We introduce MotionEdit, a novel dataset for motion-centric image editing-the task of modifying subject actions and interactions while preserving identity, structure, and physical plausibility. Unlike existing image editing datasets that focus on static appearance changes or contain only sparse, low-quality motion edits, MotionEdit provides high-fidelity image pairs depicting realistic motion transformations extracted and verified from continuous videos. This new task is not only scientifically challenging but also practically significant, powering downstream applications such as frame-controlled video synthesis and animation.
To evaluate model performance on the novel task, we introduce MotionEdit-Bench, a benchmark that challenges models on motion-centric edits and measures model performance with generative, discriminative, and preference-based metrics. Benchmark results reveal that motion editing remains highly challenging for existing state-of-the-art diffusion-based editing models. To address this gap, we propose MotionNFT (Motion-guided Negative-aware Fine Tuning), a post-training framework that computes motion alignment rewards based on how well the motion flow between input and model-edited images matches the ground-truth motion, guiding models toward accurate motion transformations. Extensive experiments on FLUX.1 Kontext and Qwen-Image-Edit show that MotionNFT consistently improves editing quality and motion fidelity of both base models on the motion editing task without sacrificing general editing ability, demonstrating its effectiveness. Our code is at https://github.com/elainew728/motion-edit/.
troduce MotionEdit-Bench, a benchmark that challenges models on motion-centric edits and measures model performance with generative, discriminative, and preferencebased metrics. Benchmark results reveal that motion editing remains highly challenging for existing state-of-the-art diffusion-based editing models. To address this gap, we propose MotionNFT (Motion-guided Negative-aware Fine-Tuning), a post-training framework that computes motion alignment rewards based on how well the motion flow between input and model-edited images matches the groundtruth motion, guiding models toward accurate motion transformations. Extensive experiments on FLUX.1 Kontext and Qwen-Image-Edit show that MotionNFT consistently improves editing quality and motion fidelity of both base models on the motion editing task without sacrificing general editing ability, demonstrating its effectiveness.
Instruction-guided image editing models have made remarkable progress recently [7,14,15,22,34], capable of transforming images based on natural language commands. While recent image editing models excel at performing appearance-only static edits that simply adjust color, texture, or object presence, they oftentimes fall short in accurately, faithfully, and naturally editing the motion, posture, or interaction between subjects in images. In this work, we aim at addressing this limitation in existing models through systematically formulating and studying motion editing as an independent and important image editing task.
We formally define the new task of motion image editing-editing that modifies the action, pose, or interaction of subjects and objects in an image according to a textual instruction, while preserving visual consistency in characters and scene. Motion editing aims at changing how subjects move, act, or interact, which is essential for applications such as frame-controlled video generation and character animation. However, existing image editing datasets and benchmarks suffer from two major bottlenecks in approaching the motion image editing task: First, they primarily focus on static editing tasks like appearance modification or replacement (e.g. OmniEdit [33] and UltraEdit [40] examples in Figure 2), neglecting the important aspect of motion editing in their data at all. Second, datasets that do include motion edits offer only a small amount of low-quality data, often with unfaithful or incoherent edit ground-truth that fail to execute the intended motion (e.g. InstructP2P [2] and MagicBrush [39] examples in Figure 2).
To bridge this research gap, we curate MOTIONEDIT, a high-quality dataset and benchmark specifically targeting motion editing, consisting of paired input-target image examples extracted and validated from continuous highresolution video frames to ensure accurate, natural, and coherent motion changes. As shown in Figure 2, MO-TIONEDIT captures realistic action and interaction changes that preserve identity, background, and style, in contrast to prior datasets where edit data is either static, unfaithful, or visually inconsistent. Moreover, our data is sourced from a large set diverse video sequences, ensuring the assessment of diverse sub-categories of motion image editing, such as posture, orientation, and interaction changes in Figure 5. Beyond constructing high quality editing data, we also devise evaluation metrics to evaluate motion edit performances of models. For discriminative evaluation, we by comparing the optical flow [11,28,30,35,36]-which captures the magnitude and direction of motion changebetween the input and model-edited images against the input-ground truth flow. For generative evaluation, we adopt Multimodal Large Language Model (MLLM)-based metrics to assess the fidelity, preservation, coherence, and overall quality of edited images. Additionally, we report pairwise win rates through head-to-head comparisons between overall edit quality of different models to reflect preference performance. Both quantitative and qualitative results across state-of-the-art image editing models on MOTIONEDIT-BENCH show that motion image editing re-
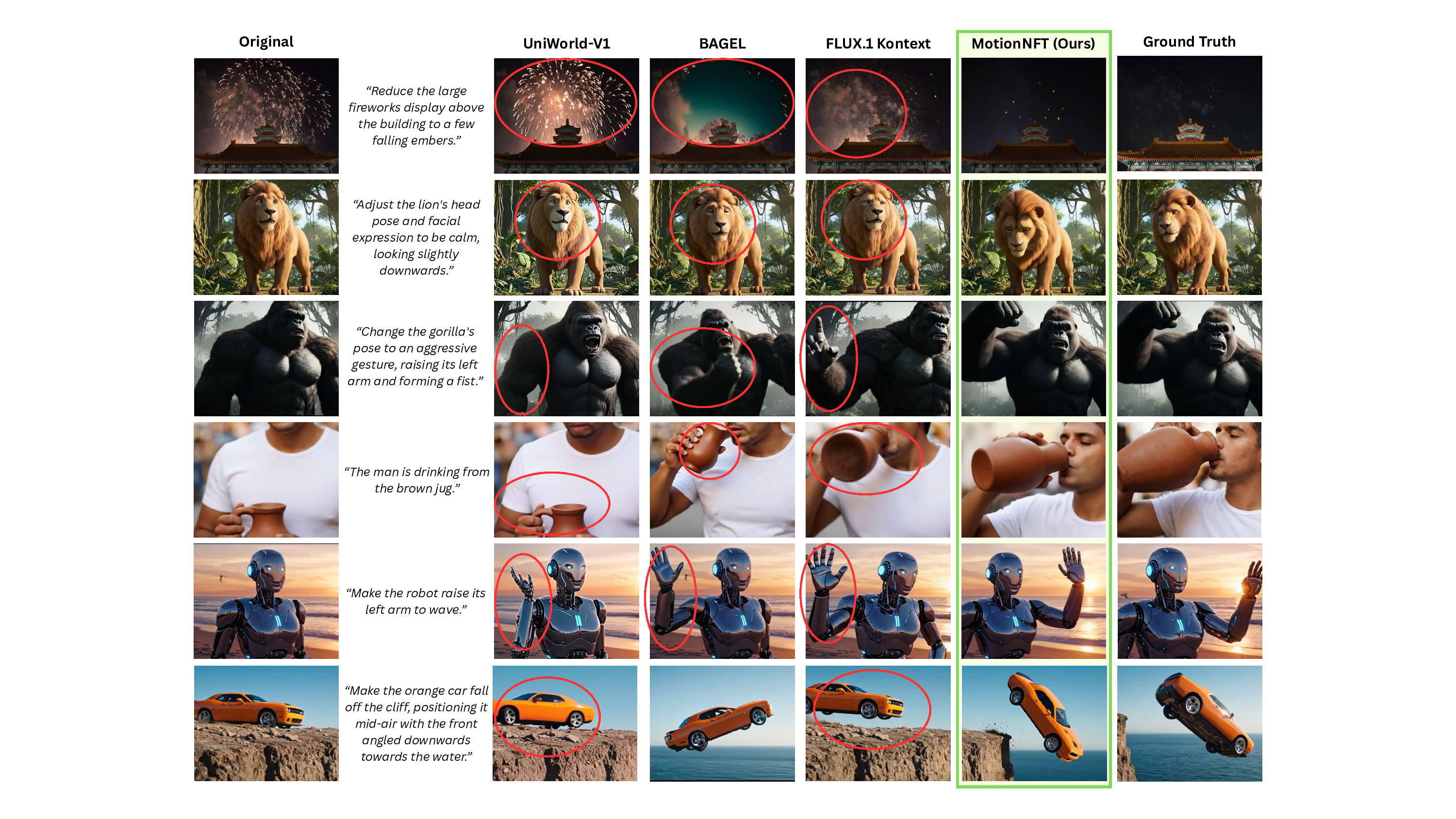
Prompt: “make Doraemon and the boy turn their bodies and head to face each other for direct interaction.” Ground Truth Q Prompt: “Have the female dental professional turn away from the male patient and bend down to adjust the dental chair.” Figure 3. Qualitative comparison of state-of-the-art image editing models on MOTIONEDIT. Existing models fail to execute the required motion edits (e.g. UNIWORLD-V1 fail to edit subject postures and FLUX.1 KONTEXT produces severe identity distortions), while our MotionNFT-trained model accurately performs the intended motion edit that closely matches the ground-truth. mains a challenging task for the majority of open-source image editing models.
To improve existing image editing models on the motion editing task, we further propose Motion-guided Negativeaware FineTuning (MOTIONNFT), a post-training framework for motion editing that extends DiffusionNFT [41] to incorporate motion-aware reward signals. Motion-NFT leverages the motion alignment measurement between input-edit and input-ground truth optical flows to construct a reward scoring framework, providing targeted guidance on motion direction and magnitude in training. As illustrated in Figure 3, MotionNFT enables models to perform accurate, geometrically consistent motion edits. Quantitative results in Table 1 further shows substantial improvement across all metrics over prior approaches. For instance, MOTIONNFT achieves over 10% improvement in overall quality and over 12% on pairwise win rates when applied on FLUX.1 Kontext [14]).
The key contributions of our paper are three-fold: • We systematically define and study the novel task of motion image editing.
Image Editing. Recent advances in text-to-image (T2I) diffusion models have greatly improved text-guided image editing [2,14,20,22,34,39]. While current models handle static appearance edits well (e.g., color changes or object 1 Dataset, code, and evaluation toolkit will be released upon acceptance.
replacement), they struggle with motion-related edits that require modifying actions or interactions (e.g., “make the man drink from the cup”). This gap largely stems from limitations in existing editing datasets. First, most benchmarks focus on static transformations-local texture changes, object replacement, or style transfer [2,33,40]-with little coverage of motion edits. Second, datasets containing motion edits are small and of low quality: motion categories are unclear, and the provided target edits are often unfaithful or physically implausible [2,16,39]. As shown in Fig. 2, these models frequently fail to achieve intended action changes and introduce visual artifacts, undermining both training supervision and evaluation reliability. These limitations underscore a key challenge in motion image editing: building datasets with precise motion-edit instructions and high-quality, faithful edited targets that preserve appearance and scene context while accurately reflecting the intended action changes. Motion Estimation in Images. Motion estimation is a long-standing problem in computer vision. Modern approaches rely on optical flow, which predicts per-pixel displacement between two images [11,28,30,35]. Recent work such as UniMatch [36] further advances largedisplacement estimation by formulating optical flow as a global matching problem unified with stereo tasks. Inspired by the effectiveness of optical flow in capturing finegrained motion changes, we propose a motion-centric reward framework based on optical flow, which quantitatively measures how accurately a model performs the intended motion edit in synthesized images.
Reinforcement Learning for Image Generation. Policygradient methods such as PPO [23,25] and GRPO [17,27] have been explored for improving image generation. More recently, DiffusionNFT [41] introduces negativeaware finetuning, which contrasts positive and negative gen-erations during the forward diffusion process to obtain an implicit policy improvement direction, steering the model toward high-reward outcomes while repelling low-reward ones. UniWorld-V2 [15] extends DiffusionNFT by integrating an MLLM-based online scoring pipeline for rating editing aspects like prompt compliance and style fidelity. However, current RL-based post-training frameworks remain motion-agnostic: they emphasize semantic correctness and visual details, yet offer no supervision on how subjects and objects should move for motion-centric edits.
The task of motion image editing has not been comprehensively explored in prior works. Therefore, we first provide a systematic definition of this novel task. Motion Image Editing. Given an input image and a natural-language instruction specifying a target motion change (e.g. “make the woman drink from the cup”), the goal is to synthesize an edited image where: (1) the edited motion faithfully reflects the intended action; (2) the resulting pose or interaction is physically plausible and respects articulated constraints (e.g., “slightly open his eyes”); (3) non-edited factors like appearance, background, and viewpoint remains consistent. Unlike traditional appearancefocused editing, motion editing requires models to interpret the instructed motion and translate it into coherent spatial changes in the image, requiring fine-grained spatial and kinematic understanding.
As discussed in Section 2, existing image editing datasets and benchmarks lack reliable ground-truth targets that correctly execute the instructed motion while preserving subject identity and scene context. Prior datasets either introduce artifacts and hallucinations, alter appearance, or unintentionally shift viewpoint or scale. Sourcing high-quality motion edit ground truth remains a challenging problem. Instead of synthesizing edited targets as in prior work [2,39], we propose a video-driven data construction pipeline that mines paired frames from dynamic video sequences to produce high-quality (input image, edit instruction, target image) triplets. These data reflect naturally occurring and coherent motion transitions grounded in video kinematics. Full details on dataset construction are in the “Additional Dataset Construction Details” Appendix section.
Video Collection To obtain frame pairs capturing clean motion transitions, we first explored conventional human action datasets such as HAA500 [6] and K400 [12]. Although diverse, these datasets often suffer from problems like low resolution, motion blur, rapid viewpoint shifts, etc., making them unsuitable for extracting faithful pre-/post-edit pairs that preserve identity and background consistency.
In contrast, recent Text-to-Video (T2V) models (e.g. Veo-3 [9], Kling-AI [13]) produce visually sharp, temporally smooth videos with stable subjects and backgrounds. We therefore draw from two publicly released T2V video collections-ShareVeo3 [31] and the KlingAI Video Dataset [21]-as our initial pool of candidate videos. We then apply further processing to extract high-quality frame pairs for our MOTIONEDIT dataset.
Frame Extraction and Automatic Validation Given the video pool, our goal is to identify frame pairs that exhibit meaningful motion changes while preserving all nonmotion factors. We segment each video into 3-second windows and sample the first and last frame of each segment, providing a broad and efficient set of candidate motion transitions. However, many sampled pairs are unusable due to camera motion, subject disappearance, environmental changes, or visual degradation. Motivated by the recent success of LLM/MLLM-based data filtering [4,5,10,32], we leverage Google’s Gemini [29] model to automatically filter these cases at scale. We prompt Gemini to evaluate each frame pair along three critical dimensions:
• Setting Consistency. Verify that background, viewpoint, and lighting remain stable despite subject motion. • Motion and Interaction Change. Identify interaction states in each frame and summarize the primary motion transition (e.g., “not holding cup → drinking”).
The model also judges whether the change is significant enough to constitute a meaningful motion edit. • Subject Integrity and Quality. Ensure the main subjects are present, identifiable, and artifact-free, avoiding cases with occlusion, shrinkage, hallucinations, and distortions.
Based on these criteria, the MLLM outputs a binary keep/discard decision. A pair is accepted only if (1) the scene remains stable, (2) the motion change is non-trivial, (3) subjects are consistent and coherent, and (4) both frames maintain high visual quality. This filtering is essential for obtaining high-quality motion edit triplets for our dataset.
While the validated frame pairs provide reliable visual reference, their corresponding edit instructions must be clear, natural, and semantically faithful to the observed change. We convert the MLLM-generated motion-change summaries into user-style editing prompts by following the prompt refinement procedure of Wu et al. [34]. This step removes unnecessary analysis details and standardizes prompts into imperative form (e.g. “Make the woman turn her head toward the dog.”), ensuring alignment between the described edit and the actual motion transition in data.
Our final MOTIONEDIT dataset consists of 10,157 motioneditable frame pairs, sourced from both Veo-3 and KlingAI video collections. Specifically, we obtain 6,006 samples from Veo-3 and 4,151 samples from KlingAI. We perform a random 90/10 train-test split, resulting in 9,142 training data and 1,015 evaluation data that constitutest MOTIONEDIT-BENCH. Each sample includes a source or input image, a target image exhibiting a real motion transition from the original video, and a precise motion edit instruction. As shown in Figure 5, data in MOTIONEDIT can be generally categorized into six motion edit types:
• Pose / Posture: Changes in body configuration position (e.g. raising hand) while keeping identity and scene fixed. • Locomotion / Distance: Changes in subject’s spatial position or distance relative to the camera or environment. • Object State / Formation: Changes in the physical form or condition of an object (e.g., deformation, expansion). • Orientation / Viewpoint: Changes in subject’s facing direction or angle without position change. • Subject-Object Interaction: Changes in how a person or agent physically interacts with an object (e.g., holding).
• Inter-Subject Interaction: Changes in the coordinated motion between two or more subjects (e.g., facing).
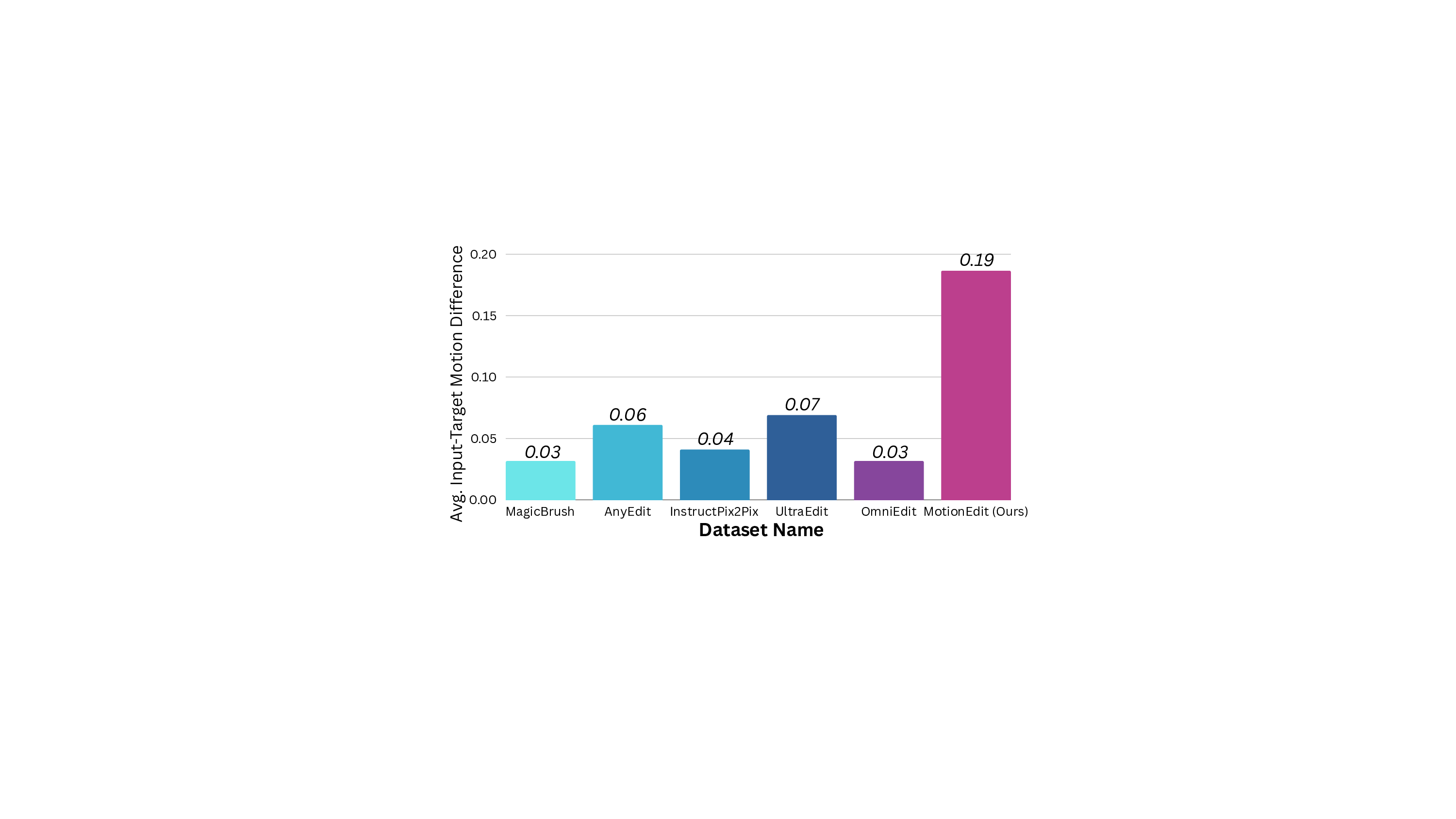
To quantify and compare the amount of motion present in before-after editing pairs between MOTIONEDIT and other editing datasets, we randomly select 100 data from each dataset and calculate the overall pixel-level motion displacement between each input image and its corresponding edited target. We measure motion changes in the image pairs with optical flow, the calculation of which is explained later in Section 4. Figure 6 reports the average input-target motion magnitude across 6 editing datasets. Prior datasets such as MagicBrush [39], AnyEdit [38], InstructPix2Pix [2], Ul-traEdit [40], and OmniEdit [33] contain relatively modest motion changes (typically around 0.05), whereas our MOTIONEDIT dataset exhibits substantially larger motion differences (0.19), representing 5.8× greater motion than MagicBrush and OmniEdit and 3× that of UltraEdit. This highlights our contribution of a significantly more challenging motion editing dataset with substantial motion transformation.
Flow Matching Models Recent progress in diffusion models has shifted from Denoising Diffusion Probabilistic Models (DDPMs) [24] to Flow Matching Models (FMMs) [14].
Given noisy sample z t and conditioning c, FMMs reformulate the noise prediction process in DDPMS by estimates a deterministic velocity field v that transports z t toward its clean counterpart. As a result, inference for FMMs reduces to the ODE dz t = v θ (z t , t, c) dt, which enables efficient generation compared to DDPM sampling. Diffusion Negative-aware Finetuning (NFT) Diffusion-NFT [41] enhances FMM reward training by learning not only a positive velocity v + (x t , c, t) that the model should move toward, but also a negative velocity v -(x t , c, t) that it should avoid. The training objective is:
where v is the target velocity and v + θ , v - θ are defined as linear combinations of the old and current policies:
A key challenge is obtaining a calibrated reward r that accurately reflects whether a sample should be treated as “positive”. Since raw rewards may differ in scale or distribution, DiffusionNFT transforms them into an optimality reward:
where Z c is a normalization factor (e.g., the global reward standard deviation). This normalization stabilizes learning and ensures consistent positive/negative assignment across prompts and reward models.
We introduce MotionNFT, a motion-aware reward framework designed for NFT training on motion-editing tasks.
Since our objective is to evaluate how accurately a model applies the intended action to subjects and objects, our reward function must quantify the alignment between modelpredicted motion and the ground-truth motion edit. Inspired by the use of optical flow for measuring motion between consecutive video frames, we adopt an optical-flow-based motion-centric scoring framework that treats each input-edit pair as an implicit “before-after” sequence. Given a triplet X = (I orig , I edited , I gt ), we compute optical flow fields using a pretrained estimator [36]. The predicted motion is V pred = F(I orig , I edited ) and the groundtruth motion is V gt = F (I orig , I gt ), where each flow lies in R H×W ×2 . We normalize both flows by the image diagonal to ensure scale consistency across resolutions.
Motion magnitude consistency. We measure the deviation between flow magnitudes using a robust ℓ 1 distance:
, where q ∈ (0, 1) is a constant term to suppress outliers.
Motion direction consistency. We compute cosinebased directional error between the unit flow vectors e dir (i, j) = 1 2 1 -vpred (i, j) ⊤ vgt (i, j) , and weight each pixel by its relative ground-truth motion magnitude. The directional misalignment is D dir = i,j w(i,j)edir(i,j) i,j w(i,j)+ε . Movement regularization. To prevent trivial edits that make almost no motion, we compare the average predicted and ground-truth magnitudes: M move = max{0, τ + 1 2 mgtmpred }, where τ is a small positive margin and m denotes the spatial mean.
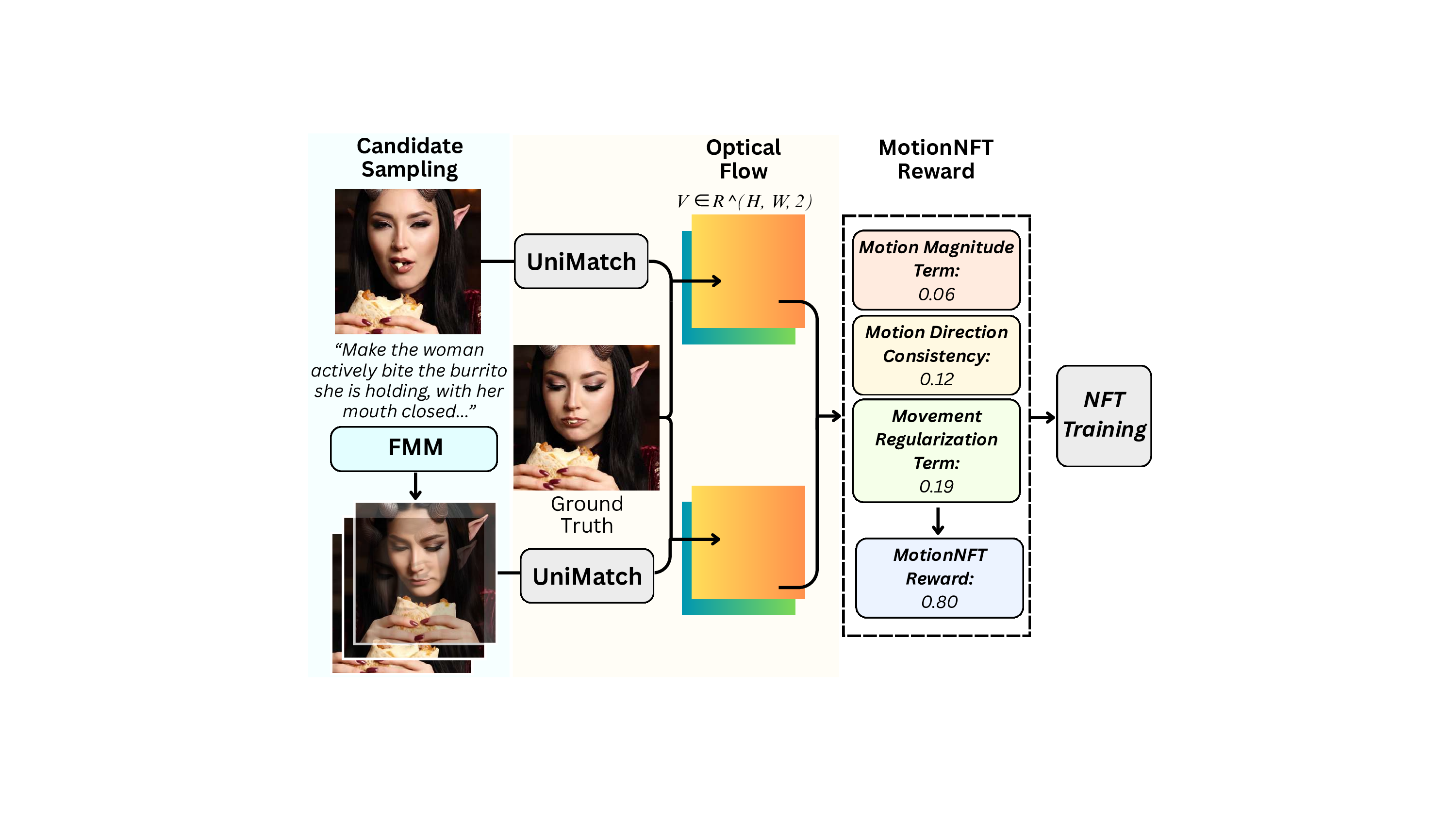
Combined reward. We aggregate the three terms into a composite distance D comb = α D mag + β D dir + λ move M move where α, β, and λ move are constants that balances term scales and weightings. The composite distance is then normalized and clipped: D = clip (D comb -D * min )/(D max -D * min ), 0, 1 , and converted into a continuous reward r cont = 1 -D. Finally, we quantize it into 6 discrete reward levels: r motion = 1 5 round(5 r cont ) ∈ {0.0, 0.2, 0.4, 0.6, 0.8, 1.0}. The resulting scalar reward is used to compute optimality rewards and update the policy model v θ under the Diffu-sionNFT objective (Eq. 4). Figure 7 illustrates the Motion-NFT reward pipeline.
We provide important details of our experimental setups. Full details are reported in the Additional Experiment Details Appendix section.
MotionNFT Training We use FLUX.1 KONTEXT [DEV] [14] and QWEN-IMAGE-EDIT [34] as base models for MotionNFT training. Following Lin et al. [15]’s implementation, we use Fully Sharded Data Parallelism (FSDP) for text encoder and apply gradient checkpointing in training for GPU memory usage optimization. To im-
We evaluate 9 opensource models on MOTIONEDIT-BENCH: Instruct-P2P [2], MagicBrush [39], AnyEdit [38], UltraEdit [40], Step1X-Edit [18], BAGEL [7], UniWorld-V1 [15], FLUX.1 Kontext [Dev] [14], and Qwen-Image-Edit [34].
Generative Metrics. Following Luo et al. [19] and Lin et al. [15], we use an MLLM to evaluate edited images with four generative metrics: Fidelity, Preservation, Coherence, and their Overall average. We choose to use Google’s Gemini [29] as the MLLM evaluator and use evaluation prompts adapted from the “action” category of Luo et al. [19]. Discriminative Motion Alignment Score (MAS).
Table 1 reports quantitative performance of 9 image editing models on MOTIONEDIT-BENCH. The first 4 columns shows MLLM generative ratings on a 0-5 scale. Our optical flow-based MAS metric measures motion consistency on a 0-100 scale. The Win Rate reflects the percentage of pairwise comparisons in which a model’s output received a higher average MLLM score than a competing one. #1: Improved Motion Editing Quality. Across both base models, MotionNFT consistently improves all aspects of generation quality on motion editing, as measured by the generative evaluator. When applied to FLUX.1 KON-Make Doraemon and the boy turn their bodies and heads to face each other for direct interaction.
Have the female dental professional turn away from the male patient and bend down to adjust the dental chair.
Reposition Training with MOTIONNFT enables Qwen-Image-Edit to produce outputs that more faithfully reflect the intended motion, e.g. rotating character directions, adjusts limb and torso positions to reflect bending or turning actions. Additionally, the resulting edits preserve identity and scene context while achieving the targeted motion change, closely matching the ground-truth transformations. These observations validates the effectiveness of incorporating motion-centric guidance in MotionNFT to execute meaningful, structure-aware motion edits that current image editing models consistently fall short in achieving.
General Image Editing Performance To verify that Mo-tionNFT preserves a model’s general editing ability, we follow previous work [15] and conduct evaluation on ImgEdit-Bench [37], a comprehensive benchmark covering 8 editing subtasks.
To verify the effect of MotionNFT’s supervision, we compare Motion-NFT against the MLLM-only RL framework in UniWorld-V2 [15]. Table 3 shows that while MLLM-only training yields modest improvements over the base models, Motion-NFT consistently achieves higher overall edit quality, better motion alignment, and superior win rates across both base models. These results demonstrate that incorporating optical flow-based motion guidance yields more targeted and effective motion-editing capabilities.
We introduced MOTIONEDIT, a high-quality dataset and benchmark for the novel motion image editing task, aiming at correct modifying subject actions and interactions in images while preserving identity and scene consistency. To improve model performance on this challenging task, we proposed MOTIONNFT, a motion-guided negative-aware finetuning framework that integrates an optical-flow-based motion reward for training. MotionNFT provides supervision on motion magnitude and direction, enabling models to understand and perform motion transformations that existing models consistently struggle with. Both quantitative and qualitative experiment results demonstrate that Motion-NFT delivers consistent gains across generative quality, motion alignment, and preference win rate on two strong base models, FLUX.1 Kontext and Qwen-Image-Edit.
In this supplementary material, we present additional details on our method design in Section 7. We also present additional experimental setups, metric design, and human validation of metric in Section 8. Furthermore, we provide results of ablation experiments in Section 9.1 to verify the effectiveness of our MOTIONNFT method. Lastly, we visualize qualitative examples comparing our method to both open-source and closed-source commercial models in 9.2, highlighting the failure cases in these models and pointing towards future research direction.
In T2I diffusion models, the forward noising process perturbs clean data x 0 from real distribution π 0 by adding a scheduled Gaussian noise ϵ ∼ N (0, I). The model then learns to reverse the noise and output clean images. The shift from Denoising Diffusion Probabilistic Models (DDPMs) to Flow Matching models (FMMs) is essentially a change in the prediction target of the model, from predicting the added noise itself (DDPM) to estimating a “velocity field” from the noise sample to the clean sample (FMM).
In mathematics formulation, FMMs define z t = α t x 0 + σ t ϵ to be a noisy interpolated latent at timestep t between the initial clean x 0 and the noise ϵ, where α t and σ t defines the scheduled noise at t. Then, for noisy sample z t and textual context c, a FMM v θ is trained to directly approximate the target constant velocity field v = dαt dt x 0 + dσt dt ϵ by minimizing the objective:
This velocity prediction allows for efficient inference by solving the deterministic Ordinary Differential Equation (ODE), dz t = v θ (z t , t, c)dt for the forward process.
DiffusionNFT [41] aims at finding not only the “positive velocity” v * (x t , t, c) = v + (x t , t, c) that the model learns to predict, but also identifying the “negative velocity” v -(x t , t, c) component that the model should steer away from. The training objective of DiffusionNFT is:
Where v is the target velocity, v + θ and v - θ are the implicit positive policy and implicit negative policy, defined as com-binations of the old policy and current training policy:
Naturally, we need an optimal reward r to accurately estimate the likelihood of the current action to fall into the “positive” subset of all samples. However, real-world reward models might differ in score distributions and scales. To this end, DiffusionNFT transforms raw rewards r raw into the optimality reward:
Where Z c is a normalizing factor (e.g. standard deviation of global rewards).
We propose a optical flow-based motion-centric reward scoring framework for our MotionNFT method to compute how closely model-predicted motion matches the ground-truth motion. Our reward scoring process is illustrated as follows:
Optical Flow Calculation Given two images I 0 and I 1 , an optical flow estimation model [36] F quantifies motion flow between them with V = F (I orig , I edited ) ∈ R H×W ×2 , where V is a vector field that represents the motion of each pixel with a 2D vector. In our case, given an input triplet X = (I orig , I edited , I gt ) containing triplets of the original image I orig , the model-edited image I edited , and the ground truth image I gt , we first calculate the optical flow between the input image and the model-edited image:
V pred = F (I orig , I pred ). Then, we construct the motion reward r m (X) to quantify the level of alignment between V pred and the ground truth motion flow derived from the input and the ground-truth edited image V gt = F (I orig , I gt ) with three consistency terms: a motion magnitude consistency term, a motion direction consistency term, and an movement regularization term. Flow normalization. Let V pred (i, j) ∈ R 2 and V gt (i, j) ∈ R 2 denote the optical flow vectors at pixel (i, j) for the model-edited and ground-truth edited images, respectively. For an image of height H and width W , we normalize the flows by the image diagonal to make the displacement magnitude comparable across resolutions:
Motion Magnitude Consistency Term. We first measure how closely the predicted flow magnitudes match the ground truth using a robust ℓ 1 distance. Let d(i, j) = Ṽpred (i, j) -Ṽgt (i, j), magnitude deviation D mag can be calculated as:
where ε > 0 is a small constant used for numerical stability and the exponent q ∈ (0, 1) enables a robust variant of the ℓ 1 distance that suppresses the influence of large outliers in the flow field while still preserving sensitivity to semantically meaningful deviations. Empirically, we set q = 0.4, which provides a stable trade-off between robustness and sensitivity for the motion-editing task.
Motion Direction Consistency Term. We additionally measure directional alignment between the two flow fields, while focusing on regions with non-trivial motion. Let:
and define unit flow directions:
We compute a cosine-based directional error per pixel: cos(i, j) = vpred (i, j) ⊤ vgt (i, j), e dir (i, j) = 1 2 1-cos(i, j) , and weight each pixel by the relative ground-truth motion magnitude:
where τ m is a small motion threshold and 1[•] is the indicator function. The directional misalignment D dir can be calculated as:
Movement Regularization Term. While D mag and D dir encourage the predicted flow to match the ground-truth motion, they do not by themselves prevent the model from collapsing to a nearly static edit. To discourage models from demonstrating this degeneration, we introduce a movement regularization term that compares the average motion magnitude of the predicted flow to that of the ground truth. We obtain the spatial means of m gt and m pred :
and define the anti-identity hinge term to be:
M move = max 0, τ + 1 2 mgt -mpred , where τ > 0 is a small margin. Intuitively, M move penalizes trivial edits that keep the image nearly identical to the input. Final: Motion-Centric Reward for training. Finally, we convert the optical flow-based alignment measure into a scalar reward for NFT training. We combine the 3 terms to obtain:
, where α, β, and λ move are hyper-parameters that balance the scales between magnitude and directional alignments, as well as assigning a small proportion to discouraging undermotion. We normalize and clip the combined term:
where D * min is the lower bound of magnitude and directional terms calculated from a pair of duplicated inputs. We then construct the continuous optical flow-based reward:
so that higher reward corresponds to better alignment with the ground-truth motion edit. Finally, to approximate discrete human ratings of edited images following [15,19], we quantize the reward to 6 equally spaced levels: MAS Calculation When quantifying the MAS between model-edited images and ground truth targets, we punish degenerate cases where the predicted motion is nearly static compared to the ground-truth motion as a hard failure case and assign the minimum score MAS = 0. This happens when
, where ρ min is a parameter determining how harsh the punishment threshold would be. In our experiments, we set ρ min = 0.01.
Following the training setup in Lin et al. [15], we train all models with learning rate set to 3e -4. For FLUX.1 Kontext [Dev] [14] as base model, we report results for 300 steps. For Qwen-Image-Edit [34] as base model, we report results for 210 steps. Due to computational limits, we set batch size to 2. For NFT training, during sampling, we set sampling inference steps to 6, number of images per prompt to 8, and number of groups to 24; for training, we set KL loss’ weight to 0.0001 and guidance strength to 1.0. For group filtering, we set the ban mean threshold to 0.9 and the standard deviation threshold to 0.05.
During inference for Qwen-Image-Edit [34] and the trained checkpoints, we set number of inference steps to 28, true cfg scale to 4.0, and guidance scale to 1.0. For inference of FLUX.1 Kontext [Dev] [14] and its trained checkpoints, we set the same number of inference steps. For inference of other open-sourced models, we follow the hyper-parameter setup in the official repositories. For UniWorld [15], we set number of inference steps to 25 and guidance scale to 3.5. For AnyEdit [38], we set guidance scale to 3, number of inference steps to 100, and original image guidance scale to 3. For UltraEdit [40], we set number of inference steps to 50, image guidance scale to 1.5, and guidance scale to 7.5. For Step-1X [18], we set number of inference steps to 28 and true cfg scale to 6.0. For all other models, we set guidance scale to 3.5 and number of inference steps to 28.
To evaluate the alignment between the MLLM-based generative metric and human judgment on motion editing quality, we conduct a human annotation study. Our annotators are a group of voluntary participants who are college-level or graduate-level students based in the United States. All annotators are proficient in English and have prior familiarity with AI research, ensuring that they understand the evaluation criteria and the purpose of the study. Prior to beginning, all annotators were informed that the anonymized results of their annotations may be used for research purposes only.
We randomly sample 100 entries from MOTIONEDIT-BENCH for human evaluation, for which we further conduct random selection of outputs from 2 different models for comparison. To ensure consistency, all annotators completed the same set of comparison tasks. Each annotation instance consists of five visual components: (1) the Input Image to be edited, (2) the Ground Truth Edited Image demonstrating the ideal motion change, (3) a Text Editing Instruction, and (4-5) two model-generated edited outputs (labeled Model 1 and Model 2). The annotators were asked to select which of the two model outputs better fulfill the requested motion edit, preserve the subject’s identity, and maintain overall visual coherence. Annotators were reminded that the Ground Truth serves as a reference only, not something to be matched pixel-wise. They were encouraged to evaluate edits based on correctness of motion transformation and appearance preservation of the final image. If both outputs appear to be comparably good, annotators were instructed to select the one that is slightly better. Annotation Instruction. Before beginning annotation, participants read the following notice and instructions:
Warning: The set of model-synthesized images displayed below might contain explicit, sensitive, or biased content.
Thank you for being a human annotator for our study on the motion image editing task! By completing this form, you confirm voluntary participation in our research and agree to share your annotation data for research purposes only.
For each example, you will see: the Input Image, the Ground Truth Edited Image, an Editing Instruction, and two model-generated outputs. Your task is to determine which model output better follows the editing instruction while preserving the identity and appearance of the subject. Consider whether the edit is applied correctly, whether the subject remains consistent with the input, and whether the final image appears coherent and natural. You may consider the Ground Truth Image to be a “reference answer” of the ideal edit.
If both outputs are similar in quality, choose the one you feel is slightly better.
Since all annotatros complete the same set of comparison tasks, each pair of model comparison was labeled by three independent annotators. Inter-annotator agreement between all human annotators, as measured by Fleiss’ κ, is 0.607, indicating good agreement among human raters. The aggregated agreement between human annotators and decisions made by the overall generative metric (averaged over Fidelity, Preservation, and Coherence) achieves a Fleiss’ κ score of 0.574, similarly demonstrating substantial alignment between human judgment and our metric. These results support the use of the MLLM-based generative evaluation metric as a practical and human-consistent measure of motion editing quality.
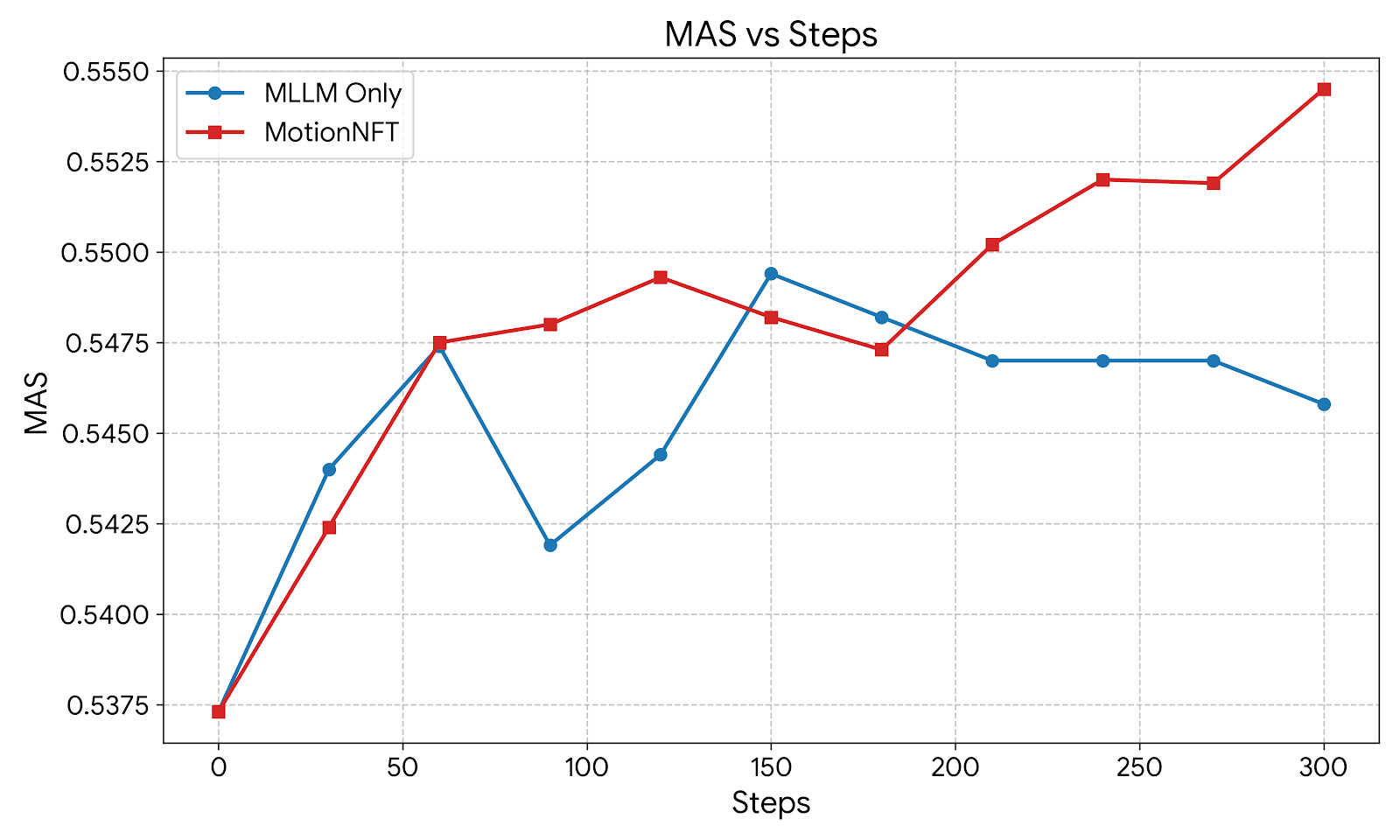
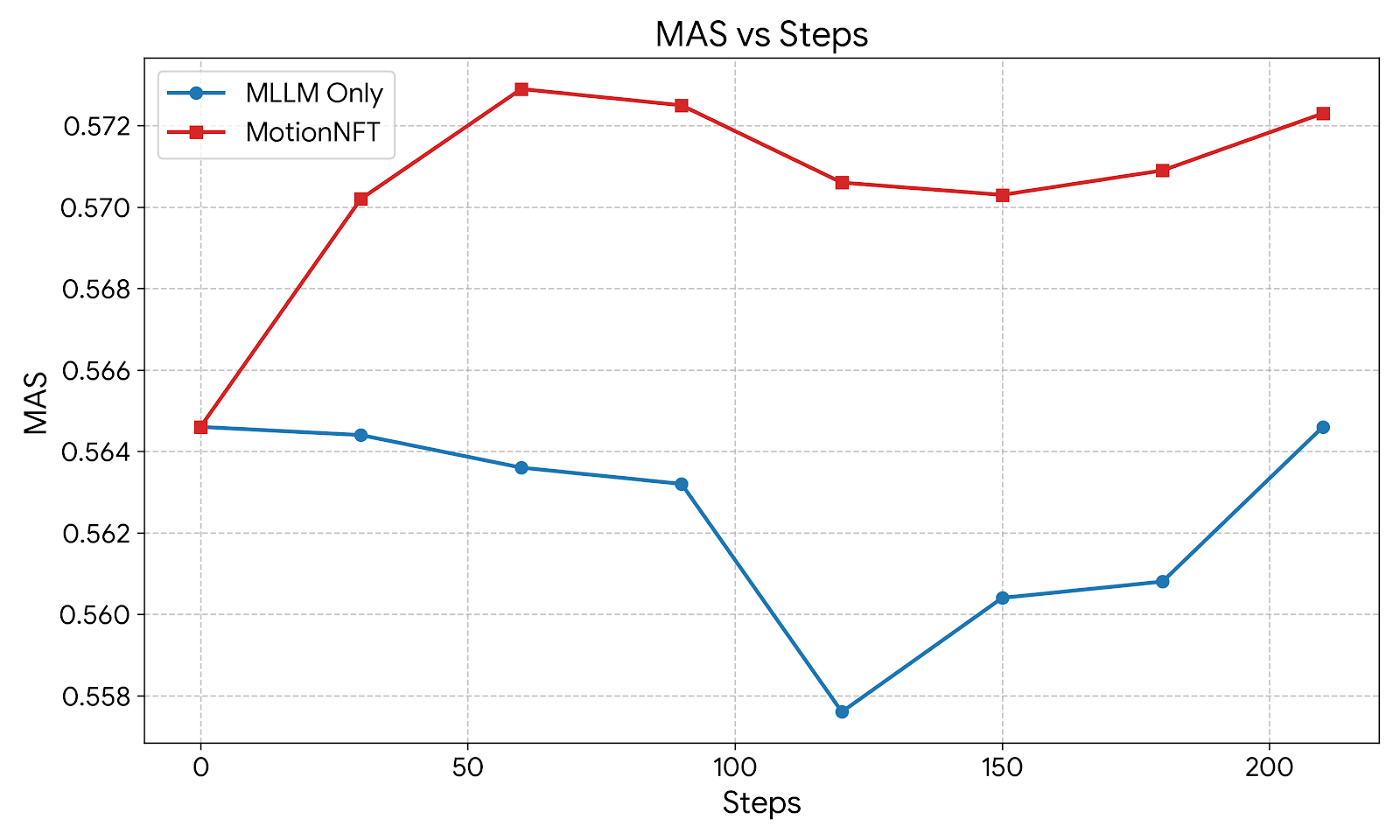
Balancing MLLM and Optical Flow-Based Rewards We investigate the optimal balancing strategy between our pro-posed optical flow-based motion alignment reward (r motion ) and the MLLM-based semantic reward (r mllm ) introduced in Uniworld-v2. Specifically, we adopt multi-objective reward NFT training with different weights for each reward. Table 1 summarizes the editing performance on our MOTIONEDIT-BENCH across varying balancing weights.
We observe that relying solely on the motion reward (1.0 * Motion) leads to a performance degradation, indicating that geometric motion cues alone are insufficient for maintaining semantic fidelity. Conversely, while the pure MLLM reward (1.0 * MLLM) provides a strong baseline, it is consistently outperformed by the combined approach. The results demonstrate that the two objectives are complementary. The balanced configuration (λ = 0.5) yields the highest performance across all metrics for both FLUX. [15] and our MOTIONNFT reward. As explained in previous sections, MAS utilizes optical flow to quantify magnitude and directional alignment level between model-edited motion and ground truth motion achieved in the target image. We observe that relying solely on the MLLM-based semantic reward results in suboptimal motion alignment; for Qwen-Image-Edit (Fig. 10), the MAS even degrades significantly during the mid-training phase. In contrast, Mo-tionNFT demonstrates robust and consistent improvement in MAS across both backbone models. By incorporating explicit motion guidance, our method prevents the model from overfitting to semantic cues at the expense of geomet- In Row 6, both baselines mistakenly flip the caterpillar’s body direction when moving it towards the center of the flower. In contrast, MotionNFT successfully executes both edits, matching the ground truth desired motion. Additionally, we observe that another failure mode in baseline methods is the preservation of setting and subject identity. In Figure 11 (Row 5), both baselines completely remove the milk jar despite it being a main subject in the image. In the last row, both baselines remove the photo frame surrounding the woman that was in the original image, failing to preserve setting consistency. Similarly, in Figure 12 row 2, we observe that using [15]’s MLLM-only reward on FLUX.1 Kontext changes the penguin’s beak in to a black color, failing to preserve its appearance while also not correctly performing the motion edit. MotionNFT, on the other hand, achieves good preservation of subject’s appearance and setting consistency.
We compare MotionNFT against leading open-source editing models, including UniWorld-V1 [15], BAGEL [7], and FLUX.1 Kontext [Dev] [14]. Visual comparisons in Figure 13 reveal that these baselines frequently struggle with precise motion controllability: • Editing Inertia: Existing models may fail to execute significant geometric transformations, defaulting to the original pose. For instance, in the “car cliff” scenario (Row 6), UniWorld-V1 fails to displace the vehicle, leaving it on the ledge with a flipped direction, while BAGEL and FLUX.1 lift the car but fail to capture the “downward angled” physics of the fall. Similarly, in the “lion” example (Row 2), all baselines fail to fully lower the head to the requested “looking downwards” pose, whereas MotionNFT achieves accurate alignment with the ground truth. • Motion Misalignment: Existing models may fail to interpret and execute the subject part and direction of the motion change. For instance, in the gorilla example (Row 3), FLUX.1 Kontext fails to put the right hand into a fist.
In the robot example (row 5), all baseline models fail to move the robot’s left arm but move the right one instead. MotionNFT, on the other hand, performs the correct motion change on the correct subject part. • Structural Distortion: When baselines do attempt large edits, they often introduce anatomical or semantic artifacts. In the “gorilla” example (Row 3), FLUX.1 Kontext distort the hand structure when attempting the “fist” gesture. In the jug drinking example (Row 4), the baselines leave residual artifacts that distorts the jug, while our method cleanly executes the edit without artifacts.
We conduct selective case studies that compares Motion-NFT with Qwen-Image-Edit as base model against leading closed-source commercial models, including Nano-Banana [8], GPT-Image-1 [22], Seedream [26], and Hunyuan Image [3]. As visualized in Figure 14, these models still exhibit distinct failure modes for motion editing: 1. Semantic Hallucination and Structural Distortion:
When complex pose changes are required, baselines often introduce artifacts or unwanted semantic changes. In the “apple” example (Row 2), Nano-Banana introduces artifact by creating an additional “feet” that steps on the apple. MotionNFT avoids these structural collapses, successfully executing the editing instructions with high anatomical fidelity. 2. Motion Misalignment: Even strong closed-source commercial models suffer from correctly identifying the subject part, direction, and magnitude of the motion change. For instance, in the anime girl example (row 1), Nano-banana demonstrates editing inertia where the motion of the subject remains the same, while GPT-Image 1, Seedream, and Hunyuan Image fail to execute the correct edit on the girl’s arm.
While MotionNFT demonstrates robust performance across a wide range of editing cases, we observe specific scenarios where it, alongside leading commercial models, encounters difficulties. Figure 15 illustrates these common failure modes that highlights persisting challenges:
• Multi-Subject Interactions: Challenging editing settings with multiple involving and non-involving subjects in images pose a major challenge for existing models. For instance, in the orca example (row 1), all models fail to position the orca in front of the polar bear while executing the motion change to make it submerge in water.
Similarly, in the crew member example (row 3), changing only the direction and the motion of one subject among a couple is difficult for existing models. • Identity Preservation Existing models still struggle to preserve subjects and their identities in complex scenes. For instance, in the chicken example (row 2), 3 models fail to preserve the chicken’s appearance. In the tent example (last row), models fail to preserve additional subjects in the scene not involved in the motion change. These cases suggest that future work incorporating stronger physics-based priors or motion guidance could further resolve the remaining challenges.
MotionNFT is designed to be lightweight and computationally efficient. A key advantage of our method is that it can be seamlessly integrated with base models such as FLUX.1 Kontext Dev and Qwen-Image-Edit with no additional inference-time cost. All experiments were conducted on a single NVIDIA GPU. Using 28 sampling steps for a single entry, inference requires approximately 48 seconds with the FLUX.1 backbone and 98 seconds with Qwen-Image-Edit. This confirms that MotionNFT enhances generation capabilities without compromising the speed or hardware requirements of the original models.
Change the woman’s right hand to operate the joystick on the control panel.
Change the person’s pose: lift the torso to an upright position, extend the right arm straight out to the side, and extend the left arm forward. Keep the current outfit and facial expression.
smile with an open mouth shape, holding a piece of the chocolate chip cookie taken from the cookie on the right.
The right chocolate chip cookie should visibly have a bite missing.
Show the man actively manipulating the puppet, with one hand touching its leg, giving the puppet slightly bent knees, and the man a focused expression.
Move the green caterpillar from the pink petal to the yellow center of the flower.
Change the polar bear’s pose to lower its head and sniff the snow.
Change the girl’s right arm pose from an extended gesture to a hand-on-hip pose, keeping her winking expression, blue hair, and outfit unchanged.
Move the white mug from the woman’s hands to the wooden table, positioned to her right.
Replace the man’s clasped hands with his right hand gently touching the woman’s left hand, comforting her.
Move the watermelon from on the woman’s head to in front of her lower body. Figure 11. Qualitative comparison of our method to Qwen-Image-Edit [34] and the MLLM-only reward training in Lin et al. [15]. The base model frequently fails to demonstrate correct motion awareness for the edit (e.g. fail to move the subject’s arms in the first row, and failing to displace the watermelon in the last row). While the MLLM-only approach improves semantic adherence, it often lacks geometric precision (e.g., caterpillar’s orientation in row 7). MotionNFT leverages optical flow to bridge this gap, achieving precise motion alignment and high fidelity to the editing instructions.
Have the female professional help the elderly woman stand up by holding her hand. Remove the man on the right.
Replace the robot’s firing projectile weapon with an activated energy sword held in its hands.
Make the boy on the left stop cleaning the wheel and look towards the girl. Make the girl stop working on the bicycle and look towards the boy on the left.
The boy on the right’s action remains unchanged.
Make the penguin’s pose passive and still, with its wings relaxed and mouth closed.
Turn the character to face away from the camera.
Change the person’s pose: lift the torso to an upright position, extend the right arm straight out to the side, and extend the left arm forward. Keep the current outfit and facial expression.
Remove the handshake between the two characters.
Change the black cat’s pose from lying on its back on the blue pillow to standing on all fours on the pillow.
Change the woman’s focused expression to a relaxed, subtle smile, and lower her right hand from the chess piece onto the table.
Change the girl’s right arm pose from an extended gesture to a hand-on-hip pose, keeping her winking expression, blue hair, and outfit unchanged. The base model often exhibits editing inertia, failing to execute structural changes such as removing the handshake (row 6) or changing the subjects’ directions (row 3). MLLM-only baseline also frequently hallucinates incorrect poses (e.g., the distorted limb placement in row 5) or fails to preserve subject identity (row 2). MotionNFT is able to interpret and execute complex motion edit instructions while preserving subject appearance and visual setting.
“Make the right foot step on the red apple, crushing it.”
. We conduct selective case studies of MotionNFT against leading closed-source commercial baselines: Nano-Banana [8], GPT-Image-1 [22], Seedream [26], and Hunyuan Image [3]. Red circles highlight failure regions where baselines exhibit spatial inertia (e.g., failing to displace the car in the bottom row) or structural hallucination (e.g., generating an artifact “foot” in the second row). While commercial models generally maintain high visual quality, they frequently struggle to ground complex motion changes or maintain visual consistency. MotionNFT accurately follows these dynamic instructions, ensuring geometric alignment with the ground truth.
“Submerge the orca into the water, with its dorsal fin and upper body visible, and position it to obscure the polar bear.”
“Turn the standing crew member to face the holographic display and the seated crew member on the left. Make them point their right hand at the holographic display.”
“Add an adult in a yellow shirt. Both adults collaboratively lift and shape the large white sheet into a tent structure.”
“Shift the giant chicken to the left and slightly upwards, revealing more of its body, and turn its head to gaze horizontally instead of downwards.” Figure 15. Additional failure cases of our model and closed-source commercial models. We observe that instructions involving multiple involving and non-involving subjects (e.g. the orca example in row 1, which requires complex 3D spatial edit) remain challenging for all evaluated methods. Current models, including ours and commercial baselines, struggle to correctly generate accurate and targeted motions on the correct subject part with the correct direction and magnitude in challenging scenarios.
“Make the woman actively bite the burrito she is holding, with her mouth closed…“FMM Optical Flow
“Make the woman actively bite the burrito she is holding, with her mouth closed…”
V ∈R ^(H, W, 2)
This content is AI-processed based on open access ArXiv data.