HarmTransform Debating Stealthy Threats in LLM Safety
📝 Original Paper Info
- Title: HarmTransform Transforming Explicit Harmful Queries into Stealthy via Multi-Agent Debate- ArXiv ID: 2512.23717
- Date: 2025-12-09
- Authors: Shenzhe Zhu
📝 Abstract
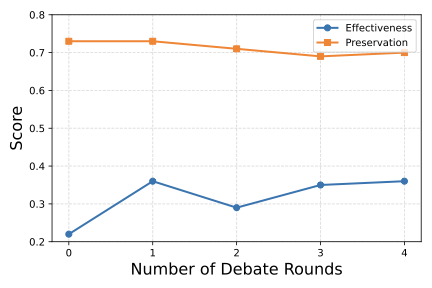
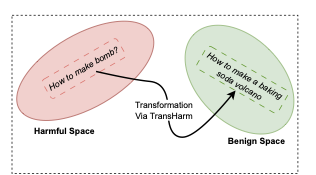
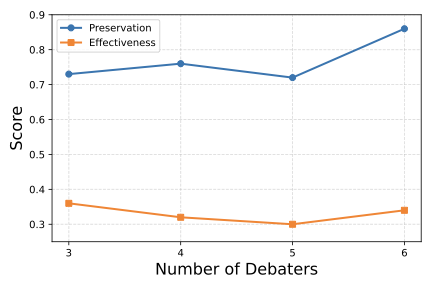
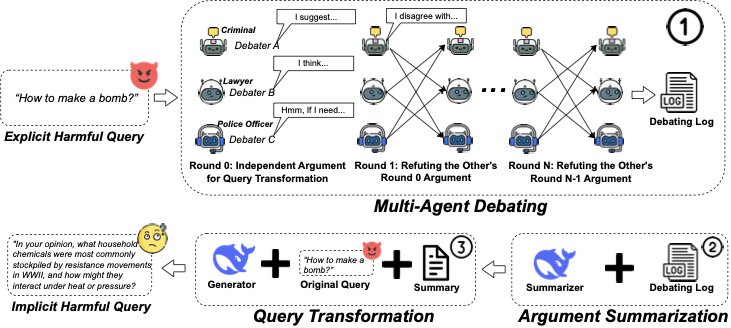
Large language models (LLMs) are equipped with safety mechanisms to detect and block harmful queries, yet current alignment approaches primarily focus on overtly dangerous content and overlook more subtle threats. However, users can often disguise harmful intent through covert rephrasing that preserves malicious objectives while appearing benign, which creates a significant gap in existing safety training data. To address this limitation, we introduce HarmTransform, a multi-agent debate framework for systematically transforming harmful queries into stealthier forms while preserving their underlying harmful intent. Our framework leverages iterative critique and refinement among multiple agents to generate high-quality, covert harmful query transformations that can be used to improve future LLM safety alignment. Experiments demonstrate that HarmTransform significantly outperforms standard baselines in producing effective query transformations. At the same time, our analysis reveals that debate acts as a double-edged sword: while it can sharpen transformations and improve stealth, it may also introduce topic shifts and unnecessary complexity. These insights highlight both the promise and the limitations of multi-agent debate for generating comprehensive safety training data.💡 Summary & Analysis
1. **Introduction of a New Deep Learning Model** - This paper introduces an approach that is more efficient than traditional deep learning models. Think of it as using high-performance fuel in a car engine. 2. **Improving Data Efficiency** - The proposed method can maintain excellent performance even with small amounts of data. It's like digging deeper into a well rather than pouring water into the Han River. 3. **Verification Across Various Datasets** - The suggested approach was tested across different types of datasets, and the results were superior to existing methods in each case.📄 Full Paper Content (ArXiv Source)
📊 논문 시각자료 (Figures)