Revisiting the Scaling Properties of Downstream Metrics in Large Language Model Training
Reading time: 2 minute
...
📝 Original Info
- Title: Revisiting the Scaling Properties of Downstream Metrics in Large Language Model Training
- ArXiv ID: 2512.08894
- Date: 2025-12-09
- Authors: Jakub Krajewski, Amitis Shidani, Dan Busbridge, Sam Wiseman, Jason Ramapuram
📝 Abstract
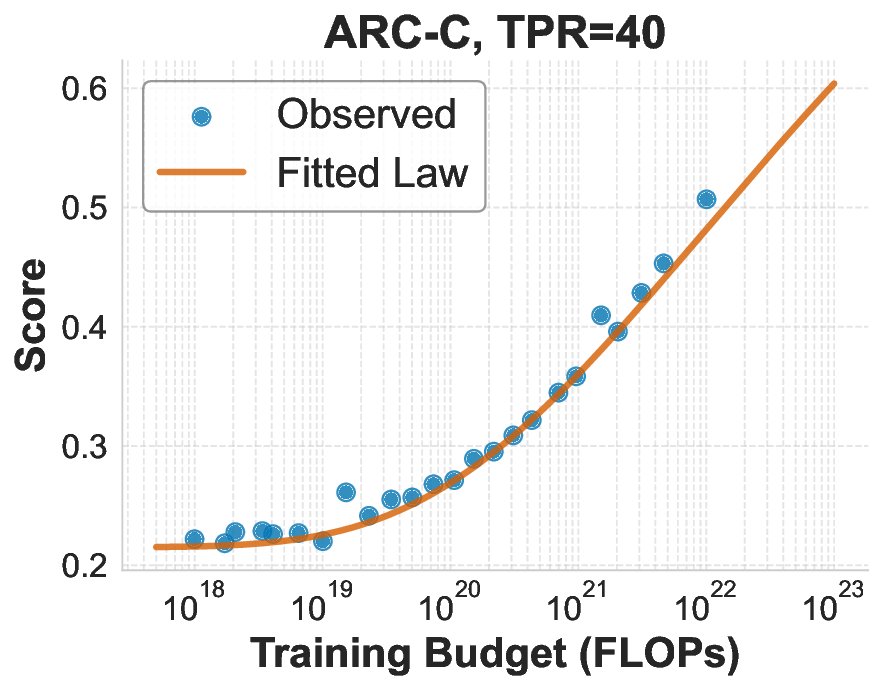
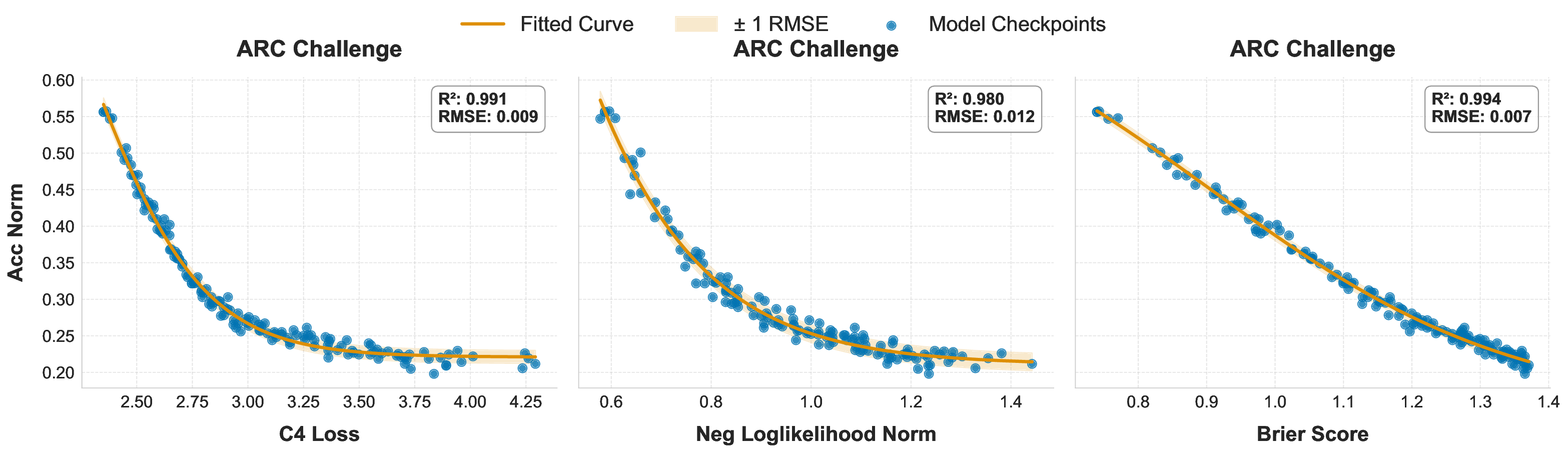
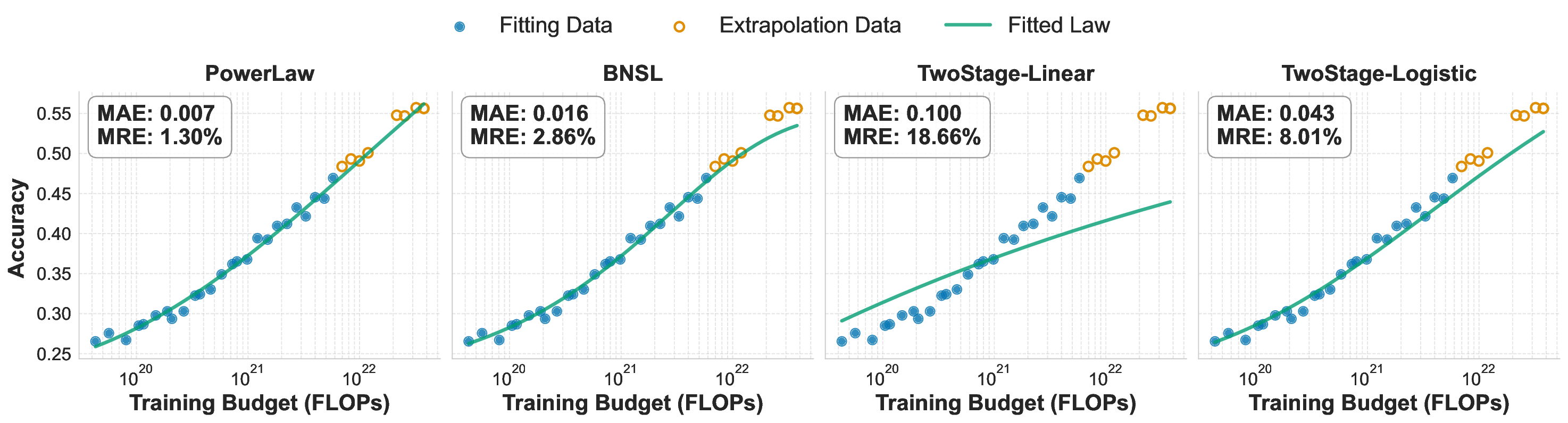
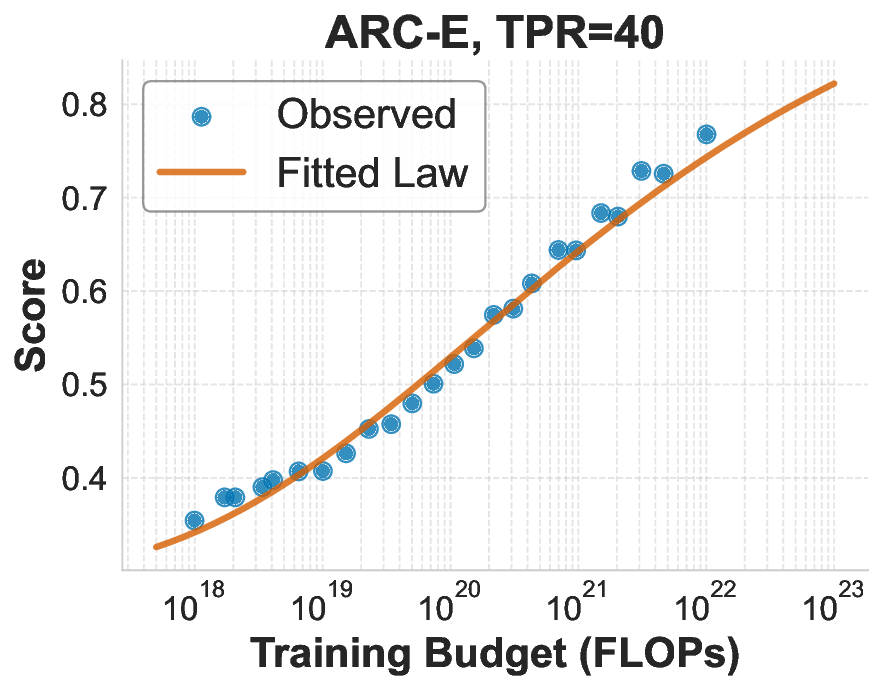
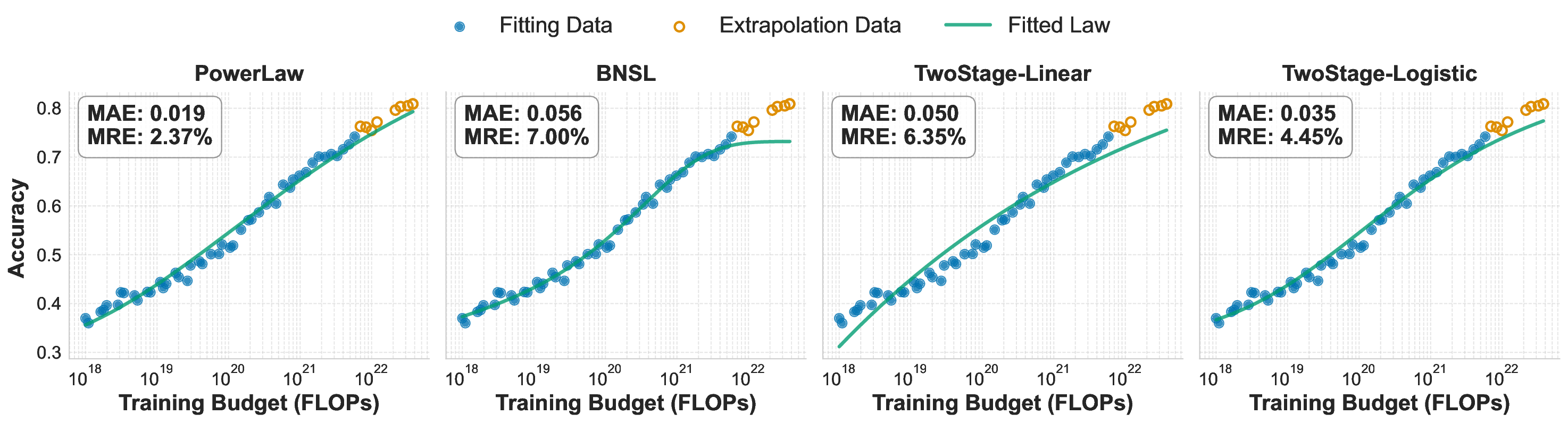
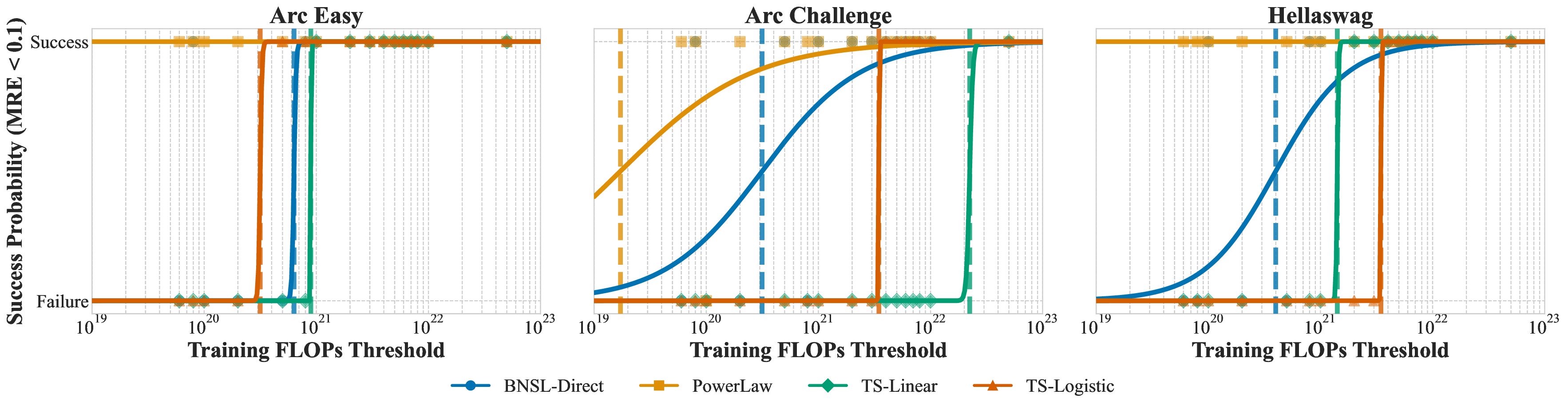
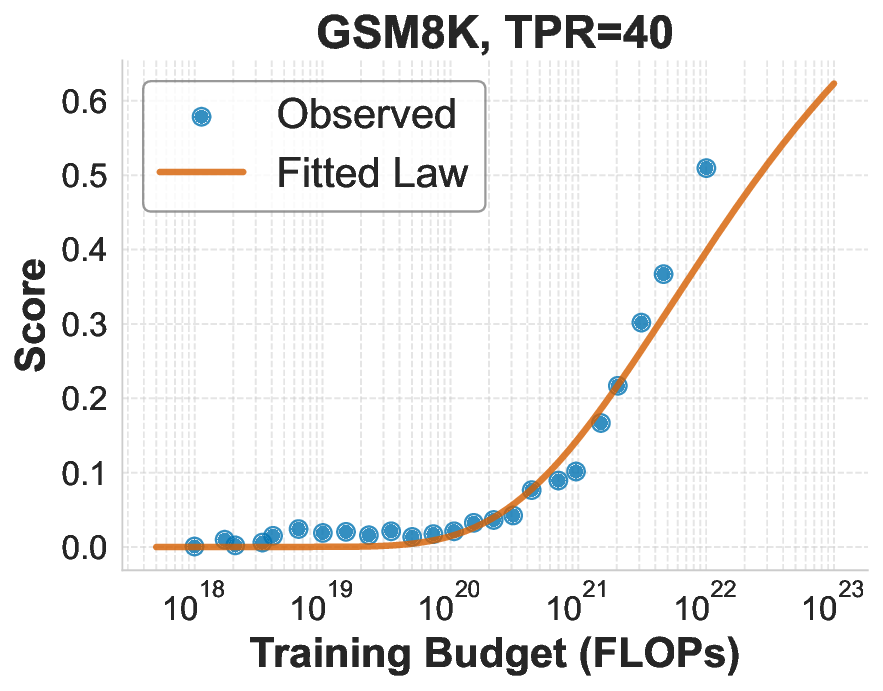
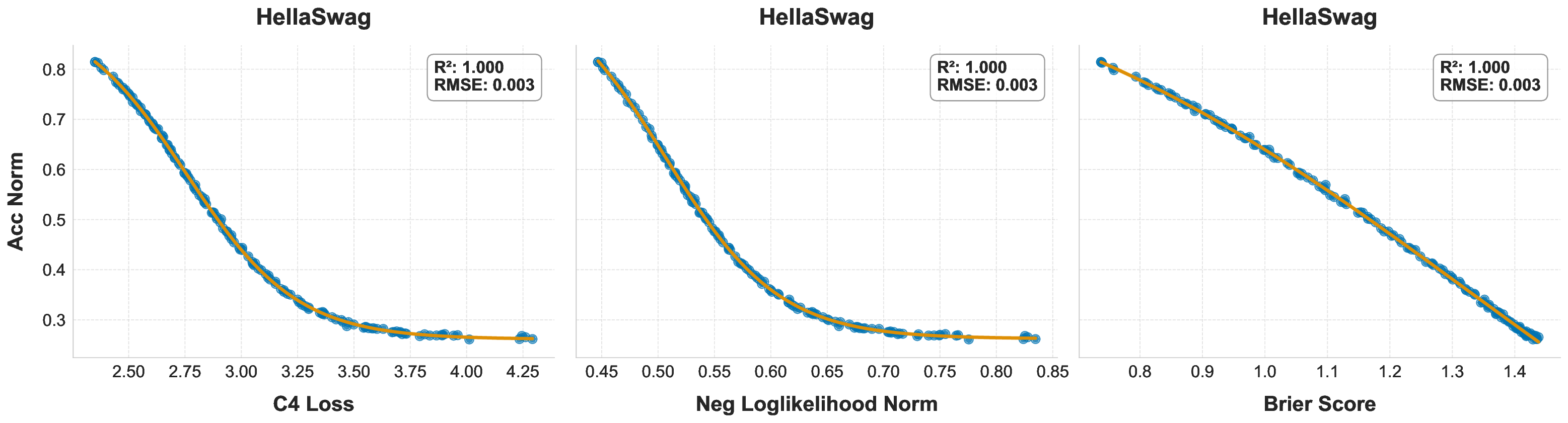
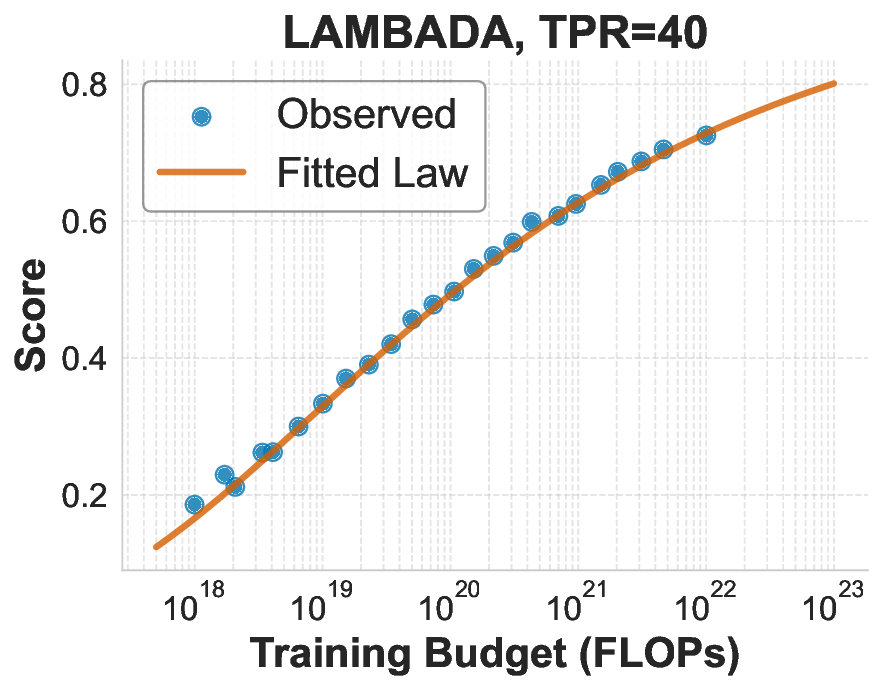
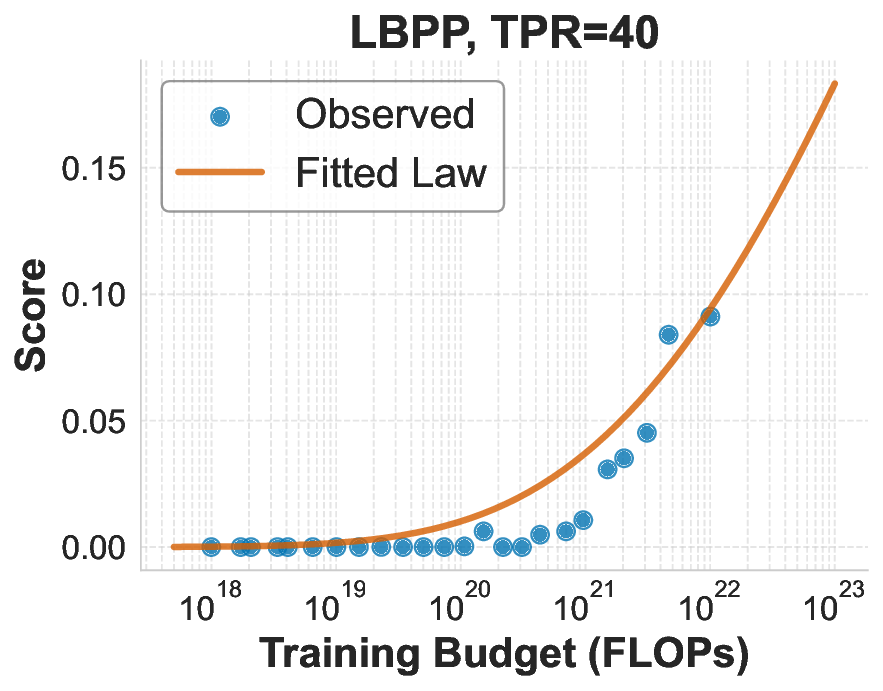
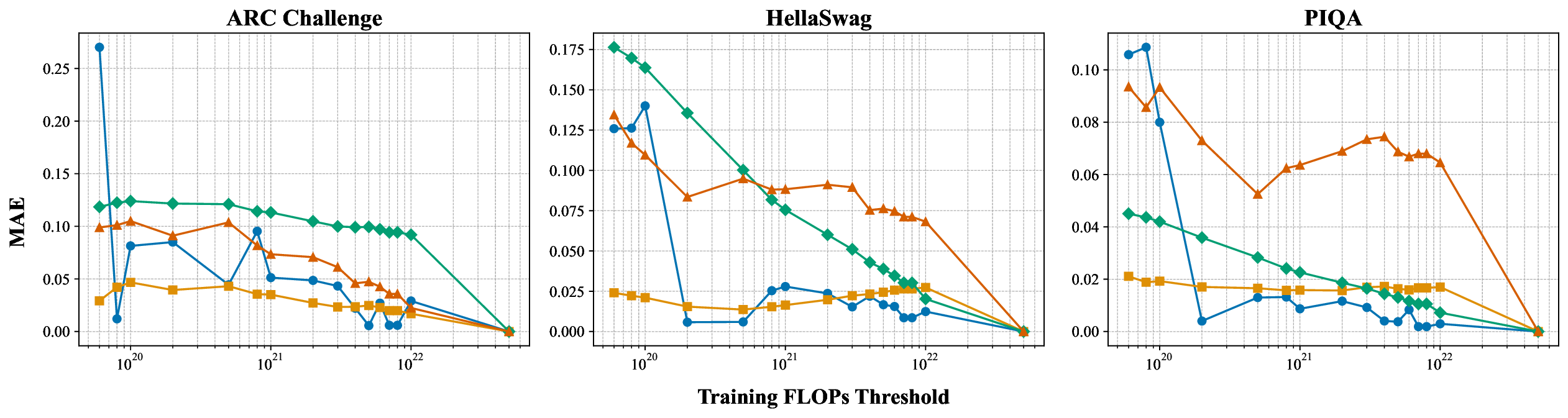
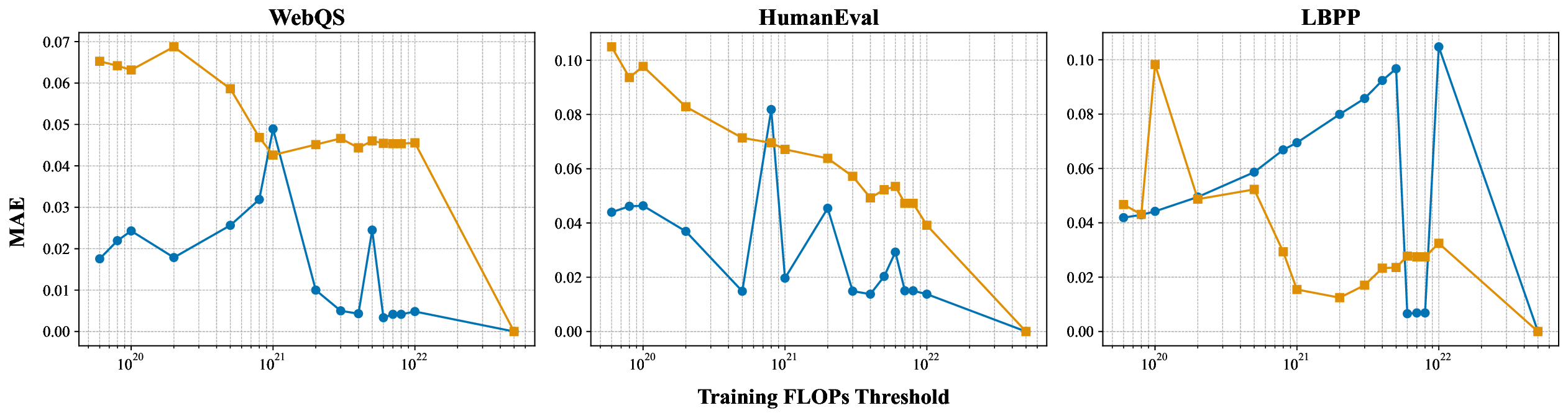
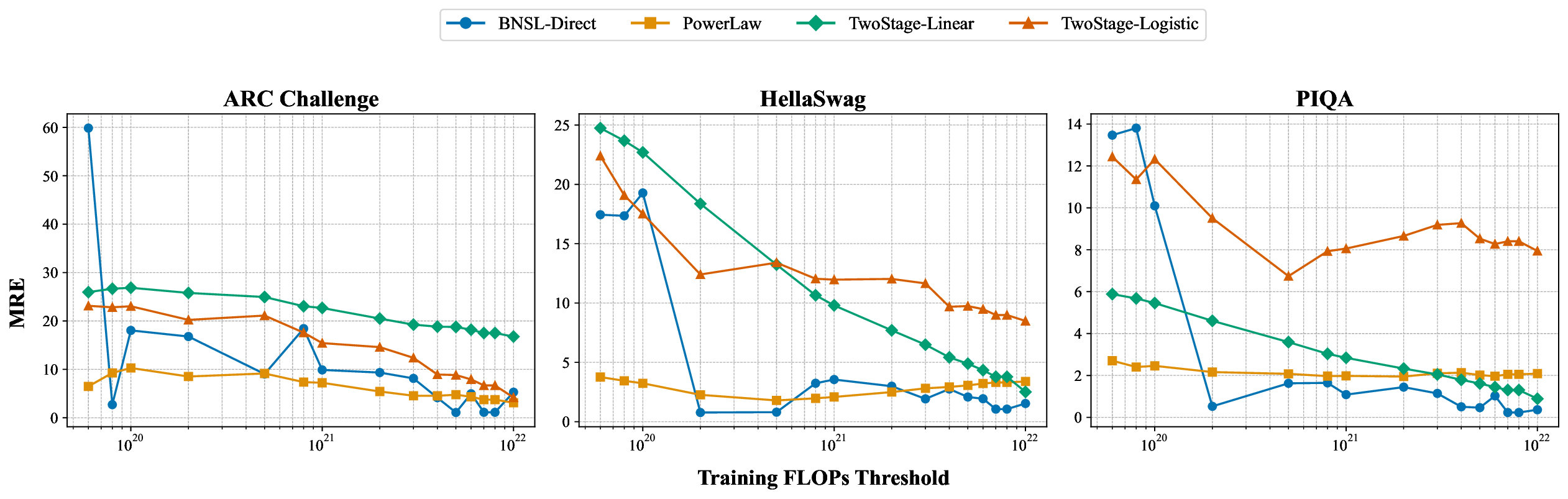
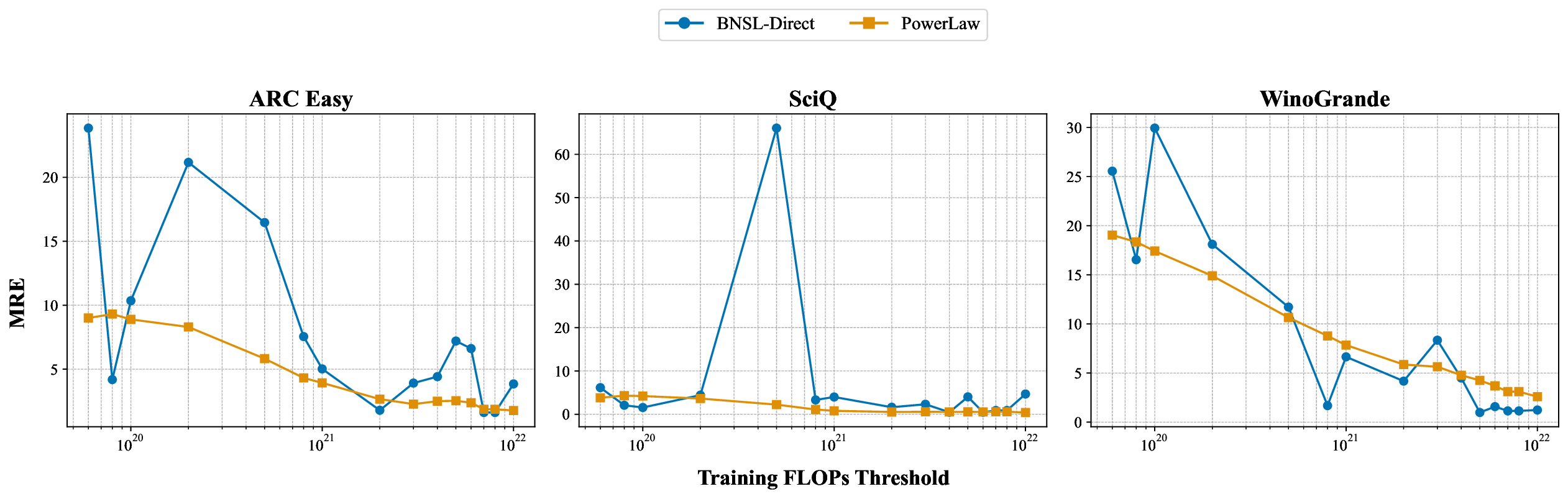
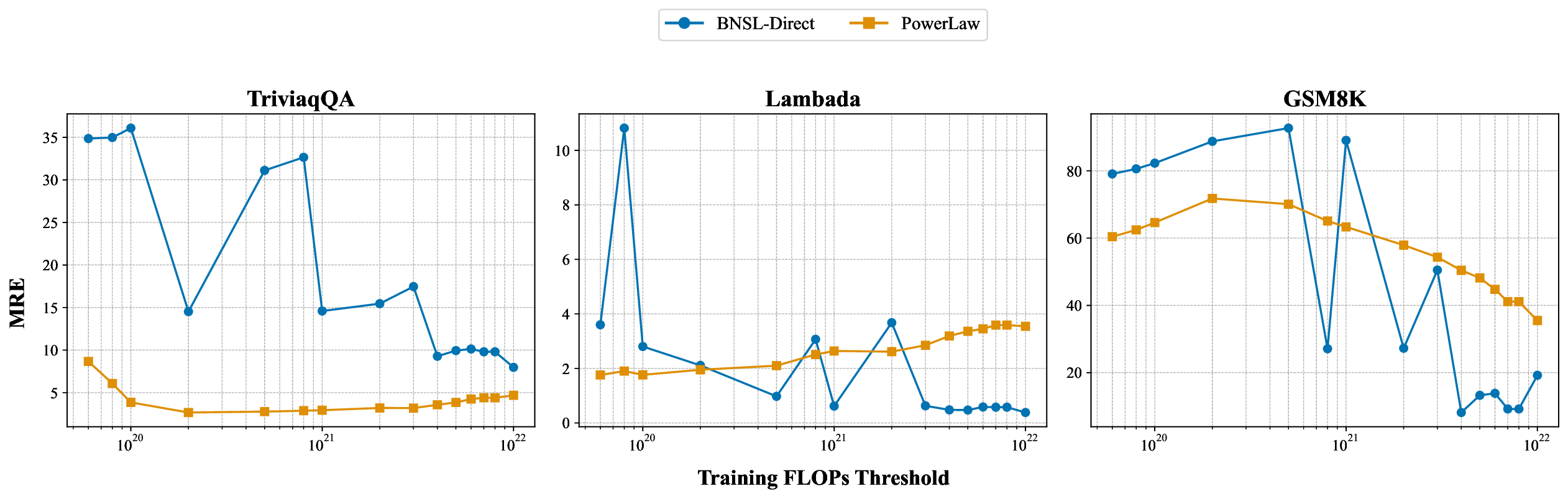
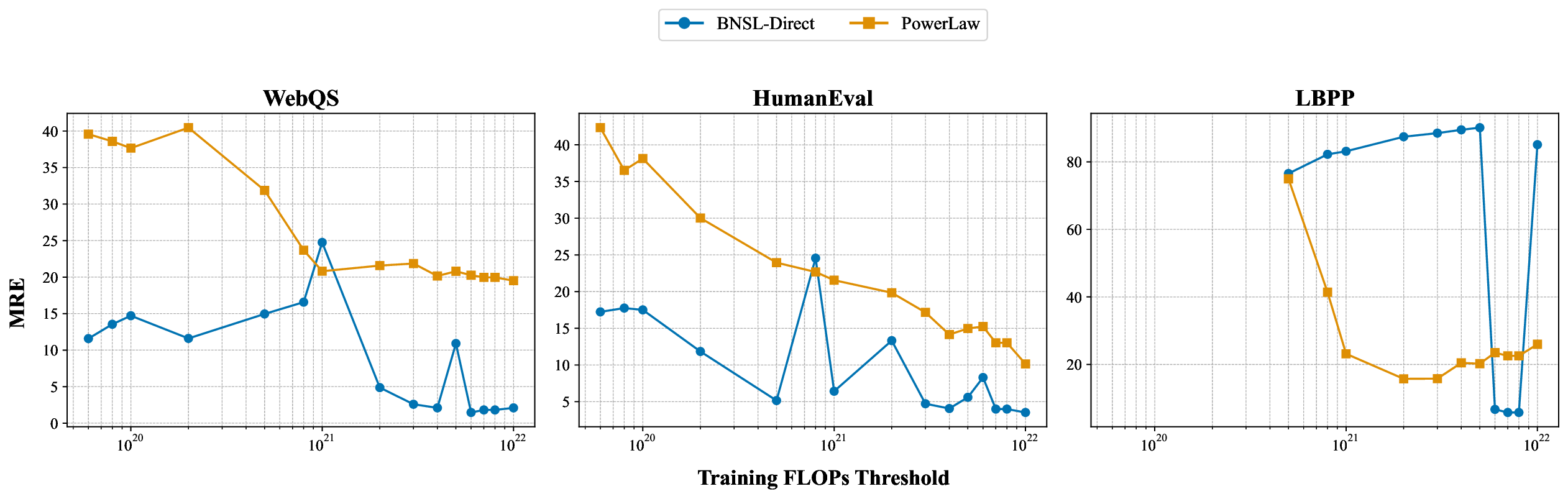
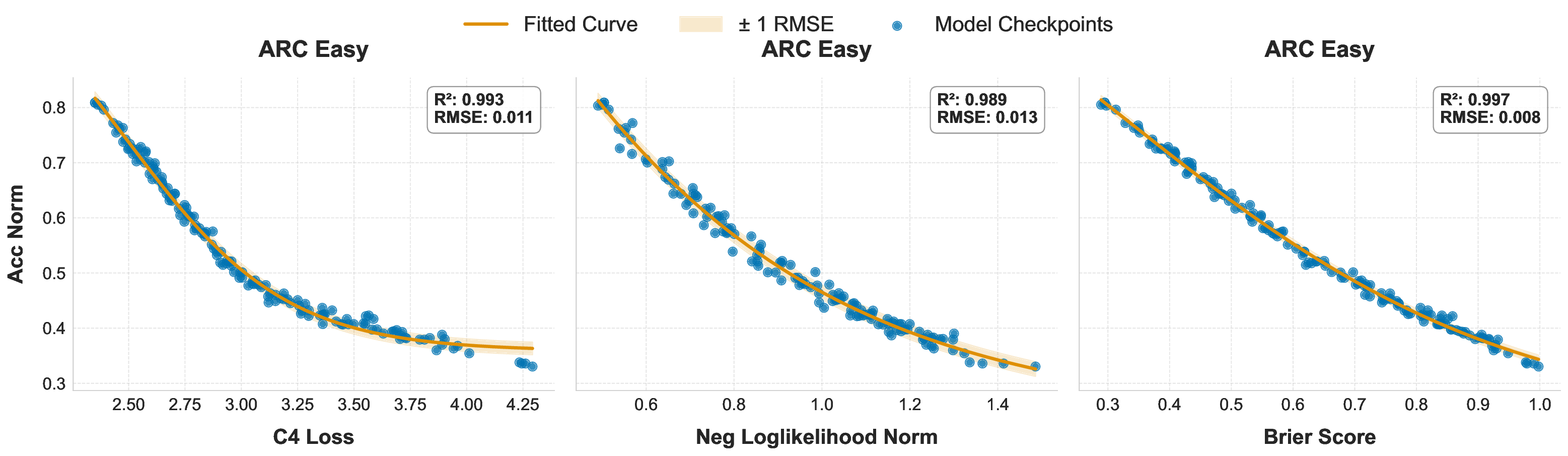
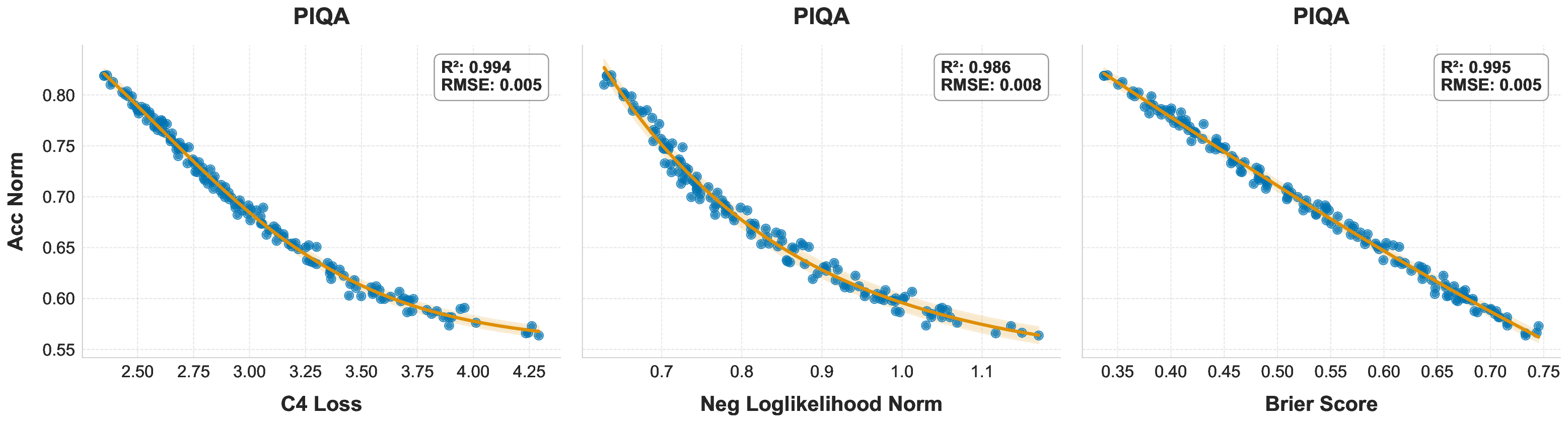
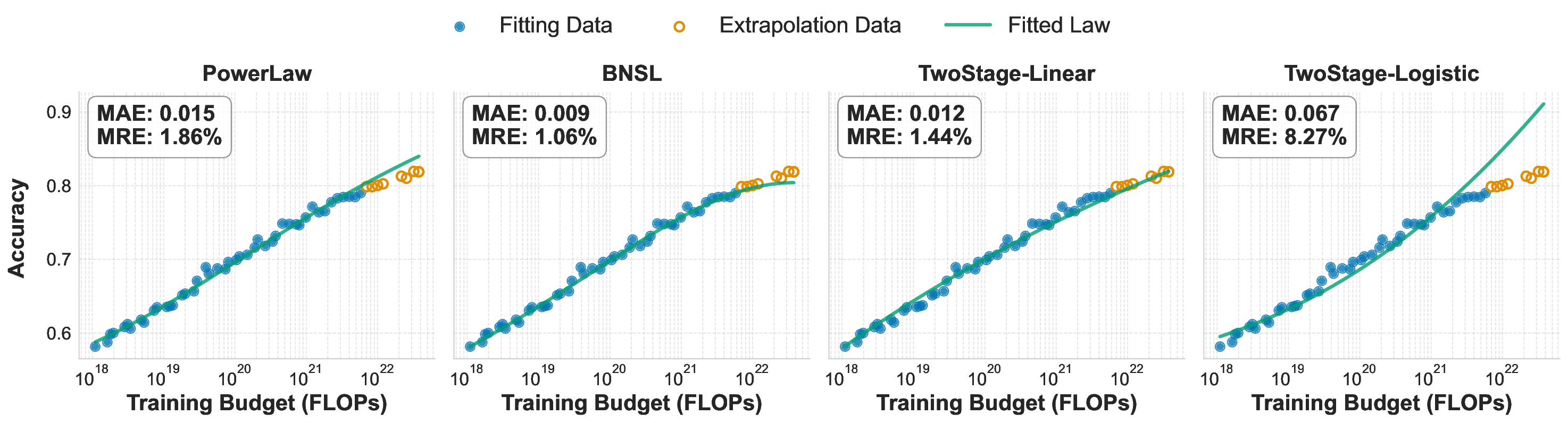
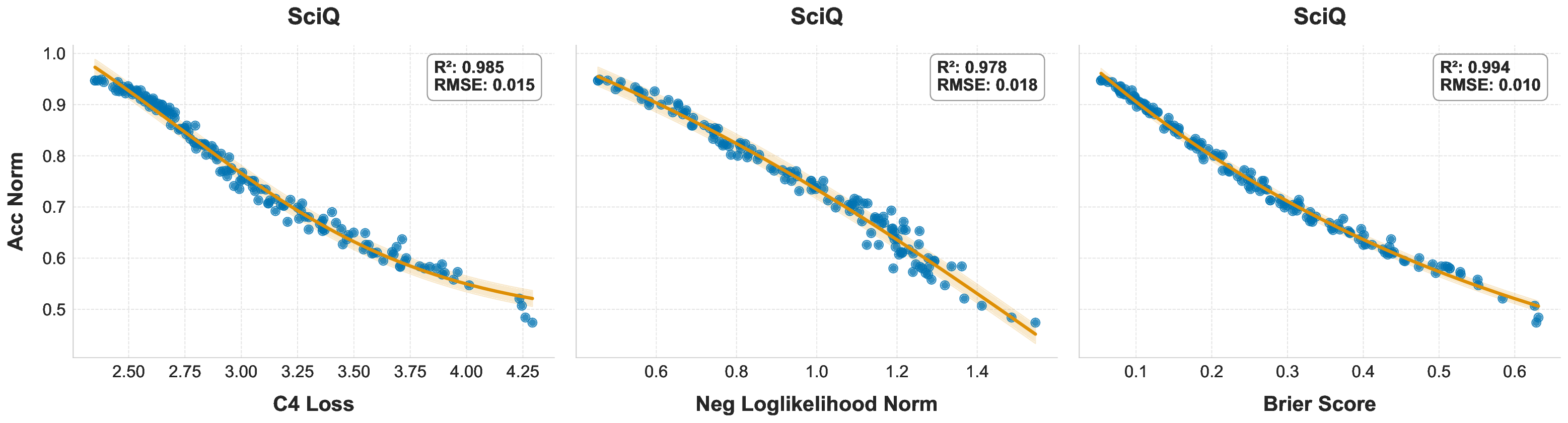
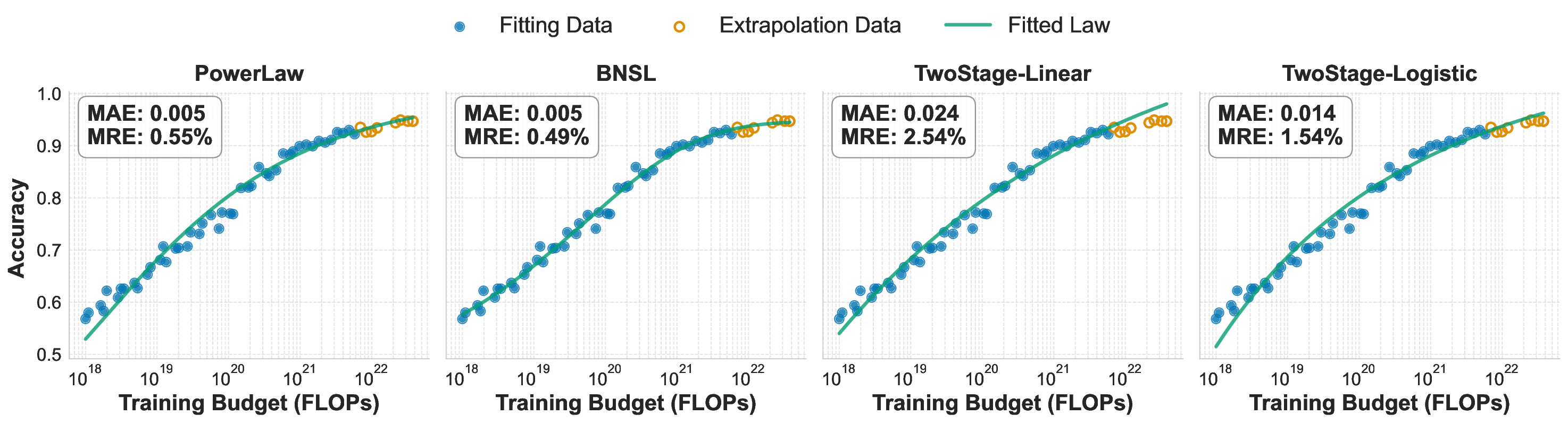
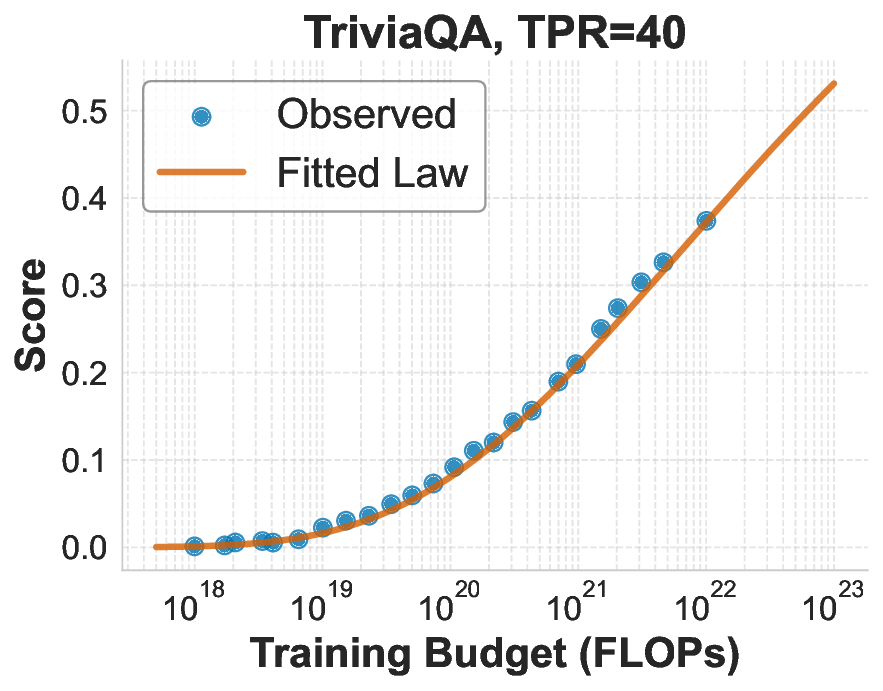
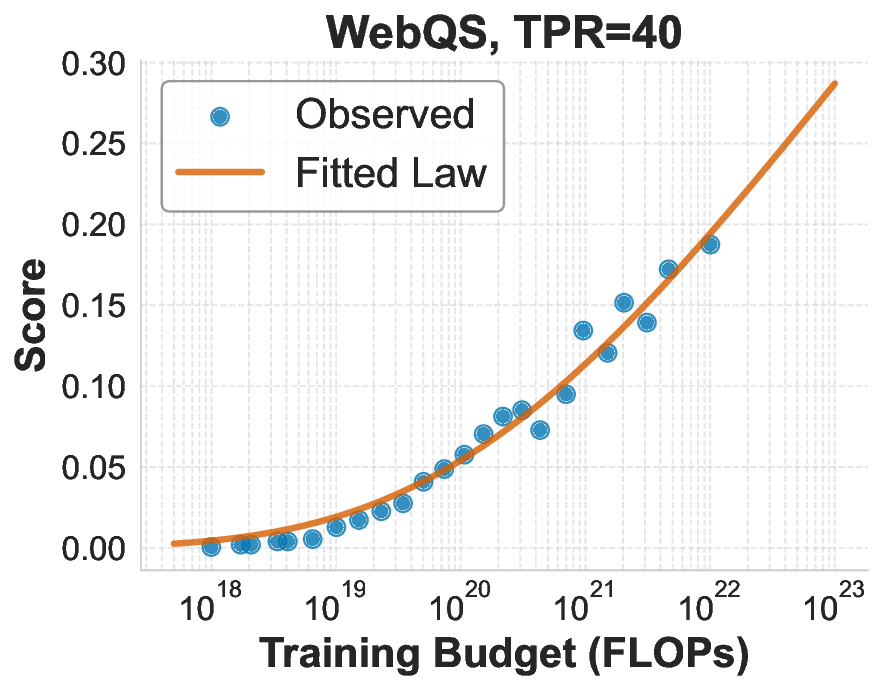
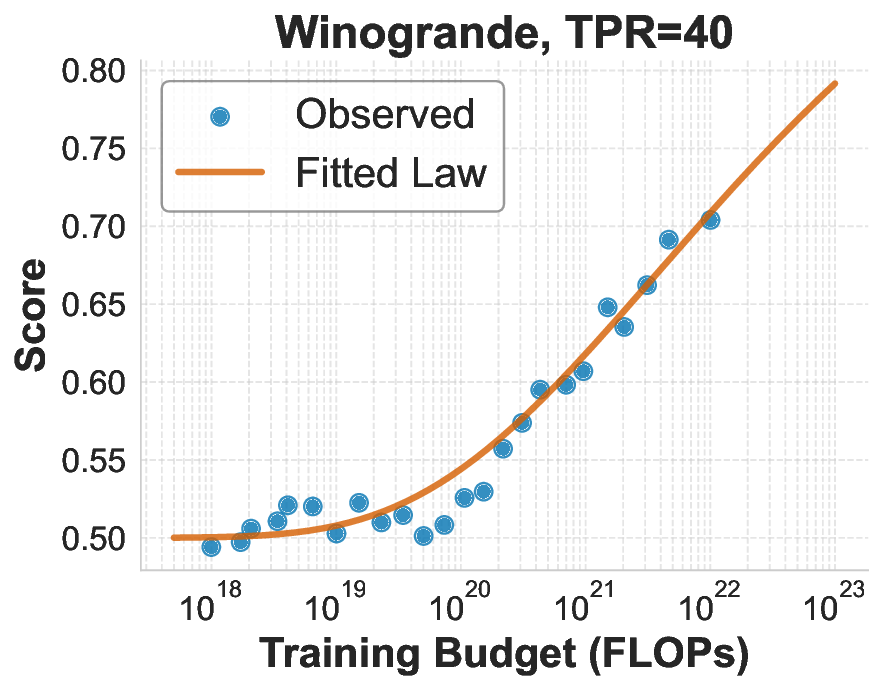
While scaling laws for Large Language Models (LLMs) traditionally focus on proxy metrics like pretraining loss, predicting downstream task performance has been considered unreliable. This paper challenges that view by proposing a direct framework to model the scaling of benchmark performance from the training budget. We find that for a fixed token-toparameter ratio, a simple power law can accurately describe the scaling behavior of log accuracy on multiple popular downstream tasks. Our results show that the direct approach extrapolates better than the previously proposed two-stage procedure, which is prone to compounding errors. Furthermore, we introduce functional forms that predict accuracy across token-to-parameter ratios and account for...📄 Full Content
📸 Image Gallery








Reference
This content is AI-processed based on open access ArXiv data.