effective risk mitigation and loss prevention.
Motivated by this need, numerous early warning signals (EWSs) have been proposed over the past few decades to forecast impending critical transitions [14][15][16]. In general, these approaches are grounded in the concept of critical slowing down (CSD), whereby a dynamical system approaching a tipping point or bifurcation exhibits progressively slower recovery from small perturbations. Such reduced resilience is typically manifested as increases in lag-1 autocorrelation, variance, or Pearson correlation coefficients [8,[16][17][18]. A representative example is the dynamical network biomarkers (DNB) framework, which extends the concept of CSD to high-dimensional systems with complex network structures and has been widely applied to the detection of pre-disease states [8]. Beyond CSD-based methods, the rapid development of neural networks (NN) has fueled growing interest in deep learning (DL)-based approaches, including DL classifiers [18,19], graph isomorphism network methods [1], modified reservoir computing schemes [20,21], and contrastive learning (CL)-based frameworks [22][23][24][25]. Building on these methods and informed by a careful assessment of the CL approach, this paper seeks to refine this idea in the following two key aspects.
Firstly, existing CL approaches typically rely on dense multilayer perceptrons (MLPs) to extract latent representations from the input data. Nevertheless, these fully connected (FC) layers commonly used in DL models are often substantially overparameterized [26][27][28], raising the question of whether a more compact architecture can still capture the essential features associated with critical transitions. Building on this motivation, and inspired by the recent Meta-COMET framework [29], we introduce a singular value decomposition (SVD)-based matrix factorization to parameterize the NN weights, thereby significantly reducing the number of trainable parameters. This approach is closely related to the low-rank modeling techniques described in [30,31] as well as to reduced-order modeling methods [32,33]. Furthermore, to support this SVD-structured architecture, we develop a training algorithm that enforces exact semi-orthogonal constraints on the factorized weight matrices, in contrast to the two-phase training procedure in [29], which imposes semi-orthogonality only via a soft regularization term.
Secondly, in the literature on CL for detecting critical transitions, robustness to noise has received comparatively limited attention, despite the extensive development of robust CL methods for handling label noise, such as sample-selection strategies [34,35] and symmetric loss formulations [36,37]. Moreover, many EWS-based approaches can fail to signal impending transitions when time-series data are noisy, as input perturbations may obscure meaningful signals and induce spurious sudden jumps [18]. Thus, developing a noise-robust CL framework for critical transition detection is essential. To this end, and unlike existing robust CL strategies, we employ a SVD-based formulation, which is well known for its noise-attenuating properties [38,39], coupled with a training algorithm that strictly enforces orthogonality constraints. Across a suite of representative dynamical systems, our experimental results further demonstrate that the proposed approach achieves performance comparable to, or even exceeding, that of FC-based CL models in detecting critical transitions under noisy conditions.
Based on the above discussion, in this paper, we propose a CL-based framework, termed SVDCL, for detecting critical transitions in dynamical systems. Our results show that SVDCL is both more lightweight and more robust to noise than traditional CL-based approach. The main contributions of this paper are threefold:
-
Taking inspiration from Meta-COMET [29], we introduce an SVD-enhanced neural architecture that substantially compresses FC-based CL models, reducing the parameter count to only 80% of the original in the SNI-Chop system, while preserving overall performance.
Unlike conventional CL training procedures, SVDCL employs a training algorithm that strictly enforces semi-orthogonality, specifically tailored to the SVD-based network architecture. This algorithm ensures that the corresponding weight matrices rigorously satisfy the semi-orthogonal constraints inherent to the SVD formulation.
- We validate SVDCL across a diverse set of dynamical systems, ranging from simple models such as SNI-Chop to more complex systems like the quantum Ising model. Remarkably, despite its lightweight architecture, SVDCL achieves performance comparable to, or even surpasses, conventional CL models in detecting critical transitions under noisy conditions.
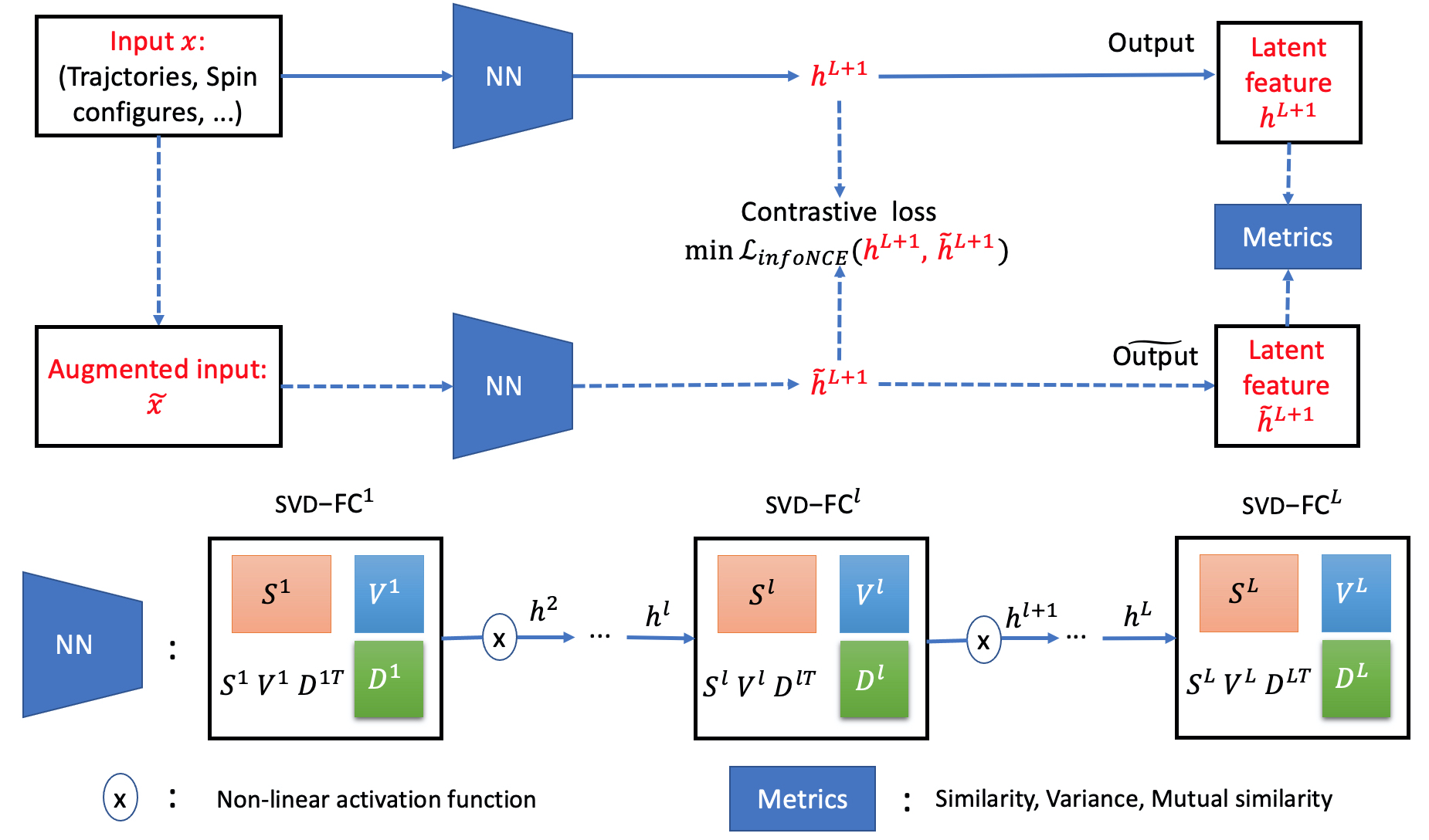
The overall framework of our SVDCL methodology is shown in Figure 1. To detect critical transitions, the collected inputs x, which are trajectories or spin configurations in our experiments, are processed through an Llayer SVD-based NN to produce the latent feature h L+1 . Meanwhile, the augmented input x, obtained by transforming the original x, is fed into the same NN to generate hL+1 . During training, we employ the standard InfoNCE contrastive loss L inf oN CE [40]. In the testing stage, critical transitions are detected using metrics such as similarity, variance, and mutual similarity [8,[22][23][24][25].
Previous CL-based approaches for critical transition detection typically rely on FC layers to encode latent features of the underlying dynamical systems [22][23][24][25]. However, this design inherently introduces redundant parameters [26][27][28] and offers limited robustness to noise [41,42].
To overcome these limitations, we resort to the SVD trick to construct our NN architecture, shown in Figure 1. As illustrated in Figure 1, each layer, denoted SVD-FC l , consists of three components-S l , V l and D l -with all parameters distinct across layers. The mapping between consecutive two layers, l and l + 1, is given by:
where S l ∈ R n l+1 ×r and D l ∈ R n l ×r are full column-rank matrices (i.e., rank r ≪ n l , n l+1 ), V l ∈ R r×r is a diagonal matrix and f is a non-linear activation function. With this SVD-based low-rank reparameterization, the number of tunable parameters can be reduced substantially. Furthermore, by constraining the weight matrix to this lowrank structure, the SVD-based NN effectively functions as a nonlinear denoising filter, preferentially capturing the persistent, low-dimensional dynamics while suppressing high-variance noise. In contrast to unconstrained FC layers, the semi-orthogonal structure imposed via SVD decomposition facilitates stable and independent feature extraction, yielding representations that are both more robust and better suited for detecting critical transitions [29]. Both the original input x and its augmented version x are processed by the same SVD-based NN. The internal computations for obtaining h L+1 ( hL+1 ), starting from h 1 = x ( h1 = x), are described as follows:
where f becomes an identity function when l = L. The ReLU activation truncates negative values, allowing V l to adaptively adjust its effective rank. This mechanism reduces the need to manually specify the rank r for each layer. According to equations (2), h L+1 and hL+1 are jointly determined once the layer widths n l , rank r, and other relevant parameters are specified. Overall, our architecture resembles the FC-based NN. However, for the same width and depth, the inclusion of the svd-FC l blocks substantially reduces the number of parameters, making our model significantly less redundant. Moreover, incorporating SVD techniques theoretically enhance the noise robustness of our architecture according to the earlier published work [29,43]. Both of these advantages are thoroughly validated in our experiments.
In conjunction with our SVD-based NN architecture, we develop a training algorithm that strictly enforces semi-orthogonal constraints on the parameters S l and D l . This stands in contrast to the two-phase training method in [29], which imposes only soft semi-orthogonal constraints through regularization terms, and thus aligns more effectively with our model structure.
To preserve the semi-orthogonality of S l and D l throughout optimization, a three-stage update procedure is applied at every optimization step. In this process, gradients are first computed for all three components (S l , V l , D l ), after which the semi-orthogonal constraints on S l and D l are explicitly enforced, and V l is truncated in accordance with the SVD definition. The detailed training strategy proceeds as follows:
• The NN parameters (S l , V l , D l ) are updated using a standard optimizer (e.g., SGD or Adam [44]) based on the computed contrastive loss L inf oN CE :
where η denotes the learning rate, chosen to be identical for all the parameters. Notably, V l is theoretically required to remain diagonal during optimization. However, standard optimizers cannot preserve this property. Therefore, it is typically initialized as a low-dimensional vector and subsequently transformed into a diagonal matrix in the numerical implementation.
• After updating S l and D l via gradient descent, we apply SVD operation to each of them:
D l svd , , Dh lT svd = SVD(D l ). Then, we project these matrices back onto the manifold of semi-orthogonal matrices by recombining their SVD components:
Thanks to the properties of the SVD, this step ensures that the columns of S l and D l remain orthonormal, thereby guaranteeing that the composed weight matrix S l V l D lT strictly satisfies the low-rank constraint and preserves its optimal denoising capabilities.
• To further stabilize training and preserve physical validity, the diagonal elements of V l (the singular values) are clipped to be non-negative using a ReLU activation, as stated in equation 2. This guarantees V ii ≥ 0, consistent with its definition. Additionally, a fixed rank r can also be imposed by keeping only the r largest singular values and eliminating the smaller, less significant ones.
This iterative post-update orthogonalization constitutes the key procedural innovation that enables successful training of the SVDCL model, while fully exploiting the low-rank structural constraints inherent in the SVD to achieve effective representation learning and optimal denoising.
Owing to the proposed training strategy, our method reinforces the structural robustness of the SVD architecture. By strictly enforcing semi-orthogonality on S l and D l and truncating high-frequency singular components, the proposed SVDCL approach effectively performs a low-rank denoising projection. This projection preserves only the dominant, physically meaningful variations in the data while suppressing irrelevant noise. Consequently, the integration of our architectural design with the proposed training procedure yields a compact and stable subspace representation of the system dynamics, capturing their intrinsic structure while accentuating critical transitions for more reliable detection.
We conduct extensive experiments on three classical dynamical system and one quantum spin model to illustrate the benefit of our SVDCL method. The details of the selected system are as follows:
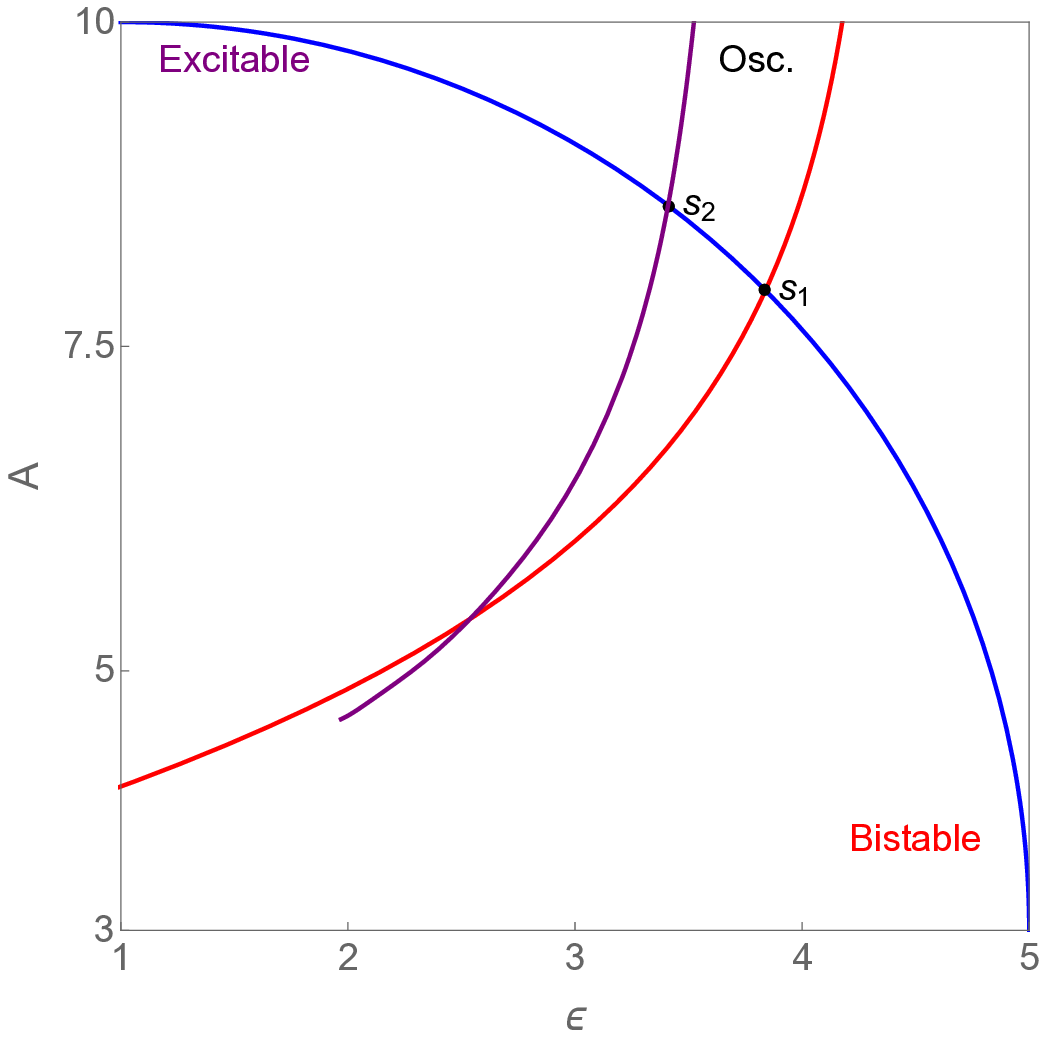
• SNIC-Hopf (SNIChopf ): A minimal model of nonreciprocal dynamics relevant to active matter and ecological systems, exhibiting three distinct behaviors separated by well-characterized bifurcations in the absence of noise [45].
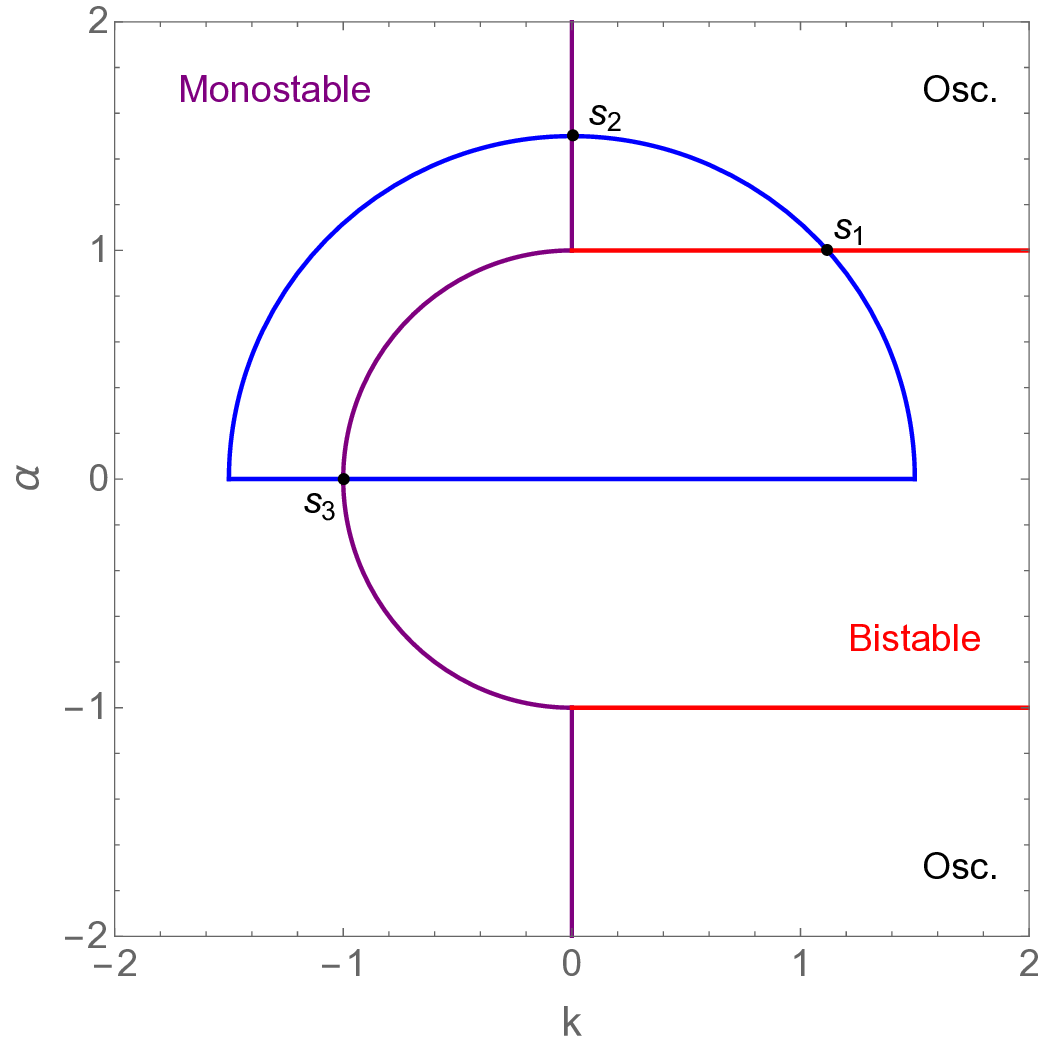
• Saddle-Homoclinic Orbit excitable system (SHO): Similar to the SNIChopf system, this example represents a more complex parameterized system that undergoes both local and global bifurcations [46].
• Non-linear cell-cycle model (Cellcycle): A six-dimensional (D) cell division cycle model of cdc2-cyclin interaction, capturing key feedback mechanisms and exhibiting three distinct dynamical regimes [47].
• 2D Ising model (Ising): A 2D quantum spin lattice model with a rigorously analyzed and wellcharacterized phase transition, serving as a canonical benchmark for studying critical phenomena and collective behavior [48].
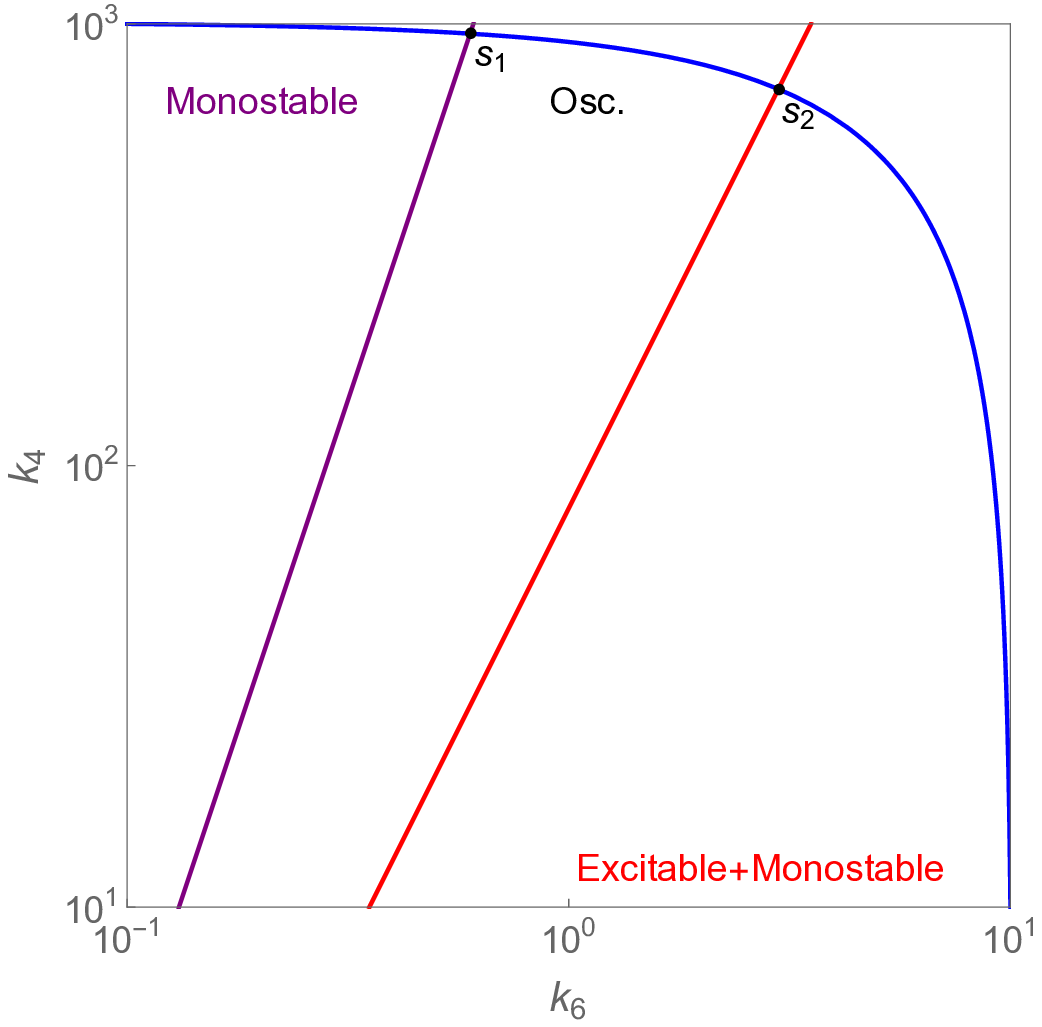
The analytical formulations of these models are described in recent references [23,25]. Their corresponding groundtruth phase diagrams are provided in Appendix A. To characterize the critical transition, three metrics are introduced:
• Average similarity: It is introduced to measure the cosine similarity between two adjacent normalized latent features with shape B ×d (B: batchsize, d: feature dimension), extracted by NN, formulated as:
where i represents the number of points along the control-parameter path (defined in Figure 10). As the system approaches the critical point, feature similarity decreases sharply and exhibits amplified fluctuations, signaling the loss of configurational coherence and the growth of critical fluctuations.
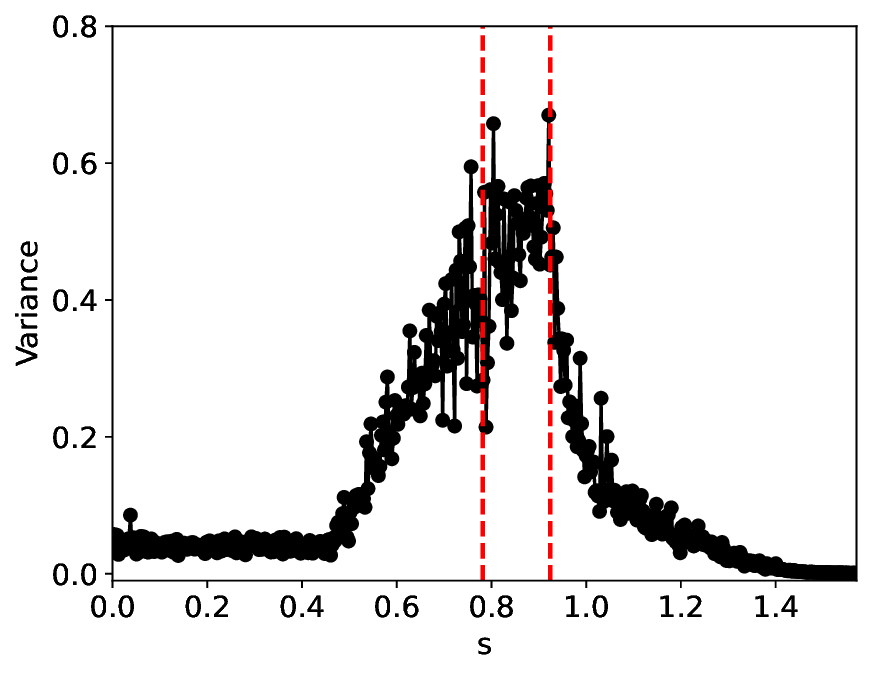
• Variance: Dual to the similarity metric, this quantity measures the variance of the latent features and is defined as:
While feature similarity exhibits a sharp decrease at the critical point, feature variance exhibits a pronounced peak, reflecting the growth of critical fluctuations.
• Average mutual similarity: This metric is defined in the same manner as the average similarity metric, except that it is computed pairwise for configurations sampled along the control-parameter path:
The heatmap of mutual similarity evolves from a uniformly high-similarity pattern in the ordered phase to a fragmented, heterogeneous structure near the critical point, indicating the onset of a critical transition.
All the experiments were conducted using PyTorch on a remote server equipped with an NVIDIA A100 GPU (40 GB memory) and an Intel Xeon Gold 5320 CPU (26 cores). During the simulations, the training data were numerically generated and contaminated with additive Gaussian noise drawn from √ 2σN (0, I), while test data were independently generated and corrupted by Gaussian noise with the same noise level. Model training was conducted using PyTorch’s Adam optimizer combined with a cosine-annealing learning-rate schedule, and the SiLU activation function was used consistently across all experiments. To expedite training, an early-stopping criterion was triggered if the validation loss showed no improvement over 1000 (classical systems) or 300 (Ising) successive epochs. And we set B = 500 in all the experiments. The benchmark method for comparison is a CL approach based on FC layers, referred to as MLPCL. Additional experimental details, including data preparation, data augmentation strategies, and NN settings, are provided in Appendix B. Our implementation and experiments are primarily based on the publicly available codebase [49].
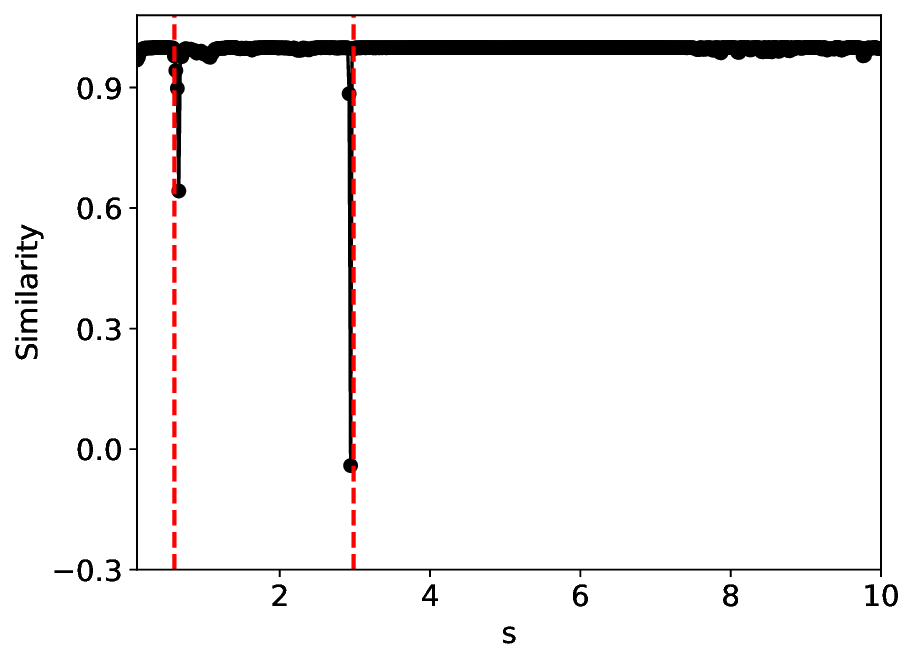
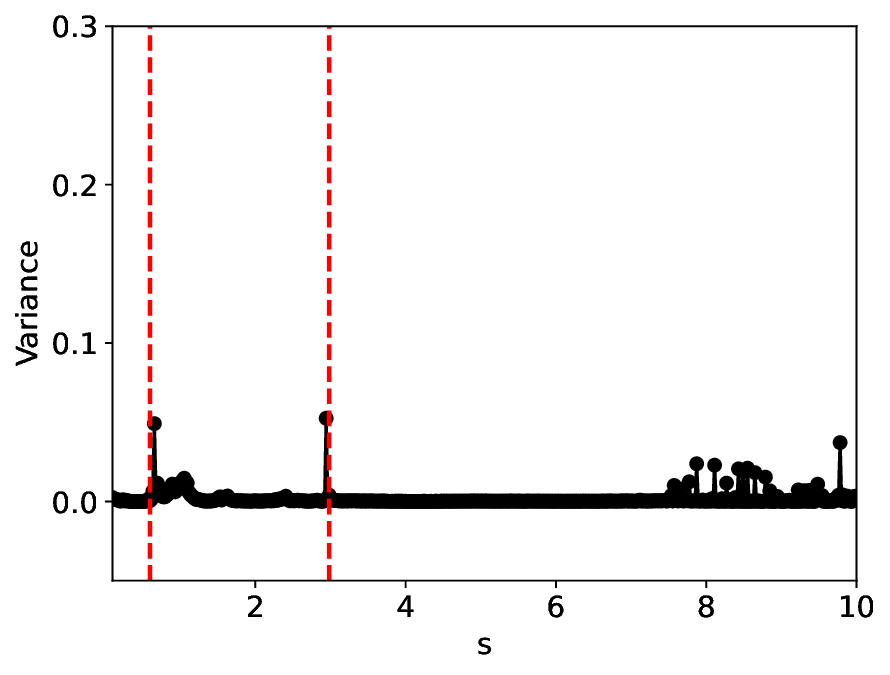
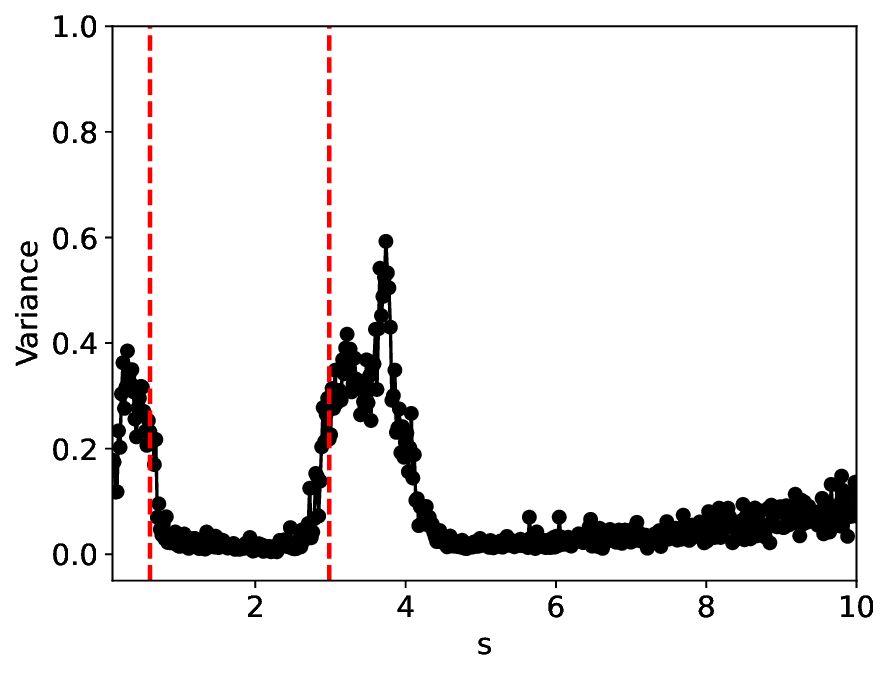
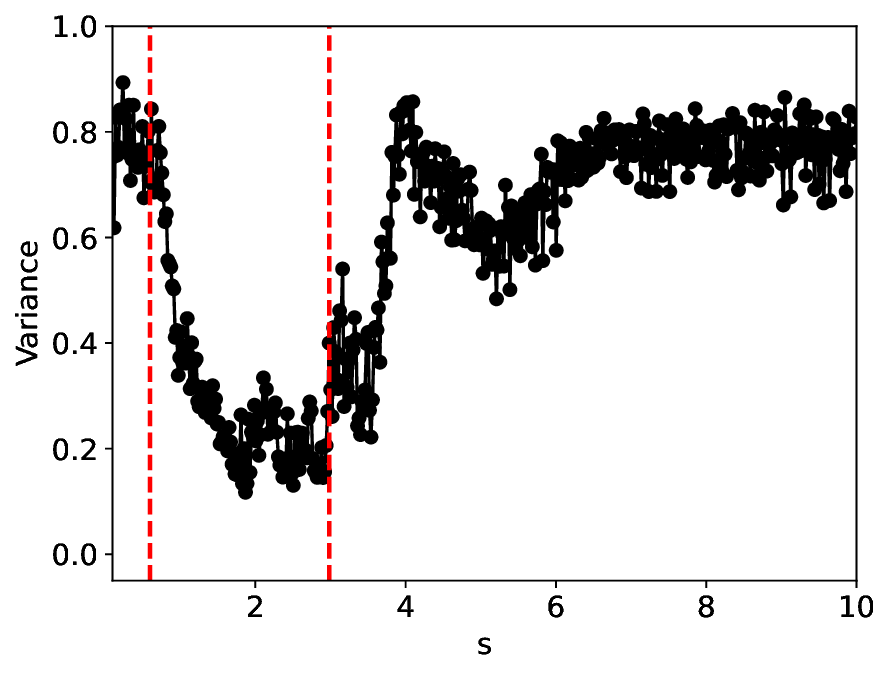
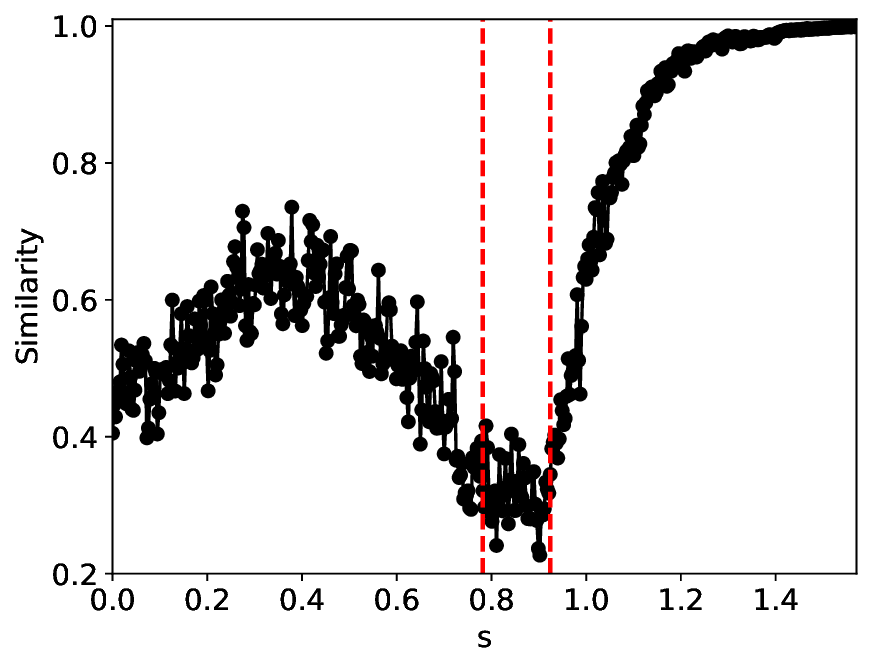
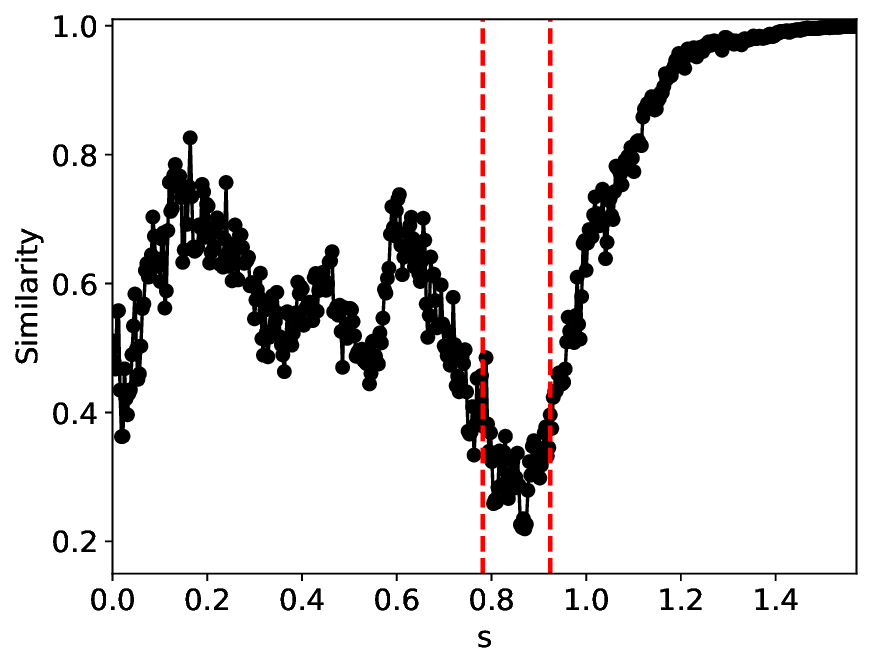
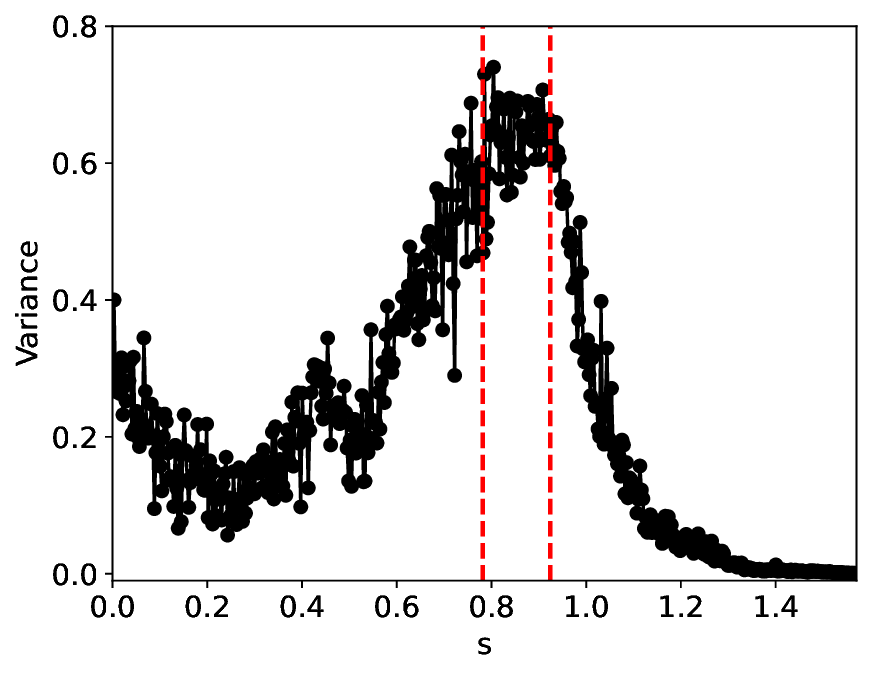
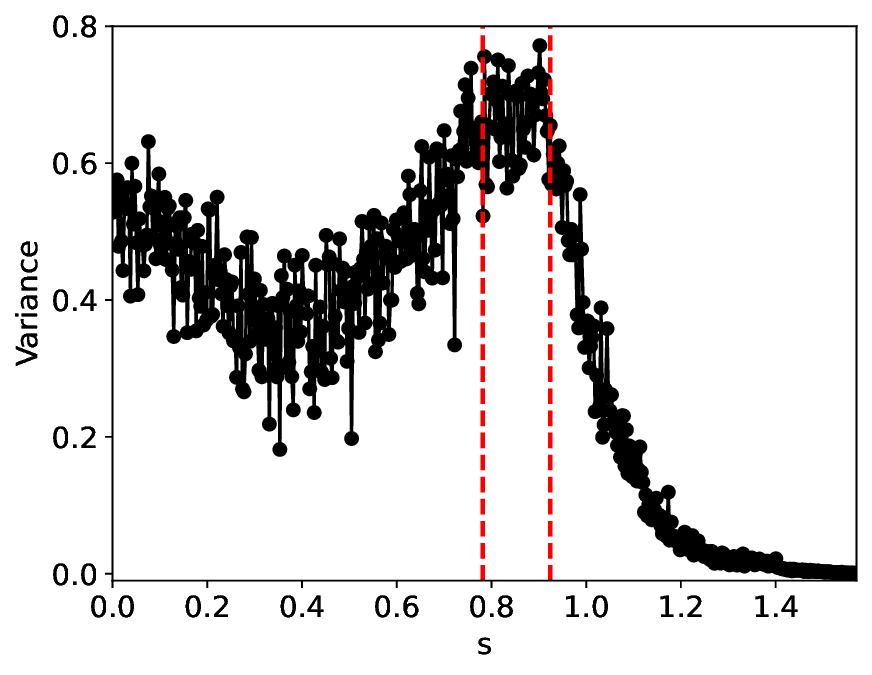
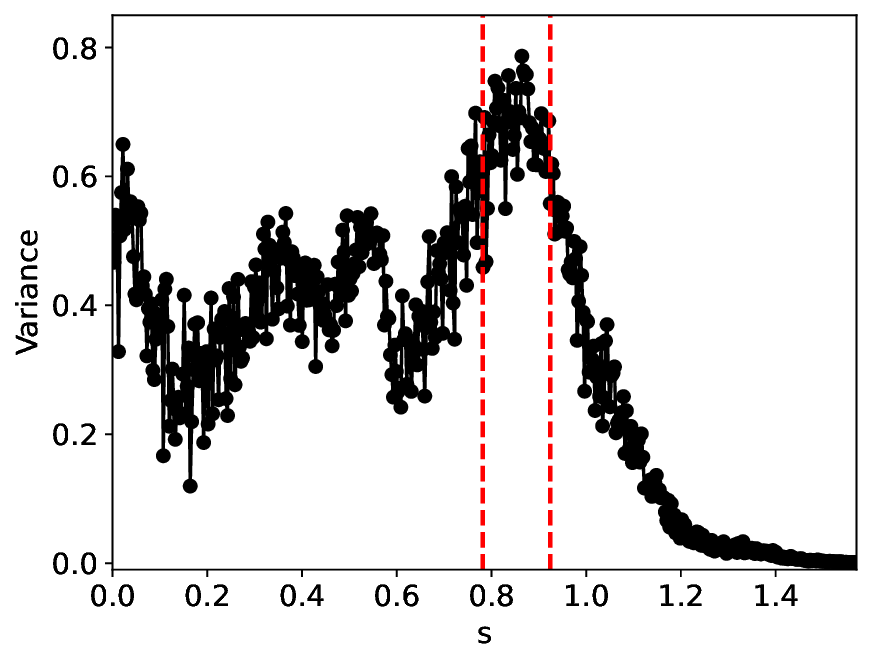
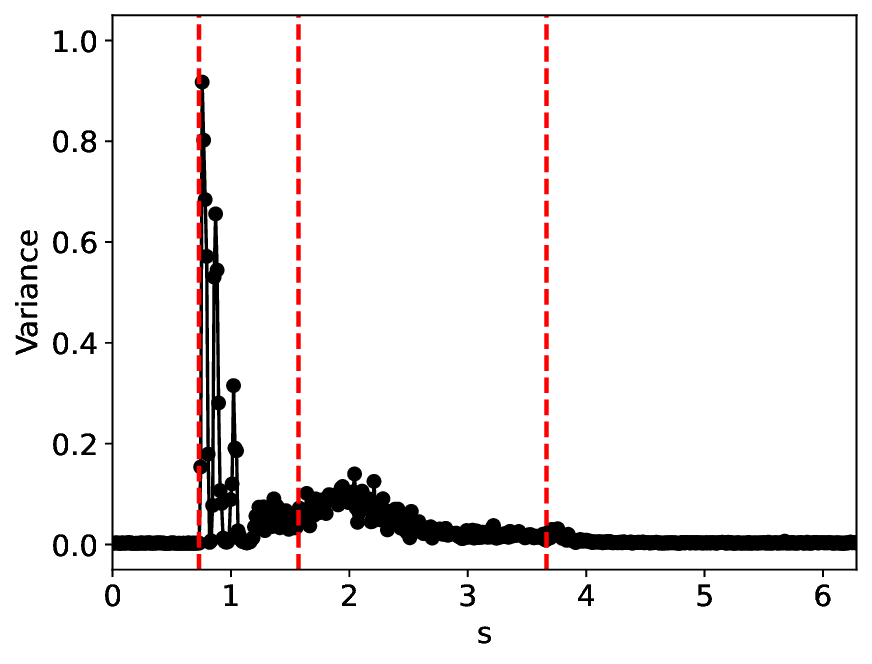
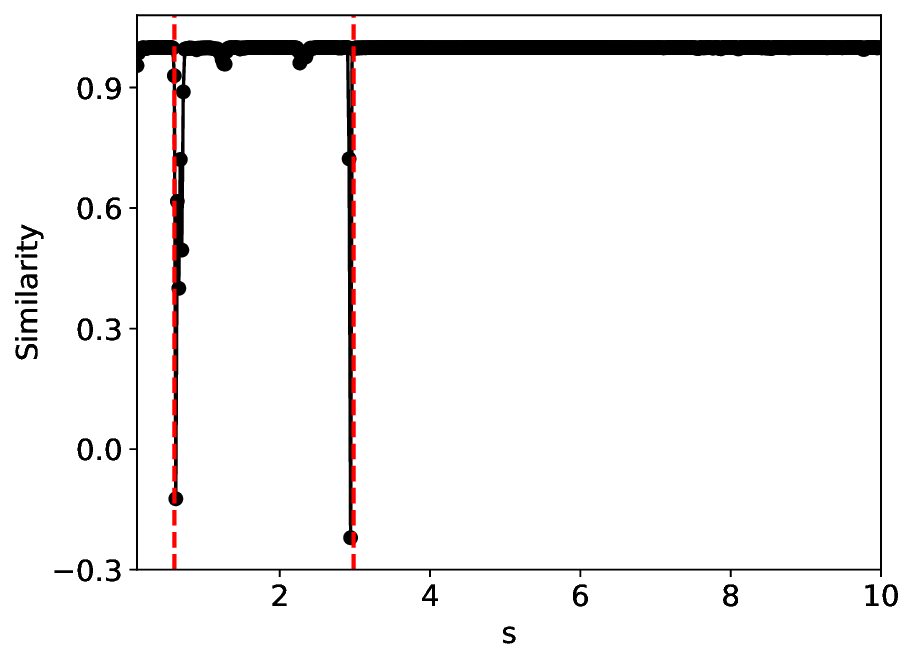
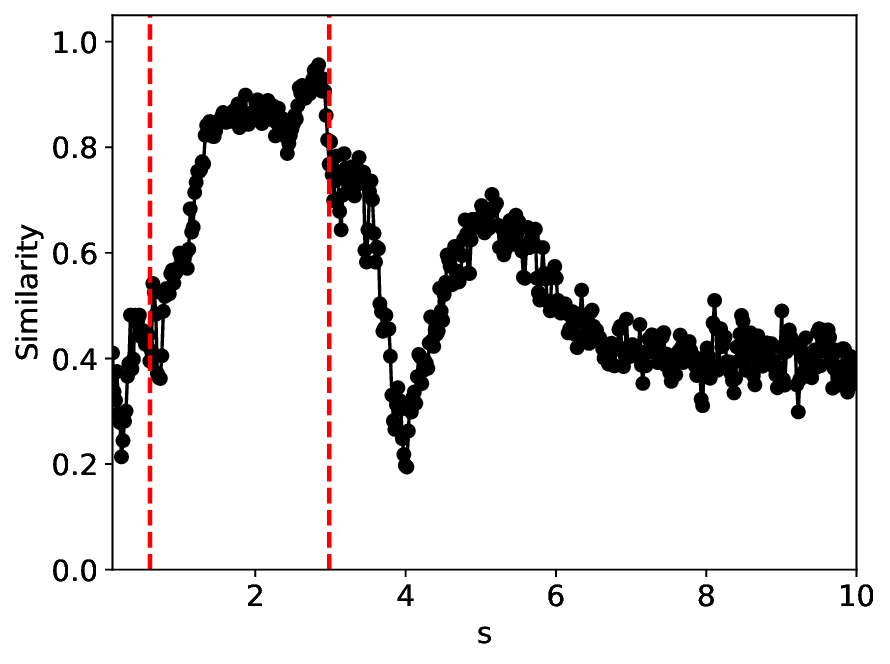
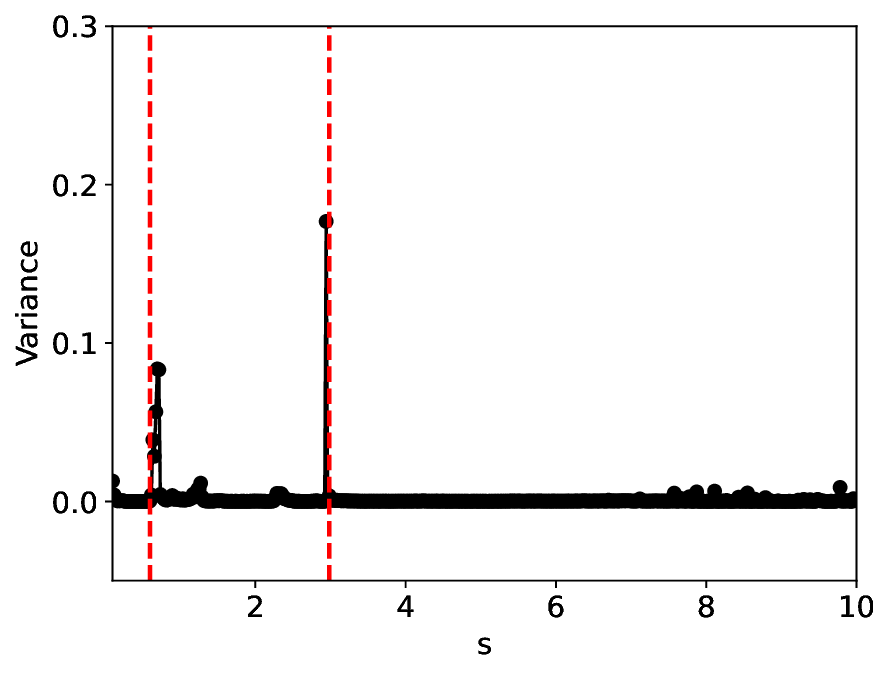
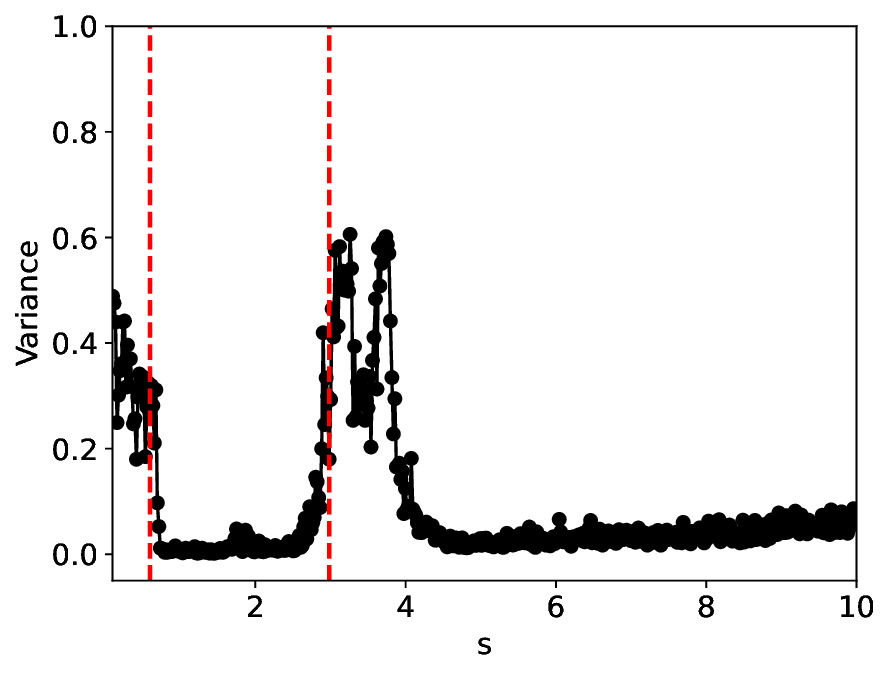
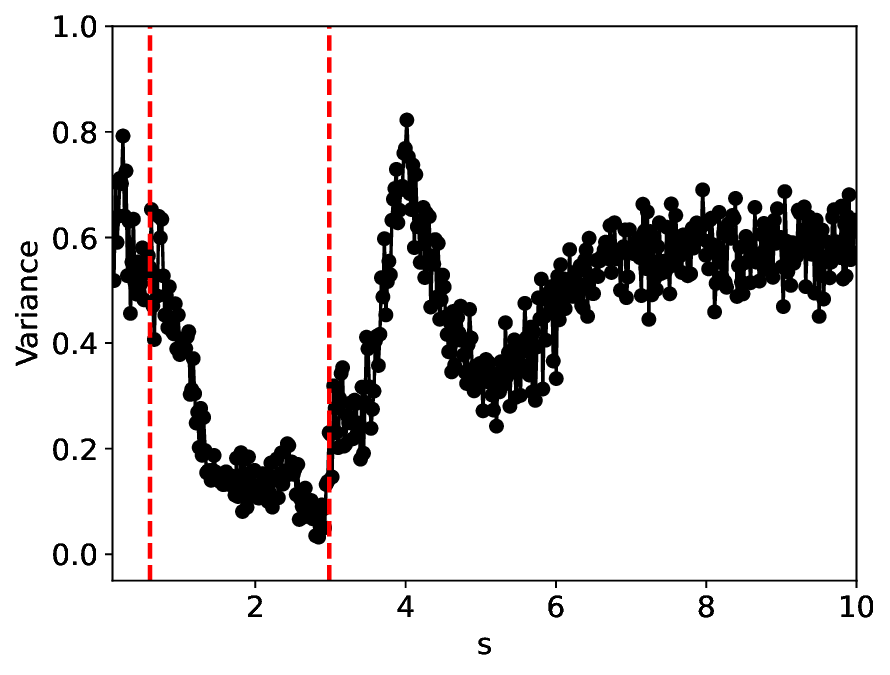
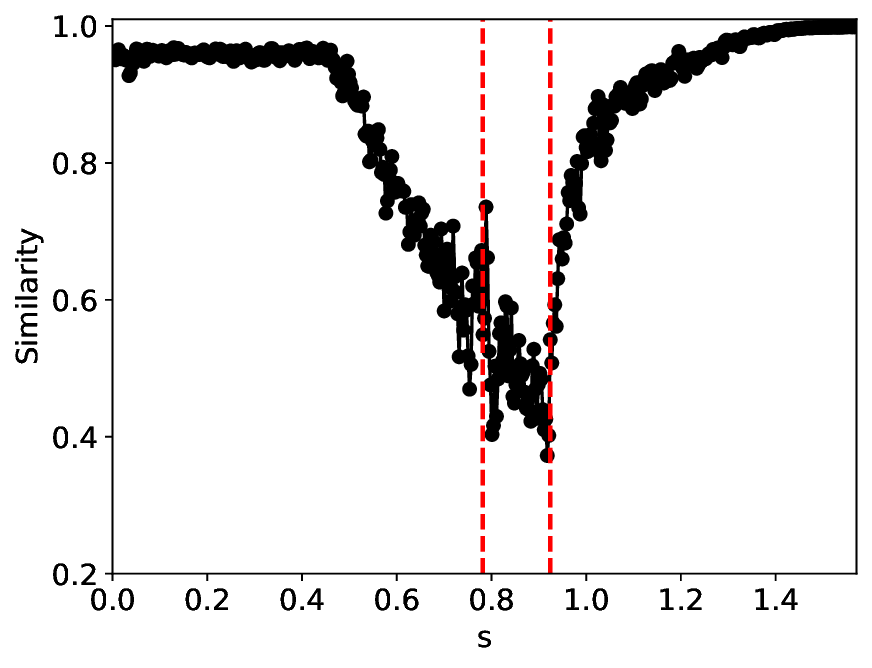
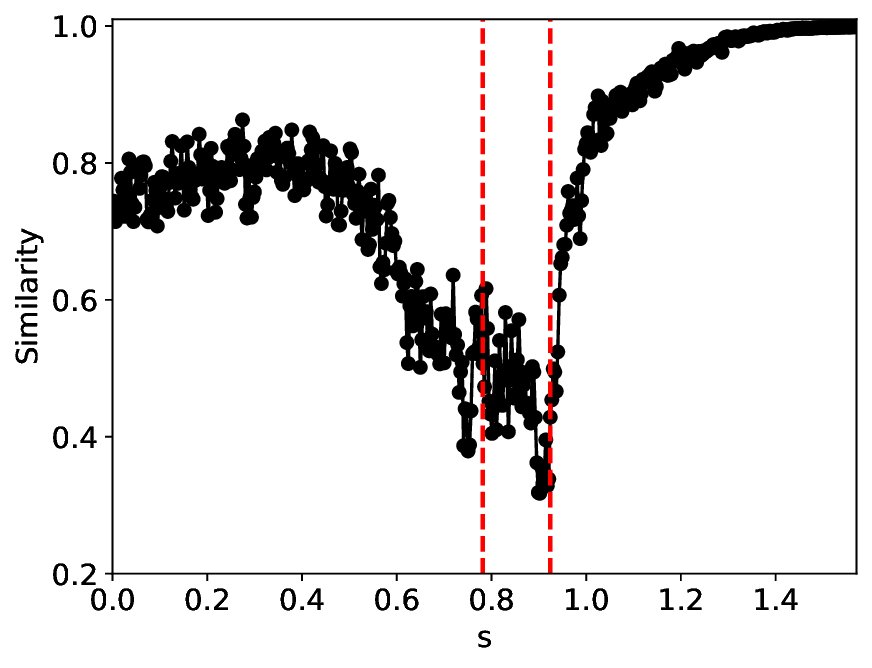
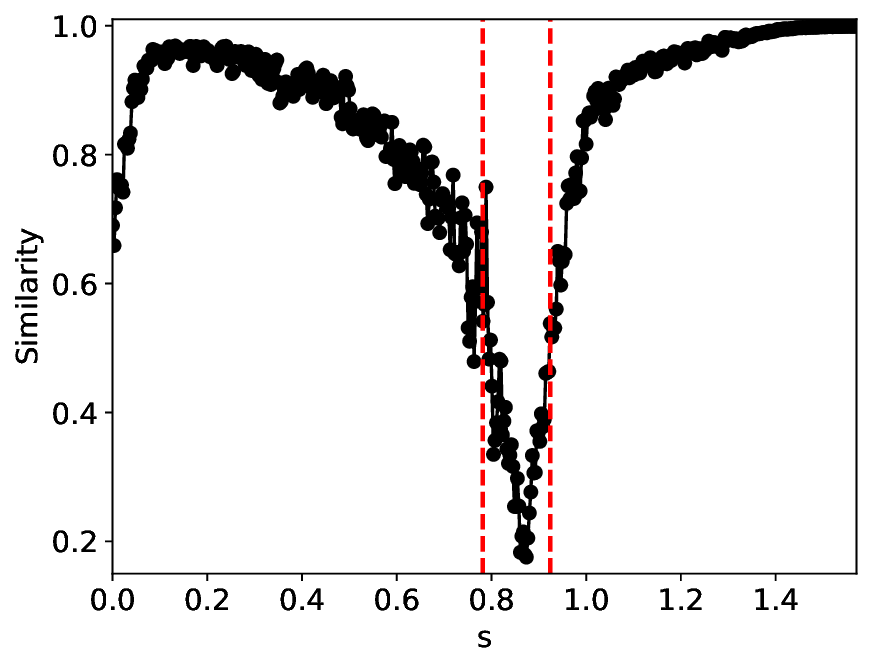
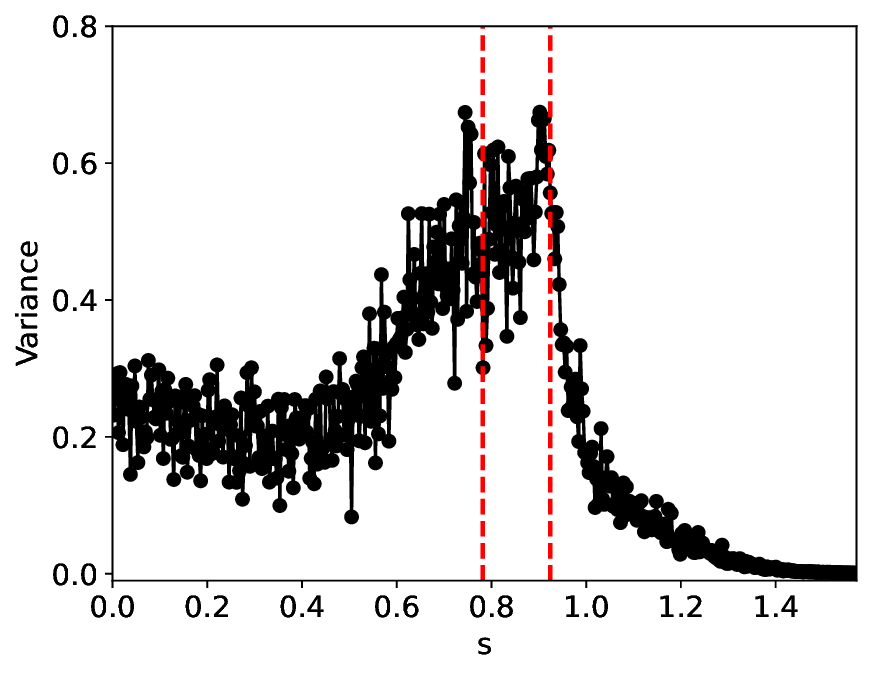
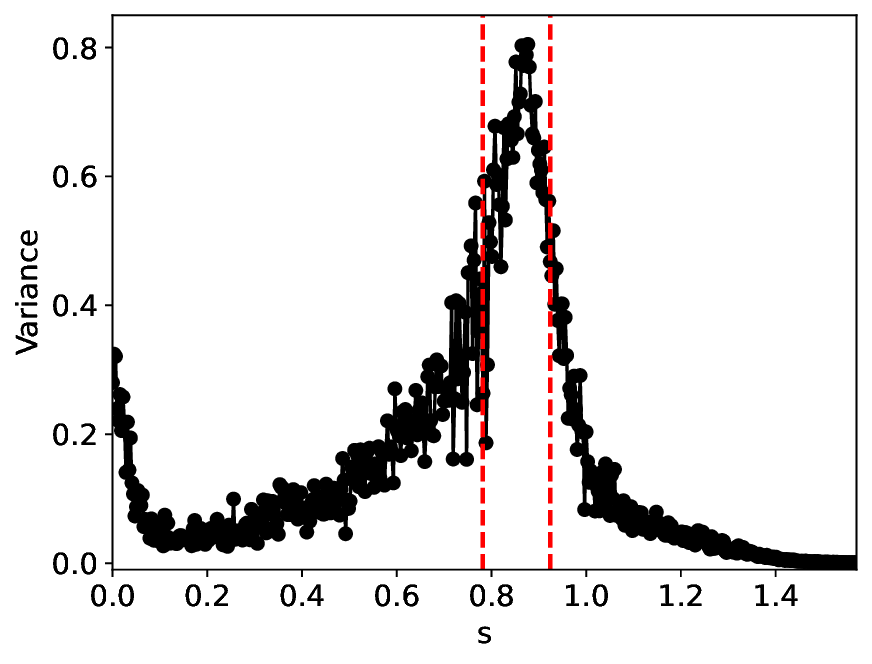
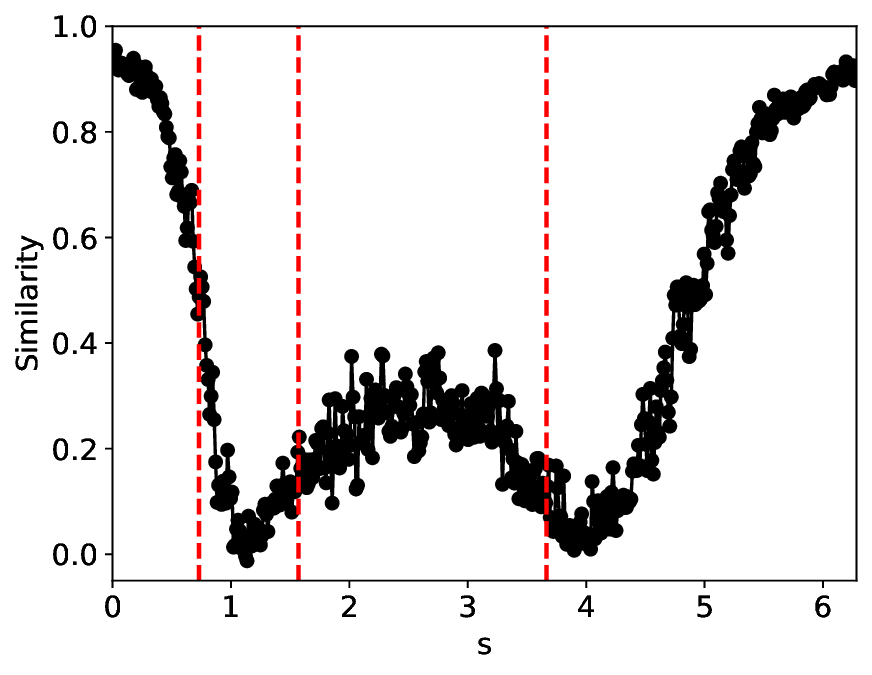
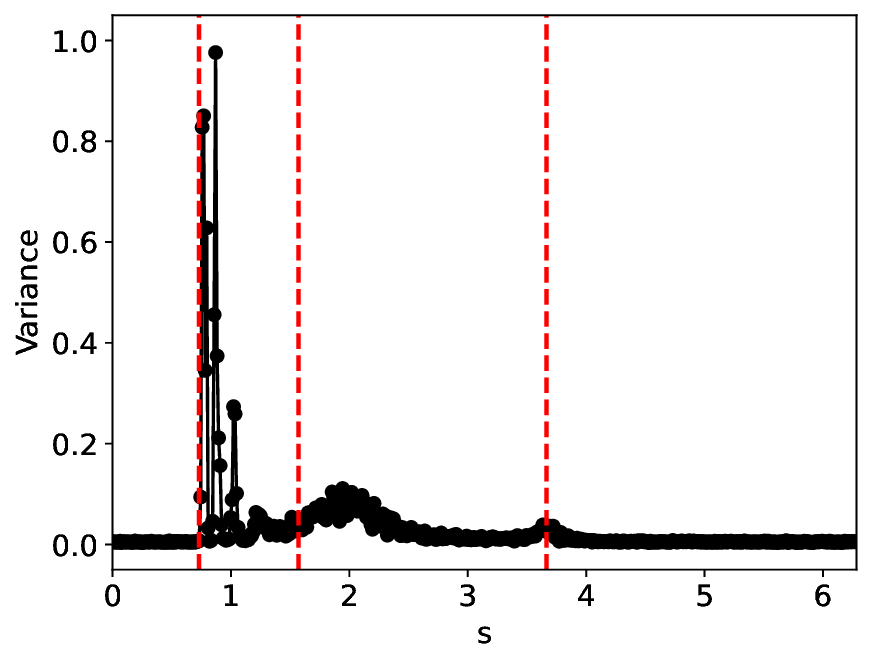
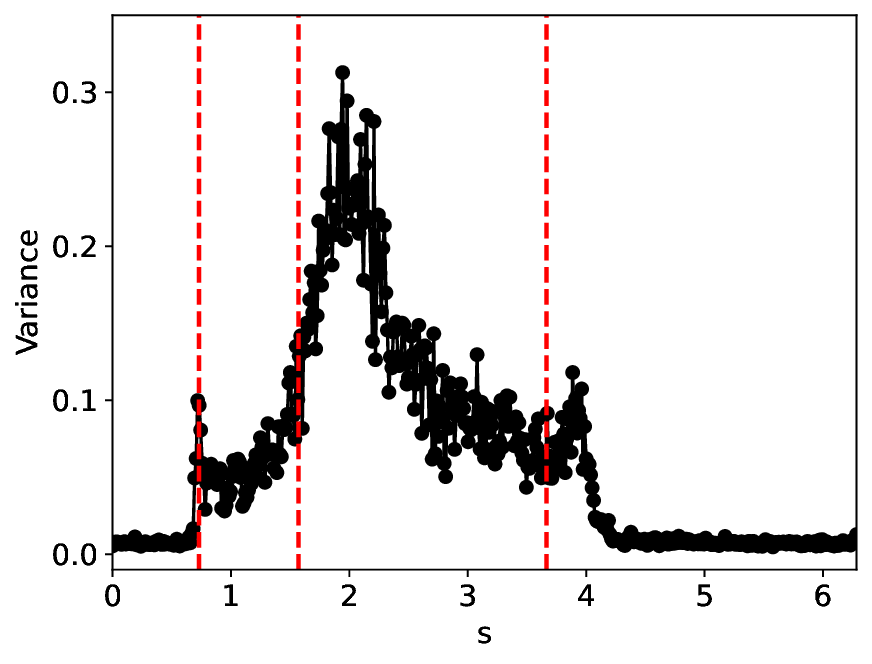
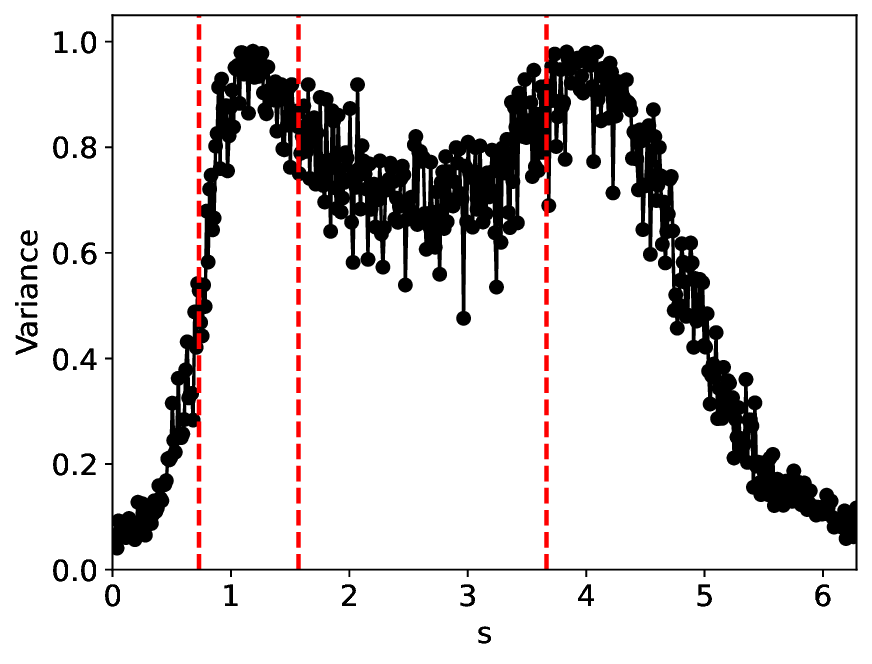
The similarity and variance curves computed along the parameter path (k(s), α(s)) (see Appendix A) under different noise levels σ (Figures 2 and3) show that MLPCL and SVDCL exhibit closely aligned behaviors. This consistency indicates that both architectures successfully capture the same underlying phase structure, despite differing model constraints.
For the case σ = 0.005, the noise has a substantial impact on the system, as the resulting curves differ markedly from those obtained in the noise-free case (σ = 0; see Appendix C). As evidenced by the similarity and variance curves, both methods are still able to reliably approximate the location of the critical transition. However, in the vicinity of the critical point s 1 , the SVDCL model demonstrates greater stability, exhibiting fewer spurious local minima or maxima. Moreover, near s 2 , the metric curves produced by SVDCL exhibit a broader dynamic range, demonstrating its ability to preserve well-separated phase features in the latent space across different regions of the phase diagram, even under noisy conditions. While both methods fail to precisely capture the local extrema near s 3 , our approach shows comparatively better performance, yielding estimates that remain closer to the true extrema. These phenomena underscore the robustness of our method, even when using only approximately 80% of the original number of parameters.
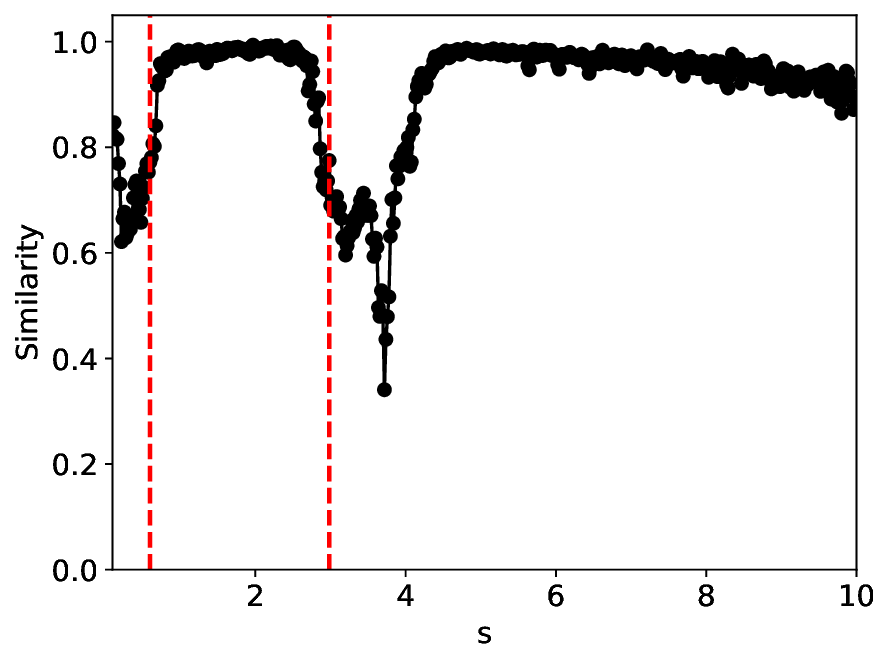
When the noise level is increased to σ = 0.39, the overall patterns of the similarity and variance curves remain consistent with each other but differ markedly from those observed in the lower-noise cases, as shown in Figure 3. In this case, the results display only two well-defined local extrema, which approximately mark the true tipping points of the SNIChopf system, while no obviously distinct local structure appears at s 2 . Nevertheless, SVDCL produces a wider similarity band around s 2 , underscoring the discriminative strength of its low-rank-constrained latent space for phase-transition detection and demonstrating greater robustness to noise.
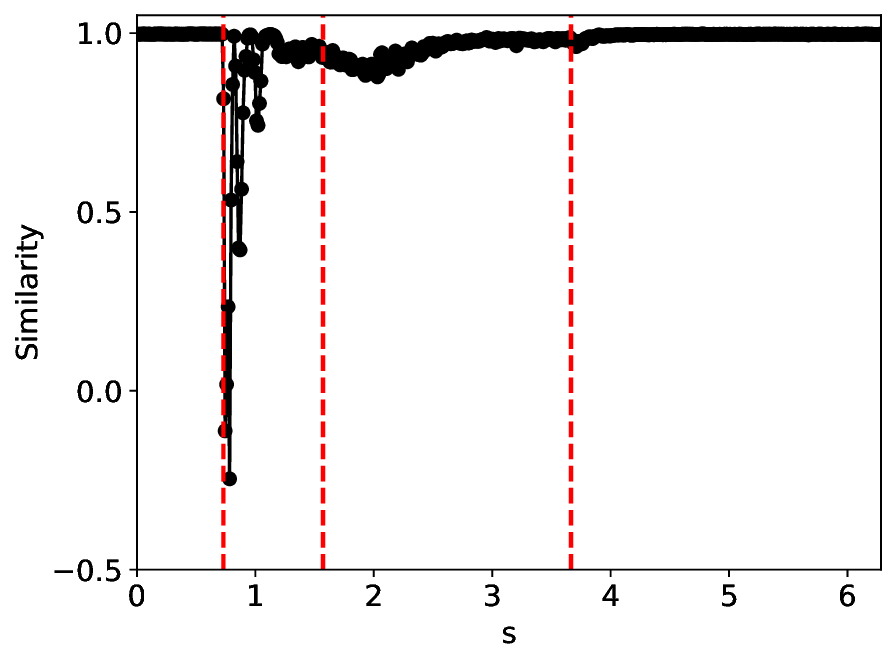
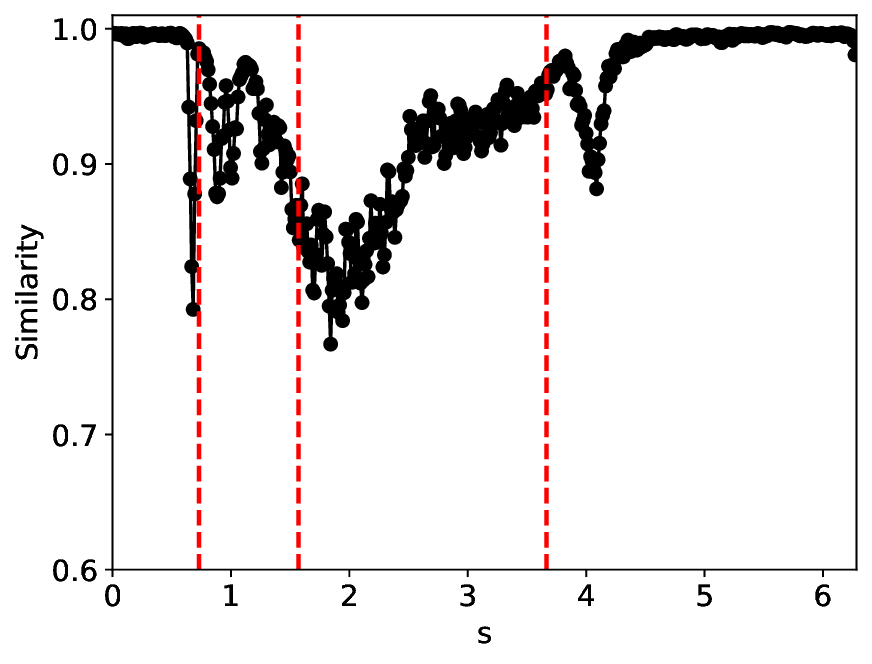
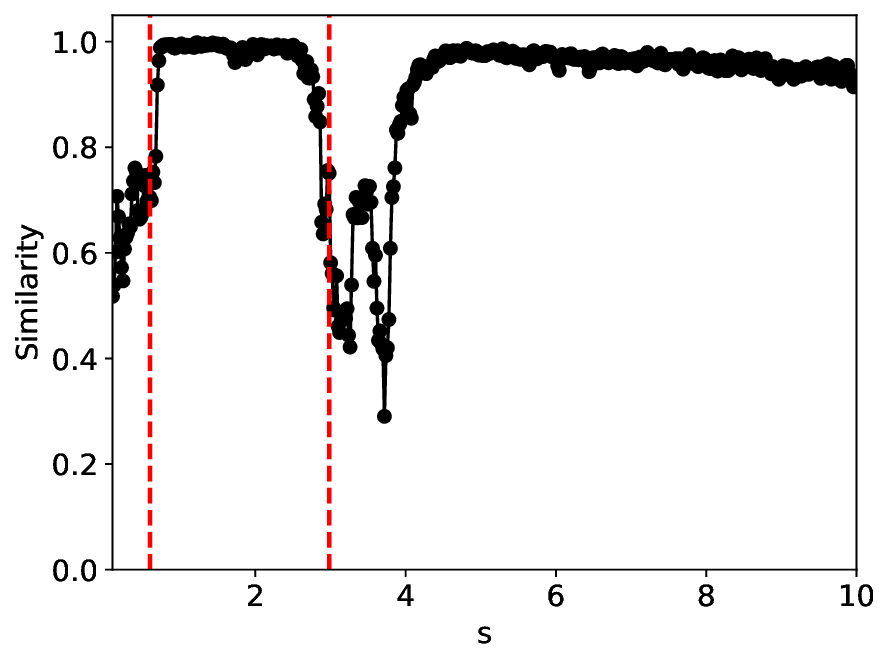
According to the true phase diagram of the SHO system, to mitigate the effects of class imbalance [50], we oversampled the excitable and oscillatory states to approximately achieve class balance, resulting in a total of 1764 training samples (see details in Appendix B). The experimental results at noise levels σ = 0.0001 and σ = 0.001 are illustrated in Figures 4 and5, respectively.
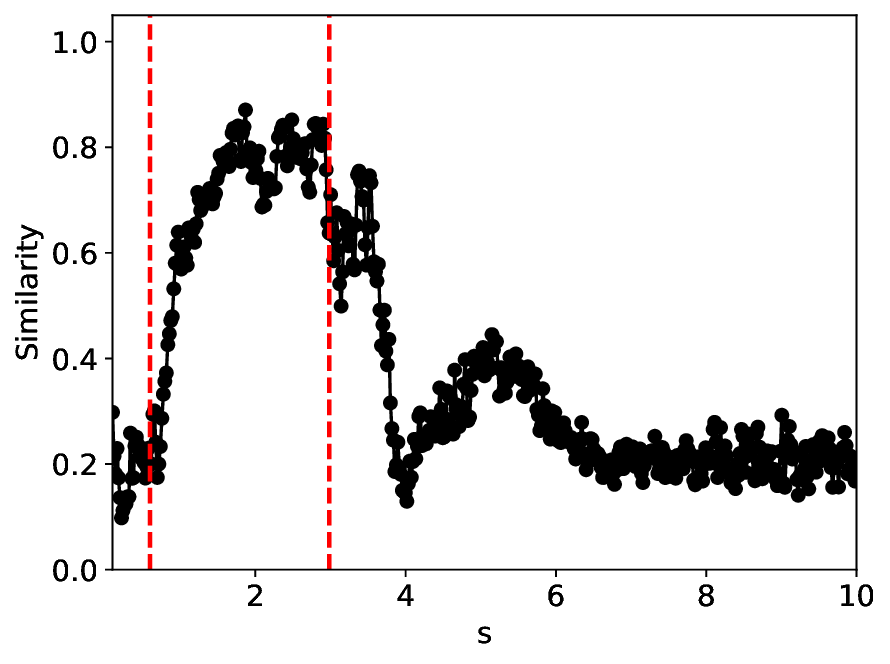
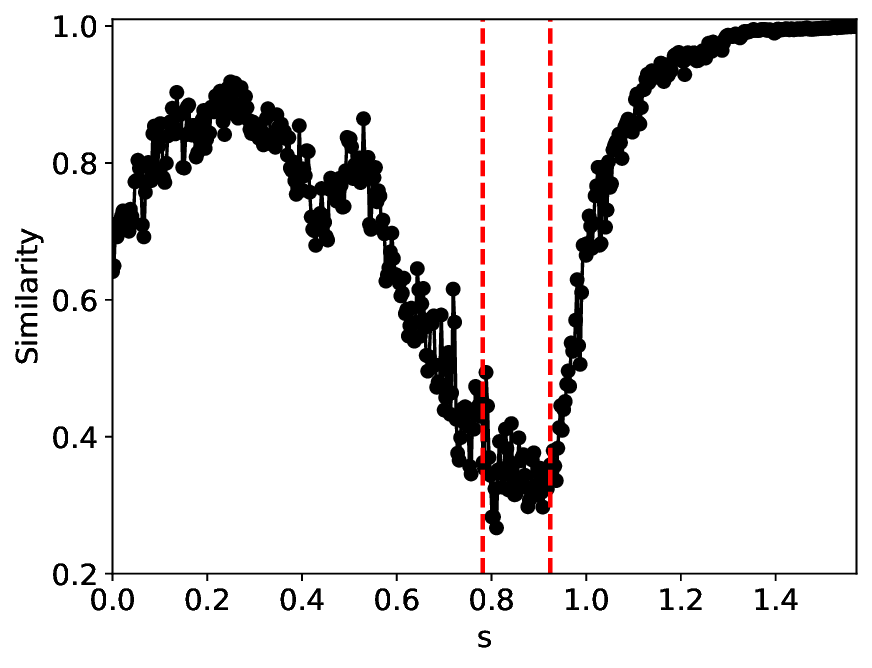
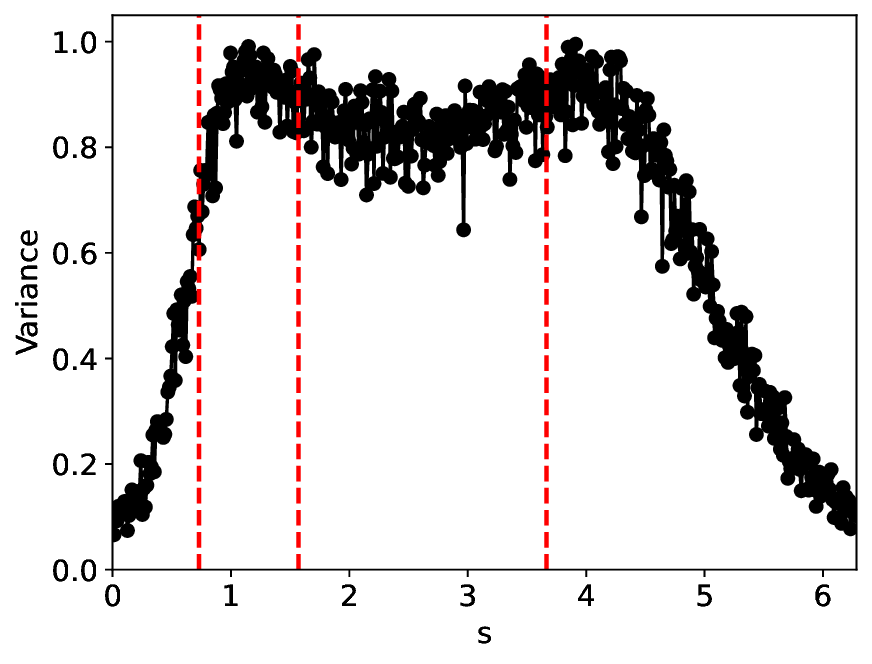
Under the σ = 0.0001 condition, the similarity and variance metrics exhibit two clear local extrema and correctly identify the critical transitions in the SHO system. Moreover, under this low noise level, the overall trends of the metrics remain largely unchanged from their noisefree counterparts (σ = 0.0; see Appendix C). Compared with MLPCL, although our method attains relatively higher similarity values near the critical points (approximately 0.3 versus 0.2 for MLPCL) and lower variance values (approximately 0.7 versus 0.8 for MLPCL), our metric curves are notably more uniform and smoother, particularly in the excitable state region. This behavior indicates superior robustness to irrelevant noise and more stable feature representation, even though our model uses approximately 20% fewer parameters.
After increasing the noise level to σ = 0.001, Figure 5 indicates that all system states-particularly the excitable and oscillatory states-are significantly degraded, as reflected by the substantially increased spread of metric values within the same state. The metric curves of both methods approximately identify the two groundtruth critical transitions. However, MLPCL performs significantly worse, with the metrics riddled with multiple spurious local minima and maxima, making reliable detection of true critical points nearly impossible without reference information. In contrast, our method provides a more consistent and accurate indication of the true critical transitions, reflecting its superior stability under this noisy condition.
Since this model primarily captures the dynamics of cyclin, cdc2, and their complexes across different phosphorylation states, we retain only two quantities [M] and [YT], scaled by [CT], as the training and test dataset (see Appendix B for details), consistent with the notation in [25,47]. After training, the test results are presented in Figures 6 and7 (see Appendix C for other related results).
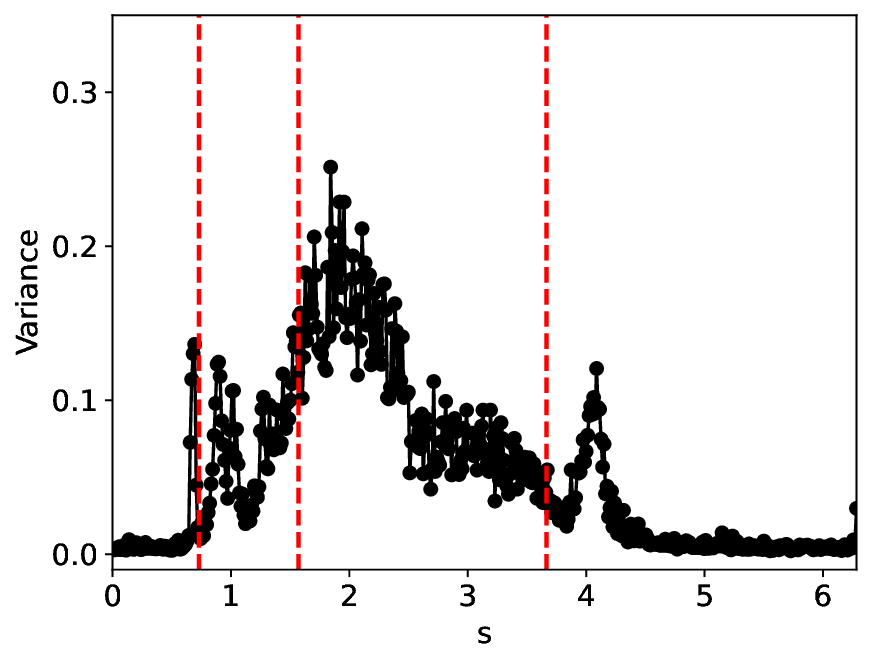
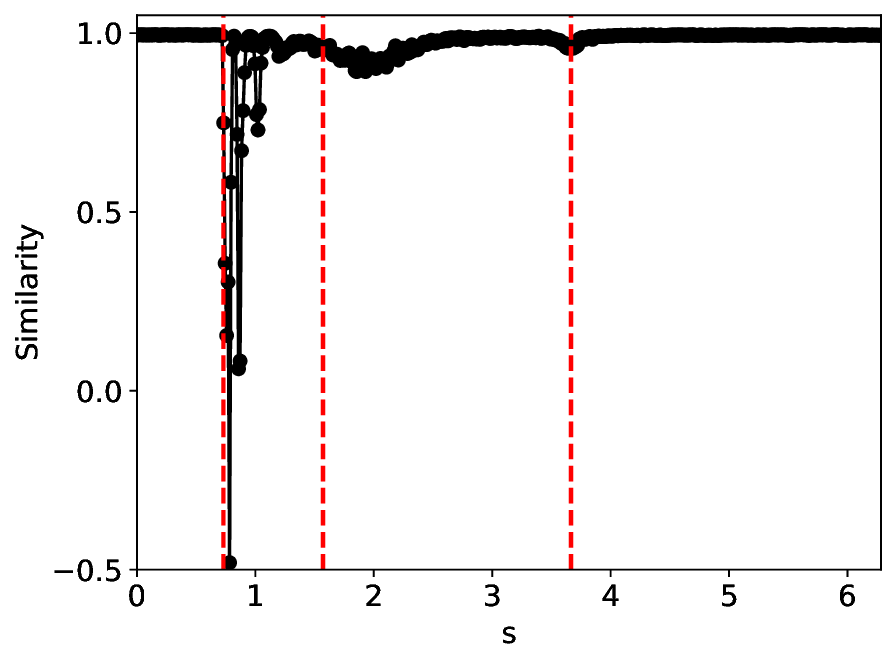
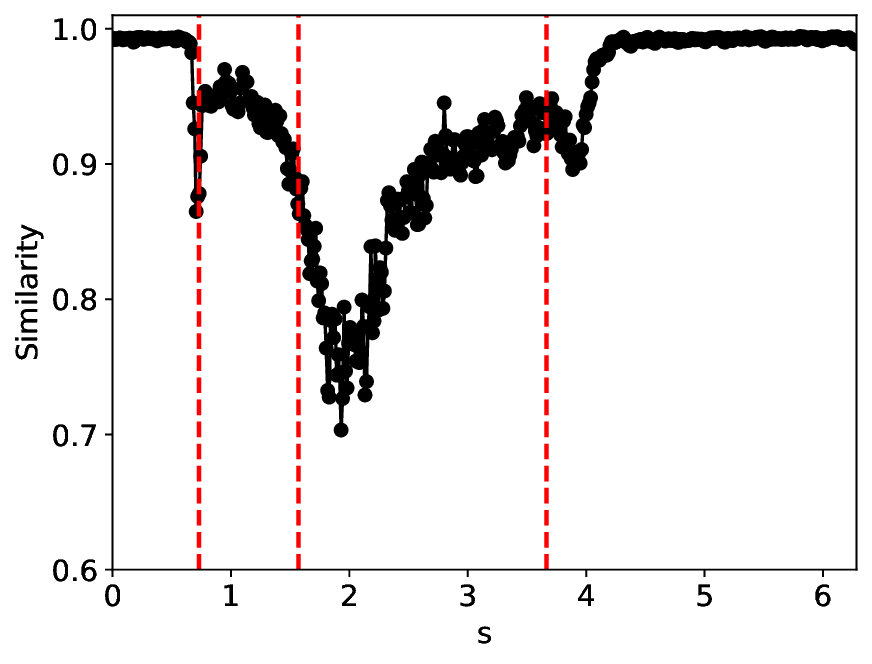
Figure 6 shows that MLPCL and SVDCL, despite having 20% fewer parameters, yield similar patterns in both similarity and variance under the condition σ = 0.01. Close to the critical point s 1 , both MLPCL and SVDCL undergo abrupt vertical jumps, signaling critical transitions. Around s 2 , the metric values of SVDCL differ from MLPCL by roughly 0.2, suggesting greater distinguishability of latent features near this critical point. Addi- 6, but with σ = 0.03. tionally, the metric curves generated by SVDCL exhibit smoother and more stable behavior for large values of s. More intriguingly, both methods feature a sharp local extremum near s = 4, which roughly corresponds to the boundary between the excitable and monostable states in this region, as reported in [25].
Besides the case of σ = 0.01, we also conducted experiemnt with a higher noise level 0.03. As shown in Figure 7, the similarity and variance curves confirm that the SVDCL method is functionally equivalent to the MLPCL method, approximately capturing the full magnitude and location of the critical transitions that characterize the Cellcycle phase transitions. This demonstrates that the SVD’s low-rank constraint is sufficient to detect the essential physics, making the SVDCL a highly compressed alternative to the full-rank MLPCL. Moreover, the critical point near s = 4 appears to persist, and our method exhibits stronger structural robustness than the MLPCL approach, particularly in this region, as evidenced by the SVDCL model achieving a wider range in both similarity and variance. The larger similarity range proves that the SVDCL extracts more discriminative features, while the larger variance range confirms its greater sensitivity to underlying physical fluctuations. By leveraging its low-rank constraint as an effective spectral filter, SVDCL yields a high-fidelity, high-SNR (Signal-to-Noise Ratio) representation that is substantially less susceptible to noise corruption than MLPCL. Remarkably, the findings indicate the possible emergence of an additional critical point near s = 6 under this condition, which we leave for future exploration.
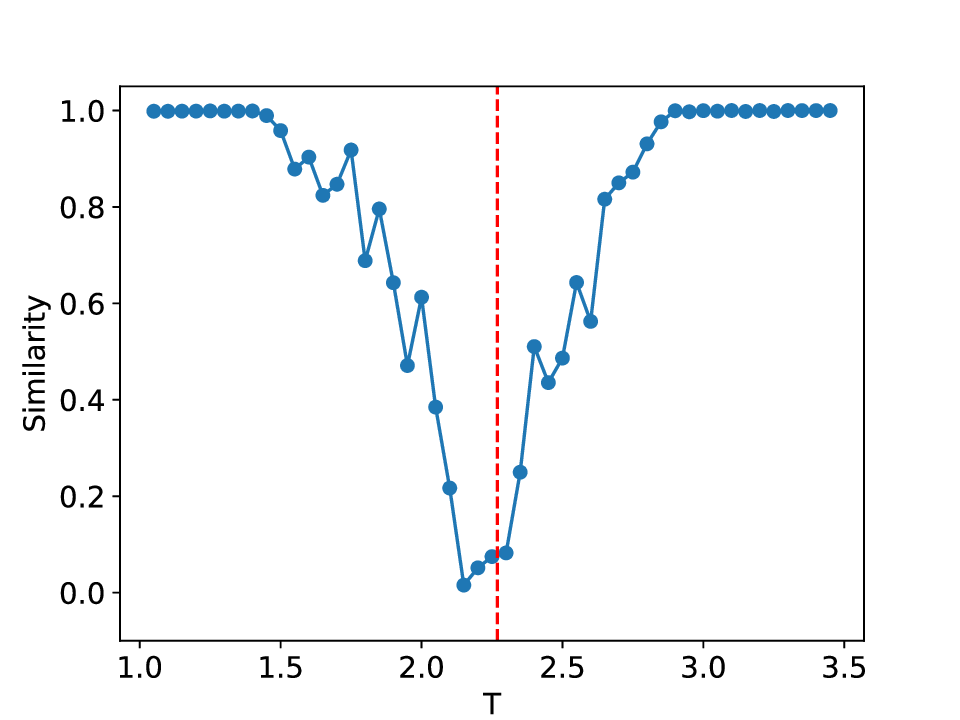
For the Ising system of linear size L, the lattice contains L 2 sites. This model exhibits a well-known phase transition at the critical temperature T c = 2.269, which separates the high-temperature disordered phase from the low-temperature ferromagnetic phase [48].
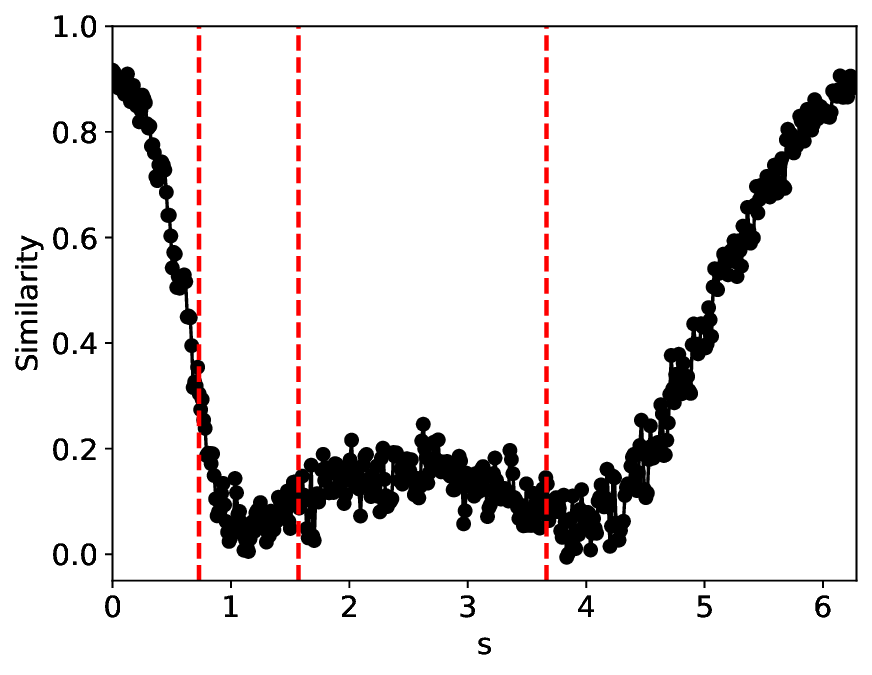
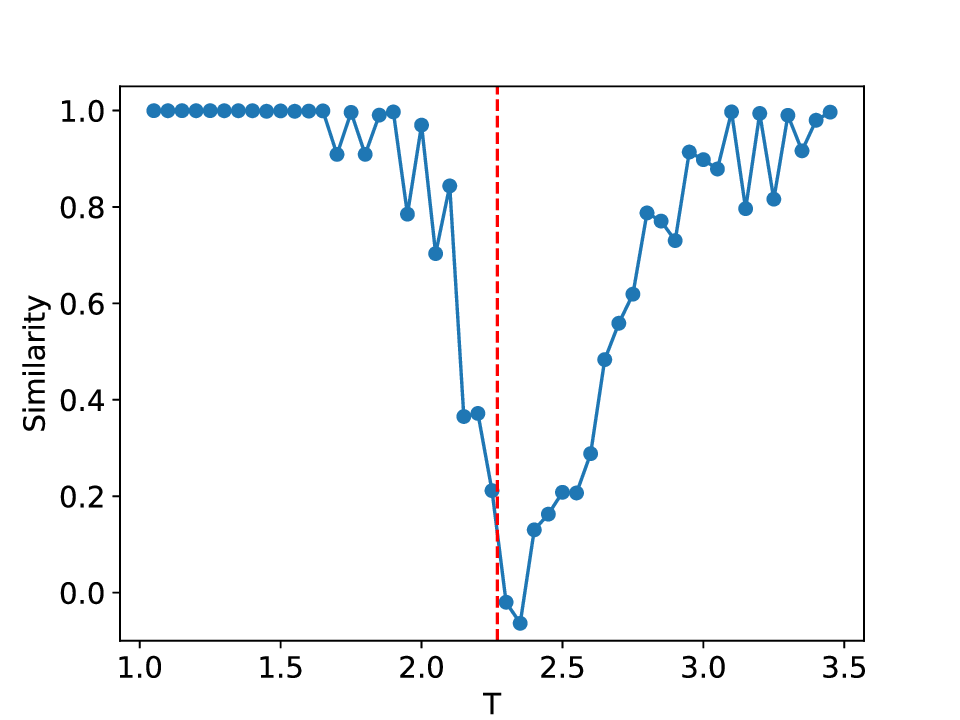
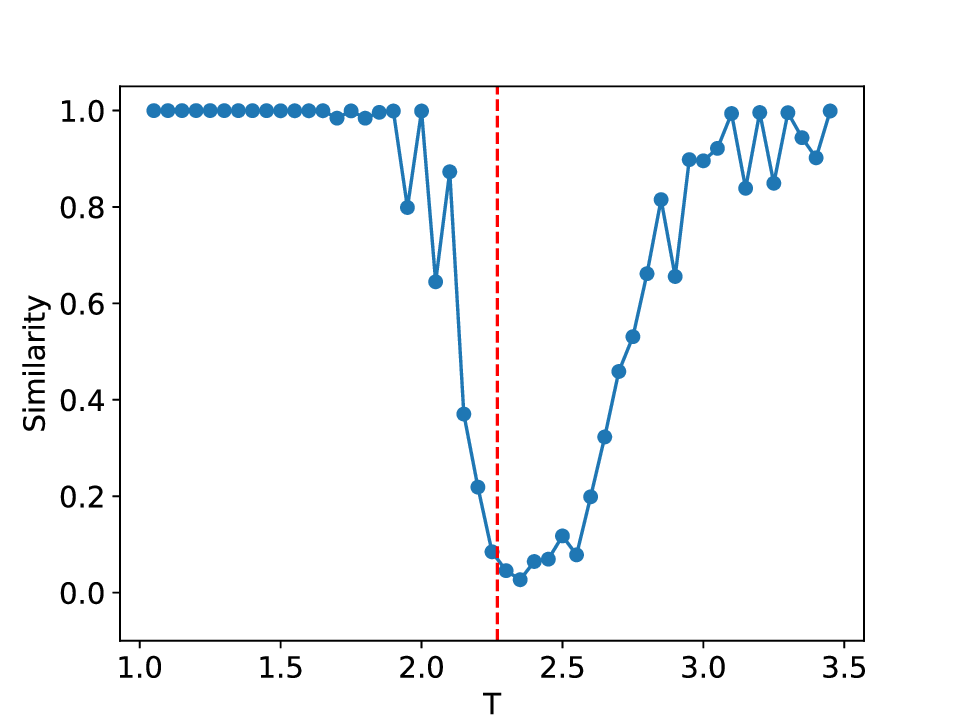
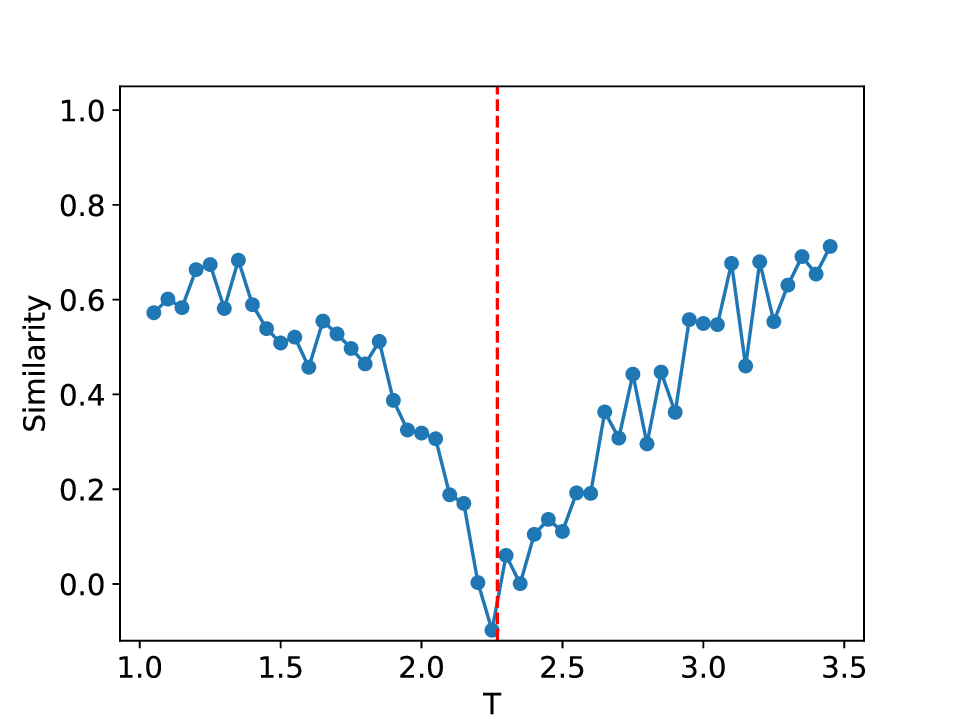
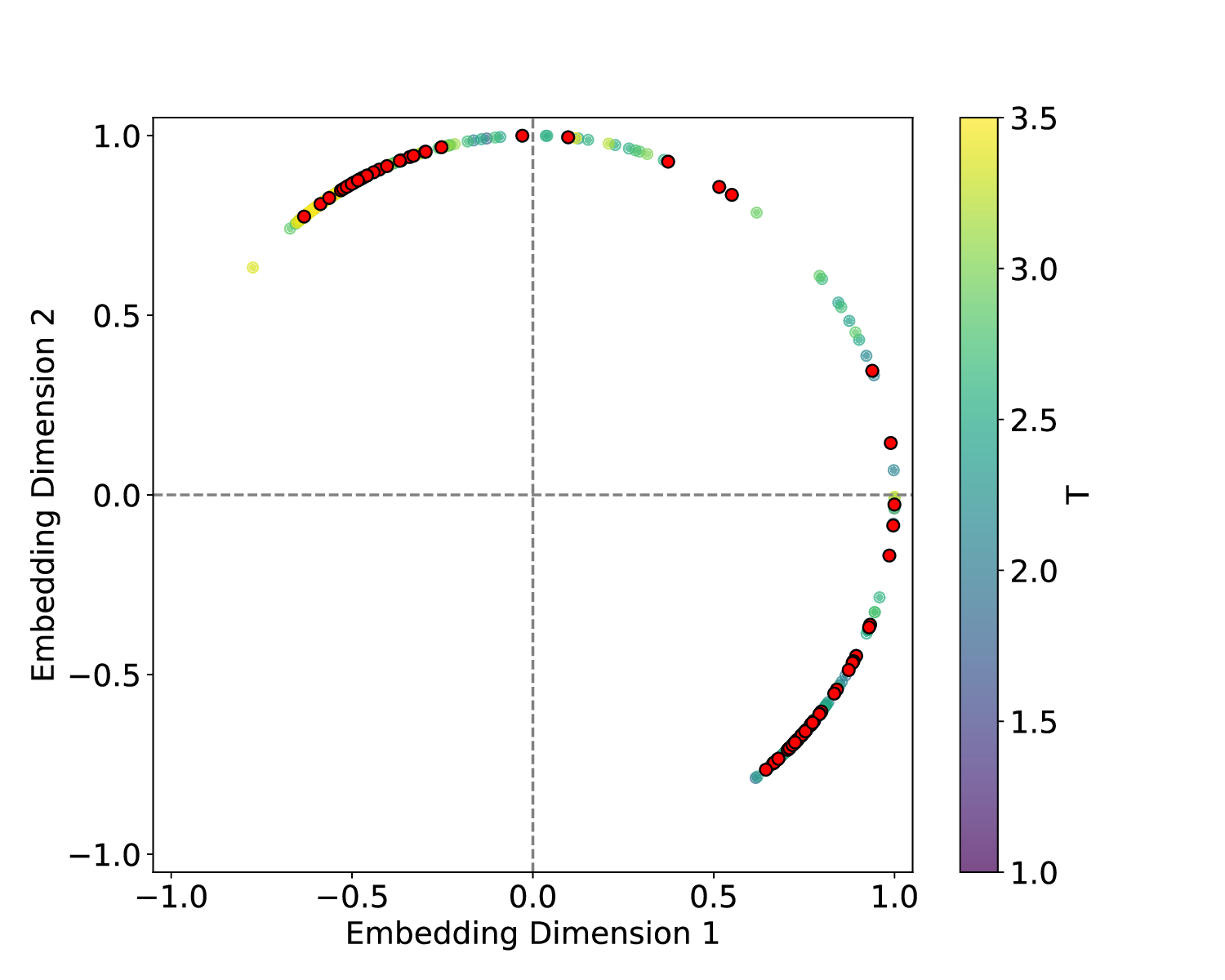
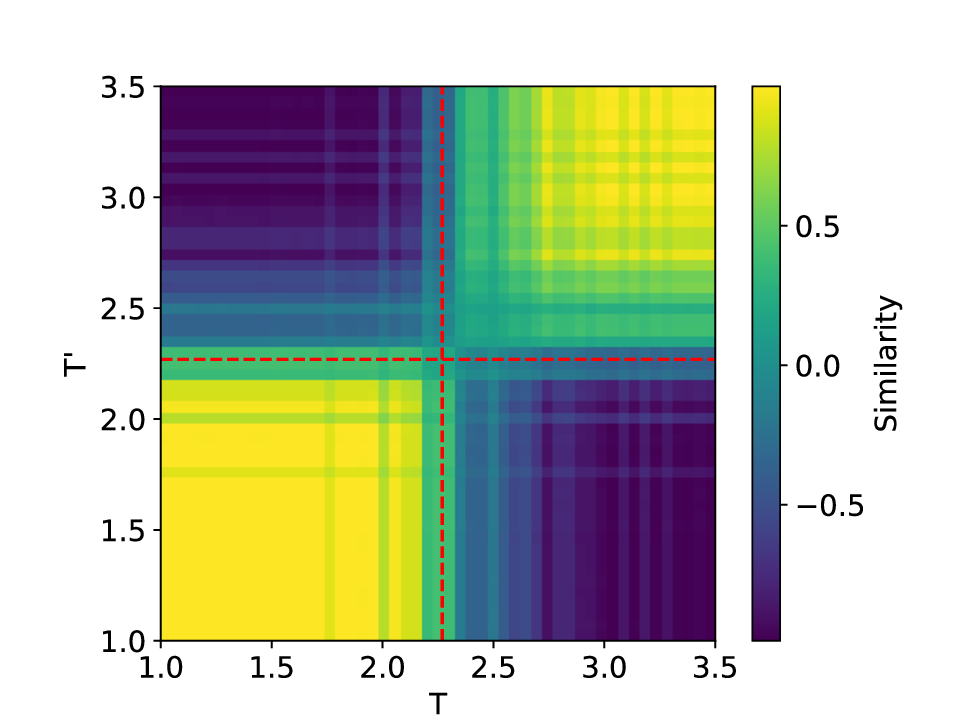
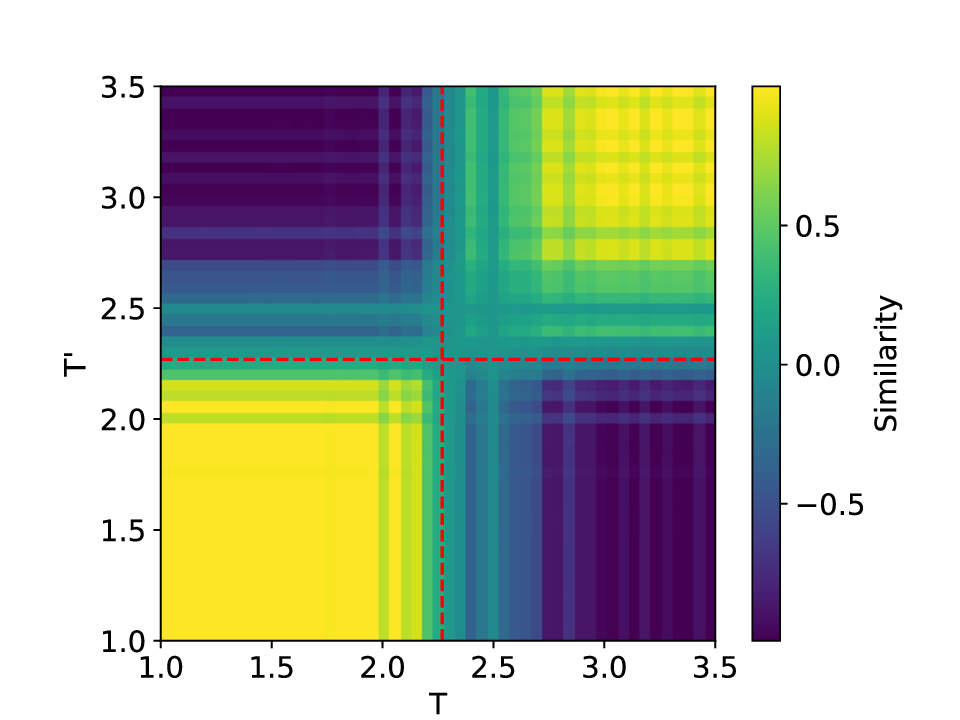
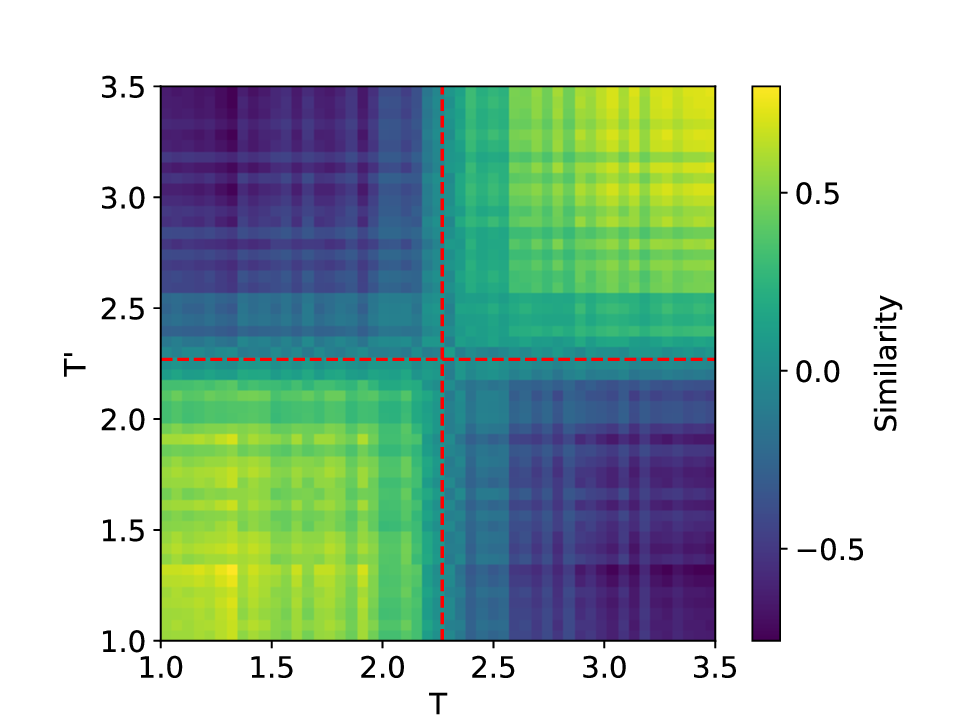
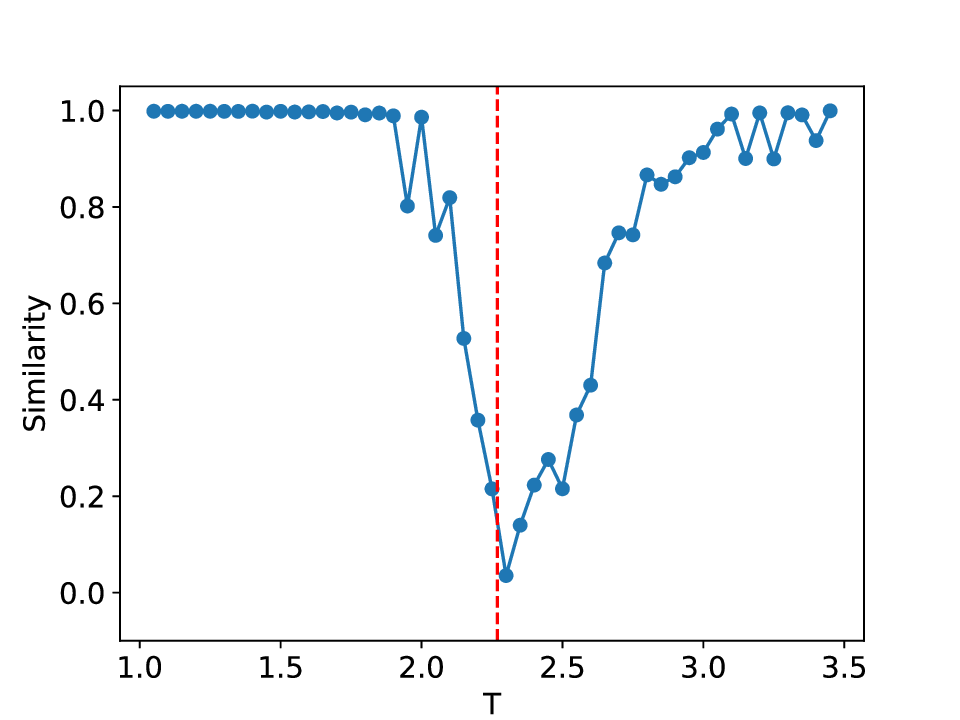
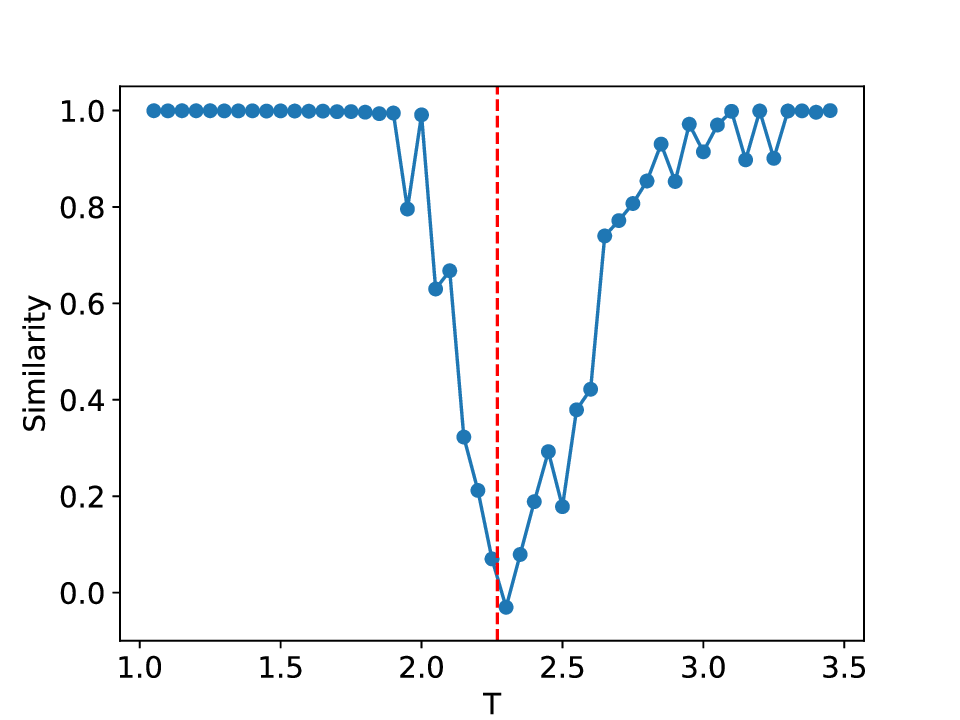
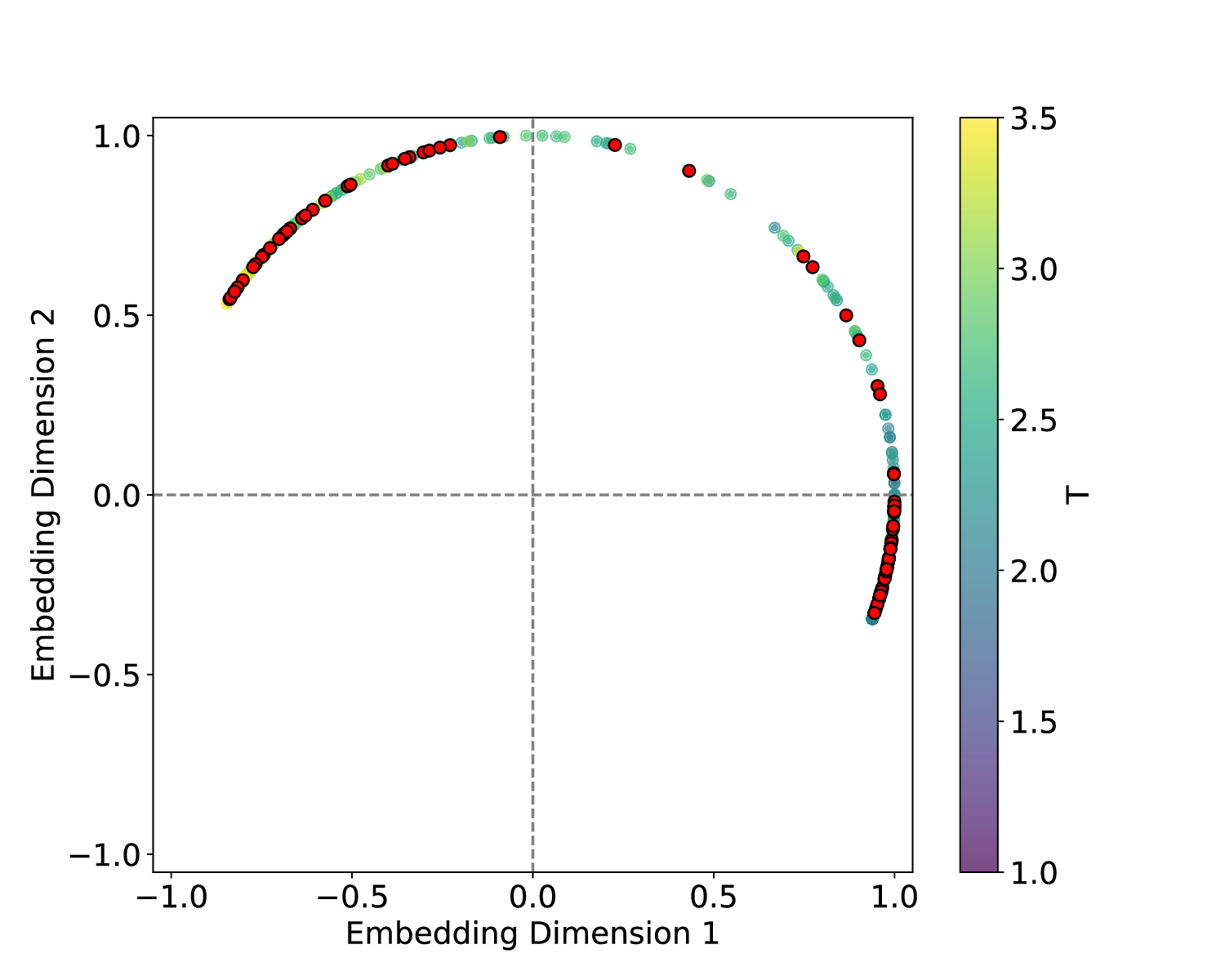
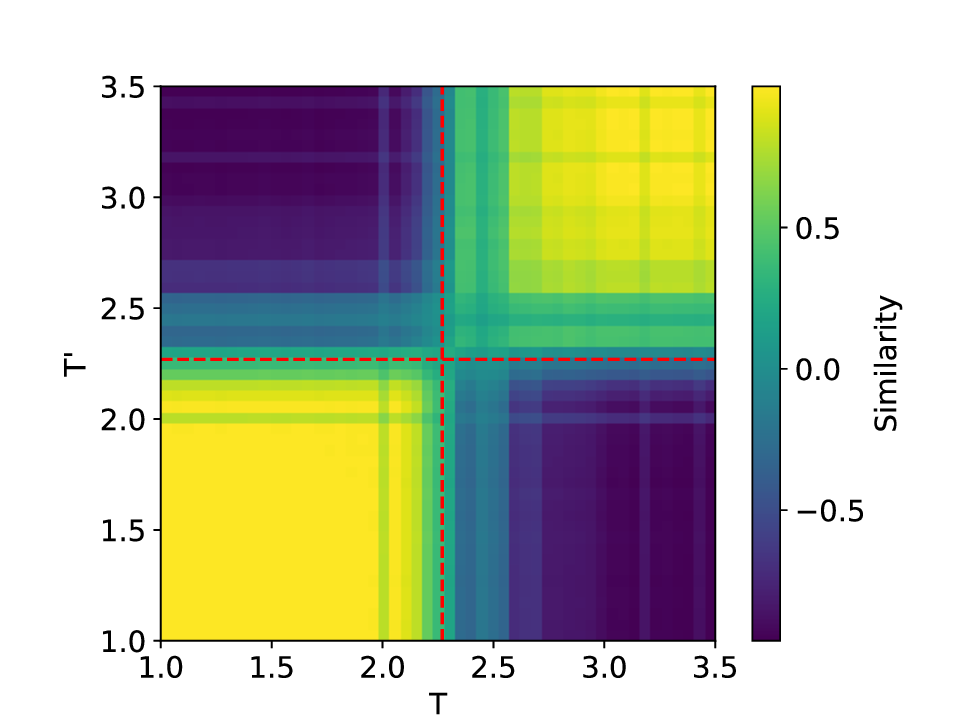
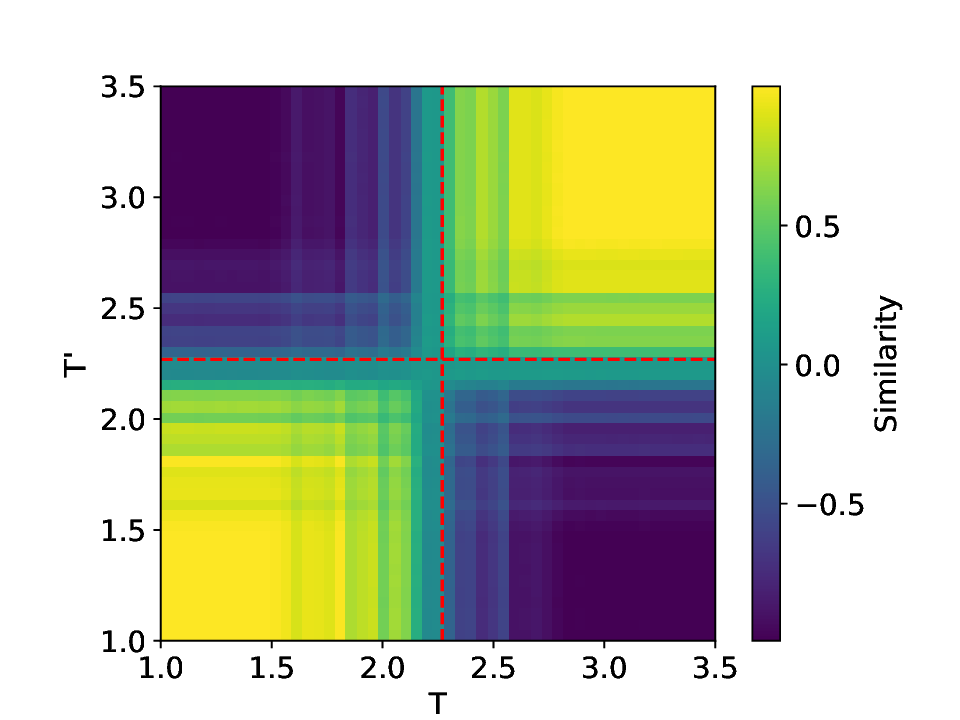
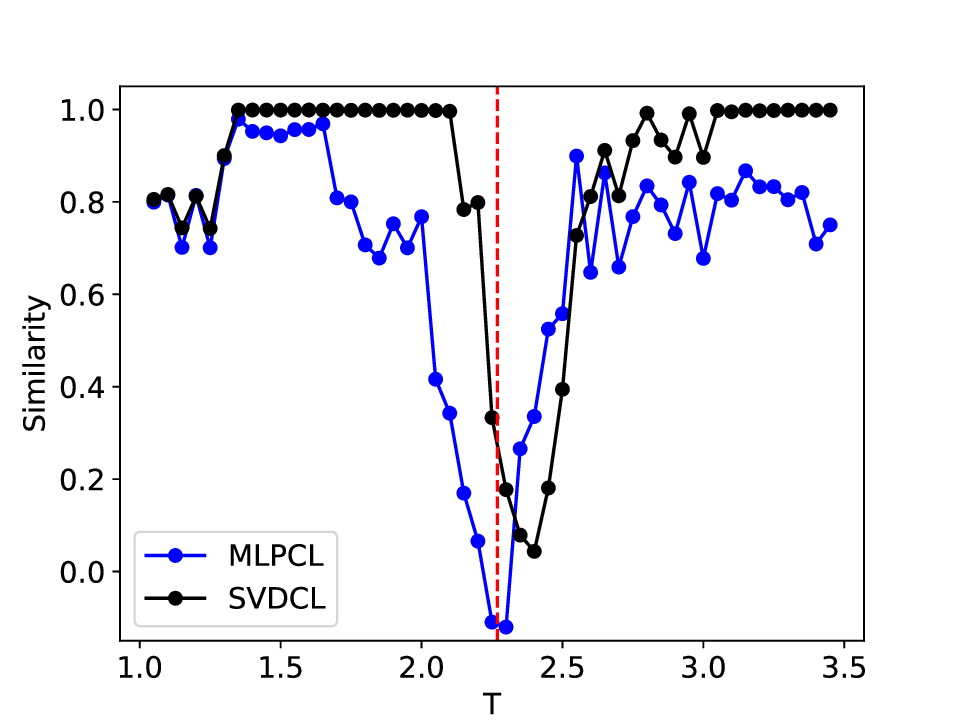
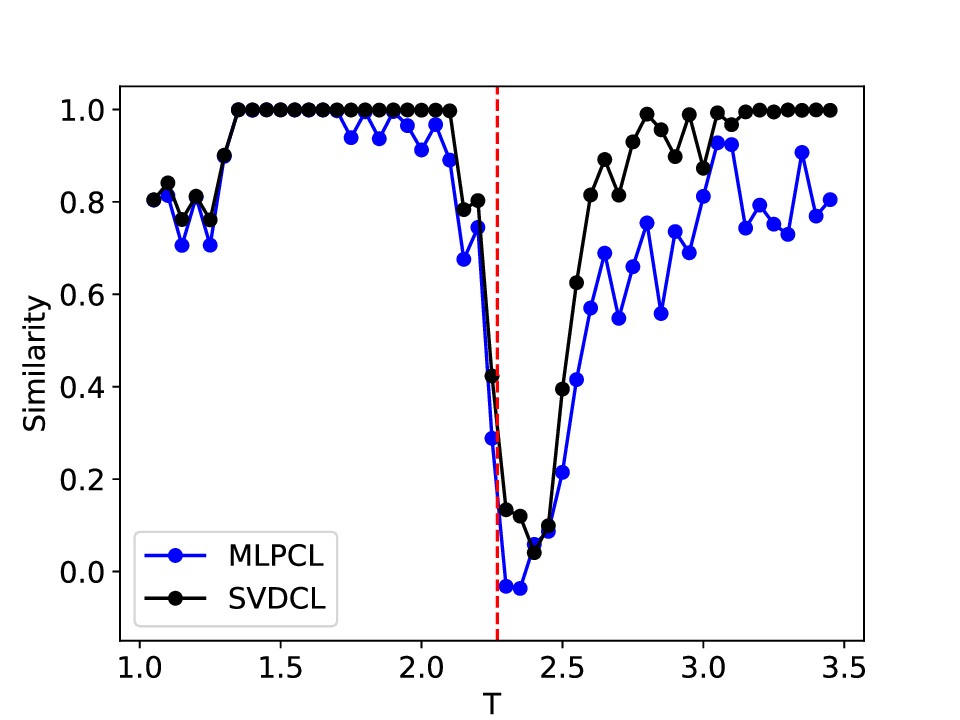
The results for the Ising model (L = 10) with noise-free data are shown in Figure 8 (see Appendix B for training settings). Despite SVDCL using only 64% of the parameters of MLPCL, the two models yield comparable results. In both cases, the characteristic ‘V’-shaped similarity curve, computed between T -∆T and T + ∆T , faithfully reflects the true phase transition. And in areas far from the phase transition, adjacent features exhibit a high degree of similarity. the heatmap shown in the middle column of Figure 8, which depicts the mutual similarity between pairwise sampled T and T ′ , effectively illustrates the outcome of the CL experiment and provides a more comprehensive view of the phase transition. The map is cleanly partitioned by the critical temperature T c into four distinct quadrants, confirming that both NNs successfully isolates the ordered and disordered phases. And the final normalized embeding 2D features of the spin configurations move along the circle after training. All these results agree well to the previous published result [23].
When σ increase to 0.3, these two methods both show robust performance and get similar results to the clean data case (see Figure 14 in Appendix D). However, at a noise amplitude of 0.5 (Figure 9), the SVDCL method remains resilient to Gaussian noise as the resulting similarity curve stays close to unity (≈ 1.0) throughout most of both phases and exhibits a smoother, lower-variance trend compared to MLPCL. Although the characteristic ‘V’-shape remains, the MLPCL’s jagged curve and reduced out-of-phase similarity (≈ 0.6) indicate that its high capacity is degraded by the noise, resulting in elevated variance and poor generalization. And the heatmap of similarity also displays more nonuniform and irregular stripes within the same phase. In addition, we also test our model for the lattice L = 20 case, similar patterns can be observed in our results (see Appendix D). These experimental results further reaffirm the robustness of our approach to noise.
In conclusion, we propose the SVDCL approach, which achieves strong representational power through a lightweight architecture and an elegant training strategy that rigorously enforces semi-orthogonality. A key strength of SVDCL is its robustness to noise, arising not only from the strict semi-orthogonal constraint on the weight parameters but also from its architectural design. The SVD-based architecture naturally functions as a spectral filter, projecting representations onto a low-rank subspace while suppressing unstable or noise-dominated modes. Together with our three-stage optimization procedure that projects deviated parameters back onto the semi-orthogonal manifold, the method robustly isolates invariant structure and mitigates noise-induced overfitting. Extensive experimental results underscore the effectiveness of our method, which arises from its deliberate architectural design and principled training strategy. Compared with MLPCL, our method preserves strong capability in detecting critical transitions in dynamical systems while offering greater inference efficiency and scalability, reducing the computational cost from O(n l n l+1 ) in FC layers to O(r(n l + n l+1 )) via SVD-based decomposition, and demonstrating enhanced robustness to noise. These promising results indicate that SVDCL has strong potential to advance future developments in scientific machine learning.
Nevertheless, the present study concentrates on 2D dynamical systems. Extending to higher dimensions substantially increases computational cost and heightens the risk of overfitting, particularly when regularization or architectural constraints are insufficient. These factors limit the model’s ability to resolve multiscale structure and to extract the latent features essential for detecting critical transitions. Moreover, as the size of the input dataset grows, training efficiency can decline due to increased memory demands and prolonged optimization. These inefficiencies may further undermine the model’s ability to represent complex scale interactions and to learn the subtle indicators of impending critical transitions. In addition, the underlying theoretical connection between critical transition phenomena and their low-rank representations remains unclear.
To overcome these limitations, future research could incorporate scalable representation-learning architectures [51,52], advances in deep causal learning [53,54], or hierarchical graph-based neural network models [55,56], thereby enhancing suitability for high-dimensional dynamical systems. Additionally, improving the interpretability of our low-rank embedding may benefit from theoretical viewpoints such as symmetry-breaking analysis [57,58] and geometry-aware manifold learning [59,60]. These perspectives can shed light on the mechanisms that make critical transitions detection possible and open new prospective pathways for advancing SVDCL and broadening its range of applications. We further hope that this work could encourage continued algorithmic and theoretical inquiry into SVDCL and the nature of critical tran- For the 2D square-lattice Ising model with nearestneighbor coupling J and no external field, the exact critical temperature (marked by the red dashed line or dots) was derived by Onsager [48]:
where we set J = 1 and k B = 1 in monte carlo simulations. Cellcycle. The purple and red curves indicate the phase boundaries, while the blue curve denotes the selected control-parameter path used for metric evaluation. The points s 1 , s 2 , s 3 (shown as red dashed lines in the other related figures) mark the intersections between the control-parameter path and the corresponding phase boundaries. to that observed for σ = 0.0. The heatmap still displays a clear separation between the yellow and darkblue regions. Moreover, our method yields a more distinct boundary than MLPCL, indicating that it is more robust to noise.
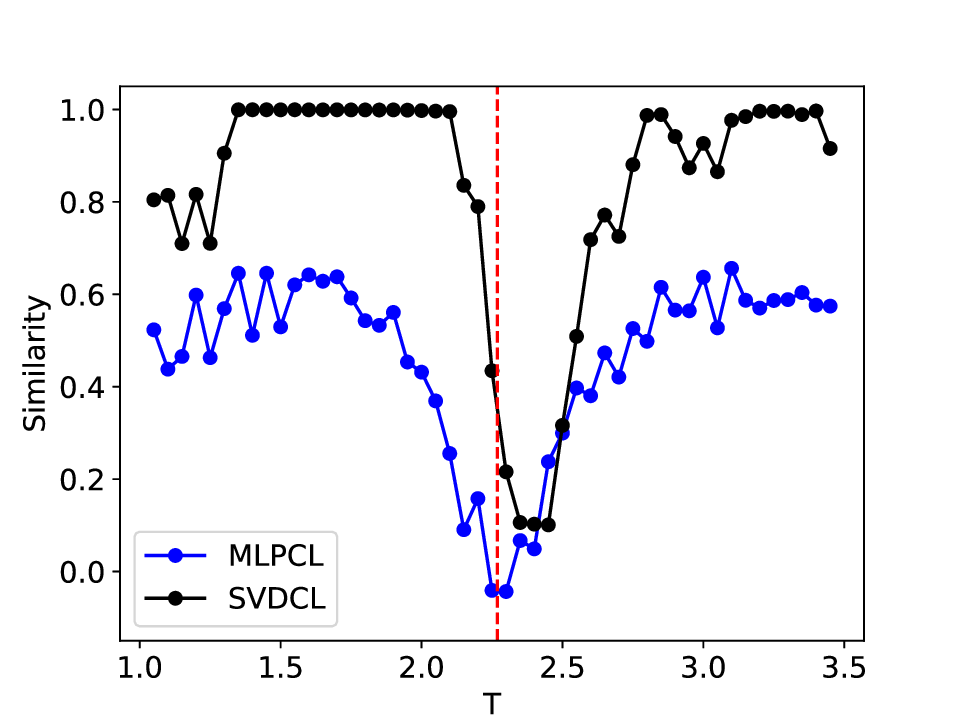
For further comparison, we also present results for the Ising model with lattice size L = 20, shown in Figure 15. As the same-scale neural network is employed, the similarity curve appears substantially more irregular in this more complex scenario. Although it uses only 61% of the parameters, our model maintains consistent performance across noise levels, indicating strong robustness to noise. While its estimate of the critical temperature is somewhat less precise, the out-of-phase similarity produced by MLPCL deteriorates sharply and is heavily corrupted by noise, preventing it from approaching unity. This behavior is consistent with the results observed for the L = 10 Ising model as σ increases from 0.0 to 0.5.
This content is AI-processed based on open access ArXiv data.